some interesting dl papersnyc.lti.cs.cmu.edu/classes/11-745/f16/slides/hanxiao-dl.pdfdeep...
TRANSCRIPT

Some Interesting DL Papers
Hanxiao Liu
September 5, 2016
1 / 22

“Deep Residual Learning for Image Recognition”
(ResNet), He et. al.
An unusual phenomenon: very deep models suffer fromlarger training loss than the shallower ones.
Conjecture: deep models may have trouble inapproximating identity mappings.
2 / 22
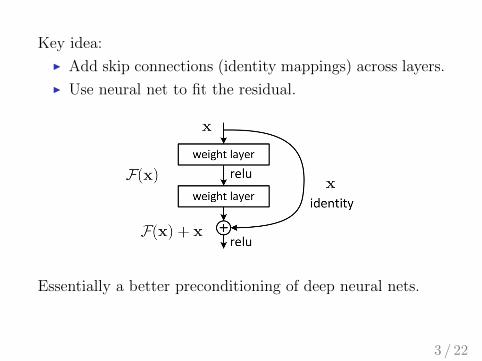
Key idea:
I Add skip connections (identity mappings) across layers.
I Use neural net to fit the residual.
Essentially a better preconditioning of deep neural nets.
3 / 22

4 / 22

“Training Neural Networks Without Gradients: A
Scalable ADMM Approach.”, Taylor et. al.
Contribution: a gradient free alg that parallels over layers
I Existing work: data parallelism or vertical parallelism.
Gradient free: Gradient ascent → EM
5 / 22

Original Opt
minW
`(W3(h2(W2h1(W1x))), y) (1)
Equivalent Opt
minW ,z,a
`(zl, y) (2)
zl = Wlal−1 l = 1 . . . L (3)
al = hl(zl) l = 1 . . . L− 1 (4)
Then apply ADMM
I subroutines are solved in closed-form.
6 / 22

“Noisy Activation Functions.”, Gulcehre et. al.
Activation functions:h(x) = sigmoid(x), tanh(x),ReLU(x) . . .
Saturation:
I (near) zero-derivative regions of h(x).
I info flow blocked during back-propagation.
7 / 22

Randomize h(x) to allow “explorations”
φ(x, ξ) = h(x) + s (5)
where the noise s ∼ N (µ, σξ)
Eξ∼N (0,1) [φ(x, ξ)] ≈ h(x) (6)
Design µ, σ to inject more noise in more saturated regions.
8 / 22

“Normalization Propagation: A Parametric
Technique for Removing Internal Covariate Shift
in Deep Networks.”, Arpit et. al.
Batch normalization (nonparametric)
I Unreliable estimation for small batch size.
I Impossible for size-1 batch.
Normalization propagation
I Assume activations at each layer to be Gaussian.
I Normalize the batch using model coefficients.
9 / 22

“Understanding and Improving Convolutional
Neural Networks via Concatenated Rectified
Linear Units.” Shang et. al.
10 / 22

Conjecture: a well-trained neural net wants the info of both(positive & negative) phases to pass through
However, commonly used ReLU h(x) = [x]+ only keeps theinfo of one phase. We want both.
Proposed: concatenated ReLU
h(x) = ([x]+, [−x]+) (7)
11 / 22

“Analysis of Deep Neural Networks with the
Extended Data Jacobian Matrix.”, Wang et. al.
Goal: come up with an empirical measure of neural nets’model complexity.
Consider a deep neural net with ReLU activations.
I Observation: For any fixed activation configuration,the neural net is just a linear transform.
Look at the spectrum (eigenvalues) of the EDJ matrix.
12 / 22

Investigated the effect of dropout as well.
13 / 22

“Learning Simple Algorithms from Examples.”
Zaremba, Wojciech, et al.
https://www.youtube.com/watch?v=GVe6kfJnRAw
14 / 22

“Learning to learn by gradient descent by
gradient descent.”, Andrychowicz, Marcin, et al.
Gradient descent
θt+1 = θt − αt∇f(θt) (8)
More generally,
θt+1 = θt + gt(∇f(θt), φ) (9)
The above is corresponding to a RNN.
15 / 22

θt+1 = θt + gt(∇f(θt), φ) (10)
16 / 22

Deep Reinforcement Learning
“Benchmarking Deep Reinforcement Learning forContinuous Control”, Duan et. al.
I A nice survey on deep RL.
“Dueling Network Architectures for Deep ReinforcementLearning”, Wang et. al.
I A specialized architecture for estimating thesate-action value function Q(s, a) in deep RL.
17 / 22

“Generative Adversarial Nets.”, Goodfellow et al.
18 / 22

“Generative Adversarial Nets.”, Goodfellow et al.
Objective
minG
maxD
V (D,G) (11)
where
V (D,G) = Ex∼pdata(x) logD(x) + Ez∼pz(z) log(1−D(G(z)))(12)
19 / 22

“Teaching Machines To Read and Comprehend.”
Hermann, Karl Moritz, et al.
The reading comprehension task.
20 / 22

“Teaching Machines To Read and Comprehend.”
Hermann, Karl Moritz, et al.
21 / 22

The End
22 / 22