uva cs 4501: machine learning lecture 14: neural network ... · network topology, network...
TRANSCRIPT

UVACS4501:MachineLearning
Lecture14:NeuralNetwork/DeepLearning
Dr.Yanjun Qi
UniversityofVirginiaDepartmentofComputerScience
3/23/18
Dr.YanjunQi/UVACS
1

Wherearewe?èFivemajorsectionsofthiscourse
q Regression(supervised)q Classification(supervised)q Unsupervisedmodelsq Learningtheoryq Graphicalmodels
3/23/18 2
Dr.YanjunQi/UVACS

Today
Ø DeepLearningØHistoryØ Whybreakthrough?Ø Recenttrends(ExtraLecturethisFriday!)
ØBasicNeuralNetwork(NN)Ø singleneuron,e.g.logisticregressionunitØ multilayerperceptron(MLP)Ø formulti-classclassification,softmax layerØ MoreabouttrainingNN
2/22/18 3
YanjunQi/UVACS

Manyclassificationmodelsinventedsincelate80’s
• Neuralnetworks• Boosting• SupportVectorMachine• RandomForest• ……
2/22/18 4
YanjunQi/UVACS

A study comparing Classifiers
3/23/18 5
Dr.YanjunQi/UVACS
Proceedingsofthe23rdInternationalConferenceonMachineLearning(ICML`06).
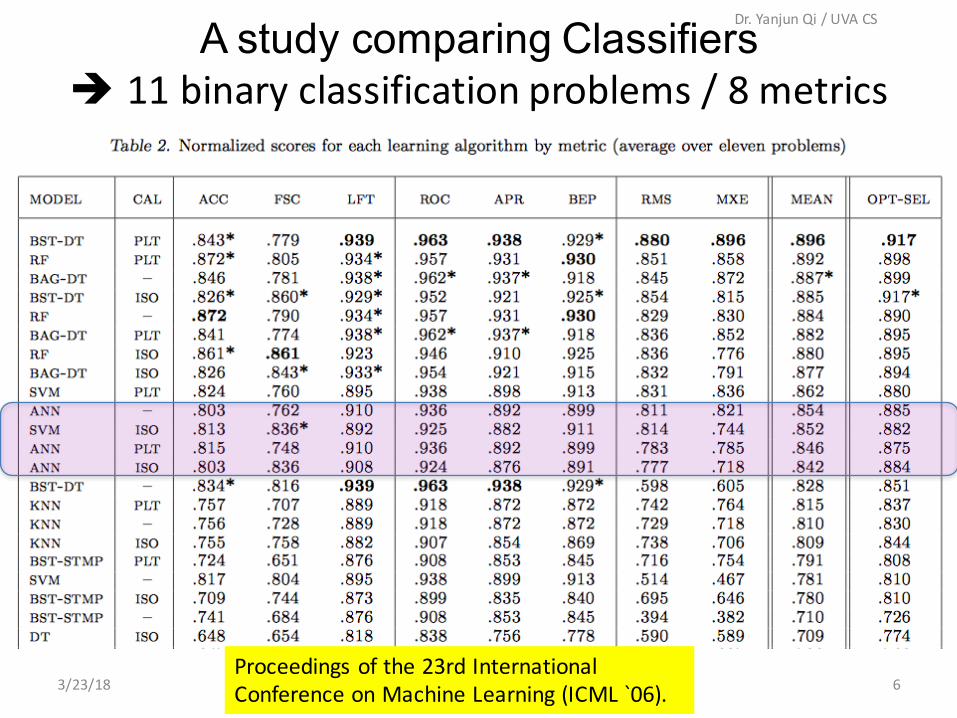
A study comparing Classifiers è 11binaryclassificationproblems/8metrics
3/23/18 6
Dr.YanjunQi/UVACS
Proceedingsofthe23rdInternationalConferenceonMachineLearning(ICML`06).

DeepLearninginthe90’s
• Prof.Yann LeCun inventedConvolutionalNeuralNetworks
• FirstNNsuccessfullytrainedwithmanylayers
2/22/18 7
YanjunQi/UVACS

“LeNet”EarlysuccessatOCR
2/22/18 8
Y.LeCun,L.Bottou,Y.Bengio,andP.Haffner,Gradient-basedlearningappliedtodocument recognition,
ProceedingsoftheIEEE86(11):2278–2324,1998.
YanjunQi/UVACS

• Prof.Schmidhuber invented"Longshort-termmemory”– RecurrentNN(LSTM-RNN)modelin1997
2/22/18 9
Sepp Hochreiter;JürgenSchmidhuber (1997)."Longshort-termmemory".NeuralComputation.9(8):1735–1780.
ImageCreditsfromChristopher
DeepLearninginthe90’s

Between~2000to~2011MachineLearningFieldInterest
• LearningwithStructures!+Convex Formulation!– Kernellearning– TransferLearning– Semi-supervised– ManifoldLearning– SparseLearning– Structuredinput-outputlearning…– Graphicalmodel
2/22/18 10
YanjunQi/UVACS

“WinterofNeuralNetworks”Since90’s!to~2011
• Non-convex
• Needalotoftrickstoplaywith– Howmanylayers?– Howmanyhiddenunitsperlayer?– Whattopologyamonglayers?…….
• Hardtoperformtheoreticalanalysis
2/22/18 11
YanjunQi/UVACS
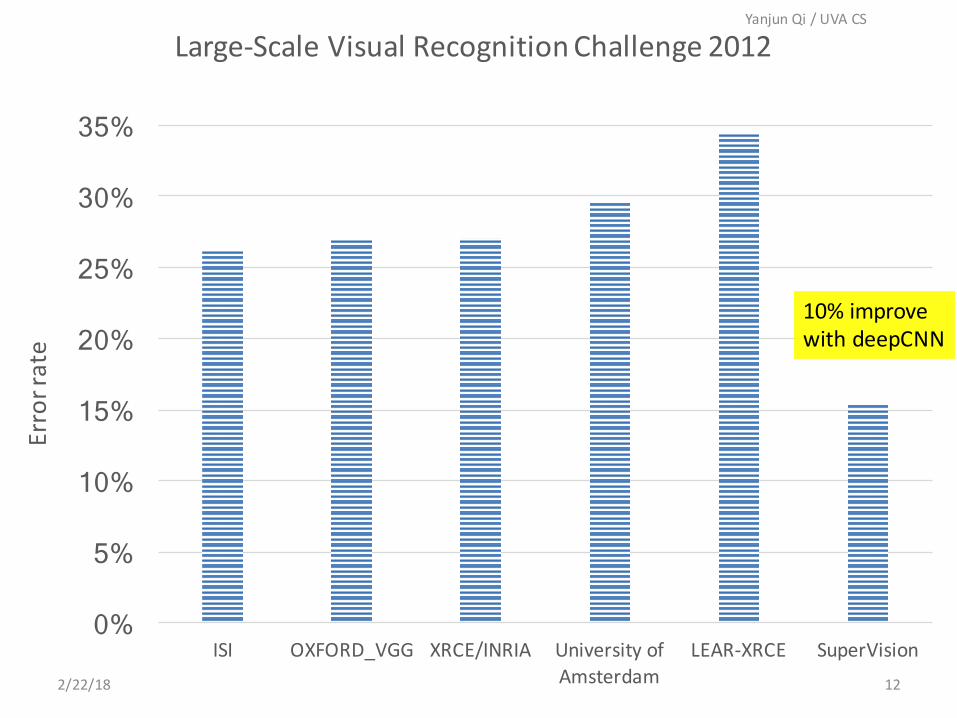
0%
5%
10%
15%
20%
25%
30%
35%
ISI OXFORD_VGG XRCE/INRIA UniversityofAmsterdam
LEAR-XRCE SuperVision
Errorrate
Large-Scale VisualRecognitionChallenge2012
10%improvewithdeepCNN
2/22/18 12
YanjunQi/UVACS
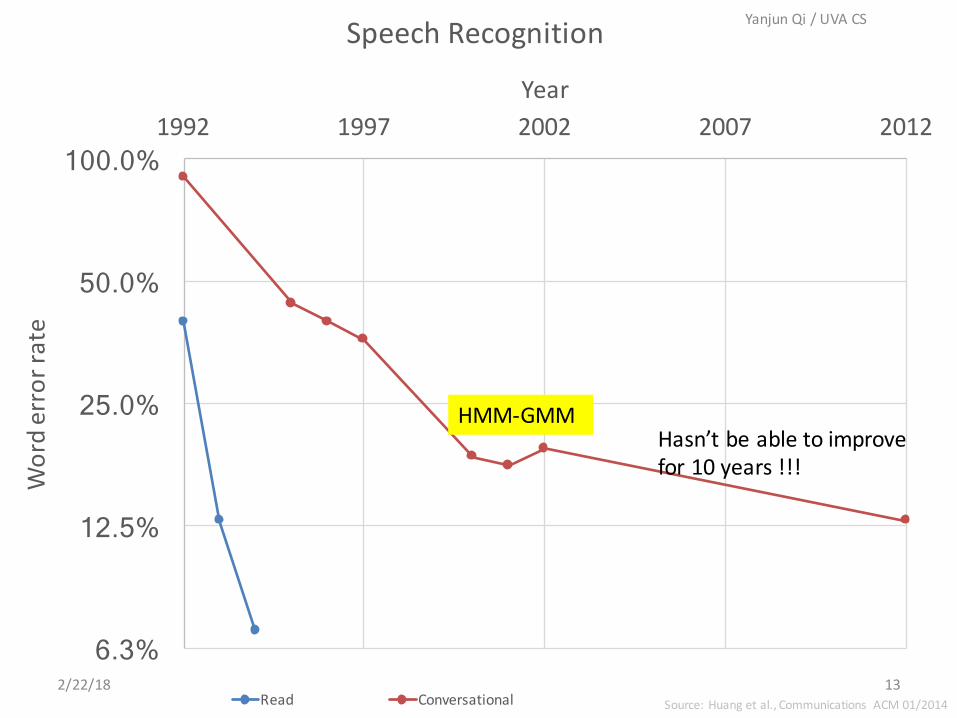
6.3%
12.5%
25.0%
50.0%
100.0% 1992 1997 2002 2007 2012
Worderrorrate
Year
SpeechRecognition
Read Conversational Source:Huangetal.,Communications ACM01/2014
HMM-GMMHasn’tbeabletoimprovefor10years!!!
2/22/18 13
YanjunQi/UVACS

Reason:Plentyof(Labeled)Data
• Text:trillionsofwordsofEnglish+otherlanguages• Visual:billionsofimagesandvideos• Audio: thousandsofhoursofspeechperday• Useractivity:queries,userpageclicks,maprequests,etc,• Knowledgegraph:billionsoflabeledrelationaltriplets
• ………
2/22/18 14Dr.JeffDean’stalk
YanjunQi/UVACS

Reason:AdvancedComputerArchitecturethatfitsDNNs
2/22/18 15
YanjunQi/UVACS
http://www.nvidia.com/content/events/geoInt2015/LBrown_DL.pdf

Today
Ø DeepLearningØHistoryØ Whybreakthrough?Ø Recenttrends(ExtraLecturethisFriday!)
ØBasicNeuralNetwork(NN)Ø singleneuron,e.g.logisticregressionunitØ multilayerperceptron(MLP)Ø formulti-classclassification,softmax layerØ MoreabouttrainingNN
2/22/18 16
YanjunQi/UVACS

WHYBREAKTHROUGH?
2/22/18 17
DeepLearningDeepReinforcementLearning
GenerativeAdversarialNetwork(GAN)

Howcanwebuildmoreintelligentcomputer/machine?
• Ableto– Perceivetheworld– Understandtheworld– Interactwiththeworld
• Thisneeds– Basicspeechcapabilities– Basicvisioncapabilities– Languageunderstanding– Userbehavior/emotionunderstanding– Beingabletothink/reason…
2/22/18 18
YanjunQi/UVACS

DNNshelpusbuildmoreintelligentcomputers(Extra)
– Perceivetheworld,• e.g.,objectiverecognition,speechrecognition,…
– Understandtheworld,• e.g.,machinetranslation,textsemanticunderstanding
– Interactwiththeworld,• e.g.,AlphaGo,AlphaZero,self-drivingcars,…
– Beingabletothink/reason,• e.g.,learntocodeprograms,learntosearchdeepNN,…
– Beingabletoimagine/tomakeanalogy,• e.g.,learntodrawwithstyles,……
2/22/18 19
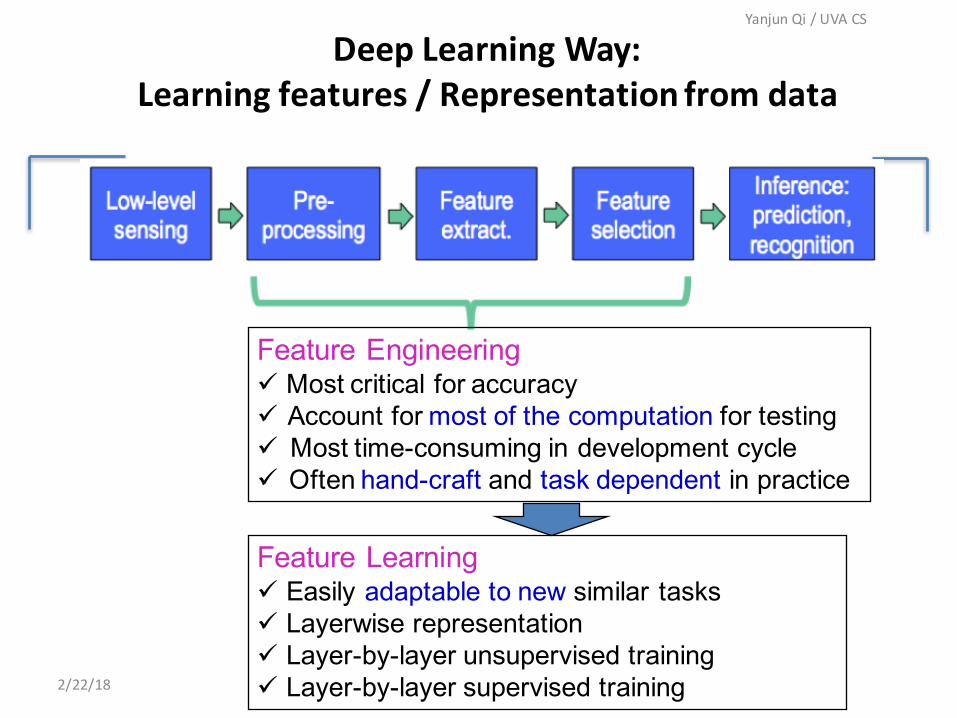
DeepLearningWay:Learningfeatures/Representationfromdata
Feature Engineering ü Most critical for accuracy ü Account for most of the computation for testing ü Most time-consuming in development cycle ü Often hand-craft and task dependent in practice
Feature Learning ü Easily adaptable to new similar tasks ü Layerwise representation ü Layer-by-layer unsupervised trainingü Layer-by-layer supervised training 202/22/18
YanjunQi/UVACS

To perceive the world: Application I:Objective Recognition / Image Labeling
“Very large-scale” ImageNet competition(training on 1.2 million images [X]
vs.1000 different word labels [Y])
212/22/18
YanjunQi/UVACS

To perceive the world:Application I:Objective Recognition / Image Labeling
Deep Convolution Neural Network (CNN) and variants have won (as best systems) on “very large-scale” ImageNetcompetition 2012-2017
222/22/18
YanjunQi/UVACS

23AdaptfromFromNIPS2017DLTrendTutorial
2/22/18
YanjunQi/UVACS

2/22/18 24AdaptfromFromNIPS2017DLTrendTutorial
YanjunQi/UVACS

To understand the world:Application II: Semantic Understanding
e.g. Wordembedding/NeuralLanguageModels
• Learn to embed each word into a vector of real values – Semantically similar words have closer embedding representations
• Progress in 2013/14– Arithmeticoperationsforsemantic/syntacticwordrelationships
25Dr.JeffDean’stalk2/22/18
YanjunQi/UVACS

2/22/18 26
YanjunQi/UVACS

27http://cs231n.stanford.edu/slides/
2/22/18
YanjunQi/UVACSe.g.

e.g.Formachinetranslationwith2RNN
2/22/18
YanjunQi/UVACS
28

To interact with the world:Application III: DeepLearningtoPlayGames
• DeepMind:– LearningtoPlay&windozensofAtarigames– newDeepReinforcementLearningalgorithms– AlphaGo /AlphaZero
2/22/18 29OlivierGrisel’s talk
YanjunQi/UVACS

Able to Reason: Application IV: DeepLearningtoExecuteandProgram
2/22/18 30OlivierGrisel’s talk
YanjunQi/UVACS

31
BuildingDeepNeuralNets
http://cs231n.stanford.edu/slides/winter1516_lecture5.pdf
fx
y

Task:
Machine (Deep) Learning in a Nutshell
Representation:
Score Function:
Search/Optimization
Check / Validate (Models, Parameters)
2/22/18 32
Yanjun Qi/UVACS

● Tasks:● Discriminativeclassification/Generative/Reinforce/Reasoning…
● FormulateInput/Output:● Datarepresentation
● ArchitectureDesign:● NetworkTopology,NetworkParameters
● Training/Searching/Learning● Withnewlosses/withnewoptimizationtricks● Newformulationoflearning● ScalingupwithGPU,Scalingupwithdistributedoptimization,e.g.AsynchronousSGD
● Validation/Trust/Test/Understand…
DESIGN DeepNN:FiveAspects(Extra)
2/22/18 33
YanjunQi/UVACS

Today
Ø DeepLearningØHistoryØ Whybreakthrough?Ø Recenttrends(ExtraLecturethisFriday!)
ØBasicNeuralNetwork(NN)Ø singleneuron,e.g.logisticregressionunitØ multilayerperceptron(MLP)Ø formulti-classclassification,softmax layerØ MoreabouttrainingNN
2/22/18 34
YanjunQi/UVACS

ez
1 + ez
One“Neuron”:ExpandedLogisticRegression
x1
x2
x3
Σ
+1
z
z = wT x + b
y = sigmoid(z) =35
p = 3
w1
w2
w3
b1SummingFunction
SigmoidFunction
Multiplyby
weights
ŷ = P(Y=1|x,w)
Input x
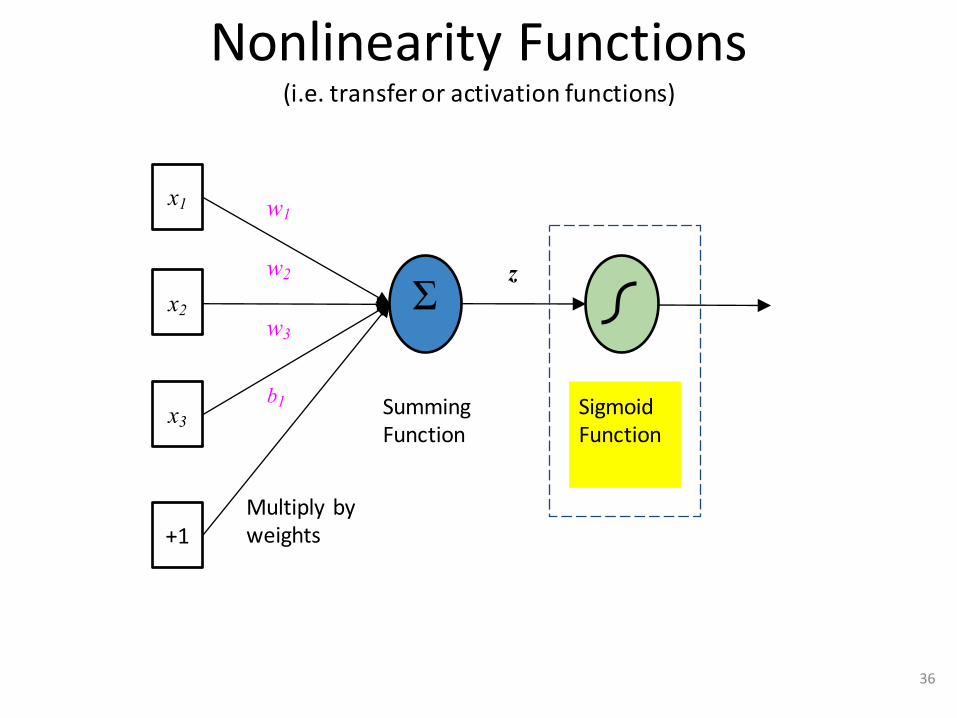
NonlinearityFunctions(i.e.transferoractivationfunctions)
x1
x2
x3
Σ
SummingFunction
SigmoidFunction
w1
w2
w3
+1
b1
z
x w
Multiplybyweights
36
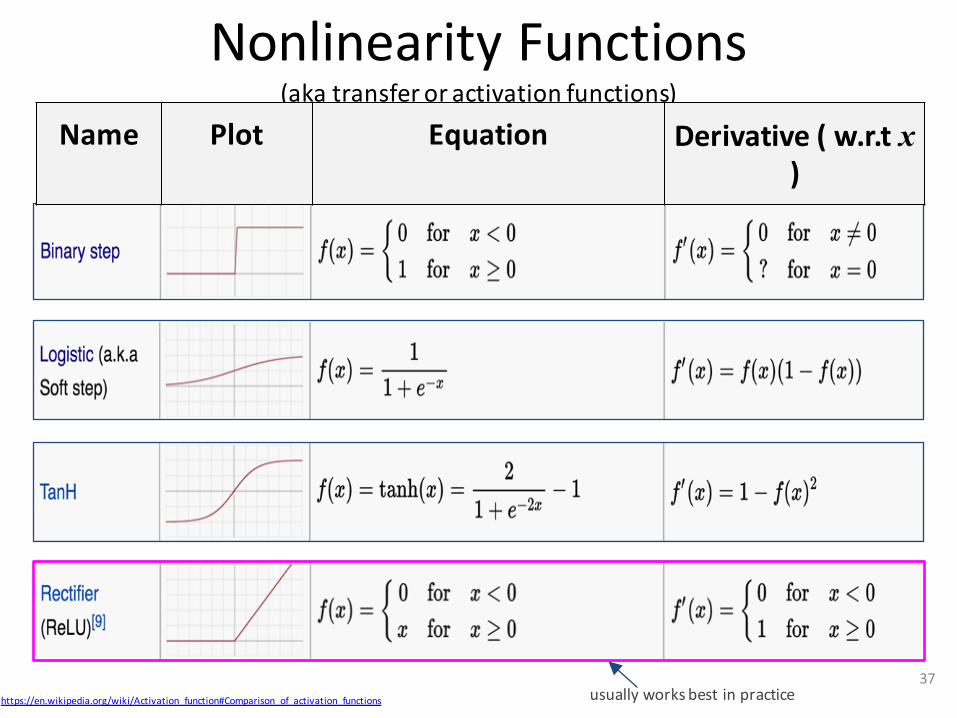
NonlinearityFunctions(akatransferoractivationfunctions)
x w
37https://en.wikipedia.org/wiki/Activation_function#Comparison_of_activation_functions
Name Plot Equation Derivative(w.r.tx )
usuallyworksbest inpractice

• Common ones include:– Threshold / Step function:
• f(v) = 1 if v > c, else -1
– Sigmoid (s shape func): • E.g. logistic func: f(v) = 1/(1 + e-v), Range [0, 1]
– Hyperbolic Tanh : • f(v) = (ev – e-v)/(ev + e-v), Range [-1,1]
• Desirable properties:– Monotonic, Nonlinear, Bounded– Easily calculated derivative
Transfer / Activation functions
00
1
z
a
zea −+=1
1
step func
sigmoid func
3/23/18
Dr.YanjunQi/UVACS
38

Perceptron:Another1-NeuronUnit(Specialformofsinglelayerfeedforward)
− TheperceptronwasfirstproposedbyRosenblatt(1958)isasimpleneuronthatisusedtoclassifyitsinputintooneoftwocategories.
− Aperceptronusesa stepfunction thatreturns+1ifweightedsumofitsinputlargeorequalto0,and-1otherwise
Σ
x1
x2
xn
w2
w1
wn
b (bias)
vy
φ(v)⎩⎨⎧
<−≥+
=0 if 10 if 1
)(vv
vϕ
Summingfunction
Activation(Step) function
3/23/18
Dr.YanjunQi/UVACS
39

Today
Ø DeepLearningØHistoryØ Whybreakthrough?Ø Recenttrends(ExtraLecturethisFriday!)
ØBasicNeuralNetwork(NN)Ø singleneuron,e.g.logisticregressionunitØ multilayerperceptron(MLP)Ø formulti-classclassification,softmax layerØ MoreabouttrainingNN
2/22/18 40
YanjunQi/UVACS

ez
1 + ez
One“Neuron”:ExpandedLogisticRegression
x1
x2
x3
Σ
+1
z
z = wT x + b
y = sigmoid(z) =41
p = 3
w1
w2
w3
b1SummingFunction
SigmoidFunction
Multiplyby
weights
ŷ = P(Y=1|x,w)
Input x

Multi-LayerPerceptronNeuralNetwork(MLP)
42
1sthiddenlayer
2ndhiddenlayer
Outputlayer
x1
x2
x3
x ŷ
W1
w3
W2

Today
Ø DeepLearningØHistoryØ Whybreakthrough?Ø Recenttrends(ExtraLecturethisFriday!)
ØBasicNeuralNetwork(NN)Ø singleneuron,e.g.logisticregressionunitØ multilayerperceptron(MLP)Ø loss,e.g.,multi-classclassification,softmax layerØ MoreabouttrainingNN
2/22/18 43
YanjunQi/UVACS

Multi-LayerPerceptron(MLP)forRegression
x1
x2
x3
+1 +1
Layer1 Layer2
Layer4+1
Layer3
Example:4layernetworkwith2outputunits:
hiddeninput outputhidden
! y!"
3/23/18
Dr.YanjunQi/UVACS
44
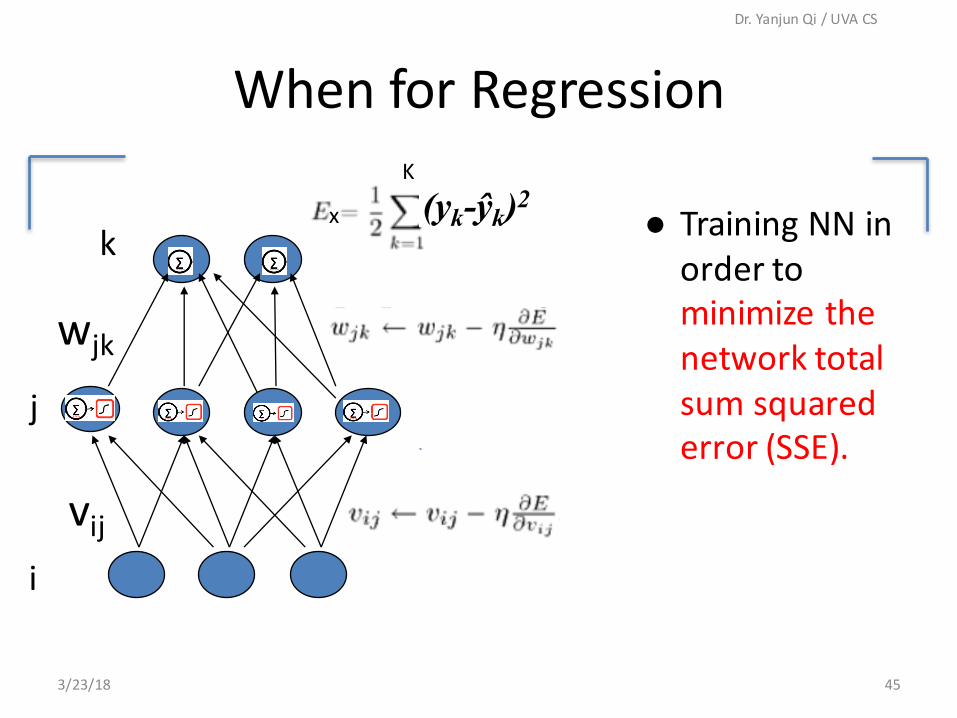
i
j
k
vij
wjk
When for Regression
● TrainingNNinordertominimizethenetworktotalsumsquarederror(SSE).
(yk-ŷk)2
3/23/18
Dr.YanjunQi/UVACS
45
x
K

String a lot of logistic units together. Example: 3 layer network:
x1
x2
x3
+1 +1
a3
a2
a1
Layer1 Layer2
Layer3
hiddeninput output
y
3/23/18
Dr.YanjunQi/UVACS
46
Multi-LayerPerceptron(MLP)forBinaryClassification

Whenforbinaryclassification(outputlayerwith1neuronforbinaryoutput)
3/23/18
Dr.YanjunQi/UVACS
47
ŷ =P(Y=1|X,Θ)
Ex(θ )= Lossx(θ )= − logPr(Y = y |X = x)= −{ yi log( yi )+(1− yi )log(1− yi )}
ForBernoullidistribution,
p(y =1| x)y (1− p)1−y
Cross-entropylossfunction, ORnamedas“deviance”,ORnegativelog-likelihood
i
j
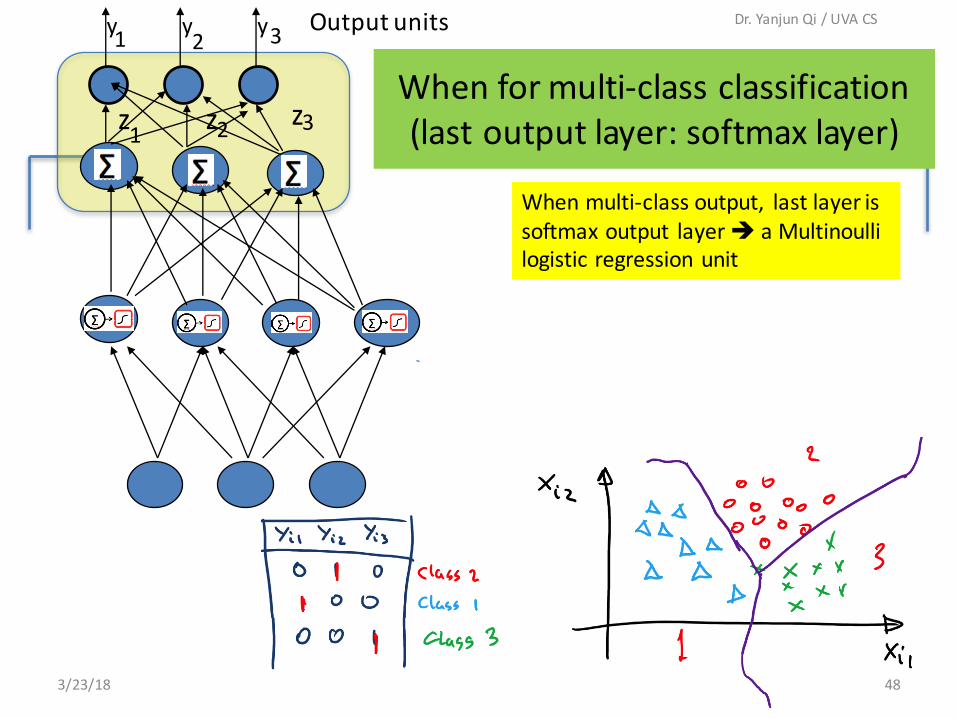
Whenformulti-classclassification(lastoutputlayer:softmax layer)
3/23/18
Dr.YanjunQi/UVACS
48
Whenmulti-classoutput, lastlayerissoftmax output layerè aMultinoullilogisticregressionunit
Outputunits
z
y
z
y
z
y1
1 2
2 3
3

Review: Multi-classvariablerepresentation
• Multi-classvariableèAnindicatorbasisvectorrepresentation
– IfoutputvariableGhasKclasses,therewillbeKindicatorvariabley_i
• Howtoclassifytomulti-class?– StrategyI:learnKdifferentregressionfunctions,thenmax
3/23/18
Dr.YanjunQi/UVACS
49
Class
N
z1(x),z2(x),z3(x),z4(x)

Strategy:Use“softmax” layerfunctionformulti-classclassification
yi =ezi
ezjj∑
∂yi∂zi
= yi (1− yi )
SoftmaxOutput
z
y
z
y
z
y1
1 2
2 3
3
3/23/18
Dr.YanjunQi/UVACS
50
“Softmax”function.Normalizingfunctionwhichconvertseachclassoutputtoaprobability.

Use“softmax” layerfunctionformulti-classclassification
3/23/18
Dr.YanjunQi/UVACS
51
Thenaturalcostfunctionisthenegativelogprobabilityoftherightanswer
è Crossentropylossfunction:
ThesteepnessoffunctionEexactlybalancestheflatnessofthesoftmax
Ex(true!y , !y)= − truey j ln
j=1....K∑ y j = − truey j ln
j∑ p( y j =1|x)
∂E∂zi
= ∂E∂ y j
∂ y j∂zij=1....K
∑ = yi −trueyiErrorcalculatedfromOutputvs.
true
“0”forallexcepttrueclass

Logistic:aspecialcaseofsoftmax fortwoclasses
• Sothelogisticisjustaspecialcasethatavoidsusingredundantparameters:– Addingthesameconstanttobothz1andz0hasnoeffect.
– Theover-parameterizationofthesoftmax isbecausetheprobabilitiesmustaddto1.
)(10101
1
11
zzzz
z
eeeey −−+
=+
=
3/23/18
Dr.YanjunQi/UVACS
52

Today
Ø DeepLearningØHistoryØ Whybreakthrough?Ø Recenttrends(ExtraLecturethisFriday!)
ØBasicNeuralNetwork(NN)Ø singleneuron,e.g.logisticregressionunitØ multilayerperceptron(MLP)Ø formulti-classclassification,softmax layerØ MoreabouttrainingNN
2/22/18 53
YanjunQi/UVACS

54
x1
x2
x3
W1
w3
W2
x ŷ E (ŷ,y)

“BlockView” ofmulti-classNN
x
1sthiddenlayer
2ndhiddenlayer Outputlayer
55
*
W1
*
W2
*
W3z1 z2 z3h1 h2
LossModule
“Softmax”
E (ŷ,y)ŷ
W isamatrix z isavector

“BlockView” ofLogisticRegression
DotProduct Sigmoid
56
Input
outputx *
W z
W isamatrix z isavector
parameterizedblock,Wneedstobelearned
NoParameterstoLearn
E (ŷ,y)ŷ loss

• ForLR:linearregression,Wehavethefollowingdescentrule:
• è Forneuralnetwork,wehavethedeltarule
Review: Stochastic GDè
3/23/18
Dr.YanjunQi/UVACS
57
Δw = −η ∂E∂Wt
tj
tj
tj J )(θ
θαθθ∂∂−=+1
!!Wt+1 =Wt −η ∂E
∂Wt =Wt +Δw

TrainingNeuralNetworks byBackpropagation - to jointly optimize all parameters
58
Howdowelearntheoptimal weightsWL forour task??● StochasticGradientdescent:
LeCunet.al.EfficientBackpropagation. 1998
Buthowdowegetgradientsoflowerlayers?● Backpropagation!
○ Repeatedapplicationofchainruleofcalculus○ Locallyminimizetheobjective○ Requiresall“blocks”ofthenetworktobedifferentiable
x ŷ
W1
w3
W2
E (ŷ,y)WL
t+1 =WLt −η
∂ExWL
t

• 1.Initialize networkwithrandom weights• 2.Forall trainingcases(examples):
– a. Presenttraininginputstonetworkandcalculateoutputofeachlayer,andfinallayer
– b. Foralllayers (startingwiththeoutputlayer,backtoinputlayer):• i.Comparenetworkoutputwithcorrectoutput
(errorfunction)• ii.Adaptweights incurrentlayer
Backpropagation
Wt+1 =Wt −η∂E∂Wt
3/23/18
Dr.YanjunQi/UVACS
59

Backpropagation
● Back-propagationtrainingalgorithm
Network activationForward Step
Error propagationBackward Step
3/23/18
Dr.YanjunQi/UVACS
60

61
“Local-ness”ofBackpropagation
fx y
“localgradients”
activations
gradients
http://cs231n.stanford.edu/slides/winter1516_lecture5.pdf

62
“Local-ness”ofBackpropagation
fx y
activations
gradients
“localgradients”

x
63
Example:SigmoidBlock
sigmoid(x) = 𝛔 (x)
∂σ∂x
=σ (1−σ )
3/23/18
Dr.YanjunQi/UVACS
64
x1
x2
1
Σ
Σ
ŷ
w1 z1w2
w3
w4
b1
b2
z2
h1
h2
Σ
w5
w6
1b3
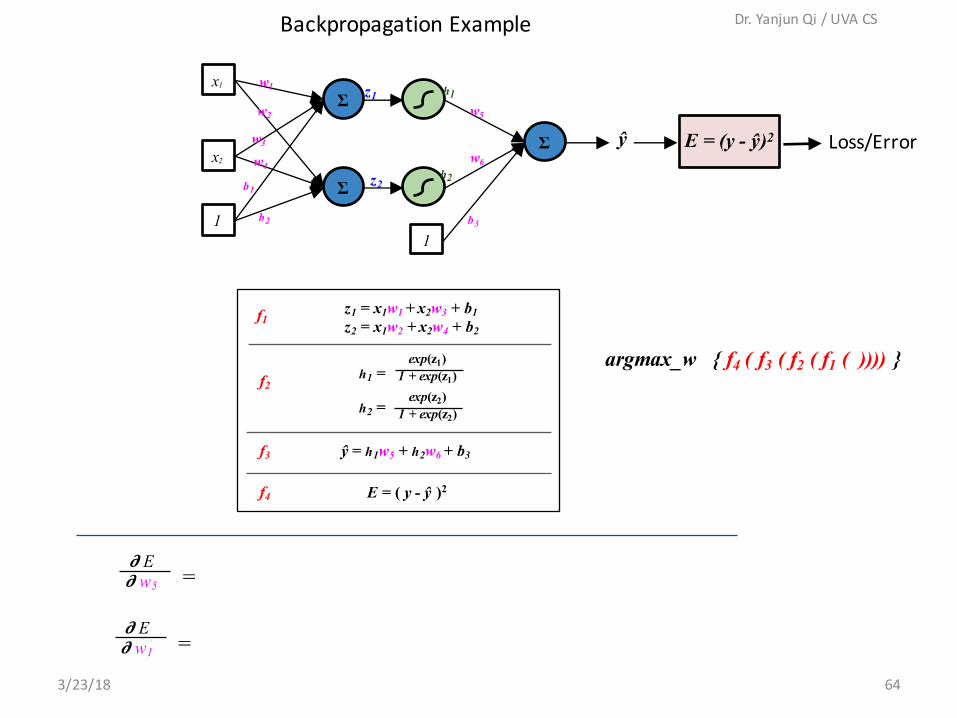
z1 = x1w1 + x2w3 + b1z2 = x1w2 + x2w4 + b2
h1 =exp(z1)
1 + exp(z1)exp(z2)
1 + exp(z2)h2 =
ŷ = h1w5 + h2w6 + b3
E = ( y - ŷ )2
f1
f2
f3
f4
BackpropagationExample
E = (y - ŷ)2
𝝏 E𝝏 w5 =
𝝏 E𝝏 w1 =
Loss/Error
argmax_w { f4 ( f3 ( f2 ( f1 ( )))) }

65
z1 = x1w1 + x2w3 + b1z2 = x1w2 + x2w4 + b2
h1 =exp(z1)
1 + exp(z1)exp(z2)
1 + exp(z2)h2 =
ŷ = h1w5 + h2w6 + b3
E = ( y - ŷ )2
f1
f2
f3
f4
argmax_w { f4 ( f3 ( f2 ( f1 ( )))) }

Howtochooselearningrate:Review: LinearRegressionwithStochastic
InLinearRegressiontrainingwithSGD,Howdowechoosethelearningrateα?• Tuning set, or• Cross validation, or• Small value for slow, conservative learning
ForDeepNN,howtochoosethelearningrate?• Many other great tools, e.g., Adam• https://arxiv.org/abs/1609.04747
3/23/18
Dr.YanjunQi/UVACS
66

Basic Neural Network
neg Log-likelihood , Cross-Entropy / MSE
SGD / Backprop
NN network Weights
Task
Representation
Score Function
Search/Optimization
Models, Parameters
3/23/18 67
Classification / Regression
Multilayer Network topology
Dr.YanjunQi/UVACS6316/f16

TodayRecap
Ø DeepLearningØHistoryØ Whybreakthrough?Ø Recenttrends(ExtraLecturethisFriday!)
ØBasicNeuralNetwork(NN)Ø singleneuron,e.g.logisticregressionunitØ multilayerperceptron(MLP)Ø formulti-classclassification,softmax layerØ MoreabouttrainingNN
2/22/18 68
YanjunQi/UVACS

References
q Dr.Yann Lecun’s deeplearningtutorialsq Dr.LiDeng’sICML2014DeepLearningTutorialq Dr.KaiYu’sdeeplearningtutorialq Dr.RobFergus’deeplearningtutorialq Prof.Nando deFreitas’slidesq OlivierGrisel’s talkatParisDataGeeks/OpenWorldForum
q Hastie,Trevor,etal.Theelementsofstatisticallearning.Vol.2.No.1.NewYork:Springer,2009.
3/23/18 69
Dr.YanjunQi/UVACS

70
x *W1
*w2z1 z2h1
E = loss =
AnotherExampleofBackpropagation(binaryclassification example)
GradientDescenttoMinimizeloss:
Needtofindthese!
E(y, ŷ) Loss/Error

71
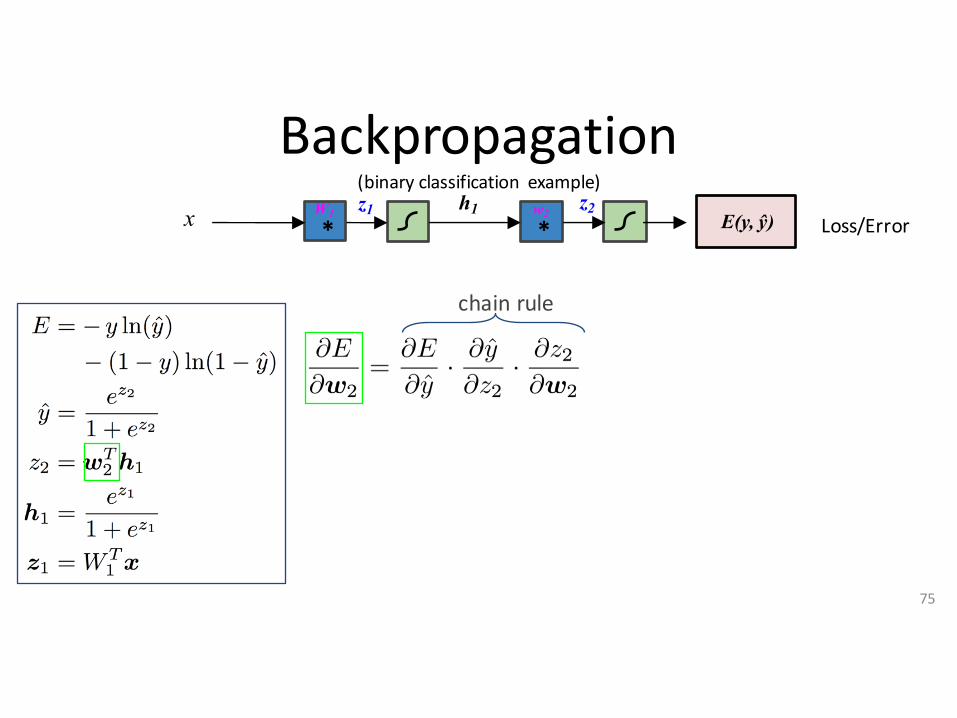
Backpropagation(binaryclassification example)
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

72
Backpropagation(binaryclassification example)
= ??
= ??
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

73
Backpropagation(binaryclassification example)
= ??
= ??
Exploitthechainrule!
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

74
Backpropagation(binaryclassification example)
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error
75
Backpropagation(binaryclassification example)
chainrule
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

76
Backpropagation(binaryclassification example)
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

77
Backpropagation(binaryclassification example)
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

78
Backpropagation(binaryclassification example)
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

79
Backpropagation(binaryclassification example)
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

80
Backpropagation(binaryclassification example)
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

81
Backpropagation(binaryclassification example)
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

82
Backpropagation(binaryclassification example)
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error

83
Backpropagation(binaryclassification example)
alreadycomputed
x *W1
*w2z1 z2h1
E(y, ŷ) Loss/Error