spatial-temporal deep neural networks for land use ... · spatial-temporal deep neural networks for...
TRANSCRIPT

Spatial-Temporal Deep Neural Networks for Land Use Classification of LandSat Images and Beyond
Xiuwen LiuDepartment of Computer Science
Florida State University
Joint work with Xiaojun Yang, Atharva Sharma, Mukadder Sodek, Di Shi, Shamik Bose, Leon Gonzalez, Cameron Farzaneh, Canlin Zhang, and Omar Azhar.

Background: Toward Global Sustainability
4/23/18 2
P. M. Vitousek, et al., “Human Domination of Earth’s Ecosystems,” Science, Vol. 277, 1997.

Background: The LandSat Program
4/23/18Source: https://landsat.usgs.gov/tools_acq.php
3

Background: Global Land Use Datasets• To support sustainability research, a number of land use datasets
on the global scale are available– The datasets vary in resolution and one of them is GlobalLand30, which
provides a 30-meter resolution
4/23/18 intro-seminar-17 4

Background: Everglade Ecosystem Modeling
4/23/18 intro-seminar-17 5

Spectral-time Curve Representation
4/23/18 6

Limitations of Pixel-based Methods
• GlobalLand30 and other datasets classify LandSat or other images pixel by pixel– The accuracy is typically low, below 60%– It does not consider spatial and temporal context of pixels
• Neighboring pixels are strong correlated• Seasonal changes also generate patterns for some land use types (such
crops)
– We like to improve the performance by incorporating contextual information
4/23/18 7

4/23/18 8
Compound Bayesian Decision Theory
þýü
îíì --=
þýü
îíì --=
==
5000)150(
exp250
1)|( ,
200)100(
exp210
1)|(
,75.0)(,25.0)(2
2
2
1
21
xxp
xxp
PP
pw
pw
ww

4/23/18 9
Compound Bayesian Decision Theory
• Results from the Bayes decision rule– The classification error is 14.2%

4/23/18 10
Results from the Bayes Decision Rule – cont.

4/23/18 11
Compound Decision Theory – cont.
• If we classify a pixel together with four nearest neighbors, then the classification error is 0.6%

4/23/18 12
Compound Decision Theory – cont.
• If we classify a pixel together with eight neighbors, then the classification error is 1.7%
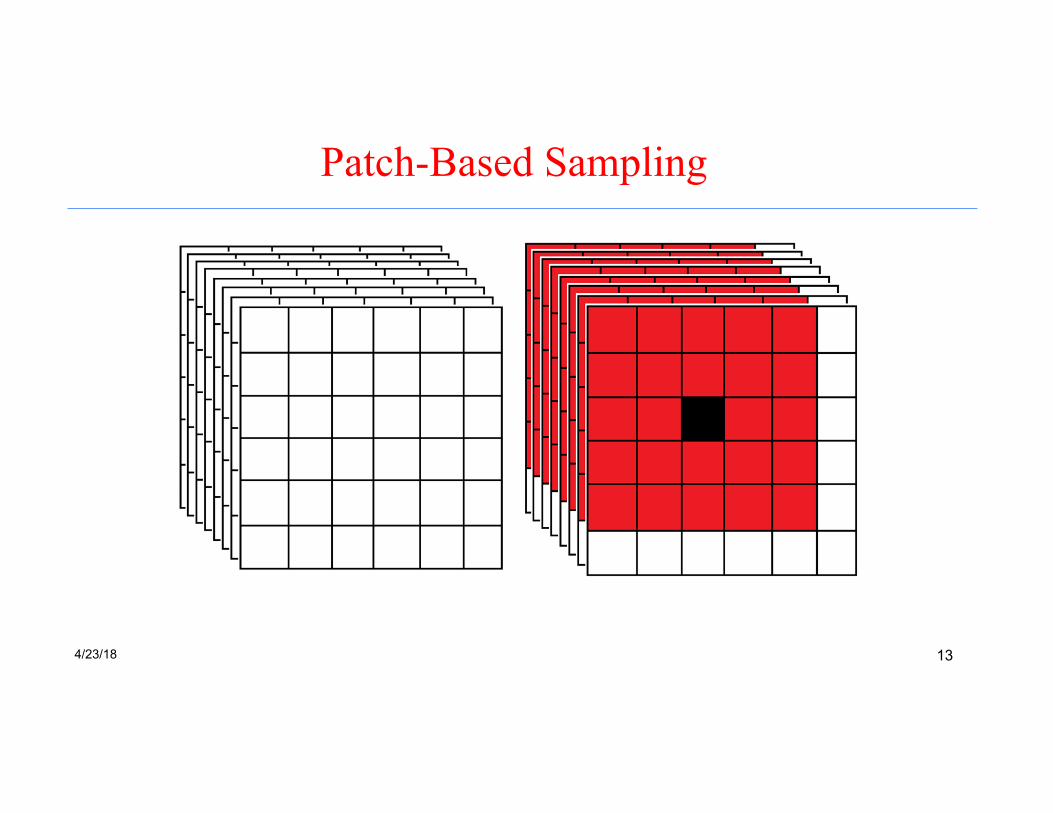
Patch-Based Sampling
4/23/18 13

Classification Using Deep Networks
4/23/18 intro-seminar-17 14

Training CNN
4/23/18 15

Training CNN
4/23/18 16

Accuracy of the Entire Area During Training
4/23/18 17

Accuracy Assessment – Training Set
4/23/18 18

Accuracy Assessment of CNN
4/23/18 19

Accuracy Assessment of Other Methods
4/23/18 20
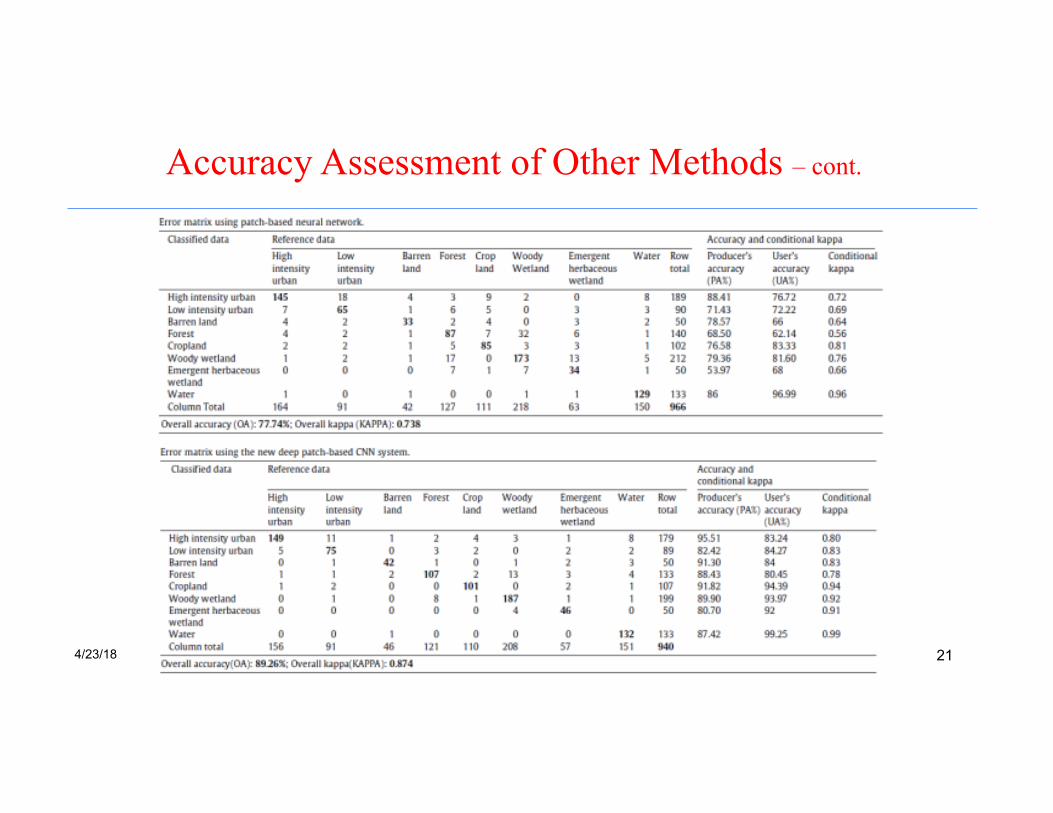
Accuracy Assessment of Other Methods – cont.
4/23/18 21

Comparisons
4/23/18 22

Comparisons
4/23/18 intro-seminar-17 23

Recurrent Neural Networks
24

Input/output Configurations
One-to-sequence Sequence-to-sequence Sequence-to-sequence
Sequence-to-one25
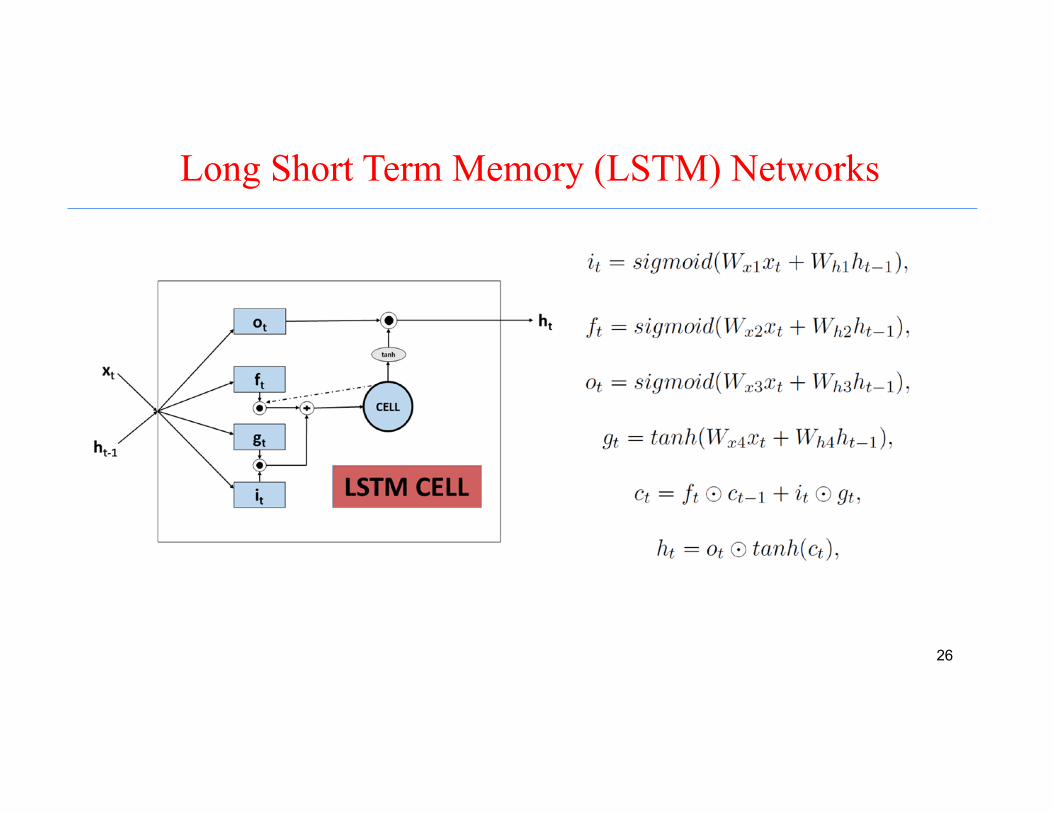
Long Short Term Memory (LSTM) Networks
26
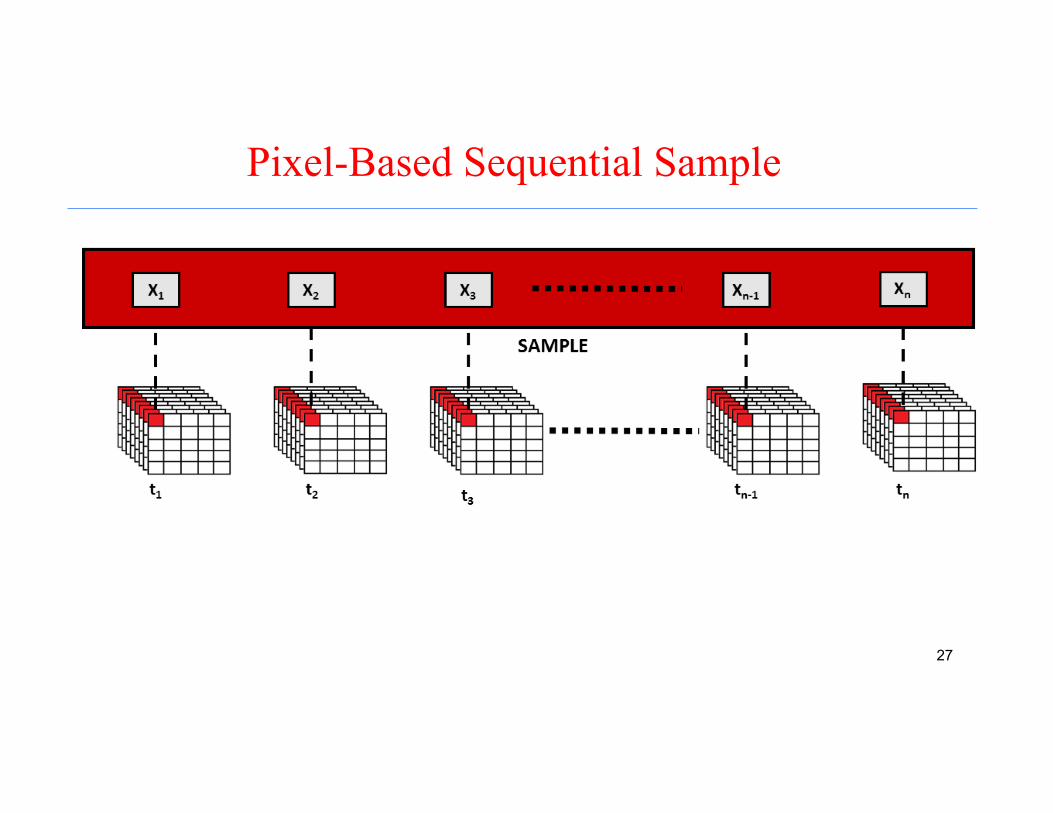
Pixel-Based Sequential Sample
27

Pixel-Based RNN System
28

Pixel-based RNN Accuracy Assessment
29

Patch-Based Sequential Sample (PB-RNN)
30

Patch-Based RNN System
31

Patch-Based Recurrent Neural Networks
4/23/18 32

Patch-Based Recurrent Neural Networks
4/23/18 33
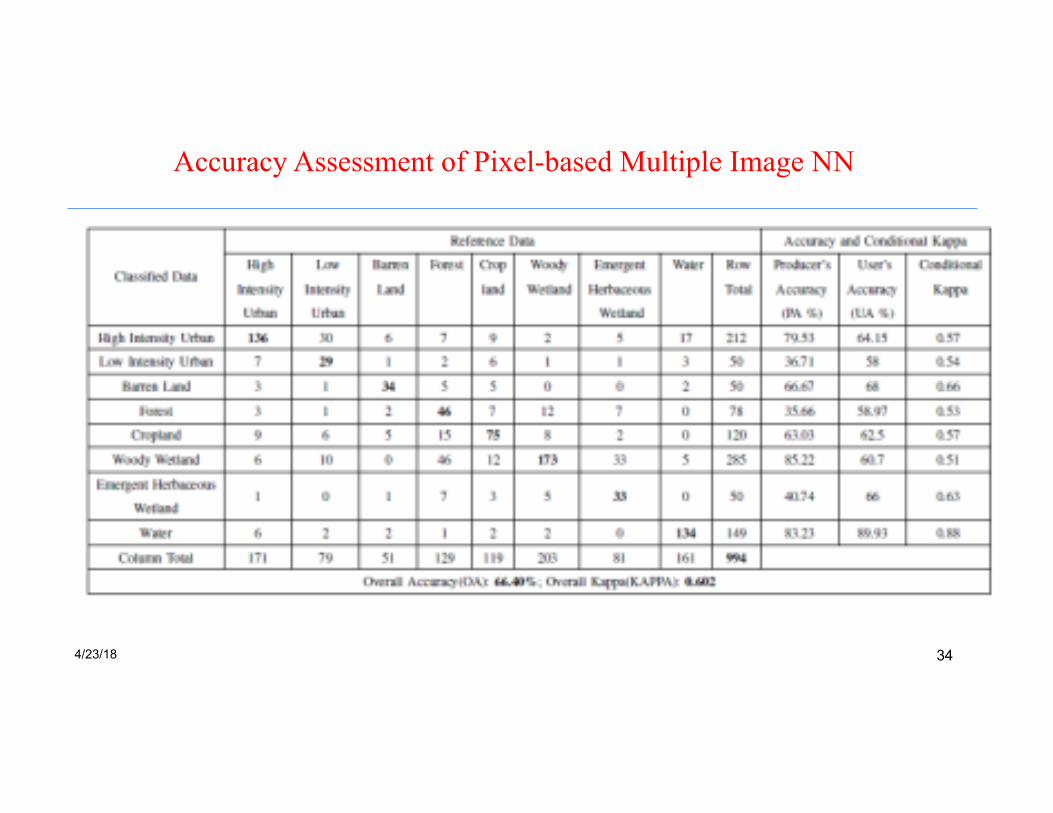
Accuracy Assessment of Pixel-based Multiple Image NN
4/23/18 34

Accuracy Assessment of Patch-based Multiple Image NN
4/23/18 35

Comparison
4/23/18 36

Bootstrapping Deep Neural Networks
• Since we have improved the performance substantially, can we bootstrap deep neural networks so that we can continually improve the performance without human intervention?– In other words, can we use our network to generate more labeled
samples and use the samples to further train the neural networks and therefore further improve the performance?
4/23/18 37

Bootstrapping Deep Neural Networks
• In other words, can we use our network to generate more labeled samples and use the samples to further train the neural networks and therefore further improve the performance?– By modeling the content and the style separately
4/23/18 38

Bootstrapping Deep Neural Networks
• To do this, we will train two neural networks– The style neural network is to normalize the features so that region-
dependent features can be removed / normalized• As the global weather patterns are predictable, the style neural network is to
capture the effects of climates on land use patterns • This network should have fewer parameters• One structure is variational autoencoder• It can be trained using samples from the same region• For LandSat images, the information is free as we have locations
4/23/18 39

Bootstrapping Deep Neural Networks
• To do this, we will train two neural networks– The style neural network is to normalize the features so that region-
dependent features can be removed / normalized• This network should have fewer parameters• One structure is variational autoencoder• It can be trained using samples from the same region• For LandSat images, the information is free as we have locations
4/23/18 40

Bootstrapping Deep Neural Networks
• To do this, we will train two neural networks– The style neural network is to normalize the features so that region-
dependent features can be removed / normalized• As the global weather patterns are predictable, the style neural network is to
capture the effects of climates on land use patterns • This network should have fewer parameters• One structure is variational autoencoder• It can be trained using samples from the same region• For LandSat images, the information is free as we have locations
4/23/18 41

Bootstrapping Deep Neural Networks – cont.
• The content neural network is similar to the neural network we have trained so that it can classify images based on normalized features– We can then use the style networks to normalize features and use the
content network for labeling and further improve its performance by continuous training

Informed Trading Strategies from Space
4/23/18 43

Bootstrapping Deep Neural Networks for Speech Recognition
• We are also applying the framework to accented speech recognition– We call this e-resource speech modeling and recognition– We will train two networks also
• An accent-normalization network to normalize and remove accents using a low dimensional variational autoencoder
• A speech recognizer will be a deep recurrent neural network to perform speech recognition
• We believe that accented speech recognition can be improved substantially, surpassing human performance
– Speaker-independent speech recognition has surpassed human performance on average
• We are working on a prototype to demonstrate the effectiveness of the framework
4/23/18 44

Bootstrapping Deep Neural Networks for Language Modeling
• We are also applying the framework to language modeling– For example, word embeddings will influence the quality of language
models based on RNNs • As RNNs are continuous, words with similar embeddings will affect each other• For words with very different multiple senses, one needs to model the senses and
the embeddings at the same time
– We will train two networks also• One network to model and classify the senses• The other one learns embeddings and language models
4/23/18 45

Deep Cyber Warriors
• A reinforcement learning approach to analyzing malware and binary programs– When analysts can analyze malicious and binary programs, they often
spend a long time to analyze them• Some of them require multiple-year efforts
– Using reinforcement learning techniques, we want to learn effective heuristics to create the most capable cyber warriors
• Without hard work• Why? Because our algorithms will figure out by learning through their experience
4/23/18 46

Deep Learning in the (Near) Future
• Now I am convinced deep learning and related techniques and applications will be further developed– Because the computers are surpassing the single human capacity in
fundamental ways• Finally we can create a system to figure out how to solve programs
on its own– We only need to set up the problem and initialize it and the system will figure
out the rest• In reinforcement learning the system will play against itself, a self-bootstrapping
framework• In supervised and unsupervised learning, the system can bootstrap itself via multiple
staging modeling and strapping with some initial labeled data• We can then enjoy life – only after we can set up and initialize the system
4/23/18 47

Inherent Challenges to Machine Learning
• Here is the abstract from “Neural Networks and the Bias/Variance Dilemma”, 1992
– “Feedforward neural networks trained by error backpropagation are examples of nonparametric regression estimators. …. In way of conclusion, we suggest that current-generation feedforward neural networks are largely inadequate for difficult problems in machine perception and machine learning, regardless of parallel-versus-serial hardware or other implementation issues. Furthermore, we suggest that the fundamental challenges in neural modeling are about representation rather than learning per se. This last point is supported by additional experiments with handwritten numerals.”
4/23/18 48

Are There Fundamental Changes in Deep Neural Networks?
• For example, should the learning still be about representation?• Deep neural networks have more layers
– The community manages to develop effective optimization algorithms and be able to minimize the loss on the training set
– Do deep neural networks generalize better?• For performance on certain applications using certain datasets, they generalize
well indeed• Do they generalize typically?
week12-Web-Application-Injection

Generalization Issues in Deep Neural Networks
• Deep neural networks have a huge capacity– They are capable of remembering all training sets even on large datasets
we have
Figure from “Understanding deep learning requires rethinking generalization,” https://arxiv.org/abs/1611.03530.

Curses of the Dimensionality
• The exponential growth of the volume with the dimension of the space is easy to understand– From a probability distribution estimation point of view, it creates two
fundamental headaches• Data sparsity headache• Computational complexity headache
• At this big data age, do we have enough data to overcome the curses?
week12-Web-Application-Injection

Blessings of the Dimensionality and Representations – cont.
• To generalize well, we need representations that are exponentially efficient
From “Mastering the game of Go without human knowledge,” Science, 2017.

Blessings of the Dimensionality and Representations – cont.
• From “The Loss Surfaces of Multilayer Networks,” 2015– “We conjecture that both simulated annealing and SGD converge to the band of low
critical points, and that all critical points found there are local minima of high quality measured by the test error. This emphasizes a major difference between large- and small-size networks where for the latter poor quality local minima have nonzero probability of being recovered.”

The Future of Deep Learning
• I strong believe that we need to develop and discover representations that can generalize exponentially well– Before we can enjoy life– The search space is, however, subject to the curses of the extreme high dimensionality
of deep neural networks

A New Course This Fall
• “Deep and Reinforcement Learning Fundamentals”• Web site: http://www.cs.fsu.edu/~liux/courses/deepRL/• Instructor: Xiuwen Liu• To be offered: Fall 2018
– Monday and Wednesday, 9:30am to 10:45am, Love 301

Thank you!
Any further questions?
4/23/18 56