the biological meaning of pairwise alignments
DESCRIPTION
Arthur Gruber. The biological meaning of pairwise alignments. Instituto de Ciências Biomédicas Universidade de São Paulo. AG-ICB-USP. What is a pairwise alignment?. Comparison of 2 sequences – nucleotide or protein sequences - PowerPoint PPT PresentationTRANSCRIPT

The biological meaning of The biological meaning of pairwise alignmentspairwise alignments
Arthur Gruber
Instituto de Ciências Biomédicas Universidade de
São Paulo
AG-ICB-USP

What is a pairwise alignment?
• Comparison of 2 sequences – nucleotide or protein sequences
• We can compare a sequence to an entire database of sequences – one pairwise alignment at a time
• Different types of alignments – global and local alignment
• Different algorithms – Needleman-Wunsch, Smith-Waterman, FastA, BLAST
AG-ICB-USP

Pairwise alignment
• Output: alignment of similar blocks or whole sequences
gi|3323386|gb|U85705.1|IFU85705 Isospora felis 28S large subunit ribosomal RNA gene, complete sequence Length = 3227 Score = 218 bits (110), Expect = 2e-54 Identities = 146/158 (92%) Strand = Plus / Minus
Query: 3 cacttttaactctctttccaaagtccttttcatctttccttcacagtacttgttcactat 62 ||||||||||||||||||||||| |||||||||||||| |||| ||||||||| |||| Sbjct: 386 cacttttaactctctttccaaagaacttttcatctttccctcacggtacttgtttgctat 327
Query: 63 cggtctcacgccaatatttagctttacgtgaaacttatcacacattttgcgctcaaatcc 122 ||||||||||||||||||||||||| ||||||||||||||||||||||||||||||||| Sbjct: 326 cggtctcgcgccaatatttagctttatgtgaaacttatcacacattttgcgctcaaatcc 267
Query: 123 caatgaacgcgactcaataaaagcgcaccgtacgtgga 160 | ||||||||||||| ||||| ||| |||||||||||| Sbjct: 266 cgatgaacgcgactctataaaggcgtaccgtacgtgga 229
AG-ICB-USP

Some applications of pairwise alignments
• Annotation – description of the characteristics of a sequence
• Function ascribing – similar sequences MAY share similar functions
• Identification of structural domains – similar sequences MAY share similar structures
• Identification of protein domains – defines protein architecture
• Phylogenetic inference – identification of similar sequences that MAY have a common ancestry
AG-ICB-USP

Some applications of pairwise alignments
• Identification of contaminant sequences in a sequencing project – query sequence x databases (bacterial, ribosomal, mitochondrial, etc.)
• Identification of vector sequences in sequencing reads – alignment and masking
AG-ICB-USP

Identity, similarity, homology
• Identity – refers to nucleotide or amino acid residues that are identical
• Similarity - measurable quantity: percentage of identities between two sequences, percentage of similar amino acid residues (conserved along the evolution).
• Homology – based on a evolutionary conclusion that implies that two sequences has a common ancestral sequence. They are said to share the same evolutionary history. Homology is not quantitative. Two sequences can be or not to be homologous.
AG-ICB-USP

Identity, similarity, homology
• A high degree of similarity between two sequences MAY suggest that they share a common evolutionary history. Other analyses and experimental work should be done to validate such hypothesis
AG-ICB-USP

Contaminant removal
• Other organisms and/or cells – co-purification
• Bacterial DNA - E. coli used as the host cell
• Human – contamination during manipulation
• Other genomes being manipulated in the lab – cross-contamination
Libraries can be contaminated by different sources
Genomic libraries:
AG-ICB-USP

Contaminant removal
• All sources already mentioned
• Ribosomal RNA – co-purification with the polyA fraction
• Organelle transcripts – mitochondrion, plastid
Libraries can be contaminated by different sources
EST libraries:
AG-ICB-USP

Vector masking
A typical read contains sequence stretches that are not originally part of the insert
insert
Vectorsequence
Vectorsequence
Sequencing reaction
AG-ICB-USP

Vector masking
Masking consists in a substitution of bases that are not part of the insert by Xs
insert
Vectorsequence
Vectorsequence
insert
Vectorsequence
Vectorsequence
xxxxxxxxxxxxxxxxxxxxxxxxx
• “X ” bases will not be taken into account by assembly/clustering programs
AG-ICB-USP

Aligning Two Sequences
Human Hemoglobin (HH):
VLSPADKTNVKAAWGKVGAHAGYEG
Sperm Whale Myoglobin (SWM):
VLSEGEWQLVLHVWAKVEADVAGHG
AG-ICB-USP

(HH) VLSPADKTNVKAAWGKVGAHAGYEG ||| | | || |
|(SWM) VLSEGEWQLVLHVWAKVEADVAGHG
• Gap Weight: 12
• Length Weight: 4
• Gaps: 0
• Percent Similarity: 40.000
• Percent Identity: 36.000
• Matrix: blosum62
Aligning Two Sequences
AG-ICB-USP

Gap Insertion/Deletion(HH) VLSPADKTNVKAAWGKVGAH-AGYEG
(SWM) VLSEGEWQLVLHVWAKVEADVAGH-G
- gap insertion/deletion• Gap Weight: 4
• Length Weight: 1
• Gaps: 2
• Percent Similarity: 54.167
• Percent Identity: 45.833
• BLOSUM62
AG-ICB-USP

Scoring
(HH) VLSPADKTNVKAAWGKVGAH-AGYEG ||| | | || || |
(SWM) VLSEGEWQLVLHVWAKVEADVAGH-G
The score of the alignment is:
Matrix value at (V,V) + (L,L) + (S,S) + (P,E) + … (penalty for gap insertion/deletion)*gaps (penalty for gap extension)*(total length of all gaps)
AG-ICB-USP

Scoring System
• Identity: An objective and quite well defined measure Count the number of identical matches, divide by length of aligned region
• Similarity: A less well defined measure
Category Amino acid
Acids and AmidesAsp (D) Glu(E) Asn (N) Gln (Q)
Basic His (H) Lys (K) Arg (R)
Aromatic Phe (F) Tyr (Y) Trp (W)
Hydrophilic Ala (A) Cys (C) Gly (G) Pro (P) Ser (S) Thr (T)
Hydrophobic Ile (I) Leu (L) Met (M) Val (V)AG-ICB-USP

Scoring system Rates of amino acid substitution are not uniform Some amino acids are more conserved than
others (e.g. C, H, W compared to A, L, I) Some substitutions are more common than others (e.g. A I, A L compared to D L) Conclusion: there are evolutionary pressures that
probably reflect structural and functional constraints
Scoring matrices – matrices that are used for scoring amino acid substitutions in pairwise alignments
They reflect substitution rates that are originated by evolutionary events
AG-ICB-USP
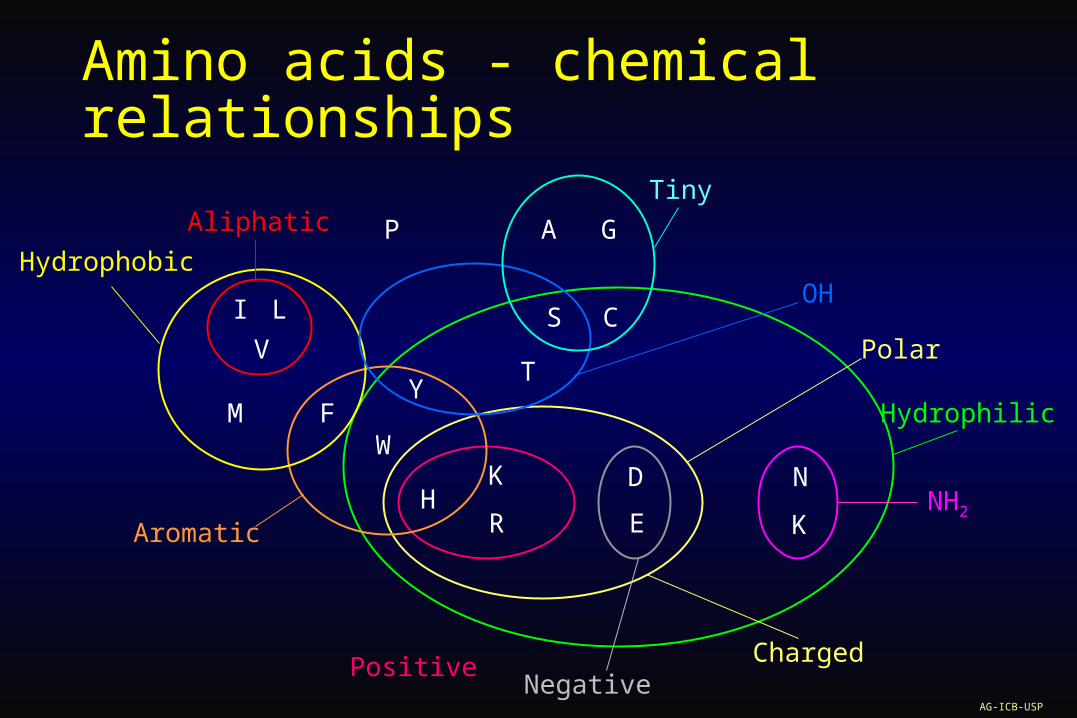
Amino acids - chemical relationships
HR
K D
E
N
K
WF
T
S C
A G
Y
L
V
I
M
P
Tiny
OH
Hydrophilic
NH2
ChargedNegative
Positive
Aromatic
Hydrophobic
Aliphatic
Polar
AG-ICB-USP

PAM Stands for Point Accepted Mutation Dayhoff Matrix, 1978 A series of matrices describing the extent to which
two amino acids have been interchanged in evolution
Very similar sequences were aligned, phylogenetic trees were built, and ancestral sequences were reconstructed
Out of these alignments, the frequency of substitution between each pair of amino acids was calculated. Using this information, PAM matrices were built (PAM1 i.e. one accepted point mutation per 100 amino acids).
AG-ICB-USP

GAP_CREATE 12GAP_EXTEND 4
A B C D E F G H I K L M N P Q R S T V WA 2 0 -2 0 0 -4 1 -1 -1 -1 -2 -1 0 1 0 -2 1 1 0 -6B 0 2 -4 3 2 -5 0 1 -2 1 -3 -2 2 -1 1 -1 0 0 -2 -5C -2 -4 12 -5 -5 -4 -3 -3 -2 -5 -6 -5 -4 -3 -5 -4 0 -2 -2 -8D 0 3 -5 4 3 -6 1 1 -2 0 -4 -3 2 -1 2 -1 0 0 -2 -7E 0 2 -5 3 4 -5 0 1 -2 0 -3 -2 1 -1 2 -1 0 0 -2 -7
F -4 -5 -4 -6 -5 9 -5 -2 1 -5 2 0 -4 -5 -5 -4 -3 -3 -1 0G 1 0 -3 1 0 -5 5 -2 -3 -2 -4 -3 0 -1 -1 -3 1 0 -1 -7H -1 1 -3 1 1 -2 -2 6 -2 0 -2 -2 2 0 3 2 -1 -1 -2 -3I -1 -2 -2 -2 -2 1 -3 -2 5 -2 2 2 -2 -2 -2 -2 -1 0 4 -5K -1 1 -5 0 0 -5 -2 0 -2 5 -3 0 1 -1 1 3 0 0 -2 -3
L -2 -3 -6 -4 -3 2 -4 -2 2 -3 6 4 -3 -3 -2 -3 -3 -2 2 -2M -1 -2 -5 -3 -2 0 -3 -2 2 0 4 6 -2 -2 -1 0 -2 -1 2 -4N 0 2 -4 2 1 -4 0 2 -2 1 -3 -2 2 -1 1 0 1 0 -2 -4P 1 -1 -3 -1 -1 -5 -1 0 -2 -1 -3 -2 -1 6 0 0 1 0 -1 -6Q 0 1 -5 2 2 -5 -1 3 -2 1 -2 -1 1 0 4 1 -1 -1 -2 -5
R -2 -1 -4 -1 -1 -4 -3 2 -2 3 -3 0 0 0 1 6 0 -1 -2 2S 1 0 0 0 0 -3 1 -1 -1 0 -3 -2 1 1 -1 0 2 1 -1 -2T 1 0 -2 0 0 -3 0 -1 0 0 -2 -1 0 0 -1 -1 1 3 0 -5V 0 -2 -2 -2 -2 -1 -1 -2 4 -2 2 2 -2 -1 -2 -2 -1 0 4 -6W -6 -5 -8 -7 -7 0 -7 -3 -5 -3 -2 -4 -4 -6 -5 2 -2 -5 -6 17
PAM250 - amino acid substitution matrix
AG-ICB-USP

BLOSUM• Stands for Blocks Substitution Matrices
• Henikoff and Henikoff, 1992
• A series of matrices describing the extent to which two amino acids are interchangeable in conserved structures
• Built by extracting replacement information from the alignments in the BLOCKS database.
AG-ICB-USP

BLOSUM
• The number in the series (BLOSUM62) represents the threshold percent similarity between sequences, for considering them in the calculation.
• For example, BLOSUM62 is derived from an alignment of sequences that share 62% similarity, BLOSUM45 is based on 45% sequence similarity in aligned sequences
AG-ICB-USP

Reference: Henikoff, S. and Henikoff, J. G. (1992). Amino acid substitution matrices from protein blocks. Proc. Natl. Acad. Sci. USA 89: 10915-10919.
A R N D C Q E G H I L K M F P S T W Y V B Z X *A 4 -1 -2 -2 0 -1 -1 0 -2 -1 -1 -1 -1 -2 -1 1 0 -3 -2 0 -2 -1 0 -4 R -1 5 0 -2 -3 1 0 -2 0 -3 -2 2 -1 -3 -2 -1 -1 -3 -2 -3 -1 0 -1 -4 N -2 0 6 1 -3 0 0 0 1 -3 -3 0 -2 -3 -2 1 0 -4 -2 -3 3 0 -1 -4 D -2 -2 1 6 -3 0 2 -1 -1 -3 -4 -1 -3 -3 -1 0 -1 -4 -3 -3 4 1 -1 -4 C 0 -3 -3 -3 9 -3 -4 -3 -3 -1 -1 -3 -1 -2 -3 -1 -1 -2 -2 -1 -3 -3 -2 -4 Q -1 1 0 0 -3 5 2 -2 0 -3 -2 1 0 -3 -1 0 -1 -2 -1 -2 0 3 -1 -4 E -1 0 0 2 -4 2 5 -2 0 -3 -3 1 -2 -3 -1 0 -1 -3 -2 -2 1 4 -1 -4 G 0 -2 0 -1 -3 -2 -2 6 -2 -4 -4 -2 -3 -3 -2 0 -2 -2 -3 -3 -1 -2 -1 -4 H -2 0 1 -1 -3 0 0 -2 8 -3 -3 -1 -2 -1 -2 -1 -2 -2 2 -3 0 0 -1 -4 I -1 -3 -3 -3 -1 -3 -3 -4 -3 4 2 -3 1 0 -3 -2 -1 -3 -1 3 -3 -3 -1 -4 L -1 -2 -3 -4 -1 -2 -3 -4 -3 2 4 -2 2 0 -3 -2 -1 -2 -1 1 -4 -3 -1 -4 K -1 2 0 -1 -3 1 1 -2 -1 -3 -2 5 -1 -3 -1 0 -1 -3 -2 -2 0 1 -1 -4 M -1 -1 -2 -3 -1 0 -2 -3 -2 1 2 -1 5 0 -2 -1 -1 -1 -1 1 -3 -1 -1 -4 F -2 -3 -3 -3 -2 -3 -3 -3 -1 0 0 -3 0 6 -4 -2 -2 1 3 -1 -3 -3 -1 -4 P -1 -2 -2 -1 -3 -1 -1 -2 -2 -3 -3 -1 -2 -4 7 -1 -1 -4 -3 -2 -2 -1 -2 -4 S 1 -1 1 0 -1 0 0 0 -1 -2 -2 0 -1 -2 -1 4 1 -3 -2 -2 0 0 0 -4 T 0 -1 0 -1 -1 -1 -1 -2 -2 -1 -1 -1 -1 -2 -1 1 5 -2 -2 0 -1 -1 0 -4 W -3 -3 -4 -4 -2 -2 -3 -2 -2 -3 -2 -3 -1 1 -4 -3 -2 11 2 -3 -4 -3 -2 -4 Y -2 -2 -2 -3 -2 -1 -2 -3 2 -1 -1 -2 -1 3 -3 -2 -2 2 7 -1 -3 -2 -1 -4 V 0 -3 -3 -3 -1 -2 -2 -3 -3 3 1 -2 1 -1 -2 -2 0 -3 -1 4 -3 -2 -1 -4 B -2 -1 3 4 -3 0 1 -1 0 -3 -4 0 -3 -3 -2 0 -1 -4 -3 -3 4 1 -1 -4 Z -1 0 0 1 -3 3 4 -2 0 -3 -3 1 -1 -3 -1 0 -1 -3 -2 -2 1 4 -1 -4 X 0 -1 -1 -1 -2 -1 -1 -1 -1 -1 -1 -1 -1 -1 -2 0 0 -2 -1 -1 -1 -1 -1 -4 * -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 -4 1
BLOSUM62 - amino acid substitution matrix
AG-ICB-USP
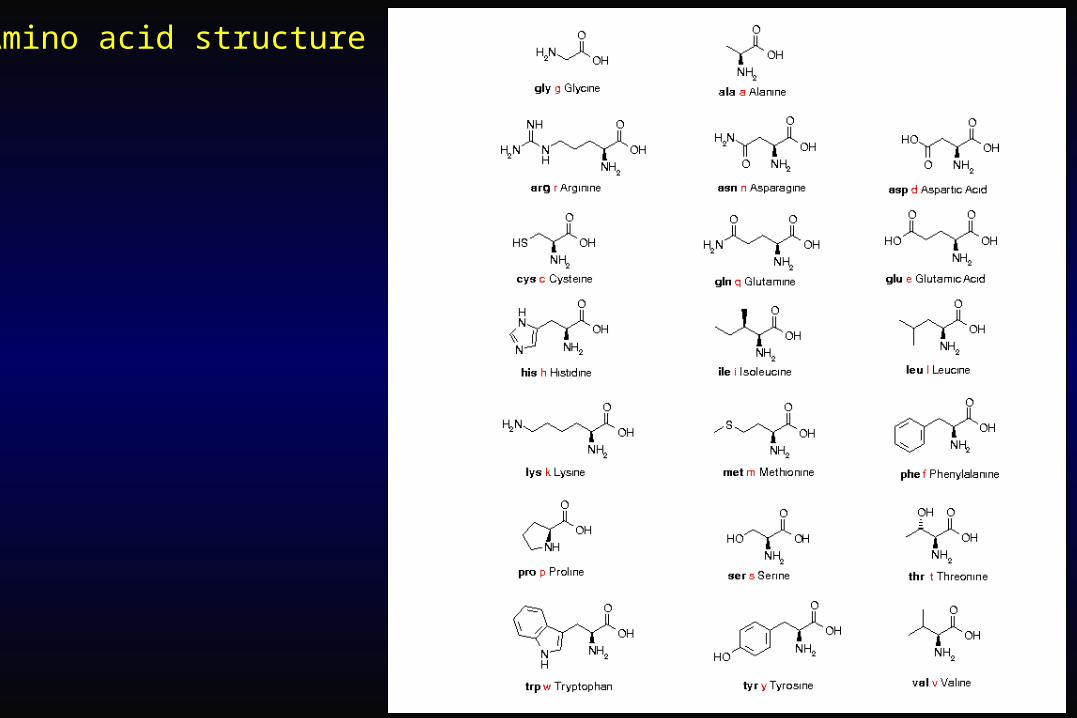
Amino acid structure

Guidelines
• Lower PAMs and higher Blosums find short local alignment of highly similar sequences
• Higher PAMs and lower Blosums find longer weaker local alignment
• No single matrix answers all questions
AG-ICB-USP

BLAST – Basic Local Alignment Search Tool
• Algorithm first described in 1990
Altschul, S.F., Gish, W., Miller, W., Myers, E.W. & Lipman, D.J. (1990) "Basic local alignment search tool." J. Mol. Biol. 215:403-410.
• And improved in 1997
Altschul, S.F., Madden, T.L., Schäffer, A.A., Zhang, J., Zhang, Z., Miller, W. & Lipman, D.J. (1997). Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res. 25: 3389-3402.
AG-ICB-USP

Blast search – four components
• Search purpose/goal
• Program
• Query sequence
• Database
AG-ICB-USP

BLAST – search purpose/goal
• What is the biological question? Examples:
• Which proteins of the database are similar to my protein sequence?
• Which proteins of the database are similar to the conceptual translation of my DNA sequence?
• Which nucleotide sequences in the database are similar to my nucleotide sequence?
• Which proteins coded by the conceptual translation of the database sequences are similar to my protein sequence?
•Which proteins coded by the conceptual translation of the database sequences are similar to the conceptual translation of my DNA sequence?
AG-ICB-USP

BLAST – search purpose/goal
• Which proteins of the database are similar to my protein sequence?
• I have sequenced a gene and derived the protein sequence by concetpual translation. Alternatively, I obtained the protein sequence directly. I am now interested to find out its possible fnction.
• Using a similarity search, I can find protein sequences in databases that are similar to mine: orthologs and paralogs.
• BLASTP – protein query x protein database
AG-ICB-USP

BLAST - search purpose/goal
• Which proteins of the database are similar to the conceptual translation of my DNA sequence?
• I have sequenced an EST (expressed sequence tag) that contains a protein coding region.
• I am interested to find out which proteins of the database are similar to the conceptual translation of my nucleic acid sequence.
• BLASTX – nucleotide (translated) query x protein database
AG-ICB-USP

BLAST – search purpose/goal
• Which nucleotide sequences of the database are similar to my DNA sequence?
• I have sequenced a DNA fragment.
• I am interested to find out which DNA sequences of the database are similar to my nucleic acid sequence.
• BLASTN – nucleotide query x nucleotide database
AG-ICB-USP
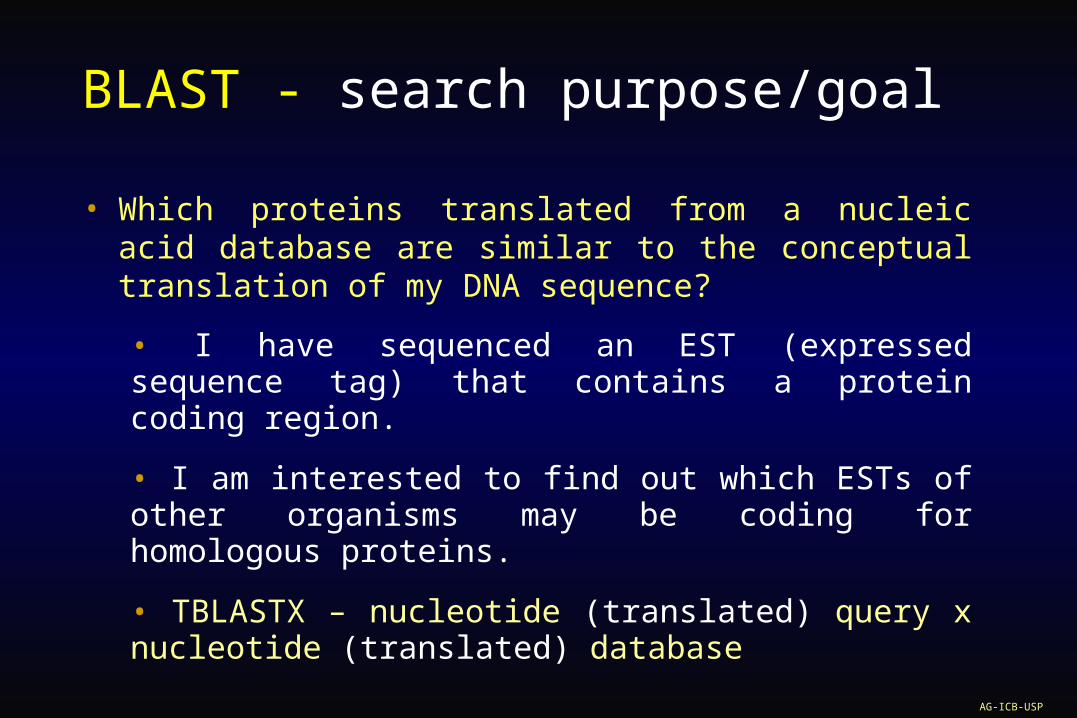
BLAST - search purpose/goal
• Which proteins translated from a nucleic acid database are similar to the conceptual translation of my DNA sequence?
• I have sequenced an EST (expressed sequence tag) that contains a protein coding region.
• I am interested to find out which ESTs of other organisms may be coding for homologous proteins.
• TBLASTX – nucleotide (translated) query x nucleotide (translated) database
AG-ICB-USP

BLAST – search purpose/goal
• Which proteins coded by the conceptual translation of the database sequences are similar to my protein sequence?
• I have a protein sequence on hands and am interested to find out which genes of other organisms may be coding for homologous proteins.
• TBLASTN – protein query x nucleotide (translated) database
AG-ICB-USP

BLAST - programs
• BLASTP – protein query x protein database
• BLASTN – nucleotide query x nucleotide database
• BLASTX – nucleotide (translated) query x protein database
• TBLASTN – protein query x nucleotide (translated) database
• TBLASTX – nucleotide query (translated) x nucleotide (translated) database
AG-ICB-USP

FastA format• The first line begins with the symbol '>' followed by
the name of the sequence
• The sequence is on the remaining lines.
• The sequence must not contain blanks.
• The sequence could be in upper or lower case.
• Below is an example sequence in FASTA format:\
>DNA sequenceGCCCCCGGCCCCGCCCCGGCCCCGCCCCCGGCCCCGCCCCGCAAGGGTCACAGGTCACGGGGCGGGGCCGAGGCGGAAGCGCCCGCAGCCCGGTACCGGCTCCTCCTGGGCTCCCTCTAGCGCCTTCCCCCCGGCCCGACTCCGCTGGTCAGCGCCAAGTGACTTACGCCCCCGACCTCTGAGCCCGGACCGCTAG
AG-ICB-USP
BLAST – query sequence

BLAST – database
AG-ICB-USP
• Nucleotide databases
• nr, refseq, est_human, est_mouse, est_others, wgs, etc.
• Protein databases – nr, Swiss-Prot, refseq, etc.
BLAST – web server
AG-ICB-USP
• BLAST web server address:
• http://blast.ncbi.nlm.nih.gov/Blast.cgi

AG-ICB-USP

AG-ICB-USP

AG-ICB-USP

AG-ICB-USP

AG-ICB-USP

AG-ICB-USP

AG-ICB-USP
AG-ICB-USP

AG-ICB-USP

• BLAST does not display ALL positive hits, only those with the highest score. You may miss some important hits!
• Do not give up when getting “no hits” results. Try changing some parameters:
– Substitution matrix
– Word size (lower values are more sensitive, but more computationally intense)
– Gap penalty
AG-ICB-USP
BLAST – some recommendations

• If you have a large number of query sequences, you should better run BLAST searches locally. WARNING NCBI limits the number of simultaneous queries.
• Do not forget: protein sequences are more conserved than the respective nucleotide sequences
– This is important if you are looking for distant orthologues
AG-ICB-USP
BLAST – some recommendations