ta hour - lecture 5 lab
TRANSCRIPT

CSElab www.cse-lab.ethz.chTA hour - Lecture 5
• Sampling from distributions
• Uniform distribution
• 1D Sampling Theorem
• Multivariate Gaussian distribution
• Rejection Sampling
• Importance Sampling
• Markov Chains
Outline

CSElab www.cse-lab.ethz.chSampling from distributions
• Motivation • Most problems have no analytical results in the Bayesian
framework
• Evaluation of the posterior distribution involves calculating the evidence, which is generally a difficult integral to do
• It is enough to draw samples from posterior for estimating the statistics of the prediction for some Quantity of Interest in a system
• Goal: Generate i.i.d. samples from a given distribution

CSElab www.cse-lab.ethz.chUniform Distribution
• Pseudo Random Number Generator
• Bayesian perspective: generate a stream of numbers for which a probability model states that the numbers are i.i.d. samples from a uniform distribution U[0,1] is highly plausible
• e.g. Linear Congruential Generator (MATLAB.4 - rand):For 32-bits, largest m = 232, and the algorithm will have a period of at most m Careful choice of a and c is needed to avoid getting periods much less than m
Given a seed I0 2 Z+, generate sequence {Ii : i > 1}
Ii = aIi�1 + c (mod m), where m, a, c 2 Z+and m is very large

CSElab www.cse-lab.ethz.ch1D Sampling Theorem
• Convert samples from U[0,1] to samples from any distribution between range [a,b]
Let PDF f(⇣), ⇣ 2 [a, b] ⇢ R,
has a strictly increasing CDF F (⇣) =
Z ⇣
af(⌘) d⌘
1
0
µ0
a b ζζ0 = F-1(µ0)
µ = F(ζ)
) ⇣ = F�1(µ) ⇠ f(⇣), where µ ⇠ U[0, 1]

CSElab www.cse-lab.ethz.ch1D Sampling Theorem
• E.g. exponential PDF
• Similar approach can be done for Standard Normal N(0,1),but the inverse of the CDF is only approximated
• Problem: CDF and/or its inverse is not always known, and it’s only for 1D
f(⇣) =1
ce�⇣/c, ⇣ > 0
)F (⇣) =
Z ⇣
0
1
ce�⌘/c d⌘ = 1� e�⇣/c
)⇣ = F�1(µ) = �c · ln(1� µ) ⇠ 1
ce�⇣/c, where µ ⇠ U[0, 1]

CSElab www.cse-lab.ethz.chMultivariate Gaussian Distribution
• Goal: sample from ,
• Factorize covariance matrix into(Choleski or LU factorization)
• Define , it’s a linear combination of
• Each component of is i.i.d. standard Gaussian
• Sample many standard Gaussian and
⇣ ⇠ N(µ,⌃)
⌃ = LLT 2 Rd⇥d
⌘ = L�1(⇣ � µ) 2 Rd
⇣ = {⇣1, . . . , ⇣d}T
⇣i
E[⌘] = L�1E[⇣ � µ] = 0
E[⌘⌘T ] = L�1⌃(LT )�1 = Id
⌘
⇣̂ = µ+ L⌘̂
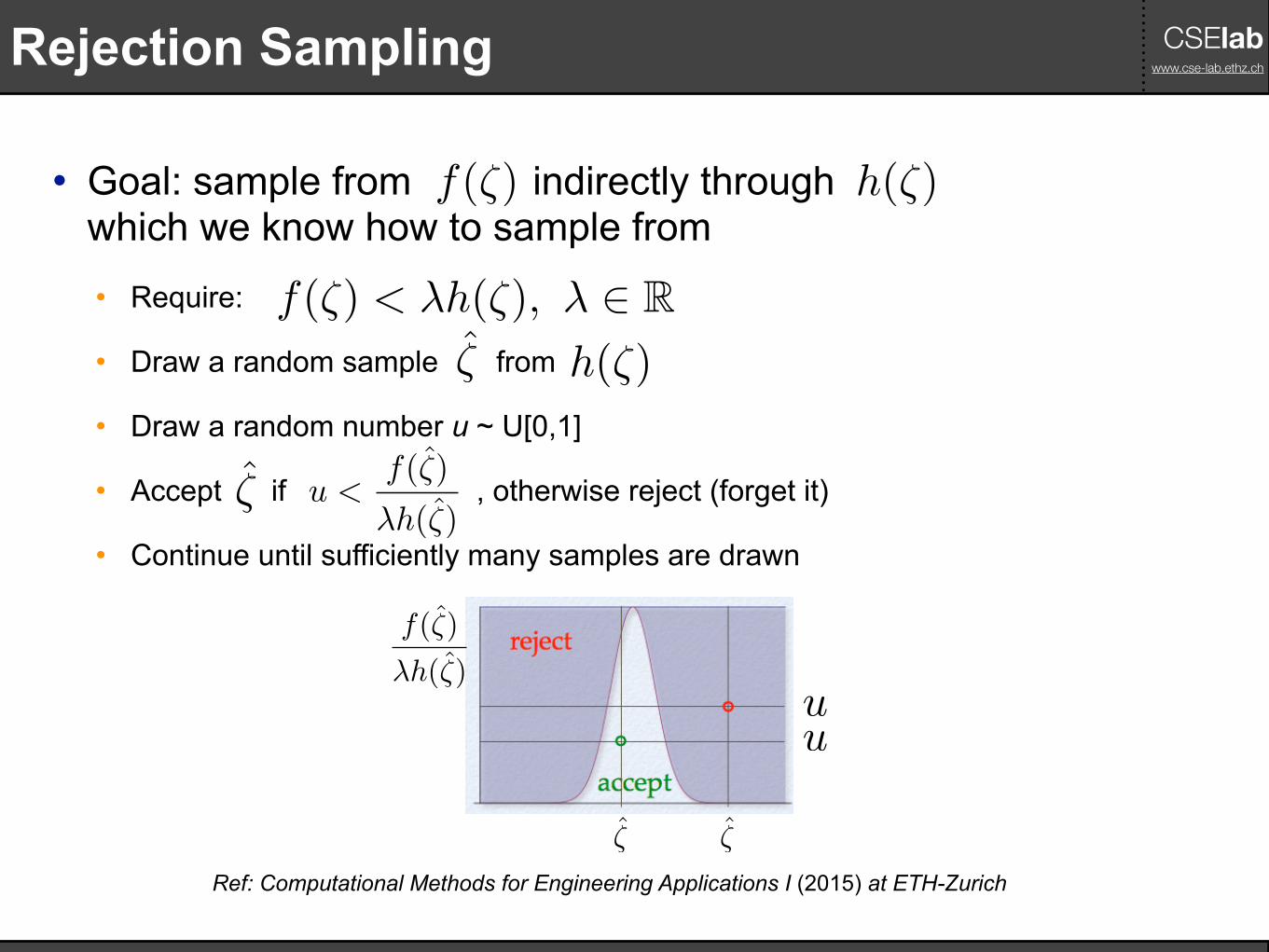
CSElab www.cse-lab.ethz.chRejection Sampling
• Goal: sample from indirectly through which we know how to sample from
• Require:
• Draw a random sample from
• Draw a random number u ~ U[0,1]
• Accept if , otherwise reject (forget it)
• Continue until sufficiently many samples are drawn
f(⇣) h(⇣)
f(⇣) < �h(⇣), � 2 R⇣̂ h(⇣)
⇣̂
Ref: Computational Methods for Engineering Applications I (2015) at ETH-Zurich
u
⇣̂
f(⇣̂)
�h(⇣̂)
u <f(⇣̂)
�h(⇣̂)
u
⇣̂

CSElab www.cse-lab.ethz.chImportance Sampling
• Goal: sample from indirectly through which we know how to sample from
f(⇣) h(⇣)
Ef [g(⇣)] =
Zg(⇣)f(⇣) d⇣
=
Zg(⇣)
f(⇣)
h(⇣)h(⇣) d⇣
⇡ 1
N
NX
i=1
wig(⇣(i))
where ⇣(i) ⇠ h(⇣) and wi /f(⇣(i))
h(⇣(i))
) f(⇣) ⇡ 1
N
NX
i=1
wi�(⇣ � ⇣(i))
Ref: http://www.inference.phy.cam.ac.uk/tcs27/talks/sampling.html#32
where ⇣(i) ⇠ h(⇣) and wi =f(⇣(i))
h(⇣(i))

CSElab www.cse-lab.ethz.chMarkov Chains
A joint PDF is from a Markov Chain
() p(x1, x2, . . . , xn) = p(x1)
nY
j=2
p(xj |xj�1)
• Draw a sample from
• Draw a sample from for j = 2,…,n
• This is readily done if or are conditional multi-dimensional Gaussian PDFs
x̂1
x̂j
p(x1)
p(xj |xj�1)
xj 2 R p(xj |xj�1)