cloud based data warehousing and analytics
TRANSCRIPT

© 2015 IBM Corporation
Cloud Based Data Warehousing and Analytics: A Real Use Case HHS-1807
Bogdan Sheptunov, Marriott
Bert Van der Linden, IBM
10/29/2015

• IBM’s statements regarding its plans, directions, and intent are subject to change or withdrawal without notice at IBM’s sole discretion.
• Information regarding potential future products is intended to outline our general product direction and it should not be relied on in making a purchasing decision.
• The information mentioned regarding potential future products is not a commitment, promise, or legal obligation to deliver any material, code or functionality. Information about potential future products may not be incorporated into any contract.
• The development, release, and timing of any future features or functionality described for our products remains at our sole discretion.
Performance is based on measurements and projections using standard IBM benchmarks in acontrolled environment. The actual throughput or performance that any user will experience will varydepending upon many factors, including considerations such as the amount of multiprogramming in theuser’s job stream, the I/O configuration, the storage configuration, and the workload processed.Therefore, no assurance can be given that an individual user will achieve results similar to those statedhere.
Please Note:
2

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Self Service Analytics In Cloud
October 5, 2015

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Journey Towards Next Analytical Platform
• Starting data warehousing architecture and its limitations
• A decision to use BigSQL on cloud
• Constraints we operate within
• Original vision
• Interesting challenges along the way
• Where we are today
• Next Steps
3

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Data Domains Spread Across Environments
4
Clickstream
ReservationsCustomer
Loyalty
Marketing
B2B Sales Call Center
Operational DataOperational DataOperational DataOperational DataOperational Data
Query single dataset
using SQL
Pull data
from multiple
datasets
User’s PC
Data Warehouse

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
CPU, Space Limited In The Environment
ETL
Ad Hoc Analytics
Reporting
In database scoring
Workloads• Warehouses are CPU bound
• User base is global, hardware
busy with update cycles
• Space limited as well
• Adding capacity requires large
investment

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Production environments governed by SDLC
• Deploying new data takes time, process
• Turning an idea into data requires a long process
Table
File
TicketDBA
Outage
Table
Idea
Project
Requirements
Outage
ETL developer
DBA

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Objective: Make Analysis More Efficient
7
• Create a hypothesis proving environment
• Leverage existing SQL skillset within the organization
• Add capacity in small increments
• Deliver a high performing system
• Add new technical capabilities in unstructured data and text
analytics

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Operating Model Changes
8
• A self service environment
• Not an operational environment, there’s no SLA on query responses
• Environment can lag behind the DW somewhat
• Still requires security measures
• Needs a new governance process
• Change the approach to data projects
• Prototype an idea with data before its productionalized

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Vision for Analytical Workspace
9
External Data
SourcesOperational DataOperational DataOperational DataOperational DataOperational Data
DW
Landing Zone .
Operational data marts
Reporting
Analytical
Workspace
Data marts

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Going to Cloud
10
• Marriott thinks “Cloud First”
• Better cost control through managing capacity
• Speed to market
• A lot of data originates in cloud or is moving towards cloud
• Leveraging Marriott cloud on Softlayer
• Interesting challenges
• Network bandwidth constraints data that does not originate in cloud
• Data needs to be appropriately secured
• Organization needs processes to function at cloud speeds

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
View With Tools
11
Operational DataOperational DataOperational DataOperational DataOperational Data
Data
Warehouses
Landing Zone
Analytical Workspace
PUSH
VIEW
PULL
LOAD
RelationalData Store
HDFSData Store
DW
LZ
On
Workstation
Server or
Workstation
On
Workstation On
Workstation
External Data External Data Sources
On
Workstation
Other ODBC
Connections
Legend:
Phase 1
Future Phase
Netezza
DPS
Federate
Dataclick
Aginity
IBM
Db2
Apache
Parquet

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Approach to Data Structures
12
- Initial focus on structured data from existing warehouses
- Source structured as stars, snowflakes
- Release 1 approach:
- Replicate existing structures as is
- Optimize physical data model for BigSQL use
- Create next generation of marts in future releases

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Pushing Data to Cloud Required a Custom App
13
- Build vs Buy – developed an application from scratch
- Metadata-driven
- Compresses data in memory, delivers to cloud using SSH/SCP
- Applied to target table through ETL code
- Implemented Change Data Capture patterns
- Implemented to send minimal data over the network
- Timestamp-based
- XID-based
- Full comparison-based / relying on existing deltas
- Full replace

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Data Publication Service
14

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Unexpected Learnings While Pushing Data
15
- Horizontal (range) partitioning a key optimization technique
- Some of the source tables not conducive to partitioning as is
- Added ETL code to append natural key
- Using Hive for ETL
- BigSQL 3.0 good at querying, bottlenecks at writes
- Writing large number of rows best done in Hive
- HiveQL a new skillset for the organization
- Time spent on addressing data quality issues
- Line terminators (OxOA, OxOC) replaced with blanks
- Backslash (\), various double quotes escaped with “\”

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
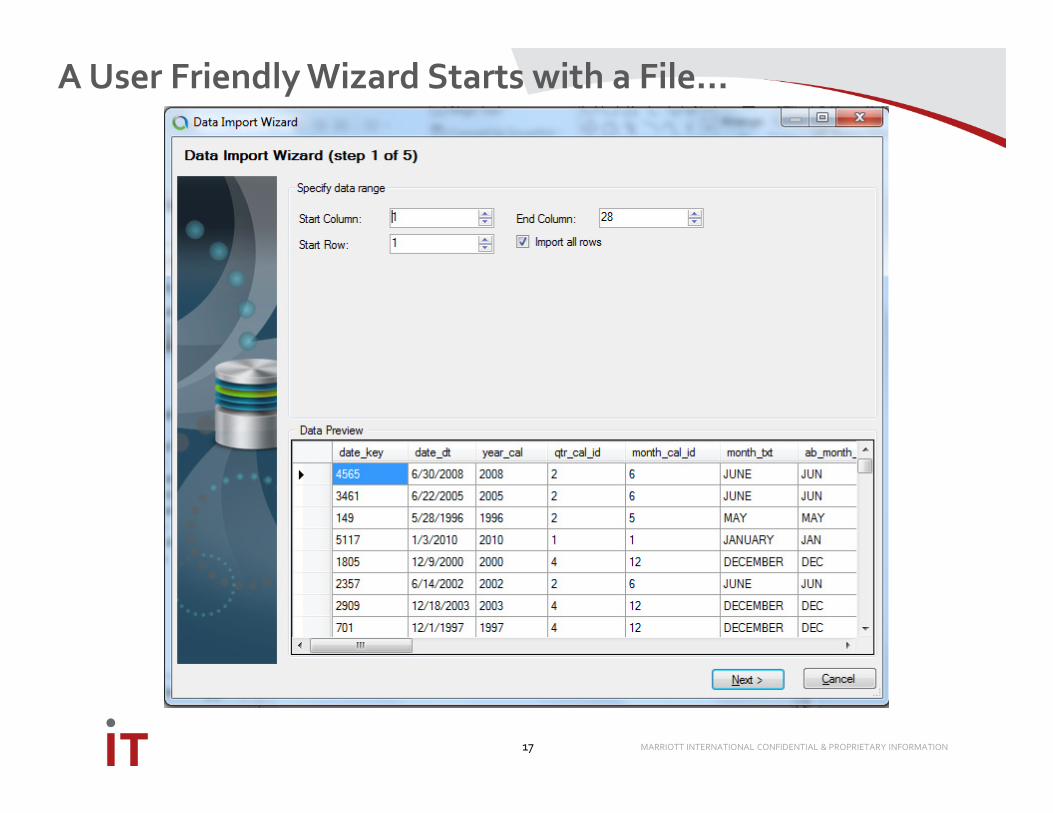
Load: Uploading Data
16
- Business problem: upload dimension or a small fact from CSV
or Excel
- Big Insights 3.0 user experience is disjointed
- Partnered with Aginity
- Workbench for Hadoop: free tool, available at
http://www.aginity.com/workbench/hadoop/
- Natively supports BigSQL
MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
A User Friendly Wizard Starts with a File…
17

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
… And ends with a table.
18
MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
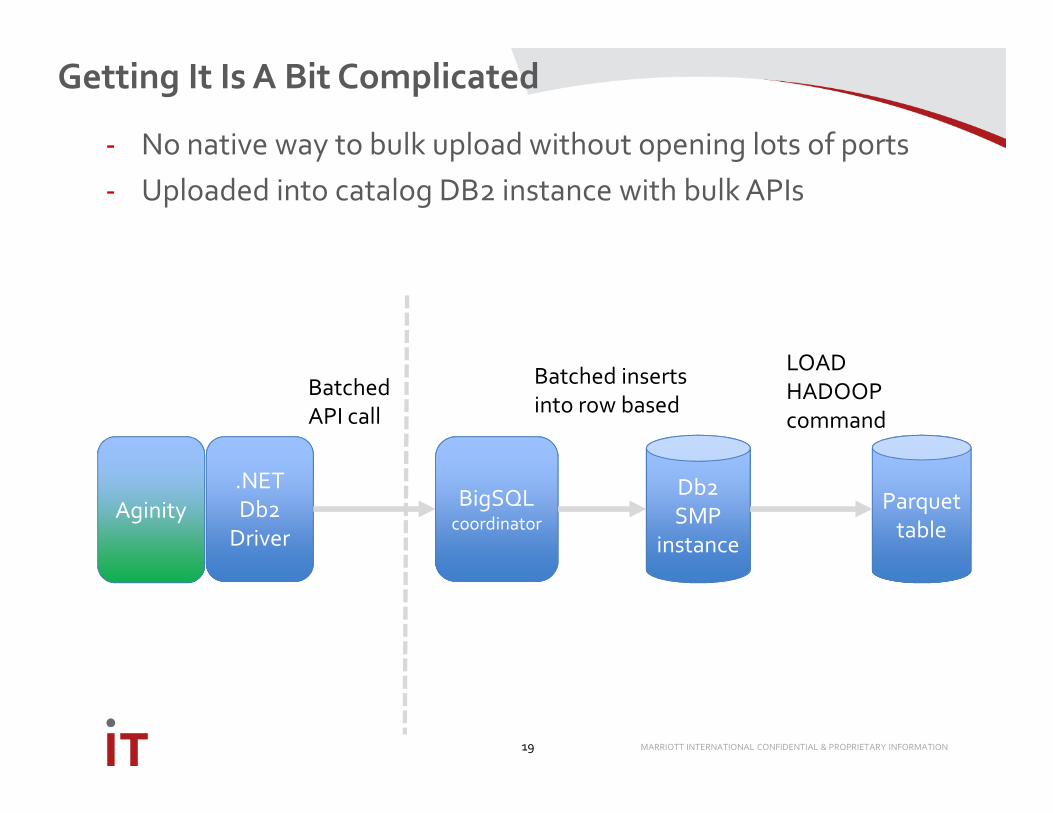
Getting It Is A Bit Complicated
19
- No native way to bulk upload without opening lots of ports
- Uploaded into catalog DB2 instance with bulk APIs
.NET
Db2
Driver
BigSQLcoordinator
Db2
SMP
instance
Parquet
table
Batched
API call
Batched inserts
into row based
LOAD
HADOOP
command
Aginity

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Other Ways of Bringing Data In
20
- View: federation works
- Successfully federated Netezza to BigSQL
- Lag between source and target creates a governance challenge
- Did not heavily exercise yet
- In cloud, difficult to quantify network usage
- Pull: DataClick implementation was postponed
- No way to do high performance uploads (ODBC driver)
- Users have to convert to Parquet, collect statistics themselves
- Impossible to trim data
- Use and administration is not trivial

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Learnings From Porting Code
21
- Getting queries from Netezza was easy
- Ported queries, not stored procedures or views
- Followed typical best practices
- Horizontal partitioning most effective performance
optimization technique
- Statistics
- Having BigSQL statistics on each column vital
- ANALYZE statement expensive, breaks occasionally, reruns
- Column group statistics help if there’s a significant skew

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Sample Run Times
22
• Data volume: about 1 tb
• Run times ratio ranges from 0.5 to 3x
Netezza BigSQL
# Query Name Seconds Seconds
1 A1 AW UAT AO Easy 258 769
2 A2 AW UAT AO Medium 1 73 168
3 A3 AW UAT AO Medium 2 156 204
4 A4 AW UAT AO Complex 1 282 436
5 A5 AW UAT AO Complex 2 529 363
6 D1 AW UAT OR Easy 716 431
7 D2 AW UAT OR Medium 254 377
8 D3 AW UAT OR Complex 1 1187 741
9 D4 AW UAT OR Complex 2 438 110
10 D5 AW UAT OR Complex 3 408 1085

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Binary Collation Is Standard in Hadoop Ecosystem
23
- “Hello” won’t match / join / sort with “Hello “
- User data, data warehouse contain trailing blanks at times
- Impossible to influence this behavior in Big Insights 3.0
- Options:
- Trim all character types during upload
- Trim at query time
- Appreciate the existing behavior :)

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Other Notes
24
- BigSQL 3.0 suitable for writing out small tables, bottlenecks
on large ones
- Ganglia irreplaceable for monitoring hardware
- Unable to push BigInsights metrics to Ganglia in 3.0
- SAS integration successful
- Great example of BigSQL thinly veiled as Db2

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Current State
25
- In production
- Some datasets already enabled, more on the way
- Initial group of users started in the environment
- Improving monitoring, error reporting and recovery practices

MARRIOTT INTERNATIONAL CONFIDENTIAL & PROPRIETARY INFORMATION
Next Steps
26
- Expanding user base
- Design next generation of data marts
- Migrating to Big Insights 4.1
- Leveraging BigSQL for large writes
- Configuring High Availability
- Using built in text analytics functions on unstructured data
- Considering high speed file transfer software as transport
layer
- Trimming character data during upload in Aginity

What I will be talking about…
• I’m going to touch on some aspects of BigSQL
• Data ingesting
� is always challenging, and we heard it from Marriott
• Spark is the new buzz word
� What does it mean for BigSQL?
27

Data Movement
• LOAD HADOOP
• DataStage
• Aspera
• Partners like Aginity
• BigSQL Federation
28

Big SQL LOAD command
• Where can the data come from?
� Database via parallel JDBC
• DB2, Netezza, Teradata, Oracle, SQL Server, MySQL, Postgres
• Generic JDBC (Informix and IMS can use this)
� CSV files on HDFS
� SFTP
• Where can the data go to?
� Any BigSQL/Hive table
• Special features:
� User can control the parallelism
� Rejected/bad rows are saved to a file
� Control of how to manipulate input data (e.g. delimiters)
� Control of how to write data (e.g. compression, reject nulls)
29

Big SQL LOAD example
• LOAD HADOOP
USING FILE URL '/tmp/data/staff.csv'
WITH SOURCE PROPERTIES('field.delimiter'=':')
INTO TABLE TEST.STAFF_F
WITH LOAD PROPERTIES ( 'num.map.tasks' = 10)
APPEND
• LOAD HADOOP
USING JDBC CONNECTION URL
'jdbc:teradata://myhost/database=GOSALES’
WITH PARAMETERS ( 'user' ='myuser',password='mypass')
FROM SQL QUERY
'SELECT * FROM COUNTRY WHERE SALESCOUNTRYCODE > 6 AND
$CONDITIONS’
SPLIT COLUMN SALESCOUNTRYCODE
INTO TABLE country_info
APPEND;
30

Information Server - DataStage
• BigInsights was shipping with a DataClick teaser-version
� That explains the lack of functionality and the lack of performance that Marriott encountered
� We don’t like teaser versions anymore…
� This is not representative of DataStage!
� Note that there are several names for the same technology and/or different configurations and deployments
• DataStage
• BigIntegrate & BigQuality
• InfoSphere Information Server
• DataWorks
• DataClick
31

IBM BigInsights BigIntegrate & BigQualityInformation Server on Hadoop
Hadoop Platform
HDFS
YARN
high speed extract / load
(redundant, reliable storage)
(cluster resource management)
BigIntegrate BigQuality
connect, transform, shape, deliver
profile, classify, cleanse, monitor
high
speed nativeaccess
high speed ingest
Data Integration, Quality and Governance Tooling
Data Engineers Data Analyst Developers

Big SQL Query federation
• Data never lives in isolation
� Either as a landing zone or a queryable archive it is desirable to query data across Hadoop and active Data warehouses
• Big SQL provides the ability to query heterogeneous systems
� Join Hadoop to other relational databases
� Query optimizer understands capabilities of external system
• Including available statistics
� As much work as possible is pushed to each system to process
33
Head Node
Big SQL
Data Node
Task Tracker
Data Node
BigSQL
Data Node
Task Tracker
Data Node
BigSQL
Data Node
Task Tracker
Data Node
BigSQL
Data Node
Task Tracker
Data Node
BigSQL

Big SQL FederationWhat does is really look like?
• After some DDL statements that creates a “nick name” for a remote table…
� create server my_db type teradata …
� create nickname T2(...) for server my_db
• This is what the SQL looks like:
� Select * from T1, T2 where T1.id = T2.id
and T2.price > 10.50
• Federation is totally invisible from SQL!!!
34

Federation supported data sources
• Teradata
� V12, 13, 14
• Oracle
� 11g, 11gR1, 11gR2, 12c
• Microsoft
� 2005, 2008, 2008R2, 2012
• DB2
� 9.7, 9.8, 10.1, 10.5
• Netezza
� 4.6, 5.0, 6.0, 7.2
• For more details:
� http://www-01.ibm.com/support/docview.wss?uid=swg27038537
35

Aginity, an IBM partner
• Chosen by Marriott
36

Aspera, and IBM company
• Claim to fame:
� Very fast data transfer via compression and connection management
• Grew into a much broader offering
• Great for cloud environments
37

Aspera Product Portfolio
TRANSFER CLIENTS WEB APPLICATIONS MANAGEMENT &
AUTOMATION
SYNCHRONIZATION
FASP™ PATENTED HIGH-SPEED TRANSPORT
TRANSFER SERVERS
Web, Desktop, Email, Mobile,
Embedded
Private On Premise
Distribution, sharing,
collaboration and exchange
Transfer management,
monitoring and automation
Scalable, high-performance
synchronization and replication
Any Data Size, Any Distance, Any Network Conditions Any Infrastructure: Block, Object, On Premise, Cloud
Public and Private Cloud Hybrid
38

Spark
39

Questions from our customers
• What about Spark?
• When should I use Spark SQL?
• When should I use BigSQL?
• Is Spark SQL fast?
40

Questions from our customers
• What about Spark?
� Spark is built for “analytics”, machine learning
� But SQL is so great that everybody has to have SQL…
� Using NoteBooks as the canvas
� Using SQL to do certain steps that are easy in SQL.
• When should I use Spark SQL?
� It will be on your fingertips when you use Spark and its tooling
� Very easy in the Java/Scala/Phyton environment of Spark
• When should I use BigSQL?
� Obvious for SQL-centric applications
� Very easy for remotely connecting via JDBC/ODBC
• Is Spark SQL fast?
41

© 2015 IBM Corporation42
Current State of the Art: Big SQL runs more SQL out-of-boxBig SQL 4.1 Spark SQL 1.5.0
1 hour 3-4 weeksPorting Effort:
Big SQL is the only engine that
can execute all 99 queries with
minimal porting effort

© 2015 IBM Corporation43
… what happens when you scale it?
Scale Single Stream 4 Concurrent Streams
1 TB • Big SQL was faster on 76 / 99 Queries
• Big SQL averaged 5.5X faster
• Removing Top / Bottom 5, Big SQL averaged 2.5X faster
• Spark SQL FAILED on 3 queries
• Big SQL was 4.4X faster*
10 TB • Big SQL was faster on 80/99 Queries
• Spark SQL FAILED on 7 queries
• Big SQL averaged 6.2X faster*
• Removing Top / Bottom 5, Big SQL averaged 4.6X faster
• Big SQL elapsed time for workload was
better than linear
• Spark SQL could not complete the workload (numerous issues). Partial results possible with only 2 concurrent streams.
*Compares only queries that both Big SQL and Spark SQL could complete (benefits Spark SQL)
More Users
More
Data

© 2015 IBM Corporation44
Choose the Right Tool for the Right Job
Machine Learning transformation
Simpler SQL
Good Performance
Ideal tool for BI Data
Analysts and production
workloads
Ideal tool for Data Scientists
and discovery
Big SQL Spark SQL
Migrating existing workloads to Hadoop
Security
Many Concurrent Users
Best in-class Performance
Big SQL & Spark SQL co-exist in the cluster

We Value Your Feedback!
Don’t forget to submit your Insight session and speaker feedback! Your feedback is very important to us – we use it
to continually improve the conference.
Access the Insight Conference Connect tool at insight2015survey.com to quickly submit your surveys from
your smartphone, laptop or conference kiosk.
45

46
Notices and Disclaimers
Copyright © 2015 by International Business Machines Corporation (IBM). No part of this document may be reproduced or transmitted in any form without written permission from IBM.
U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM.
Information in these presentations (including information relating to products that have not yet been announced by IBM) has been reviewed for accuracy as of the date of initial publication and could include unintentional technical or typographical errors. IBM shall have no responsibility to update this information. THIS DOCUMENT IS DISTRIBUTED "AS IS" WITHOUT ANY WARRANTY, EITHER EXPRESS OR IMPLIED. IN NO EVENT SHALL IBM BE LIABLE FOR ANY DAMAGE ARISING FROM THE USE OF THIS INFORMATION, INCLUDING BUT NOT LIMITED TO, LOSS OF DATA, BUSINESS INTERRUPTION, LOSS OF PROFIT OR LOSS OF OPPORTUNITY. IBM products and services are warranted according to the terms and conditions of the agreements under which they are provided.
Any statements regarding IBM's future direction, intent or product plans are subject to change or withdrawal without notice.
Performance data contained herein was generally obtained in a controlled, isolated environments. Customer examples are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual performance, cost, savings or other results in other operating environments may vary.
References in this document to IBM products, programs, or services does not imply that IBM intends to make such products, programs or services available in all countries in which IBM operates or does business.
Workshops, sessions and associated materials may have been prepared by independent session speakers, and do not necessarily reflect the views of IBM. All materials and discussions are provided for informational purposes only, and are neither intended to, nor shall constitute legal or other guidance or advice to any individual participant or their specific situation.
It is the customer’s responsibility to insure its own compliance with legal requirements and to obtain advice of competent legal counsel as to the identification and interpretation of any relevant laws and regulatory requirements that may affect the customer’s business and any actions the customer may need to take to comply with such laws. IBM does not provide legal advice or represent or warrant that its services or products will ensure that the customer is in compliance with any law.

47
Notices and Disclaimers (con’t)
Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products in connection with this publication and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products. IBM does not warrant the quality of any third-party products, or the ability of any such third-party products to interoperate with IBM’s products. IBM EXPRESSLY DISCLAIMS ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
The provision of the information contained herein is not intended to, and does not, grant any right or license under any IBM patents, copyrights, trademarks or other intellectual property right.
• IBM, the IBM logo, ibm.com, Aspera®, Bluemix, Blueworks Live, CICS, Clearcase, Cognos®, DOORS®, Emptoris®, Enterprise Document Management System™, FASP®, FileNet®, Global Business Services ®, Global Technology Services ®, IBM ExperienceOne™, IBM SmartCloud®, IBM Social Business®, Information on Demand, ILOG, Maximo®, MQIntegrator®, MQSeries®, Netcool®, OMEGAMON, OpenPower, PureAnalytics™, PureApplication®, pureCluster™, PureCoverage®, PureData®, PureExperience®, PureFlex®, pureQuery®, pureScale®, PureSystems®, QRadar®, Rational®, Rhapsody®, Smarter Commerce®, SoDA, SPSS, Sterling Commerce®, StoredIQ, Tealeaf®, Tivoli®, Trusteer®, Unica®, urban{code}®, Watson, WebSphere®, Worklight®, X-Force® and System z® Z/OS, are trademarks of International Business Machines Corporation, registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at "Copyright and trademark information" at: www.ibm.com/legal/copytrade.shtml.

© 2015 IBM Corporation
Thank You