silt: a memory-efficient, high-performance key-value store hyeontaek lim, bin fan, david g. andersen...
TRANSCRIPT

SILT: A Memory-Efficient,High-Performance Key-Value Store
Hyeontaek Lim, Bin Fan, David G. AndersenMichael Kaminsky†
Carnegie Mellon University†Intel Labs
2011-10-24

2
Key-Value Store
Clients
PUT(key, value)value = GET(key)
DELETE(key)
Key-Value StoreCluster
• E-commerce (Amazon)• Web server acceleration (Memcached)• Data deduplication indexes• Photo storage (Facebook)

• Many projects have examined flash memory-based key-value stores– Faster than disk, cheaper than DRAM
• This talk will introduce SILT,which uses drastically less memory than previous systemswhile retaining high performance.
3

Flash Must be Used Carefully
4
Random reads / sec 48,000
$ / GB 1.83
Fast, but not THAT fast
Space is precious
Another long-standing problem: random writes are slow and bad for flash life (wearout)

DRAM Must be Used EfficientlyDRAM used for index (locate) items on flash1 TB of data to store on flash4 bytes of DRAM for key-value pair (previous state-of-the-art)
5Key-value pair size (bytes)
Index size (GB)
10 100 1000 100001
10
100
1000 32 B: Data deduplication => 125 GB!
168 B: Tweet => 24 GB
1 KB: Small image => 4 GB

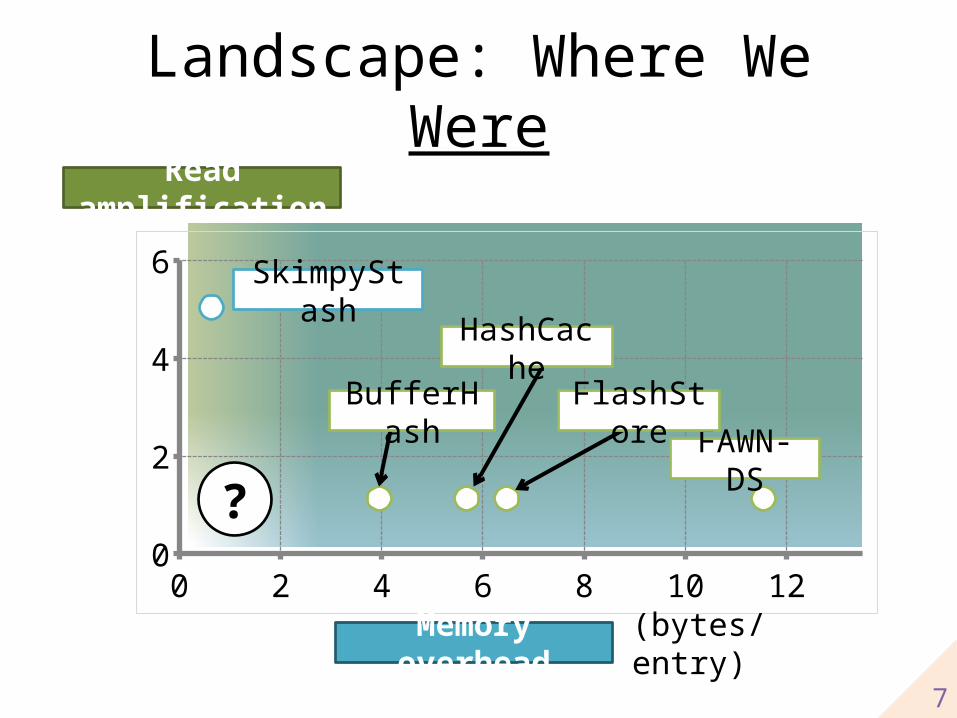
Three Metrics to Minimize
Memory overhead
Read amplification
Write amplification
• Ideally 0 (no memory overhead)
• Limits query throughput• Ideally 1 (no wasted flash reads)
• Limits insert throughput• Also reduces flash life expectancy• Must be small enough for flash to last a few years
= Index size per entry
= Flash reads per query
= Flash writes per entry
6
0 2 4 6 8 10 120
2
4
6
Landscape: Where We WereRead amplification
Memory overhead (bytes/entry)
FAWN-DS
HashCache
BufferHash FlashStore
SkimpyStash
7
?

Seesaw Game?
Memory efficiency High performance
8
FAWN-DS
HashCacheBufferHash
FlashStoreSkimpyStash
How can we improve?

9
SILT Sorted Index(Memory efficient)
SILT Log Index(Write friendly)
Solution Preview: (1) Three Stores with (2) New Index Data Structures
MemoryFlash
SILT Filter
Inserts only go to Log
Data are moved in background
Queries look up stores in sequence (from new to old)

LogStore: No Control over Data Layout
6.5+ bytes/entry 1Memory overhead Write amplification
Inserted entries are appended
On-flash log
Memory
Flash
Still need pointers:size ≥ log N bits/entry
10
SILT Log Index (6.5+ B/entry)
(Older) (Newer)
Naive Hashtable (48+ B/entry)

SortedStore: Space-Optimized Layout
0.4 bytes/entry High
On-flash sorted array
Memory overhead Write amplification
Memory
Flash
11
SILT Sorted Index (0.4 B/entry)
Need to perform bulk-insert to amortize cost

Combining SortedStore and LogStore
On-flash log
SILT Sorted Index
Merge
12
SILT Log Index
On-flash sorted array
<SortedStore> <LogStore>

Achieving both Low Memory Overhead and Low Write Amplification
13
SortedStore LogStore
SortedStore
LogStore
• Low memory overhead• High write amplification
• High memory overhead• Low write amplification
Now we can achieve simultaneously:Write amplification = 5.4 = 3 year flash lifeMemory overhead = 1.3 B/entry
With “HashStores”, memory overhead = 0.7 B/entry!(see paper)

1.010.7 bytes/entry 5.4Memory overhead Read amplification Write amplification
14
SILT’s Design (Recap)
On-flash sorted array
SILT Sorted Index
On-flash log
SILT Log Index
On-flash hashtables
SILT Filter
Merge Conversion
<SortedStore> <LogStore><HashStore>

Review on New Index Data Structures in SILT
Partial-key cuckoo hashing
For HashStore & LogStoreCompact (2.2 & 6.5 B/entry)
Very fast (> 1.8 M lookups/sec)
15
SILT Filter & Log Index
Entropy-coded tries
For SortedStoreHighly compressed (0.4 B/entry)
SILT Sorted Index

Compression in Entropy-Coded Tries
16
Hashed keys (bits are random) # red (or blue) leaves ~ Binomial(# all leaves, 0.5) Entropy coding (Huffman coding and more)
(More details of the new indexing schemes in paper)
0 1
0
0 0
0
0
0
1
1
1
11
1

0 2 4 6 8 10 120
2
4
6
Landscape: Where We AreRead amplification
Memory overhead (bytes/entry)
FAWN-DS
HashCache
BufferHash FlashStore
SkimpyStash
17
SILT

Evaluation
1. Various combinations of indexing schemes2. Background operations (merge/conversion)3. Query latency
Experiment SetupCPU 2.80 GHz (4 cores)
Flash driveSATA 256 GB
(48 K random 1024-byte reads/sec)
Workload size 20-byte key, 1000-byte value, ≥ 50 M keysQuery pattern Uniformly distributed (worst for SILT)
18

LogStore Alone: Too Much Memory
19
Workload: 90% GET (50-100 M keys) + 10% PUT (50 M keys)

LogStore+SortedStore: Still Much Memory
20
Workload: 90% GET (50-100 M keys) + 10% PUT (50 M keys)

Full SILT: Very Memory Efficient
21
Workload: 90% GET (50-100 M keys) + 10% PUT (50 M keys)

Small Impact from Background Operations
33 K
22
40 K
Workload: 90% GET (100~ M keys) + 10% PUT
Oops! burstyTRIM by ext4 FS

Low Query Latency
23
# of I/O threads
Workload: 100% GET (100 M keys)Best tput @ 16 threads
Median = 330 μs99.9 = 1510 μs

24
Conclusion
• SILT provides both memory-efficient andhigh-performance key-value store– Multi-store approach– Entropy-coded tries– Partial-key cuckoo hashing
• Full source code is available– https://github.com/silt/silt

Thanks!
25