the university of electro-communications tokyo, japan (uec ...mm.cs.uec.ac.jp/deep2.pdf ·...
TRANSCRIPT

The University of Electro-Communications
Tokyo, JAPAN (UEC)
「物体認識論」
総合情報学科 第6学期講義
第11回目(講義7回目)(16/01/12)
講義担当:柳井
http://mm.cs.uec.ac.jp/object/

第1回 (10/06):画像認識とは?イントロダクション.身の回りでの応用例から最新研究まで
第2回 (10/20):画像認識の基礎.画像処理.エッジ検出.色ヒストグラムに基づく画像検索.
第3回 (10/27):【演習1】 MATLAB の基礎.顔検出,物体検出を試してみる.
第4回 (11/10):【演習2】 MATLABでの画像の取り扱い.色ヒストグラムに基づく画像検索.
第5回 (11/17):様々な特徴量.輝度勾配ヒストグラム.局所特徴量.SIFT特徴量.
第6回 (11/24):一般物体認識.BoF法による特徴ベクトル生成.K-Means法.
第7回 (12/01):【演習3】 局所特徴量の抽出.特定物体認識.
第8回 (12/08):機械学習法.Nearest Neighbor法.線形/非線形SVM.NaiveBayes法.
第9回 (12/15):【演習4】 BoFベクトルの生成.K-means法.
第10回 (12/22):Deep Learningによる画像認識の基礎.確率的勾配降下法.
第11回 (1/12):Deep Learningの各種レイヤ-.誤差逆伝搬法.認識結果の評価方法.
第12回 (1/19):【演習5】 BoFと機械学習を用いた一般物体認識.
第13回 (1/26):【演習6】 Deep Learningによる一般物体認識.
第14回 (2/02):【演習7】 レポート課題説明(1):Web画像の自動収集.
第15回 (2/09):【演習8】 レポート課題説明(2):画像分類と,Web画像の再ランキング.
今回の予定本日の予定 (講義最終回)
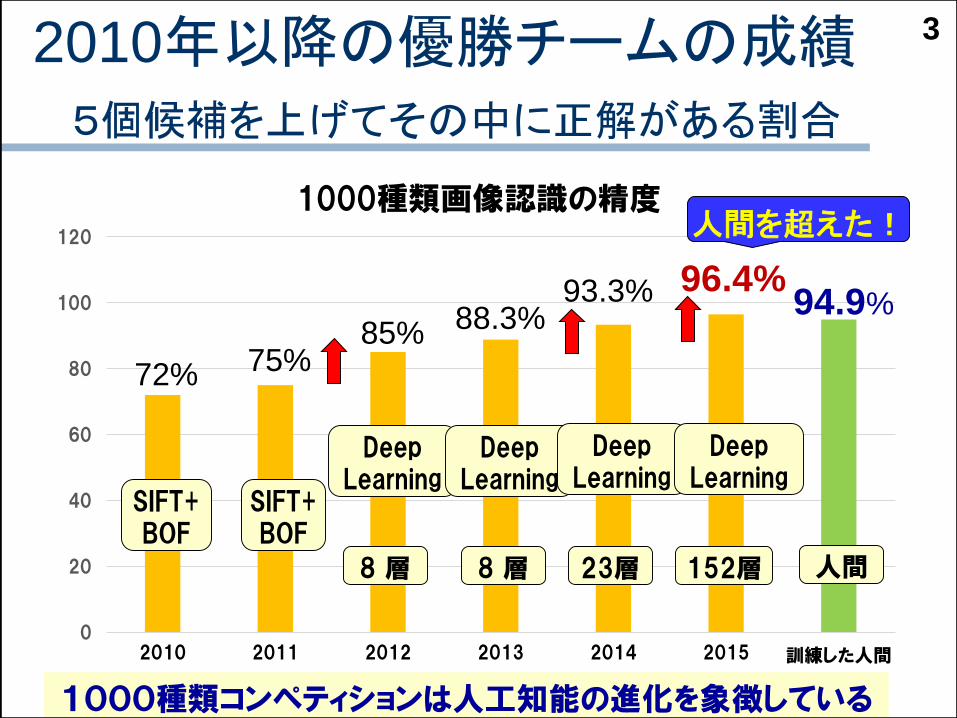
2010年以降の優勝チームの成績5個候補を上げてその中に正解がある割合
0
20
40
60
80
100
120
2010 2011 2012 2013 2014 2015 訓練した人間
1000種類画像認識の精度
3
94.9%
72%
SIFT+BOF
75%
SIFT+BOF
85%
DeepLearning
8 層
88.3%
8 層
DeepLearning
93.3%
23層
DeepLearning
96.4%
152層
DeepLearning
人間を超えた!
人間
1000種類コンペティションは人工知能の進化を象徴している

1000種類画像認識国際コンペティション2012年 Deep Learning ショック!
Deep Learning(深層学習)を使った
参加チーム(トロント大)
従来手法(BoF)による参加チーム(トロント大以外すべて)
この表はエラー率なので,正解率は 100%-(エラー率)
85%
75%
1位と2位の差が10%!
トロント大チームは画像認識研究者
ではない.DeepLearningの研究グループ.

画像認識の多くの問題でDeep Learningが認識性能を大幅に向上させる.(動画以外)これまでの常識が全部ひっくり返った
出現頻度
代表的パターン
認識画像 局所パターン 代表パターンヒストグラム
機械学習分類器
認識結果
2013~
画像認識におけるパラダイムシフト
元の画像
認識結果
Deep Neural Network
誰も予想できない急激な進歩.
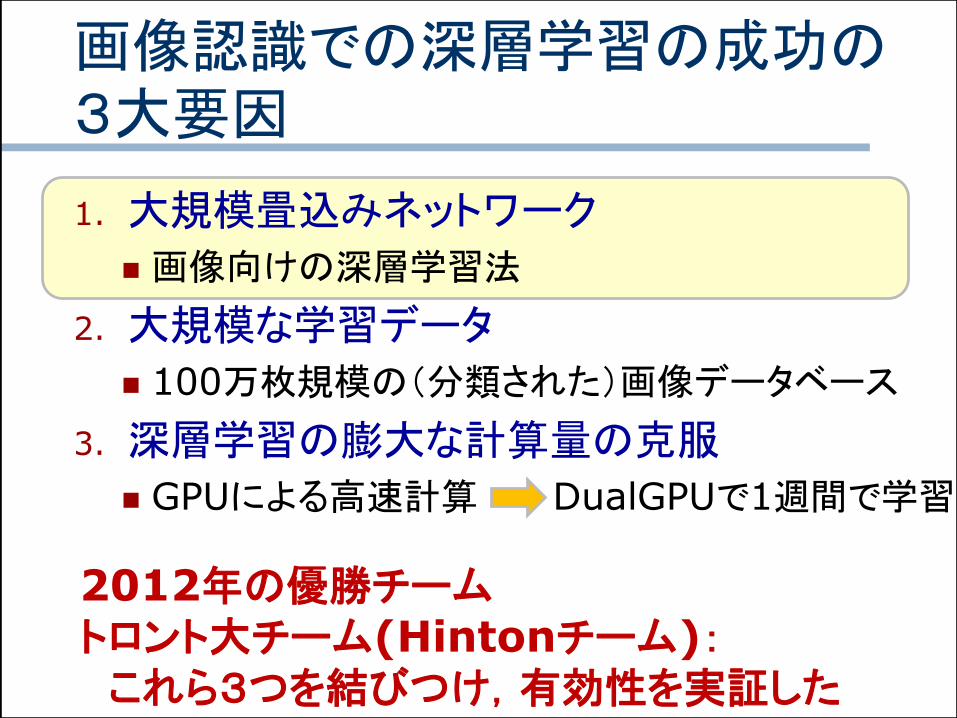
画像認識での深層学習の成功の3大要因
1. 大規模畳込みネットワーク
画像向けの深層学習法
2. 大規模な学習データ
100万枚規模の(分類された)画像データベース
3. 深層学習の膨大な計算量の克服
GPUによる高速計算 DualGPUで1週間で学習
2012年の優勝チームトロント大チーム(Hintonチーム):これら3つを結びつけ,有効性を実証した

[1] 畳み込みネットワーク
認識画像
出現頻度
代表的パターン
局所パターン 代表パターンヒストグラム
認識結果
特徴抽出部分に相当分類部分に相当
特徴抽出から分類まで,すべて多層ネットワークで行う.入力が画像で,出力がクラス確率.End-to-end ネット.
「自動車」
224x224
RGB画像
クラス確率ベクトル
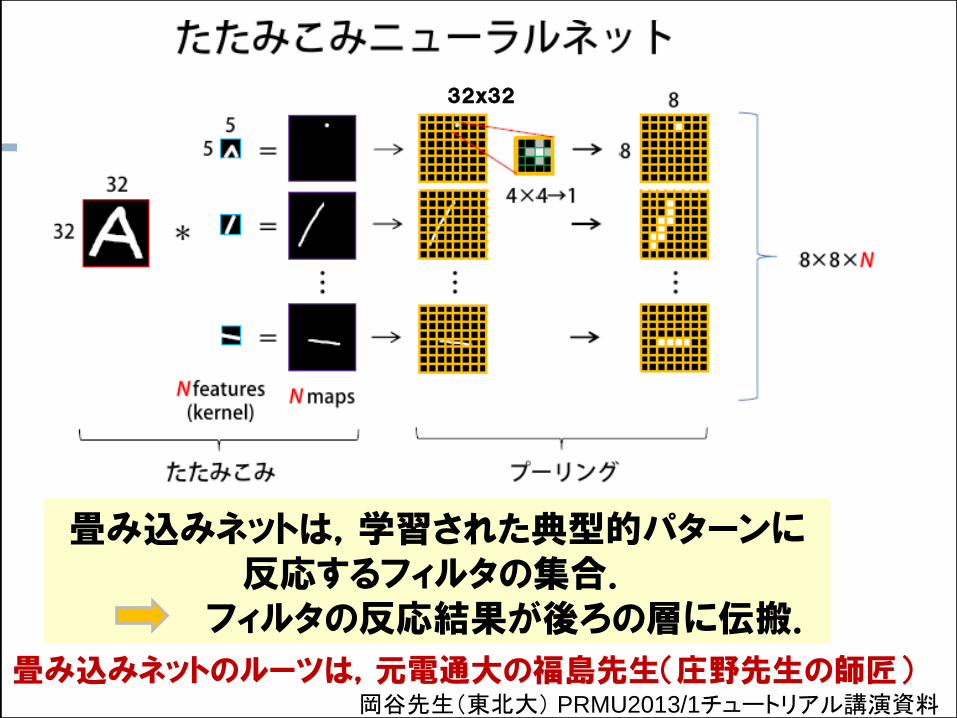
岡谷先生(東北大) PRMU2013/1チュートリアル講演資料
32x32
畳み込みネットは,学習された典型的パターンに反応するフィルタの集合.
フィルタの反応結果が後ろの層に伝搬.
畳み込みネットのルーツは,元電通大の福島先生(庄野先生の師匠)

学習されたフィルタが反応するパターン低次層:直線や円など単純パターンに反応
9
Zeiler, M. and Fergus, R.: "Visualizing and Understanding Convolutional Networks", ECCV, (2014).
「自動車」

学習されたフィルタが反応するパターン中間層:タイヤや格子模様など物体のパーツに反応
10
Zeiler, M. and Fergus, R.: "Visualizing and Understanding Convolutional Networks", ECCV, (2014).
「自動車」
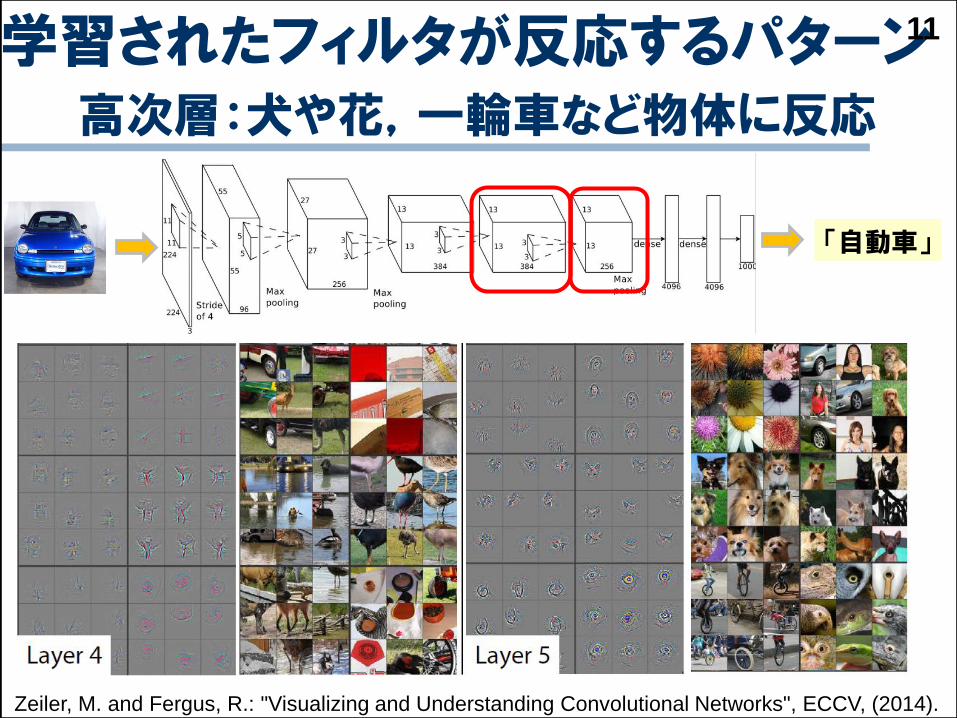
学習されたフィルタが反応するパターン高次層:犬や花,一輪車など物体に反応
11
Zeiler, M. and Fergus, R.: "Visualizing and Understanding Convolutional Networks", ECCV, (2014).
「自動車」

画像認識での深層学習の成功の3大要因
1. 大規模畳込みネットワーク
画像向けの深層学習法
2. 大規模な学習データ
100万枚規模の(分類された)画像データベース
3. 深層学習の膨大な計算量の克服
GPUによる高速計算 DualGPUで1週間で学習
2012年のトロント大チーム(Hintonチーム):これら3つを結びつけ,有効性を実証した
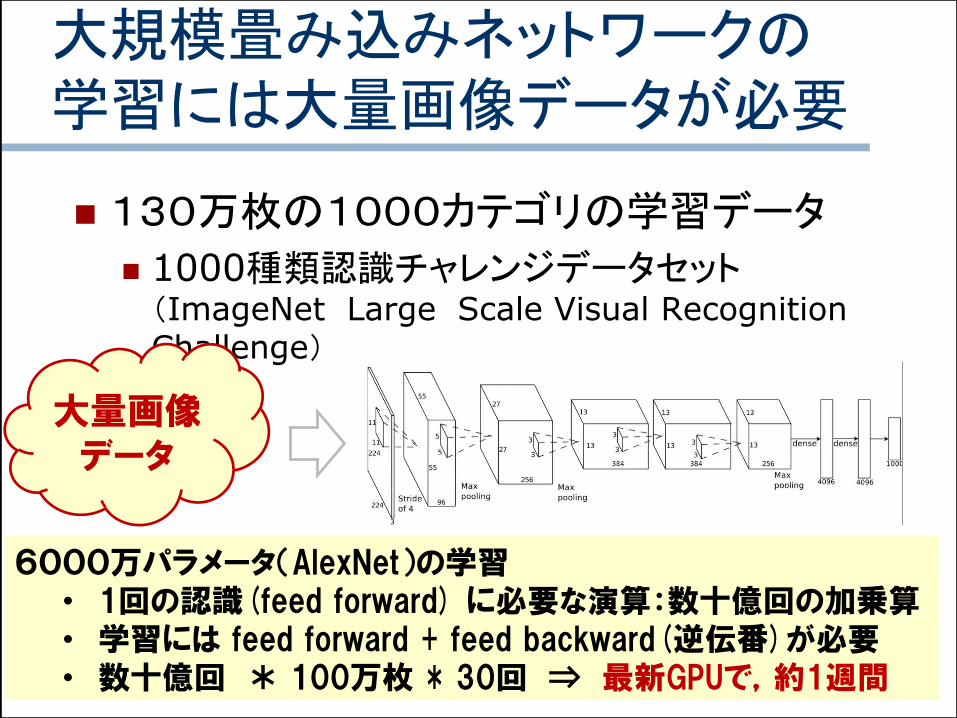
大規模畳み込みネットワークの学習には大量画像データが必要
130万枚の1000カテゴリの学習データ
1000種類認識チャレンジデータセット(ImageNet Large Scale Visual Recognition Challenge)
大量画像データ
6000万パラメータ(AlexNet)の学習• 1回の認識(feed forward) に必要な演算:数十億回の加乗算• 学習には feed forward + feed backward(逆伝番)が必要• 数十億回 * 100万枚 * 30回 ⇒ 最新GPUで,約1週間

クラウドソーシングサービス (2005年)
Amazon Mechanical Turk
世界中の“人力”の利用 : crowd-sourcing
学習画像データ作成,認識結果評価に利用可能.
14
安価な対価(例えば,1枚0.1セント程度)で画像をチェックしてくれる.
世界中から作業者をWebで集める.

研究者の意図が一切入ってない⇒ 現実の「写真」に近い.
ImageNet
あらゆる言葉に関する画像をデータベース化.Wordnetの画像版.
名詞句21,841語の画像を合計14,197,122枚.
階層構造を持つ大規模画像DBの意義
画像認識の学習・評価データ.
画像と意味の大規模分析.
15
http://www.image-net.org/
[Deng et al. CVPR2009]
多言語テキスト検索による画像収集
クラウドソーシングによるクリーニング
image-net.orgで公開.
誰でも利用可.
(Stanford大)

画像認識での深層学習の成功の3大要因
1. 大規模畳み込みネットワーク
画像向けの深層学習法
2. 大規模な学習データ
100万枚規模の(分類された)画像データベース
3. 深層学習の膨大な計算量の克服
GPUによる高速計算 DualGPUで1週間で学習
2012年のトロント大チーム(Hintonチーム):これら3つを結びつけ,有効性を実証した
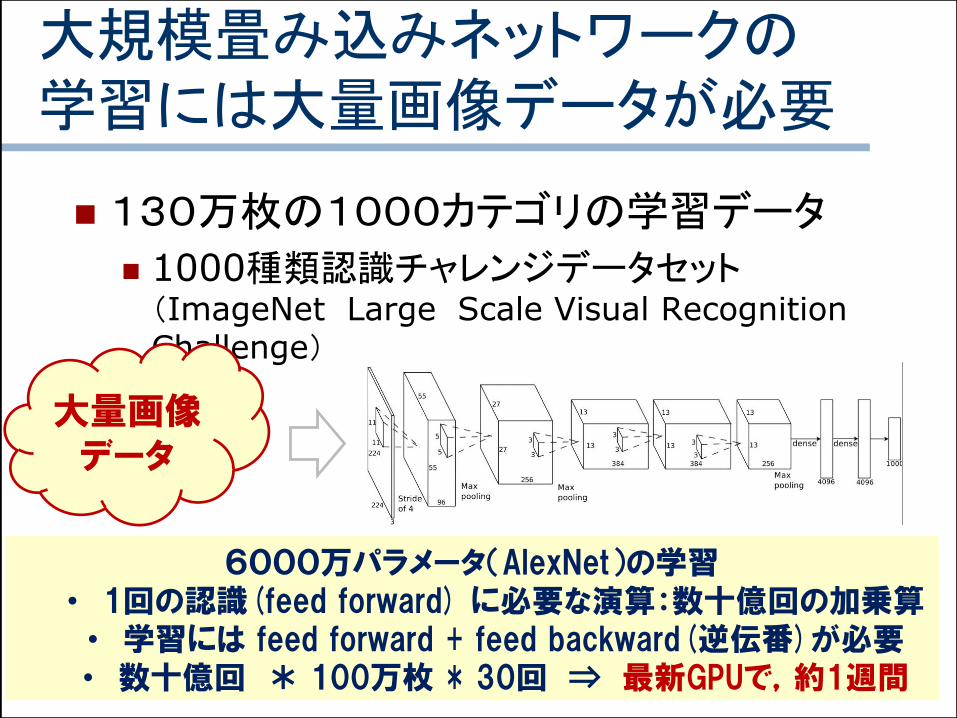
大規模畳み込みネットワークの学習には大量画像データが必要
130万枚の1000カテゴリの学習データ
1000種類認識チャレンジデータセット(ImageNet Large Scale Visual Recognition Challenge)
大量画像データ
6000万パラメータ(AlexNet)の学習• 1回の認識(feed forward) に必要な演算:数十億回の加乗算
• 学習には feed forward + feed backward(逆伝番)が必要• 数十億回 * 100万枚 * 30回 ⇒ 最新GPUで,約1週間

GPUはdeep learningに必須
CPUのみの計算の 10~50倍程度高速化.
GTX Titan Black/X,980Ti, Tesla K20/40/80
PCクラスタから,GPUクラスタへ.
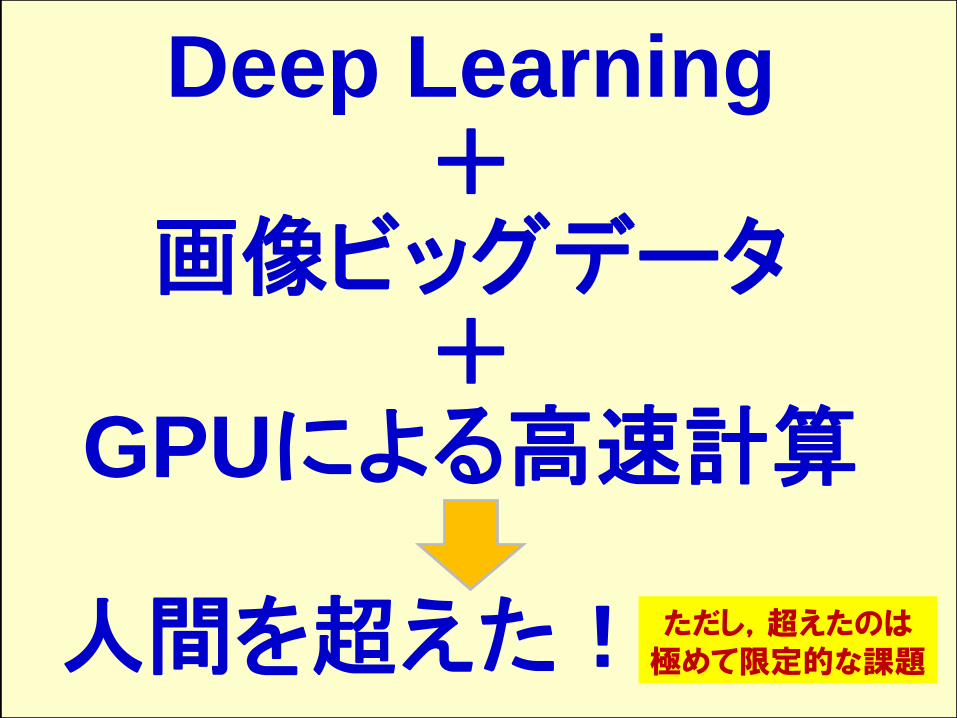
Deep Learning+
画像ビッグデータ+
GPUによる高速計算
人間を超えた! ただし,超えたのは極めて限定的な課題

一般物体認識の分類 (1)
画像全体のカテゴリー分類
画像アノテーション:複数ラベルの付与
文生成:画像内容を説明する文を自動生成
クマ トラ ゾウ
ゾウキバ空草草原
クマ草水
トラ草草原
クマが水の上を歩いています
.
トラが草原にいます.
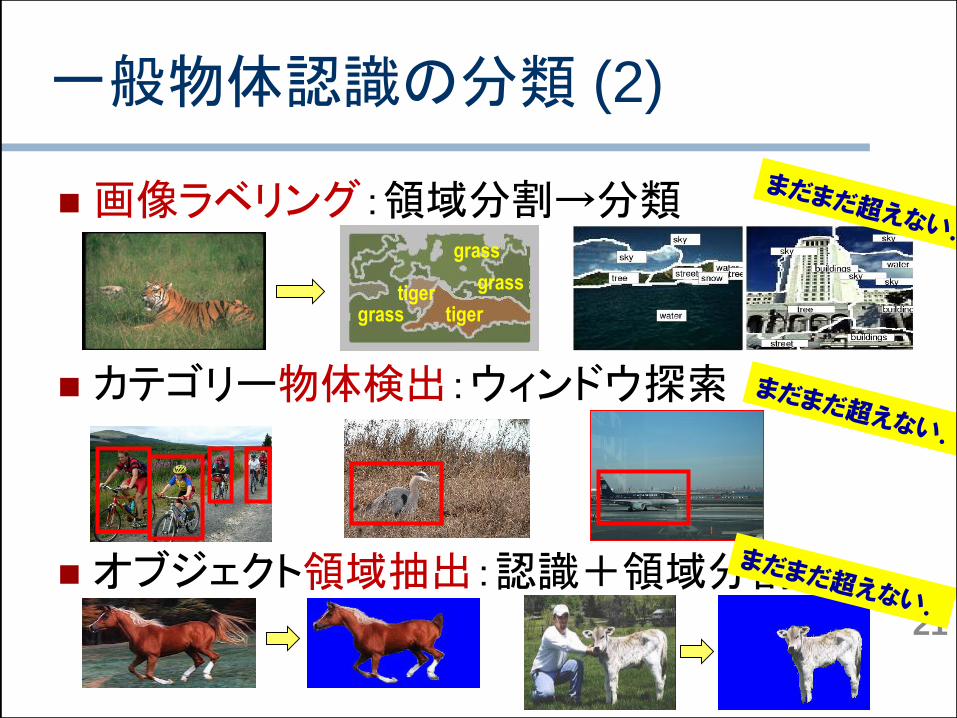
画像ラベリング:領域分割→分類
カテゴリー物体検出:ウィンドウ探索
オブジェクト領域抽出:認識+領域分割
一般物体認識の分類 (2)
21
tiger
grass
grass
grass
tiger

古典的ニューラルネットワーク(Neural Network)

ニューラルネットワーク
人間の脳をモデル化した学習手法
多数のニューロンの結合によって学習器を構築
階層型(リカレント型)と相互結合型
パラメータWiとθを学習によって求める
fは,シグモイド関数を用いることが一般的.
単体ニューロンはパーセプトロン(1957),
階層型はBP学習(1986).

1980~90年代の階層型ニューラルネットワークの構造
入力層
中間層
出力層
1980~90年代のNeural network
入力,中間,出力の3層構成(中間層は2層以上の場合もあるが,一般的には1層のみ)
全結合層のみ.各層のセル数もあまり多くない.
あまり大規模なネットワークは利用されない ⇒パラメータが多すぎて,学習が困難.⇒ 2000年前後のSVMの登場によって,忘れられた!

Deep Neural Network
ILSVRC 2012 での,衝撃的な復活!

Deep Learning (特に,Deep
Convolutional Neural Network, DCNN)
昔のニューラルネットがdeepになって復活.
Layerが増えて,多層化.
単純なニューロン (𝑦 = 𝑓 ∑𝑤𝑖𝑥𝑖 )だけではなく,convolutional network の導入.(1990年代から既にあ
ったが,有効性がさほど認識されていなかった.)
Sigmoid関数 (𝑓 𝑥 = 1/(1 + 𝑒𝑥))の代わりにRectified Linear Unit (ReLU) (𝑓 𝑥 = max(0, 𝑥)) の導入.
大量のデータによる学習.(例えば,1000種類120万枚) (+dropoutによる過学習の防止)
計算機の高速大容量化.GPUによる高速計算.
•でも,学習方法は,Back Propagationで昔と同じ.
26
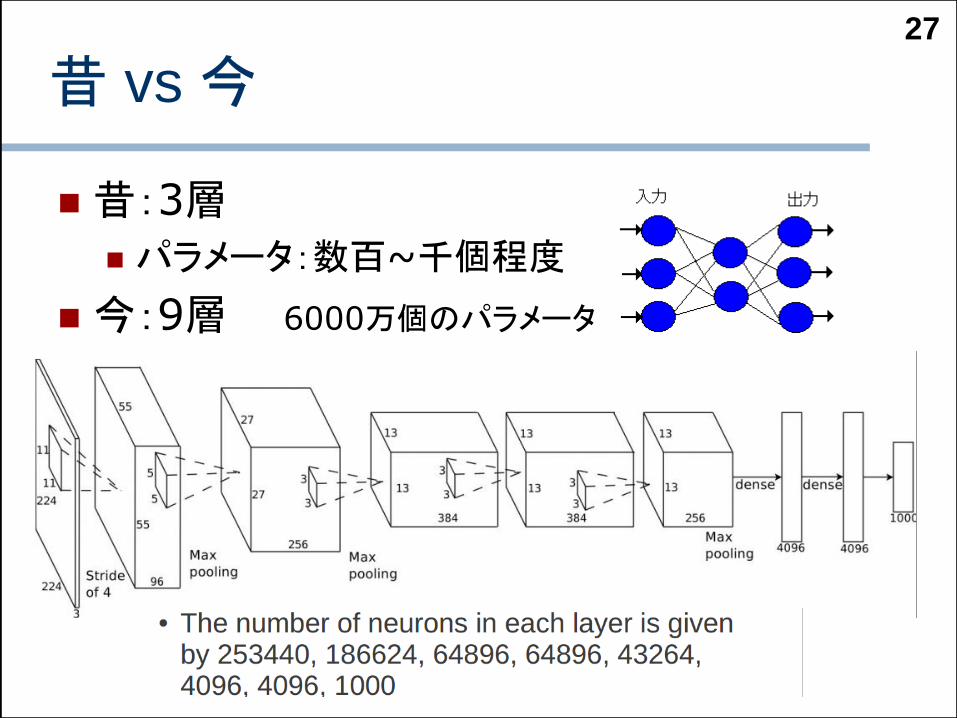
昔 vs 今
昔:3層
パラメータ:数百~千個程度
今:9層 6000万個のパラメータ
27
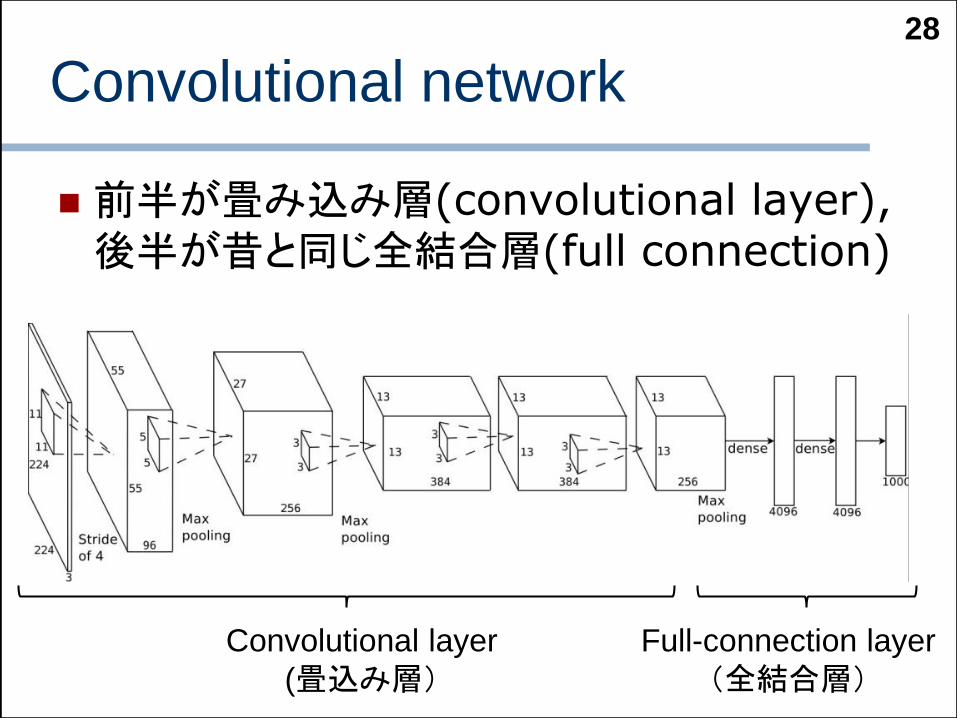
Convolutional network
前半が畳み込み層(convolutional layer),後半が昔と同じ全結合層(full connection)
28
Convolutional layer
(畳込み層)Full-connection layer
(全結合層)

Deep Neural Network
の基本原理

画像認識システムとは?
画像を入力すると,クラス確率を返すシステム.
事前の学習が必要: クラスクラス付き画像画像
30
「ライオン」
認識結果
「山」
「椅子」
クラス確率
「ライオン」
「山」
「椅子」
ラベル付き学習データ
特徴抽出
機械学習
モデルの学習
学習
未知の画像?
特徴抽出
学習済モデルによる分類
分類 [0.85,
0.10,
0.05]
𝒚 = 𝑓(𝒙)𝑓 ∶ 画像認識システム
𝒙 ∶画像(ベクトル)
𝒚 ∶ クラス確率(ベクトル)

画像認識システム𝑓(𝒙)の構築従来手法: SIFT⇒BoF⇒SVM
いかに 𝒚 = 𝑓(𝒙)を設計するか?
局所パターン(SIFT)⇒ BoFベクトル⇒ SVMによる分類
31
𝒚 = 𝑓(𝒙)𝑓 ∶ 画像認識システム
𝒙 ∶画像(ベクトル)
𝒚 ∶ クラス確率(ベクトル)
出現頻度
代表的パターン
認識画像 局所パターン 代表パターンヒストグラム SVM分類器
クラス確率(尤度)
𝒚
𝒙
𝑓(𝒙)

画像認識システム𝑓(𝒙)の構築深層学習 (Deep Learning)
いかに 𝒚 = 𝑓(𝒙)を設計するか?
多層のニューラルネットワーク: 画像からクラス確率まで
end-to-end(端から端まで)変換.
32
𝒚 = 𝑓(𝒙)𝑓 ∶ 画像認識システム
𝒙 ∶画像(ベクトル)
𝒚 ∶ クラス確率(ベクトル)
クラス確率(尤度)
𝒚
𝒙
𝑓(𝒙)
認識画像Deep Neural Network

Deep Neural Networkの学習
学習データに基づいて,任意の 関数𝑓(𝒙) を構築する手法.
33
𝒇(画像) ⇒ (ライオン確率,椅子確率,山確率)
𝑓(𝒙)
Deep Neural Network
「ライオン」
「山」
「椅子」
大量のラベル付き学習データ

Deep Neural Network
の詳細
(ここまでのスライドは前回の復習)
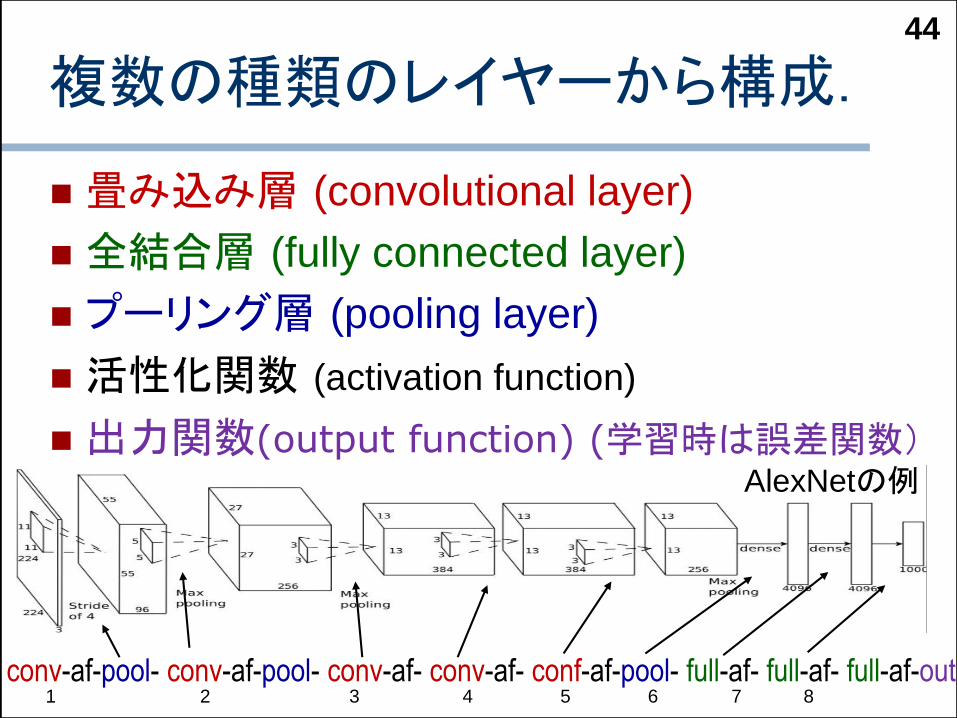
複数の種類のレイヤーから構成.
畳み込み層 (convolutional layer)
全結合層 (fully connected layer)
プーリング層 (pooling layer)
活性化関数 (activation function)
出力関数(output function) (学習時は誤差関数)
44
conv-af-pool- conv-af-pool- conv-af- conv-af- conf-af-pool- full-af- full-af- full-af-out
AlexNetの例
1 2 3 4 5 6 7 8
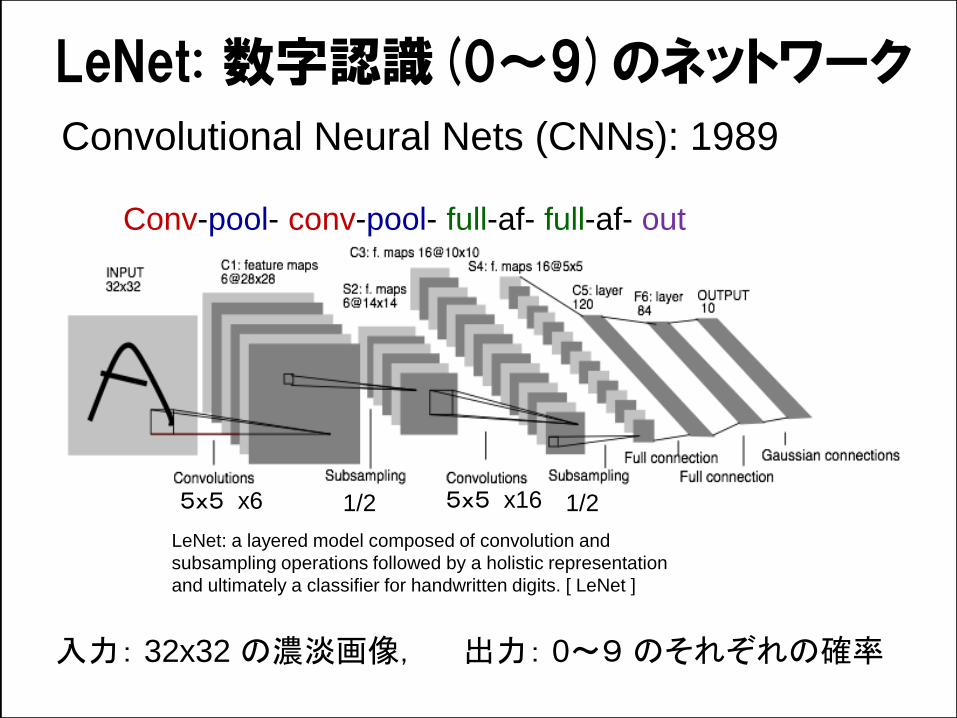
Convolutional Neural Nets (CNNs): 1989
LeNet: a layered model composed of convolution and
subsampling operations followed by a holistic representation
and ultimately a classifier for handwritten digits. [ LeNet ]
LeNet: 数字認識(0~9)のネットワーク
入力: 32x32 の濃淡画像, 出力: 0~9 のそれぞれの確率
Conv-pool- conv-pool- full-af- full-af- out
5x5 x6 5x5 x161/2 1/2

基本構成: 畳み込み⇒全結合
畳み込み⇒活性化関数⇒プ―リング の繰り返し
畳み込み層 (convolutional layer): フィルタリング
活性化関数 (activation function): 非線形関数
プーリング層 (pooling layer): 画像の縮小
全結合⇒活性化関数 の繰り返し
全結合層 (fully connected layer): 全結合ネット
活性化関数 (activation function): 非線形関数
出力関数(output function): 最終出力値を作成
46
前半部(特徴抽出)
後半部(分類器)
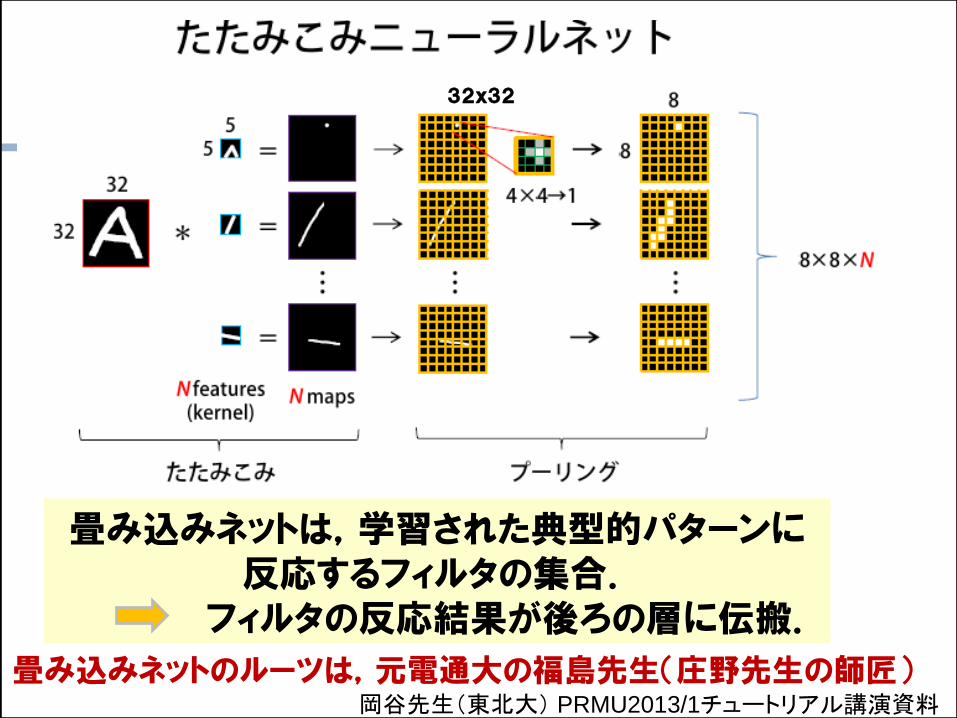
岡谷先生(東北大) PRMU2013/1チュートリアル講演資料
32x32
畳み込みネットは,学習された典型的パターンに反応するフィルタの集合.
フィルタの反応結果が後ろの層に伝搬.
畳み込みネットのルーツは,元電通大の福島先生(庄野先生の師匠)
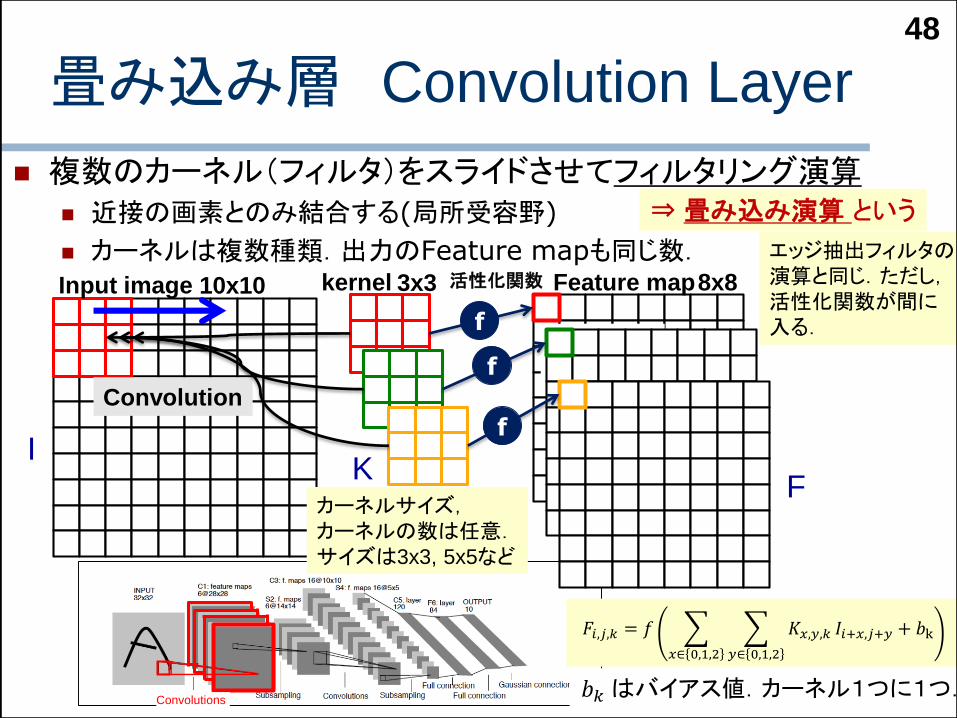
畳み込み層 Convolution Layer
複数のカーネル(フィルタ)をスライドさせてフィルタリング演算 近接の画素とのみ結合する(局所受容野)
カーネルは複数種類.出力のFeature mapも同じ数.
48
活性化関数Input image Feature map10x10 8x8
Convolution
Respons
e
kernel 3x3
f
f
f
Convolutions
エッジ抽出フィルタの演算と同じ.ただし,活性化関数が間に入る.
カーネルサイズ,カーネルの数は任意.サイズは3x3, 5x5など
⇒畳み込み演算 という
𝐹𝑖,𝑗,𝑘 = 𝑓
𝑥∈ 0,1,2
𝑦∈ 0,1,2
𝐾𝑥,𝑦,𝑘 𝐼𝑖+𝑥,𝑗+𝑦 + 𝑏k
FK
I
𝑏𝑘 はバイアス値.カーネル1つに1つ.
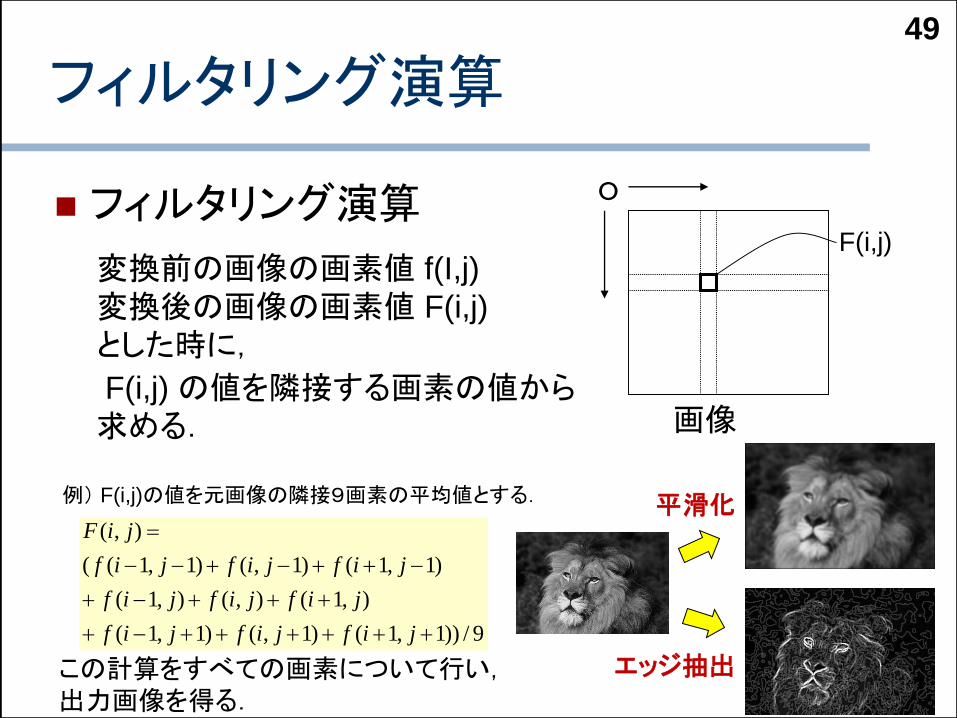
49
フィルタリング演算
フィルタリング演算
画像
O
F(i,j)
F(i,j) の値を隣接する画素の値から求める.
この計算をすべての画素について行い,出力画像を得る.
9/))1,1()1,()1,1(
),1(),(),1(
)1,1()1,()1,1((
),(
jifjifjif
jifjifjif
jifjifjif
jiF
変換前の画像の画素値 f(I,j)
変換後の画像の画素値 F(i,j)
とした時に,
例) F(i,j)の値を元画像の隣接9画素の平均値とする.
エッジ抽出
平滑化

50[参考] フィルタリングによる平滑化:ノイズ除去 少しぼやけるがノイズは減少
3x3マスク
1/9 1/9 1/9
平滑化フィルタ1
(平均フィルタ)
1/10 1/10 1/10
平滑化フィルタ2
9/))1,1()1,()1,1(
),1(),(),1(
)1,1()1,()1,1((
),(1
jifjifjif
jifjifjif
jifjifjif
jif
10/))1,1()1,()1,1(
),1(),(2),1(
)1,1()1,()1,1((
),(2
jifjifjif
jifjifjif
jifjifjif
jif
1/9 1/9 1/9
1/9 1/9 1/9
1/10 2/10 1/10
1/10 1/10 1/10

入力が3次元 (RGB) の場合
3次元のカーネルを2次元でスライドさせてフィルタリング演算
51
活性化関数
Input image
Feature map
10x10x3
8x8
Convolution
Respons
e
kernel 3x3
f
f
f
Convolutions
カーネルも3次元になる.でも,出力値は1つだけ.
F𝑖,𝑗,𝑘 = 𝑓(∑𝑧∈{0,1,2} ∑𝑥∈{0,1,2} ∑𝑦∈{0,1,2} 𝐾𝑥,𝑦,𝑧,𝑘 𝐼𝑖+𝑥,𝑗+𝑦,𝑧 + 𝑏𝑘)
FK
I
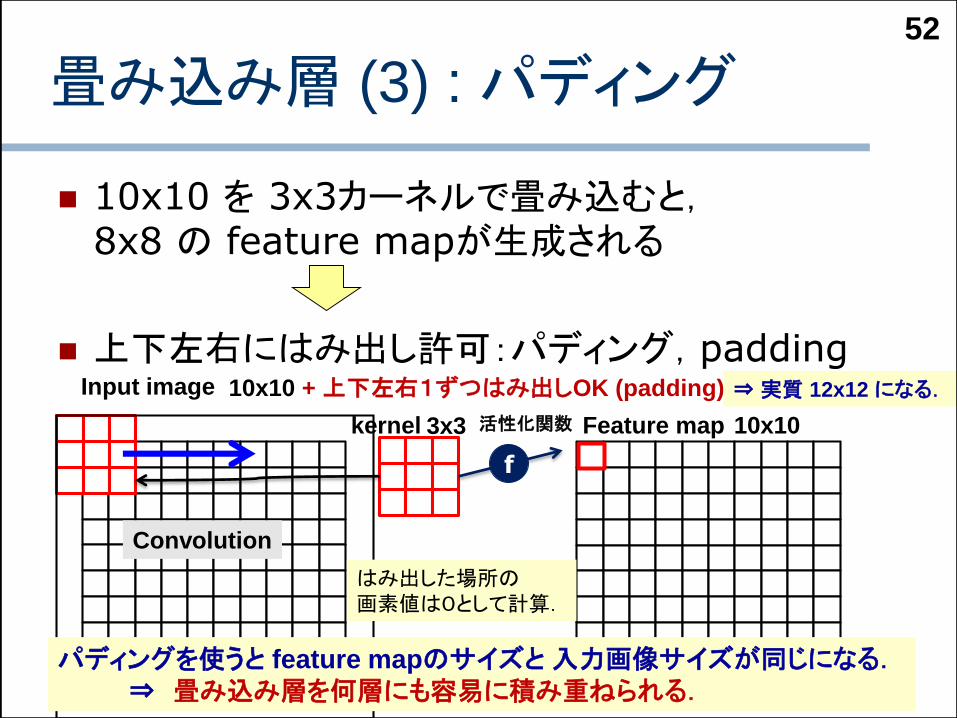
畳み込み層 (3) : パディング
10x10 を 3x3カーネルで畳み込むと,8x8 の feature mapが生成される
上下左右にはみ出し許可:パディング,padding
52
活性化関数
Input image
Feature map
10x10 + 上下左右1ずつはみ出しOK (padding)
10x10
Convolution
kernel 3x3
f
⇒実質 12x12 になる.
パディングを使うと feature mapのサイズと入力画像サイズが同じになる.⇒ 畳み込み層を何層にも容易に積み重ねられる.
はみ出した場所の画素値は0として計算.

畳み込み層 (4) : ストライド
通常は1画素ずつずらして,畳み込み.Stride=1
2画素ずつずらすと,feature mapサイズが半分.Stride=2
53
活性化関数Input image
Feature map10x10
4x4 (stride=2)
Convolution
kernel 3x3
f
畳み込みは計算量が多いので,画像サイズが大きい場合の最初に利用.⇒ ストライド2で,計算量は 1/4になる.
5x5 にしたい場合は,パディングと併用する.
stride 1(通常)の場合は,8x8

プ―リング層 Pooling Layer
最大プ―リングMax pooling
2x2の各領域での最大値
2x2の各領域での平均値
54
Sampling
• Feature mapのサイズを縮小: 最大,平均の2種類
平均プ―リングAverage pooling
6x4 feature map3x2 feature map
通常は2x2 stride 2でFeature mapサイズを1/2 にする.3x3 stride 2 で,1/2 にする場合もある.
2x2 stride2 で,max filterを掛けるのと同じ
2x2 stride2 で,平均フィルタを掛けるのと同じ
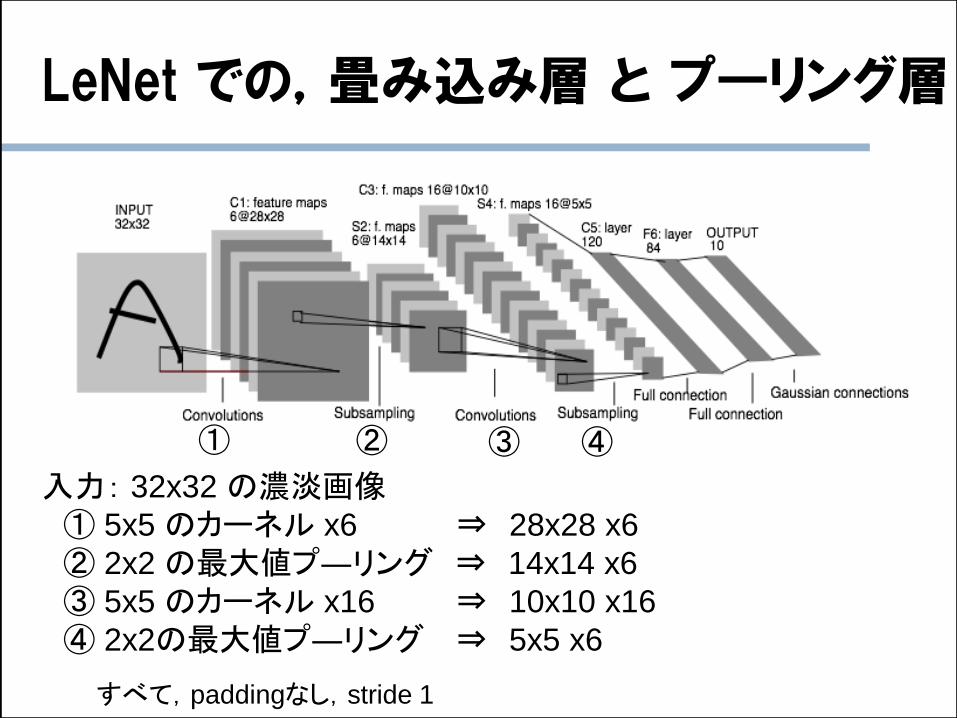
LeNet での,畳み込み層 と プ―リング層
入力: 32x32 の濃淡画像① 5x5 のカーネル x6 ⇒ 28x28 x6
② 2x2 の最大値プ―リング ⇒ 14x14 x6
③ 5x5 のカーネル x16 ⇒ 10x10 x16
④ 2x2の最大値プ―リング ⇒ 5x5 x6
① ② ③ ④
すべて,paddingなし,stride 1
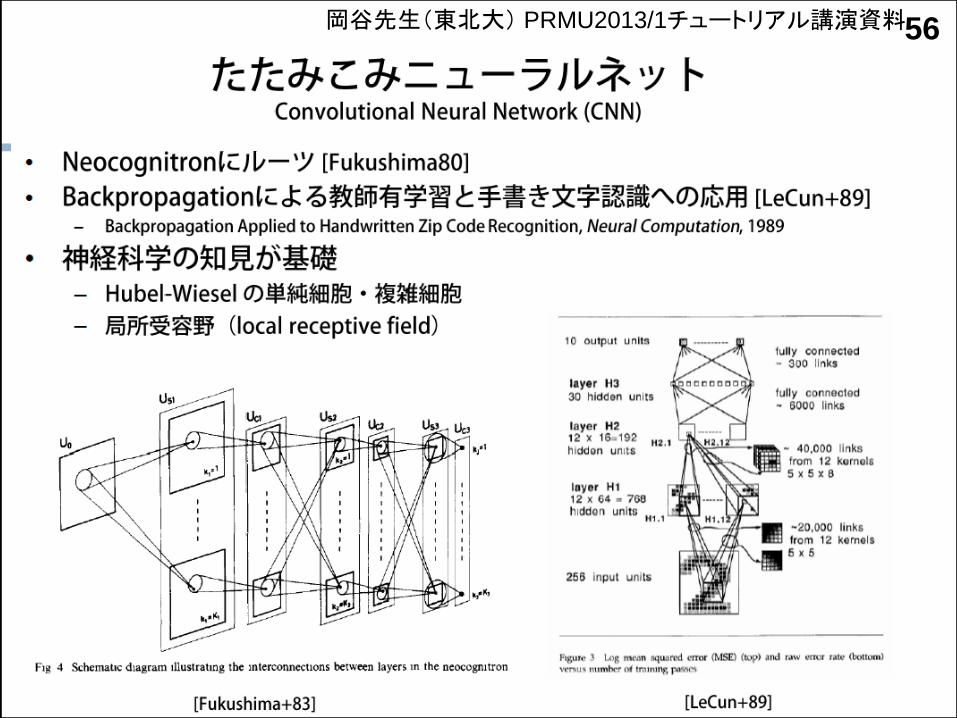
56岡谷先生(東北大) PRMU2013/1チュートリアル講演資料

57

58
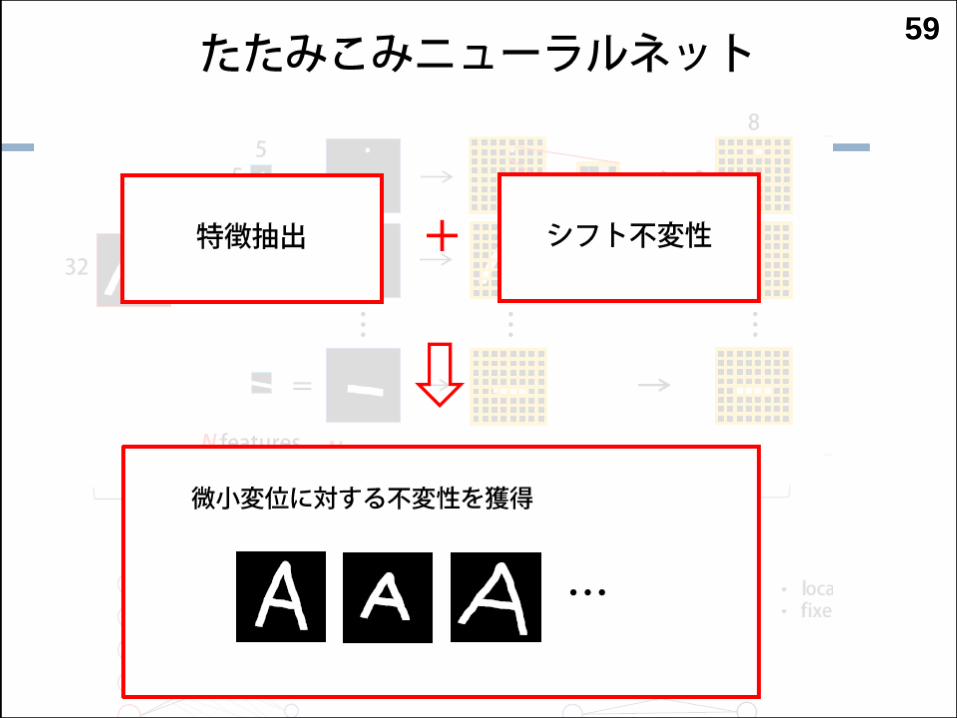
59

全結合層 Fully connection layer
x1
x2
x3
xi
h1
h2
hj
各ノードとの結合重み バイアス値(スカラー値)
例えば、は
を算出し、 活性化関数f に与えて値を得る
hj = f (WT x+bj )
60
Full
connection
w11
w12
w21
w1 j
w22w31
w32
w3 j
wij
wi2wi1
行列とベクトルの積.
すべてのfeature maps を1列に並べてn次元ベクトルとし,m×n行列を掛けて,m次元ベクトルを出力.
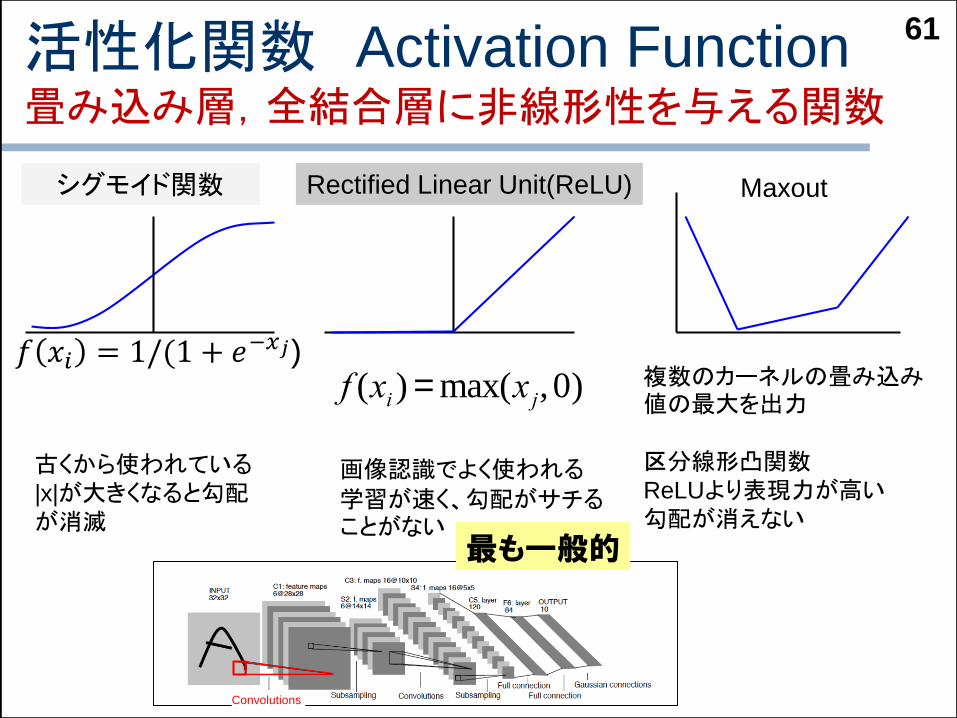
活性化関数 Activation Function畳み込み層,全結合層に非線形性を与える関数
シグモイド関数 Rectified Linear Unit(ReLU) Maxout
古くから使われている|x|が大きくなると勾配が消滅
画像認識でよく使われる
学習が速く、勾配がサチることがない
複数のカーネルの畳み込み値の最大を出力
区分線形凸関数ReLUより表現力が高い勾配が消えない
f (xi ) = max(x j, 0)
61
Convolutions
𝑓 𝑥𝑖 = 1/(1 + 𝑒−𝑥𝑗)
最も一般的

出力層 Output Layer
画像分類の場合は Softmax関数P(y1)
P(y2)
P(yM)
出力の値の和が1⇒ 確率と見なせる.
各クラスの確率を算出して、最大値を認識クラスとする
目的に応じた関数: 分類の場合は softmax関数
x1
x2
x3
xi
h1
h2
hM
62
前層
出力層
classification
各クラスの確率
P(yi ) =exp(hi )
exp(hj )j=1
M
å
出力層の要素数 = 分類クラス数 とする.最終出力はクラス確率ベクトル.
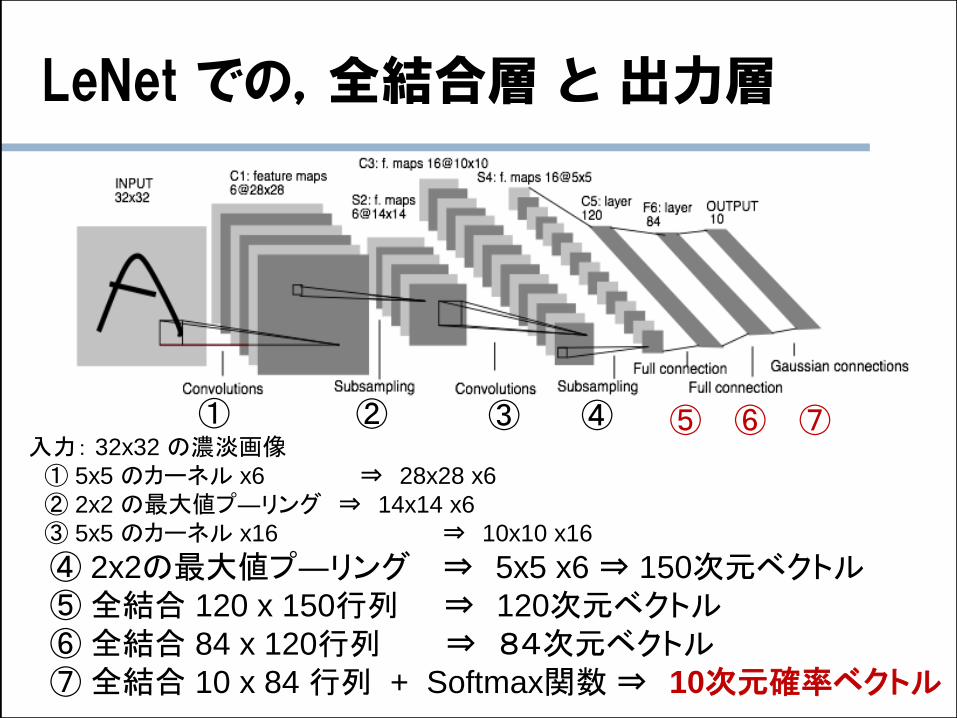
LeNet での,全結合層 と 出力層
入力: 32x32 の濃淡画像① 5x5 のカーネル x6 ⇒ 28x28 x6
② 2x2 の最大値プ―リング ⇒ 14x14 x6
③ 5x5 のカーネル x16 ⇒ 10x10 x16
④ 2x2の最大値プ―リング ⇒ 5x5 x6 ⇒ 150次元ベクトル⑤全結合 120 x 150行列 ⇒ 120次元ベクトル⑥全結合 84 x 120行列 ⇒ 84次元ベクトル⑦全結合 10 x 84 行列 + Softmax関数⇒ 10次元確率ベクトル
① ② ③ ④ ⑤ ⑥ ⑦
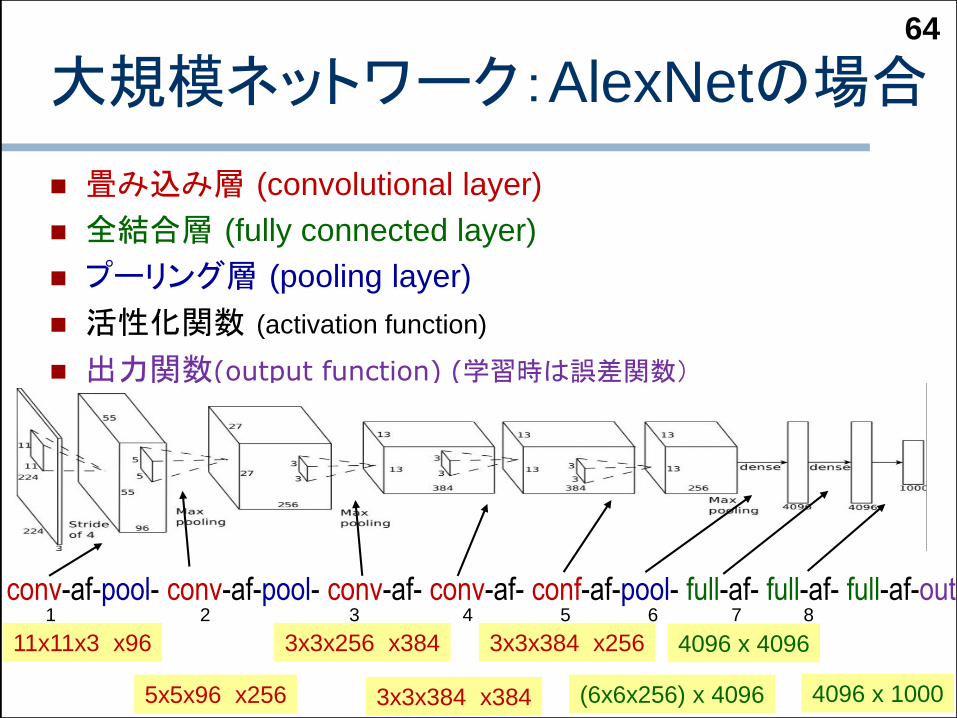
大規模ネットワーク:AlexNetの場合
畳み込み層 (convolutional layer)
全結合層 (fully connected layer)
プーリング層 (pooling layer)
活性化関数 (activation function)
出力関数(output function) (学習時は誤差関数)
64
conv-af-pool- conv-af-pool- conv-af- conv-af- conf-af-pool- full-af- full-af- full-af-out1 2 3 4 5 6 7 8
11x11x3 x96
5x5x96 x256
3x3x256 x384
3x3x384 x384
3x3x384 x256
(6x6x256) x 4096
4096 x 4096
4096 x 1000

パラメータ数の計算
畳み込み層と全結合層のみがパラメータを保持
⇒ 約6000万個のパラメータ⇒ これを学習することが,必要.
65
11*11*3*96
= 34,848
5*5*96*256
= 614,400
3*3*256*384
= 884,736
3*3*384*384
= 1,327,104
3*3*384*256
= 884,736
6*6*256*4096
= 37,784,736
4096*4096
= 16,777,216
4096*1000
= 4,096,000合計 61,520,660 パラメータ

Deep Networkの学習
ネットワークで画像認識するには,全てのパラメータの学習が必要
学習時には,出力関数の代わりに,誤差関数(loss function)を用意し,誤差関数を最小化するように,勾配降下法(最急降下法)で学習する.
66

NeuralNetの学習
61,618,964 個の内部パラメータ 𝒘を持つ関数 𝑓(𝒙) をいかに学習するか?
67
𝒇( ) ⇒ ( 1.00, 0.00, 0.00 )
𝒇( ) ⇒ ( 0.00, 1.00, 0.00 )
𝒇( ) ⇒ ( 0.00, 0.00, 1.00 )
となるように 内部パラメータ 𝒘を求める.

誤差関数
内部パラメータ 𝒘をまずランダムで初期化.
画像を入れると 出力値𝒑(ほぼランダム)が出る 理想値𝒚
69
𝒇𝟎( ) ⇒ (0.23,0.53,0.31) ⇐ (1.00, 0.00, 0.00)
𝒇𝟎( ) ⇒ (0.30,0.27,0.43) ⇐ (0.00, 1.00, 0.00)
𝒇𝟎( ) ⇒ (0.49,0.38,0.13) ⇐ (0.00, 0.00, 1.00)
カテゴリ分類のLoss関数(誤差関数) 𝐿 𝑤 = − ∑𝑁 ∑𝑗 𝑦𝑗,𝑛 log 𝑝𝑗,𝑛
(交差エントロピー (cross entropy)関数)
誤差𝐸 = 全学習データNの出力値𝒑と 学習ラベル値(理想値)𝒚 との差

学習データ全てに渡って𝐸を最小化
初期ネットワーク𝑓(𝒙𝑖)の 出力値𝒑𝒊と理想値𝒚𝒊の誤差𝐸𝑖
70
学習画像1 𝒇𝟎( )⇒ (0.23,0.53,0.31)⇐ (1.00, 0.00, 0.00) ⇒ 𝑬𝟏
学習画像𝟐 𝒇𝟎( )⇒ (0.30,0.27,0.43)⇐ (0.00, 1.00, 0.00)⇒ 𝑬𝟐
学習画像𝑵 𝒇𝟎( )⇒ (0.49,0.38,0.13)⇐ (0.00, 0.00, 1.00)⇒ 𝑬𝑵
𝐸 = ∑𝑖 𝐸𝑖 が最小になるように内部パラメータ 𝒘を学習.以下では,𝐸は𝒘によって決まるので,𝐸(𝒘) と書く.
最急降下法(勾配降下法)で解く!𝒘𝑡+1 = 𝒘𝑡 − 𝜂𝜕𝐸
𝜕𝒘(𝜂:小さい値.学習率. 0.001)
勾配と逆方向に𝒘を少しずつ変化させる
𝐸(𝒘)
𝒘
𝜕𝐸
𝜕𝒘−𝜂𝜕𝐸
𝜕𝒘
𝒘𝑡𝒘𝑡+1
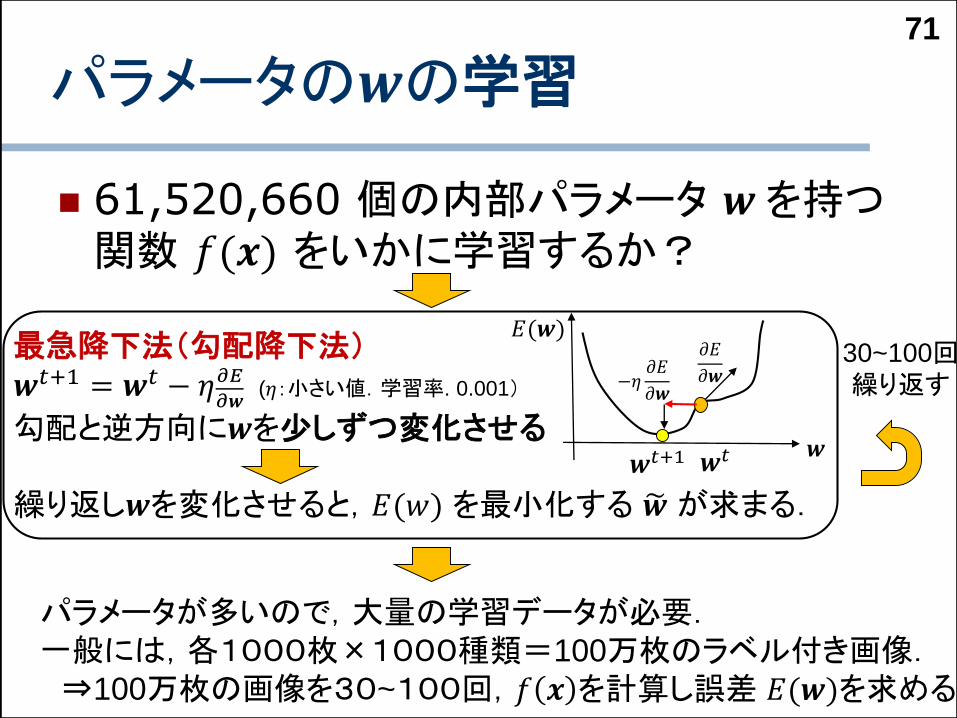
パラメータの𝒘の学習
61,520,660 個の内部パラメータ 𝒘を持つ関数 𝑓(𝒙) をいかに学習するか?
71
最急降下法(勾配降下法)𝒘𝑡+1 = 𝒘𝑡 − 𝜂𝜕𝐸
𝜕𝒘(𝜂:小さい値.学習率. 0.001)
勾配と逆方向に𝒘を少しずつ変化させる
繰り返し𝒘を変化させると,𝐸(𝑤) を最小化する 𝒘が求まる.
𝐸(𝒘)
𝒘
𝜕𝐸
𝜕𝒘−𝜂𝜕𝐸
𝜕𝒘
𝒘𝑡𝒘𝑡+1
パラメータが多いので,大量の学習データが必要.一般には,各1000枚×1000種類=100万枚のラベル付き画像.⇒100万枚の画像を30~100回,𝑓 𝒙 を計算し誤差 𝐸(𝒘)を求める
30~100回繰り返す

順伝搬 と逆伝搬による学習72
順伝搬を行い,誤差関数の値を計算.誤差を小さくするようにパラメータを更新(逆伝搬).
Input:画像:xラベル:y
学習セット:(I1,y1),…, (xn,yn)
順伝搬現パラメータ群により各学習データの認識を行う
逆伝搬認識結果(誤差)をもとに,パラメータ群を更新する
Convolution
Fullly connection
Loss function
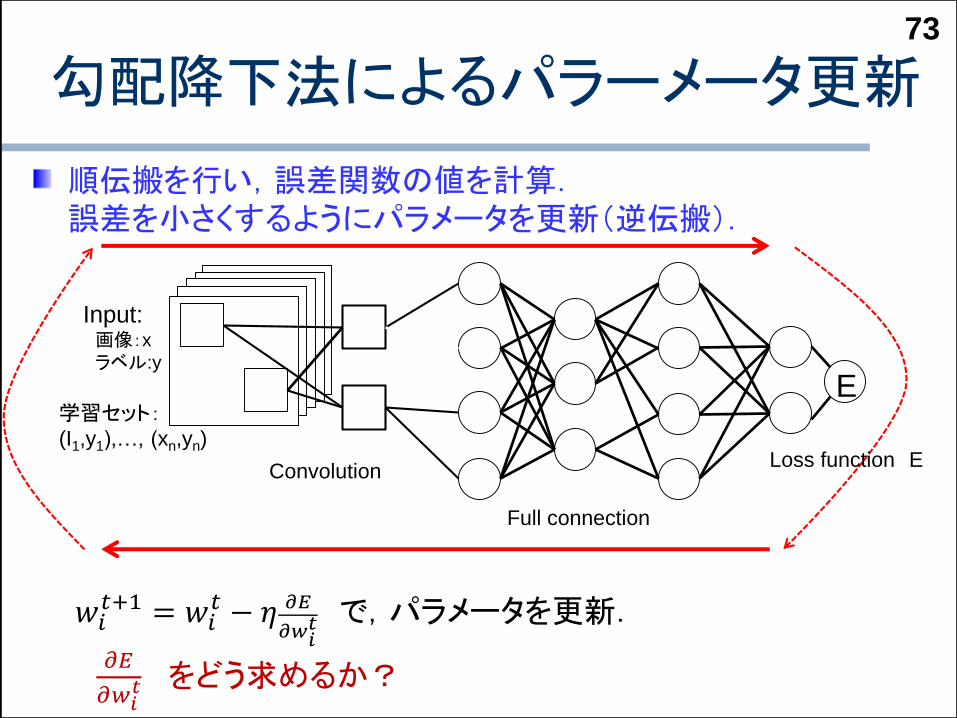
勾配降下法によるパラーメータ更新73
順伝搬を行い,誤差関数の値を計算.誤差を小さくするようにパラメータを更新(逆伝搬).
Convolution
Full connection
𝑤𝑖𝑡+1 = 𝑤𝑖
𝑡 − 𝜂 𝜕𝐸
𝜕𝑤𝑖𝑡 で,パラメータを更新.
𝜕𝐸
𝜕𝑤𝑖𝑡 をどう求めるか?
Input:画像:xラベル:y
学習セット:(I1,y1),…, (xn,yn)
Loss function E
E
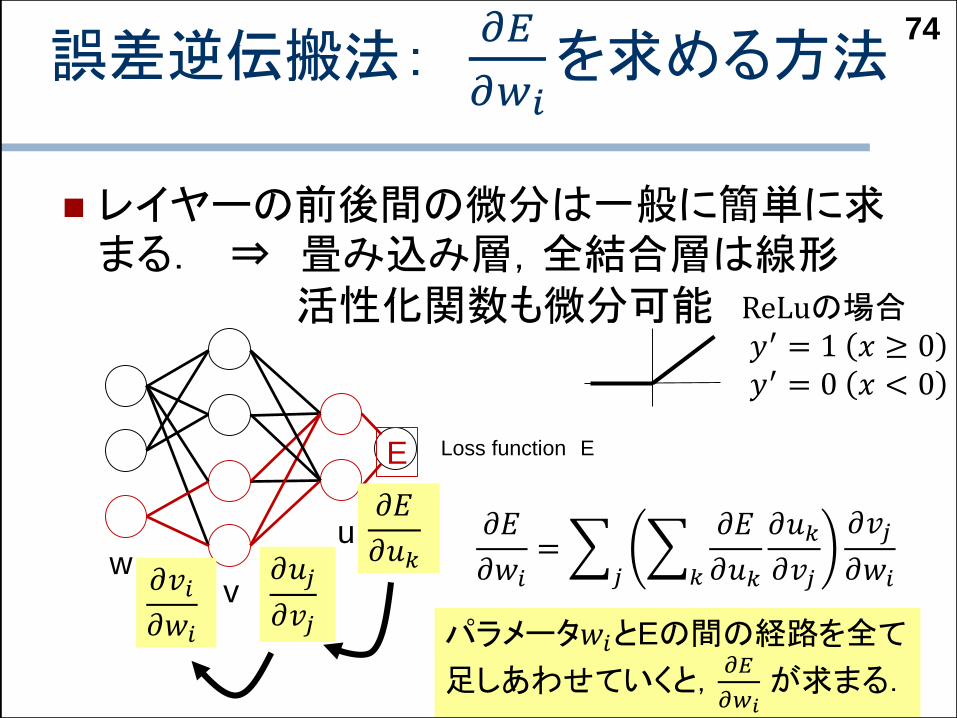
誤差逆伝搬法:𝜕𝐸
𝜕𝑤𝑖を求める方法
レイヤーの前後間の微分は一般に簡単に求まる. ⇒ 畳み込み層,全結合層は線形
活性化関数も微分可能
74
Loss function EE
ReLuの場合𝑦′ = 1 𝑥 ≥ 0𝑦′ = 0 𝑥 < 0
𝜕𝐸
𝜕𝑤𝑖=
𝑗
𝑘
𝜕𝐸
𝜕𝑢𝑘
𝜕𝑢𝑘
𝜕𝑣𝑗
𝜕𝑣𝑗
𝜕𝑤𝑖
u
vw
𝜕𝐸
𝜕𝑢𝑘𝜕𝑢𝑗
𝜕𝑣𝑗
𝜕𝑣𝑖
𝜕𝑤𝑖 パラメータ𝑤𝑖とEの間の経路を全て
足しあわせていくと,𝜕𝐸
𝜕𝑤𝑖が求まる.

順伝搬 と逆伝搬による学習75
順伝搬を行い,誤差関数の値を計算.誤差を小さくするようにパラメータを更新(逆伝搬).
Input:画像:xラベル:y
学習セット:(I1,y1),…, (xn,yn)
順伝搬現パラメータ群により各学習データの認識を行う
逆伝搬認識結果(誤差)をもとに,パラメータ群を更新する
Convolution
Fullly connection
Loss function
𝑤𝑖𝑡+1 = 𝑤𝑖
𝑡 − 𝜂 𝜕𝐸
𝜕𝑤𝑖𝑡

パラメータ𝒘が求まると,𝑓(𝒙)の学習が完了 ⇒ GPUで1週間
関数 𝑓(𝒙) = 学習済の画像認識関数
76
𝑓(𝒙) ⇒ (ライオン確率,椅子確率,山確率)
𝑓( ) ⇒ ( 0.95, 0.04, 0.01 )
𝑓( ) ⇒ ( 0.03, 0.95, 0.02 )
𝑓( ) ⇒ ( 0.02, 0.05, 0.93 )
となって,ニューラルネットワークの内部パラメータ𝒘が学習できた.

ポイント
勾配降下法を使うので,𝐸(𝒘) が微分可能でないといけない.⇒ 実際のネットワークは微分可能になっている.
6000万次元の𝒘が正しく学習されるには,大量のデータがあることが望ましい⇒ 一般には100万枚
上手く学習されれば,RGBの画素値を入力として,出力がクラス確率となる, 𝑓(𝒙)が求まる.
77
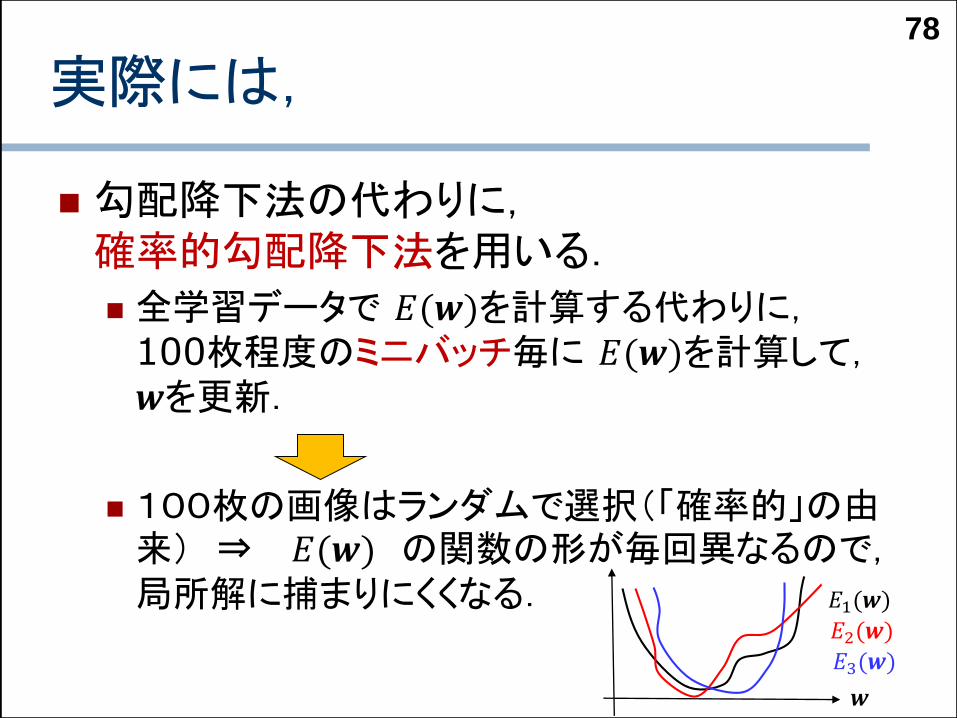
実際には,
勾配降下法の代わりに,確率的勾配降下法を用いる.
全学習データで 𝐸(𝒘)を計算する代わりに,100枚程度のミニバッチ毎に 𝐸(𝒘)を計算して,𝒘を更新.
100枚の画像はランダムで選択(「確率的」の由来) ⇒ 𝐸(𝒘) の関数の形が毎回異なるので,局所解に捕まりにくくなる.
78
𝐸1(𝒘)
𝒘
𝐸2(𝒘)
𝐸3(𝒘)
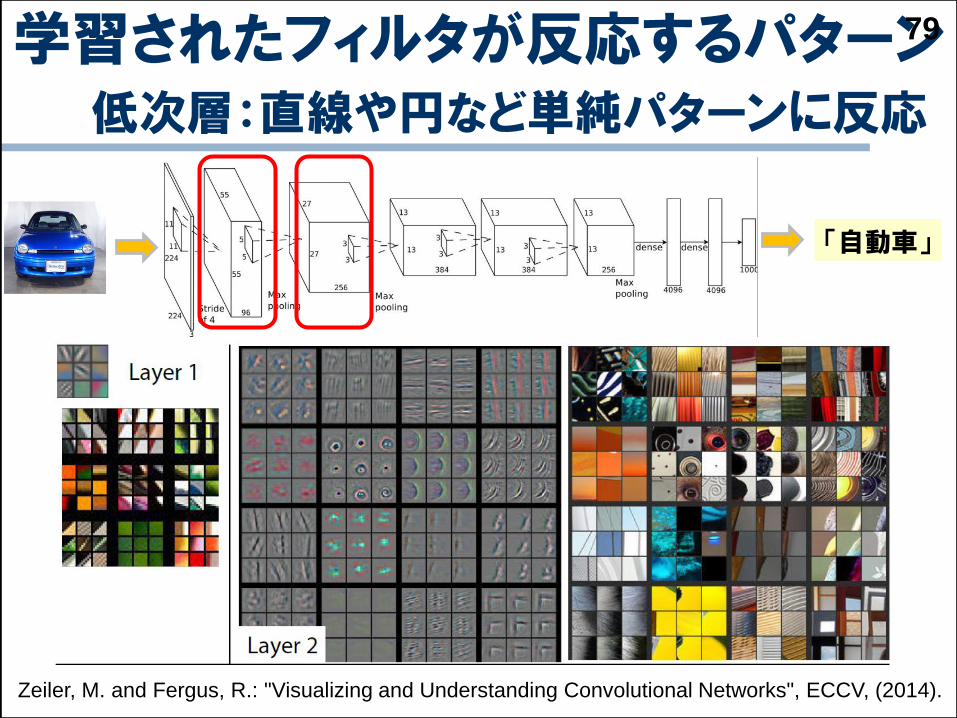
学習されたフィルタが反応するパターン低次層:直線や円など単純パターンに反応
79
Zeiler, M. and Fergus, R.: "Visualizing and Understanding Convolutional Networks", ECCV, (2014).
「自動車」

学習されたフィルタが反応するパターン中間層:タイヤや格子模様など物体のパーツに反応
80
Zeiler, M. and Fergus, R.: "Visualizing and Understanding Convolutional Networks", ECCV, (2014).
「自動車」
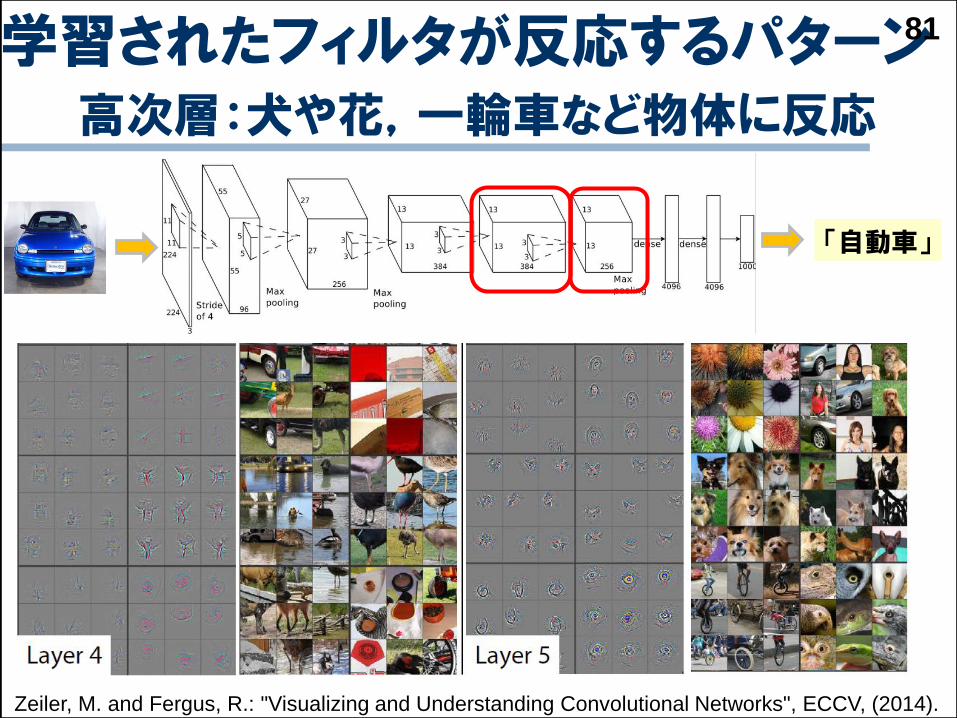
学習されたフィルタが反応するパターン高次層:犬や花,一輪車など物体に反応
81
Zeiler, M. and Fergus, R.: "Visualizing and Understanding Convolutional Networks", ECCV, (2014).
「自動車」

認識性能を向上させるための方法
82

Dropout 全結合層の過学習を抑制する
(学習方法のおさらい)
入力データのラベルとネットワークの出力の誤差を元にパラメータを更新
Input layer
Kernel
K1
Kn
Fully connected layerの一部のノードからの結合を取り除く(0にする)
だいたい50%
各mini-batchで異なる結合をランダムに取り除く
近似的なアンサンブル学習
G. Hinton, N.Srivastava, A.Krizhevsky, I.Sutskever, and R.Salakhutdinov, “Improving neural
networks by preventing co-adaptation of feature detectors.”, arXiv preprint arXiv:1207.0580, 2012.
83

学習画像の生成
Elastic Distortion
位置や大きさだけでなく,形状の変化も適用
P.Y. Simard, D. Steinkraus, and J.C. Platt, “Best practices for convolutional neural networks
applied to visual document analysis.”, ICDAR2003.
Data Augmentation
位置や大きさを変えて学習データ数を増やす
84
221
x221
256x256
256x256の画像からの221x221のランダム切り出し.左右反転(flip).
学習データの水増し

Pre-Training と Fine-tuning
事前に大規模データで学習(pre-training)して,小規模なデータでチューニング(fine-tuning)する.
ImageNet1000で学習したネットワークを小規模データセットにチューニングする.
レイヤーの一部(通常は,最終レイヤー)を差替え
85
例えば,1000から30のlayerに変更して,再学習(fine-tuning).

代表的なネットワーク
LeNet 最初の畳み込みネット
AlexNet
トロント大 Hintonグループ, ILSVRC2012のwinner
VGG 16/19 Oxford Zissermanグループ
ILSVRC2014で2位
Network-in-network: 全結合なし NUS
GoogLeNet グーグル
ILSVRC2014のwinner
86
Y. LeCun, et.al. “Gradient-based Learning Applied to Document Recognition, Proc. of The
IEEE, 1998.

Convolutional Neural Nets (CNNs): 1989
LeNet: a layered model composed of convolution and
subsampling operations followed by a holistic representation
and ultimately a classifier for handwritten digits. [ LeNet ]
LeNet
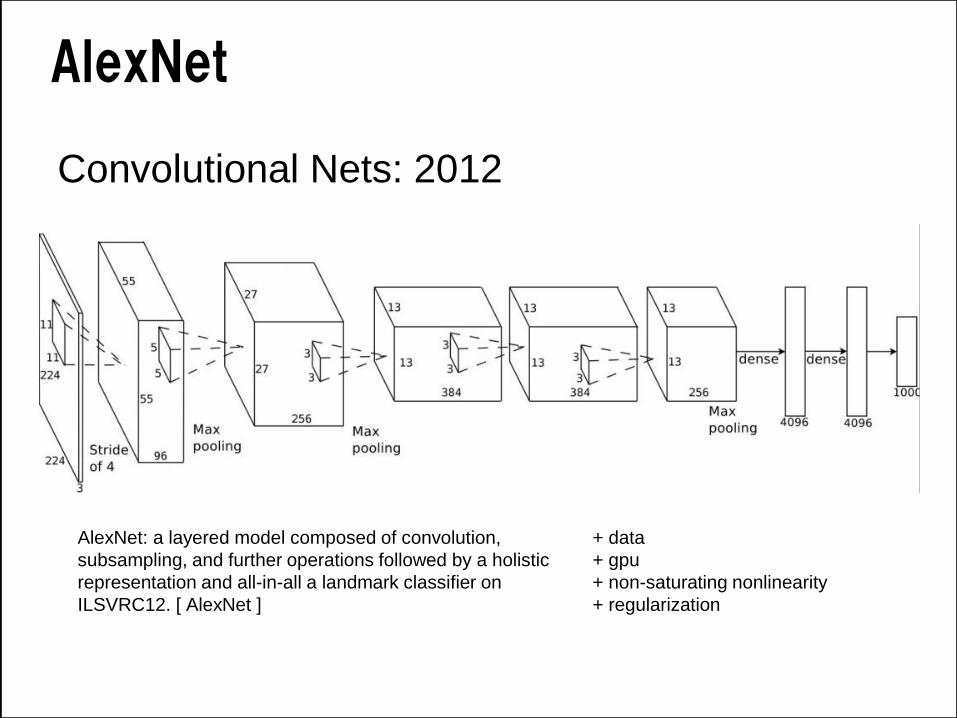
Convolutional Nets: 2012
AlexNet: a layered model composed of convolution,
subsampling, and further operations followed by a holistic
representation and all-in-all a landmark classifier on
ILSVRC12. [ AlexNet ]
+ data
+ gpu
+ non-saturating nonlinearity
+ regularization
AlexNet

Convolutional Nets: 2012
AlexNet: a layered model composed of convolution, pooling,
and further operations followed by a holistic representation
and all-in-all a landmark classifier on
ILSVRC12. [ AlexNet ]
The fully-connected “FULL” layers are linear classifiers /
matrix multiplications. ReLU are rectified-linear non-
linearities on the output of layers.
figure credit Y. LeCun and M.A. Ranzato, ICML ‘13 tutorialparameters FLOPs
AlexNet

合計19層(16層)Conv, conv ,max poolの組み合わせが5つ(4つ)
Convはすべて 3x3, stride 1, padding 1
例) conv-64 : 3x3x64 x64
よりDeepにすると,精度が向上⇒ AlexNetに比べて精度が高い.
計算量,パラメータ量も大幅に多いが,認識精度が高い.ILSVRC2014で2位.
Very Deep Network
VGG net 16/19

ⓒ 2014 UEC Tokyo.
Network-in-Network (NIN)
• パラメータ増加の原因の full connectionを除去
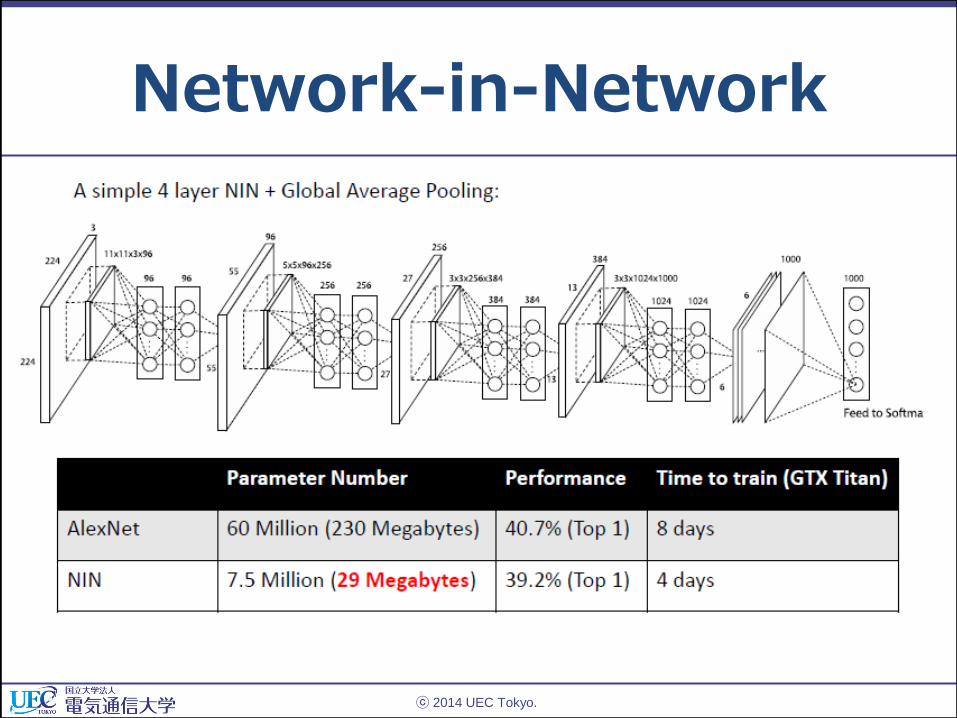
ⓒ 2014 UEC Tokyo.
Network-in-Network
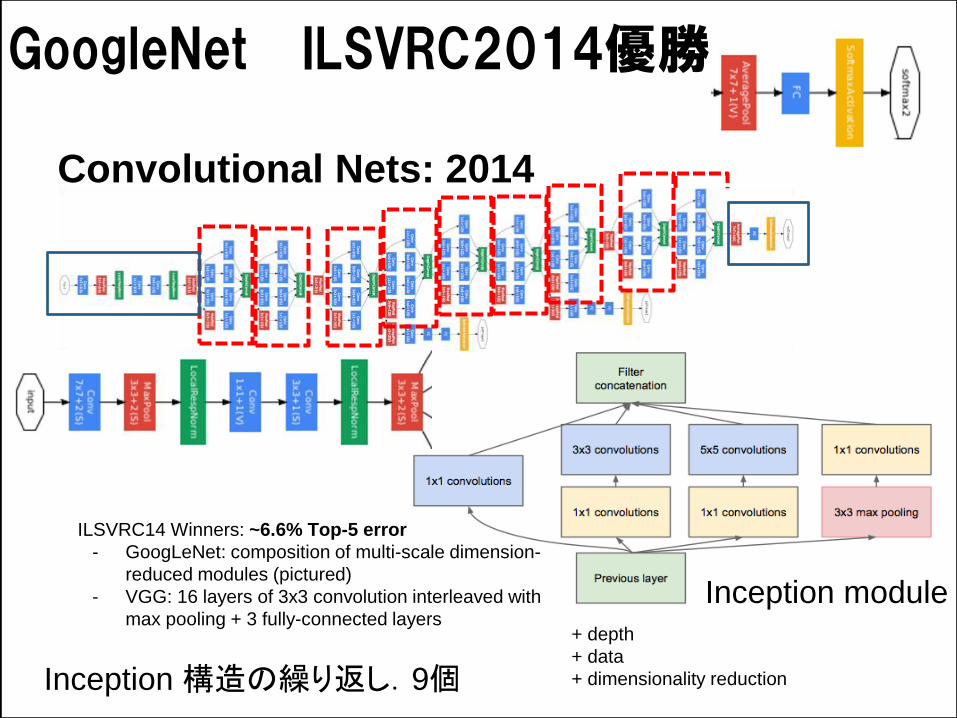
Convolutional Nets: 2014
ILSVRC14 Winners: ~6.6% Top-5 error
- GoogLeNet: composition of multi-scale dimension-
reduced modules (pictured)
- VGG: 16 layers of 3x3 convolution interleaved with
max pooling + 3 fully-connected layers + depth
+ data
+ dimensionality reduction
GoogleNet ILSVRC2014優勝
Inception 構造の繰り返し.9個
Inception module

Inception Network
for ILSVRC 2015
GoogleNetの拡張版
C.Szegedy et al.: Rethinking the Inception
Architecture for Computer Vision, arxiv 1512.00567 (2015).
Inceptionが10層3.46%

ImageNet Challenge 2015
3.57%
人間超え!
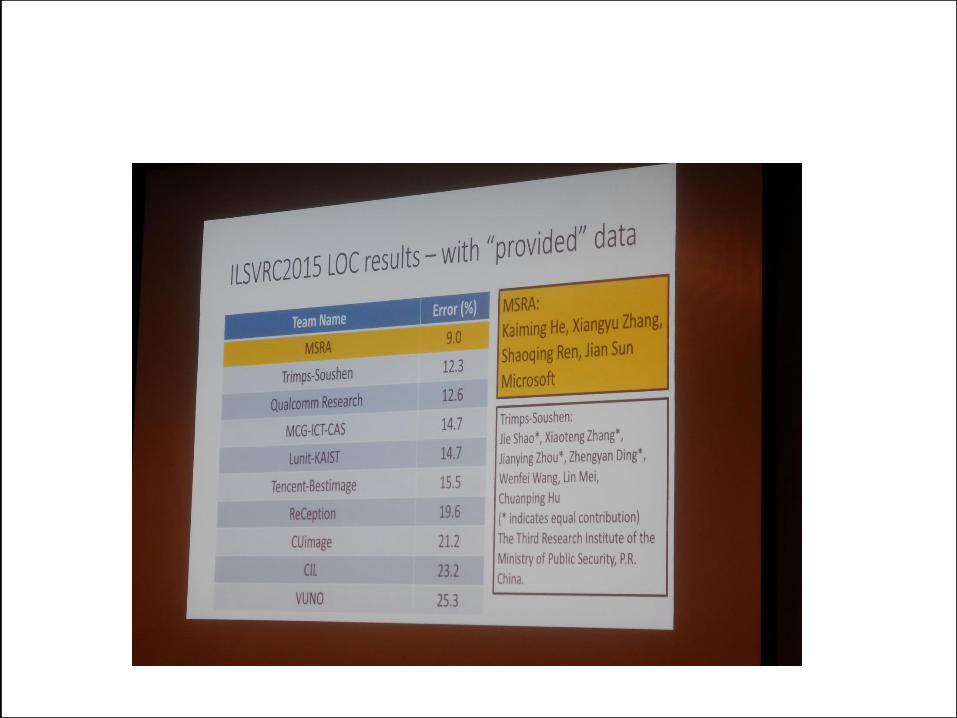

MSRAが全部1位!!

レイヤーの数が増加.152!

2012 ⇒ 2013 ⇒ 2014

⇒ 2015 152層!
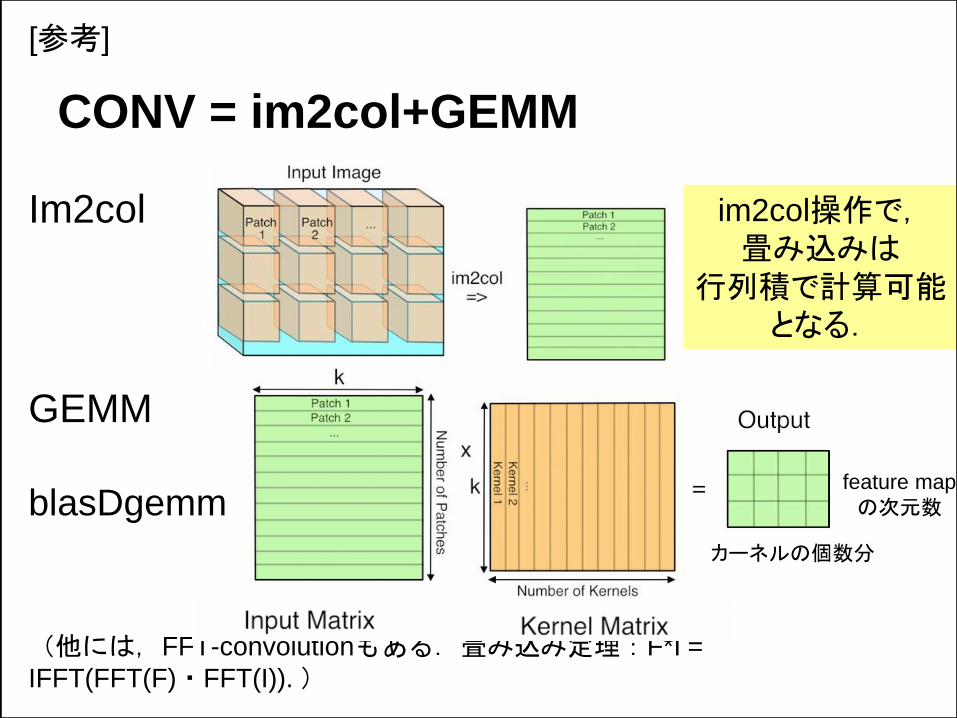
CONV = im2col+GEMM
Im2col
GEMM
blasDgemm
(他には,FFT-convolutionもある.畳み込み定理:F*I =
IFFT(FFT(F)・FFT(I)). )
カーネルの個数分
im2col操作で,畳み込みは
行列積で計算可能となる.
feature map
の次元数
[参考]
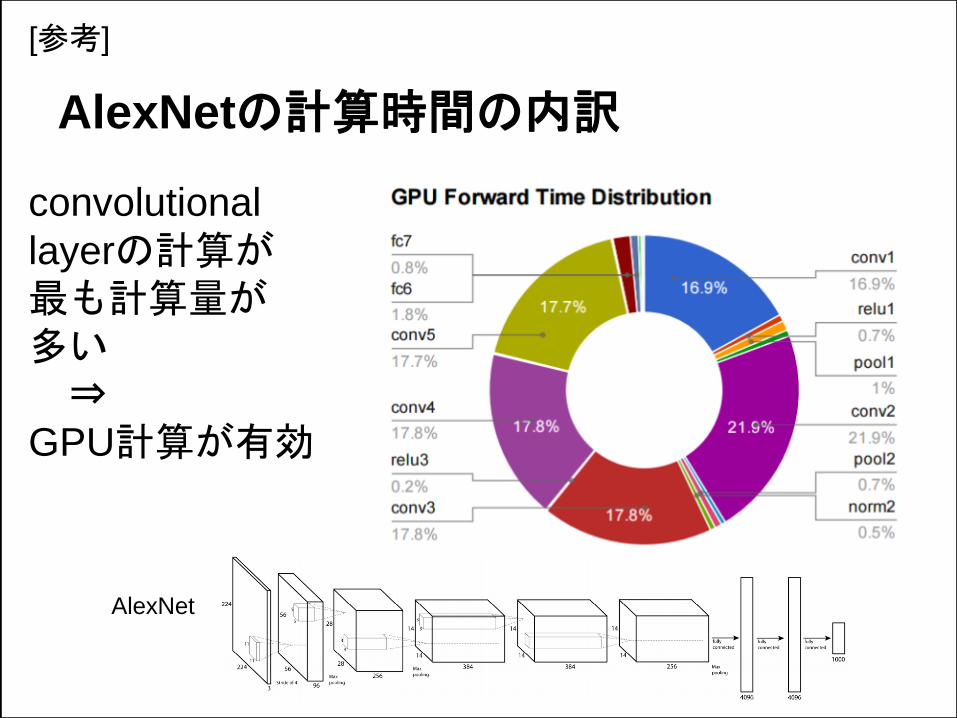
AlexNetの計算時間の内訳
convolutional
layerの計算が最も計算量が多い⇒
GPU計算が有効
AlexNet
[参考]

行列積:GEMMDeep Learningの計算の大部分は行列積
BLAS(Basic Linear Algebra Subprograms
(BLAS)) : 行列積の基本API を利用する.GEMM (GEneric Matrix Multiplication)
BLASの実装MKL (Intel Math Kernel Library)
ATLAS Automatically Tuned Linear Algebra Software
OpenBLAS : SSEなどのSIMD命令を利用した最適化
CuBLAS : NVIDIA GPU Cuda版のBLAS
CuDNN : Deep Learningの各レイヤを直接計算するNVIDIA GPU用のライブラリ
[参考]
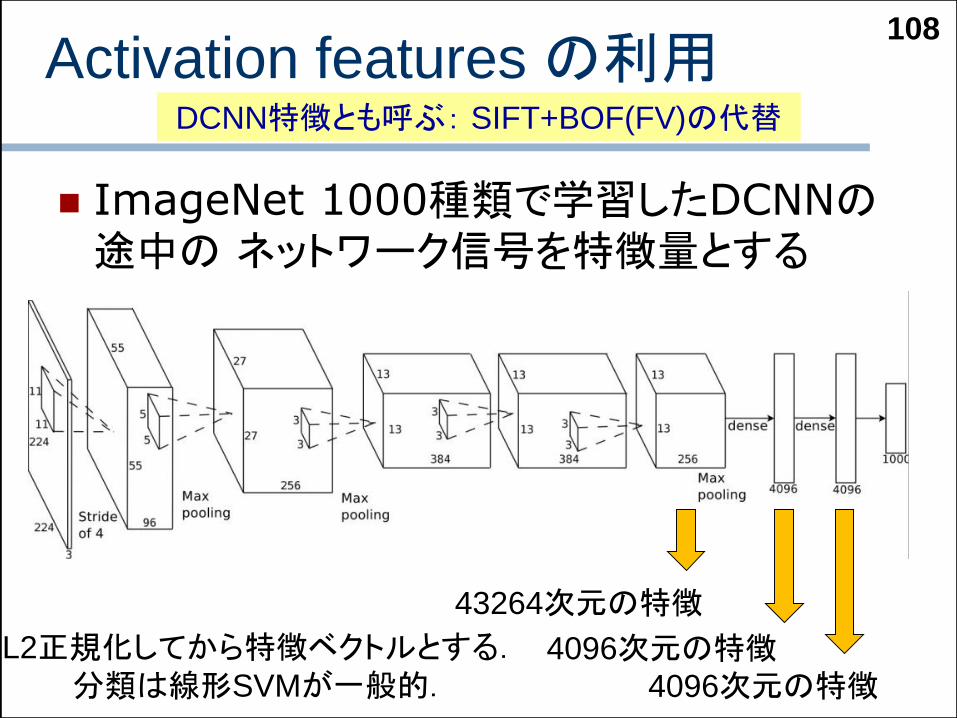
Activation features の利用
ImageNet 1000種類で学習したDCNNの途中の ネットワーク信号を特徴量とする
108
43264次元の特徴
4096次元の特徴4096次元の特徴
L2正規化してから特徴ベクトルとする.分類は線形SVMが一般的.
DCNN特徴とも呼ぶ: SIFT+BOF(FV)の代替

DCNN特徴で,類似画像検索.109

ⓒ 2014 UEC Tokyo.
• ImageNet2000 categories
– 1000 food-related categories from ImageNet
21,000 categories
+
– ImageNet1000 ImageNet categories
= 2000 categories
食事画像データの認識 DCNNをImageNet1000+Food関連1000カテゴリで学習

ⓒ 2014 UEC Tokyo.
• DCNN Features with ImageNet 2000 categories
– Using Caffe
– The dimension is 6144 (modified from 4096 to 6144)
– L2-normalized
• Training time
– About one week
– GPU, Nvidia Geforce TITAN BLACK, 6GB
Pre-training DCNN

ⓒ 2014 UEC Tokyo.
• UEC-FOOD 100
Experimental results
5%up
14%up

ⓒ 2014 UEC Tokyo.
• UEC-FOOD 256
Experimental results
4.7%up
15%up

DS1-11:DeepFoodCam : DCNNによる101種類食事認識アプリ
岡元 晃一, 柳井 啓司(電気通信大学)
93.5%の精度(5位以内)と高速実行を実現!
アプリ内でのディープラーニングによる101種類認識
スマホアプリでの食事認識!
Food Recognition App with DCNN

100種類食事認識データセットUEC-FOOD100 (13000枚)

100種類食事認識
従来手法 ディープラーニング(圧縮なし,32bit)
ディープラーニング(圧縮あり,8bit)
ディープラーニング(圧縮あり,4bit)
65.3% 75.3% 74.5% 72.9%
86.7% 94.0% 93.5% 92.9%
1.3MB 26MB 6.5MB 3.3MB
Top1
Top5
メモリ
問題点: GPUなしPCで認識時間が1秒程度.モバイル用に高速化を研究中.
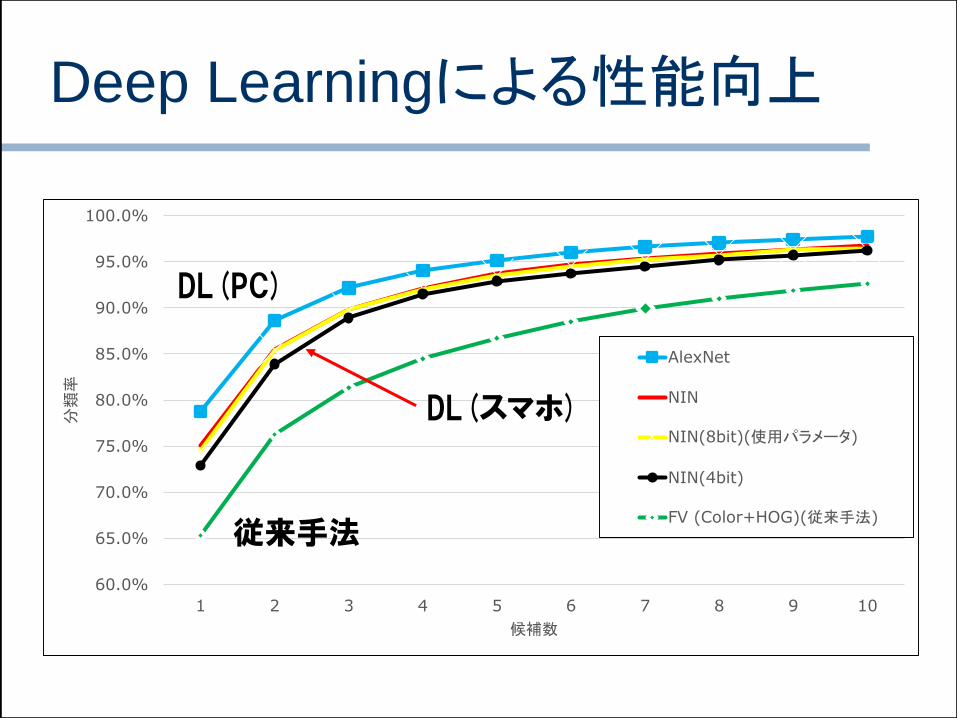
Deep Learningによる性能向上
60.0%
65.0%
70.0%
75.0%
80.0%
85.0%
90.0%
95.0%
100.0%
1 2 3 4 5 6 7 8 9 10
分類率
候補数
AlexNet
NIN
NIN(8bit)(使用パラメータ)
NIN(4bit)
FV (Color+HOG)(従来手法)
従来手法
DL(PC)
DL(スマホ)

第1回 (10/06):画像認識とは?イントロダクション.身の回りでの応用例から最新研究まで
第2回 (10/20):画像認識の基礎.画像処理.エッジ検出.色ヒストグラムに基づく画像検索.
第3回 (10/27):【演習1】 MATLAB の基礎.顔検出,物体検出を試してみる.
第4回 (11/10):【演習2】 MATLABでの画像の取り扱い.色ヒストグラムに基づく画像検索.
第5回 (11/17):様々な特徴量.輝度勾配ヒストグラム.局所特徴量.SIFT特徴量.
第6回 (11/24):一般物体認識.BoF法による特徴ベクトル生成.K-Means法.
第7回 (12/01):【演習3】 局所特徴量の抽出.特定物体認識.
第8回 (12/08):機械学習法.Nearest Neighbor法.線形/非線形SVM.NaiveBayes法.
第9回 (12/15):【演習4】 BoFベクトルの生成.K-means法.
第10回 (12/22):Deep Learningによる画像認識の基礎.確率的勾配降下法.
第11回 (1/12):Deep Learningの各種レイヤ-.誤差逆伝搬法.認識結果の評価方法.
第12回 (1/19):【演習5】 BoFと機械学習を用いた一般物体認識.
第13回 (1/26):【演習6】 Deep Learningによる一般物体認識.
第14回 (2/02):【演習7】 レポート課題説明(1):Web画像の自動収集.
第15回 (2/09):【演習8】 レポート課題説明(2):画像分類と,Web画像の再ランキング.
今回の予定次回の予定 (次回からすべてIED)