vision-language integration in ai: a reality check katerina pastra and yorick wilks department of...
TRANSCRIPT

Vision-Language Integration in AI:a reality check
Katerina Pastra and Yorick Wilks
Department of Computer Science, Natural Language Processing
Group,
University of Sheffield, U.K.

Setting the context
Artificial Intelligence:From technical integration of modalities multimodal meaning integrationFrom Multimedia Intellimedia + Intelligent InterfacesPurpose: intelligent, natural, coherent communication
We focus on: vision and language integration Visual modalities = images (visual perception and/or visualisation representations physically realised as e.g. 2D/3D graphics, photos…) Linguistic modalities = text and/or speech

The problem
What is computational V-L integration? (definition) How is it achieved computationally? (state of the art, practices, tendencies, needs) How far can we go? (implementation suggestions, the VLEMA prototype)
Multimodal Integration: an old AI aspiration (cf. Kirsch 1964) A wide variety of V-L integration prototypes in AI
but lack of an AI study of V-L integration, lack of a reality check

In search of a definition
Defining computational V-L Integration: could a review of related applied AI research hold the answer ?
Related work: Srihari 1994: review of V-L integration prototypes
limited number of prototypes reviewed
suggestions and implementations are mixed
no clear focus on how integration is achieved
system classification according to input type
includes cases of quasi-integration
criteria for such a review ???
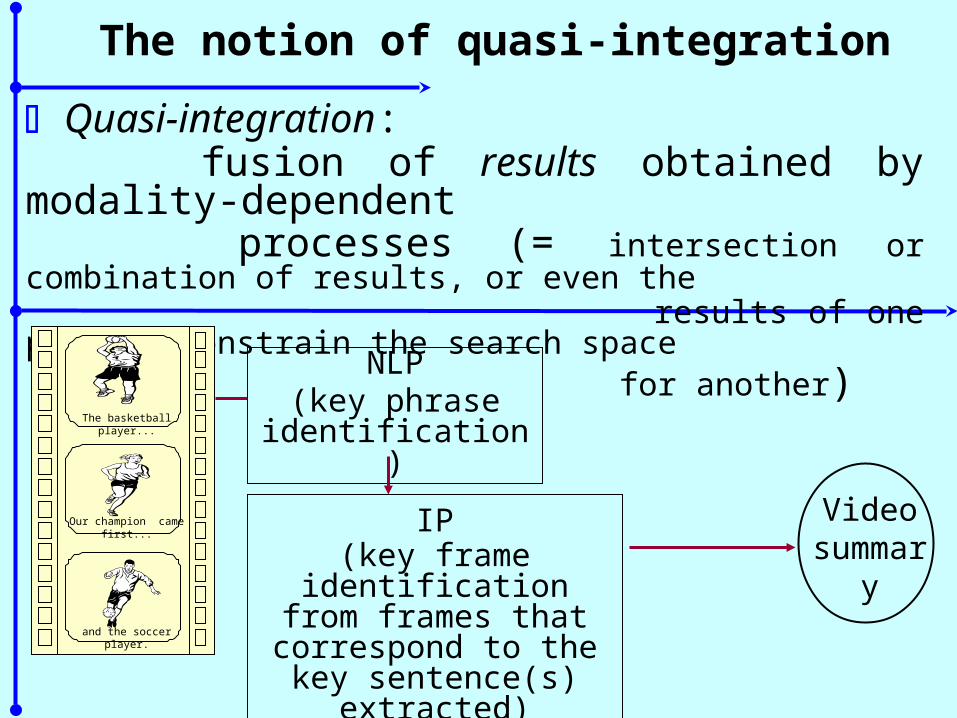
The notion of quasi-integration
Quasi-integration: fusion of results obtained by modality-dependent processes (= intersection or combination of results, or even the results of one process constrain the search space for another)
The basketball player...
Our champion came first...
and the soccer player.
NLP(key phrase
identification)
IP(key frame identification
from frames that correspond to the key sentence(s) extracted)
Video summary

Defining integration through classification
It is diachronic: from SHRDLU (Winograd ´72) to conversational robots of the new millennium (e.g. Shapiro and Ismail 2003, Roy et al. 2003)
Main criterion for considering a prototype for review: V-L integration to be essential for the task the prototype is built for.
Specifics of the review:
It crosses over into diverse AI areas and applications: more than 60 prototypes reviewed from IR to Robotics
System classification criterion: the integration purpose served

Classification of V-L integration prototypes
System type Integration Process
Performance Enhancement
Mediumx analysis Mediumy analysis
(NL IU, or NLIU)
Medium Translation
Source medium analysis Target medium gen.
(image language or image language)
Multimedia Generation
Abstracted data Multimedia generation
(tabular data or knowledge representation)
Situated
Dialogue
Multimedia analysis Medium/multimedia gen.
(NL analysis and shared visual scene action/MM)

Examples
System InputIntegration Resources
Integration Mechanisms
Output
PICTIONPhotos, captions (EN)
Integr. KB Semantic Networks
Face identification
SOCCER
Soccer video, trajectories
GSD/frame, event model
Event model inst., verbalisation history...
Textual (GER) event description
MAGICPatient file Schemas Schema inst.
media selector, co-reference
Speech or text (EN), animation
CASSIESpeech (EN), 3D blocks
KL-PML asso lists
Unification Object ident. limited conversation

Beyond differences
different visual and linguistic modalities involved
different tasks performed
different integration purposes served, but
Integration resources = Associations between :
Visual and corresponding linguistic information e.g. words/concepts and visual features or image models
Form: lists, integrated KB, scene/event models in KR
Integration mechanisms = KR instantiation, translation rules, media selection, coordination…
similar integration resources are used (though represented and instantiated differently)

A descriptive definition
Descriptive Definition =
a) Intensional Definition (what the term is e.g. its genus et differentia)
b) Extensional Definition (what the term applies to)
a) Computational Vision-Language Integration is a process of associating visual and corresponding linguistic pieces of information
(indirect back-up from Cognitive Science: cf. notion of learned associations in Minsky´s "Society of Mind" 1986, and Jackendoff´s theory of associating concepts and 3D models, 1987)
b) Computational Vision-Language Integration may take the form of one of 4 integration processes according to the integration purpose to be served

The AI quest for V-L Integration
Argument :
In relying on human created data, state of the art V-L integration systems avoid core integration challenges and therefore fail to perform real integration
Simulated or manually abstracted visual input is used to avoid difficulties in image analysis Applications are restricted to blocksworlds/miniworlds scaling issues Manually constructed integration resources used to avoid difficulties in associating V-LDifficulties in integration: correspondence problem etc. but, difficulties lie there where developers intervene...

How far can we go?
Challenging current practices in V-L integration system development requires that an ambitious system specification is formulated
A prototype should:
work with real visual scenes analyse its visual data automatically associate images and language automatically
Is it feasible to develop such a prototype ???

An optimistic answer
VLEMA: A Vision-Language intEgration MechAnism
Input: automatically re-constructed static scenes in
3D (VRML format) from RESOLV (robot-surveyor) Integration task: Medium Translation
from images (3D sitting rooms) to text (what and where in EN)
Domain: estates surveillance Horizontal prototype Implemented in shell programming and ProLog

The Input

OntoVis+ KB
“…a heater … and a sofa with 3 seats…”
Description
Data Transformations
Object Segmentation
Object Naming
System Architecture

The Output
Wed Jul 7 13:22:22 GMTDT 2004
VLEMA V1.0
Katerina Pastra@University of Sheffield
Description of the automatically constructed VRML file
“development-scene.wrl”
This is a general view of a room.
We can see the front wall, the left-side wall, the floor,
A heater on the lower part of the front-wall and a sofa with 3 seats.
The heater is shorter in length than the sofa.
It is on the right of the sofa.

Conclusion
*** Could occasional reality checks re-direct (part of) AI research ? ***
Descriptive definition of V-L integration in AI
a theoretical explanatory one in:
K. Pastra (2004), “Viewing Vision-Language Integration as a Double-Grounding Case”, Proceedings of the AAAI Fall Symposium Series, Washington DC.
Review and critique of the state of the art in AI
The VLEMA prototype – a baseline for future research that will challenge current practices