ziv bar-yossefmaxim gurevich google and technion technion texpoint fonts used in emf. read the...
TRANSCRIPT

Estimating the ImpressionRank of Web Pages
Ziv Bar-Yossef Maxim GurevichGoogle and Technion Technion

Impressions and ImpressionRankImpression of page/site x
on a keyword w:A user sends w to a search
engineThe search engine returns
x as one of the resultsThe user sees the result x
ImpressionRank of x:# of impressions of x
Within a certain time frameMeasure of page/site
visibility in a search engine
Each result has an impression on the keyword “www 2009”:•www.2009.org•www2009.org/calls.html•www.loginconference.com• ...

Popular Keyword ExtractionThe Popular Keyword Extraction problem:
Input: web page x, int kOutput: k keywords on which x has the most
impressions among all keywordsExample: x = www.johnmccain.com
sarah palin john mccain cindy mccain

MotivationPopularity rating of pages and sitesSite analytics
Enable site owners to determine their visibility in different search engines
Combine with traffic data to derive click-through rates
Compare to other sitesKeyword suggestions for online advertisingSocial analysisSearch engine evaluationFinding similar pages

Internal Measurements of ImpressionRank and Popular Keyword ExtractionSearch engines can compute both
ImpressionRank and popular keywords based on their query logs
Query logs are not publicly released due to privacy concerns
Caveats:Only search engines can do thisNon-transparent

External Measurements of ImpressionRank and Popular Keyword Extraction
Main cost measure: # of requests to the search engine and to the suggestion server
ImpressionRank estimator / Popular keyword extractor
ImpressionRank / Popular Keywords
Target page URL

Our ContributionsReduce ImpressionRank Estimation to
Popular Keyword ExtractionFirst external algorithm for popular keyword
extractionAccurateUses relatively few search engine requestsApplies to:
Single web pages (www.cnn.com) Web sites (www.cnn.com/*) Domains (*.cnn.com/*)

Related WorkKeyword extraction [Frank et al 99, Turney 00, …]
Keyword suggestions (for online advertising) [Yih et al 06, Fuxman et al 08]
Query by Document [Yang et al 09]
Commercial traffic reporting [GoogleTrends, comScore, Nielsen, Compete]

RoadmapThe naïve popular keyword extraction
algorithmThe improved popular keyword extraction
algorithmBest-First Search
Experimental results
Search Engine
Suggestion
Server
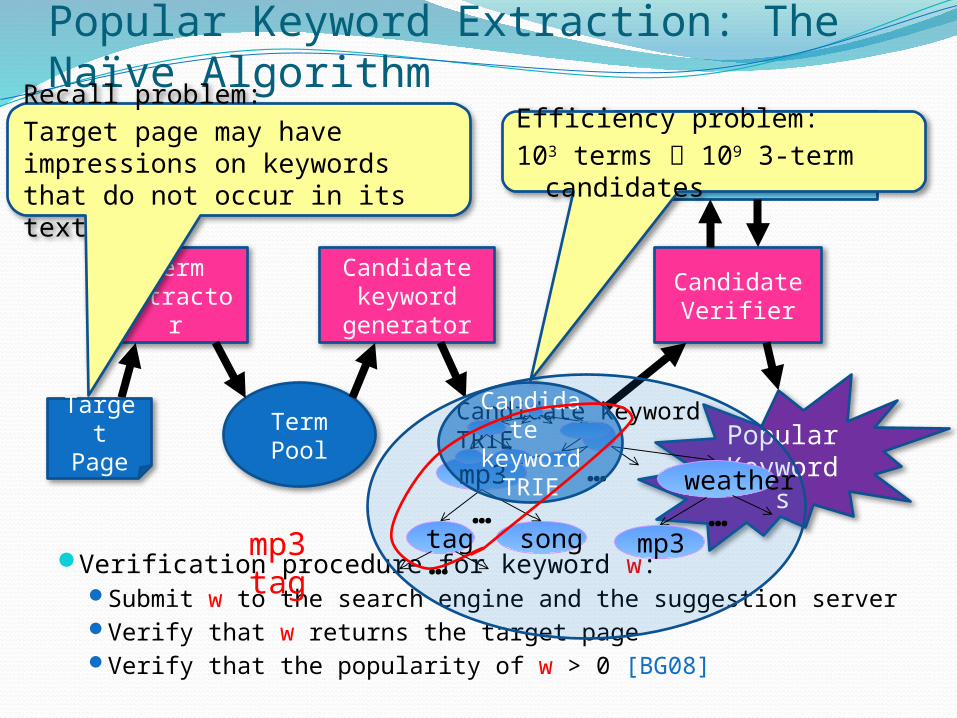
Popular Keyword Extraction: The Naïve Algorithm
Verification procedure for keyword w:Submit w to the search engine and the suggestion serverVerify that w returns the target pageVerify that the popularity of w > 0 [BG08]
Candidate Verifier
Term Extractor
Term Pool
Candidate keyword
generator
Popular Keywor
ds
Recall problem:Target page may have impressions on keywords that do not occur in its text
Efficiency problem:103 terms 109 3-term
candidates
…mp3
songtag
weather…
Candidate keyword TRIE
mp3…
…
Target Page
Candidate
keywordTRIE
mp3 tag

Candidate keyword
generator
Best-First Search
Popular Keywords
Popular Keyword Extraction: The Improved Algorithm
Candidate Verifier
Term Extractor
Term Pool
Target Page
Candidate
keywordTRIE
Target
Page Similar
PagesAnchor Text
Search Engine
Suggestion
Server

…mp3 weather…
mp3songtag…
Candidate keyword TRIE
Best-First Search
Best-First Search
Candidate Verifier
3 5
8
Goals:Prune as many candidates
as possibleVerify the most promising
candidates first
Start with single term candidates
Score candidatesWhile not exceeded search
engine request budgetw = top scoring candidateSend w to the verifierDecide whether to prune wIf not prune w
Expand w – generate and score the children of w
Search Engine
Suggestion Server

PruningPruning decision for keyword w:
Submit query inurl:<target url> w If no results, prune w and all its descendants
Retrieve suggestions for w If no results, prune w and all its descendants
Pruning eliminates the vast majority of candidates
A single search/suggestion request may eliminate thousands of candidates

ScoringThe Best-First search algorithm considers only the
top scoring candidates given the budgetWant to predict
Whether the search engine returns the target page on w
Whether w is a popular keywordscore(w) = tf(w) idf(w) popularity_score(w)
, , and : relative weights of the scoring components
Predicts whether the search engine returns the target
page on w
Predicts the popularity of w

How to Compute Candidate ScoresEvery time the algorithm expands a keyword, it needs to
compute scores for all its childrenThere could be thousands of such children
TF ScoreStraightforward. No search requests needed.
IDF Score Approximated based on an offline corpus. No search
requests needed.Popularity Score
[BarYossefGurevich 08]: Algorithm for estimating keyword popularity using the query suggestion service Too costly: may use dozens of suggestion requests per estimate
We present a new algorithm that estimates popularity for all the children in bulk Uses hundreds of suggestion requests to estimate the popularity
of all the children Estimates are less accurate

Cheap Popularity EstimationInput: a keyword wGoal: Estimate popularity of all w’s children
Bucket children according to their first characterEstimate relative popularity of each bucketEstimate the relative popularity within each bucket
Estimate of popularity_score(pre
fix)
BG08 Popularity Estimator
mp3_
a … s t
mp3 song
mp3 tagmp3 table
…5 6
24
5
mp3 smp3 t
Example: w = “mp3”children: “mp3 song”, “mp3 tag”, “mp3 table”, …

Popular Keyword Extraction Algorithm: Quality AnalysisPrecision: 100%
All extracted keywords return the target pageRecall: do we miss some popular keywords?
More difficult to measure – no ground truth to compare to
Estimate lower bound on the recall
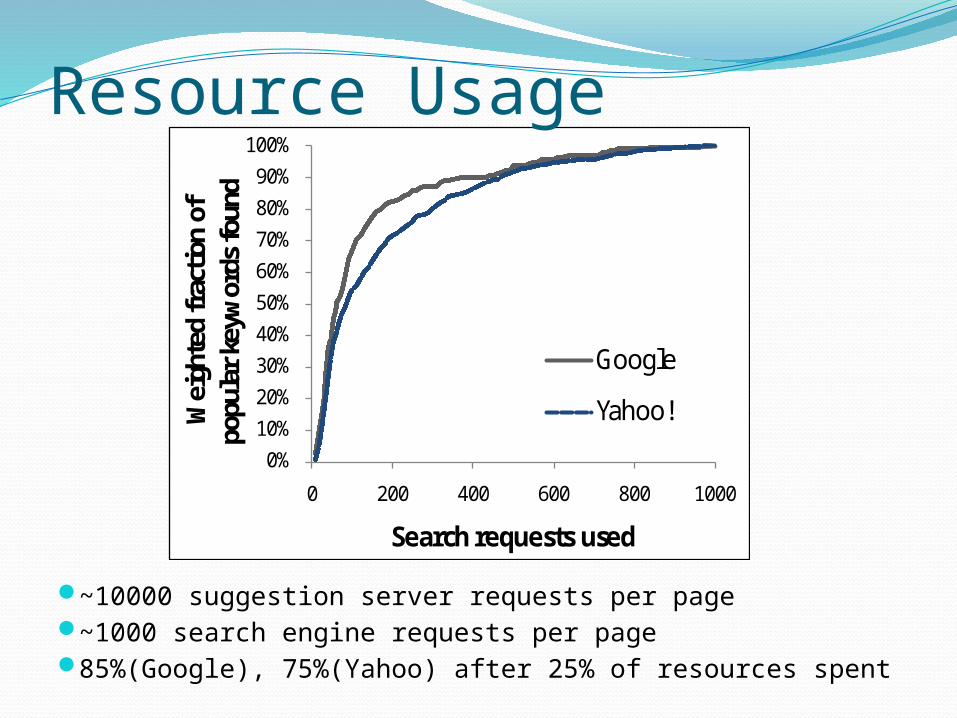
Google: recall > 90%Yahoo!: recall = 70% - 80%
0%10%20%30%40%50%60%70%80%90%
100%
0 200 400 600 800 1000
Wei
ghte
d fr
actio
n of
po
pula
r ke
ywor
ds fo
und
Search requests used
Yahoo!
Resource Usage
~10000 suggestion server requests per page~1000 search engine requests per page85%(Google), 75%(Yahoo) after 25% of resources spent

Google Yahoo! Compete
Rela
tive
Impr
essio
nRan
kcnn.comnytimes.comwashingtonpost.com
ImpressionRank of News Sites(March 2009)
weathercnn
videoobama
weathercnn
bristol palinnews
amazonmoviesbarack obama
stimulus package
new york timesbarack obama

Google Yahoo! Compete
Rela
tive
Impr
essio
nRan
ken.wikipedia.org www.youtube.comwww.facebook.com www.myspace.com
ImpressionRank of Social Sites(March 2009)

ConclusionsFirst external algorithms for
ImpressionRank estimationPopular keyword extraction
Future workImprove efficiencyImprove recall

Thank You