why multi-threading/multi-core? clock rates are stagnant future cpus will be predominantly multi-...
TRANSCRIPT

Why multi-threading/multi-core?Why multi-threading/multi-core?
Clock rates are stagnantFuture CPUs will be predominantly multi-thread/multi-core
Xbox 360 has 3 coresPS3 will be multi-core>70% of PC sales will be multi-core by end of 2006
Most Windows Vista systems will be multi-core
Two performance possibilities:Single-threaded? Minimal performance growthMulti-threaded? Exponential performance growth

Design for MultithreadingDesign for MultithreadingGood design is critical
Bad multithreading can be worse than no multithreading
Deadlocks, synchronization bugs, poor performance, etc.

Bad MultithreadingBad Multithreading
Thread 1
Thread 2
Thread 3
Thread 4
Thread 5

Rendering ThreadRendering ThreadRendering Thread
Game Thread
Good MultithreadingGood Multithreading
Main Thread
Physics
Rendering Thread
Animation/Skinning
Particle Systems
Networking
File I/O
Game Thread

Another Paradigm: CascadesAnother Paradigm: CascadesThread 1
Thread 2
Thread 3
Thread 4
Thread 5
Input
Physics
AI
Rendering
Present
Frame 1Frame 2Frame 3Frame 4
Advantages:Synchronization points are few and well-defined
Disadvantages:Increases latency (for constant frame rate)
Needs simple (one-way) data flow

Typical Threaded TasksTypical Threaded Tasks
File Decompression
Rendering
Graphics Fluff
Physics

File DecompressionFile Decompression
Most common CPU heavy thread on the Xbox 360
Easy to multithread
Allows use of aggressive compression to improve load times
Don’t throw a thread at a problem better solved by offline processing
Texture compression, file packing, etc.

RenderingRendering
Separate update and render threadsRendering on multiple threads (D3DCREATE_MULTITHREADED) works poorly
Exception: Xbox 360 command buffers
Special case of cascades paradigmPass render state from update to render
With constant workload gives same latency, better frame rateWith increased workload gives same frame rate, worse latency

Graphics FluffGraphics Fluff
Extra graphics that doesn't affect playProcedurally generated animating cloud textures
Cloth simulations
Dynamic ambient occlusion
Procedurally generated vegetation, etc.
Extra particles, better particle physics, etc.
Easy to synchronize
Potentially expensive, but if the core is otherwise idle...?

Physics?Physics?
Could cascade from update to physics to rendering
Makes use of three threads
May be too much latency
Could run physics on many threadsUses many threads while doing physics
May leave threads mostly idle elsewhere

Rendering ThreadRendering Thread
Overcommitted Multithreading?Overcommitted Multithreading?Physics
Rendering Thread
Animation/Skinning
Particle Systems
Game Thread

How Many Threads?How Many Threads?No more than one CPU intensive software thread per core
3-6 on Xbox 3601-? on PC (1-4 for now, need to query)
Too many busy threads adds complexity, and lowers performance
Context switches are not free
Can have many non-CPU intensive threads
I/O threads that block, or intermittent tasks

Case Study: Kameo (Xbox 360)Case Study: Kameo (Xbox 360)
Started single threaded
Rendering was taking half of time—put on separate thread
Two render-description buffers created to communicate from update to render
Linear read/write access for best cache usage
Doesn't copy const data
File I/O and decompress on other threads

Separate Rendering ThreadSeparate Rendering Thread
Update Thread
Buffer 1
Render Thread
Buffer 0

Case Study: Kameo (Xbox 360)Case Study: Kameo (Xbox 360)
Core
Thread
Software threads
00 Game update
1 File I/O
10 Rendering
1
20 XAudio
1 File decompression
Total usage was ~2.2-2.5 cores

Case Study: Project Gotham RacingCase Study: Project Gotham RacingCor
eThread
Software threads
00 Update, physics, rendering, UI1 Audio update, networking
10 Crowd update, texture
decompression1 Texture decompression
20 XAudio1
Total usage was ~2.0-3.0 cores

Available Synchronization ObjectsAvailable Synchronization Objects
Events
Semaphores
Mutexes
Critical Sections
Don't use SuspendThread()Some title have used this for synchronization
Can easily lead to deadlocks
Interacts badly with Visual Studio debugger

Exclusive Access: MutexExclusive Access: Mutex// InitializeHANDLE mutex = CreateMutex(0, FALSE, 0);
// Usevoid ManipulateSharedData() { WaitForSingleObject(mutex, INFINITE); // Manipulate stuff... ReleaseMutex(mutex);}
// DestroyCloseHandle(mutex);

Exclusive Access: CRITICAL_SECTIONExclusive Access: CRITICAL_SECTION// InitializeCRITICAL_SECTION cs;InitializeCriticalSection(&cs);
// Usevoid ManipulateSharedData() { EnterCriticalSection(&cs); // Manipulate stuff... LeaveCriticalSection(&cs);}
// DestroyDeleteCriticalSection(&cs);

Lockless programmingLockless programming
Trendy technique to use clever programming to share resources without lockingIncludes InterlockedXXX(), lockless message passing, Double Checked Locking, etc.Very hard to get right:
Compiler can reorder instructions
CPU can reorder instructions
CPU can reorder reads and writes
Not as fast as avoiding synchronization entirely

Lockless Messages: BuggyLockless Messages: Buggy
void SendMessage(void* input) { // Wait for the message to be 'empty'. while (g_msg.filled) ; memcpy(g_msg.data, input, MESSAGESIZE); g_msg.filled = true;}
void GetMessage() { // Wait for the message to be 'filled'. while (!g_msg.filled) ; memcpy(localMsg.data, g_msg.data, MESSAGESIZE); g_msg.filled = false;}

Synchronization tips/costs:Synchronization tips/costs:
Synchronization is moderately expensive when there is no contention
Hundreds to thousands of cycles
Synchronization can be arbitrarily expensive when there is contention!Goals:
Synchronize rarely
Hold locks briefly
Minimize shared data

Threading File I/O & DecompressionThreading File I/O & Decompression
First: use large reads and asynchronous I/O
Then: consider compression to accelerate loading
Don't do format conversions etc. that are better done at build time!
Have resource proxies to allow rendering to continue

File I/O Implementation DetailsFile I/O Implementation Details
vector<Resource*> g_resources;
Worst design: decompressor locks g_resources while decompressing
Better design: decompressor adds resources to vector after decompressing
Still requires renderer to synch on every resource access
Best design: two Resource* vectorsRenderer has private vector, no locking required
Decompressor use shared vector, syncs when adding new Resource*
Renderer moves Resource* from shared to private vector once per frame

Profiling multi-threaded apps Profiling multi-threaded apps
Need thread-aware profilersProfiling may hide many synchronization stallsHome-grown spin locks make profiling harderConsider instrumenting calls to synchronization functions
Don't use locks in instrumentation
Windows: Intel VTune, AMD CodeAnalyst, and the Visual Studio Team System ProfilerXbox 360: PIX, XbPerfView, etc.

PIX timing capturePIX timing capture
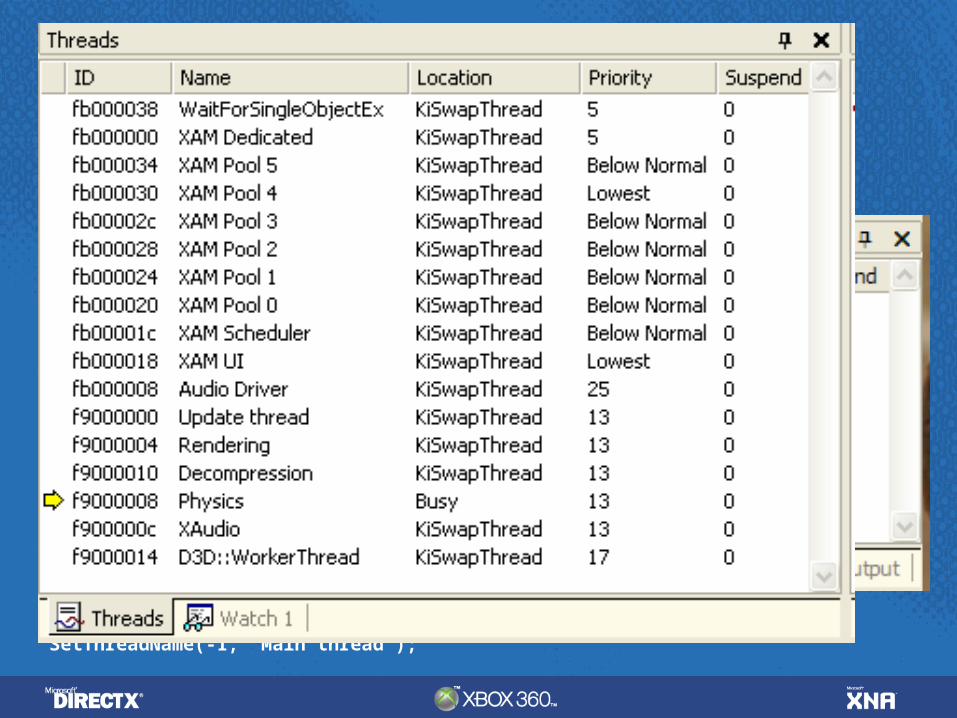
Naming ThreadsNaming Threadstypedef struct tagTHREADNAME_INFO { DWORD dwType; // must be 0x1000 LPCSTR szName; // pointer to name (in user addr space) DWORD dwThreadID; // thread ID (-1=caller thread) DWORD dwFlags; // reserved for future use, must be zero} THREADNAME_INFO;
void SetThreadName( DWORD dwThreadID, LPCSTR szThreadName) { THREADNAME_INFO info; info.dwType = 0x1000; info.szName = szThreadName; info.dwThreadID = dwThreadID; info.dwFlags = 0;
__try { RaiseException( 0x406D1388, 0, sizeof(info)/sizeof(DWORD),
(DWORD*)&info ); } __except(EXCEPTION_CONTINUE_EXECUTION) { }}
SetThreadName(-1, "Main thread");

Windows tipsWindows tips
Avoid using wglMakeCurrent or this.Invoke()
Best to do all rendering calls from a single thread
Test on multiple machines and configurations
Single-core, SMT (i.e. Hyper-Threading), Dual-core, Intel and AMD chips, Multi-socket multicore (4+ cores)