short and precise patient self-assessment of heart failure...
TRANSCRIPT

Short and Precise Patient Self-Assessment of Heart Failure Symptoms
Using a Computerized Adaptive Test (HF-CAT)
Rose et al: Heart Failure CAT
Matthias Rose MD PhD 1,2,3, Milena Anatchkova PhD 1, Jason Fletcher PhD 4,
Arthur E. Blank PhD 4, Jakob Bjørner MD PhD 5, Bernd Löwe MD PhD 3,
Thomas S. Rector PhD 6, John E. Ware PhD 1,7
1Department of Quantitative Health Sciences, University of Massachusetts, Worcester, MA, USA 2Department of Psychosomatic Medicine, Charité – University Medicine Berlin, Germany 3University Medical Center Hamburg-Eppendorf and Schön Klinik Hamburg-Eilbek, Germany 4Department of Family and Social Medicine, Albert Einstein College of Medicine, Bronx, NY, USA 53i QualityMetric, Lincoln, RI, USA 6VA Medical Center and Department of Medicine, University of Minnesota, Minneapolis, MN, USA 7John Ware Research Group, Incorporated, Worcester, MA, USA
Correspondence to Matthias Rose Department of Psychosomatic Medicine, Charité – University Medicine Berlin, Germany Charitéplatz 1 10117 Berlin, Germany office +49 30 450 553002 fax +49 30 450 553989 [email protected]
Journal Subject Codes: 110
DOI: 10.1161/CIRCHEARTFAILURE.111.964916
Medicine Berlinininnnnn, ,nnnnnnnikikikikikikik H H H H H H Hamamamamamamambububububububurgrgrgrgrgrgrg-E-E-E-E-E-E-Eililililillilllege e e e e ee ofofofofofofof M M M M M M Mededededededediciciciciciciciiinini
Lr n
h
Lincoln, RI, USA r and Department of Medicine, University of Minnesota, Min
h Group, Incorporated, Worcester, MA, USA
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

Abstract
Background—Assessment of dyspnea, fatigue and physical disability is fundamental to the
monitoring of patients with heart failure (HF). A plethora of patient-reported measures exist,
but most are too burdensome or imprecise to be useful in clinical practice. New techniques
used for computer adaptive tests (CAT) may be able to address these problems. The purpose
of this study was to build a CAT for patients with HF.
Methods and Results—Item banks of 74 queries (‘items’) were developed to assess self-
reported physical disability, fatigue and dyspnea. All queries were administered to 658 adults
with HF to build three item banks. The resulting HF-CAT was administered to 100 ancillary
HF-patients (NYHA I 11%, II 53%, III&IV 36%). In addition, the physical function and
vitality domains of the SF-36 questionnaire, an established shortness-of-breath-scale (SOB),
and the Minnesota Living with Heart Failure Questionnaire (MLHFQ) were applied. The HF-
CAT assessment took 3:09 1:52 minutes to complete and score. All HF-CAT scales
demonstrated good construct validity through high correlations with the corresponding SF-36
physical function (r=-.87), vitality (r=-.85) scales, and the SOB scale (r=.84). Simulation
studies showed a more precise measurement of all HF-CAT scales over a larger range than
comparable static tools. HF-CAT scales identified significant differences between patients
classified by the NYHA symptom criteria, similar to the MLHFQ.
Conclusions—A new CAT for HF patients was built using modern psychometric methods.
Initial results demonstrate its potential to increase the feasibility, and precision of patient self-
assessments of symptoms of HF with minimized respondent burden.
Clinical Trial Registration—URL: http://www.projectreporter.nih.gov. Unique identifier:
1R43HL083622-01.
Key Words: heart failure, patient-reported outcomes, computer adaptive tests
n, the physicacaaaaaal llllll
rtnesesesesesesess-s-s-s-s-ss-ofofofofofofof-b-b-b-b-b-b-brerererererereatatatatatatathhhhhhh
Living with Heart Failur Questionnaire (MLHFQ) were app
o F
construct validity through high correlations with the corresp
r 4
more precise measurement of all HF CAT scales over a larg
Living with Heart Failure Questionnaire (MLHFQ) were app
ook 3:09 1:52 minutes to complete and score. All HF
construct validity through high correlations with the corresp
r=-.87), vitality (r=-.85) scales, and the SOB scale (r=.84
more precise measurement of all HF CAT scales over a larg
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

The cardinal manifestations of heart failure (HF) are dyspnea and fatigue, limited tolerance of
physical activity, fluid retention, pulmonary congestion and peripheral edema. Therefore, HF
is a clinical diagnosis that is largely based on physical examination and a careful history about
typical subjective symptoms in the presence of cardiac dysfunction (1). A patient-centered
measurement approach is particularly important in HF, to provide clinicians with tools to help
them to monitor the syndrome, to compare improvements under different forms of therapy,
and to identify risk of deterioration. The NYHA classification has been used for this purpose,
but is being criticized for its questionable reliability (2,3) and rarely used outside clinical
studies or specialized units.
Generally, patient self-assessments have been shown to be the more reliable assessments of
subjective symptoms, which is one reason for a growing interest in subjective health status
measures from the scientific community, clinical practitioners, as well as from the
industry (4,5). Self-assessed symptoms are used to predict declines in health status of patients
with HF (6), total expenses for HF care (7), hospitalization or even mortality (8,9). Their
widespread use has been recommended to increase quality of care (10), and 30% of all new
drug developments use Patient-Reported Outcomes (PROs) as their primary or co-primary
endpoint (11).
However, with traditional methods, a comprehensive and reliable ‘static’ measure is likely to
be long and time-consuming to administer and score. If questionnaire data need to be
analyzed manually assessments become cost-prohibitive for use in routine clinical practice,
and individual patient reports cannot be provided timely. Short-forms limit the respondent
burden, but often show more ceiling- or floor effects and lack the precision required at the
ddddd rararararerererrerr lylylylylylyy u u u u seseseseeeed d d d dd d oouououooou
e a
m e
e scientific community, clinical practitioners, as well
elf-assessments have been shown to be the more reliable a
ms, which is one reason for a growing interest in subjective
e scientific community, clinical practitioners, as well
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

individual patient level (12,13). Measurement precision to guide individual decision-making
must be substantially higher than for group comparisons, because true change must be
separated from measurement error for every single assessment (13). For example, if a
confidence interval of 95% is required, a traditional tool with good psychometric properties
for group comparisons (e.g. with Cronbach =.80) would only allow for interpretation of
score differences of almost one standard deviation when used for an individual (14).
Moreover, classic psychometric methods cannot be used to determine the measurement
precision for an individual measurement. As a result, none of the existing tools has become a
standard measure in clinical practice (15,16). Enhancing the precision, accessibility and
interpretability of patient reported outcome (PRO) measures could make heart failure
management more efficient and effective in meeting patient care needs.
With the presented study we apply computerized adaptive testing (CAT) methods, a
measurement technology (17) which is used widely in educational testing (18). We aimed to
build a system which will allow routine, comprehensive assessment of pathognomonic
symptoms. The use of CAT techniques also promise to provide more precise measures, with
fewer items, and an effective resolution to the classic conflict between practicality and
precision faced by traditional measurement methodology (12). CATs tailor each assessment to
the individual’s status on what is being measured, applying only items which are most
appropriate for her/his current health status. Responses to each CAT-item direct the choice of
the following CAT-item towards the most informative for this particular assessment. A
patient indicating higher levels of disability within the first questions would only be asked
about this level of ability. Omitting the use of uninformative items not relevant for a given
precision, acacaccccccc
s coooooooulululululululd d d d d dd mamamamamamamakekekekekekek
e
d
o .
efficient and effective in meeting patient care needs.
d study we apply computerized adaptive testing (CAT
ology (17) which is used widely in educational testing (18).
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

functional limitation focuses the assessment, decreases the respondent burden, and increases
the measurement precision achievable with a given number of items.
CATs select the items out of a larger item bank representing the entire range of the construct
being measured. Most of the item banks are built upon the principles of the Item-Response
Theory (IRT). The National Institutes of Health (NIH) are intensively promoting use of these
methods to develop a comprehensive Patient-Reported Outcomes Measurement Information
System (PROMIS) as part of their roadmap initiatives (http://nihroadmap.nih.gov/). Authors
of this paper are part of the PROMIS initiative, which aims to provide a standard assessment
for generic health status measures in the near future (19).
The goal of this study was to develop CATs for dyspnea, fatigue and physical function for the
assessment of patients with HF, and to evaluate their acceptability, precision and validity.
Methods
Development of the items
After review of the relevant literature we developed a set of 74 patient questions (items)
covering the three primary physical impairments commonly reported by patients with HF:
physical function/disability (24 items), dyspnea (30 items) and vitality/fatigue (20 items). The
queries were designed to be short enough to fit on a portable phone screen for home
assessments (Figure 1). Items were selected to represent the entire continuum of each aspect
of HF from no to severe impairment. All three item banks have been scored in the direction
that higher scores indicate more impairment (i.e. physical disability, fatigue, and dyspnea).
dy was to develop CATs for dyspnea, fatigue and physical fu
n d
dy was to develop CATs for dyspnea, fatigue and physical fu
nts with HF, and to evaluate their acceptability, precision and
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

The item bank development was performed separately for each of the three domains of
physical function, dyspnea, and fatigue following the same procedures as described in
previous studies (20,21). After the item banks had been developed we used them as a basis for
a CAT. A new software solution was developed to work on a Personal Digital Assistant. The
CAT logic can be set to stop after the measurement reaches a particular precision or after a
maximum of items had been administered. For this study phase the CAT was set to assess
each of the three different domains with a standard error of SE < 3.3 (corresponding to a
reliability of Cronbach > .90 for samples with a standard deviation of 10) or a maximum
number of 7 items per scale.
Participants
The data for the CAT item bank development (IB sample) were collected via the Internet from
English speaking adults with HF. All respondents were recruited by YouGov. YouGov uses a
methodology called sample matching for the selection of study samples from pools of opt-in
respondents (22). Sample matching starts with an enumeration of the target population. For
patient recruitments, the target population is all adults with similar sociodemographic
characteristics like patients with a particular condition, as enumerated in consumer databases
(e.g. maintained by Acxiom, Experian, and InfoUSA). Then a random sample is drawn from
the target population. Finally for each member of the target sample, a matching member of the
internet pool of opt-in respondents is selected, resulting in a “matched sample”. Matching was
based on age, gender and race. The resulting matched sample has similar characteristics to the
target population and, will have similar properties to a true random sample. For this study
14,028 adults have been approached until the target number of patients with heart failure had
been enrolled. All newly developed items were administered randomly.
T e
d Y
l t hi f th l ti f t d l f
T item bank development (IB sample) were collected via the
dults with HF. All respondents were recruited by YouGov. Y
l t hi f th l ti f t d l f
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

The same data collection method and vendor has been used for many similar projects,
including a NIH roadmap initiative for the development of generic PRO tools
(www.nihpromis.org). To ensure a sufficient distribution of responses for the item parameter
estimation, we used a quota of 1/3 of patients with minor, medium, and severe impairment
based on one screening question describing the level of impairment analogous to the NYHA-
classification (I/II/ III).
To help ensure the quality of the data we applied the following exclusion criteria: (a) average
answering time per item was less than 5 seconds, (b) subjects who did not indicate they had
HF and one underlying cause for HF, (c) subjects who did not indicate that the HF diagnosis
was given by a physician, (d) last visit to a physician was more than 6 months ago, or (e)
current medication did not indicate at least one drug used for the treatment of HF (diuretics,
ACEI or ARB, -blockers, digoxin).
To examine the characteristics of the HF-CAT different simulation studies were conducted as
described earlier (20,23). These analyses are based on the real data provided for all items in
the bank by the patients in the online survey. Only small subsets of those item responses are
used to estimate the patient score for the CAT simulation (in IRT terms called ‘theta score’).
The quality of the items in the bank defines the precision of the score at different ranges. The
‘test information curve’ identifies floor- and ceiling effects and if the measurement range of
the tool fits to the symptoms of the sample. To illustrate this for the HF-CAT, the precision of
the score estimate was plotted as a function of the patient scores (20).
To evaluate the construct validity of the HF-CAT, items from the following established tools
were also included in the data collection: the SF-36® Health Survey scales for Physical
Functioning (PF) and Vitality (VT) (24), four items from the Medical Health Outcomes
nnnnnnndidididicacacaccacc tetetee t t ttttthahahahaaaat t t thththththththeee e eee
re ththhhhthhananananananan 6666666 mmmmmmmonononononononthy ( ) p y
d
o
racteristics of the HF CAT different simulation studies were
y ( ) p y
did not indicate at least one drug used for the treatment of
ockers, digoxin).
racteristics of the HF-CAT different simulation studies were
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

Survey (HOS) to assess Shortness of Breath (SOB) (25) and the Minnesota Living with Heart
Failure Questionnaire (26) (MLHFQ, 21 items) as a legacy tool for measuring HF as indicated
by patients’ perceptions of its overall effects on their lives.
A separate sample of 100 consecutive participants was recruited for the validity test
conducted at the heart failure clinic of the Montefiore Medical Center, Bronx, NY (MMC
sample). The clinic was selected as it usually does not use PRO assessments, and
predominantly serves a low income, diverse population. We considered this environment as
particularly challenging to test a new technology, assuming relatively low health literacy
levels. In addition, we felt that an evaluation of psychometric properties would be more
relevant in a less educated sample, as the validity of the IRT assumptions have been evaluated
already in the development sample, which was affluent and well-educated (Table 1). Patients
with previously diagnosed heart failure were invited to participate in the study. Consenting
participants were asked to complete the actual HF-CAT on a hand-held computer (Personal
Digital Assistant, PDA) and a series of paper- and pencil-assessments including socio-
demographic questions, the MLHFQ, and a survey evaluation the experience with the HF-
CAT. All participants completed both instruments. Participants were randomly assigned to
one of two groups within a cross-over design where the order of presentation of the HF-CAT
assessment and the MLHFQ was counterbalanced. Patients were placed in the waiting area
and asked to follow the standard instructions provided for each measure.
Medical information, including the NYHA class was extracted from the medical files. The
NYHA class is determined routinely for all patients at every visit at the MMC Heart Failure
Clinic based on the clinical assessment of the treating physician. The NYHA class was
iic c c cccc prprprprprprpropopopopopoppererererererertititit eseseseseseses w w w w w w woo
umptptptttpttioioioioioioionsnsnsnsnsnsns hhhhhhhavavavavavavaveeeeeee bp y p
o b
g y
s u
p y p
opment sample, which was affluent and well-educated (Tabd
gnosed heart failure were invited to participate in the study
sked to complete the actual HF-CAT on a hand-held compu
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

determined without knowledge of the results of patient self-assessments. Patients gave written
informed consent and received a $25 incentive for their participation in the study.
Results
Samples
After applying the inclusion and exclusion criteria, the final item development sample (IB
sample) consisted of 658 participants, 60 13 years old (49% female) who had experienced
HF for 8.8 7.9 years (Table 1). Patients reported the following conditions beside their HF:
43% coronary heart disease, 42% previous heart attacks, 18% cardiomyopathy, 14% valvular
heart disease, 5.2% rheumatic fever, 60% hypertension, 31% arrhythmias, 40% diabetes.
Alcohol abuse was reported by 5.9%.
The Montefiore Medical Center clinical sample (MMC sample, n=100) was predominantly
male (62%), with a mean age of 58 years. The sample was diverse including a majority of
African-American patients and a large proportion of Hispanics. One third of the population
had a comparatively low household income. The severity of their heart failure symptoms
assessed by the New York Heart Association (NYHA) classification was 11% in class I, 53%
in class II, 36% in class III or IV.
HF-CAT Development
Item Banks Development: In the final calibrated item banks there were 21 items assessing
Physical Disability, 20 items assessing Fatigue and 29 items in the Dyspnea bank with
satisfactory item fit (Table 2). Most informative (i.e. with a high discrimination parameter:
‘slope’) was the item asking about the ability to run errands, an item referring to a feeling of
g conditions bbeseeeeee
ardiiomomomomomomomyoyoyoyoyoyoyopapapapapapapathththththththyy,yyyyy
% 4
r
e p
% rheumatic fever, 60% hypertension, 31% arrhythmias, 4
reported by 5.9%.
edical Center clinical sample (MMC sample, n=100) was p
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

being “worn out”, and the item asking if the patient will be short of breath walking from one
room to another.
Simulation Studies: The precision of every score estimate can be displayed as a function of
the level of function, or the severity of the symptoms. The results of the simulation studies
showed that a highly precise score (comparable to an internal consistency of >.90) can be
estimated with 5 items for each domain over a range of nearly three SDs. (Figure 2, left side).
The concordance between the results of the CATs and the entire item bank was very good for
all of the constructs as illustrated by the extremely high correlations (r=0.95-0.97), showing
that the 5 item CAT can essentially capture the information provided by the entire bank. As
expected there were high correlations between the simulated CAT scale scores and the
corresponding SF-36 Health Survey’s Physical Function (r=-.87), and Vitality scales (r=-.84),
as well as the static Shortness of Breath measurement (r=.83). Compared to all legacy tools,
the HF-CAT provides a more precise measurement over a larger measurement range (Figure
2, right side). For Physical Disability a similar measurement precision like with SF-36
Physical Function scale can be achieved with ½ the number of items (Figure 2, upper left
corner).
HF-CAT Evaluation
Respondent burden: On average 4-5 items were administered for the assessment of physical
disability, fatigue and dyspnea to achieve the predefined level of precision (Table 3). The
average time for administration of the entire HF-CAT with all three domains was 3 minutes
(3 2 min).
atatatatatatatioioioioioioionsnsnsnsnsnsns ( ( ( ( ( ((r=r=r=r=r=r=r=0.0.00000 95959595959595-0-0-0-0-0-00
T can essentially capture the information provided by the en
r c
6
Shortness of Breath measurement (r .83). Compared to all
T can essentially capture the information provided by the en
re high correlations between the simulated CAT scale sc
6 Health Survey’s Physical Function (r=-.87), and Vitality s
Shortness of Breath measurement (r=.83). Compared to all
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

Validity: We used the MLHFQ to help evaluate the constructs of the HF-CAT and the NYHA
class to evaluate its discriminative validity (Table 3). The mean MLHFQ score of the sample
was 38 ± 25, the mean score of the HF-CAT were 59.6 ± 8.4 for Physical Disability,
52.6 ± 8.5 for Fatigue, and 54.8 ± 13.3 for Dyspnea. There were no order effects for any
measure. The HF-CAT scales for physical disability, fatigue, dyspnea correlated significantly
with the MLHFQ total score (r = 0.71, r = 0.63, r = 0.68 respectively).
A general linear model was used to evaluate the ability of the HF-CAT scales to statistically
differentiate patients with different levels of symptom severity as measured by the clinician’s
NYHA classification (Table 3). The main effects for all the measures were significant, with
very similar discriminative ability (Eta², F-values) for the HF-CAT Physical Disability and
Dyspnea scales, and the MLHFQ scale.
User Experience: As this study took place in a low income, less educated, minority population
we had been particularly interested in the subjective user experience with a computer
assessment. 98% of the patients found the HF-CAT assessment overall very easy or easy,
100% thought it was very easy or easy to follow the instructions, and 95% said it was very
easy or easy to read the questions on the screen. 98% judged the time for the assessment as
‘just right’, and 90% considered the questions as relevant. 98% had been willing to use the
device again on the next visit.
eaeaaaaaassssurururrurrreseseses w w wwwwwererererrrre e e e e e e sisisisisisisiggggggg
CATTTTTTT PhPhPhPhPhPhPhysysysysysysysicicicicicicicalalalalalaa Dy ( ) y
d
s this stu took ace in a low income, less educated, minor
cularly interested in the subjective user experience with
y ( ) y
d the MLHFQ scale.
s this study took place in a low income, less educated, minor
cularly interested in the subjective user experience with
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

Discussion
For the first time we applied computerized adaptive testing methods to develop and evaluate
an ultra-short assessment system for patients with HF (HF-CAT) in clinical practice. The tool
allows routine, comprehensive assessment of three primary problems that are commonly
experienced by patients with heart failure. If the emotional or social impact of the disease is of
additional interest, further tools, e.g. from the PROMIS, need to be added for a
comprehensive coverage of the health-related quality of life construct.
Feasibility
The feasibility of the HF-CAT in its PDA version was evaluated in a low income, low
educated minority population in the Bronx, NY. It was demonstrated that the HF-CAT is a
practical tool well accepted. Nevertheless, it was tested under study conditions, and
participants might have been biased receiving an incentive for their participation. To our
knowledge, only one report about the acceptance of CATs within clinical practice settings is
available. A similar CAT, also being displayed on a PDA, is in routine clinical use since
2004. Patients answering this CAT also report a high acceptability. All most all of the 423
consecutive patients considered the handling as easy and felt that the use of the PDA made
sense (27).
Several other studies report about the reception of CATs under study conditions. The majority
of patients in a feasibility test of a pain CAT found the CAT application to be useful, relevant,
of appropriate length, and easy to complete (28). Similarly the majority of respondents in a
feasibility study of an asthma impact CAT found it easy to complete and of appropriate length
(29). The results of a feasibility test of a diabetes CAT gave somewhat mixed results. While
both English-speaking and Spanish-speaking participants agreed that a paper-and-pencil
uateteeeeeed d d ddd d ininininininin a a a aa aa l llll llowowowowowowow
p
o
h p
t b t th t f CAT ithi li i l t
population in the Bronx, NY. It was demonstrated that the
accepted. Nevertheless, it was tested under study co
have been biased receiving an incentive for their particip
t b t th t f CAT ithi li i l t
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

assessment was more burdensome than a CAT, the Spanish-speaking participants preferred
the paper tool and were more willing to complete a paper tool in the future (30).
Respondent Burden
One important contribution of the Computer Adaptive Test technology will be to reduce the
respondent burden without compromising the precision and validity of the assessment, by
tailoring each assessment to the patient’s condition. This advantage was demonstrated earlier,
for example, in a simulation study of the Activities of Daily Living CAT, which found that
the CAT provided similar results to a static version while reducing the number of items
administered by 50% (31). Results from other studies indicate that scores similar to those
obtained with full-length item banks (ranging in length from 18 to 585 items) can be achieved
through much shorter CATs when measuring functional status (32-34), mental health status
(21,27,35,36) or the impact of conditions like headache (23,37), diabetes (30), chronic
pain (28), and asthma (29). Most actual CAT applications used between 5-7 items to measure
one construct. The present HF-CAT applied between 4-5 items per scale and the average total
time for the entire assessment and scoring was 3 min, i.e. 1 min per scale (which could be
applied individually). The assessment time of the MLHFQ electronically measured in a
previous study was 4 2 min (38), and time administer the Kansas City Cardiomyopathy
Questionnaire (KCCQ), another common tool for the assessment of HF patients, is reported to
be 4-6 minutes without scoring (39).
g
ivingngggggg C CCCCCCATATATATATATAT, , ,,, whwhwhwhwhwhwhii
m
% m
e a
similar results to a static version while reducing the num
% (31). Results from other studies indicate that scores simtt
ength item banks (ranging in length from 18 to 585 items) ca
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

In summary, the HF-CAT provides a precise measure over a large measurement range with
minimal respondent burden. As far it is known today, it seems that CATs offer an effective
resolution to the classic conflict between practicality and precision faced by traditional
measurement technology (12).
Validity
Studies of CAT applications in diseases, like depression (27,35), or headache (40), have
shown that their measurement advantages can transfer to increased validity in identifying
differences between groups known to differ in clinical characteristics, compared to static
tools. The three scales of the HF-CAT also discriminated between groups of patients of
different NYHA classification equally as well as a legacy tool measuring the impact of heart
failure, using four times more items. These initial results show that the HF-CAT has the
potential to provide a valid, highly relevant assessment of patients with heart failure.
Serial Measurements
For the assessment of HF patients, we believe it is important to assess the health status of the
patient at the point of care as well as at the patient’s home. As many elderly patients do not
have access to the internet or are not familiar with its use, one way to do so is the use of a
smart phone and or interactive voice recognition. Most established tools include items which
are not suitable to be used over the phone. IRT methods allow using much simpler items over
the phone and more comprehensive items at the doctor’s office, and scoring both assessments
on the same measurement metric . This allows having a smart phone administer the HF-CAT
at the patient’s home, and have the same patient answering the more comprehensive
PROMIS-CAT on a tablet PC at the doctor’s office. IRT-based measurements of health
outcomes are independent of the particular items being administered and from the test
eeeeeetwtwtwtwtwtwtweeeeeeeeeeeeeen n nnnnn grgrgrgrgrgrgrouououououououpspspspspspsps oo o ooo
assification equally as well as a legacy tool measuring the im
t -
l
t
assification equally as well as a legacy tool measuring the im
times more items. These initial results show that the HF-t
a valid, highly relevant assessment of patients with heart fail
t
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

administrator. The same value for the same domain yields the same interpretation, whereas
results from different traditional tools cannot be compared directly making serial health status
monitoring less practicable.
Limitations
Despite many encouraging findings with recent CAT developments, a number of issues still
need to be addressed. Within this study we have only used outpatients to evaluate the HF-
CAT, which limits the generalizability to less severely disabled patients. However, one of the
most relevant advantages of CATs is that they can essentially eliminate floor and ceiling
effects by applying items tailored to the test-taker. Our simulation studies have shown that the
current item bank covers more than three standard deviations above the population mean,
which is where a hospitalized population of HF patients usually scores.
We did not evaluate the test-retest reliability for the HF-CAT. Similarly, we have not used the
HF-CAT in an intervention study to test its responsiveness to treatments. However, several
studies have reported on the ability of other CATs to detect change. For example, in a
telephone study of 540 headache patients, a CAT for headache impact was demonstrated to be
more responsive to self-evaluated changes of headache impact than a corresponding 54-item
bank (23). In a longitudinal, prospective cohort study of 94 patients discharged from inpatient
rehabilitation, the CAT version of the Activity Measure for Post-Acute Care was found to be
comparable in responsiveness to the 66-item static version (41). Similarly, in a series of
articles, Hart et al. report on the results of validation studies of condition-specific CATs,
using large data sets from patients receiving rehabilitation services across multiple U.S.
clinics (33,34).
oooon n nnnnn stststststststudududududududieieieieieieiessss s ss hahahahahahahaveveveveveveve s ssssss
covers more than three standard deviations above the popa
s
v
ti t d t t t it i t t t t H
covers more than three standard deviations above the popa
spitalized population of HF patients usually scores.
the test-retest reliability for the HF-CAT. Similarly, we hav
ti t d t t t it i t t t t H
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

Summary
In summary, we have developed a promising method to measure patient-reported dyspnea,
fatigue and physical function for use in the care of patients with heart failure. This new
measure is part of a rapidly growing number of new assessment tools utilizing the advantages
of item response theory and computerized adaptive test techniques (16,19,42), with some of
them being used in clinical practice already (27,43). However, whether these encouraging
improvements in measurement will transfer to improved care and ultimately health of heart
failure patients warrants further studies.
Sources of Funding
The work has been supported in part by an NIH/NLHBI grant (1 R43 HL083622-01, PI Rose)
Disclosures
None.
References
1. Hunt SA, Baker DW, Chin MH, Cinquegrani MP, Feldman AM, Francis GS, Ganiats TG, Goldstein S, Gregoratos G, Jessup ML, Noble RJ, Packer M, Silver MA, Stevenson LW, Gibbons RJ, Antman EM, Alpert JS, Faxon DP, Fuster V, Jacobs AK, Hiratzka LF, Russell RO, Smith SC, Jr.: ACC/AHA guidelines for the evaluation and management of chronic heart failure in the adult: executive summary. A report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines. J Am Coll Cardiol. 2001;38:2101-2113.
2. Bennett JA, Riegel B, Bittner V, Nichols J: Validity and reliability of the NYHA classes for measuring research outcomes in patients with cardiac disease. Heart Lung. 2002;31:262-270.
s 2
Sources of Funding
supported in part by an NIH/NLHBI grant (1 R43 HL083622
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

3. Goldman L, Hashimoto B, Cook EF, Loscalzo A: Comparative reproducibility and validity of systems for assessing cardiovascular functional class: advantages of a new specific activity scale. Circulation. 1981;64:1227-1234.
4. Lett HS, Blumenthal JA, Babyak MA, Sherwood A, Strauman T, Robins C, Newman MF: Depression as a risk factor for coronary artery disease: evidence, mechanisms, and treatment. Psychosom Med. 2004;66:305-315.
5. Konstam V, Moser DK, De Jong MJ: Depression and anxiety in heart failure. J Card Fail. 2005;11:455-463.
6. Rumsfeld JS, Havranek E, Masoudi FA, Peterson ED, Jones P, Tooley JF, Krumholz HM, Spertus JA: Depressive symptoms are the strongest predictors of short-term declines in health status in patients with heart failure. J Am Coll Cardiol. 2003;42:1811-1817.
7. Sullivan M, Simon G, Spertus J, Russo J: Depression-related costs in heart failure care. Arch Intern Med. 2002;162:1860-1866.
8. Rumsfeld JS, Jones PG, Whooley MA, Sullivan MD, Pitt B, Weintraub WS, Spertus JA: Depression predicts mortality and hospitalization in patients with myocardial infarction complicated by heart failure. Am Heart J. 2005;150:961-967.
9. Junger J, Schellberg D, Muller-Tasch T, Raupp G, Zugck C, Haunstetter A, Zipfel S, Herzog W, Haass M: Depression increasingly predicts mortality in the course of congestive heart failure. Eur J Heart Fail. 2005;7:261-267.
10. Cleary PD, Edgman-Levitan S: Health care quality. Incorporating consumer perspectives. JAMA. 1997;278:1608-1612.
11. Burke, L. FDA Perspectives on IRT/CAT. DIA Workshop on Advances in Health Outcomes Measurement: Exploring the Current State and the Future Applications of Item Response Theory, Item Banks, and Computer-adaptive Testing, Bethesda, June 25. 2004.
12. McHorney CA, Cohen AS: Equating health status measures with item response theory: illustrations with functional status items. Med Care. 2000;38:II43-II59.
13. Rose M, Bezjak A: Logistics of collecting patient-reported outcomes (PROs) in clinical practice: an overview and practical examples. Qual Life Res. 2009;18:125-136.
14. McHorney CA, Tarlov AR: Individual-patient monitoring in clinical practice: are available health status surveys adequate? Qual Life Res. 1995;4:293-307.
15. Rector TS: A conceptual model of quality of life in relation to heart failure. J Card Fail. 2005;11:173-176.
16. Garin O, Ferrer M, Pont A, Rue M, Kotzeva A, Wiklund I, Van GE, Alonso J: Disease-specific health-related quality of life questionnaires for heart failure: a systematic review with meta-analyses. Qual Life Res. 2009;18:71-85.
B,B W WWWWWWeieieieieieieintntntntntntntrararararararaububububububub W W WW W W WSSSSSSSs wiiiiiiiththththththth mymymymymymymyocococococococararararararardidd
y
l Ar
E
dgman Levitan S: Health care quality Incorporating consume
y heart failure. Am Heart J. 2005;150:961-967. JJ
llberg D, Muller-Tasch T, Raupp G, Zugck C, Haunstetter Aass M: Depression increasingly predicts mortality in the cour
Eur J Heart Fail. 2005;7:261-267.
gman Levitan S: Health care quality Incorporating consume
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

17. Bjorner JB, Chang CH, Thissen D, Reeve BB: Developing tailored instruments: item banking and computerized adaptive assessment. Qual Life Res. 2007;16 Suppl 1:95-108.
18. Wainer H, Dorans NJ, Eignor D, Flaugher R, Green BF, Mislevy RJ, Steinberg L, Thissen D: Computerized Adaptive Testing: A primer. Mahwah, NJ, Lawrence Erlbaum Associates, 2000.
19. Cella D, Yount S, Rothrock N, Gershon R, Cook K, Reeve B, Ader D, Fries JF, Bruce B, Rose M: The Patient-Reported Outcomes Measurement Information System (PROMIS): progress of an NIH Roadmap cooperative group during its first two years. Med Care. 2007; 45:S3-S11.
20. Rose M, Bjorner JB, Becker J, Fries JF, Ware JE: Evaluation of a preliminary physical function item bank supported the expected advantages of the Patient-Reported Outcomes Measurement Information System (PROMIS). J Clin Epidemiol. 2008;61:17-33.
21. Fliege H, Becker J, Walter OB, Bjorner JB, Klapp BF, Rose M: Development of a computer-adaptive test for depression (D-CAT). Qual Life Res. 2005;14:2277-2291.
22. Rubin D.B.: Matched Sampling for Causal Effects. New York, Cambridge University Press, 2006
23. Ware JE, Jr., Kosinski M, Bjorner JB, Bayliss MS, Batenhorst A, Dahlof CG, Tepper S, Dowson A: Applications of computerized adaptive testing (CAT) to the assessment of headache impact. Qual Life Res. 2003; 12:935-952.
24. Ware JE, Jr., Dewey J: How to Score Version Two of the SF-36 Health Survey. Lincoln, RI, QualityMetric Incorporated, 2000.
25. National Committee for Quality Assurance. Specifications for the Medicare Health Outcomes Survey. HEDIS® . 6. 2004. Washington, DC, National Committee for Quality Assurance.
26. Rector T, Cohn J: Patients'self-assessment of their congestive heart failure. Part 2: Content, reliability and validity of a new measure, the Minnesota Living with Heart Failure questionnaire. Heart Failure. 1987;3:198-209.
27. Fliege H, Becker J, Walter OB, Rose M, Bjorner JB, Klapp BF: Evaluation of a computer-adaptive test for the assessment of depression (D-CAT) in clinical application. Int J Methods Psychiatr Res. 2009;18:23-36.
28. Anatchkova MD, Saris-Baglama RN, Kosinski M, Bjorner JB: Development and preliminary testing of a computerized adaptive assessment of chronic pain. J Pain. 2009; 10:932-943.
29. Turner-Bowker DM, Saris-Baglama RN, Anatchkova M, Mosen DM: A Computerized Asthma Outcomes Measure Is Feasible for Disease Management. Am J Pharm Benefits. 2010;2:119-124.
ReReReReReReRessssss.. . . . . . 2020202020202005050505050505;1;1;1;1;1;1;14:4:4:4:4:4:4:22222222222222
ork CCCCCCCamamamamamamambrbrbrbrbrbrbridididididididgegegegeggg
K Cp sa
Dewey J: How to Score Version Two of the SF 36 Health Sur
Kosinski M, Bjorner JB, Bayliss MS, Batenhorst A, Dahlof Cpplications of computerized adaptive testing (CAT) to the assact. Qual Life Res. 2003; 12:935-952.
Dewey J: How to Score Version Two of the SF 36 Health Sur
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

30. Schwartz C, Welch G, Santiago-Kelley P, Bode R, Sun X: Computerized adaptive testing of diabetes impact: a feasibility study of Hispanics and non-Hispanics in an active clinic population. Qual Life Res. 2006;15:1503-1518.
31. Chien TW, Wu HM, Wang WC, Castillo RV, Chou W: Reduction in patient burdens with graphical computerized adaptive testing on the ADL scale: tool development and simulation. Health Qual Life Outcomes. 2009;7:39.
32. Haley SM, Gandek B, Siebens H, Black-Schaffer RM, Sinclair SJ, Tao W, Coster WJ, Ni P, Jette AM: Computerized adaptive testing for follow-up after discharge from inpatient rehabilitation: II. Participation outcomes. Arch Phys Med Rehabil. 2008;89:275-283.
33. Hart DL, Wang YC, Stratford PW, Mioduski JE: Computerized adaptive test for patients with knee impairments produced valid and responsive measures of function. J Clin Epidemiol. 2008;61:1113-1124.
34. Hart DL, Werneke MW, Wang YC, Stratford PW, Mioduski JE: Computerized adaptive test for patients with lumbar spine impairments produced valid and responsive measures of function. Spine (Phila Pa 1976). 2010;35:2157-2164.
35. Gibbons RD, Weiss DJ, Kupfer DJ, Frank E, Fagiolini A, Grochocinski VJ, Bhaumik DK, Stover A, Bock RD, Immekus JC: Using computerized adaptive testing to reduce the burden of mental health assessment. Psychiatr Serv. 2008;59:361-368.
36. Walter OB, Becker J, Bjorner JB, Fliege H, Klapp BF, Rose M: Development and evaluation of a computer adaptive test for 'Anxiety' (A-CAT). Qual Life Res. 2007;16 Suppl 1:143-155.
37. Bayliss MS, Dewey JE, Dunlap I, Batenhorst AS, Cady R, Diamond ML, Sheftell F: A study of the feasibility of Internet administration of a computerized health survey: the headache impact test (HIT). Qual Life Res. 2003;12:953-961.
38. Bennett SJ, Oldridge NB, Eckert GJ, Embree JL, Browning S, Hou N, Chui M, Deer M, Murray MD: Comparison of quality of life measures in heart failure. Nurs Res. 2003;52:207-216.
39. Green CP, Porter CB, Bresnahan DR, Spertus JA: Development and evaluation of the Kansas City Cardiomyopathy Questionnaire: a new health status measure for heart failure. J Am Coll Cardiol; 2000;35:1245-1255.
40. Martin M, Kosinski M, Bjorner JB, Ware JE, Jr., Maclean R, Li T: Item response theory methods can improve the measurement of physical function by combining the modified health assessment questionnaire and the SF-36 physical function scale. Qual Life Res. 2007;16:647-660.
41. Haley SM, Fragala-Pinkham M, Ni P: Sensitivity of a computer adaptive assessment for measuring functional mobility changes in children enrolled in a community fitness programme. Clin Rehabil. 2006;20:616-622.
alalalalalalalididididididid a a aa a a andndndndndndnd r r r rrrresesesesesesespopopopopopoponsnsnsnsnsnsns
W Jk r
n
e ma e55
Weiss DJ, Kupfer DJ, Frank E, Fagiolini A,ff Grochocinski VJk RD, Immekus JC: Using computerized adaptive testing to r
ntal health assessment. Psychiatr Serv. 2008;59:361-368.
ecker J, Bjorner JB, Fliege H, Klapp BF, Rose M: Developma computer adaptive test for 'Anxiety' (A-CAT). Qual Life Re55
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

42. Ruo B, Choi SW, Baker DW, Grady KL, Cella D: Development and validation of a computer adaptive test for measuring dyspnea in heart failure. J Card Fail. 2010;16:659-668.
43. Becker J, Fliege H, Kocalevent RD, Bjorner JB, Rose M, Walter OB, Klapp BF: Functioning and validity of a Computerized Adaptive Test to measure anxiety (A-CAT). Depress Anxiety. 2008;25:E182-E194.
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from
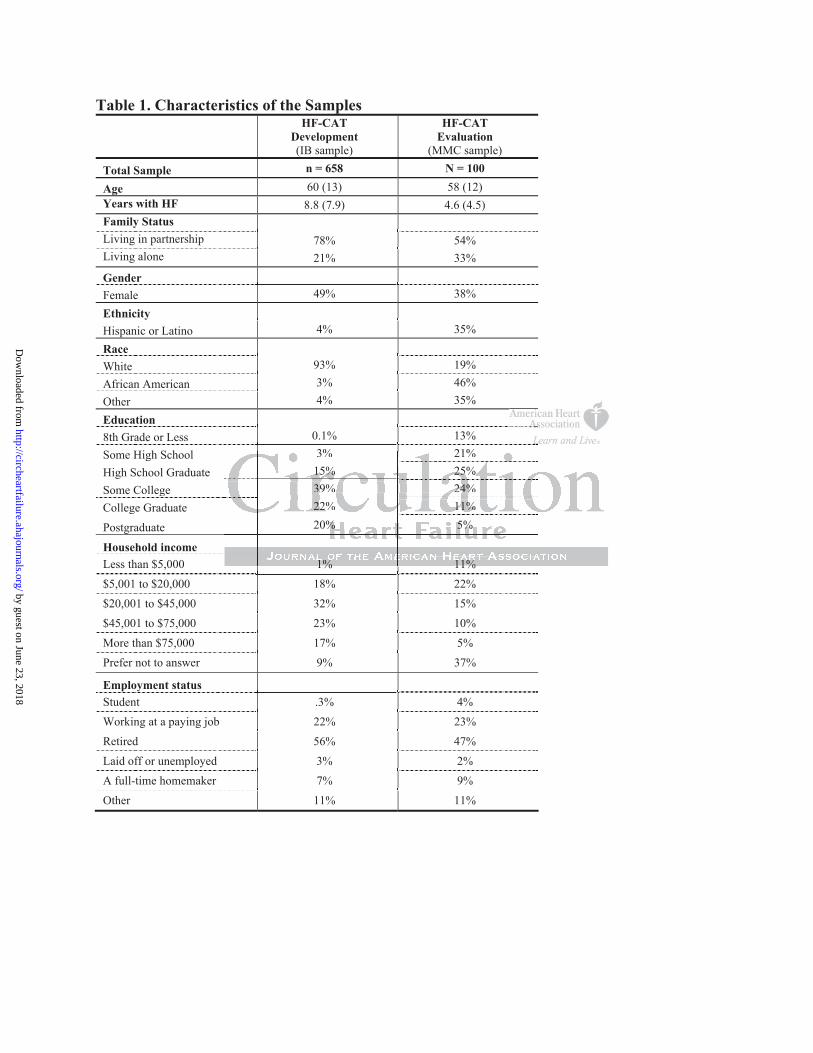
Table 1. Characteristics of the SamplesHF-CAT
Development(IB sample)
HF-CATEvaluation
(MMC sample)
Total Sample n = 658 N = 100
Age 60 (13) 58 (12) Years with HF 8.8 (7.9) 4.6 (4.5) Family Status Living in partnership 78% 54% Living alone 21% 33%
Gender Female 49% 38%
Ethnicity Hispanic or Latino 4% 35%
yyyy
Race White 93% 19% African American 3% 46% Other 4% 35%
Education 8th Grade or Less 0.1% 13% Some High School 3% 21% High School Graduate 15% 25%
g
Some College 39% 24% g
College Graduate 22% 11% g
Postgraduate 20% 5% g
Household income
Less than $5,000 1% 11%
$5,001 to $20,000 18% 22% $20,001 to $45,000 32% 15%
$45,001 to $75,000 23% 10%
More than $75,000 17% 5% Prefer not to answer 9% 37%
Employment status
Student .3% 4% pppp yyyy
Working at a paying job 22% 23%
Retired 56% 47%
Laid off or unemployed 3% 2% A full-time homemaker 7% 9%
Other 11% 11%
3% 21%
1% 11%
3% 21% 15% 25% 39% 24% 22% 11% 20% 5%
1% 11%
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from
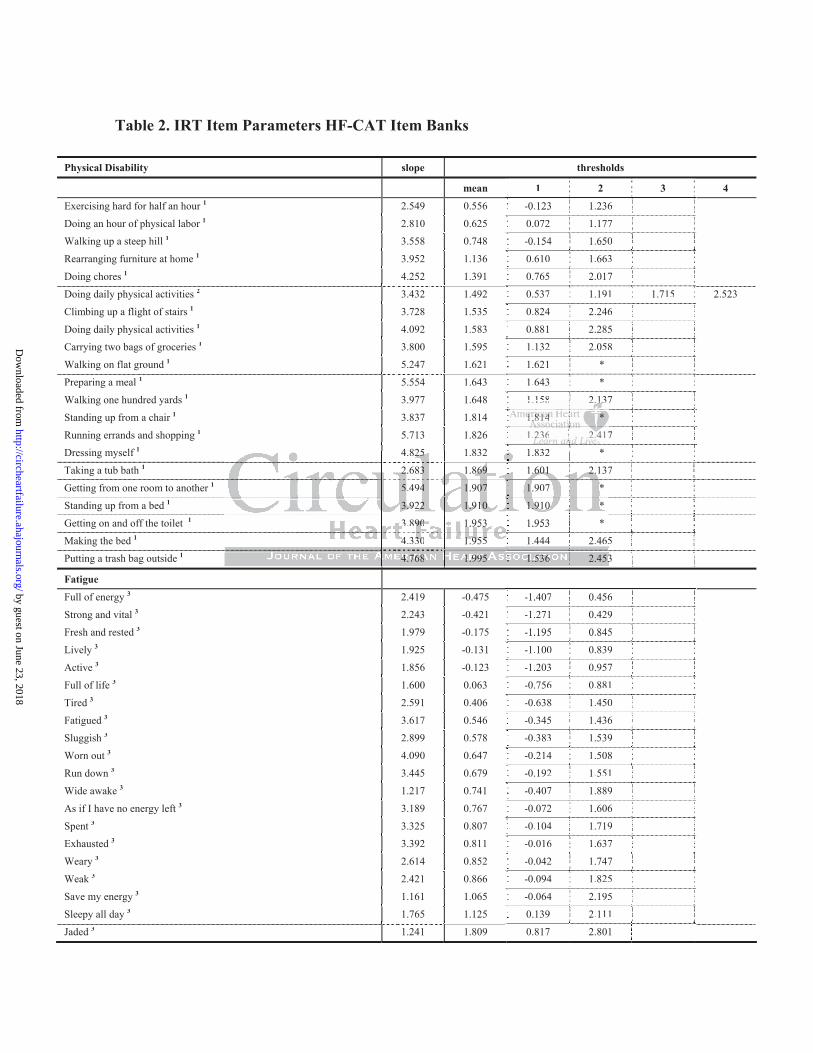
Table 2. IRT Item Parameters HF-CAT Item Banks
Physical Disability slope thresholds
mean 1 2 3 4 1 2 3
Exercising hard for half an hour 1 2.549 0.556 -0.123 1.236 -0.123 1.236
Doing an hour of physical labor 1 2.810 0.625 0.072 1.177 0.072 1.177
Walking up a steep hill 1 3.558 0.748 -0.154 1.650 -0.154 1.650
Rearranging furniture at home 1 3.952 1.136 0.610 1.663 0.610 1.663
Doing chores 1 4.252 1.391 0.765 2.017 0.765 2.017
Doing daily physical activities 2 3.432 1.492 0.537 1.191 1.715 2.5230.537 1.191 1.715
Climbing up a flight of stairs 1 3.728 1.535 0.824 2.246 0.824 2.246
Doing daily physical activities 1 4.092 1.583 0.881 2.285 0.881 2.285
Carrying two bags of groceries 1 3.800 1.595 1.132 2.058 1.132 2.058
Walking on flat ground 1 5.247 1.621 1.621 * 1.621 *
Preparing a meal 1 5.554 1.643 1.643 * 1.643 *
Walking one hundred yards 1 3.977 1.648 1.158 2.137 1 158 2.137
Standing up from a chair 1 3.837 1.814 1.814 *
Running errands and shopping 1 5.713 1.826 1.236 2.417 7
Dressing myself 1 4.825 1.832 1.832 * 1 832 *
Taking a tub bath 1 2.683 1.869 1.601 2.137 7
Getting from one room to another 1 5.494 1.907 1.907 *
Standing up from a bed 1 3.922 1.910 1.910 *
Getting on and off the toilet 1 3.890 1.953 1.953 *
Making the bed 1 4.330 1.955 1.444 2.465 5
Putting a trash bag outside 1 4.768 1.995 1.536 2.453 3
Fatigue
Full of energy 3 2.419 -0.475 -1.407 0.456 -1.407 0.456
Strong and vital 3 2.243 -0.421 -1.271 0.429 -1.271 0.429
Fresh and rested 3 1.979 -0.175 -1.195 0.845 -1.195 0.845
Lively 3 1.925 -0.131 -1.100 0.839 -1.100 0.839
Active 3 1.856 -0.123 -1.203 0.957 -1.203 0.957
Full of life 3 1.600 0.063 -0.756 0.881 -0.756 0.881
Tired 3 2.591 0.406 -0.638 1.450 -0.638 1.450
Fatigued 3 3.617 0.546 -0.345 1.436 -0.345 1.436
Sluggish 3 2.899 0.578 -0.383 1.539 -0.383 1.539
Worn out 3 4.090 0.647 -0.214 1.508 -0.214 1.508
Run down 3 3.445 0.679 -0.192 1.551 -0.192 1.551
Wide awake 3 1.217 0.741 -0.407 1.889 -0.407 1.889
As if I have no energy left 3 3.189 0.767 -0.072 1.606 -0.072 1.606
Spent 3 3.325 0.807 -0.104 1.719 -0.104 1.719
Exhausted 3 3.392 0.811 -0.016 1.637 -0.016 1.637
Weary 3 2.614 0.852 -0.042 1.747 -0.042 1.747
Weak 3 2.421 0.866 -0.094 1.825 -0.094 1.825
Save my energy 3 1.161 1.065 -0.064 2.195 -0.064 2.195
Sleepy all day 3 1.765 1.125 0.139 2.111 0.139 2.111
Jaded 3 1.241 1.809 0.817 2.801
1.158 2.1.11111373333
1.81.81.81.81.81.81.814141414141414 **
1.21.2222223636 2.42.444117
4.825 1 832 1 832 *
7
5
3
4.825 1.832 1.832 *
2.683 1.869 1.601 2.137
5.494 1.907 1.907 *
3.922 1.910 1.910 *
3.890 1.953 1.953 *
4.330 1.955 1.444 2.465
4.768 1.995 1.536 2.453
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from
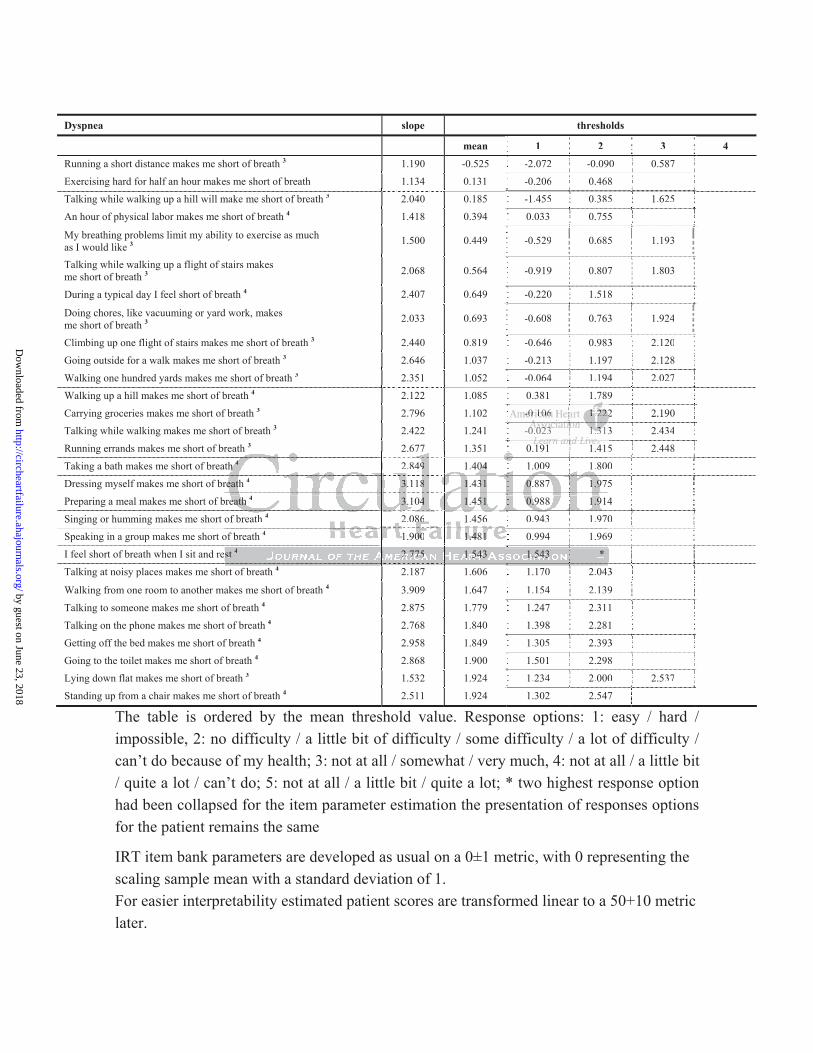
Dyspnea slope thresholds
mean 1 2 3 4 1 2 3
Running a short distance makes me short of breath 3 1.190 -0.525 -2.072 -0.090 0.587 -2.072 -0.090 0.587
Exercising hard for half an hour makes me short of breath 1.134 0.131 -0.206 0.468 -0.206 0.468
Talking while walking up a hill will make me short of breath 3 2.040 0.185 -1.455 0.385 1.625 -1.455 0.385 1.625
An hour of physical labor makes me short of breath 4 1.418 0.394 0.033 0.755 0.033 0.755
My breathing problems limit my ability to exercise as much as I would like 3 1.500 0.449 -0.529 0.685 1.193 -0.529 0.685 1.193
Talking while walking up a flight of stairs makes me short of breath 3 2.068 0.564 -0.919 0.807 1.803 -0.919 0.807 1.803
During a typical day I feel short of breath 4 2.407 0.649 -0.220 1.518 -0.220 1.518
Doing chores, like vacuuming or yard work, makes me short of breath 3 2.033 0.693 -0.608 0.763 1.924 -0.608 0.763 1.924
Climbing up one flight of stairs makes me short of breath 3 2.440 0.819 -0.646 0.983 2.120 -0.646 0.983 2.120
Going outside for a walk makes me short of breath 3 2.646 1.037 -0.213 1.197 2.128 -0.213 1.197 2.128
Walking one hundred yards makes me short of breath 3 2.351 1.052 -0.064 1.194 2.027 -0.064 1.194 2.027
Walking up a hill makes me short of breath 4 2.122 1.085 0.381 1.789 0.381 1.789
Carrying groceries makes me short of breath 3 2.796 1.102 -0.106 1.222 2.190 2 2.190
Talking while walking makes me short of breath 3 2.422 1.241 -0.023 1.313 2.434 3 2.434
Running errands makes me short of breath 3 2.677 1.351 0.191 1.415 2.448 0.191 1.415 2.448
Taking a bath makes me short of breath 4 2.849 1.404 1.009 1.800 0
Dressing myself makes me short of breath 4 3.118 1.431 0.887 1.975 5
Preparing a meal makes me short of breath 4 3.104 1.451 0.988 1.914 4
Singing or humming makes me short of breath 4 2.086 1.456 0.943 1.9700
Speaking in a group makes me short of breath 4 1.900 1.481 0.994 1.969 9
I feel short of breath when I sit and rest 4 2.775 1.543 1.543 *
Talking at noisy places makes me short of breath 4 2.187 1.606 1.170 2.043 1.170 2.043
Walking from one room to another makes me short of breath 4 3.909 1.647 1.154 2.139 1.154 2.139
Talking to someone makes me short of breath 4 2.875 1.779 1.247 2.311 1.247 2.311
Talking on the phone makes me short of breath 4 2.768 1.840 1.398 2.281 1.398 2.281
Getting off the bed makes me short of breath 4 2.958 1.849 1.305 2.393 1.305 2.393
Going to the toilet makes me short of breath 4 2.868 1.900 1.501 2.298 1.501 2.298
Lying down flat makes me short of breath 3 1.532 1.924 1.234 2.000 2.537 1.234 2.000 2.537
Standing up from a chair makes me short of breath 4 2.511 1.924 1.302 2.547
The table is ordered by the mean threshold value. Response options: 1: easy / hard / impossible, 2: no difficulty / a little bit of difficulty / some difficulty / a lot of difficulty / can’t do because of my health; 3: not at all / somewhat / very much, 4: not at all / a little bit / quite a lot / can’t do; 5: not at all / a little bit / quite a lot; * two highest response option had been collapsed for the item parameter estimation the presentation of responses options for the patient remains the same
IRT item bank parameters are developed as usual on a 0±1 metric, with 0 representing the scaling sample mean with a standard deviation of 1. For easier interpretability estimated patient scores are transformed linear to a 50+10 metric later.
-0.-0.-0.-0.-0.-0.-0.10610610610610610610 1.21.21.21.21.21.21.222222222222222
-0.000000 023023023023023023 1 31 31 31 31 31.31.31313
reath 2.677 1.351 0.191 1.415
a 0
r 5
b 4
0
o 9
4
reath 2.677 1.351 0.191 1.415
ath 4 2.849 1.404 1.009 1.800
reath 4 3.118 1.431 0.887 1.975
breath 4 3.104 1.451 0.988 1.914
of breath 4 2.086 1.456 0.943 1.970
of breath 4 1.900 1.481 0.994 1.969
st 4 2.775 1.543 1.543 *4
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

The slope parameter is also called discrimination parameter. Higher slope parameters indicate a better discrimination, which makes the item more valuable, i.e. ‘informative’, for the score estimation: the capability e.g. to ‘run errands’ is more informative to determine the physical disability of a patient than e.g. her or his ability to ‘put the trash outside the house’.
The thresholds of an item show at which score level a particular response option is the most likely to be endorsed. For the item ‘running errands’ the threshold 1.236 separates the response ‘easy’ from ‘hard’, and the threshold 2.417 ‘hard’ from ‘impossible’. If a patient scores 3 standard deviations above the population mean s/he is most likely to answer the item ‘running errands is …’ with ‘impossible’, as her/his score is above the threshold of 2.417. If her/his level of disability is only 1.5 SD above the U.S. population mean s/he is likely to endorse ‘hard’, as the score is between the thresholds 1.236 and 2.417. The mean threshold illustrates the position of the item on the metric, which can be seen as ‘item difficulty’ in traditional terms. The table is sorted by the mean threshold. n threshold.
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from
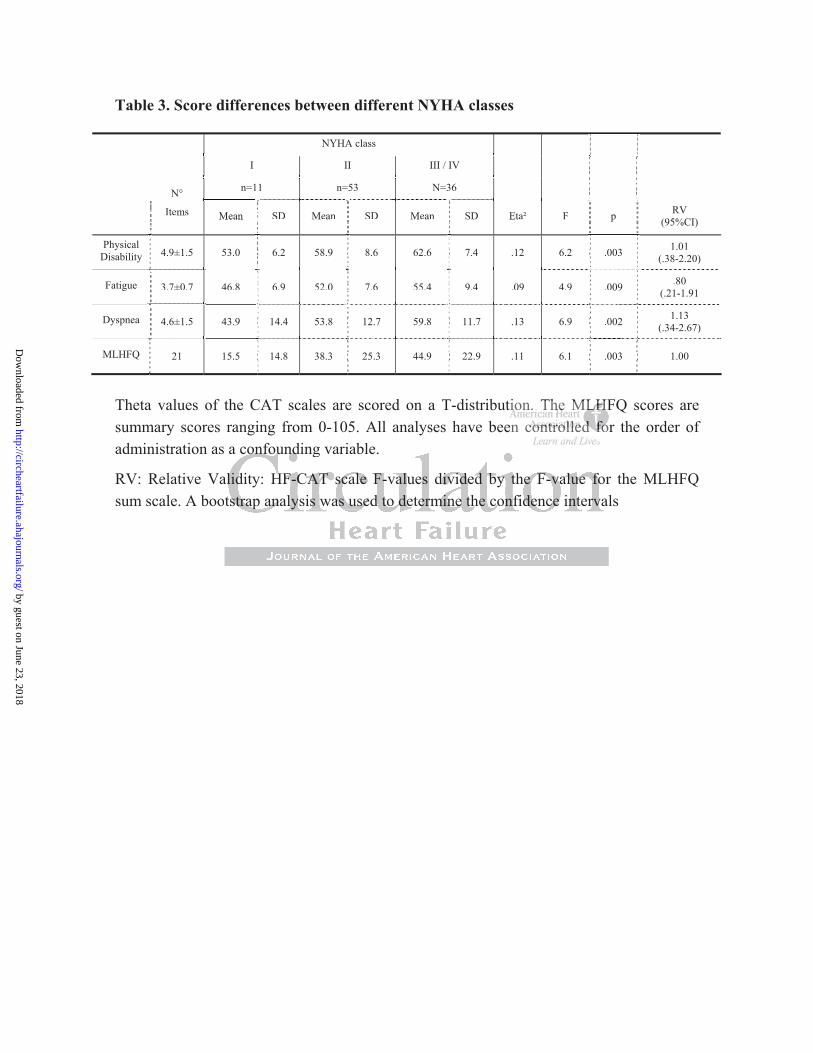
Table 3. Score differences between different NYHA classes
NYHA class
I II III / IV
n=11 n=53 N=36
N°
Items Mean SD Mean SD Mean SD Eta² F p RV (95%CI) SD Eta² FSD MeanSD MeanItems Mean p
Physical Disability 4.9±1.5 53.0 6.2 58.9 8.6 62.6 7.4 .12 6.2 .003 1.01
(.38-2.20) .003
Fatigue 3.7±0.7 46.8 6.9 52.0 7.6 55.4 9.4 .09 4.9 .009 .80 (.21-1.91 3.7±0.7 46.8 6.9 52.0 7.6 55.4 9.4 .09 4.9 .80 (.21-1.91 .009
Dyspnea 4.6±1.5 43.9 14.4 53.8 12.7 59.8 11.7 .13 6.9 .002 1.13 (.34-2.67) 6.9 1.13 (.34-2.67)4.6±1.5 .13 11.7 59.8 12.7 53.8 14.4 43.9 .002
MLHFQ 21 15.5 14.8 38.3 25.3 44.9 22.9 .11 6.1 .003 1.00
Theta values of the CAT scales are scored on a T-distribution. The MLHFQ scores are summary scores ranging from 0-105. All analyses have been controlled for the order of administration as a confounding variable.
RV: Relative Validity: HF-CAT scale F-values divided by the F-value for the MLHFQ sum scale. A bootstrap analysis was used to determine the confidence intervals
iiiiiionono . . ThThhhhhe e eeeee MLMLLMLLLLHFHFHHHHHen cccccccononononononontrtrtrtrtrtrtrolololololololleleleleleleledd ddddd fofofofofofofo
a confounding variable.
alidity: HF-CAT scale F-values divided by the F-value forl
a confounding variable.
alidity: HF-CAT scale F-values divided by the F-value fortstrap analysis was used to determine the confidence interval
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

Figure Legends
Figure 1. HF CAT patient interface and examples for one item of each bank
Figure 2. Measurement precision in relation to measurement range
The x-axis shows the patient score. In IRT terminology this score is referred to as the ‘theta score’. To make the HF-CAT and the legacy tools comparable both instruments are scored on the same metric as determined by the developed item banks. The y-axis shows the 95% confidence interval of the patient score, the smaller the y-value the higher the precision of the score. The dotted lines show confidence intervals which would be comparable to an internal constancy of Cronbach 0.80, 0.90, and 0.95 for illustrative purposes.
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

With the following questions we would like to assess your current health status …
I feel tired …
not at all
somewhat
very much
I feel short of breath when I sit and rest …
not at all
a little bit
quite a lot
For me, running errands is …
easy
hard
impossible
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

0
0,1
0,2
0,3
0,4
0,5
0,6
-3 -2 -1 0 1 2 3 4
0
0,1
0,2
0,3
0,4
0,5
0,6
-3 -2 -1 0 1 2 3 4
0
0,1
0,2
0,3
0,4
0,5
0,6
-3 -2 -1 0 1 2 3 40
0,1
0,2
0,3
0,4
0,5
0,6
-3 -2 -1 0 1 2 3 4
0
0,1
0,2
0,3
0,4
0,5
0,6
-3 -2 -1 0 1 2 3 40
0,1
0,2
0,3
0,4
0,5
0,6
-3 -2 -1 0 1 2 3 4
Physical Disability
SF-36 PF 10 items
HF-CAT 5 items
Item Bank 20 items
Item Bank 20 items
Dyspnea
Item Bank 29 items
DyspneaHOS4 items
HF-CAT 4 items
Item Bank 29 items
FatigueSF-36 VT 4 items
HF-CAT 5 items
Item Bank 20 items
Fatigue
Item Bank 20 items
30 40 50 60 70 80 30 40 50 60 70 80
30 40 50 60 70 80 30 40 50 60 70 80
30 40 50 60 70 80 30 40 50 60 70 80
HF-CAT 10 items
SF-36 PF 10 items
HOS4 items
HF-CAT 5 items
SF-36 VT 4 items
HF-CAT 4 items
Physical Disability
12
10
8
6
4
2
12
10
8
6
4
2
12
10
8
6
4
2
12
10
8
6
4
2
12
10
8
6
4
2
12
10
8
6
4
2
95%
CI
patient score patient score
=.80*
=.90*
=.95*
95%
CI
95%
CI
HOSHOSHH4 i4 i4 i4 i4 i4 i4 itemtemtemtemtemtemtemss
CATCATC temtemtemtememtememsssssss
8
Item Bank 29 items
8
6
4
2 by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from

Thomas S. Rector and John E. WareMatthias Rose, Milena Anatchkova, Jason Fletcher, Arthur E. Blank, Jakob Bjørner, Bernd Löwe,
Adaptive Test (HF-CAT)Short and Precise Patient Self-Assessment of Heart Failure Symptoms Using a Computerized
Print ISSN: 1941-3289. Online ISSN: 1941-3297 Copyright © 2012 American Heart Association, Inc. All rights reserved.
is published by the American Heart Association, 7272 Greenville Avenue, Dallas, TX 75231Circulation: Heart Failure published online April 23, 2012;Circ Heart Fail.
http://circheartfailure.ahajournals.org/content/early/2012/04/23/CIRCHEARTFAILURE.111.964916World Wide Web at:
The online version of this article, along with updated information and services, is located on the
http://circheartfailure.ahajournals.org//subscriptions/
is online at: Circulation: Heart Failure Information about subscribing to Subscriptions:
http://www.lww.com/reprints Information about reprints can be found online at: Reprints:
document. Permissions and Rights Question and Answer process is available in the
click Request Permissions in the middle column of the Web page under Services. Further information about thisEditorial Office. Once the online version of the published article for which permission is being requested is located,
can be obtained via RightsLink, a service of the Copyright Clearance Center, not theCirculation: Heart Failure Requests for permissions to reproduce figures, tables, or portions of articles originally published inPermissions:
by guest on June 23, 2018http://circheartfailure.ahajournals.org/
Dow
nloaded from