www.brianhitchcock.net. brian hitchcock ocp dba 8i global sales it sun microsystems...
TRANSCRIPT

www.brianhitchcock.net


Session #403NLS and The Case of the Missing Kanji
NLS -- National Language SupportKanji -- Japanese characters
www.brianhitchcock.net

Brian Hitchcock October 21, 2001 Page 4
www.brianhitchcock.net
How It All Started
Existing Sybase database and application Needed to convert to Oracle Use Oracle Migration Workbench
– OMWB works well
I wasn’t told there was multi-byte data in the Sybase database
After the migration to Oracle– Kanji data were missing

Brian Hitchcock October 21, 2001 Page 5
www.brianhitchcock.net
Kanji Become Lost
How was Kanji stored in Sybase? How was application working with
Sybase? Why lost when migrated to Oracle? How to fix in Oracle? Would application work with Oracle?

Brian Hitchcock October 21, 2001 Page 6
www.brianhitchcock.net
Before Upgrade to Oracle
Source SystemEUC-JP character encoding
Application Sybase Dbcharacter set ISO1
NetscapeBrowser
EUC-JP character code forthis character is 0xB0A1
0xB0A1 0xB0A1
0xB0A1
Source system inserts bytesof Kanji characters into db
Browser examines each byte,detects multi-byte characters,displays Kanji character
Select “Japanese (Auto-Detect)”character set in Netscape to viewKanji characters
Applicationretrieves char datagenerates HTML
Brian Hitchcock October 21, 2001 Page 7
www.brianhitchcock.net
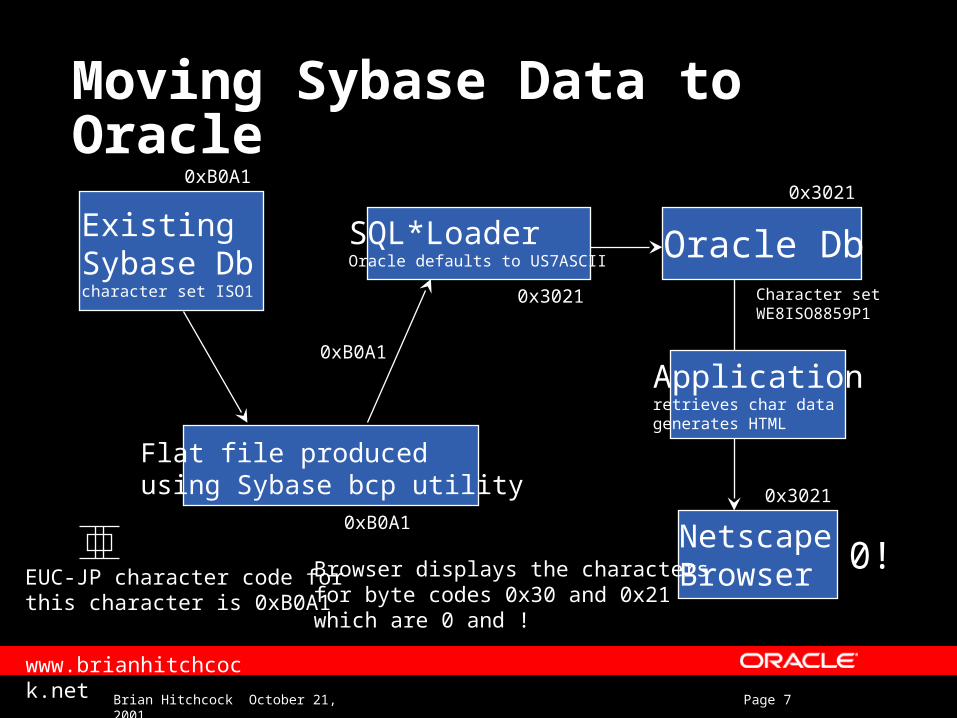
Moving Sybase Data to Oracle
Flat file producedusing Sybase bcp utility
Existing Sybase Dbcharacter set ISO1
NetscapeBrowserEUC-JP character code for
this character is 0xB0A1
0xB0A10x3021
0x3021
Character setWE8ISO8859P1
Browser displays the charactersfor byte codes 0x30 and 0x21which are 0 and !
0!
SQL*LoaderOracle defaults to US7ASCII
0xB0A1
0x3021
Oracle Db
0xB0A1
Applicationretrieves char datagenerates HTML

Brian Hitchcock October 21, 2001 Page 8
www.brianhitchcock.net
Moving Sybase Data to Oracle What happened?
– Oracle database is US7ASCII character set 7-bits per character
– Import stripped the 8th bit off each byte 8th bit set to 0
– 8-bit characters are now 7-bit characters– Original character data is lost– 8-bit characters can’t be represented in the
US7ASCII character set
Brian Hitchcock October 21, 2001 Page 9
www.brianhitchcock.net
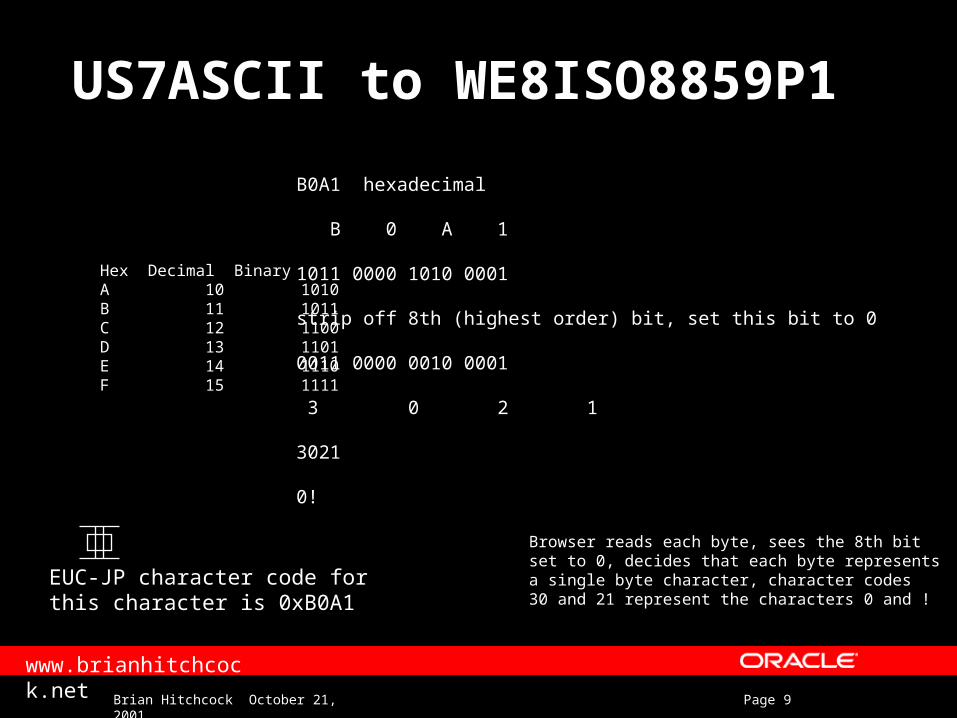
US7ASCII to WE8ISO8859P1
B0A1 hexadecimal
B 0 A 1
1011 0000 1010 0001
strip off 8th (highest order) bit, set this bit to 0
0011 0000 0010 0001
3 0 2 1
3021
0!
EUC-JP character code forthis character is 0xB0A1
Browser reads each byte, sees the 8th bitset to 0, decides that each byte representsa single byte character, character codes 30 and 21 represent the characters 0 and !
Hex Decimal BinaryA 10 1010B 11 1011C 12 1100D 13 1101E 14 1110F 15 1111
Brian Hitchcock October 21, 2001 Page 10
www.brianhitchcock.net
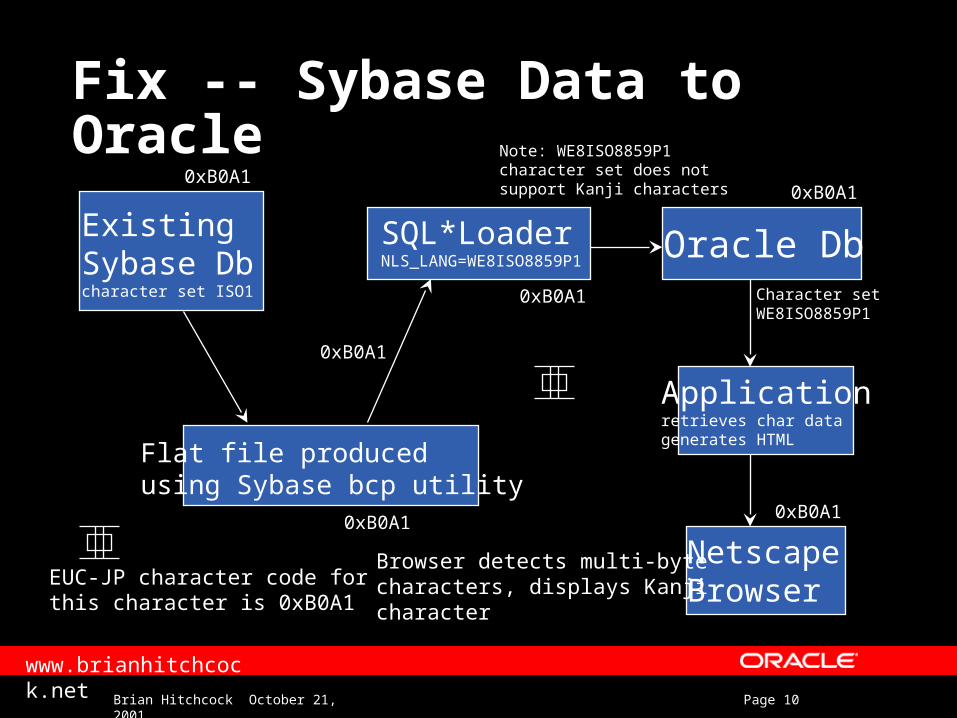
Fix -- Sybase Data to Oracle
Flat file producedusing Sybase bcp utility
Existing Sybase Dbcharacter set ISO1
NetscapeBrowserEUC-JP character code for
this character is 0xB0A1
0xB0A10xB0A1
0xB0A1
Character setWE8ISO8859P1
Browser detects multi-bytecharacters, displays Kanjicharacter
SQL*LoaderNLS_LANG=WE8ISO8859P1
0xB0A1
0xB0A1
Oracle Db
0xB0A1
Applicationretrieves char datagenerates HTML
Note: WE8ISO8859P1character set does notsupport Kanji characters

Brian Hitchcock October 21, 2001 Page 11
www.brianhitchcock.net
Current Oracle Production
Source SystemEUC-JP character encoding
Application Oracle Dbcharacter set WE8ISO8859P1
NetscapeBrowser
EUC-JP character code forthis character is 0xB0A1
0xB0A1 0xB0A1
0xB0A1
Source system inserts bytesof Kanji characters into db
Browser examines each byte,detects multi-byte characters,displays Kanji character
Select “Japanese (Auto-Detect)”character set in Netscape to viewKanji characters
Applicationretrieves char datagenerates HTML
Note: WE8ISO8859P1character set does notsupport Kanji characters

Brian Hitchcock October 21, 2001 Page 12
www.brianhitchcock.net
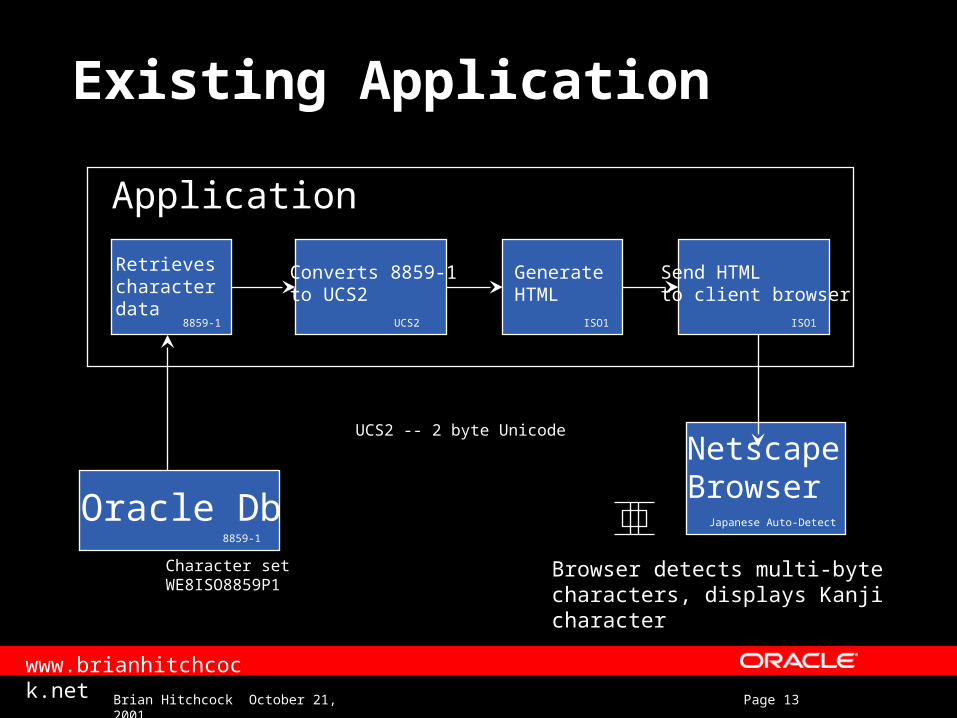
Existing Application
How does it store/retrieve Kanji?– Multi-byte Kanji characters– Stored in WE8ISO8859P1 (single-byte) db– Application
JDBC retrieves bytes from WE Oracle db Java generates HTML, sent to client browser Netscape, view HTML using “Japanese (Auto-
Detect)” character set Display Kanji
Brian Hitchcock October 21, 2001 Page 13
www.brianhitchcock.net
Existing Application
NetscapeBrowser
Character setWE8ISO8859P1
Oracle Db
Application
Retrieves character data
GenerateHTML
Send HTMLto client browser
Browser detects multi-bytecharacters, displays Kanjicharacter
ISO1
Converts 8859-1to UCS2
UCS2 ISO18859-1
Japanese Auto-Detect
8859-1
UCS2 -- 2 byte Unicode

Brian Hitchcock October 21, 2001 Page 14
www.brianhitchcock.net
Existing Application
Each piece of software makes some decision (default) about character set
You need to understand this process for your application

Brian Hitchcock October 21, 2001 Page 15
www.brianhitchcock.net
What Really Happened?
Source Kanji data– From EUC-JP character set– Multi-byte
Kanji multi-byte stored in Sybase db– Default character set ISO-1
8-bit, single-byte
Kanji multi-byte stored in Oracle db– Character set WE8ISO8859P1
8-bit, single-byte

Brian Hitchcock October 21, 2001 Page 16
www.brianhitchcock.net
Convert to UTF8
Why?– Eliminate all the issues shown so far– Store multiple languages correctly
Correctly encoded– Support clients inserting data in languages
other than Japanese Kanji– Existing application can only support
languages based on Latin characters and Kanji

Brian Hitchcock October 21, 2001 Page 17
www.brianhitchcock.net
Conversion is Simple -- Isn’t It? Export WE8ISO8859P1 database
– Set export client NLS_LANG– AMERICAN_AMERICA.WE8ISO8859P1
Import into UTF8 database– Set import client NLS_LANG– AMERICAN_AMERICA.WE8ISO8859P1
Test application– Application works!– Is everything OK?

Brian Hitchcock October 21, 2001 Page 18
www.brianhitchcock.net
Meanwhile, Back at the Ranch While application testing is going on
– Insert sample bytes for Kanji into WE db Use Oracle SQL CHR() function
– Export from WE db, import into UTF8 db– Examine same bytes in UTF8 db– Compare UTF8 bytes to manually generated
UTF8 bytes for the Kanji characters– NOT the same bytes!
What does this mean?
Brian Hitchcock October 21, 2001 Page 19
www.brianhitchcock.net
UTF8 Encoding Process
Think your life is boring?
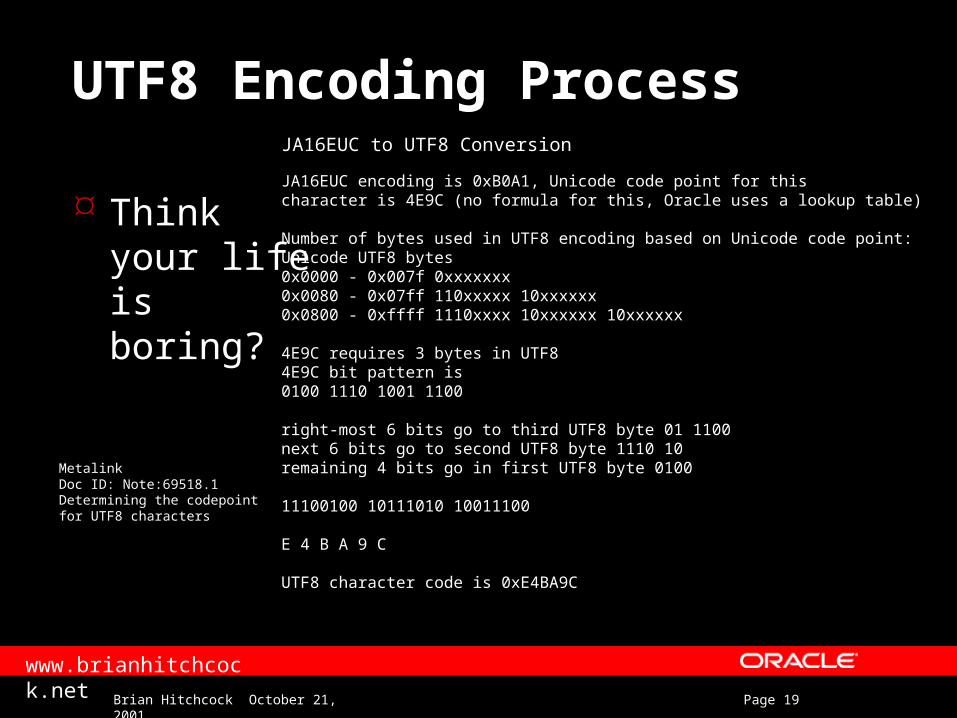
JA16EUC to UTF8 Conversion
JA16EUC encoding is 0xB0A1, Unicode code point for this character is 4E9C (no formula for this, Oracle uses a lookup table)
Number of bytes used in UTF8 encoding based on Unicode code point: Unicode UTF8 bytes 0x0000 - 0x007f 0xxxxxxx 0x0080 - 0x07ff 110xxxxx 10xxxxxx 0x0800 - 0xffff 1110xxxx 10xxxxxx 10xxxxxx
4E9C requires 3 bytes in UTF8 4E9C bit pattern is 0100 1110 1001 1100
right-most 6 bits go to third UTF8 byte 01 1100 next 6 bits go to second UTF8 byte 1110 10 remaining 4 bits go in first UTF8 byte 0100
11100100 10111010 10011100
E 4 B A 9 C
UTF8 character code is 0xE4BA9C
MetalinkDoc ID: Note:69518.1Determining the codepointfor UTF8 characters
Brian Hitchcock October 21, 2001 Page 20
www.brianhitchcock.net
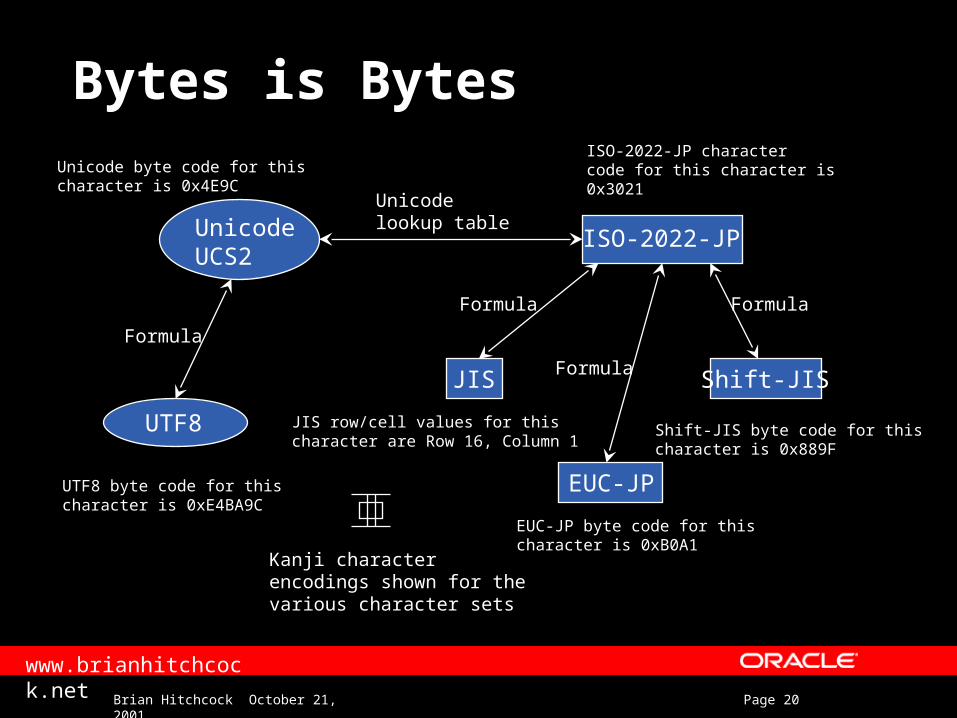
Bytes is Bytes
UnicodeUCS2
UTF8
ISO-2022-JP
JIS
EUC-JP
Shift-JIS
UTF8 byte code for thischaracter is 0xE4BA9C
Kanji characterencodings shown for thevarious character sets
Unicode byte code for thischaracter is 0x4E9C
ISO-2022-JP charactercode for this character is0x3021
JIS row/cell values for thischaracter are Row 16, Column 1
EUC-JP byte code for thischaracter is 0xB0A1
Shift-JIS byte code for thischaracter is 0x889F
Formula
FormulaFormula
Formula
Unicodelookup table

Brian Hitchcock October 21, 2001 Page 21
www.brianhitchcock.net
Conversion Issue
Application Oracle Dbcharacter set WE8ISO8859P1
Export File
Import loadsexport filecharacter set WE8ISO8859P1
Oracle DbCharacter setUTF8
NetscapeBrowserView file
0xB0A1
0xB0A1
0xB0A1
0xC2B0, 0xC2A1
0xC2B0, 0xC2A1
EUC-JP character code forthis character is 0xB0A1
Oracle export hard codes the source db character set into the export file
Flat fileSelect char dataSpool to file
Browser displays the characters forcharacter codes 0xC2B0, 0xC2A1which are the degree sign and theinverted exclamation mark °¡
Correct UTF8 byte code for thischaracter is 0xE4BA9C

Brian Hitchcock October 21, 2001 Page 22
www.brianhitchcock.net
Import to UTF8 ConversionExisting WE8ISO8859P1 data to UTF8 Conversion
EUC-JP encoding for the character is 0xB0A1, but import detects that the datacame from a single-byte export file (WE8ISO8859P1)
Import reads each byte, one at a time, 0xB0A1 becomes 0xB0 followed by 0xA1, and converts these to the Unicode (UCS2) equivalent -- for single-byte character codes, the Unicode equivalent simply has two leading bytes of 0's -- 0xB0 and0xA1 become U+00B0 and U+00A1, import then converts from UCS2 to UTF8
Number of bytes used in UTF8 encoding based on Unicode code point:
Unicode UTF8 bytes0x0000 - 0x007f 0xxxxxxx 0x0080 - 0x07ff 110xxxxx 10xxxxxx 0x0800 - 0xffff 1110xxxx 10xxxxxx 10xxxxxx
00B0 and 00A1 both require 2 bytes in UTF8
00B0 bit pattern is 00A1 bit pattern is
0000 0000 1011 0000 0000 0000 1010 0001
right-most 6 bits go to second UTF8 bytenext 5 bits go in first UTF8 byte
1100 0010 1011 0000 1100 0010 1010 0001 C 2 B 0 C 2 A 1
WE8ISO8859P1 character code 0xB0A1 becomes UTF character codes 0xC2B0, 0xC2A1
The correct conversion of this EUC-JP character code 0xB0A1 to UTF8 is 0xE4BA9C

Brian Hitchcock October 21, 2001 Page 23
www.brianhitchcock.net
What Happened?
Oracle did exactly what is was told to do– Take bytes from WE database– Convert to UTF8 bytes– Export file was made from WE database– WE is single-byte character set– Convert each byte one at a time to UTF8– Kanji character consists of 2 bytes in WE db– Converting each byte to UTF8 not the same
as converting the pair of bytes to UTF8
Yeah, but, application works! (?)

Brian Hitchcock October 21, 2001 Page 24
www.brianhitchcock.net
Where’s the Problem?
UTF8 db has Kanji as 0xC2B0, 0xC2A1 Correct UTF8 encoding is 0xE4BA9C If new, correctly encoded Kanji is inserted
– Database contains two sets of bytes for same Kanji character
– How does app deal with this?
Existing app only works using Netscape Japanese (Auto-Detect) character set
– App is not really UTF8, only works for Japanese characters

Brian Hitchcock October 21, 2001 Page 25
www.brianhitchcock.net
How Does Application Work? Review
– Oracle db created using UTF8 character set– Java retrieves char data (bytes) from UTF8 db
Converts to UCS2 (Unicode)– Java code generates HTML– Client browser displays Kanji characters
Netscape, “Japanese (Auto-Detect)” char set
Application still works– bytes in UTF8 db don’t represent UTF8 encoded
Kanji
Brian Hitchcock October 21, 2001 Page 26
www.brianhitchcock.net
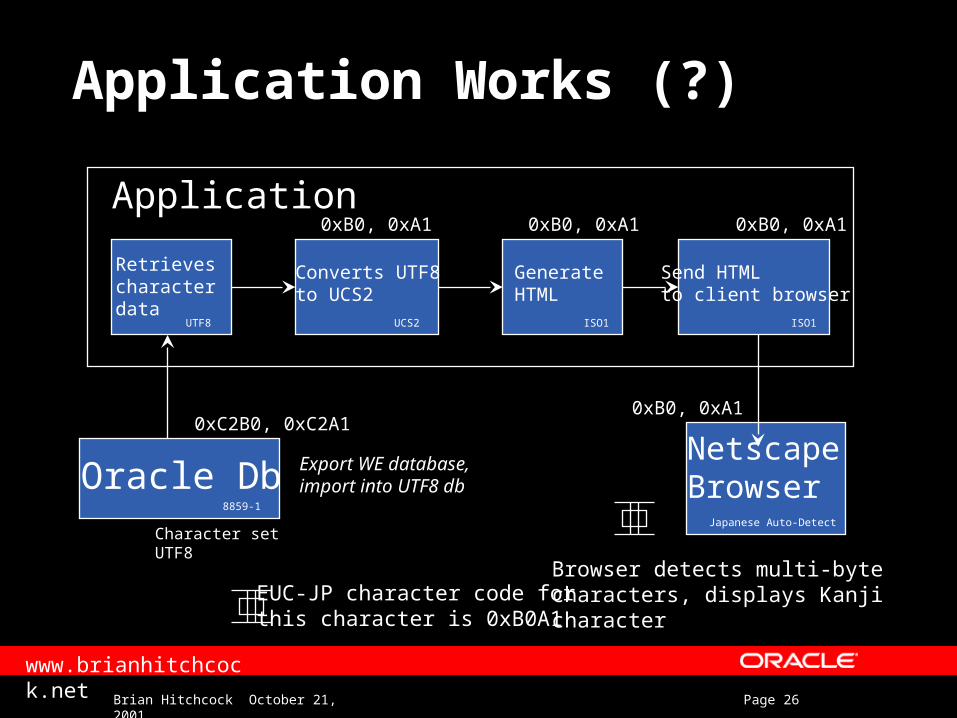
Application Works (?)
NetscapeBrowser
Character setUTF8
Oracle Db
Application
Retrieves character data
Converts UTF8to UCS2
GenerateHTML
Send HTMLto client browser
Browser detects multi-bytecharacters, displays Kanjicharacter
ISO1UCS2 ISO1UTF8
Japanese Auto-Detect
8859-1
0xC2B0, 0xC2A1
0xB0, 0xA1 0xB0, 0xA1 0xB0, 0xA1
0xB0, 0xA1
EUC-JP character code forthis character is 0xB0A1
Export WE database,import into UTF8 db

Brian Hitchcock October 21, 2001 Page 27
www.brianhitchcock.net
Test Application
Insert bytes for correctly encoded Kanji– Into UTF8 db– Use CHR() function
Display this data using existing application– Does NOT display Kanji!
Using “Japanese (Auto-Detect)” character set– Try Netscape UTF8 character set
Doesn’t display Kanji– UTF8 character set should work, shouldn’t it?

Brian Hitchcock October 21, 2001 Page 28
www.brianhitchcock.net
Where Are We?
Correctly encoded UTF8 multi-byte character data for Kanji does not work with existing application
Simply “converting” (export WE, import to UTF8) doesn’t result in correctly encoded UTF8 character data
Need to figure out what app code is doing– Whoever wrote it is gone– The usual state of affairs

Brian Hitchcock October 21, 2001 Page 29
www.brianhitchcock.net
How To Debug App Code?
Don’t use app code– write very simple Java Servlet
(The Java Diva helps with this…)– Servlet simply retrieves character data from
db Runs in iPlanet web server
– generates HTML for client browser
Use servlet to retrieve correct UTF8 Kanji– Does not display Kanji!
Fix servlet then can fix application code?

Brian Hitchcock October 21, 2001 Page 30
www.brianhitchcock.net
Modified Servlet Code
res.setContentType("text/html;charset=UTF-8"); PrintWriter out = new PrintWriter( new OutputStreamWriter(res.getOutputStream(),"UTF-8"),true);
out.println("<META HTTP-EQUIV=" + DQ + "Content-Type" + DQ + " CONTENT=" + DQ + "text/html; charset=utf-8" + DQ + ">");

Brian Hitchcock October 21, 2001 Page 31
www.brianhitchcock.net
Fix Application
Make same changes to application code Browser displays Kanji correctly
– Manually generated, correctly encoded UTF8
Application interacts with Dynamo– Need to reconfigure Dynamo for UTF8 data
Application fixed (?)– Works with correctly encoded UTF8 multi-
byte data

Brian Hitchcock October 21, 2001 Page 32
www.brianhitchcock.net
Is Application really fixed? Fixed app retrieves correctly encoded UTF8
character data What about existing character data?
– Data that was exported from WE and imported into UTF8 db
Use fixed app code to retrieve existing data– Existing Kanji are not displayed
Original app did display existing data...– Existing data is not correctly encoded UTF8
Brian Hitchcock October 21, 2001 Page 33
www.brianhitchcock.net
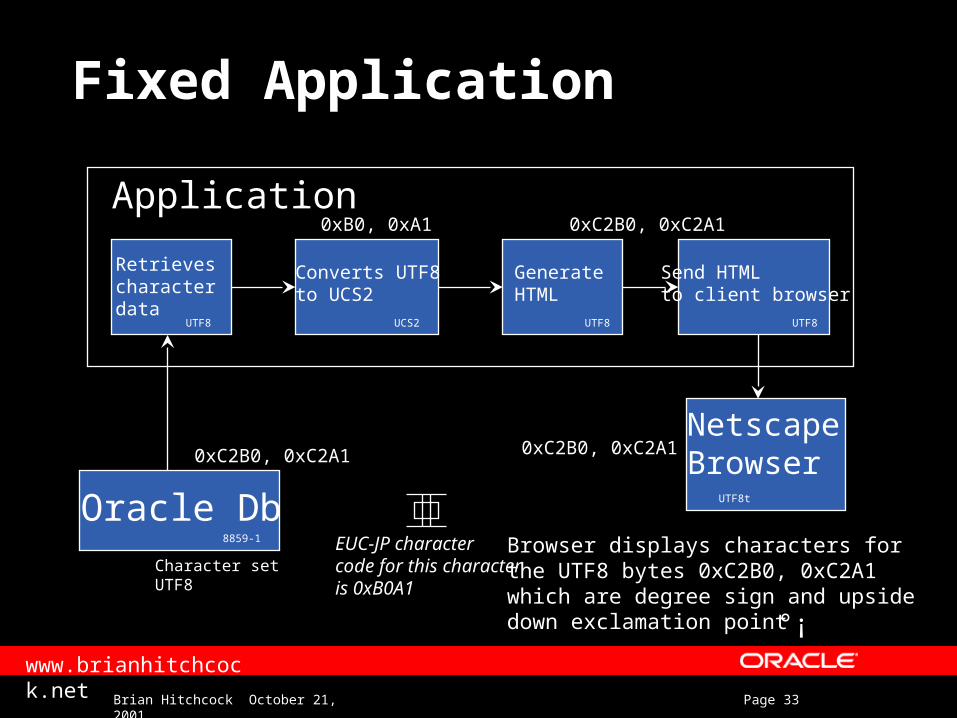
Fixed Application
NetscapeBrowser
Character setUTF8
Oracle Db
Application
Retrieves character data
Converts UTF8to UCS2
GenerateHTML
Send HTMLto client browser
Browser displays characters forthe UTF8 bytes 0xC2B0, 0xC2A1which are degree sign and upsidedown exclamation point
UTF8UCS2 UTF8UTF8
UTF8t
8859-1
0xC2B0, 0xC2A1 0xC2B0, 0xC2A1
0xB0, 0xA1 0xC2B0, 0xC2A1
EUC-JP charactercode for this characteris 0xB0A1
°¡

Brian Hitchcock October 21, 2001 Page 34
www.brianhitchcock.net
How To Fix Existing Data?
What’s wrong with existing data (UTF8 db)– Character data is not correctly encoded UTF8– It is UTF8 encoded Unicode of each single byte
that was exported from WE database
Before importing into UTF8 database?– EUC-JP character set (Latin ASCII and Kanji)– Stored in single-byte WE database
Need to convert UTF8 of WE of EUC-JP to correct UTF8 bytes for Kanji

Brian Hitchcock October 21, 2001 Page 35
www.brianhitchcock.net
Review of Bytes is Bytes
Original Kanji character 0xB0A1 (EUC-JP) Inserted into Oracle database
– 0xB0, 0xA1 in WE8ISO8859P1 db
Exported/imported into Oracle UTF8 db– Individual bytes converted to UTF8
Original Kanji character was 2 bytes Became 4 bytes in UTF8 db 0xC2B0, 0xC2A1
Correct UTF8 bytes are 0xE4BA9C
Brian Hitchcock October 21, 2001 Page 36
www.brianhitchcock.net
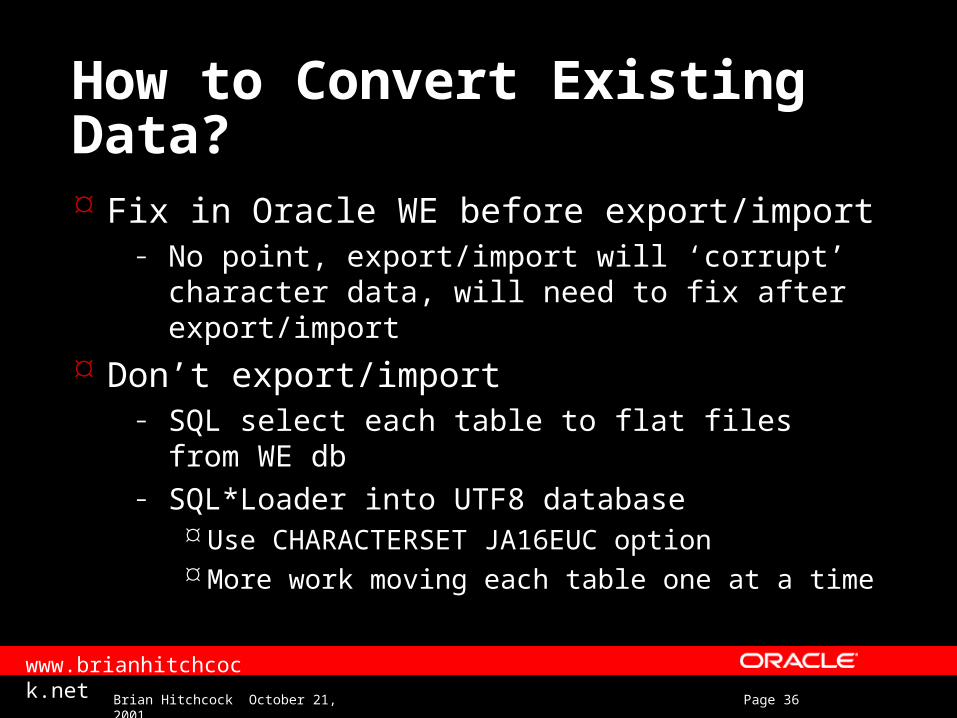
How to Convert Existing Data? Fix in Oracle WE before export/import
– No point, export/import will ‘corrupt’ character data, will need to fix after export/import
Don’t export/import– SQL select each table to flat files from WE
db– SQL*Loader into UTF8 database
Use CHARACTERSET JA16EUC option More work moving each table one at a time
Brian Hitchcock October 21, 2001 Page 37
www.brianhitchcock.net
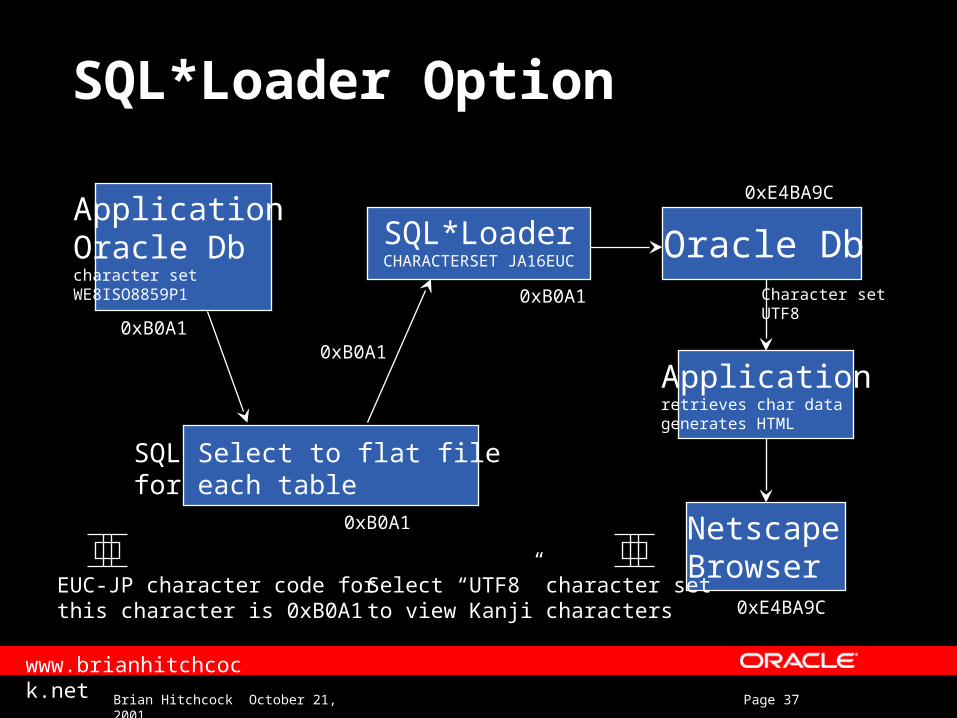
SQL*Loader Option
SQL Select to flat filefor each table
NetscapeBrowser
0xE4BA9C
0xE4BA9C
Character setUTF8
SQL*LoaderCHARACTERSET JA16EUC
0xB0A1
0xB0A1
Oracle Db
0xB0A1
Application Oracle Dbcharacter set WE8ISO8859P1
0xB0A1
EUC-JP character code forthis character is 0xB0A1
Select “UTF8” character setto view Kanji characters
Applicationretrieves char datagenerates HTML

Brian Hitchcock October 21, 2001 Page 38
www.brianhitchcock.net
Convert Existing Data
Fix data after import into UTF8 database– Export from WE, import into UTF8 database– Use Oracle SQL CONVERT() function
CONVERT() from UTF8 to WE8ISO8859P1 CONVERT() from JA16EUC to UTF8
– Need to CONVERT() each column of each table that contains multi-byte data How to be sure which columns to CONVERT()? CONVERT() all columns that contain char data?
– Must test using CONVERT() to verify it works
Brian Hitchcock October 21, 2001 Page 39
www.brianhitchcock.net
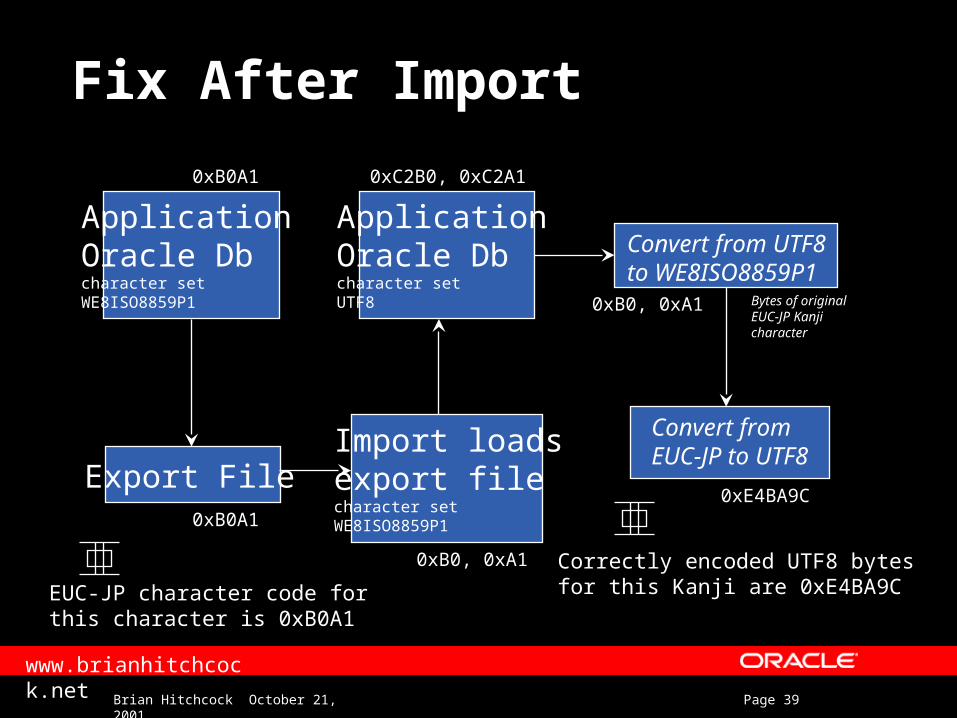
Fix After Import
Application Oracle Dbcharacter set WE8ISO8859P1
Export FileImport loadsexport filecharacter set WE8ISO8859P1
0xB0A1
0xB0A1
0xB0, 0xA1
0xB0, 0xA1
EUC-JP character code forthis character is 0xB0A1
Application Oracle Dbcharacter set UTF8
0xC2B0, 0xC2A1
Convert from UTF8to WE8ISO8859P1
Convert fromEUC-JP to UTF8
0xE4BA9C
Bytes of originalEUC-JP Kanjicharacter
Correctly encoded UTF8 bytesfor this Kanji are 0xE4BA9C

Brian Hitchcock October 21, 2001 Page 40
www.brianhitchcock.net
Oracle CONVERT()
Syntax, examples– select CONVERT(<column>, <destination
char set>, <source char set>) select CONVERT(<column>,
WE8ISO8859P1, UTF8) select CONVERT(<column>, UTF8, JA16EUC)
– Don’t re-run CONVERT() without testing re-run may corrupt data regenerate original source data, re-run
CONVERT()

Brian Hitchcock October 21, 2001 Page 41
www.brianhitchcock.net
Overall Conversion Process What we did…
– Identify tables/columns contain multi-byte data
– Export from WE database– Import into UTF8 database
rows=n, create tables, don’t load data– Widen columns for UTF8 multi-byte data
increase to 3 times original width– Import into UTF8 database (again)
ignore=y, load data into existing tables

Brian Hitchcock October 21, 2001 Page 42
www.brianhitchcock.net
Overall Conversion Process Continued
– CONVERT() columns that contain multi-byte data
– Test, compare with data from existing application/data
Conversion includes converting all pieces of the application, not just the Oracle database

Brian Hitchcock October 21, 2001 Page 43
www.brianhitchcock.net
Details - Source Char Set?
How did I determine this?– Original Kanji data was from EUC-JP– How was this determined?
Examine bytes of original character data Display Original Kanji characters Find single Kanji in Japanese dictionary
Gives row-cell code of Kanji in JIS-0208 Using other reference sources
manually generate bytes for the Kanji in various encodings
Compare with bytes of original Kanji data

Brian Hitchcock October 21, 2001 Page 44
www.brianhitchcock.net
Rosetta Stone?
Oracle8i National Language Support Guide Release 2 (8.1.6) December 1999 Part No. A76966-01 page 3-22

Brian Hitchcock October 21, 2001 Page 45
www.brianhitchcock.net
Reference Books Used
The New Nelson Japanese-English Character Dictionary By John H. Haig,Andrew N. Nelson Published by Periplus Editions, Ltd Date Published: 11/1996 ISBN: 0804820368
The Unicode Standard: With CD-ROM By Unicode Consortium Published by Addison Wesley Longman, Inc. Date Published: 04/1995 ISBN: 0201483459
CJKV Information Processing By Ken Lunde,Gigi Estabrook (Editor) Published by O'Reilly & Associates, Incorporated Date Published: 01/1999 ISBN: 1565922247

Brian Hitchcock October 21, 2001 Page 46
www.brianhitchcock.net
Lessons Learned Oracle (and Sybase) don’t store characters
– They store bytes, strings of bytes
Normally, Oracle does NO checking of character set
– does NOT check that bytes inserted represent correct characters in database character set
Only under specific circumstances does Oracle “apply” a character set to char data
Changing character set affects more than just the database

Brian Hitchcock October 21, 2001 Page 47
www.brianhitchcock.net
Lessons Learned
Bytes of character from any char set can be stored in db of any charset
– EUC-JP char in WE db, in UTF8 db– bytes in db are not ‘correct’ bytes for the
character in the db character set– all apps, users, dbs must know that db
contains char data from other char set– Any char set conversion may corrupt the
char data -- import WE into UTF8 db

Brian Hitchcock October 21, 2001 Page 48
www.brianhitchcock.net
Lessons Learned Simply exporting db, importing into UTF8 does
not solve the problems Testing requires generating correctly encoded
character data Every piece of an application makes a decision
about character set (default) If all data in db really is in the db char set
– export, import to db of other char set works
Need to see original character data– Verify data after char set conversion

Brian Hitchcock October 21, 2001 Page 49
www.brianhitchcock.net
Fill Out a Survey and Get a Chance to Win a Compaq
iPAQ!
We want to know what you think!
Fill out the survey that was handed out at the beginning of the session for a chance to win a
Compaq iPAQ. Remember to include your name and email in the available section and we will
enter your name into two daily drawings to win an iPAQ