ПВТ - весна 2015 - Лекция 2. posix threads. Основные понятия...
TRANSCRIPT

Лекция 2. POSIX Threads. Жизненный цикл потоков. Планирование. Критические секции. Синхронизация
Пазников Алексей АлександровичКафедра вычислительных систем СибГУТИ
Сайт курса: http://cpct.sibsutis.ru/~apaznikov/teaching/Q/A: https://piazza.com/sibsutis.ru/spring2015/pct2015spring
Параллельные вычислительные технологииВесна 2015 (Parallel Computing Technologies, PCT 15)

POSIX threads (pthreads)
▪ POSIX: Portable Operating Systems Interface for uniX
▪ Стандартный API для работы с потоками в UNIX-подобных системах с 1995 г. (IEEE/ANSI 1003.1c-1995)
▪ Низкоуровневый интерфейс для многопоточного программирования в среде C/UNIX
▪ Основа для других высокоуровных моделей (C++11-threads, OpenMP, Java threads, etc)
2

Модель pthreads
▪ Модель fork-join: потоки могут порождать (spawn, start) другие потоки и ждать их завершения.
▪ Выполнение потоков планируется ОС, они могут выполняться последовательно или параллельно, могут назначаться на произвольные ядра.
▪ Потоки работают независимо, асинхронно.
▪ Для координации доступа должны использоваться механизмы (мьютексы, условные переменные и др.) взаимного исключения
3

Жизненный цикл потоков
4
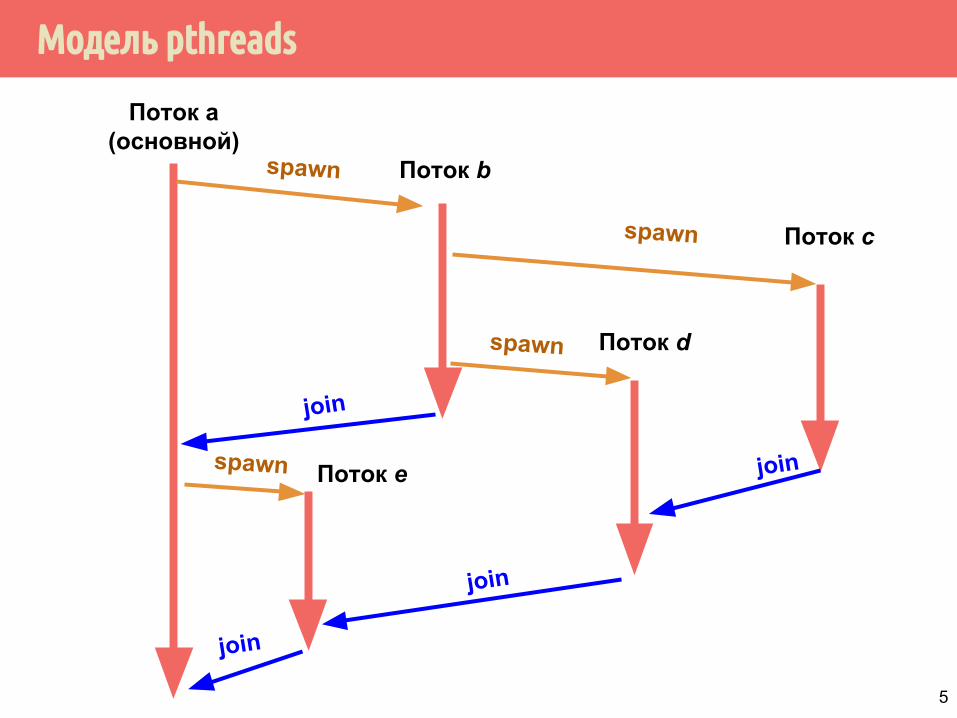
Модель pthreads
Поток а (основной)
Поток b
Поток c
Поток d
Поток e
spawn
spawn
spawn
spawn
join
join
join
join
5

Как использовать
▪ Подключить заголовочный файл <pthread.h>
▪ Все функции начинаются с префикса pthread_
▪ Проверять код ошибки (if (rc != 0) { … })
▪ Компилировать
gcc -Wall -pedantic -O2 -pthread \
-o prog prog.c
6

Порождение потока
int pthread_create(pthread_t *tid, const pthread_attr_t *attr, void *(*start_routine) (void *) fun, void *arg);
tid - идентификатор потока (для завершения, синхронизации и т.д.)attr - параметры потока (например, минимальный размер стека)fun - функция для запуска (принимает и возвращает указатель void*)arg - аргументы функции
7

Порождение и завершение потока
работа ожидание
pthread_create() pthread_join(t2)
pthread_exit(status)
T1
T2
8
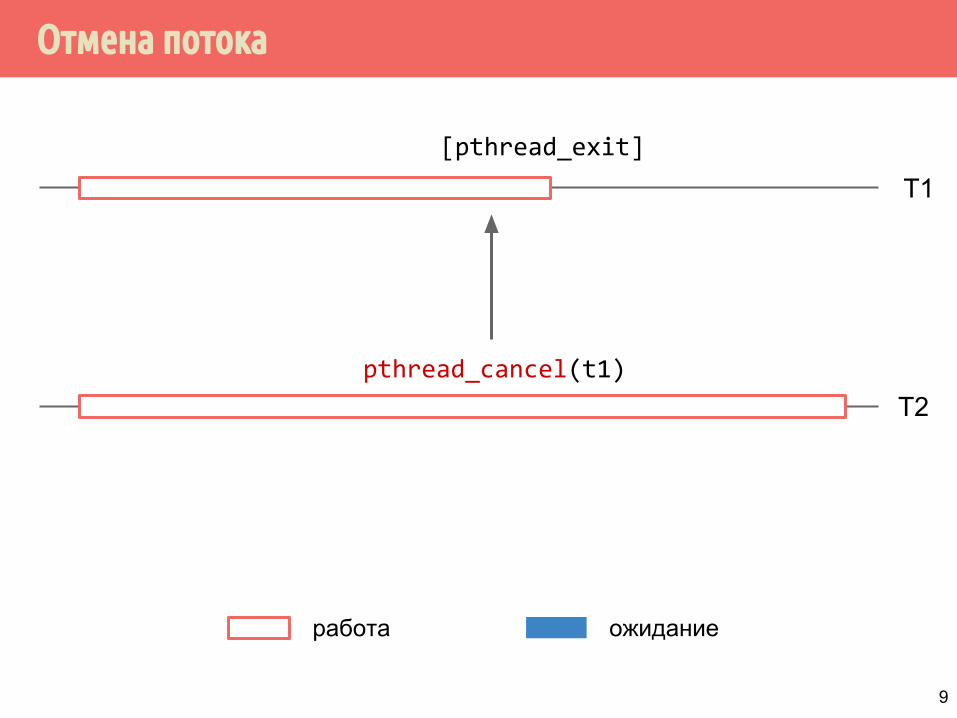
Отмена потока
работа ожидание
pthread_cancel(t1)
T1
T2
[pthread_exit]
9

Порождение и завершение потоков - пример
void *func_a(void *);void *func_b(void *);void *func_c(void *);void *func_d(void *);void *func_e(void *);
pthread_t ta, tb, tc, td, te, tmain;
10

Порождение и завершение потоков - пример (прод.)
void *func_a(void *arg){
sleep(1);pthread_create(&td, &attr, func_d, NULL);sleep(3);/* same as pthread_exit((void*)123); */return((void *) 123);
}
11

Порождение и завершение потоков - пример (прод.)
void *func_b(void *arg){
sleep(4);pthread_exit(NULL);
}
12

Порождение и завершение потоков - пример (прод.)
void *func_c(void *arg){
int err;if (err = pthread_join(tmain, &status)) {
printf(“pthread_join failed:%s”, strerror(err));exit(1);
}
sleep(1);
pthread_create(&tb, &attr, func_b, NULL);
sleep(4);
pthread_exit((void *) 321);}
13

Порождение и завершение потоков - пример (прод.)
void *func_d(void *arg){
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, NULL);pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, NULL);
sleep(1);
pthread_create(&te, &attr, func_e, NULL);
sleep(5);
return((void *) 111);}
14

Порождение и завершение потоков - пример (прод.)
void *func_e(void *arg){
sleep(3);
if (err = pthread_join(ta, &status)) {printf(“pthread_join failed: %s”,
strerror(err));exit(1);
}
sleep(2);
if (err = pthread_join(tc, &status)) {printf(“pthread_join failed: %s”,
strerror(err));exit(1);
}
15

Порождение и завершение потоков - пример (прод.)
if (err = pthread_join(td, &status)) {printf(“pthread_join failed: %s”,
strerror(err));exit(1);
}
sleep(1);
pthread_exit((void *) 88);}
16

Порождение и завершение потоков - пример (прод.)
int main(){
main_thr = pthread_self();
sleep(1);
pthread_create(&ta, &attr, func_a, NULL);
sleep(1);
pthread_create(&tc, &attr, func_c, NULL);
sleep(2);
pthread_cancel(td);
sleep(1);
pthread_exit((void *) NULL);}
17
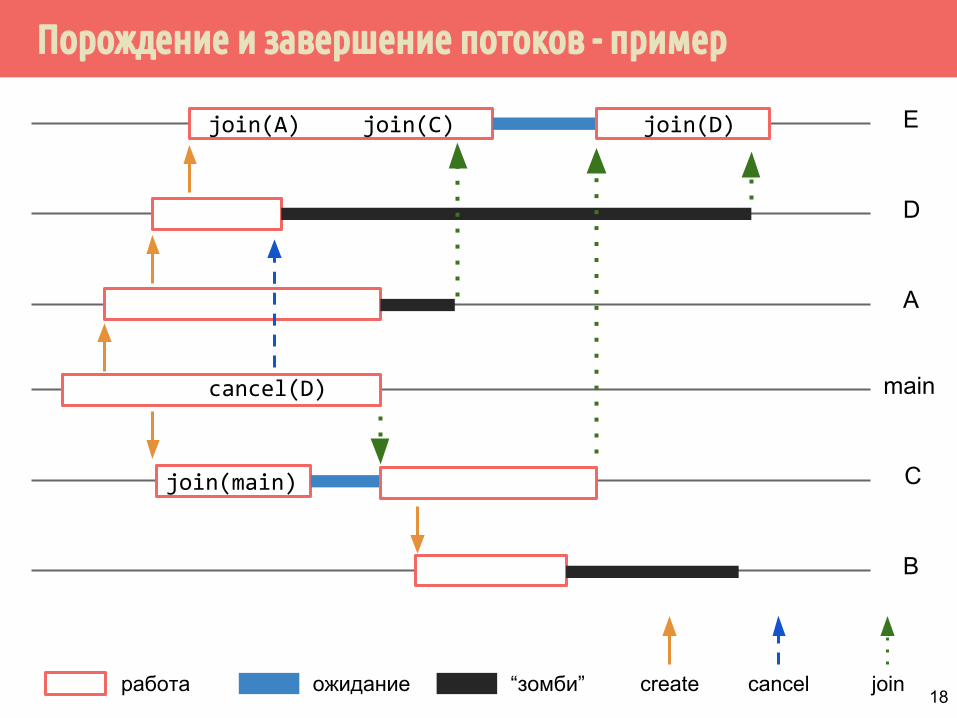
Порождение и завершение потоков - пример
работа ожидание
Ejoin(A) join(C)
“зомби”
join(D)
D
A
main
C
B
create cancel join
cancel(D)
join(main)
18

Передача аргументов потоку
typedef struct bounds { int threadnum; int begin; int end;} bounds_t;
int main() { pthread_t tid[nthreads]; int ti, rc; bounds_t *bounds_arg = (bounds_t *) malloc(sizeof(bounds_t) * nthreads);
for (ti = 0; ti < nthreads; ti++) { bounds_arg[ti].threadnum = ti; bounds_arg[ti].begin = ti * 10 + 1; bounds_arg[ti].end = (ti + 1) * 10; pthread_create(&tid[ti], NULL, thread_func, &bounds_arg[ti]); }
/* join all threads... */
free(bounds_arg);
19
Передача аргументов потоку
void *thread_func(void *arg) { struct bounds *mybounds;
mybounds = (struct bounds *) arg;
printf("hello, i am %d thread, my bounds: %d and %d\n", mybounds->threadnum, mybounds->begin, mybounds->end);
pthread_exit(NULL);}
20
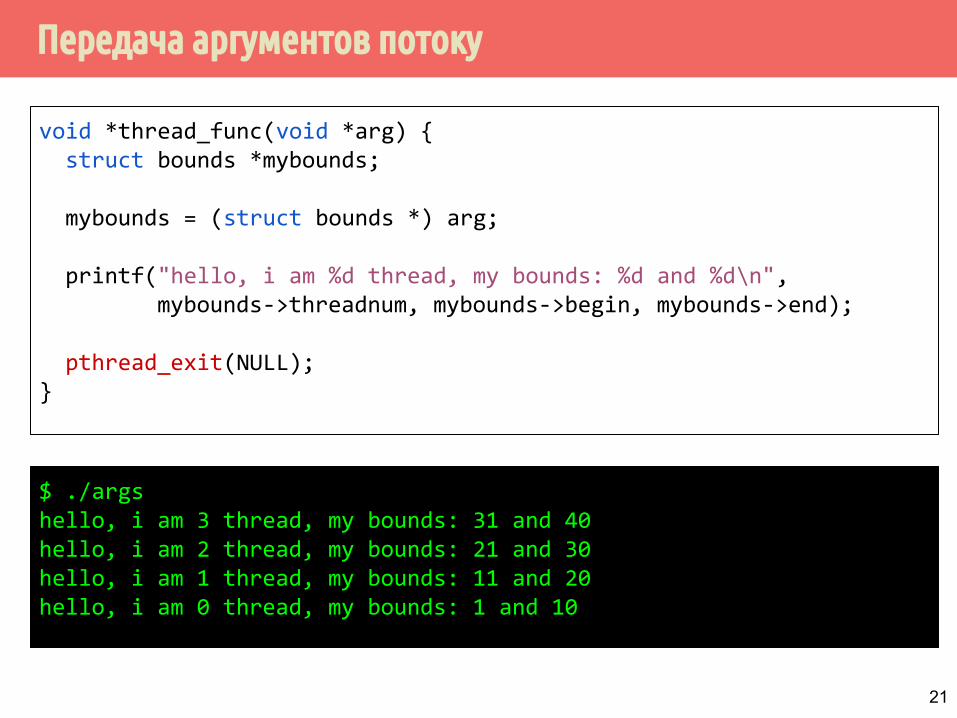
Передача аргументов потоку
void *thread_func(void *arg) { struct bounds *mybounds;
mybounds = (struct bounds *) arg;
printf("hello, i am %d thread, my bounds: %d and %d\n", mybounds->threadnum, mybounds->begin, mybounds->end);
pthread_exit(NULL);}
21
$ ./args hello, i am 3 thread, my bounds: 31 and 40hello, i am 2 thread, my bounds: 21 and 30hello, i am 1 thread, my bounds: 11 and 20hello, i am 0 thread, my bounds: 1 and 10

Планирование выполнения потоков
22
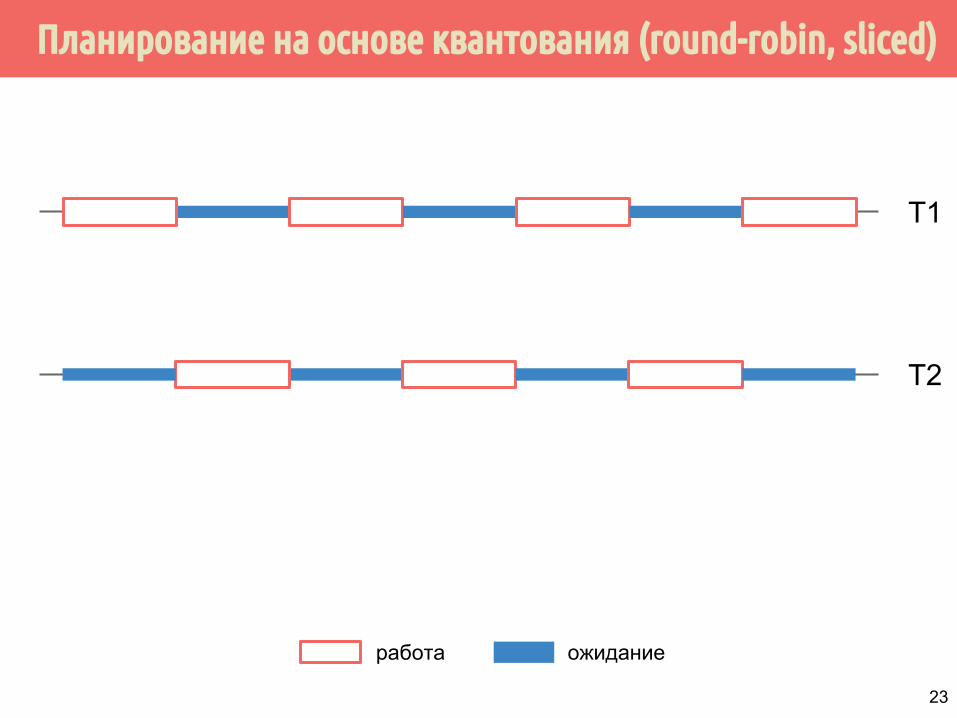
Планирование на основе квантования (round-robin, sliced)
T1
T2
работа ожидание
23
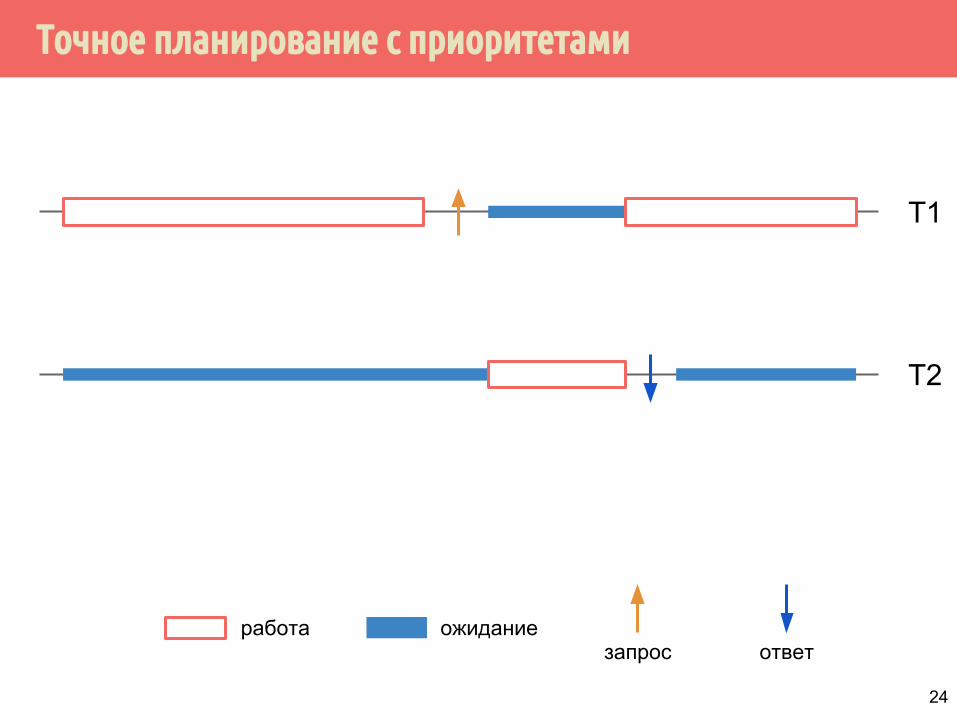
Точное планирование с приоритетами
T1
T2
работа ожиданиезапрос ответ
24

Чем может быть вызвана активация потока
1. Синхронизация (synchronization). T1 запрашивает мьютекс, и если он занят потоком T2, то Т1 встаёт в очередь, тем самым давая возможность другим потокам запуститься.
2. Вытеснение (preemption). Происходит событие, в результате которого высокоприоритетный поток Т2 может запуститься. Тогда поток Т1 с низким приоритетом вытесняется, и Т2 запускается.
3. Уступание (yielding). Программист явно вызывает sched_yield() во время работы Т1, и тогда планировщик ищет другой поток Т2, который может запуститься, и запускает его.
4. Квантование (time-slicing). Квант времени для потока Т1 истёк. Тогда поток Т2 получает квант и запускается.
25
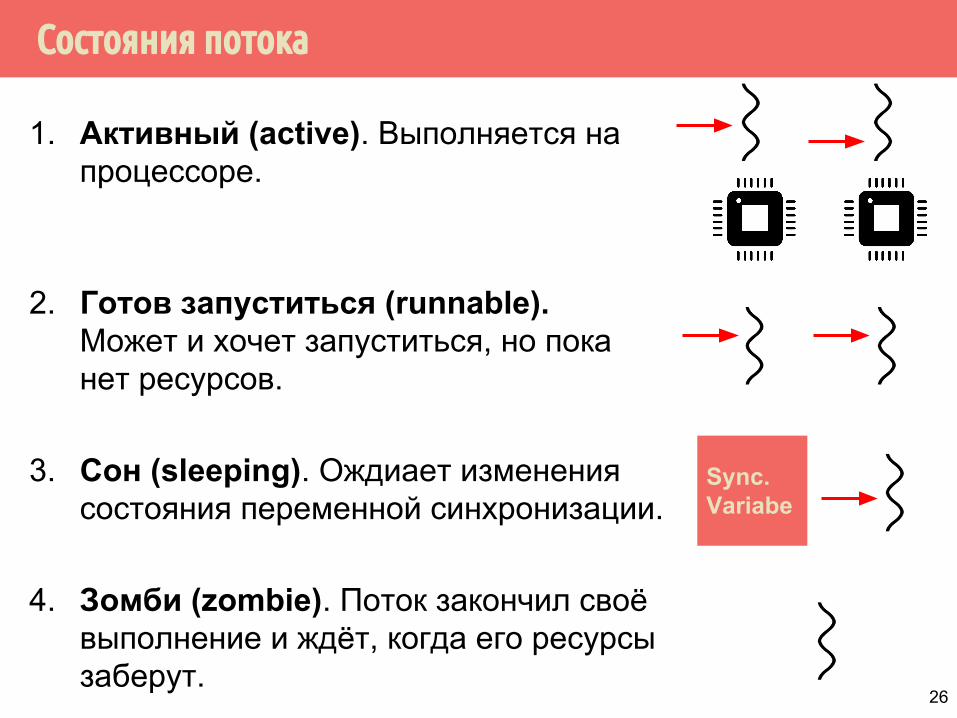
Состояния потока
1. Активный (active). Выполняется на процессоре.
2. Готов запуститься (runnable). Может и хочет запуститься, но пока нет ресурсов.
3. Сон (sleeping). Ождиает изменения состояния переменной синхронизации.
4. Зомби (zombie). Поток закончил своё выполнение и ждёт, когда его ресурсы заберут.
Sync. Variabe
26
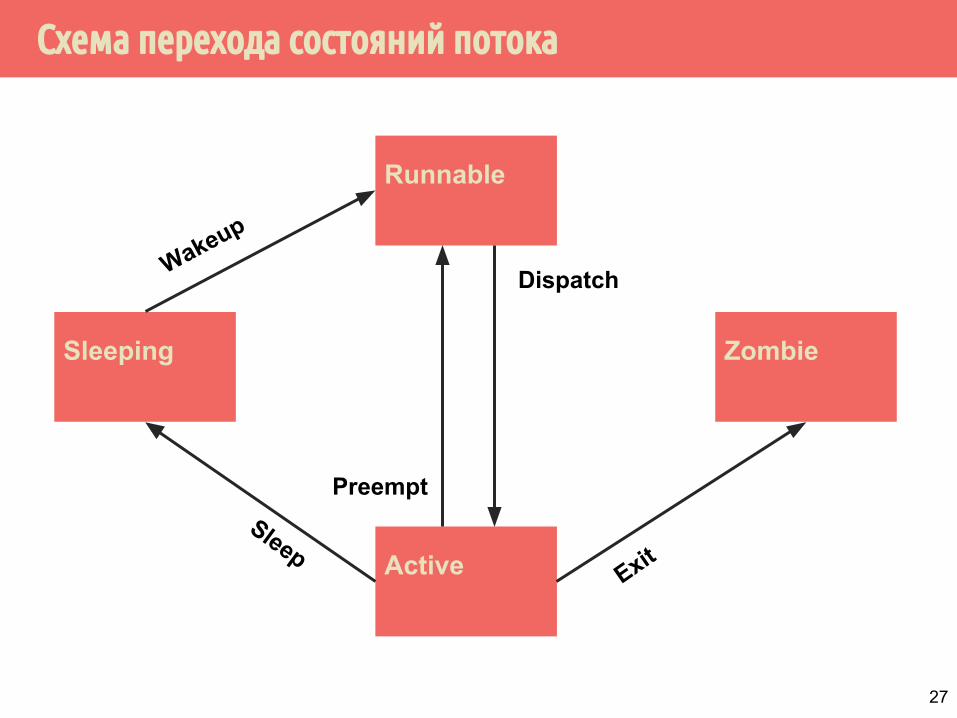
Схема перехода состояний потока
Runnable
Active
ZombieSleeping
Dispatch
Preempt
ExitSleep
Wakeup
27

Пример планирования потоковT1 T2 T3
lock
unlocklock
Held 1
Sleepers ⚫
Time
0
lock
unlocklock1
T2 ⚫
Held 1
Sleepers ⚫
lock
unlocklock2
Held 0
Sleepers ⚫
lock
unlocklock3
Held 1
Sleepers ⚫
SIG
28
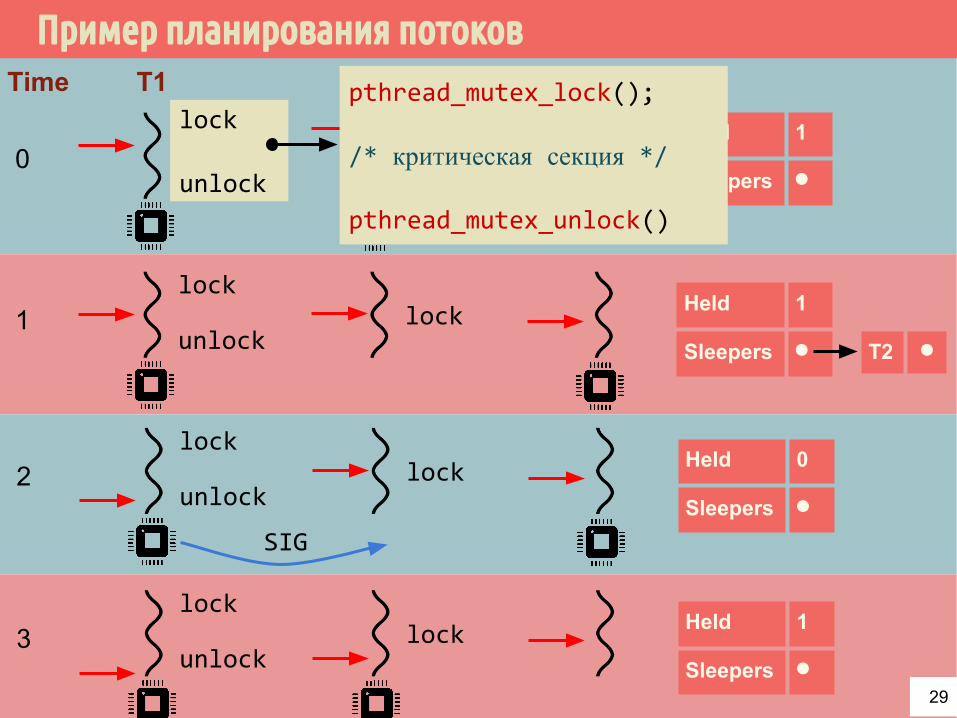
Пример планирования потоковT1 T2 T3
lock
unlocklock
Held 1
Sleepers ⚫
Time
0
lock
unlocklock1
T2 ⚫
Held 1
Sleepers ⚫
lock
unlocklock2
Held 0
Sleepers ⚫
lock
unlocklock3
Held 1
Sleepers ⚫
SIG
pthread_mutex_lock();
/* критическая секция */
pthread_mutex_unlock()
lock
unlock
29
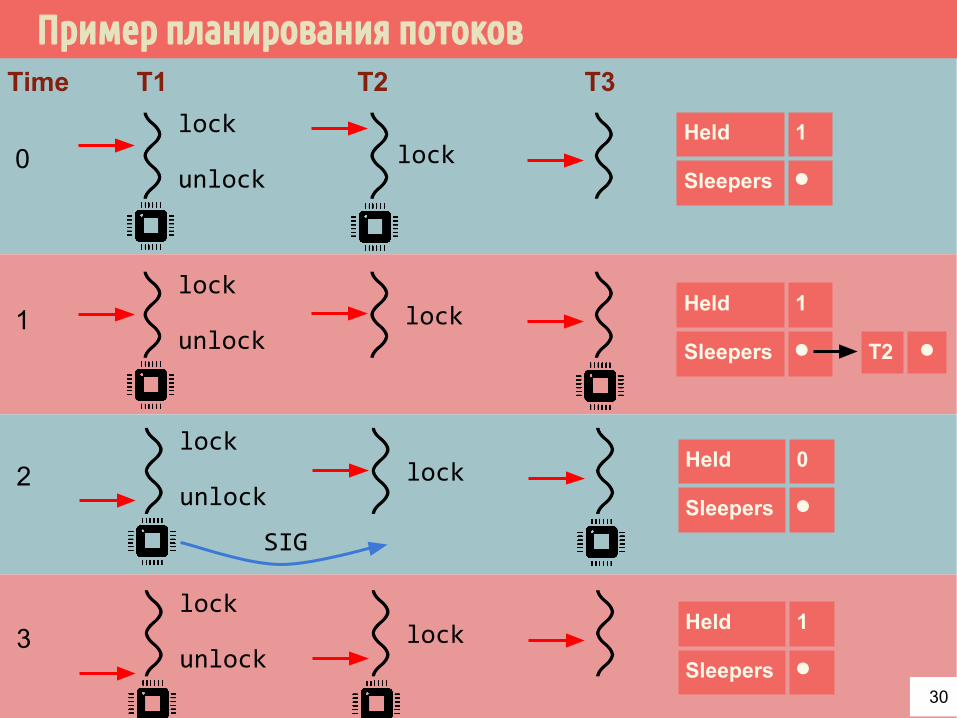
Пример планирования потоковT1 T2 T3
lock
unlocklock
Held 1
Sleepers ⚫
Time
0
lock
unlocklock1
T2 ⚫
Held 1
Sleepers ⚫
lock
unlocklock2
Held 0
Sleepers ⚫
lock
unlocklock3
Held 1
Sleepers ⚫
SIG
30

Как задать политику планирования в pthread
struct sched_param {
int sched_priority;
};
int pthread_setschedparam(pthread_t thread,
int policy,
const struct sched_param *param);
int pthread_getschedparam(pthread_t thread,
int *policy,
struct sched_param *param);
Real-time policies:
● SCHED_FIFO
● SCHED_RR
● SCHED_DEADLINE
Normal policies:
● SCHED_OTHER
● SCHED_BATCH
● SCHED_IDLE
0
1..99
31

Нормальное планирование: SCHED_OTHER
SCHED_OTHER
▪ Планирование с разделением времени по умолчанию в Linux.
▪ Используется динамический приоритет, основанный на значении nice value (nice, setpriority, sched_setattr), которое повышается каждый раз, когда поток может запуститься (runnable), но откладывается планировщиком.
▪ Обеспечивает справедливое (fair) планирование.
32

Нормальное планирование: SCHED_BATCH
SCHED_BATCH (начиная с 2.6.16)▪ Похоже на SCHED_OTHER (планирует потоки в
соответствии с динамическим приоритетом)
▪ Планировщик всегда предполагает, что поток требователен к ресурсу процессора (CPU-intensive).
▪ Планировщик назначает штрафы (penalty) на активацию потока.
▪ Для неинтерактивных задач, выполняющих большой объем вычислений без уменьшение значения nice или
▪ В задачах, для которых требуется детерминированное поведение при планировании (пакетная обработка задач - batch processing).
33

Нормальное планирование: SCHED_BATCH
SCHED_IDLE (начиная с 2.6.23)
▪ Планирование низкоприоритетных задач.
▪ Приоритет со значением nice ниже +19.
34
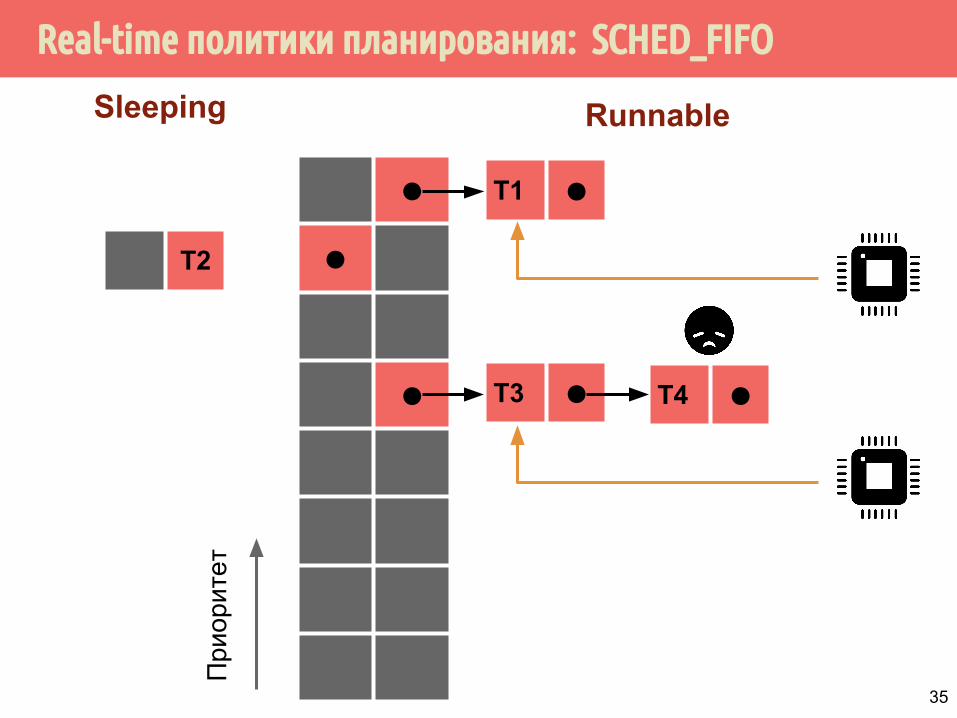
Real-time политики планирования: SCHED_FIFO
⬤
⬤
⬤
При
орит
ет
T3 ⬤ T4 ⬤
T1 ⬤
T2
Sleeping Runnable
35
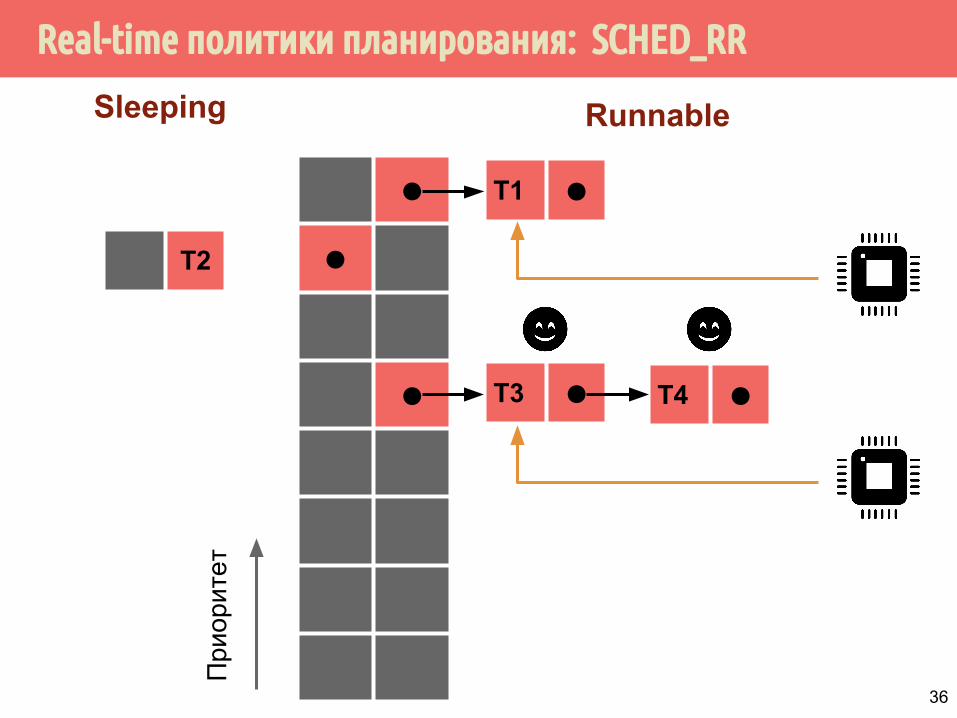
Real-time политики планирования: SCHED_RR
⬤
⬤
⬤
При
орит
ет
T3 ⬤ T4 ⬤
T1 ⬤
T2
Sleeping Runnable
36

Real-time политики планирования: SCHED_DEADLINE
SCHED_DEADLINE (начиная с 3.14)● Спорадическая модель планирования.
● Основан на алгоритмах GEDF (Global Earliest Deadline First) и CBS (Constant Bandwidth Server)
● Спорадическое пакет задач (sporadic task) - последовательность задач, где каждая задача запускается не более 1 раза за период.
● Каждая задача также имеет относительный дедлайн (relative deadline), до которого она должна завершиться, и время вычислений, в течение которого она будет занимать процессор.
37

Real-time политики планирования: SCHED_DEADLINE
SCHED_DEADLINE (начиная с 3.14)● Момент, когда пакет задач должен начаться
выполняться из-за того, что пришла новая задача, называется время поступления.
● Время начала выполнения - это время, когда пакет начинает выполняться.
● Абсолютный дедлайн = относительный дедлайн + время поступления.
38
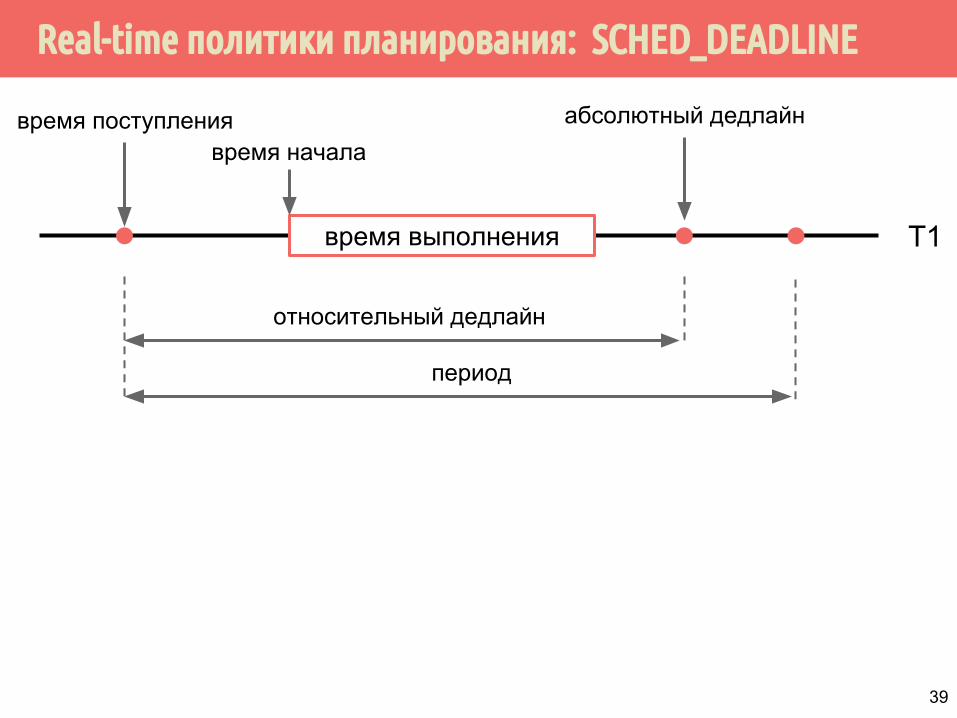
Real-time политики планирования: SCHED_DEADLINE
T1время выполнения
время поступлениявремя начала
абсолютный дедлайн
относительный дедлайн
период
39
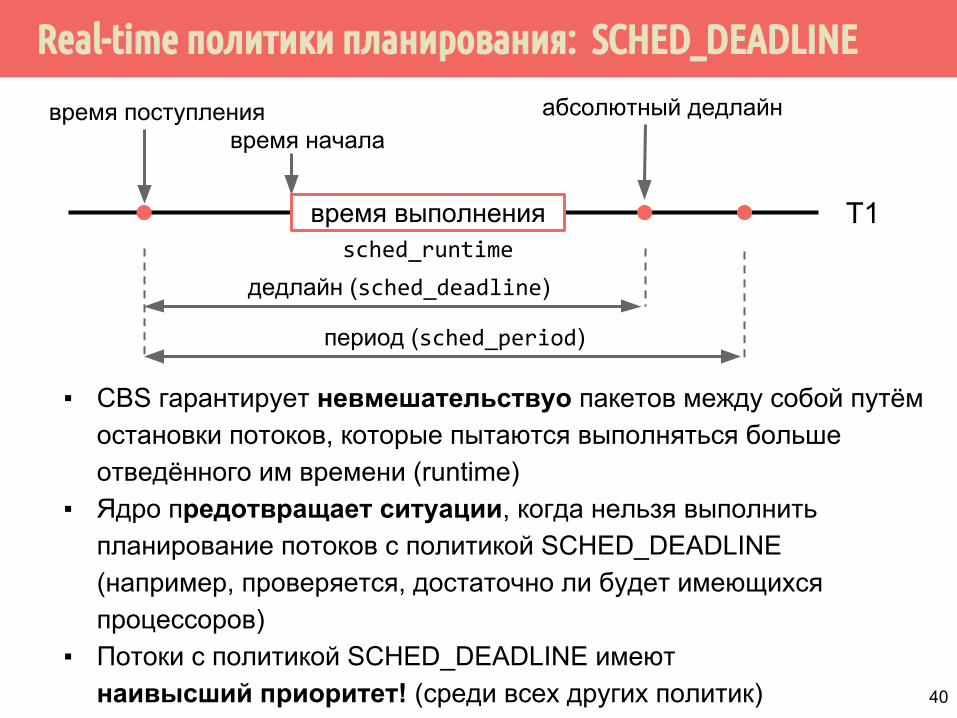
Real-time политики планирования: SCHED_DEADLINE
▪ CBS гарантирует невмешательствуо пакетов между собой путём остановки потоков, которые пытаются выполняться больше отведённого им времени (runtime)
▪ Ядро предотвращает ситуации, когда нельзя выполнить планирование потоков с политикой SCHED_DEADLINE (например, проверяется, достаточно ли будет имеющихся процессоров)
▪ Потоки с политикой SCHED_DEADLINE имеют наивысший приоритет! (среди всех других политик)
T1время выполнения
время поступлениявремя начала
абсолютный дедлайн
дедлайн (sched_deadline)
период (sched_period)
sched_runtime
40

Правила использования real-time политик планирования
▪ По возможности, никогда не использовать real-time политики.
▪ Если вам требуется полное внимание пользователя на чём-то постоянно изменяющемся (движение курсора, поток видео или аудио)
▪ Осуществление обратной связи и контроль (управление машинами, роботами)
▪ Сбор и обработка статистики в реальном времени.
41

Советы
▪ Оптимизируйте работу кэша
▫ Переключения контекста вызывают копирование кэша - это очень долго.
▫ Используйте привязку выполнения потоков к ядрам процессора (processor affinity).
▪ Если вы много думаете об планировании - вероятно, вы делаете что-то не так.
42

Взаимное исключение потоков. Критические секции
43

Проблема взаимного исключения
44
while (!bDone) { DWORD rc = glpi(buffer, &returnLength);
if (FALSE == rc) { if (GetLastError() == ERROR_INSUFFICIENT_BUFFER) { if (buffer) free(buffer);
buffer = reinterpret_cast<PSYSTEM_LOGICAL_PROCESSOR_INFORMATION>( ::malloc( returnLength ) );
if (NULL == buffer) { // allocation failed return; } } else { // System error // _tprintf(TEXT("\nError %d\n"), GetLastError()); return; } }
while (!bDone) { DWORD rc = glpi(buffer, &returnLength);
if (FALSE == rc) { if (GetLastError() == ERROR_INSUFFICIENT_BUFFER) { if (buffer) free(buffer);
buffer = reinterpret_cast<PSYSTEM_LOGICAL_PROCESSOR_INFORMATION>( ::malloc( returnLength ) );
if (NULL == buffer) { // allocation failed return; } } else { // System error // _tprintf(TEXT("\nError %d\n"), GetLastError()); return; } }T1
T2
while (!bDone) { DWORD rc = glpi(buffer, &returnLength);
if (FALSE == rc) { if (GetLastError() == ERROR_INSUFFICIENT_BUFFER) { if (buffer) free(buffer);
buffer = reinterpret_cast<PSYSTEM_LOGICAL_PROCESSOR_INFORMATION>( ::malloc( returnLength ) );
if (NULL == buffer) { // allocation failed return; } } else { // System error // _tprintf(TEXT("\nError %d\n"), GetLastError()); return; } }
while (!bDone) { DWORD rc = glpi(buffer, &returnLength);
if (FALSE == rc) { if (GetLastError() == ERROR_INSUFFICIENT_BUFFER) { if (buffer) free(buffer);
buffer = reinterpret_cast<PSYSTEM_LOGICAL_PROCESSOR_INFORMATION>( ::malloc( returnLength ) );
if (NULL == buffer) { // allocation failed return; } } else { // System error // _tprintf(TEXT("\nError %d\n"), GetLastError()); return; } }
Проблема взаимного исключения
45
T1
T2

Проблема взаимного исключения
Записать значение переменной i в регистр (регистр = 5)
Поток A: i = i + 1t
Увеличить содержимое регистра (регистр = 6)
Сохранить значение регистра в перменную i (регистр = 6)
Записать значение переменной i в регистр (регистр = 5)
Поток B: i = i + 1
Увеличить содержимое регистра (регистр = 6)
Сохранить значение регистра в перменную i (регистр = 6)
i
5
5
6
6
46

Проблема взаимного исключения
bal = GetBalance(account);
bal += bal * InterestRate;
PutBalance(account, bal);
bal = GetBalance(account);
bal += deposit;
PutBalance(account, bal);
Поток 1 Поток 2
● Критическая секция - участок кода, доступ к которого должен обеспечиваться полностью без прерываний.
● ВСЕ общие данные должны быть защищены.
● Общие данные - те, к которым могут иметь доступ несколько потоков (глобальные, статические переменные и др.).
47

Проблема взаимного исключения
bal = GetBalance(account);
bal += bal * InterestRate;
PutBalance(account, bal);
bal = GetBalance(account);
bal += deposit;
PutBalance(account, bal);
Поток 1 Поток 2
Реализация синхронизация требует аппаратной поддержки атомарной операции test and set (проверить и установить).
test_and_set(address){
result = Memory[address]Memory[address] = 1return result;
}
Установить новое значение (обычно 1) в ячейку и
возвратить старое значение.
48

Простейшая реализация взаимного исключения
// инициализация (к моменту вызова CriticalSection // не гарантируется, что skip == false)skip = false
function CriticalSection() {
while test_and_set(lock) = true
skip // ждать, пока не получится захватить
// только один поток может быть в критической секцииcritical section
// освободить критическую секциюlock = false
}
49

Простейшая реализация взаимного исключения
enter_region: ; Начало функции tsl reg, flag ; Выполнить test_and_set. ; flag - разделяемая переменная, ; которая копируется в регистр ; и затем устанавливается в 1. cmp reg, #0 ; Был flag равен 0 в entry_region? jnz enter_region ; Перейти на начало, если reg ≠ 0 ; то есть flag ≠ 0 на входе ret ; Выход. Флаг был равен 0 на входе. ; Если достигли этой точки, значит ; мы внутри критической секции!
leave_region: move flag, #0 ; записать 0 во флаг ret ; вернуться в вызывающую функцию
50

Мьютексы
/* инициализация мьютекса */int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
/* или */pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
/* уничтожение мьютекса (освобождение ресурсов) */int pthread_mutex_destroy(pthread_mutex_t *mutex);
/* заблокировать мьютекс */int pthread_mutex_lock(pthread_mutex_t *mutex);
/* заблокировать мьютекс и не ожидать разблокировки */int pthread_mutex_trylock(pthread_mutex_t *mutex);
/* разблокировать мьютекс */int pthread_mutex_unlock(pthread_mutex_t *mutex);
51
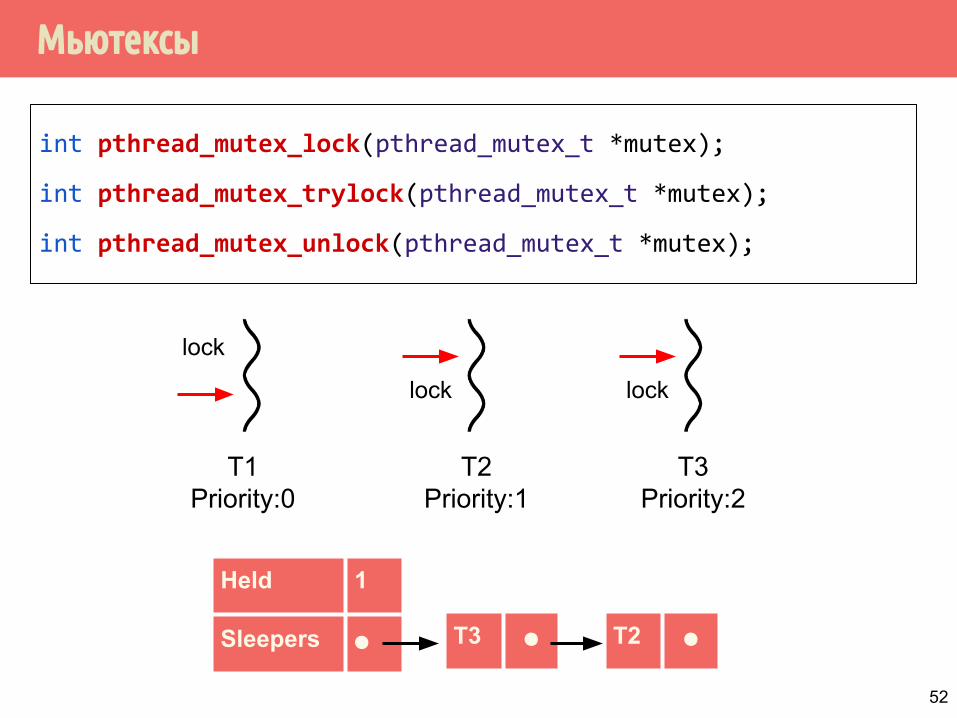
Мьютексы
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
T1Priority:0
T2Priority:1
T3Priority:2
T3 ⚫
Held 1
Sleepers ⚫ T2 ⚫
lock
lock lock
52
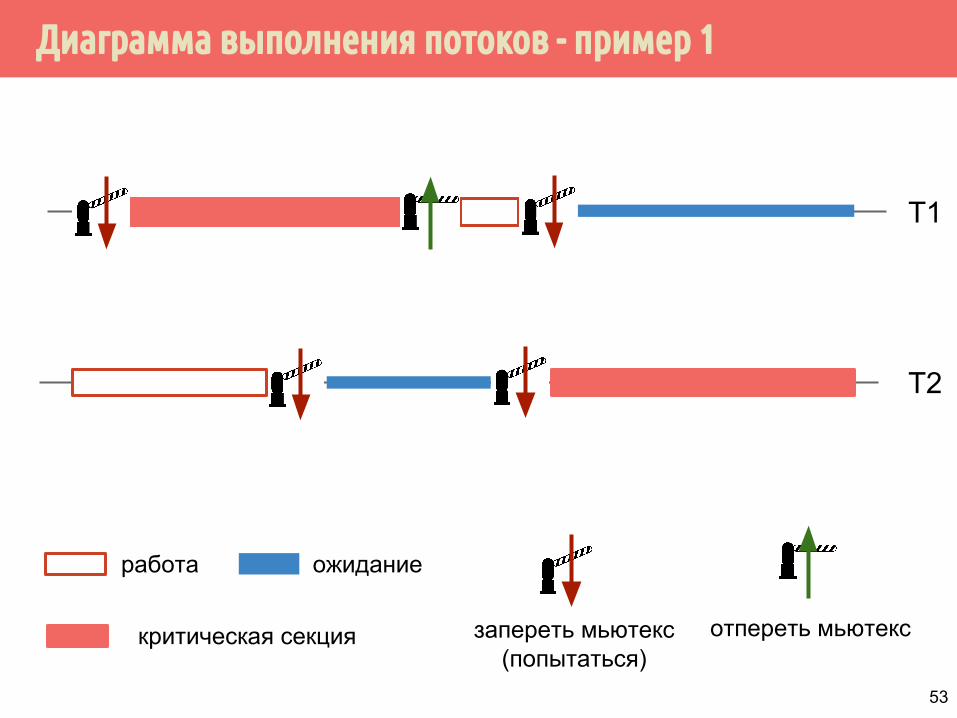
Диаграмма выполнения потоков - пример 1
T1
T2
работа ожидание
запереть мьютекс(попытаться)
отпереть мьютекскритическая секция
53
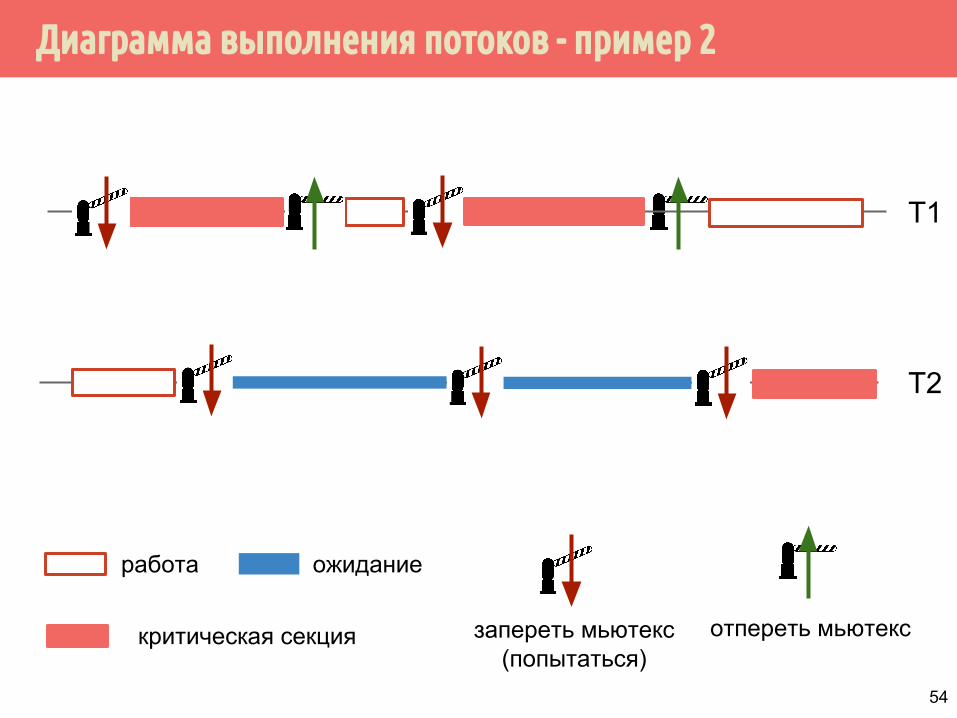
Диаграмма выполнения потоков - пример 2
T1
T2
работа ожидание
запереть мьютекс(попытаться)
отпереть мьютекскритическая секция
54

Вставка и удаление из списка
void add(list_t *item)
{
pthread_mutex_lock(&lock);
item->next = request;
list = item;
pthread_mutex_unlock(&lock);
}
item_t *remove()
{
pthread_mutex_lock(&lock);
item = item->next;
list = list->next;
pthread_mutex_unlock(&lock);
return request;
}
Item 2 Item 1Item 3List
55
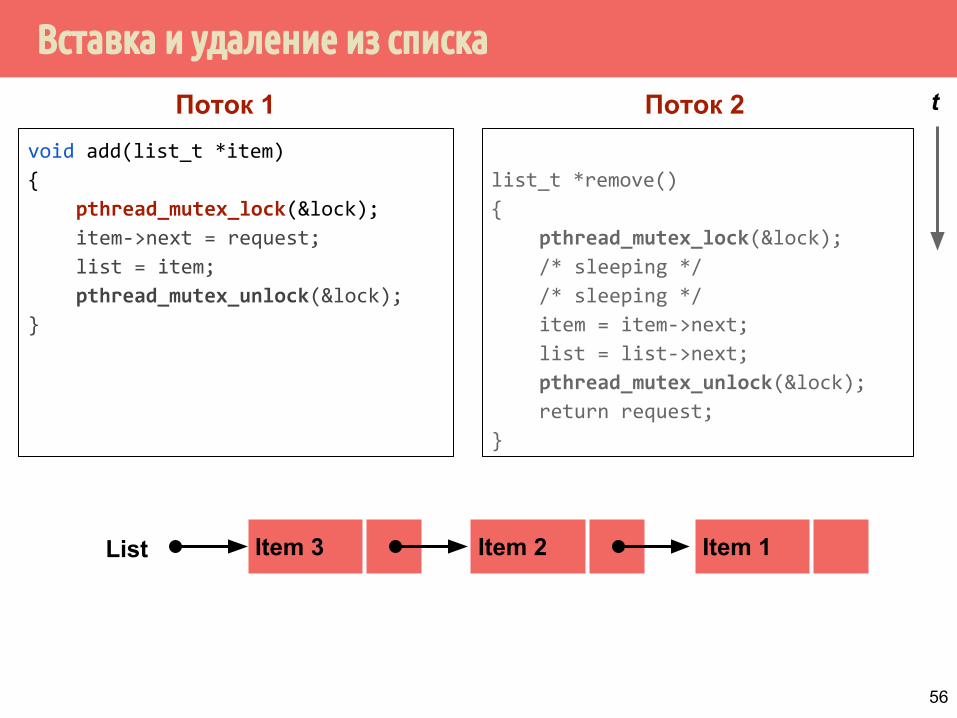
Вставка и удаление из списка
void add(list_t *item)
{
pthread_mutex_lock(&lock);
item->next = request;
list = item;
pthread_mutex_unlock(&lock);
}
list_t *remove()
{
pthread_mutex_lock(&lock);
/* sleeping */
/* sleeping */
item = item->next;
list = list->next;
pthread_mutex_unlock(&lock);
return request;
}
Item 2 Item 1Item 3List
Поток 1 Поток 2 t
56
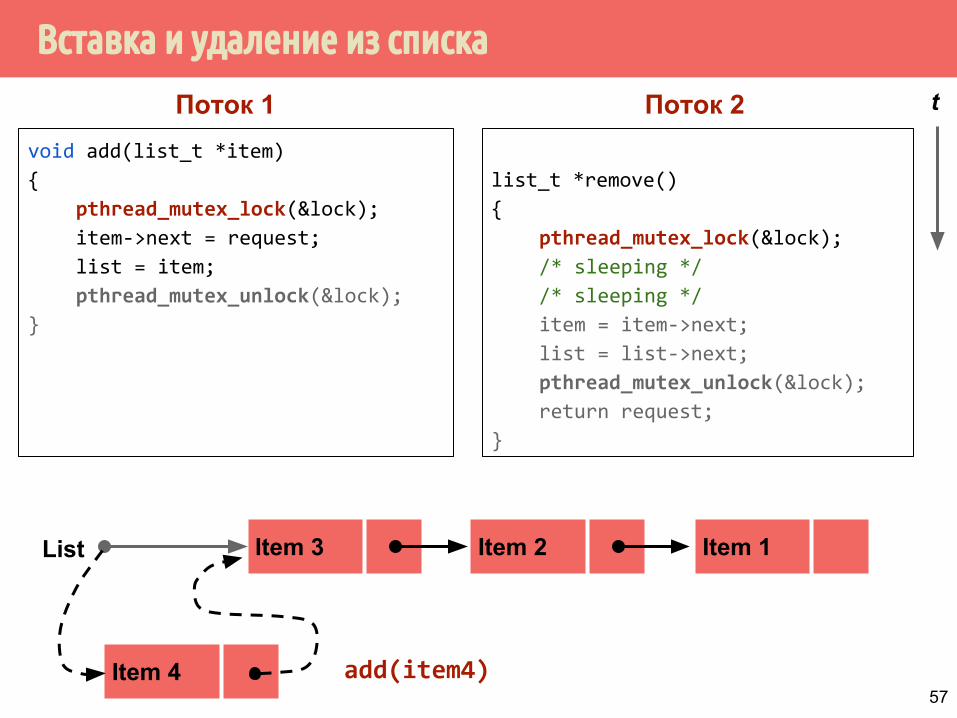
Вставка и удаление из списка
void add(list_t *item)
{
pthread_mutex_lock(&lock);
item->next = request;
list = item;
pthread_mutex_unlock(&lock);
}
list_t *remove()
{
pthread_mutex_lock(&lock);
/* sleeping */
/* sleeping */
item = item->next;
list = list->next;
pthread_mutex_unlock(&lock);
return request;
}
Item 2 Item 1Item 3List
Поток 1 Поток 2 t
Item 4 add(item4)57

Вставка и удаление из списка
void add(list_t *item)
{
pthread_mutex_lock(&lock);
item->next = request;
list = item;
pthread_mutex_unlock(&lock);
}
list_t *remove()
{
pthread_mutex_lock(&lock);
/* sleeping */
/* sleeping */
item = item->next;
list = list->next;
pthread_mutex_unlock(&lock);
return request;
}
Item 2 Item 1Item 3List
Поток 1 Поток 2 t
Item 4
58

Вставка и удаление из списка
void add(list_t *item)
{
pthread_mutex_lock(&lock);
item->next = request;
list = item;
pthread_mutex_unlock(&lock);
}
list_t *remove()
{
pthread_mutex_lock(&lock);
/* sleeping */
/* sleeping */
item = item->next;
list = list->next;
pthread_mutex_unlock(&lock);
return request;
}
Item 2 Item 1Item 3List
Поток 1 Поток 2 t
Item 4
59

Вставка и удаление из списка
void add(list_t *item)
{
pthread_mutex_lock(&lock);
item->next = request;
list = item;
pthread_mutex_unlock(&lock);
}
list_t *remove()
{
pthread_mutex_lock(&lock);
/* sleeping */
/* sleeping */
item = item->next;
list = list->next;
pthread_mutex_unlock(&lock);
return request;
}
Item 2 Item 1Item 3List
Поток 1 Поток 2 t
Item 4
Поток 3:
remove()
60
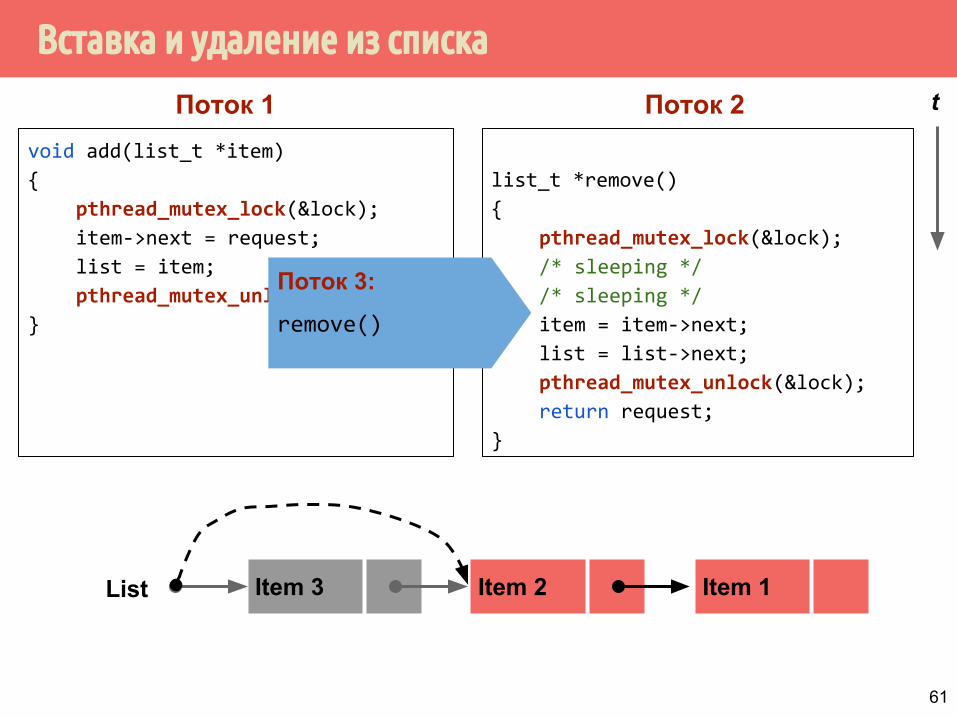
Вставка и удаление из списка
void add(list_t *item)
{
pthread_mutex_lock(&lock);
item->next = request;
list = item;
pthread_mutex_unlock(&lock);
}
list_t *remove()
{
pthread_mutex_lock(&lock);
/* sleeping */
/* sleeping */
item = item->next;
list = list->next;
pthread_mutex_unlock(&lock);
return request;
}
Поток 1 Поток 2 t
Поток 3:
remove()
Item 2 Item 1Item 3List
61
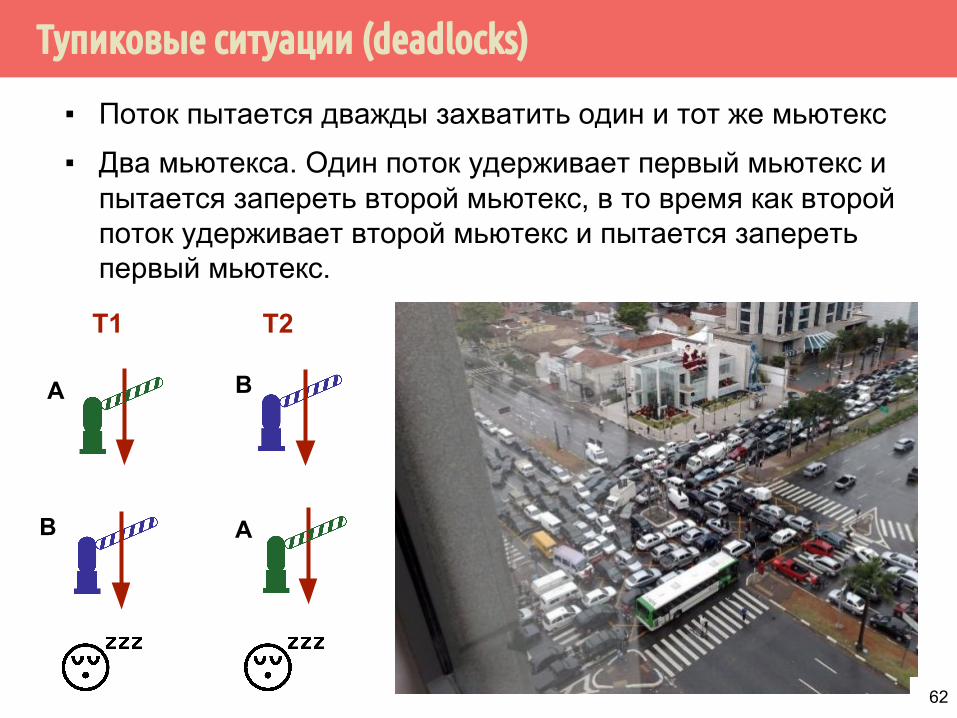
Тупиковые ситуации (deadlocks)
▪ Поток пытается дважды захватить один и тот же мьютекс
▪ Два мьютекса. Один поток удерживает первый мьютекс и пытается запереть второй мьютекс, в то время как второй поток удерживает второй мьютекс и пытается запереть первый мьютекс.
А B
АB
T1 T2
62
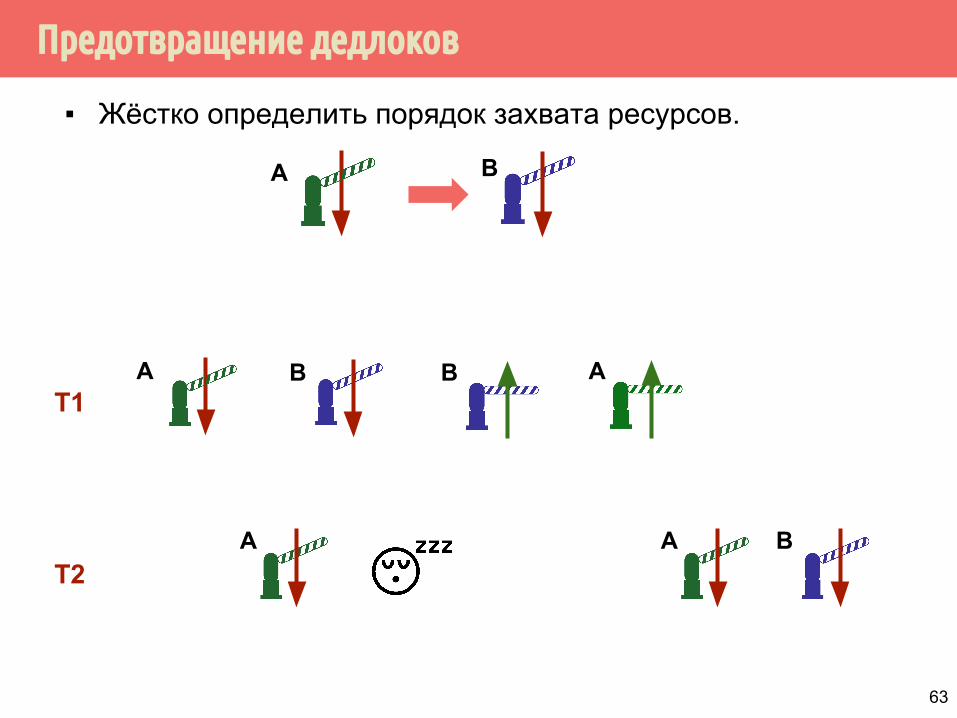
Предотвращение дедлоков
▪ Жёстко определить порядок захвата ресурсов.
А B
А
А
BT1
T2А B
АB
63

Пример работы двух мьютексов
int hash_func(fp) { }
pthread_mutex_t hashlock = PTHREAD_MUTEX_INITIALIZER;
struct elem *ht[SIZE];
struct elem {
int count;
pthread_mutex_t lock;
struct elem *next;
int id;
/* … */
}
64
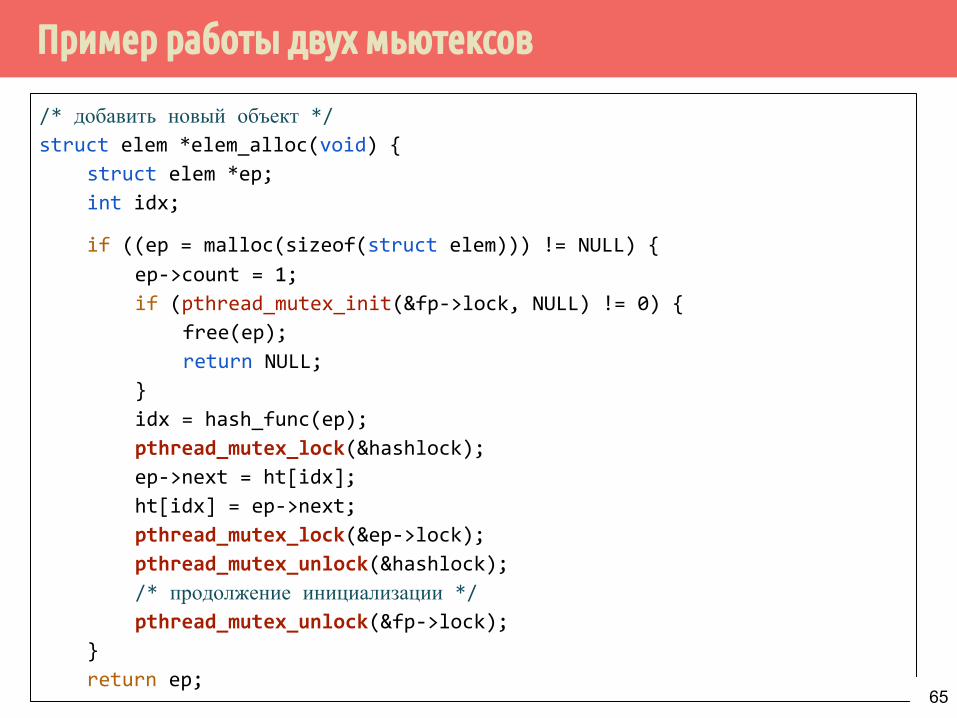
Пример работы двух мьютексов
/* добавить новый объект */struct elem *elem_alloc(void) {
struct elem *ep;
int idx;
if ((ep = malloc(sizeof(struct elem))) != NULL) {
ep->count = 1;
if (pthread_mutex_init(&fp->lock, NULL) != 0) {
free(ep);
return NULL;
}
idx = hash_func(ep);
pthread_mutex_lock(&hashlock);
ep->next = ht[idx];
ht[idx] = ep->next;
pthread_mutex_lock(&ep->lock);
pthread_mutex_unlock(&hashlock);
/* продолжение инициализации */pthread_mutex_unlock(&fp->lock);
}
return ep;65

Пример работы двух мьютексов
/* добавить ссылку на объект */void add_reference(struct elem *ep) {
pthread_mutex_lock(&ep->lock);
ep->count++;
pthread_mutex_unlock(&ep->lock);
}
/* найти существующий объект */struct elem *find_elem(int id) {
struct elem *ep;
int idx;
idx = hash_func(ep);
pthread_mutex_lock(&hashlock);
for (ep = ht[idx]; ep != NULL; ep = ep->next) {
if (ep->id == id) {
add_reference(ep); break;
}
}
pthread_mutex_unlock(&hashlock);
return ep;
} 66
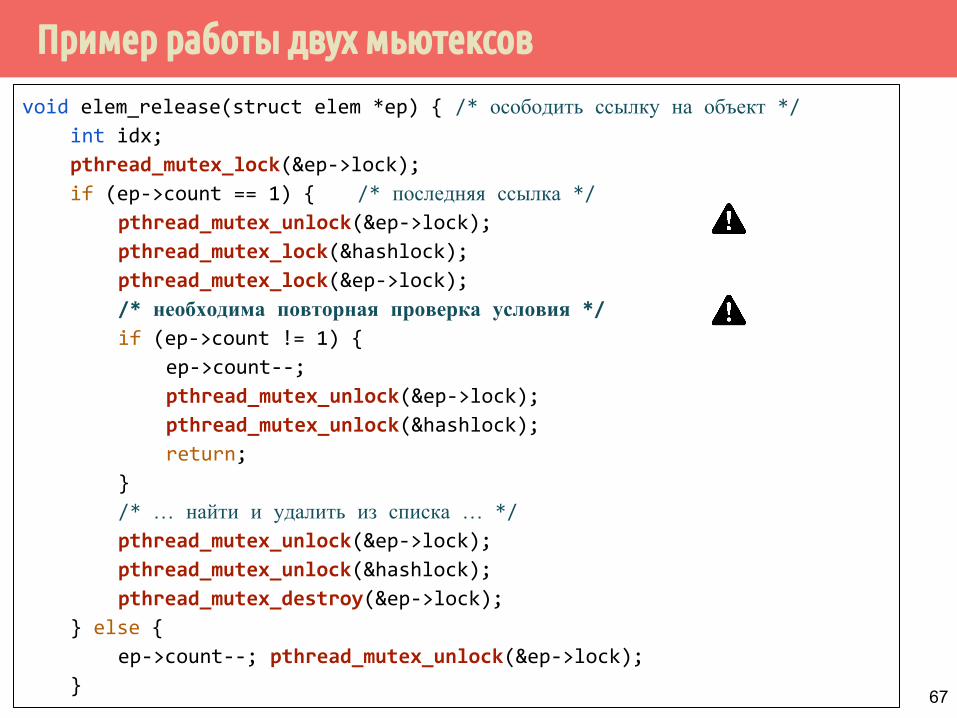
Пример работы двух мьютексов
void elem_release(struct elem *ep) { /* осободить ссылку на объект */int idx;
pthread_mutex_lock(&ep->lock);
if (ep->count == 1) { /* последняя ссылка */pthread_mutex_unlock(&ep->lock);
pthread_mutex_lock(&hashlock);
pthread_mutex_lock(&ep->lock);
/* необходима повторная проверка условия */if (ep->count != 1) {
ep->count--;
pthread_mutex_unlock(&ep->lock);
pthread_mutex_unlock(&hashlock);
return;
}
/* … найти и удалить из списка … */
pthread_mutex_unlock(&ep->lock);
pthread_mutex_unlock(&hashlock);
pthread_mutex_destroy(&ep->lock);
} else {
ep->count--; pthread_mutex_unlock(&ep->lock);
} 67
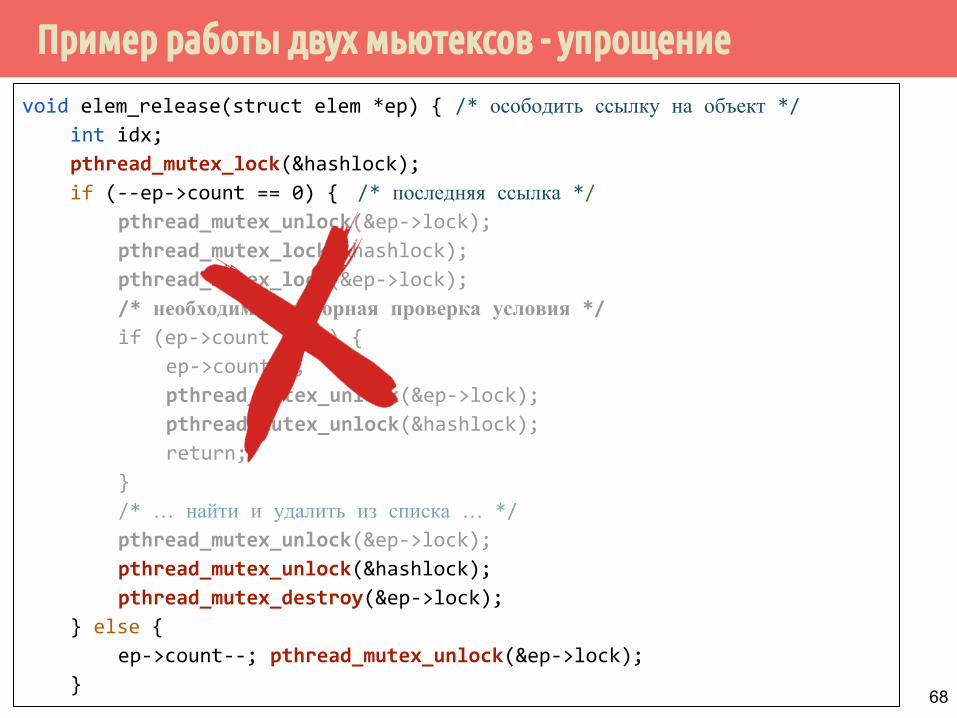
Пример работы двух мьютексов - упрощение
void elem_release(struct elem *ep) { /* осободить ссылку на объект */int idx;
pthread_mutex_lock(&hashlock);
if (--ep->count == 0) { /* последняя ссылка */pthread_mutex_unlock(&ep->lock);
pthread_mutex_lock(&hashlock);
pthread_mutex_lock(&ep->lock);
/* необходима повторная проверка условия */if (ep->count != 1) {
ep->count--;
pthread_mutex_unlock(&ep->lock);
pthread_mutex_unlock(&hashlock);
return;
}
/* … найти и удалить из списка … */
pthread_mutex_unlock(&ep->lock);
pthread_mutex_unlock(&hashlock);
pthread_mutex_destroy(&ep->lock);
} else {
ep->count--; pthread_mutex_unlock(&ep->lock);
}68

Выбор критических секций
При разработке многопоточных программ необходимо учитывать балланс между эффективностью блокировки и её сложностью, которые определяются детализацией (“зернистостью”) критической секции.
▪ Грубая детализация (coarse-grained) критических секций - низкая эффективность, но простота разработки и поддержания кода.
▪ Мелкая детализация (fine-grained) критических секция - высокая эффективность (которая может снизиться из-за избыточного количества критических секций), но сложность кода
69
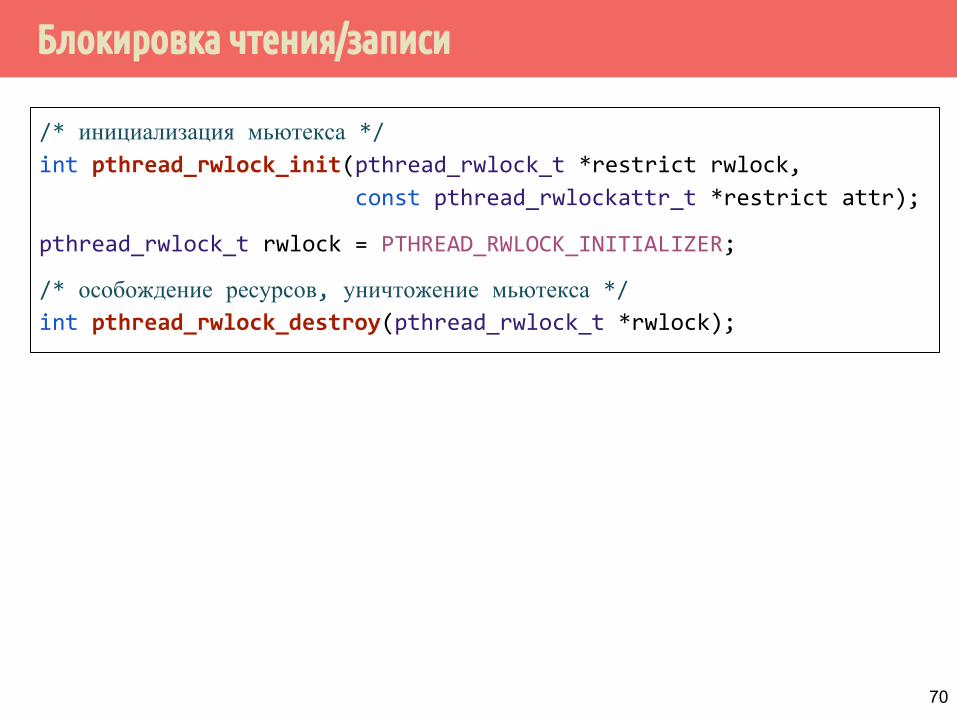
Блокировка чтения/записи
/* инициализация мьютекса */int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,
const pthread_rwlockattr_t *restrict attr);
pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;
/* особождение ресурсов, уничтожение мьютекса */int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
70

Блокировка чтения/записи
/* инициализация мьютекса */int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,
const pthread_rwlockattr_t *restrict attr);
pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;
/* особождение ресурсов, уничтожение мьютекса */int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
/* захватить мьютекс на чтение */int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
/* захватить мьютекс на запись */int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
/* освободить мьютекс */int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
71
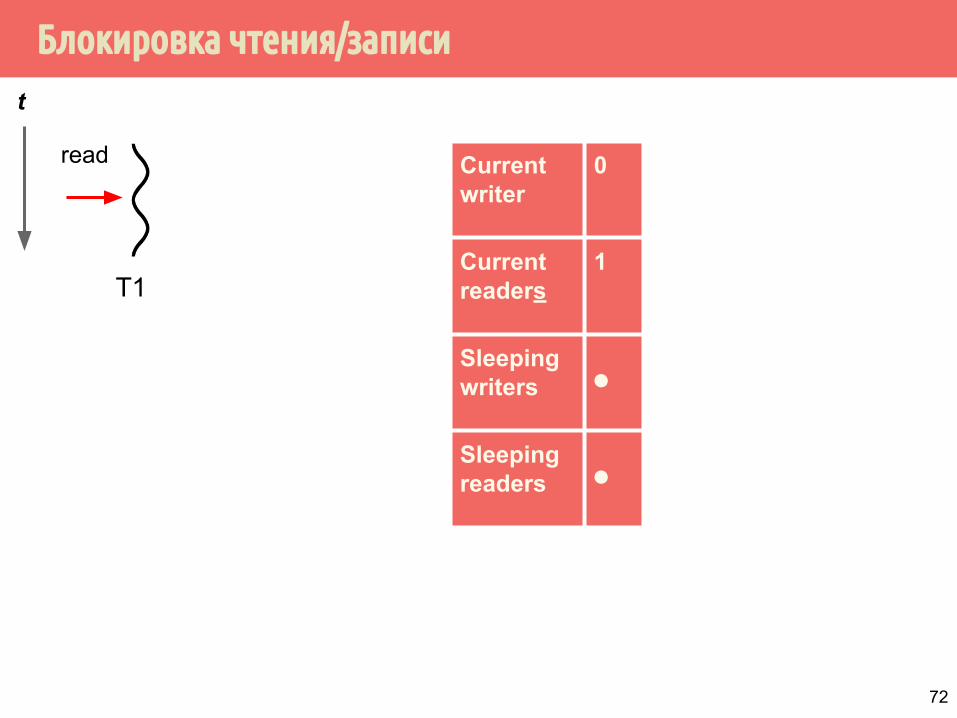
Блокировка чтения/записи
Current writer
0
Current readers
1
Sleeping writers ⚫
Sleeping readers ⚫
t
read
T1
72
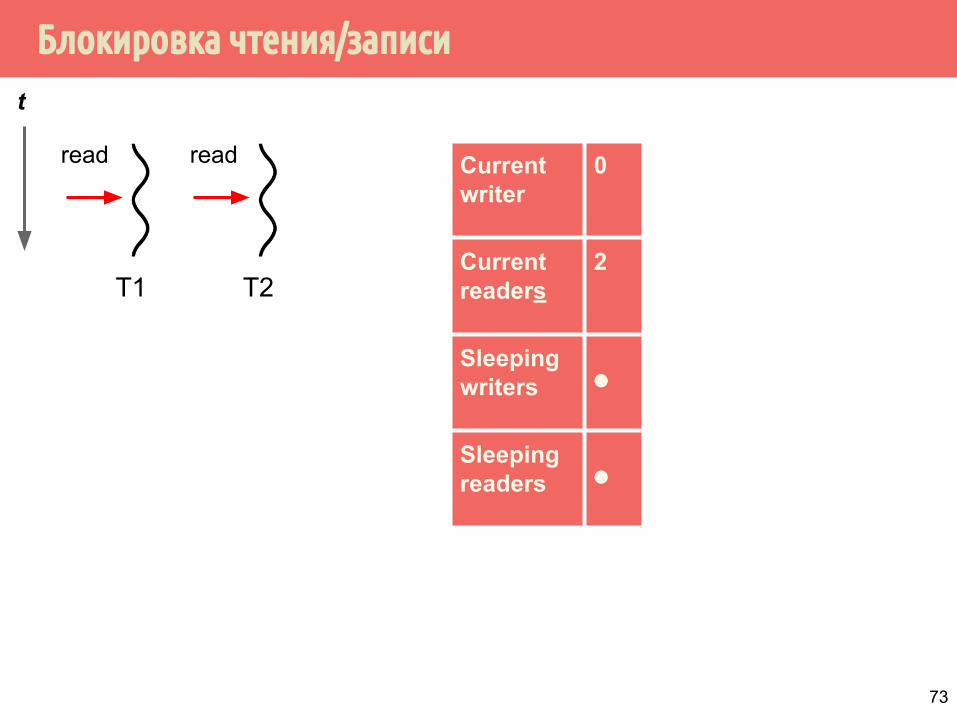
Блокировка чтения/записи
T1
Current writer
0
Current readers
2
Sleeping writers ⚫
Sleeping readers ⚫
t
T2
read read
73
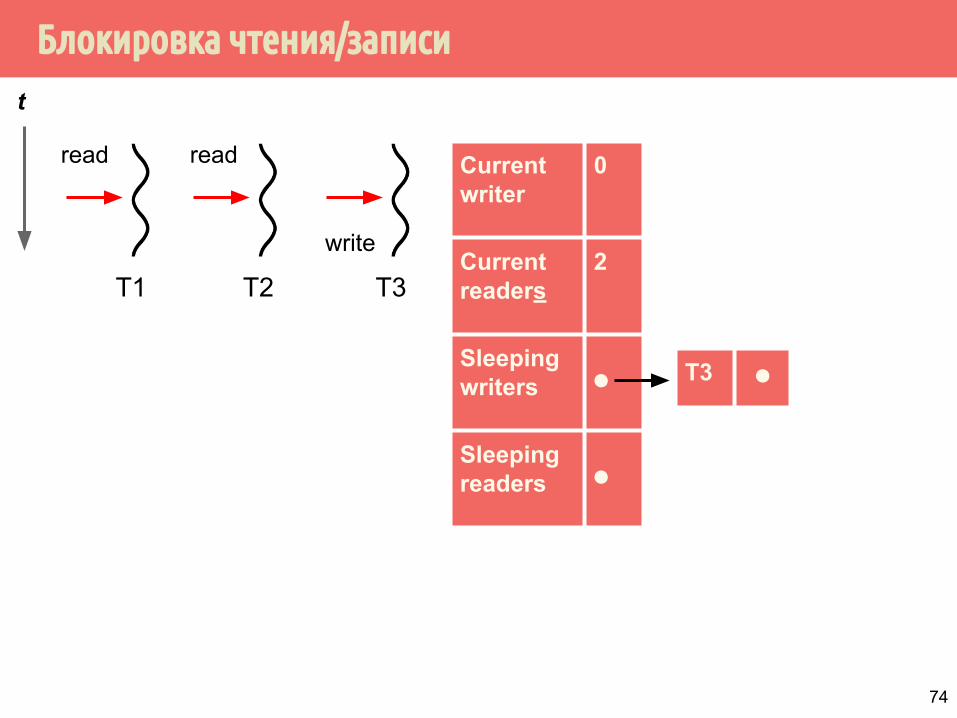
Блокировка чтения/записи
T1
Current writer
0
Current readers
2
Sleeping writers ⚫
Sleeping readers ⚫
t
T2 T3
read read
write
T3 ⚫
74
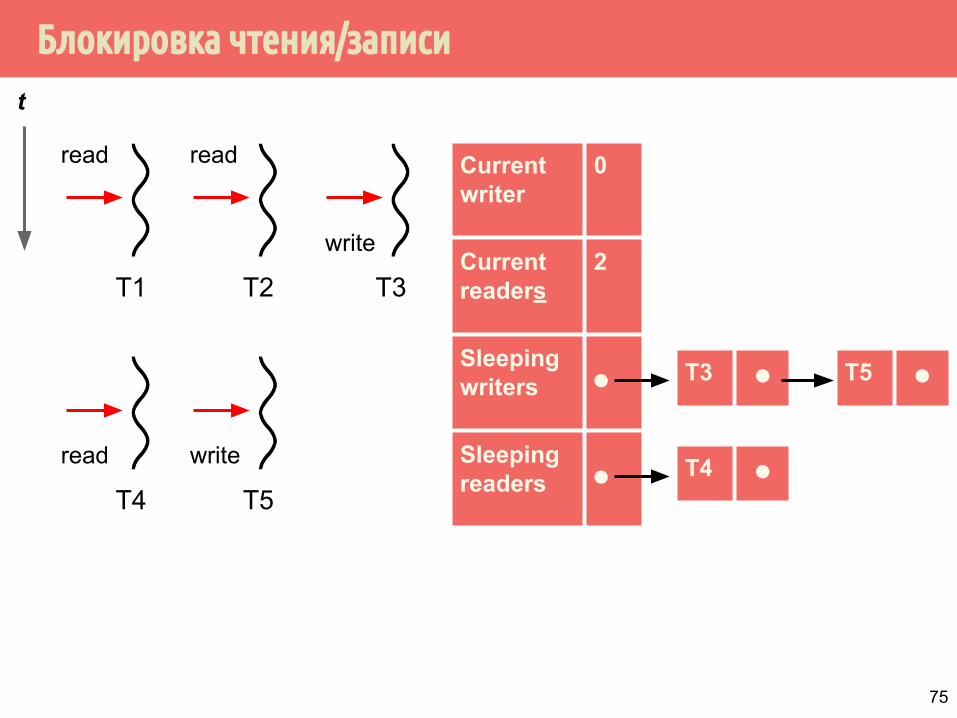
Блокировка чтения/записи
T1
T4 ⚫
Current writer
0
Current readers
2
Sleeping writers ⚫
Sleeping readers ⚫
t
T2 T3
read read
write
T4 T5
read write
T3 ⚫ T5 ⚫
75

Блокировка чтения/записи
T1
T4 ⚫
Current writer
0
Current readers
2
Sleeping writers ⚫
Sleeping readers ⚫
t
T2 T3
read read
write
T4 T5
read write
T3 ⚫ T5 ⚫
T6 T7
read read
T6 ⚫
T7 ⚫
76
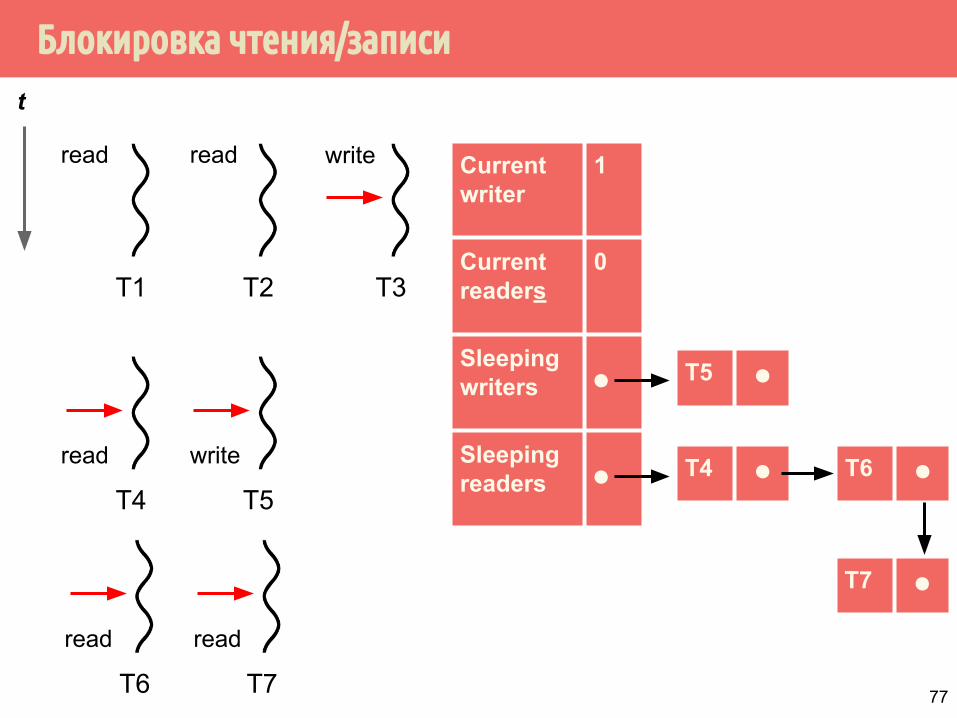
Блокировка чтения/записи
T1
T4 ⚫
Current writer
1
Current readers
0
Sleeping writers ⚫
Sleeping readers ⚫
t
T2 T3
read read write
T4 T5
read write
T5 ⚫
T6 T7
read read
T6 ⚫
T7 ⚫
77
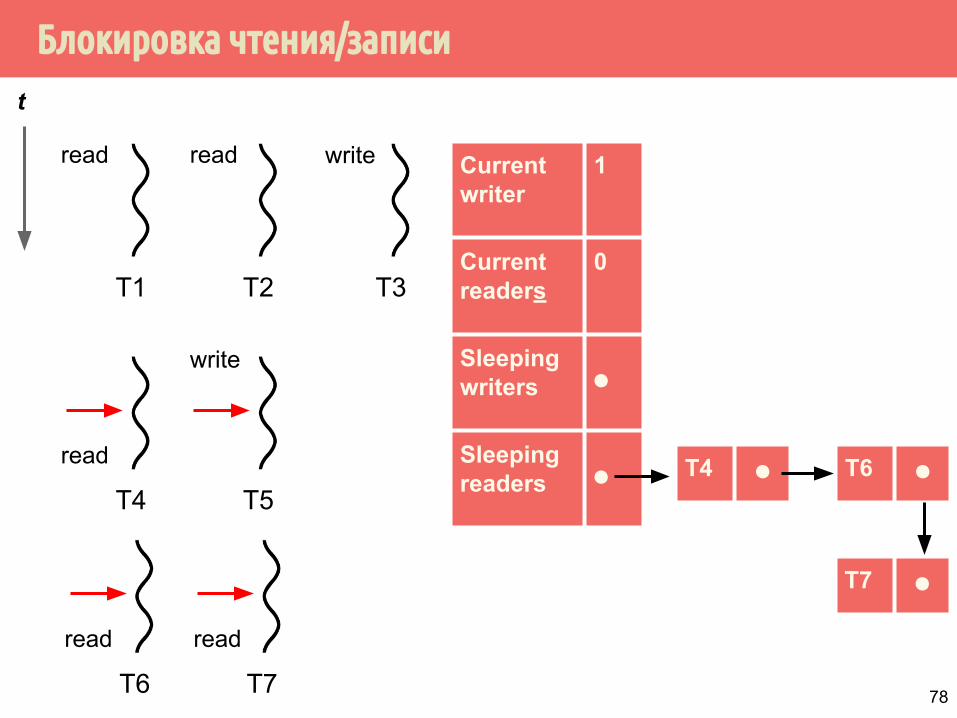
Блокировка чтения/записи
T1
T4 ⚫
Current writer
1
Current readers
0
Sleeping writers ⚫
Sleeping readers ⚫
t
T2 T3
read read write
T4 T5
read
write
T6 T7
read read
T6 ⚫
T7 ⚫
78
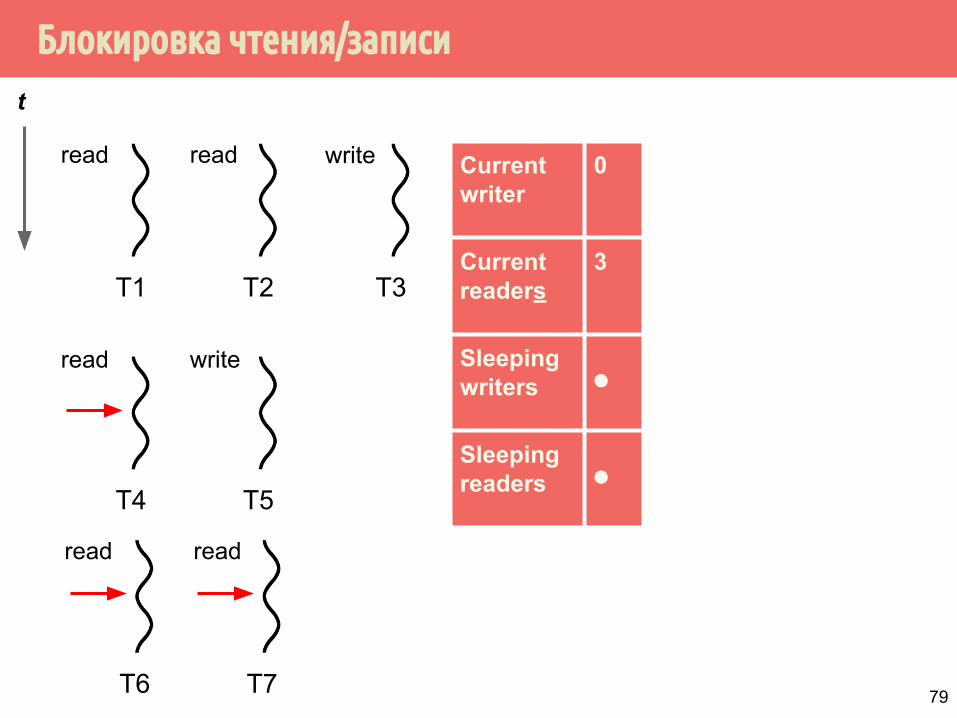
Блокировка чтения/записи
T1
Current writer
0
Current readers
3
Sleeping writers ⚫
Sleeping readers ⚫
t
T2 T3
read read write
T4 T5
read write
T6 T7
read read
79

Блокировка чтения/записи - пример
void add(item_t *item)
{
pthread_rwlock_wrlock(&lock);
item->next = request;
list = item;
pthread_rwlock_unlock(&lock);
}
item_t *remove()
{
pthread_rwlock_wrlock(&lock);
item = item->next;
list = list->next;
pthread_rwlock_unlock(&lock);
return request;
}
item_t *find(int id) {
pthread_rwlock_rdlock(&lock);
for (item = list; item != NULL; item = item->next) {
if (item->id == id) {
return item; break;
}
}
pthread_rwlock_unlock(&lock);
}80

Блокировка чтения/записи - пример
void add(item_t *item)
{
pthread_rwlock_wrlock(&lock);
item->next = request;
list = item;
pthread_rwlock_unlock(&lock);
}
item_t *remove()
{
pthread_rwlock_wrlock(&lock);
item = item->next;
list = list->next;
pthread_rwlock_unlock(&lock);
return request;
}
item_t *find(int id) {
pthread_rwlock_rdlock(&lock);
for (item = list; item != NULL; item = item->next) {
if (item->id == id) {
return item; break;
}
}
pthread_rwlock_unlock(&lock);
}
Блокировки чтения/записи не масштабируются из-за того, что при увеличении числа потоков все потоки обращаются к структуре, обеспечивающей подсчёт читающих потоков и модифицируют её. Это вызывает очень частое обновление кэш-линии, в которой хранится эта структура.
81

Рекурсивные мьютексы
▪ Рекурсивный мьютекс позволяет одному и тому же потоку многократно запирать мьютекс, не отпирая его.
▪ Мьютекс освобождается тогда, когда количество отпираний совпадает с количеством запираний.
int pthread_mutexattr_getpshared(const pthread_mutexattr_t
*restrict attr,
int *restrict pshared);
int pthread_mutexattr_setpshared(pthread_mutexattr_t *attr,
int pshared);
pshared:
▫ PTHREAD_MUTEX_NORMAL - стандартный мьютекс, не производит дополнительную проверку на наличие ошибок
▫ PTHREAD_MUTEX_ERRORCHECK - мьютекс, которые выполняет проверку на наличие ошибок
▫ PTHREAD_MUTEX_RECURSIVE - рекурсивный мьютекс82
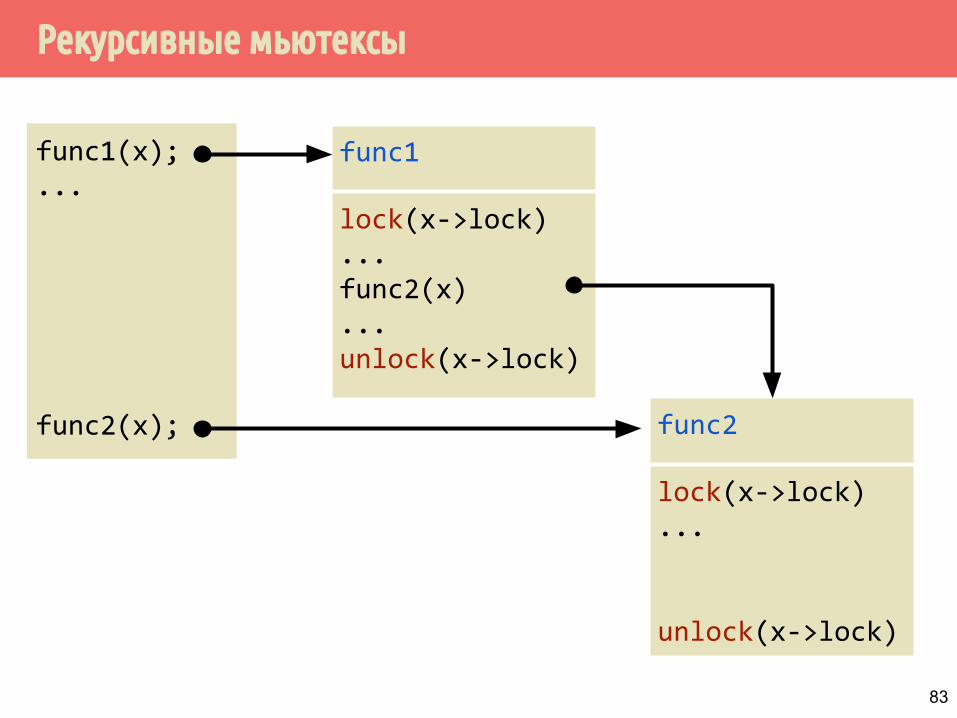
Рекурсивные мьютексы
func1
lock(x->lock)...func2(x)...unlock(x->lock)
func2
lock(x->lock)...
unlock(x->lock)
func1(x);...
func2(x);
83
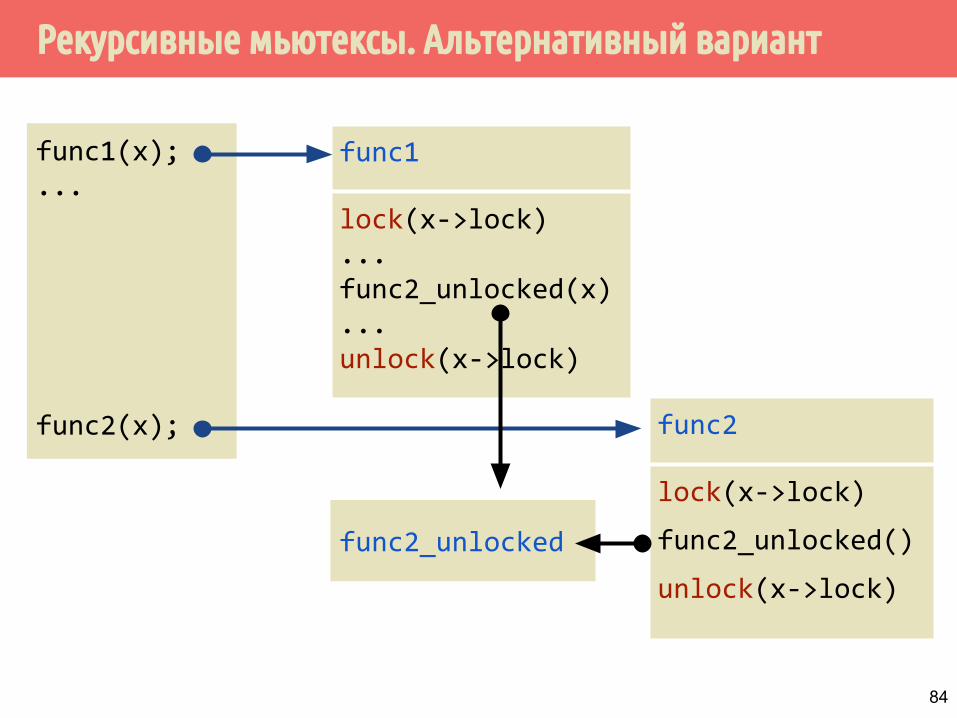
Рекурсивные мьютексы. Альтернативный вариант
func1
lock(x->lock)...func2_unlocked(x)...unlock(x->lock)
func2
lock(x->lock)
func2_unlocked()
unlock(x->lock)
func1(x);...
func2(x);
func2_unlocked
84
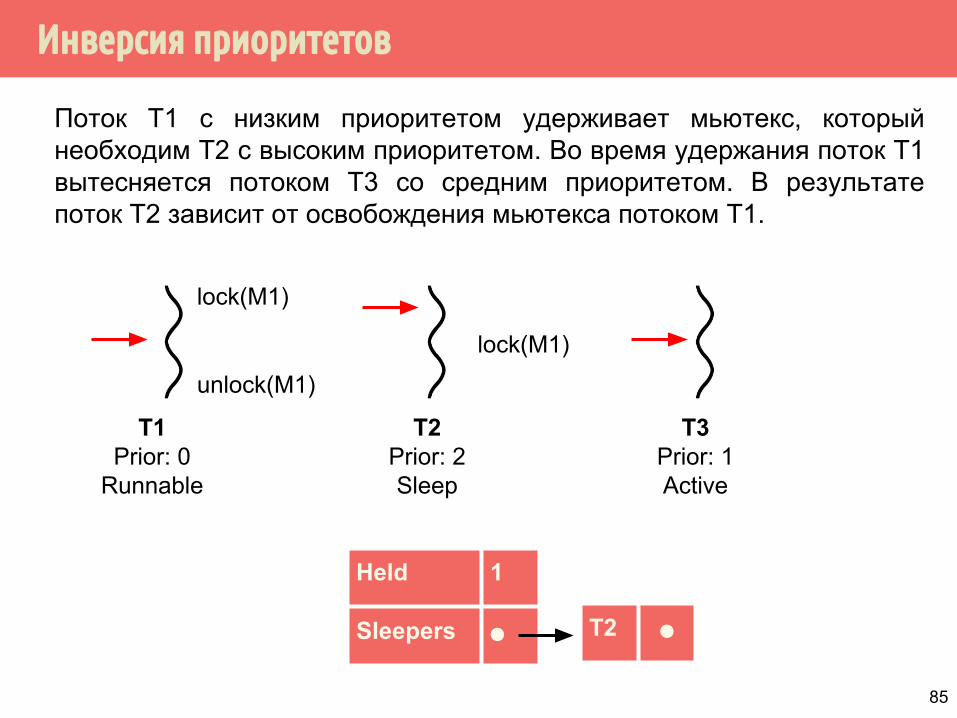
Инверсия приоритетов
Поток Т1 с низким приоритетом удерживает мьютекс, который необходим Т2 с высоким приоритетом. Во время удержания поток Т1 вытесняется потоком Т3 со средним приоритетом. В результате поток Т2 зависит от освобождения мьютекса потоком Т1.
T1Prior: 0
Runnable
T2Prior: 2Sleep
T3Prior: 1Active
lock(M1)
lock(M1)
unlock(M1)
T2 ⚫
Held 1
Sleepers ⚫
85

Инверсия приоритетов. Решения
■ Priority Ceiling MutexУстанавливается максимальный приоритет для потока, который захватывает мьютекс. Каждый поток, который захватывает мьютек, автоматически получает этот приоритет (даже если у него был ниже).
int pthread_mutexattr_getprioceiling(const pthread_mutexattr_t
*restrict attr, int *restrict prioceiling);
int pthread_mutexattr_setprioceiling(pthread_mutexattr_t *attr,
int prioceiling);
int pthread_mutex_getprioceiling(const pthread_mutex_t *mutex,
int *restrict prioceiling);
int pthread_mutex_setprioceiling(pthread_mutex_t *restrict mutex,
int prioceiling, int *restrict old_ceiling);
■ Priority Inheritance MutexesПоток Т1 захватывает мьютекс без изменения своего приоритета. Когда второй поток Т2 пытается захватить, владелец Т1 мьютекса получает приоритет потока Т2.
86
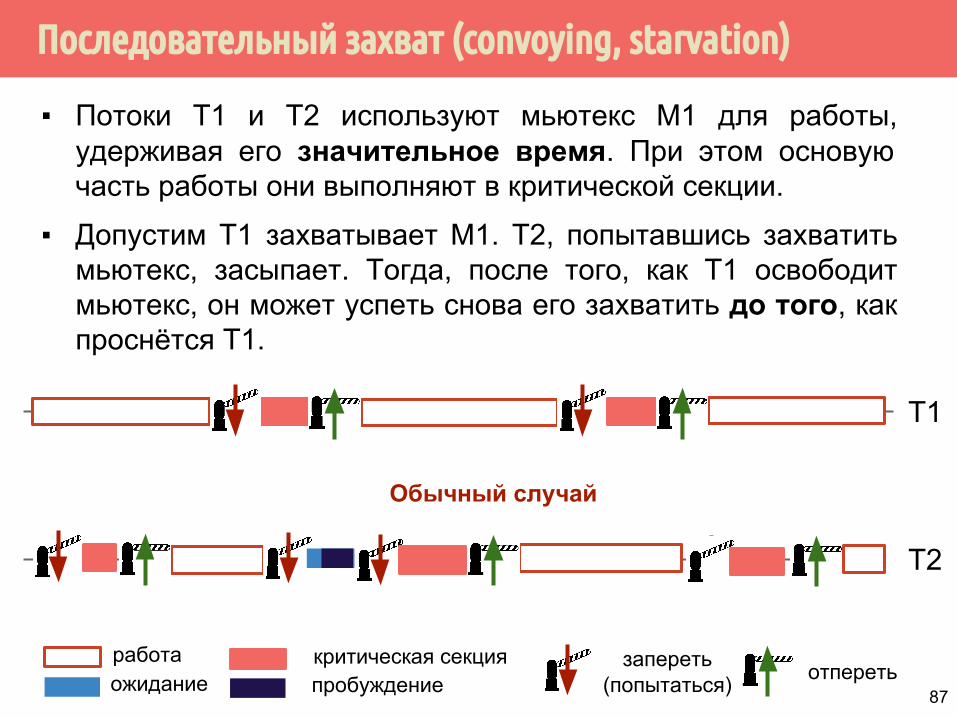
Последовательный захват (convoying, starvation)
▪ Потоки Т1 и Т2 используют мьютекс М1 для работы, удерживая его значительное время. При этом основую часть работы они выполняют в критической секции.
▪ Допустим Т1 захватывает М1. Т2, попытавшись захватить мьютекс, засыпает. Тогда, после того, как Т1 освободит мьютекс, он может успеть снова его захватить до того, как проснётся Т1.
T1
работаожидание
запереть(попытаться) отпереть
критическая секцияпробуждение
T2
Обычный случай
87
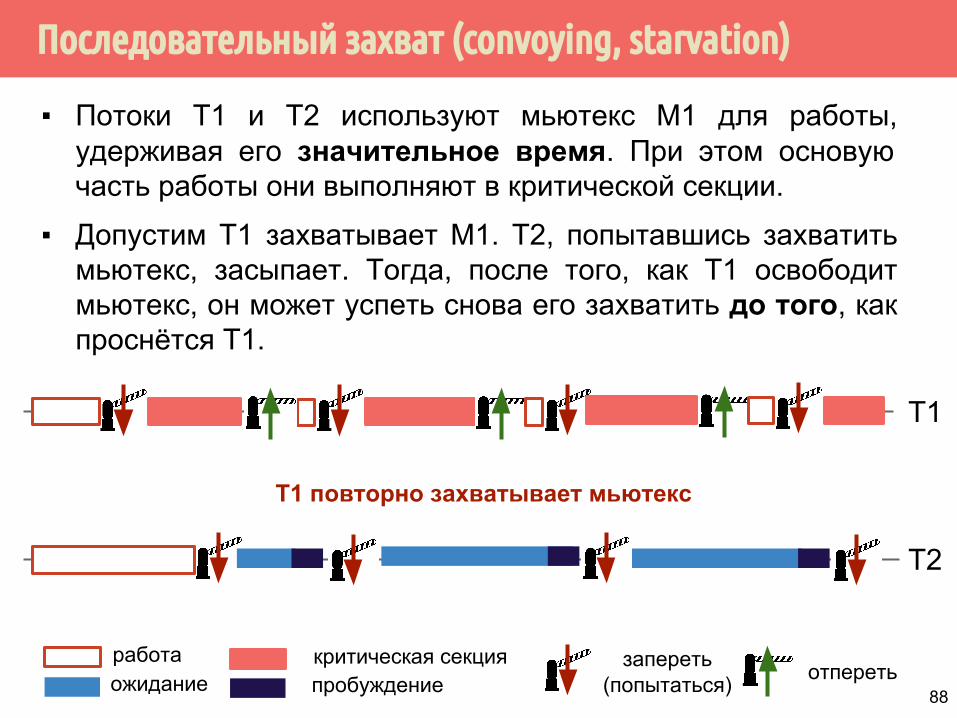
Последовательный захват (convoying, starvation)
▪ Потоки Т1 и Т2 используют мьютекс М1 для работы, удерживая его значительное время. При этом основую часть работы они выполняют в критической секции.
▪ Допустим Т1 захватывает М1. Т2, попытавшись захватить мьютекс, засыпает. Тогда, после того, как Т1 освободит мьютекс, он может успеть снова его захватить до того, как проснётся Т1.
T1
работаожидание
запереть(попытаться) отпереть
критическая секцияпробуждение
T2
Т1 повторно захватывает мьютекс
88

Последовательный захват (convoying, starvation)
Решение - использование FIFO-мьютекса: владелец мьютекса (Т1) после освобождения мьютекса автоматически передаёт права на захват мьютекса первому потоку в очереди, который ожидает освобождения мьютекса.
T1
работаожидание
запереть(попытаться) отпереть
критическая секцияпробуждение
T2
Использование FIFO-мьютекса
89

Проблема обедающих философов
90

Проблема обедающих философов
91
Цикл жизни философа:1. размышлять2. взять вилки3. есть4. отдать вилки

Проблема обедающих философов
92
Взаимная блокировка!

Проблема обедающих философов: решение 1
93
Один из философов берёт вилки в другом порядке

Проблема обедающих философов: решение 1
pthread_mutex_t fork[N];
void *philosopher(void *arg) {
int* phil_idx = (int*) arg; /* 0, 1, ..., N – 1 */
int first_fork, second_fork;
for (;;) {
first_fork = phil_idx;
second_fork = (phil_idx + 1) % N;
pthread_mutex_lock(fork[first_fork]);
pthread_mutex_lock(fork[second_fork]);
eat();
pthread_mutex_unlock(fork[first_fork]);
pthread_mutex_unlock(fork[second_fork]);
reflect();
}
return 0;
}94
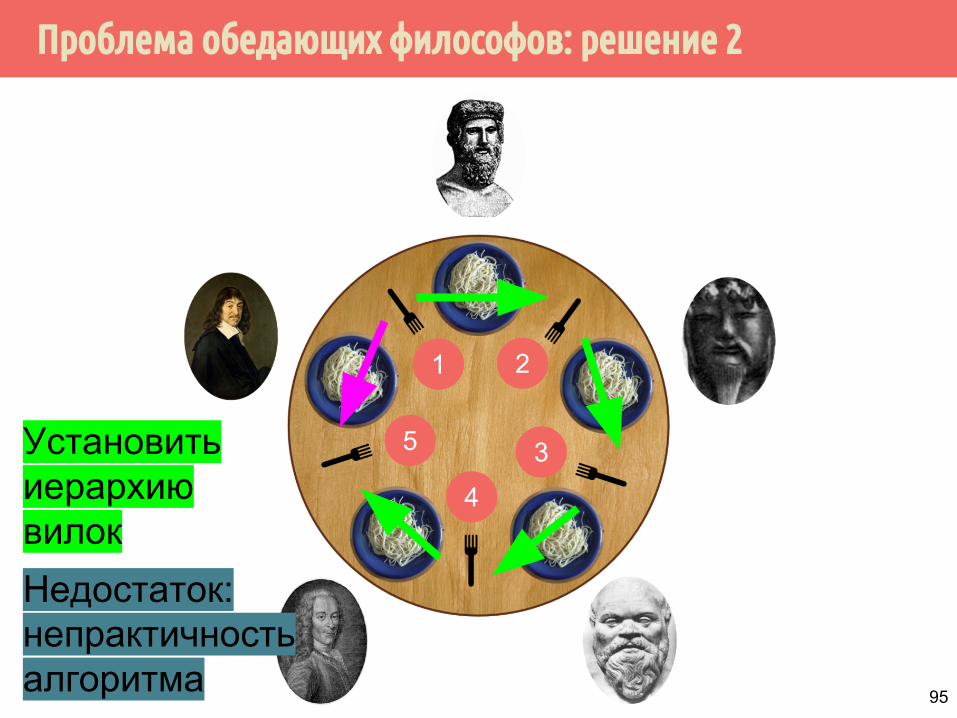
Проблема обедающих философов: решение 2
95
Установить иерархию вилокНедостаток:непрактичность алгоритма
1 2
3
4
5

Проблема обедающих философов: решение 3
96
Проверить, свободны ли обе вилки, затем взять.Недостаток:голодание

Синхронизация
97
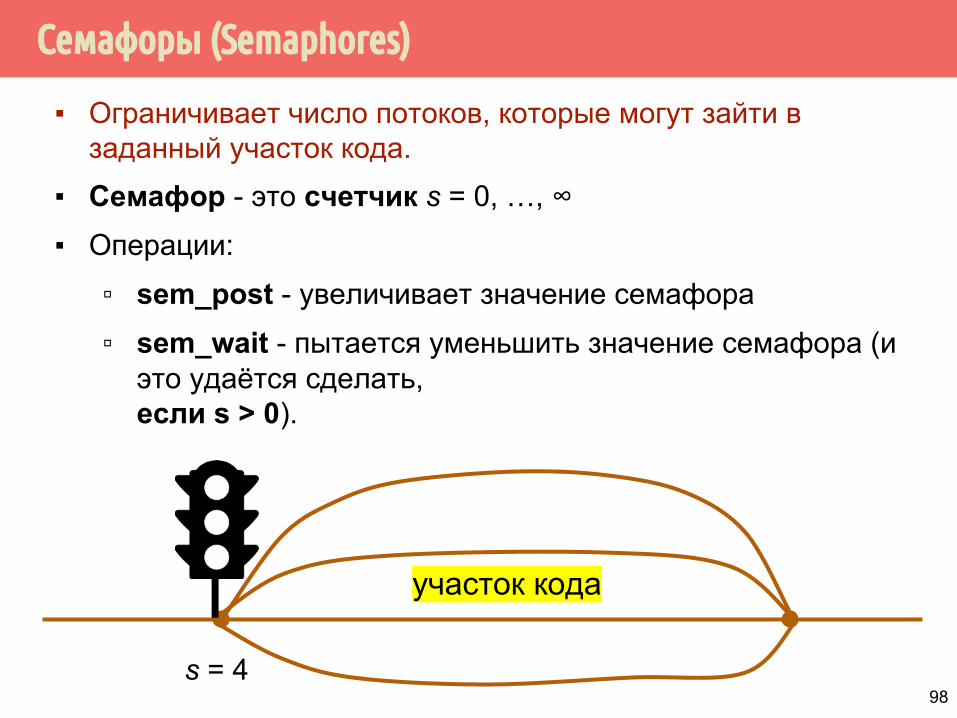
Семафоры (Semaphores)
▪ Ограничивает число потоков, которые могут зайти в заданный участок кода.
▪ Семафор - это счетчик s = 0, …, ∞
▪ Операции:
▫ sem_post - увеличивает значение семафора
▫ sem_wait - пытается уменьшить значение семафора (и это удаётся сделать, если s > 0).
98s = 4
участок кода

Семафоры (Semaphores) в pthreads
/* проинициализировать семафор */int sem_init(sem_t *sem, int pshared,
unsigned int value);
/* уничтожить семафор */int sem_destroy(sem_t *sem);
/* уменьшить семафор на 1 * (заблокировать единицу ресурса) */int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_timedwait(sem_t *sem,
const struct timespec *abs_timeout);
/* увеличить семафор на 1 * (разблокировать единицу ресурса) */int sem_post(sem_t *sem);
99
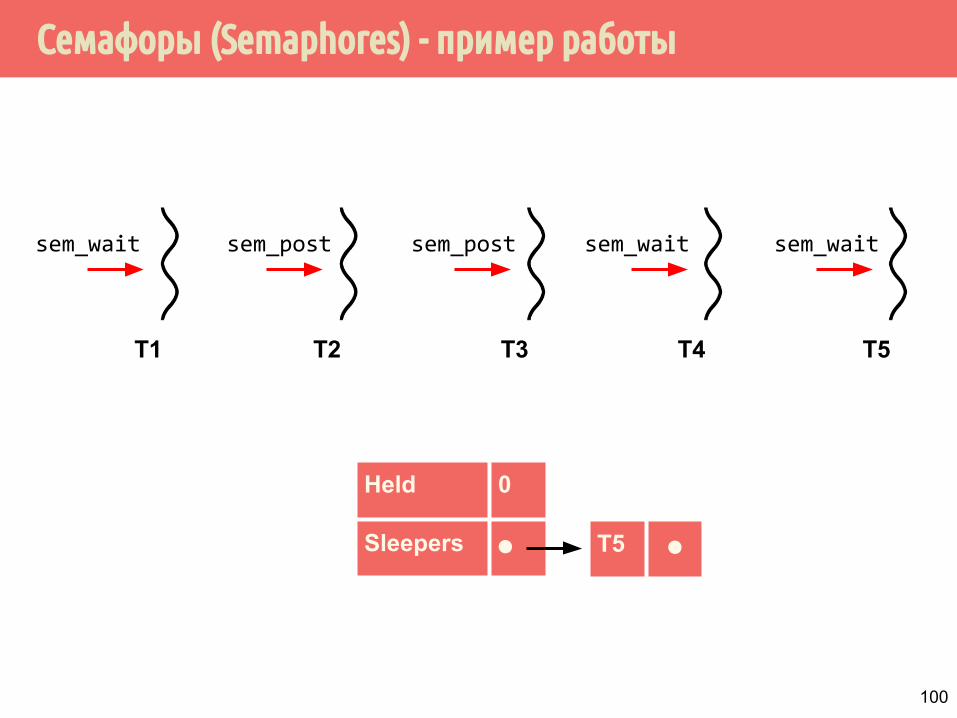
Семафоры (Semaphores) - пример работы
T1
sem_wait
T5 ⚫
Held 0
Sleepers ⚫
T2
sem_post
T3
sem_post
T4
sem_wait
T5
sem_wait
100

Семафоры (Semaphores) - пример работы
работаожидание
wait(попытаться) post
критическая секция
T1
T2
T3
T4
T5
101

Семафоры. Пример: производитель/потребитель
/* безопасная версия sem_wait, учитывающая * прерывания во время выполнения sem_wait */void _sem_wait(sem_t *sem)
{
while (sem_wait(sem) != 0) { }
}
/* получить по сети запрос и выделить под него память */request_t *get_request()
{
request_t *request;
request_t = (request*) malloc(sizeof(request_t));
request->data = read_from_net();
return request;
}
102

Семафоры. Пример: производитель/потребитель
sem_init(&request_length, 0);
...
/* производитель */void *producer(void *arg) {
request_t *request;
for (;; ) {
request = get_request(); /* получить запрос */add(request); /* добавить в список */sem_post(&request_lenght); /* увеличить семафор */
}
}
/* обработать поступивший запрос */void process_request(request_t *request) {
process(request->data);
free(request);
}103

Семафоры. Пример: производитель/потребитель
/* потребитель */void *consumer(void *arg) {
request_t *request;
for (;;) {
_sem_wait(&request_lenght); /* уменьшить семафор */request = remove(); /* удалить запрос */process_request(request); /* обработать запрос */
}
}
104

Производитель/потребитель с ограничением длины очереди
sem_init(&request_length, 0);
sem_init(&request_slots, queue_length);
...
/* производитель ресурсов проверяет, есть ли свободные * слоты для нового запроса и добавляет запрос */void *producer(void *arg)
{
request_t *request;
for (;;) {
request = get_request();
_sem_wait(&request_slots);
add(request);
sem_post(&request_length);
}
}105

Производитель/потребитель с ограничением длины очереди
/* потребитель проверяет, есть ли запросы, * затем увеличивает семафор свободных слотов * и обрабатывает запрос */void *consumer(void *arg)
{
request_t *request;
for (;;) {
_sem_wait(&requests_lenght);
request = remove();
sem_post(&request_slots);
process_request(request);
}
}
106
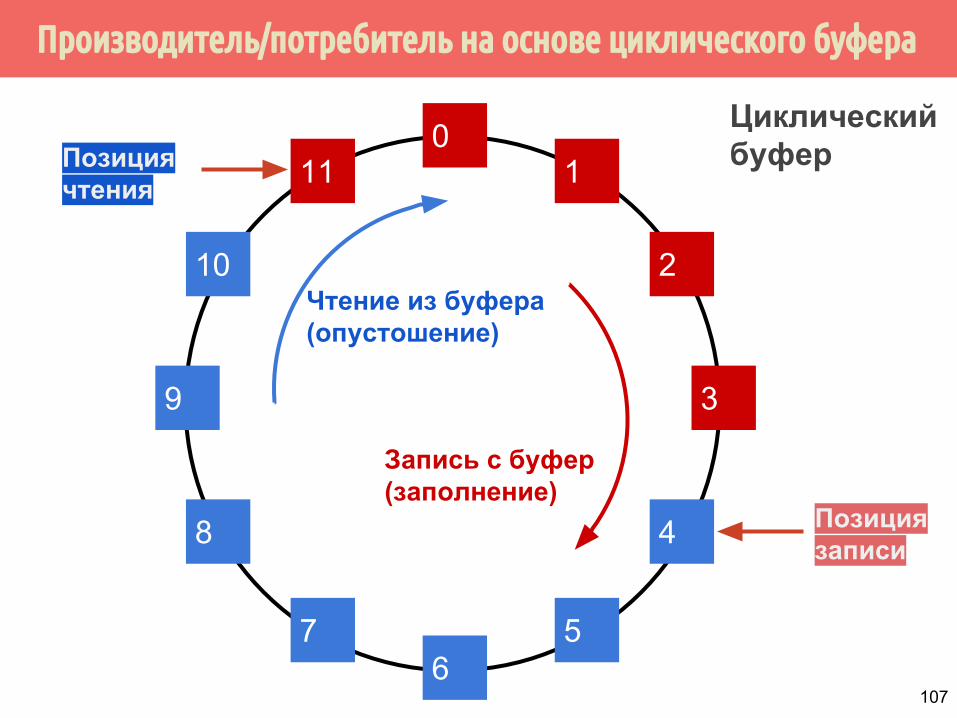
Производитель/потребитель на основе циклического буфера
107
39
2
110
1
10
48
576
Циклический буфер
Запись с буфер (заполнение)
Чтение из буфера (опустошение)
Позиция чтения
Позиция записи
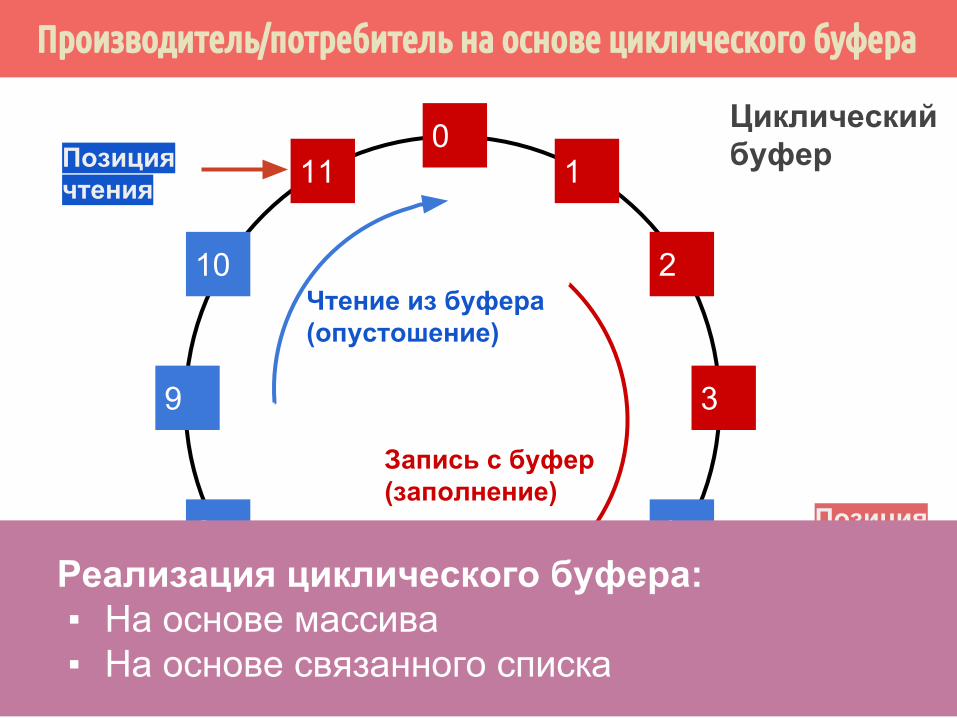
Производитель/потребитель на основе циклического буфера
108
39
2
110
1
10
48
576
Циклический буфер
Запись с буфер (заполнение)
Чтение из буфера (опустошение)
Позиция чтения
Позиция записи
Реализация циклического буфера:▪ На основе массива▪ На основе связанного списка

Производитель/потребитель на основе циклического буфера
109
sem_init(&request_length, 0);
sem_init(&request_slots, buf_length);
...
/* производитель */void *producer(void *arg) {
request_t *request;
for (;;) {
request = get_request();
_sem_wait(&request_slots);
pthread_mutex_lock(lock);
buf[write_pos] = request;
write_pos = (write_pos + 1) % buf_len;
pthread_mutex_unlock(lock);
sem_post(&request_length);
}
}

Производитель/потребитель с ограничением длины очереди
/* потребитель */void *consumer(void *arg)
{
request_t *request;
for (;;) {
_sem_wait(&requests_lenght);
pthread_mutex_lock(lock);
request = buf[read_pos];
read_pos = (read_pos + 1) % buf_len;
pthread_mutex_unlock(lock);
sem_post(&request_slots);
process_request(request);
}
}
110

Условные переменные (Condition variables)
▪ Условные переменные позволяют потока ожидать наступления некоторого события, избегая состояния гонки.
▪ Сами условные переменные защищаются мьютексами.▪ Условные переменные - обобщение семафоров.
/* инициализация условных переменных */int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr);
/* или */pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
/* освободить ресурсы, занимаемые условной переменной */int pthread_cond_destroy(pthread_cond_t *cond);
111

Условные переменные (Condition variables)
/* ожидать наступления события cond */int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex);
/* ожидать наступления события не дольше timeout */int pthread_cond_timedwait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex,
const struct timespec *restrict abstime);
/* возобновить работу одного потока, ожидающего наступления события cond */int pthread_cond_signal(pthread_cond_t *cond);
/* возобновить работу всех потоков, * ожидающих наступления события cond */int pthread_cond_broadcast(pthread_cond_t *cond);
112
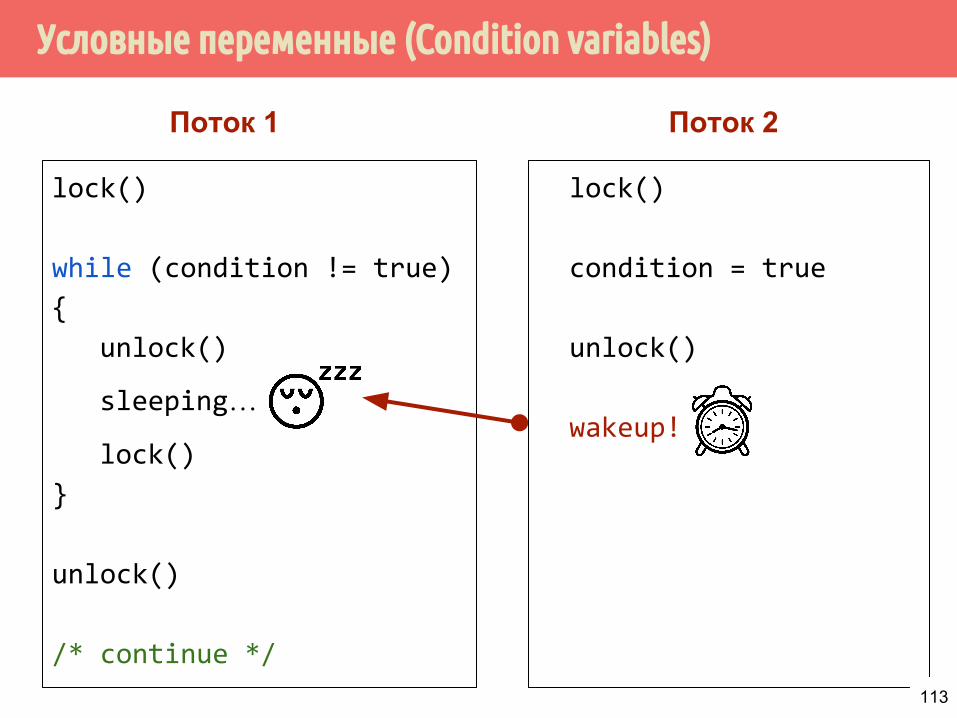
Условные переменные (Condition variables)
lock()
while (condition != true)
{
unlock()
sleeping…
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
condition = true
unlock()
wakeup!
113
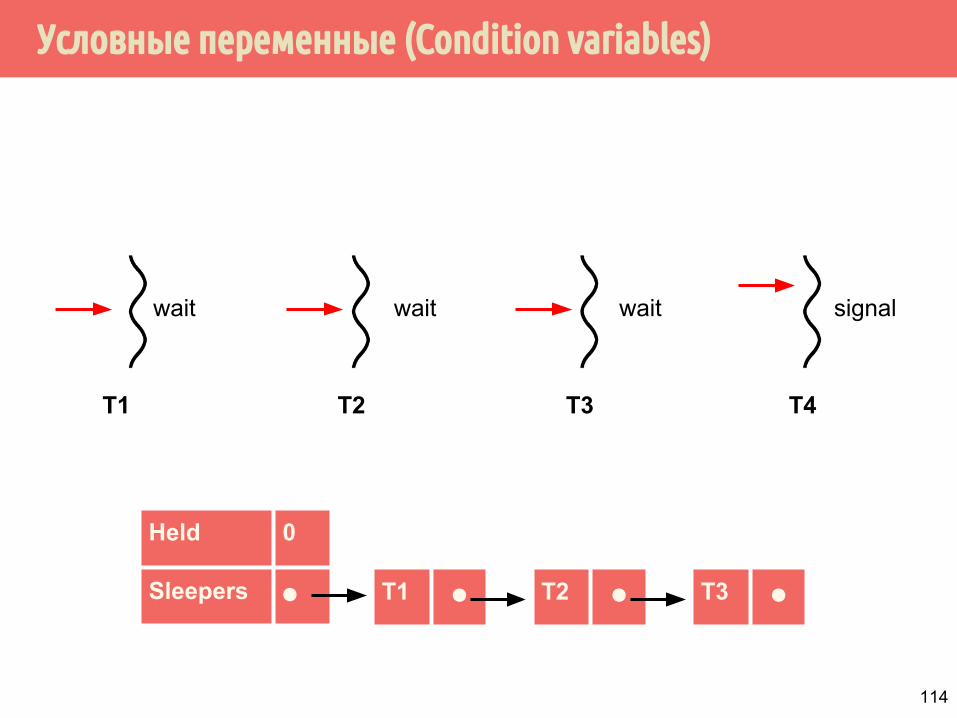
Условные переменные (Condition variables)
T1 T2 T3
wait wait wait
T4
signal
T1 ⚫
Held 0
Sleepers ⚫ T2 ⚫ T3 ⚫
114
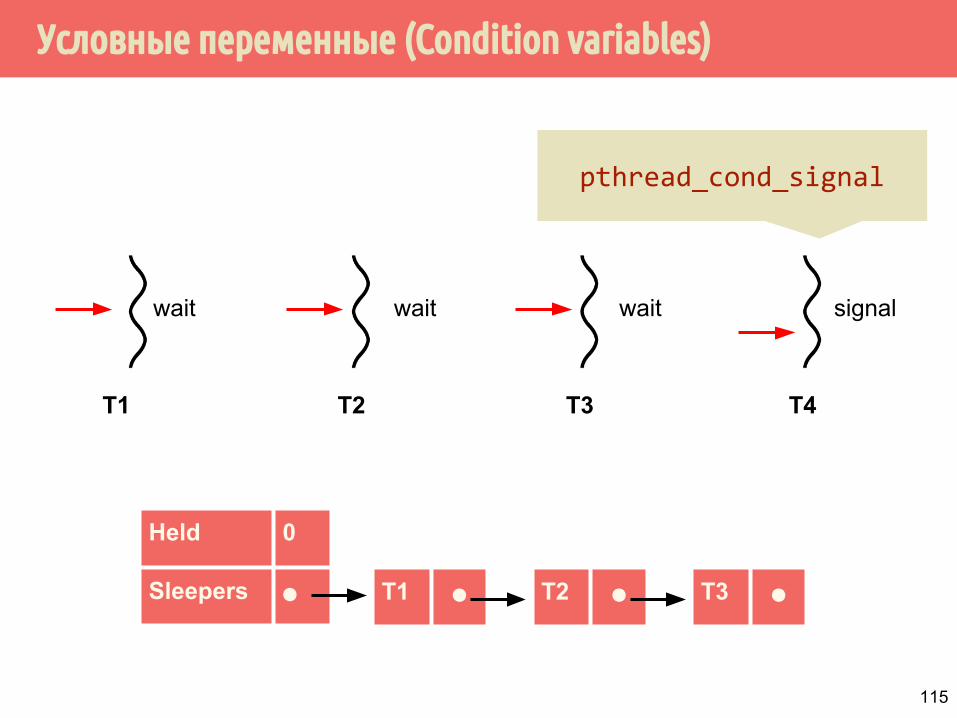
Условные переменные (Condition variables)
T1 T2 T3
wait wait wait
T4
signal
T1 ⚫
Held 0
Sleepers ⚫ T2 ⚫ T3 ⚫
pthread_cond_signal
115
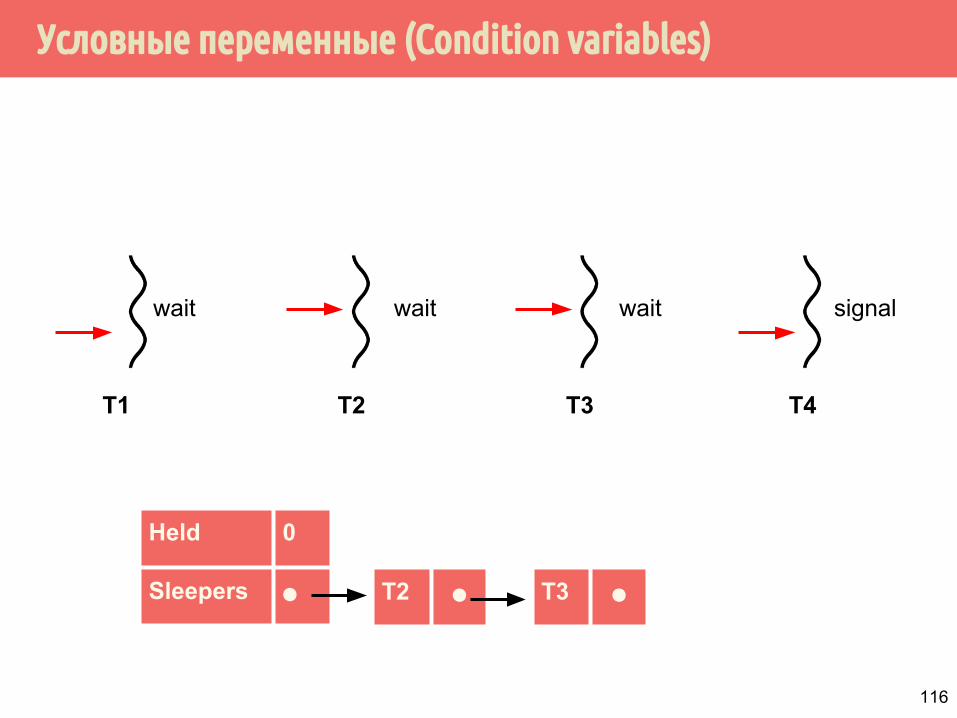
Условные переменные (Condition variables)
T1 T2 T3
wait wait wait
T4
signal
T2 ⚫
Held 0
Sleepers ⚫ T3 ⚫
116

Условные переменные (Condition variables)
T1 T2 T3
wait wait wait
T4
signal
T1 ⚫
Held 0
Sleepers ⚫ T2 ⚫ T3 ⚫
pthread_cond_broadcast
117
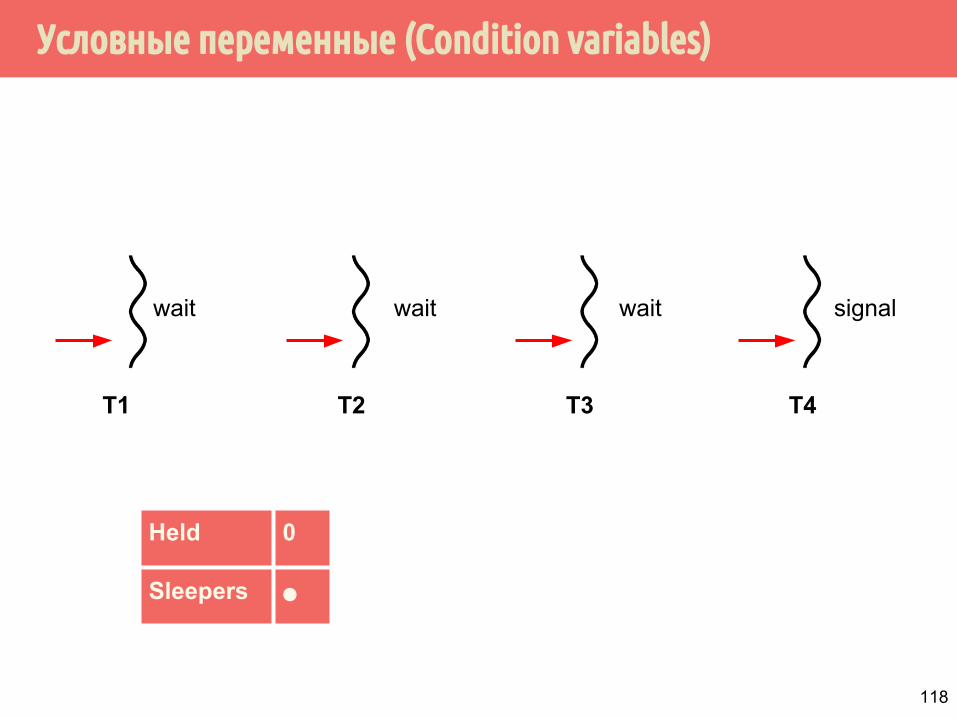
Условные переменные (Condition variables)
T1 T2 T3
wait wait wait
T4
signal
Held 0
Sleepers ⚫
118

Условные переменные
pthread_mutex_lock(&m);
while (!condition) {
pthread_cond_wait(&c, &m);
}
do_something();
pthread_mutex_unlock(&m);
Поток 1 Поток 2
pthread_mutex_lock(&m);
condition = true;
pthead_mutex_unlock(&m);
pthread_cond_signal(&c);
119

Условные переменные
struct msg {
struct msg *m_next;
/* ... другие поля структуры ... */};
struct msg *workq;
pthread_cond_t qready = PTHREAD_COND_INITIALIZER;
pthread_mutex_t qlock = PTHREAD_MUTEX_INITIALIZER;
120

Условные переменные
void process_msg(void)
{
struct msg *mp;
for (;;) {
pthread_mutex_lock(&qlock);
while (workq == NULL)
pthread_cond_wait(&qready, &qlock);
mp = workq;
workq = mp->m_next;
pthread_mutex_unlock(&qlock);
/* теперь обрабатываем сообщение */}
}
121

Условные переменные
void enqueue_msg(struct msg *mp)
{
pthread_mutex_lock(&qlock);
mp->m_next = workq;
workq = mp;
pthread_mutex_unlock(&qlock);
pthread_cond_signal(&qready);
}
122

Проблема дополнительного ожидания
lock()
while (condition != true)
{
unlock()
sleeping…
lock()
}
unlock()
/* continue */
Поток 1
pthread_cond_wait(&cond,
&mutex);
123
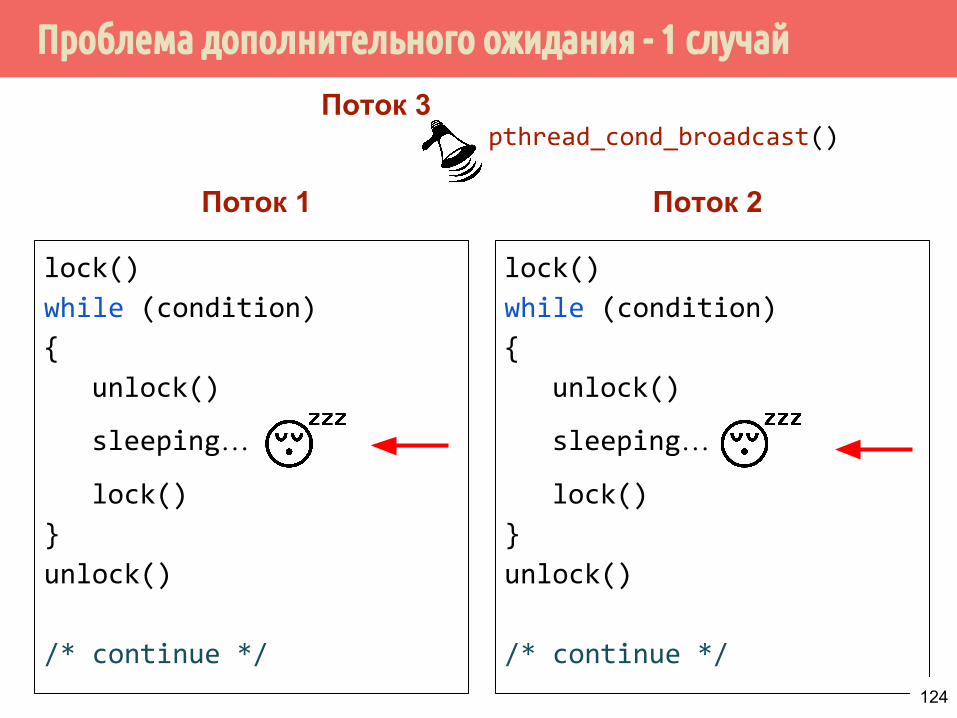
Проблема дополнительного ожидания - 1 случай
lock()
while (condition)
{
unlock()
sleeping…
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
sleeping…
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
124

Проблема дополнительного ожидания - 1 случай
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
125
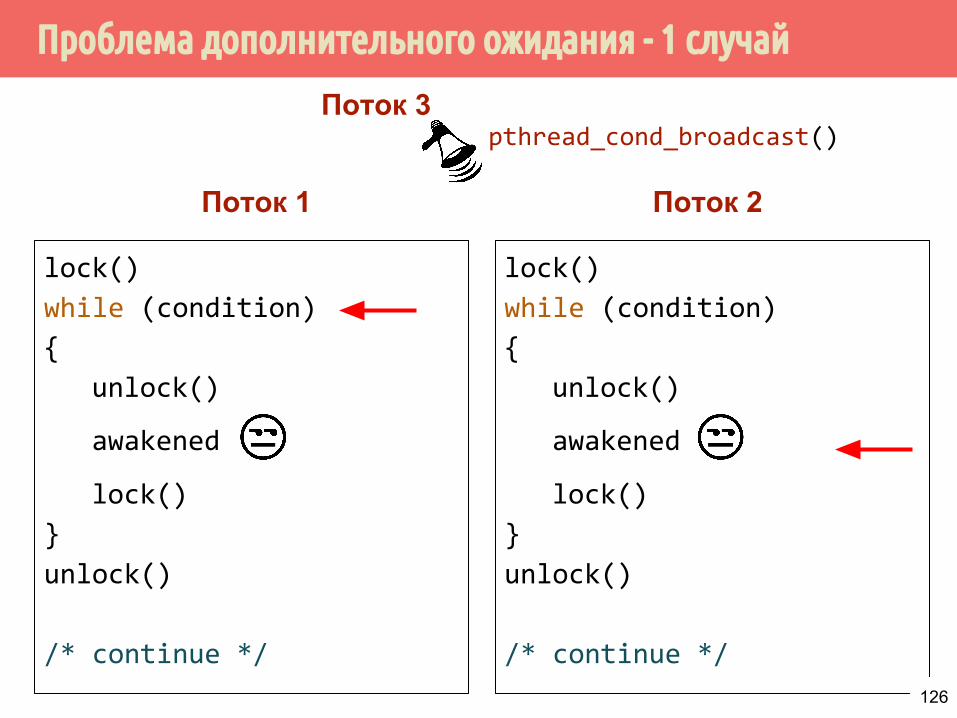
Проблема дополнительного ожидания - 1 случай
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
126

Проблема дополнительного ожидания - 1 случай
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
127
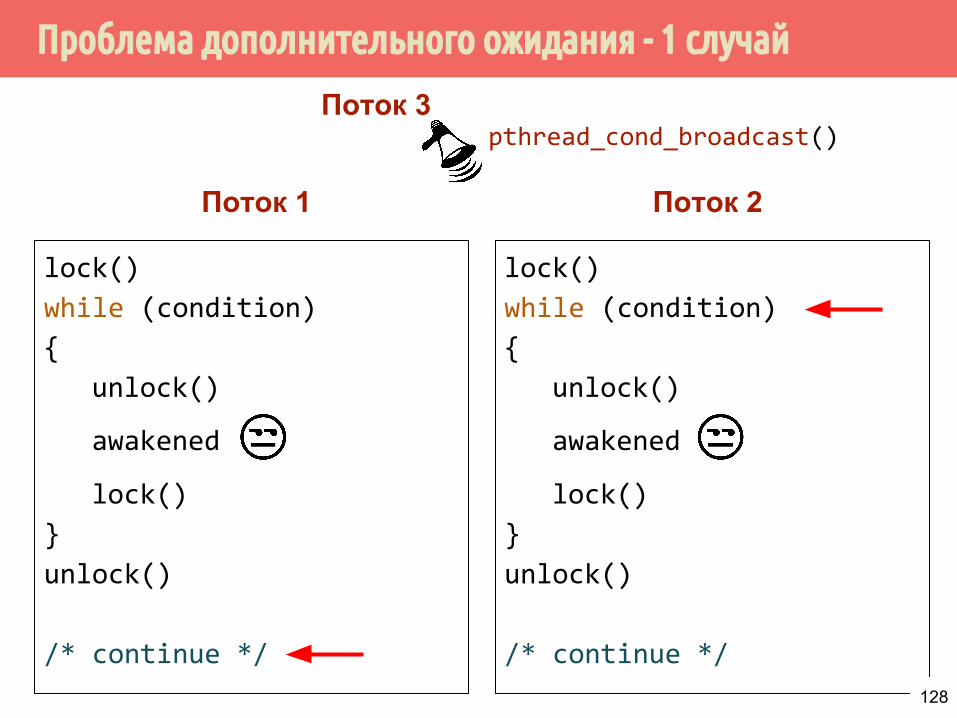
Проблема дополнительного ожидания - 1 случай
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
128
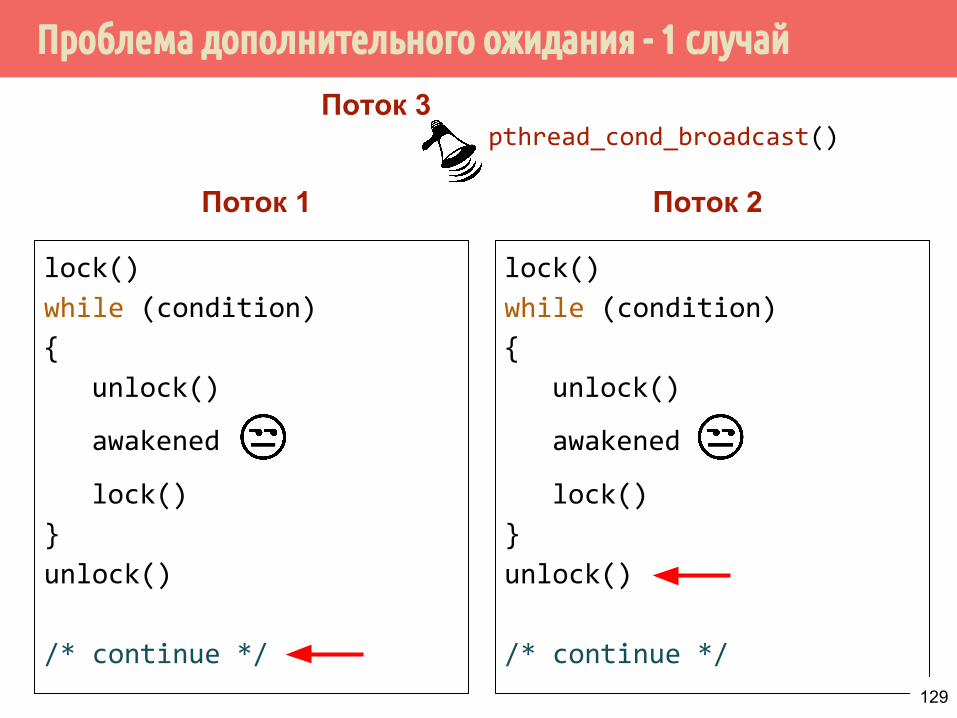
Проблема дополнительного ожидания - 1 случай
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
129
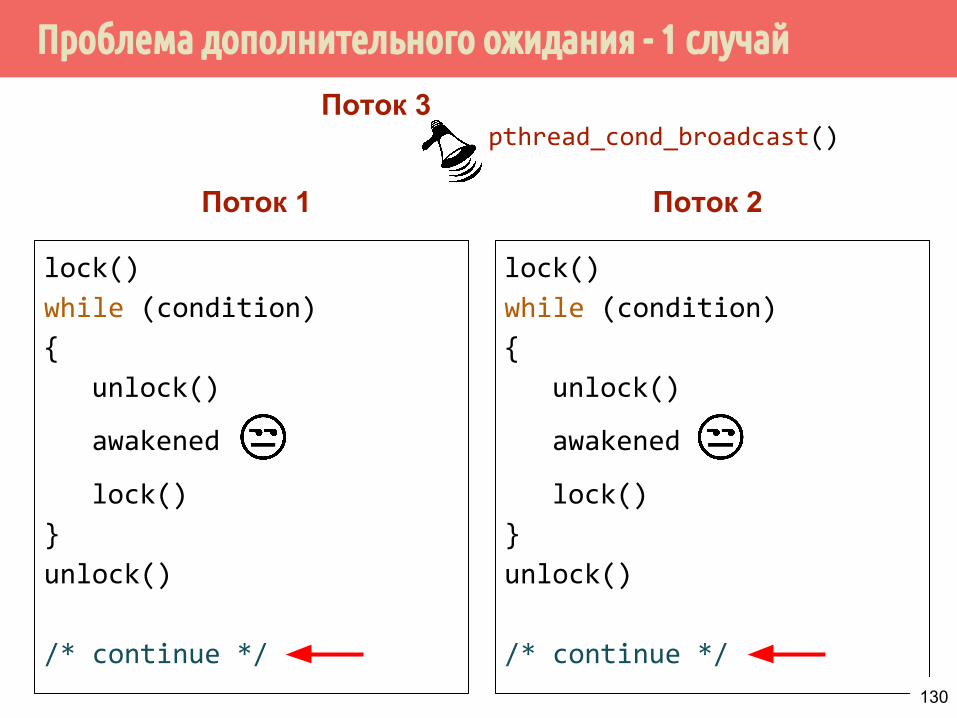
Проблема дополнительного ожидания - 1 случай
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
130
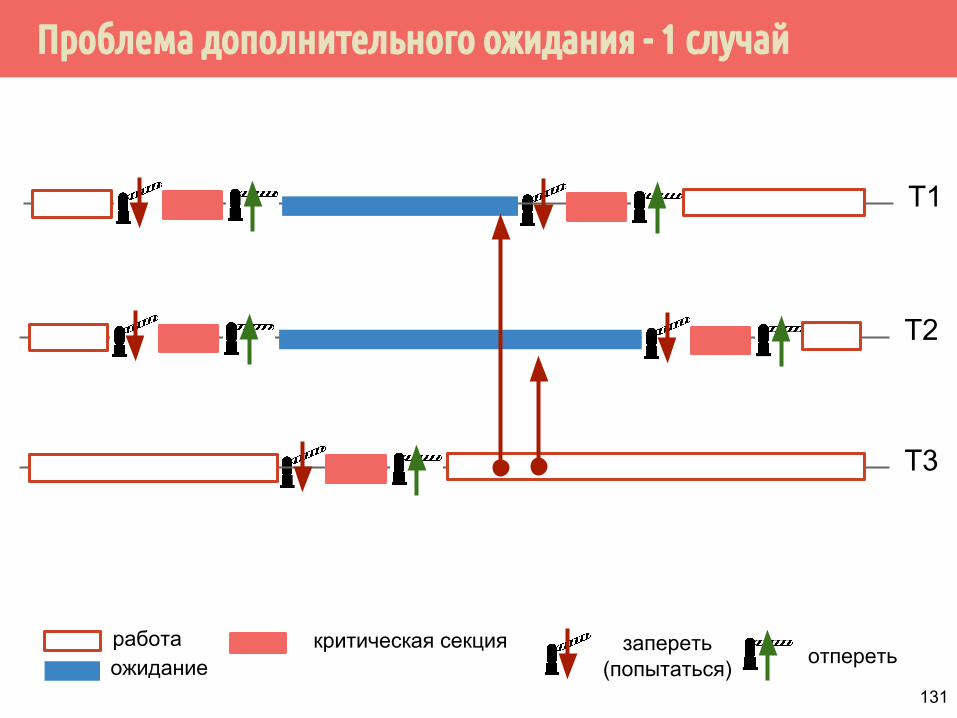
Проблема дополнительного ожидания - 1 случай
T1
работаожидание
запереть(попытаться) отпереть
критическая секция
T2
T3
131
Проблема дополнительного ожидания - 2 случай
lock()
while (condition)
{
unlock()
sleeping…
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
sleeping…
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
132
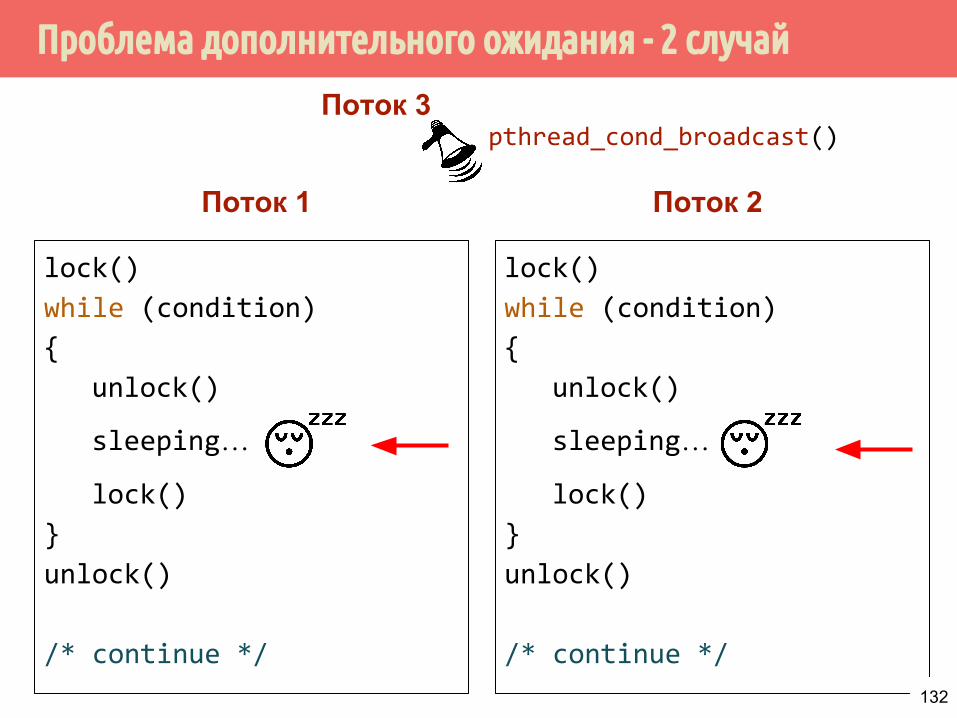
Проблема дополнительного ожидания - 2 случай
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
133
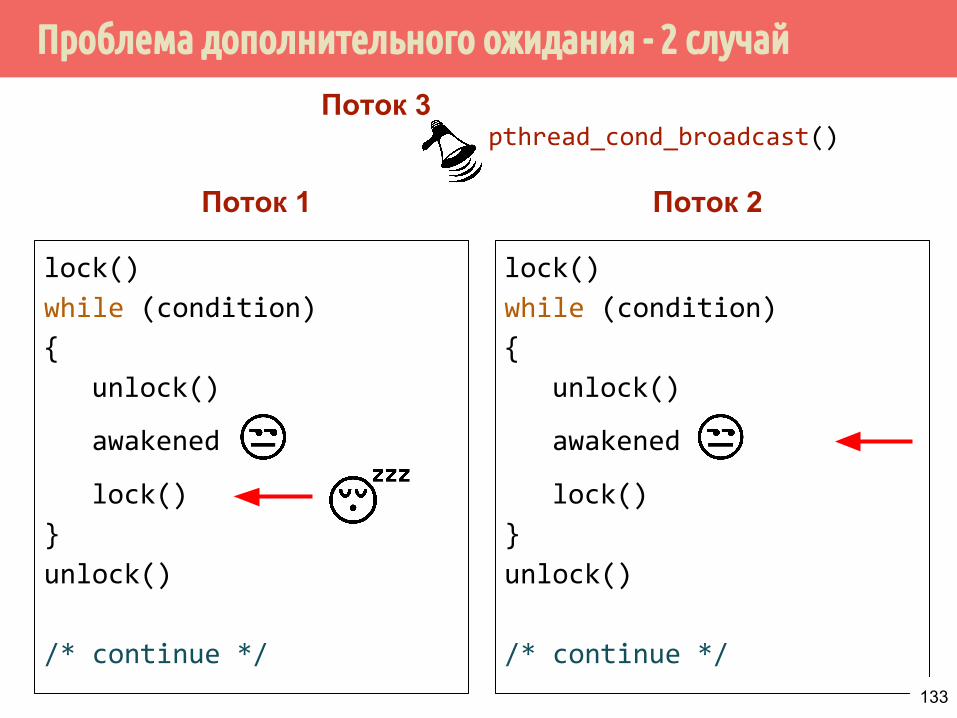
Проблема дополнительного ожидания - 2 случай
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 1 Поток 2
lock()
while (condition)
{
unlock()
awakened
lock()
}
unlock()
/* continue */
Поток 3pthread_cond_broadcast()
134
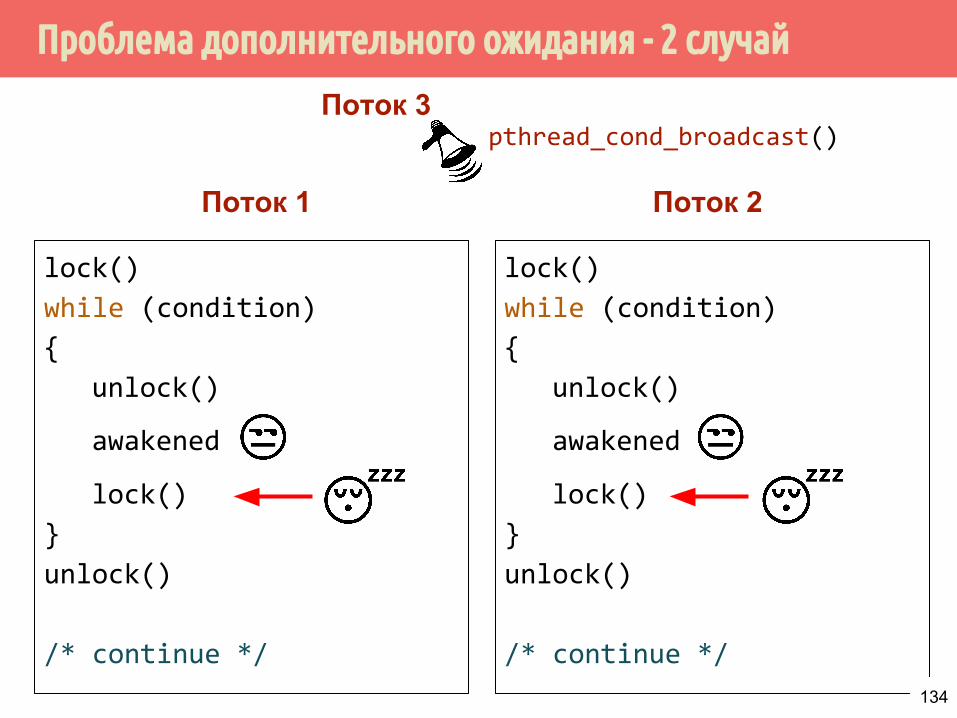
Проблема дополнительного ожидания - 2 случай
T1
работаожидание
запереть(попытаться) отпереть
критическая секция
T2
T3
135
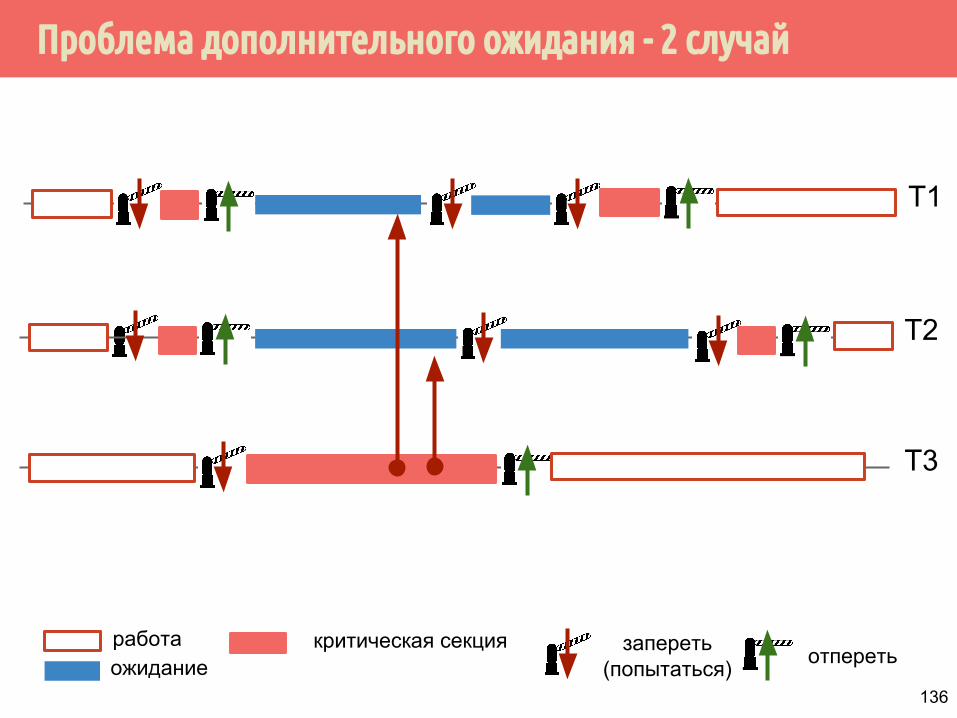
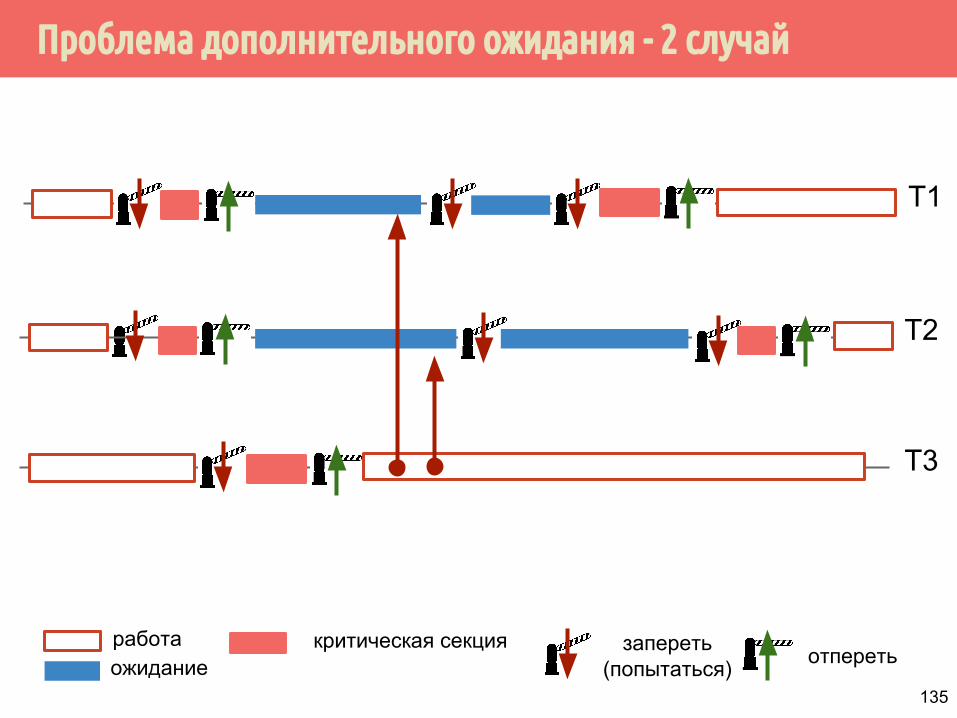
Проблема дополнительного ожидания - 2 случай
T1
работаожидание
запереть(попытаться) отпереть
критическая секция
T2
T3
136

Производитель/потребитель с ограничением длины очереди
/* производитель (на основе условных переменных) */void *producer(void *arg)
{
request_t *request;
for (;;) {
pthread_mutex_lock(&request_lock);
while (length >= queue_length)
pthread_cond_wait(&request_producer,
&requests_lock);
add(request);
lenght++;
pthread_mutex_unlock(&request_lock);
pthread_cond_signal(&request_consumer);
}
}137

Производитель/потребитель с ограничением длины очереди
/* потребитель (на основе условных переменных) */void *consumer(void *arg)
{
request_t *request;
for (;;) {
pthread_mutex_lock(&request_lock);
while (length == 0)
pthread_cond_wait(&request_consumer,
&requests_lock);
request = remove();
length--;
pthread_mutex_unlock(&request_lock);
pthread_cond_signal(&request_producer);
process_request(request);
}
} 138

Производитель/потребитель на основе циклического буфера
139
39
2
110
1
10
48
576
Циклический буфер
Запись с буфер (заполнение)
Чтение из буфера (опустошение)
Позиция чтения
Позиция записи

Производитель/потребитель на основе циклического буфера
/* производитель */void *producer(void *arg) {
request_t *request;
for (;;) {
pthread_mutex_lock(&request_lock);
while (length >= queue_length)
pthread_cond_wait(&request_producer,
&requests_lock);
buf[write_pos] = request;
write_pos = (write_pos + 1) % buf_len;
count++; /* число заполненных ячеек */ pthread_mutex_unlock(&request_lock);
pthread_cond_signal(&request_consumer);
}
}
140

Производитель/потребитель на основе циклического буфера
/* потребитель */void *consumer(void *arg) {
request_t *request;
for (;;) {
pthread_mutex_lock(&request_lock);
while (length == 0)
pthread_cond_wait(&request_consumer,
&requests_lock);
request = buf[read_pos];
read_pos = (read_pos + 1) % buf_len;
pthread_mutex_unlock(&request_lock);
pthread_cond_signal(&request_producer);
process_request(request);
}
}
141

Задача о спящем парикмахере
142
Посетители
Парикмахер
Задача о спящем парикмахере
143
В салоне никого нет, парикмахер спит
Задача о спящем парикмахере
144
Посетитель садится в кресло, парикмахер его стрижёт.
Задача о спящем парикмахере
145
Парикмахер занят, посетитель садится в кресло, засыпает.
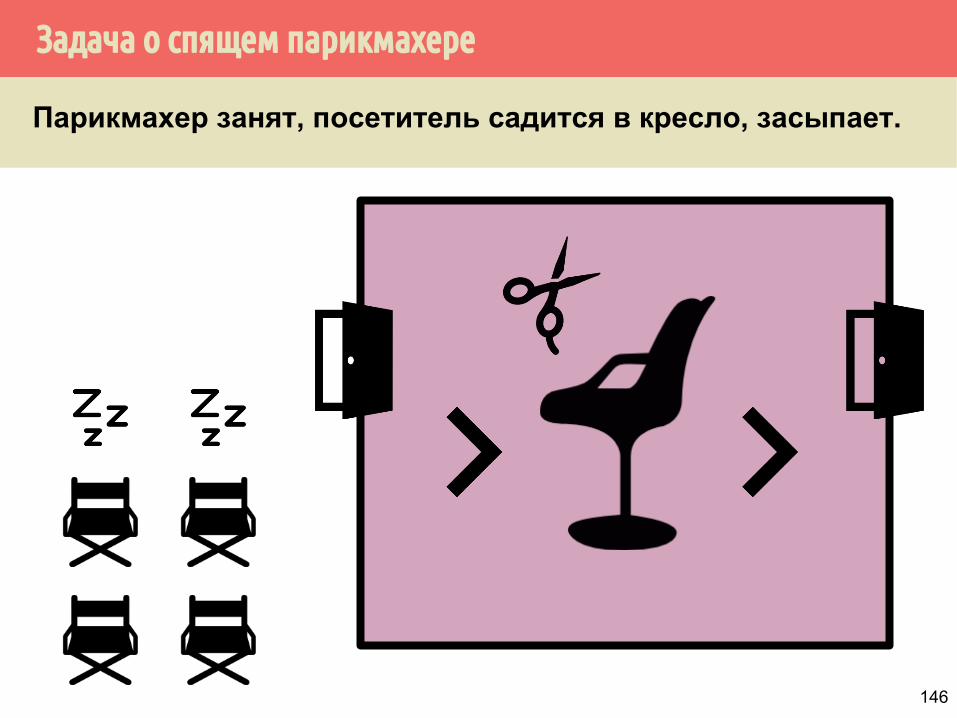
Задача о спящем парикмахере
146
Парикмахер занят, посетитель садится в кресло, засыпает.
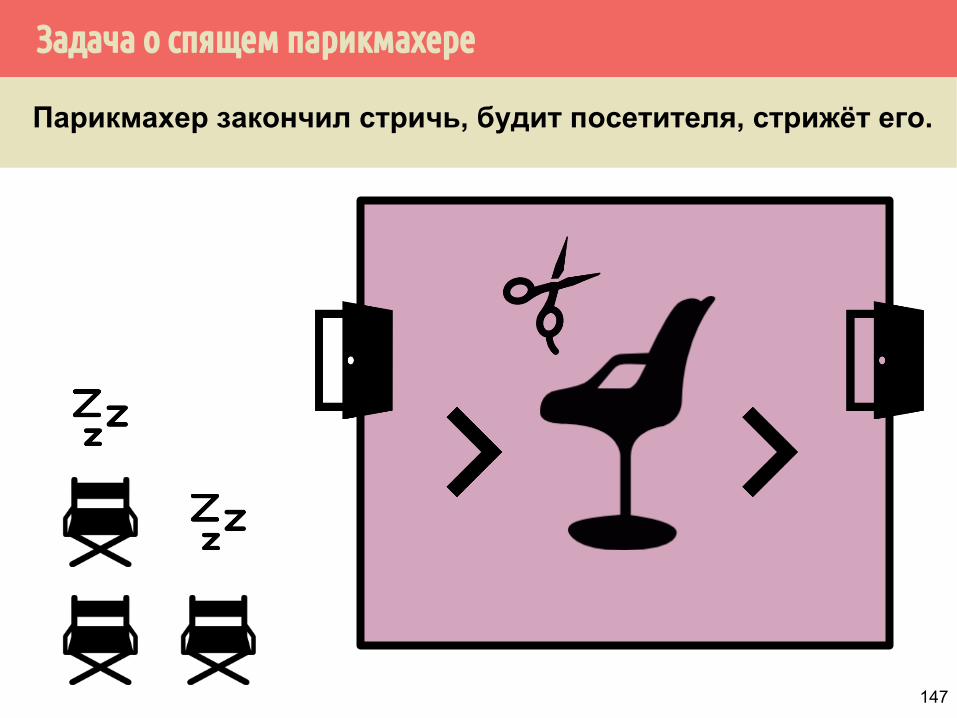
Задача о спящем парикмахере
147
Парикмахер закончил стричь, будит посетителя, стрижёт его.

Задача о спящем парикмахере - решение
/* true, если парикмахер ожидает посетителя и сидит в кресле */bool barber = false;
/* true, если посетитель сел в кресло но парикмахер ещё не занят */bool chair = false;
/* true, если выходная дверь открыта, но посетитель ещё * не вышел */bool open = false;
/* получает сигнал, когда barber == true */pthread_cond_t barber_available;
/* получает сигнал, когда chair == true */pthread_cond_t chair_occupied;
/* получает сигнал, когда open == true */pthread_cond_t door_open;
/* получает сигнал, когда open == false */pthread_cond_t customer_left;
148

Задача о спящем парикмахере - решение
/* посетитель */void customer(void *arg) { get_haircut(); }
void get_haircut() { /* подстричься */ pthread_mutex_lock(barber_lock);
while (barber == false) /* ожидание освобождение парикмахера */ pthread_cond_wait(barber_available);
barber = false; /* парикмахер больше не спит */ chair = true; /* посетитель занимает кресло */ pthread_mutex_unlock(barber_lock);
pthread_cond_signal(chair_occupied);
/* ... стрижка ... */ pthread_mutex_lock(door_lock);
while (open == false) /* ждём пока парикмахер откроет дверь */ pthread_cond_wait(door_open);
open = false; /* выходим */ pthread_mutex_unlock(door_lock)
pthread_cond_signal(customer_left);
} 149

Задача о спящем парикмахере - решение
void *barber(void *arg) {
for (;;) {
get_next_customer(); /* позвать следующего клиента */ finished_cut(); /* закончить стрижку */ }
}
/* позвать следующего клиента */void get_next_customer() {
barber = true; /* парикмахер сводобен */ pthread_cond_signal(barber_available); /* позвать посетителя */
pthread_mutex_lock(chair_lock);
while (chair == false) /* ожидать, пока посетитель не сядет */ pthread_cond_wait(chair_occupied); /* в кресло */ chair = false; /* кресло занято */ pthread_mutex_unlock(chair_lock);
}
150

Задача о спящем парикмахере - решение
/* закончить стрижку */void finished_cut() {
open = true; /* открыть дверь */ pthread_cond_signal(door_open); /* пригласить клиента */
pthread_mutex_lock(door_lock);
while (open == true) /* дождаться, пока */ pthread_cond_wait(customer_left); /* клиент выйдет */ pthread_mutex_unlock(door_lock);
}
151

Мониторы
● Потокобезопасная инкапсюляция общих данных
● В С - путём объявления всех переменных внутри функции, которая выполняет доступ
● В С++ - инкапсюляция путем создания объекта
● Мониторы “заставляют” пользователя совершать действия над общими переменным через код монитора.
● Мониторы, однако, не позволяют реализовать все типы блокировок (например, пересекующиеся блокировки или использование неблокирующих “trylock” блокировок).
152
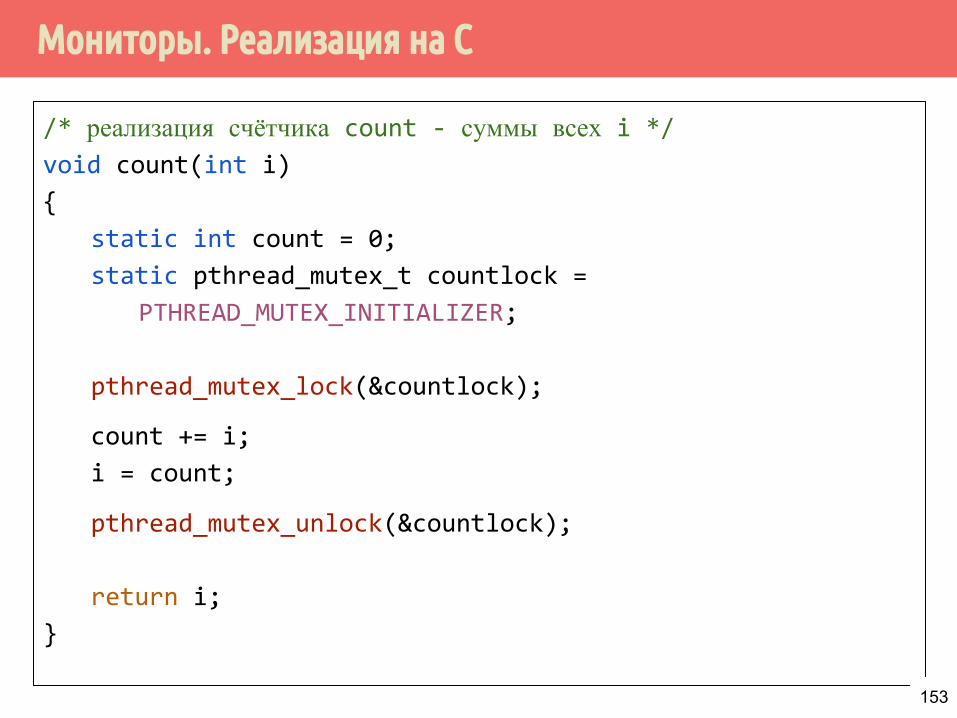
Мониторы. Реализация на С
/* реализация счётчика count - суммы всех i */void count(int i)
{
static int count = 0;
static pthread_mutex_t countlock =
PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_lock(&countlock);
count += i;
i = count;
pthread_mutex_unlock(&countlock);
return i;
}
153

Мониторы. Реализация на С++
class Monitor
{
pthread_mutex_t *mutex;
public:
Monitor(pthread_mutex_t *m);
virtual ~Monitor();
};
Monitor::Monitor(pthread_mutex_t *m) {
mutex = m;
pthread_mutex_lock(mutex);
}
Monitor::~Monitor() {
pthread_mutex_unlock(mutex);
}154

Мониторы. Реализация на С++
void foo()
{
Monitor m(&data_lock);
int temp;
// ...
func(temp);
// ...
// Вызов деструктора снимает блокировку}
155

Спинлоки
▪ Спинлоки подобны мьютексам, но
▪ Это более простой и быстрый механизм синхронизации (“test&set” или что-то ещё)
▪ Поток, пытаясь запереть спинлок, не блокируется (если спинлок занят) - вместо этого он циклически пробует запереть спинлок, пока это у него не получится.
▪ Подходит для мелкозернистого параллелизма (КС небольшая и блокируется на короткий срок).
▪ Критическая секция является местом частого возникновения конфликтов.
▪ Для многоядерных систем.
▪ Проблема с приоритетами потоков!156

Спинлоки
/* инициализация */int pthread_spin_init(pthread_spinlock_t *lock,
int pshared);
/* уничтожение */int pthread_spin_destroy(pthread_spinlock_t *lock);
/* запирание мьютекса */int pthread_spin_lock(pthread_spinlock_t *lock);
int pthread_spin_trylock(pthread_spinlock_t *lock);
/* отпирание мьютекса */int pthread_spin_unlock(pthread_spinlock_t *lock);
157

Спинлоки
pthread_spinlock_t spinlock;
rc = pthread_spin_init(&spinlock, PTHREAD_PROCESS_PRIVATE);
if (rc != 0)
/* … */
/* … */
pthread_spin_lock(&spinlock);
/* “лёгкая” критическая секция, * которая выполняется очень быстро */if a[i] > k
count++;
pthread_spin_unlock(&spinlock);
/* … */
pthread_spin_destory(&spinlock);158

Барьеры
▪ Позволяют выполнить синхронизацию для множества потоков.
▪ Достигшие барьера потоки блокируются до тех пор, пока все потоки множества не достигнут барьера.
▫ По достижении барьера, поток уменьшает счётчик барьера и засыпает.
▫ Когда последний поток достигает барьера, он уменьшает счётчик до 0 и разблокирует все потоки.
159

Барьеры
▪ Позволяют выполнить синхронизацию для множества потоков.
▪ Достигшие барьера потоки блокируются до тех пор, пока все потоки множества не достигнут барьера.
▫ По достижении барьера, поток уменьшает счётчик барьера и засыпает.
▫ Когда последний поток достигает барьера, он уменьшает счётчик до 0 и разблокирует все потоки.
160

Барьеры
▪ Позволяют выполнить синхронизацию для множества потоков.
▪ Достигшие барьера потоки блокируются до тех пор, пока все потоки множества не достигнут барьера.
▫ По достижении барьера, поток уменьшает счётчик барьера и засыпает.
▫ Когда последний поток достигает барьера, он уменьшает счётчик до 0 и разблокирует все потоки.
161

Барьеры
▪ Позволяют выполнить синхронизацию для множества потоков.
▪ Достигшие барьера потоки блокируются до тех пор, пока все потоки множества не достигнут барьера.
▫ По достижении барьера, поток уменьшает счётчик барьера и засыпает.
▫ Когда последний поток достигает барьера, он уменьшает счётчик до 0 и разблокирует все потоки.
162

Барьеры
▪ Позволяют выполнить синхронизацию для множества потоков.
▪ Достигшие барьера потоки блокируются до тех пор, пока все потоки множества не достигнут барьера.
▫ По достижении барьера, поток уменьшает счётчик барьера и засыпает.
▫ Когда последний поток достигает барьера, он уменьшает счётчик до 0 и разблокирует все потоки.
163

Барьеры
▪ Позволяют выполнить синхронизацию для множества потоков.
▪ Достигшие барьера потоки блокируются до тех пор, пока все потоки множества не достигнут барьера.
▫ По достижении барьера, поток уменьшает счётчик барьера и засыпает.
▫ Когда последний поток достигает барьера, он уменьшает счётчик до 0 и разблокирует все потоки.
164

Барьеры
/* инициализация и уничтожение */int pthread_barrier_init(pthread_barrier_t *restrict barrier,
const pthread_barrierattr_t *restrict attr,
unsigned count);
int pthread_barrier_destroy(pthread_barrier_t *barrier);
/* синхронизовать потоки в точке вызова функции */int pthread_barrier_wait(pthread_barrier_t *barrier);
/* инициализация уничтожение атрибутов */int pthread_barrierattr_init(pthread_barrierattr_t *attr);
int pthread_barrierattr_destroy(pthread_barrierattr_t *attr);
/* задание атрибутов (PTHREAD_PROCESS_SHARED, PTHREAD_PROCESS_PRIVATE)*/int pthread_barrierattr_getpshared(const pthread_barrierattr_t
*restrict attr,
int *restrict pshared);
int pthread_barrierattr_setpshared(pthread_barrierattr_t *attr,
int pshared);165
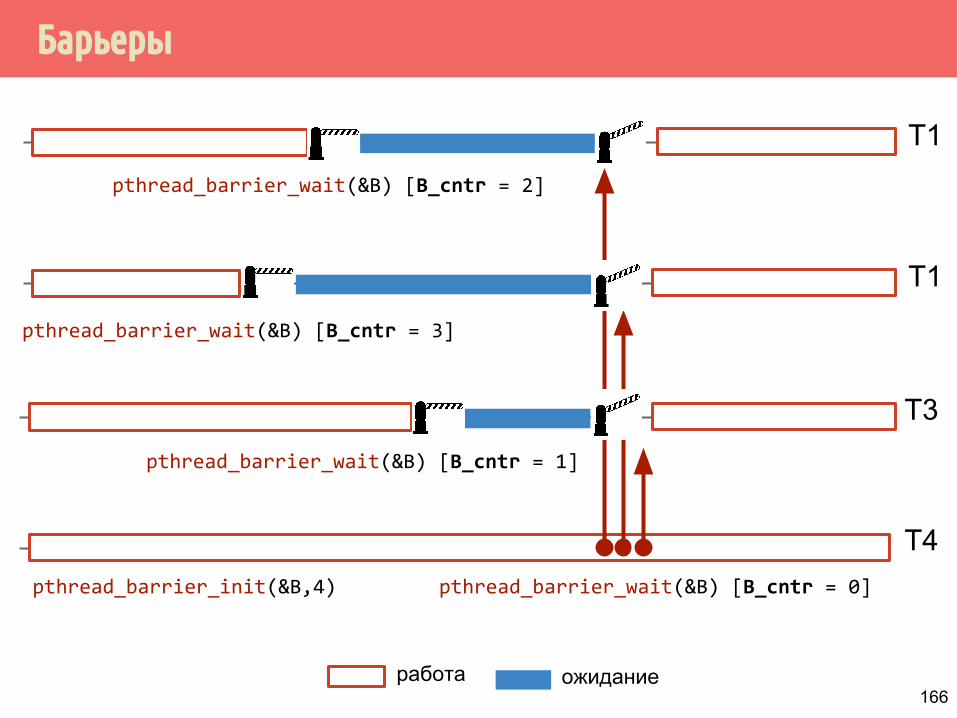
Барьеры
T1
работа
T3
T4
ожидание
T1
pthread_barrier_wait(&B) [B_cntr = 0]
pthread_barrier_wait(&B) [B_cntr = 1]
pthread_barrier_wait(&B) [B_cntr = 3]
pthread_barrier_wait(&B) [B_cntr = 2]
pthread_barrier_init(&B,4)
166

Барьеры. Пример
1. Проинициализировать массив а.
2. Параллельно домножить все элемента массива на k.
3. Вывести полученный массив на экран.
4. Параллельно вычислить квадратный корень над всеми элементами массива.
5. Вывести полученный массив на экран.
6. Параллельно вычислить остаток от деления на 2 всех элементов массива.
7. Вывести полученный массив на экран.
167

Барьеры
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include <pthread.h>
enum { SIZE = 20, NTHREADS = 4, K = 100 };
pthread_barrier_t oper_barrier, output_barrier;
int *volatile a;
168

Барьеры
int main(int argc, const char *argv[]) {
pthread_t tid[NTHREADS];
int threadnum[NTHREADS];
int rc, ithr, i;
pthread_barrier_init(&oper_barrier, NULL, NTHREADS + 1);
pthread_barrier_init(&output_barrier, NULL, NTHREADS + 1);
a = (int *) malloc(SIZE * sizeof(int));
/* Serial initialization */
srand(time(NULL));
for (i = 0; i < SIZE; i++) {
a[i] = rand() % 100;
}
169

Барьеры
for (ithr = 0; ithr < NTHREADS; ithr++) {
threadnum[ithr] = ithr;
rc = pthread_create(&tid[ithr], NULL,
&thread, &threadnum[ithr]);
if (rc != 0) {
fprintf(stderr, "pthread_create failed()"); free(a);
return 1;
}
}
pthread_barrier_wait(&opt_barrier);
printf("\nArray after 1st stage:\n");
for (i = 0; i < SIZE; i++) printf("%d ", a[i]);
fflush(stdout);
pthread_barrier_wait(&output_barrier);
pthread_barrier_wait(&oper_barrier);170

Барьеры
printf("\n\nArray after 2nd stage:\n");
for (i = 0; i < SIZE; i++) printf("%d ", a[i]);
fflush(stdout);
pthread_barrier_wait(&output_barrier);
for (ithr = 0; ithr < NTHREADS; ithr++)
pthread_join(tid[ithr], NULL);
printf("\n\nArray after 3rd stage:\n");
for (i = 0; i < SIZE; i++) printf("%d ", a[i]);
pthread_barrier_destroy(&oper_barrier);
pthread_barrier_destroy(&output_barrier);
free(a);
return 0;
}
171

Барьеры
void *thread(void *arg) {
int i, *threadnum = (int *) arg;
int lower_bound = *threadnum * (SIZE / NTHREADS);
int upper_bound = lower_bound + SIZE / NTHREADS;
for (i = lower_bound; i < upper_bound; i++)
a[i] = a[i] * K;
pthread_barrier_wait(&oper_barrier);
pthread_barrier_wait(&output_barrier);
for (i = lower_bound; i < upper_bound; i++)
a[i] = sqrt(a[i]);
pthread_barrier_wait(&oper_barrier);
pthread_barrier_wait(&output_barrier);
for (i = lower_bound; i < upper_bound; i++) {
a[i] = a[i] % 2;
return NULL;
} 172