solving quality control problems using genetic algorithms douglas c. montgomery professor of...
Post on 19-Dec-2015
220 views
TRANSCRIPT

Solving Quality Control Problems Using Genetic Algorithms
Douglas C. Montgomery
Professor of Engineering and Statistics
Arizona State University

This is joint work with:
• Alejandro Heredia-Langner, Pacific Northwest Labs (former PhD student, ASU)
• W. Matthew Carlyle, Naval Postgraduate School (former IE faculty member, ASU)
• Connie M. Borror, IE faculty member, ASU
• George C. Runger, IE faculty member, ASU

Many problems in quality control involve complicated optimization problems
• The inspection problem
…Stage
1
Stage
2
Stage
m
n1, c1nm, cmn2, c2
Carlyle, W. M., Montgomery, D. C., and Runger, G. C. (2000), “Optimization Problems and Methods in Quality Control and Improvement” (with discussion), Journal of Quality Technology, Vol. 32, No. 1, pp. 1-31.

In the inspection problem we wish to
• Determine the parameters of the inspection scheme (the n’s and the c’s)
• Optimize some important measure of effectiveness, such as maximize average outgoing quality at the final stage (m)
• Not exceed a budget for inspection • Other criteria are also encountered in
practice

The inspection problem was brought to our attention by a medical device manufacturer
• FDA mandated inspections at each stage• m = 6 stages• Inspection is expensive, so is cost of
inspection errors• Their solution was to “guess” at the n’s and
c’s (simple but ugly)• Optimal solution involves dynamic
programming (elegant but still ugly)

Genetic Algorithms
• Initially created by the computer science community to study the behavior of simple, communal individuals under controlled conditions
• Currently used as a tool to solve combinatorial optimization problems
• Genetic Algorithms (GA) are loosely based on Darwin’s theory of evolution where a number of individuals compete for a limited amount of resources (survival of the fittest)
• Mutation, mating and natural selection are implemented using individuals (or chromosomes) coded as strings of numbers (genes)
• The fitness of these solutions is measured using an appropriate objective function

The GA methodology
• A chromosome is a potential problem solution, a vector whose entries (or genes) represent the decision variables in the problem
• Every solution or chromosome can be evaluated with respect to an objective function, resulting in a fitness value
• Binary versus real encoding
-0.4207 -1 0.0004 -0.7779 0.7786 0.4214 1 0.688783
Fitness value
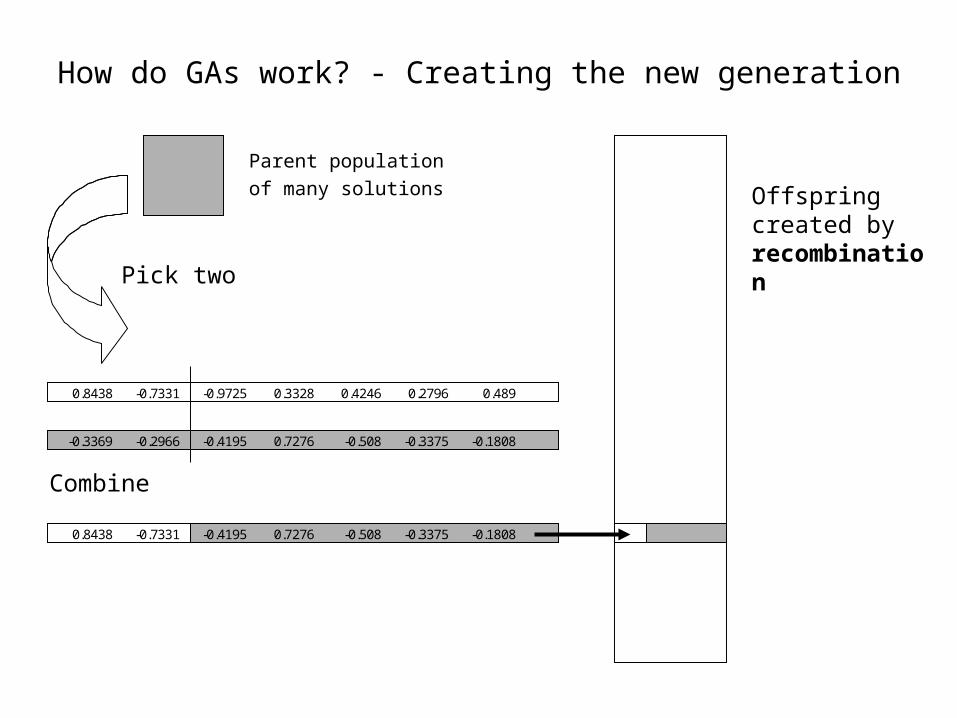
0.8438 -0.7331 -0.9725 0.3328 0.4246 0.2796 0.489
-0.3369 -0.2966 -0.4195 0.7276 -0.508 -0.3375 -0.1808
0.8438 -0.7331 -0.4195 0.7276 -0.508 -0.3375 -0.1808
Parent population
of many solutions
Combine
How do GAs work? - Creating the new generation
Pick two
Offspring created by recombination
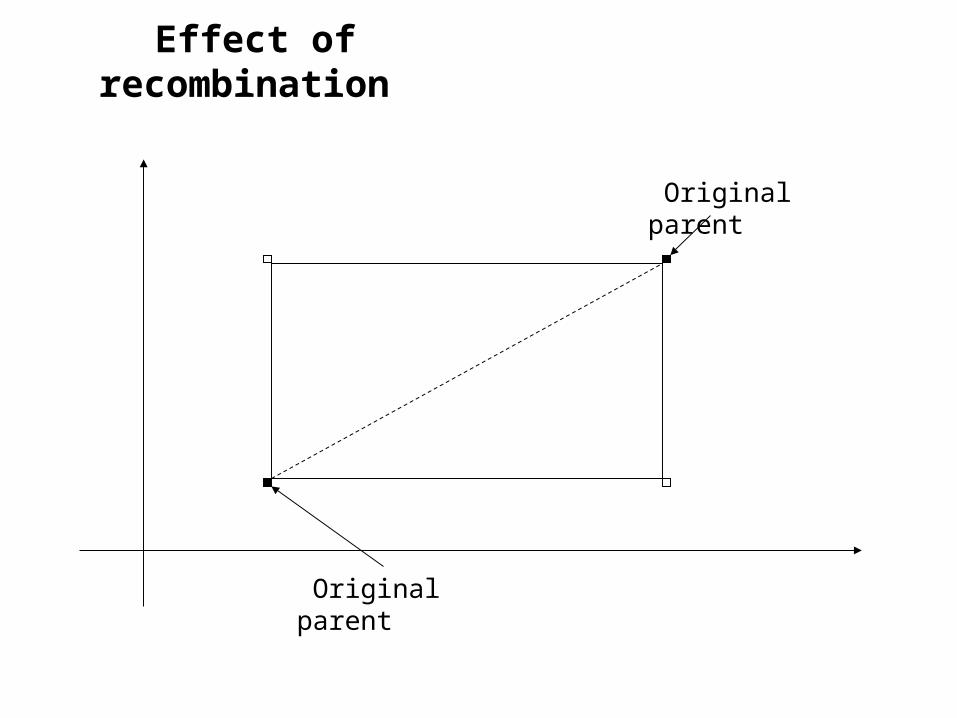
Effect of recombination
Original parent
Original parent

Some recombination mechanisms
Discrete - Two distinct chromosomes are selected at random and broken (also at random) in two or more places. The new individual is formed by adjoining pieces of alternate parents.
Generalized - Two chromosomes are chosen at random and the genes of the new individual formed as a convex combination of the parents (only for real-valued chromosomes)
Panmictic - Chromosomes are selected successively and each provides one entry for the new individual

New Parent population
Offspring
Selection
After recombination, rank the offspring chromosomes by fitness value and choose the best ones
0.499 -0.84 -0.8726 0.6583 -0.918 0.9343 -0.582-0.1486 -0.5293 0.2073 -0.2282 -0.6173 0.5159 0.39660.7245 -0.167 0.5506 -0.3708 -0.8161 -0.1938 -0.3415
-0.6915 -0.0935 -0.0113 -0.7107 -0.6113 -0.9396 0.88160.1349 -0.6101 -0.8096 -0.4237 -0.8655 -0.821 -0.2157
-0.4124 0.2061 0.8145 0.8521 0.7048 -0.3126 0.0747-0.9239 -0.7112 0.0145 0.7912 0.1539 -0.2345 -0.6079-0.685 -0.3794 0.9142 0.8155 0.6902 0.0595 0.43350.648 -0.2298 -0.4086 0.2021 -0.9994 0.0848 -0.3531
-0.6483 -0.087 -0.1457 -0.137 0.8165 0.9881 0.51790.2508 -0.9947 0.0093 -0.1496 -0.9884 -0.0667 -0.5273
-0.1838 -0.8911 -0.5631 0.2494 -0.6642 0.1238 0.42210.0478 -0.4847 0.2214 0.5717 -0.8764 -0.7338 0.0211
-0.3586 0.8218 -0.9275 -0.5354 0.0749 -0.1982 -0.47270.4684 0.3446 0.2418 0.7949 0.9557 -0.1391 0.83330.0127 -0.644 0.3153 0.7457 -0.0107 -0.8447 -0.80250.1561 -0.3716 0.9049 -0.6125 0.9669 -0.1522 -0.0889
-0.1453 -0.1984 -0.2148 0.5104 -0.9921 -0.4123 0.96380.5645 -0.2325 0.7672 0.4118 0.5581 -0.6325 0.7611
-0.0308 -0.2585 -0.2905 -0.7866 -0.8502 -0.6229 -0.3629-0.672 -0.9942 0.8791 -0.7761 0.9714 0.0695 0.594
-0.1952 -0.9436 -0.6409 0.4087 0.3529 0.0746 0.6361-0.8286 0.7676 0.6327 -0.3304 0.0616 -0.8641 0.1280.5811 -0.9395 -0.1288 0.0141 -0.9965 0.3845 0.8242
.
.
.
.
.
.
.
.
.
.
.
.

Some selection mechanisms
Proportional - Chromosomes are chosen using some biased probabilistic method where fitter individuals stand a better chance of being selected
Ranking - Offspring chromosomes are ranked according to fitness value and the new parent population formed choosing the best individuals sequentially
Extinctive - Some individuals are explicitly excluded from the selection process (this can be implemented with any of the above procedures)

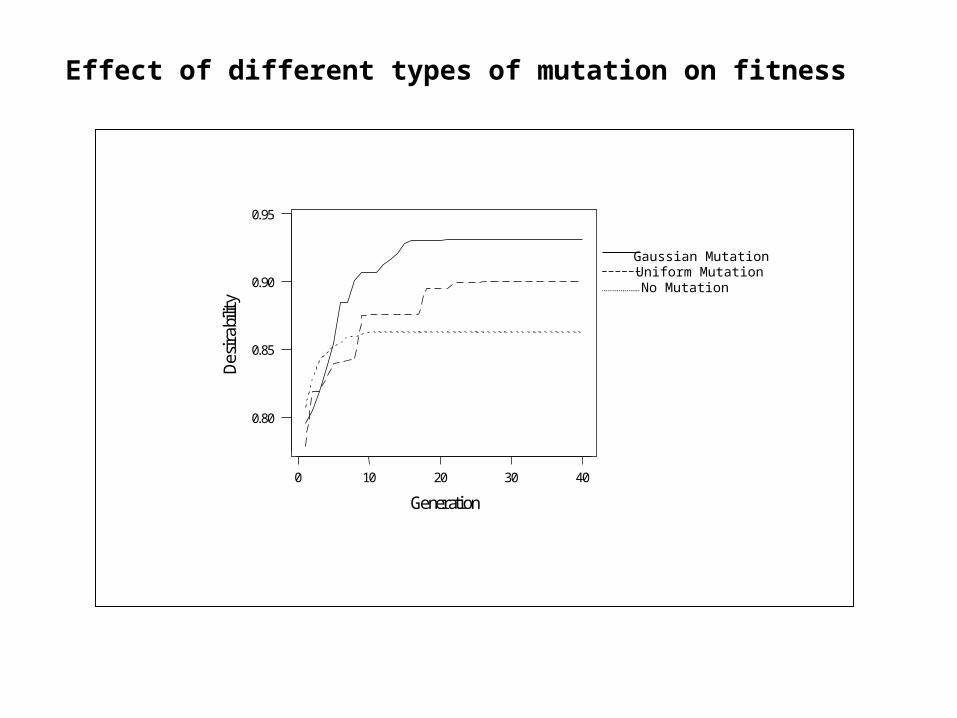
Mutation
A few of the individuals in the parent population are altered using normally distributed disturbances. This is called Gaussian mutation.
Random uniform mutation replaces selected genes with others chosen from the available pool.
X2
X1
Original parent
Likely position of
offspring
-0.1486 -0.5293 0.2073 -0.2282 -0.6173 0.5159 0.3966
-0.0093 0.0017 -0.0126 -0.0022 0.0064 -0.0091 -0.0068
-0.1579 -0.5276 0.1947 -0.2304 -0.6109 0.5068 0.3898
+
0 10 20 30 40
0.80
0.85
0.90
0.95
Generation
Des
irabi
lity
Gaussian MutationUniform MutationNo Mutation
Effect of different types of mutation on fitness

Some results for the inspection problem
Heredia-Langner, A., Montgomery, D. C., and Carlyle, W. M. (2002), “Solving a Multistage Partial Inspection Problem using Genetic Algorithms”, International Journal of Production Research, Vol. 40, No. 8, pp. 1923-1940.
•Use of the GA resulted in an annual savings of about $250K over the current “best-guess” solution
•AOQ was approximately the same
•Solved several other variations of the problem with different (multiple) objectives, including maximizing the probability of lot acceptance at each stage
•Couldn’t do this with the DP approach

GAs and Experimental Design• We use designed experiments to obtain information about
how some independent variables affect the response (or responses) of interest
• Our objective is usually to find a simple model for that relationship
• If an adequate model is found, it can be employed for factor screening or to optimize the values of the responses
• Good experimental designs use resources effectively and efficiently
• There are many “standard” designs (factorials, fractional factorials, central composite, etc.)

What designs should be used?
• If we have a “regular”experimental region
• Then, most of the time, we know what kind of experiment (number and position of trials) we want to run
Temperature
-1 Pressure +1
C
once
n tra
ti on
-1
+1
-1
+1

Why do we use “optimal” or computer-generated designs?
• Useful whenever we cannot employ more traditional designs (full or fractional factorials...) due to:
• Natural constraints in the design space (such as mixture experiments)
• Unusual requirements for sample sizes or block sizes• The model under consideration is not standard• Cost, time, run order or other restrictions• In these cases we would still like to employ a set of
experimental runs that are, in some sense, good

Some “Alphabetic” Design Optimality Criteria
• Maximize the precision of estimation of the parameters in the proposed model (D)
• Minimize the sum of the variances of the estimates of the model parameters (A)
• Minimize the maximum variance of an estimated model parameter (E)
• Minimize the average prediction variance of the model throughout the experimental region (V, Q or IV)
• Cover the design region uniformly (S)
• Minimize the maximum prediction variance (G)
• Just about anything else that can yield a reasonable design (including a combination of the criteria above)

Some optimality criteria
Nix
xxx
xxK
Min
i
N
mR
m
1
'
1
21
)()('
][X
X)(X'
D-optimality seeks to minimize the volume of the joint confidence region of the model parameters. It can be expressed as a determinant maximization problem
Q-optimality minimizes the average scaled prediction variance over the entire design region (the m identifies an experimental run in model form)
Nix
xxx
N
i
N
p
1
'
/max
21 ][X
X)(X'

Methods for Constructing Alphabetically Optimal Designs
• Exchange algorithms– Most widely used– Basis of commercial software packages
• Branch and bound algorithms (Welch, 1982)• Simulated annealing (Haines, 1987)• Genetic algorithms (relatively recent)
Hamada, M., Martz, H. F., Reese, C. J., and Wilson, A. G (2001), “Finding Near-Optimum Bayesian Experimental Designs Via Genetic algorithms”, The American Statistician, Vol. 55, pp. 175-181
Heredia-Langner, A., Carlyle, W. M., Montgomery, D. C., Borror, C. M., and. Runger, G. C. (2003), “Genetic Algorithms for the Construction of D-Optimal Designs”, to appear in the Journal of Quality Technology.

Example : A mixture problem with one processing variable
• The objective is to find a G-optimal design (minimize the maximum prediction variance over the feasible region)
1321 xxx
1,0,14 x
3
1
3
1
4
1
24441)(
i j jkkjjki xxxxyE

Results• Both the original method (B&B) and the GA are able to find the same
design but…
• The best design reported in the original reference was found after running the D-optimal algorithm multiple times and not by using the G-optimal algorithm
• The G-optimal algorithm in the original reference was unable to find a good design
10 20 30 40 50 60 70 80 90 100
0.5
1.0
1.5
2.0
Generations
1 /
|X'X
|
Evolution of best individual in 10 independent trials for Example 2
1/Fitness

Example: Model-Robust Efficient Designs
Consider the problem of destructively sampling a radioactive rod so that its concentration of active material as a function of length can be modeled with a polynomial equation
This problem originally appeared in Cook, R.D. and Nachtsheim, C. J. (1982). “Model-Robust, Linear-Optimal Designs.” Technometrics 24, pp. 49-54.

Creating Model-Robust Efficient Designs
• Up to seven samples could be taken and analyzed
• Models ranging from a simple linear to a sixth-degree polynomial were considered as equally likely candidates
0 1
20 1 2
2 30 1 2 3
2 3 40 1 2 3 4
2 3 4 50 1 2 3 4 5
2 3 4 5 60 1 2 3 4 5 6
( )
( )
( )
( )
( )
( )
E y x
E y x x
E y x x x
E y x x x x
E y x x x x x
E y x x x x x x
We are interested in modeling concentration as a function of position, but we don’t know which model is appropriate

Some results
The efficiencies of simpler models are always affected the most
Q-E
ffic
ienc
ies
Cook and Nachtsheim
GA
0.7
0.75
0.8
0.85
0.9
0.95
1
1 2 3 4 5 6
Order of model

Some Results
• The solution method employed by the original researchers (based on an exchange method) can only handle one-variable designs
• This isn’t a problem for the GA• The model-robust design problem is a very
commonly-encountered version of the optimal design problem, and it’s notoriously ugly
• The GA can provide very good solutions to some quite complex model-robust design problems
Heredia-Langner, A., Montgomery, D. C., Carlyle, W. M., and Borror, C. M.(2002), “Model-Robust Optimal Designs: A Genetic Algorithm Approach”, in revision at the Journal of Quality Technology.

Conclusions
• GAs can be used to construct a variety of efficient experimental designs
• GAs work well for some of the most common design optimality criteria and even for some non-traditional ones
• GAs are usually very effective for large, complex experimental design problems for which other methods may not work at all. This makes design efficiency comparisons difficult
• GAs can be applied to many of the most common types of optimization problems encountered in statistical quality control and improvement