consistent probabilistic outputs for protein function prediction william stafford noble department...
TRANSCRIPT

Consistent probabilistic outputs for protein function prediction
William Stafford NobleDepartment of Genome Sciences
Department of Computer Science and EngineeringUniversity of Washington

Outline
• Motivation and background
• Methods– Shared base method– Reconciliation methods
• Results

The problem
Given:• protein sequence,• knockout phenotype,• gene expression
profile,• protein-protein
interactions, and • phylogenetic profile
Predict• a probability for every
term in the Gene Ontology
Heterogeneous dataMissing dataMultiple labels per geneStructured output

Consistent predictions
Cytoplasmic membrane-bound
vesicle(GO:0016023)
Cytoplasmic vesicle
(GO:0031410)
is a
The probability that protein X is a cytoplasmic membrane-bound vesicle must be less than or equal to the probability that protein X is a cytoplasmic vesicle.

Data sets


Kernels

SVM → Naïve BayesData 1
Data 2
Data 3
Data 4
Data 5
Data 6
Data 7
Data 8
Data 33
SVM/AL 1
SVM/AL 2
SVM/AL 3
SVM/AL 4
SVM/AL 5
SVM/AL 6
SVM/AL 7
SVM/AL 8
SVM/AL 33
Product, plus Bayes’ rule
Probability 1
Probability 2
Probability 3
Probability 4
Probability 6
Probability 8
Probability 33
Probability
Gaussian
Asymmetric Laplace

SVM → logistic regressionData 1
Data 2
Data 3
Data 4
Data 5
Data 6
Data 7
Data 8
Data 33
SVM 1
SVM 2
SVM 3
SVM 4
SVM 5
SVM 6
SVM 7
SVM 8
SVM 33
Logisticregressor 1
Logisticregressor 2
Logisticregressor 3
Logisticregressor 11
Predict 1
Predict 2
Predict 3
Predict 4
Predict 6
Predict 8
Predict 33
Probability

Reconciliation Methods
• 3 heuristic methods
• 3 Bayesian networks
• 1 cascaded logistic regression
• 3 projection methods

Heuristic methods
• Max: Report the maximum probability of self and all descendants.
• And: Report the product of probabilities of all ancestors and self.
• Or: Compute the probability that at least one descendant of the GO term is “on,” assuming independence.
jDj
i ppi
ˆmax
• All three methods use probabilities estimated by logistic regression.
iAj
ji pp ˆ
iDj
ji pp ˆ11

Bayesian network
• Belief propagation on a graphical model with the topology of the GO.
• Given Yi, the distribution of each SVM output Xi is modeled as an independent asymmetric Laplace distribution.
• Solved using a variational inference algorithm.• “Flipped” variant: reverse the directionality of edges in the graph.

Cascaded logistic regression
• Fit a logistic regression to the SVM output only for those proteins that belong to all parent terms.
• Models the conditional distribution of the term, given all parents.
• The final probability is the product of these conditionals:
iAj
ji pp

Ejipp
pp
ij
Iiii
Iipi
, , s.t.
ˆ 2
,min
Isotonic regression
• Consider the squared Euclidean distance between two sets of probabilities.
• Find the closest set of probabilities to the logistic regression values that satisfy all the inequality constraints.

Ejipp
pp
ij
Iiii
Iipi
, , s.t.
ˆ 2
,min
Ejipp
ppD
ij
Iiii
Iipi
, , s.t.
ˆmin ,
Isotonic regression
• Consider the squared Euclidean distance between two sets of probabilities.
• Find the closest set of probabilities to the logistic regression values that satisfy all the inequality constraints.
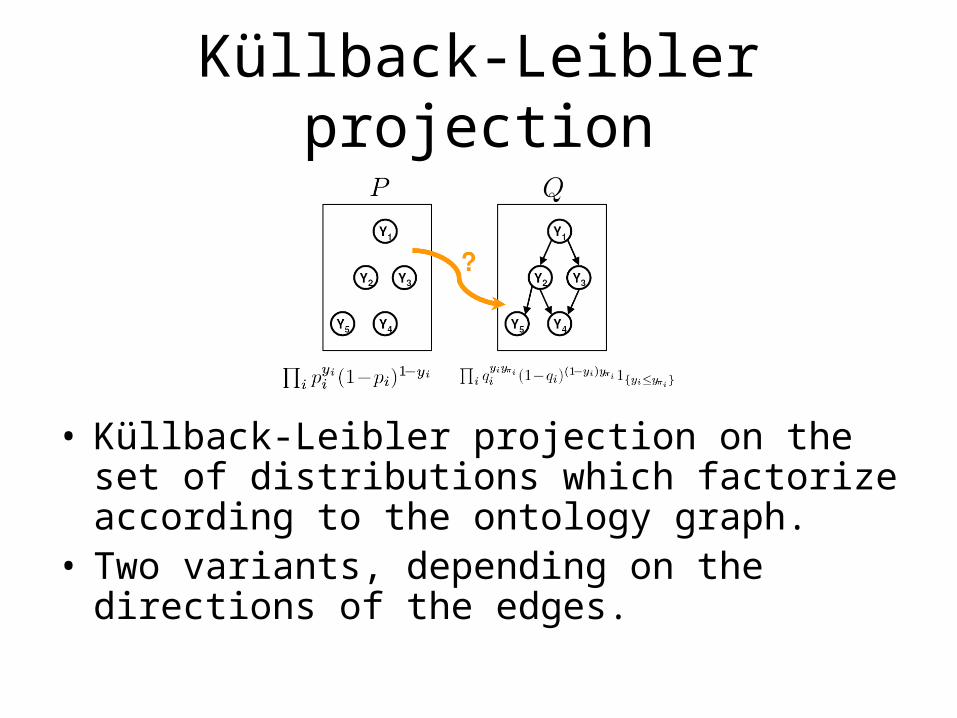
Küllback-Leibler projection
• Küllback-Leibler projection on the set of distributions which factorize according to the ontology graph.
• Two variants, depending on the directions of the edges.
Likelihood ratiosobtained from
logistic regression
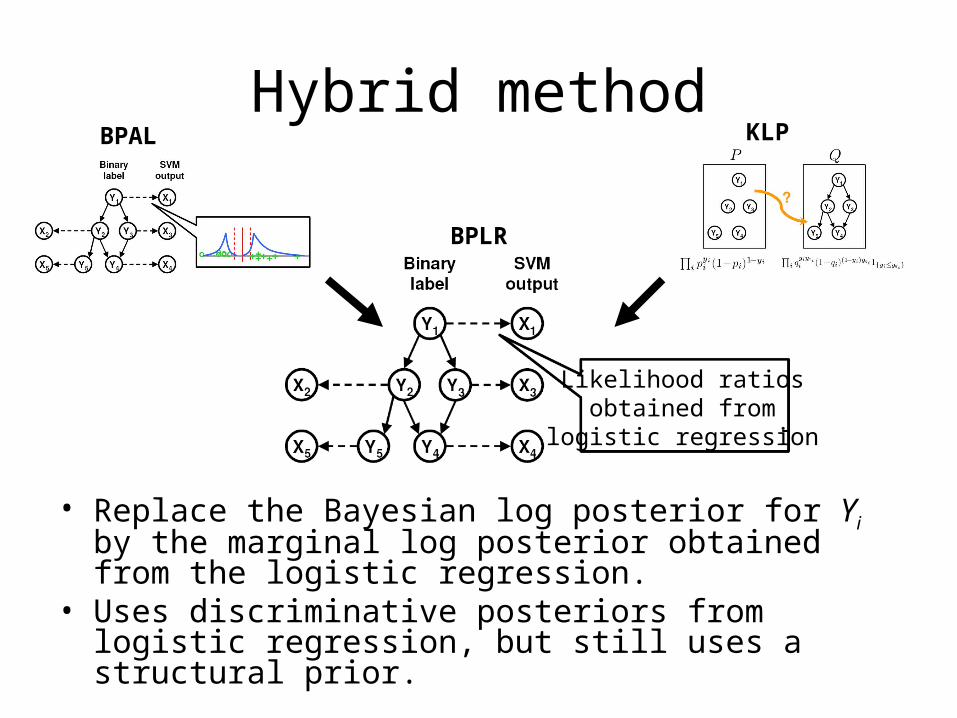
Hybrid method
• Replace the Bayesian log posterior for Yi by the marginal log posterior obtained from the logistic regression.
• Uses discriminative posteriors from logistic regression, but still uses a structural prior.
BPAL KLP
BPLR

Axes of evaluation
• Ontology– biological process– cellular compartment– molecular function
• Term size – 3-10 proteins– 11-30 proteins– 31-100 proteins– 100-200 proteins
• Evaluation mode– Joint evaluation– Per protein– Per term
• Recall– 1%– 10%– 50%– 80%

Legend
Belief propagation, asymmetric Laplace
Belief propagation, asymmetric Laplace, flipped
Belief propagation, logistic regression
Cascaded logistic regression
Isotonic regression
Logistic regressionKüllback-Leibler projection
Küllback-Leibler projection, flipped
Naïve Bayes, asymmetric Laplace

Pre
cisi
on
TP
/(T
P+
FP
)
Recall TP / (TP+FN)
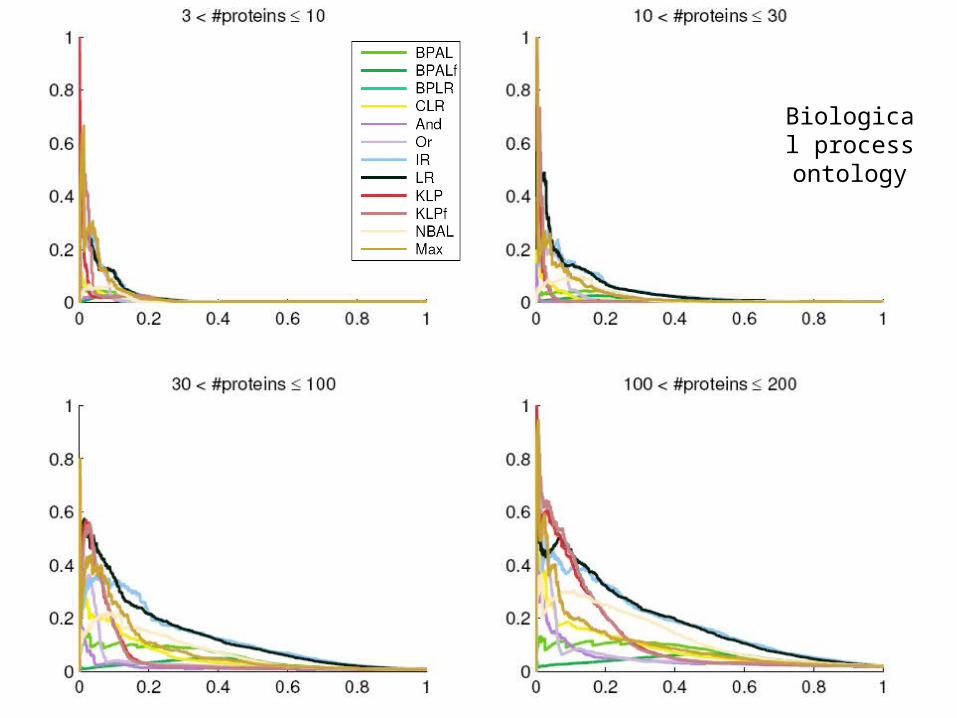
Joint evaluation
Biological process ontology
Large terms (101-200)
Biological process ontology

Molecular function ontology

Cellular compartment
ontology

Conclusions: Joint evaluation
• Reconciliation does not always help.
• Isotonic regression performs well overall, especially for recall > 20%.
• For lower recall values, both Küllback-Leibler projection methods work well.

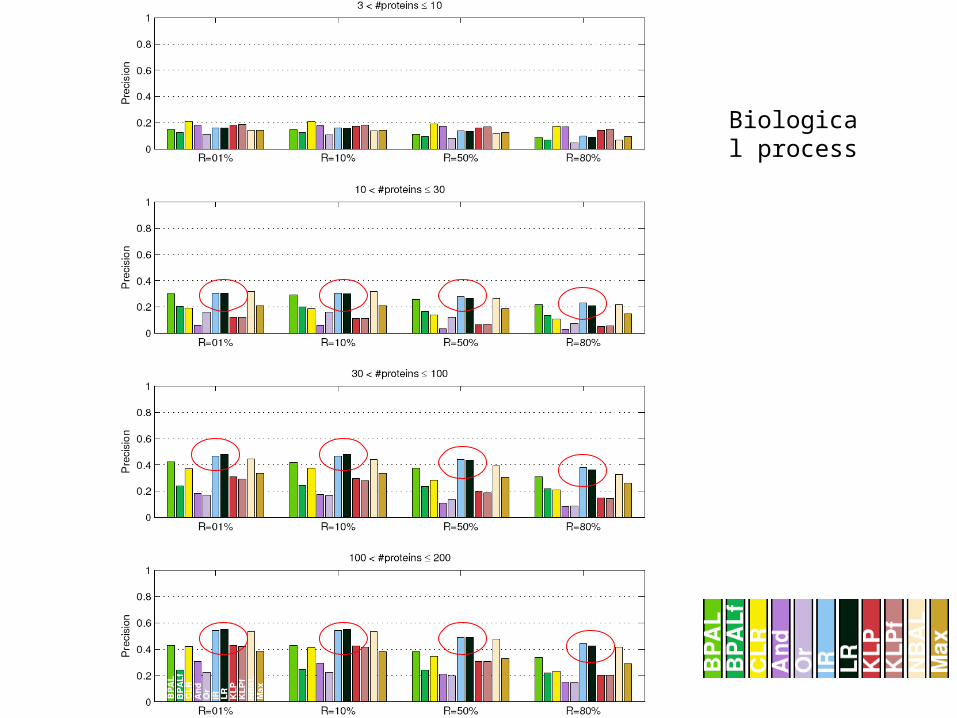
Average precision per protein
Biological process
All term sizes
Biological process

Statistical significanceBiological process
Large terms

Biological process
Large terms

Biological process
101-
200
31-1
0011
-30
3-10
953 proteins
435 proteins
239 proteins
100 proteins

Molecular function
101-
200
31-1
0011
-30
3-10
476 proteins
142 proteins
111 proteins
35 proteins

Cellular component
101-
200
31-1
0011
-30
3-10
196 proteins
135 proteins
171 proteins
278 proteins

Conclusions: per protein
• Several methods perform well– Unreconciled logistic regression– Unreconciled naïve Bayes– Isotonic regression– Belief propagation with asymmetric Laplace
• For small terms– For molecular function and biological process, we do
not observe many significant differences.– For cellular components, belief propagation with
logistic regression works well.

Average precision per term
Biological process
All term sizes

Biological process
101-
200
31-1
0011
-30
3-10
953 terms
435 terms
239 terms
100 terms

Molecular function
101-
200
31-1
0011
-30
3-10
476 terms
142 terms
111 terms
35 terms

Cellular component
101-
200
31-1
0011
-30
3-10
152 terms
97 terms
48 terms
30 terms

Conclusions
• Reconciliation does not always help.
• Isotonic regression (IR) performs well overall.
• For small biological process and molecular function terms, it is less clear that IR is one of the best methods.

Acknowledgments
Guillaume Obozinski
Charles Grant
Gert Lanckriet
Michael Jordan
The mousefunc organizers• Tim Hughes• Lourdes Pena-Castillo• Fritz Roth• Gabriel Berriz• Frank Gibbons
Per term for small termsBiological process
Molecular function
Cellular component