14 - atmega en c
DESCRIPTION
microTRANSCRIPT

Estructura de un programa en C
Tomaremos en cuenta este sencillísimo ejemplo, escrito para los compiladores AVR IAR C y AVR GCC.
/******************************************************************************
* FileName: main.c
* Purpose: LED parpadeantwe
* Processor: ATmel AVR
* Compiler: AVR IAR C & AVR GCC (WinAVR)
* Author: Shawn Johnson. http://www.cursomicros.com.
*****************************************************************************/
#include "avr_compiler.h"
//****************************************************************************
// delay_ms
//****************************************************************************
void delay_ms(unsigned int t)
{
while(t--)
delay_us(1000);
}
//****************************************************************************
// Función principal
//****************************************************************************
int main(void)
{
DDRB = 0x01; // Configurar pin PB0 como salida

for( ;; )
{
PORTB |= 0x01; // Poner 1 en pin PB0
delay_ms(400); //
PORTB &= 0xFE; // Poner 0 en pin PB0
delay_ms(300);
}
}
No hay que ser muy perspicaz para descubrir lo que hace este programa: configura el pin PB0 como salida y luego lo setea y lo limpia tras pausas. Es como hacer parpadear un LED conectado al pin PB0. Parpadea porque el bloque de while se ejecuta cíclicamente.
Los elementos más notables de un programa en C son las sentencias, las funciones, las directivas, los comentarios y los bloques. A continuación, una breve descripción de ellos.
Los comentarios
Los comentarios tienen el mismo propósito que en ensamblador: documentar y “adornar” el código. Es todo es texto que sigue a las barritas // y todo lo que está entre los signos /* y */. Se identifican fácilmente porque suelen aparecer en color verde.
Ejemplos.
// Éste es un comentario simple
/*
Ésta es una forma de comentar varias líneas a la vez.
Sirve mucho para enmascarar bloques de código.
*/
Las sentencias
Un programa en C, en lugar de instrucciones, se ejecuta por sentencias. Una sentencia es algo así como una mega instrucción, que hace lo que varias instrucciones del ensamblador.

Salvo casos particulares, donde su uso es opcional, una sentencia debe finalizar con un punto y coma (;). Así que también podemos entender que los ; sirven para separar las sentencias. Alguna vez leí que el compilador C lee el código como si lo absorbiera con una cañita, línea por línea, una a continuación de otra (evadiendo los comentarios por supuesto). Por ejemplo, la función main del programa de arriba bien puede escribirse del siguiente modo.
//****************************************************************************
// Función principal
//****************************************************************************
int main(void) { DDRB = 0x01; for( ;; ) { PORTB |= 0x01; delay_ms(400);
PORTB &= 0xFE; delay_ms(300); } }
¿Sorprendido? Podrás deducir que los espacios y las tabulaciones solo sirven para darle un aspecto ordenado al código. Es una buena práctica de programación aprender a acomodarlas.
Las sentencias se pueden clasificar en sentencias de asignación, sentencias selectivas, sentencias iterativas, de llamadas de función, etc. Las describiremos más adelante.
Los bloques
Un bloque establece y delimita el cuerpo de las funciones y algunas sentencias mediante llaves ({}).
Como ves en el ejemplo de arriba, las funciones main y pausa tienen sus bloques, así como los bucles while y for. Creo que exageré con los comentarios, pero sirven para mostrarnos dónde empieza y termina cada bloque. Podrás ver cómo las tabulaciones ayudan a distinguir unos bloques de otros. Afortunadamente, los editores de los buenos compiladores C pueden resaltar cuáles son las llaves de inicio y de cierre de cada bloque. Te será fácil acostumbrarte a usarlas.
Las directivas
Son conocidas en el lenguaje C como directivas de preprocesador, de preprocesador porque son evaluadas antes de compilar el programa. Como pasaba en el ensamblador, las directivas por sí mismas no son código ejecutable. Suelen ser indicaciones sobre cómo se compilará el código.
Entre las pocas directivas del C estándar que también son soportadas por los compiladores C para AVR están #include (para incluir archivos, parecido al Assembler), #define (mejor que el #define del ensamblador) y las #if, #elif, #endif y similares. Fuera de ellas, cada compilador maneja sus propias directivas y serán tratadas por separado.
Las funciones

Si un programa en ensamblador se puede dividir en varias subrutinas para su mejor estructuración, un programa en C se puede componer de funciones. Por supuesto que las funciones son muchísimo más potentes y, por cierto, algo más complejas de aprender. Por eso ni siquiera el gran espacio que se les dedica más adelante puede ser suficiente para entenderlas plenamente. Pero, no te preocupes, aprenderemos de a poco.
En un programa en C puede haber las funciones que sean posibles, pero la nunca debe faltar la función principal, llamada main. Donde quiera que se encuentre, la función main siempre será la primera en ser ejecutada. De hecho, allí empieza y no debería salir de ella.
Variables y Tipos de Datos
En ensamblador todas las variables de programa suelen ser registros de la RAM crudos , es decir, datos de 8 bits sin formato. En los lenguajes de alto nivel estos registros son tratados de acuerdo con formatos que les permiten representar números de 8, 16 ó 32 bits (a veces más grandes), con signo o sin él, números enteros o decimales. Esos son los tipos de datos básicos.
Las variables de los compiladores pueden incluso almacenar matrices de datos del mismo tipo (llamadas arrays) o de tipos diferentes (llamadasestructuras). Estos son los tipos de datos complejos.
Los siguientes son los principales tipos de datos básicos del lenguaje C. Observa que la tabla los separa en dos grupos, los tipos enteros y los tipos de punto flotante.
Tabla de variables y tipos de datos del lenguaje C
Tipo de dato Tamaño en bitsRango de valores que puede adoptar
char 8 0 a 255 ó -128 a 127
signed char 8 -128 a 127
unsigned char 8 0 a 255
(signed) int 16 -32,768 a 32,767
unsigned int 16 0 a 65,536
(signed) short 16 -32,768 a 32,767
unsigned short 16 0 a 65,536
(signed) long 32 -2,147,483,648 a 2,147,483,647

Tabla de variables y tipos de datos del lenguaje C
Tipo de dato Tamaño en bitsRango de valores que puede adoptar
unsigned long 32 0 a 4,294,967,295
(signed) long long (int) 64 -263 a 263 - 1
unsigned long long(int)
64 0 a 264 - 1
float 32 ±1.18E-38 a ±3.39E+38
double 32 ±1.18E-38 a ±3.39E+38
double 64 ±2.23E-308 a ±1.79E+308
Afortunadamente, a diferencia de los compiladores para PIC, los compiladores para AVR suelen respetar bastante los tipos establecidos por el ANSI C. Algunos compiladores también manejan tipos de un bit como bool (o boolean) o bit, pero con pequeñas divergencias que pueden afectar la portabilidad de los códigos además de confundir a los programadores. Esos tipos son raramente usados.
Por defecto el tipo double es de 32 bits en los microcontroladores. En ese caso es equivalente al tipo float. Los compiladores más potentes como AVR IAR C y AVR GCC sin embargo ofrecen la posibilidad de configurarlo para que sea de 64 bits y poder trabajar con datos más grandes y de mayor precisión.
Los especificadores signed (con signo) mostrados entre paréntesis son opcionales. Es decir, da lo mismo poner int que signed int, por ejemplo. Es una redundancia que se suele usar para “reforzar” su condición o para que se vea más ilustrativo.
El tipo char está pensado para almacenar caracteres ASCII como las letras. Puesto que estos datos son a fin de cuentas números también, es común usar este tipo para almacenar números de 8 bits. Es decir es equivalente a signed char o unsigned char, dependiendo de la configuración establecida por el entorno compilador. Y como es preferible dejar de lado estas cuestiones, si vamos a trabajar con números lo mejor es poner el especificador signed ounsigned en el código.
Quizá te preguntes cuál es la diferencia entre los tipos de datos int y short si aparentemente tienen el mismo tamaño y aceptan el mismo rango de valores. Esa apariencia es real en el entorno de los microcontroladores AVR. Es decir, al compilador le da lo mismo si ponemos int oshort. Sucede que el tipo short fue y siempre debería ser de 16 bits, en tanto que int fue concebido para adaptarse al bus de datos del procesador. Esto todavía se cumple en la programación de las

computadoras, por ejemplo, un dato int es de 32 bits en un Pentium IV y es de 64 bits en un procesador Core i7. De acuerdo con este diseño un tipo int debería ser de 8 bits en un megaAVR y de 32 bits en un AVR32. Sin embargo, la costumbre de relacionar el tipo intcon los 16 bits de las primeras computadoras como las legendarias 286 se ha convertido en tradición y en regla de facto para los microcontroladores. Actualmente solo en CCS C el tipo intes de 8 bits. Es irónico para ser el compilador que menos respeta los tipos de datos del ANSI C.
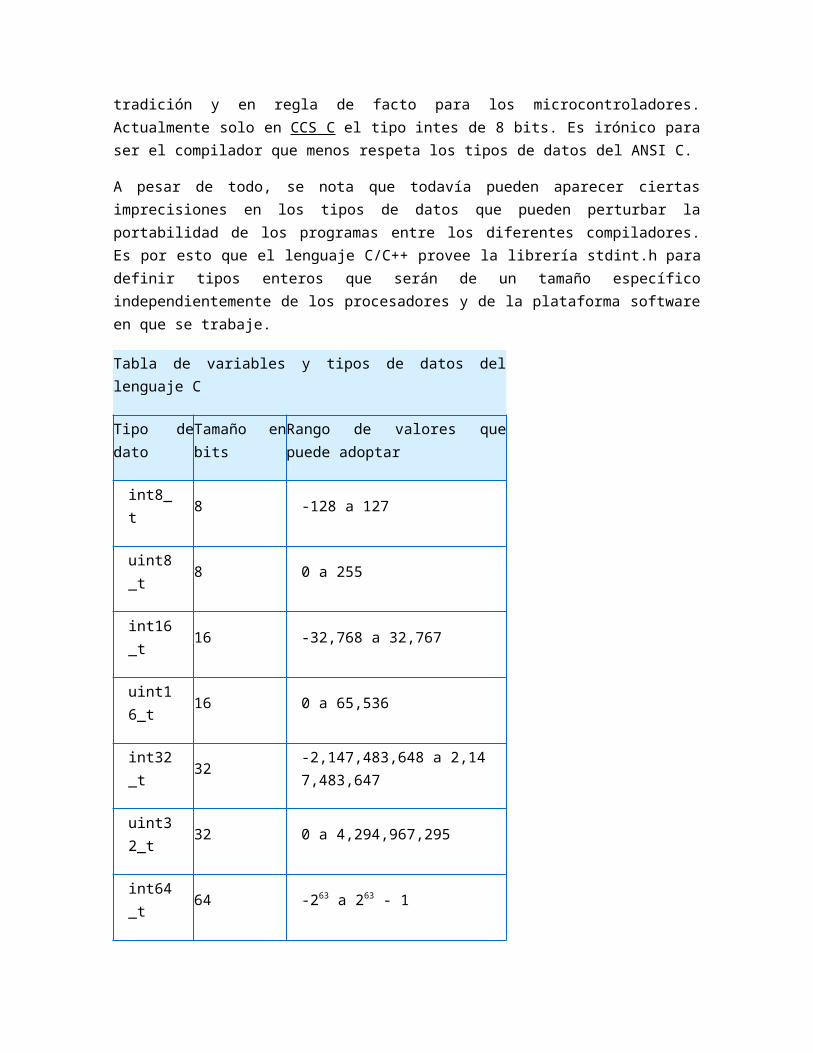
A pesar de todo, se nota que todavía pueden aparecer ciertas imprecisiones en los tipos de datos que pueden perturbar la portabilidad de los programas entre los diferentes compiladores. Es por esto que el lenguaje C/C++ provee la librería stdint.h para definir tipos enteros que serán de un tamaño específico independientemente de los procesadores y de la plataforma software en que se trabaje.
Tabla de variables y tipos de datos del lenguaje C
Tipo de dato Tamaño en bitsRango de valores que puede adoptar
int8_t 8 -128 a 127
uint8_t 8 0 a 255
int16_t 16 -32,768 a 32,767
uint16_t 16 0 a 65,536
int32_t 32 -2,147,483,648 a 2,147,483,647
uint32_t 32 0 a 4,294,967,295
int64_t 64 -263 a 263 - 1
uint64_t 64 0 a 264 - 1
Es fácil descubrir la estructura de estos tipos para familiarizarse con su uso. Para ello debemos en primer lugar incluir en nuestro programa el archivo stdint.h con la siguiente directiva.
#include <stdint.h>
Esta inclusión ya está hecha en el archivo avr_compiler.h que se usa en todos los programas de cursomicros, así que no es necesario volverlo a hacer. Aunque el objetivo de este archivo es permitir la compatibilidad de códigos entre los compiladores AVR IAR C y AVR GCC, debemos saber que en AVR IAR C el archivo avr_compiler.h solo está disponible al usar la librería DLIB. Como las

prácticas de cursomicros trabajan sobre la librería CLIB, he evitado recurrir a los tipos extendidos de stdint.h.
Finalmente, existen además de los vistos arriba otros tipos y especificadores de datos que no son parte del lenguaje C pero que fueron introducidos por los compiladores pensando en las características especiales de los microcontroladores. Muchos de ellos son redundantes o simples alias y algunos que sí son de utilidad como el tipo PGM_P los veremos en su momento.
Declaración de variables
Esta parte es comparable, aunque lejanamente a cuando se identifican las variables del ensamblador con la directiva .def. No se puede usar una variable si antes no se ha declarado. La forma general más simple de hacerlo es la siguiente:
data_type myvar;
donde data_type es un tipo de dato básico o complejo, del compilador o definido por el usuario y myvar es un identificador cualquiera, siempre que no sea palabra reservada.
Ejemplos.
unsigned char d; // Variable para enteros de 8 bits sin signo
char b; // Variable de 8 bits (para almacenar
// caracteres ascii)
signed char c; // Variable para enteros de 8 bits con signo
int i; // i es una variable int, con signo
signed int j; // j también es una variable int con signo
unsigned int k; // k es una variable int sin signo
También es posible declarar varias variables del mismo tipo, separándolas con comas. Así nos ahorramos algo de tipeo. Por ejemplo:
float area, side; // Declarar variables area y side de tipo float
unsigned char a, b, c; // Declarar variables a, b y c como unsigned char
Especificadores de tipo de datos
A la declaración de una variable se le puede añadir un especificador de tipo como const, static,volatile, extern, register, etc. Dichos especificadores tienen diversas funciones y, salvo const, se suelen usar en programas más elaborados. Como no queremos enredarnos tan pronto, lo dejaremos para otro momento.
Una variable const debe ser inicializada en su declaración. Después de eso el compilador solo permitirá su lectura mas no su escritura. Ejemplos:
const int a = 100; // Declarar constante a
int b; // Declarar variable b
//...
b = a; // Válido
b = 150; // Válido
a = 60; // Error! a es constante
a = b; // Error! a es constante
Por más que las variables constantes sean de solo lectura, ocuparán posiciones en la RAM del microcontrolador. En CodeVisionAVR es posible configurar para que sí residan en FLASH pero por compatibilidad se usa muy poco. Por eso muchas veces es preferible definir las constantes del programa con las clásicas directivas #define (como se hace en el ensamblador).
#define a 100 // Definir constante a
Sentencias selectivas
Llamadas también sentencias de bifurcación, sirven para redirigir el flujo de un programa según la evaluación de alguna condición lógica.
Las sentencias if e if–else son casi estándar en todos los lenguajes de programación. Además de ellas están las sentencias if–else escalonadas y switch–case.
La sentencia if
La sentencia if (si condicional, en inglés) hace que un programa ejecute una sentencia o un grupo de ellas si una expresión es cierta. Esta lógica se describe en el siguiente esquema.

Diagrama de flujo de la sentencia if.
La forma codificada sería así:
sentenciaA;
if ( expression ) // Si expression es verdadera,
// ejecutar el siguiente bloque
{ // apertura de bloque
sentenciaB;
sentenciaC;
// algunas otras sentencias
} // cierre de bloque
sentenciaX;
Después de ejecutar sentenciaA el programa evalúa expression. Si resulta ser verdadera, se ejecutan todas las sentencias de su bloque y luego se ejecutará la sentenciaX.
En cambio, si expression es falsa, el programa se salteará el bloque de if y ejecutará sentenciaX.
La sentencia if – else
La sentencia if brinda una rama que se ejecuta cuando una condición lógica es verdadera. Cuando el programa requiera dos ramas, una que se ejecute si cierta expression es cierta y otra si es falsa, entonces se debe utilizar la sentecia if – else. Tiene el siguiente esquema.

Diagrama de flujo de la sentencia if – else.
Expresando lo descrito en código C, tenemos: (Se lee como indican los comentarios.)
SentenciaA;
if ( expression ) // Si expression es verdadera, ejecutar
{ // este bloque
sentenciaB;
sentenciaC;
// ...
}
else // En caso contrario, ejecutar este bloque
{
sentenciaM;
sentenciaN;
// ...
}
sentenciaX;
// ...
Como ves, es bastante fácil, dependiendo del resultado se ejecutará uno de los dos bloques de la sentencia if – else, pero nunca los dos a la vez.

La sentencia if – else – if escalonada
Es la versión ampliada de la sentencia if – else.
En el siguiente boceto se comprueban tres condiciones lógicas, aunque podría haber más. Del mismo modo, se han puesto dos sentencias por bloque solo para simplificar el esquema.
if ( expression_1 ) // Si expression_1 es verdadera ejecutar
{ // este bloque
sentencia1;
sentencia2;
}
else if ( expression_2 ) // En caso contrario y si expression_2 es
{ // verdadera, ejecutar este bloque
sentencia3;
sentencia4;
}
else if ( expression_3 ) // En caso contrario y si expression_3 es
{ // verdadera, ejecutar este bloque
sentencia5;
sentencia6;
}
else // En caso contrario, ejecutar este bloque
{
sentencia7;
sentencia8;
}; // ; opcional
// todo...

Las “expresiones” se evalúan de arriba abajo. Cuando alguna de ellas sea verdadera, se ejecutará su bloque correspondiente y los demás bloques serán salteados. El bloque final (de else) se ejecuta si ninguna de las expresiones es verdadera. Además, si dicho bloque está vacío, puede ser omitido junto con su else.
La sentencia switch
La sentencia switch brinda una forma más elegante de bifurcación múltiple. Podemos considerarla como una forma más estructurada de la sentencia if – else – if escalonada, aunque tiene algunas restricciones en las condiciones lógicas a evaluar, las cuales son comparaciones de valores enteros.
Para elaborar el código en C se usan las palabras reservadas switch, case, break y default.
El siguiente esquema presenta tres case’s pero podría haber más, así como cada bloque también podría tener más sentencias.
switch ( expression )
{
case constante1: // Si expression = constante1, ejecutar este bloque
sentencia1;
sentencia2;
break;
case constante2: // Si expression = constante2, ejecutar este bloque
sentencia3;
sentencia4;
break;
case constante3: // Si expression = constante3, ejecutar este bloque
sentencia5;
sentencia6;
break;
default: // Si expression no fue igual a ninguna de las
// constantes anteriores, ejecutar este bloque
sentencia7;

sentencia8;
break;
}
sentenciaX;
// todo...
donde constante1, constante2 y constante3 deben ser constantes enteras, por ejemplo, 2, 0x45, ‘a’, etc. (‘a’ tiene código ASCII 165, que es, a fin de cuentas, un entero.)
expresion puede ser una variable compatible con entero. No es una expresión que conduce a una condición lógica como en los casos anteriores.
El programa solo ejecutará uno de los bloques dependiendo de qué constante coincida con la expression. Usualmente los bloques van limitados por llaves, pero en este caso son opcionales, dado que se pueden distinguir fácilmente. Los bloques incluyen la sentencia break. ¿Qué es eso?
La sentencia break hace que el programa salga del bloque de switch y ejecute la sentencia que sigue (en el boceto, sentenciaX). ¡Atento!: de no poner break, también se ejecutará el bloque del siguiente case, sin importar si su constante coincida con expression o no.
No sería necesario poner el default si su bloque estuviera vacío.
Sentencias iterativas
Las sentencias de control iterativas sirven para que el programa ejecute una sentencia o un grupo de ellas un número determinado o indeterminado de veces. Así es, esta sección no habla de otra cosa que de los bucles en C.
El lenguaje C soporta tres tipos de bucles, las cuales se construyen con las sentencias while, do– while y for. El segundo es una variante del primero y el tercero es una versión más compacta e intuitiva del bucle while.
La sentencia while
El cuerpo o bloque de este bucle se ejecutará una y otra vez mientras (while, en inglés) una expresión sea verdadera.

Diagrama de flujo de las sentencia while.
El bucle while en C tiene la siguiente sintaxis y se lee así: mientras (while) expression sea verdadera, ejecutar el siguiente bloque.
sentenciaA;
while ( expression ) // Mientras expression sea verdadera, ejecutar el
// siguiente bloque
{
sentenciaB;
sentenciaC;
// ...
}; // Este ; es opcional
sentenciaX;
// ...
Nota que en este caso primero se evalúa expression. Por lo tanto, si desde el principio la expression es falsa, el bloque de while no se ejecutará nunca. Por otro lado, si la expression no deja de ser verdadera, el programa se quedará dando vueltas “para siempre”.
La sentencia do - while
Como dije antes, es una variación de la sentencia while simple. La principal diferencia es que la condición lógica (expression) de este bucle se presenta al final. Como se ve en la siguiente figura, esto implica que el cuerpo o bloque de este bucle se ejecutará al menos una vez.

Diagrama de flujo de las sentencia do – while.
La sintaxis para la sentencia do – while es la siguiente y se lee: Ejecutar (do) el siguiente bloque, mientras (while) expression sea verdadera.
sentenciaA;
do
{
sentenciaB;
sentenciaC;
// ...
} while ( expression ); // Este ; es mandatorio
sentenciaX;
// ...
La sentencia for
Las dos sentencias anteriores, while y do – while, se suelen emplear cuando no se sabe de antemano la cantidad de veces que se va a ejecutar el bucle. En los casos donde el bucle involucra alguna forma de conteo finito es preferible emplear la sentencia for. (Inversamente, al ver un for en un programa, debemos suponer que estamos frente a algún bucle de ese tipo.)
Ésta es la sintaxis general de la sentencia for en C:
for ( expression_1 ; expression_2 ; expression_3 )
{

sentencia1;
sentencia2;
// ...
}; // Este ; es opcional
Ahora veamos por partes cómo funciona:
expression_1 suele ser una sentencia de inicialización.
expression_2 se evalúa como condición lógica para que se ejecute el bloque.
expression_3 es una sentencia que debería poner coto a expression_2.
Por la forma y orden en que se ejecutan estas expresiones, el bucle for es equivalente a la siguiente construcción, utilizando la sentencia while. Primero se ejecuta expression_1 y luego se ejecuta el bloque indicado tantas veces mientras expression_2 sea verdadera.
expression_1;
while ( expression_2 )
{
sentencia1;
sentencia2;
// ...
expression_3;
}
No obstante, de esa forma se ve más rara aún; así que, mejor, veamos estos ejemplos, que son sus presentaciones más clásicas. (i es una variable y a y b son constantes o variables):
for ( i = 0 ; i < 10 ; i++ )
{
sentencias;
}

Se lee: para (for) i igual a 0 hasta que sea menor que 10 ejecutar sentencias. La sentencia i++indica que i se incrementa tras cada ciclo. Así, el bloque de for se ejecutará 10 veces, desde quei valga 0 hasta que valga 9.
En este otro ejemplo las sentencias se ejecutan desde que i valga 10 hasta que valga 20. Es decir, el bucle dará 11 vueltas en total.
for ( i = 10 ; i <= 20 ; i++ )
{
sentencias;
}
El siguiente bucle for empieza con i inicializado a 100 y su bloque se ejecutará mientras i sea mayor o igual a 0. Por supuesto, en este caso i se decrementa tras cada ciclo.
for ( i = 100 ; i >= 0 ; i-- )
{
sentencias;
}
Se pueden hacer muchas más construcciones, todas coincidentes con la primera plantilla, pero también son menos frecuentes.
Sentencias con bloques simples
Cuando las sentencias selectivas (como if) o de bucles (como while o for) tienen cuerpos o bloques que constan de solo una sentencia, se pueden omitir las llaves. Aun así, es aconsejable seguir manteniendo las tabulaciones para evitarnos confusiones.
Por ejemplo, las siguientes sentencias:
if(a > b)
{
a = 0;
}
if(a == b)

{
a++;
}
else
{
b--;
}
while( a >= b)
{
a = a + b;
}
for(i=0; i<=10; i++)
{
a = a*2;
}
bien se pueden escribir de la siguiente forma:
if(a > b)
a = 0;
if(a == b)
a++;
else
b--;

while( a >= b)
a = a + b;
for(i=0; i<=10; i++)
a = a*2;
Los operadores
Sirven para realizar operaciones aritméticas, lógicas, comparativas, etc. Según esa función se clasifican en los siguientes grupos.
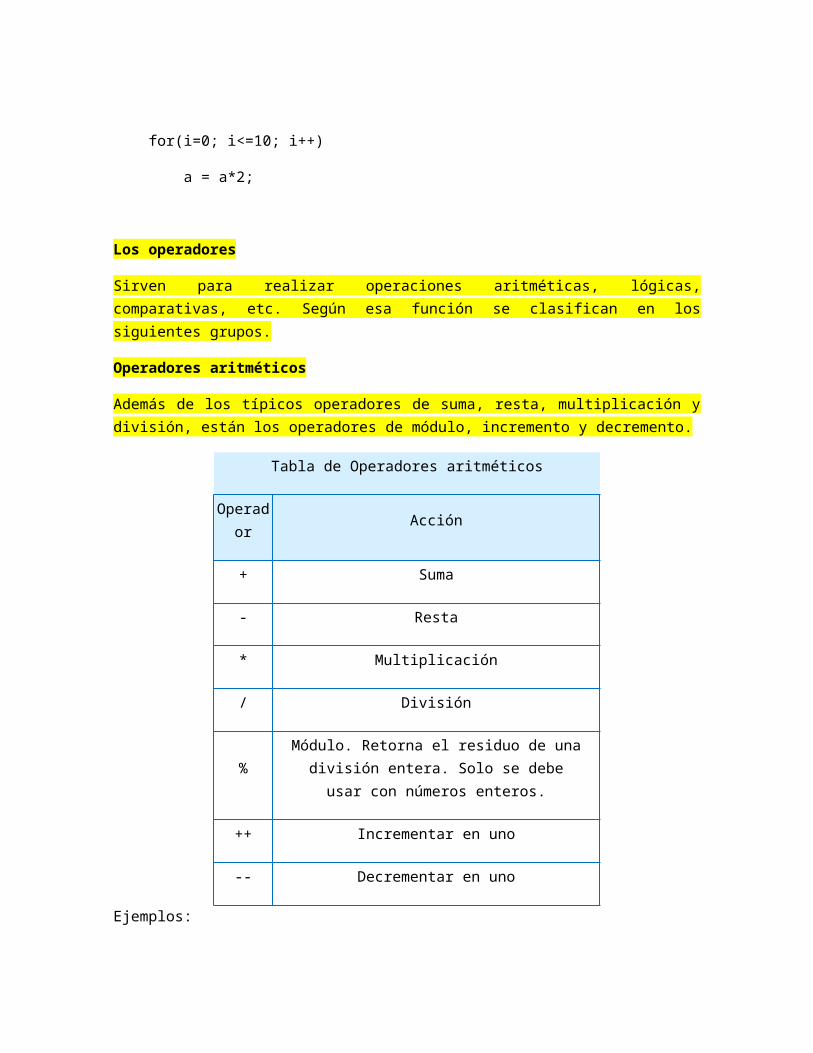
Operadores aritméticos
Además de los típicos operadores de suma, resta, multiplicación y división, están los operadores de módulo, incremento y decremento.
Tabla de Operadores aritméticos
Operador Acción
+ Suma
- Resta
* Multiplicación
/ División
%Módulo. Retorna el residuo de una división
entera. Solo se debe usar con números enteros.
++ Incrementar en uno
-- Decrementar en uno
Ejemplos:
int a, b, c; // Declarar variables a, b y c

a = b + c; // Sumar a y b. Almacenar resultado en c
b = b * c; // Multiplicar b por c. Resultado en b
b = a / c; // Dividir a entre c. Colocar resultado en b
a = a + c – b; // Sumar a y c y restarle b. Resultado en a
c = (a + b) / c; // Dividir a+b entre c. Resultado en c
b = a + b / c + b * b; // Sumar a más b/c más b×b. Resultado en b
c = a % b; // Residuo de dividir a÷b a c
a++; // Incrementar a en 1
b--; // Decrementar b en 1
++c; // Incrementar c en 1
--b; // Decrementar b en 1
¿Te recordaron a tus clases de álgebra del colegio? A diferencia de esas matemáticas, estas expresiones no son ecuaciones; significan las operaciones que indican sus comentarios.
Por lo visto, los operadores ++ y -- funcionan igual si están antes o después de una variable en una expresión simple. Sin embargo, hay una forma (tal vez innecesaria y confusa para un novato, pero muy atractiva para los que ya estamos acostumbrados a su uso) que permite escribir código más compacto, es decir, escribir dos sentencias en una.
Si ++ o -- están antes del operando, primero se suma o resta 1 al operando y luego se evalúa la expresión.
Si ++ o -- están después del operando, primero se evalúa la expresión y luego se suma o resta 1 al operando.
int a, b; // Declarar variables enteras a y b
a = b++; // Lo mismo que a = b; y luego b = b + 1;
a = ++b; // Lo mismo que b = b + 1; y luego a = b;
if (a++ < 10) // Primero comprueba si a < 10 y luego
{ // incrementa a en 1

// algún código
}
if (++a < 10) // Primero incrementa a en 1 y luego
{ // comprueba si a < 10
// algún código
}
Operadores de bits
Se aplican a operaciones lógicas con variables a nivel binario. Aquí tenemos las clásicas operaciones AND, OR inclusiva, OR exclusiva y la NEGACIÓN. Adicionalmente, he incluido en esta categoría los operaciones de desplazamiento a la derecha y la izquierda.
Si bien son operaciones que producen resultados análogos a los de las instrucciones de ensamblador los operadores lógicos del C pueden operar sobre variables de distintos tamaños, ya sean de 1, 8, 16 ó 32 bits.
Tabla de operadores de bits
Operador Acción
& AND a nivel de bits
| OR inclusiva a nivel de bits
^ OR exclusiva a nivel de bits
~ Complemento a uno a nivel de bits
<< Desplazamiento a la izquierda
>> Desplazamiento a la derecha
Ejemplos:
char m; // variable de 8 bits
int n; // variable de 16 bits

m = 0x48; // m será 0x48
m = m & 0x0F; // Después de esto m será 0x08
m = m | 0x24; // Después de esto m será 0x2F
m = m & 0b11110000; // Después de esto m será 0x20
n = 0xFF00; // n será 0xFF00
n = ~n; // n será 0x00FF
m = m | 0b10000001; // Setear bits 0 y 7 de variable m
m = m & 0xF0; // Limpiar nibble bajo de variable m
m = m ^ 0b00110000; // Invertir bits 4 y 5 de variable m
m = 0b00011000; // Cargar m con 0b00011000
m = m >> 2; // Desplazar m 2 posiciones a la derecha
// Ahora m será 0b00000110
n = 0xFF1F;
n = n << 12; // Desplazar n 12 posiciones a la izquierda
// Ahora n será 0xF000;
m = m << 8; // Después de esto m será 0x00
Fíjate en la semejanza entre las operaciones de desplazamiento con >> y << y las operaciones del rotación del ensamblador. Cuando una variable se desplaza hacia un lado, los bits que salen por allí se pierden y los bits que entran por el otro lado son siempre ceros. Es por esto que en la última sentencia, m = m << 8, el resultado es 0x00. Por cierto, en el lenguaje C no existen operadores de rotación. Hay formas alternativas de realizarlas.
Desplazamientos producidos por los operadores << y >>.

Operadores relacionales
Se emplean para construir las condiciones lógicas de las sentencias de control selectivas e iterativas, como ya hemos podido apreciar en las secciones anteriores. La siguiente tabla muestra los operadores relacionales disponibles.
Tabla de Operadores relacionales
Operador Acción
== Igual
!= No igual
> Mayor que
< Menor que
>= Mayor o igual que
<= Menor o igual que
Operadores lógicos
Generalmente se utilizan para enlazar dos o más condiciones lógicas simples. Por suerte, estos operadores solo son tres y serán explicados en las prácticas del curso.
Tabla de Operadores lógicos
Operador Acción
&& AND lógica
|| OR lógica
! Negación lógica
Ejemplos:
if( !(a==0) ) // Si a igual 0 sea falso
{
// sentencias
}
if( (a<b) && (a>c) ) // Si a<b y a>c son verdaderas
{
// sentencias
}
while( (a==0) || (b==0) ) // Mientras a sea 0 ó b sea 0
{
// sentencias
}
Composición de operadores
Se utiliza en las operaciones de asignación y nos permite escribir código más abreviado. La forma general de escribir una sentencia de asignación mediante los operadores compuestos es:
obtect op= expression;
que es equivalente a la sentencia
object = object op expression;
op puede ser cualquiera de los operadores aritméticos o de bit estudiados arriba. O sea, oppuede ser +, - , *, /, %, &, | , ^, ~, << ó >>. Nota: no debe haber ningún espacio entre el operador y el signo igual.
Ejemplos:
int a; // Declarar a
a += 50; // Es lo mismo que a = a + 50;
a += 20; // También significa sumarle 20 a a
a *= 2; // Es lo mismo que a = a * 2;
a &= 0xF0; // Es lo mismo que a = a & 0xF0;
a <<= 1; // Es lo mismo que a = a << 1;

Precedencia de operadores
Una expresión puede contener varios operadores, de esta forma:
b = a * b + c / b; // a, b y c son variables
A diferencia del lenguaje Basic, donde la expresión se evalúa de izquierda a derecha, en esta sentencia no queda claro en qué orden se ejecutarán las operaciones indicadas. Hay ciertas reglas que establecen dichas prioridades; por ejemplo, las multiplicaciones y divisiones siempre se ejecutan antes que las sumas y restas. Pero es más práctico emplear los paréntesis, los cuales ordenan que primero se ejecuten las operaciones de los paréntesis más internos. Eso es como en el álgebra elemental de la escuela, así que no profundizaré.
Por ejemplo, las tres siguientes sentencias son diferentes.
b = (a * b) + (c / b);
b = a * (b + (c / b));
b = ((a * b) + c)/ b);
También se pueden construir expresiones condicionales, así:
if ( (a > b) && ( b < c) ) // Si a>b y b<c, ...
{
// ...
}
Las funciones
Una función es un bloque de sentencias identificado por un nombre y puede recibir y devolver datos. En bajo nivel, en general, las funciones operan como las subrutinas de Assembler, es decir, al ser llamadas, se guarda en la Pila el valor actual del PC (Program Counter), después se ejecuta todo el código de la función y finalmente se recobra el PC para regresar de la función.
Dada su relativa complejidad, no es tan simple armar una plantilla general que represente a todas las funciones. El siguiente esquema es una buena aproximación.
data_type1 function_name (data_type2 arg1, data_type3 arg2, ... )
{

// Cuerpo de la función
// ...
return SomeData; // Necesario solo si la función retorna algún valor
}
Donde:
function_name es el nombre de la función. Puede ser un identificador cualquiera.
data_type1 es un tipo de dato que identifica el parámetro de salida. Si no lo hubiera, se debe poner la palabra reservada void (vacío, en inglés).
arg1 y arg2 (y puede haber más) son las variables de tipos data_type1, data_type2..., respectivamente, que recibirán los datos que se le pasen a la función. Si no hay ningún parámetro de entrada, se pueden dejar los paréntesis vacíos o escribir un void entre ellos.
Funciones sin parámetros
Para una función que no recibe ni devuelve ningún valor, la plantilla de arriba se reduce al siguiente esquema:
void function_name ( void )
{
// Cuerpo de la función
}
Y se llama escribiendo su nombre seguido de paréntesis vacíos, así:
function_name();
La función principal main es otro ejemplo de función sin parámetros. Dondequiera que se ubique, siempre debería ser la primera en ejecutarse; de hecho, no debería terminar.
void main (void)
{
// Cuerpo de la función
}

Funciones con parámetros (por valor)
Por el momento, solo estudiaremos las funciones que pueden tener varios parámetros de entrada pero solo uno de salida.
Si la función no tiene parámetros de entrada o de salida, debe escribirse un void en su lugar. El valor devuelto por una función se indica con la palabra reservada return.
Según el comportamiento de los parámetros de entrada de la función, estos se dividen enparámetros por valor y parámetros por referencia. Lo expuesto en este apartado corresponde al primer grupo porque es el caso más ampliamente usado. Con esto en mente podemos seguir.
Para llamar a una función con parámetros es importante respetar el orden y el tipo de los parámetros que ella recibe. El primer valor pasado corresponde al primer parámetro de entrada; el segundo valor, al segundo parámetro; y así sucesivamente si hubiera más.
Cuando una variable es entregada a una función, en realidad se le entrega una copia suya. De este modo, el valor de la variable original no será alterado. Mejor, plasmemos todo esto en el siguiente ejemplo.
int minor ( int arg1, int arg2, int arg3 )
{
int min; // Declarar variable min
min = arg1; // Asumir que el menor es arg1
if ( arg2 < min ) // Si arg2 es menor que min
min = arg2; // Cambiar a arg2
if ( arg3 < min ) // Si arg3 es menor que min
min = arg3; // Cambiar a arg3
return min; // Retornar valor de min
}
void main (void)
{

int a, b, c, d; // Declarar variables a, b, c y d
/* Aquí asignamos algunos valores iniciales a 'a', 'b' y 'c' */
/* ... */
d = minor(a,b,c); // Llamar a minor
// En este punto 'd' debería ser el menor entre 'a', 'b' y 'c'
while (1); // Bucle infinito
}
En el programa mostrado la función minor recibe tres parámetros de tipo int y devuelve uno, también de tipo int, que será el menor de los números recibidos.
El mecanismo funciona así: siempre respetando el orden, al llamar a minor el valor de a se copiará a la variable arg1; el valor de b, a arg2 y el valor de c, a arg3. Después de ejecutarse el código de la función el valor de retorno (min en este caso) será copiado a una variable temporal y de allí pasará a d.
Aunque el C no es tan implacable con la comprobación de tipos de datos como Pascal, siempre deberíamos revisar que los datos pasados sean compatibles con los que la función espera, así como los datos recibidos, con los que la función devuelve. Por ejemplo, estaría mal llamar a la función minor del siguiente modo:
d = minor(-15, 100, 5.124); // Llamar a minor
Aquí los dos primeros parámetros están bien, pero el tercero es un número decimal (de 32 bits), no compatible con el tercer parámetro que la función espera (entero de 16 bits). En estos casos el compilador nos mostrará mensajes de error, o cuando menos de advertencia.
Parámetros por referencia
La función que recibe un parámetro por referencia puede cambiar el valor de la variable pasada. La forma clásica de estos parámetros se puede identificar por el uso del símbolo &, tal como se ve en el siguiente boceto de función.
int minor ( int & arg1, int & arg2, int & arg3 )
{
// Cuerpo de la función.

// arg1, arg2 y arg3 son parámetros por referencia.
// Cualquier cambio hecho a ellos desde aquí afectará a las variables
// que fueron entregadas a esta función al ser llamada.
}
No voy profundizar al respecto porque he visto que muchos compiladores C no soportan esta forma. Otra forma de pasar un parámetro por referencia es mediante los punteros, pero eso lo dejamos para el final porque no es nada nada fácil para un novato.
Prototipos de funciones
El prototipo de una función le informa al compilador las características que tiene, como su tipo de retorno, el número de parámetros que espera recibir, el tipo y orden de dichos parámetros. Por eso se deben declarar al inicio del programa.
El prototipo de una función es muy parecido a su encabezado, se pueden diferenciar tan solo por terminar en un punto y coma (;). Los nombres de las variables de entrada son opcionales.
Por ejemplo, en el siguiente boceto de programa los prototipos de las funciones main, func1 yfunc2 declaradas al inicio del archivo permitirán que dichas funciones sean accedidas desde cualquier parte del programa. Además, sin importar dónde se ubique la función main, ella siempre será la primera en ejecutarse. Por eso su prototipo de función es opcional.
#include <avr.h>
void func1(char m, long p); // Prototipo de función "func1"
char func2(int a); // Prototipo de función "func2"
void main(void); // Prototipo de función "main". Es opcional
void main(void)
{
// Cuerpo de la función
// Desde aquí se puede acceder a func1 y func2
}

void func1(char m, long p)
{
// Cuerpo de la función
// Desde aquí se puede acceder a func2 y main
}
char func2(int a)
{
// Cuerpo de la función
// Desde aquí se puede acceder a func1 y main
}
La llamada a main, por supuesto, no tiene sentido; solo lo pongo para ilustrar.
Si las funciones no tienen prototipos, el acceso a ellas será restringido. El compilador solo verá las funciones que están implementadas encima de la función llamadora o, de lo contrario, mostrará errores de “función no definida”. El siguiente boceto ilustra este hecho. (Atiende a los comentarios.)
#include <avr.h>
void main(void)
{
// Cuerpo de la función
// Desde aquí no se puede acceder a func1 ni func2 porque están abajo
}
void func1(char m, long p)
{
// Cuerpo de la función
// Desde aquí se puede acceder a main pero no a func2
}

char func2(int a)
{
// Cuerpo de la función
// Desde aquí se puede acceder a func1 y main
}
Para terminar, dado que los nombres de las variables en los parámetros de entrada son opcionales, los prototipos de func1 y func2 también se pueden escribir asi
void func1(char, long);
char func2(int );
Variables locales y variables globales
Los lenguajes de alto nivel como el C fueron diseñados para desarrollar los programas más grandes y complejos que se puedan imaginar, programas donde puede haber cientos de variables, entre otras cosas. ¿Imaginas lo que significaría buscar nombres para cada variable si todos tuvieran que ser diferentes? Pues bien, para simplificar las cosas, el C permite tener varias variables con el mismo nombre.
Así es. Esto es posible gracias a que cada variable tiene un ámbito, un área desde donde será accesible. Hay diversos tipos de ámbito, pero empezaremos por familiarizarnos con los dos más usados, que corresponden a lasvariables globales y variables locales.
Las variables declaradas fuera de todas las funciones y antes de sus implementaciones tienen carácter global y podrán ser accedidas desde todas las funciones.
Las variables declaradas dentro de una función, incluyendo las variables del encabezado, tienen ámbito local. Ellas solo podrán ser accedidas desde el cuerpo de dicha función.
De este modo, puede haber dos o más variables con el mismo nombre, siempre y cuando estén en diferentes funciones. Cada variable pertenece a su función y no tiene nada que ver con las variables de otra función, por más que tengan el mismo nombre.
En la mayoría de los compiladores C para microcontroladores las variables locales deben declararse al principio de la función.
Por ejemplo, en el siguiente boceto de programa hay dos variables globales (speed y limit) y cuatro variables locales, tres de las cuales se llaman count. Atiende a los comentarios.
char foo(long ); // Prototipo de función

int speed; // Variable global
const long limit = 100; // Variable global constante
void inter(void)
{
int count; // Variable local
/* Este count no tiene nada que ver con el count
de las funciones main o foo */
speed++; // Acceso a variable global speed
vari = 0; // Esto dará ERROR porque vari solo pertenece
// a la función foo. No compilará.
}
void main(void)
{
int count; // Variable local count
/* Este count no tiene nada que ver con el count
de las funciones inter o foo */
count = 0; // Acceso a count local
speed = 0; // Acceso a variable global speed
}
char foo(long count) // Variable local count
{
int vari; // Variable local vari

}
Algo muy importante: a diferencia de las variables globales, las variables locales tienen almacenamiento temporal, es decir, se crean al ejecutarse la función y se destruyen al salir de ella. ¿Qué significa eso? Lo explico en el siguiente apartado.
Si dentro de una función hay una variable local con el mismo nombre que una variable global, la precedencia en dicha función la tiene la variable local. Si te confunde, no uses variables globales y locales con el mismo nombre.
Variables static
Antes de nada debemos aclarar que una variable static local tiene diferente significado que unavariable static global. Ahora vamos a enfocarnos al primer caso por ser el más común.
Cuando se llama a una función sus variables locales se crearán en ese momento y cuando se salga de la función se destruirán. Se entiende por destruir al hecho de que la locación de memoria que tenía una variable será luego utilizada por el compilador para otra variable local (así se economiza la memoria). Como consecuencia, el valor de las variables locales no será el mismo entre llamadas de función.
Por ejemplo, revisa la siguiente función, donde a es una variable local ordinaria.
void increm()
{
int a; // Declarar variable a
a++; // Incrementar a
}
Cualquiera que haya sido su valor inicial, ¿crees que después de llamar a esta función 10 veces, el valor de a se habrá incrementado en 10?... Pues, no necesariamente. Cada vez que se llame a increm se crea a, luego se incrementa y, al terminar de ejecutarse la función, se destruye.
Para que una variable tenga una locación de memoria independiente y su valor no cambie entre llamadas de función tenemos dos caminos: o la declaramos como global, o la declaramos comolocal estática. Los buenos programadores siempre eligen el segundo.
Una variable se hace estática anteponiendo a su declaración el especificador static. Por defecto las variables estáticas se auto inicializan a 0, pero se le puede dar otro valor en la misma declaración (dicha inicialización solo se ejecuta la primera vez que se llama a la función), así:
static int var1; // Variable static (inicializada a 0 por defecto)

static int var2 = 50; // Variable static inicializada a 50
Ejemplos.
void increm()
{
static int a = 5; // Variable local estática inicializada a 5
a++; // Incrementar a
}
void main()
{
int i; // Declarar variable i
// El siguiente código llama 10 veces a increm
for(i=0; i<10; i++)
increm();
// Ahora la variable a sí debería valer 15
while(1); // Bucle infinito
}
Variables volatile
A diferencia de los ensambladores, los compiladores tienen cierta “inteligencia”. Es decir, piensan un poco antes de traducir el código fuente en código ejecutable. Por ejemplo, veamos el siguiente pedazo de código para saber lo que suele pasar con una variable ordinaria:
int var; // Declarar variable var
//...
var = var; // Asignar var a var

El compilador creerá (probablemente como nosotros) que la sentencia var = var no tiene sentido (y quizá tenga razón) y no la tendrá en cuenta, la ignorará. Ésta es solo una muestra de lo que significa optimización del código. Luego descubrirás más formas de ese trabajo.
El ejemplo anterior fue algo burdo, pero habrá códigos con redundancias aparentes y más difíciles de localizar, cuya optimización puede ser contraproducente. El caso más notable que destacan los manuales de los compiladores C para microcontroladores es el de las variables globales que son accedidas por la función de interrupción y por cualquier otra función.
Para que un compilador no intente “pasarse de listo” con una variable debemos declararla comovolatile, anteponiéndole dicho calificador a su declaración habitual.
Por ejemplo, en el siguiente boceto de programa la variable count debe ser accedida desde la función interrupt como desde la función main; por eso se le declara como volatile. Nota: el esquema de las funciones de interrupción suele variar de un compilador a otro. Éste es solo un ejemplo.
volatile int count; // count es variable global volátil
void interrupt(void) // Función de interrupción
{
// Código que accede a count
}
void main(void) // Función principal
{
// Código que accede a count
}
Arrays y Punteros
Probablemente éste sea el tema que a todos nos ha dado más de un dolor de cabeza y que más hemos releído para captarlo a cabalidad. Hablo más bien de los punteros. Si ellos el C no sería nada, perdería la potencia por la que las mejores empresas lo eligen para crear sus softwares de computadoras.

Pero bueno, regresando a lo nuestro, estos temas se pueden complicar muchísimo más de lo que veremos aquí. Solo veremos los arrays unidimensionales y los punteros (que en principio pueden apuntar a todo tipo de cosas) los abocaremos a los datos básicos, incluyendo los mismos arrays. Aun así, te sugiero que tengas un par de aspirinas al lado.
Los arrays o matrices
Un array es una mega variable compuesto de un conjunto de variables simples del mismo tipo y ubicadas en posiciones contiguas de la memoria. Con los arrays podemos hacer todos lo que hacíamos con las tablas (de búsqueda) del ensamblador y muchísimo más.
Un array completo tiene un nombre y para acceder a cada uno de sus elementos se utilizan índices entre corchetes ([ ]). Los índices pueden estar indicados por variables o constantes. En el siguiente esquema se ve que el primer elemento de un array tiene índice 0 y el último, N-1, siendo N la cantidad de elementos del array.
Estructura de un array unidimensional de N elementos.
Declaración de arrays
Para declarar un array unidimensional se utiliza la siguiente sintaxis:
data_type identifier[ NumElementos ];
Donde data_type es un tipo de dato cualquiera, identifier es el nombre del array yNumElementos es la cantidad de elementos que tendrá (debe ser un valor constante).
De este modo, el índice del primer elemento es 0 y el del último es NumElements - 1.
Por ejemplo, las siguientes líneas declaran tres arrays.
char letters10]; // letters es un array de 10 elementos de tipo char
long HexTable[16]; // HexTable es un array de 16 elementos de tipo long
int address[100]; // address es un array de 100 elementos de tipo int
Para el array letters el primer elemento es letters[0] y el último, letters[9]. Así, tenemos 10 elementos en total. Si quisiéramos asignar a cada uno de los elementos de letters los caracteres desde la ‘a’ hasta la ‘j’, lo podríamos hacer individualmente así:
letters[0] = 'a'; // Aquí el índice es 0

letters[1] = 'b'; // Aquí el índice es 1
letters[2] = 'c'; // ...
letters[3] = 'd'; //
letters[4] = 'e';
letters[5] = 'f';
letters[6] = 'g';
letters[7] = 'h';
letters[8] = 'i';
letters[9] = 'j'; // Aquí el índice es 9
Pero así no tiene gracia utilizar arrays. En este caso lo mejor es utilizar un bucle, así: (Nota: los caracteres son, al fin y al cabo, números en códigos ASCII y se les puede comparar.)
char c;
for ( c = 'a'; c <= 'j'; c++ )
letters[i] = c;
Inicialización de arrays
Los elementos de un array se pueden inicializar junto con su declaración. Para ello se le asigna una lista ordenada de valores encerrados por llaves y separados por comas. Por supuesto, los valores deben ser compatibles con el tipo de dato del array. Este tipo de inicialización solo está permitido en la declaración del array.
Ejemplos:
unsigned char mask[3] = { 0xF0, 0x0F, 0x3C }; // Ok
int a[5] = { 20, 56, 87, -58, 5000 }; // Ok
char vocals[5] = { 'a', 'e', 'i', 'o', 'u' }; // Ok
int c[4] = { 5, 6, 0, -5, 0, 4 }; // Error, demasiados inicializadores
También es posible inicializar un array sin especificar en su declaración el tamaño que tendrá, dejando los corchetes vacíos. El tamaño será pre calculado y puesto por el compilador. Ésta es una forma bastante usada en los arrays de texto, donde puede resultar muy incómodo estar contando las letras de una cadena. Por ejemplo:

int a[] = { 70, 1, 51 }; // Un array de 3 elementos
char vocals[] = { 'a', 'e', 'i', 'o', 'u' }; // Un array de 5 elementos
char msg[] = "Este es un array de caracteres"; // Un array of 31 elementos
¿Por qué el último array tiene 31 elementos si solo se ven 30 letras? Lo sabremos luego.
Cadenas de texto terminadas en nulo
Son arrays de tipo de dato char. Hay dos características que distinguen a estas cadenas de los demás arrays. Primero: su inicialización se hace empleando comillas dobles y segundo, el último término del array es un carácter NULL (simplemente un 0x00). De ahí su nombre.
Ejemplos:
char Greet[10] = "Hello"; // Un array de 10 elementos
char msg[] = "Hello"; // Un array de 6 elementos
El array Greet tiene espacio para 10 elementos, de los cuales solo los 5 primeros han sido llenados con las letras de Hello, el resto se rellena con ceros.
El array msg tiene 6 elementos porque además de las 5 letras de “Hello” se le ha añadido unNull (0x00) al final (claro que no se nota). Es decir, la inicialización de msg es equivalente a:
char msg[] = { 'H', 'e', 'l', 'l', 'o', 0x00}; // Un array de 6 elementos
Visto gráficamente, msg tendría la siguiente representación:
Estructura de una cadena de texto.
Los punteros
Los punteros suelen ser el tema que más cuesta entender en programación. Pero si ya llegaste aquí, es el momento menos indicado para detenerte.
Los punteros son un tipo de variables muy especial. Son variables que almacenan las direcciones físicas de otras variables. Si tenemos la dirección de una variable, tenemos acceso a esa variable de manera indirecta y podemos hacer con ellas todo lo que queramos.

Declaración de punteros
Los punteros pueden apuntar a todo tipo de variables, pero no a todas al mismo tiempo. La declaración de un puntero es un tanto peculiar. En realidad, se parece a la declaración de una variable ordinaria solo que se pone un asterisco de por medio. En este punto debes recordar las declaraciones de todo tipo de variables que hemos visto, incluyendo las influenciadas por los calificadores const, static, etc. Todas excepto los arrays; ¿por qué?
La forma general de declarar un puntero es la siguiente:
data_type * PointerName;
Los siguientes ejemplos muestran lo fácil que es familiarizarse con la declaración de los punteros:
int * ip; // ip es un puntero a variable de tipo int
char * ucp; // cp es un puntero a variable de tipo char
unsigned char * ucp; // Puntero a variable de tipo unsigned char
const long * clp; // Puntero a constante de tipo long
float * p1, *p2; // Declara dos punteros a variable de tipo float
Apuntando a variables
Decimos que una variable puntero “apunta” a una variable x si contiene la dirección de dicha variable. Para ello se utiliza el operador &, el cual extrae la dirección de la variable a la que acompaña. Un puntero siempre debería apuntar a una variable cuyo tipo coincida con el tipo del puntero.
En los siguientes ejemplos vemos cómo apuntar a variables de tipo básico, como int, char o float. Más adelante veremos cómo apuntar a arrays.
void main (void)
{
int height, width;
char a, b, c;
float max;
int * ip; // ip es un puntero a variable tipo int
char * cp; // cp es un puntero a variable tipo char

float * fp; // Puntero a variable tipo float
ip = &height; // Con esto ip tendrá la dirección de height
ip = &width; // Ahora ip apunta a width
cp = &a; // cp apunta a a
cp = &c; // Ahora cp apunta a c
cp = &a; // Ahora cp apunta a a otra vez
fp = &max; // fp apunta a max
fp = &height; // Error! height no es una variable float
//...
}
Asignaciones indirectas mediante punteros
Una vez que un puntero apunte a una variable cualquiera, se puede acceder a dicha variable utilizando el nombre del puntero precedido por un asterisco, de esta forma:
void main (void)
{
int height, width, n; // Variables ordinarias
int * p, * q; // p y q son punteros a variables de tipo int
p = &height; // p apunta a height
*p = 10; // Esto es como height = 10
p = &width; // p apunta a width

*p = 50; // Esto es como width = 50
height = *p; // Esto es como height = width
q = &height; // q apunta a height
n = (*p + *q)/2; // Esto es como n = (height + width)/2
//...
}
La expresión *p se debería leer: “la variable apuntada por p”. Eso también ayuda mucho a comprender a los punteros.
¿Y para esto se inventaron los punteros? Yo me preguntaba lo mismo en mis inicios. El tema de los punteros se puede complicar casi “hasta el infinito”, por eso quiero ir con cuidado y poco a poco para que nadie se pierda.
Punteros y arrays
¿Cómo se declara un puntero a un array? Un puntero a un array es simplemente un puntero al tipo de dato del array. Cuando se asigna un puntero a un array, en realidad el puntero toma la dirección de su primer elemento, a menos que se especifique otro elemento.
Luego, bastaría con modificar el valor del puntero para que apunte a los otros elementos del array. Todo lo indicado se refleja en el siguiente código:
void main (void)
{
int * p; // Declara p como puntero a int
int n; // Alguna variable
int mat[3] = { 78, 98, 26 }; // Array de variables int
p = &mat; // p apunta a mat (a su primer elemento)

n = *p; // Esto da n = 78
p++; // Incrementar p para apuntar a siguiente elemento
n = *p; // Esto da n = 98
p++; // Incrementar p para apuntar a siguiente elemento
n = *p; // Esto da n = 26
*p = 10; // Con esto mat[3] valdrá 10
p--; // Decrementar p para apuntar a elemento anterior
*p = 100; // Con esto mat[2] valdrá 100
p = mat; // p apunta a mat. Es lo mismo que p = &mat
p = NULL; // Desasignar p. Lo mismo que p = 0x0000
// ...
}
En el fondo los arrays y los punteros trabajan de la misma forma, por lo menos cuando referencian a variables almacenadas en la RAM del microcontrolador. La única diferencia es que los arrays no pueden direccionar a datos diferentes de su contenido; por eso también se les llama punteros estáticos. En la práctica esto significa que un array es siempre compatible con un puntero, pero un puntero no siempre es compatible con un array.
Por ejemplo, a un array no se le puede asignar otro array ni se le pueden sumar o restar valores para que apunten a otros elementos. Por lo demás, las operaciones de asignación son similares para punteros y arrays, tal como se puede apreciar en el siguiente código. (Por si las moscas,str1 es el array y str2, el puntero.)
void main(void)
{
char str1[] = { 'A', 'r', 'r', 'a', 'y' };
char * str2 = { 'P', 'o', 'i', 'n', 't', 'e', 'r' };

char a;
a = str1[0]; // Esto da a = 'A'
a = str1[3]; // Esto da a = 'a'
a = str2[0]; // Esto da a = 'P'
a = str2[3]; // Esto da a = 'n'
str1 += 2; // Error! Str1 es estático
str2 += 2; // Correcto. Ahora str2 apunta a 'i'
str1++; // Error otra vez! Str1 es estático
str2++; // Correcto. Ahora str2 apunta a 'n'
a = *str2; // Esto da a = 'n'
// ...
}
Paso de punteros y arrays a funciones
¿Recuerdas el paso de variables por valor y por referencia? Pues aquí vamos de nuevo.
Bien, recordemos: una variable pasada por valor a una función, en realidad le entrega una copia suya; por lo que la variable original no tiene por qué ser afectada por el código de la función. Ahora bien, pasar una variable por referencia significa que se pasa la dirección de dicha variable. Como consecuencia, la función tendrá acceso a la variable original y podrá modificar su contenido. Esto podría resultar riesgoso, pero, bien usada, la técnica es una potente arma.

Ya que los punteros operan con direcciones de variables, son el medio ideal para trabajar conparámetros por referencia. Hay dos casos de particular interés: uno, cuando deseamos en serio que la variable pasada a la función cambie a su regreso; y dos, cuando la variable pasada es demasiado grande (un array) como para trabajar con copias. De hecho, los arrays siempre se pasan por referencia ya que también son punteros al fin.
La sintaxis de los punteros en el encabezado de la función no es nada nuevo, teniendo en cuenta que también tienen la forma de declaraciones de variables.
En el siguiente ejemplo la función interchange intercambia los valores de las dos variables recibidas. En seguida explicaré por qué varía un poco la forma en que se llama a la función.
void interchange( int * p1, int * p2 )
{
int tmp = *p1; // Guardar valor inicial de variable apuntada por p1.
*p1 = *p2; // Pasar valor de variable apuntada por p2 a...
// variable apuntada por p1.
*p2 = tmp; // Variable apuntada por p2 valdrá tmp.
}
void main (void)
{
int i, j;
/* Hacer algunas asignaciones */
i = 10;
j = 15;
/* Llamar a función interchange pasando las direcciones de i y j */
interchange( &i, &j );
// En este punto i vale 15 y j vale 10
// ...
}

Al llamar a interchange le entregamos &i y &j, es decir, las direcciones de i y j. Por otro lado, la función interchange recibirá dichos valores en p1 y p2, respectivamente. De ese modo, p1 y p2estarán apuntando a i y j, y podremos modificar sus valores.
Ten presente que se mantiene la forma de asignación “puntero = &variable” (puntero igual a dirección de variable).
Ahora veamos ejemplos donde la forma de asignación cambia a “puntero = puntero”. Esto incluye a los arrays porque, recordemos, un puntero siempre puede ser tratado como un array, aunque lo contrario no siempre es posible.
En el siguiente programa array1 y array2 se pasan a la función prom, la cual devuelve el valor promedio de los elementos del array recibido. Como para ese cálculo se necesita conocer la cantidad de elementos que tiene el array, prom recibe dicho valor en el parámetro size.
float prom ( int * p, int size )
{
int i; float tmp = 0;
for ( i=0; i<size; i++ ) // Bucle para contar i desde 0 hasta size-1.
tmp += p[i]; // Sumar elemento p[i] a tmp.
return ( tmp/size ); // Retornar valor promediado.
}
void main (void)
{
int array1[4] = { 51, 14, 36, 78 }; // Un array de 4 elementos
int array2[] = { -85, 4, 66, 47, -7, 85 }; // Un array de 6 elementos
float avrg; // Una variable tipo float, para decimales
avrg = prom (array1, 8);
// Ahora avrg debería valer (51 + 14 + 36 + 78 )/8 = 44.75

avrg = prom (array2, 6);
// Ahora avrg debería valer (-85 + 4 + 66 + 47 - 7 + 85 )/6 = 18.3333
while( 1 ); // Bucle infinito
}
Finalmente, veamos un programa donde se utilizan las Cadenas de texto terminadas en nulo.
Este programa tiene dos funciones auxiliares: mayus convierte la cadena recibida en mayúsculas, y lon calcula la longitud del texto almacenado en el array recibido. Ambas funciones reciben el array pasado en un puntero p dado que son compatibles.
void mayus( char * p )
{
while( *p ) // Mientras carácter apuntado sea diferente de 0x00
{
if( ( *p >= 'a' ) && ( *p <= 'z' ) ) // Si carácter apuntado es
// minúscula
*p = *p - 32; // Hacerlo mayúscula
p++; // Incrementar p para apuntar sig. carácter
}
}
int lon( char * p)
{
int i = 0; // Declarar variable i e iniciarla a 0.
while( *p ) // Mientras carácter apuntado sea diferente de 0x00
{
i++; // Incrementar contador.
p++; // Incrementar p para apuntar sig. carácter

}
return i; // Retornar i
}
void main (void)
{
int L;
char song1[20] = "Dark Blue";
char song2[20] = "Staring Problem";
char song3[20] = "Ex-Girlfriend";
/* Obtener longitudes de los arrays de texto */
L = lon(song1); // Debería dar L = 9
L = lon(song2); // Debería dar L = 15
L = lon(song3); // Debería dar L = 13
/* Convertir cadenas en mayúsculas */
mayus(song1 ); // Es lo mismo que mayus(&song1);
// Ahora song1 debería valer "DARK BLUE"
mayus(song2 ); // Es lo mismo que mayus(&song2);
// Ahora song2 debería valer "STARING PROBLEM"
mayus(song3 ); // Es lo mismo que mayus(&song3);
// Ahora song3 debería valer "EX-GIRLFRIEND"

while(1); // Bucle infinito
}
En el programa se crean tres arrays de texto de 20 elementos (song1, song2 y song3), pero el texto almacenado en ellos termina en un carácter 0x00.
Según la tabla de caracteres ASCII, las letras mayúsculas están ubicadas 32 posiciones por debajo de las minúsculas. Por eso basta con sumarle o restarle ese valor a un carácter ASCII para pasarlo a mayúscula o minúscula.
En ambas funciones el puntero p navega por los elementos del array apuntado hasta que encuentra el final, indicado por un carácter nulo (0x00).
Arrays constantes
No es que me haya atrasado con el tema, es solo que los arrays constantes son uno de los temas cuyo tratamiento varía mucho entre los distintos compiladores. Veamos en qué.
Un array constante es uno cuyos elementos solo podrán ser leídos pero no escritos; tan simple como eso.
En principio, para que un array sea constante a su clásica declaración con inicialización de un array se le debe anteponer el calificador const. No es posible declarar un array constante vacío y llenar sus elementos después pues eso equivaldría a modificar sus elementos. Enseguida tenemos ejemplos de declaración de arrays constantes:
const int a[5] = { 20, 56, 87, -58, 5000 }; // Array constante
const char vocals[5] = { 'a', 'e', 'i', 'o', 'u' }; // Array constante
const char text[] = "Este es un array constante de caracteres";
De este modo, los arrays a, vocals y text serán de solo lectura, y sus elementos podrán ser leídos, mas no escritos. El compilador mostrará mensajes de error si en lo que resta del programa encuentra intentos de cambio, por ejemplo, como
a[4] = 100; // Esto generará un error en tiempo de compilación
vocals[0] = 'a'; // Error! no se puede escribir por mas que sea el mismo dato
Ahora bien, que los datos no cambien durante la ejecución del programa no necesariamente significa los arrays constantes estén ubicados en la memoria FLASH. En algunos compiladores de PICs, como CCS C y Hitech C, sí ocurre así, pero el lenguaje C solo dice que estos datos son inmodificables, no dice dónde deben residir. Recordemos que las variables en un programa de

computadora, constantes o no, van siempre en la RAM. Para las computadoras no es problema porque les "sobra" la RAM, cosa que no sucede en los microcontroladores.
Variables PROGMEM y su acceso
Por otro lado, los compiladores de AVR ofrecen métodos alternos para declarar arrays, o variables en general, que puedan residir en la memoria FLASH. Con eso no solo se destina la preciada RAM a otras variables sino que se pueden usar grandes arrays constantes que simplemente no podrían caber en la RAM. Como todo esto va al margen de lo que diga el ANSI C, cada compilador ha establecido su propia sintaxis para hacerlo.
Empecemos por examinar el estilo de AVR GCC. Por ejemplo, si queremos que los tres primeros arrays de esta página se almacenen en la FLASH debemos declararlas e inicializarlas de esta forma
PROGMEM const int a[5] = { 20, 56, 87, -58, 5000 }; // Array constante
PROGMEM const char vocals[5] = { 'a', 'e', 'i', 'o', 'u' }; // Array constante
PROGMEM const char text[] = "Este es un array constante de caracteres";
Observa que fue tan simple como añadirles al inicio la palabra reservada PROGMEM. El calificadorconst era opcional en las versiones pasadas de AVR GCC como la que viene con AVR Studio 5, pero es necesaria en las versiones recientes como la que trae Atmel Studio 6. De todos modos es sencillo. Lo complicado viene después. Para acceder a los elementos de estos arrays hay que emplear una forma un tanto exótica. Se deben usar algunas macros propias del compilador, todas proveídas por la librería pgmspace.h. Las principales son estas cuatro
pgm_read_byte. Lee de un array residente en FLASH un entero compuesto por un byte de dato. En el lenguaje C los únicos datos de este tamaño son del tipo char y sus derivadossigned char y unsigned char.
pgm_read_word. Lee de un array residente en FLASH un entero compuesto por 2 bytes. En el C serían arrays de tipo (signed) int, unsigned int, (signed) short y unsigned short.
pgm_read_dword. Lee de un array residente en FLASH un entero compuesto por 4 bytes. En el C serían arrays de tipo (signed) long y unsigned long.
pgm_read_float. Lee de un array residente en FLASH un número de punto flotante compuesto por 4 bytes. En el lenguaje C serían arrays de tipo float y double operando en modo de 32 bits.
Estas macros reciben como argumento la dirección de un elemento del array en FLASH. Como la dirección de una variable cualquiera en el C se obtiene al aplicarle el operador &, las macros citadas trabajan de esta forma.
PROGMEM const int a[5] = { 20, 56, 87, -58, 5000 }; // Array constante
PROGMEM const char vocals[5] = { 'a', 'e', 'i', 'o', 'u' }; // Array constante

PROGMEM const char text[] = "Este es un array constante de caracteres";
int var;
char c;
var = pgm_read_word(&a[1]); // Con esto var valdrá 56
c = pgm_read_byte(&vocals[3]); // Con esto c valdrá 'o'
c = pgm_read_byte(&text[11]); // Con esto c valdrá 'a'
El manual de AVR GCC nos presenta una forma que puede resultar más fácil de asimilar el acceso a los elementos de estos arrays: dice que primero asumamos acceder al elemento como si perteneciera a un array ordinario (residente en RAM), por ejemplo:
var = a[1];
luego le aplicamos el operador &
var = &a[1];
y finalmente le aplicamos la macro respectiva.
var = pgm_read_word( &a[1] ); // Con esto var valdrá 56
Por supuesto que en nuestro programa deberemos poner solo la última expresión. Es muy importante recordar esto puesto que las expresiones previas son también válidas para el compilador y no generará errores. Solo nos daremos con la sorpresa de ver nuestro programa funcionando desastrosamente. Me pasa con frecuencia porque en mis códigos tengo la costumbre de ubicar primero los arrays en la RAM para luego de obtener buenos resultados mudarla a la memoria FLASH. Si eres nuevo te recomiendo seguir la misma práctica. Trabajar con datos en FLASH desde el inicio requiere de mucha experiencia. Hay otras macros y tipos de datos que debemos saber usar, y si no estamos seguros de lo que hacemos, repito, el compilador no nos ayudará.
Los parámetros que reciben como argumento las macros pgm_read_byte, pgm_read_word,pgm_read_dword y pgm_read_float son direcciones de 16 bits. Esto quiere decir que mediante ellas podemos acceder a los arrays cuyos elementos cubren un espacio de 216 = 65536 bytes de la memoria FLASH. En la gran mayoría de los casos es mucho más de lo que se necesita, considerando que solo hay dos megaAVR que superan esa memoria, los ATmega128 y los ATmega256. Pero si se presentara la descomunal situación donde

tengamos que trabajar con arrays de más de 64 KB, la librería pgmspace.h nos provee de otras macros ad hoc. Retomamos este aspecto al final de la página.
Variables PROGMEM locales
Las variables PROGMEM tienen un espacio asignado en la memoria que no cambia durante la ejecución del programa. Parece una perogrullada pero los lectores perspicaces saben que ese comportamiento es propio de dos tipos de variables del C: las variables globales y las variables static locales. Todos los otros tipos de variables tienen posiciones dinámicas.
Más que una coincidencia, lo dicho arriba es una condición necesaria para todas las variables almacenadas en la FLASH para AVR IAR C y AVR GCC. Es decir, en estos compiladores las variables PROGMEM deben o ser globales o static locales. Todos los ejemplos mostrados arriba funcionan bien asumiendo que están declaradas a nivel global. Si los colocamos dentro de una función habrá problemas.
Por ejemplo, el siguiente extracto de función no dará errores en AVR GCC pero el programa funcionará defectuosamente, a pesar de que los arrays están declarados e inicializados conforme a lo estudiado previamente.
/*****************************************************************************
* Toca las notas del ringtone apuntado por pRingtone.
****************************************************************************/
void Tune(PGM_P pRingtone)
{ // C C# D D# E F F#
PROGMEM const unsigned int NoteFreqs[] = {262,277,294,311,330,349,370};
PROGMEM const unsigned char Octaves[] = {6,7,5};
PROGMEM const unsigned int Bpms[] = {0,812,406,270,203,162,135};
PROGMEM const unsigned char Durations[] = {4,8,1,2};
/* ... */
}
Sucede que los arrays están declarados como si fueran locales ordinarias. Si los hubiéramos declarado globalmente estaría bien. Pero como son locales es necesario que sean además de

tipo static. Como sabemos, estas variables en C se forman añadiéndoles la palabra reservadastatic a su declaración habitual. Con esto aclarado, el código anterior trabajará perfectamente si lo escribimos de esta forma.
/*****************************************************************************
* Toca las notas del ringtone apuntado por pRingtone.
****************************************************************************/
void Tune(PGM_P pRingtone)
{ // C C# D D# E F F#
static PROGMEM const unsigned int NoteFreqs[] = {262,277,294,311,330,349,370};
static PROGMEM const unsigned char Octaves[] = {6,7,5};
static PROGMEM const unsigned int Bpms[] = {0,812,406,270,203,162,135};
static PROGMEM const unsigned char Durations[] = {4,8,1,2};
/* ... */
}
Ese trozo de código pertenece al programa de la práctica reproductor de ringtones PICAXE. Si deseas comprobar lo expuesto puedes descargarlo y recompilarlo haciendo las modificaciones explicadas.
Los punteros PGM_P y PGM_VOID_P
Justo en el ejemplo anterior aparece el tipo de dato PGM_P en una de sus funciones que es permitir el paso de variables a funciones. Ese tema lo profundizaremos luego.
El tipo de dato PGM_P es un puntero a una variable residente en la memoria FLASH. Su definición en el archivo pgmspace.h de AVR GCC es
#define PGM_P const PROGMEM char *
pero el archivo pgmspace.h de AVR IAR C lo define como
#define PGM_P const char __flash *

Con el fin de que los programas de cursomicros sean lo más transparentes posible trato de evitar el uso excesivo de los #defines que conducen a términos innecesarios. El hecho de estar estudiando PGM_P sugiere que se trata de una excepción. Notemos en primer lugar que el archivo avr_compiler.h que se usa en esta web define PROGMEM como __flash con lo cual las dos expresiones de arriba serían idénticas asumiendo que en AVR GCC const PROGMEM charequivale a const char PROGMEM y también a PROGMEM const char, siendo esta última presentación la forma en que hemos venido trabajando. Debido a ello en muchas ocasiones podremos prescindir de PGM_P, pero surgirán algunos casos en que AVR IAR C muestre su disconformidad por ese reacomodo de términos. PGM_P no solo termina de arreglar estos desajustes sino que facilita notablemente la escritura del código ante la aparición de construcciones más complejas como las que veremos después.
Si PGM_P define un tipo puntero que apunta a variables char (o de un byte en general), alguien podría preguntar cuáles son los punteros para las variables de tipo int, short, float, etc. No hay definiciones especiales para esos casos. Podemos crearlas por cuenta propia si deseamos pero será raramente necesario porque a fin de cuentas el puntero seguirá siendo de 16 bits. Solo suele interesar la dirección de un dato. Para leer ese dato con el formato deseado habrá que usar la macro adecuada, entre pgm_read_byte, pgm_read_word, pgm_read_dword ypgm_read_float, junto a las conversiones de datos respectivos.
Ejemplo, en el siguiente programa que está escrito para los compiladores AVR IAR C y AVR GCCNotes es un array de enteros de 16 bits y Octaves un array de enteros de 8 bits, ambos residentes en la FLASH.
#include "avr_compiler.h"
PROGMEM const unsigned int Notes[] = {262, 277, 294, 311, 494};
PROGMEM const unsigned char Octaves[] = {6, 7, 5};
int main(void)
{
PGM_P p; // Declarar el puntero p
unsigned char c;
unsigned int n;
p = (PGM_P)Octaves; // Apuntar al array Octaves

c = pgm_read_byte(p + 1); // Obtener el elemento Octaves[1]
p = (PGM_P)Notes; // Apuntar al array Notes
n = pgm_read_word((PROGMEM int*)p + 3); // Obtener Notes[3]
while(1);
}
Como los arrays pueden ser entendidos como punteros también, en principio se podrían hacer las asignaciones a p directamente como p = Notes, pero para evitar protestas del compilador se deben usar conversiones de tipo, poniendo al lado izquierdo y entre paréntesis el tipo de la variable que recibe el valor, en este caso PGM_P porque p es de ese tipo. De ese modo p podrá apuntar a arrays de cualquier tipo.
Por otro lado, para leer los elementos del array Octaves usamos la macro pgm_read_byteporque es un array de bytes y para Notes usamos pgm_read_word porque es un array de enteros de 2 bytes.
A pgm_read_byte se le envía el puntero p más el índice del elemento accedido. Recordemos que estas macros reciben direcciones y como los punteros contienen direcciones, no es necesario sacar direcciones mediante el operador &. Este caso fue sencillo porque el tipo de Octave se acoplaba fácilmente a PGM_P.
pgm_read_word también espera recibir una dirección pero no se le puede enviar a pdirectamente como en el caso previo. Es preciso hacer una conversión de tipo para que el valor de p sea entendido como una dirección de variables de 2 bytes. Por eso colocamos al lado izquierdo de p la expresión (PROGMEM int *) que se adapta al tipo del array Notes. También se pudo haber puesto (PROGMEM const unsigned int *) para una mejor claridad en la correspondencia. Lo que cuenta es que implique un tipo de 2 bytes.
El hecho de usar el tipo PGM_P hace presuponer que solo se trabajará con variables de bytes que son accedidas mediante la macro pgm_read_byte. De hecho es así en la gran mayoría de los casos y todo queda bien. La legibilidad se pierde en programas como el ejemplo previo donde el mismo puntero se usa también para acceder a un array de enteros de 2 bytes. Si de todos modos vamos a estar haciendo conversiones de tipos lo más recomendable sería usar un puntero "neutro" lo cual deja por sentado que trabajará sobre variables de distintos tipos.
Ese tipo de puntero existe y se llama PGM_VOID_P. Es aceptado así en los compiladores AVR IAR C y AVR GCC. Es un puntero a void definido en AVR GCC como const void PROGMEM * y en AVR IAR C como const void __flash *. Lo importante es que su empleo es similar al puntero PGM_P, así

que lo asimilaremos de inmediato. El programa anterior por ejemplo se puede reescribir de la siguiente forma. (El código quedó con mejor acabado y con una linda simetría.)
#include "avr_compiler.h"
PROGMEM const unsigned int Notes[] = {262, 277, 294, 311, 494};
PROGMEM const unsigned char Octaves[] = {6, 7, 5};
int main(void)
{
PGM_VOID_P p; // Declarar el puntero p
unsigned char c;
unsigned int n;
p = (PGM_VOID_P)Octaves; // Apuntar al array Octaves
c = pgm_read_byte((PROGMEM char*)p + 1); // Obtener el elemento Octaves[1]
p = (PGM_VOID_P)Notes; // Apuntar al array Notes
n = pgm_read_word((PROGMEM int*)p + 3); // Obtener Notes[3]
while(1);
}
Los punteros PGM_P y PGM_VOID_P también pueden actuar sobre variables de tipo complejo. Estamos hablando por ejemplo de estructuras definidas por el usuario. Por el mismo hecho de ser variables complejas poner aquí un programa de demostración abarcaría demasiado espacio. Prefiero remitirme a la librería para USB que distribuye Atmel. Me parece un perfecto ejemplo. Puedes encontrarla en varias notas de aplicación como AVR270, AVR271, AVR272 y AVR273, por citar algunas. En el archivo usb_standar_request.c se declara y usa el puntero pbuffer de tipoPGM_VOID_P para acceder a los descriptores de USB que por su tamaño residen en la FLASH.

Esa librería USB se vale de un archivo llamado compiler.h para guardar la compatibilidad de códigos entre los compiladores AVR IAR C y AVR GCC para los que está escrita. Contiene varias imprecisiones que, imagino, se deben a los defectos que AVR GCC presentaba antiguamente, cuando se escribió la librería. Igual vale la pena revisarla.
Variables PROGMEM como argumentos de funciones
En primer lugar recordemos que los argumentos de las funciones deben ser del mismo tipo que las variables que se le envían. Si las variables son residentes en la FLASH, lo cual deja suponer que son arrays o estructuras complejas, el método a usar son los punteros, no solo por el tamaño de esas variables sino por la capacidad de adaptación de los punteros que estudiamos en la sección anterior.
Allí se describió la operación de los punteros PGM_P y PGM_VOID_P y se explicó lo imprescindibles que serían. No es recomendable que los argumentos de las funciones sean punteros con tipos diferentes de PGM_P o PGM_VOID_P. Solo ellos garantizan que nuestros programas funcionarán bien en los dos compiladores AVR IAR C y AVR GCC. Dicho eso, podemos pasar al ejemplo.
En el siguiente programa la función print imprime un mensaje por el puerto serie, similar a puts de la librería stdio.h del compilador. La función puts solo trabaja con mensajes en la RAM a diferencia de print que recibe arrays residentes en la FLASH. Los dos compiladores que usamos también ofrecen funciones de FLASH y a eso pretendemos llegar: a su uso.
#include "avr_compiler.h"
#include "usart.h"
PROGMEM const char rt01[] = "\r Deck the halls";
PROGMEM const char rt02[] = "\r Jingle bells";
PROGMEM const char rt03[] = "\r We wish you a merry christmas";
PROGMEM const char rt04[] = "\r Silent night";
/*****************************************************************************
* Envía por el USART el texto pasado en p
****************************************************************************/

void print(PGM_P p)
{
char c;
while( (c = pgm_read_byte(p++)) != 0x00 )
putchar(c);
}
/******************************************************************************
* Main function
*****************************************************************************/
int main(void)
{
usart_init(); // Inicializar USART
print(rt01); // Imprimir mensaje de rt01
print(rt02); // ...
print(rt03); // ...
print(rt04); // ...
while (1);
}
Creo que el código está bastante claro. Como los arrays son de texto (de caracteres de 1 byte), se optó por el puntero PGM_P y por la macro pgm_read_byte para la que no fue necesaria una conversión de tipo. La conversión de tipo para p es opcional, por ejemplo, también se pudo escribir print((PGM_P)rt01).

Y ahora la pregunta que nos trae aquí: ¿Se puede enviar a una función una variable en flash directamente? Es decir, qué pasa si en vez de declarar los arrays por separado, los escribimos directamente en el argumento de la siguiente forma.
print("\r Deck the halls"); // Imprimir este mensaje
print("\r Jingle bells"); // ...
print("\r We wish you a merry christmas"); // ...
print("\r Silent night"); // ...
El compilador AVR GCC todavía acepta las sentencias y construye el programa limpiamente, sin presentar errores, ni siquiera advertencias. Pero el resultado es un programa mostrando mamarrachos en vez de los villancicos esperados. El compilador AVR IAR C , por su parte, simplemente no admite el código fuente. ¿Qué pasó?
Como variables locales ordinarias que son, los compiladores tratan de implementar las cadenas pasadas en la memoria RAM. AVR IAR C nota la incompatibilidad de tipos y rechaza el código de plano, en tanto que AVR GCC sí cumple el cometido pasando por alto la divergencia de tipos porque, recordemos, este compilador hace la diferencia en el momento de acceder a las variables usando sus macros como pgm_read_byte. Esa macro recibe en el programa una dirección RAM (también de 16 bits) y la usa para leer de la memoria FLASH como si las cadenas de texto estuvieran allí. Lee "cualquier cosa" menos las cadenas.
Alguien más avezado podría decir que eso se puede arreglar con conversiones de tipos por ejemplo reescribiendo las sentencias así
print((PGM_P)("\r Deck the halls")); // Imprimir este mensaje
print((PGM_P)("\r Jingle bells")); // ...
print((PGM_P)("\r We wish you a merry christmas")); // ...
print((PGM_P)("\r Silent night")); // ...
El código vuelve a compilarse limpiamente. Hasta AVR IAR C es engañado. Pero cuando vemos el programa en acción descubrimos que solo nos hemos engañado a nosotros mismos. En este programa los garabatos que se visualizan en el terminal serial nos quitaron la venda de los ojos rápidamente, felizmente. En otras circunstancias detectar el error hubiera costado más. Las cadenas siguen siendo colocadas en la RAM. Recordemos que para que las variables residan en la FLASH deben o ser globales o static locales. Lo primero es obviamente un imposible; y lo segundo, que sean static, solo es posible en el compilador AVR GCC gracias a una macro llamadaPSTR que inicializa el array como static y toma su dirección automáticamente. La siguiente construcción entonces funcionará como se desea pero solo en este compilador.

print(PSTR("\r Deck the halls")); // Imprimir este mensaje
print(PSTR("\r Jingle bells")); // ...
print(PSTR("\r We wish you a merry christmas")); // ...
print(PSTR("\r Silent night")); // ...
Solo por curiosidad, la macro PSTR tiene la siguiente definición. PSTR es ampliamente usada cuando se trabaja con las funciones _P del compilador AVR GCC. Así que hablaremos más de ella en adelante.
#define PSTR(s) (__extension__({static const char __c[] PROGMEM = (s); &__c[0];}))
Arrays de cadenas PROGMEM
Este es un tema recurrente en programación.
Para crear un array de cadenas en FLASH primero se declaran e inicializan las cadenas de la forma ya conocida y luego se construye el array con los nombres de las cadenas. Esta regla es única, inflexible, limitante e igualmente válida para los dos compiladores que usamos, AVR IAR Cy AVR GCC. Con un ejemplo lo vamos a entender mejor.
El objeto del siguiente programa es idéntico al ejemplo de la sección anterior: el programa debe mostrar los mismos mensajes almacenados en la FLASH solo que esta vez se les desea acceder mediante un índice, por eso los mensajes están agrupados en un array.
#include "avr_compiler.h"
#include "usart.h"
PROGMEM const char ringt01[] = "\r Deck the halls";
PROGMEM const char ringt02[] = "\r Jingle bells";
PROGMEM const char ringt03[] = "\r We wish you a merry christmas";
PROGMEM const char ringt04[] = "\r Silent night";
PGM_P ringtones[] =
{

ringt01,
ringt02,
ringt03,
ringt04
};
/******************************************************************************
* Main function
*****************************************************************************/
int main(void)
{
usart_init(); // Inicializar USART
puts_P(ringtones[0]); // Imprimir Deck the halls
puts_P(ringtones[1]); // Imprimir Jingle bells
puts_P(ringtones[2]); // Imprimir We wish you a merry christmas
puts_P(ringtones[3]); // Imprimir Silent night
while (1);
}
La función puts_P es proveída por los compiladores. Es similar a la función puts pero las cadenas que recibe deben ubicarse en la FLASH. En otras palabras, puts_P es similar a la función printque creamos en el ejemplo previo.
Se nota que el array ringtones ha sido declarado para ubicarse en la RAM, por eso accedemos a sus elementos de forma regular y no empleando macros. Se hizo así porque cada elemento es un puntero de 2 bytes y como solo son 4 punteros, no ocupan mucho espacio. Si hubiera muchos más elementos en el array ringtones, la situación cambiaría y sería mejor que también residiera en la FLASH. Eso lo veremos al final.

Elaborar el array y el contenido de sus elementos por separado es incómodo por el hecho de tener que poner nombres a cada elemento, nombres que no son necesarios en otra parte del programa, pero no hay otro camino. Quisiéramos que fuera posible implementar el array por ejemplo como se muestra abajo donde cada elemento se inicializa directamente, pero eso solo es factible en otros compiladores como CodeVisionAVR o SDCC. Por lo que dicen sus manuales, en los compiladores AVR IAR C y AVR GCC en el mejor de los casos esto solo ubicará los elementos en la RAM. En AVR GCC ni siquiera la macro PSTR, que sirve para inicializar en línea datos residentes en FLASH, podrá ayudarnos esta vez. Y, lo olvidaba, no intentes forzar el destino del array o de sus elementos utilizando conversiones de tipos. Solo evadirás los errores y advertencias, pero los datos seguirán yendo a la RAM y el programa funcionará incorrectamente. (Haz clic aquí si quieres ver la versión CodeVisionAVR de este programa.)
PGM_P ringtones[] =
{
"\r Deck the halls",
"\r Jingle bells",
"\r We wish you a merry christmas",
"\r Silent night"
};
Esa presentación coincide con la forma en que hemos estado trabajando antes: primeroPROGMEM, luego const y al final el tipo de dato. En AVR IAR C una permutación a veces producirá incompatibilidades. Por tanto, el uso de PGM_P más que una cuestión de simplificación es una necesidad que facilitará la compatibilidad de códigos.
Como dijimos antes, cada elemento del array ringtones es un puntero de 2 bytes y en conjunto no ocupan mucha RAM en este programa. Ahora bien si nuestro código requiriera incluso ese espacio para otros datos o si el array es bastante más grande, entonces el mismo arrayringtones también debería almacenarse en la memoria FLASH. Solo hay un arreglo para esto y, como ya discutimos demasiado, vamos directamente a poner la forma que debe tener el programa en ese caso.
#include "avr_compiler.h"
#include "usart.h"
PROGMEM const char ringt01[] = "\r Deck the halls";
PROGMEM const char ringt02[] = "\r Jingle bells";

PROGMEM const char ringt03[] = "\r We wish you a merry christmas";
PROGMEM const char ringt04[] = "\r Silent night";
PROGMEM PGM_P const ringtones[] =
{
ringt01,
ringt02,
ringt03,
ringt04
};
/******************************************************************************
* Main function
*****************************************************************************/
int main(void)
{
usart_init(); // Inicializar USART
puts_P((PGM_P)pgm_read_word(&ringtones[0])); // Imprimir 'Deck the halls'
puts_P((PGM_P)pgm_read_word(&ringtones[1])); // Imprimir 'Jingle bells'
puts_P((PGM_P)pgm_read_word(&ringtones[2])); // Imprimir 'We wish you a ...
puts_P((PGM_P)pgm_read_word(&ringtones[3])); // Imprimir 'Silent night'
while (1);
}

La conversión de tipo con (PGM_P) no es necesaria para AVR IAR C y para AVR GCC sirve para evitar warnings aunque el programa funciona igual.
Cambiando de tema, en AVR GCC el programa se compila en 528 bytes de memoria FLASH y 20 bytes de RAM. En CodeVisionAVR había tomado 490 bytes de FLASH y solo 8 bytes de RAM. Es uno de los inusuales casos donde gana CodeVisionAVR, normalmente ni se le acerca. Pero AVR IAR C lo hizo en 375 bytes de FLASH y 70 bytes de RAM. Parece que AVR IAR C hubiera puesto los datos en la RAM, pero no. Es el estilo de este compilador tomar un poco más de RAM para ahorrar más FLASH. En los tres casos la compilación se realizó con la optimización a máximo nivel.
Arrays más que grandes
Los parámetros que reciben como argumento las macros pgm_read_byte, pgm_read_word,pgm_read_dword y pgm_read_float son direcciones de 16 bits. Esto quiere decir que mediante ellas podemos acceder a los arrays cuyos elementos cubren un espacio de 216 = 65536 bytes de la memoria FLASH. En la gran mayoría de los casos es mucho más de lo que se necesita, considerando que solo hay dos megaAVR que superan esa memoria, los ATmega128 y los ATmega256. Pero si se presentara la descomunal situación donde tengamos que trabajar con arrays de más de 64 KB, la librería pgmspace.h nos provee de otras macros ad hoc.
pgm_read_byte_far. Accede a arrays de enteros de 1 byte.
pgm_read_word_far. Accede a arrays de enteros de 2 bytes.
pgm_read_dword_far. Accede a arrays de enteros de 4 bytes.
pgm_read_float_far. Accede a arrays de decimales 4 bytes.
Sin ser muy observadores notamos que sus nombres provienen de las macros anteriores. Ahora llevan el sufijo _far. Estas macros reciben como argumento direcciones de 32 bits con lo que teóricamente tienen un alcance de hasta 4 GB de datos en FLASH. Como en la práctica los punteros X, Y y Z de los AVR de 8 bits solo llegan a ser de 24 bits, su alcance es en realidad de 16 MB. El uso de estas macros es completamente igual al de sus pares de 16 bits, por eso se ven como redundantes los siguientes ejemplos. Las variables sobre las que actúan también deben ser declaradas con PROGMEM.
PROGMEM const int a[5] = { 20, 56, 87, -58, 5000 }; // Array constante
PROGMEM const char vocals[5] = { 'a', 'e', 'i', 'o', 'u' }; // Array constante
PROGMEM const char text[] = "Este es un array constante de caracteres";
int var;

char c;
var = pgm_read_word_far(&a[1]); // Con esto var valdrá 56
c = pgm_read_byte_far(&vocals[3]); // Con esto c valdrá 'o'
c = pgm_read_byte_far(&text[11]); // Con esto c valdrá 'a'
Podemos entender que los únicos AVR que aceptan estas macros son los que tienen más de 64 KB de memoria FLASH. Con esos AVR, es posible usar los dos tipos de macros, las de 16 bits y las de 32 bits, sin embargo no siempre serán igual de eficientes. Si el código de arriba, por ejemplo, estuviera escrito para un ATmega1284P, el acceso se dilataría ligeramente al tenerse que trabajar con 32 bits. Puede ser un detalle insignificante pero a veces servirá para optimizar procesos.
Para complementar el tema, diremos que si existen macros con _far (lejos, en inglés), en la librería pgmspace.h también hay macros con el apéndice _near (cerca). Estas nuevas macros sonpgm_read_byte_near, pgm_read_word_near, pgm_read_dword_near y pgm_read_float_near. Pero no te preocupes si crees que el tema se va recargando demasiado. No se tratan más que de alias de las primeras macros de 16 bits que estudiamos arriba, por ejemplo,pgm_read_byte_near es lo mismo que pgm_read_byte, y así con las demás. Es bueno saberlo para no quedar sorprendidos por los códigos de quienes prefieren usar la una u otra forma.