weighted distortion methods for error resilient video...
TRANSCRIPT

Weighted distortion methods for errorresilient video coding
Sunday Nyamweno
Department of Electrical & Computer EngineeringMcGill UniversityMontreal, Canada
August 2012
A dissertation in partial fulfillment of the requirements for the degree of Doctor ofPhilosophy.
c⃝ 2012 Sunday Nyamweno

i
Abstract
Wireless and Internet video applications are hampered by bit errors and packet errors,
respectively. In addition, packet losses in best effort Internet applications limit video
communication applications. Because video compression uses temporal prediction,
compressed video is especially susceptible to the problem of transmission errors in
one frame propagating into subsequent frames. It is therefore necessary to develop
methods to improve the performance of compressed video in the face of channel
impairments. Recent work in this area has focused on estimating the end-to-end
distortion, which is shown to be useful in building an error resilient encoder. However,
these techniques require an accurate estimate of the channel conditions, which is not
always accessible for some applications.
Recent video compression standards have adopted a Rate Distortion Optimiza-
tion (RDO) framework to determine coding options that address the trade-off be-
tween rate and distortion. In this dissertation, error robustness is added to the RDO
framework as a design consideration. This dissertation studies the behavior of motion-
compensated prediction (MCP) in a hybrid video coder, and presents techniques of
improving the performance in an error prone environment. An analysis of the motion
trajectory gives us insight on how to improve MCP without explicit knowledge of
the channel conditions. Information from the motion trajectory analysis is used in a
novel way to bias the distortion used in RDO, resulting in an encoded bitstream that
is both error resilient and bitrate efficient.
We also present two low complexity solutions that exploit past inter-frame depen-
dencies. In order to avoid error propagation, regions of a frame are classified according
to their potential of having propagated errors. By using this method, we are then
able to steer the MCP engine towards areas that are considered “safe” for predic-
tion. Considering the impact error propagation may have in a RDO framework, our
work enhances the overall perceived quality of compressed video while maintaining
high coding efficiency. Comparison with other error resilient video coding techniques
show the advantages offered by the weighted distortion techniques we present in this
dissertation.

ii
Sommaire
Les applications video pour l’Internet et les systemes de communication sans fil
sont respectivement entravees par les erreurs de paquets et de bits. De plus, les
pertes de paquets des meilleures applications Internet limitent les communications
video. Comme la compression video utilise des techniques de prediction temporelle,
les transmissions de videos comprimes sont particulierement sensibles aux erreurs se
propageant d’une trame a l’autre. Il est donc necessaire de developper des techniques
pour ameliorer la performance de la compression video face au bruit des canaux de
transmission. De recents travaux sur le sujet ont mis l’emphase sur l’estimation de
la distorsion point-a-point, technique utile pour construire un codeur video tolerant
aux erreurs. Ceci etant dit, cette approche requiert une estimation precise des con-
ditions du canal de transmission, ce qui n’est pas toujours possible pour certaines
applications.
Les standards de compression recents utilisent un cadre d’optimisation debit dis-
torsion (RDO) afin de determiner les options de codage en fonction du compromis
souhaite entre distorsion et taux de transmission. Dans cette these, nous ajoutons
la robustesse aux erreurs au cadre RDO en tant que critere de conception. Nous
etudions le comportement de la prediction de mouvement compense (MCP) dans un
codeur video hybride et presentons des techniques pour en ameliorer la performance
dans des environnements propices aux erreurs. L’analyse de la trajectoire du mouve-
ment nous permet d’ameliorer la MCP sans connatre explicitement les conditions du
canal de transmission. L’information de l’analyse de la trajectoire du mouvement est
utilisee de facon a contrer le biais de la distorsion utilisee dans le cadre RDO, ce qui
permet d’obtenir un encodage binaire d’un taux efficace et resistant aux erreurs.
Nous presentons egalement deux techniques a faible complexite qui exploitent
la dependance entre la trame a coder et les trames qui precedent. Afin d’eviter la
propagation des erreurs, les regions d’une trame sont classees en fonction de leur
potentiel a contenir des erreurs propagees. Avec cette methode, nous sommes a
meme de diriger l’outil MCP vers les regions ou la prediction peut etre faite de facon
“securitaire”. Considerant l’impact que peut avoir la propagation des erreurs dans un
cadre RDO, nos travaux ameliorent la qualite globale percue de videos comprimes tout
en maintenant de bons taux de transmission. Des comparaisons avec les meilleures

iii
techniques robustes de codage video presentement utilisees demontrent les avantages
offerts par les techniques de distorsion ponderee presentees dans cette these.

iv
Acknowledgments
First, I am very grateful to my supervisor, Professor Fabrice Labeau, for giving me
the opportunity and freedom to pursue my graduate studies, and not to mention the
tremendous scientific and moral support he provided over the years.
I am also thankful to my Ph.D. committee members Professor Peter Kabal and
Professor Leszek Szczecinski for their time and critique during my studies. I am also
extremely indebted to Ramdas Satyan and Burak Solak for their collaborations and
numerous discussions that made this thesis possible. I would also like to thank Dr.
Hugues Mercier for the French translation of this dissertation’s abstract.
Over the years that it took to complete my Ph.D., many people have passed
through the laboratories of the MC 7th floor, specifically the doors of Telecommuni-
cations & Signal Processing Lab: Rui, Djelil, Aarthi, Helen, Mohsen, Amir, Tamim
to mention a few, and made a contribution to my work by providing pertinent advice,
discussion, friendship, and support. Without their contributions this thesis would
have been a lot thinner.
To the team at CBC/Radio-Canada’s New Broadcast Technologies division, your
contribution during the final stages of this process is much appreciated.
Last, but never least, I daily thank God for being my Rock. To my wife Bupe:
thank you for your patience and love and for always believing in me. To my parents
Simon and Agnes Mauncho, your endless support, sacrifice and encouragement has
been a strong driving force. My siblings Freddy, Stella, Nkrumah and MwaOseko
nzima- Asante sana. Pamoja tumefika!

v
Contents
1 Introduction 1
1.1 The Need for Error Resilience . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Related Work: Classifying Error Resilient Techniques . . . . . . . . . 5
1.2.1 Encoder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.2.2 Decoder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.2.3 Encoder/Decoder . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Thesis Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.4 Thesis Organization . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2 Literature Review 11
2.1 H.264/AVC Advanced Video Coding . . . . . . . . . . . . . . . . . . 13
2.1.1 Error Resilience Tools in H.264/AVC . . . . . . . . . . . . . . 14
2.2 Rate Distortion Optimization for Video . . . . . . . . . . . . . . . . . 21
2.2.1 ER-RDO Mode Decision . . . . . . . . . . . . . . . . . . . . . 23
2.2.2 ER-RDO Motion Estimation . . . . . . . . . . . . . . . . . . . 24
2.3 End-to-End Distortion Estimation . . . . . . . . . . . . . . . . . . . . 24
2.3.1 K-decoders . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.3.2 Block Weighted Distortion Estimate (BWDE) . . . . . . . . . 25
2.3.3 Recursive Optimal Per-Pixel Estimate (ROPE) . . . . . . . . 26
2.3.4 Distortion Map . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.3.5 Stochastic Frame Buffers (SFB) . . . . . . . . . . . . . . . . . 29
2.3.6 Residual-Motion-Propagation-Correlation (RMPC) Distortion
Estimation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.4 Channel Characterization . . . . . . . . . . . . . . . . . . . . . . . . 32

vi Contents
2.4.1 Gilbert Model . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.4.2 Inaccurate Channel Estimates . . . . . . . . . . . . . . . . . . 34
2.5 Error Resilience Based on Motion Estimation . . . . . . . . . . . . . 35
2.5.1 Tree Structured Motion Estimation (TSME) . . . . . . . . . . 36
2.5.2 Multihypothesis Motion Compensated prediction (MHMCP) . 37
2.5.3 Alternate Motion Compensated Prediction (AMCP) . . . . . . 38
2.5.4 Non Standard Compliant Techniques . . . . . . . . . . . . . . 39
2.6 Chapter Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3 Weighted Distortion 41
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.2 Weighted Distortion for Motion Estimation and Mode Decision . . . . 43
3.2.1 Motion Estimation Weighting Factor . . . . . . . . . . . . . . 45
3.2.2 Depth Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.2.3 Mode Decision Weighting Factor . . . . . . . . . . . . . . . . 52
3.3 Weighted Redundant Macroblocks . . . . . . . . . . . . . . . . . . . . 54
3.4 Simulation Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
3.4.1 Weighted Motion Estimation . . . . . . . . . . . . . . . . . . . 56
3.4.2 Simplified Motion Estimation . . . . . . . . . . . . . . . . . . 60
3.4.3 Weighted Mode Decision and Motion Estimation . . . . . . . 64
3.4.4 Impact on Prediction Chain . . . . . . . . . . . . . . . . . . . 70
3.4.5 Weighted Redundant Macroblocks . . . . . . . . . . . . . . . . 71
3.5 Chapter Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4 Low-Complexity Weighted Distortion 75
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
4.2 Pixel-based Backward Tracking . . . . . . . . . . . . . . . . . . . . . 76
4.2.1 Motion Estimation and Mode Decision . . . . . . . . . . . . . 79
4.3 Macroblock-based Backward Tracking . . . . . . . . . . . . . . . . . . 81
4.3.1 Intra Limited Prediction (ILP) . . . . . . . . . . . . . . . . . 82
4.3.2 Intra-distance Derived Weighting (IDW) . . . . . . . . . . . . 84
4.3.3 Complexity Analysis . . . . . . . . . . . . . . . . . . . . . . . 86
4.4 Simulation Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87

Contents vii
4.4.1 Macroblock-based Backward Tracking . . . . . . . . . . . . . . 88
4.4.2 Pixel-based Backward Tracking . . . . . . . . . . . . . . . . . 92
4.4.3 All Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
4.4.4 Gilbert Channel . . . . . . . . . . . . . . . . . . . . . . . . . . 99
4.4.5 Talking-head Sequence (News) . . . . . . . . . . . . . . . . . . 99
4.5 Chapter Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
5 Conclusion 103
5.1 Research Achievements . . . . . . . . . . . . . . . . . . . . . . . . . . 104
5.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
A Additional Simulations 107
A.1 Uniform Channel Simulations . . . . . . . . . . . . . . . . . . . . . . 107
A.2 Gilbert Channel Simulations . . . . . . . . . . . . . . . . . . . . . . . 108
B Distortion Modelling 115
B.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
B.2 Exponential Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
B.3 Simulation Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
B.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
References 127

viii

ix
List of Figures
1.1 Typical video communication system. . . . . . . . . . . . . . . . . . . 2
1.2 Error propagation due to loss of MB # 8 in frame # 20 of the Football
sequence. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1 Scope of the H.264/AVC standard and this thesis. . . . . . . . . . . . 11
2.2 Basic macroblock coding structure for the H.264/AVC Encoder . . . . 13
2.3 PSNR vs Frame for two different encoding schemes of the Football
sequence. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4 Gilbert model with GOOD representing the state of correctly received
packets and BAD represents packet loss. . . . . . . . . . . . . . . . . 33
2.5 Error propagation due to motion compensated prediction in hybrid
video coding. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
2.6 Frame prediction structure in TSME. . . . . . . . . . . . . . . . . . . 36
2.7 Macroblock prediction structure in MHMCP. . . . . . . . . . . . . . . 37
2.8 Frame prediction structure in AMCP showing alternating point. . . . 38
3.1 For each macroblock, minimizing di + λri for a given λ is equivalent
finding the first point on the R-D curve slope of λ . . . . . . . . . . 44
3.2 Tracking the number of pixels that are affected by the loss of an MB
over N frames . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.3 Obtaining weight wme from count C during overlap. . . . . . . . . . . 48
3.4 Distribution of the depth of influence that each MB has in a sequence. 50
3.5 Change in Count C, value for each MB as you look deeper in the
sequence. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51

x List of Figures
3.6 RD curves for Football and NBA sequences (QCIF format) in a chan-
nel with 20% packet loss rate. K dec 20 is the K-decoders method
designed for a channel with 20% packet loss while K dec 1 is designed
for 1% channel loss. Rand Intra 15 is 15% Intra Updating, count79
is the weighted procedure looking 79 frames ahead and std is standard
H.264 without error resilience tools. . . . . . . . . . . . . . . . . . . . 58
3.7 Performance at different loss rates for Football and NBA sequences
(QCIF format) with a fixed bitrate for each method. K dec 20 is the
K-decoders method designed for a channel with 20% packet loss, K dec
1 is designed for 1% channel loss and K dec Matched is K decoders
matched to the channel loss rate. Rand Intra 15 is 15% Intra Updat-
ing, count79 is the weighted procedure looking 79 frames ahead and
std is standard H.264 without error resilience tools. . . . . . . . . . . 59
3.8 RD curves for NBA and Football sequences (QCIF Format). no error
(no transmission distortion). with error (10% packet loss rate). countN
is the weighted procedure looking N frames ahead, count is the weighted
procedure looking 79 frames ahead and std is standard H.264 without
error resilience tools. . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.9 Performance at different loss rates for a fixed bitrate for NBA and
Football sequences (QCIF Format). countN is the weighted procedure
looking N frames ahead, count is the weighted procedure looking 79
frames ahead and std is standard H.264 without error resilience tools. 63
3.10 Subjective results for Football frame 28 with 20% packet loss rate. . . 65
3.11 RD curves for Football and NBA sequences (QCIF format) in a channel
with 10% packet loss rate. K dec 3 is the K-decoders method designed
for a channel with 3% packet loss while K dec 10 has 10% channel loss.
Rand Intra 20 is 20% Intra Updating and wme&wmdT is the weighted
procedure applied to both mode decision and motion estimation with
a threshold value of T . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.12 RD curves for Football and NBA sequences (CIF format) in a channel
with 10% packet loss rate for Weighted mode decision and motion
estimation compared to K-decoders. . . . . . . . . . . . . . . . . . . 67

List of Figures xi
3.13 PSNR vs loss percentage; Football and NBA sequences with fixed bi-
trate. K dec 3 is the K-decoders method designed for a channel with
3% packet loss while K dec Matched is matched to the channel loss
rate. Rand Intra 20 is 20% Intra Updating and wme&wmdT is the
weighted procedure applied to both mode decision and motion estima-
tion with a threshold value of T . . . . . . . . . . . . . . . . . . . . . . 68
3.14 Count C values for NBA and Football sequence at frame 10, show-
ing the change in distribution after applying our weighted distortion
technique. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
3.15 RD curves for Football and Foreman sequences (QCIF Format) in a
channel with 10% packet loss rate. Weighted Redun.10 is our method
with the 10% of the most sensitive MBs coded redundantly, Random
Redun.10 represents randomly coding 10% of the MBs redundantly,
Rand Intra 10 is 10% Random Intra Updating and std is standard
H.264/AVC. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.1 Backward prediction trail of pixels J , K and L of MB 49 in frame n
used for pixel-based backward motion dependency tracking. . . . . . . 78
4.2 Weight distribution of tracked distortion for Akiyo sequence at frame 40. 80
4.3 Weight distribution of tracked distortion for Football sequence at frame
40. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.4 Motion estimation search range of 9 MBs including 1 INTRA MB with
2 potential candidate reference regions; A and B. . . . . . . . . . . . 83
4.5 PSNR vs frame for Football with losses in frame 7, 33 and 56 using 4
different encoding schemes. . . . . . . . . . . . . . . . . . . . . . . . . 84
4.6 RD curves for Football and NBA sequences (QCIF Format) in a chan-
nel with 10% packet loss rate. Rand IR 15 is 15% Intra Refresh, ILP
is the Intra Limited Prediction method and IDW-N is the weighted
procedure with incremental weighting, N according to distance from
last refresh. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89

xii List of Figures
4.7 RD curves for Football and NBA sequences (CIF Format) in a channel
with 10% packet loss rate. Rand IR 15 is 15% Intra Refresh and IDW-
N is the weighted procedure with incremental weighting, N according
to distance from last refresh. . . . . . . . . . . . . . . . . . . . . . . . 90
4.8 PSNR vs loss percentage Football and NBA sequences with fixed bi-
trate. Rand IR 15 is 15% Intra Refresh, ILP is the Intra Limited
Prediction method and IDW-N is the weighted procedure with incre-
mental weighting, N according to distance from last refresh. . . . . . 91
4.9 RD curves for Football and NBA sequences (CIF format, 30fps) in a
channel with 10% packet loss rate comparing Random Intra Updating,
K-decoders, IDW of Section 4.3 and Weighted Motion & Mode decision
of Section 3.2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
4.10 RD curves for Football and NBA sequences (QCIF format) in a channel
with 10% packet loss rate. BK is our pixel-based backward tracking
method of Section 4.2, K dec 3 is the K-decoders method designed for
a channel with 3% packet loss while K dec 10 has 10% channel loss.
Rand Intra 15 is 15% Intra Updating. . . . . . . . . . . . . . . . . . 95
4.11 RD curves for Football and NBA sequences (QCIF Format) in a chan-
nel with 10% packet loss rate. Rand IR 15 is 15% Random Intra Re-
fresh and IDW-N is the weighted procedure with incremental weight-
ing, N according to distance from last refresh. . . . . . . . . . . . . . 96
4.12 Subjective results for Football frame 50 with 10% packet loss rate of
current error resilient methods. . . . . . . . . . . . . . . . . . . . . . 97
4.13 Subjective results for Football frame 50 with 10% packet loss rate of
our proposed techniques. . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.14 RD curves for Football and NBA sequences (QCIF Format) in a Gilbert
channel with 5% packet loss rate and burst length of 15. . . . . . . . 101
4.15 RD curves for Football and NBA sequences (QCIF Format) in a Gilbert
channel with 10% packet loss rate and burst length of 10. . . . . . . . 102
A.1 RD curves for Mobile and Stefan sequences (QCIF Format) in a uni-
form loss channel with 10% packet loss rate. This Figure represents
similar conditions as Fig. 4.11 . . . . . . . . . . . . . . . . . . . . . . 109

List of Figures xiii
A.2 RD curves for Foreman and News sequences (QCIF Format) in a uni-
form loss channel with 10% packet loss rate. This Figure represents
similar conditions as Fig. 4.11 . . . . . . . . . . . . . . . . . . . . . . 110
A.3 RD curves for Mobile and Stefan sequences (QCIF Format) in a Gilbert
channel with 5% packet loss rate and burst length of 15. This Figure
represents similar conditions as Fig. 4.14 . . . . . . . . . . . . . . . . 111
A.4 RD curves for Foreman and News sequences (QCIF Format) in a
Gilbert channel with 5% packet loss rate and burst length of 15. This
Figure represents similar conditions as Fig. 4.14 . . . . . . . . . . . . 112
A.5 RD curves for Mobile and Stefan sequences (QCIF Format) in a Gilbert
channel with 10% packet loss rate and burst length of 10. This Figure
represents similar conditions as Fig. 4.15 . . . . . . . . . . . . . . . . 113
A.6 RD curves for Foreman and News sequences (QCIF Format) in a
Gilbert channel with 10% packet loss rate and burst length of 10. This
Figure represents similar conditions as Fig. 4.15 . . . . . . . . . . . . 114
B.1 Weighted distortion vs. Standard H.264 distortion for INTRA modes
of all macroblocks of the NBA sequence. . . . . . . . . . . . . . . . . 119
B.2 Weighted distortion vs. Standard H.264 distortion for INTRA modes
of all macroblocks of the FOOTBALL sequence. . . . . . . . . . . . . 120
B.3 Weighted distortion with T=0.5 vs. Standard H.264 distortion for
INTRA modes of the NBA sequence. . . . . . . . . . . . . . . . . . . 121
B.4 Weighted distortion with T=0.5 vs. Standard H.264 distortion for
INTRA modes of the FOOTBALL sequence. . . . . . . . . . . . . . . 122
B.5 K-decoders distortion vs. Standard H.264 distortion for INTRA modes
of the NBA sequence. . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
B.6 K-decoders distortion vs. Standard H.264 distortion for INTRA modes
of the FOOTBALL sequence. . . . . . . . . . . . . . . . . . . . . . . 124
B.7 RD curves for NBA and Football sequences in a channel with 10%
packet loss rate for distortion modeling. The Distortion modelling and
wmdT methods both use wme for motion estimation . . . . . . . . . . 125

xiv

xv
List of Tables
2.1 Key terms used in block-based hybrid video coding. . . . . . . . . . . 12
3.1 Motion Vector Tracking Algorithm. . . . . . . . . . . . . . . . . . . . 47
3.2 Timing information for reduced lookahead methods. . . . . . . . . . . 52
3.3 ∆ PSNR and ∆ bitrate incurred by using various RD optimization
methods when compared to Standard in an error free environment. . 60
3.4 ∆ PSNR and ∆ bit-rate incurred by using various RD optimization
methods when compared to Random Intra 20 in an error free environ-
ment. T is the threshold value in (3.4) . . . . . . . . . . . . . . . . . 69
4.1 Complexity comparison of the various weighted distortion techniques. 87
4.2 ∆ PSNR and ∆ bit-rate incurred by using IDW-N when compared to
Random IR 15 in an error free environment for QCIF sequences. . . . 88

xvi

xvii
List of Acronyms
AFD Average Fade Duration
ARQ Automatic Repeat Request
AVC Advanced Video Coding
CIF Common Intermediate Format
DCT Discrete Cosine Transform
E2E End-to-End
ER Error Resilient
FEC Forward Error Correction
FMO Flexible Macroblock Ordering
fps Frames per second
IDW Intra Distance-derived Weighting
ILP Intra Limited Prediction
IR Intra Refresh
ISDN Integrated Services Digital Network
JM Joint Model
kbps Kilo bits per second
LARDO Loss Aware Rate Distortion Optimization
LMMC Long-term Memory Motion Compensation
LCR Level Cross Rate
MB Macroblock
MD Multiple Description
MCP Motion-Compensated Prediction
MHMCP Multi-Hypothesis Motion Compensated Prediction
MPEG Motion Pictures Expert Group

xviii List of Tables
MTU Maximum Transmission Unit
MV Motion Vector
NACK Negative Acknowledgement
PLR Packet Loss Rate
PSNR Peak Signal to Noise Ratio
QCIF Quarter Common Intermediate Format
QP Quantization Parameter
RD Rate-Distortion
RDO Rate-Distortion Optimization
ROPE Recursive Optimal per Pixel Estimate
RS Redundant Slices
RPS Reference Picture Selection
RTCP Real-time Transport Control Protocol
RTP Real-time Transport Protocol
TCP Transmission Control Protocol
UDP User Datagram Protocol
UEP Unequal Error Protection
VLC Variable Length Code
VOD Video on Demand

xix
List of Symbols
Ds(n) Average source coding distortion in frame n
Dt(n) Average transmission distortion in frame n
D(n) Overall distortion of frame n
DSAD Sum of Absolute Difference distortion
DSSD Sum of Squared Difference distortion
D(n, i) Overall distortion of pixel i in frame n
Daccum(n, i) Accumulated concealment distortion for pixel i in frame n
Dcon(n, i) Concealment distortion for pixel i in frame n
E{} Expected value
r(n, i) Quantized residue of pixel i in frame n
F (n, i) Pixel in the original video frame
F (n, i) Encoder reconstructed value of pixel i in frame n
F (n, i) Decoder reconstructed value of pixel i in frame n
Jmd Lagrangian rate distortion function for mode decision
Jme Lagrangian rate distortion function for motion estimation
p Packet loss probability
R Bitrate
Rmv Bitrate for motion vectors
wmd Weight factor for mode decision
wme Weight factor for motion estimation
λmd Lagrange multiplier for mode decision
λme Lagrange multiplier for motion estimation

xx

1
Chapter 1
Introduction
Digital video communication is rapidly growing, with industry experts predicting that
mobile video will more than double every year between 2012 and 2015 [1]. Cisco Visual
Networking index has estimated that mobile video will account for two thirds of all
mobile traffic by 2015. With the ever growing need for video in mobile networks, the
need to develop efficient compression techniques that can withstand varying channel
conditions will continue to grow.
Video compression is necessitated by the fact that raw video signals require a pro-
hibitively large amount of storage space which also prohibits transmission. Robust
video compression that potentially withstands varied network conditions has been at
the forefront of research in both academia and industry. The video standardization
process illustrates how pioneering innovation leads to practical products able to ad-
dress the ever increasing user demands. This has given rise to consumer applications
such as [2]:
• Broadcast over cable, satellite, cable modem, DSL, terrestrial,
• Interactive or serial storage on optical and magnetic devices, DVD,
• Conversational services over ISDN, Ethernet, LAN, DSL, wireless and mobile
networks, modems, or mixtures of these,
• Video-on-demand or multimedia streaming services over ISDN, cable modem,
DSL, LAN, wireless networks,

2 Introduction
• Multimedia messaging services (MMS) over ISDN, DSL, ethernet, LAN, wireless
and mobile networks.
Of these applications, we are mostly concerned with packetized video over unreli-
able networks, such as best effort IP networks or wireless networks. This is definitely
a practical concern as content producers attempt to service a wide range of devices
from Large screen TVs to small screen smart phones. Adaptive bitrate (ABR) has
emerged as the technology of choice to service a growing set of devices with different
limitations [3]. ABR involves generating multiple renditions of a single high qual-
ity source at different resolutions and bitrates. The target device then selects the
rendition that matches the available bandwidth and CPU capacity. This thesis will
introduce new methods of protecting video data that is sent over unreliable links,
which would be the lower resolution/bitrate renditions in an ABR scenario.
A typical video communication system is highlighted in Fig. 1.1. The input video
sequence is compressed at the encoder, followed by packetization and multiplexing
with extra data, for instance audio. Depending on the selected network, the packets
may undergo channel coding, usually in the form of forward error correction (FEC) to
offer some level of protection over hostile networks. At the receiver side, the packets
are FEC decoded and reassembled to form a bitstream that is fed into a decoder.
Encoder
Multiplex
Packetization
&
Channel Coding
Network
De-Multipex
De-Packetization
&
Channel Decoding
DecoderOriginal
Video
Reconstructed
Video
Extra
Data
Extra
Data
Fig. 1.1 Typical video communication system.
Without a reliable dedicated link between the source and destination, data pack-
ets may be lost over the network as is the case with internet or wireless networks.
In addition, video playback usually has stringent playback requirements, meaning
video packets that arrive late are usually treated as lost. Video transmission over
noisy channels has quickly become an area of practical importance with the prolif-
eration of mobile devices. Unreliable channels present a formidable design challenge
for compressed video. A wealth of research has subsequently developed to protect

1.1 The Need for Error Resilience 3
compressed video in the midst of transmission errors. The main aim is to build a
video communication system that is robust to transmission errors by not adversely
affecting the reconstructed video quality. Compression at the encoder tries to remove
as much redundancy as possible; however, redundancy is required to cope with losses
and errors. Therefore, there exists a trade off between compression efficiency and ro-
bustness against loss or corruption that needs to be addressed, under the constraints
of available bandwidth and acceptable reproduction quality. This work looks at how
these issues can be tackled in the encoder module of Fig. 1.1.
Video communications have high bandwidth requirements and as such usually
take place over networks that do not offer any guarantees on quality of service (QoS).
Robustness against poor channel conditions therefore needs to be handled using ap-
plication level techniques. These techniques adapt the behavior of the video commu-
nication system to eliminate, or at least minimize the impact of loss on the quality of
reproduced video. To achieve this, it is necessary to investigate the nature of video
compression to gain insight into what possible improvements will allow for robust
communication.
Video coding standards have historically achieved great success by adopting a
block-based hybrid coding paradigm which combines motion-compensated prediction
(MCP), transform coding and entropy coding. However, hybrid video coding schemes
are highly susceptible to errors during transmission. Transmission errors in predictive
coding causes error propagation due to a mismatch between the encoder and decoder
reference predictions. This is commonly referred to as the drifting phenomenon [4].
In addition, entropy coding that uses Variable Length Codes (VLC) can lose synchro-
nization due to single bit errors [4, 5].
1.1 The Need for Error Resilience
The drifting phenomenon can have disastrous effects on video reproduction quality
because a decoding error in one frame will multiply itself in future frames. We
demonstrate this fact by looking at the impact of replacing a block of pixels (16x16
pixels), also known as a macroblock (MB) in one frame with the co-located MB in the
previous frame. Replacing lost frame data with information from previously received
frames is a common form of error concealment used in video compression. Using the

4 Introduction
H.264/Advanced Video Coding (AVC) standard, which has MBs of size 16x16 pixels,
we show the impact of replacing the eighth MB in Frame 20 with the eighth MB in
Frame 19 in Fig 1.2. The error introduced in Frame 20 spreads wildly into future
frames mainly due to MCP. Motion-compensated prediction uses information from
previous frames, and if those frames are in error, temporal prediction will continually
propagate this error indefinitely.
(a) Frame 20 (b) Frame 25 (c) Frame 35
(d) Frame 40 (e) Frame 45 (f) Frame 55
Fig. 1.2 Error propagation due to loss of MB # 8 in frame # 20 of theFootball sequence.
By showing the impact that loss of a small 16x16 pixel region can have on com-
pressed video, we hope to motivate the importance of error resilience. Practical
encoders place a number of MBs in packets that are sent over packet switched net-
works. If some packets are lost, and the losses are spread over different frames, the
error propagation problem becomes markedly complex. The resulting spatio-temporal
error propagation is typical of any video coding algorithm that utilizes predictive cod-
ing. The lingering errors are visually annoying and can have a profound impact on
the subjective quality. While there is some leakage in the prediction loop that will
ensure transmission errors decay over time, the leakage is not strong enough. Rapid
recovery can only be achieved by coding frame regions without reference to previous
frames, which is quite costly in terms of bitrate.

1.2 Related Work: Classifying Error Resilient Techniques 5
1.2 Related Work: Classifying Error Resilient Techniques
In order to address the spatial and temporal spread of error witnessed in Fig 1.2, error
resilient (ER) encoding is necessary and continues to draw a great deal of research
interest. ER techniques that address these limitations of compressed video can be
summarized into 3 broad categories:
1. Encoder adding redundancy at source coder, channel coder, or both
2. Decoder error concealment upon detection of errors
3. Encoder/Decoder feedback based methods
1.2.1 Encoder
In the absence of transmission errors, ER coders typically require more bits for the
same level of fidelity. This makes ER coders typically less efficient compared to
coders that are optimized for coding efficiency. The design goal in ER coders is to
achieve a maximum gain in error resilience with the smallest amount of redundancy.
There are many ways to introduce redundancy in the bitstream. The most successful
techniques study the statistical nature of transmission errors and use this to build a
robust encoder. A detailed review of these methods is presented in Chapter 2.
Other techniques, such as Multiple Description (MD) video coding, Layered Cod-
ing with Unequal Error Protection (UEP), and Robust Entropy coding methods have
been reported with varying degrees of success [6]. Multiple description video coders
generate two or more bitstreams that can be independently decoded with a basic
fidelity level, or jointly decoded with improved quality. Some techniques have ex-
ploited features of the H.264/AVC video coding standard to generate balanced de-
scriptions [7, 8]. MD allows for graceful quality degradation when each description’s
quality level is selected appropriately. Graceful degradation of the impact of errors
can also be achieved by applying UEP to different parts of the bitstream. For exam-
ple, separating the motion information from the texture data and applying stronger
protection to the motion vectors has been shown to improve the decoded video qual-
ity [9]. Layered or scalable video coding refers to encoding several levels of fidelity
onto a single bitstream. The higher layers depend on successful decoding of the lower

6 Introduction
layers, meaning that stronger protection should be applied to the lower layers ensuring
a certain quality level at the decoder in the presence of errors [10].
Techniques that exploit channel usage can also be classified in this category, and
include techniques such as bitstream prioritization [11–13], and FEC [14–16]. Some
interesting work has been done on error resilient techniques that look at better ex-
ploitation of the network channel or even modifying the characteristics of the channel.
The main technologies are based on path diversity [17–20], network coding [21, 22]
and cross-layer design/optimization [23,24].
While the effectiveness of these techniques has been demonstrated in certain sce-
narios, they do not address the heart of the problem, which is predictive coding. In
this dissertation, we tackle directly the problems caused by predictive coding. An
understanding of how error propagates helps us build a prediction mechanism that is
more robust to errors.
1.2.2 Decoder
Error concealment techniques improve the reproduction quality at the decoder upon
detection of errors. Error detection usually involves examination the received bit-
stream for inconsistencies in the received syntax [25, 26]. Error concealment tech-
niques are particulary useful because they normally do not require any additional
redundancy. With the block-based hybrid coding paradigm, there are three types of
information that may need to be estimated in a damaged MB: the texture informa-
tion, including the pixel or DCT coefficient values for either an original image block
or a prediction error block, the motion information, and finally the coding mode of
the block. The methods that attempt to recover this information can be classified as
either spatial or temporal error concealment techniques.
Spatial Error Concealment (SEC)
SEC methods generally recover texture information of missing MBs through interpo-
lation from neighboring correctly received MBs. It is mostly suited for image coding or
Intra coded pictures in a video sequence. Intra coded frames are compressed without
reference to previously coded pictures. Some earlier methods used bilinear interpo-
lation [27], with more recent ones using adaptive directional interpolation depend-

1.2 Related Work: Classifying Error Resilient Techniques 7
ing on sequence characteristics [28] or directional entropy of neighboring edges [29].
Neighboring pixels are used to interpolate the missing data thereby improving the
reproduction quality. For these techniques to work the neighboring pixels must be
received correctly requiring MBs within a single frame to be packetized separately.
A number of tools are included in the H.264/AVC codec to allow for this and will be
reviewed in Section 2.1.1.
Hybrid techniques that use both spatial and temporal information also exist. For
example, it is well-known that images of natural scenes have predominantly low fre-
quency components, i.e. the color values of spatially and temporally adjacent pixels
vary smoothly, except in regions with edges. Texture recovery techniques use this
knowledge to perform some spatio-temporal interpolation [30].
Temporal Error Concealment (TEC)
The simplest method of concealing errors within a predictive coding context is to
replace lost MBs with the last correctly received block/frame. However, more so-
phisticated methods exploit spatial correlations [27, 31, 32] or frequency characteris-
tics [33–37] of still images. Motion information and mode decision recovery techniques
usually rely on statistical information from correctly received blocks [36,38,39]. More
recently the directional entropy [28] and boundary block matching [36] techniques
have been combined by adaptively integrating the two error concealment approaches
with an adaptive weight-based switching algorithm [40].
Error concealment has also been performed using a motion vector tracking algo-
rithm similar to that proposed in this dissertation [41]. The tracking algorithm may
have some similarities, however we present a novel encoder based technique rather
than a decoder based method in this thesis.
Decoder error concealment is a powerful tool and in fact, most of the methods pre-
sented in Chapter 2 require that the encoder know the concealment strategy used in
order to adopt its encoding strategy. However, decoder based techniques are limited
in their effectiveness compared to encoder techniques as they take a curative approach
rather than a preventative approach to solve the drifting phenomenon problem. Ad-
ditionally, decoder based techniques usually increase the decoding complexity which
can be a problem for most hardware decoders found on mobile devices that have

8 Introduction
stringent power requirements. This means there is still a need for efficient encoder
based techniques that can present an error resilient bitstream to be consumed through
unreliable channels.
1.2.3 Encoder/Decoder
Given feedback from the decoder early methods adopted an Automatic Repeat Re-
quest (ARQ) approach based on retransmission of missing packets [4, 42–44]. How-
ever, these methods are not appropriate for most video applications because of the
increased end-to-end latency. A better approach adjusts the encoder prediction upon
receiving channel feedback, by sending a correcting signal that is able to update the
decoder prediction to match that in the encoder [45,46]. These methods may not be
suitable for low delay applications such as video telephony.
1.3 Thesis Contributions
This thesis presents a detailed study on the impact of the most basic building block
in a video coder, the macroblock, with the view to improving the error resilience
performance of compressed video. By investigating the nature of error propagation in
a predictive coding framework we are able to build a more robust encoding system.
Unlike current techniques that investigate the statistical nature of transmission errors,
our methods are flexible to changing channel conditions and do not rely on accurate
channel estimation.
This thesis uses the H.264/AVC video coding standard and all bitstreams gener-
ated are fully standard compliant, meaning every decoder conforming to the standard
will produce similar output. Several contributions have been made to the area of error
resilient video compression. These contributions are:
• Weighted Distortion. Conventional motion estimation used in rate-distortion
(RD) optimized video coding is formulated for an error-free environment. Spe-
cial considerations have to be made when transmitting video in lossy networks.
We demonstrate a novel method of weighting the distortion used in RD opti-
mized motion-compensated prediction. By determining an appropriate weight-
ing factor, motion vectors can be biased towards macroblocks that have less

1.4 Thesis Organization 9
influence on the motion propagation path. We therefore propose tracking the
influence that each macroblock has along the motion propagation path to de-
termine the weights. Information from the future motion trajectory of an MB
reveals a weighting strategy that is able to yield considerable performance im-
provements [47,48].
• Weighted Redundancy. By understanding how prediction dependencies evolve
over time, we are able to identify regions within a frame that should be coded
redundantly. Coding some MBs redundantly is a robust form of error resilience,
and our technique presents an efficient way of selecting which MBs to code
redundantly [49].
• Simplified Weighted Distortion. Two low-complexity weighting methods are
developed that exploit key dependencies between frames. We are able to steer
the prediction engine towards areas that are considered “safe” for prediction by
evaluating:
1. Historical pixel dependencies
2. Individual MB sensitivity to errors [50]
We demonstrate that while historical motion trajectory information is useful in
developing error resilient strategies, an MB’s future impact is more effective in
curtailing the detrimental impact of transmission errors.
1.4 Thesis Organization
In order to familiarize the reader with the subject matter at hand, an extensive litera-
ture survey of the topics covered in this dissertation is presented in Chapter 2. Specif-
ically, an introduction to the basic structure of the H.264/AVC standard is provided,
with detailed coverage of its error resilient features. Also included is an overview of
current error resilient - rate distortion optimization (ER-RDO) techniques. Finally,
the reader is introduced to end-to-end distortion estimation techniques, with some
emphasis on the importance of accurate channel estimation.
Chapters 3 and 4 present our proposed techniques of performing weighted dis-
tortion. In Chapter 3 an examination of the forward motion trajectory reveals pa-

10 Introduction
rameters that are useful in performing weighted distortion, despite its computational
complexity. Chapter 4 investigates two low complexity weighted distortion techniques,
one at a pixel level, and an even simpler one performed at the MB level. Chapter 5
presents some concluding remarks and possible future work.

11
Chapter 2
Literature Review
Hybrid video coding has formed the basis of video compression for the past two
decades. Starting from the H.261 and MPEG-1 standards in the early nineties, to
the recently standardized H.264/AVC and its scalable extension, the primary focus
in the evolution of video coding has continued to be an increase in source coding
efficiency [51, 52]. The term “hybrid” refers to the combination of a block-based
predictive coding stage that removes temporal redundancies and a transform-domain
quantization stage that removes spatial redundancies. The H.264/AVC is a hybrid
video codec that has quickly become the industry standard for efficient video com-
pression. Some key terms used in block based hybrid video encoding are tabulated
in Table 2.1.
textPre-Processing Encoding
Scope of this work
textDecoding
Scope of the standard
Post-Processing
& Error Recovery
Source
Destination
Fig. 2.1 Scope of the H.264/AVC standard and this thesis.
Similar to prior video coding standards, H.264/AVC standardizes only the de-

12 Literature Review
Table 2.1 Key terms used in block-based hybrid video coding.TERM DESCRIPTION
Pixel Also known as picture element; the smallest coding unit of animage.
Luma Luminance (luma, Y) component represents the brightness in animage. Typically, there is a luma component for each pixel.
Chroma A pair of chrominance (chroma, Cb or Cr) components representsthe blue and the red video color difference signal.
Sample Refers to a Luma or Chroma component.
Sampling Format Refers to the ratio of luma and chroma samples per pixel. InH.264/AVC the default sampling format is 4:2:0, which is alsoused in this thesis. In the 4:2:0 sampling format there is a lumasample for each pixel and a chroma sample pair for every fourpixels.
Macroblock (MB) A 16 × 16 matrix of pixels. A macroblock may be divided intosmaller submacroblocks (subMB).
Block A M ×N matrix of samples also referred to as a subMB.
Frame An array of pixels representing a single time instant of a videosequence. In this thesis, the terms frame and picture are usedinterchangeably.
Motion Estimation The process of finding a matching block in previously codedframe(s).
Motion Compensation Computing the difference between the current and matching blockin previously coded frame(s).
Residue Represents the difference signal between the predicted and currentMB.
Motion Vector Offset between a block and its prediction. Because an MB cancontain several submacroblocks, each subMB has its own motionvector
Transform Converting a set of samples from the spatial domain into frequencydomain transform coeficients.
Entropy Coding Representing video data (eg, motion vectors, transform coeffi-cients...) through lossless compression.

2.1 H.264/AVC Advanced Video Coding 13
coding process by imposing restrictions on the bitstream and syntax, as depicted in
Fig. 2.1. This gives the designer maximum freedom in encoder implementation and
guarantees that every conforming decoder will produce similar output when given
an H.264/AVC compliant bitstream [2]. The methods presented in this thesis fo-
cus on improving the encoding process in an error prone environment, resulting in
a robust standard compliant bitstream. The basic structure of H.264/AVC and its
error resilience features are described below. More technical information can be found
in [2, 51].
2.1 H.264/AVC Advanced Video Coding
The basic structure of H.264/AVC divides the input video frame into macroblocks
(MBs) of size 16x16 pixels for encoding as illustrated in Fig. 2.2 [2]. Macroblocks
Intra
Pred.
Mode
Decision
...... INTRA
SKIP
INTERMotion
Estimation
DCT/
Quant.
Motion
Vectors
Reconstruction and
Reference Frame Buffering
Input Video
Frame
Entropy
coding Output
bitstream
F(n,i)-r(n,i)
F(n-1,i)
‹
r(n,i)
‹
r(n,i)
‹
Split into
macroblocks of
16x16 pixels
Fig. 2.2 Basic macroblock coding structure for the H.264/AVC Encoder
are coded separately and grouped together into a slice. There are two main types of
coding for each MB; INTRA and INTER coding.
• In INTRA coding, a prediction signal is generated from information contained

14 Literature Review
within the current frame only. These MBs are often referred to as I macroblocks.
• INTER macroblocks (also P macroblocks) generate prediction signals from pre-
viously coded frames.
A motion vector (MV) is used to refer to a region in a previously coded picture,
which forms the prediction signal for the current MB. A residual signal is then gen-
erated by subtracting the prediction signal from the input video signal. This residual
is then transform coded and quantized. An additional coding mode called SKIP is
also included in the standard. SKIP is a special case of INTER where no residue
is transmitted. The final compressed bitstream is then generated by entropy coding
the quantized transform coefficients, motion vectors, and control data. To ensure
that the prediction signal at the decoder matches the encoder prediction, the decoder
operation must be incorporated in the encoder as seen in Fig. 2.2.
Several advancements compared to earlier hybrid video coding schemes such as
H.261, H.262 (MPEG-2), H.263 and MPEG-4 Part 2 have allowed H.264/AVC to
achieve very high compression efficiency (upto 50% higher compression efficiency
compared to older standards [2]). The most notable improvements are; multiframe
motion-compensated prediction (MCP), smaller block size MCP up to 4x4, gener-
alized B-picture concepts, quarter-pixel motion accuracy, intra coding using spatial
prediction, in-loop deblocking filter and context adaptive entropy coding [2]. In ad-
dition to these compression efficiency features, H.264/AVC also incorporates some
tools for error resiliency that have been present in earlier compression standards and
some new ones.
2.1.1 Error Resilience Tools in H.264/AVC
MCP is an integral part of all major video compression schemes because of its ability
to remove the temporal redundancy inherent in a sequence of pictures. However, it
also leads to degraded performance in lossy environments as it spreads errors along
the motion prediction path [45,53,54], as we showed in Chapter 1. When transmitting
through unreliable channels, a mismatch between the encoder and decoder predictions
due to packet losses causes the error to extend as prescribed by motion vectors. Error
resilient tools are therefore necessary to mitigate the effects of the spatio-temporal

2.1 H.264/AVC Advanced Video Coding 15
error spread due to motion vectors. H.264/AVC includes the following tools to combat
transmission errors:
1. Intra Updating
2. Picture segmentation (slices)
3. Multiple reference frames
4. Redundant slices (RS)
5. Flexible macroblock ordering (FMO)
6. Data partitioning
These tools are discussed in detail in the following sections. It is important to note
that while these tools offer some level of protection to the compressed bitstream, they
do not fundamentally change the encoding process to be error resilient. This thesis
is focused on improving the encoding process to be robust to network losses.
Intra Updating
INTRA coding has been identified as the most effective way of terminating the error
spread [45, 55] because it does not rely on information contained in previous frames.
Therefore, one fundamental way of attaining error resilience is to use more INTRA
MBs in a video frame. For example, an extreme case would be coding the entire
frame as an Intra frame (all MBs coded as INTRA) which would stop the error
propagation instantly. This approach is not advisable because it would result in
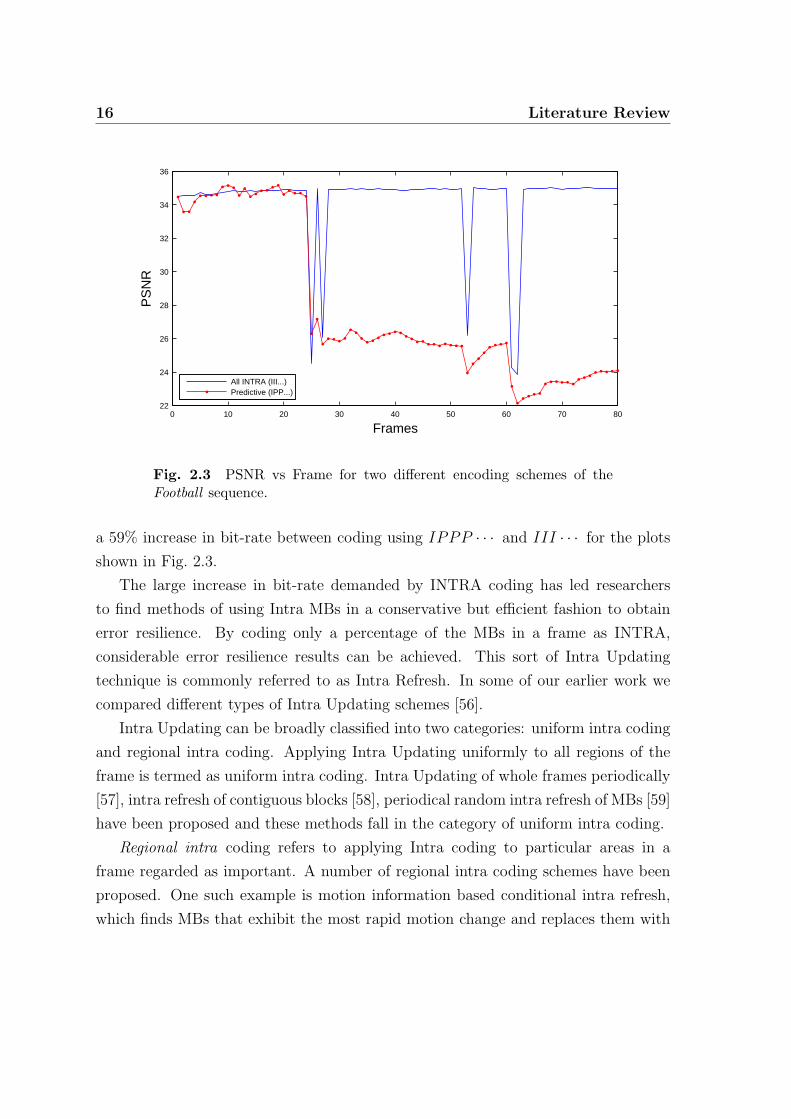
an enormous increase in bit-rate. We have plotted in Fig. 2.3 PSNR values versus
frame number for the case when all frames are coded as INTRA (III · · · ) and when
predictive coding is used (IPPP · · · ). We see from this plot that coding with all
INTRA recovers instantly from errors, while predictive coding with IPPP · · · does
not recover from errors due to error propagation. After an error occurs, the motion
vectors continuously refer to erroneous regions resulting in the error being extended
across several frames. This poor performance of predictive coding in an error-prone
environment is the primary motivation for this work. It should be noted that there is
16 Literature Review
0 10 20 30 40 50 60 70 8022
24
26
28
30
32
34
36
Frames
PS
NR
All INTRA (III...)Predictive (IPP...)
Fig. 2.3 PSNR vs Frame for two different encoding schemes of theFootball sequence.
a 59% increase in bit-rate between coding using IPPP · · · and III · · · for the plots
shown in Fig. 2.3.
The large increase in bit-rate demanded by INTRA coding has led researchers
to find methods of using Intra MBs in a conservative but efficient fashion to obtain
error resilience. By coding only a percentage of the MBs in a frame as INTRA,
considerable error resilience results can be achieved. This sort of Intra Updating
technique is commonly referred to as Intra Refresh. In some of our earlier work we
compared different types of Intra Updating schemes [56].
Intra Updating can be broadly classified into two categories: uniform intra coding
and regional intra coding. Applying Intra Updating uniformly to all regions of the
frame is termed as uniform intra coding. Intra Updating of whole frames periodically
[57], intra refresh of contiguous blocks [58], periodical random intra refresh of MBs [59]
have been proposed and these methods fall in the category of uniform intra coding.
Regional intra coding refers to applying Intra coding to particular areas in a
frame regarded as important. A number of regional intra coding schemes have been
proposed. One such example is motion information based conditional intra refresh,
which finds MBs that exhibit the most rapid motion change and replaces them with

2.1 H.264/AVC Advanced Video Coding 17
INTRA MBs [60]. This method was adopted in MPEG-4 in its Annex E. Another
method defines an isolated region (starting from the MB at the center of the frame)
and intra updates it. This region gradually grows from frame to frame (in a box out
clockwise fashion) [61]. The growth rate is made identical to the packet loss rate.
The locations of the isolated region in the subsequent frame is predicted only from
the isolated region of the previous frame. It has also been noted that people tend
to pay more attention to a particular area (region of interest) of a video frame [62].
Intra Updating is therefore concentrated on this region. Another interesting approach
divides a frame into N equal regions and intra updates each region at a time. This
updated region is then used as prediction for next frames and the regions not intra
updated are usually avoided for prediction [63].
One of the new features in H.264/AVC that improves compression efficiency is
intra coding using spatial prediction. This feature allows INTRA MBs to predict
from nearby INTER MBs. However, in an error prone environment errors in INTER
MBs would be allowed to propagate into INTRA MBs. This would eliminate the
ability of an INTRA macroblock to terminate error propagation. In this work and
similar work that relies on INTRA MBs to eliminate error propagation [6, 64] this
feature must be disabled1.
Picture Segmentation
Picture segmentation is achieved by grouping an integer number of MBs together to
form a slice. A slice may contain an entire frame or only one MB. The primary reason
for implementing slices was to allow for the adaptation of the coded slice size to the
maximum transmission unit (MTU) size of the network [2]. This allows H.264/AVC
to easily adapt to different network conditions. Having too many slices per frame
incurs an overhead in the form of packet headers. The packet header overhead for
RTP/UDP/IP transmission is 40 octets [65], which can be quite high if too many
slices are used.
For transmission of video in wireless environments it is common to encode a row
of macroblocks in one packet [53,66]. This method is preferred to encoding an entire
frame in one slice because loss of a packet will result in only a portion of the frame
1In the H.264/AVC JM reference software this feature is disabled by setting the UseConstrained-IntraPred flag in the encoder.

18 Literature Review
rather than the entire frame being corrupted. H.264/AVC also provides provisions
for slice interleaving. This means that slices from different frames will arrive in an
order other than the display order. Slice interleaving is useful in the presence of burst
errors as it would spread the error across multiple frames [67]. However, this would
incur a delay at the decoder as it waits for out of order slices and it therefore may
not be suitable for low-delay applications.
Multiple Reference Frames
H.264/AVC uses multiple reference frames for improving compression efficiency, but
it is also useful as an error resilience tool. Rather than using INTRA refresh to
prevent temporal error propagation, the presence of multiple reference frames allows
for feedback-based reference picture selection (RPS) [68]. The decoder informs the
encoder through a feedback channel of which frames were received in error, allowing
the encoder to select reference frames that were received correctly for future frames.
Error propagation can be entirely stopped after a delay equivalent to the networks
round trip time. The coding efficiency of INTER-coding with RPS is higher than
INTRA picture coding if the reference picture is not too far away [69].
Exploiting the presence of older reference frames for error resilience was also
demonstrated in a feedback system through a technique known as Long-Term Memory
Motion Compensation (LMMC). LMMC combines the RPS concept described above
with an error distortion modelling technique that looks at the potential decoder dis-
tortion caused by each frame in the reference picture buffer [54]. LMMC also uses a
feedback channel to improve its distortion estimation and reference picture selection
strategies. The techniques presented in this dissertation achieve error resilience while
still exploiting the coding efficiency offered by INTER coding as well, without the
requirement of a feedback channel.
Redundant Slices (RS)
Redundant slices permit the insertion of one or more duplicate representations of
the same MBs in one slice directly into the bitstream. The difference between this
approach and packet repetition at the link layer is that the redundant representation
can be coded at a lower fidelity. For example, the primary slice may be generated

2.1 H.264/AVC Advanced Video Coding 19
using a lower quantization parameter (QP) (good quality) and the RS could be coded
at a higher QP (low quality) [64]. When the primary slices of a frame are received
correctly, the decoder discards all the redundant slices in the bitstream associated
with the frame. On the other hand, if any of the primary slices are lost or received
with errors, the decoder can use a correctly decoded redundant slice to replace the
corrupted slice, thus minimizing the drifting phenomenon. It should be noted that
this approach cannot completely eliminate error propagation, unless the RS is coded
at the same fidelity as the primary slice and both primary and redundant slices are
not lost.
The additional redundancy depends on the available channel conditions (band-
width, channel loss rate). Some research has been done to adapt the RS selection
in H.264/AVC to varying channel conditions [70, 71]. A multiple description scheme
based on RS has recently been shown to improve error robustness [7]. However, these
methods do not address the problem of error propagation and require knowledge of
the network state. By considering the impact of error propagation, we develop a new
method of selecting which MBs to code redundantly and demonstrate its effectiveness
in Chapter 3.
Flexible Macroblock Ordering (FMO)
Macroblock to slice mapping is usually selected in raster scan fashion. FMO allows
for different MB to slice mappings that can help the error resilient performance of
H.264/AVC. The spatial distribution of MBs suggested by FMO means that when
a slice is lost, errors would be spread around the frame thereby avoiding error ac-
cumulation in certain regions. This improves the error concealment performance if
the MBs surrounding the lost MB are received correctly. New MB to slice mappings
are constantly being developed that show some improvement to those specified in the
standard [71, 72]. FMO basically rearranges MB locations, and does not fundamen-
tally change the encoding process as proposed in this work. This means FMO can
easily be added to the methods described in this work to improve their performance.

20 Literature Review
Data Partitioning
All information necessary to decode an MB is usually contained in a single bitstream.
Data partitioning places this data in three separate partitions; A, B and C.
• Partition A contains header information for the slice and for all MBs in the
slice. This includes MB types, MVs, QP, etc.
• Partition B contains residual data for I MBs
• Partition C contains residual data for P MBs
Partition A is the most important because both Partitions B and C require this
header information. It is therefore common to offer extra protection to Partition
A than B or C through Unequal Error Protection (UEP) [73, 74]. Partition B is
also more important than Partition C because Intra MBs are able to eliminate error
propagation along the motion prediction path. This is discussed in greater detail in
Section 2.1.1. Data Partitioning allows for higher quality decoder reconstruction if
Partition A or B have a higher probability of arriving safely through UEP.
Notation
For the remainder of this thesis, we will refer to F (n, i) as the i-th pixel in the n-th
frame of the original video sequence. F (n, i) will refer to the reconstructed value
of the pixel at the encoder. This is the same as the decoder reconstruction when
there are no transmission errors. F (n, i) will refer to the decoder reconstructed value
(possibly with transmission errors). Ds(n) will refer to the source coding distortion
and Dt(n) will refer to the transmission distortion. Mean squared error (MSE) will
be used as the distortion criterion. The transmission distortion and source distortion
are defined as Dt(n) = E{[F (n, i) − F (n, i)]2} and Ds(n) = E{[F (n, i) − F (n, i)]2}respectively. The end-to-end expected distortion per pixel is defined as
D(n, i) = E{[F (n, i)− F (n, i)]2}. (2.1)
Motion vectors will refer to pixel j in frame ref , the residue will therefore be
given by r(n, i) = F (n, i)− F (ref, j). This residue is transform coded and quantized,
r(n, i) before being transmitted to the decoder.

2.2 Rate Distortion Optimization for Video 21
All the methods discussed in Section 2.3 assume that compressed video packets
are lost with uniform probability p, and that p is available at the encoder. In the
event of a transmission error, the decoder conceals the error by copying pixel k from
the previous frame, n − 1. We can now represent the decoder reconstruction in an
error prone environment as
F (n, i) =
{F (ref, j) + r(n, i) w.p. 1− p
F (n− 1, k) w.p. p(2.2)
2.2 Rate Distortion Optimization for Video
The rate-distortion efficiency of today’s video compression schemes is based on a
sophisticated interaction between a variety of coding choices. The encoder has to
choose from coding options such as: motion vector, quantization level, block size,
prediction mode, reference frame, etc. Coding mode selection is complicated by
the fact that different coding choices have varying efficiency at different bit-rates or
reproduction quality. Different scene content would require different coding options,
for example, static background would benefit from the SKIP2 coding option while
finer motion activity may require smaller block sizes and several motion vectors. The
encoder’s task can thus be summarized as: Minimize distortion D, subject to the
constraint Rc on number of bits R [75]. This is a constrained minimization problem
minD subject to R < Rc (2.3)
that is commonly solved using Lagrangian optimization. Each MB therefore under-
goes Lagrangian minimization to find the optimal coding mode o∗, according to
o∗ = argmino∈O
D(o) + λ ·R(o) (2.4)
where O is the set of all coding options, {modes, MVs, reference frames, block-
sizes}. Calculating (2.4) for all possible combinations of coding options O is not
practical. In the H.264/AVC test model, this problem is simplified by breaking down
2SKIP is a special INTER mode where no residue or motion vectors are sent. It is commonlyused for stationary background or motionless objects

22 Literature Review
the Lagrangian minimization into 2 steps; first motion estimation followed by mode
decision [64].
During motion estimation, motion vectors are selected to minimize the Lagrangian
cost functional
Jme = DSAD + λme(QP ) ·Rmv (2.5)
where λme(QP ) is the Lagrange multiplier that depends on the quantization parame-
ter QP and Rmv denotes the number of bits required to code the motion vectors. The
sum of absolute difference (DSAD) can be used as the distortion measure for motion
estimation in the H.264/AVC JM reference software [76].
DSAD =∑i∈MB
|F (n, i)− F (ref, j)| (2.6)
where F (ref, j) is the jth pixel in reference frame ref , which is referred to by the
candidate MV. Two other distortion measures are available in the reference software
for motion estimation: 1) Sum of squared errors (SSE) and 2) Sum of Absolute
Transformed/Hadamard Differences (SATD), with SAD offering reduced complexity
compared to SSE and SATD. Motion estimation is a very time consuming operation
as the motion vectors have to be calculated for different block sizes. It is common to
restrict the spatial search range to a certain radius in order to speed up the operation.
Even faster motion estimation algorithms have been proposed that narrow the number
of candidate MVs required to inspect by using novel search patterns [77].
Once optimal MVs are determined, the encoder then selects the best coding mode
(with different block sizes) {inter4x4, inter8x8,...,inter 16x16,skip,intra4x4,...,intra16x16}according to
Jmd = DSSD + λmd(QP ) ·R (2.7)
where the Lagrangian multiplier for mode decision is given by,
λmd(QP ) = 0.85× 2.0(QP−12)/3

2.2 Rate Distortion Optimization for Video 23
and for motion estimation is given by
λme(QP ) =√λmd(QP ).
The sum of squared differences (DSSD) is used as the distortion measure.
DSSD =∑i∈MB
∣∣∣F (n, i)− F (ref, j)∣∣∣2 (2.8)
This operation selects the best mode in the RD sense.
Selecting coding options in this manner is optimal only if the distortion used
in the encoder is identical to that used in the decoder. When transmission errors
occur, a mismatch exists between the encoder and decoder predictions, therefore the
encoder and decoder distortions do not match and RD optimization as described
above is no longer optimal. The quest for RDO techniques specifically designed for
video in lossy environments has ushered a field of research in error robust - rate
distortion optimization (ER-RDO) [30, 55, 64, 78–81]. The main premise behind ER-
RDO techniques is to obtain a suitable estimate of the overall end-to-end distortion.
Once a suitable end-to-end distortion estimate, Dest is found, the literature sug-
gests doing one of three things; replacing DSSD in (2.7) with Dest, replacing DSAD in
(2.5) with Dest or both. The Lagrangian parameter, λ may also be adjusted to reflect
the channel’s lossy nature [30,79].
2.2.1 ER-RDO Mode Decision
Because INTRA MBs terminate error propagation, finding the optimal allocation
of INTRA MBs has historically been the focus of most of the ER-RDO schemes.
Numerous rate-distortion (RD) optimized methods have been proposed for mode de-
cision [30, 55, 78, 80] and will be discussed in Section 2.3. In these instances, RD
optimized mode decision is performed with a suitable estimate of the end-to-end
distortion. Mode decisions will therefore take into account the potential loss of pack-
ets. These methods are considerably simpler to implement than ER-RDO Motion
Estimation techniques because there are fewer options to go through.

24 Literature Review
2.2.2 ER-RDO Motion Estimation
Rate Distortion Optimization for motion vectors in a lossy environment has not gar-
nered as much research interest as mode decision. As a result there are few methods
that address this subject. Because of INTER modes compression efficiency and the
fact that INTER prediction is responsible for error propagation, finding effective MVs
in lossy environments is however important.
Motion vector optimization in lossy environments has been demonstrated by Yang
and Rose [82] and later by Wan and Izquierdo [81]. Both methods use the recursive
optimal per-pixel estimate (ROPE) [80] to estimate the end-to-end distortion. Due
to the random nature of transmission errors, ROPE treats the decoder reconstructed
pixels as random variables and attempts to model the transmission distortion at the
encoder in a statistical sense. This value of distortion is then used to optimize the
motion vectors in an RD framework. ROPE is discussed in greater detail in Section
2.3.3. In contrast, our weighted distortion method looks forward at the impact of
each MB in future frames, and uses this information in a novel manner to improve
the motion vector selection.
2.3 End-to-End Distortion Estimation
A majority of the current literature on error resilient video coding is based on the
encoder estimating the expected distortion incurred at the decoder. The main chal-
lenges in accurately determining the distortion incurred at the decoder is developing
an accurate model of the transmission errors at the encoder. In this section we look
at the available techniques for estimating end-to-end distortion.
2.3.1 K-decoders
This is a highly complex but accurate distortion estimation procedure that relies
on implementing K decoders in the encoder [30] and has been incorporated in the
H.264/AVC test model [64,76] for addressing ER-RDO. It assumes the encoder has K
copies of the random variable channel behavior, C(k), and averages these to determine
the end-to-end distortion. The distortion for each pixel of (2.1) can be estimated as

2.3 End-to-End Distortion Estimation 25
D(n, i) =1
K
K∑k=1
∣∣∣F (n, i)−(F (n, i)|C(k)
)∣∣∣2 (2.9)
As K → ∞ the encoder is able to obtain the expected distortion at the decoder.
However, the complexity of this method increases as K increases. It has been sug-
gested that K = 30 is suitable for most applications [30], and very accurate results
have been reported for K = 500 [78]. The computational complexity and implemen-
tation cost prevent this method from being used in practice, especially for large values
of K. The K-decoders method has been included in the H.264/AVC reference soft-
ware [76] as the ER-RDO technique of choice. We compare the techniques developed
in this thesis to this method.
2.3.2 Block Weighted Distortion Estimate (BWDE)
This method by Cote et al. [55] represents some of the earliest work in obtaining an
estimate of the overall end-to-end distortion. The distortion estimate is computed on
an MB basis as
D(n) = (1− p)D1(n) + pD2(n) (2.10)
where
D1(n) = Ds(n) +L∑l=1
pD2(n− l), (2.11)
and L is the number of successive frames since the last Intra frame. D2(n) is a
weighted average of the concealment distortion of the previous frame MBs that are
mapped by motion compensation. The weighting corresponds to their relative cover-
age. Each MB stores D2(n) for computation of D1(n) in subsequent frames. It should
be noted that this method assumes the current block is received accurately and con-
siders whether the previous block was lost and concealed. This simple method ignores
the error propagation associated with temporal error concealment and is therefore not
very accurate.

26 Literature Review
2.3.3 Recursive Optimal Per-Pixel Estimate (ROPE)
This method was initially developed to determine the optimal Intra rate for an error
prone environment [80]. It is widely cited as an industry benchmark in the field of
distortion estimation. ROPE works by tracking the distortion at a pixel level. Due
to the random nature of transmission errors, this method treats the decoder recon-
structed value F (n, i) as a random variable and attempts to model the transmission
distortion at the encoder in a statistical sense [80]. By expanding (2.1) we obtain
D(n) = [F (n, i)]2 − 2 · F (n, i) · E{F (n, i)}+ E{[F (n, i)]2} (2.12)
Equation (2.12) reveals an estimate of the first and second moment for each pixel
F (n, i) is required. Zhang et al. [80] developed a recursive procedure to estimate
these two quantities for each pixel depending on whether the pixel belongs to an
Intra or Inter MB.
Intra MB
There are three cases to consider for Intra MBs.
Case 1 If a packet is received correctly then then the encoder reconstruction of a
pixel i is equal to the decoder reconstruction i.e. F (n, i) = F (n, i). This event occurs
with a probability (1− p).
Case 2 If a packet is lost then the decoder will check if the previous packet is received
correctly. If the previous packet is intact then the median motion vector (MV) of the
nearest MBs is calculated and the missing pixel is replaced with that pointed to by the
median MV in the previous frame i.e. F (n, i) = F (n − 1, k), where k represents the
location of the pixel in the previous frame which is displaced from the original spatial
location due to the median MV. This event occurs with a probability p · (1− p).
Case 3 If the previous packet is lost as well then MV estimate is set to zero and
the pixel gets the value from the corresponding location from the previous frame i.e.
F (n, i) = F (n − 1, i). This event occurs with a probability of p2. The first and the
second moments can now be obtained as follows
E{F (n, i)} = (1− p)(F (n, i)) + p(1− p)E{F (n− 1, k)}+ p2E{F (n− 1, i)} (2.13)

2.3 End-to-End Distortion Estimation 27
E{(F (n, i))2} = (1− p)(F (n, i))2 + p(1− p)E{[F (n− 1, k)]2}+ p2E{[F (n− 1, i)]2}(2.14)
Inter MB
Assume that the true motion vector of an MB is such that a pixel i is predicted from
a pixel j in the previous frame i.e. encoder prediction is F (n − 1, j). The video
compression scheme only sends the quantized prediction residue given by
r(n, i) = F (n, i)− F (n− 1, j) (2.15)
along with the motion vectors. If the current packet is received correctly, the decoder
has access to both the residue and the MVs. Due to the possibility of errors, the
decoder uses F (n− 1, j) in reconstructing the current pixel
F (n, i) = r(n, i) + F (n− 1, j) (2.16)
As mentioned earlier the decoder reconstruction values may not match those used
by the encoder, due to transmission errors. The temporal error propagation is evident
here, even though subsequent frames are received correctly. Error concealment is
performed similar to Intra MBs. The first and second moments are given by
E{F (n, i)
}= (1− p) ·
(r(n, i) + E
{F (n− 1, j)
})+ p · (1− p) · E
{F (n− 1, k)
}+ p2 · E
{F (n− 1, i)
}(2.17)
E
{(F (n, i)
)2}
= (1− p) · E{(
r(n, i) + F (n− 1, j))2}+ p · (1− p) · E
{(F (n− 1, k))2
}+ p2 · E
{(F (n− 1, i))2
}(2.18)
E
{(F (n, i)
)2}
= (1− p) ·((r(n, i))2 + 2 · r(n, i) · E{F (n− 1, j)}+ E{(F (n− 1, j))2}
)+ p · (1− p) · E{(F (n− 1, k))2}+ p2 · E{(F (n− 1, i))2} (2.19)

28 Literature Review
The recursions of (2.13), (2.14) , (2.17) and (2.19) are performed at the encoder in
anticipation of the transmission distortion that will be incurred [80]. This method
provides very accurate distortion estimation for motion vectors with integer accuracy
however, it is computationally intensive since it involves tracking two moments at ev-
ery pixel. It is also not applicable to subpixel motion estimation used in H.264/AVC.
An improvement to ROPE for subpixel motion estimation using a 6-tap filter on
the first moment and on the square root of the second moment of the reconstructed
pixel value [78] allows ROPE to be used in H.264/AVC. Another improvement for
application in H.264/AVC uses a cross-correlation estimate [83].
2.3.4 Distortion Map
Another recursive approach based on creating an error propagation distortion map
has been suggested by Guo et. al. [78]. By combining (2.1) and (2.2), the end-to-end
distortion for each pixel can be represented as
D(n, i) = (1− p)E
{(F (n, i)− (F (ref, j)− r(n, i))
)2}
+pE
{(F (n, i)− F (n− 1, k)
)2}
= (1− p)E
{(F (n, i)− F (n, i)
)2}+ (1− p)E
{(F (ref, j)− F (ref, j)
)2}
+pE
{(F (n, i)− F (n− 1, k)
)2}
= (1− p)Ds(n, i) + (1− p)Dep(ref, j) + pDec(n, i) (2.20)
where Ds(n, i) is the source distortion, Dep(n, i) is the error propagated (from the
reference frame) distortion andDec(n, i) is the error concealment distortion. Complete
derivations of these quantities can be found in [78], and are summarized below for
brevity.
Dec(n, i) = Dec o(n, i) +Dep(n− 1, k) (2.21)
where Dec o is the original frame error concealment, which is the MSE between the

2.3 End-to-End Distortion Estimation 29
original and error concealment pixel and is readily available at the encoder. Dep(n−1, i) is the previous frame error propagation.
Dep(n, i) = (1− p)Dep(ref, j) + pDec r(n, i) + pDep(n− 1, k) (2.22)
where Dec r(n, i) is the reconstructed frame error concealment, which is the MSE
between the reconstructed and error concealment pixel at the encoder. A recursive
relationship for determining the error propagation emerges in (2.22). A distortion map
Dep is therefore defined for each frame on a block basis. Since INTRA macroblocks
terminate error propagation, INTRA pixels have a Dep(n, i) value of zero. The first
frame is coded as an INTRA frame and therefore has Dep = 0 and subsequent P
frames obtain their Dep value according to (2.22). This method has been included in
the H.264/SVC 3 JSVM reference software as the ER-RDO technique of choice [84].
This distortion estimation process results in a relatively accurate estimate of the
overall end-to-end distortion, but has been developed for loss aware mode decision
making, and not motion estimation. It is sensitive to accurate channel estimation, p.
Another drawback of this approach is that the derivation is based on the assumption
of previous frame error concealment strategy. Generalizing to more sophisticated error
concealment strategies such as motion copy [76] or hybrid error concealment [85] is
not straightforward. The weighted distortion measures introduced in this thesis do
not depend on the error concealment scheme, and should be able to offer sufficient
protection regardless of error concealment strategy employed.
2.3.5 Stochastic Frame Buffers (SFB)
Recursion is the common theme in all the solutions presented thus far, and the
stochastic frame buffer approach of Harmanci and Tekalp [79] follows suit. The deriva-
tion of this method is identical to ROPE in Section 2.3.3, except that this method
does not store the actual pixel values. In ROPE, the end-to-end distortion estimate
is used in mode decision only, and the residual values sent to the decoder are calcu-
lated according to (2.15). However, it has been shown that this residue calculation is
not optimal in an error prone environment [79] and actually depends on E{F (n, i)},3H.264/SVC (Scalable Video Coding), is the scalable extension to the H.264/AVC video coding
standard.

30 Literature Review
E{F (n, i)2} the first and second moments for each pixel. This method stores these
moments in stochastic frame buffers and uses them for residual calculation, motion
estimation and mode decision. The SFB replaces the regular frame buffer, therefore
actual pixel values are no longer needed.
2.3.6 Residual-Motion-Propagation-Correlation (RMPC) Distortion
Estimation
Recently the importance non-linear clipping noise in distortion estimation has been
investigated. Transmission errors cause the decoder to approximate pixel values at
the decoder which may include clipping noise that may be ignored by other distortion
estimation methods [86, 87]. RMPC was developed for estimating frame level trans-
mission distortions (RMPC-FTD) and pixel level transmission distortions (RMPC-
PTD) at the encoder as a non-linear time variant function of frame statistics, system
parameters and channel statistics [86]. In deriving their model, Chen and Wu as-
sume that data partitioning is employed so that residual information is sent separate
packets from motion vector information. Using UEP in order to improve the likeli-
hood of receiving motion vector packets can potentially improve the error resilience
performance as it allows the decoder to perform better error concealment. This ap-
proach is slightly different from the methods described above, which assume residual
information is lost along with motion vector information. The resulting end to end
distortion for RMPC-PTD takes on the following general form.
D(n, i) = DRCE(n, i) +DMVCE(n, i) +Dprop(n, i) +Dcorr(n, i) (2.23)
where DRCE(n, i) is the residual concealment error (RCE), DMVCE(n, i) is the
motion vector concealment error MVCE, Dprop(n, i) is the propagated error plus clip-
ping noise, and Dcorr(n, i) represents correlations between RCE and MCVE. This
distortion decomposition facilitates the derivation of a simple closed-form formula for
each of the four distortion terms.
For the specific case of video transmission without data partitioning, the end to
end distortion is described by expanding equation (2.1),

2.3 End-to-End Distortion Estimation 31
D(n, i) = E{[F (n, i)− F (n, i) + F (n, i)− F (n, i)]2}
= E{[F (n, i)− F (n, i) +Dtx(n, i)]2}
= [F (n, i)− F (n, i)]2 + E{[Dtx(n, i)]2}
+2(F (n, i)− F (n, i)) · E{Dtx(n, i)} (2.24)
We see that [F (n, i) − F (n, i)] is the quantization error and E{Dtx(n, i)} is the
transmission error. Assuming previous frame error concealment at the decoder E{Dtx(n, i)}is obtained as follows for Intra MBs
E{Dtx(n, i)} = p ·(F (n, i)− F (n− 1, i) + E{Dtx(n− 1, i)}
)and for Inter MBs
E{Dtx(n, i)} = p ·(F (n, i)− F (n− 1, i) + E{Dtx(n− 1, i)}
)+(1− p) ·
(E{Dtx(n− j, i)}+ ∆(n, i)
)where ∆(n, i) is the clipping noise at the decoder.
The distortion in (2.24) can be used in mode decision, after the first and second
moments, E{Dtx(n, i)} and E{[Dtx(n, i)]2} respectively of the transmission errors
are estimated. This is different than the ROPE algorithm which estimates the first
and second moments of the decoder reconstructed pixel mainly because it considers
clipping noise at the decoder when estimation Dtx(n, i).
Full derivation of the quantities described above can be found in [86, 87], and
have been omitted here for brevity. They show that to estimate Dtx(n, i), knowledge
of the prevailing channel conditions are required. In this dissertation we present
methods of mitigating the effects of error propagation when channel information is
unavailable. While this work presents an interesting advancement in the area of
distortion estimation, we do not present any distortion estimation procedure in this
work, but rather develop a novel method of biasing the source coding distortion to
take into account the prediction dependencies.

32 Literature Review
The distortion estimate generated by the K-decoders method will asymptotically
reach the expected distortion as K → ∞. The estimation accuracy of the K-decoders
for large values of K method has been noted in various comparisons [78, 87]. It
is referred to as Law of Large Number (LLN) when compared to RMCP [86, 87]
where the authors acknowledge for K > 50 the distortion estimate generated by
K-decoders exhibits less variance compared to K = 30. The resulting performance
improvement of RCMP over K-decoders with K = 30 is reported as 0.3 dB on average
[87]. Distortion Map method compared to K-decoders with K = 30 is reported as
providing on average a 0.5 dB in accuracy [78]. As stated earlier the computational
complexity is significantly reduced by using either RMCP or Distortion Map, however,
the resulting PSNR performance is not always considerable.
In this dissertation we are more concerned with the impact of imperfect channel
estimation on overall performance and not estimation accuracy or distortion esti-
mation complexity. Because the K-decoders method will asymptotically reach the
expected distortion as K → ∞, we feel it will offer us the best comparison technique
to determine the impact of imperfect channel estimation. For this reason we have
selected to use the K-decoders method as a comparison technique in our simulations.
2.4 Channel Characterization
The end-to-end distortion estimation techniques reviewed in Section 2.3 all require
knowledge of the channel behaviour. They all assume a uniform loss probability
model, and that the channel is able to furnish the encoder a priori with an estimate
of the expected packet loss rate, p. However, this assumption may not always accu-
rately model a wireless environment which is described by bursty packet loss. While
techniques such as FMO or slice interleaving can help spread the error within and
across frames respectively, the uniform loss probability model is still very conservative
in mobile environments.
The packet loss rate p can be provided to the encoder through feedback from RTCP
which can easily calculate the average packet loss rate witnessed at the decoder,
but may not be suitable for wireless environments. To more accurately describe

2.4 Channel Characterization 33
the wireless environment, the Gilbert model has been suggested, which looks at the
probability of being in a loss state rather than the average loss probability [88].
2.4.1 Gilbert Model
A Markov model has been used to capture the temporal loss dependency that is
present in bursty loss channels [89]. A two-state Markov model shown in Figure 2.4
is commonly referred to as the Gilbert model.
GOOD BAD
p
q
1-q 1-p
Fig. 2.4 Gilbert model with GOOD representing the state of correctlyreceived packets and BAD represents packet loss.
q denotes the probability that the next packet is lost, provided the previous one has
arrived; p represents the probability that the next packet is received correctly given
that the current one was lost. (1p) is the conditional loss probability. Typically,
p + q < 1. If p + q = 1, the Gilbert model will have the Bernoulli model properties.
From the above definition, we can compute PGOOD and PBAD, the state probability
for GOOD and BAD states respectively. In the Gilbert model they also represent the
mean arrival and loss probability, respectively.
PGOOD =p
p+ qPBAD =
q
p+ q(2.25)
Pk (the probability distribution of loss runs of length k, i.e., k consecutive losses) has
a geometric distribution.
The ROPE algorithm has been extended to incorporate the Gilbert model for
mode selection [90] and to determine multiple description parameters [91] in a wireless

34 Literature Review
environment.
An extension to the Gilbert model used for modeling Internet losses determines
the mean burst length (MBL) and mean inter-loss distance (MILD), which can be
made available from RTCP feedback. MBL and MILD can then be used to improve
FEC performance in a wireless environment [88] or to determine FMO and dynamic
redundant slice allocation strategies [92]. All together, this suggests the assumption
of uniform probability is inadequate for wireless channels. We therefore include some
simulations in Chapter 4 that show the improvement possible by using our methods
in a bursty loss channel.
2.4.2 Inaccurate Channel Estimates
Inaccurate channel estimates can severely impact the performance of the techniques
presented in Section 2.3. Some simulation results have been reported showing the
decreased performance of SFBs when the channel model does not match the model
used in the derivation [79]. An investigation of the ROPE method discussed in Sec-
tion 2.3.3 concluded that the estimation performance is compromised by mismatch
conditions [93]. It is reasonable to conclude that the success of all these methods
hinges on accurate estimates of p. The weighted distortion methods we present in
this dissertation do not require p and are therefore robust to changing channel con-
ditions.
When channel feedback is available there is a debate as to whether applying distor-
tion estimation techniques for ER-RDO presented in Section 2.2 is better than retrans-
mitting lost information in response to feedback. The big advantage of feedback-based
retransmission is its inherent adaptiveness to varying loss rates, as retransmissions
are only triggered if the information is actually lost [94]. Several feedback based en-
hancements have been proposed to video coders that force the encoder to INTRA
update some regions [54,68], or send corrective signals based on information from the
decoder [94–96]. The overhead required by retransmission based techniques is a direct
result of the packet loss rate experienced on the channel, and the encoder does not
need to estimate information about the expected channel condition. For bidirectional
conversational services like video telephony, however, the benefit of packet retrans-
mission is limited because of the stringent timing requirements which is typically in

2.5 Error Resilience Based on Motion Estimation 35
the range of 150−250 ms [94]. The presence of feedback therefore has its advantages,
however, in its absence the techniques present here will offer considerable alternatives.
2.5 Error Resilience Based on Motion Estimation
A number of methods have attempted to directly address error propagation by mod-
ifying various aspects of the motion estimation process. Before reviewing some of
these methods, let us examine how error propagates in a hybrid video compression
scheme. The impact of error propagation was illustrated in Fig. 1.2. This happens
when motion vectors point to a corrupted area in a reference frame, leading to the
referring area in the current frame being corrupted. The corrupted area may move
or may increase or decrease in size due to the process of motion compensation in
predicted pictures, as shown in Fig. 2.5
Erroneous MB in
reference frame
MB in current frame with
motion vectors
Error spreading in
current frame
Fig. 2.5 Error propagation due to motion compensated prediction inhybrid video coding.
Generally, the distorted area spreads temporally and may decrease in intensity
throughout the sequence. Continued referencing to the distorted area will cause
the spread, but motion compensation from error-free areas will cause some of the
distortion to dissipate in subsequent predicted frames. The techniques that achieve
error resilience through motion estimation attempt to reduce this spreading effect
by selecting reference frames in a manner that will reduce the length of the error
propagation train.

36 Literature Review
2.5.1 Tree Structured Motion Estimation (TSME)
Tree structured motion estimation (TSME) rearranges the traditional linear predic-
tion structure for motion estimation to the tree structure [97]. They define three
types of frames; root frames, stem frames and branch frames. Root frames are Intra
coded frames. Stem frames occur every N frames and can only predict from previous
root frames or stem frames. Branch frames are placed between stem frames. The
prediction dependencies of TSME are depicted in Fig 2.6.
0
1 2 N-1
N
N+1
2N
2N-1
Fig. 2.6 Frame prediction structure in TSME.
Compared to linear prediction this structure reduces error propagation by con-
taining the spread of errors within the branch frames. If N is sufficiently large, there
will be little correlation between stem frames resulting in mostly INTRA coded MBs
in stem frames. The increased presence of INTRA MBs is stem frame has been
suggested by the authors [97] as a reason for its effectiveness.
It should be noted that a prediction structure similar to TSME is used by scalable
video coding (SVC) to separate a video signal into temporal layers. The stem frames
would represent the base layer and the enhancement layer would be derived from
the branch frames. This suggests that SVC has some error resilience inherent in its
prediction mechanism, by localizing error propagation effects.
Another similar technique, designed at the macroblock level, achieves error re-
silience through the insertion of periodic macroblocks [98]. A periodic MB is defined
as an MB whose reference is N frames away. The stem frame of TSME can be con-
sidered as a frame made up entirely of periodic MBs. Periodic MBs help break the
prediction chain that causes error propagation, and create “safe” (less likely to have

2.5 Error Resilience Based on Motion Estimation 37
propagated errors) areas of prediction within a frame. The error resilience perfor-
mance of periodic MBs is on par with INTRA updating, but the bitrate required for
INTRA updating is shown to be significantly higher [98]. The idea that INTER MBs
can be made error resilient demonstrated by this technique is a motivating factor for
the low complexity techniques we develop in Chapter 4.
2.5.2 Multihypothesis Motion Compensated prediction (MHMCP)
The presence of multiple reference frames also allows for another error robust scheme
known as multihypothesis motion compensated prediction (MHMCP). In MHMCP
a prediction reference is generated by a linear combination of multiple signals (hy-
potheses) from previously encoded frames [99] as illustrated in Fig. 2.7.
Frame n-2 Frame n-1 Frame nFrame n-K
Fig. 2.7 Macroblock prediction structure in MHMCP.
MHMCP was initially proposed for its compression efficiency in low bitrate video
coding [100], but later its error resilience properties were revealed [99]. Better sup-
pression of short-term errors compared to INTRA updating has been cited as one of
MHMCP’s major advantages [99], however, it is not H.264/AVC standard compati-
ble because it would require a change in the H.264/AVC syntax to signal the motion
vectors of MB’s in previous frames.
A standard compatible version of MHMCP that uses only 2 hypotheses (2HMCP)
is possible if B-pictures are used and appropriate modifications are made at the en-
coder to have the B-pictures point to previous frames in the display order. 2HMCP
was implemented for H.264 [101], where each MB (except for the INTRA-frame and
the first INTER-frame) is predicted from a weighted average of 2 MBs from frames
in the reference frame buffer, and the weight is fixed for each prediction (hypothesis).

38 Literature Review
Given the presence of 2 hypothesis, Tsai et. al. [101] are able to derive an effective
error concealment strategy at the decoder. Since the decoder know which hypothesis
is lost, it will only use the correctly received (“clean”) hypothesis for prediction at
the decoder, thereby reducing the error propagation effect.
2.5.3 Alternate Motion Compensated Prediction (AMCP)
Alternate Motion Compensated Prediction (AMCP) improves upon the error re-
silience performance of 2HMCP, by combining 2HMCP with 1HMCP in an alternating
pattern [102]. As illustrated in Fig. 2.8, prediction begins with every odd frame us-
ing 1HMCP and the even frames use 2HMCP, with this pattern alternating every N
frames. This creates a tree like dependency similar to TSME in the prediction chain
that helps localize the error propagation effects.
I P M P M P P M P M M P M P
N0KEY
P : 1HMCP
M: 2HMCPAlternating
Point
Fig. 2.8 Frame prediction structure in AMCP showing alternatingpoint.
Adjusting N and the weights used for the linear combination of the 2HMCP
portion of AMCP helps to tailor the error resilience performance. AMCP reduces the
likelihood that the area being predicted from contains errors by combining the tree
structure with 2HMCP. Our methods of creating “safe” prediction areas by redirecting
motion vectors accordingly will be revealed in Chapters 3 and 4.

2.5 Error Resilience Based on Motion Estimation 39
2.5.4 Non Standard Compliant Techniques
Some effective non-standard compliant strategies which have served as inspiration for
this thesis deserve highlighting. These methods are considered non-standard because
they involve redesigning the prediction mechanism at the decoder, thereby violating
the scope of the standard as depicted in Fig 2.1. Given the freedom to re-design
the prediction mechanism at the decoder, it is possible to limit error propagation by
adding some leakage to the prediction loop. An example is to employ leaky predic-
tion, which scales down reconstructed frames to generate reference frames that yield
exponential decay of propagated errors [103]. Yang and Rose [104, 105] extended
the leaky prediction concept to developed a generalized source channel prediction
(GSCP) scheme where reference frames are recursively generated from previous ref-
erence frames according to
F (n, i) = α · F (n, i)− (1− α) · F (n− 1, i) (2.26)
where F (n, i) represents the current reference frame. The filtering effect of (2.26)
results in a bitstream that is more robust to error propagation, but less correlated
with the original frame, which generally impacts coding efficiency.
An improvement to GSCP was obtained by exploiting the presence of INTRA
MBs in previously coded frames. Because INTRA MBs do not propagate errors,
rather than relying on (2.26) for all pixels in the reference frames, INTRA pixels are
directly copied to F (n, i) [106]. This improves the coding efficiency of GSCP because
it does not apply the filtering of (2.26) to the INTRA pixels. It also maintains a high
coding efficiency because INTRA MBs do not contain any propagated errors. We use
a similar strategy in deriving our simplified weighted distortion techniques as we rely
on the presence of I-MBs in the reference frames.
While these techniques present interesting ideas on limiting error propagation, they
do not all consider the rate distortion trade-off. In this work, we develop methods
that address all of the three major considerations in video compression over unreliable
links: rate, distortion and resilience. We present a framework that takes into account
all these three factors during both motion estimation and mode decision.

40 Literature Review
2.6 Chapter Summary
In this chapter, details regarding the basic structure of hybrid video coding along
with standard and non-standard error resilient strategies for video communication
over unreliable links were presented.
Section 2.1 started with a tutorial on the H.264/AVC video coding standard.
Special attention was paid to the error resilient tools present in the standard. We
saw early on that Intra Updating is the most effective method of combating error
propagation in compressed video. Because INTRAmacroblocks reduce a video coder’s
compression efficiency, it is necessary to find the best tradeoff between efficiency and
resilience.
This led to a discussion on rate-distortion optimization (RDO) for video com-
pression in Section 2.2, where we saw that RDO is optimal only for an error free
scenario. End-to-end distortion estimation improves the performance of compressed
video over noisy channels. Several techniques that perform RDO with estimates of
the end-to-end distortion were presented in Section 2.3. All these techniques require
an estimate of the channel loss probability, which we highlited as a potential limiting
factor in Section 2.4
In Section 2.5, error resilient strategies that manipulate the prediction structure
were presented, with emphasis on the robust encoding of P-MBs. P-MBs have a higher
coding efficiency than I-MBs, but are susceptible to error propagation, therefore the
methods presented here try to find effective ways of using P-MBs. We also briefly
introduced some non-standard error resilient strategies that achieve error resilience
by changing the prediction strategy at the decoder.
Throughout the chapter we alluded to our proposed solutions that address the
deficiencies of the current techniques by being robust to inaccurate channel estimates
and offering considerable gains in an error prone scenario. Chapters 3 and 4 will
present our two solutions: forward based and backward based tracking for weighted
distortion.

41
Chapter 3
Weighted Distortion
We learnt in Chapter 2 that motion compensated prediction (MCP) is an integral
part of most of the major video compression schemes because of its ability to remove
the temporal redundancy inherent in a sequence of pictures. However, it also leads
to degraded performance in lossy environments as it spreads errors along the motion
prediction path [45, 53, 54]. When transmitting compressed video through unreliable
channels, a mismatch between the encoder and decoder predictions due to macroblock
(MB) losses causes the error to extend as prescribed by motion vectors. In this
Chapter, we present a new way of mitigating the effects of the spatio-temporal error
spread due to motion vectors by first determining the trajectory of each MB across
frames.
Looking forward at the impact of slice/MB loss was implemented as an error
tracking method [45,107] in H.263 (an earlier video coding standard). Error tracking
was used in a feedback channel to improve compressed video performance in an error
prone channel [45]. In this method, the decoder sends a NACK indicating which
macroblocks (MBs) have been lost, while the encoder buffers the error energy due to
concealment for the last several frames. The encoder is therefore able to determine
the error distribution in future frames and introduces INTRA MBs to the areas where
errors have propagated in the current frame. This method is useful for conversational
services where a feedback channel is available but introduces delay in the encoder.
On the other hand, our method focuses on building a better encoder that does not
rely on decoder feedback to combat losses during transmission. What’s more, we are

42 Weighted Distortion
able to maintain a high coding efficiency by working within the RDO framework.
Another error resilient strategy based on the forward tracking of the motion tra-
jectory known as Intelligent Macroblock Update (IMU) was proposed for H.263 [107].
The H.263 standard requires that each MB in INTER frames shall be coded in IN-
TRA mode at least once for each 132 frames. This means that error recovery can
take a prohibitively long time. IMU analyzes the temporal dependencies of MBs in
successive frames and selectively updates the MBs that have the highest impact on
later frames [107]. This technique can improve performance, but does not consider
the rate-distortion tradeoff in making its decisions, and thus can significantly reduce
its coding efficiency. It also does not attempt to improve motion vector selection for
error resilience as we do in this thesis.
3.1 Introduction
Motivated by the fact that motion vectors have a direct impact on the error prop-
agation, we study the influence an MB has along its propagation path and devise
a weighting mechanism to appropriately bias the distortion values used in RDO. In
order to mitigate the negative effects of MB loss, we have to first determine what in-
fluence an MB has along the motion propagation path. Our proposed method tracks
motion vectors to determine problematic areas in a video sequence.
The technique presented in this chapter is a two-pass encoding method, where
the second pass uses the tracking information obtained during the first pass in a
novel way to improve error resilience. Two-pass encoding is quite commonly used
in various rate control algorithms employed by practical encoders such as the x264
[108] and mainconcept [109] encoders. The drawback is that it introduces delay in
the encoding process that prohibits its use in real time applications. As such the
algorithms developed in this chapter are more suitable to VOD or multicast type of
applications. Later in Chapter 4 we present simplified algorithms that would have
broader applicability.
As presented in Chapter 2, ER-RDO video coding schemes [30,55,78,80] generally
replace DSSD of (2.7) with an estimate of the end-to-end distortion, and perform
mode decision. Our approach diverges from this distortion modelling paradigm, but
instead addresses the error propagation aspect that is due to motion compensated

3.2 Weighted Distortion for Motion Estimation and Mode Decision 43
prediction. ER-RDO techniques look backwards and, given a certain loss probability
p, try to determine the likelihood that errors have propagated to a particular region.
In contrast, our method looks forward at the motion trajectory and uses this to
improve the encoders performance in error prone scenarios. A major advantage of our
method is that we do not require an estimate of the channel’s packet loss probability p,
which all the distortion modelling methods discussed in Section 2.3 need. Obtaining
accurate channel loss estimates requires feedback and can be problematic in the case
of rapidly changing channel conditions.
Our method is shown to improve performance across a variety of channel condi-
tions without requiring an explicit estimate of p. Our solution addresses the draw-
backs of the distortion modelling methods by introducing a bias that penalizes the
distortion of MBs that have a greater influence on error propagation. We apply this
technique to motion estimation and to mode decisions as well. In addition, we will
show how this technique can be used to improve the performance of the redundant
slice feature present in the H.264/AVC specification.
This chapter is organized as follows: In Section 3.2, our weighted distortion
method is presented. Two weighting strategies are developed, one for motion estima-
tion and the other for mode decision, together forming a novel platform for resilient
video coding. The versatility of the weighting strategy is demonstrated by using it
to improve the performance of the redundant slice feature present of the H.264/AVC
standard in Section 3.3. Experimental results are shown in Section 3.4, followed by a
summary in Section 3.5.
3.2 Weighted Distortion for Motion Estimation and Mode
Decision
To determine the λ in 2.4 that is suitable for all video sequences, empirical experiments
were conducted on a variety of sequences using different coding options for each
sequence [75, 110]. The rate R and distortion D points for all coding options and
sequences are plotted on a Rate-Distortion plane as shown in 3.1.
The convex hull of the RD curve in 3.1 symbolizes the boundary of achievable
performance. The value of λ represents the slope of the line that touches this convex
hull. This theoretical formulation is the basis for RD optimization in video, however,

44 Weighted Distortion
R
D
x
x
x
x
x
x
x
x
Operating
points
x
ri
di
λ·ri
Convex hull of
R-D operating points
Fig. 3.1 For each macroblock, minimizing di + λri for a given λ isequivalent finding the first point on the R-D curve slope of λ
in practice D, R and λ are subject to approximations and compromises [75].
When resilience has to be considered during video encoding, it amounts to adding
another dimension to the RD curve of 3.1. This would mean plotting extra RD oper-
ating points for various channel loss conditions, resulting in a 2-dimensional λ plane.
In this section, we develop the foundation of a resilient video encoder which considerts
the trade off betweed rate, distortion and resillience. Knowing that predictive coding
is primarily responsible for error propagation, we introduce a weighting factor that
adds resilience considertaion to RD optimization.
In this section we develop the basis of a suitable alternative
By weighting the DSAD of (2.5) in proportion to an MB’s influence on the motion
propagation path, we are able to mitigate the detrimental effects of error propagation.
Equation (2.5) is modified as follows,
Jme = wme ·DSAD + λme ·Rmv (3.1)
where wme is the weighting factor for motion estimation, and is a function of the
candidate prediction region as will be described in Section 3.2.1.
Equation (3.1) is motivated by the fact that the more future frames depend on a
particular block, the less we want to predict from it. Therefore, this weighting of the

3.2 Weighted Distortion for Motion Estimation and Mode Decision 45
source distortion allows the encoder to select motion vectors from regions that have
a smaller impact in the future. As a result, the motion trajectory will now be more
sparse, removing the long prediction chains that cause motion propagation errors to
linger in future frames, as will be shown in section 3.4.4
Significant gains can be achieved by only performing weighted distortion on the
Motion Estimation module of Fig. 2.2. However, further gains can be realized when
weighted distortion is applied to mode decisions as well. Therefore, we also modify
(2.7), to take into account an MB’s sensitivity to losses as follows,
Jmd = wmd ·DSSD + λmd ·R (3.2)
where wmd is the weighting factor for mode decision, and is derived from motion
vectors as will be described in Section 3.2.3.
When there is a strong dependence on a particular block in future frames, making
these blocks INTRA can help reduce the error propagation effect. The purpose of
wmd is to favour the selection of INTRA MBs for those MBs that affect many pixels
in the future. This is a desirable outcome because INTRA MBs do not propagate
any errors, making them “safer” to predict from. However, we should not forget that
INTRA MBs usually require a higher bitrate, and that RD optimization allows to
find a trade off between bitrate and reproduction quality.
What we introduce by using wmd in RD optimized mode decisions, is added con-
sideration of the resilience offered by using INTRA MBs, while still paying attention
to the bitrate and quality implications. The result is a prediction region with a re-
duced chance of containing propagated errors, thereby reducing the error propagation
effect in the event of the MB’s loss.
Selecting the appropriate weighting factor is crucial to this method’s success. In
the upcoming sections we describe how we obtained wme and wmd.
3.2.1 Motion Estimation Weighting Factor
To obtain the weighting factor, we track the influence an MB has along the motion
propagation path using its motion vectors. This process entails a two-pass encoding
process where in the first pass the motion vectors are computed according to (2.5),
during which the influence of each MB is tracked. The tracking reveals the number

46 Weighted Distortion
Frame n Frame n+1 Frame n+2 Frame n+N-1
A
B
Fig. 3.2 Tracking the number of pixels that are affected by the loss ofan MB over N frames
of pixels in future frames that would be affected by the loss of each MB. We then use
this information in the second pass to optimize the motion vector selection according
to (3.1).
A graphical representation of the tracking procedure is depicted in Fig. 3.2, where
the trajectory of two macroblocks, ‘A’ and ‘B’ is highlighted. Macroblock ‘A’ affects
many pixels in the future, while macroblock ‘B’ is referred to by only one macroblock
in frame n + 1. Our algorithm will therefore penalize macroblock ‘A’ more than
macroblock ‘B’. In the first pass, the weight for ‘A’ and ‘B’ in frame n are determined,
with ‘A’ being much higher than ‘B’. In the second pass, while encoding frame n+1,
the weights of ‘A’ and ‘B’ are used to determine Jme of (3.1) resulting in MBs with
lower weights (such as ‘B’) being preferred over MBs with higher weights (such as
‘A’).
Intuitively this is a reasonable approach, because if an MB is referred to by many
pixels in the future, then we expect it to be highly sensitive to transmission errors.
In the introductory chapter to this thesis we saw the impact that losing a single
macroblock can have on future frames in Fig. 1.2. By tracking MB dependencies
we attempt to capture the future impact of each MB, allowing us to identify which
areas are referred to often in the future. Our method would then reduce the usage of
these sensitive MBs for prediction, thereby lowering their susceptibility to errors. The
number of future frames to search, N , is a design criterion that trades off computation
time and algorithm effectiveness. We will discuss this trade-off in Section 3.2.2.
Table 3.1 shows the motion vector tracking algorithm used to determine the num-

3.2 Weighted Distortion for Motion Estimation and Mode Decision 47
Table 3.1 Motion Vector Tracking Algorithm.1) Compute the motion vectors for all the MBs in the chosen N frames
using (2.5)2) For an MB in the current frame search for the MB/sub MB(s) in the
next frame which reference this MB.3) A count, C, is incremented for each pixel that references the current
MB.4) The MB/ sub MB(s) which was referenced is chosen and a search is
performed in the consecutive frame to obtain MB/ sub MB (s) whichreferences these and Step 3 is repeated.
5) Step 4 is performed for all the MBs in the current frame. Thus a count,C, is generated for every MB in the frame.
6) Proceed to next frame and repeat Steps 2 to 5 for all the N framesconsidered.
ber of pixels in the future that are affected by the loss of a particular MB. The value
of wme in (3.1) used in our simulations is derived from the C value obtained by the al-
gorithm described in Table 3.1. Note that H.264/AVC allows INTRA MBs to predict
from nearby INTER MBs; to avoid errors in the INTER MBs propagating into the
INTRA MBs, the UseConstrainedIntraPred 4 flag must be set in the encoder. This
slightly reduces the coding efficiency of H.264/AVC, but is necessary for any error
resilient scheme that uses INTRA MBs to curtail error propagation. In this work,
we only consider integer-pel accuracy for simplicity, however, it is possible to apply
motion vector tracking to fractional-pel accuracy by adjusting the number of pixels
affected according to the filter used.
Once the C value for each MB has been determined, error resilient motion esti-
mation can begin. The weight wme takes into account any overlapping MBs in the
previous frame. If the candidate motion vector (MV) points to a region in the pre-
vious frame that overlaps a number of MBs, wme is computed in proportion to the
overlap area as depicted in Fig. 3.3.
Therefore if Ci represents the count from MB i, Ai is the area of MB i and ai is
the overlap area in MB i as shown in Fig. 3.3, the weight will be given by;
4This flag in the H.264/AVC reference software when set disallows inter pixels from being usedfor intra prediction [76]. Without this restriction errors in INTER MBs will propagate into INTRAMBs resulting in poor performance.

48 Weighted Distortion
Fig. 3.3 Obtaining weight wme from count C during overlap.
wme =4∑
i=1
aiAi
Ci (3.3)
This proportional representation of weight is necessary to ensure the proper bias is
given to each MB.
Note that the overall reproduction quality of the resulting P frame remains con-
sistent whether (2.5) is used or (3.1) is used. This will be demonstrated in Section
3.4 when we look at the impact of using our method compared to a reference signal
that does not employ error resilience on a lossless channel. It will be demonstrated
that our method does not introduce a drastic quality degradation in the case of no
transmission errors. This means that our method selects less efficient motion vectors,
thereby increasing the residual data resulting in P frames of similar PSNR values.
Additionally, our testing showed that if we use (3.1) up until for example frame N=5
and use (2.5) in subsequent frames, the motion vector assignment obtained in the 1st
pass will still remain valid. Therefore, we do not have to recompute (2.5) for each
frame after applying (3.1).
3.2.2 Depth Analysis
An examination of the motion vector trajectory revealed that the number of future
frames affected by the loss of an MB varies. We therefore define the depth of influence
as the number of frames in the future that a single MB affects. In this section, we

3.2 Weighted Distortion for Motion Estimation and Mode Decision 49
study the depth of influence in order to determine an appropriate search depth that
will tradeoff between complexity and accuracy.
Tracking the C values can be computationally intensive, especially in sequences
displaying complex motion patterns, and with lots of frames. To address this issue,
we have developed a low computational complexity alternative that only looks N = 3
or N = 5 frames ahead for illustrative purposes. It is possible to implement the
algorithm for different values of N , depending on the delay that can be tolerated
at the encoder. Our simulations will show that substantial improvements can be
achieved with shorter lookahead periods, while saving computation time.
Our proposed low complexity alternatives are able to capture enough information
about the motion vector trends to be able to generate useful weight information.
We draw this conclusion by looking at the depth of influence each MB has within a
sequence, thereby evaluating how important depth is in determining weights wme and
wmd. We therefore plot the distribution of MBs with respect to the depth of influence
these MBs have on the video sequence in Fig. 3.4. This is done for the Football and
NBA sequence, though similar observations are made with various other sequences.
Fig. 3.4 reveals that as you look deeper in the sequence, more information is
available on an MB’s influence. The Football sequence of Fig. 3.4a has an almost
uniform distribution, suggesting that there will be gradual improvement in the weight
estimate as one looks deeper in the sequence. On the other hand, the distribution of
the NBA sequence in Fig. 3.4b suggests that most of the MBs influence is concentrated
within a depth of 30. To see how the count C values evolve as one looks deeper into
the sequence we plot a 3D graph with the MB number located on the x-axis, depth
on the y-axis and Count C on the z-axis in Fig. 3.5.
The evolution of count values displays a gradual increase as you look deeper
into the sequence in Fig. 3.5 for both the Football and NBA sequence. Since the
count values are used to bias the distortion values in (3.1), a gradual increase would
suggest that early termination of the tracking would lead to useful information. This
is because shorter search depths are still able to inform us of which MBs are more
sensitive than others to errors.
The main advantage of the shorter search depths is that they are able to improve
the encoding time as demonstrated in Table 3.2. Table 3.2 shows the encoding time
for a QCIF sequence using an Intel i5 2.8Ghz PC running a 32 bit version of the
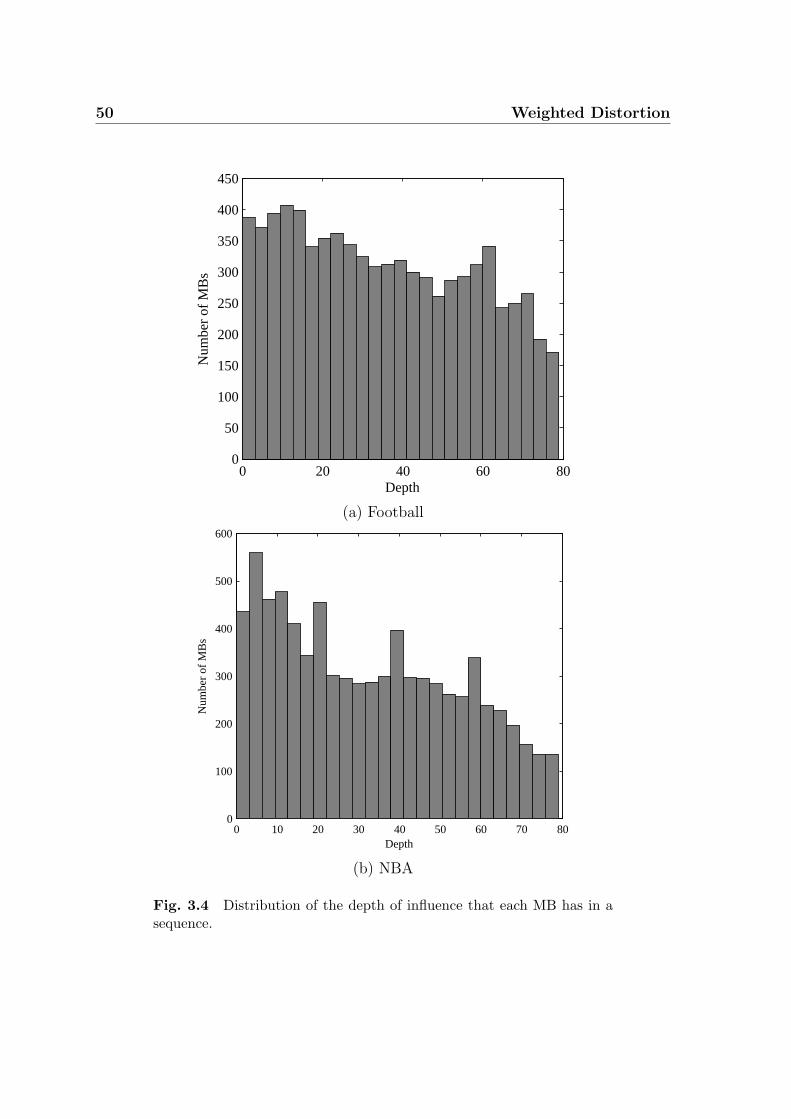
50 Weighted Distortion
0 20 40 60 800
50
100
150
200
250
300
350
400
450
Num
ber
of M
Bs
Depth
(a) Football
0 10 20 30 40 50 60 70 800
100
200
300
400
500
600
Num
ber
of M
Bs
Depth
(b) NBA
Fig. 3.4 Distribution of the depth of influence that each MB has in asequence.

3.2 Weighted Distortion for Motion Estimation and Mode Decision 51
(a) Football
(b) NBA
Fig. 3.5 Change in Count C, value for each MB as you look deeper inthe sequence.

52 Weighted Distortion
Table 3.2 Timing information for reduced lookahead methods.
Encoding Time(min:sec)
Standard H.264 04:06count 3 09:16count 5 10:22count 79 15:03
JM reference software [76] with our algorithm. While the total encoding time is
approximately triple compared to standard H.264 by using count 79 it is slightly
above double for count 3. Even though the shorter lookahead periods result in
less efficient timing information, the resilience performance achieved by using shorter
lookahead is greater than standard H.264 encoding. It is important to note that
some implementation enhancements are possible by using assembler for some of the
search and compare operations in our algorithm, however, this was not pursued in
greater detail as we focused on demonstrating the effectiveness of using tracking
information to achieve error resilience.
Altogether, this means our low complexity alternatives will arrive at the weight in-
formation faster at the expense of more accurate weight information. This conclusion
is verified in the Section 3.4.2.
3.2.3 Mode Decision Weighting Factor
Coding a macroblock as either INTER or INTRA has significant and conflicting im-
plications on the error resilience and coding efficiency of a video compression scheme.
The simulation results in Section 3.4.1 reveal the efficacy of applying weighted mo-
tion estimation. In this section, we seek to enhance the performance achieved from
weighted motion estimation by finding a weighting strategy for mode decisions, that
addresses the tradeoff between resilience and rate.
We stated earlier in Section 2.1.1 that INTRA MBs generally have a higher bitrate
compared to INTER MBs because they do not remove temporal redundancy. We
also stated that from an error resilience standpoint, the fact that they do not employ
temporal prediction means that they do not cause error propagation.
Keeping in mind the resilience-efficiency tradeoff, we present a weighting strategy

3.2 Weighted Distortion for Motion Estimation and Mode Decision 53
that is applied to INTRA modes only, with the intention of reducing their distortion
value in proportion to the number of pixels they affect in the future. To that end we
develop a weight factor wmd, for the INTRA mode, that is based on the count value
Ci, of MB i according to,
wmd =
{1− Ci
Cmaxif 1− Ci
Cmax< T
T if 1− Ci
Cmax> T
(3.4)
where Ci
Cmaxis the count value for an MB normalized by the maximum count value
of the frame Cmax. T is a threshold value that allows for increased error resilience
performance. We select 0 < T ≤ 1 , to ensure a fractional reduction in the distortion
and prevent negative values of distortion. Negative values of distortion would put
unfair emphasis on rate in determining coding options.
With the weight assignment of 3.4 a value of T = 0 would mean the encoder would
pick the coding option that offers the lowest rate. With T = 1, the encoder would
select the mode that offers the best RD tradeoff with some concern for resillieance.
Care should be taken when selecting T because as T → 0 more emphasis is paid on
rate than distortion leading to a lower quality encoding. On the other hand as T → 1
some MBs that have a high impact in the future may be coded as INTER causing
them to propagate errors. We show in our simulations the results of various values of
T .
The rationale behind selecting this value for wmd is similar to that of wme, in
that we want to favour INTRA mode selection for those MBs that are referenced
often in the future. In addition, our mode decision method ensures that the sensitive
MBs are error free by coding them as INTRA rather than INTER. This allows these
areas to be safely used in the future by reducing the risk of error propagation. It is
important to note that wmd does not simply code MBs that affect numerous pixels
in the future as INTRA. Its application in (3.2) will ensure that if coding as INTRA
would require a prohibitively large rate, INTER mode would be more appropriate.
Our proposed method therefore takes into account the rate-distortion tradeoff as well
as error resilience in making decisions
This weighting method for mode decisions can be viewed as an Intra updating
scheme similar to those presented in Section 2.1.1. It is more robust than Random
Intra updating because it is able to adapt the Intra updating strategy according to

54 Weighted Distortion
sequence specific characteristics. By using information from the motion trajectory
for mode decision and motion estimation we are able to distinguish our technique
from the error resilience tools included in H.264/AVC, as presented in Section 2.1.1,
because we combine efficient Intra updating with efficient motion vector selection
within the RD framework.
3.3 Weighted Redundant Macroblocks
Redundant Slices (RS) are an error resilient feature of the H.264/AVC standard.
Error resilience is achieved by the encoder transmitting a redundant slice for each
primary coded slice. If the primary slice is received in error, the decoder can decode
the redundant slice, thus achieving error robustness [111]. Redundant slices are very
effective when there is a high probability of losing the primary slice [111]. Transmit-
ting one redundant slice for each primary slice can also result in a prohibitively large
increase in bitrate. Therefore a lot of effort has gone into effective ways of utilizing
the redundant slice. Coarsely quantizing the redundant representation [111] can help
achieve the reduction in rate, but with the introduction of a slight mismatch when
the redundant slice is used at the decoder. Combining redundant slices with other
H.264/AVC features such as reference picture selection [112] has been shown to im-
prove the coding efficiency while maintaining error resilience, however, this method
codes entire pictures rather than regions of a picture.
Flexible Macroblock Ordering (FMO) is another error resilient feature of H.264/AVC
which creates slices from MBs in an order that is not a consecutive raster scan of MBs.
Slices are generated from spatially distributed MBs using an MB to slice mapping
that can change for every frame [92]. The combination of FMO and redundant slices
offers the opportunity of retransmitting only the areas that are considered sensitive,
for example, only generating redundant slices for the foreground image [113, 114].
This region of interest based re-transmission method has been shown to improve cod-
ing efficiency in certain scenarios, but is not universally applicable to all types of
video sequences, especially those with significant background activity [92, 113, 114].
Using fading channel statistics, a dynamic redundant slice allocation procedure was
developed that can improve the error resilience in fading channels [92]. Rather than
sending redundant slices for each slice, the method in [114] applies Reed-Solomon

3.4 Simulation Results 55
codes across the redundant slices and transmits only the resulting parity symbols at
a low excess bit rate. Using the parity symbols, the receiver can recover the redundant
slices and use them for error robustness [114]. The combination of FMO and RS has
also been suggested for a sensitivity metric based on end to end distortion estimates,
however, this method requires channel loss information which we try to avoid in our
proposed technique [115].
While FMO can offer the opportunity of sending redundant slices for only the
regions deemed important, it does not offer a great degree of flexibility in which MBs
in a particular frame should be retransmitted. Schmidt and Rose [116] used a scheme
where the redundant frame contained a redundant representation of the MBs that
needed to be retransmitted and all other MBs were coded as SKIPs. This allowed for
the encoding of redundant MBs using the ROPE algorithm [80] while maintaining a
low overhead due to the SKIP signalling.
In our proposed scheme, we use the same motion vector tracking algorithm de-
scribed in Table 3.1 to determine MB sensitivity through the count, C value. From
the C value, we select a percentage of the most sensitive MB to code redundantly. Ac-
tual encoding is done by coding a redundant frame with the selected redundant MBs
and all other MBs are coded as SKIP, similar to the method employed by Schmidt
and Rose [116].
Our redundant MB strategy selects M of the MBs with the highest count in each
frame, and sends redundant copies of these. The reasoning behind our approach is
that because these MBs affect the most number of pixels in the future, we should
provide them with added protection, by sending redundant copies of them. We will
see from our simulation results in Section 3.4 that sending M of the most significant
MBs in terms of future impact performs better than randomly selecting MBs to make
redundant or even Random Intra updating. By changing M we can vary the level of
protection required, and we can also reduce the quantization noise on the redundant
representations by increasing the quantization parameter (QP).
3.4 Simulation Results
Our simulations were conducted according to the testing conditions outlined by the
Joint Video Team (JVT) [65], which is responsible for standardizing H.264/AVC. We

56 Weighted Distortion
therefore assume RTP/UDP/IP transmission, where packets that are lost, damaged
or arrive after the video playback schedule are discarded without retransmission. The
decoder performs error concealment by copying the missing MBs from the previous
frame. A total of 4,000 coded pictures were transmitted through a packet erasure
channel with uniform loss probability of p. Eighty (80) frames of QCIF and CIF
sequences were encoded in IPPP... format and the bitstream was repeated 50 times to
form 4,000 coded pictures. For each frame, a row of MBs was placed in a slice, which
formed an RTP packet. Integer-pel accuracy is used and Quantization Parameter
(QP) is varied to achieve different encoding rates. We look at the impact of error
propagation due to transmission over a packet loss network, by calculating the average
PSNR of the whole sequence.
3.4.1 Weighted Motion Estimation
In Section 3.2.1 we presented our technique of selecting robust motion vectors by
weighting the distortion used in RD optimized video. Now we will show that our
method produces significant performance gains in a packet loss environment. We
demonstrate the effectiveness of this novel scheme by plotting the RD curves for
Football and NBA (QCIF Format) with errors (20% random burst packet loss channel)
in Fig. 3.6 and we also show the performance at different channel loss rates for a fixed
bitrate in Fig. 3.7. Additional simulation results in a 10% uniform packet loss channel
and bursty loss channel are presented in Appendix A.1 and Appendix A.2 for Football,
NBA, Mobile, Stefan, Foreman and News sequences.
To determine the benefit of smarter motion vector allocation in the proposed
algorithm, the RD performance of the K-decoders method introduced in Section 2.3.1
and Random Intra updating is compared. This is done to ensure a fair comparison
with current error resilient strategies because the K-decoders method asymptotically
approaches the true distortion as K goes to infinity. We also introduce a mismatch
condition for the K-decoders method to highlight the effectiveness of our method in
the presence of erroneous channel information.
The results show that compared to Random Intra updating and a mismatched
K-decoder, the system employing our proposed algorithm outperforms them in RD
performance, and at different packet loss rates. For instance, in Fig. 3.6a, the weight-

3.4 Simulation Results 57
ing procedure described by Equation (3.1) improves on both Random Intra Updating
and mismatched K-decoders by up to 1.8 dB. The Rand Intra 15 curve in Fig. 3.6
represents 15% Intra Updating and the count79 shows the weighted procedure with
N = 79 (i.e. the whole sequence) combined with 15% Intra Updating. The reason
for combining Random Intra updating with weighted distortion, is to show how the
weighting procedure can further improve Random Intra updating. Random Intra
updating as implemented in the JM reference software [76] has a cyclic refresh pat-
tern ensuring each MB is Intra updated after a certain period. This prevents certain
MBs from having long propagation trails, and combined with robust motion vectors,
results in the superior performance witnessed in Fig. 3.6 and Fig. 3.7.
In Fig. 3.6, all the sequences are sent through a channel experiencing 20% packet
loss. Because the K-decoders methods assumes knowledge of channel conditions, the
K dec 20 curve refers to the K-decoders method designed for a channel with 20%
packet loss. The mismatch condition is represented by K dec 1, which refers to the
K-decoder method designed for a channel with 1% channel loss. We see that in the
mismatch case our method outperforms the K-decoders method. Results of the low
complexity techniques with N = 3 and N = 5 are presented in the next Section.
By fixing the bitrate of all the methods under consideration and passing them
through different channel loss conditions, we see in Fig. 3.7 that our motion vector
weighting algorithm outperforms standard H.264/AVC, Random Intra updating and
a mismatched K-decoders implementation. As mentioned earlier our implementation
has the added advantage of not needing to adjust the encoding to varying channel
conditions, but still maintains improved performance at different loss rates.
There is a bitrate penalty incurred by employing an ER-RDO method in an error
free environment as outlined in Table 3.3. In order to compute this bitrate penalty, we
use the Bjøntegard formula [117] to calculate the average PSNR and bitrate difference
between the error free RD curves. This gives us an indication of the additional
resources required by the error resilient strategies under investigation in comparison
to a standard decoder. For example, in Table 3.3 we see that the K-decoders method
designed for a 20% packet loss requires on average a 24% increase in bitrate for
the Football sequence compared to a standard encoder employing no error resilient
strategies. While this bitrate increase can be prohibitively large for some applications,
it would result in the best performance for the severe condition of 20% packet loss

58 Weighted Distortion
150 200 250 300 350 400 450 500 55020
21
22
23
24
25
26
27
28
29
30
Bit−rate (kb/s)
PS
NR
(dB
)
K dec 20K dec 1Rand Intra 15count79std
(a) Football
300 350 400 450 500 550 600 650 700 750 80019
20
21
22
23
24
25
26
27
28
29
Bit−rate (kb/s)
PS
NR
(dB
)
K dec 20K dec 1Rand Intra 15count79std
(b) NBA
Fig. 3.6 RD curves for Football and NBA sequences (QCIF format) ina channel with 20% packet loss rate. K dec 20 is the K-decoders methoddesigned for a channel with 20% packet loss while K dec 1 is designed for1% channel loss. Rand Intra 15 is 15% Intra Updating, count79 is theweighted procedure looking 79 frames ahead and std is standard H.264without error resilience tools.

3.4 Simulation Results 59
3 5 10 2022
24
26
28
30
32
34
pkt loss rate (%)
PS
NR
(dB
)
K dec Matchedcount 79K dec 1Rand Intra 15stdK dec 20
(a) Football @ 350 kb/s
3 5 10 2020
22
24
26
28
30
32
pkt loss rate (%)
PS
NR
(dB
)
K dec Matchedcount 79K dec 1Rand Intra 15stdK dec 20
(b) NBA @ 450 kb/s
Fig. 3.7 Performance at different loss rates for Football and NBA se-quences (QCIF format) with a fixed bitrate for each method. K dec 20
is the K-decoders method designed for a channel with 20% packet loss, Kdec 1 is designed for 1% channel loss and K dec Matched is K decodersmatched to the channel loss rate. Rand Intra 15 is 15% Intra Updating,count79 is the weighted procedure looking 79 frames ahead and std isstandard H.264 without error resilience tools.

60 Weighted Distortion
rate.
On the other hand, our method requires about 15% increase in bitrate and offers
an improvement of up to the 1.8dB compared to K dec 1 for severely bad channel
loss rates we witnessed in Fig 3.6, and also steady performance improvement at lower
loss rates illustrated in Fig 3.7. While the mismatched K-decoders method K dec 1
requires a 9% increase in bitrate, we see that its error resilience performance is not
as good as our method. When the bitrates are fixed as in Fig. 3.7, this fact becomes
even more evident.
Table 3.3 ∆ PSNR and ∆ bitrate incurred by using various RD opti-
mization methods when compared to Standard in an error free environ-
ment.
MethodsFootball NBA
∆ PSNR ∆ rate(%) ∆ PSNR ∆ rate(%)
K dec 20 2.22 24.40 2.93 25.59
K dec 1 0.75 8.84 0.89 7.95
Count79 1.76 15.77 1.66 14.65
Rand Intra 15 0.59 6.93 0.55 5.10
3.4.2 Simplified Motion Estimation
The Depth Analysis performed in Section 3.2.2 suggested that reduced look-ahead
periods may offer lower complexity alternatives at the expense of accurate weight
estimation. We set out to verify this assertion in this section. The simulation results
presented here only investigate what effect varying the number of frames used to
track motion vectors has on the error resilience performance. As such we make no
comparisons to other error resilient methods as this has been done in Section 3.4.1
and will be done in Section 3.4.3.
As a baseline we compare weighted motion estimation to a standard H.264/AVC
coder without any error resilience features, and our simulations clearly show the
need for error resilience in a packet loss environment at the expense of only a slight
increase in bitrate. Fig. 3.8 shows plots of the RD curves for Football and NBA (QCIF
Format) with no transmission errors (labelled no error) and with errors (labelled

3.4 Simulation Results 61
with error). The no error curves in Fig. 3.8a and Fig. 3.8b reveal that our encoding
method imposes only a slight increase in bitrate at a particular PSNR value. In
Section 3.4.1 we tabulated the case of no transmission errors, but in this instance we
show them on RD curves to give a clear illustration of how little overhead is required
by employing Equation (3.1) for motion estimation.
The N = 3 and N = 5 frame look-ahead period is represented by count3 and
count5 respectively in Fig. 3.8, and count looks forward until the end of the sequence.
The with error curves show the improvement that is possible by employing our
motion estimation procedure. Moreover, they demonstrate the performance benefits
offered by longer look-ahead periods.
The with error curves show that the count3 and count5 performance are sim-
ilar, offering up to a 2dB improvement in the Football sequence and up to 1dB in
NBA. Using count offers even better performances because the weight values ob-
tained provide a more accurate reflection of a MBs impact. In situations of limited
computational or time resources the shorter look-ahead periods are a viable option.
For other applications such as video archival, where time constraints are not a major
concern, it maybe useful to create robust compressed video streams by looking deeper
into the sequence.
This improved performance is not limited to the 10% packet loss case displayed
in Fig. 3.8, but is also witnessed at different packet loss rates as shown in Fig. 3.9.
For different loss rates our method outperforms standard H.264/AVC with the low-
complexity alternatives offering substantial benefit as well. In addition, Fig. 3.9 shows
a gradual improvement for longer look-ahead periods as well.
The objective results described above clearly show the improvement offered by a
judicious use of motion vectors. To gain a better understanding of what this means
on actual video sequences we plot Frame 28 of the Football sequence in Fig. 3.10, com-
paring standard H.264/AVC to weighted distortion using various look-ahead periods,
N . Looking at the number “82” we see the gradual improvement on reproduction
quality offered by going from standard H.264, to count N = 3, to count N = 5
and to a count N = 79. These subjective results further demonstrate the importance
of appropriate motion vectors when transmitting compressed video over unreliable
links. As more information about how a macroblock affects future pictures becomes
available, better decisions can be made in the encoder leading to the performance
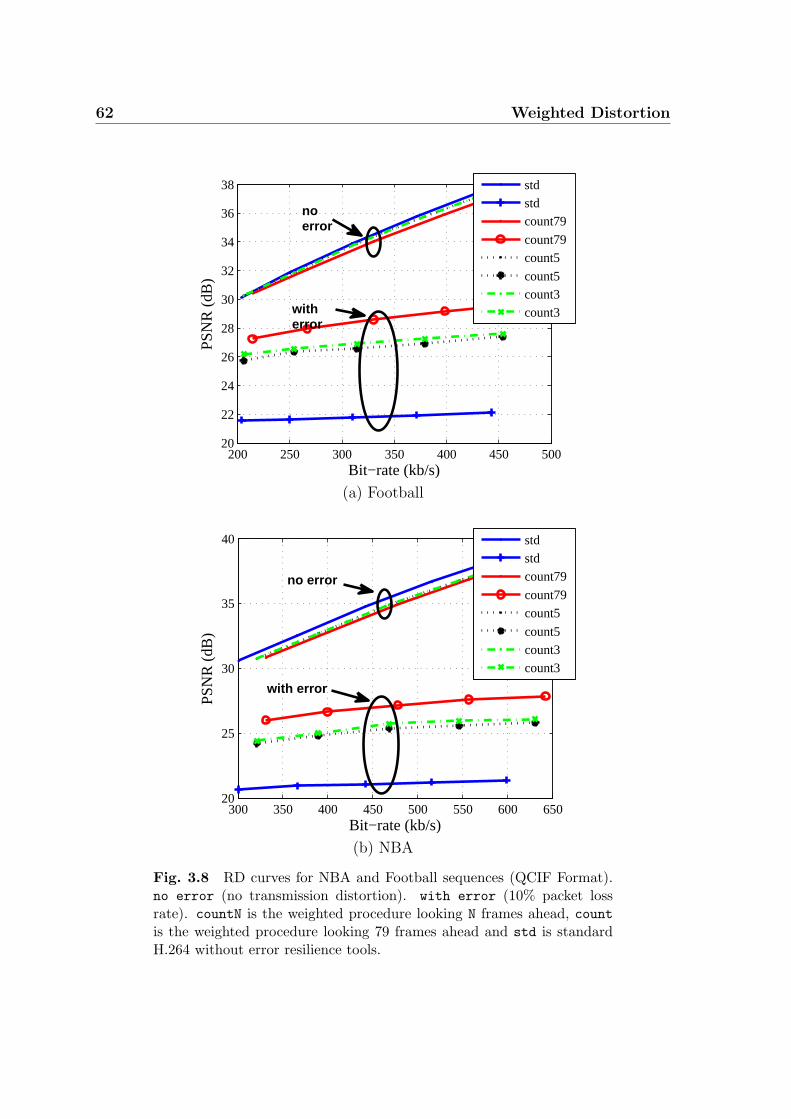
62 Weighted Distortion
200 250 300 350 400 450 50020
22
24
26
28
30
32
34
36
38
Bit−rate (kb/s)
PS
NR
(dB
)
stdstdcount79
count79count5
count5count3count3with
error
noerror
(a) Football
300 350 400 450 500 550 600 65020
25
30
35
40
Bit−rate (kb/s)
PS
NR
(dB
)
stdstdcount79
count79count5
count5count3count3
with error
no error
(b) NBA
Fig. 3.8 RD curves for NBA and Football sequences (QCIF Format).no error (no transmission distortion). with error (10% packet lossrate). countN is the weighted procedure looking N frames ahead, countis the weighted procedure looking 79 frames ahead and std is standardH.264 without error resilience tools.
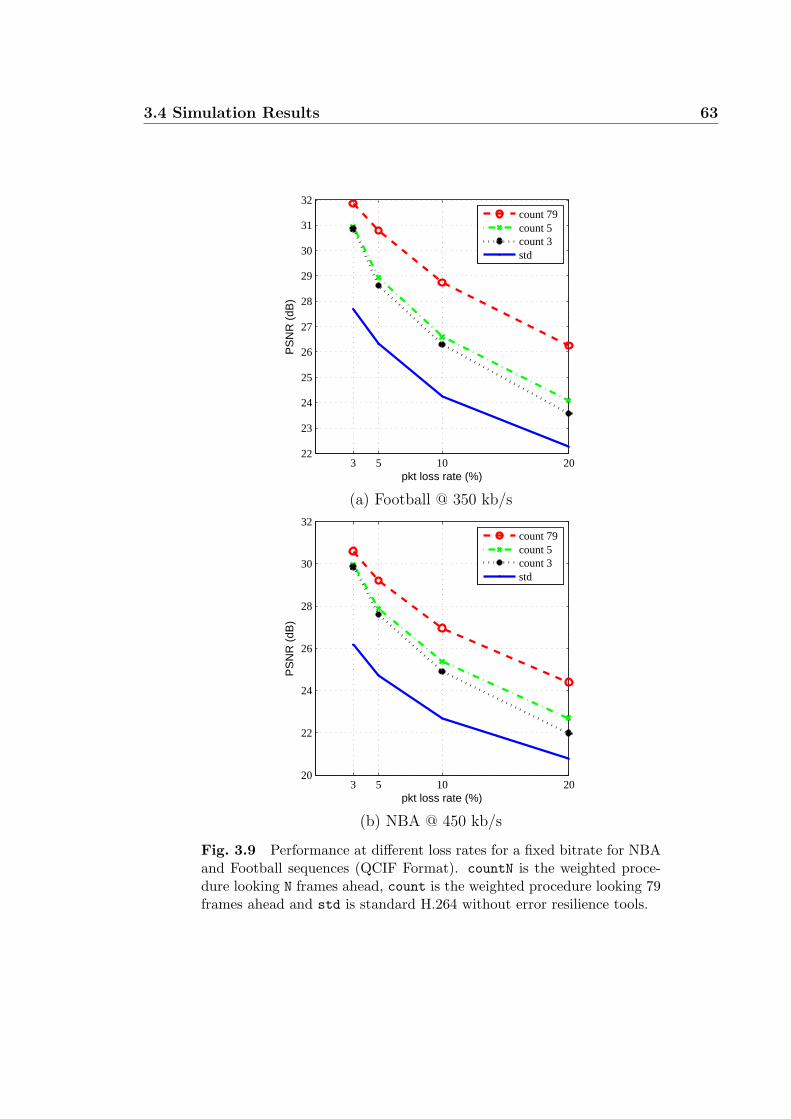
3.4 Simulation Results 63
3 5 10 2022
23
24
25
26
27
28
29
30
31
32
pkt loss rate (%)
PS
NR
(dB
)
count 79count 5count 3std
(a) Football @ 350 kb/s
3 5 10 2020
22
24
26
28
30
32
pkt loss rate (%)
PS
NR
(dB
)
count 79count 5count 3std
(b) NBA @ 450 kb/s
Fig. 3.9 Performance at different loss rates for a fixed bitrate for NBAand Football sequences (QCIF Format). countN is the weighted proce-dure looking N frames ahead, count is the weighted procedure looking 79frames ahead and std is standard H.264 without error resilience tools.

64 Weighted Distortion
shown in Fig. 3.8, Fig. 3.9 and Fig. 3.10.
3.4.3 Weighted Mode Decision and Motion Estimation
In Sections 3.4.1 and 3.4.2 we witnessed the benefits afforded by carefully selecting
motion vectors in an error prone environment. Now we combine Equations (3.1)
and (3.2) to elucidate the benefit of weighting the distortions used in both motion
estimation and mode decision. Some comparisons between ROPE and K-decoders
[30, 53] suggest little or no difference in the resultant error resilience performance of
these methods at fixed bitrates. Therefore, in order to compare our proposed method
with current error resilient strategies, the K-decoders method (with K = 30) will
give us a fair comparison. Additional simulations in Chapter 4 are conducted with
K = 100.
In our simulations, we use (3.4) in (3.2) on INTRA modes only in order to penalize
MBs that have a long prediction trail. Applying wmd in (3.2) reduces the distortion
value used in RD mode decisions for INTRA MBs thereby favouring their selection,
while still paying attention to the bitrate implications.
The threshold value T , described in Section 3.2.3, permits the designer to im-
prove the error resilience performance of our weighted procedure while maintaining
a modest increase in bitrate as our results will show. For illustrative purposes, we
show results for T = 1.0, T = 0.5 and T = 0.3. These decreasing values of T mean
that the INTRA mode distortion values are reducing, resulting in an increase in error
resilience performance. We avoid negative values of wmd, because they would put
unfair emphasis on bitrate alone in determining coding options.
Unlike the results presented in Section 3.4.1, where we relied on Random Intra up-
dating to provide the INTRA MBs, here INTRA mode selection is heavily influenced
by an MB’s future impact.
Figures 3.11 and 3.12 display the rate-distortion curves resulting from the combi-
nation of Weighted Mode Decision and Motion Estimation. We show the result for
both a QCIF and CIF video sequence in Fig. 3.11 and Fig. 3.12 respectively. It is
useful to show the result for both QCIF and CIF sequences to prove that our tracking
idea scales well at different resolutions. The demand for Hi-Definition video continues
to increase and it is important to have error resilient strategies that are applicable in

3.4 Simulation Results 65
(a) standard H.264 (b) count N=3
(c) count N=5 (d) count N=79
Fig. 3.10 Subjective results for Football frame 28 with 20% packet lossrate.
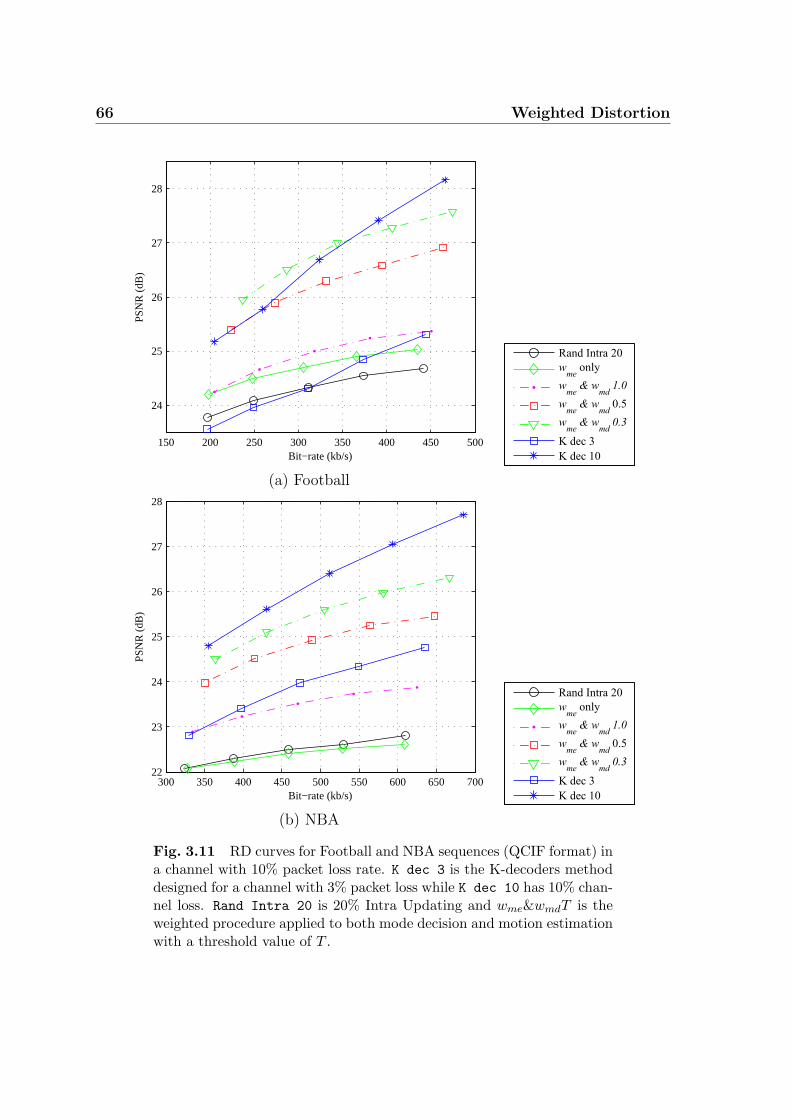
66 Weighted Distortion
150 200 250 300 350 400 450 500
24
25
26
27
28
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 20
wme
only
wme
& wmd
1.0
wme
& wmd
0.5
wme
& wmd
0.3
K dec 3
K dec 10
(a) Football
300 350 400 450 500 550 600 650 70022
23
24
25
26
27
28
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 20
wme
only
wme
& wmd
1.0
wme
& wmd
0.5
wme
& wmd
0.3
K dec 3
K dec 10
(b) NBA
Fig. 3.11 RD curves for Football and NBA sequences (QCIF format) ina channel with 10% packet loss rate. K dec 3 is the K-decoders methoddesigned for a channel with 3% packet loss while K dec 10 has 10% chan-nel loss. Rand Intra 20 is 20% Intra Updating and wme&wmdT is theweighted procedure applied to both mode decision and motion estimationwith a threshold value of T .
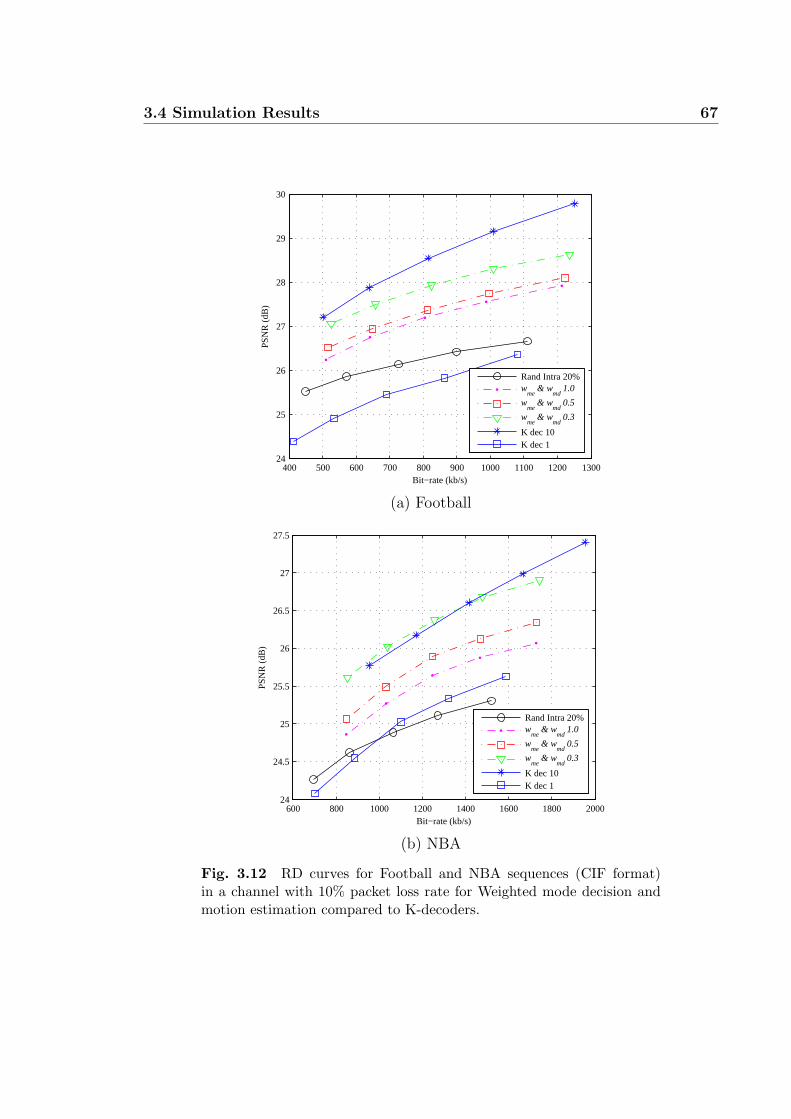
3.4 Simulation Results 67
400 500 600 700 800 900 1000 1100 1200 130024
25
26
27
28
29
30
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 20%w
me & w
md 1.0
wme
& wmd
0.5
wme
& wmd
0.3
K dec 10K dec 1
(a) Football
600 800 1000 1200 1400 1600 1800 200024
24.5
25
25.5
26
26.5
27
27.5
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 20%w
me & w
md 1.0
wme
& wmd
0.5
wme
& wmd
0.3
K dec 10K dec 1
(b) NBA
Fig. 3.12 RD curves for Football and NBA sequences (CIF format)in a channel with 10% packet loss rate for Weighted mode decision andmotion estimation compared to K-decoders.
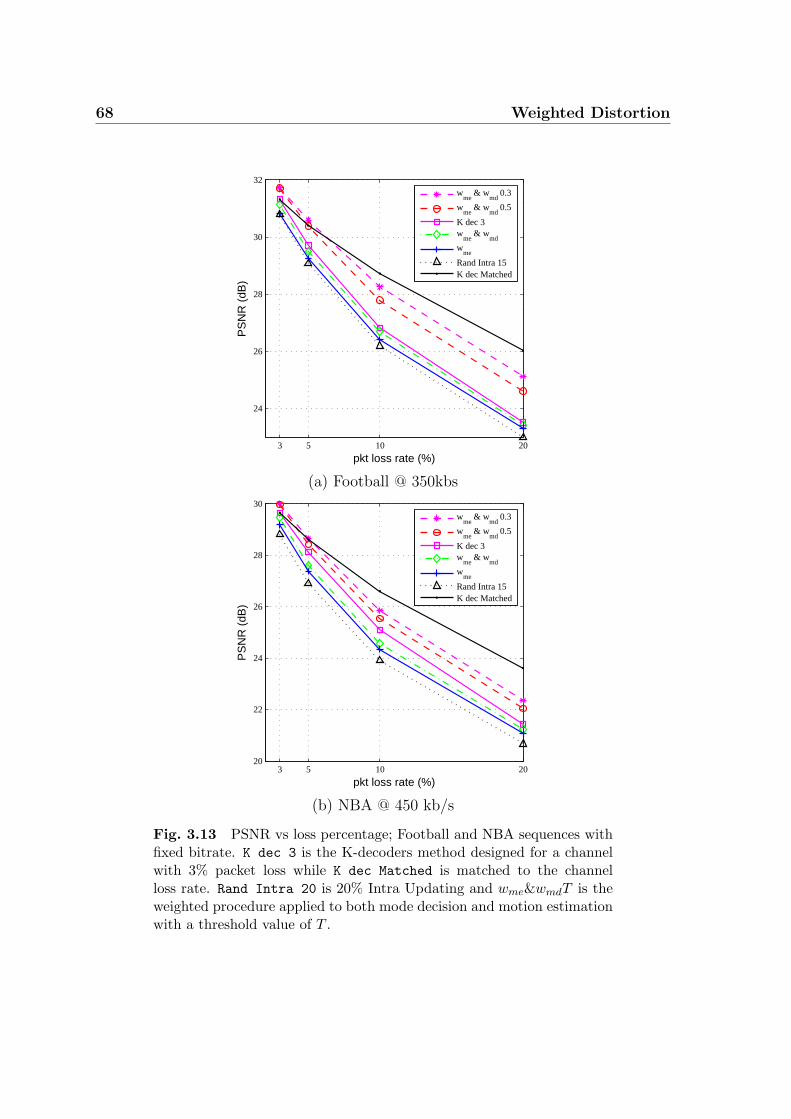
68 Weighted Distortion
3 5 10 20
24
26
28
30
32
pkt loss rate (%)
PS
NR
(dB
)
w
me & w
md 0.3
wme
& wmd
0.5
K dec 3w
me & w
md
wme
Rand Intra 15K dec Matched
(a) Football @ 350kbs
3 5 10 2020
22
24
26
28
30
pkt loss rate (%)
PS
NR
(dB
)
w
me & w
md 0.3
wme
& wmd
0.5
K dec 3w
me & w
md
wme
Rand Intra 15K dec Matched
(b) NBA @ 450 kb/s
Fig. 3.13 PSNR vs loss percentage; Football and NBA sequences withfixed bitrate. K dec 3 is the K-decoders method designed for a channelwith 3% packet loss while K dec Matched is matched to the channelloss rate. Rand Intra 20 is 20% Intra Updating and wme&wmdT is theweighted procedure applied to both mode decision and motion estimationwith a threshold value of T .

3.4 Simulation Results 69
a myriad of situations.
It is clear from Fig. 3.11 that our proposed method outperforms 20% Random
Intra Updating by up to 3.5 dB with a threshold of T = 0.3. Our method also
performs better than K-decoders which is not matched to the channel loss rate. The
addition of wmd improves on the use of wme alone because it results in INTRA MBs
for those regions that are referenced often. As mentioned earlier, obtaining accurate
estimates of channel loss rates is difficult in practice, therefore mismatch between
actual and estimated channel performance is of practical concern. Figures 3.11 and
3.12 also show that our methods with different values of T perform better than the
K-decoder method with a channel encoding mismatch.
Table 3.4 ∆ PSNR and ∆ bit-rate incurred by using various RD op-
timization methods when compared to Random Intra 20 in an error free
environment. T is the threshold value in (3.4)
MethodsFootball NBA
∆ PSNR ∆ rate(%) ∆ PSNR ∆ rate(%)
K dec 10 1.42 16.73 2.67 20.53
K dec 3 0.39 4.67 1.20 10.88
wme only 0.19 2.04 0.33 2.75
wme & wmd T=1.0 0.37 3.92 0.46 3.87
wme & wmd T=0.5 0.59 6.16 0.71 5.97
wme & wmd T=0.3 0.86 8.72 1.12 9.11
Though Figures 3.11 and 3.12 show the result in a 10% packet loss channel only,
our method however is able to perform well under different channel conditions. This
is witnessed in Fig. 3.13, which shows the PSNR vs loss rate for a fixed bitrate.
After discussing the improved error resilient performance afforded by employing
our technique, we draw attention to the slight increase in resources required by our
technique in an error free channel. There is a slight increase in bitrate incurred by
using our method in an error free environment. By comparing the RD curves of
the error free case using the Bjøntegard formula [117], we get the results tabulated in
Table 3.4 which shows the bitrate penalty incurred by using an error resilient strategy
compared to Random Intra 20. We see that for Football, K dec 3 requires about 5%

70 Weighted Distortion
increase in bitrate and our method with T=0.5 requires about 6% increase and for
NBA K dec 3 requires a 11% bit-rate increase, our method with T = 0.5 requires a
6%. This table shows us that the penalty incurred by using our methods in an error
free case is better in the case of NBA and comparatively close in the case of Football.
3.4.4 Impact on Prediction Chain
We attributed the effectiveness of our weighted distortion technique to its ability to
remove long prediction chains that cause motion propagation errors to linger in future
frames. Here we demonstrate that this is indeed true by showing the change in count
C values after applying our weighted distortion method.
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
(a) Football standard H.264/AVC
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
(b) Football weighted distortion
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
(c) NBA standard H.264/AVC
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
(d) NBA weighted distortion
Fig. 3.14 Count C values for NBA and Football sequence at frame 10,showing the change in distribution after applying our weighted distortiontechnique.
In Fig. 3.14 we show the Count C value of Frame 10 of the Football and NBA

3.4 Simulation Results 71
QCIF format sequence obtained from the the algorithm in Table 3.1, before and
after applying our weighted distortion technique. Standard H.264/AVC shows a large
variation in count information as seen in Fig. 3.14a and Fig. 3.14c for the Football and
NBA sequence respectively. However, after applying our weighted distortion methods,
the count distribution is overall smaller and more uniform as seen in Fig. 3.14b and
Fig. 3.14d. This means that the prediction strategy our method uses does not have
long prediction chains resulting in the improvements witnessed here.
3.4.5 Weighted Redundant Macroblocks
We have demonstrated the effectiveness of applying our tracking method to the RD
optimization of motion vectors and mode decisions. We now demonstrate that the
tracking algorithm we use here can also improve on some of H.264/AVC’s error re-
silient features, namely redundant macroblock selection. Because our tracking algo-
rithm reveals MB sensitivity, it is fair to assume that the sensitive macroblocks could
benefit from added protection. We therefore show the RD curves in Fig. 3.15 result-
ing from employing the weighted redundancy strategy discussed in Section 3.3. In
Fig. 3.15 Weighted Redun.10 is our method with the 10% of the most sensitive MBs
coded redundantly, Random Redun.10 represents randomly coding 10% of the MBs
redundantly, Rand Intra 10 is 10% Random Intra Updating and std is standard
H.264/AVC.
A somewhat similar RS sensitivity metric based on the variance of motion vec-
tors between neighbouring 4x4 regions also demonstrated performance improvements
compared to randomly selecting MBs to code redundantly [115]. However, the success
of this method is based on advanced error concealment mechanisms being employed
at the decoder. In our method, we rely on previous frame copy error concealment and
from Fig. 3.15 we see that by using our weighting procedure we are able to perform
better than randomly selecting which MBs to encode redundantly. The RD curves
also show an improvement compared to Random Intra updating at the same percent-
age of 10%. In this case the results are shown for Foreman and Football, however,
similar results were witnessed in other sequences.
For the Football sequence gains of about 2.0 dB over Random Redundant coding
were witnessed in Fig. 3.15. The Foreman sequence did not show gains as strong as
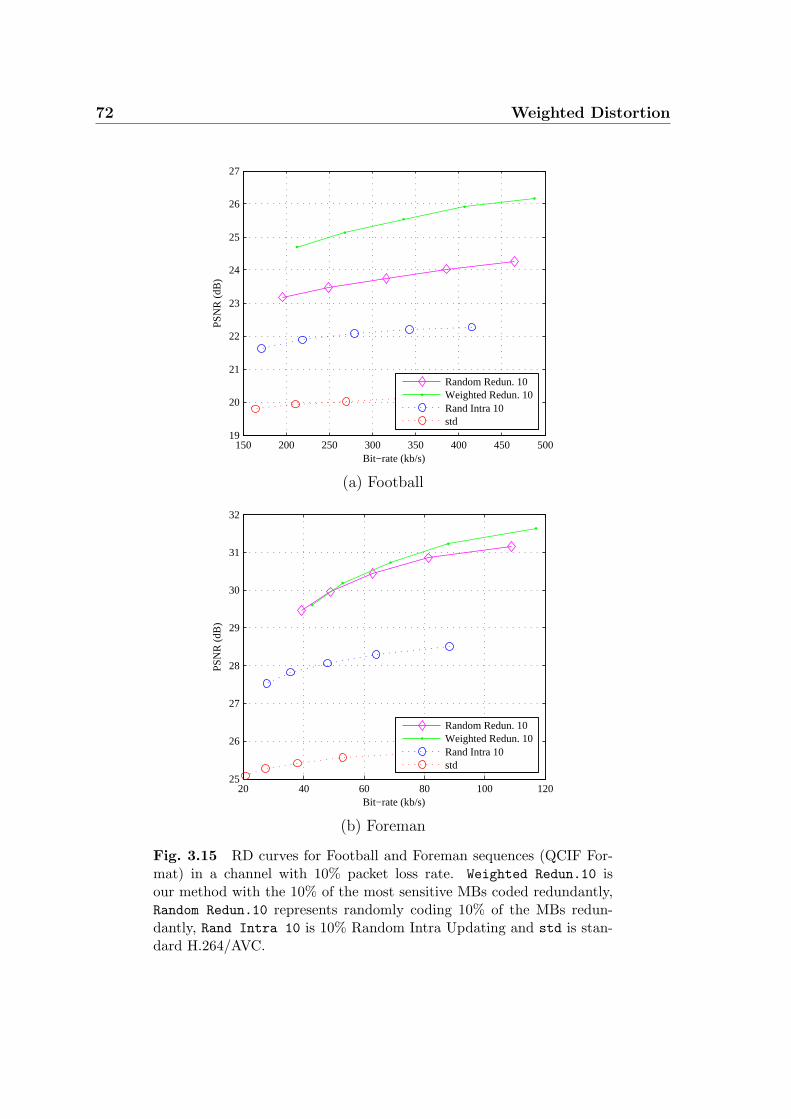
72 Weighted Distortion
150 200 250 300 350 400 450 50019
20
21
22
23
24
25
26
27
Bit−rate (kb/s)
PS
NR
(dB
)
Random Redun. 10Weighted Redun. 10Rand Intra 10std
(a) Football
20 40 60 80 100 12025
26
27
28
29
30
31
32
Bit−rate (kb/s)
PS
NR
(dB
)
Random Redun. 10Weighted Redun. 10Rand Intra 10std
(b) Foreman
Fig. 3.15 RD curves for Football and Foreman sequences (QCIF For-mat) in a channel with 10% packet loss rate. Weighted Redun.10 isour method with the 10% of the most sensitive MBs coded redundantly,Random Redun.10 represents randomly coding 10% of the MBs redun-dantly, Rand Intra 10 is 10% Random Intra Updating and std is stan-dard H.264/AVC.

3.5 Chapter Summary 73
Football, which we attribute to comparatively slower motion content. Note that the
operating range of our method for Foreman is between 30-32 dB, while Football is
between 25-26 dB. This means that Foreman is already operating at a high visual
quality level.
3.5 Chapter Summary
In this chapter, a method for achieving robust video communication by weighting the
distortion values used in Rate Distortion optimized video compression was presented.
Based on the motion trajectory, we were able to identify sections of a video sequence
that have higher potential of propagating errors, and appropriately alter the motion
vectors to avoid long prediction chains. The deeper within a sequence we search
for motion vector dependance, the more accurate our weighting distortion algorithm
performs, albeit at the expense of increased computational time. This allowed us to
develop effective low complexity weighting strategies based on search depth.
We also showed that the combination of motion vector selection and mode decision
making with potential future impact in mind can improve the operation of H.264/AVC
in a packet loss environment. We highlighted a drawback of current error resilient
video coding techniques is that they require channel state information. As such,
we were able to reach a significant result where our methods improve video coding
performance without knowledge of the channel conditions. In fact, we were able to
show that in the presence of erroneous channel loss probabilities, our method can
outperform the popular K-decoders method that is incorporated in the H.264/AVC
reference software.
Not only is the tracking algorithm presented in this chapter useful for RD opti-
mization of video coding decisions, but we showed that it can be used to improve the
performance of error resilient features present in the H.264/AVC video coding stan-
dard. By revealing MB sensitivity, MB tracking resulted in an effective redundant
MB selection procedure.
Reducing the computation time required for the algorithm presented in this chap-
ter can be achieved by finding a weighting factor in single pass rather than the two-
pass method described herein. This will be the topic of discussion for the next chapter.

74

75
Chapter 4
Low-Complexity Weighted
Distortion
The weighted distortion method described in Section 3.2 requires two-pass encoding
and can be computationally intensive, even for the reduced complexity methods we
mentioned that only look a few frames ahead. In order to avoid the second pass,
we attempt to achieve error resilience by using historical information present when
encoding the current frame. Diametrically opposed to the motion tracking method
presented in Chapter 3, we present two techniques that look backwards rather than
forwards, and are able to achieve robust video compression.
4.1 Introduction
We know that motion vectors (MV) are primarily responsible for the spread of error
between and within frames, but would like to reduce the complexity incurred during
the “track then encode” procedure of Chapter 3. We therefore present an alterna-
tive “track while encoding” technique for robust video communication. Even though
“track while encoding” does not achieve error resilience on the same level as “track
then encode”, significant gains are possible with the advantage of reduced complex-
ity. In this Chapter, we introduce a pixel-based and even simpler macroblock-based
tracking algorithm that derives its weighting strategy from backward tracking.
Error tracking based on historical pixel dependency was demonstrated for an IN-
TRA mode selection algorithm that relied on feedback from the channel [46, 118].

76 Low-Complexity Weighted Distortion
The encoder is informed of macroblocks that were received in error via NACK mes-
sages from the channel. While encoding the current frame, the encoder would look
backwards for each pixels historical dependency, to determine whether they referred
to an MB that was received in error. The macroblocks containing numerous con-
taminated pixels would then be INTRA updated. This is different from the feedback
based forward tracking algorithm for INTRA updating used by Girod and Farber [45].
The main advantage of backward dependency tracking of [46, 118] compared to the
forward tracking of [45, 107] is the that the backward tracking is pixel based while
the forward is macroblock based, making the former more accurate. In this Chapter,
we leverage the ability of the backward tracking techniques to make real-time coding
decisions as an advantage compared to forward tracking which requires two-pass en-
coding. This allows for a faster decision making process, and just like in Chapter 3,
channel information is not required to improve error resilience.
The details of a novel pixel-based backward tracking algorithm for generating
weight values is presented in Section 4.2. We will show how this algorithm is ap-
plied to both motion estimation and mode decision to improve their error resilient
performance. In Section 4.3, backward tracking is applied on a macroblock basis to
create a simplified weighting strategy for motion estimation. Experimental results of
the pixel-based backward tracking algorithm and the combination of Random Intra
Updating with the MB-based weighting strategy are presented in Section 4.4 followed
by a summary in Section 4.5.
4.2 Pixel-based Backward Tracking
Predictive coding as applied in video compression relies on information contained in
previously coded frames. Based on the motion trajectory, each MB refers to various
regions in previous frames which have the potential of propagating errors into an
MB. In pixel-based backward tracking we rely on the accuracy offered by pixel-based
processing to devise a weighting strategy for motion estimation. The precision of
a pixel-based tracking method allows the encoder to accurately determine all the
potential error patterns that may affect each pixel. In fact, pixel-based tracking was
used to generate a corrective signal for postprocessing of late asynchronous transfer
mode (ATM) cells in H.261 packet video [119]. In this scheme, late cells arriving in

4.2 Pixel-based Backward Tracking 77
an auxiliary buffer were processed and properly added to the current decoded picture
in order to prevent error propagation effects. This method would however not be
suitable for conversational applications with strict playback requirements.
In our pixel-based backward tracking, we use historical information to determine
the amount of concealment distortion that is likely to propagate into a particular
pixel. We do this by first doing a backward based motion dependency tracking similar
to [46,118]. For each pixel that an MB refers to, we track the concealment distortion
based on the error concealment strategy employed at the decoder. This gives us a
measure of an MB’s sensitivity to being contaminated by erroneous MBs in the past.
In this work, we assume previous frame error concealment, where if an MB is lost
it is replaced by the previous collocated MB. It is possible to adapt the backward
tracking technique presented here to any error concealment technique employed at
the decoder. The encoder needs only to know how the decoder treats erroneous MBs
to adapt its concealment distortion based on the decoder behaviour.
The basic idea is to determine the sensitivity to error that each pixel possesses
and use this information to improve the error resilience performance. An illustration
of the prediction structure showing how we determine pixel sensitivity is shown in
Fig. 4.1 for a QCIF format video sequence with 99 MBs. Pixels J , K and L of MB 49
in Frame n predict from MB 61, 39 and 59 in Frame n− 1 respectively. Because MB
39 is INTRA it will not have any propagated errors, therefore Pixel K will not have
any propagated distortion from MB 39. Pixel J predicts from MB 61, which if lost
will be concealed by MB 61 in Frame n − 2 (dashed line). Tracking pixel J further
we see it predicts from MB 53 which is INTRA, and therefore will not contain any
propagated errors. Pixel L however, has a longer dependency trail, predicting from
MB 59 in frame n − 1, which predicts from MB 66 in frame n − 2 and so on. This
means that pixel L and has a higher possibility of propagating errors. This backward
tracking concealment dependency is performed for all pixels in frame n.
A mathematical designation of the historical pixel dependencies as depicted in
Fig. 4.1 is useful in explaining how the tracking algorithm we use works. Each pixel’s
location (i.e. (x, y) co-ordinates ) in an image can be represented by a vector P. For
INTER MBs each pixel has an associated motion vector, and can be represented by
a vector MVP. The backward motion dependency for pixels in the previous frame
can be represented as
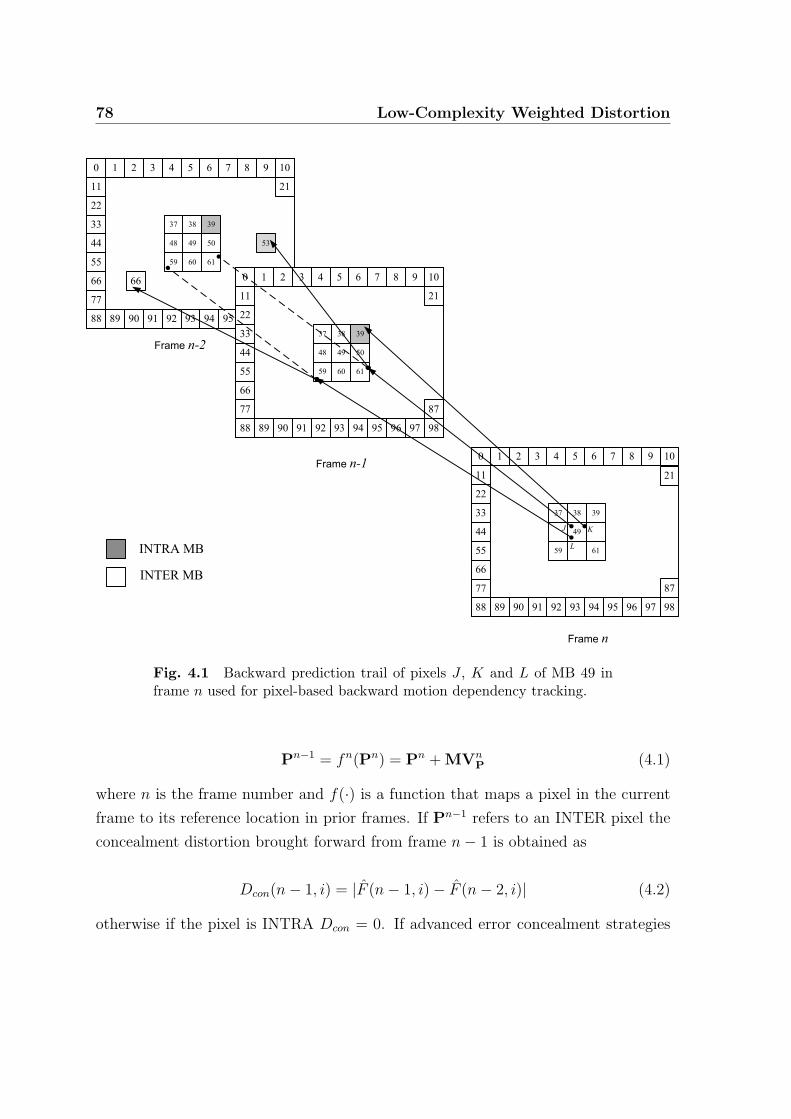
78 Low-Complexity Weighted Distortion
49 50
6160
48
59
38 3937
1 20 4 53 7 86 109
11
22
33
44
55
66
77
88 89 90 92 9391 95 9694 9897
49 50
6160
48
59
38 3937
1 20 4 53 7 86 109
11
22
33
44
55
66
77
88 89 90 92 9391 95 9694 9897
49
6159
38 3937
1 20 4 53 7 86 109
11
22
33
44
55
66
77
88 89 90 92 9391 95 9694 9897
66
53
Frame n-2
Frame n-1
Frame n
INTRA MB
INTER MB
J K
L
87
21
87
21
21
Fig. 4.1 Backward prediction trail of pixels J , K and L of MB 49 inframe n used for pixel-based backward motion dependency tracking.
Pn−1 = fn(Pn) = Pn +MVnP (4.1)
where n is the frame number and f(·) is a function that maps a pixel in the current
frame to its reference location in prior frames. If Pn−1 refers to an INTER pixel the
concealment distortion brought forward from frame n− 1 is obtained as
Dcon(n− 1, i) = |F (n− 1, i)− F (n− 2, i)| (4.2)
otherwise if the pixel is INTRA Dcon = 0. If advanced error concealment strategies

4.2 Pixel-based Backward Tracking 79
are being used, Dcon would change according to the concealment technique used.
Therefore for pixel P in frame M , we can determine the motion dependency in
the Lth preceding frame recursively according to
PM−L = fM−L+1fM−L+2 · · · fM(PM). (4.3)
This allows us accumulate Dcon along the backward motion propagation path
to determine the possibility that a particular pixel is susceptible to contamination.
While accumulating Dcon we found that it was important to introduce some leakage
into the distortion accumulation. This is to prevent too much emphasis being placed
on pixels that are far away. The accumulated distortion is derived from Dcon of (4.2)
according to
Daccum(n, i) =M∑k=1
1
kDcon(n− k, i) (4.4)
In spite of the fact that this algorithm requires tracing the motion dependency
for each pixel, it actually exhibits very low complexity because only simple additions
and shifts are needed. As for storage, Daccum the size of one frame is required for
the current frame being coded only. Complexity comparisons of the various methods
presented in this dissertation are made in section 4.3.3.
4.2.1 Motion Estimation and Mode Decision
The backward tracking procedure gives us a measure of the concealment distortion
for a given backward motion trajectory. This allows us to steer the prediction engine
towards pixels that are less likely to contain a high value of propagated distortion.
This is different to the method presented in Section 3.2, where we directed the pre-
diction engine away from MBs that propagate errors into future frames. We therefore
apply
Jme = [DSAD +∑i∈MB
Daccum(n, i)] + λme ·R (4.5)
to the motion estimation lagrangian cost functional of (3.1).
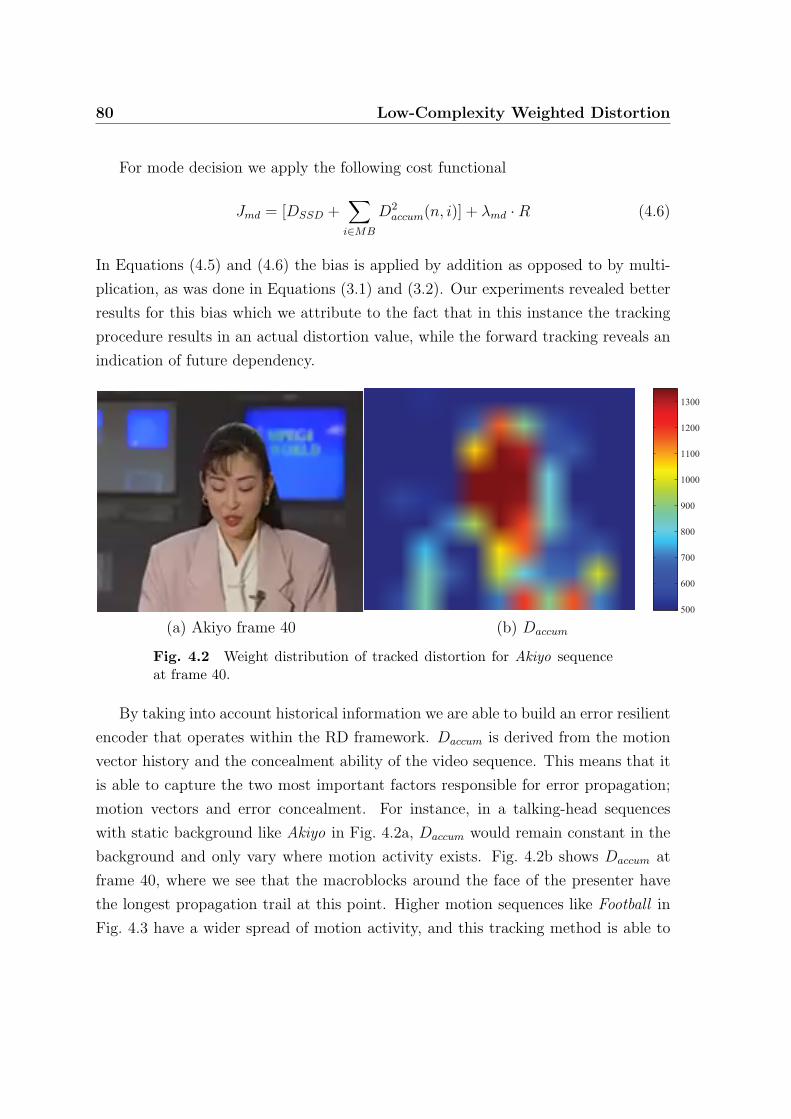
80 Low-Complexity Weighted Distortion
For mode decision we apply the following cost functional
Jmd = [DSSD +∑i∈MB
D2accum(n, i)] + λmd ·R (4.6)
In Equations (4.5) and (4.6) the bias is applied by addition as opposed to by multi-
plication, as was done in Equations (3.1) and (3.2). Our experiments revealed better
results for this bias which we attribute to the fact that in this instance the tracking
procedure results in an actual distortion value, while the forward tracking reveals an
indication of future dependency.
(a) Akiyo frame 40500
600
700
800
900
1000
1100
1200
1300
(b) Daccum
Fig. 4.2 Weight distribution of tracked distortion for Akiyo sequenceat frame 40.
By taking into account historical information we are able to build an error resilient
encoder that operates within the RD framework. Daccum is derived from the motion
vector history and the concealment ability of the video sequence. This means that it
is able to capture the two most important factors responsible for error propagation;
motion vectors and error concealment. For instance, in a talking-head sequences
with static background like Akiyo in Fig. 4.2a, Daccum would remain constant in the
background and only vary where motion activity exists. Fig. 4.2b shows Daccum at
frame 40, where we see that the macroblocks around the face of the presenter have
the longest propagation trail at this point. Higher motion sequences like Football in
Fig. 4.3 have a wider spread of motion activity, and this tracking method is able to

4.3 Macroblock-based Backward Tracking 81
effectively isolate the motion details. Around frame 40 of the Football sequence, the
bottom two rows and rightmost two rows are relatively static compared to the rest
of the image. Pixel-based tracking is once again able to capture this information as
seen in Fig. 4.3b.
(a) Football frame 40
2500
3000
3500
4000
4500
5000
5500
6000
6500
7000
(b) Daccum
Fig. 4.3 Weight distribution of tracked distortion for Football sequenceat frame 40.
The distortion biasing strategies of (4.5) and (4.6) would be able to isolate the
potential problem areas and adjust the cost function for better error resilience. This
is verified in Section 4.4 which presents some simulation results.
4.3 Macroblock-based Backward Tracking
The macroblock-based tracking we introduce in this section seeks to find a weighting
strategy based on historical macroblock dependencies. The basic idea introduced
here has its roots in the NEWPRED scheme which uses feedback information to
stop error propagation [96, 120]. NEWPRED uses feedback information about lost
or correctly received packets to restrict the prediction to those image areas that have
been successfully decoded. NEWPRED was developed as an addition to the H.261
standard, but the presence of multiple reference frames as an error resilient feature of
the H.264/AVC standard (as discussed in Section 2.1) makes it possible to incorporate
NEWPRED in a standard compatible way through feedback based Reference Picture

82 Low-Complexity Weighted Distortion
Selection (RPS) [94]. NEWPRED and similar techniques are frame based strategies
and also rely on feedback information. In macroblock-based backward tracking we
want to find “safe” areas of prediction at the macroblock level.
Motivated by the idea of limiting prediction areas, we make further simplification
to the pixel-based backward tracking algorithm described in Section 4.2. The weight-
ing strategy we develop in this section is based on the distance from the last Intra
refresh. We intend to simplify how we generate the weight, wme in (3.1) by recognizing
that Intra MBs do not rely on previously coded MBs, and therefore do not propagate
any errors. For that reason, we assume that it is safer to predict from Intra MBs as
opposed to Inter MBs, which have the possibility of containing propagated errors. We
therefore propose a weighting mechanism that is based on this fact, and demonstrate
some significant gains. To motivate our assertion that predicting from Intra MBs is
safer than Inter MBs, we first show the effect of only predicting from Intra regions,
and then describe our Intra-distance Derived weighting (IDW) technique.
4.3.1 Intra Limited Prediction (ILP)
We look at the impact of using only Intra MBs in the previous frame for prediction
in Intra Limited Prediction (ILP). This is achieved by assigning Count values Ci for
each macroblock i in the reference frame according to,
Ci =
{1 if MB is Intra
K if MB is Inter(4.7)
where K ≫ 1. The weight values wme of (3.1) are then determined according to (3.3)
using Ci from (4.7).
This weight assignment favours prediction from Intra MBs in the previous frame.
If the search range for motion estimation does not include any Intra MB pixels,
motion vectors will be selected according to (2.5), thereby maintaining the encoders
coding efficiency. If the candidate region contains an overlap of Inter and Intra MBs
as depicted in Fig. 4.4, The weight assignment strongly favours predicting entirely
from the Intra MB.
As an illustration, we show the search range for motion estimation containing 8
Inter MBs and 1 Intra MB in Fig 4.4. Superimposed are two candidate prediction

4.3 Macroblock-based Backward Tracking 83
regions; A and B. It is quite possible that A represents the best choice in terms
of coding efficiency, however, we would prefer to predict purely from the Intra if we
wanted the most error resilient reference region. ILP weighting strategy tends to
predict entirely from the Intra MB.
Fig. 4.4 Motion estimation search range of 9 MBs including 1 INTRAMB with 2 potential candidate reference regions; A and B.
Predicting from Intra MBs rather than Inter MBs present in the search range
helps in limiting error propagation, thereby allowing the decoder to recover faster
from errors during transmission. We demonstrate the reduced recovery time of the
ILP scheme by plotting the PSNR vs frame number of a sequence encoded with the
H.264/AVC JM reference software [76]. Fig. 4.5 shows 4 different encoding schemes;
1. All frames coded as Intra (all INTRA)
2. 15% Random Intra Refresh (Rand IR 15)
3. Intra Limited Prediction (ILP)
4. Default H.264/AVC JM reference software [76] without ER tools (default JM)
It is clear from Fig 4.5 that ILP improves the time it takes to recover from errors
compared to Random IR. We also again see the need for error resilient encoding as
default H.264 suffers greatly in an error prone environment. All Intra represents the
best error resilience performance we can hope for, and the ILP method approaches
this performance. Faster recovery from errors improves the overall subjective quality
as the visual impact of errors dissipates quickly. It is worth noting that the Football

84 Low-Complexity Weighted Distortion
0 10 20 30 40 50 60 70 8024
26
28
30
32
34
36
Frame
PSN
R (
dB)
ILP
Rand IR 15
all INTRA
default JM
Fig. 4.5 PSNR vs frame for Football with losses in frame 7, 33 and 56using 4 different encoding schemes.
sequence in Fig. 4.5 was encoded using a QP of 28 and resulted in bitrates of 267
Kb/s for default JM, 291 Kb/s for Rand IR 15, 314 Kb/s for ILP and 453 Kb/s
for All Intra. We see that the All Intra has a much higher bitrate than the default
encoding, and that Rand IR 15 and ILP result in a slight increase in bitrate compared
to default encoding.
4.3.2 Intra-distance Derived Weighting (IDW)
Using the count assignment of (4.7) improves the error resilience performance only
when Intra MBs are present within the motion estimation search range. In this
implementation we use 10% Random Intra Refreshing (IR) to ensure that Intra MBs
are present in the search range. Error resilience is achieved by selecting a candidate
prediction region that is more robust.
When an overlapping situation occurs in the search range as depicted in Fig. 4.4,
the best trade off between efficiency and resilience may be achieved by selecting
B instead of the Intra block as would be the case in ILP. Intra-distance Derived
Weighting presented in this section tries to find a weighting strategy that will result
in B being selected.
If all MBs in the search range are Inter, then it would be fitting to choose the MB

4.3 Macroblock-based Backward Tracking 85
with the least amount of propagated distortion. Intuitively an Inter MB predicted
from an Intra MB would have no propagation distortion, provided the Intra MB
was received correctly. Thus Inter MBs which have a long trail of prediction from
other Inter MBs have a higher possibility of containing propagated distortion. This
was also true for the pixel-based backward tracking algorithm of Section 4.2 where
Daccum increased as the pixels prediction trail grew longer. Based on this observation,
we propose a more elegant count assignment that allows for reduced bitrate, while
maintaining excellent error resilience performance. The idea is to gradually increase
the count as the temporal distance from the last Intra refresh increases. We refer to
this scheme as IDW-N where N refers to the incremental step, and the count values
are assigned as follows,
Ci =
1 if MB is Intra
N if MB was refreshed 1 frame prior
2N if MB was refreshed 2 frames prior...
mN if MB was refreshed m frames prior
(4.8)
IDW-1 represents a count increment of 1 for each frame that an MB is not refreshed.
This means that MBs that have not been refreshed recently get a higher count than
newly refreshed MBs, leading to a motion vector assignment that favours areas with
a reduced chance of propagating errors. This method also works with fractional-pel
accuracy, as the count values do not depend directly on the motion trajectory, but
on the distance from the last Intra MB. The Random IR method implemented in
the H.264/AVC JM reference software [76] ensures that each MB is refreshed after
a certain period, depending on the refresh rate and frame size. This means that
the distance form the last Intra is not allowed to grow arbitrarily large, preventing
certain areas from being used for prediction. Because Random IR is being used to
insert Intra MBs, there is no need to perform a simplified weighted mode decision.
Placing the Ci values from (4.8) into (3.3) leads to a weight value wme that favors
predicting from recently updated macroblocks. Motion vectors are selected according
to (3.1), as was done in Chapter 3.

86 Low-Complexity Weighted Distortion
4.3.3 Complexity Analysis
Both the macroblock-based and pixel-based methods introduced in this chapter have
reduced complexity compared to the forward tracking methods of Chapter 3. This
is mainly due to the single pass strategy afforded by looking backwards rather than
forward at the motion trajectory. There is also an additional storage requirement for
these methods.
The K-decoders method of Section 2.3.1 involves reconstructing pixel values for
inter-modes which would require 1 ADD and calculation the E2E distortion would
require 1 ADD and 1 MUL. Intra modes do not need pixel reconstruction therefore
only require 1 ADD and 1 MUL [87]. Given that H.264 has 7 inter-modes and 13
intra-modes, this means that the K-decoders method would need 27K ADDS and
20K MULs. Storage for all the K simulated decoders are also required.
The forward tracking method of Chapter 3 would require 1 ADD in the first pass
to accumulate the Count value, 2 MULs to generate the weight value in (3.3). The
second pass requires 1 MUL for all the motion vectors within the search range, S,
and 1 MUL for all the modes in (3.2). This means a total of 1 ADD and 20+S MULs
are required for the forward tracking methods. Storage for the Count values of every
MB is also required, along with more time to perform the tracking.
In this chapter we presented two methods that have reduced complexity primarily
because they do not require the two passes necessary in Chapter 3. Since the same
equations (3.1) and (3.2) are used, the computation complexity remains similar. As
for storage, the pixel based method requires one floating point number per pixel of
storage and IDW requires 1 unsigned int per MB. Table 4.1 displays the algorithmic
complexity of the various methods on a pixel level, the storage requirements and the
encoding times for 80 frames of a CIF sequence.
The encoding times for the various methods in Table 4.1 clearly show that the
computation time is almost halved by using backward as opposed to forward tracking.
These timings were obtained from an Intel i5 2.8Ghz PC running a 32 bit version of
a modified JM reference software [76]. It is important to note that speed tuning was
not performed on the implemented algorithms and further performance improvements
can be made by implementing the tracking algorithm in assembler. The goal of the
dissertation was to demonstrate the benefit of weighted distortion and not speed
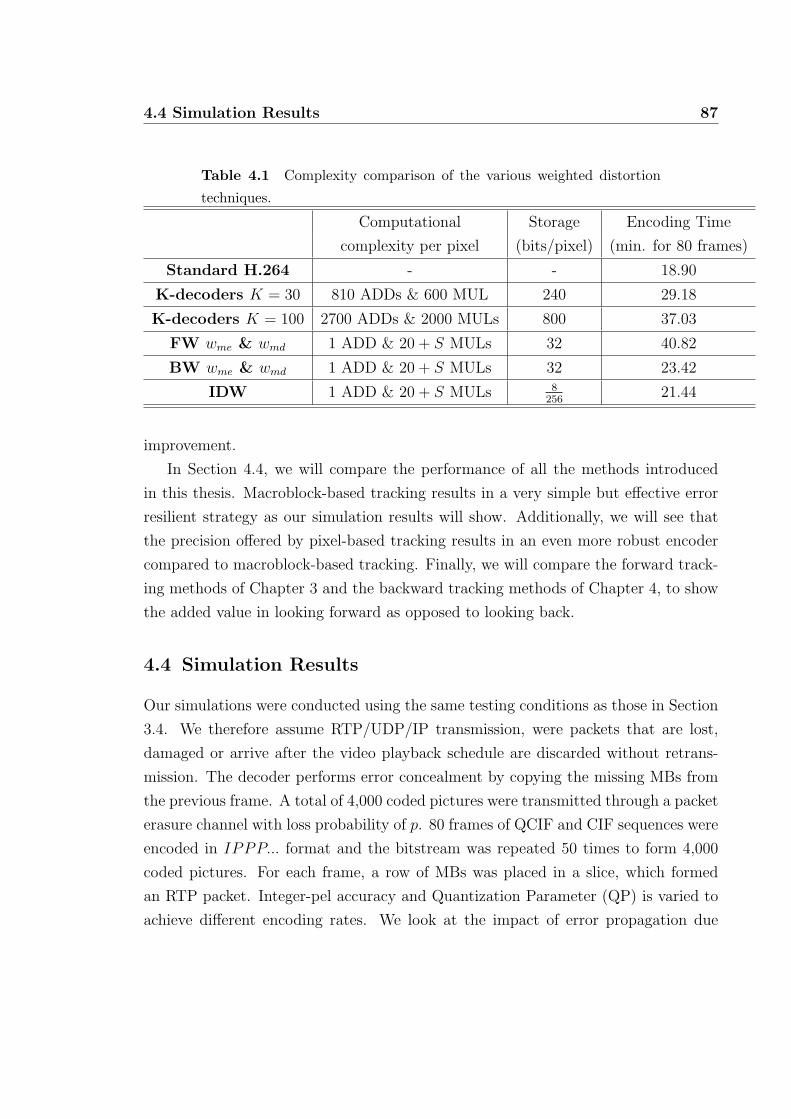
4.4 Simulation Results 87
Table 4.1 Complexity comparison of the various weighted distortion
techniques.
Computational Storage Encoding Time
complexity per pixel (bits/pixel) (min. for 80 frames)
Standard H.264 - - 18.90
K-decoders K = 30 810 ADDs & 600 MUL 240 29.18
K-decoders K = 100 2700 ADDs & 2000 MULs 800 37.03
FW wme & wmd 1 ADD & 20 + S MULs 32 40.82
BW wme & wmd 1 ADD & 20 + S MULs 32 23.42
IDW 1 ADD & 20 + S MULs 8256
21.44
improvement.
In Section 4.4, we will compare the performance of all the methods introduced
in this thesis. Macroblock-based tracking results in a very simple but effective error
resilient strategy as our simulation results will show. Additionally, we will see that
the precision offered by pixel-based tracking results in an even more robust encoder
compared to macroblock-based tracking. Finally, we will compare the forward track-
ing methods of Chapter 3 and the backward tracking methods of Chapter 4, to show
the added value in looking forward as opposed to looking back.
4.4 Simulation Results
Our simulations were conducted using the same testing conditions as those in Section
3.4. We therefore assume RTP/UDP/IP transmission, were packets that are lost,
damaged or arrive after the video playback schedule are discarded without retrans-
mission. The decoder performs error concealment by copying the missing MBs from
the previous frame. A total of 4,000 coded pictures were transmitted through a packet
erasure channel with loss probability of p. 80 frames of QCIF and CIF sequences were
encoded in IPPP... format and the bitstream was repeated 50 times to form 4,000
coded pictures. For each frame, a row of MBs was placed in a slice, which formed
an RTP packet. Integer-pel accuracy and Quantization Parameter (QP) is varied to
achieve different encoding rates. We look at the impact of error propagation due
88 Low-Complexity Weighted Distortion
to transmission over a packet loss network, by calculating the average PSNR of the
whole sequence.
4.4.1 Macroblock-based Backward Tracking
In Section 4.3 we presented our macroblock-based weighting technique derived from
the Intra refresh distance. Now we will show that our method produces significant
performance gains in a packet loss environment. We demonstrate the effectiveness
of this novel scheme by plotting the RD curves for Football and NBA with errors
(10% packet loss channel) in Figures 4.6 and 4.7 for QCIF and CIF video sequences
respectively. In addition, we show the performance at different channel loss rates for
a fixed bitrate in Fig. 4.8.
Fig. 4.6 shows that our method improves 15% Random IR by up to 1.4 dB with
a weight increment of N = 5. We also see that as the increment value N increases
we get improved performance until N = 5, where the performance is comparable to
ILP. Our method also is able to perform well under different channel conditions as
displayed in Fig 4.8, which shows the PSNR vs loss rate curves for a fixed bitrate.
The rate-distortion curves are shown for both QCIF and CIF resolutions in Figures
4.6 and 4.7 respectively, in order to show that our tracking idea scales well at different
resolutions.
Table 4.2 ∆ PSNR and ∆ bit-rate incurred by using IDW-N when
compared to Random IR 15 in an error free environment for QCIF se-
quences.
MethodsFootball NBA
∆ PSNR ∆ rate(%) ∆ PSNR ∆ rate(%)
IDW-1 0.23 2.60 0.24 2.05
IDW-2 0.29 3.29 0.37 3.16
IDW-5 0.31 3.59 0.41 3.43
ILP 0.34 3.85 0.47 4.00
A discussion of the improved performance will not be complete without discussing
the resource requirements imposed by our method. The reason for comparing our
techniques with 15% Random IR is because the bitrate increase required by our
methods is relatively small as presented in Table 4.2. There is a slight increase
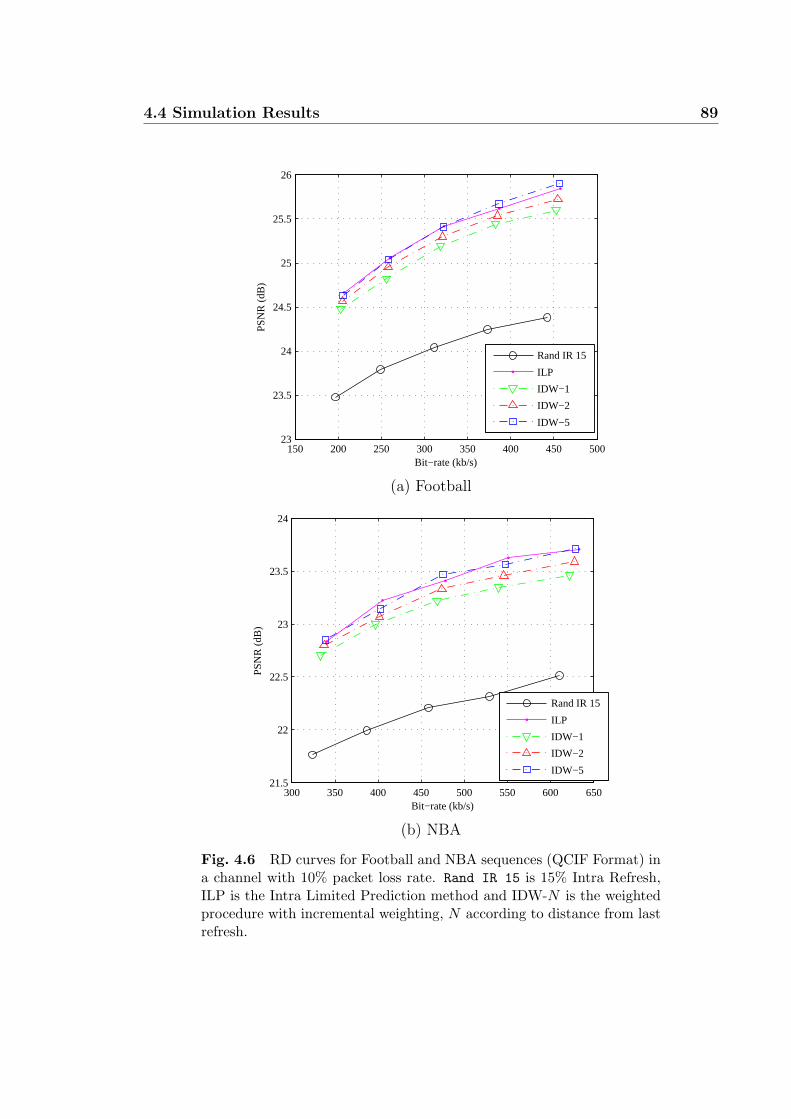
4.4 Simulation Results 89
150 200 250 300 350 400 450 50023
23.5
24
24.5
25
25.5
26
Bit−rate (kb/s)
PS
NR
(dB
)
Rand IR 15
ILP
IDW−1
IDW−2
IDW−5
(a) Football
300 350 400 450 500 550 600 65021.5
22
22.5
23
23.5
24
Bit−rate (kb/s)
PS
NR
(dB
)
Rand IR 15
ILP
IDW−1
IDW−2
IDW−5
(b) NBA
Fig. 4.6 RD curves for Football and NBA sequences (QCIF Format) ina channel with 10% packet loss rate. Rand IR 15 is 15% Intra Refresh,ILP is the Intra Limited Prediction method and IDW-N is the weightedprocedure with incremental weighting, N according to distance from lastrefresh.
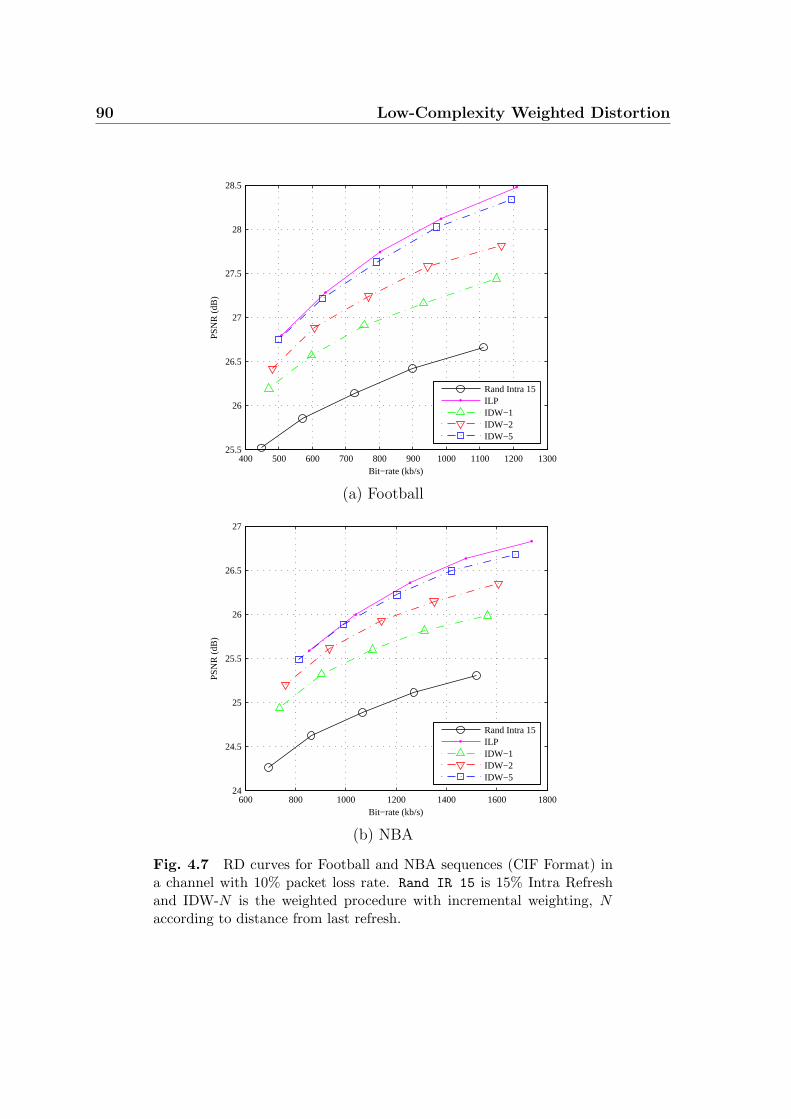
90 Low-Complexity Weighted Distortion
400 500 600 700 800 900 1000 1100 1200 130025.5
26
26.5
27
27.5
28
28.5
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15ILPIDW−1IDW−2IDW−5
(a) Football
600 800 1000 1200 1400 1600 180024
24.5
25
25.5
26
26.5
27
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15ILPIDW−1IDW−2IDW−5
(b) NBA
Fig. 4.7 RD curves for Football and NBA sequences (CIF Format) ina channel with 10% packet loss rate. Rand IR 15 is 15% Intra Refreshand IDW-N is the weighted procedure with incremental weighting, Naccording to distance from last refresh.
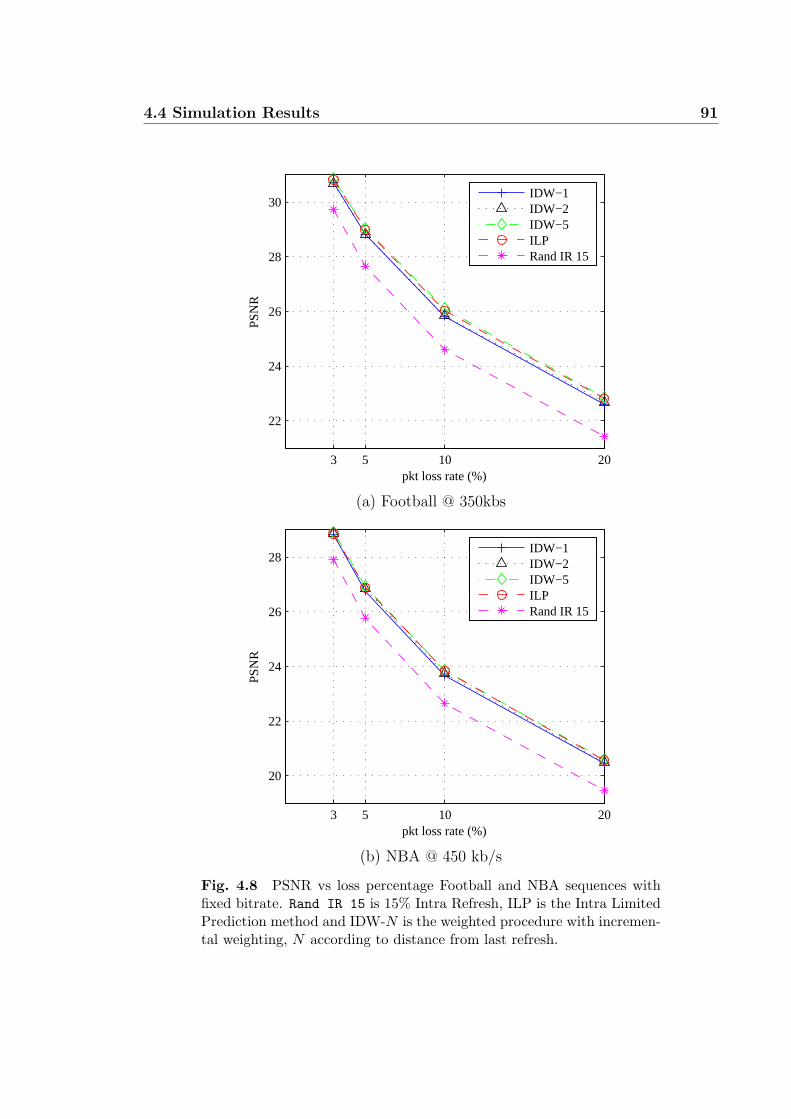
4.4 Simulation Results 91
3 5 10 20
22
24
26
28
30
pkt loss rate (%)
PS
NR
IDW−1IDW−2IDW−5ILPRand IR 15
(a) Football @ 350kbs
3 5 10 20
20
22
24
26
28
pkt loss rate (%)
PS
NR
IDW−1IDW−2IDW−5ILPRand IR 15
(b) NBA @ 450 kb/s
Fig. 4.8 PSNR vs loss percentage Football and NBA sequences withfixed bitrate. Rand IR 15 is 15% Intra Refresh, ILP is the Intra LimitedPrediction method and IDW-N is the weighted procedure with incremen-tal weighting, N according to distance from last refresh.

92 Low-Complexity Weighted Distortion
in bitrate incurred by using IDW-N in an error free environment as tabulated in
Table 4.2. This table compares the RD curves of our methods with that of 15%
Random Intra updating in an error free environment. The values were calculated using
Bjøntegaard’s formula [117]. We note from the Table that ILP has a slightly higher
bitrate than IDW-5, however, the curves of Fig. 4.6 reveal similar RD performance
in a lossy environment. This shows that Intra Distance weighting improves coding
efficiency while maintaining good error resilience performance.
We turn the discussion back to one of our major conclusions, that the forward
techniques of Chapter 3 and the backward techniques of Chapter 4 display improved
performance without explicitly requiring an increase in bitrate. To this end we show
the results for CIF sequences at 30fps. We display a comparison of the IDW technique
with our forward tracking technique presented in Chapter 3 as well as K-decoders,
with and without mismatch, for Football and NBA in Fig. 4.9. While IDW offers sig-
nificant reduction in computation complexity when compared to our forward tracking
weighted distortion techniques of Chapter 3, we see in Fig. 4.9 that the performance
on the RD curve is slightly less than that demonstrated by forward tracking.
In both Football and NBA and numerous other sequences we see that the per-
formance of both our methods is better than K-decoders when there is a mismatch
between the encoder channel estimation and the practical channel realizations. This
is a suitable result especially for situations where practical channel conditions cannot
be determined accurately, for example, broadcast channels where tracking the channel
conditions of each user is a difficult challenge for a central broadcaster.
4.4.2 Pixel-based Backward Tracking
After introducing our pixel-based backward tracking method in Section 4.2, we now
present some simulation results to verify its effectiveness. Pixel-based backward track-
ing performs better than K-decoders when there is a mismatch in the channel estimate
as displayed in Fig. 4.10. There is approximately 1dB decrease in performance on
average compared to the K-decoders method that is matched to the channel loss rate.
We also note from Fig. 4.10 that the motion estimation weight of (4.5) performs
close to the combined motion estimation and mode decision curve, especially at lower
bitrates.
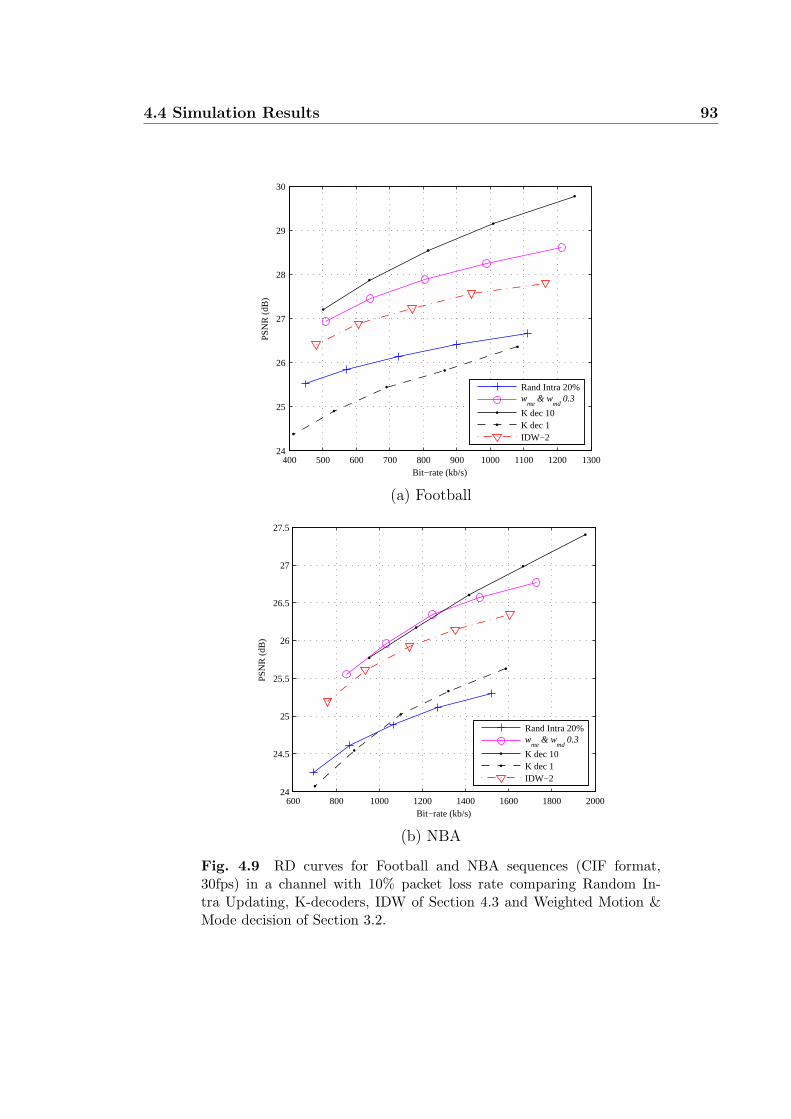
4.4 Simulation Results 93
400 500 600 700 800 900 1000 1100 1200 130024
25
26
27
28
29
30
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 20%w
me & w
md 0.3
K dec 10K dec 1IDW−2
(a) Football
600 800 1000 1200 1400 1600 1800 200024
24.5
25
25.5
26
26.5
27
27.5
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 20%w
me & w
md 0.3
K dec 10K dec 1IDW−2
(b) NBA
Fig. 4.9 RD curves for Football and NBA sequences (CIF format,30fps) in a channel with 10% packet loss rate comparing Random In-tra Updating, K-decoders, IDW of Section 4.3 and Weighted Motion &Mode decision of Section 3.2.

94 Low-Complexity Weighted Distortion
Because of the recursive nature of the backwards tracking algorithm as presented
in Equation (4.3), the only added complexity is in the storage of the pixel based
tracked distortion values, and an addition for computing Daccum for each pixel. The
comparison of backward tracking with forward tracking is made in the next section.
4.4.3 All Methods
Throughout this thesis we have presented 3 different weighting strategies that are
applied to a Rate Distortion (RD) optimization of a video coder. We showed that
each method has different parameters that can be adjusted for added resilience. It is
therefore worth comparing all the methods presented herein under the same test con-
ditions, to fully understand their potential. The plot of Fig. 4.11 shows the forward
tracking method of Section 3.2 (FW wme & wmd), the pixel-based backward tracking
of Section 4.2 (BK wme and BK wme & wmd) and the macroblock-based technique
introduced in Section 4.3 (IDW-5) on the same graph compared to Random Intra
updating (Rand Intra 15) and the K-decoders method (K-dec 10 and K-dec 3).
We learn from Fig. 4.11 that forward tracking offers the best error resilient per-
formance and we attribute this to its ability to prevent error propagation before
it happens. The pixel based backward tracking is better than macroblock-based,
mainly because it more accurately captures historical motion trails due to its pixel
level precision. Once again we see that all the methods presented here offer improved
performance when channel estimates are unreliable.
The objective results described above clearly show the improvement offered by
the weighted distortion paradigm we introduced in this thesis. To gain a better
understanding of what this means on actual video sequences we plot Frame 53 of
the Football sequence in Fig. 4.12 and Fig. 4.13. We compare current error resilient
coding techniques in Fig. 4.12 and the novel methods introduced in this thesis in
Fig. 4.13.
These subjective results clearly demonstrate the importance of our motion trajec-
tory analysis in improving the quality of compressed video over unreliable links. The
visual reproduction quality of all our methods; IDW-5, BK wme & wmd, FW wme and
FW wme & wmd in Fig. 4.13 is better than current methods; 15% Random Intra Up-
dating and K-decoders with (p = 3%) in Fig. 4.12. We also note that for a matched
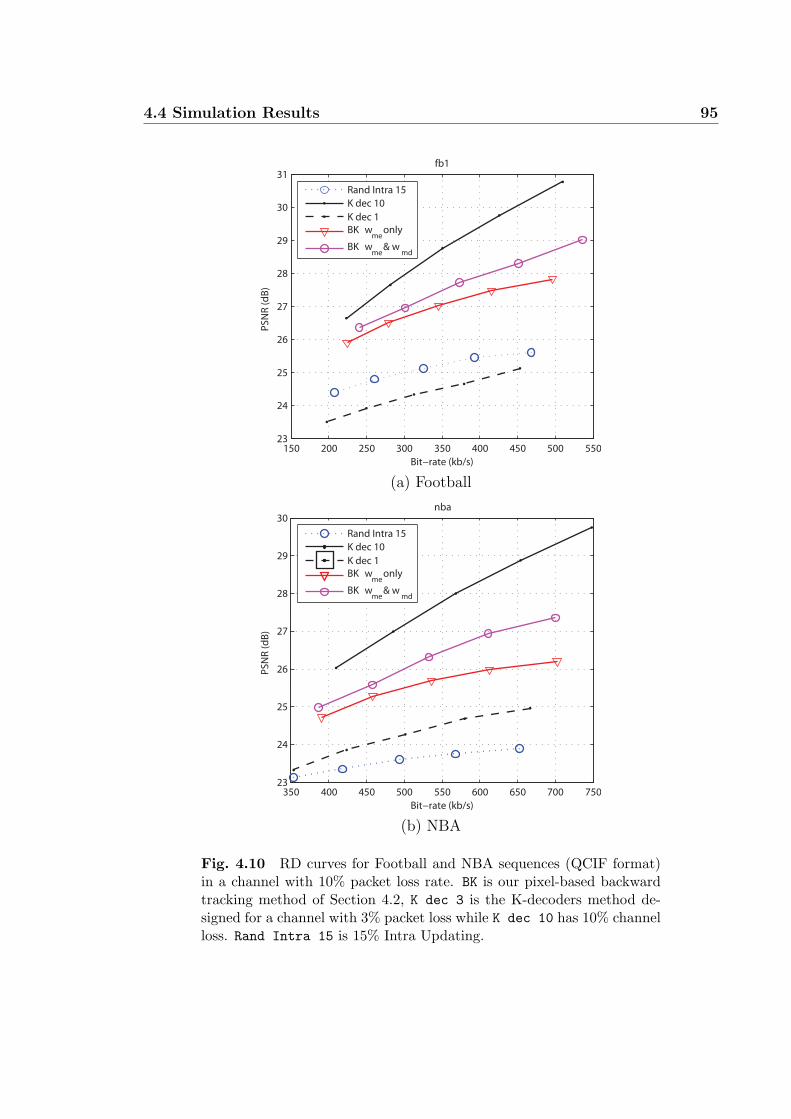
4.4 Simulation Results 95
150 200 250 300 350 400 450 500 55023
24
25
26
27
28
29
30
31fb1
Bit−rate (kb/s)
PSNR (dB)
Rand Intra 15
K dec 10
K dec 1
BK wme only
BK wme
& wmd
(a) Football
350 400 450 500 550 600 650 700 75023
24
25
26
27
28
29
30nba
Bit−rate (kb/s)
PSNR (dB)
Rand Intra 15
K dec 10
K dec 1
BK wme only
BK wme
& wmd
(b) NBA
Fig. 4.10 RD curves for Football and NBA sequences (QCIF format)in a channel with 10% packet loss rate. BK is our pixel-based backwardtracking method of Section 4.2, K dec 3 is the K-decoders method de-signed for a channel with 3% packet loss while K dec 10 has 10% channelloss. Rand Intra 15 is 15% Intra Updating.
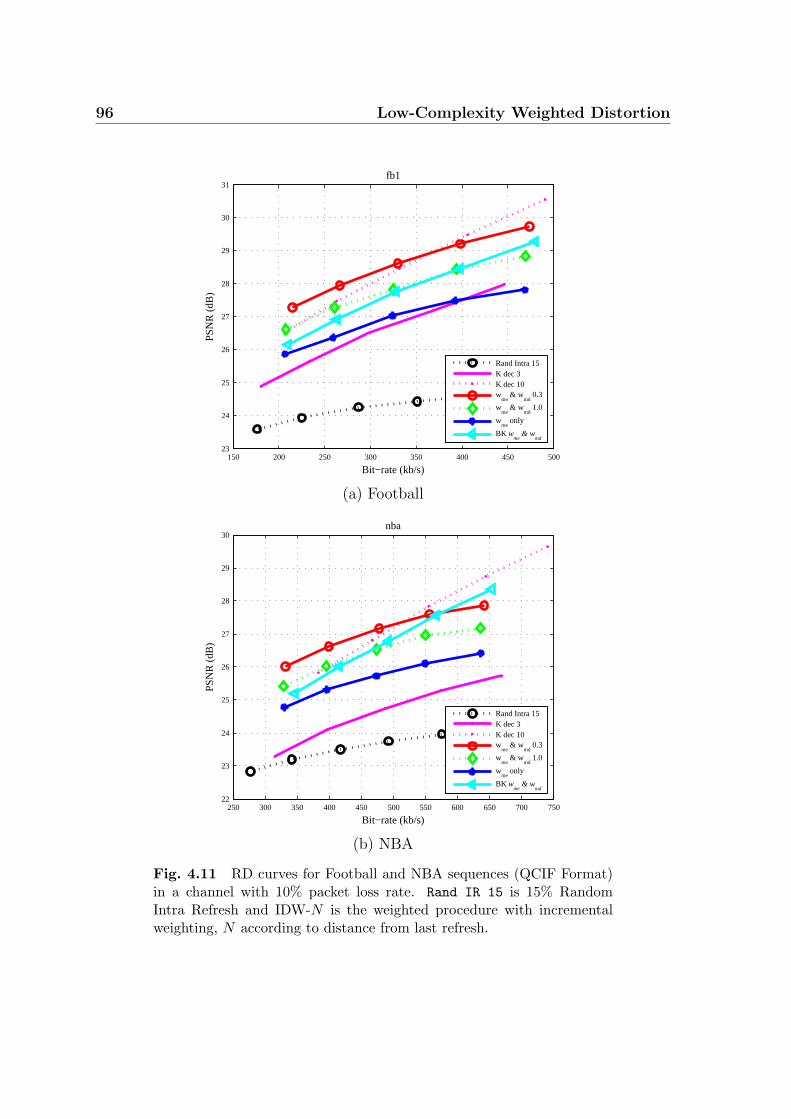
96 Low-Complexity Weighted Distortion
150 200 250 300 350 400 450 50023
24
25
26
27
28
29
30
31fb1
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(a) Football
250 300 350 400 450 500 550 600 650 700 75022
23
24
25
26
27
28
29
30nba
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(b) NBA
Fig. 4.11 RD curves for Football and NBA sequences (QCIF Format)in a channel with 10% packet loss rate. Rand IR 15 is 15% RandomIntra Refresh and IDW-N is the weighted procedure with incrementalweighting, N according to distance from last refresh.

4.4 Simulation Results 97
(a) standard H.264 (b) 15% Random Intra
(c) K-decoders with p = 3 (d) K-decoders with p = 10
Fig. 4.12 Subjective results for Football frame 50 with 10% packet lossrate of current error resilient methods.

98 Low-Complexity Weighted Distortion
(a) IDW (with N = 5) (b) BK wme and wme
(c) FW wme only (d) FW wme and wme
Fig. 4.13 Subjective results for Football frame 50 with 10% packet lossrate of our proposed techniques.

4.4 Simulation Results 99
K-decoder in Fig. 4.12d, compared to our forward tracking method of Section 3.2 (FW
wme & wmd) in Fig. 4.13d the resulting video quality is quite similar. We also note
from Table 3.4 that the matched K-decoder requires a higher bitrate than our method.
This subjective result suggests that our trajectory analysis method can improve the
visual quality while maintaining a low bitrate overhead compared to K-decoders.
4.4.4 Gilbert Channel
As presented in Section 2.4, bursty channels typify the conditions experienced in
wireless environments, which are characterized by extended periods of packet loss.
The Gilbert channel model is useful in simulating bursty behaviour and is investigated
in this section. We use the average packet loss rate p and average burst length Lb to
describe the bursty channel, which is derived from the probability of a packet being
in either a GOOD (PGOOD) or BAD (PBAD) state as described in Section 2.4.1. The
rate-distortion curves for Football and NBA are shown below, with additional results
for Mobile, Stefan, Foreman and News presented in Appendix A.2.
Figure 4.14 shows all the methods discussed in this thesis being passed through
a bursty channel with p = 5 and Lb = 15 and Figure 4.15 has p = 10 and Lb = 10.
Both figures reaffirm the conclusions made in the uniform channel simulations. In
fact for all sequences, with the notable exception of News, our methods perform as
good if not better than a matched K-decoder in a bursty loss channel. This may be
attributed to the fact that the K-decoder method is designed for transmission in a
uniform loss channel.
4.4.5 Talking-head Sequence (News)
The News sequence has lots of SKIP MBs in the background and therefore does
not need Intra updating in the background as there is little change in this region of
the picture. We notice that News does not perform well with our forward tracking
methods. We attribute this to our use of intra updating combined with tracking. We
also see that Random Intra updating does not perform well compared to K-decoders.
Random intra updating and our forward tracking methods increase the bitrate by
placing Intra MBs in background areas where it is not necessary. This means the
resulting bitrate increase does not result in improved error resilience for talking-head

100 Low-Complexity Weighted Distortion
sequences.
Attempting to tweak this behavior, by not counting SKIP as a prediction leads to
performance degradation in other sequences, because errors in SKIPs do propagate.
Our backward tracking performed significantly better compared to forward tracking
for this sequence, as it does not unnecessarily add INTRA updated to the background.
We therefore demonstrate that using motion vector tracking to perform error
resilience in the presence of inaccurate channel information is particularly useful for
sequences with significant movement like Football, NBA, Mobile, Stefan and Foreman.
4.5 Chapter Summary
In this chapter, simplified weight generation techniques were presented that can be
used to perform weighted distortion as presented in Chapter 3. Rather than looking
forward at the motion trajectory as was done in Chapter 3, in this chapter we looked
backwards for motion dependencies. The historical motion trajectory is able to iden-
tify sections of a video sequence that have higher potential of containing propagating
errors, and appropriately alter the motion vectors to avoid these areas.
We presented a precise pixel-based recursive algorithm that tracks the concealment
distortion to determine the amount of distortion being referred to by a pixel. This
allowed us to develop a weighting strategy that avoids pixels with long prediction
chains. Further simplification was made with a macroblock-based technique that
examines the last time an MB was refreshed. This allowed us to classify macroblocks
within the motion estimation search range according to their potential of containing
propagated errors.
Through simulation we established the effectiveness of the above techniques espe-
cially when compared to error robust rate distortion optimized techniques with poor
channel knowledge. A comparison of forward and backward tracking revealed that
forward tracking is generally more effective than backward tracking.

4.5 Chapter Summary 101
150 200 250 300 350 400 450 50024
26
28
30
32
34
36
38fb1
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 1K dec 5w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(a) Football
250 300 350 400 450 500 550 600 650 700 75026
28
30
32
34
36
38nba
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 1K dec 5w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(b) NBA
Fig. 4.14 RD curves for Football and NBA sequences (QCIF Format)in a Gilbert channel with 5% packet loss rate and burst length of 15.
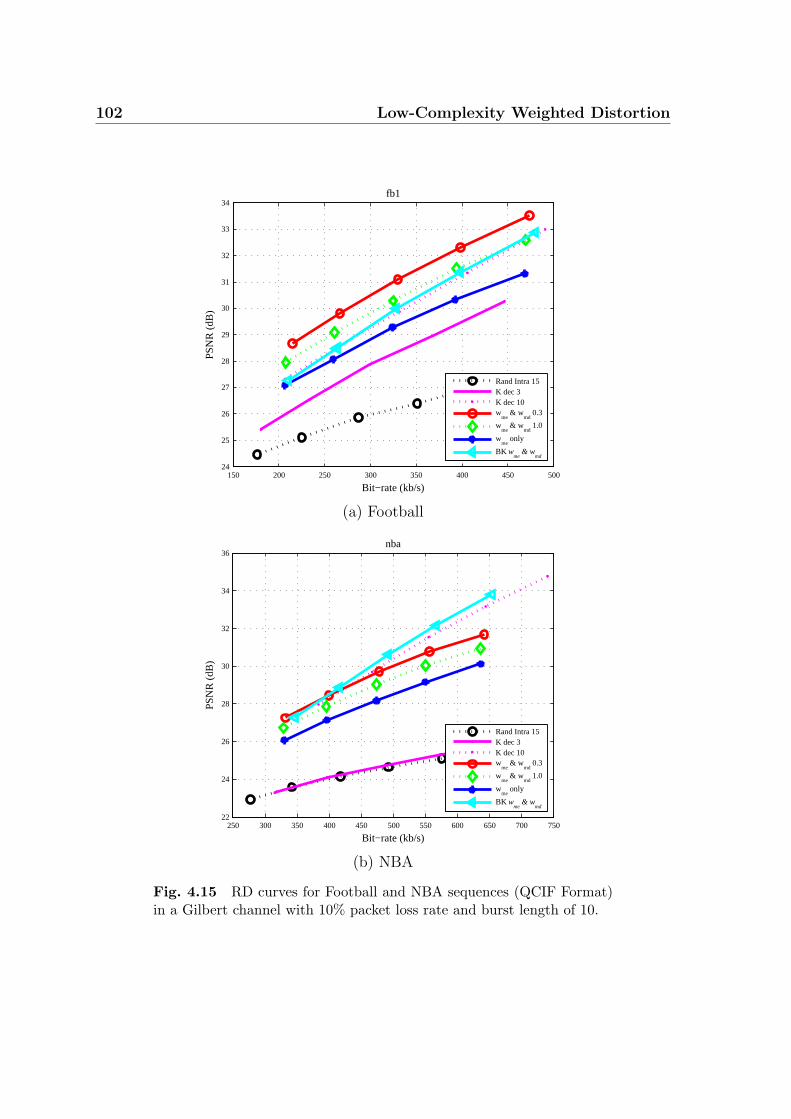
102 Low-Complexity Weighted Distortion
150 200 250 300 350 400 450 50024
25
26
27
28
29
30
31
32
33
34fb1
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(a) Football
250 300 350 400 450 500 550 600 650 700 75022
24
26
28
30
32
34
36nba
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(b) NBA
Fig. 4.15 RD curves for Football and NBA sequences (QCIF Format)in a Gilbert channel with 10% packet loss rate and burst length of 10.

103
Chapter 5
Conclusion
In this thesis, we studied the motion trajectory of motion compensated prediction
(MCP) in order to improve the error resilience performance of video compression.
Most existing error resilient strategies depend on finding an estimate of the end-to-
end distortion, and therefore require knowledge of the prevailing channel conditions.
The novelty in this work is in using the prediction dependencies inherent in MCP
to bias the source distortion values. This resulted in our major achievement, which
is being able to improve MCP for error resilience without explicit knowledge of the
channel conditions.
A number of contributions have been made in the field of error resilient video
coding over lossy networks. We developed the general framework for biasing the
source distortion in rate distortion optimized video compression to allow for error re-
silient video coding. By weighting the distortion values in RD optimization, we were
able to improve performance of H.264/AVC video compression in lossy environments
with only a slight increase in bitrate. This achievement was made through an under-
standing of how error propagates in predictive coding, thereby using knowledge of a
macroblock’s influence in the future, as well as historical pixel dependencies to select
better coding options in an error prone environment. To that end, we developed 3
different distortion weighting techniques based on the motion trajectory. Simulations
conducted in bursty channels, which more accurately describe the experience wit-
nessed in wireless environments further highlighted the effectiveness of our methods.
The research achievements of this thesis are summarized herein.

104 Conclusion
5.1 Research Achievements
In Chapter 3, we developed a forward tracking algorithm that captured future MB
dependencies. Resilient video compression was therefore achieved by performing
both motion estimation and mode decision using the motion trajectory information.
Through experimental results, we demonstrated that the proposed technique can pro-
vide significant improvements in error prone scenarios when applied to motion vectors
only, and that the combination of motion vector selection and mode decision making
presented the greatest benefit. We also addressed the complexity issue by introducing
shorter lookahead periods. Though longer tracking of MB dependencies offered better
resilient performance, significant gains are possible with shorter tracking periods for
applications that require faster encoding. In addition, we showed that our distortion
biasing technique is particularly effective when channel state information is unreli-
able. Accurate channel knowledge is a requirement for current error resilient coding
techniques, making our method particularly useful for applications where channel
knowledge is impractical, such as multicast channels.
Forward tracking information was also used in conjunction with H.264/AVC’s
redundant slice mechanism to achieve better error resilient performance. Knowledge
of MB sensitivity is useful in determining a redundant macroblock selection process.
For this purpose, we verified experimentally that given a percentage of MB to code
redundantly, our tracking algorithm showed a better redundant macroblock allocation
strategy than some current methods.
In Chapter 4, we addressed the complexity issue associated with the 2-pass encod-
ing technique of our forward tracking algorithm and developed a single pass technique
by looking at historical motion trajectories. We developed a pixel-based backward
tracking algorithm that computes the concealment distortion to determine the amount
of distortion being referred to by a pixel. The precision offered by pixel-based track-
ing resulted in an accurate weighting strategy that avoids pixels with long prediction
trails. The recursive nature of the algorithm meant that it is relatively simple to
implement when the storage requirement of the frame distortion buffer is met. In-
formation from historical tracking was used for both motion estimation and mode
decision, and once again showed the benefit of applying error resilient strategies to
both.

5.2 Future Work 105
Further simplification was made possible by a macroblock-based backward track-
ing algorithm that allowed us to classify macroblocks within the motion estimation
search range according to their potential of containing propagated errors. This simple
but effective technique preyed on the presence on Intra MBs within the search range
and steered motion vectors towards these Intra MBs, resulting in a more reliable
prediction trail that reduces the chances of propagated errors.
5.2 Future Work
Although a major emphasis of the work presented in this dissertation has been the
improvement of coding decisions without channel knowledge, It may be useful to
investigate how channel information can be incorporated into the weighted distortion
paradigm. There are certain applications, such as video telephony where reliable
channel information is available. This would present an interesting avenue for further
investigation. The threshold value T , from our forward tracking algorithm discussed
in Section 3.2.3 and the incremental step size N , of equation (4.8) from macroblock-
based backward tracking may be explored further and possibly linked with channel
loss probabilities.
End-to-End (E2E) distortion estimation techniques have established themselves as
the defacto standard in error resilient video encoding. Further investigation on how
our proposed weighting strategies relates to E2E distortion estimation can present
interesting insights and possible performance improvements. Preliminary investiga-
tion into this subject is presented in Appendix A, but further detailed examination
is required.
In addition to our demonstration of the effectiveness of weighted distortion tech-
niques in wireless environments, developing video compression techniques that exploit
the characteristics of bursty channels can prove be very useful. Wireless networks are
characterized by bursty error characteristics due to slow fading and fast fading. Con-
stantly fluctuating channel conditions make it difficult for error control strategies to
be performed at the link layer. It is therefore necessary to perform some form of error
protection at the application/packet level [88]. The quality of the transmitted signal
in a wireless environment is usually described by the Average Fade Duration (AFD)
and Level Cross Rate (LCR). These quantities have been used to determine FEC

106 Conclusion
redundancy allocation [88] and to determine the best location of redundant slices in
a H.264/AVC bitstream [71]. Future work in adopting video encoding decision based
on wireless channel characteristics can be very useful. For example, a weighted dis-
tortion strategy based on AFD and/or LCR can be extended from the work presented
in this thesis.

107
Appendix A
Additional Simulations
A.1 Uniform Channel Simulations
In Section 2.4 the Gilbert channel model used in this thesis was introduced and some
results presented in Chapter 4. In Fig. 4.11 we saw the RD curves for the Football
and NBA sequence in a 10% uniform packet loss channel. In this appendix, RD curves
for Mobile, Stefan, Foreman and News are presented in Fig. A.1 and A.2 for a 10%
loss channel to augment the discussion presented in the thesis.

108 Additional Simulations
A.2 Gilbert Channel Simulations
In Section 2.4 the Gilbert channel model used in this thesis was introduced and some
results presented in Chapter 4. In Fig. 4.14 we saw the RD curves for the Football
and NBA sequence in a Gilbert channel with 5% packet loss rate and burst length
of 15, we also saw in Fig. 4.15 RD curves for the Football and NBA sequence in a
Gilbert with 10% packet loss rate and burst length of 10.
In this appendix RD curves for Mobile, Stefan, Foreman and News are presented
for the same channel loss conditions shown earlier in Figs A.3, A.4, A.5 and A.6.
These figures illustrate the effectiveness of the various methods introduced in this
thesis in a variety of channel loss conditions. The results presented here further
illustrate the importance of judicious motion vector assignment in achieving error
resilience. We also show that for talking head sequences with low motion and limited
background activity like News, backward tracking techniques are the most effective
of our methods. This is because little error propagation is witnessed in these type of
sequences, lending themselves well to the backward tracking techniques of Chapter 4.
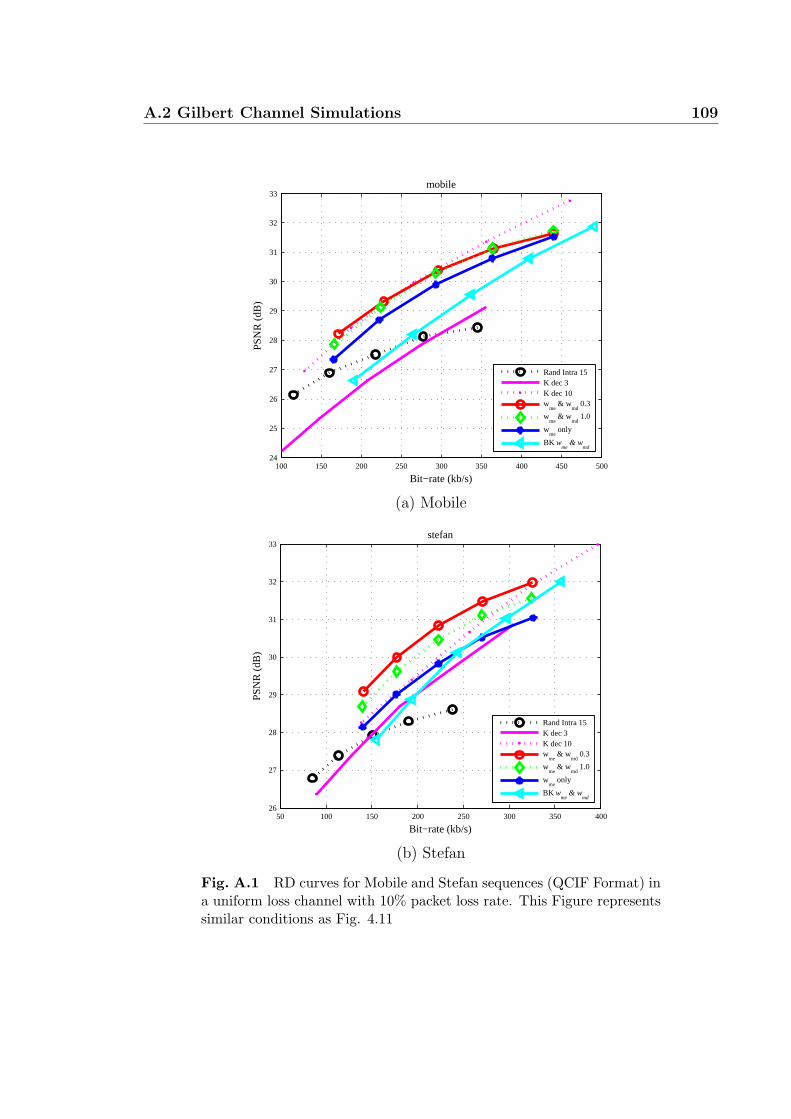
A.2 Gilbert Channel Simulations 109
100 150 200 250 300 350 400 450 50024
25
26
27
28
29
30
31
32
33mobile
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(a) Mobile
50 100 150 200 250 300 350 40026
27
28
29
30
31
32
33stefan
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(b) Stefan
Fig. A.1 RD curves for Mobile and Stefan sequences (QCIF Format) ina uniform loss channel with 10% packet loss rate. This Figure representssimilar conditions as Fig. 4.11
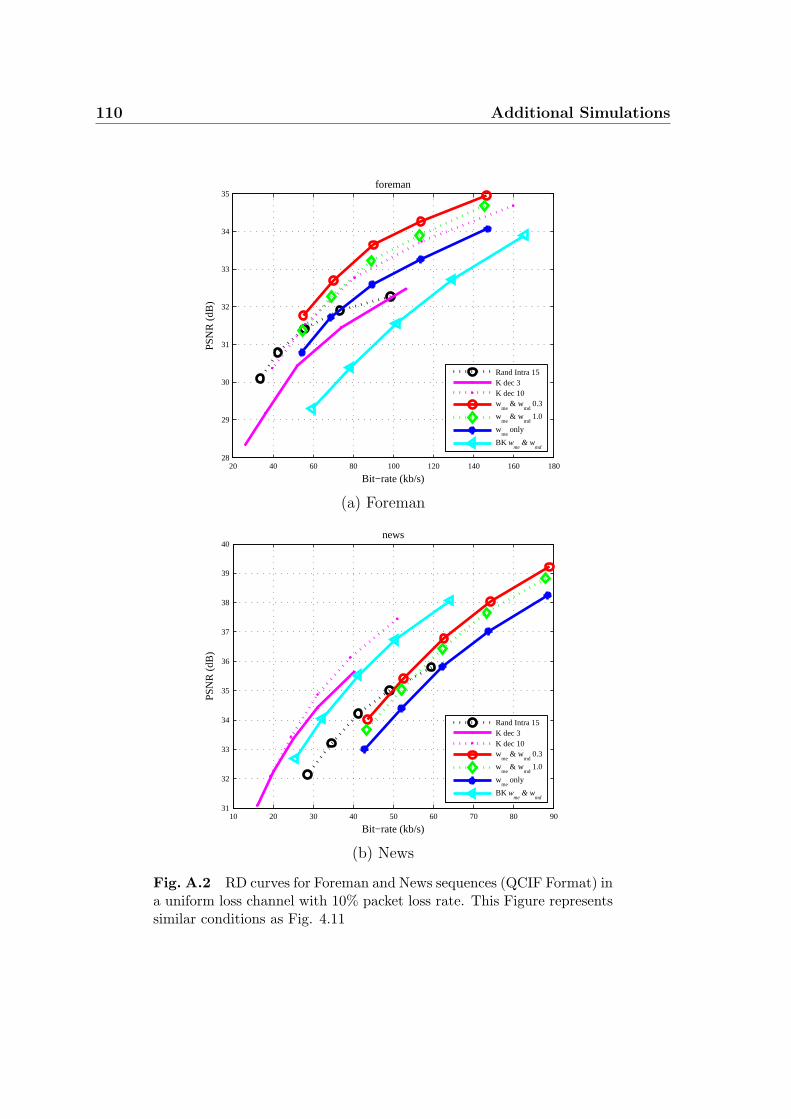
110 Additional Simulations
20 40 60 80 100 120 140 160 18028
29
30
31
32
33
34
35foreman
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(a) Foreman
10 20 30 40 50 60 70 80 9031
32
33
34
35
36
37
38
39
40news
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(b) News
Fig. A.2 RD curves for Foreman and News sequences (QCIF Format) ina uniform loss channel with 10% packet loss rate. This Figure representssimilar conditions as Fig. 4.11

A.2 Gilbert Channel Simulations 111
50 100 150 200 250 300 350 400 450 50022
24
26
28
30
32
34
36
38mobile
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 1K dec 5w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(a) Mobile
50 100 150 200 250 300 350 40024
26
28
30
32
34
36
38stefan
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 1K dec 5w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(b) Stefan
Fig. A.3 RD curves for Mobile and Stefan sequences (QCIF Format) ina Gilbert channel with 5% packet loss rate and burst length of 15. ThisFigure represents similar conditions as Fig. 4.14

112 Additional Simulations
20 40 60 80 100 120 140 160 18024
26
28
30
32
34
36
38foreman
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 1K dec 5w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(a) Foreman
10 20 30 40 50 60 70 80 9030
32
34
36
38
40
42news
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 1K dec 5w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(b) News
Fig. A.4 RD curves for Foreman and News sequences (QCIF Format)in a Gilbert channel with 5% packet loss rate and burst length of 15. ThisFigure represents similar conditions as Fig. 4.14

A.2 Gilbert Channel Simulations 113
100 150 200 250 300 350 400 450 50022
24
26
28
30
32
34
36mobile
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(a) Mobile
50 100 150 200 250 300 350 40024
26
28
30
32
34
36stefan
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(b) Stefan
Fig. A.5 RD curves for Mobile and Stefan sequences (QCIF Format)in a Gilbert channel with 10% packet loss rate and burst length of 10.This Figure represents similar conditions as Fig. 4.15
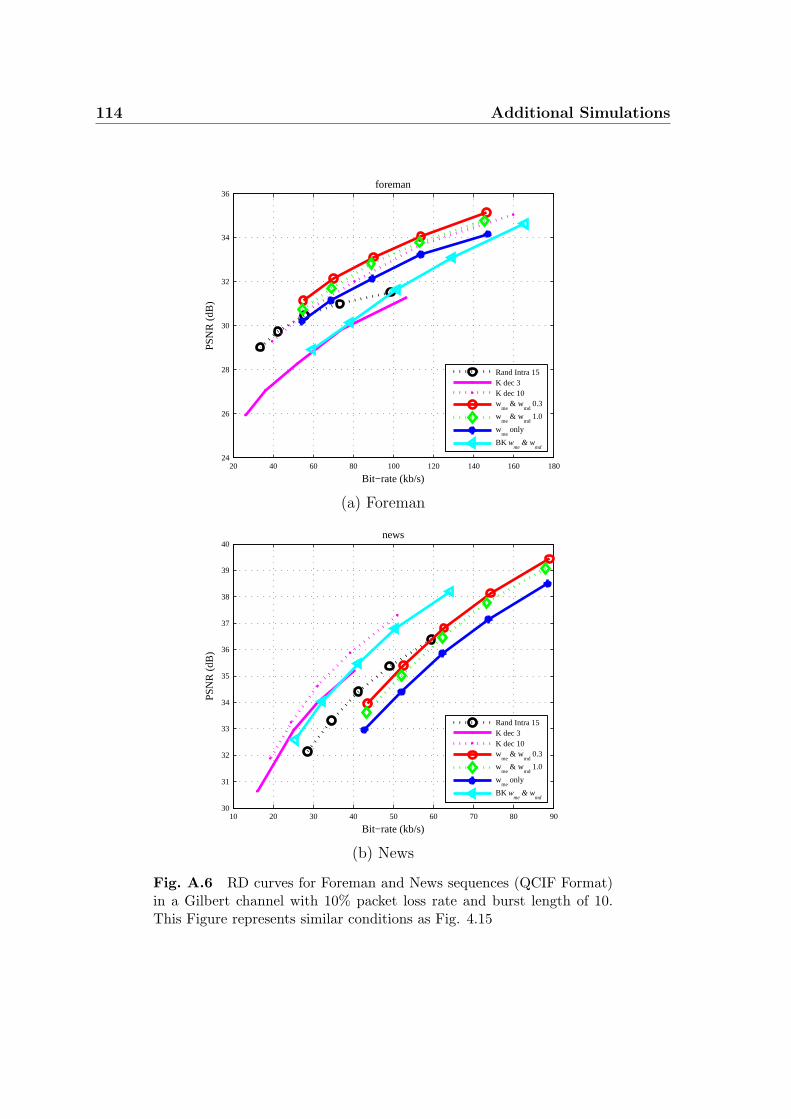
114 Additional Simulations
20 40 60 80 100 120 140 160 18024
26
28
30
32
34
36foreman
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(a) Foreman
10 20 30 40 50 60 70 80 9030
31
32
33
34
35
36
37
38
39
40news
Bit−rate (kb/s)
PS
NR
(dB
)
Rand Intra 15K dec 3K dec 10w
me & w
md 0.3
wme
& wmd
1.0
wme
only
BK wme
& wmd
(b) News
Fig. A.6 RD curves for Foreman and News sequences (QCIF Format)in a Gilbert channel with 10% packet loss rate and burst length of 10.This Figure represents similar conditions as Fig. 4.15

115
Appendix B
Distortion Modelling
In Section 2.3 we presented a detailed discussion of the current state-of-the art End-
to-End (E2E) Distortion estimation methods present in literature. E2E distortion
estimation has proven to be very effective at improving error resilience at the encoder.
As an extension to the Weighted Distortion (WD) techniques presented in this thesis,
the relationship between the distortion values of our methods with that of the INTRA
MBs in standard H.264/AVC encoder is investigated in this Appendix. The result of
which is a different method of biasing the distortion values of Standard H.264/AVC
for error resilience. The results presented here are compelling enough to warrant
further investigation.
B.1 Introduction
In Section 3.2.3 our Mode Decision weighting factor was introduced, whereby we
devised a method of penalizing the distortion values of INTRA mode decisions. We
did so by proportionally weighting the distortion of each INTRA mode according to
the number of pixels it affects in the future. Efficient selection of INTRA coding can
help tackle the resilience-efficiency tradeoff, and it is this tradeoff that our methods
have addressed through out this dissertation.
As an addendum to the work presented in Chapter 3, we analyze the effective-
ness of our Mode Decision weighting factor. A detailed examination of how our
mode decision weighting factor affects the distortion values of a INTRA MBs in stan-
dard H.264/AVC encoder is presented. Additionally, we look at how the K-decoders

116 Distortion Modelling
method affects standard H.264/AVC INTRA mode distortion values, and draw some
useful insights that can form the platform for further investigation.
B.2 Exponential Model
To begin our analysis, we remember the weighted distortion value for mode decision
wmd from Equation (3.4) (reprinted here for convenience)
wmd = T − Ci
Cmax
,
was applied to INTRA modes only. Figures B.1 and B.2, show the Weighted Dis-
tortion versus standard H.264/AVC distortion values for INTRA modes of all mac-
roblocks in the NBA and Football sequence (QCIF Format) respectively. The weight-
ing strategy
wmd ·DSSD,
of Equation (3.2) results in a reduction of the Weighted Distortion values compared
to standard H.264/AVC as displayed in Figures B.1 and B.2 when the threshold
value T = 1. Applying a threshold value of T = 0.5 results in the distortion vs.
distortion plots of Figures B.3 and B.4. Reducing the threshold value, T resulted in
an improvement in performance witnessed in Fig. 3.12, which we contend is a result
of the reduction in distortion values as presented in Figures B.3 and B.4 compared
to Figures B.1 and B.2.
There is also a reduction in the distortion values when comparing the K-decoders
(with p = 10%) method of Section 2.3.1 with standard H.264/AVC as presented in
Figures B.5 and B.6 for NBA and Football respectively. However, when comparing
the reduction offered by K-decoders compared with that of applying wmd, we see that
the K-decoders method in Figures B.5 and B.6 is less aggressive by not forcing some
distortion values near the 0 value as with our weighted distortion method in Figures
B.3 and B.4. Instead, the K-decoder distortion values exhibit a strong exponential
bias as shown by the yellow curve in Figures B.5 and B.6.
We propose modelling the J-decoders exponential function by fitting an appropri-
ate curve according to,

B.3 Simulation Results 117
Dmodel = 1 + A(1− e(−1λDstd)), (B.1)
whereDmodel is the distortion derived from the exponential model, Dstd is the standard
H.264/AVC distortion, A is an amplitude factor and λ a decay constant.
For the NBA sequence in Fig. B.5 A = 10, 000 and λ = 10, 000 and for the
Football sequence in B.6, A = 10, 000 and λ = 8, 000. We found these values by doing
a minimum squared error (MMSE) curve fit to the distortion vs distortion points.
The A and λ values appear to be sequence specific, and still more work remains in
finding out efficient ways of estimating these quantities for different sequences.
Video classification techniques can be used to create generic values of A and λ that
can be applied to a class of video sequences. Video classification has been applied
in a variety of areas such as to improve coding efficiency [121], video indexing [122],
genre classification [123] and so on. Applying some of these techniques to resilient
video coding could result in appropriate values of A or λ for a set of video sequences.
Using the fitted curves in Figures B.5 and B.6 to obtain A or λ, some preliminary
results are presented in the following section.
B.3 Simulation Results
Our simulations were conducted using the same testing conditions as those in Section
3.4 and Section 4.4. We therefore assume RTP/UDP/IP transmission, were packets
that are lost, damaged or arrive after the video playback schedule are discarded with-
out retransmission. The decoder performs error concealment by copying the missing
MBs from the previous frame. A total of 4,000 coded pictures were transmitted
through a packet erasure channel with loss probability of p. 80 frames of QCIF se-
quences were encoded in IPPP... format and the bitstream was repeated 50 times
to form 4,000 coded pictures. For each frame, a row of MBs was placed in a slice,
which formed an RTP packet. Integer-pel accuracy is used and Quantization Param-
eter (QP) is varied to achieve different encoding rates. We look at the impact of
error propagation due to transmission over a packet loss network, by calculating the
average PSNR of the whole sequence.
Our simulations also use Equation (3.1) for motion vector selection, and we try

118 Distortion Modelling
to find a better mode decision method in this Appendix. In order to determine the
effectiveness of the exponential distortion model presented in Section B.2, we compare
its performance to that of the Weighted Distortion methods introduced in Chapter 3.
We therefore apply Equation (B.1) (with A = 10, 000, λ = 10, 000 and for the NBA
sequence and A = 10, 000, λ = 8, 000 for the Football sequence) to INTRA mode
distortion values in (2.7) and show the RD curves in Fig. B.7.
Fig. B.7 shows that the distortion model of (B.1) improves on our Weighted
Distortion method (wmd with T = 0.5) by up to 1 dB. The gain is most visible
especially at higher bitrates.
B.4 Conclusions
The distortion modelling technique presented in this Appendix presents an interesting
alternative to the Weighted Distortion methods discussed in this thesis and results in
a significant performance improvement to warrant further investigation. The biggest
challenge in developing this method further is to find an effective ways of classifying
video sequences so as to have generic values on A and λ that can be easily applied to
a class of video sequences.
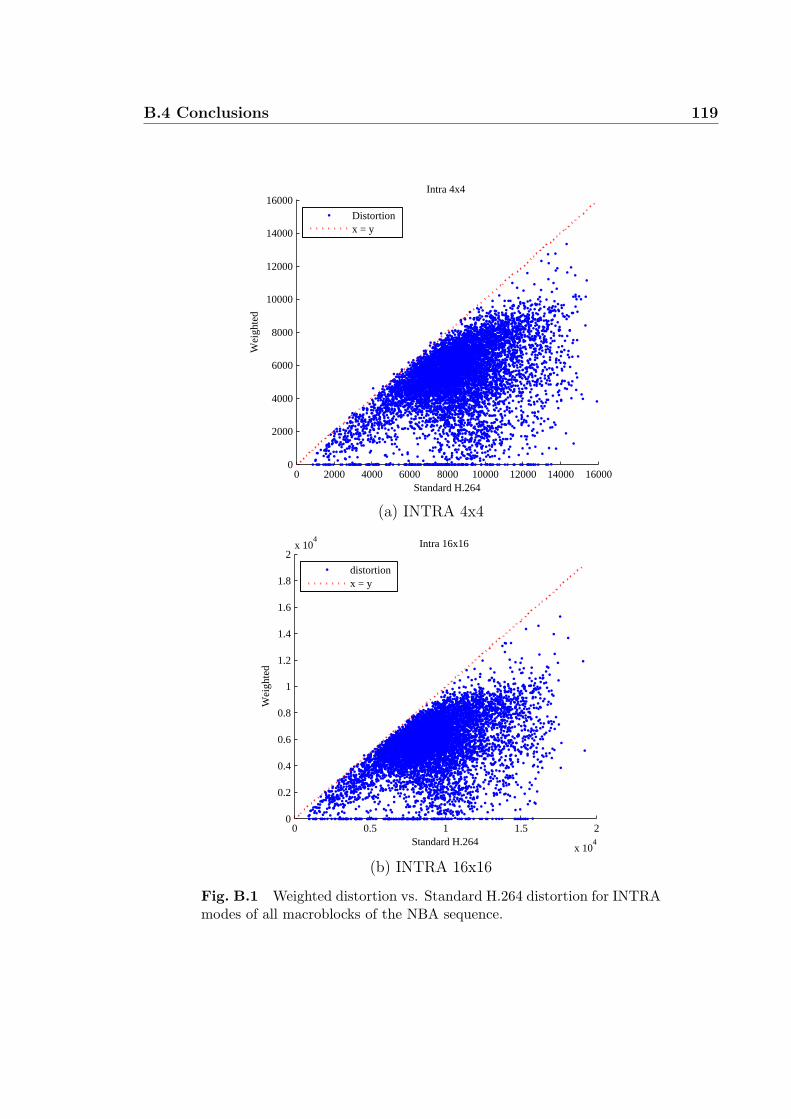
B.4 Conclusions 119
0 2000 4000 6000 8000 10000 12000 14000 160000
2000
4000
6000
8000
10000
12000
14000
16000
Standard H.264
Wei
ghte
d
Intra 4x4
Distortionx = y
(a) INTRA 4x4
0 0.5 1 1.5 2
x 104
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2x 10
4
Standard H.264
Wei
ghte
d
Intra 16x16
distortionx = y
(b) INTRA 16x16
Fig. B.1 Weighted distortion vs. Standard H.264 distortion for INTRAmodes of all macroblocks of the NBA sequence.
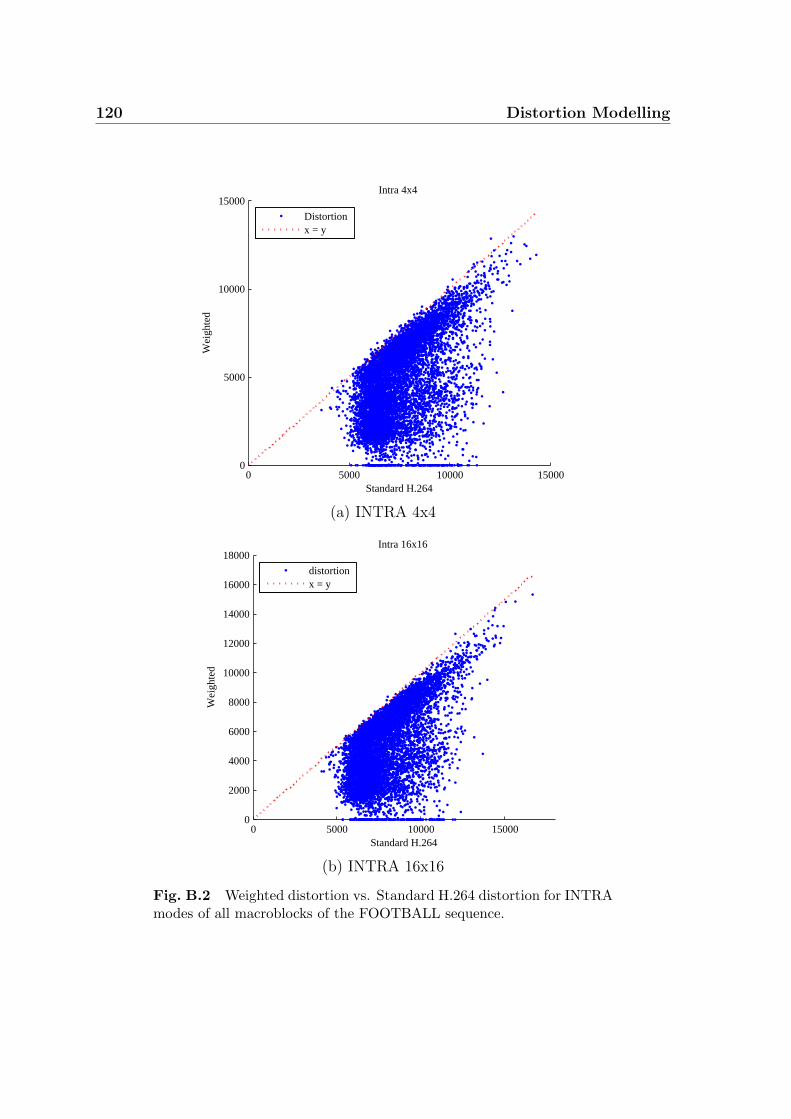
120 Distortion Modelling
0 5000 10000 150000
5000
10000
15000
Standard H.264
Wei
ghte
dIntra 4x4
Distortionx = y
(a) INTRA 4x4
0 5000 10000 150000
2000
4000
6000
8000
10000
12000
14000
16000
18000
Standard H.264
Wei
ghte
d
Intra 16x16
distortionx = y
(b) INTRA 16x16
Fig. B.2 Weighted distortion vs. Standard H.264 distortion for INTRAmodes of all macroblocks of the FOOTBALL sequence.

B.4 Conclusions 121
0 2000 4000 6000 8000 10000 12000 14000 160000
2000
4000
6000
8000
10000
12000
14000
16000
Standard H.264
Wei
ghte
d
Intra 4x4
Distortionx = y
(a) INTRA 4x4
0 0.5 1 1.5 2
x 104
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2x 10
4
Standard H.264
Wei
ghte
d
Intra 16x16
distortionx = y
(b) INTRA 16x16
Fig. B.3 Weighted distortion with T=0.5 vs. Standard H.264 distortionfor INTRA modes of the NBA sequence.
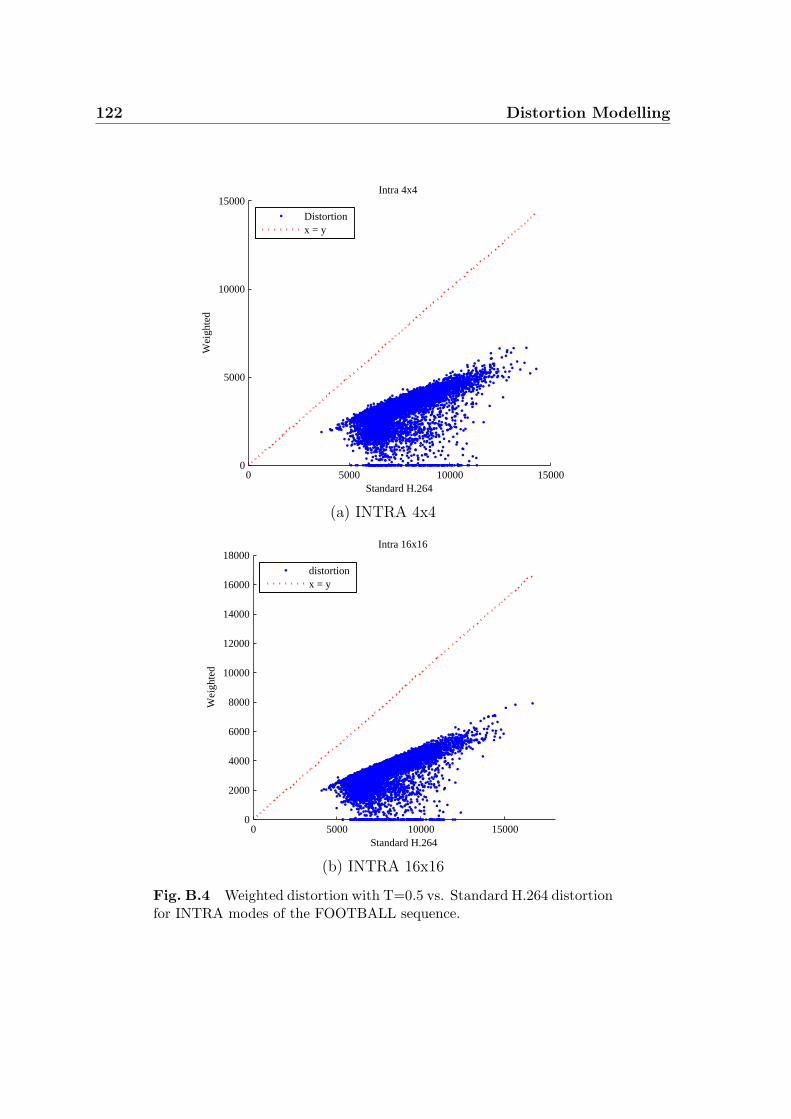
122 Distortion Modelling
0 5000 10000 150000
5000
10000
15000
Standard H.264
Wei
ghte
dIntra 4x4
Distortionx = y
(a) INTRA 4x4
0 5000 10000 150000
2000
4000
6000
8000
10000
12000
14000
16000
18000
Standard H.264
Wei
ghte
d
Intra 16x16
distortionx = y
(b) INTRA 16x16
Fig. B.4 Weighted distortion with T=0.5 vs. Standard H.264 distortionfor INTRA modes of the FOOTBALL sequence.

B.4 Conclusions 123
0 2000 4000 6000 8000 10000 12000 14000 160000
2000
4000
6000
8000
10000
12000
14000
16000
Standard H.264
K−
deco
ders
10%
Intra 4x4
Distortionx = yExponetial model
(a) INTRA 4x4
0 2000 4000 6000 8000 10000 12000 14000 160000
2000
4000
6000
8000
10000
12000
14000
16000
Standard H.264
K−
deco
ders
10%
Intra 4x4
Distortionx = yExponetial model
(b) INTRA 16x16
Fig. B.5 K-decoders distortion vs. Standard H.264 distortion for IN-TRA modes of the NBA sequence.

124 Distortion Modelling
0 5000 10000 150000
5000
10000
15000
Standard H.264
K−
deco
ders
10%
Intra 4x4
Distortionx = yExponetial model
(a) INTRA 4x4
0 5000 10000 150000
2000
4000
6000
8000
10000
12000
14000
16000
18000
Standard H.264
K−
deco
ders
10%
Intra 16x16
distortionx = yExponetial model
(b) INTRA 16x16
Fig. B.6 K-decoders distortion vs. Standard H.264 distortion for IN-TRA modes of the FOOTBALL sequence.
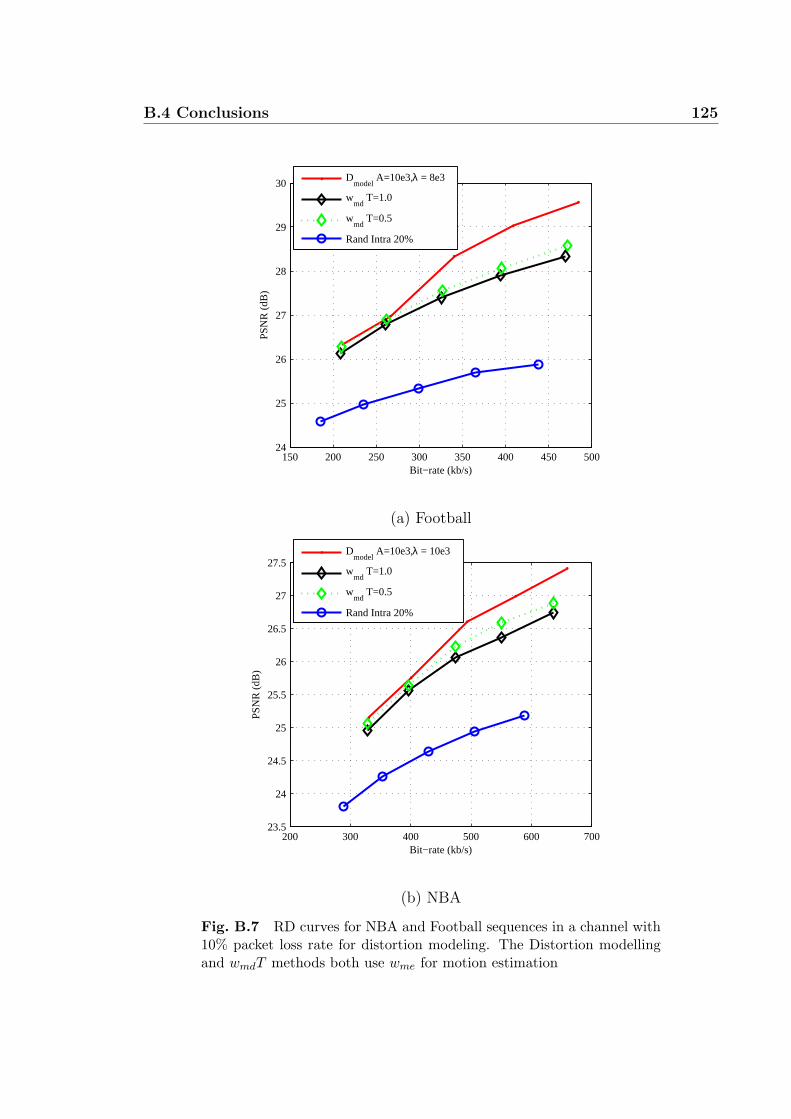
B.4 Conclusions 125
150 200 250 300 350 400 450 50024
25
26
27
28
29
30
Bit−rate (kb/s)
PS
NR
(dB
)
Dmodel
A=10e3,λ = 8e3
wmd
T=1.0
wmd
T=0.5
Rand Intra 20%
(a) Football
200 300 400 500 600 70023.5
24
24.5
25
25.5
26
26.5
27
27.5
Bit−rate (kb/s)
PS
NR
(dB
)
D
model A=10e3,λ = 10e3
wmd
T=1.0
wmd
T=0.5
Rand Intra 20%
(b) NBA
Fig. B.7 RD curves for NBA and Football sequences in a channel with10% packet loss rate for distortion modeling. The Distortion modellingand wmdT methods both use wme for motion estimation

126

127
References
[1] Cisco, “Cisco visual networking index: Global mobile data traffic forecast up-date, 2010-2015.” http://www.cisco.com, Feb. 2011.
[2] T. Wiegand, G. Sullivan, G. Bjøntegaard, and A. Luthra, “Overview of theH.264/AVC video coding standard,” IEEE Trans. Circuits Syst. Video Technol.,vol. 13, no. 7, pp. 560–576, Jul. 2003.
[3] A. Begen, T. Akgul, and M. Baugher, “Watching video over the web: Part 1:Streaming protocols,” IEEE Internet Computing, vol. 15, pp. 54–63, Apr. 2011.
[4] A. H. Sadka, Compressed Video Communications. New York, NY, USA: HalstedPress, 2002.
[5] Y. Wang, S. Wenger, J. Wen, and A. Katsaggelos, “Review of error resilientcoding techniques for real-time video communications,” IEEE Signal ProcessingMagazine, vol. 17, no. 4, pp. 61–82, Jul. 2000.
[6] M. Hannuksela, Error-resilient communication using the H.264/AVC video cod-ing standard. PhD thesis, Tampere University of Technology, Tampere, Finland,Mar. 2009.
[7] T. Tillo, M. Grangetto, and G. Olmo, “Redundant slice optimal allocation forH.264 multiple description coding,” IEEE Trans. Circuits Syst. Video Technol.,vol. 18, no. 1, pp. 59–70, Jan. 2008.
[8] C.-C. Su, H. H. Chen, J. J. Yao, and P. Huang, “H.264/AVC-based multipledescription video coding using dynamic slice groups,” Signal Processing: ImageCommunication, vol. 23, no. 9, pp. 677–691, Jul. 2008.
[9] T. Stockhammer and M. Bystrom, “H.264/AVC data partitioning for mobilevideo communication,” in Proc. ICIP ’04, vol. 1, pp. 545–548, Oct. 2004.
[10] A. Naghdinezhad, M. Hashemi, and O. Fatemi, “A novel adaptive unequalerror protection method for scalable video over wireless networks,” in Proc.ISCE 2007, pp. 1–6, Jun. 2007.

128 References
[11] T. Turletti and C. Huitema, “RTP payload format for H.261 video streams,”in IETF RFC 2032, Oct. 1996.
[12] C. Zhu, “RTP payload format for H.263 video streams,” in IETF draft, Mar.1997.
[13] H. Sun and J. Zdepsky, “Error concealment strategy for picture header loss inMPEG compressed video,” in Proc. of SPIE Conf. High-Speed Networking andMultimedia Computing, vol. 2188, pp. 145–152, Feb. 1994.
[14] P. A. Chou, A. E. Mohr, A. Wang, and S. Mehrotra, “Error control for receiver-driven layered multicast of audio and video,” IEEE Trans. Multimedia, vol. 3,pp. 108–122, Mar. 2001.
[15] W. Tan and A. Zakhor, “Video multicast using layered FEC and scalable com-pression,” IEEE Trans. Circuits Syst. Video Technol., vol. 11, pp. 373–386,Mar. 2001.
[16] R. Zhang, S. L. Regunathan, and K. Rose, “End-to-end distortion estimationfor RD-based robust delivery of pre-compressed video,” in Proc. of Asilomar’01, vol. 1, pp. 210–214, Nov. 2001.
[17] J. Apostolopoulos, “Reliable video communication over lossy packet networksusing multiple state encoding and path diversity,” in Proc. of SPIE VCIP,vol. 4310, pp. 392–409, Jan. 2001.
[18] J. G. Apostolopoulos, T. Wong, W. Tan, and S. J. Wee, “On multiple descrip-tion streaming with content delivery networks,” in Proc. of IEEE INFOCOM,vol. 3, pp. 1736–1745, Nov. 2002.
[19] T. Nguyen and A. Zakhor, “Distributed video streaming over the internet,” inProc. of SPIE Conference on Multimedia Computing and Networking, pp. 186–195, Jan. 2002.
[20] V. N. Padmanabhan, H. J. Wang, and P. A. Chou, “Resilient peer-to-peerstreaming,” Microsoft Research Technical Report, 2003. MSR-TR-2003-11.
[21] P. A. Chou, Y. Wu, and K. Jain, “Practical network coding,” in Proc. of Aller-ton Conference on Communication, Control and Computing, Oct. 2003.
[22] Y. Wu, P. A. Chou, and S.-Y. Kung, “Minimum-energy multicast in mobile adhoc networks using network coding,” IEEE Trans. Commun., vol. 53, pp. 1906–1918, Nov. 2005.

References 129
[23] Y. Wu, P. A. Chou, Q. Zhang, K. Jain, W. Zhu, and S.-Y. Kung, “Networkplanning in wireless ad hoc networks: a cross-layer approach,” IEEE J. Sel.Areas Commun., vol. 23, no. 1, pp. 136–150, Jan. 2005.
[24] E. Setton, T. Yoo, X. Zhu, A. Goldsmith, and B. Girod, “Cross-layer designof ad hoc networks for real-time video streaming,” IEEE Wireless Communica-tions, vol. 12, pp. 59–65, Aug. 2005.
[25] R. Farrugia and C. Debono, Digital Video, ch. 4 Resilient Digital Video Trans-mission over Wireless Channels using Pixel-Level Artefact Detection Mecha-nisms, pp. 71–96. Floriano De Rango (Editor): Intech, Feb. 2010.
[26] W. J. Chu and J. J. Leou, “Detection and concealment of transmission errorsin H.261 images,” IEEE Trans. Circuits Syst. Video Technol., vol. 8, pp. 74–84,Feb. 1998.
[27] S. Aign and K. Fazel, “Temporal & spatial error concealment techniques forhierarchical MPEG-2 video codec,” in Proc. of IEEE ICC, vol. 3, pp. 1778–83,Jun. 1995.
[28] W.-Y. Kung, C.-S. Kim, and C.-C. Kuo, “Spatial and temporal error conceal-ment techniques for video transmission over noisy channels,” IEEE Trans. Circ.Sys. Video Tech, vol. 16, pp. 789–803, Jul. 2006.
[29] X. Zhan and X. Zhu, “Refined spatial error concealment with directional en-tropy,” Wireless Communications, Networking and Mobile Computing, 2009.WiCom ’09., pp. 1–4, Sept. 2009.
[30] T. Stockhammer, D. Kontopodis, and T. Wiegand, “Rate-distortion optimiza-tion for JVT/H.26L video coding in packet loss environment,” in Proc. of PacketVideo Workshop 2002, (Pittsburg, PA), Apr. 2002.
[31] Y. Wang, Q. F. Zhu, and L. Shaw, “Maximally smooth image recovery in trans-form coding,” IEEE Trans. Commun., vol. 41, no. 10, pp. 1544–51, Oct. 1993.
[32] H. Sun and W. Kwok, “Concealment of damaged block transform coded imagesusing projections onto convex sets,” IEEE Trans. Image Proc., vol. 4, no. 4,pp. 470–477, Apr. 1995.
[33] R. Aravind, M. R. Civanlar, and A. R. Reibman, “Packet loss resilience ofMPEG-2 scalable video coding algorithms,” IEEE Trans. Circuits Syst. VideoTechnol., vol. 6, no. 5, pp. 426–435, Oct. 1996.
[34] Y. Wang and Q. F. Zhu, “Error control and concealment for video communica-tion: a review,” Proc. of the IEEE, vol. 86, no. 5, pp. 974–997, Mar. 1998.

130 References
[35] Y. Wang, S. Wenger, J. Wen, and A. K. Katsaggelos, “Error resilient videocoding techniques,” IEEE Signal Processing Magazine, vol. 17, pp. 61–82, Jul.2000.
[36] W. M. Lam, A. R. Reibman, and B. Liu, “Recovery of lost or erroneouslyreceived motion vectors,” in Proc. of ICASSP 09, vol. 5, pp. 417–20, Apr. 1993.
[37] J. Lu, M. L. Lieu, K. B. Letaief, and J. I. Chuang, “Error resilient transmissionof H.263 coded video over mobile networks,” in Proc. of ISCAS 98, vol. 4,pp. 502–505, Jun. 1998.
[38] M.-J. Chen, L.-G. Chen, and R.-M. Weng, “Error concealment of lost motionvectors with overlapped motion compensation,” IEEE Trans. Circuits Syst.Video Technol., vol. 7, pp. 560–563, Jun. 1997.
[39] J. Zhang, J. Arnold, M. Frater, and M. Pickering, “Video error concealmentusing decoder motion vector estimation,” in Proc. of TENCON ’97 IEEE, vol. 2,pp. 777–780, Dec. 1997.
[40] B. Yan and H. Gharavi, “A hybrid frame concealment algorithm forH.264/AVC,” IEEE Trans. Image Process, vol. 19, pp. 98–107, Jan. 2010.
[41] Y.-C. Lee, Y. Altunbasak, and R. Mersereau, “Multiframe error concealmentfor mpeg-coded video delivery over error-prone networks,” IEEE Trans. ImageProcess, vol. 11, pp. 1314–1331, Nov. 2002.
[42] M. Podolsky, S. McCanne, and M. Vetterli, “Soft ARQ for layered streamingmedia,” Journal of VLSI Signal Processing Systems, vol. 27, no. 1-2, pp. 81–97,Feb. 2001.
[43] P. A. Chou and Z. Miao, “Rate-distortion optimized streaming of packetizedmedia,” IEEE Trans. Multimedia, vol. 8, pp. 390–404, Apr. 2006.
[44] Z. Miao and A. Ortega, “Expected run-time distortion based scheduling fordelivery of scalable media,” in Proc. of Packet Video Workshop, Apr. 2002.
[45] B. Girod and N. Farber, “Feedback-based error control for mobile video trans-mission,” Proc. of the IEEE, vol. 87, no. 10, pp. 1707–1723, Oct. 1999.
[46] P.-C. Chang and T.-H. Lee, “Precise and fast error tracking for error-resilienttransmission of h.263 video,” IEEE Trans. Circuits Syst. Video Technol., vol. 10,pp. 600–607, Jun. 2000.

References 131
[47] S. Nyamweno, R. Satyan, S. Solak, and F. Labeau, “Weighted distortion forrobust video coding,” in Proc. of Asilomar ’08, (Pacific Grove, CA), pp. 1277–1281, Oct. 2008.
[48] S. Nyamweno, R. Satyan, and F. Labeau, “Error resilient video coding viaweighted distortion,” in Proc. ICME ’09, (New York, NY), pp. 734–737, Jul.2009.
[49] S. Nyamweno, R. Satyan, and F. Labeau, “Weighted distortion methods forerror resilient video coding,” IEEE Trans. Multimedia, 2010. under review.
[50] S. Nyamweno, R. Satyan, and F. Labeau, “Intra-distance derived weighted dis-tortion for error resilience,” in Proc. of ICIP ’09, (Cairo, Egypt), pp. 1057–1060,Nov. 2009.
[51] I. E. Richardson, H.264 and MPEG-4 Video Compression: Video Coding forNext-generation Multimedia. Chichester,West Sussex PO19 8SQ, England: JohnWiley & Sons, Inc., 2003.
[52] F. C. Pereira and T. Ebrahimi, The MPEG-4 Book. Upper Saddle River, NJ,USA: Prentice Hall PTR, 2002.
[53] Y. Zhang, W. Gao, Y. Lu, Q. Huang, and D. Zhao, “Joint source-channelrate distortion optimization for H.264 video coding over error-prone networks,”IEEE Trans. Multimedia, vol. 9, no. 3, pp. 445–454, Apr. 2007.
[54] T. Wiegand, N. Farber, K. Stuhlmuller, and B. Girod, “Error-resilient videotransmission using long-term memory motion-compensated prediction,” IEEEJ. Sel. Areas Commun, vol. 18, no. 6, pp. 1050–1062, Jun. 2000.
[55] G. Cote, S. Shirani, and F. Kossentini, “Optimal mode selection and synchro-nization for robust video communications over error-prone networks,” IEEE J.Sel. Areas Commun, vol. 18, no. 6, pp. 952–965, Jun. 2000.
[56] R. Satyan, S. Nyamweno, and F. Labeau, “Comparison of intra updating meth-ods for H.264,” 10th Int. Symposium on Wireless Personal Multimedia Com-munications (WPMC ’07), pp. 996–999, Dec. 2007.
[57] T. Turletti and C. Huitema, “Videoconferencing on the internet,” IEEE/ACMTrans. Networking, vol. 4, no. 3, pp. 340–351, Jun. 1996.
[58] Q. F. Zhu and L. Kerofsky, “Joint source coding, transport processing and errorconcealment for H.323-based packet video,” in Proc. Society of PhotographicInstrumentation Engineers, vol. 3653, pp. 52–62, Jan. 1999.

132 References
[59] G. Cote and F. Kossentini, “Optimal intra coding of blocks for robust videocommunication over the internet,” Signal Processing: Image Communications,vol. 15, no. 1-2, pp. 25–34, Sept. 1999.
[60] P. Haskell and D. Merrerschmitt, “Resynchronization of motion compensatedvideo affected by ATM cell loss,” in Proc. IEEE Int. Conf. Acoustics, Speech,and Signal Processing (ICASSP ’93), vol. 3, pp. 545–548, Mar. 1992.
[61] Y. K. Wang, M. M. Hannuksela, and M. Gabbouj, “Error-robust inter/intramode selection using isolated regions,” in Proc. of Int. Packet Video Workshop,pp. 290–294, Apr. 2003.
[62] Q. Chen, Z. Chen, X. Gu, and C. Wang, “Attention-based adaptive intra refreshfor error-prone video transmission,” IEEE Communications Magazine, vol. 45,no. 1, pp. 52–60, Jan. 2007.
[63] M. Schreier, R and A. Rothermel, “Motion adaptive intra refresh for the H.264video coding standard,” IEEE Trans. Consum. Electron., vol. 52, no. 1, pp. 249–253, Feb. 2006.
[64] T. Stockhammer, M. M. Hannuksela, and T. Wiegand, “H.264/AVC in wirelessenvironments,” IEEE Trans. Circ. Sys. Video Tech., vol. 13, no. 7, pp. 657–673,Jul. 2003.
[65] Y. Wang, S. Wenger, and M. Hannuksela, “Common conditions of svc errorresilience testing.” ISO/IEC JTC 1/SC29/WG 11, JVT-P206d1, Jul. 2005.
[66] Z. He and H. Xiong, “Transmission distortion analysis for real-time video en-coding and streaming over wireless networks,” IEEE Trans. Circuits Syst. VideoTechnol., vol. 16, no. 9, pp. 1051–1062, Sept. 2006.
[67] S. Kumar, L. Xu, M. K. Mandal, and S. Panchanathan, “Error resiliencyschemes in H.264/AVC standard,” Journal of Visual Communication and ImageRepresentation, vol. 17, no. 2, pp. 425–450, Apr. 2006.
[68] Y. Wang, S. Wenger, J. Wen, and A. Katsaggelos, “Error resilient video codingtechniques,” IEEE Signal Processing Magazine, vol. 17, pp. 61–82, Jul. 2000.
[69] C. Z. Y.-K. Wang and H. Li, “Error resilient video coding using flexible referenceframes,” in Proc. SPIE VCIP, vol. 5960, (Pittsburg, PA), pp. 691–702, Jul.2005.
[70] Z. Wu and J. Boyce, “Adaptive error resilient video coding based on redundantslices of H.264/AVC,” in Proc. of ICME, pp. 2138–2141, Jul. 2007.

References 133
[71] B. Katz, S. Greenberg, N. Yarkoni, N. Blaunstien, and R. Giladi, “New error-resilient scheme based on FMO and dynamic redundant slices allocation forwireless video transmission,” IEEE Trans. Broadcast., vol. 53, no. 1, pp. 308–319, Mar. 2007.
[72] T. Ogunfunmi and W. Huang, “A flexible macroblock ordering with 3DMBAMAP for H.264/AVC,” IEEE International Symposium on Circuits andSystems, 2005. ISCAS 2005., vol. 4, pp. 3475–3478, May 2005.
[73] M. Ghandi, B. Barmada, E. Jones, and M. Ghanbari, “Unequally error pro-tected data partitioned video with combined hierarchical modulation and chan-nel coding,” Proc. of ICASSP ’06, vol. 2, pp. II–529–531, May 2006.
[74] O. Harmanci and A. Tekalp, “Optimization of H.264 for low delay video commu-nications over lossy channels,” Proc. of ICIP ’04, vol. 5, pp. 3209–3212, 24-27Oct. 2004.
[75] G. Sullivan and T. Wiegand, “Rate-distortion optimization for video compres-sion,” IEEE Signal Processing Magazine, vol. 15, no. 6, pp. 74–90, Nov. 1998.
[76] “H.264/AVC Reference Software (ver JM 16.0).” [Available Online]http://iphome.hhi.de/suehring/tml/.
[77] C. Zhu, X. Lin, and L.-P. Chau, “Hexagon-based search pattern for fast blockmotion estimation,” IEEE Trans. Circuits Syst. Video Technol., vol. 12, no. 5,pp. 349–355, May 2002.
[78] Y. Zhang, W. Gao, Y. Lu, Q. Huang, and D. Zhao, “Joint source-channelrate-distortion optimization for H.264 video coding over error-prone networks,”IEEE Trans. Multimedia, vol. 9, no. 3, pp. 445–454, Apr. 2007.
[79] O. Harmanci and A. M. Tekalp, “A stochastic framework for rate-distortion op-timized video coding over error-prone networks,” IEEE Trans. Image Process.,vol. 16, no. 3, pp. 684–697, Mar. 2007.
[80] R. Zhang, S. L. Regunathan, and K. Rose, “Video coding with optimalinter/intra-mode switching for packet loss resilience,” IEEE J. Sel. Areas Com-mun., vol. 18, no. 6, pp. 966–976, Jun. 2000.
[81] S. Wan and E. Izquierdo, “Rate-distortion optimized motion-compensated pre-diction for packet loss resilient video coding,” IEEE Trans. Image Process.,vol. 16, no. 5, pp. 1327–1338, May 2007.

134 References
[82] H. Yang and K. Rose, “Rate-Distortion optimized motion estimation for er-ror resilient video coding,” in Proc. of ICASSP’05, vol. 2, (Philadelphia, PA),pp. 173–178, Mar. 2005.
[83] H. Yang, “Advances in recursive per-pixel end-to-end distortion estimation forrobust video coding in H.264/AVC,” IEEE Trans. Circuits Syst. Video Technol.,vol. 17, no. 7, pp. 845–856, Jul. 2007.
[84] “H.264/SVC Reference Software (JSVM 9.19) and manual.” [Available Online]CVS sever at garcon.ient.rwth-aachen.de, Jan. 2010.
[85] O. Hadar, M. Huber, R. Huber, and S. Greenberg, “New hybrid error con-cealment for digital compressed video,” EURASIP J. Appl. Signal Process.,vol. 2005, no. 1, pp. 1821–1833, Jan. 2005.
[86] Z. Chen and D. Wu, “Prediction of transmission distor-tion for wireless video communication. part I: Analysis,” inhttp://www.wu.ece.ufl.edu/mypapers/journal-1.pdf, Aug. 2010.
[87] Z. Chen and D. Wu, “Prediction of transmission distortion for wireless videocommunication: Algorithm and application,” J. Vis. Comun. Image Represent.,vol. 21, pp. 948–964, Nov. 2010.
[88] A. Nafaa, T. Taleb, and L. Murphy, “Forward error correction strategies formedia streaming over wireless networks,” IEEE Communications Magazine,vol. 46, no. 1, pp. 72–79, Jan. 2008.
[89] H. Sanneck and G. Carle, “A framework model for packet loss metrics based onloss runlengths,” in In SPIE/ACM SIGMM Multimedia Computing and Net-working Conference, pp. 177–187, Jan. 2000.
[90] W. Wang, Z. Xia, H. Cui, and K. Tang, “Robust H.264/AVC transmission withoptimal mode selection and data partitioning,” in Proc. of ISCIT 2005, vol. 2,pp. 1444–1447, Oct. 2005.
[91] B. A. Heng, J. G. Apostolopoulos, and J. S. Lim, “End-to-end rate-distortionoptimized md mode selection for multiple description video coding,” EURASIPJ. Appl. Signal Process., vol. 2006, pp. 261–261, Jan. 2006.
[92] B. Katz, S. Greenberg, N. Yarkoni, N. Blaunstien, and R. Giladi, “New error-resilient scheme based on fmo and dynamic redundant slices allocation for wire-less video transmission,” IEEE Trans. Broadcast., vol. 53, pp. 308–319, Mar.2007.

References 135
[93] H. Yang and K. Rose, “Mismatch impact on per-pixel end-to-end distortionestimation and coding mode selection,” in Proc. of ICME, pp. 2178–2181, Jul.2007.
[94] W. Tu and E. Steinbach, “Proxy-based reference picture selection for errorresilient conversational video in mobile networks,” IEEE Trans. Circuits Syst.Video Technol., vol. 19, no. 2, pp. 151–164, Feb. 2009.
[95] M. Dawood, R. Hamzaoui, S. Ahmad, and M. Al-Akaidi, “Error-resilient packetswitched H.264 mobile video telephony with lt coding and reference pictureselection,” in Proc. of EUSIPCO 09, pp. 2211–2215, Aug. 2009.
[96] S. Fukunaga, T. Nakai, and H. Inoue, “Error resilient video coding by dynamicreplacing of reference pictures,” in Proc. of GLOBECOM ’96., vol. 3, pp. 1503–1508, Nov. 1996.
[97] Y. Wang and Y. D. Srinath, “Error resilient video coding with tree structuremotion compensation and data partitioning,” in Proc. of Packet Video Work-shop (PV 2002), Apr. 2002.
[98] J. Zheng and L.-P. Chau, “Error-resilient coding of H.264 based on periodicmacroblock,” IEEE Trans. Broadcast., vol. 52, pp. 223–229, Jun. 2006.
[99] W.-Y. Kung, C.-S. Kim, and C.-C. Kuo, “Analysis of multihypothesis motioncompensated prediction (MHMCP) for robust visual communication,” IEEETrans. Circuits Syst. Video Technol., vol. 16, no. 1, pp. 146–153, Jan. 2006.
[100] G. J. Sullivan, “Multi-hypothesis motion compensation for low bit-rate videocoding,” in Proc. of ICASSP ’93, vol. 5, pp. 437–440, Apr. 1993.
[101] Y.-C. Tsai, C.-W. Lin, and C.-M. Tsai, “H.264 error resilience coding based onmulti-hypothesis motion-compensated prediction,” Signal Processing: ImageCommunication, vol. 22, no. 9, pp. 734–751, Oct. 2007.
[102] M. Ma, O. C. Au, L. Guo, S.-H. G. Chan, X. Fan, and L. Hou, “Alternatemotion-compensated prediction for error resilient video coding,” J. Vis. Comun.Image Represent., vol. 19, no. 7, pp. 437–449, Oct. 2008.
[103] D. J. Connor, “Techniques for reducing the visibility of transmission errors indigitally encoded video signals,” IEEE Trans. Commun., vol. 21, no. 6, pp. 695–706, Jun. 1973.
[104] H. Yang and K. Rose, “Generalized source-channel prediction for error resilientvideo coding,” Proc. of ICASSP’06, vol. 2, pp. II–533–536, 14-19 May 2006.

136 References
[105] H. Yang and K. Rose, “Optimizing motion compensated prediction for errorresilient video coding,” IEEE Trans. Image Proc., vol. 19, pp. 108–118, Jan.2010.
[106] R. Satyan, S. Nyamweno, and F. Labeau, “Novel prediction schemes for errorresilient video coding,” Signal Processing: Image Communication, vol. 25, no. 9,pp. 648–659, May 2010.
[107] M. H. Willebeek-LeMair, Z. Y. Shae, and Y. C. Chang, “Robust h.263 videocoding for transmission over the internet,” in Proc. INFOCOM 98, pp. 225–232,Mar. 1998.
[108] L. Merritt and R. Vanam, “X264: A high performance H.264/AVC encoder.”http://akuvian.org/src/x264/overview x264 v8 5.pdf, Jul. 2011.
[109] Mainconcept, “Mainconcept reference 2.2.” [Available Online]http://www.mainconcept.com, Jul. 2011.
[110] T. Wiegand and B. Girod, “Lagrange multiplier selection in hybrid video codercontrol,” in Proc. of ICIP, p. 542545, Oct. 2001.
[111] A. C. P. Baccichet, “Error resilience by means of coarsely quantized redundantdescriptions.” JVT-S046, Apr. 2006.
[112] C. Zhu, Y.-K. Wang, M. M. Hannuksela, and H. Li, “Error resilient video codingusing redundant pictures,” IEEE Trans. Circuits Syst. Video Technol., vol. 19,no. 1, pp. 3–14, Jan. 2009.
[113] P. Baccichet, S. Rane, A. Chimienti, and B. Girod, “Robust low-delay videotransmission using H.264/AVC redundant slices and flexible macroblock order-ing,” in Proc of. ICIP 2007, vol. 4, (San Antonio, TX), pp. 93–96, Sept. 2007.
[114] P. B. S. Rane and B. Girod, “Systematic lossy error protection based onH.264/AVC redundant slices and flexible macroblock ordering.” JVT-S025, Apr.2006.
[115] P. Ferre, D. Agrafiotis, and D. Bull, “A video error resilience redundant slicesalgorithm and its performance relative to other fixed redundancy schemes,”Signal Processing: Image Communication, vol. 25, no. 3, pp. 163–178, 2010.
[116] J. C. Schmidt and K. Rose, “Macroblock-based retransmission for error re-silience video streaming,” in Proc. ICIP ’08, (San Diego, CA), pp. 2308–737,Jul. 2009.

References 137
[117] G. Bjøntegaard, “Calculation of average PSNR differences between RD-curves.”ITU-T Q.6/SG16 VCEG, VCEG-M33, Apr. 2001.
[118] Z. Wang, R. Hu, Y. Fu, and G. Tian, “Error and rate joint control for wirelessvideo streaming,” in Proc. of WiCOM 2006, pp. 1–5, Sep. 2006.
[119] M. Ghanbari, “Postprocessing of late cells for packet video,” IEEE Trans. Cir-cuits Syst. Video Technol., vol. 6, no. 6, pp. 669–678, Dec. 1996.
[120] ITU-T/SG15/WP15/1/LBC-95-033, “An error resilience method based on backchannel signalling and FEC,” 1996. Telenor R&D, San Jose.
[121] A. Deshpande and R. Aygun, “Motion based video classification for sprite gen-eration,” in Proc of DEXA ’09, pp. 231–235, Sept 2009.
[122] Y. Haoran, D. Rajan, and C. Liang-Tien, “An efficient video classification sys-tem based on HMM in compressed domain,” in Proc. of ICIS-PCM 2003, vol. 3,pp. 1546–1550, Dec. 2003.
[123] R. Glasberg, S. Schmiedeke, P. Kelm, and T. Sikora, “An automatic systemfor real-time video-genres detection using high-level-descriptors and a set ofclassifiers,” in Proc. of ISCE 2008, pp. 1–4, Apr. 2008.