thesis presentation yakham ndiaye november, 13 the 2001
DESCRIPTION
Interoperability of a Scalable Distributed Data Manager with an Object-relational DBMS. Thesis presentation Yakham NDIAYE November, 13 the 2001. Objective. Develop techniques for the interoperability of a DBMS with an external SDDS file. - PowerPoint PPT PresentationTRANSCRIPT

1
Interoperability of a Scalable Distributed Data Manager with an
Object-relational DBMS
Thesis presentationThesis presentation
Yakham NDIAYEYakham NDIAYE
November, 13November, 13thethe 2001 2001

2
Develop techniques for the interoperability of a DBMS with an external SDDS file.
Examine various architectural issues, making such a coupling the most efficient.
Validate our technical choices by the prototyping and the experimental performances analysis.
Our approach is at the crossing the main memory DBMS, the object-relational-DBMS with the foreign functions, and the distributed/parallel DBMS.
ObjectiveObjective

3
Multicomputers SDDSs AMOS-II & DB2 DBMSs Coupling SDDS and AMOS-II Coupling SDDS and DB2 Experimental analysis Conclusion
PlanPlan

4
MulticomputersMulticomputers
A collection of loosely coupled computers
Computers inter-connected by high-speed local area networks.
Cost/Performance
offers potentially storage and processing capabilities rivaling a supercomputer at a fraction of the cost.
New architectural concepts offer to applications the cumulated CPU and storage
capabilities of a large number of inter-connected computers.

5
• New data structures specifically for Multicomputers• Data are structured
- records with keys parallel scans & function shipping
• Data are on servers
- waiting for access
• Overflowing servers split into new servers
- appended to the file without informing the clients
• Queries come from multiple autonomous clients
- Access initiators
- Not using any centralized directory for access computations
• See for more : http://ceria.dauphine.fr
SDDSSDDS

6
AMOS-II : Active Mediating Object System A main memory database system. Declarative query language : AMOSQL. External data sources capability. External program interfaces AMOS-II using :
- Call-level interface (call-in)
- Foreign functions (call-out)
See the AMOS-II page for more:
http://www.dis.uu.se/~udbl/
AMOS-II DBMSAMOS-II DBMS

7
IBM object-relational DBMS
« DB2 Universal Database ». Typical representative of a commercial relational-object DBMS. Capabilities to handle external data through the user-defined
functions (UDF).
DB2 Universal Database DB2 Universal Database

8
Coupling StrategiesCoupling Strategies
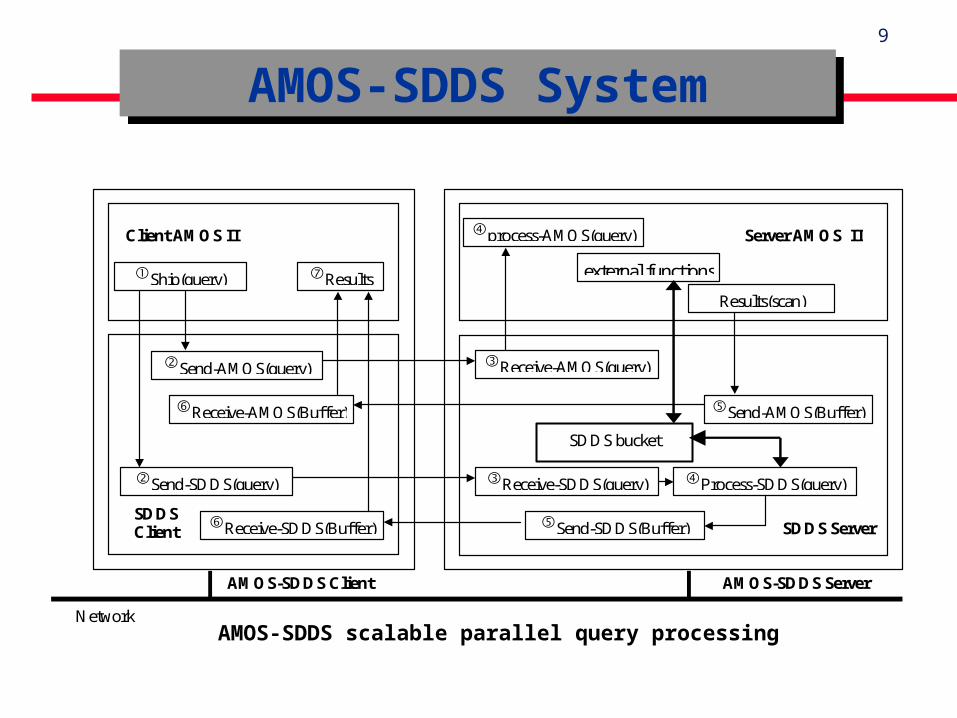
AMOS-SDDS Strategy :
- for a scalable RAM file supporting database queries
- Use a DBMS for manipulations best handled through by the query language ;
- Direct fast data access for manipulations not supported well, or at all, by a DBMS ;
- Distributed queries processing with functions shipping.
9
AMOS-SDDS SystemAMOS-SDDS System
AMOS-SDDS scalable parallel query processing
Network
AMOS-SDDS Server AMOS-SDDS Client
SDDS Client
Client AMOS II Server AMOS II process-AMOS(query)
Ship(query) Results
Send-AMOS(query)
Send-AMOS(Buffer)
Receive-AMOS(query)
SDDS Server
Results(scan)
external functions
SDDS bucket
Send-SDDS(query) Process-SDDS(query)
Send-SDDS(Buffer)
Receive-AMOS(Buffer)
Receive-SDDS(Buffer)
Receive-SDDS(query)

10
Coupling StrategiesCoupling Strategies
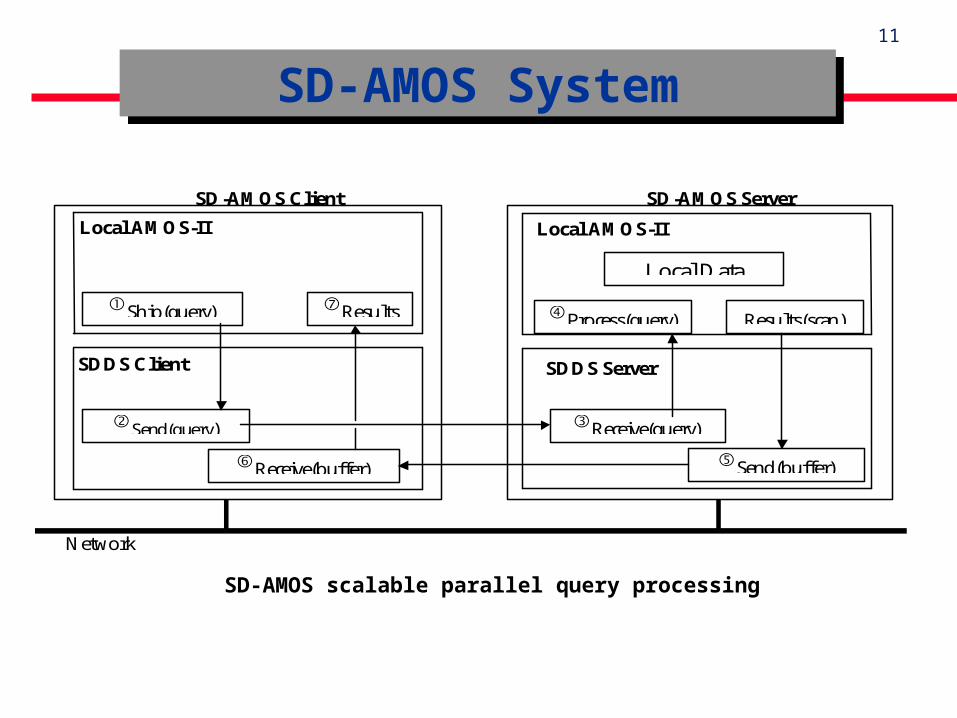
SD-AMOS Strategy :
- Uses AMOS-II as the memory manager at each SDDS storage site ;
- Scalable generalization of a parallel DBMS ;
- Data partitioning becomes dynamic.
11
SD-AMOS SystemSD-AMOS System
SD-AMOS scalable parallel query processing
Network
SD-AMOS Server SD-AMOS Client
SDDS Client
Local AMOS-II Local AMOS-II
Ship(query) Results
Send(query)
Receive(buffer) Send(buffer)
Receive(query)
SDDS Server
Results(scan)
Local Data
Process(query)
12
Couplage SDDS & DB2Couplage SDDS & DB2
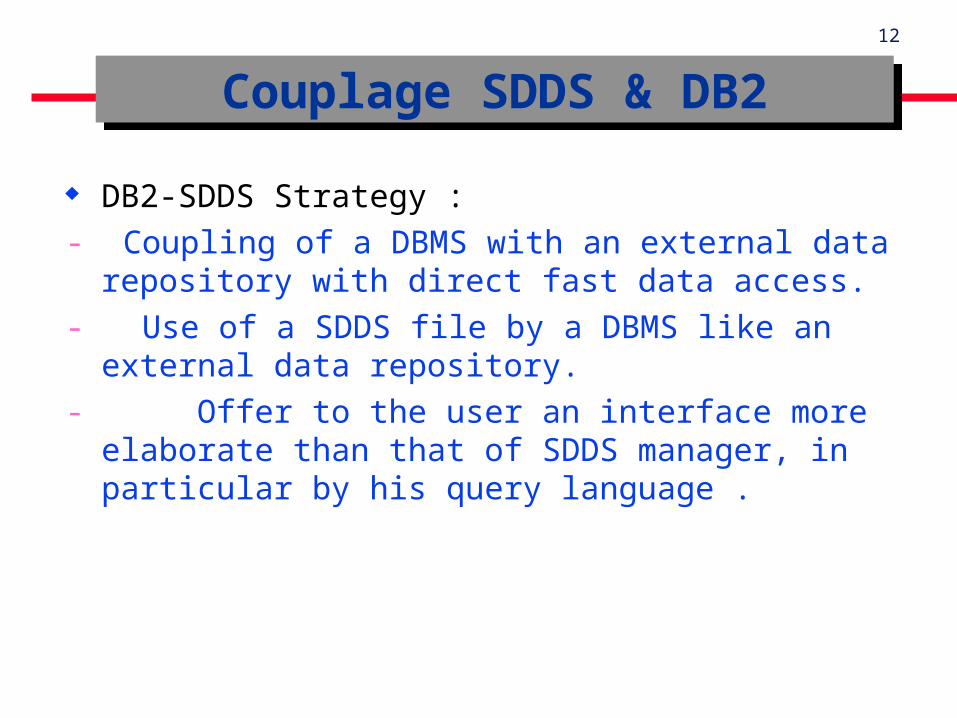
DB2-SDDS Strategy :
- Coupling of a DBMS with an external data repository with direct fast data access.
- Use of a SDDS file by a DBMS like an external data repository.
- Offer to the user an interface more elaborate than that of SDDS manager, in particular by his query language .
13
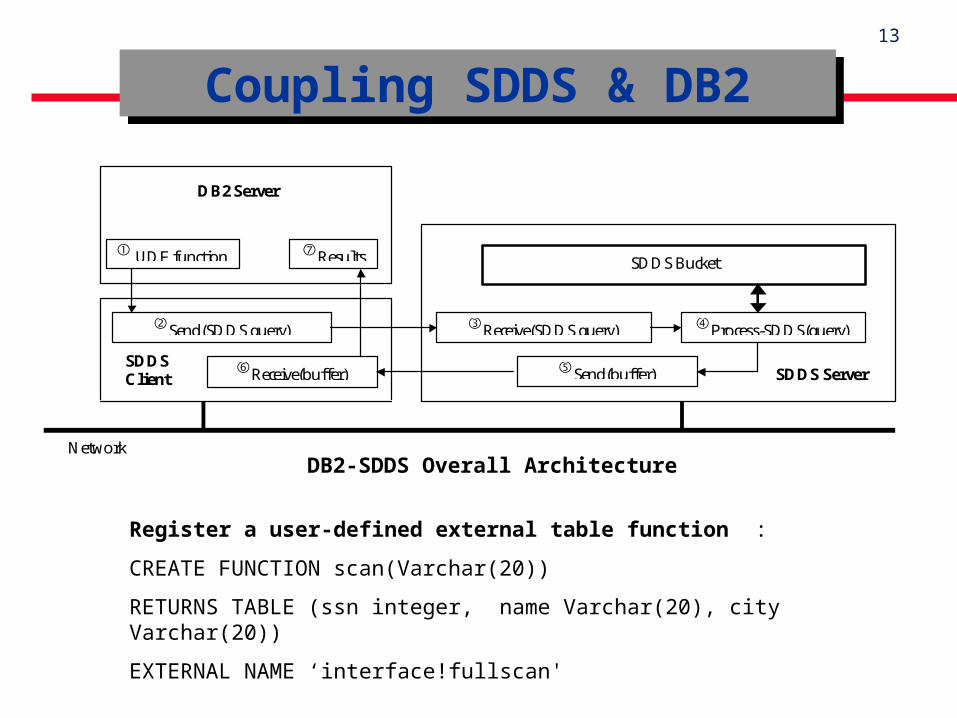
Coupling SDDS & DB2Coupling SDDS & DB2
DB2-SDDS Overall Architecture
Network
SDDS Client
DB2 Server
UDF function Results
SDDS Server
SDDS Bucket
Send(SDDS query) Process-SDDS(query)
Send(buffer) Receive(buffer)
Receive(SDDS query)
Register a user-defined external table function :
CREATE FUNCTION scan(Varchar(20))
RETURNS TABLE (ssn integer, name Varchar(20), city Varchar(20))
EXTERNAL NAME ‘interface!fullscan'
14
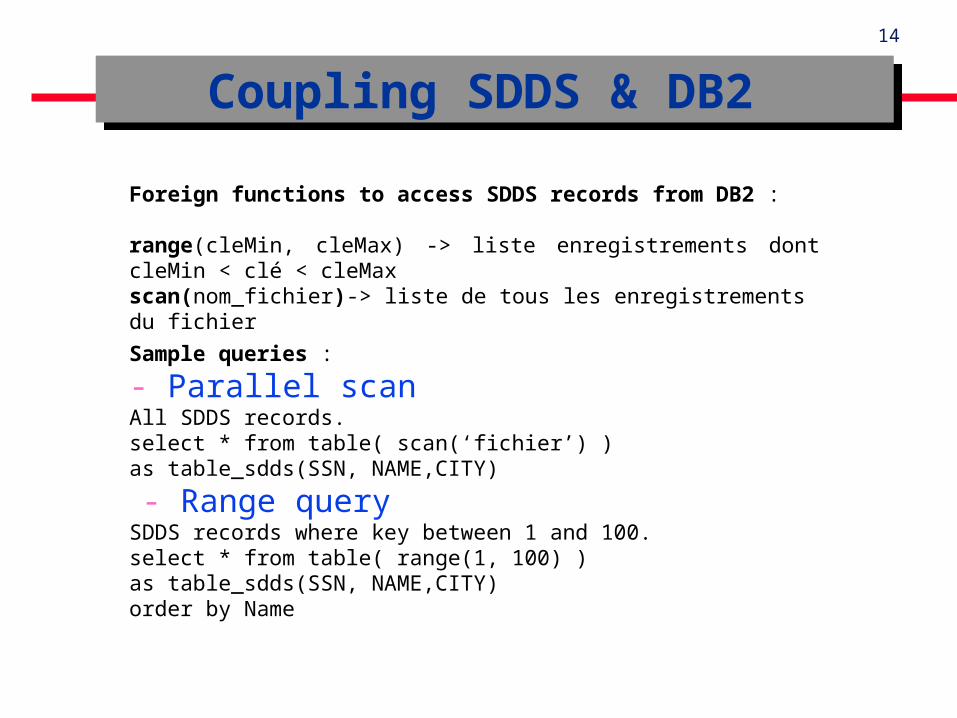
Coupling SDDS & DB2 Coupling SDDS & DB2
Foreign functions to access SDDS records from DB2 :
range(cleMin, cleMax) -> liste enregistrements dont cleMin < clé < cleMax scan(nom_fichier)-> liste de tous les enregistrements du fichier
Sample queries :
- Parallel scanAll SDDS records.select * from table( scan(‘fichier’) ) as table_sdds(SSN, NAME,CITY)
- Range querySDDS records where key between 1 and 100.select * from table( range(1, 100) ) as table_sdds(SSN, NAME,CITY)order by Name
15
Six Pentium III 700 MHz with 256 MB of RAM running Windows 2000
On a 100Mbit/s Ethernet network. One site is used as Client and the five other as Servers We run many servers at the same machine (up to 3 per machine). File scaled from 1 to 15 servers.
The HardwareThe Hardware

16
Benchmark data : Table Person (SS#, Name, City).
Size 20,000 to 300,000 tuples of 25 bytes.
50 Cities.
Random distribution.
Benchmark query : « couples of persons in the same city » Query 1, the file resides at a single AMOS-II.
Query 2, the file resides at AMOS-SDDS.
Join evaluation : Two strategies.
Measures :
- Speed-up & Scale-up
Processing time of aggregate functions
Benchmark queriesBenchmark queries

17
Server Query ProcessingServer Query Processing
E-strategy Data stay external to AMOS
» within the SDDS bucket
Custom foreign functions perform the query
I-strategy Data are dynamically imported into AMOS-II
» Possibly with the local index creation
» Deleted after the processing
» Good for joins
AMOS performs the query
18
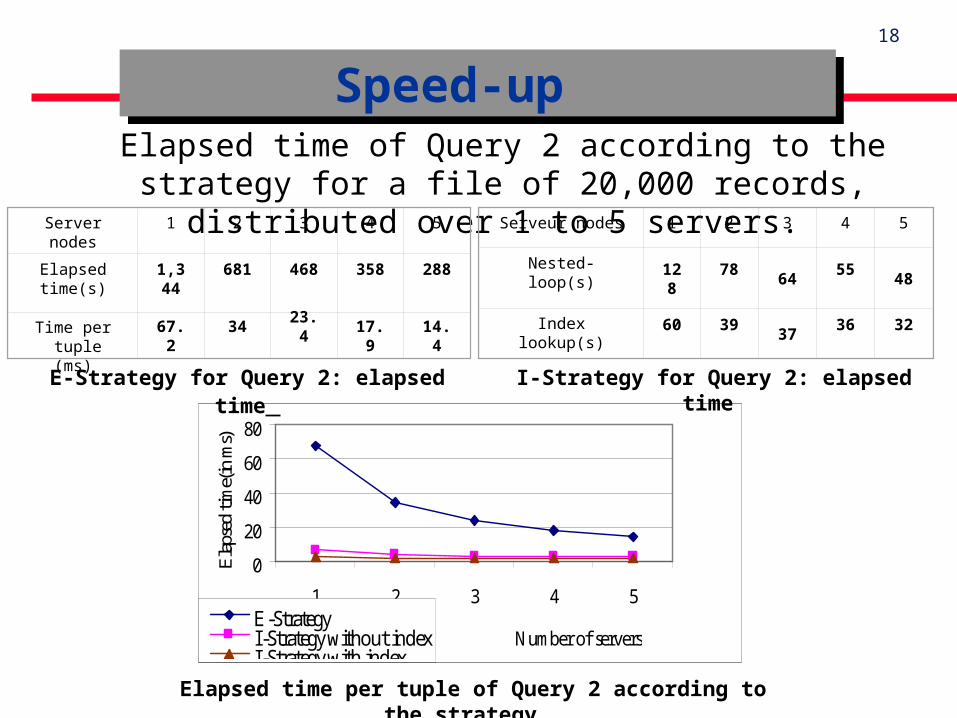
Speed-up Speed-up Elapsed time of Query 2 according to the strategy for a file of 20,000
records, distributed over 1 to 5 servers. Server nodes
1 2 3 4 5
Elapsed time(s)
1,344
681 468 358 288
Time per tuple (ms)
67.2
3423.4
17.9
14.4
Serveur nodes 1 2 3 4 5
Nested-loop(s) 128
7864
5548
Index lookup(s) 60 3937
36 32
0
20
40
60
80
1 2 3 4 5
Number of servers
Ela
psed
tim
e(in
ms)
E-Strategy I-Strategy without indexI-Strategy with index
I-Strategy for Query 2: elapsed time
E-Strategy for Query 2: elapsed time
Elapsed time per tuple of Query 2 according to the strategy

19
The results showed an important advantage of I-Strategy on E-Strategy for the evaluation of the join query.
For 5 servers, the rate is 6 times for the nested loop, and 9 times if an index is creates.
The favorable result makes us study the scale-up characteristics of AMOS-SDDS on a file that scales up to 300,000 tuples.
Discussion Discussion
20
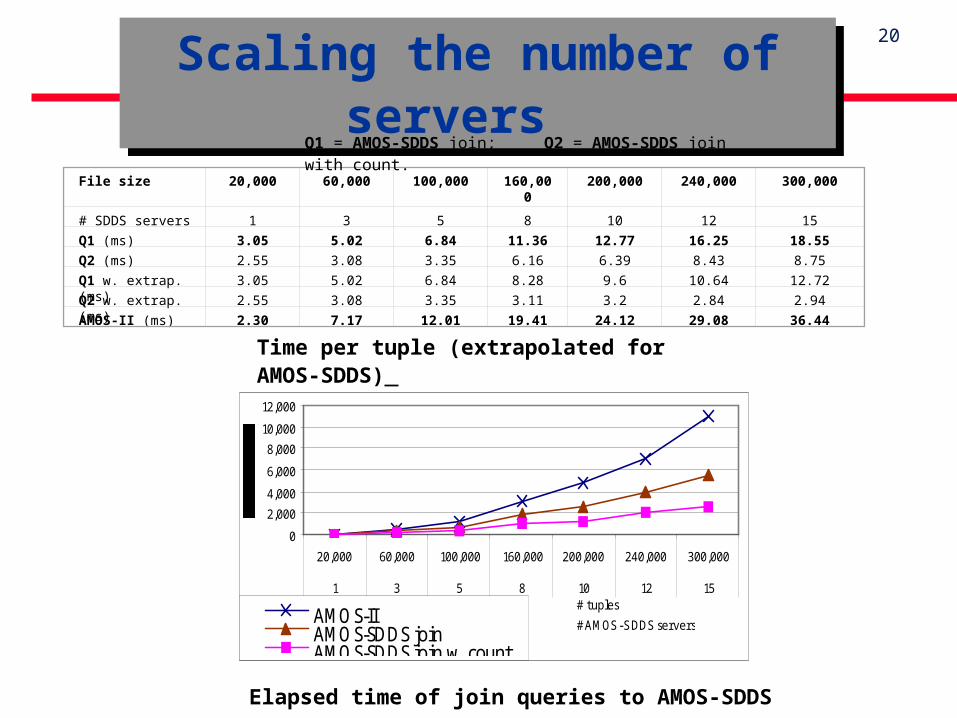
Scaling the number of servers
Scaling the number of servers
Elapsed time of join queries to AMOS-SDDS
File size 20,000 60,000 100,000 160,000 200,000 240,000 300,000
# SDDS servers 1 3 5 8 10 12 15
Q1 (ms) 3.05 5.02 6.84 11.36 12.77 16.25 18.55
Q2 (ms) 2.55 3.08 3.35 6.16 6.39 8.43 8.75
Q1 w. extrap. (ms) 3.05 5.02 6.84 8.28 9.6 10.64 12.72
Q2 w. extrap. (ms) 2.55 3.08 3.35 3.11 3.2 2.84 2.94
AMOS-II (ms) 2.30 7.17 12.01 19.41 24.12 29.08 36.44
Q1 = AMOS-SDDS join; Q2 = AMOS-SDDS join with count.
Time per tuple (extrapolated for AMOS-SDDS)
0
2,000
4,000
6,000
8,000
10,000
12,000
20,000 60,000 100,000 160,000 200,000 240,000 300,000
1 3 5 8 10 12 15# tuples
#AMOS-SDDS serversAMOS-II AMOS-SDDS joinAMOS-SDDS join w. count

21
Scaling the number of servers
Scaling the number of servers
Expected time per tuple of join queries to AMOS-SDDS
05
10152025303540
20,000 60,000 100,000 160,000 200,000 240,000 300,000
1 3 5 8 10 12 15
File size: # tuples
Tim
e pe
r tup
le (m
s)
AMOS-IIAMOS-SDDS joinAMOS-SDDS join w. count
Results are extrapolated to 1 server per machine.- Basically, the CPU component of the elapsed time is divided by 3
The extrapolation of the processing time of the join query with count shows a linear scalability of the system.
Processing time per tuple remains constant (2.94ms) when the file size and the number of servers increase by the same factor.
22
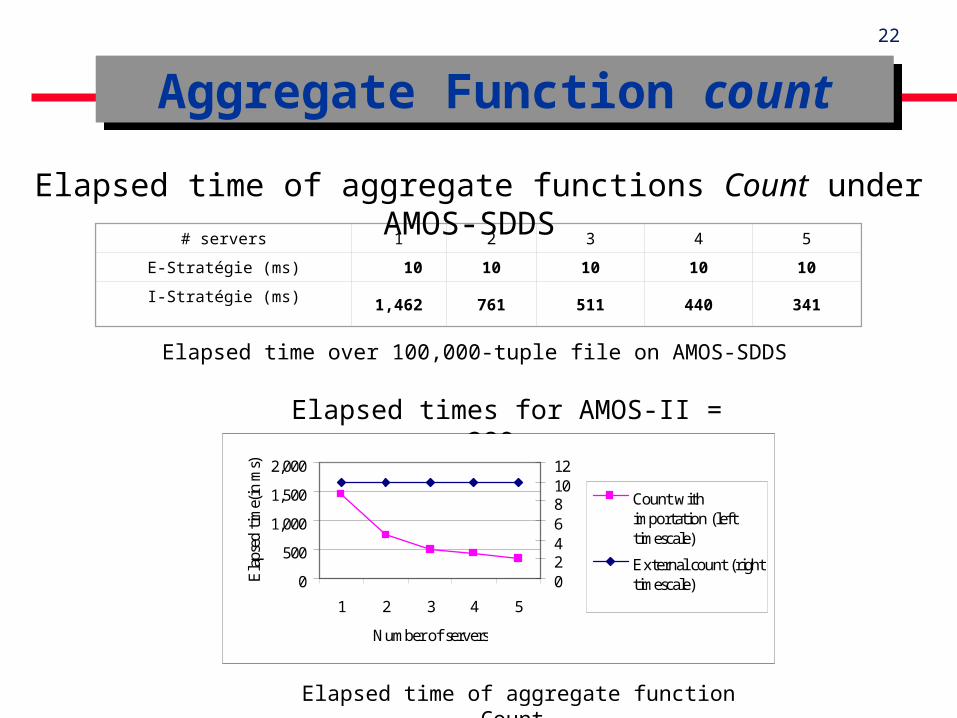
Aggregate Function countAggregate Function count
Elapsed time of aggregate function Count
# servers 1 2 3 4 5
E-Stratégie (ms) 10 10 10 10 10
I-Stratégie (ms) 1,462 761 511 440 341
Elapsed times for AMOS-II = 280ms
0
500
1,000
1,500
2,000
1 2 3 4 5
Number of servers
Ela
psed
tim
e(in
ms)
024681012
Count withimportation (lefttimescale)
External count (righttimescale)
Elapsed time of aggregate functions Count under AMOS-SDDS
Elapsed time over 100,000-tuple file on AMOS-SDDS
23
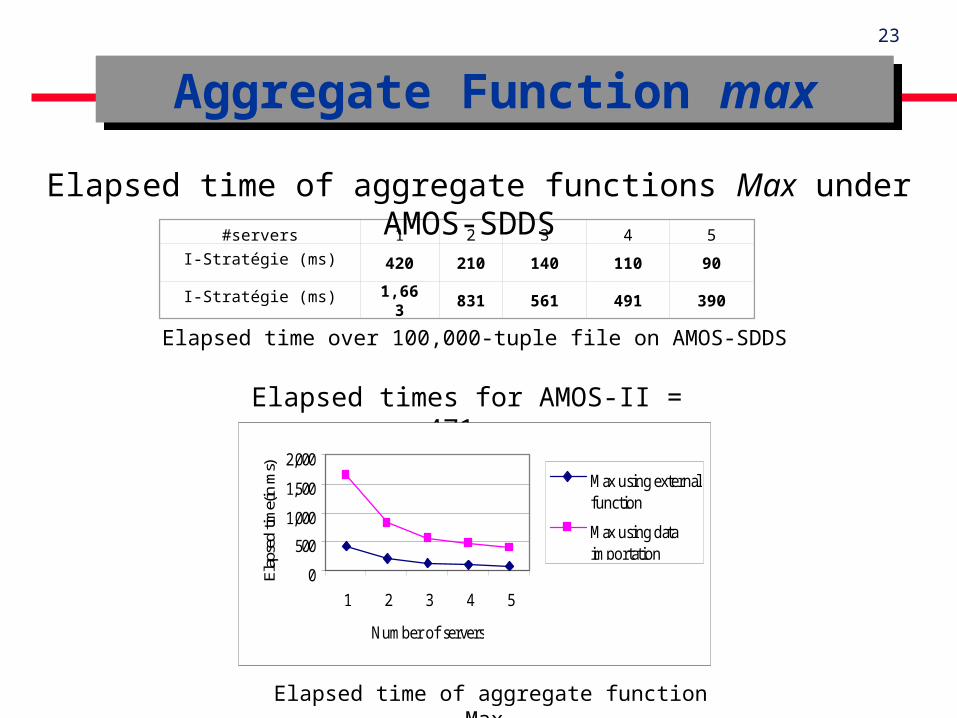
Aggregate Function maxAggregate Function max
Elapsed time of aggregate function Max
#servers 1 2 3 4 5
I-Stratégie (ms) 420210
140 110 90
I-Stratégie (ms) 1,663
831
561 491 390
Elapsed times for AMOS-II = 471ms
0
500
1,000
1,500
2,000
1 2 3 4 5
Number of servers
Elap
sed
time(
in m
s)
Max using externalfunction
Max using dataimportation
Elapsed time over 100,000-tuple file on AMOS-SDDS
Elapsed time of aggregate functions Max under AMOS-SDDS

24
Contrary to the join query, the external strategy is gaining for the evaluation of aggregate functions.
For count function, improvement is about 34 times. For max function, improvement is about 4 times. Due to the importation cost and to a SDDS property : the
current number of records is a parameter of a bucket. Linear Speed-up : processing time decreases with the number
of servers. The use of the external functions can thus be very
advantageous for certain kind of operations.
Discussion Discussion
25
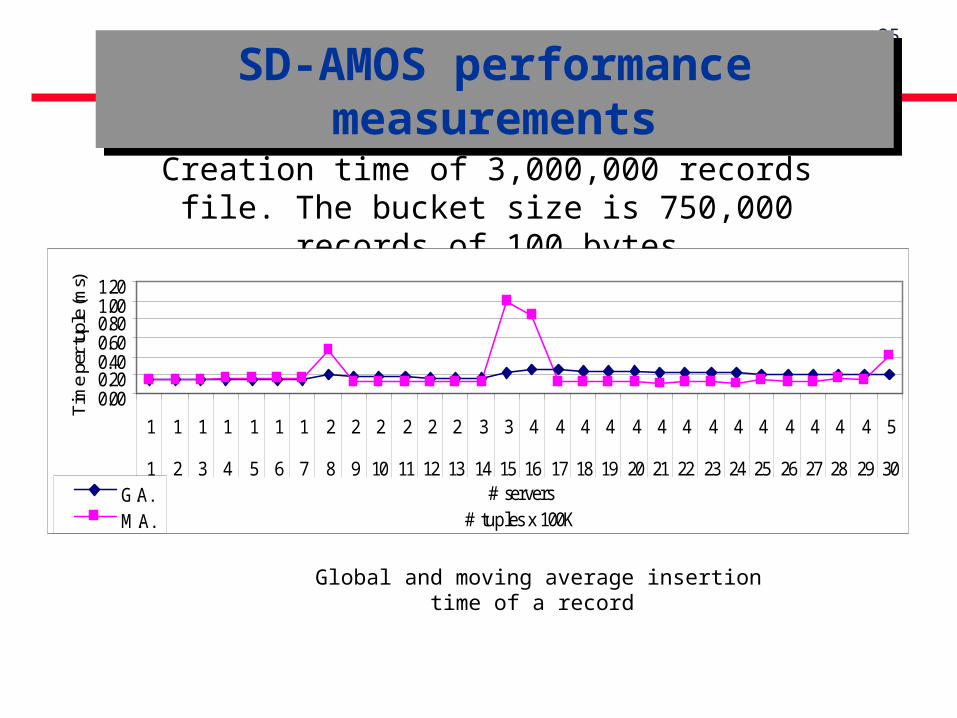
SD-AMOS performance measurements
SD-AMOS performance measurements
Creation time of 3,000,000 records file. The bucket size is 750,000 records of 100 bytes
Global and moving average insertion time of a record
0.000.200.400.600.801.001.20
1 1 1 1 1 1 1 2 2 2 2 2 2 3 3 4 4 4 4 4 4 4 4 4 4 4 4 4 4 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30# servers
# tuples x 100K
Tim
e pe
r tup
le (m
s)
G.A.M.A.
26
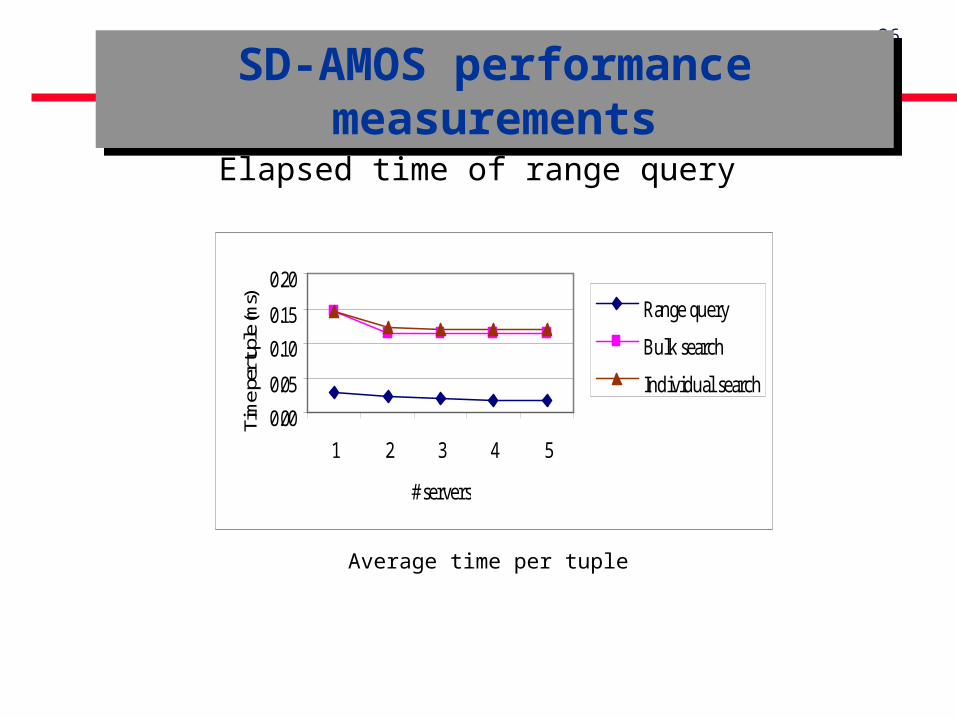
SD-AMOS performance measurements
SD-AMOS performance measurements
Elapsed time of range query
Average time per tuple
0.00
0.05
0.10
0.15
0.20
1 2 3 4 5
#servers
Tim
e per
tupl
e (m
s) Range query
Bulk search
Individual search

27
The average insertion time of a record with the splits is of 0.15ms.
The average access time to a record on a distributed file is of 0.12ms.
- It is 100 times faster than that with a traditional file on disc. Linear scalability : The insertion time and the access time per
tuple remains constant when the file size and the number of servers increase.
Discussion Discussion
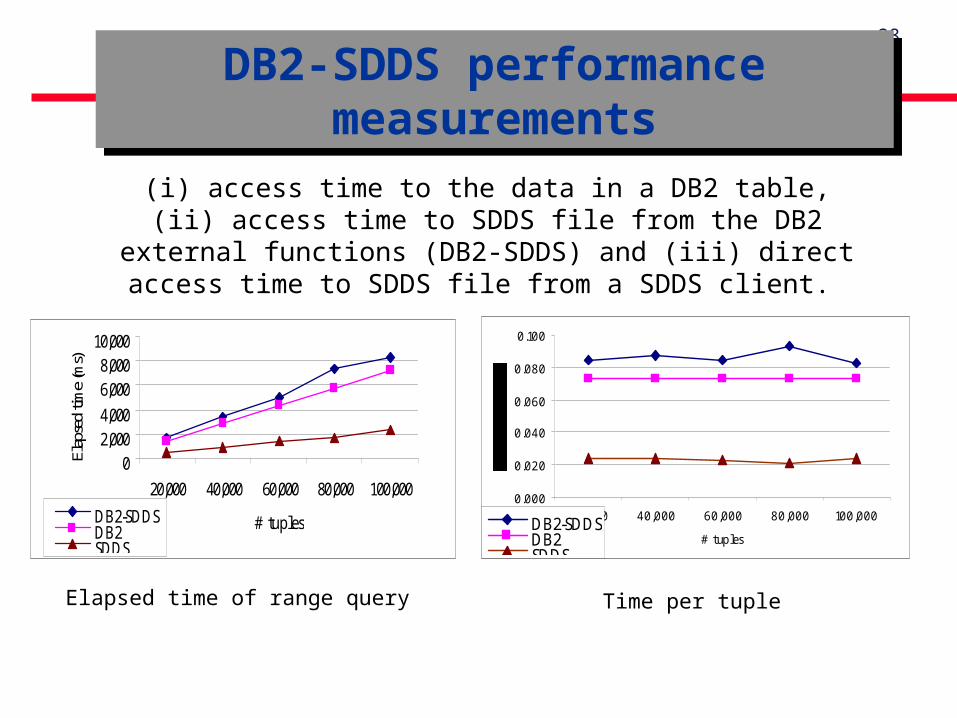
28
DB2-SDDS performance measurements
DB2-SDDS performance measurements
02,0004,0006,0008,000
10,000
20,000 40,000 60,000 80,000 100,000
# tuples
Elap
sed
time
(ms)
DB2-SDDSDB2SDDS
0.000
0.020
0.040
0.060
0.080
0.100
20,000 40,000 60,000 80,000 100,000
# tuplesDB2-SDDSDB2SDDS
Elapsed time of range query Time per tuple
(i) access time to the data in a DB2 table, (ii) access time to SDDS file from the DB2 external functions (DB2-SDDS) and (iii) direct access
time to SDDS file from a SDDS client.

29
Access time to SDDS file is much faster than the access time to a DB2 table: 0.02ms versus 0.07ms.
Access time to external data from DB2 (0.08ms), is less fast than the access to the internal data (0.07ms).
Coupling cost An application has :
- fast direct access to the data
- through the DBMS, access by the query language
Discussion Discussion

30
We have coupled a SDDS manager with a main-memory DBMS AMOS-II and DB2 to improve the current technologies for high-performance databases and for the coupling with external data repositories.
The experiments we have reported in the Thesis prove the efficiency of the system.
AMOS-SDDS et DB2-SDDS : use of a SDDS file by a DBMS and the parallel query processing on the server sites.
SD-AMOS : appears as a scalable generalisation of a parallel main-memory DBMS where the data partitioning becomes automatic.
Conclusion Conclusion

31
Other types of DBMS queries. Client's scalable distributed query decomposer. challenging appears the design of a scalable distributed query
optimizer handling the dynamic data partitioning.
Future Work Future Work

32
EndEnd
Thank You for Your AttentionThank You for Your Attention
CERIA Université Paris IX Dauphine