text categorization moshe koppel lecture 12:latent semantic indexing
DESCRIPTION
Text Categorization Moshe Koppel Lecture 12:Latent Semantic Indexing. Adapted from slides by Prabhaker Raghavan, Chris Manning and TK Prasad. Clustering documents (and terms). Latent Semantic Indexing Term-document matrices are very large - PowerPoint PPT PresentationTRANSCRIPT

Text CategorizationMoshe Koppel
Lecture 12:Latent Semantic Indexing
Adapted from slides by
Prabhaker Raghavan, Chris Manning and TK Prasad

Clustering documents (and terms)
Latent Semantic Indexing Term-document matrices are very large But the number of topics that people talk
about is small (in some sense) Clothes, movies, politics, …
Can we represent the term-document space by a lower dimensional latent space?

Term-Document Matrix
Represent each document as a numerical vector in the usual way.
Align the vectors to form a matrix.
Note that this is not a square matrix.

Term-Document Matrix
Represent each document as a numerical vector in the usual way.
Align the vectors to form a matrix.
Note that this is not a square matrix.
In a perfect world, the term-doc matrix might look like this:

Intuition from block matrices
Block 1
Block 2
…
Block k0’s
0’s
= Homogeneous non-zero blocks.
Mterms
N documents
What’s the rank of this matrix?

Intuition from block matrices
Block 1
Block 2
…
Block k0’s
0’sMterms
N documents
Vocabulary partitioned into k topics (clusters); each doc discusses only one topic.

Intuition from block matrices
Block 1
Block 2
…
Block kFew nonzero entries
Few nonzero entries
wipertireV6
carautomobile
110
0
Likely there’s a good rank-kapproximation to this matrix.

8
Dimension Reduction and Synonymy
Dimensionality reduction forces us to omit “details”.We have to map different words (= different dimensions of the full space) to the same dimension in the reduced space.The “cost” of mapping synonyms to the same dimension is much less than the cost of collapsing unrelated words.We’ll select the “least costly” mapping.Thus, will map synonyms to the same dimension.But, will avoid doing that for unrelated words.
8

Formal Objectives
Given a term-doc matrix, M, we want to find a matrix M’ that is “similar” to M but of rank k (where k is much smaller than the rank of M).
So we need some formal measure of “similarity” between two matrices.
And we need an algorithm for finding the matrix M’.
Conveniently, there are some neat linear algebra tricks for this.
So, let’s review a bit of linear algebra.

Eigenvalues & Eigenvectors
Eigenvectors (for a square mm matrix S)
How many eigenvalues are there at most?
only has a non-zero solution if
this is a m-th order equation in λ which can have at most m distinct solutions (roots of the characteristic polynomial) – can be complex even though S is real.
eigenvalue(right) eigenvector
Example

Useful Facts about Eigenvalues & Eigenvectors
0 and , 2121}2,1{}2,1{}2,1{ vvvSv
For symmetric matrices, eigenvectors for distincteigenvalues are orthogonal
TSS and 0 if ,complex for IS
All eigenvalues of a real symmetric matrix are real.

Example
Let
Then
The eigenvalues are 1 and 3 (nonnegative, real). The eigenvectors are orthogonal (and real):
21
12S
.01)2(21
12 2
IS
1
1
1
1
Real, symmetric.
Plug in these values and solve for eigenvectors.
Prasad

Let be a square matrix with m linearly independent eigenvectors (a “non-defective” matrix)
Theorem: Exists an eigen decomposition
(cf. matrix diagonalization theorem)
Columns of U are eigenvectors of S
Diagonal elements of are eigenvalues of
Eigen/diagonal Decomposition
diagonal
Unique for
distinct eigen-values
Prasad 13L18LSI

Diagonal decomposition: why/how
nvvU ...1Let U have the eigenvectors as columns:
n
nnnn vvvvvvSSU
............
1
1111
Then, SU can be written
And S=UU–1.
Thus SU=U, or U–1SU=

Key Point So Far
We can decompose a square matrix into a product of matrices one of which is an eigenvalue diagonal matrix.
But we’d like to say more: when the square matrix is also symmetric, we have a better theorem.
Note that even that isn’t our ultimate destination, since the term-doc matrices we deal with aren’t even square matrices.
One step at a time…

If is a symmetric matrix:
Theorem: There exists a (unique) eigen
decomposition
where: Q-1= QT
Columns of Q are normalized eigenvectors
Columns are orthogonal.
(everything is real)
Symmetric Eigen Decomposition
TQQS

Now…
Let’s find some analogous theorem for non-square matrices.

Singular Value Decomposition
TVUA
MM MN V is NN
For an M N matrix A of rank r there exists a factorization(Singular Value Decomposition = SVD) as follows:
The columns of U are orthogonal eigenvectors of AAT.
The columns of V are orthogonal eigenvectors of ATA.
ii
rdiag ...1 Singular values.
Eigenvalues 1 … r of AAT are the eigenvalues of ATA.
Prasad

Eigen Decomposition and SVD
Note that AAT and ATA are symmetric square matrices.
AAT = UVTVUT = U2UT
That’s just the usual eigen decomposition for a symmetric square matrix.
AAT and ATA have special relevance for us. aij
represents the dot-product similarity of row (column) i with row (column) j. (For docs, it’s the number of common terms; for terms, the number of common docs.)
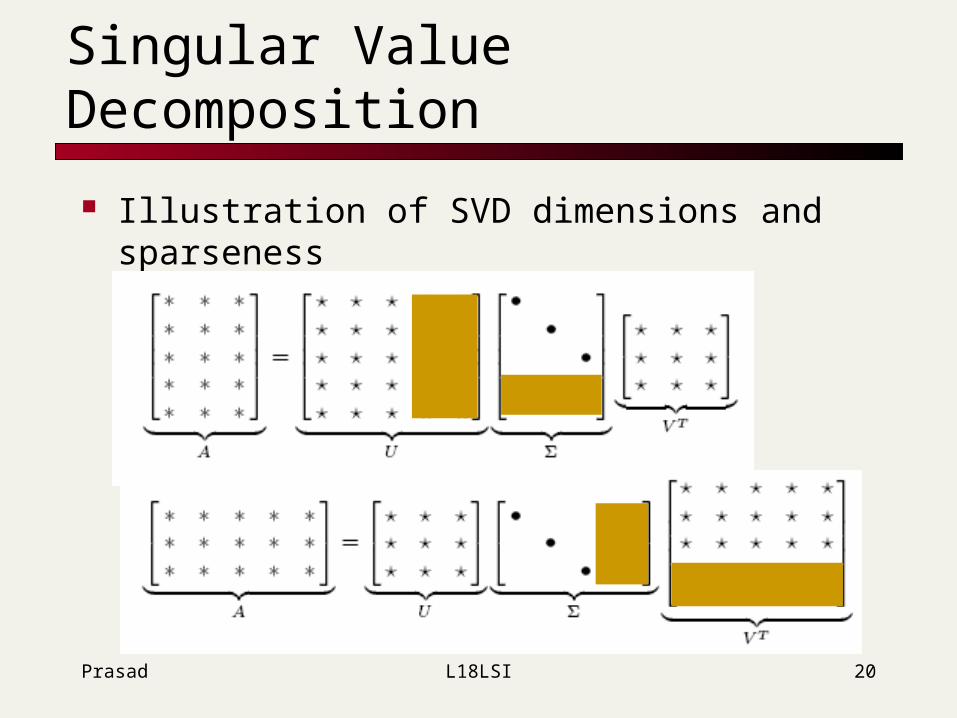
Singular Value Decomposition
Illustration of SVD dimensions and sparseness
Prasad 20L18LSI

21
Example of A = UΣVT : The matrix A
This is a standard term-document matrix. Actually, we use a non-weighted matrix here to simplify the example.

22
Example of A = UΣVT : The matrix U
One row per term, one column per min(M,N) where M is the number of terms and N is the number of documents. This is an orthonormal matrix:(i) Row vectors have unit length. (ii) Any two distinct row vectorsare orthogonal to each other. Think of the dimensions (columns) as “semantic” dimensions that capture distinct topics like politics, sports, economics. Each number uij in the matrix indicates how strongly related term i is to the topic represented by semantic dimension j .

23
Example of A = UΣVT : The matrix Σ
This is a square, diagonal matrix of dimensionality min(M,N) × min(M,N). The diagonal consists of the singular values of A. The magnitude of the singular value measures the importance of the corresponding semantic dimension. We’ll make use of this by omitting unimportant dimensions.

24
Example of A = UΣVT : The matrix VT
One column per document, one row per min(M,N) where M is the number of terms and N is the number of documents. Again: This is an orthonormal matrix: (i) Column vectors have unit length. (ii) Any two distinct column vectors are orthogonal to each other. These are again the semantic dimensions from the term matrix U that capture distinct topics like politics, sports, economics. Each number vij in the matrix indicates how strongly related document i is to the topic represented by semantic dimension j .

25
Example of A = UΣVT : All four matrices
25

26
LSI: Summary
We’ve decomposed the term-document matrix A into a product of three matrices.The term matrix U – consists of one (row) vector for each termThe document matrix VT – consists of one (column) vector for each documentThe singular value matrix Σ – diagonal matrix with singular values, reflecting importance of each dimension
26

SVD can be used to compute optimal low-rank approximations.
Approximation problem: Find Ak of rank k such that
Ak and X are both mn matrices.
Typically, want k << r.
Low-rank Approximation
Frobenius normFkXrankX
k XAA
min)(:

Solution via SVD
Low-rank Approximation
set smallest r-ksingular values to zero
Tkk VUA )0,...,0,,...,(diag 1
k

If we retain only k singular values, and set the rest to 0, then we don’t need the matrix parts in red
Then Σ is k×k, U is M×k, VT is k×N, and Ak is M×N This is referred to as the reduced SVD
It is the convenient (space-saving) and usual form for computational applications
Reduced SVD
k 29

Approximation error
How good (bad) is this approximation? It’s the best possible, measured by the Frobenius
norm of the error:
where the i are ordered such that i i+1. Suggests why Frobenius error drops as k increases.
1)(:
min
kFkFkXrankX
AAXA

SVD low-rank approx. of term-doc matrices
Whereas the term-doc matrix A may have M=50000, N=10 million (and rank close to 50000)
For example, we can construct an approximation A100 with rank 100. Of all rank 100 matrices, it would have the lowest
Frobenius error. We can think of it as clustering our docs (or our
terms) to 100 clusters. The low-dimensional space reflects semantic
associations (latent semantic space). Similar terms map to similar location in low dimensional space.

Latent Semantic Indexing (LSI)
Perform a low-rank approximation of document-term matrix (typical rank 100-300)
General idea Map documents (and terms) to a low-dimensional
representation. The low-dimensional space reflects semantic
associations (latent semantic space). Similar terms map to similar location in low dimensional space

Some wild extrapolation
The “dimensionality” of a corpus is the number of distinct topics represented in it.
More mathematical wild extrapolation: if A has a rank k approximation of low
Frobenius error, then there are no more than k distinct topics in the corpus.
Prasad 33L18LSI

34
Recall unreduced decomposition A=UΣVT
34

35
Reducing the dimensionality to 2
35

36
Reducing the dimensionality to 2
Actually, weonly zero outsingular valuesin Σ. This hasthe effect ofsetting thecorrespondingdimensions inU and V T tozero whencomputing theproductA = UΣV T .
36

37
Original matrix A vs. reduced A2 = UΣ2VT
We can viewA2 as a two-dimensionalrepresentationof the matrix.
We haveperformed adimensionalityreduction totwo dimensions.
37

38
Why is the reduced matrix “better”
38
Similarity of d2 and d3 in the original space: 0.
Similarity of d2 und d3 in the reduced space:0.52 * 0.28 + 0.36 * 0.16 + 0.72 * 0.36 + 0.12 * 0.20 + - 0.39 * - 0.08 ≈ 0.52

39
Why the reduced matrix is “better”
39
“boat” and “ship” are semantically similar.
The “reduced” similarity measure reflects this.

Toy Illustration
Latent semantic space: illustrating example
courtesy of Susan Dumais

LSI has many applications
The general idea is quite standard linear algebra.
It’s original application in comp ling was information retrieval (Deerwester, Dumais et al).
In IR it overcomes two problems: polysemy and synonymy.
In fact, it is rarely used in IR because most IR problems involve huge corpora and SVD algorithms aren’t efficient enough for use on such large corpora.

Extensions
Subsequent work (Hoffman) extended LSI to probabilistic LSI.
That was further extended (Blei, Ng & Jordan) to Latent Dirichlet Analysis (LDA).