análise de cluster - análise de agrupamento - analysis cluster
DESCRIPTION
Análise de ClusterTRANSCRIPT

Analysis Cluster
Wagner Oliveira de Araujo Clarimar José Coelho
Technical Report - RT-MSTMA_004-09 - RelatórioTécnico
May - 2009 - Maio
The contents of this document are the sole responsibility of the authors.O conteúdo do presente documento é de única responsabilidade dos autores.
Mestrado Sociedade, Tenologia e Meio AmbienteCentro Universitário de Anápolis
www.unievangelica.edu.br

Análise de Cluster
Wagner Oliveira de Araujo ∗
Clarimar José Coelho †
Resumo. Este meta-artigo descreve sinteticamente a Análise de Cluster no intuitode oferecer esclarecimento quanto a similaridade com foco dados métricos e não-métricos , além da demonstração da utilização do método hierárquico com uma pe-quena explicação sobre o método não hierárquico. Todos os exemplos foram utiliza-dos o aplicativo MaTLab para demonstrar na prática o funcionamento dos métodos.
1 IntroduçãoAnálise de Clusters é o nome para um grupo de técnicas multivariadas cuja a finalidade
primária é agregar objetos com base nas características que eles possuem.A análise de Clusters classifica objetos (por exemplo, respondentes, produtos ou outras
entidade) de modo que cada objeto é muito semelhante aos outros no clusters em relação a al-gum critério de seleção predeterminado. Os cluters resultantes de objetos devem então exibirelevada homogeneidade interna(dentro dos clusters). Assim, se a classificação for bem su-cedida, os objetos dentro dos clusters estarão próximos quando representados graficamente ediferentes cluters estarão distantes.
A matriz de dados pode ser escrita da seguinte forma:
Y =
y′1y′2...
y′n
=
(y(1), y(2), . . . , y(p)
)
Onde y′i é uma linha (vetor de observação) e y(j) é uma coluna (correspondendo um va-
riável). Nós geralmente desejamos nos agrupar o n y′is de (linhas) em agrupamentos de g. Nós
também podemos agrupar as colunas y(j), j = 1, 2,. . . ,p.
2 Medidas de similaridadeO conceito de similaridade é fundamental na análise de cluster. A similaridade entre
objetos é uma medida de correspondência ou semelhança entre objetos a serem agrupados.
∗Mestrando em Sociedade, Tecnologia e Meio Ambiente – Responsável pelo texto do artigo.†Orientador, Centro Universitário de Anápolis – UniEVANGÉLICA
1

2
A similaridade entre objetos pode ser medida de diversas maneiras, mas três métodos do-minam as aplicações de análise de agrupamentos: medidas correlacionais, medidas de distânciae medidas de associação. Cada um desses métodos representa uma perspectiva particular dasimilaridade, dependendo de seus objetivos e do tipo de dados. Tanto as medidas correlaci-onais quanto as medidas de distância requerem dados métricos, ao passo que as medidas deassociação são para dados não-métricos.
2.1 Distância EuclideanaDiversas medidas de distâncias estão disponíveis. A mais comumente usada é a distância
euclideana. Um exemplo de como a distância euclideana é obtida é mostrado geometricamentena Figura 1. Suponha que dois pontos em duas dimensões tenham coordenadas (X1, Y1) e(X2, Y2), respectivamente. A distância euclideana entre os pontos é o comprimento da hipote-nusa de um triângulo retângulo, conforme se calcula pela formula sob a Figura. Esse conceitoé facilmente generalizado para mais de duas variáveis. A distância euclideana é empregadapara calcular medidas especificas, como a distância euclideana simples e a distância euclideanaquadrada absoluta, que é a soma dos quadrados das diferenças, sem calcular a raiz quadrada.A distância euclideana quadrada tem a vantagem de que não é necessário calcular a raiz qua-drada, o que acelera sensivelmente o tempo de computação, e é a distância recomendada paraos métodos de cluster centróide e Ward.
d(x, y) =√
(x− y)′(x− y) =
√√√√p∑
j=1
(xj − yj)2 (1)
Figura 1: Distância euclideana entre dois objetos medidos sobre duas variáveis X e Y
d(x, y) =√
(x− y)′S−1(x− y) (2)
A escala de mensuração de variáveis é importante consideração quando usamos a distân-cia Euclideana. Mudando a escala podemos afetar as distâncias relativas entre os ítens. Porexemplo, suponha três itens têm o seguinte medidas de bivariadas (y1, y2): (2, 5), (4, 2), (7, 9).Usando dij como dado pela Equação 1, a matriz D = (dij) para estes itens é:
Observe o código nos Exemplos 1 e 2 das páginas 14 e 15.
Y =
2 54 27 9

3
D1 =
0.0 3.6 6.43.6 0.0 7.66.4 7.6 0.0
Porém, se nós multiplicamos y1 antes das 100 como, por exemplo, mudando de metrospara centímetros, a matriz será:
Observe o código nos Exemplos 6 e 7
Y =
200 5400 2700 9
D2 =
0 200 500200 0 300500 300 0
2.2 Métrica de MinkowskiOutra distância sugerida por exemplo a métrica de Minkowski.Para r = 2, d(x, y) em (7) se torna a distância Euclideana dado dentro (1). Para p = 2 e
r = 1, (7) a mensuração "city block" distância entre duas observações.
d(x, y) =
[p∑
j=1
|xj − yj|r] 1
r
(3)
Observe o código no Exemplo 17
3 Hierarquia de ClusterOs procedimentos hierárquicos envolvem a construção de uma hierarquia de uma estrutura
do tipo árvore.Uma característica importante dos procedimentos hierárquicos é que os resultados de um
estágio anterior são sempre aninhados com os resultados de um estágio posterior, criando algoparecido com uma árvore.
Cinco algoritmos aglomerativos populares usados para desenvolver agregados são (1) Vi-zinho mais próximo, (2) Vizinho mais distante, (3) Média, (4) Método de Ward e (5) Centróide.
3.1 Vizinho mais próximoO procedimento de vizinho mais próximo é baseado em distância mínima. Ele encontra
os dois objetos separados pela menor distância e os coloca no primeiro cluster. Em seguida,a próxima distância mais curta é determinada, e um terceiro objeto se junta aos dois primeirospara formar um agregado, ou um novo cluster de dois membros é formado. O processo continuaaté que todos os objetos formem um só agregado.
D(A,B) = min{d(yi, yj), para yi dentro A e yi dentro B}

4
Figura 2: Medidas de distância do vizinho mais próximo
Var. interna entre agrupamentoVar. interna nos agrupamentos
Figura 3: Diagrama de cluster que mostra a variação entre e dentro do cluster
Tabela 1: City Crime Rates per 100,000 PopulationCity Murder Rape Robbery Assault Burglary Larceny Auto TheftAtlanta 16.5 24.8 106 147 1112 905 494Boston 4.2 13.3 122 90 982 669 954Chicago 11.6 24.7 340 242 808 609 645Dallas 18.1 34.2 184 293 1668 901 602Denver 6.9 41.5 173 191 1534 1368 780Detroit 13 35.7 477 220 1566 1183 788Hartford 2.5 8.8 68 103 1017 724 468Honolulu 3.6 12.7 42 28 1457 1102 637Houston 16.8 26.6 289 186 1509 787 697Kansas City 10.8 43.2 255 226 1494 955 765Los Angeles 9.7 51.8 286 355 1902 1386 862New Orleans 10.3 39.7 266 283 1056 1036 776New York 9.4 19.4 522 267 1674 1392 848Portland 5 23 157 144 1530 1281 488Tucson 5.1 22.9 85 148 1206 756 483Washington 12.5 27.6 524 217 1496 1003 793

5
Observe o código nos Exemplos 11 até 16 nas páginas 20 até 25.Hartigan (1975 apud RENCHER, 2002, p. 28) comparou as taxas de crime por 100.000 da
população para várias cidades americanas. Os dados estão em Tabela 1 (EUA anuário estatísticode 1970). Para ilustrar o uso da matriz de distância dentro do vizinho mais próximo do cluster,nós usamos as primeiras seis observações da Tabela 1 da cidade de Atlanta ate Detroit.
A distância da matriz D e dado por:
Cidade Distância entre as cidadesAtlanta 0 536.6 516.4 590.2 693.6 716.2Boston 536.6 0 447.4 833.1 915.0 881.1Chicago 516.4 447.4 0 924.0 1073.4 971.5Dallas 590.2 833.1 924.0 0 527.7 464.5Denver 693.6 915.0 1073.4 527.7 0 358.7Detroit 716.2 881.1 971.5 464.5 358.7* 0
A distância menor é 358.7 entre Denver e Detroit, e então estas são juntas ao primeiropasso para formar C1 = {Denver, Detroit}. No próximo passo, a matriz de distância é calculadapara Atlanta, Boston, Chicago, Dallas, e C1:
Cidade Distâcia entre as cidadesAtlanta 0 536.6 516.4 590.2 693.6Boston 536.6 0 447.4 833.1 881.1Chicago 516.4 447.4* 0 924.0 971.5Dallas 590.2 833.1 924.0 0 464.5C1 693.6 881.1 971.5 464.5 0
A distância menor é 447.4 entre Boston e Chicago. Então C2 = {Boston, Chicago}.Próximo passo, a matriz de distância é calculada para Atlanta, Dallas, C1, e C2:
Cidade Distância entre as cidadesAtlanta 0 516.4 590.2 693.6C2 516.4 0 833.1 881.1Dallas 590.2 833.1 0 464.5C1 693.6 881.1 464.5* 0
A distância menor é 464.5 entre Dallas e C1, de forma que C3 = {Dallas, C1}.A matriz dedistância para Atlanta, C2, e C3 é determinada por:
Cidade Distância entre as cidadesAtlanta 0 516.4 590.2C2 516.4* 0 833.1C3 590.2 833.1 0
A distância menor é 516.4 que define C4 = {Atlanta, C2}. A distância matriz para C3 eC4 é:
Cidade Distância entre as cidadesC3 0 590.2C4 590.2 0
A distância menor é 0 que define C5={C3, C4 }

6
Cidade Distância entre as cidadesC5 590.2
O último agrupamento é determinado por C5 = {C3,C4}. O dendrograma para os passosobservado na Figura 4.
5 6 4 1 2 3350
400
450
500
550
600
Figura 4: Dendrograma do vizinho mais próximo das seis observações aplicados para dados decrimes conforme Tabela 1
Observe os Exemplos (8 até 10) através do código em MatLab
3.2 Vizinho mais distanteO procedimento de vizinho mais distante é semelhante ao do vizinho mais próximo, ex-
ceto em que o critério de cluster se baseia em distância máxima. Por essa razão, às vezes é cha-mado método do diâmetro. A distância máxima entre indivíduos em cada agregado representaa menor esfera(diâmetro mínimo) que pode incluir todos os objetos em ambos os agrupamen-tos. Esse método é chamado de ligação completa porque todos os objetos em um cluster sãoconectados um com o outro a alguma distância máxima ou similaridade mínima.
Figura 5: Medidas de distância do vizinho mais distante
D(A,B) = max{d(yi, yj), para yi dentro A e yi dentro B}

7
Como no Exemplo 3.1 do vizinho mais próximo, ilustramos o uso da matriz de distânciano vizinho mais distante que cresce com as primeiras seis observações dos dados da Tabela 1.A matriz de distância é exatamente igual ao Exemplo 3.1:
Cidade Distância entre as cidadesAtlanta 0 536.6 516.4 590.2 693.6 716.2Boston 536.6 0 447.4 833.1 915.0 881.1Chicago 516.4 447.4 0 924.0 1073.4 971.5Dallas 590.2 833.1 924.0 0 527.7 464.5Denver 693.6 915.0 1073.4 527.7 0 358.7Detroit 716.2 881.1 971.5 464.5 358.7 0
A distância menor é 358.7 entre Denver e Detroit, e estes dois formam o primeiro agru-pamento, C1 = {Denver, Detroit}. No próximo passo, a matriz de distância é calculada paraAtlanta, Boston, Chicago, Dallas, e C1:
Cidades Distância entre as cidadesAtlanta 0 536.6 516.4 590.2 716.2Boston 536.6 0 447.4 833.1 915.0Chicago 516.4 447.4 0 924.0 1073.4Dallas 590.2 833.1 924.0 0 527.7C1 716.2 915.0 1073.4 527.7 0
A distância menor é 447.4 entre Boston e Chicago. Então, C2 = {Boston, Chicago}. Aopróximo passo, distâncias é calculado para Atlanta, Dallas, C1, e C2:
Cidade Distância entre as cidadesAtlanta 0 536.6 590.2 716.2C2 536.6 0 924.0 833.1Dallas 590.2 924.0 0 527.7C1 693.6 881.1 527.7 0
A menor distância , 527.7, define C3 = {Dallas,C1}. A matriz de distância para Atlanta,C2, e C3 é determinada por
Cidades Distâncias entre as cidadesAtlanta 0 536.6 716.2C2 536.6 0 1073.4C3 590.2 1073.4 0
A menor distância é 536.6 entre Atlanta e C3, de forma que C4 = {Atlanta, C2}. A matrizde distância para C3 e C4 é
Cidades Distância entre as cidadesC3 0 1073.4C4 1073.4 0
A menor distância é 0 entre C3 e C4. Logo C5={1073.4}
Cidade Distância entre as cidadesC5 1073.4
O último agrupamento é determinado por C5 = {C3,C4}. Observe o dendrograma naFigura 2.
Veja os Exemplos (18 até 20) através do código em MatLab

8
5 6 4 1 2 3
400
500
600
700
800
900
1000
1100
Figura 6: Dendrograma para vizinho mais distante das seis primeira observações aplicados paradados de crimes conforme Tabela 1
1 15 7 12 2 3 4 9 10 6 16 5 8 14 11 13
200
400
600
800
1000
1200
1400
Figura 7: Dendrograma para vizinho mais distante das dezesseis observações aplicados paradados de crimes conforme Tabela 1

9
3.3 Média dos gruposMédia entre todos os pares de indivíduos constituídos por todos os elementos dos dois
grupos. O método de média dos grupos começa da mesma forma que o vizinho mais próximoe vizinho mais distante, mas o critério de cluster é a distância média de todos os indivíduos emum cluster aos demais em um outro. Essas técnicas não dependem de valores extremos, comoocorre com os vizinhos mais próximos e mais distantes, e a partição é baseada em todos oselementos dos agregados, ao invés de um único par de membros extremos.
Se dois clusters A e B são combinados usando o método Centróide, e se A contém umnúmero grande de itens que B,então o novo Centróide yAB = (nAyA+nByB)
nA+nBpode ser muito
relacionado para yA quanto para yB. Para evitar o aumento e vetores de media de acordo como tamanho do cluster, nos podemos usar a media(media dos pontos) da linha trabalhada A e Bcomo o ponto para computar novas distâncias para outros clusters:
mAB =1
2(yA + yB) (4)
Veja a utilização da média nos Exemplos 27 e 32.
3.4 CentróidesMédia das variáveis caracterizadoras dos indivíduos de cada grupos. No método cen-
tróide, a distância entre dois agrupamentos é a distância (geralmente euclideana quadrada oueuclideana simples) entre seus centróides. Centróides são os valores médios das observaçõessobre as variáveis na variável estatística de agrupamento Neste método, toda vez que indivíduossão reunidos, um novo centróide é computado. Os centróides migram quando ocorrem fusõesde agregados. Em outras palavras, existe uma mudança no centróide do agrupamento toda vezque um novo individuo ou grupo de indivíduos é acrescentado a um agregado já existente.
D(A,B) = d(yA, yB),
Onde yA e yB são os vetores media para os vetores de observação dentro A e o vetoresde observação em yB, respectivamente, e d(yA, yB). Nós definimos yA e yB do modo habitual,quer dizer, yA =
∑nA
i=1yi
nA. Os dois cluster unidos pela distância menor entre centroide a cada
passo. Depois de dois clusters A e são unidos B, o centroide do novo cluster AB é determinadopela média ponderada.
Veja a utilização do Método Centróide nos Exemplos 39 e 44.
yAB =nAyA + nByB
nA + nB
3.5 WardPrimeiro são calculadas as médias das variáveis de cada grupo; em seguida, é calculado o
quadrado da distância Euclideana entre essas médias e os valores da variáveis para cada indiví-duo. Por fim, somam-se as distâncias para todos os indivíduos e otimiza-se a variância mínimadentro dos grupos.
Método Wards, também chamado de acréscimo da soma dos quadrados, usado dentro docluster do quadrado da distância e entre o cluster quadrado da distância. Se AB são obtidos por

10
1 15 7 12 2 3 4 9 10 6 16 5 8 14 11 13
200
300
400
500
600
700
800
Figura 8: Dendrograma para media cluster aplicados para dados de crimes conforme Tabela 1
1 15 7 2 3 12 4 9 10 5 8 14 6 16 13 11
200
250
300
350
400
450
500
550
600
650
700
Figura 9: Dendrograma para centróide aplicados para dados de crimes conforme Tabela 1

11
combinações, clusters A e B, quando a soma da distância dentro cluster (os itens para o clustersão médias dos vetores) são:
SSEA =
nA∑j=1
(xi − yA)′(xi − yA) (5)
SSEB =
nB∑j=1
(xi − yB)′(xi − yB) (6)
SSEAB =
nAB∑j=1
(xi − yAB)′(xi − yAB) (7)
Onde yAB = (nAyA+nByB)(nA+nB)
como em nA, nB e nAB = nA + nB são números de pontosdentro A,B, e AB, respectivamente. Desde que estas somas das distâncias são equivalentes paradentro do cluster a soma dos quadrados, eles são denotados por SSEA, SSEB, e SSEAB.
O método Ward’s e executado nos clusters A e B que minimizam o aumento dentro SSE,definido por:
IAB = SSEAB − (SSEA + SSEB) (8)
Pode ser apresentado o aumento IAB dentro de duas formas equivalentes:
IAB = nA(yA − yAB)′(yA − yAB) + nB(yB − yAB)
′(yB − yAB) (9)
=nAnB
nA + nB
(yA − yB)′(yA − yB) (10)
Assim por, minimizando o aumento dentro SSE é equivalente para minimizar a distanciaentre cluster . Se A é consistente somente o yi e B consiste somente para yj , quando SSEA eSSEB são zero, e Equação 8 e Equação 10 é reduzida para:
Iij = SSEAB =1
2(yi − yj)
′(yi − yj) =
1
2d2(yi, yj) (11)
Se a distância d(yA, yB) é quadrado e comparado para Equação 10, e somente a diferençaé o coeficiente nAnB
(nA+nB)para o Método de Ward’s. Assim o tamanho do cluster tem um impacto
dentro do método de Ward’s mas não sobre o método Centroide. Escrevendo nAnB
(nA+nB)dentro da
Equação 10 temos:
nAnB
nA + nB
=1
1nA
+ 1nB
Nos vimos que como nA e nB aumentados, nAnB
(nA+nB). Escrevendo o coeficiente temos:
nAnB
nA + nB
=nA
1 + nA
nB
Nos vimos que temos nB aumentado com nA fixado, nAnB
(nA+nB). Então comparando com o
método Centróide, o método de Ward’s é mais provável para ser executado em pequenos clusterou clusters de tamanho iguais.
Veja a utilização do Método Ward nos Exemplos 33 e 38.

12
1 15 7 2 3 12 4 9 10 6 16 5 8 14 11 13
200
400
600
800
1000
1200
Figura 10: Dendrograma para método de Ward aplicados para dados de crimes conforme Tabela1
4 Métodos Não HierárquicoOs procedimentos não-hierárquicos não envolvem o processo de construção em árvore.
Em vez disso, designam objetos a agrupamentos assim que o número de agregados a seremformada tenha sido especificado. Procedimentos de agrupamento não-hierárquicos frequente-mente são chamados de agrupamento de K médias, e geralmente usam uma das três abordagensa seguir para designar observações individuais a um dos agrupamentos.
4.1 Referência SequencialComeça pela seleção de uma semente de agrupamento e inclui todos os objetos dentro
de uma distância pré-especificada. Quando todos os objetos dentro da distancia são incluídos,uma segunda semente de agrupamento é selecionada e todos os objetos dentro da distânciapré-especificada são incluídos. Em seguida, uma terceira semente é selecionada e o processocontinua como anteriormente. Quando um objeto é agrupado com uma semente, já não é maissemente em potencial para estágios futuros.
4.2 Referência ParalelaO método escolhe diversas sementes de agrupamento simultaneamente no começo e de-
signa objetos dentro da distância de referencia ate a semente mais próxima. A medida que oprocesso se desenvolve, as distancias de referencia podem ser ajustadas para incluir menos oumais objetos nos agrupamentos. Ainda assim, em algumas variantes desse método, os objetospermanecem não agrupados se estiverem fora da distancia de referencia pré-especificada a partirde qualquer semente de agrupamento.
4.3 OtimizaçãoO procedimento de otimização, é semelhante aos outros dois métodos não-hierárquicos,
exceto em que ele permite a redesignação de objetos. Se, no curso da designação de objetos,

13
um deles se torna mais próximo de um outro agregado que não é agrupamento no qual eleestá associado no momento, então um procedimento de otimização transfere o objeto para oagregado mais semelhante(mais próximo).

14
ReferênciasHAIR, J. F.; ANDERSON, R. E.; TATHAM, R. L.; BLACK, W. C. Multivariate Data Analsys.
5.ed. New Jersey-USA: Prentice-Hall, 1998.
MANLY, B. J. F. Métodos Estatísticos Multivariados: uma introdução. 3.ed. Porto Alegre:Bookman, 2005.
RENCHER, A. C. Methods of Multivariate Analysis. 2.ed. Nova York: John Wiley & Sons,Inc, 2002.
APÊNDICE A - Código MatLab
Exemplo 1 – Código Distância Euclides (Entrada de dados)1 >> X=[2,5;4,2;7,9]2 Y=pdist(X,’euclidean’)3 Y=pdist(X)4 squareform(Y)5 Z = linkage(Y)6 dendrogram(Z)

15
Exemplo 2 – Código Distância de Euclides (Saída de dados)1 X =2
3 2 54 4 25 7 96
7
8 Y =9
10 3.6056 6.4031 7.615811
12
13 Y =14
15 3.6056 6.4031 7.615816
17
18 ans =19
20 0 3.6056 6.403121 3.6056 0 7.615822 6.4031 7.6158 023
24
25 Z =26
27 1.0000 2.0000 3.605628 4.0000 3.0000 6.403129
30
31 ans =32
33 100.001034 102.003735
36 >>
Exemplo 3 – Código Distância de Euclides (Entrada de dados)1 X=[16.5,24.8,106,147,1112,905,494;4.2,13.3,122,90,982,669,954;2 11.6,24.7,340,242,808,609,645;18.1,34.2,184,293,1668,901,602;3 6.9,41.5,173,191,1534,1368,780;13,35.7,477,220,1566,1183,788]4 Y=pdist(X,’euclidean’)5 Y=pdist(X)6 squareform(Y)

16
Exemplo 4 – Código Distância de Euclides (Saída de dados)1 X =2
3 1.0e+003 *4
5 0.0165 0.0248 0.1060 0.1470 1.1120 0.9050 0.49406 0.0042 0.0133 0.1220 0.0900 0.9820 0.6690 0.95407 0.0116 0.0247 0.3400 0.2420 0.8080 0.6090 0.64508 0.0181 0.0342 0.1840 0.2930 1.6680 0.9010 0.60209 0.0069 0.0415 0.1730 0.1910 1.5340 1.3680 0.7800
10 0.0130 0.0357 0.4770 0.2200 1.5660 1.1830 0.788011
12
13 Y =14
15 1.0e+003 *16
17 Columns 1 through 718
19 0.5366 0.5164 0.5902 0.6936 0.7162 0.4474 0.833120
21 Columns 8 through 1422
23 0.9150 0.8811 0.9240 1.0734 0.9715 0.5277 0.464524
25 Column 1526
27 0.358728
29 Y =30
31 1.0e+003 *32
33 Columns 1 through 734
35 0.5366 0.5164 0.5902 0.6936 0.7162 0.4474 0.833136
37 Columns 8 through 1438
39 0.9150 0.8811 0.9240 1.0734 0.9715 0.5277 0.464540
41 Column 1542
43 0.3587

17
Exemplo 5 – Código Distância de Euclides (Saída de dados)1 ans =2
3 1.0e+003 *4
5 0 0.5366 0.5164 0.5902 0.6936 0.71626 0.5366 0 0.4474 0.8331 0.9150 0.88117 0.5164 0.4474 0 0.9240 1.0734 0.97158 0.5902 0.8331 0.9240 0 0.5277 0.46459 0.6936 0.9150 1.0734 0.5277 0 0.3587
10 0.7162 0.8811 0.9715 0.4645 0.3587 011
12 >>
Exemplo 6 – Código Distância de Euclides (Entrada de dados)1 X=[200,5;400,2;700,9]2 Y=pdist(X,’euclidean’)3 Y=pdist(X)4 squareform(Y)
Exemplo 7 – Código Distância de Euclides (Saída de dados)1 >>2 X =3
4 200 55 400 26 700 97
8
9 Y =10
11 200.0225 500.0160 300.081712
13
14 Y =15
16 200.0225 500.0160 300.081717
18
19 ans =20
21 0 200.0225 500.016022 200.0225 0 300.081723 500.0160 300.0817 024
25 >>

18
Exemplo 8 – Código Vizinho mais próximo (Entrada de dados)1 X=[16.5,24.8,106,147,1112,905,494;4.2,13.3,122,90,982,669,954;2 11.6,24.7,340,242,808,609,645;18.1,34.2,184,293,1668,901,602;3 6.9,41.5,173,191,1534,1368,780;13,35.7,477,220,1566,1183,788]4 Y=pdist(X,’euclidean’)5 Y=pdist(X)6 squareform(Y)7
8 %’single’ Shortest distance (default) (Single Linkage)9 %’complete’ Largest distance (Complete Linkage)
10 %’average’ Average distance(Average Linkage)11 %’centroid’ Centroid distance. The output Z is meaningful only12 % if Y contains Euclidean distances.13 %’ward’ Incremental sum of squares (Ward’s Method)14 % Z = linkage(Y,’method’)15
16 Z = linkage(Y)17 dendrogram(Z)

19
Exemplo 9 – Código Vizinho mais próximo (Saída de dados)1 >>2 X =3
4 1.0e+003 *5
6 0.0165 0.0248 0.1060 0.1470 1.1120 0.9050 0.49407 0.0042 0.0133 0.1220 0.0900 0.9820 0.6690 0.95408 0.0116 0.0247 0.3400 0.2420 0.8080 0.6090 0.64509 0.0181 0.0342 0.1840 0.2930 1.6680 0.9010 0.6020
10 0.0069 0.0415 0.1730 0.1910 1.5340 1.3680 0.780011 0.0130 0.0357 0.4770 0.2200 1.5660 1.1830 0.788012
13
14 Y =15
16 1.0e+003 *17
18 Columns 1 through 719
20 0.5366 0.5164 0.5902 0.6936 0.7162 0.4474 0.833121
22 Columns 8 through 1423
24 0.9150 0.8811 0.9240 1.0734 0.9715 0.5277 0.464525
26 Column 1527
28 0.358729
30
31 Y =32
33 1.0e+003 *34
35 Columns 1 through 736
37 0.5366 0.5164 0.5902 0.6936 0.7162 0.4474 0.833138
39 Columns 8 through 1440
41 0.9150 0.8811 0.9240 1.0734 0.9715 0.5277 0.464542
43 Column 1544
45 0.3587

20
Exemplo 10 – Código Vizinho mais próximo (Saída de dados)1 ans =2
3 1.0e+003 *4
5 0 0.5366 0.5164 0.5902 0.6936 0.71626 0.5366 0 0.4474 0.8331 0.9150 0.88117 0.5164 0.4474 0 0.9240 1.0734 0.97158 0.5902 0.8331 0.9240 0 0.5277 0.46459 0.6936 0.9150 1.0734 0.5277 0 0.3587
10 0.7162 0.8811 0.9715 0.4645 0.3587 011
12
13 Z =14
15 5.0000 6.0000 358.665416 2.0000 3.0000 447.403317 4.0000 7.0000 464.467718 1.0000 8.0000 516.370019 10.0000 9.0000 590.175320
21
22 ans =23
24 100.001125 102.000526 103.000527 104.000528 105.000529
30 >>
Exemplo 11 – Código Vizinho mais próximo (Entrada de dados)1 X=[16.5,24.8,106,147,1112,905,494;4.2,13.3,122,90,982,669,954;2 11.6,24.7,340,242,808,609,645;18.1,34.2,184,293,1668,901,602;3 6.9,41.5,173,191,1534,1368,780;13,35.7,477,220,1566,1183,788;4 2.5,8.8,68,103,1017,724,468;3.6,12.7,42,28,1457,1102,637;5 16.8,26.6,289,186,1509,787,697;10.8,43.2,255,226,1494,955,765;6 9.7,51.8,286,355,1902,1386,862;10.3,39.7,266,283,1056,1036,776;7 9.4,19.4,522,267,1674,1392,848;5,23,157,144,1530,1281,488;8 5.1,22.9,85,148,1206,756,483;12.5,27.6,524,217,1496,1003,793]9 plot(X,’*’)
10 grid on11 Y = pdist(X)12 squareform(Y)13 Z = linkage(Y)14 dendrogram(Z)
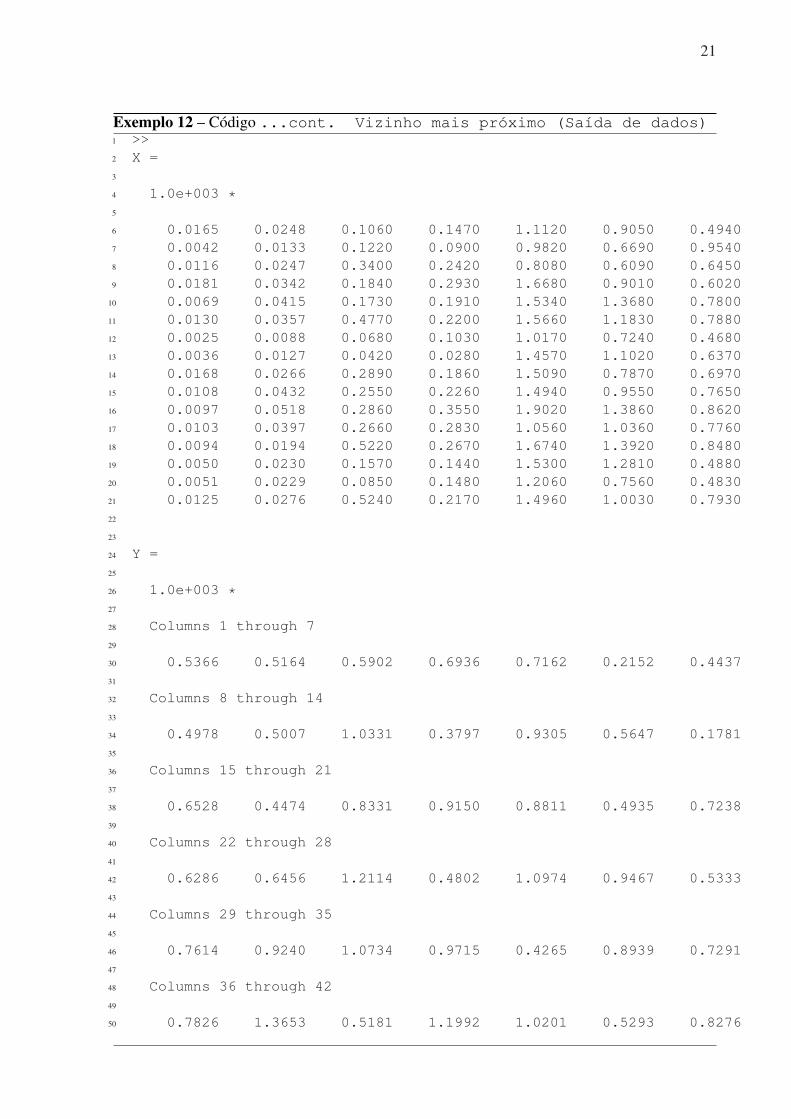
21
Exemplo 12 – Código ...cont. Vizinho mais próximo (Saída de dados)1 >>2 X =3
4 1.0e+003 *5
6 0.0165 0.0248 0.1060 0.1470 1.1120 0.9050 0.49407 0.0042 0.0133 0.1220 0.0900 0.9820 0.6690 0.95408 0.0116 0.0247 0.3400 0.2420 0.8080 0.6090 0.64509 0.0181 0.0342 0.1840 0.2930 1.6680 0.9010 0.6020
10 0.0069 0.0415 0.1730 0.1910 1.5340 1.3680 0.780011 0.0130 0.0357 0.4770 0.2200 1.5660 1.1830 0.788012 0.0025 0.0088 0.0680 0.1030 1.0170 0.7240 0.468013 0.0036 0.0127 0.0420 0.0280 1.4570 1.1020 0.637014 0.0168 0.0266 0.2890 0.1860 1.5090 0.7870 0.697015 0.0108 0.0432 0.2550 0.2260 1.4940 0.9550 0.765016 0.0097 0.0518 0.2860 0.3550 1.9020 1.3860 0.862017 0.0103 0.0397 0.2660 0.2830 1.0560 1.0360 0.776018 0.0094 0.0194 0.5220 0.2670 1.6740 1.3920 0.848019 0.0050 0.0230 0.1570 0.1440 1.5300 1.2810 0.488020 0.0051 0.0229 0.0850 0.1480 1.2060 0.7560 0.483021 0.0125 0.0276 0.5240 0.2170 1.4960 1.0030 0.793022
23
24 Y =25
26 1.0e+003 *27
28 Columns 1 through 729
30 0.5366 0.5164 0.5902 0.6936 0.7162 0.2152 0.443731
32 Columns 8 through 1433
34 0.4978 0.5007 1.0331 0.3797 0.9305 0.5647 0.178135
36 Columns 15 through 2137
38 0.6528 0.4474 0.8331 0.9150 0.8811 0.4935 0.723839
40 Columns 22 through 2841
42 0.6286 0.6456 1.2114 0.4802 1.0974 0.9467 0.533343
44 Columns 29 through 3545
46 0.7614 0.9240 1.0734 0.9715 0.4265 0.8939 0.729147
48 Columns 36 through 4249
50 0.7826 1.3653 0.5181 1.1992 1.0201 0.5293 0.8276
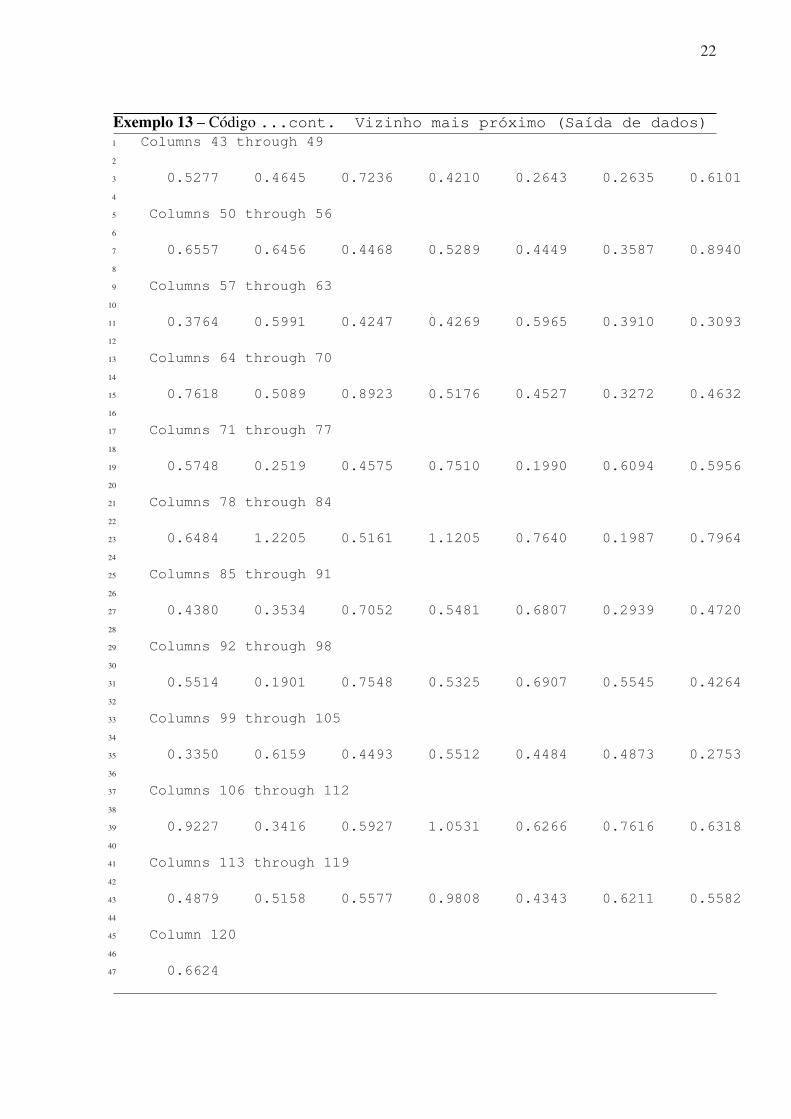
22
Exemplo 13 – Código ...cont. Vizinho mais próximo (Saída de dados)1 Columns 43 through 492
3 0.5277 0.4645 0.7236 0.4210 0.2643 0.2635 0.61014
5 Columns 50 through 566
7 0.6557 0.6456 0.4468 0.5289 0.4449 0.3587 0.89408
9 Columns 57 through 6310
11 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309312
13 Columns 64 through 7014
15 0.7618 0.5089 0.8923 0.5176 0.4527 0.3272 0.463216
17 Columns 71 through 7718
19 0.5748 0.2519 0.4575 0.7510 0.1990 0.6094 0.595620
21 Columns 78 through 8422
23 0.6484 1.2205 0.5161 1.1205 0.7640 0.1987 0.796424
25 Columns 85 through 9126
27 0.4380 0.3534 0.7052 0.5481 0.6807 0.2939 0.472028
29 Columns 92 through 9830
31 0.5514 0.1901 0.7548 0.5325 0.6907 0.5545 0.426432
33 Columns 99 through 10534
35 0.3350 0.6159 0.4493 0.5512 0.4484 0.4873 0.275336
37 Columns 106 through 11238
39 0.9227 0.3416 0.5927 1.0531 0.6266 0.7616 0.631840
41 Columns 113 through 11942
43 0.4879 0.5158 0.5577 0.9808 0.4343 0.6211 0.558244
45 Column 12046
47 0.6624

23
Exemplo 14 – Código ...cont. Vizinho mais próximo (Saída de dados)1 ans =2
3 1.0e+003 *4
5 Columns 1 through 76
7 0 0.5366 0.5164 0.5902 0.6936 0.7162 0.21528 0.5366 0 0.4474 0.8331 0.9150 0.8811 0.49359 0.5164 0.4474 0 0.9240 1.0734 0.9715 0.4265
10 0.5902 0.8331 0.9240 0 0.5277 0.4645 0.723611 0.6936 0.9150 1.0734 0.5277 0 0.3587 0.894012 0.7162 0.8811 0.9715 0.4645 0.3587 0 0.892313 0.2152 0.4935 0.4265 0.7236 0.8940 0.8923 014 0.4437 0.7238 0.8939 0.4210 0.3764 0.5176 0.609415 0.4978 0.6286 0.7291 0.2643 0.5991 0.4527 0.595616 0.5007 0.6456 0.7826 0.2635 0.4247 0.3272 0.648417 1.0331 1.2114 1.3653 0.6101 0.4269 0.4632 1.220518 0.3797 0.4802 0.5181 0.6557 0.5965 0.5748 0.516119 0.9305 1.0974 1.1992 0.6456 0.3910 0.2519 1.120520 0.5647 0.9467 1.0201 0.4468 0.3093 0.4575 0.764021 0.1781 0.5333 0.5293 0.5289 0.7618 0.7510 0.198722 0.6528 0.7614 0.8276 0.4449 0.5089 0.1990 0.796423
24 Columns 8 through 1425
26 0.4437 0.4978 0.5007 1.0331 0.3797 0.9305 0.564727 0.7238 0.6286 0.6456 1.2114 0.4802 1.0974 0.946728 0.8939 0.7291 0.7826 1.3653 0.5181 1.1992 1.020129 0.4210 0.2643 0.2635 0.6101 0.6557 0.6456 0.446830 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309331 0.5176 0.4527 0.3272 0.4632 0.5748 0.2519 0.457532 0.6094 0.5956 0.6484 1.2205 0.5161 1.1205 0.764033 0 0.4380 0.3534 0.7052 0.5481 0.6807 0.293934 0.4380 0 0.1901 0.7548 0.5325 0.6907 0.554535 0.3534 0.1901 0 0.6159 0.4493 0.5512 0.448436 0.7052 0.7548 0.6159 0 0.9227 0.3416 0.592737 0.5481 0.5325 0.4493 0.9227 0 0.7616 0.631838 0.6807 0.6907 0.5512 0.3416 0.7616 0 0.557739 0.2939 0.5545 0.4484 0.5927 0.6318 0.5577 040 0.4720 0.4264 0.4873 1.0531 0.4879 0.9808 0.621141 0.5514 0.3350 0.2753 0.6266 0.5158 0.4343 0.558242

24
Exemplo 15 – Código ...cont. Vizinho mais próximo (Saída de dados)1 Columns 15 through 162
3 0.1781 0.65284 0.5333 0.76145 0.5293 0.82766 0.5289 0.44497 0.7618 0.50898 0.7510 0.19909 0.1987 0.7964
10 0.4720 0.551411 0.4264 0.335012 0.4873 0.275313 1.0531 0.626614 0.4879 0.515815 0.9808 0.434316 0.6211 0.558217 0 0.662418 0.6624 019
20
21 Z =22
23 1.0000 15.0000 178.139224 9.0000 10.0000 190.106725 17.0000 7.0000 198.719826 6.0000 16.0000 199.019727 20.0000 13.0000 251.908028 4.0000 18.0000 263.486829 22.0000 21.0000 275.282130 8.0000 14.0000 293.870831 5.0000 24.0000 309.289332 23.0000 11.0000 341.622433 26.0000 25.0000 353.436134 19.0000 12.0000 379.707135 28.0000 27.0000 426.352636 29.0000 3.0000 426.468837 30.0000 2.0000 447.403338

25
Exemplo 16 – Código ...Final. Vizinho mais próximo (Saída de dados)1 ans =2
3 3.00634 102.00465 103.00216 104.00217 105.00208 106.00139 107.0012
10 108.001111 109.001112 110.001113 111.000914 112.000615 113.000616 114.000617 115.000618
19 >>

26
Exemplo 17 – Código Métrica de Minkowski1 %Dados de entrada2 >> X=[2,5;4,2;7,9]3 Y=pdist(X,’minkowski’)4 Y=pdist(X)5 squareform(Y)6 Z = linkage(Y)7 dendrogram(Z)8
9 %Dados de saída10 X =11
12 2 513 4 214 7 915
16
17 Y =18
19 3.6056 6.4031 7.615820
21
22 Y =23
24 3.6056 6.4031 7.615825
26
27 ans =28
29 0 3.6056 6.403130 3.6056 0 7.615831 6.4031 7.6158 032
33
34 Z =35
36 1.0000 2.0000 3.605637 4.0000 3.0000 6.403138
39
40 ans =41
42 100.000943 102.003544
45 >>
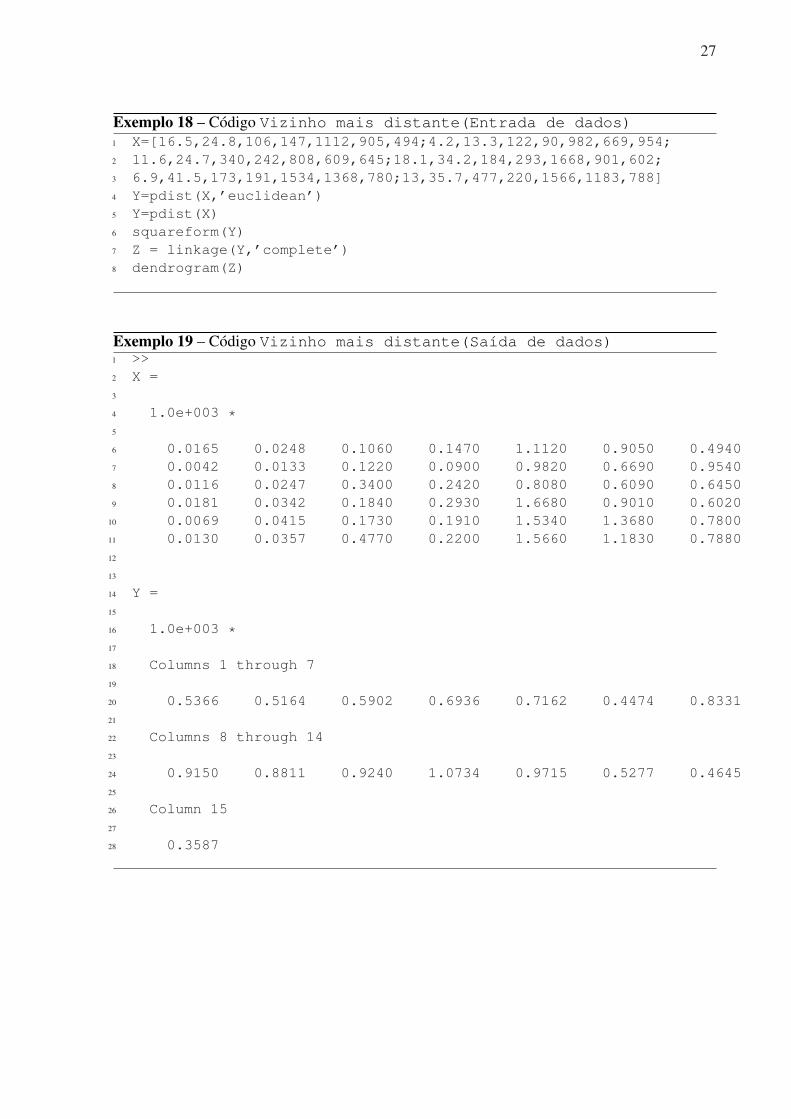
27
Exemplo 18 – Código Vizinho mais distante(Entrada de dados)1 X=[16.5,24.8,106,147,1112,905,494;4.2,13.3,122,90,982,669,954;2 11.6,24.7,340,242,808,609,645;18.1,34.2,184,293,1668,901,602;3 6.9,41.5,173,191,1534,1368,780;13,35.7,477,220,1566,1183,788]4 Y=pdist(X,’euclidean’)5 Y=pdist(X)6 squareform(Y)7 Z = linkage(Y,’complete’)8 dendrogram(Z)
Exemplo 19 – Código Vizinho mais distante(Saída de dados)1 >>2 X =3
4 1.0e+003 *5
6 0.0165 0.0248 0.1060 0.1470 1.1120 0.9050 0.49407 0.0042 0.0133 0.1220 0.0900 0.9820 0.6690 0.95408 0.0116 0.0247 0.3400 0.2420 0.8080 0.6090 0.64509 0.0181 0.0342 0.1840 0.2930 1.6680 0.9010 0.6020
10 0.0069 0.0415 0.1730 0.1910 1.5340 1.3680 0.780011 0.0130 0.0357 0.4770 0.2200 1.5660 1.1830 0.788012
13
14 Y =15
16 1.0e+003 *17
18 Columns 1 through 719
20 0.5366 0.5164 0.5902 0.6936 0.7162 0.4474 0.833121
22 Columns 8 through 1423
24 0.9150 0.8811 0.9240 1.0734 0.9715 0.5277 0.464525
26 Column 1527
28 0.3587

28
Exemplo 20 – Código Vizinho mais distante(Saída de dados)1 Y =2
3 1.0e+003 *4
5 Columns 1 through 76
7 0.5366 0.5164 0.5902 0.6936 0.7162 0.4474 0.83318
9 Columns 8 through 1410
11 0.9150 0.8811 0.9240 1.0734 0.9715 0.5277 0.464512
13 Column 1514
15 0.358716
17
18 ans =19
20 1.0e+003 *21
22 0 0.5366 0.5164 0.5902 0.6936 0.716223 0.5366 0 0.4474 0.8331 0.9150 0.881124 0.5164 0.4474 0 0.9240 1.0734 0.971525 0.5902 0.8331 0.9240 0 0.5277 0.464526 0.6936 0.9150 1.0734 0.5277 0 0.358727 0.7162 0.8811 0.9715 0.4645 0.3587 028
29
30 Z =31
32 1.0e+003 *33
34 0.0050 0.0060 0.358735 0.0020 0.0030 0.447436 0.0040 0.0070 0.527737 0.0010 0.0080 0.536638 0.0100 0.0090 1.073439
40
41 ans =42
43 100.000944 102.000245 103.000246 104.000247 105.000248
49 >>

29
Exemplo 21 – Código Vizinho mais distante de todas as cidades(Entrada de dados)1 >> X=[16.5,24.8,106,147,1112,905,494;4.2,13.3,122,90,982,669,954;2 11.6,24.7,340,242,808,609,645;18.1,34.2,184,293,1668,901,602;3 6.9,41.5,173,191,1534,1368,780;13,35.7,477,220,1566,1183,788;4 2.5,8.8,68,103,1017,724,468;3.6,12.7,42,28,1457,1102,637;5 16.8,26.6,289,186,1509,787,697;10.8,43.2,255,226,1494,955,765;6 9.7,51.8,286,355,1902,1386,862;10.3,39.7,266,283,1056,1036,776;7 9.4,19.4,522,267,1674,1392,848;5,23,157,144,1530,1281,488;8 5.1,22.9,85,148,1206,756,483;12.5,27.6,524,217,1496,1003,793]9 Y = pdist(X)
10 squareform(Y)11 Z = linkage(Y,’complete’)12 dendrogram(Z)

30
Exemplo 22 – Código Vizinho mais distante de todas as cidades (Saídade dados)1 >>2 X =3
4 1.0e+003 *5
6 0.0165 0.0248 0.1060 0.1470 1.1120 0.9050 0.49407 0.0042 0.0133 0.1220 0.0900 0.9820 0.6690 0.95408 0.0116 0.0247 0.3400 0.2420 0.8080 0.6090 0.64509 0.0181 0.0342 0.1840 0.2930 1.6680 0.9010 0.6020
10 0.0069 0.0415 0.1730 0.1910 1.5340 1.3680 0.780011 0.0130 0.0357 0.4770 0.2200 1.5660 1.1830 0.788012 0.0025 0.0088 0.0680 0.1030 1.0170 0.7240 0.468013 0.0036 0.0127 0.0420 0.0280 1.4570 1.1020 0.637014 0.0168 0.0266 0.2890 0.1860 1.5090 0.7870 0.697015 0.0108 0.0432 0.2550 0.2260 1.4940 0.9550 0.765016 0.0097 0.0518 0.2860 0.3550 1.9020 1.3860 0.862017 0.0103 0.0397 0.2660 0.2830 1.0560 1.0360 0.776018 0.0094 0.0194 0.5220 0.2670 1.6740 1.3920 0.848019 0.0050 0.0230 0.1570 0.1440 1.5300 1.2810 0.488020 0.0051 0.0229 0.0850 0.1480 1.2060 0.7560 0.483021 0.0125 0.0276 0.5240 0.2170 1.4960 1.0030 0.793022
23
24 Y =25
26 1.0e+003 *27
28 Columns 1 through 729
30 0.5366 0.5164 0.5902 0.6936 0.7162 0.2152 0.443731
32 Columns 8 through 1433
34 0.4978 0.5007 1.0331 0.3797 0.9305 0.5647 0.178135
36 Columns 15 through 2137
38 0.6528 0.4474 0.8331 0.9150 0.8811 0.4935 0.723839
40 Columns 22 through 2841
42 0.6286 0.6456 1.2114 0.4802 1.0974 0.9467 0.533343
44 Columns 29 through 3545
46 0.7614 0.9240 1.0734 0.9715 0.4265 0.8939 0.7291

31
Exemplo 23 – Código Vizinho mais distante de todas as cidades (Saídade dados)1 Columns 36 through 422
3 0.7826 1.3653 0.5181 1.1992 1.0201 0.5293 0.82764
5 Columns 43 through 496
7 0.5277 0.4645 0.7236 0.4210 0.2643 0.2635 0.61018
9 Columns 50 through 5610
11 0.6557 0.6456 0.4468 0.5289 0.4449 0.3587 0.894012
13 Columns 57 through 6314
15 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309316
17 Columns 64 through 7018
19 0.7618 0.5089 0.8923 0.5176 0.4527 0.3272 0.463220
21 Columns 71 through 7722
23 0.5748 0.2519 0.4575 0.7510 0.1990 0.6094 0.595624
25 Columns 78 through 8426
27 0.6484 1.2205 0.5161 1.1205 0.7640 0.1987 0.796428
29 Columns 85 through 9130
31 0.4380 0.3534 0.7052 0.5481 0.6807 0.2939 0.472032
33 Columns 92 through 9834
35 0.5514 0.1901 0.7548 0.5325 0.6907 0.5545 0.426436
37 Columns 99 through 10538
39 0.3350 0.6159 0.4493 0.5512 0.4484 0.4873 0.275340
41 Columns 106 through 11242
43 0.9227 0.3416 0.5927 1.0531 0.6266 0.7616 0.631844
45 Columns 113 through 11946
47 0.4879 0.5158 0.5577 0.9808 0.4343 0.6211 0.558248
49

32
Exemplo 24 – Código Vizinho mais distante de todas as cidades (Saídade dados)1
2 Column 1203
4 0.66245
6
7 ans =8
9 1.0e+003 *10
11 Columns 1 through 712
13 0 0.5366 0.5164 0.5902 0.6936 0.7162 0.215214 0.5366 0 0.4474 0.8331 0.9150 0.8811 0.493515 0.5164 0.4474 0 0.9240 1.0734 0.9715 0.426516 0.5902 0.8331 0.9240 0 0.5277 0.4645 0.723617 0.6936 0.9150 1.0734 0.5277 0 0.3587 0.894018 0.7162 0.8811 0.9715 0.4645 0.3587 0 0.892319 0.2152 0.4935 0.4265 0.7236 0.8940 0.8923 020 0.4437 0.7238 0.8939 0.4210 0.3764 0.5176 0.609421 0.4978 0.6286 0.7291 0.2643 0.5991 0.4527 0.595622 0.5007 0.6456 0.7826 0.2635 0.4247 0.3272 0.648423 1.0331 1.2114 1.3653 0.6101 0.4269 0.4632 1.220524 0.3797 0.4802 0.5181 0.6557 0.5965 0.5748 0.516125 0.9305 1.0974 1.1992 0.6456 0.3910 0.2519 1.120526 0.5647 0.9467 1.0201 0.4468 0.3093 0.4575 0.764027 0.1781 0.5333 0.5293 0.5289 0.7618 0.7510 0.198728 0.6528 0.7614 0.8276 0.4449 0.5089 0.1990 0.796429
30 Columns 8 through 1431
32 0.4437 0.4978 0.5007 1.0331 0.3797 0.9305 0.564733 0.7238 0.6286 0.6456 1.2114 0.4802 1.0974 0.946734 0.8939 0.7291 0.7826 1.3653 0.5181 1.1992 1.020135 0.4210 0.2643 0.2635 0.6101 0.6557 0.6456 0.446836 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309337 0.5176 0.4527 0.3272 0.4632 0.5748 0.2519 0.457538 0.6094 0.5956 0.6484 1.2205 0.5161 1.1205 0.764039 0 0.4380 0.3534 0.7052 0.5481 0.6807 0.293940 0.4380 0 0.1901 0.7548 0.5325 0.6907 0.554541 0.3534 0.1901 0 0.6159 0.4493 0.5512 0.448442 0.7052 0.7548 0.6159 0 0.9227 0.3416 0.592743 0.5481 0.5325 0.4493 0.9227 0 0.7616 0.631844 0.6807 0.6907 0.5512 0.3416 0.7616 0 0.557745 0.2939 0.5545 0.4484 0.5927 0.6318 0.5577 046 0.4720 0.4264 0.4873 1.0531 0.4879 0.9808 0.621147 0.5514 0.3350 0.2753 0.6266 0.5158 0.4343 0.5582

33
Exemplo 25 – Código Vizinho mais distante de todas as cidades (Saídade dados)1 Columns 15 through 162
3 0.1781 0.65284 0.5333 0.76145 0.5293 0.82766 0.5289 0.44497 0.7618 0.50898 0.7510 0.19909 0.1987 0.7964
10 0.4720 0.551411 0.4264 0.335012 0.4873 0.275313 1.0531 0.626614 0.4879 0.515815 0.9808 0.434316 0.6211 0.558217 0 0.662418 0.6624 019
20
21 Z =22
23 1.0e+003 *24
25 0.0010 0.0150 0.178126 0.0090 0.0100 0.190127 0.0060 0.0160 0.199028 0.0170 0.0070 0.215229 0.0040 0.0180 0.264330 0.0080 0.0140 0.293931 0.0110 0.0130 0.341632 0.0050 0.0220 0.376433 0.0020 0.0030 0.447434 0.0210 0.0190 0.464535 0.0200 0.0120 0.516136 0.0270 0.0250 0.536637 0.0260 0.0240 0.599138 0.0290 0.0230 0.754839 0.0280 0.0300 1.3653

34
Exemplo 26 – Código Vizinho mais distante de todas as cidades (Saídade dados)1
2 ans =3
4 100.00125 102.00136 103.00097 104.00098 105.00099 106.0006
10 107.000611 108.000612 109.000613 110.000514 111.000515 112.000416 113.000417 114.000418 115.000419
20 >>
Exemplo 27 – Código Média de Cluster (Entrada de dados)1 X=[16.5,24.8,106,147,1112,905,494;4.2,13.3,122,90,982,669,954;2 11.6,24.7,340,242,808,609,645;18.1,34.2,184,293,1668,901,602;3 6.9,41.5,173,191,1534,1368,780;13,35.7,477,220,1566,1183,788;4 2.5,8.8,68,103,1017,724,468;3.6,12.7,42,28,1457,1102,637;5 16.8,26.6,289,186,1509,787,697;10.8,43.2,255,226,1494,955,765;6 9.7,51.8,286,355,1902,1386,862;10.3,39.7,266,283,1056,1036,776;7 9.4,19.4,522,267,1674,1392,848;5,23,157,144,1530,1281,488;8 5.1,22.9,85,148,1206,756,483;12.5,27.6,524,217,1496,1003,793]9 Y = pdist(X)
10 squareform(Y)11 Z = linkage(Y,’average’)12 dendrogram(Z)

35
Exemplo 28 – Código Média de Cluster (Saída de dados)1 >>2 X =3
4 1.0e+003 *5
6 0.0165 0.0248 0.1060 0.1470 1.1120 0.9050 0.49407 0.0042 0.0133 0.1220 0.0900 0.9820 0.6690 0.95408 0.0116 0.0247 0.3400 0.2420 0.8080 0.6090 0.64509 0.0181 0.0342 0.1840 0.2930 1.6680 0.9010 0.6020
10 0.0069 0.0415 0.1730 0.1910 1.5340 1.3680 0.780011 0.0130 0.0357 0.4770 0.2200 1.5660 1.1830 0.788012 0.0025 0.0088 0.0680 0.1030 1.0170 0.7240 0.468013 0.0036 0.0127 0.0420 0.0280 1.4570 1.1020 0.637014 0.0168 0.0266 0.2890 0.1860 1.5090 0.7870 0.697015 0.0108 0.0432 0.2550 0.2260 1.4940 0.9550 0.765016 0.0097 0.0518 0.2860 0.3550 1.9020 1.3860 0.862017 0.0103 0.0397 0.2660 0.2830 1.0560 1.0360 0.776018 0.0094 0.0194 0.5220 0.2670 1.6740 1.3920 0.848019 0.0050 0.0230 0.1570 0.1440 1.5300 1.2810 0.488020 0.0051 0.0229 0.0850 0.1480 1.2060 0.7560 0.483021 0.0125 0.0276 0.5240 0.2170 1.4960 1.0030 0.793022
23
24 Y =25
26 1.0e+003 *27
28 Columns 1 through 729
30 0.5366 0.5164 0.5902 0.6936 0.7162 0.2152 0.443731
32 Columns 8 through 1433
34 0.4978 0.5007 1.0331 0.3797 0.9305 0.5647 0.178135
36 Columns 15 through 2137
38 0.6528 0.4474 0.8331 0.9150 0.8811 0.4935 0.723839
40 Columns 22 through 2841
42 0.6286 0.6456 1.2114 0.4802 1.0974 0.9467 0.533343
44 Columns 29 through 3545
46 0.7614 0.9240 1.0734 0.9715 0.4265 0.8939 0.729147
48 Columns 36 through 4249
50 0.7826 1.3653 0.5181 1.1992 1.0201 0.5293 0.8276
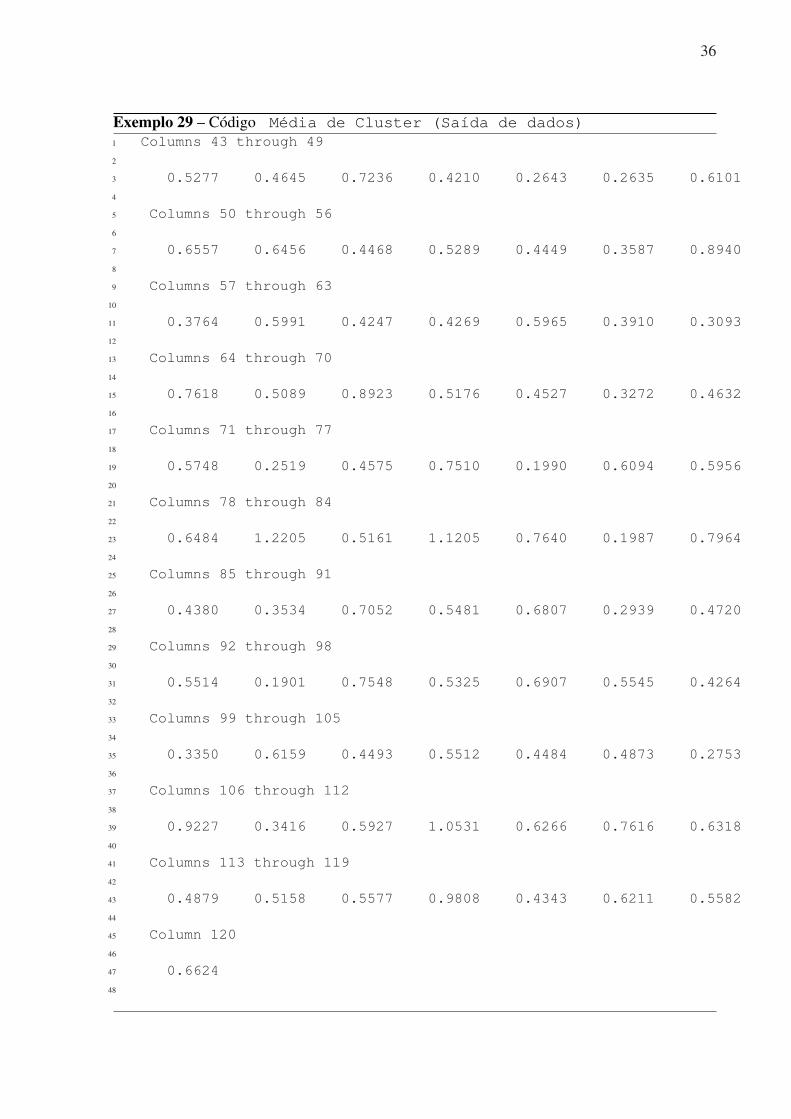
36
Exemplo 29 – Código Média de Cluster (Saída de dados)1 Columns 43 through 492
3 0.5277 0.4645 0.7236 0.4210 0.2643 0.2635 0.61014
5 Columns 50 through 566
7 0.6557 0.6456 0.4468 0.5289 0.4449 0.3587 0.89408
9 Columns 57 through 6310
11 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309312
13 Columns 64 through 7014
15 0.7618 0.5089 0.8923 0.5176 0.4527 0.3272 0.463216
17 Columns 71 through 7718
19 0.5748 0.2519 0.4575 0.7510 0.1990 0.6094 0.595620
21 Columns 78 through 8422
23 0.6484 1.2205 0.5161 1.1205 0.7640 0.1987 0.796424
25 Columns 85 through 9126
27 0.4380 0.3534 0.7052 0.5481 0.6807 0.2939 0.472028
29 Columns 92 through 9830
31 0.5514 0.1901 0.7548 0.5325 0.6907 0.5545 0.426432
33 Columns 99 through 10534
35 0.3350 0.6159 0.4493 0.5512 0.4484 0.4873 0.275336
37 Columns 106 through 11238
39 0.9227 0.3416 0.5927 1.0531 0.6266 0.7616 0.631840
41 Columns 113 through 11942
43 0.4879 0.5158 0.5577 0.9808 0.4343 0.6211 0.558244
45 Column 12046
47 0.662448

37
Exemplo 30 – Código Média de Cluster (Saída de dados)1 ans =2
3 1.0e+003 *4
5 Columns 1 through 76
7 0 0.5366 0.5164 0.5902 0.6936 0.7162 0.21528 0.5366 0 0.4474 0.8331 0.9150 0.8811 0.49359 0.5164 0.4474 0 0.9240 1.0734 0.9715 0.4265
10 0.5902 0.8331 0.9240 0 0.5277 0.4645 0.723611 0.6936 0.9150 1.0734 0.5277 0 0.3587 0.894012 0.7162 0.8811 0.9715 0.4645 0.3587 0 0.892313 0.2152 0.4935 0.4265 0.7236 0.8940 0.8923 014 0.4437 0.7238 0.8939 0.4210 0.3764 0.5176 0.609415 0.4978 0.6286 0.7291 0.2643 0.5991 0.4527 0.595616 0.5007 0.6456 0.7826 0.2635 0.4247 0.3272 0.648417 1.0331 1.2114 1.3653 0.6101 0.4269 0.4632 1.220518 0.3797 0.4802 0.5181 0.6557 0.5965 0.5748 0.516119 0.9305 1.0974 1.1992 0.6456 0.3910 0.2519 1.120520 0.5647 0.9467 1.0201 0.4468 0.3093 0.4575 0.764021 0.1781 0.5333 0.5293 0.5289 0.7618 0.7510 0.198722 0.6528 0.7614 0.8276 0.4449 0.5089 0.1990 0.796423
24 Columns 8 through 1425
26 0.4437 0.4978 0.5007 1.0331 0.3797 0.9305 0.564727 0.7238 0.6286 0.6456 1.2114 0.4802 1.0974 0.946728 0.8939 0.7291 0.7826 1.3653 0.5181 1.1992 1.020129 0.4210 0.2643 0.2635 0.6101 0.6557 0.6456 0.446830 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309331 0.5176 0.4527 0.3272 0.4632 0.5748 0.2519 0.457532 0.6094 0.5956 0.6484 1.2205 0.5161 1.1205 0.764033 0 0.4380 0.3534 0.7052 0.5481 0.6807 0.293934 0.4380 0 0.1901 0.7548 0.5325 0.6907 0.554535 0.3534 0.1901 0 0.6159 0.4493 0.5512 0.448436 0.7052 0.7548 0.6159 0 0.9227 0.3416 0.592737 0.5481 0.5325 0.4493 0.9227 0 0.7616 0.631838 0.6807 0.6907 0.5512 0.3416 0.7616 0 0.557739 0.2939 0.5545 0.4484 0.5927 0.6318 0.5577 040 0.4720 0.4264 0.4873 1.0531 0.4879 0.9808 0.621141 0.5514 0.3350 0.2753 0.6266 0.5158 0.4343 0.558242
43

38
Exemplo 31 – Código Média de Cluster (Saída de dados)1 Columns 15 through 162
3 0.1781 0.65284 0.5333 0.76145 0.5293 0.82766 0.5289 0.44497 0.7618 0.50898 0.7510 0.19909 0.1987 0.7964
10 0.4720 0.551411 0.4264 0.335012 0.4873 0.275313 1.0531 0.626614 0.4879 0.515815 0.9808 0.434316 0.6211 0.558217 0 0.662418 0.6624 019
20
21 Z =22
23 1.0000 15.0000 178.139224 9.0000 10.0000 190.106725 6.0000 16.0000 199.019726 17.0000 7.0000 206.940127 4.0000 18.0000 263.875428 8.0000 14.0000 293.870829 11.0000 13.0000 341.622430 5.0000 22.0000 342.862831 21.0000 19.0000 383.266432 2.0000 3.0000 447.403333 20.0000 12.0000 461.231534 25.0000 24.0000 477.721535 27.0000 26.0000 504.228436 28.0000 23.0000 562.400637 29.0000 30.0000 770.872838

39
Exemplo 32 – Código Média de Cluster (Saída de dados)1
2 ans =3
4 100.00275 102.00236 103.00187 104.00188 105.00189 106.0012
10 107.001211 108.001212 109.001213 110.001114 111.001115 112.001016 113.001017 114.001018 115.001019
20 >>
Exemplo 33 – Código Método de Ward (Entrada de dados)1 X=[16.5,24.8,106,147,1112,905,494;4.2,13.3,122,90,982,669,954;2 11.6,24.7,340,242,808,609,645;18.1,34.2,184,293,1668,901,602;3 6.9,41.5,173,191,1534,1368,780;13,35.7,477,220,1566,1183,788;4 2.5,8.8,68,103,1017,724,468;3.6,12.7,42,28,1457,1102,637;5 16.8,26.6,289,186,1509,787,697;10.8,43.2,255,226,1494,955,765;6 9.7,51.8,286,355,1902,1386,862;10.3,39.7,266,283,1056,1036,776;7 9.4,19.4,522,267,1674,1392,848;5,23,157,144,1530,1281,488;8 5.1,22.9,85,148,1206,756,483;12.5,27.6,524,217,1496,1003,793]9 Y = pdist(X)
10 squareform(Y)11 Z = linkage(Y,’ward’)12 dendrogram(Z)

40
Exemplo 34 – Código Método de Ward (Saída de dados)1 X =2
3 1.0e+003 *4
5 0.0165 0.0248 0.1060 0.1470 1.1120 0.9050 0.49406 0.0042 0.0133 0.1220 0.0900 0.9820 0.6690 0.95407 0.0116 0.0247 0.3400 0.2420 0.8080 0.6090 0.64508 0.0181 0.0342 0.1840 0.2930 1.6680 0.9010 0.60209 0.0069 0.0415 0.1730 0.1910 1.5340 1.3680 0.7800
10 0.0130 0.0357 0.4770 0.2200 1.5660 1.1830 0.788011 0.0025 0.0088 0.0680 0.1030 1.0170 0.7240 0.468012 0.0036 0.0127 0.0420 0.0280 1.4570 1.1020 0.637013 0.0168 0.0266 0.2890 0.1860 1.5090 0.7870 0.697014 0.0108 0.0432 0.2550 0.2260 1.4940 0.9550 0.765015 0.0097 0.0518 0.2860 0.3550 1.9020 1.3860 0.862016 0.0103 0.0397 0.2660 0.2830 1.0560 1.0360 0.776017 0.0094 0.0194 0.5220 0.2670 1.6740 1.3920 0.848018 0.0050 0.0230 0.1570 0.1440 1.5300 1.2810 0.488019 0.0051 0.0229 0.0850 0.1480 1.2060 0.7560 0.483020 0.0125 0.0276 0.5240 0.2170 1.4960 1.0030 0.793021
22
23 Y =24
25 1.0e+003 *26
27 Columns 1 through 728
29 0.5366 0.5164 0.5902 0.6936 0.7162 0.2152 0.443730
31 Columns 8 through 1432
33 0.4978 0.5007 1.0331 0.3797 0.9305 0.5647 0.178134
35 Columns 15 through 2136
37 0.6528 0.4474 0.8331 0.9150 0.8811 0.4935 0.723838
39 Columns 22 through 2840
41 0.6286 0.6456 1.2114 0.4802 1.0974 0.9467 0.533342
43 Columns 29 through 3544
45 0.7614 0.9240 1.0734 0.9715 0.4265 0.8939 0.729146
47 Columns 36 through 4248
49 0.7826 1.3653 0.5181 1.1992 1.0201 0.5293 0.827650

41
Exemplo 35 – Código Método de Ward (Saída de dados)1 Columns 43 through 492
3 0.5277 0.4645 0.7236 0.4210 0.2643 0.2635 0.61014
5 Columns 50 through 566
7 0.6557 0.6456 0.4468 0.5289 0.4449 0.3587 0.89408
9 Columns 57 through 6310
11 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309312
13 Columns 64 through 7014
15 0.7618 0.5089 0.8923 0.5176 0.4527 0.3272 0.463216
17 Columns 71 through 7718
19 0.5748 0.2519 0.4575 0.7510 0.1990 0.6094 0.595620
21 Columns 78 through 8422
23 0.6484 1.2205 0.5161 1.1205 0.7640 0.1987 0.796424
25 Columns 85 through 9126
27 0.4380 0.3534 0.7052 0.5481 0.6807 0.2939 0.472028
29 Columns 92 through 9830
31 0.5514 0.1901 0.7548 0.5325 0.6907 0.5545 0.426432
33 Columns 99 through 10534
35 0.3350 0.6159 0.4493 0.5512 0.4484 0.4873 0.275336
37 Columns 106 through 11238
39 0.9227 0.3416 0.5927 1.0531 0.6266 0.7616 0.631840
41 Columns 113 through 11942
43 0.4879 0.5158 0.5577 0.9808 0.4343 0.6211 0.558244
45 Column 12046
47 0.6624

42
Exemplo 36 – Código Método de Ward (Saída de dados)1 ans =2
3 1.0e+003 *4
5 Columns 1 through 76
7 0 0.5366 0.5164 0.5902 0.6936 0.7162 0.21528 0.5366 0 0.4474 0.8331 0.9150 0.8811 0.49359 0.5164 0.4474 0 0.9240 1.0734 0.9715 0.4265
10 0.5902 0.8331 0.9240 0 0.5277 0.4645 0.723611 0.6936 0.9150 1.0734 0.5277 0 0.3587 0.894012 0.7162 0.8811 0.9715 0.4645 0.3587 0 0.892313 0.2152 0.4935 0.4265 0.7236 0.8940 0.8923 014 0.4437 0.7238 0.8939 0.4210 0.3764 0.5176 0.609415 0.4978 0.6286 0.7291 0.2643 0.5991 0.4527 0.595616 0.5007 0.6456 0.7826 0.2635 0.4247 0.3272 0.648417 1.0331 1.2114 1.3653 0.6101 0.4269 0.4632 1.220518 0.3797 0.4802 0.5181 0.6557 0.5965 0.5748 0.516119 0.9305 1.0974 1.1992 0.6456 0.3910 0.2519 1.120520 0.5647 0.9467 1.0201 0.4468 0.3093 0.4575 0.764021 0.1781 0.5333 0.5293 0.5289 0.7618 0.7510 0.198722 0.6528 0.7614 0.8276 0.4449 0.5089 0.1990 0.796423
24 Columns 8 through 1425
26 0.4437 0.4978 0.5007 1.0331 0.3797 0.9305 0.564727 0.7238 0.6286 0.6456 1.2114 0.4802 1.0974 0.946728 0.8939 0.7291 0.7826 1.3653 0.5181 1.1992 1.020129 0.4210 0.2643 0.2635 0.6101 0.6557 0.6456 0.446830 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309331 0.5176 0.4527 0.3272 0.4632 0.5748 0.2519 0.457532 0.6094 0.5956 0.6484 1.2205 0.5161 1.1205 0.764033 0 0.4380 0.3534 0.7052 0.5481 0.6807 0.293934 0.4380 0 0.1901 0.7548 0.5325 0.6907 0.554535 0.3534 0.1901 0 0.6159 0.4493 0.5512 0.448436 0.7052 0.7548 0.6159 0 0.9227 0.3416 0.592737 0.5481 0.5325 0.4493 0.9227 0 0.7616 0.631838 0.6807 0.6907 0.5512 0.3416 0.7616 0 0.557739 0.2939 0.5545 0.4484 0.5927 0.6318 0.5577 040 0.4720 0.4264 0.4873 1.0531 0.4879 0.9808 0.621141 0.5514 0.3350 0.2753 0.6266 0.5158 0.4343 0.558242

43
Exemplo 37 – Código Método de Ward (Saída de dados)1 Columns 15 through 162
3 0.1781 0.65284 0.5333 0.76145 0.5293 0.82766 0.5289 0.44497 0.7618 0.50898 0.7510 0.19909 0.1987 0.7964
10 0.4720 0.551411 0.4264 0.335012 0.4873 0.275313 1.0531 0.626614 0.4879 0.515815 0.9808 0.434316 0.6211 0.558217 0 0.662418 0.6624 019
20
21 Z =22
23 1.0e+003 *24
25 0.0010 0.0150 0.126026 0.0090 0.0100 0.134427 0.0060 0.0160 0.140728 0.0170 0.0070 0.152729 0.0040 0.0180 0.201030 0.0080 0.0140 0.207831 0.0110 0.0130 0.241632 0.0050 0.0220 0.254433 0.0020 0.0030 0.316434 0.0250 0.0120 0.364635 0.0210 0.0190 0.384036 0.0200 0.0260 0.479037 0.0270 0.0240 0.534338 0.0290 0.0230 0.602639 0.0280 0.0300 1.3076

44
Exemplo 38 – Código Método de Ward (Saída de dados)1 ans =2
3 100.00334 102.00295 103.00246 104.00247 105.00248 106.00189 107.0018
10 108.001811 109.001812 110.001713 111.001714 112.001615 113.001616 114.001617 115.001618
19 >>
Exemplo 39 – Código Método Centróide (Entrada de dados)1 X=[16.5,24.8,106,147,1112,905,494;4.2,13.3,122,90,982,669,954;2 11.6,24.7,340,242,808,609,645;18.1,34.2,184,293,1668,901,602;3 6.9,41.5,173,191,1534,1368,780;13,35.7,477,220,1566,1183,788;4 2.5,8.8,68,103,1017,724,468;3.6,12.7,42,28,1457,1102,637;5 16.8,26.6,289,186,1509,787,697;10.8,43.2,255,226,1494,955,765;6 9.7,51.8,286,355,1902,1386,862;10.3,39.7,266,283,1056,1036,776;7 9.4,19.4,522,267,1674,1392,848;5,23,157,144,1530,1281,488;8 5.1,22.9,85,148,1206,756,483;12.5,27.6,524,217,1496,1003,793]9 Y = pdist(X)
10 squareform(Y)11 Z = linkage(Y,’centroid’)12 dendrogram(Z)

45
Exemplo 40 – Código Método Centróide (Saída de dados)1 X =2
3 1.0e+003 *4
5 0.0165 0.0248 0.1060 0.1470 1.1120 0.9050 0.49406 0.0042 0.0133 0.1220 0.0900 0.9820 0.6690 0.95407 0.0116 0.0247 0.3400 0.2420 0.8080 0.6090 0.64508 0.0181 0.0342 0.1840 0.2930 1.6680 0.9010 0.60209 0.0069 0.0415 0.1730 0.1910 1.5340 1.3680 0.7800
10 0.0130 0.0357 0.4770 0.2200 1.5660 1.1830 0.788011 0.0025 0.0088 0.0680 0.1030 1.0170 0.7240 0.468012 0.0036 0.0127 0.0420 0.0280 1.4570 1.1020 0.637013 0.0168 0.0266 0.2890 0.1860 1.5090 0.7870 0.697014 0.0108 0.0432 0.2550 0.2260 1.4940 0.9550 0.765015 0.0097 0.0518 0.2860 0.3550 1.9020 1.3860 0.862016 0.0103 0.0397 0.2660 0.2830 1.0560 1.0360 0.776017 0.0094 0.0194 0.5220 0.2670 1.6740 1.3920 0.848018 0.0050 0.0230 0.1570 0.1440 1.5300 1.2810 0.488019 0.0051 0.0229 0.0850 0.1480 1.2060 0.7560 0.483020 0.0125 0.0276 0.5240 0.2170 1.4960 1.0030 0.793021
22
23 Y =24
25 1.0e+003 *26
27 Columns 1 through 728
29 0.5366 0.5164 0.5902 0.6936 0.7162 0.2152 0.443730
31 Columns 8 through 1432
33 0.4978 0.5007 1.0331 0.3797 0.9305 0.5647 0.178134
35 Columns 15 through 2136
37 0.6528 0.4474 0.8331 0.9150 0.8811 0.4935 0.723838
39 Columns 22 through 2840
41 0.6286 0.6456 1.2114 0.4802 1.0974 0.9467 0.533342
43 Columns 29 through 3544
45 0.7614 0.9240 1.0734 0.9715 0.4265 0.8939 0.729146
47 Columns 36 through 4248
49 0.7826 1.3653 0.5181 1.1992 1.0201 0.5293 0.827650
46
Exemplo 41 – Código Método Centróide (Saída de dados)1 Columns 43 through 492
3 0.5277 0.4645 0.7236 0.4210 0.2643 0.2635 0.61014
5 Columns 50 through 566
7 0.6557 0.6456 0.4468 0.5289 0.4449 0.3587 0.89408
9 Columns 57 through 6310
11 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309312
13 Columns 64 through 7014
15 0.7618 0.5089 0.8923 0.5176 0.4527 0.3272 0.463216
17 Columns 71 through 7718
19 0.5748 0.2519 0.4575 0.7510 0.1990 0.6094 0.595620
21 Columns 78 through 8422
23 0.6484 1.2205 0.5161 1.1205 0.7640 0.1987 0.796424
25 Columns 85 through 9126
27 0.4380 0.3534 0.7052 0.5481 0.6807 0.2939 0.472028
29 Columns 92 through 9830
31 0.5514 0.1901 0.7548 0.5325 0.6907 0.5545 0.426432
33 Columns 99 through 10534
35 0.3350 0.6159 0.4493 0.5512 0.4484 0.4873 0.275336
37 Columns 106 through 11238
39 0.9227 0.3416 0.5927 1.0531 0.6266 0.7616 0.631840
41 Columns 113 through 11942
43 0.4879 0.5158 0.5577 0.9808 0.4343 0.6211 0.558244
45 Column 12046
47 0.6624

47
Exemplo 42 – Código Método Centróide (Saída de dados)1 ans =2
3 1.0e+003 *4
5 Columns 1 through 76
7 0 0.5366 0.5164 0.5902 0.6936 0.7162 0.21528 0.5366 0 0.4474 0.8331 0.9150 0.8811 0.49359 0.5164 0.4474 0 0.9240 1.0734 0.9715 0.4265
10 0.5902 0.8331 0.9240 0 0.5277 0.4645 0.723611 0.6936 0.9150 1.0734 0.5277 0 0.3587 0.894012 0.7162 0.8811 0.9715 0.4645 0.3587 0 0.892313 0.2152 0.4935 0.4265 0.7236 0.8940 0.8923 014 0.4437 0.7238 0.8939 0.4210 0.3764 0.5176 0.609415 0.4978 0.6286 0.7291 0.2643 0.5991 0.4527 0.595616 0.5007 0.6456 0.7826 0.2635 0.4247 0.3272 0.648417 1.0331 1.2114 1.3653 0.6101 0.4269 0.4632 1.220518 0.3797 0.4802 0.5181 0.6557 0.5965 0.5748 0.516119 0.9305 1.0974 1.1992 0.6456 0.3910 0.2519 1.120520 0.5647 0.9467 1.0201 0.4468 0.3093 0.4575 0.764021 0.1781 0.5333 0.5293 0.5289 0.7618 0.7510 0.198722 0.6528 0.7614 0.8276 0.4449 0.5089 0.1990 0.796423
24 Columns 8 through 1425
26 0.4437 0.4978 0.5007 1.0331 0.3797 0.9305 0.564727 0.7238 0.6286 0.6456 1.2114 0.4802 1.0974 0.946728 0.8939 0.7291 0.7826 1.3653 0.5181 1.1992 1.020129 0.4210 0.2643 0.2635 0.6101 0.6557 0.6456 0.446830 0.3764 0.5991 0.4247 0.4269 0.5965 0.3910 0.309331 0.5176 0.4527 0.3272 0.4632 0.5748 0.2519 0.457532 0.6094 0.5956 0.6484 1.2205 0.5161 1.1205 0.764033 0 0.4380 0.3534 0.7052 0.5481 0.6807 0.293934 0.4380 0 0.1901 0.7548 0.5325 0.6907 0.554535 0.3534 0.1901 0 0.6159 0.4493 0.5512 0.448436 0.7052 0.7548 0.6159 0 0.9227 0.3416 0.592737 0.5481 0.5325 0.4493 0.9227 0 0.7616 0.631838 0.6807 0.6907 0.5512 0.3416 0.7616 0 0.557739 0.2939 0.5545 0.4484 0.5927 0.6318 0.5577 040 0.4720 0.4264 0.4873 1.0531 0.4879 0.9808 0.621141 0.5514 0.3350 0.2753 0.6266 0.5158 0.4343 0.558242

48
Exemplo 43 – Código Método Centróide (Saída de dados)1 Columns 15 through 162
3 0.1781 0.65284 0.5333 0.76145 0.5293 0.82766 0.5289 0.44497 0.7618 0.50898 0.7510 0.19909 0.1987 0.7964
10 0.4720 0.551411 0.4264 0.335012 0.4873 0.275313 1.0531 0.626614 0.4879 0.515815 0.9808 0.434316 0.6211 0.558217 0 0.662418 0.6624 019
20 Warning: Non-monotonic cluster tree -- the centroid method is probably21 not appropriate.22 > In C:\MATLAB6p5\toolbox\stats\linkage.m at line 16623 In C:\MATLAB6p5\work\cluster3.m at line 424
25 Z =26
27 1.0000 15.0000 178.139228 17.0000 7.0000 186.971629 9.0000 10.0000 190.106730 6.0000 16.0000 199.019731 4.0000 19.0000 246.161032 8.0000 14.0000 293.870833 5.0000 22.0000 311.596034 20.0000 13.0000 340.781535 21.0000 23.0000 411.065736 25.0000 24.0000 385.580537 2.0000 3.0000 447.403338 18.0000 27.0000 440.837939 28.0000 12.0000 393.713940 26.0000 11.0000 501.282841 29.0000 30.0000 675.2379

49
Exemplo 44 – Código Método Centróide (Saída de dados)1 ans =2
3 100.00094 102.00025 103.00026 104.00027 105.00028 106.00029 107.0002
10 108.000211 109.000212 110.000213 111.000214 112.000215 113.000216 114.000217 115.000218
19 >>