1 natural language processing (5) zhao hai 赵海 department of computer science and engineering...
TRANSCRIPT

1
Natural Language Processing(5)
Zhao Hai 赵海
Department of Computer Science and Engineering
Shanghai Jiao Tong University

2
Lexicons and Lexical Analysis
Collocation
Hypothesis Testing
T Test
Mutual Information
Outline

3
Lexicons and Lexical Analysis (254)
Collocation (35)Hypothesis Testing (1/5)
One difficulty that we have glossed over so far is that high
frequency and low variance can be accidental.
For example, if the two constituent words of a frequent bigram
like new companies are frequently occurring words (as new and
companies are), then we expect the two words to co-occur a lot
just by chance, even if they do not form a collocation.

4
Lexicons and Lexical Analysis (255)
Collocation (36)Hypothesis Testing (2/5)
What we really want to know is whether two words occur
together more often than chance.
Assessing whether or not something is a chance event is one
of the classical problems of statistics. It is usually couched in
terms of hypothesis testing.

5
Lexicons and Lexical Analysis (256)
Collocation (37)Hypothesis Testing (3/5)
We formulate a null hypothesis H0 that there is no association
between the words beyond chance occurrences, compute the
probability p that the event would occur.
If H0 were true, and then reject H if p is too low (typically if
beneath a significance level of p < 0.05, 0.01, 0.0005, or 0.001)
and retain H0 as possible otherwise.

6
Lexicons and Lexical Analysis (257)Collocation (38)
Hypothesis Testing (4/5)
We need to formulate a null hypothesis which states what should be true if two words do not form a collocation.
For such a free combination of two words we will assume that each of the words w1 and w2 is generated completely independently of the other, and so their chance of coming together is simply given by:

7
Lexicons and Lexical Analysis (258)
Collocation (39)Hypothesis Testing (5/5)
The model implies that the probability of co-occurrence is just
the product of the probabilities of the individual words.
This is a rather simplistic model, and not empirically accurate,
but for now we adopt independence as our null hypothesis.

8
Lexicons and Lexical Analysis (259)Collocation (40)
The T Test (1)
We need a statistical test that tells us how probable or
improbable it is that a certain constellation will occur.
A test that has been widely used for collocation discovery is the
t test.
The t test looks at the mean and variance of a sample of
measurements, where the null hypothesis is that the sample is
drawn from a distribution with mean μ.

9
Lexicons and Lexical Analysis (260)
Collocation (41)The T Test (2)
where is the sample mean, is the sample variance, N is the
sample size, andμis the mean of the distribution.
If the t statistic is large enough we can reject the null hypothesis.

10
Lexicons and Lexical Analysis (261)
Collocation (42)The T Test (3)
The test t looks at the difference between the observed ( )
and expected (μ) means, scaled by the variance of the data.
It tells us how likely one is to get a sample of that mean and
variance (or a more extreme mean and variance) assuming that
the sample is drawn from a normal distribution with mean μ.

11
Lexicons and Lexical Analysis (262)
Collocation (43)The T Test (4)
For instance, our null hypothesis is that the mean height of a
population of men is 158cm.
We are given a sample of 200 men with = 169 and =
2600 and want to know whether this sample is from the general
population (the null hypothesis) or whether it is from a different
population of smaller men.

12
Lexicons and Lexical Analysis (263)
Collocation (44)The T Test (5)
This gives us the following t according to the above formula:
We can also find out exactly how large it has to be by looking
up the table of the t distribution.

13
Lexicons and Lexical Analysis (264)
Collocation (45)The T Test (6)
If we look up the value of t that corresponds to a confidence
level of α= 0.005, we will find 2.576. Since the t we got is larger
than 2.576, we can reject the null hypothesis with 99.5%
confidence.
So we can say that the sample is not drawn from a population
with mean 158cm, and our probability of error is less than 0.5%.

14
Lexicons and Lexical Analysis (265)
Collocation (46)The T Test (7)
To see how to use the t test for finding collocations, let us
compute the t value for new companies.
We think of the text corpus as a long sequence of N bigrams,
and the samples are then indicator random variables that take on
the value 1 when the bigram of interest occurs, and are 0
otherwise.

15
Lexicons and Lexical Analysis (266)
Collocation (47)The T Test (8)
Using maximum likelihood estimates, we can compute the
probabilities of new and companies as follows.
In the corpus, new occurs 15,828 times, companies 4,675
times, and there are 14,307,668 tokens overall.

16
Lexicons and Lexical Analysis (267)Collocation (48)
The T Test (9)
The null hypothesis is that occurrences of new and companies are independent.
If the null hypothesis is true, then the process of randomly generating bi-grams of words and assigning
1 to the outcome new companies and
0 to any other outcome
can be treated as a Bernoulli trial.

17
Lexicons and Lexical Analysis (268)
Collocation (49)The T Test (10)
The mean for this distribution is ; and the variance
is , which is approximately p. The approximation
holds since for most bigrams p is small.
It turns out that there are actually 8 occurrences of new companies
among the 14307668 bigrams in our corpus. So, for the sample, we
have that the sample mean is:
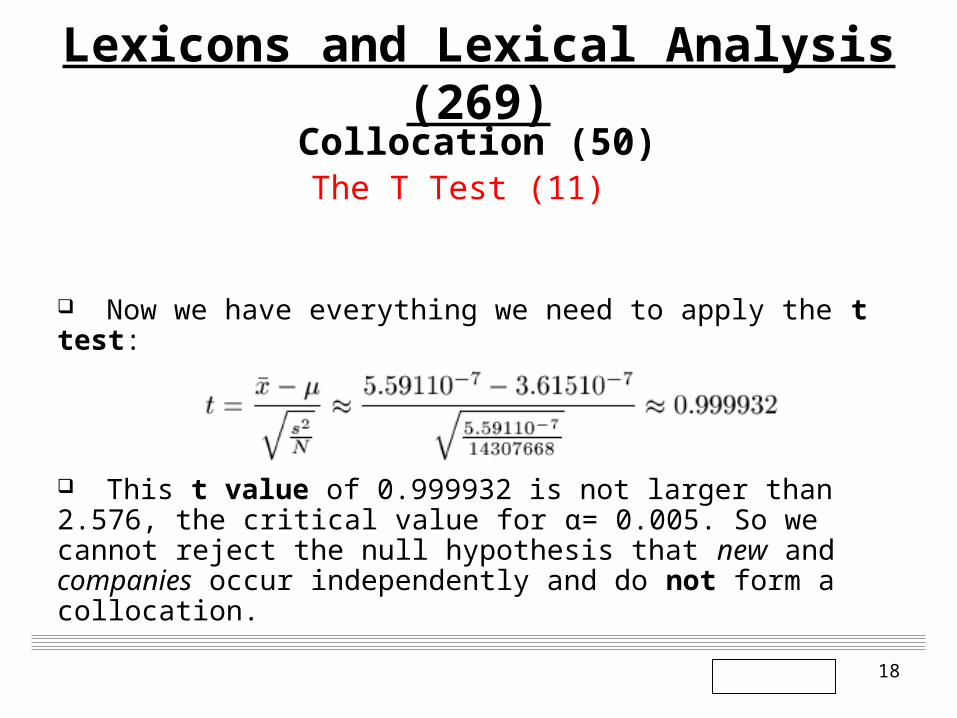
18
Lexicons and Lexical Analysis (269)
Collocation (50)The T Test (11)
Now we have everything we need to apply the t test:
This t value of 0.999932 is not larger than 2.576, the critical value for α= 0.005. So we cannot reject the null hypothesis that new and companies occur independently and do not form a collocation.

19
Lexicons and Lexical Analysis (270)
Collocation (51)The T Test (12)

20
Lexicons and Lexical Analysis (271)
Collocation (52)The T Test (13)
The above table shows t values for ten bigrams that occur
exactly 20 times in the corpus.
For the top five bigrams, we can reject the null hypothesis that
the component words occur independently for α= 0.005, so these
are good candidates for collocations.
The bottom five bigrams fail the test for significance, so we
will not regard them as good candidates for collocations.

21
Lexicons and Lexical Analysis (272)
Collocation (53)The T Test (14)
Note that a frequency-based method would not be able to rank
the ten bigrams since they occur with exactly the same frequency.
We can see that the t test takes into account the number of co-
occurrences of the bigram relative to the frequencies of
the component words.

22
Lexicons and Lexical Analysis (273)
Collocation (54)The T Test (15)
If a high proportion of the occurrences of both words
(Ayatollah Ruhollah, videocassette recorder) or at least a very
high proportion of the occurrences of one of the words (unsalted)
occurs in the bigram, then its t value is high.
This criterion makes intuitive sense.

23
Lexicons and Lexical Analysis (274)
Collocation (55)The T Test (16)
The analysis in the table includes some stop words (Note: A stop word is a word that is common and frequently used, such as the, a, for, of, etc.) – without stop words, it is actually hard to find examples that fail significance. It turns out that most bigrams attested in a corpus occur significantly more often than chance.
For 824 out of the 831 bigrams that occurred 20 times in our corpus the null hypothesis of independence can be rejected.

24
Lexicons and Lexical Analysis (275)
Collocation (56)The T Test (17)
But we would only classify a fraction as true collocations. The reason for this surprisingly high proportion of possibly
dependent bigrams is that language itself – if compared with a random word generator – is very regular so that few completely unpredictable events happen.
The t test and other statistical tests are most useful as a method for ranking collocations. The level of significance itself is less useful.

25
Lexicons and Lexical Analysis
Collocation
Hypothesis Testing
T Test
Mutual Information
Outline

26
Lexicons and Lexical Analysis (276)
Entropy (1/5)
The entropy (or self-information) is the average uncertainty of a single random variable:
H(p) = H(X) = -∑p(x)log2p(x)
x ∈χ
Note: Let p(x) be the probability mass function of a random variable X, over a discrete set of symbols (or alphabet) χ:
p(x) = P (X = x), x ∈χ

27
Lexicons and Lexical Analysis (277)
Entropy (2/5)
Entropy measures the amount of information in a random variable. It is normally measured in bits (hence the log to the base 2), but using any other base yields only a linear scaling of results. For example, suppose you are reporting the result of rolling an 8-sided die. Then the entropy is:
8 8 1 1 1
H(X) = -∑p(i)log2p(i) = -∑ log = -log =log 8 = 3 bits
i=1 i=1 8 8 8

28
Lexicons and Lexical Analysis (278)
Entropy (3/5)
The joint entropy of a pair of discrete random variables X, Y
is the amount of information needed on average to specify both
their values. It is defined as:
H(X, Y) = - ∑∑ p(x, y)logp(x, y)
x ∈χy ∈У

29
Lexicons and Lexical Analysis (279)
Entropy (4/5)
The condition entropy of a discrete random variables Y given another X, for X, Y, p(x, y), expresses how much extra information you still need to supply on average to communicate Y given that the other party knows X:
H(Y|X) = ∑p(x) H(Y|X=x) = ∑p(x) [-∑ p(y|x)logp(y|x)]
x ∈χ x ∈χ y ∈У
= - ∑ ∑ p(x, y)logp(y|x) x ∈χy ∈У

30
Lexicons and Lexical Analysis (280)
Entropy (5/5)
There is a Chain rule for entropy:
H(X, Y) = H(X) + H(Y|X)
H(X1, …, Xn) = H(X1) + H(X2|X1) + … + H(Xn|X1, X2, …, Xn-1)
By this Chain rule:
H(X, Y) = H(X) + H(Y|X) = H(Y) + H(X|Y), therefore,
H(X) - H(X|Y) = H(Y) - H(Y|X)

31
Lexicons and Lexical Analysis (281)
Mutual Information (1/7)
This difference is called the mutual information between X
and Y: I(X,Y)=H(X) - H(X|Y) = H(Y) - H(Y|X)
It is the reduction in uncertainty of one random variable due to
knowing about another.
In other words, the amount of information one random
variable contains about another.

32
Lexicons and Lexical Analysis (282)
Mutual Information (2/7)
H(X) H(Y)
H(X, Y)
I(X; Y)
H(X|Y)
H(Y|X)

33
Lexicons and Lexical Analysis (283)
Mutual Information (3/7)
Mutual information is a symmetric, non-negative measure of
the common information in the two variables.
People often think of mutual information as a measure of
dependence between variables.
However, it is actually better to think of it as a measure of
independence because:

34
Lexicons and Lexical Analysis (284)
Mutual Information (4/7)
It is 0 only when two variables are independent, but
For two dependent variables, mutual information grows not only with the degree of dependence, but also according to the entropy of the variables.
I(X; Y) = H(X) - H(X|Y) = H(X) + H(Y) - H(X, Y)
1 1
= ∑p(x)log + ∑p(y)log + ∑p(x, y)logp(x, y) χ p(x) У p(y) χ, У

35
Lexicons and Lexical Analysis (285)
Mutual Information (5/7)
p(x, y)
= ∑p(x, y)log χ, У p(x) p(y)
Since H(X|X) = 0, note that: H(X) = H(X) – H(X|X) = I(X; X) This illustrates both why entropy is also called self-information, and how the mutual information between two totally dependent variables is not constant but depends on their entropy.

36
Lexicons and Lexical Analysis (286)
Mutual Information (6/7)
An information-theoretically motivated measure for discovering
interesting collocations is pointwise mutual information (Church et al. (1991), Church & Hanks (1989) and Hindle (1990)).
Fano (1961) originally defined mutual information between
particular events x’ and y’, in our case the event is occurrence of
particular words.

37
Lexicons and Lexical Analysis (287)
Mutual Information (7/7)
This type of mutual information is roughly a measure of how
much one word tells us about the other.

38
Lexicons and Lexical Analysis (287)
About Definitions
The definition of mutual information used here is common in
corpus linguistic studies, but is less common in Information
Theory. It is important to check what a mathematical concept is a
formalization of.
We will see that pointwise mutual information is of limited
utility for acquiring the types of linguistic properties.

39
Lexicons and Lexical Analysis (288)
Mutual Information Exp. (1/3)
These two types of mutual information are quite different
creatures.
When we apply this definition to the 10 collocations from the
previous table, we get the same ranking as with the t test. See the
following table:

40
Lexicons and Lexical Analysis (289)
Mutual Information Exp. (2/3)

41
Lexicons and Lexical Analysis (290)
Mutual Information Exp. (3/3)
As usual, we use maximum likelihood estimates to compute the probabilities, for example:
The amount of information we have about the occurrence of Ayatollahat position i in the corpus increases by 18.38 bits if we are told that Ruhollah occurs at position i + 1. In other words, we can be much more certain that Ruhollah will occur next if we are told that Ayatollah is the current word.
42
Lexicons and Lexical Analysis (291)
Mutual Information Fails: χ2 test (1/5)
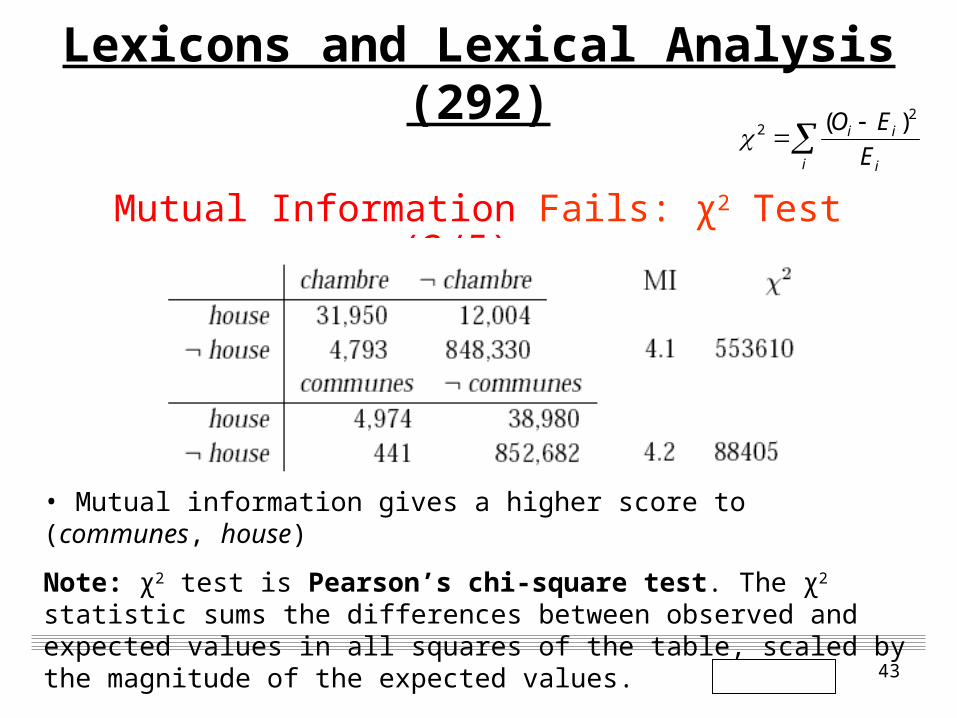
Unfortunately, this measure of “increased information” is in many cases not a good measure of what an interesting correspondence between two events is. Consider the two examples in the following table of counts of word correspondences between French and English sentences in the Hansard corpus, an aligned corpus of debates of the Canadian parliament. Let’s see two French words,
chambre room, house communes common
43
Lexicons and Lexical Analysis (292)
Mutual Information Fails: χ2 Test (2/5)
• Mutual information gives a higher score to (communes, house)
Note: χ2 test is Pearson’s chi-square test. The χ2 statistic sums the differences between observed and expected values in all squares of the table, scaled by the magnitude of the expected values.
i i
ii
E
EO 22 )(

44
Lexicons and Lexical Analysis (293)
Mutual Information Fails: χ2 Test (3/5)
The reason that house frequently appears in translations of
French sentences containing chambre and communes is that the
most common use of house is the phrase House of Commons
which corresponds to Chambre de communes in French.
But it is easy to see that communes is a worse match for house
than chambre since most occurrences of house occur without
communes on the French side.

45
Lexicons and Lexical Analysis (294)
Mutual Information Fails: χ2 Test (4/5)
The χ2 test is able to infer the correct correspondence
whereas mutual information gives preference to the
incorrect pair (communes, house).

46
Lexicons and Lexical Analysis (295)
Mutual Information Fails: χ2 Test (5/5)
The higher mutual information value for communes reflects
the fact that communes causes a larger decrease in uncertainty.
In contrast, the χ2 is a direct test of probabilistic dependence,
which in this context we can interpret as the degree of association
between two words and hence as a measure of their quality as
translation pairs and collocations.

47
Lexicons and Lexical Analysis (296)
Frequency Matters (1/5) The table shows a second problem with using mutual information for finding collocations. Statistics over different sized corpora.

48
Lexicons and Lexical Analysis (297)
Frequency Matters (2/5)
We show ten bigrams that occur exactly once in the first 1000
documents of the reference corpus and their mutual information
score based on the 1000 documents.
The right half of the table shows the mutual information score
based on the entire reference corpus (about 23,000 documents).

49
Lexicons and Lexical Analysis (298)
Frequency Matters (3/5)
The larger corpus of 23,000 documents makes some better
estimates possible, which in turn leads to a slightly better
ranking.
The bigrams marijuana growing and new converts (arguably
collocations) have moved up and Reds survived (definitely not a
collocation) has moved down.

50
Lexicons and Lexical Analysis (299)
Frequency Matters (4/5)
However, what is striking is that even after going to a 10
times larger corpus 6 of the bigrams still only occur once.
As a consequence, they have inaccurate maximum likelihood
estimates and artificially inflated mutual information scores.
All 6 are not collocations.

51
Lexicons and Lexical Analysis (300)
Frequency Matters (5/5)
None of the measures works very well for low-frequency events.
But there is evidence that sparseness is a particularly difficult
problem for mutual information.

52
Lexicons and Lexical Analysis (301)
When Mutual Information Works (1/5)
Consider two extreme cases: perfect dependence of the occurrences of the
two words and perfect independence of that.
For perfect dependence (they only occur together ) we have:
That is, among perfectly dependent bigrams, as they get rarer, their mutual
information increases.

53
Lexicons and Lexical Analysis (302)
When Mutual Information Works (2/5)
For perfect independence (the occurrence of one does not give us any
information about the occurrence of the other ) we have:

54
Lexicons and Lexical Analysis (303)
When Mutual Information Works (3/5)
We can say that mutual information is a good measure of
independence. Values close to 0 indicate independence
(independent of frequency).
But it is a bad measure of dependence because for
dependence the score depends on the frequency of the individual
words.

55
Lexicons and Lexical Analysis (304)
When Mutual Information Works (4/5)
Other things being equal, bigrams composed of low-frequency
words will receive a higher score than bigrams composed of
high-frequency words.
That is the opposite of what we would want a good measure to
do since higher frequency means more evidence and we would
prefer a higher rank for bigrams for whose interestingness we have
more evidence.

56
Lexicons and Lexical Analysis (305)
When Mutual Information Works (5/5)
One solution that has been proposed for this is to use a cutoff
and to only look at words with a frequency of at least 3.
However, such a move does not solve the underlying problem,
but only ameliorates its effects.
Since pointwise mutual information does not capture the
intuitive notion of an interesting collocation very well, it is often
not used when it is made available in practical applications.

57
Lexicons and Lexical Analysis (307)
Summary (1/5)
There are actually different definitions of the notion of collocation.
For instance, a sequence of two or more consecutive words, that has
characteristics of a syntactic and semantic unit, and whose exact and
unambiguous meaning or connotation cannot be derived directly from
the meaning or connotation of its components (Choueka, 1988).

58
Lexicons and Lexical Analysis (308)
Summary (2/5)
The following criteria are typical of linguistic treatments of collocations. Non-compositionality is the main one we have relied on here.
Non-compositionality. The meaning of a collocation is not a straightforward composition of the meanings of its parts. Either the meaning is completely different from the free combination (such as idioms) or there is a connotation or added element of meaning that cannot be predicted from the parts.

59
Lexicons and Lexical Analysis (309)
Summary (3/5)
Non-substitutability. We cannot substitute near-synonyms for
the components of a collocation. For example, we can’t say
yellow wine instead of white wine even though yellow is as a
good description of the color of white wine as white is (it is kind
of a yellowish white).

60
Lexicons and Lexical Analysis (310)
Summary (4/5)
Non-modifiability. Many collocations cannot be freely
modified with additional lexical material or through grammatical
transformations. This is especially true for frozen expressions
like idioms. For example, we can’t modify frog in to get a frog in
one’s throat (喉咙不适 ) into to get an ugly frog in one’s throat
although usually nouns like frog can be modified by adjectives
like ugly.

61
Lexicons and Lexical Analysis (311)
Summary (5/5)
A nice way to test whether a combination is a collocation is to
translate it into another language.
If we cannot translate the combination word by word, then that
is evidence that we are dealing with a collocation. For example,
translating make a decision into French one word at a
time we get faire une décision which is incorrect.
prendre une décision should be the correct translation

62
Lexicons and Lexical Analysis (312)
References
K. W. Church and P. Hanks. 1990. Word Association Norms, Mutual Information and Lexicography. Computational Linguistics, Vol. 16, No.1. T. Fontenelle et al. 1994. Survey of Collocation Extraction Tools. Technical Report, University of Liege, Liege, Belgium. J. Hodges et al. 1996. An Automated System that Assists in the Generation of Document Indexes. Natural Language Engineering No. 2.