with amundsen, an open-source metadata platform solving
TRANSCRIPT

Solving Data Discovery Challenges with Amundsen, an open-source metadata platform
Tao Feng | [email protected] Software Engineer

Who
● Engineer at Lyft Data Platform and Tools
● Apache Airflow PMC and Committer ● Working on different data products
(Airflow, Amundsen, etc), and led data org cost attribution effort
● Previously at Linkedin, Oracle

Agenda
● What is Data Discovery
● Challenges in Data Discovery
● Introducing Amundsen
● Amundsen Architecture
● Deep Dive
● Impact and Future Work

What is Data Discovery

Data-Driven Decisions
Analysts Data Scientists GeneralManagers
Engineers ExperimentersProductManagers
● Axiom: Good decisions are based in data
● Who needs Data? Anyone who wants to make good decisions
○ HR wants to ensure salaries are competitive with market
○ Politician wants to optimize campaign strategy

Data-Driven Decisions
1. Data is Collected
2. Analyst Finds the Data
3. Analyst Understands the Data
4. Analyst Creates Report
5. Analyst Shares the Results
6. Someone Makes a Decision

Challenges in Data Discovery

● Why:
- An unknown number of RSVPs will no-show
- Need to procure pizza, drinks, chairs, etc
Case Study
● How: Use data from past meetups to build a predictive model
● Goal: Predict Meetup Attendance

● Ask a friend or expert
● Ask in a Slack channel
● Search in the Github repos, or other documents
Step 2: Find the Data

● We find a table called core.meetup_events with columns:
attending, not_attending, date, init_date
● Does attending mean they actually showed up or just RSVPed?
● What's the difference between date and init_date?
● Is this data trustworthy and reliable?
Step 3: Understand the Data

Step 3: Understand the Data
● Ask the data owner, but how do we find the owner?
● Look for further documentation on Github, Confluence, etc
● Run queries and try to figure it out
SELECT * FROM core.meetup_events LIMIT 100;

Data Discovery is Not Productive
● Data Scientists spend up to 30% of their
time in Data Discovery
● Data Discovery in itself provides little to
no intrinsic value. Impactful work
happens in Analysis.
● The answer to these problems is
Metadata

Introducing

What is Amundsen
• In a nutshell, Amundsen is a data discovery and metadata platform for improving the productivity of data analysts, data scientists, and engineers when interacting with data.
• Amundsen is currently hosted at Linux Foundation AI (LFAI) as its incubation project with open governance and RFC process. (e.g blog post)

Lyft data discovery before Amundsen exists
• Only a few (20ish) core tables are listed
• Metadata refreshed through a cron job, no human curation
• Metadata includes: owner, code, ETL SLA(static defined), table/column description
• The metadata not easy to extend
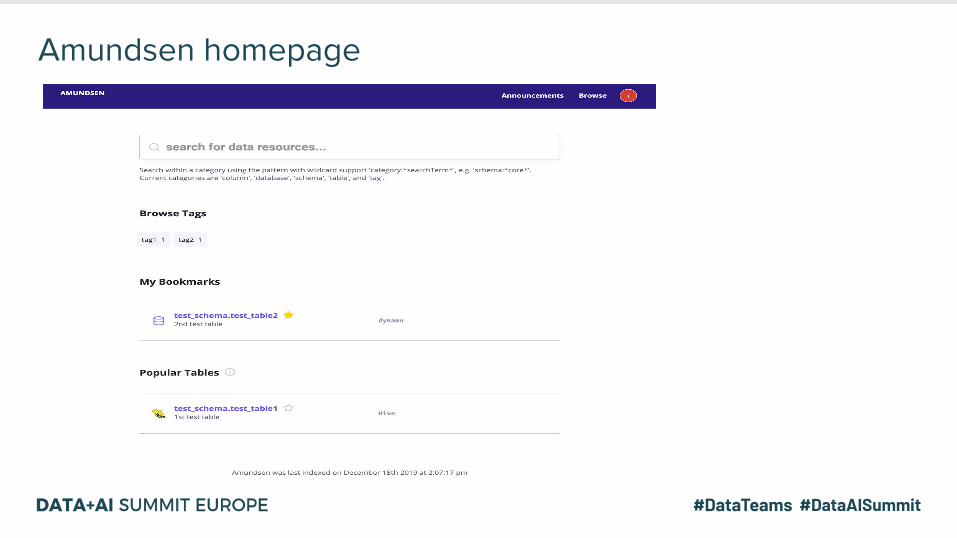
Amundsen homepage

Search for datasets

See details of the data set

See detailed descriptions and profile of the column

See dashboards built on this data set

Search for existing dashboards/reports

Dashboard detail page

Search for co-workers!

Search for data owned and used by your peers

Architecture

Postgres Hive Redshift ... PrestoMode
Dashboard
Databuilder Crawler
Neo4j ElasticSearch
Metadata Service Search Service
Frontend ServiceML FeatureService
SecurityService
Other Microservices
Metadata Sources
Pluggable Pluggable

Frontend Service

Metadata Service
• A proxy layer to interact with graph database with API‒ Supports different graph dbs: 1) Neo4j (Cypher based), 2) AWS Neptune
(Gremlin based)‒ Supports Apache Atlas as meta-storedata engine
• Support Rest APIs for other services pushing / pulling metadata directly‒ Service communication authorized through Envoy RBAC at Lyft

Search Service
• A proxy layer to interact with the search backend‒ Currently it supports Elasticsearch, and Apache Atlas as search backend.
• Support different search patterns‒ Fuzzy search: search based on popularity‒ Multi facet search

Databuilder

Metadata Sources

Databuilder in action

How is the databuilder orchestrated?
Amundsen uses a workflow engine (e.g Apache Airflow) to orchestrate Databuilder jobs

Current built-in connectors

Deep Dive

Metadata model

1. What kind of information? (aka ABC of metadata)Application ContextMetadata needed by humans or applications to operate
● Where is the data?● What are the semantics of the data?
BehaviorHow is data created and used over time?
● Who’s using the data?● Who created the data?
ChangeChange in data over time
● How is the data evolving over time?● Evolution of code that generates the data
TODAY

Short answer: Any data within your organization
Long answer:
2. About what data?
Data stores
Schema registry
Events / Schemas
StreamsPeople
Employees
TODAY
NotebooksDashboard / Reports
Processes
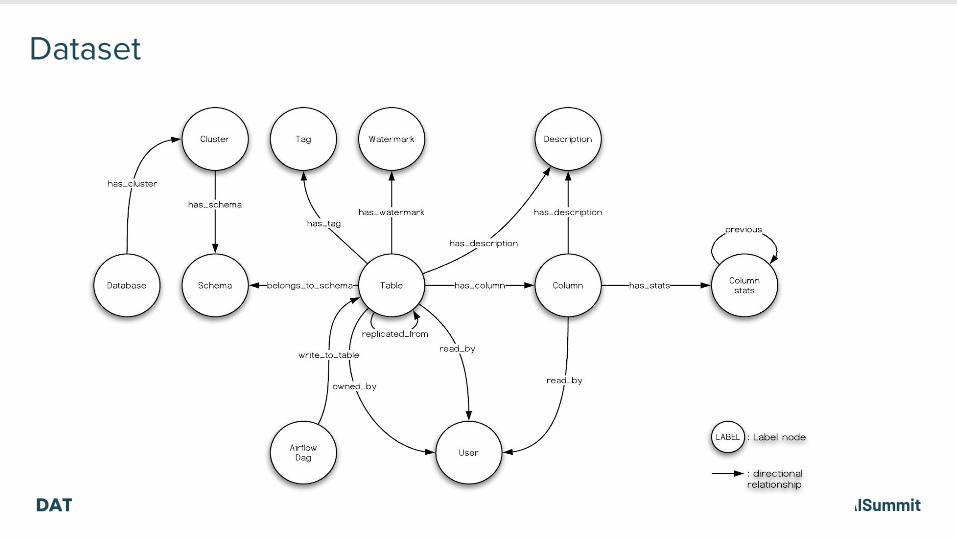
Dataset

Dataset
• Includes metadata both manual curated and programmatic curated• Current metadata:
‒ Table description, column, column descriptions‒ Last updated timestamp‒ Partition date range‒ Tags‒ Owners, Frequent users‒ Column stats, column usage‒ Used in which dashboard‒ Produced by which Airflow(ETL) task‒ Github source definition ‒ Unstructured metadatas: (e.g data retention) which is easy to extend to cover different companies
metadata requirements
• Challenge: not every dataset defines the same set of metadata or follows the same practice
‒ Tier, SLA (operation metadata)

User
• User has the most context / tribal knowledge around data assets. • Connect user with data entities to surface those tribal knowledge.

Dashboard
• Dashboard represents existing users research analysis.

Dashboard
• Current metadata:‒ Description‒ Owner‒ Last updated timestamp, last successful run timestamp, last run status‒ Tables used in dashboard, queries, charts‒ Dashboard preview‒ Tags
• Challenge:‒ Not every dashboard metadata applicable for other dashboard type

Push vs Pull

Pull model vs. Push model
Pull Model Push Model
● Periodically update the index by pulling from the system (e.g. database) via crawlers.
● The system (e.g. DB) pushes to a message bus which downstream subscribes to.
● Message format serves as the interface● Allows for near-real time indexing
Crawler
Database Data graph
Scheduler
Database Message queue
Data graph
Preferred if● Near-real time indexing is important● Clean interface exists
Preferred if● Waiting for indexing is ok● Easy to bootstrap central metadata

Metadata ingestion
• Pull model ingestion with neo4j, AWS Neptune as backend.‒ We could extend to a push and pull hybrid model if needed
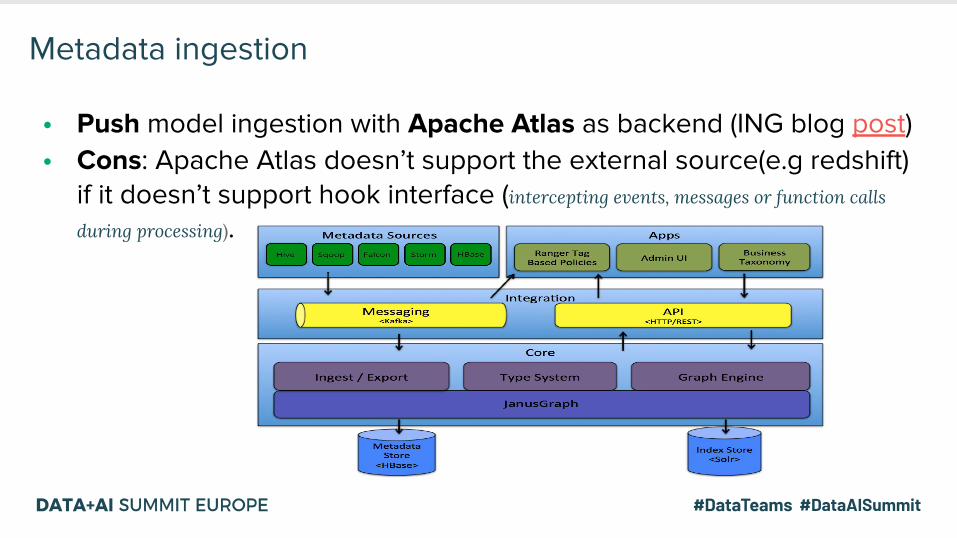
Metadata ingestion
• Push model ingestion with Apache Atlas as backend (ING blog post)• Cons: Apache Atlas doesn’t support the external source(e.g redshift)
if it doesn’t support hook interface (intercepting events, messages or function calls
during processing).

Why Graph Database?

Why graph database
• Data entities with its relationships could be represented as a graph• Performance is better than RDBMS once numbers of nodes and
relationships are in large scale• Adding a new metadata is easy as it is just adding a new node in the
graph

Search Tradeoff

Search Results Ranked on Relevance and Popularity

Relevance - search for “apple” on Google
Low relevance High relevance

Popularity - search for “apple” on Google
Low popularity High popularity

Search Results - Striking the balance
Relevance Popularity
● Names, Description, Tags, [Owners, Frequent users]
● Different weights for different metadata. e.g., resource name
● Querying activity● Lower weight for automated
querying● Higher weight for ad-hoc
querying

Metadata Source Of Truth

Metadata source of truth
• Centralize all the fragmented metadata• Treat Amundsen graph as metadata source of truth
‒ Unless upstream source of truth is available (E.g at Lyft, we define metadata for events in IDL repo)

Other features

Announcement page
• Plugin client to support new feature or new datasets

Central data quality issue portal
• Central portal for users to report data issues.
• Users could see all the past issues as well.
• Users could request further context / descriptions from owners through the portal.

Data Preview
• Supports data preview for datasets.
• Plugin client with different BI Viz tools (e.g Apache Superset).
• Delegate the user authz to Superset to verify whether the given user could access the data.

Data Exploration
• Supports integration between Amundsen and BI Viz tool for data exploration (e.g Apache Superset by default).
• Allows users to do complex data exploration.

Impact

“This is God’s work” - George X, ex-head of Analytics, Lyft
“I was on call and I’m confident 50% of the questions could have been answered by a simple search in Amundsen” - Bomee P, DS, Lyft
Amundsen @ Lyft: 750+ WAUs, 150k+ tables, 4k+ employee pages, 10k+ dashboards

Amundsen Open Source
950+
Community members
150+
Companies in the community
25+
Companies using in production

Amundsen Open Source CommunityP
rom
inen
t use
rsA
ctiv
e co
mm
unity

Edmunds.com
• Data Discovery use case and integrated with in-house Data quality
service (e.g blog post)
• Integrating with Databricks’ Delta analytics platform

ING
• Data Discovery on top of Amundsen with Apache Atlas
• Contributed a lot of security integrations to Amundsen (e.g blog post)

Workday
• Data Discovery on their analytics platform, named Goku
• Amundsen is Landing page for Goku
• 1400 users using their platform

Square
• Compliance and regulatory use cases
• Used by security analysis
• Contribute the Gremlin / AWS Neptune integration
• Production phase (e.g blog post)

Recent Contributions from the community
• Redash dashboard integration (Asana)
• Tableau dashboard integration (Gusto)
• Looker dashboard integration (in progress, Brex )
• Integrating with Delta analytics platform (In progress, Edmunds)
• ...

Future

Data LineagePattern Description Example Key Benefit Key Challenge
Tool Contributed Lineage
The tool creating the data asset also writes the lineage
1) Informatica2) Hive hook
expose lineage
At time of creation No standard way to write lineage;
Manual linked by User
Manual added and described how datasets are linked
Does not scale
Inferred from DAG
Extract dependencies based on scheduling
1) Airflow lineage
2) Marquez
Automatable Doesn’t support field/column level lineage
Inferred from SQL Programmatic extracting lineage with SQL dialect
https://github.com/uber/queryparser
Accurate, supports all sql dialect
SQL is easier, but long tail of support of others (Spark)

Data Lineage
• Current main Q4 focus‒ working on UX design for table lineage
• RFC is coming‒ Provide data model for data lineage‒ Provide UI for data lineage‒ Allows different ingestion mechanisms (Push based, SQL parsing, etc)

Machine Learning Feature as entity
• ML Feature as a separate resource entity‒ Surface feature stats‒ Surface feature and upstream dataset lineage‒ Surface various metadatas around ML features

Metadata platform
• Support other services metadata programmatic graphql API access use cases
‒ Expose metadata (e.g which table joined with what table more frequently) to BI sql Viz tool
‒ Integrate with data quality service to surface health score, data quality information in Amundsen
• Support hybrid(pull + push) metadata ingestion‒ Build SDK to push metadata to Amundsen either through API or through Kafka

Q & A

Feedback
Your feedback is important to us.
Don’t forget to rateand review the sessions.