Μ speech recognition for illiterate access to information...
TRANSCRIPT

Paper Identification Number: 344
Μ
Abstract—In rural Tamil Nadu and other predominantlyilliterate communities throughout the world, computers andtechnology are currently inaccessible without the help of aliterate mediator. Speech recognition has often been suggestedas a key to universal access, but success stories of speech-driveninterfaces for illiterate end users are few and far between. Thechallenges of dialectal variation, multilingualism, culturalbarriers, choice of appropriate content, and, most importantly,the prohibitive expense of creating the necessary linguisticresources for effective speech recognition are intractable usingtraditional techniques.
This paper, presents an inexpensive approach for generatingthe linguistic resources needed to support Tamil Market, aspoken dialog system that provides daily prices for crops,agricultural techniques, and daily local news bulletins to ruralfarmers in Tamil Nadu. In our approach, data collection isintegrated into dialog design: users of a given village arerecorded during interactions, and their speech semi-automatically integrated into the acoustic models for thatvillage, thus generating the linguistic resources needed forautomatic recognition of their speech.
Our design is multi-modal, scalable, and modifiable. It is theresult of an international, cross-disciplinary collaborationbetween researchers and NGO workers that serve the rural poorin Tamil Nadu. Our ground work includes user studies,stakeholder interviews and field recordings of literate andilliterate agricultural workers in three districts of Tamil Naduover the summer and fall of 2005. Automatic speech recognitionexperiments simulating the spoken dialog systems' performanceduring initialization and gradual integration of acoustic datainformed the holistic structure of the design.
Our research addresses the unique social and economicchallenges of the developing world by relying on modifiable andhighly transparent software and hardware, by building onlocally available resources, and by emphasizing communityoperation and ownership through training and education.Tamil Market is scheduled for deployment in the spring of2006.
Index Terms—User interface, human factors, speechrecognition, spoken dialog system, illiteracy, IT for developingregions.
I.BACKGROUND
A. Agriculture in developing regions
Agriculture is the main source of employment for over 40%of the labor force in developing regions around the world. Todate, in the poorest nations of the world, over 80% of localhouseholds depend on some form of agriculture for sustenance[1]. In Tamil Nadu, 37.47% of full-time workers and 71.64%of marginal workers are in the agricultural sector – a majorityof them small cultivators or seasonal laborers. Cultivators
Μanuscript received December 20, 2001. The work was supported by theNSF, grant ANI-0335289
need price information to make decisions about the mixture ofcrops to produce, when and where to purchase fertilizer orequipment, where to sell harvested goods, and which price toaccept. Farmers in Tamil Nadu are typically familiar withlocal prices and nearby market prices, but rarely know dailyprices at nearby urban centers (Fig. 1).
Due to a variety of factors, including local business andpersonal networks, limited access to capital, and inability totransport and store perishables, farmers in Tamil Nadu aretraditionally reliant on brokers or “middlemen” to collectproducts directly from the farm and transport them to regionalwholesale markets. Access to price information is a criticalgap in the decision-making chain: If farmers are unaware ofthe market value of their agricultural goods, they have nonegotiating power, and may accept rates at a loss to theirpotential income. Illiterate farmers are especially likely to beuninformed, since they rely exclusively on their ownexperiences or by information carried by word of mouth.
Fig. 1. Rural farmers in the Sempatti village plaza, Madurai district.
Though the ability and inclination to base sale decisions onprice information is open to question [2], studies havesuggested that price and market information can improvefarmer welfare [3], [4] and that IT-based informationnetworks can help raise the price of goods sold for smallfarmers [5]. In addition, a substantial body of evidenceindicates that literacy increases farmer productivity andearning potential [6], [7]. Literacy is also an important factorin social potential, such as children's health and nutrition [8].
Speech-driven interfaces have often been suggested as keyto universal access in countries like India, where two thirds ofthe 870 illiterates in the world today are found [9]. In ruralTamil Nadu, illiteracy rates can be as high as 50% for menand 80% for women [10]. Traditional speech technologies anduser interface design, developed for (and by) literate users in
1
Speech Recognition for Illiterate Access toInformation and Technology
ICTD2006

Paper Identification Number: 344
resource-rich countries, are a misfit for users in developingregions. We offer instead a novel design for a spoken dialogsystem (SDS) that is scalable, modifiable, and designed towork in a limited resource environment. Our initial resultsoffer a strong case for further investigation in adapting speechtechnologies to the social and economic realities of developingregions.
B.MSSRF knowledge centers
The MS Swaminathan Research Foundation (MSSRF) is anestablished NGO in Tamil Nadu dedicated to a pro-nature,pro-poor and pro-women approach to fostering economicgrowth in rural, agricultural areas. MSSRF communitycenters, known as Village Knowledge Centres (VKCs),throughout the state provide general information on marketprices of agricultural goods, weather, local news, employment,and government policies and services. Volunteers from thecommunity, or “knowledge workers,” provide the rural poorwith training and educational materials on health, social issues,and entrepreneurial development.
Much of our research has been in the VKC networks in theunion territory of Pondicherry, which is monitored fromChennai, the state capital and MSSRF’s headquarters. Eachmorning, volunteers travel to nearby markets and collectinformation about market prices and report back to MSSRFcontacts. The information is consolidated, digitized, anddisseminated to all VKCs through one of the followingcommunication links: phone, dial-up voice transfer, or wi-fi.The following morning, villagers may access information at anearby VKC by reading posted bulletins (Fig. 2), listening toloudspeaker broadcasts, or, in the case of illiterate communitymembers, working one-on-one with a knowledge worker [11].
Fig. 2. Daily postings of weather, news, and market prices in the Sempattivillage knowlege center. Illiterate villagers require an interpreter to gain accessto this information.
C. Speech-driven interfaces for developing regions
A spoken dialog system (SDS), which would allow users toaccess information by voice, either over the phone lines or at akiosk, could play a role in overcoming current barriers of costand literacy. Speech-driven user interfaces (UI) are cheaperthan display-based UI solutions and more accessible than text-based UI solutions. An application for rural Indianinformation technology (IT) that provides general information
on health, weather, employment, news, and agricultural priceswould enhance the social and economic development of therural poor [12] and could be constructed around a limited-vocabulary speech-driven interface.
Speech-driven UI solutions are often suggested to increaseaccess for users in developing regions, but they are rarelyattempted, due primarily to the challenges of multilingualism,dialectal and cultural diversity, as well as the prohibitive costsof developing the linguistic resources needed to power speechrecognition.
India has 22 “scheduled” (official) languages but estimatesrange from 450 [13] to 850 languages [14] overall. India isthe 9th most linguistically diverse country, with a 93%probability that any two people of the country selected atrandom will have different mother tongues [13]. An SDSdesigned to recognize the word choice and pronunciation ofusers in one village will likely fail for villagers a few hundredkilometers away. Likewise, the relevance of informationvaries from region to region (e.g., tide and sea conditions onthe coast,. rainwater collection in dry regions), necessitating adifferent set of command words in each case.
Speech technologies, such as automatic speech recognition(ASR). require the collection and hand annotation of a largecorpus of speech and a dictionary of all possible words in thelanguage with all possible pronunciations for each word. Theavailability of linguistic resources, such as training data andpronunciation dictionaries, which are arguably the most costlypart of development, are taken for granted by developers withEnglish-speaking users in mind, for example. Only a handfulof speech technology efforts [15]-[17], have been dedicated toTamil, however, which is spoken by over 60 million people inTamil Nadu, Sri Lanka, and elsewhere [18]. The majority ofthe world's languages are spoken in developing regions andhave no associated linguistic resources.
Power, connectivity, and limited infrastructure are allsignificant obstacles in developing regions. Finally, userinterface design requires a familiarity with the cultural andeconomic context of the user. As a whole, people who havenever learned to read or write are poorly understood byresearchers and developers of technology.
D.User interface design for illiterate users
Illiteracy is usually used to describe an individuals'competency at the tasks of reading and writing. A functionalilliterate is an individual who may have had some exposure toeducation, but whose low competency at these tasks preventsthe individual from wholly participating in society. Samelanguage subtitles and other attempts to reinforce literacy bycombining text and images have met with some success [19].
Other efforts to provide immediate IT access to illiterates indeveloping regions, where “gaining access to target users,rural Indian villagers with literacy challenges, forexperimentation would be challenging and costly,” [20] haveattempted to address the inappropriateness of traditional HCIdesign techniques. However, their solutions are not informedby actual user studies in developing regions and heavily relyon the use of icons [21], requiring users to memorize a set ofsymbols and their corresponding meanings, which is
2

Paper Identification Number: 344
essentially a literate task.One UI design study for a financial management system for
micro-credit groups in rural India conducted extensivecontextual field studies and Parikh et al. [22] found that manyof the women they worked with could read and write numbersand perform calculations. The developers used this numericalliteracy as partial leverage in their graphic-based interface,which they tested iteratively to arrive at an interface that waswell understood by most users. The use of colors, especiallyreds and yellows, were useful to illiterate users in identifyingrelevant parts of the interface. Although numbers were wellunderstood among their numerically literate users in thecontext of performing calculations, when they were used torepresent a concept, users experienced difficulty inremembering the intended meaning.
Cognitive and brain activation studies on literate andilliterate subjects have shown that learning the skill of writingduring childhood alters the functional organization of the adultbrain, in particular, the phonological processing of spokenlanguage [23], [24]. In these studies, women who had neverbeen to school were tested on their ability to repeat words andpseudowords (words phonetically similar to comprehensiblewords, but with no meaning). The illiterate women performedonly slightly worse on the word repetition task than literatewomen but were much less adept at repeating nonsense words,often producing phonologically similar actual words instead.The results of this study tell us little about differences inspeech production among literate and illiterate groups, whichwe will discuss in a later section. However, the difficulty inrepeating pseudowords among illiterate participants suggeststhat successful UI solutions for this group will rely oncommand words that are familiar and relevant to everydaylanguage use.
E.Our approach
In this paper, we investigate the possibilities for a speech-driven UI design for illiterate users in developing regions whomay have never been exposed to education. We propose amulti-modal interface that requires no training and providesusers with a variety of visual and audio cues and input options,allowing each user the flexibility to interact with theapplication to the best of their ability and the systems' ability.
This paper describes an SDS built from standard speechtechnologies to be accessible to illiterate users and scalable toother dialects or content. The rest of the paper is organized asfollows: In section 2, we outline results from a preliminaryuser study. In section 3, we present our findings from fieldrecordings of the speech of rural Tamilians in three districts ofTamil Nadu, In section 4, we present a series of experimentsusing standard ASR techniques with limited available trainingdata and linguistic resources. In section 5, we present theresulting design for our dialog system. Section 6 drawsconclusions and discusses future work.
II.TAMIL MARKET
A. Initial approach
Initially, we chose to restrict ourselves to the relativelyunexplored domain of speech. We developed Tamil Market,an SDS that provides weather, market prices for crops, and
agricultural information to users who navigate by uttering asmall vocabulary of Tamil command words (Fig. 3).
TM: Welcome to Tamil Market. I can tell you about cropprices, weather, and rainwater collection.
Would you like to hear about crop prices? Please say“yes” or “no.”
User: Yes.TM: Please say the name of the crop you would like
today's market price for. User: Wheat.TM: I'm sorry, I didn't understand what you said.I will tell you all the crop prices in rupees per kilo. Wheat,
9, Rice, 10, Onion, 5.5, [...]Fig. 3. An English translation of a sample dialog with Tamil Market.
Initial proposals to use a set of application-independentcommand words, such as “back,” “next,” and “repeat” wererejected, since they would force users to memorize a set ofarbitrary commands, they were likely to change meaning fromvillage to village, and they were often metaphors from theexperience of navigating through a web page or other text-based media. Instead, Tamil Market primarily operates on thewords “yes” (aamaam) and “no” (illai), terms thought to belikely to retain meaning and function across different dialectsand which build on the experience of accessing information byword of mouth. Tamil Market also requires severalapplication-specific command words, for example, the namesof crops.
Tamil Market requires no training, prompting the user forexpected input options at each stage, and it providesinformation even when no input is given, as is likely for first-time users or users unfamiliar with technology. Gracefulfailures in the design ensure that when input is lacking or mis-recognized for any reason, the user will still be provided withuseful information, albeit not in the most direct way.
B. User Study
The result was a rigid but accessible SDS that ran on a PClaptop and to which participants spoke using a custom phonemic, a computer microphone and speaker embedded in arecycled phone handset (Fig. 4). Tamil Market was testedamong illiterates and semi-literates in three districts of TamilNadu in a Wizard-of-Oz user study, in which one of theresearchers played the role of the recognizer and sporadicallyinjected errors approximately 2% of the time [25].
3

Paper Identification Number: 344
Fig. 4. Initial Tamil Market user study.
C. Results and Design Considerations
We found participants quite adept at using the system withno training, even though many had never before used a phoneor computer. User errors usually occurred at the beginning ofthe interaction with Tamil Market and consisted of no input,complete sentences, or unexpected words or pronunciations.
Participants valued accuracy of information and time ofinteraction, which averaged about three minutes. Participantsexpressed pride and excitement at hearing a computer speaktheir language and were forgiving of the 2% injectedrecognition errors. Participants also offered many suggestionsabout the content of Tamil Market, including an interest invarieties of crops, grades of crops, prices at the local market,block market, and wholesale market.
Interest in Tamil Market correlated to distance from thenearest marketplace. Participants who lived far from a marketreported that if the information was accurate, they would bewilling to pay the price of a phone call (one rupee, equivalentto $0.02) to use such a system. In villages near a majormarket, however, at least one individual would visit the marketeach day and could easily report the market prices to othermembers of that village.
We found that illiterates were reluctant to participate in thestudy and had greater difficulty restricting their input torecognizable forms, despite explicit prompts, but reportedconfidence that with training they could operate such a system.
Our main finding was that an SDS like Tamil Market canbe operated by rural farmers of varying degrees of literacywith very little training. The study also confirmed the need fordaily market prices in an accessible form for this population.Illiterate users would likely perform better with more trainingor additional cues, such as graphic output. Finally, despiteexplicit prompts in the dialog system, participants respondusing a wide variety of command words that change inpronunciation and form from district to district, with a rangeof variations difficult to predict in advance.
III. SPEECH RECORDINGS IN TAMIL NADU
Speech recordings of rural villagers in three districts ofTamil Nadu were conducted during one field visit in 2004 andanother in 2005 to quantify linguistic variations by geographyand literacy and to determine what Tamil resources arenecessary to power an SDS like Tamil Market.
A. Data collection
During two field visits, the speech of 77 volunteers wasrecorded in three separate districts in Tamil Nadu, India (Fig.5). All volunteers were native speakers of Tamil over the ageof 18. The researchers sought a balance of gender, educationlevel, and age among participants, but the demographics ofthis study varied greatly by site (Table 1) and by recruitingmethod.
Fig. 5. Tamil Nadu, India.
Coimbatore volunteers were either undergraduate studentsat Amrita University or laborers, mostly illiterate, recruited byword of mouth; this method proved to be unsuccessful for thelatter group. In Pondicherry, literate farmers and their wiveswere recruited as volunteers by MSSRF. In Madurai district,volunteers were recruited through MSSRF and Aravind eyecamps, where free eye care is provided in rural villages tobetween 200 and 500 people a day. We found that workingalongside trusted organizations that serve the rural poor wasthe most efficient method for recruiting and recordingvillagers, especially illiterate volunteers.
Site (Year)Number
ofSpeakers
Average Age of
Females Males%
Illiterate
Coimbatore (2005)
15 20.7 31.4 13%
Madurai (2005)
33 49.3 55.7 39%
Pondicherry (2005)
7 37.5 47.3 0%
Pondicherry (2004)
22 n/a n/a 0%
All Data 77 35.8 44.8 19.50%
Table 1. Number, age, gender, and literacy of speakers by site. “n/a”signifies that speaker information is not available.
The age of speakers ranges from 18 to 80 years old, with an
4

Paper Identification Number: 344
average age of 40. The men in this study average almost 10years older than the women. University students contribute toa younger average age in Coimbatore. Eye care patients inMadurai represented an older demographic.
Traditional data collection for small vocabulary speechdatabases relies on read speech in a quiet, controlled setting.Recordings for this study were conducted in the quietestavailable space, which, in many cases, meant recordingoutside or in noisy rooms.
Equipment and elicitation techniques varied by site, sinceresearchers had to be flexible to environmental conditions.Initially, literate Tamil speakers in Pondicherry (2004) wererecorded saying 30 Tamil command words (e.g., “repeat”,“send,” “next”) in relatively quiet offices with a lapelmicrophone or computer table microphone and a laptoprunning mouse-driven software that displayed a written wordand recorded the speaker saying the target word.
Fig. 6. Recording a literate woman in Ettimadai, Coimbatore district.
Data collection in rural Tamil Nadu (2005) relied instead onflashcards and the phone mic connected to a Sony MDWalkman (MZ-NH900)(Fig. 6). This allowed the speaker tocomfortably hold the microphone close to the mouth butslightly to the side of the lips, to avoid ‘”p-pops,” bursts ofhigh airflow during speech. In addition to capturing qualityspeech recordings in a variety of environmental conditions(average signal to noise ratio was 29), the phone mic avoidedthe need to clip or fasten equipment to the speaker's clothingand did not require the use of a table.
Bilingual flashcards with digits 0-10 written in bothnumerical and orthographic form were randomized and shownto speakers one at a time (Table 2). Speakers were recordedreading the numbers aloud. The protocol was repeated fivetimes per speaker. If a participant could not read theflashcards, a researcher or interpreter would translate theflashcards into a display of fingers. (A fist represented zero.)The flexible protocol allowed us direct method for evaluatingcompetency at literacy and numerical literacy. Both theflashcards and finger counting methods were designed to elicitsingle word utterances free from any external influences inword choice or pronunciation.
All participants also answered a questionnaire to determinelinguistic and educational background with the aid of a local
interpreter. All speech was recorded at 44kHz, stereo, thendownsampled to 16kHz, mono. Finally the speech waveformwas extracted with a collar of approximately 100 ms ofsilence.
TABLE 2
DIGITS ELICITED FOR SPEECH RECORDINGS
Numerals Tamil Script EnglishTransliteration
International PhoneticAlphabet IPA
0 பஜயம pUjyam /pūʤam/1 ஒணண oNNu /ʷoɲ:ɯ/2 ெெணட rendu /reɲɖɯ/
3 மண mUNu /mūɲɯ/4 நால nAlu /nālɯ/5 அஞச anju /aɲʤɯ/6 ஆற ARu /ārɯ/7 ஏழ ELu /ʲēẓɯ/8 எடட ettu /ʲeʈʈɯ/
9 ஒமோோாத ompOthu /ʷombōðɯ/10 ோதத paththu /pat̪t̪ɯ/
Recording illiterate speakers saying the words for digits 0-10 took approximately six times as long as recording the samedata from literate speakers. This discrepancy was due todifficulties explaining the task, limitations in the protocol (noreading aloud), inflexible and demanding occupations ofparticipants, and apprehension involving participation,resulting in many missed appointments. In addition, illiteratespeakers in this study had limited access to infrastructureappropriate for recording (no housing, no power, publicbuildings), and longer social protocols for foreign visitors.
Fig. 7. Recording an illiterate woman in Ettimadai, Coimbatore district.
5

Paper Identification Number: 344
B.Linguistic variation by literacy
One topic we sought to explore with our field recordingswas whether illiterate speech varied substantially from literatespeech. Unfortunately, in our data, the differences betweenliterate and illiterate speakers were due to differences inelicitation protocols and environmental factors rather thanlinguistic characteristics of speech production. We attemptedan adaptive experimental protocol but failed to anticipate thecognitive difference between the task of determining a numberof displayed fingers and the task of reading numbers aloud[26]. The elicitation technique developed for illiterate speakersresulted in significant implications in the speech domain, suchas more disfluencies (filled pauses, false starts, repetitions),and shouting (e.g., “um…thr...no! FOUR! Four.”). This effectwas compounded by the environmental conditions:Recordings often took place outside or in a crowded room,where the task of guessing the number of displayed fingerswas often irresistible to “helpful” bystanders.
Although our data are inconclusive regarding any effectliteracy has on the phonetic characteristics of speechproduction, we observed that illiterates are more likely toproduce words and pronunciations specific to their region thanvillagers who have attended school and been exposed tomaterials and instruction in “standard” Tamil.
C. Linguistic variation by geography
Like most languages, Tamil varies by geography (6 maindialects), social factors (caste, education), and register (spokenvs. written). Tamil spoken in Chennai and throughout the EastCoast (including Pondicherry) has emerged as the modernstandard; the Tamil of press, literature, and radio. Modernstandard Tamil is considered accessible to most speakers ofmainland Tamil, regardless of literacy [18].
We hypothesized that words for digits 0-10 would besimilar across Tamil Nadu, though pronunciations might vary.Pronunciation of the consonant in the Tamil word for “seven”,(eLu) for example, varied significantly (p<0.01, N=385) bygeography. Speakers from Pondicherry use an /l/-like lateralapproximate, whereas speakers in Coimbatore and Maduraidistricts use the phoneme unique to Tamil, a retroflex palatalfricative (similar to a /zh/ with the tongue curled backwards).Age, gender, and education level were not predictive factors inthis phonetic variation.
Unexpectedly, we found significant variation (p<0.01,N=379) in word choice for the Tamil word for “zero”. Evenamong literate speakers reading a flashcard explicitly marked,பஜயம (pUjyam), 3 speakers in Coimbatore and 6 inMadurai said, zeero or jeero. In Madurai district, 11 speakerssaid saiber. All three forms are borrowings, from Hindi,English, and Arabic, respectively, as Tamil does not have itsown term for “zero.” Age, gender, and education level werenot predictive factors in this variation.
D.Results and design considerations
Our main finding in recording the speech of rural villagersof Tamil Nadu is that traditional data collection techniquesfavor literate speakers and that villagers only 300 kilometers
apart use different words and different pronunciations foreveryday concepts that are difficult to predict in advance. AnSDS that adapts to its users by learning their choice andpronunciation of command words would avoid the challengeof anticipating appropriate command words. In addition, thetime-consuming, artificial step of recording disjointedinstances of speech, which is particularly ill-suited to anilliterate population, would be unnecessary. Instead, byintegrating data collection into the SDS, the needs of the user(gaining access to relevant information) and the needs of thesystem (gathering instances of speech to enable recognition)are simultaneously met.
Further benefits to an SDS with integrated data collectionand more detailed design considerations are discussed in thefollowing section.
IV. LIMITED RESOURCE ASR
Traditional ASR techniques depend on the existence ofpronunciation dictionaries for the target language and solvethe problem of dialectal variation by training robust acousticmodels from very large amounts of manually transcribedspeech and sophisticated adaptation techniques. Currently,promising solutions to the development of large vocabularyASR of Tamil, for which there are no equivalent linguisticresources, are being proposed in techniques for bootstrappingand mixing models from acoustically similar dialects orlanguages [15]. Instead of pursuing a long term goal of largevocabulary recognition for all Tamil speakers, we limit ourscope to a single village and focus our efforts on a modifiable,transparent SDS powered by a small vocabulary whole-wordrecognizer that is robust to noise, microphone changes, anddialectal variation by virtue of its simplicity.
In this section, we present a series of speech recognitionexperiments trained on the annotated speech we collected fromour field recordings to demonstrate the performance of asimple, whole-word Tamil recognizer with limited availablelinguistic resources.
A. Phoneme versus whole-word models
We adopt whole-word models for small vocabulary ASRbecause we believe it will a facilitate rapid, low-cost SDSdeployment for Tamil and other languages with limitedavailable linguistic resources. Although phoneme models aremore flexible to the addition of new words, they require thecostly development of a pronunciation dictionary: A list ofeach word ASR may encounter and all of its possiblepronunciations. As previously mentioned, pronunciationdictionaries are currently unavailable for most languages ofthe world and may be too costly to develop for a specificapplication.
Once a pronunciation dictionary is available for a givenlanguage, phoneme models yield equivalent recognitionperformance for known words, and, unlike whole-wordmodels, enable the recognition of words that are not includedin the training data by extrapolating from phoneme models ofwords that are.
6
Paper Identification Number: 344
B.Task complexity
We trained a whole-word recognizer using the HiddenMarkov Tool Kit (HTK) on speech from 22 speakersPondicherry (2004). The models used 18 states with 6diagonal gaussians per state. As expected, when the remainingspeech was input for recognition, in three separate trials, (allwords from our data, only digits, and six select commandwords) word error rates dropped for tasks with fewer optionsfor correct word identity (Fig. 8).
Single whole-word recognition of a small vocabulary ofcommand words at a time achieves high accuracy with verylittle training data. and is sufficient to power an SDS likeTamil Market, which is designed primarily around the words“yes” and “no.” Other command words will likely exhibitgreater dialectal variation.
Fig. 8. Recognition errors by task complexity.
C. Dialectal variation
To evaluate the influence of phonetic and lexical variationson our small vocabulary, whole-word recognizer, we usedHTK to train a system to recognize digits (equivalent to the 11word task in Fig. 8) based on the speech of 22 Pondicherry(2004) speakers. We then tested the recognizers performanceon speakers from all three districts in our study (Fig. 9). Digitsspoken by Pondicherry (2005) speakers reveal error ratesaround 2% or less. Coimbatore and Madurai speakers causedsignificantly higher word error rates (p<0.01, N=3168). Mosterrors were in the recognition of the words for “zero” and“seven” Including alternate pronunciations in the whole-worddictionary slightly improves recognizer performance.
Fig. 9. Word error rate for digits by site. Errors for the words “zero” and“seven” are explicitly indicated. Training data from Pondicherry (2004)speakers.
We considered the possibility that the lower word error rateswere caused by a quieter environment for Pondicherryrecordings, many of which took place in an office, but signalto noise ratios (SNR) per speaker, automatically extractedusing a speech/non speech detector, had no significant effecton word error rates.
D.Available training data
Recognition performance is best when substantial trainingdata is available. Given that resources are limited indeveloping regions, and that data collection is challenging andlabor intensive, we ran a simulation to determine how littledata is needed to achieve acceptable error rates for theoperation of an SDS like Tamil Market.
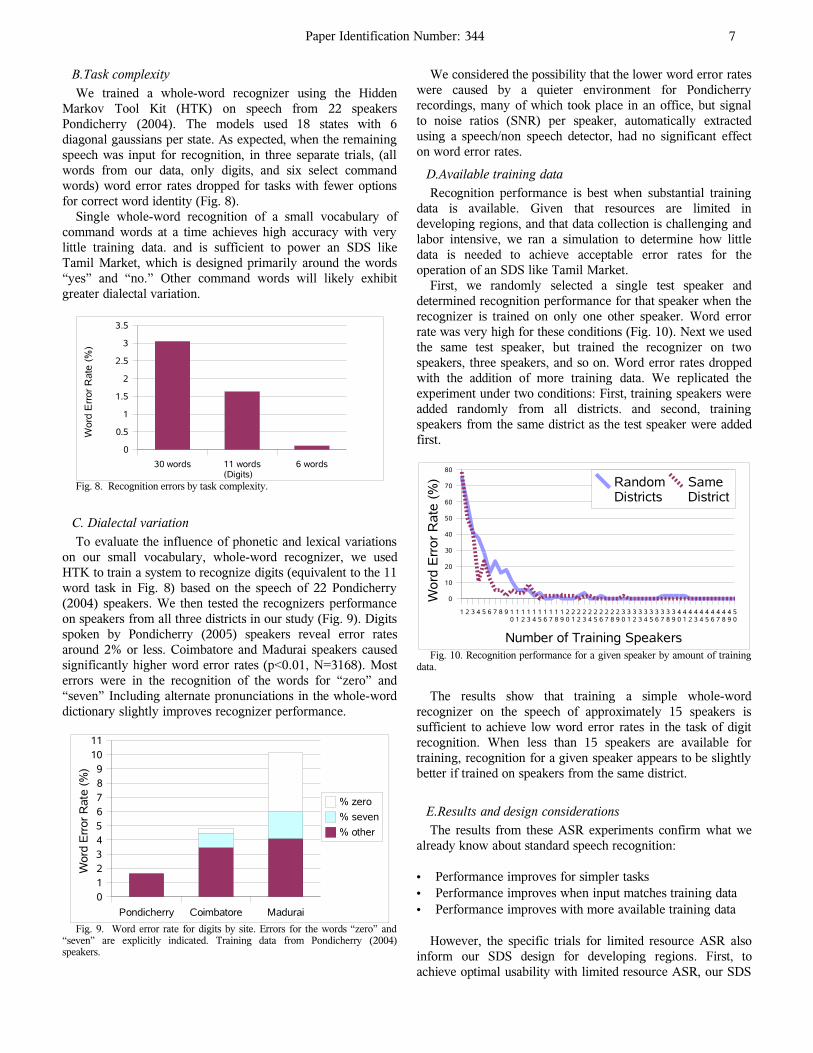
First, we randomly selected a single test speaker anddetermined recognition performance for that speaker when therecognizer is trained on only one other speaker. Word errorrate was very high for these conditions (Fig. 10). Next we usedthe same test speaker, but trained the recognizer on twospeakers, three speakers, and so on. Word error rates droppedwith the addition of more training data. We replicated theexperiment under two conditions: First, training speakers wereadded randomly from all districts. and second, trainingspeakers from the same district as the test speaker were addedfirst.
Fig. 10. Recognition performance for a given speaker by amount of trainingdata.
The results show that training a simple whole-wordrecognizer on the speech of approximately 15 speakers issufficient to achieve low word error rates in the task of digitrecognition. When less than 15 speakers are available fortraining, recognition for a given speaker appears to be slightlybetter if trained on speakers from the same district.
E.Results and design considerations
The results from these ASR experiments confirm what wealready know about standard speech recognition:
• Performance improves for simpler tasks• Performance improves when input matches training data • Performance improves with more available training data
However, the specific trials for limited resource ASR alsoinform our SDS design for developing regions. First, toachieve optimal usability with limited resource ASR, our SDS
7
1 2 3 4 5 6 7 8 9 10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
0
10
20
30
40
50
60
70
80
Random Districts
Same District
Number of Training Speakers
Wo
rd E
rro
r R
ate
(%
)
Pondicherry Coimbatore Madurai
0123456789
1011
% zero
% seven
% other
Wor
d E
rror
Rat
e (%
)
30 words 11 words (Digits)
6 words
0
0.5
1
1.5
2
2.5
3
3.5
Wor
d E
rror
Rat
e (
%)

Paper Identification Number: 344
design should limit the complexity of the ASR task toapproximately ten words or less at any given dialog node.Second, ASR performance by site further supports ourproposal to integrate data collection into the SDS design, thusensuring that input and training data match not only in dialect,but in other nonlinguistic factors, such as channel and roomacoustics. Finally, during deployment of an SDS like TamilMarket in a given village, ASR performance for a set of corecommand words, (e.g.,“yes” and “no”) could be cheaply andquickly initialized with the speech of only 15 volunteers, thusoptimizing overall SDS usability while acoustic models forother vocabulary words may still be impoverished.
Although the whole-word recognizer we developed from asmall corpus of Tamil speech by no means represents cutting-edge speech technology, its performance in these trials, incombination with the Tamil Market user study, in whichuntrained, semi-literate users were able to access desiredinformation despite errors in recognition at approximately 2%,demonstrates that standard ASR developed from limitedlinguistic resources is sufficiently robust to power an SDSdesigned for such conditions.
V.CURRENT DESIGN
The direction of our work is motivated by the desire toaddress the needs and conditions of the majority of the worlds'population whose lives could greatly benefit from theknowledge and services taken for granted in a handful ofwestern countries, but whose social and economic conditionscreate a formidable barrier to gaining access to suchinformation. For this, we rely on field researchers, grassrootNGO workers and our partner organizations to articulate theneeds of populations in developing regions.
According to MSSRF, the needs of rural villagers varyfrom district to district. Village knowledge centers (VKCs) inPondicherry would benefit from an SDS like Tamil Market toprovide tidal information and sea conditions to localfishermen, who currently rely on a daily broadcast overloudspeakers for this information. VKCs in dry Maduraidistrict wish to distribute agricultural techniques andinformation over a phone line to increase access and decreaseorganizational costs, which currently demand a one to oneratio of illiterate community members to knowledge workers.Throughout Tamil Nadu, wages are low and illiteracy rates arehigh.
As researchers, we chose to pursue speech technology, andin particular, a SDS solution to UI design for rural Tamiliansof all literacy levels. Instead of requiring users to memorize aset of inappropriate command words or icons or attempting toanticipate the content of an SDS for each possible deployment,We explore a holistic design for an SDS that is powered bylimited resource ASR, that can be cheaply initialized andrapidly deployed, that is modifiable by a trained communitymember, that semi-automatically adapts to the dialect of itsusers; and, ideally, that scales not only to new dialects but alsoto other languages. Crucial to the success of this technology isthat the SDS and the villagers' speech recordings are ownedand operated by the community, requiring substantial focus ontraining and education during deployment but a high
likelihood of sustainability after deployment.
A. Multi-modal input
Tamil Market was initially a speech interface designed torun over a phone line. Our field work and previous UI studiessuggest that a parallel kiosk version, which combines speechwith additional input (touch, typing) and output domains(graphics, local text) can provide multiple cues tounsophisticated or new users and, in the case of functionalilliterates, reinforce literacy. Touch screen combined withdigital photographs or graphics produced by a local artist is anideal input for users of all literacy levels, but its cost andrelative fragility make it inaccessible for a community centerin rural Tamil Nadu.
We constructed a cheap and modifiable flex button system(similar to cash distribution machines) by soldering buttonsrecuperated from recycled computer parts to the function keysof a dedicated keyboard (Fig. 11). The result is a system thataccepts touch input as well as speech and whose constructionis transparent, cheap, and easy to construct from locallyavailable materials. The multi-modal kiosk outputs digitalphotographs and corresponding Tamil text for commandwords, while still adhering to the same audio dialog structureas before, which provides relevant information even when theuser provides no input (graceful failures) or unrecognizedinput. Once acoustic models are adequate for recognition,power users will find that voice input allows the most directroute to specific information.
Fig. 11. Tamil Market kiosk prototype. Phone mic and modified keyboardwith flex buttons are made from locally available recycled components.
B.Integrated data collection and semi-automatic ASRadaption
We have provided several reasons for our proposal tointegrate the collection of linguistic samples into the SDS. Webelieve that this method for recording speech does not favorliterate users over illiterate users and provides the best matchof training and input data, resulting in robust ASRperformance despite limited linguistic data.
8

Paper Identification Number: 344
The only substantial changes to the SDS initially presentedis the addition of a “push-to-talk” feature to the phone mic, aswell as a corresponding indicator light. When the button isdepressed, speech is recorded in an audio file and submittedfor recognition and subsequent operation of the SDS (Fig. 12).The ability of the user to access desired information isunaffected by this modification.
TM: Please say the name of the crop you would liketoday's market price for.
User: Wheat. →saved as an audio file
TM: I'm sorry, I didn't understand what you said.I will tell you all the crop prices in rupees per kilo. Wheat,
9, Rice, 10, Onion, 5.5 [...]Fig. 12. An English translation of a sample dialog with Tamil Market.
The challenge of this approach is knowing which of therecorded audio files should be incorporated into the acousticmodels. The “push-to-talk” button helps separate intendedspeech from other audio data. Our user study, however,showed that no input, complete sentences, and otherunrecognizable input are common user responses to TamilMarket. Including mislabeled or inappropriate audio data inacoustic model training would be detrimental to overallrecognition performance. Discarding files that are smallerthan 50 ms or longer than 100 ms, could also help to filter outcomplete sentences or truncated speech.
Suppose that most of the remaining acoustic files consistmostly of single word utterances; the identity of the utteredword must be known for the data to be included in ASRtraining. Without listening to each file, however, it will beimpossible to know with certainty what the recordings contain.The ideal solution is to have a semi-skilled person, in this case,a trained VKC volunteer, listen to each file, discard it ifnecessary, and label it by its content if it is an instance of asingle word utterance. This process is time consuming,however, so we propose a machine learning techniqueoriginally developed for speaker recognition to automaticallyorganize the data by word identity.
In a study on speaker segmentation and clustering, Ajmeraet al [27] used the Bayesian Information Criterion (BIC) toperform speaker clustering without any prior knowledge ofthe identities or the number of speakers. We are currentlyinvestigating the use of this algorithm to cluster like wordsfrom recorded input.
In standard speech recognizer training, Mel-frequencycepstral coefficients are extracted every 10 ms. A recognizer istrained on the feature data and its corresponding transcribedphonemes. Each phoneme is then represented by an n-stateHidden Markov Model (HMM), in which each state can bemodeled by a Gaussian mixture. At first, HMM's of utterancesof the same word are likely to be assigned to different clusters(Fig. 13). Given {w1, w2, w3, ... wn,} the audio data to beidentified, we want to find the optimal number of clusters andtheir acoustic models according to the likelihood of the data.The BIC is used as a merging criterion, as it imposes a trade-off between model quality and model complexity. Models are
merged only if the log likelihood of the data given thecombined model is higher than that of the sum of the twoseparate models.
Fig.13. Merging Algorithm
Preliminary results from simulations of acoustic data areencouraging, showing that the same algorithm used to clusterspeakers can be applied to cluster words, without knowing inadvance what forms or what pronunciations are used in agiven village. However, initialization of the models andoptimization of the algorithm for small amounts of data mustbe explored to apply this algorithm to actual acoustic data. Wehope to include this algorithm in our next deployment.Recorded input can then be clustered into a manageablenumber of groups, likely to consist of the same word, greatlysimplifying the amount of time needed to annotated audioinput and generate acceptable acoustic models at each newdeployment or modification to the system.
C.Community owned and operated
Historically, society has seldom given poor peopleownership over the tools of production [28]. Research anddevelopment efforts in the field of IT for developing regionsare finding that involving the community in design andcreation ensures that proposed solutions meet the needs of thecommunity and provides the best chance for the sustainabilityof the technology in the community. Tamil Market has beenfrom its inception a result of co-design and collaboration ruralfarmers and the NGO volunteers who serve them. Futuredeployments of this application will focus on training MSSRFvolunteers to produce their own content using the system,rather than the simple consumption of hard coded information,as we believe that people living in poverty can producetechnological content that generates economic benefit. Welook forward to seeing Tamil Market modified and customizedby trained MSSRF volunteers and the rural villagers theyserve.
VI. FUTURE PLANS AND CONCLUSIONS
There are very few proposals for speech driven applicationsdespite the need for UI solutions to universal access. The lowliteracy and educational levels of the rural poor, as well astheir unfamiliarity with technology makes the design ofappropriate speech technologies a challenging task. We soughtto address this problem by developing Tamil Market, a multi-modal, inexpensive spoken dialog system that is powered by asmall-vocabulary single word recognizer that is robust inlimited tasks despite minimal linguistic training data. Theintegrated design for the SDS and the ASR that powers it stemfrom actual user studies, field recordings, and a series of ASR
9

Paper Identification Number: 344
experiments, which show that illiterate users can operate andbenefit from simple speech-driven technologies. Unliketraditional speech technology techniques, our design addressesproblems of multilingualism, literacy, and linguistic variationby restricting its scope to a single village, and allowing insteadfor high scalability and modifiablity, resulting in a solution webelieve will be rapidly deployable, useful, and well suited tolimited resource environments.
ACKNOWLEDGMENT
The authors thank their volunteers, their family, thePrabakers and all colleagues who contributed to developmentof our research through their encouragement and insights.
REFERENCES
[1] "Why Agriculture Still Matters," Chapter 3, World Employment Report2004-04: Employment, Productivity and Poverty Reduction, InternationalLabour Organization (ILO), December 2004.[2] Hornik, R. Development communication: Information, agriculture, andnutrition in the third world. New York: Longman, 1988. [3] Eggleston, K., R. Jensen, and R. Zeckhauser, “Information andcommunication technologies, markets and economic development.” In Globalinformation technology report 2001–2002: Readiness for the networked world,G. Kirkman and J. Sachs, eds. Oxford, UK: Oxford University Press, 2002, pp.62–74. [4] Prahalad, C.K. and A. Hammond, “Serving the poor profitably”, HarvardBusiness Review, 2002.[5] Kumar, R. 2004. "eChoupals: A Study on the Financial Sustainability ofVillage Internet Centers in Rural Madhya Pradesh" Information Technologyand International Development (ITID), Vol. 2., Issue 1, Spring, 2004.[6] Psacharopoulos, G. “Returns to investment in education: a global update.”World Bank PDR, Working Paper 1067. Washington DC: World Bank, 1993.[7] Directorate of Census Operations, Tamil Nadu Primary Census Abstract,Census, 2001.[8] Borooah, V. K., “Gender Bias among Children in India in Their Diet. andImmunization against Disease” Social Science and Medicine 58, pp. 1719-1731,2004.[9] United Nations. Unesco Institute of Statistics. Http://www.uis.unseco.org,,accessed April 11, 2005.[10] Provisional Population Totals: India. Census of India 2001, Paper 1 of2001. Office of the Registrar General, India. 2001[11] Balaji. V., K. Rajamohan, R. Rajasekarapandy, S. Senthilkumaran,"Towards a knowledge system for sustainable food security: The informationvillage experiment in Pondicherry," in IT Experience in India : Bridging theDigital Divide, Kenneth Keniston and Deepak Kumar, eds., New Delhi, Sage,2004.[12] Sustainable Access in Rural India (SARI). http://www.tenet.res.in/sari,accessed February 9th, 2005.[13]SIL International, http://www.sil.org/literacy/LitFacts.htm, accessedFebrurary 9th, 2005.[14] Noronha, F., “Indian language solutions for GNU/Linux” Linux Journal,2002.[15] Udhyakumar, N., R. Swaminathan, R., and S. K. Ramakrishnan,“Multilingual speech recognition for information retrieval in Indian context.”, inProc. Student Research Workshop, HLT/NAACL, Boston, USA, 2004.[16] Saraswathi, S. and T. V. Geetha, “Building language models for Tamilspeech recognition system.” Proceedings of AACC 2004.[17] A. Nayeemulla Khan and B. Ygnanarayana, “Development of a speechrecognition system for Tamil for restricted small tasks”[18] Comrie, B. The World's Major Languages. New York: Oxford UniversityPress, 1987.[19] Kothari, B. and J. Takeda, “Same Language Subtitling for Literacy: SmallChange for Colossal Gains”, Information and Communication Technology inDevelopment: Cases from India, in S. Bhatnagar and R. Schware (Eds), SagePublications, 2000.[20] Huenerfauth, M. Developing design recommendations for computerinterfacees accessible to illiterate users. Masters Thesis, University CollegeDublin, August, 2002.[21] Goetze, M., and T. Strothotte, “An approach to help functionally illiteratepeople with graphical reading aids.” Smart Graphics Symposium UK, 2001.
[22] Parikh, T., G. Kaushik, and A. Chavan, “Design studies for a financialmanagement system for micro-credit groups in rural india.” Proceedings of theACM conference on universal usability, 2003.[23] Castro-Caldas, A., K. M. Petersson, A. Reis, S. Stone-Elander and M.Ingvar. “The Illiterate Brain.” Brain 121, 1053-1063. 1998.[24] Petersson, K. M., A. Reis, S. Askelöf, A. Castro-Caldas, and M. Ingvar,“Language processing modulated by literacy: a network analysis of verbalrepetition in literate and illiterate subjects.” Journal of Cognitive Neuroscience12:3, 2000.pp. 364-382.[25] not included for review version to maintain author anonymity[26] Butterworth, B., M. Zorzi, L. Girelli, A.R. Jonckheere, “Storage andRetrieval of Addition Facts: The role of number comparison.” The quarterlyjournal of experimental psychology. 54A(4), 1005-1029, 2001.[27] J. Ajmera and C. Wooters, “A robust speaker clustering algorithm,”inASRU’03, US Virgin Islands, USA, Dec. 2003.[28] Gordo, B., “Overcoming digital deprivation.” IT&Society, Vol. 1, Issue 5,Summer, 2003.
10