stanag 6001- opi testing julie j. dubeau bucharest bilc 2008
TRANSCRIPT

STANAG 6001-OPI Testing
Julie J. Dubeau
Bucharest BILC 2008

Julie J. Dubeau
Bill Who???

Julie J. Dubeau

Julie J. Dubeau
Are We All On the Same Page?
An Exploratory Study of OPI Ratings
Across NATO CountriesUsing the NATO STANAG 6001 Scale*
*This research was completed in 2006 as part of a M.A. Thesis in Applied Linguistics

Julie J. Dubeau
Presentation Outline Context Research Questions Literature Review Methodology Results
– Ratings– Raters– Scale
Conclusion

Julie J. Dubeau
NATO Language Testing Context
Standardized Language Profile (SLP) based on the NATO STANDARDIZATION AGREEMENT (NATO STANAG) 6001 Language Proficiency Levels (Ed 1? Ed 2?)
– 26 NATO countries, 20 Partnership for Peace (PfP) countries & others…

Julie J. Dubeau
Interoperability Problem?Language training is central within armed forces due
to the increasing number of peace-support operations, and is considered as having an important role in achieving interoperability among the various players.
“The single most important problem identified by almost all partners as an impediment to developing interoperability with the Alliance has been shortcomings in communications” (EAPC (PARP) D, 1997, 1, p.10).

Julie J. Dubeau
Overarching Research Question
Since no known study had investigated inter-rater reliability in this context, the main research question was:
How comparable or consistent are ratings across NATO raters and countries?

Julie J. Dubeau
Research Questions
Research questions pertaining to the ratings RQ1
Research questions pertaining raters’ training and background RQ2
Research questions pertaining to the rating process and to the scale RQ3

Julie J. Dubeau
Research Questions
RQ1-Ratings: How do ratings of the same oral proficiency
interviews (OPIs) compare from rater to rater? Would the use of plus levels increase rater
agreement? How do the ratings of the OPIs compare from
country to country? Are there differences in scores within the same
country?

Julie J. Dubeau
Research QuestionsRQ2-Raters’ training and background: Are there differences in ratings between raters
who have received varying degrees of tester/rater training and STANAG training?
Did very experienced raters score more reliably than lesser experienced ones? Are experienced raters scoring as reliably as trained raters?
Are there differences in ratings between participants who test part-time versus full-time, are native or non-native speakers of English, and are from ‘Older’ and ‘Newer’ NATO countries?

Julie J. Dubeau
Research Questions
RQ3-Rating process and scale use:
Do differing rating practices affect ratings? Do raters appear to use the scale in similar
ways? What are the raters’ comments regarding the
use and application of the scale?

Julie J. Dubeau
Literature Review Testing Constructs
– What are we testing?• General proficiency & Why• Rating scales
Rater Variance– How do raters vary?
• Rater/scale interaction• Rater training & background

Julie J. Dubeau
Methodology
Design of study: Exploratory survey– 2 Oral Proficiency Interviews (OPIs A & B)– Rater data questionnaire– Questionnaire accompanying each sample OPI
Participants : Countries recruited at BILC Seminar in Sofia 2005
103 raters from 18 countries and 2 NATO units

Julie J. Dubeau
Analysis:– Rating comparisons
– Original ratings– ‘Plus’ ratings
– Rater comparisons– Training– Background
– Country to country comparisons• Within country dispersion
– Rating process• Rating factors
– Rater/scale interaction• Scale user-friendliness

Julie J. Dubeau
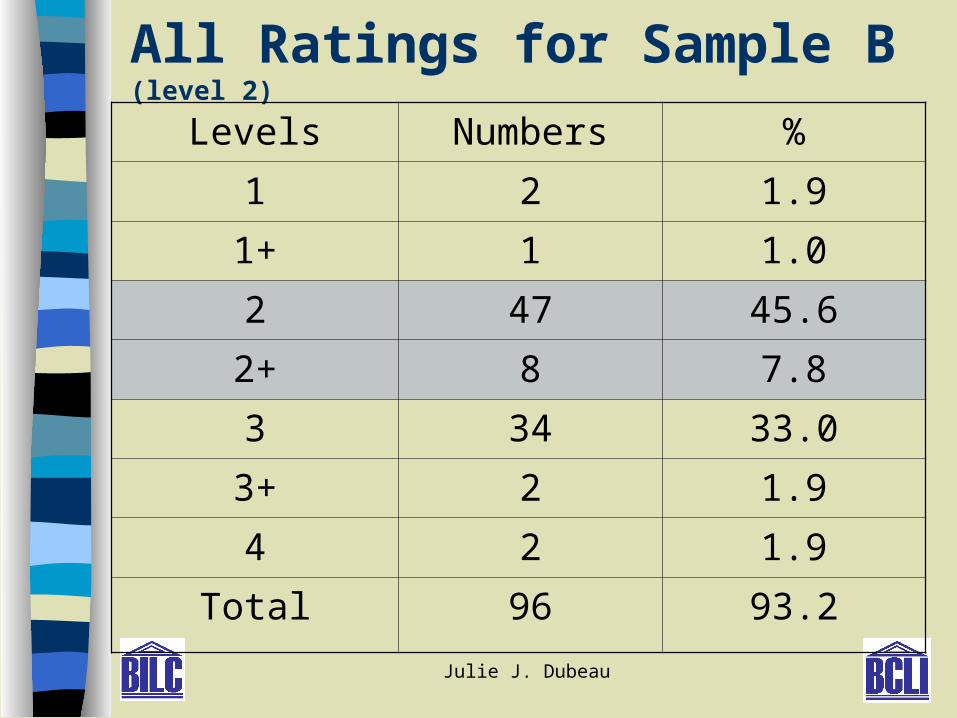
Results RQ1- Summary
Ratings : To compare OPI ratings and to explore the efficacy of ‘plus ratings’.
– Some rater-to-rater differences
– ‘Plus’ levels brought ratings closer to the mean
– Some country-to-country differences
– Greater ‘within-country’ dispersion in some
countries
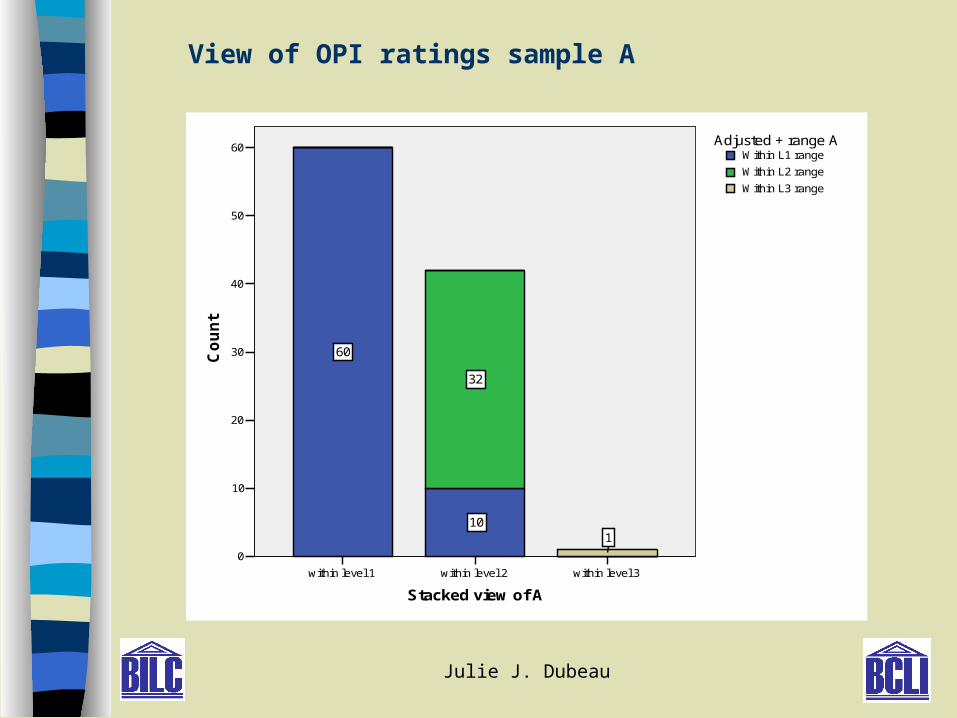
Julie J. Dubeau
within level 3within level 2within level 1
Stacked view of A
60
50
40
30
20
10
0
Co
un
t
1
32
10
60
Within L3 range
Within L2 range
Within L1 rangeAdjusted + range A
View of OPI ratings sample A
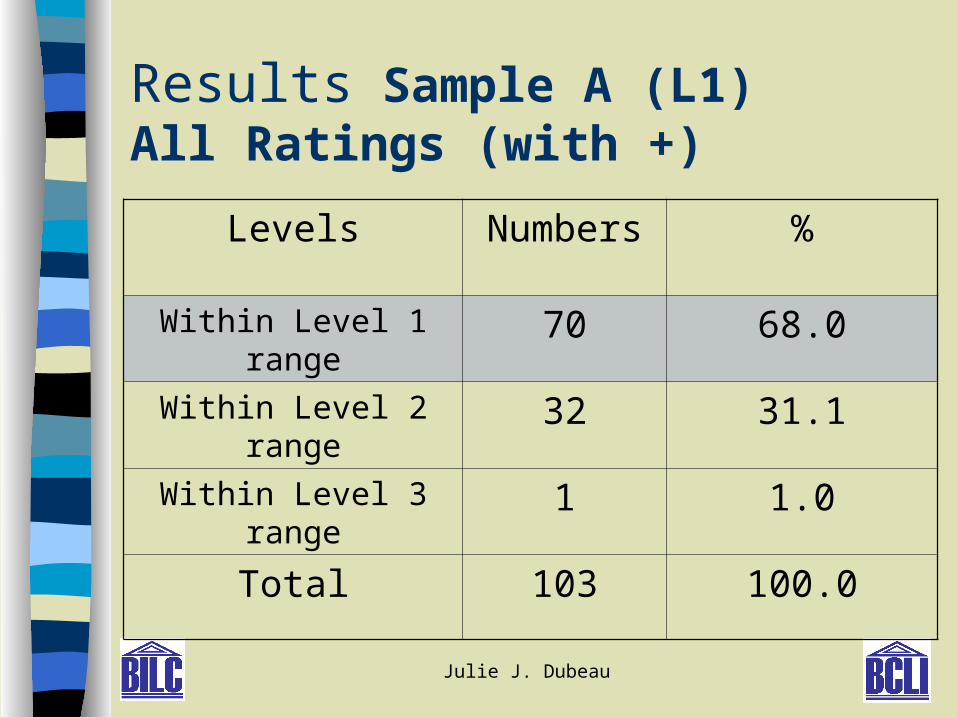
Julie J. Dubeau
Results Sample A (L1)All Ratings (with +)
Levels Numbers %
Within Level 1 range 70 68.0
Within Level 2 range 32 31.1
Within Level 3 range 1 1.0
Total 103 100.0
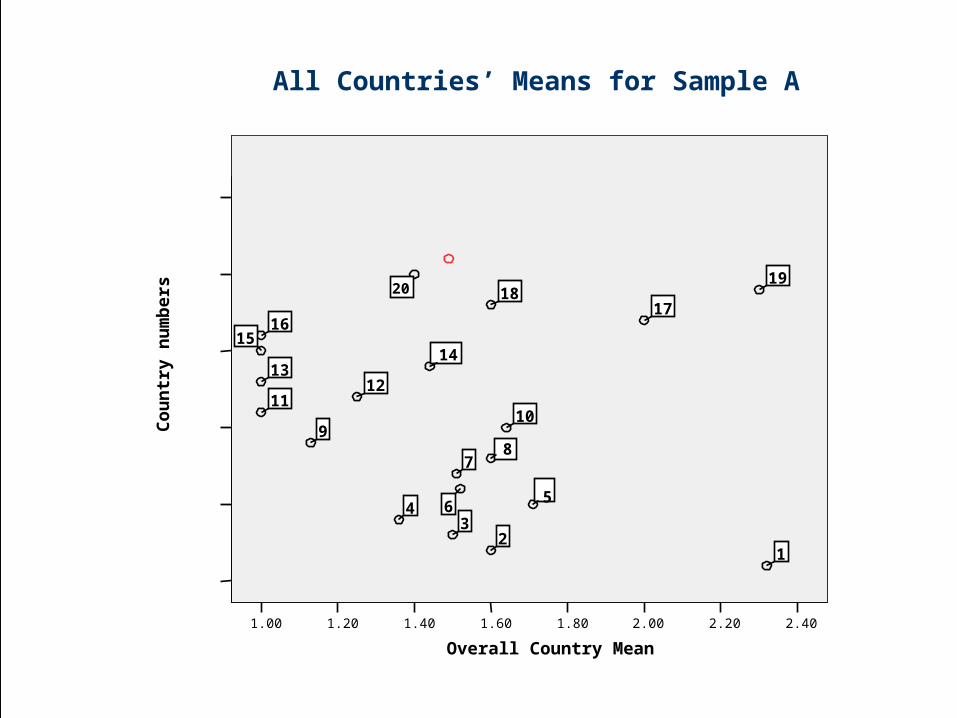
Julie J. Dubeau
All Countries’ Means for Sample A
2.402.202.001.801.601.401.201.00
Overall Country Mean
Co
un
try
nu
mb
ers 20
1918
1716
1514
1312
1110
98
7
65
43
21
Julie J. Dubeau
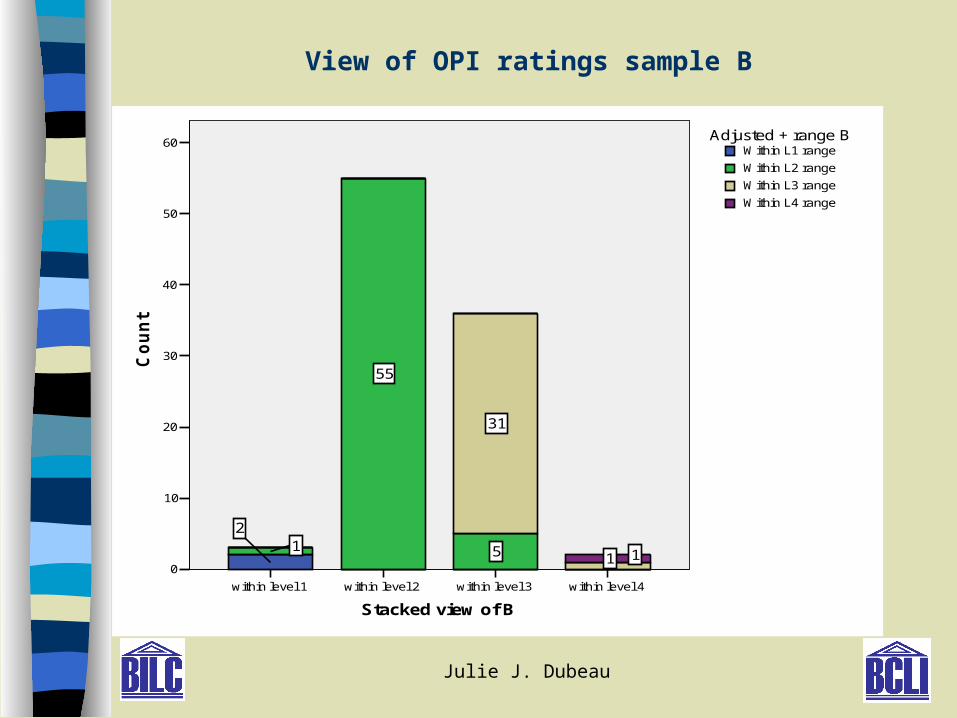
All Ratings for Sample B (level 2)
Levels Numbers %
1 2 1.9
1+ 1 1.0
2 47 45.6
2+ 8 7.8
3 34 33.0
3+ 2 1.9
4 2 1.9
Total 96 93.2
Julie J. Dubeau
View of OPI ratings sample B
within level 4within level 3within level 2within level 1
Stacked view of B
60
50
40
30
20
10
0
Co
un
t
1 1
31
5
55
12
Within L4 range
Within L3 range
Within L2 range
Within L1 rangeAdjusted + range B
Julie J. Dubeau
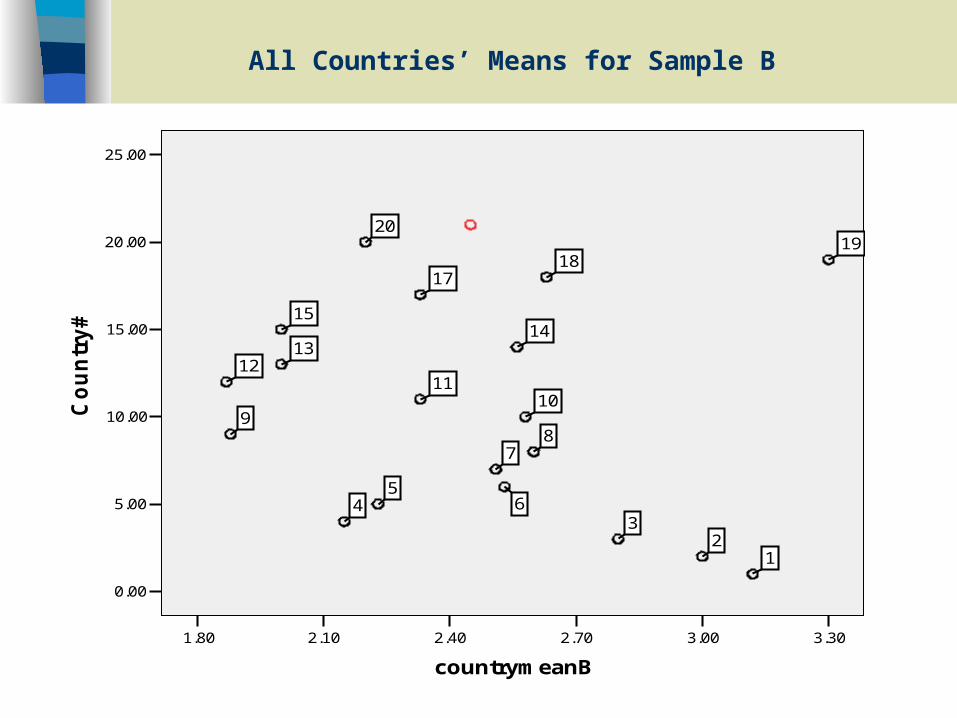
All Countries’ Means for Sample B
3.303.002.702.402.101.80
countrymeanB
25.00
20.00
15.00
10.00
5.00
0.00
Co
un
try
#
2019
1817
1514
1312
1110
98
7
65
43
21

Julie J. Dubeau
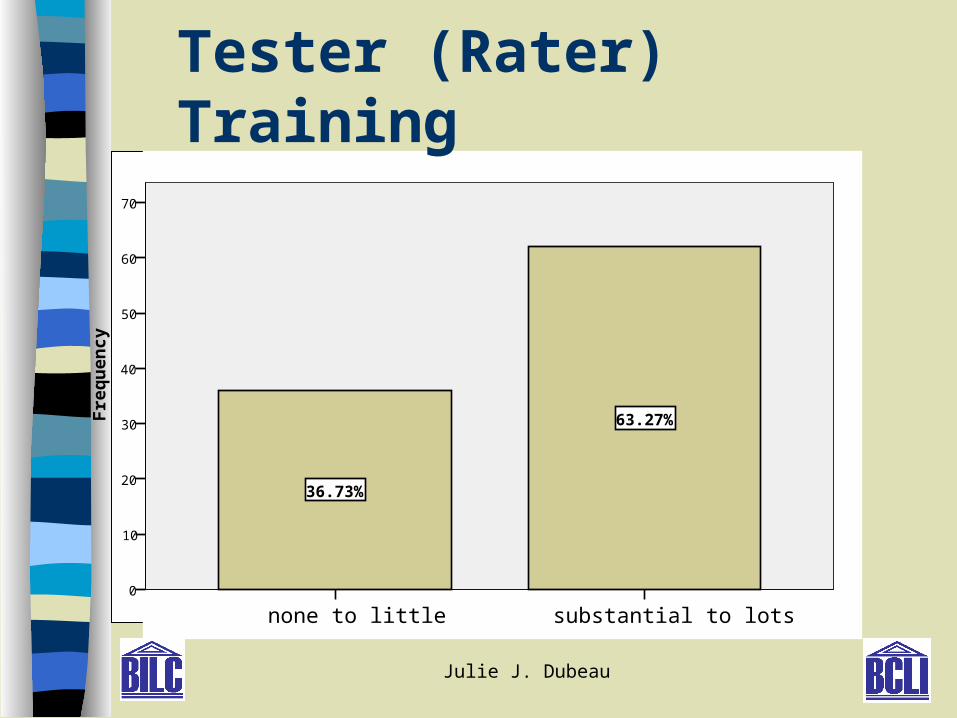
Results RQ2- Summary Raters: To investigate rater training and scale training
and see how (or if) they impacted the ratings, and to explore how various background characteristics impacted the ratings– Trained raters scored within the mean, especially
for sample B– Experienced raters did not do as well as scale-
trained raters – Full-time raters scored closer to mean– ‘New’ NATO raters scored slightly closer to mean– NNS raters scored slightly closer to mean
Julie J. Dubeau
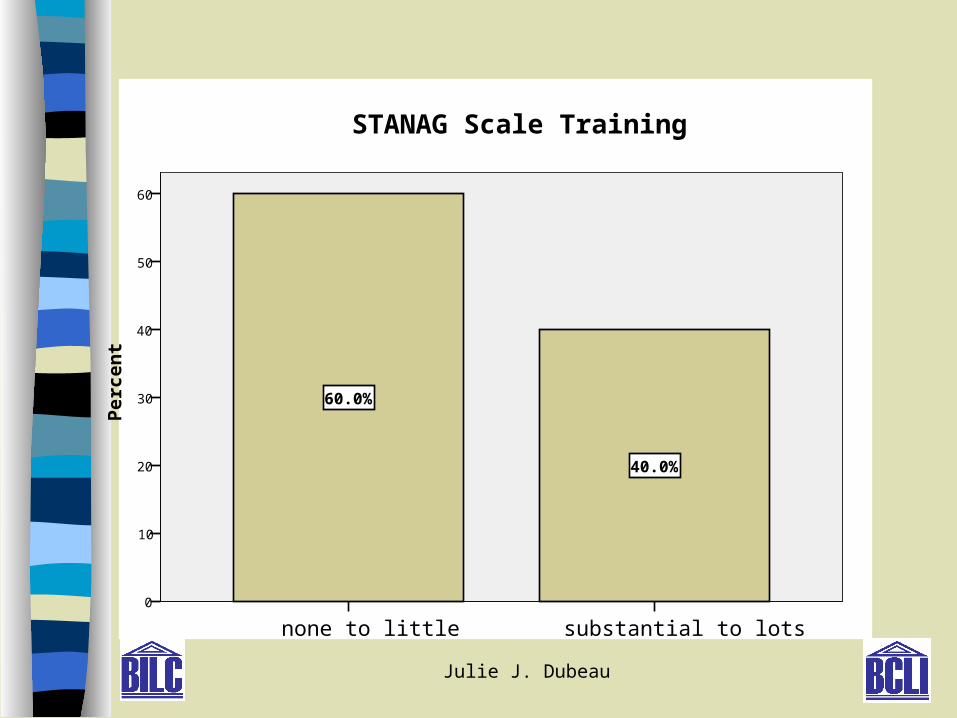
substantial to lotsnone to little
70
60
50
40
30
20
10
0
Fre
qu
ency
63.27%
36.73%
Tester (Rater) Training
Julie J. Dubeau
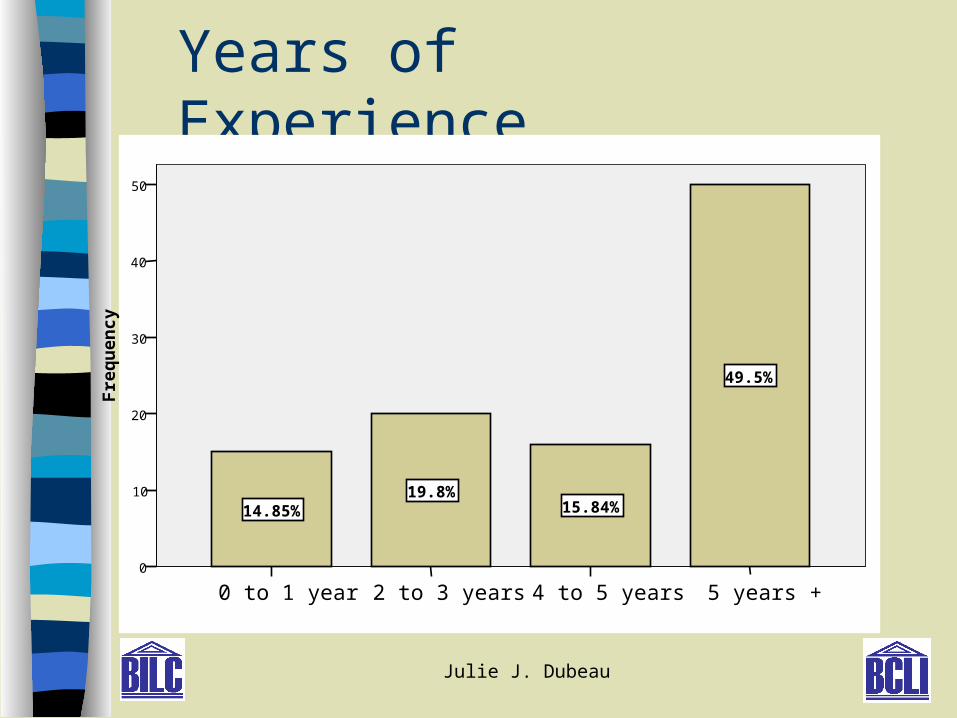
Years of Experience
5 years +4 to 5 years2 to 3 years0 to 1 year
50
40
30
20
10
0
Fre
qu
ency
49.5%
15.84%19.8%
14.85%
Julie J. Dubeau
substantial to lotsnone to little
60
50
40
30
20
10
0
Per
cen
t
40.0%
60.0%
STANAG Scale Training
Julie J. Dubeau
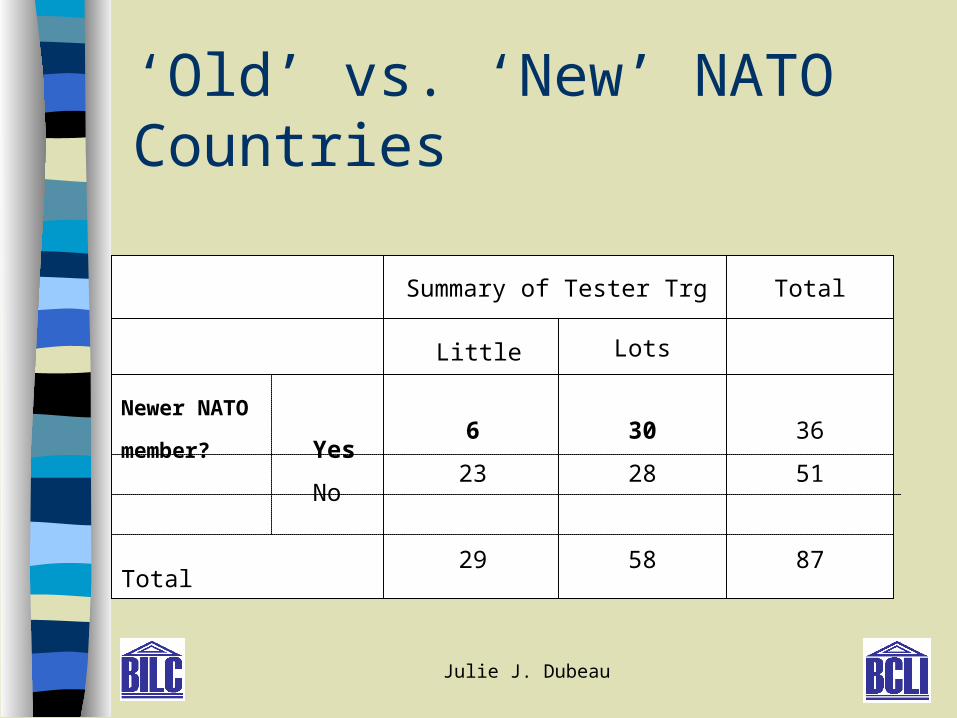
‘Old’ vs. ‘New’ NATO Countries
Summary of Tester Trg
Little Lots
Total
1420236
Newer NATO
member? Yes
No
Total
6
23
29
30
28
58
36
51
87
Julie J. Dubeau
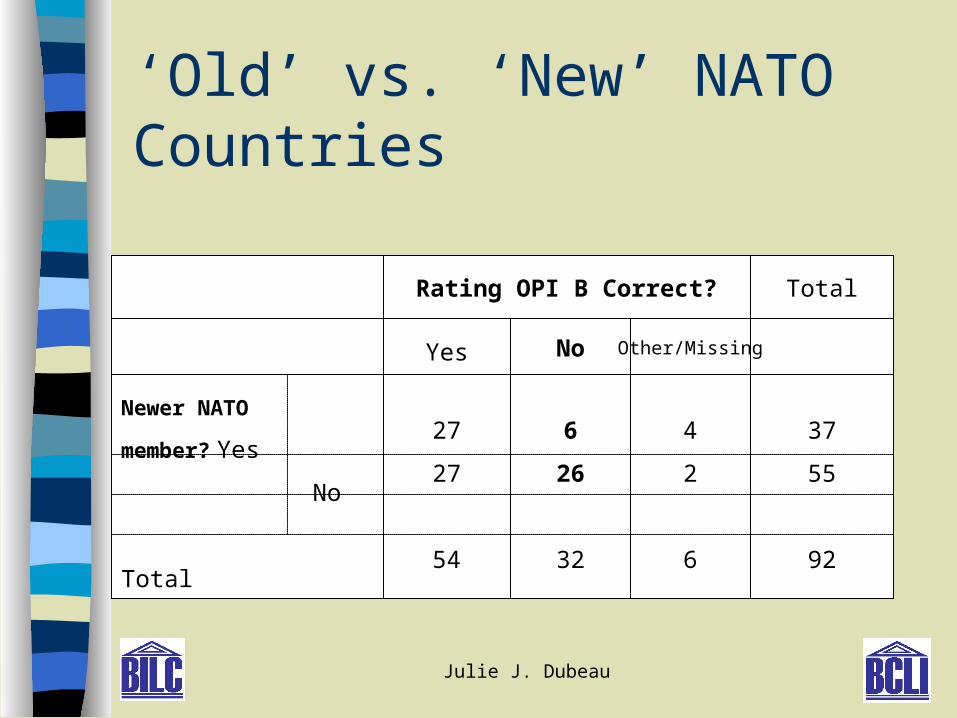
‘Old’ vs. ‘New’ NATO Countries
Rating OPI B Correct?
Yes No
Total
1420236
Newer NATO
member? Yes
No
Total
27
27
54
6
26
32
37
55
92
Other/Missing
4
2
6

Julie J. Dubeau
Results Raters’ Background
Conducts Testing Full-time?• Yes 34 (33.0 %)
• No 67 (65.0 %)
• Full-time testers more reliable (accurate)
– NNS (60%) raters better trained?
– ‘New’ raters better trained?

Julie J. Dubeau
Results RQ3- Summary
Scale: To explore the ways in which raters used the various STANAG statements and rating factors to arrive at their ratings.
– Rating process did not affect ratings significantly
– 3 main ‘types’ of raters emerged:• Evidence-based• Intuitive• Extra-contextual

Julie J. Dubeau
Results An ‘evidenced-based’ rating for Sample B (level 2):
I compared the candidate’s performance with the STANAG criteria (levels 2 and 3) and decided that he did not meet the requirements for level 3 with regard to flexibility and the use of structural devices. Errors were frequent not only in low frequency structures, but in some high frequency areas as well. (Rater 90 – rated 2)

Julie J. Dubeau
Results An ‘intuitive’ rating for Sample A (level 1):
I would say that just about every single sentence in the interpretation of the level 2 speaking could be applied to this man. And because of that I would say that he is literally at the top of level 2. He is on the verge of level 3 literally. So I would automatically up him to a low 3. (Rater 1- rated 3)

Julie J. Dubeau
Results An ‘extra-contextual’ rating for Sample A (level 1):
Level 3 is the basic level needed for officers in
(my country). I think the candidate could
perform the tasks required of him. He could
easily be bulldozed by native speakers in a
meeting, but would hold his own with non-native
speakers. He makes mistakes that very rarely
distort meaning and are rarely disturbing. (Rater
95 – rated 2)

Julie J. Dubeau
Implications
Training not equal in all countries
Scale interpretation
Plus levels useful
Different grids, speaking tests
Institutional perspectives

Julie J. Dubeau
Limitations & Future Research
Participants may not have rated this way in their own countries
OPIs new to some participants
Future research could– Get participants to test– Investigate rating grids– Look at other skills

Julie J. Dubeau
Conclusion of Research
So, are we all on the same page?
YES! BUT… Plus levels were instrumental in bridging
gap
Training was found to be key to reliability
More in-country training should be the first
step toward international benchmarking.

Thank You!Are We All On the Same Page? An Exploratory Study of OPI RatingsAcross NATO CountriesUsing the NATO STANAG 6001 Scale
The full thesis is available on the CDA website
http://www.cda-acd.forces.gc.caOr google Dubeau thesis