topic 7 support vector machine for classification
Post on 21-Dec-2015
244 views
TRANSCRIPT

Topic 7Topic 7Support Vector Machine for Support Vector Machine for
ClassificationClassification

Outline
Linear Maximal Margin Classifier for Linearly Separable Data
Linear Soft Margin Classifier for Overlapping Classes
The Nonlinear Classifier

Linear Maximal Margin Classifier for linearly Separable Data

Goal: seeking an optimal separating plane.– That is, among all the hyperplanes that minimizes th
e training error (empirical risk), find the one with the largest margin.
A classifier with a larger margin might have better performance in generalization; on the other hand, a classifier with a smaller margin might have a higher expected risk.
Linear Maximal Margin Classifier for linearly Separable Data

1)2.(y class tobelongsit 0 if
and 1),(y 1 class tobelongs pattern0 If
2
1
bxw
xbxw
i
ii
Canonical hyperplane
1||min
bxw iT
Xxi
1. Minimize the training error

w
2margin
maximize margin → minimize wTw
2. Maximize the margin

l
ii
l
iii
l
iiii ybxwywwL
1112
1
l
i
l
jjijiji
l
ii
l
i
l
jjijiji
l
iiii
xxyyL
xxyyxwyww
1 11
1 11
2
1

Linear Maximal Margin Classifier for linearly Separable Data

Rosenblatt’s Algorithm
hyperplane separating thedefine to),( return
loopfor the withinicationmisclassif no s there'until
for end
if end
; ;1
then0,* if
to1for
repeat :3 step
max: choose :2 step
;0;0 :1 step
2
1
1
b
Rybb
bxxyy
li
xUR
b
iii
l
jijjji
l
ii

Pattern= Target= norm = [1 1 1 [ 1.4142 1 2 1 2.2361 2 -1 1 2.2361 2 0 1 2.0000 -1 2 -1 2.2361 -2 1 -1 2.2361 -1 -1 -1 1.4142 -2 -2 -1 ] 2.8284 ] -> R
•K=[ 2 3 1 2 1 -1 -2 -4 3 5 0 2 3 0 -3 -6 1 0 5 4 -4 -5 -1 -2 2 2 4 4 -2 -4 -2 -4 1 3 -4 -2 5 4 -1 -2 -1 0 -5 -4 4 5 1 2 -2 -3 -1 -2 -1 1 2 4 -4 -6 -2 -4 -2 2 4 8 ]

1st iteration α=[0 0 0 0 0 0 0 0], b=0, R=2.8284 x1=[1 1]; y1=1; k(:,1)=[2 3 1 2 1 -1 -2 -4]
X2=[1 2]; y2=1; k(:,2)=[3 5 0 2 3 0 -3 -6]
X3=[2 -1];y3=1;k(:,3)=[1 0 5 4 -4 -5 -1 -2] 1*[1*1+8]=9>0 X4=[2 0];y4=1; k(:,4)=[2 2 4 4 -2 -4 -2 -4] 1*[1*2+8]=10>0
88284.2*8284.2*10b 0], 0 0 0 0 0 0 [1
000*,*1
i
l
jijjji ybxxyy
011]83*1[*1,*1
bxxyy
l
jijjji

1st iteration
X5=[-1 2];y5=-1;k(:,5)=[1 3 -4 -2 5 4 -1 -2]
(-1)*[1*1+8]= -9
α=[1 0 0 0 1 0 0 0], b=8-8=0 X6=[-2 1];y6=-1;k(:,6)=[-1 0 -5 -4 4 5 1 2]
(-1)*[1*(-1)+(-1)*4+0]= 5>0 X7=[-1 -1];y7=-1;k(:,7)=[-2 -3 -1 -2 -1 1 2 4]
(-1)*[1*(-2)+(-1)*(-1)+0]=1>0 X8=[-2 -2];y8=-1;k(:,8)=[-4 -6 -2 -4 -2 2 4 8]
(-1)*[1*(-4)+(-1)*(-2)+0]=2>0

2ed iteration α=[1 0 0 0 1 0 0 0], b=0, R=2.8284 x1=[1 1]; y1=1; k(:,1)=[2 3 1 2 1 -1 -2 -4] 1*[1*2+(-1)*1+0]=1>0 X2=[1 2]; y2=1; k(:,2)=[3 5 0 2 3 0 -3 -6] 1*[1*3+(-1)*3+0]=0 α=[1 1 0 0 1 0 0 0], b=0+8=8 X3=[2 -1];y3=1;k(:,3)=[1 0 5 4 -4 -5 -1 -2] 1*[1*1+1*0+(-1)*(-4)+8]=14>0 X4=[2 0];y4=1; k(:,4)=[2 2 4 4 -2 -4 -2 -4] 1*[1*2+1*2+(-1)*(-2)+8]=14>0

2ed iteration
X5=[-1 2];y5=-1;k(:,5)=[1 3 -4 -2 5 4 -1 -2]
(-1)*[1*1+1*3+(-1)*5+8]= -7
α=[1 1 0 0 2 0 0 0], b=8-8=0 X6=[-2 1];y6=-1;k(:,6)=[-1 0 -5 -4 4 5 1 2]
(-1)*[1*(-1)+1*0+(-2)*4+0]=9>0 X7=[-1 -1];y7=-1;k(:,7)=[-2 -3 -1 -2 -1 1 2 4]
(-1)*[1*(-2)+1*(-3)+(-2)*(-1)+0]=3>0 X8=[-2 -2];y8=-1;k(:,8)=[-4 -6 -2 -4 -2 2 4 8]
(-1)*[1*(-4)+1*(-6)+(-2)*(-2)+0]=6>0

3rd iteration α=[1 1 0 0 2 0 0 0], b=0, R=2.8284 x1=[1 1]; y1=1; k(:,1)=[2 3 1 2 1 -1 -2 -4] 1*[1*2+1*3+(-2)*1+0]=3>0 X2=[1 2]; y2=1; k(:,2)=[3 5 0 2 3 0 -3 -6] 1*[1*3+1*(5)+(-2)*3+0]=2>0 X3=[2 -1];y3=1;k(:,3)=[1 0 5 4 -4 -5 -1 -2] 1*[1*1+1*0+(-2)*(-4)+0]=9>0 X4=[2 0];y4=1; k(:,4)=[2 2 4 4 -2 -4 -2 -4] 1*[1*2+1*2+(-2)*(-2)+0]=8>0 X5=[-1 2];y5=-1;k(:,5)=[1 3 -4 -2 5 4 -1 -2]
(-1)*[1*1+1*3+(-2)*5+0]= 6>0 X6=[-2 1];y6=-1;k(:,6)=[-1 0 -5 -4 4 5 1 2]
(-1)*[1*(-1)+1*0+(-2)*4+0]=9>0 X7=[-1 -1];y7=-1;k(:,7)=[-2 -3 -1 -2 -1 1 2 4]
(-1)*[1*(-2)+1*(-3)+(-2)*(-1)+0]=3>0 X8=[-2 -2];y8=-1;k(:,8)=[-4 -6 -2 -4 -2 2 4 8]
(-1)*[1*(-4)+1*(-6)+(-2)*(-2)+0]=6>0

f(x)=sum(z.*y.*k(x,x)')+b=1*(1*x1+1*x2)+1*(1*x1+2*x2)+2*(-1*x1+2*x2)+0=7x2

Linear Maximal Margin Classifier for linearly Separable Data

Linear Maximal Margin Classifier for linearly Separable Data
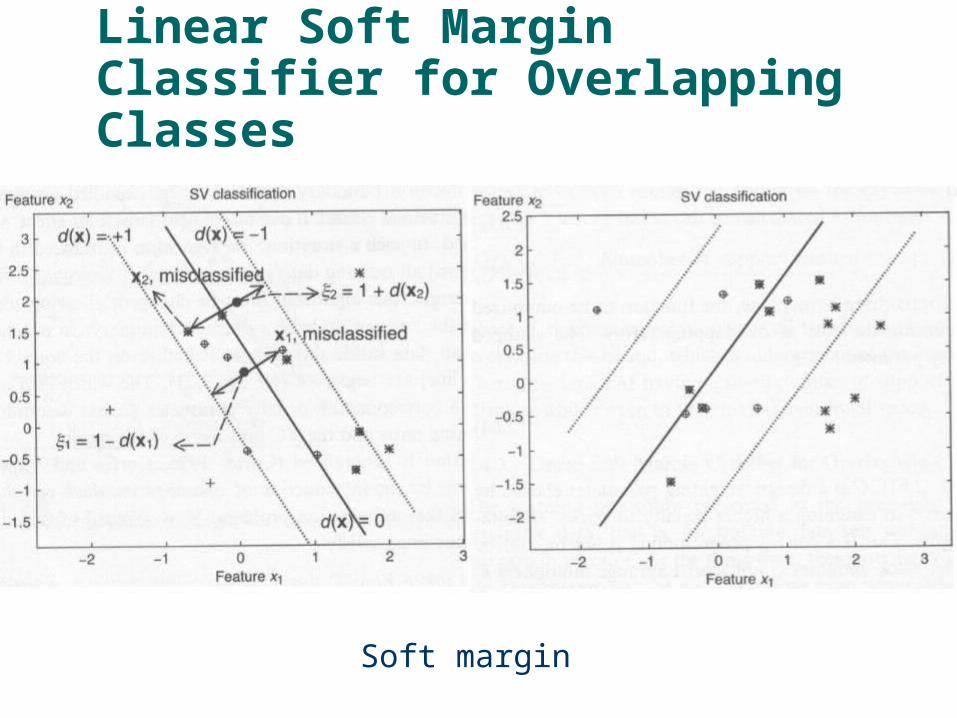
Linear Soft Margin Classifier for Overlapping Classes
Soft margin

0 ,0 ,0 ,0*
0 ,0*
* ,0*
,1][)(2
1
0 , 1][
1
1,
111
iiiiii
l
iii
l
iiii
i
l
ii
l
iii
Tii
l
ii
T
iiiT
i
CCL
yb
L
xyww
L
bxwyCwwL
bxwy
l
i
l
jj
Tijiji
l
ii
l
iikiiik
xxyyL
xxKyyb
1 11
1
**
2
1
0any for ),,(*

2-parameter Sequential Minimal Optimization Algorithm
At every step, SMO chooses two Lagrange multiplier to jointly optimize, finds the optimal values for these multipliers, and updates the SVM to reflect the new optimal values.
Heuristic to choose which multipliers to optimize– first multiplier is the multiplier of the pattern with
the largest current prediction error– Second multiplier is the multiplier of the pattern
with the smallest current prediction error
})({max iii
yxf
})({min iii
yxf

Step 1. Choose 2 multiplier2 α1 and α2
Step 2. Define bounds for α2
If y1≠y2,
If y1=y2,
Step 3. Update α2
Step 4. Update α1
})({min};)({max 21 iii
iii
yxfEyxfE


K=[ 2 3 1 1 2 1 -1 0 -2 -4 3 5 1 0 2 3 0 0 -3 -6 1 1 1 2 2 -1 -2 0 -1 -2 1 0 2 5 4 -4 -5 0 -1 -2 2 2 2 4 4 -2 -4 0 -2 -4 1 3 -1 -4 -2 5 4 0 -1 -2 -1 0 -2 -5 -4 4 5 0 1 2 0 0 0 0 0 0 0 0 0 0 -2 -3 -1 -1 -2 -1 1 0 2 4 -4 -6 -2 -2 -4 -2 2 0 4 8]
Pattern= [1 1; 1 2; 1 0; 2 -1; 2 0; -1 2; -2 1; 0 0; -1 -1; -2 -2]
Target= [ 1; 1; -1; 1; 1; -1; -1; 1; -1; -1 ]
C=0.8

1st iteration
F(x)-Y=[0 -1.4 3.4 7.1 5.7 -8 -10.9 -2.9 -3.8 -6.7]’ α=[0.8 0 0 0.8 0 0.3 0.8 0 0 0]‘ b=1-(0.8*1*2+0.8*1*1+0.3*(-1)*1+0.8*(-1)*(-1))
=1-2.9= -1.9 f(x)=sum(z.*y.*k(x,x)')+b=0.8*(1*x1+1*x2)+0.8*(2*x1-1*x2)
+(-1)*(-0.3*x1+0.6*x2)+(-1)*(-1.6*x1+0.8*x2)-1.9
=4.3x1+1.4x2-1.9
e1 e2


U=0, V=0.8η=k(4,4)+k(7,7)-2*k(4,7)=5+5-2*(-5)=20α2_new=0.8+((-1)*(7.1-(-10.9))./20)= -0.1α2_new,clipped=0 α1_new=0
α=[0.8 0 0 0 0 0.3 0 0 0 0]‘b=1-(0.8*1*2+0.3*(-1)*1)=1-1.3= -0.3f(x)=0.8*(1*x1+1*x2)+ (-1)*(-0.3*x1+0.6*x2)-0.3 =1.1x1+0.2x2-0.3


2ed iteration
F(x)-Y=[0 0.2 1.8 0.7 0.9 0 -1.3 -1.3 -0.6 -1.9]’ α=[0.8 0 0 0 0 0.3 0.8 0 0 0]‘ U=0, V=0 η=k(3,3)+k(10,10)-2*k(3,10)=1+8-2*(-2)=13 α2_new=0+((-1)*(1.8-(-1.9))./13)=0.28 α2_new,clipped=0 α1_new=0 α=[0.8 0 0 0 0 0.3 0 0 0 0]‘
e1 e2

Trained by Rosenblatt’s Algorithm

Let α1*y1+α2*y2=R
Case 1: y1=1, y2=1 (α1>=0, α2>=0, α1+α2=R>=0)
α1
α2
R=0
R=C
R=2C
C
C
If C<R<2C,
If 0<R<=C,
],[2 CCRnew
],0[2 Rnew

Case 2: y1=-1, y2=1 (R=-α1+α2)
α1
α2
R=-CR=0
R=C
C
C
If -C<R<0,
If 0=<R<C,
],0[2 CRnew
],[2 CRnew

Case 3: y1=-1, y2=-1 (-α1-α2=R<=0)
α1
α2
R=0
R=-C
R=-2C
C
C
If -2C<R<-C,
If -C<=R<0,
],[2 CCRnew
],0[2 Rnew

Case 2: y1=1, y2=-1 (R=α1-α2)
α1
α2
R=CR=0
R=-C
C
C
If 0<=R<C,
If -C<R<0,
],0[2 RCnew
],[2 CRnew

The Nonlinear Classifier

The Nonlinear Classifier