cours de mesurage – l’Évaluation psychologique du ... · 1. introduction un problème...
TRANSCRIPT

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 1
Cours de Mesurage – L’Évaluation Psychologique duChangement par la Technique des Auto-évaluations
Stéphane VautierUniversité de Toulouse
Abstract
Suppose Paul has rated himself yesterday and today by filling in an anxietyquestionnaire, and obtained the scores of 25 and 50 points. If it can be deducedthat he has become more anxious, this is a valid interpretation of his test scores.The interpretation is sound if the theory used to interpret the ratings is true. Aninterpretation based on Classical Test Theory is not valid because of measurementerror. A valid interpretation can be based on the principle of a step function. It isdeveloped for the case of two items, and tested against evidence from a previoustest-retest study. We argue that measurement of transient attributes with theself-rating technique is not achieved, and suggest an approach to the assessment ofchange that complements the difference score by taking the multivariate feature ofstate anxiety’s description into account.
RésuméSupposez que Paul s’est auto-évalué hier et aujourd’hui en remplissant un ques-tionnaire d’anxiété, et qu’il a obtenu les scores de 25 et 50 points. Si on peutdéduire qu’il est devenu plus anxieux, on a une interprétation valide de ses scorespsychométriques. L’interprétation est valable (sound) si la théorie utilisée pour in-terpréter ses réponses est vraie. Une interprétation fondée sur la Théorie Classiquedes Tests n’est pas valide à cause de l’erreur de mesure. Une interprétation validepeut reposer sur le principe d’une fonction par palier. Ce principe est élaboré pourle cas de deux items, puis mis à l’épreuve avec les données d’une étude test-retestantérieure. Nous soutenons que le mesurage de grandeurs psychologiques labiles àl’aide de la technique des auto-évaluations n’est pas effectif, et suggérons une ap-proche de l’évaluation du changement qui complète l’utilisation de la différence desscores en tenant compte du caractère multivarié des descriptions de l’anxiété-état.
Keywords: Anxiety; Description; Measurement error; Psychological assessment,Psychological measurement; Psychometrics; Reliability; Self-rating; State anxiety;Test scores; Validity.
Mots-clés Anxiété; Anxiété-état; Auto-évaluation; Description; Erreur de mesure;Évaluation psychologique; Fidélité; Mesurage psychologique; Psychométrie;Scores psychométriques; Validité.

1. Introduction
Un problème contemporain soulevé par le mesurage psychologique consiste à réconcilierl’éthique de la recherche scientifique et la demande sociale d’évaluation de grandeurs psy-chologiques comme l’anxiété-état. L’anxiété-état est une notion qui s’oppose à l’anxiété-trait par lecaractère transitoire, et non pas stable, qui lui est conféré. Notre stratégie dans ce cours consiste àappréhender le problème du mesurage psychologique non pas dans son ensemble, mais par le biaisd’une situation concrète d’évaluation. Cette situation est celle de notre ami hypothétique que nousnommerons Paul. Notre ami Paul a évalué son anxiété à deux occasions, en remplissant la formedite ‘état’ de l’inventaire d’anxiété état-trait (en anglais, STAI, Spielberger, Gorsuch, Lushene, Vagget Jacobs, 1993). Son score d’anxiété-état était de 25 points hier et de 50 points aujourd’hui. Laquestion qui se pose est de savoir si nous pouvons conclure que Paul est devenu plus anxieux.
1.1. La validité des arguments
Pour répondre à cette question nous allons devoir entrer dans diverses considérationsthéoriques. Le concept de validité doit être discuté dans le contexte du mesurage de l’anxiétéde Paul. La conception dite conventionnelle de la validité dans le domaine de l’évaluation psy-chotechnique est énoncée dans les Standards for Educational and Psychological Testing (AmericanEducational Research Association, American Psychological Association et National Council onMeasurement in Education, 1999) :
Validity refers to the degree to which evidence and theory support the interpretationsof test scores entailed by proposed uses of tests . . . . The process of validation in-volves accumulating evidence to provide a sound scientific basis for the proposed scoreinterpretations. (p. 9)
En français, cette définition peut se traduire de la manière suivante :
La validité désigne le degré auquel les faits et les arguments théoriques soutiennent lesinterprétations des scores psychométriques qui découlent de ce que l’on se propose defaire avec les tests . . . . Le processus de la validation implique l’accumulation des faitspour produire une base scientifique valable sur laquelle fonder ces interprétations.
Dans un article récent consacré à cette définition de la validité, Newton (2012) oppose la validitédes interprétations à ce qu’il appelle la "conception philosophique courante" (broder philosophicalconception, p. 17), qui peut être résumée de la manière suivante. Un argument de la forme ‘si palors c’ est valide si la conclusion c se déduit de la prémisse p. L’argument est valable (sound)s’il est valide et si p est vraie (e.g., Fogelin et Sinnott-Armstrong, 2001; Wheeler, 2001). Ainsi, sil’argument est valable, sa conclusion est vraie.
Nous ne percevons pas d’antagonisme fondamental entre la définition des Standards etl’acception logique de la validité. Quoique nous ignorions comment mesurer un degré de support(voir aussi Krause, 2012), l’idée d’un support partiel n’exclut pas le cas particulier d’une interpréta-tion des scores psychométriques qui soit évaluée comme pleinement vs. aucunement supportée par
Ce cours a été élaboré dans le cadre d’une collaboration avec Michiel Veldhuis, actuellement en doctorat à l’Universitéd’Utrecht. Page web: http://w3.octogone.univ-tlse2.fr/vautier/ Courriel: [email protected].

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 2
les faits et la théorie. Si l’interprétation découle logiquement des faits et de la théorie, elle est validedu point de vue logique comme du point de vue des Standards. Cependant, l’approche logiquede la validité d’un argument ne se termine pas par un jugement de validité. Si l’interprétation estlogiquement valide, la question suivante est celle de la valeur (soundness) de tout l’argument. Cettequestion relève essentiellement du test et de la corroboration de la théorie (Popper, 1959, 1992),comme la définition des Standards le suggère explicitement.
Revenons à l’anxiété de Paul. Poser le problème de la validation nécessite de formuler leproblème de l’évaluation sous la forme ‘si p alors c’, pour que nous puissions évaluer si la con-clusion suit par déduction. Ainsi, la prémisse doit comprendre non seulement les faits mais aussila théorie qui permet de les interpréter de telle sorte que la conclusion suive par déduction. Parconséquent, l’argument interprétatif (Kane, 1992, 2001, 2006) s’exprime de la manière suivante :
Si Paul a obtenu les scores de 25 hier et de 50 aujourd’hui, et si la théorie est vraie,alors Paul est devenu plus anxieux.
Le clinicien peut vouloir évaluer le cours de l’anxiété de Paul pour toutes sortes de raisons.Ici, nous centrons notre analyse sur la finalité descriptive et non pas prescriptive de l’évaluation(Kane, 2001, pp. 338-339). Nous commençons par examiner comment justifier que la conclusion‘Paul est devenu plus anxieux’ est logiquement valide. Le STAI a été développé pour la recherche etpour la pratique clinique. L’arrière-plan psychométrique de l’interprétation des scores est la théorieclassique des tests (TCT, Lord et Novick, 1968) mise en œuvre dans la tradition de l’analyse facto-rielle (e.g., Nesselroade et Cable, 1974; Spielberger, Vagg, Barker, Donham et Westberry, 1980) etdans la tradition des modèles d’équations structurelles (e.g., Steyer, Ferring et Schmitt, 1992; Steyer,Majcen, Schwenkmezger et Buchner, 1989; Vautier, 2004; Vautier et Jmel, 2003; Vautier et Pohl,2009). On s’accorde à considérer qu’un score d’anxiété-état se décompose comme la somme d’unscore vrai et d’une erreur de mesure. Le score vrai de Paul hier est la moyenne de la série infiniedes scores qui auraient pu être observés hier lorsqu’il a complété le questionnaire d’anxiété-état ;de la même façon, le score vrai de Paul aujourd’hui est la moyenne de la série infinie des scores quiauraient pu être observés aujourd’hui lorsqu’il a à nouveau complété le questionnaire. Si le scorevrai est identifié avec ce que le test a pour but de mesurer, i.e., l’anxiété-état, le test est valide, ausens de Borsboom, Mellenbergh et van Heerden (2004) et de Borsboom, Cramer, Kievit, Scholtenet Franic (2009) – un test est valide s’il mesure ce qu’il est censé mesurer. Identifier le score vraiavec l’anxiété-état d’une certaine personne à un certain moment est une convention linguistique.Mais cette convention soulève un problème de validité parce que l’erreur de mesure devient unesource d’invalidité. Comme le score de 25 points est le résultat d’une expérience aléatoire unique,l’erreur de mesure qui lui est associée, à savoir la différence entre le score observé et le score vrai,est aussi le résultat d’une expérience aléatoire unique ; de la même manière, le score de 50 pointsest le résultat d’une expérience aléatoire unique, et l’erreur de mesure qui lui est associée résulted’une expérience aléatoire unique.
Quel que soit le modèle statistique utilisé pour les analyses de fidélité, la fidélité est la pro-priété d’une variable galtonienne (Danziger, 1987, 1990; Danziger et Dzinas, 1997; Lamiell, 2003,2013), c’est-à-dire, d’une variable définie sur un agrégat de personnes, tandis que ce qui est enjeu est la valeur du résultat de deux expériences aléatoires uniques pour l’interprétation des scoresde Paul hier et aujourd’hui. Comme les variables du test et du retest définies pour Paul hier etaujourd’hui varient dans l’ensemble des scores observables {20, 21, . . . , 80}, les scores vrais re-spectifs se trouvent quelque part dans l’intervalle [20, 80]. L’erreur de mesure se trouve autour du

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 3
score vrai dans un intervalle dont l’étendue maximale vaut 60 – il suffit que la probabilité des scoresextrêmes ne soit pas nulle. Comme le score vrai est inconnu, l’utilisateur du test doit considérer quel’erreur de mesure associée à tout score observé se trouve dans l’intervalle ] − 60, +60[.1 Ainsi,parmi les multiples possibilités de réalisation des scores de Paul, 25 et 50 points, un exemple estque le score vrai vaut 40 au test et au retest, avec une erreur de mesure de −15 au test, et de +10 auretest. Ainsi on a bien les scores observés de Paul hier, 40 − 15 = 25 et aujourd’hui, 40 + 10 = 50,auquel cas ces scores ne reflètent pas la stabilité du score vrai. Si nous venions à conclure sur labase de ces données et de la décomposition par la TCT que Paul est devenu plus anxieux, nous seri-ons fourvoyés. La prémisse de l’argument est vraie, puisque la décomposition des scores observésselon la TCT est tautologique et que nous n’avons pas de raison sérieuse de douter de la véracité desscores observés, mais l’argument est logiquement invalide. Par conséquent, l’utilisateur du test quiadopte la perspective logique pour évaluer la validité des arguments ne peut pas justifier que Paulest devenu plus anxieux en s’appuyant sur la validation du STAI.
1.2. À la recherche d’un principe de mesurage testable
Mais tout ceci ne suffit pas pour rejeter l’approche logique de la validité des arguments. Pourconclure de manière valide que Paul est devenu plus anxieux étant donnés ses scores d’anxiété-état,nous avons besoin d’un principe théorique qui lie logiquement l’anxiété de Paul et ses réponses auquestionnaire, de telle sorte que ses scores réfèrent à ses réponses. Notre approche est cohérenteavec le ‘programme fort’ de Cronbach (1988) pour la validation de construit et avec l’appel deBorsboom et al. (2004) à une "théorie du comportement de réponse" (theory of response behavior,p. 1062) ou au "processus de production des données" (data-generating process, Borsboom, 2008,p. 41). Les observations obtenues par la technique courante des auto-évaluations possèdent unecaractéristique particulière qui a des conséquences radicales pour la formulation du problème de lavalidité. Comme Vautier, Mullet et Bourdet-Loubère (2003) l’on remarqué, le répondant joue lerôle de la jauge. Les items du test sont nécessaires pour que la jauge fonctionne, mais le véritableinstrument de mesure est la jauge elle-même. C’est une métaphore trompeuse que d’appeler lequestionnaire d’anxiété-état du STAI un instrument de mesure, parce qu’un instrument, ou encoreun appareil (apparatus, Trendler, 2009), fonctionne, et il se trouve qu’un questionnaire ne fonctionnepas. Le questionnaire d’anxiété-état est nécessaire pour le fonctionnement du répondant. Ainsi,notre compréhension de la tradition scientifique est que toute évaluation scientifique de l’anxiété dePaul nécessite logiquement que les réponses de Paul aux items du questionnaire, et non pas les itemsdu questionnaire, soient validées, c’est-à-dire considérées comme des mesures de quelque chose.Avant que les réponses de Paul puissent être utilisées comme données dans des inférences validesà propos du cours de son anxiété, Paul doit être considéré comme s’auto-évaluant conformément àcertaines attentes théoriques.
Selon Trendler (2009), "In general we don’t use natural objects (i.e., objects as we find themin nature) for the purpose of apparatus construction; we usually have to tool and machine themfirst" (p. 586). Bien que ‘l’équation personnelle’ soit une notion bien connue dans l’histoire dela psychologie et des statistiques (Boring, 1957, chapitre 8; Stigler, 1986, chapitre 7), il sembleétrange d’avoir à valider une personne. Mais, tout comme l’observation téléscopique le fait pour
1Quand le score vrai tend vers 20, l’erreur de mesure maximale tend vers 60; quand le score vrai tend vers 80, l’erreurde mesure minimale tend vers −60. Pour une analyse détaillée du concept de score vrai, voir Vautier, Veldhuis, Lacot etMatton (2012).

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 4
l’astronome, la technique des auto-évaluations confère un rôle essentiel au répondant dans le pro-cessus de production des données. S’il était possible de lier son anxiété à ses réponses par le biaisd’une fonction de liaison (ou encore, de manière équivalente, de mesurage), cette fonction pourraitexpliquer comment les réponses de Paul (au test et au retest) dépendent de la variation de la quan-tité de son anxiété. En adoptant l’approche argumentative de la validité défendue par Kane (1992,2001, 2004a, 2004b, 2006), une telle tâche constitue la première partie de la tâche de validation, àsavoir la formulation de l’argument interprétatif – la seconde partie consiste à évaluer sa composantethéorique, c’est-à-dire la fonction de liaison. La formulation aurait alors la forme suivante :
Données = fonction(quantité d’anxiété de Paul) (1)
Pour valider les réponses de Paul, (i) cette fonction doit être intelligible et, dans le cadre d’unephilosophie réaliste de la recherche scientifique (Borsboom et al., 2004, 2009; Hood, 2009; Michell,2005) (ii) une variation dans les données assortie de l’hypothèse d’un principe théorique de liaisondevrait nous permettre de déduire que l’anxiété de Paul a changé. De plus, ce principe théoriquedoit être testable (ou encore et de manière équivalente, falsifiable).
Il importe que la forme numérique des données puisse être justifiée, parce que ce qui estobservé est un 20-uplet de réponses – il s’agit en effet d’une description vectorielle, multivariée,et non pas d’une description scalaire, univariée. À cet égard, examinons cette définition spécifiqued’un argument interprétatif selon Kane (2001) : "The interpretive argument involves a networkof inferences and assumptions leading from the observed scores to the conclusions and decisionsbased on the observed scores, and provides an explicit and fairly detailed statement of the proposedinterpretation" (p. 339). Nous pouvons traduire en français de la manière suivante : "l’argumentinterprétatif implique un faisceau d’inférences et d’hypothèses qui conduit des scores observés auxconclusions et aux décisions fondées sur les scores observés, et fournit une formulation expliciteet assez détaillée de l’interprétation proposée". Si les scores observés sont les scores du test aulieu des scores des items, cette définition confère de manière non critique le statut de données à ceque nous appelons ici les scores d’anxiété-état, puisque les données sont premièrement les réponsesaux items. Ainsi, une telle définition de l’argument interprétatif exclurait l’évaluation rationnellede l’argument implicite selon lequel un score est une mesure (i.e., le résultat d’un mesurage) – si,selon Kane (2011), "interpreting [test] scores as estimates of a trait is a choice" (p. 13), il n’y apas d’évaluation du tout mais un appel à une convention. Si les scores observés sont les scoresdes items, nous sommes d’accord avec Kane que "In some cases, it may be necessary to reject aproposed interpretation as untenable" (Kane, 2001, p. 339).
Les scores d’anxiété-état résultent de la somme des étiquettes numériques utilisées pour or-donner les réponses à tout item conformément à la sémantique de l’anxiété. Johnson (1943) aqualifié une telle pratique d’indexation numérologique ("index-numerology", voir aussi Essex etSmythe, 1999; Johnson, 1935). Comme l’écrit Brown (1992), "The very vagueness and multiplicityof metaphorical meaning is what makes it so powerful a social adhesive. Metaphor, through itsfamiliar literal referent, appears to offer self-evident, socially shared meaning to the unfamiliar" (p.13). Ce que nous pouvons traduire de la manière suivante : "Le caractère authentiquement vagueet multiple de la signification métaphorique est ce qui en fait un aussi puissant liant social. La mé-taphore, de par ses références littérales, semble offrir à celui qui n’est pas familier [avec ce dont ils’agit en fait] une signification qui va de soi, socialement partagée". Pour être intelligible sans lerecours à la métaphore, une somme de nombre naturels doit référer au comptage d’unités (voir aussiMaraun, 1998, pp. 455-456). Or les étiquettes ordinales d’une échelle de réponse ne réfèrent pas à

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 5
un comptage d’unités mais à des ordinaux. Par exemple, ‘1’ réfère à la première réponse possibledans l’échelle "‘Non’ (1), ‘Plutôt non’ (2), ‘Plutôt oui’ (3), et ‘Oui’ (4)" dans l’item ‘Je me senstendu(e) : 1, 2, 3, 4’.2 Par conséquent, la somme de nombres ordinaux n’a pas de sens propre :la première réponse ‘+’ la seconde réponse ne mesure ni une distance (échelle d’intervalle), ni unrang (échelle ordinale) ni un cardinal (comptage). Michell (2002) écrit que "Rating scale responseformats are bounded interval scales" (p. 1008 ; les formats de réponse d’une échelle évaluative sontdes échelles d’intervalle). Nous aurions préféré "les formats de réponse d’une échelle évaluativesont des intervalles" pour des raisons que nous détaillons dans la prochaine section. Par exemple,comme 4 − 3 = 2 − 1 = 1, ‘Oui − Plutôt oui’ devrait signifier la même chose que ‘Plutôt non −Non’, mais quelle est cette chose ? L’addition et la soustraction ne sont pas définies sur une échelleévaluative, pas plus que sur un ensemble d’échelles évaluatives.
À proprement parler, un score d’anxiété-état est une étiquette pour un sous-ensemble de 20-uplets. Par exemple, le score 25 réfère à l’ensemble de tous les 20-uplets tels que la somme des20 nombres qui codent les réponses vaut 25 – les nombres qui codent les réponses sont 1, 2, 3et 4. Ainsi, la proposition ‘Le score d’anxiété-état de Paul hier est 25’ signifie que son 20-upletde réponses observées hier appartient à l’ensemble ‘25’. De la même manière, la proposition ‘Lescore d’anxiété-état de Paul aujourd’hui est 50’ signifie que son 20-uplet de réponses observéesaujourd’hui appartient à l’ensemble ‘50’. Il ne suit pas que Paul est devenu plus anxieux parce queles nombres ne réfèrent pas à des quantités mais à des sous-ensembles – la proposition ‘25 < 50’est littéralement vide de sens. Éventuellement la proposition ‘la taille (ou encore le cardinal) del’ensemble 25 < la taille de l’ensemble 50’ pourrait être vraie, mais l’anxiété de Paul est clairementautre chose que la taille d’un sous-ensemble de 20-uplets.
Ce n’est pas tout. Au lieu de parler d’anxiété(-état) nous devons utiliser la notion de quan-tité d’anxiété de Paul dans un sens étroit et technique, ce qui illustre la différence entre un con-cept pré-scientifique et un concept scientifique (Bachelard, 1983) : tandis que l’anxiété-état réfèreà un sentiment qui mêle l’appréhension, l’incertitude et la peur irrationnelle (e.g., Spielberger etRickman, 1991), ce qui est un concept de la vie de tous les jours ("common-or-garden variety",Maraun, 1998, p. 436; voir aussi pp. 453-455, p. 458), la quantité d’anxiété de Paul est le conceptlogico-empirique d’un point dans un intervalle fini et continu – un segment –, qui est le domaine dedéfinition d’une fonction de liaison. Sa grammaire est simple et restrictive : le point peut bougersur le segment. Borsboom et al. (2004) défendent la définition "A measurement instrument is validif it measures what it purports to measure", et ils écrivent que "the question of what it is, precisely,that is measured can simply be resolved by pointing to the processes that lead to the measurementoutcomes" (p. 1067 – traduction : la question de savoir ce que c’est, précisément, qui est mesuré,trouve sa réponse dans le processus qui conduit aux résultats du mesurage –; voir aussi Borsboom etal., 2009). Mais de quel type de description s’agit-il? Un instrument peut fonctionner comme prévumême si nous ignorons pourquoi et même si nous ignorons quelle sorte d’essence ou de propriétéil mesure. Dans cette définition, la condition "if it measures what it purports to measure" pourraitavantageusement être remplacée par "s’il fonctionne comme prévu".
Par principe, la falsification est une question de logique (Popper, 1959, 1992) et on peutobjecter que les phénomènes empiriques décrits sous la forme de 20-uplets de réponses ne dépendentpas uniquement de la quantité d’anxiété. Dire que les données dépendent seulement de la fonction
2L’appel de Krause (2012) à des gradations, reconnues par consensus, de la ‘dimension psychologique’, n’est pasviable puisque le principe même de la technique des auto-évaluations consiste à confier au répondant la tâche de donnerune signification à l’échelle d’évaluation de l’item.

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 6
de la quantité d’anxiété de Paul est une idéalisation (voir Borsboom, 2008; Michell, 2013; Trendler,2009). Certes, étant donnés les faits falsifiants, on pourrait suggérer qu’il est néanmoins utile derechercher des explications pour cette situation inattendue par la théorie. L’instrument de mesure(i.e., Paul en train de s’évaluer à l’aide des items du questionnaire d’anxiété-état du STAI) pourraitencore être validé si on admet que parfois des données aberrantes sont observées et doivent êtreécartées. Mais être en position d’argumenter dans ce sens entraîne un coût pratique. En pratique,Paul n’est testé que quelques fois, ce qui est loin de suffire pour disposer du nombre d’observationsqui serait nécessaire pour poursuivre l’investigation. Supposons que le coût pratique ait été dûmentpayé. Si les faits falsifiants ne sont pas rares, on peut encore conjecturer que la fonction de laquantité d’anxiété de Paul est néanmoins correcte dans certaines conditions, même si elles sontinconnues. Le problème qui se pose alors est de savoir si les facteurs inconnus qui affectent sesréponses peuvent être découverts, pour spécifier les conditions qui garantissent une inférence valideà partir de la variation dans les données et de la fonction. Si les facteurs responsables ne sontpas découverts, ou s’ils ne peuvent pas être contrôlés, aucune conclusion valide ne peut être tiréede la variation dans les données et de la fonction, et la communauté engagée dans l’évaluationde l’anxiété-état devrait reconnaître que Paul ne se comporte pas comme un ‘anxioscope’ – noustraçons le parallèle avec la distinction entre un thermoscope et un thermomètre (voir Chang, 2004,pp. 41-42) pour souligner qu’un anxioscope n’est pas destiné au mesurage de quantités numériques.Même si cela est extrêmement insatisfaisant du point de vue de la demande sociale, nous avons àreconnaître que nous n’avons pas de connaissance scientifique (i.e., falsifiable et corroborée) de lamanière dont nous pourrions mesurer l’anxiété de Paul.
1.3. Parfois, la description et non pas le mesurage, peut suffire pour l’évaluation
Nous espérons qu’il est possible d’attirer l’attention des étudiants en psychologie sur le faitque le mesurage de l’anxiété-état par la technique des auto-évaluations nécessite un processus demesurage attribué au répondant, avec comme conséquence qu’un ‘anxioscope’ fondé sur la tech-nique d’auto-évaluation est un aboutissement prématuré, voire même impossible. Néanmoins, ilest encore possible de traiter les réponses à un questionnaire d’anxiété-état comme de l’informationutile dans le cadre d’une attitude théorique qui évite l’utilisation du concept nébuleux d’une quantitélatente qui réfère d’une part à un sentiment et d’autre part à un réseau de modèles statistiques gal-toniens (pour une analyse de la question dans une perspective plus large, voir Borsboom et al., 2009et Maraun et Gabriel, 2013). En pratique, les psychologues cliniciens qui utilisent des question-naires d’anxiété n’ont pas besoin de prétendre qu’ils mesurent quantitativement le cours de l’anxiétéde Paul, étant donné qu’une conclusion comme ‘Paul est devenu plus anxieux’ est métrologique-ment faible même si elle est sémantiquement forte. De plus, notre propre expérience suggère qu’ilsne se sentent pas à l’aise avec une interprétation littérale du terme mesurer (ou mesurage) puisque,lorsqu’on les interroge, ils se hâtent d’ajouter que les scores doivent être traités comme des don-nées floues qui doivent être agrégées à d’autres types de données, afin de former une impression.Nous allons donc soutenir que l’espoir que les répondants pourraient fonctionner comme des ‘anxio-scopes’ est sans doute naïf, et suggérer une autre approche de l’évaluation, qui épouse une positionplus rigoureuse concernant le langage descriptif employé pour concevoir la dynamique des signescliniques.
La première partie du cours présente le principe d’une fonction par palier et ses conséquencestestables lorsqu’il est généralisé à un test à deux items. Dans la seconde partie nous analysonsl’information théorique fournie par le test de ce principe sur des données test-retest collectées lors

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 7
Figure 1. Fonction par palier à seuils inconnus A, B, C associés à une échelle de Likert en quatrepoints.
d’une étude antérieure (Vautier et Jmel, 2003). Enfin, nous évaluons la situation actuelle qui consisteà prétendre qu’on sait mesurer sans aucun principe de mesurage, ou sans principe de mesuragecorrect, ainsi que les conséquences pratiques à en tirer pour l’évaluation de l’anxiété-état.
2. Comment Relier l’Anxiété aux Réponses ?
2.1. Une fonction par palier
Une fonction par palier est représentée sur la Figure 1. L’axe des abscisses représente ledomaine de la quantité de l’anxiété de Paul, ce qui est autant une question de définition ou encorede convention (Krause, 2012; Maraun, 1998), qu’une question d’affirmation existentielle ou on-tologique (Borsboom et al., 2004). Une origine est postulée, ce qui doit être interprété de manièreabsolue comme l’absence d’anxiété ; une quantité négative d’anxiété n’existe pas. Il existe probable-ment une quantité maximale d’anxiété au-delà de laquelle Paul n’est plus en état de s’auto-évaluer,ce maximum étant cependant inconnu. L’axe des ordonnées représente les quatre réponses possi-bles, qui sont ‘Non’ (1), ‘Plutôt non’ (2), ‘Plutôt oui’ (3) et ‘Oui’ (4). Maintenant, considérons toutevariation de la quantité d’anxiété de Paul : comment cette variation se traduit-elle sur l’échelle deréponse ? Et que nous apprend la variation observée sur l’échelle de réponse en termes de quantitéd’anxiété de Paul ?

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 8
Lorsque la quantité d’anxiété de Paul augmente de 0 jusqu’à une valeur inconnue A, Paulinvariablement choisit de répondre ‘1’ à l’item ‘Je me sens tendu(e)’. Inversement, lorsque nousobservons la réponse ‘1’, la quantité d’anxiété de Paul se trouve quelque part dans [0, A[. Lorsquecette quantité d’anxiété augmente de A à B tel que B > A, Paul invariablement choisit de répondre‘2’ à l’item. Inversement, lorsque nous observons la réponse ‘2’, la quantité d’anxiété de Paul setrouve quelque part dans [A, B[. Lorsque sa quantité augmente de B à C tel que C > B, Paulinvariablement choisit de répondre ‘3’ à l’item. Inversement, lorsque nous observons la réponse‘3’, la quantité d’anxiété de Paul se trouve quelque part dans [B, C[. Lorsque sa quantité d’anxiétéaugmente de C au maximum, Paul invariablement choisit de réponse ‘4’ à l’item. Inversement,lorsque nous observons la réponse ‘4’, la quantité d’anxiété se trouve quelque part au-dessus de C.Dans cette théorie, les seuils A, B et C sont évidemment inconnus.
Dire que l’item ‘Je me sens tendu(e) : 1, 2, 3, 4’ mesure la quantité d’anxiété de Paul estune convention linguistique. Elle dit que si un changement dans l’échelle de réponse est observé,un changement dans la quantité d’anxiété s’est produit. Mais la réciproque est fausse. Par exemple,considérons la valeur 0 < α < A. Si l’anxiété de Paul augmente de 0 à α, ce changement ne peutpas être détecté par ses réponses. Comme Borsboom (2008) l’a expliqué (voir p. 34), même siune fonction par palier est vraie, c’est-à-dire qu’une "causal chain (i.e., the measurement process)that links the [latent] variable structure to the data structure [is] deterministic" (p. 32), la quantitéd’anxiété ne peut pas être considérée comme observée. Les réponses ne réfèrent pas à des degrésmais à des intervalles ordonnés dont les étendues sont inconnues.
Une remarque épistémologique importante s’impose ici : c’est un fait logique que la quantitéd’anxiété n’est pas manipulable. Tout au moins, nous ignorons comment faire cela de manièrecontrôlée et éthique. Cette remarque est pertinente si l’on se souvient que Cronbach et Meehl(1955), dans leur présentation de la notion de validité de construit, utilisent l’exemple qui consisteà dire à un étudiant qu’il a raté son examen de psychologie (telling "a student that he has failed aPsychology I exam", p. 283). Ce qu’ils manipulaient en fait n’est pas la quantité d’anxiété, maisce qui est dit à l’étudiant. Il serait absurde d’affirmer que la quantité d’anxiété a été manipulée,puisque cette quantité réfère à quelque chose d’hypothétique. Maraun (1998) a fait une remarquesimilaire : "tacking the variable ‘amount of deprivation’ for the level of a drive is a misuse of theconcept of drive" (pp. 456-456). Dans la même veine, Borsboom (2008), Hood (2009) et Trendler(2009) ont respectivement observé : "We do not know how to establish that two people are equallyintelligent, independently of looking at their test scores" (p. 38); "What would it be to manipulatea psychological trait. . . ?" (p. 467), et "how should we identify, say, constant levels of ability?" (p.591). À cet égard, la définition de Borsboom et al.’s (2004), "a test is valid for measuring an attributeif and only if (a) the attribute exists and (b) variations in the attribute causally produce variationsin the outcomes of the measurement procedure" (p. 1061), s’avère quelque peu mystérieuse. Pourvalider un test à la Borsboom et al., on doit pouvoir assurer qu’une variation s’est produite au niveaude l’attribut. Mais comment faire si l’attribut n’a pas déjà été mesuré ? Hood (2009) a commentécette définition de la manière suivante : "Epistemology is conspicuously sidestepped in Borsboomet al.’s analysis. This is unfortunate since a metaphysical account of validity without a concomitantepistemology would seem to be of limited utility" (p. 462).
2.2. Deux fonctions par palier
Considérons maintenant un deuxième item d’anxiété-état, par exemple ‘Je me fais du souci :1, 2, 3, 4’. Encore une fois, nous pouvons définir une fonction par palier à seuils A′, B′, C′. Le

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 9
résultat crucial est que nous avons affaire à un nouveau monde d’observables. Le nouveau systèmede description est bivarié. Ses événements élémentaires sont des vecteurs, par opposition à desscalaires (Vautier, 2013, 2011). Le nouveau système de description est le produit cartésien
D = {1, 2, 3, 4}2
= {11, 12, 13, 14, 21, 22, 23, 24, 31, 32, 33, 34, 41, 42, 43, 44},(2)
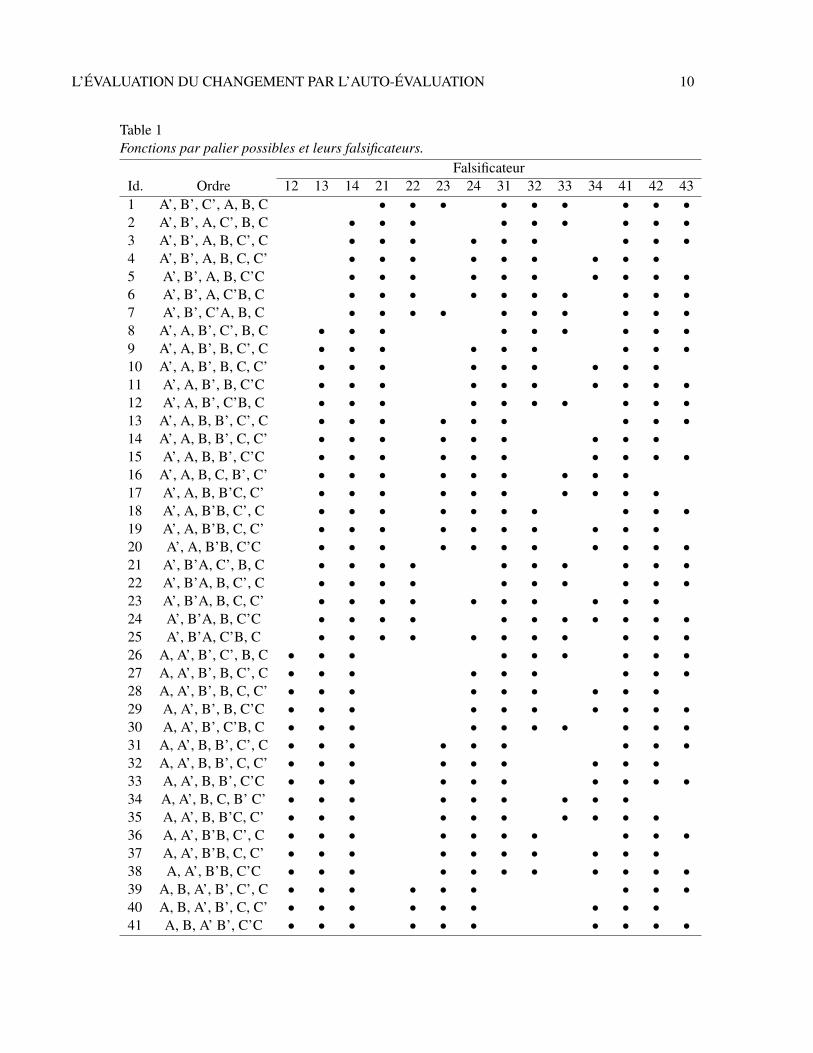
où toute paire ordonnée d = ab réfère aux réponses au premier et au deuxième item, respectivement.Comme les réponses, i.e., les couples de réponses, de Paul sont dans D, le problème de mesuragedevient : comment ses réponses hier et aujourd’hui nous permettent-elles d’inférer quelque choseà propos de son anxiété. En d’autres termes, quel principe théorique pouvons-nous définir pourinterpréter les données en termes d’anxiété de Paul ? Pour définir un principe théorique, nous avonsà expliciter comment les seuils A, B, C du premier item et les seuils A′, B′, C′ du second itemsont ordonnés. La Table 1 énumère 63 rangements, ou, de manière équivalente, fonctions par palierpossibles.
Par exemple, la fonction f1 : [0, max]→ {1, 2, 3, 4}2 est définie de la manière suivante :
å ∈ [0, A′[⇒ f1(å) = 11, (3)
å ∈ [A′, B′[⇒ f1(å) = 12, (4)
å ∈ [B′, C′[⇒ f1(å) = 13, (5)
å ∈ [C′, A[⇒ f1(å) = 14, (6)
å ∈ [A, B[⇒ f1(å) = 24, (7)
å ∈ [B, C[⇒ f1(å) = 34, (8)
å ∈ [C, max] ⇒ f1(å) = 44, (9)
où le symbole bizarre ‘å’ sert à désigner la quantité d’anxiété de Paul comme quelque chose qui peutêtre mesuré par ses réponses. La signification transportée par le terme ‘anxiété-état’ ne peut logique-ment pas s’imposer à å.3 Si f1 explique correctement comment Paul, en tant que jauge de sa propreanxiété, procède lorsqu’il répond aux deux items, les réponses {11, 12, 13, 14, 24, 34, 44} désig-nent sept intervalles ordonnés. Cet ensemble constitue un échelle ordinale à condition d’accepterque ces intervalles puissent être considérés comme des degrés – c’est-à-dire que leur étendue estnégligeable.4
Bien que Maraun (1998) ait écrit que "It is incoherent to claim that whether, and how, some-thing can be measured is a matter of empirical discovery" (p. 436), ce qui est compréhensible dansle cas d’une description univariée, une fonction par palier à deux items constitue un principe demesurage testable. Si toute réponse s’explique par f1, la réponse 21 ne peut être observée, parceque pour évaluer le premier item à 2, la quantité d’anxiété de Paul doit être supérieure à A, et que
3Nous sympathisons avec Borsboom et al. (2009) lorsqu’ils observent que "[the word ‘construct’] is used both torefer to the theoretical term used in a theory (i.e., a symbol), and to designate the (possible) referent of the term (i.e.,the phenomenon that is targeted by a researcher who uses a measurement instrument). This double usage has created anenormous amount of confusion" (p. 138). Néanmoins, nous espérons que, bien que cet usage soit "entrenched in bothconstruct validity theory and methodological language" (p. 138), il n’est pas trop tard pour reconnaître que les efforts desscientifiques n’ont pas à être commandés par le désir de valider des théories falsifiées, des arguments valides mais faux,ou des arguments invalides.
4Guttman (1944) a généralisé la fonction par palier à plusieurs items dans le contexte galtonien (voir aussi Torgerson,1958, chapitre 12).
L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 10
Table 1Fonctions par palier possibles et leurs falsificateurs.
FalsificateurId. Ordre 12 13 14 21 22 23 24 31 32 33 34 41 42 431 A’, B’, C’, A, B, C • • • • • • • • •
2 A’, B’, A, C’, B, C • • • • • • • • •
3 A’, B’, A, B, C’, C • • • • • • • • •
4 A’, B’, A, B, C, C’ • • • • • • • • •
5 A’, B’, A, B, C’C • • • • • • • • • •
6 A’, B’, A, C’B, C • • • • • • • • • •
7 A’, B’, C’A, B, C • • • • • • • • • •
8 A’, A, B’, C’, B, C • • • • • • • • •
9 A’, A, B’, B, C’, C • • • • • • • • •
10 A’, A, B’, B, C, C’ • • • • • • • • •
11 A’, A, B’, B, C’C • • • • • • • • • •
12 A’, A, B’, C’B, C • • • • • • • • • •
13 A’, A, B, B’, C’, C • • • • • • • • •
14 A’, A, B, B’, C, C’ • • • • • • • • •
15 A’, A, B, B’, C’C • • • • • • • • • •
16 A’, A, B, C, B’, C’ • • • • • • • • •
17 A’, A, B, B’C, C’ • • • • • • • • • •
18 A’, A, B’B, C’, C • • • • • • • • • •
19 A’, A, B’B, C, C’ • • • • • • • • • •
20 A’, A, B’B, C’C • • • • • • • • • • •
21 A’, B’A, C’, B, C • • • • • • • • • •
22 A’, B’A, B, C’, C • • • • • • • • • •
23 A’, B’A, B, C, C’ • • • • • • • • • •
24 A’, B’A, B, C’C • • • • • • • • • • •
25 A’, B’A, C’B, C • • • • • • • • • • •
26 A, A’, B’, C’, B, C • • • • • • • • •
27 A, A’, B’, B, C’, C • • • • • • • • •
28 A, A’, B’, B, C, C’ • • • • • • • • •
29 A, A’, B’, B, C’C • • • • • • • • • •
30 A, A’, B’, C’B, C • • • • • • • • • •
31 A, A’, B, B’, C’, C • • • • • • • • •
32 A, A’, B, B’, C, C’ • • • • • • • • •
33 A, A’, B, B’, C’C • • • • • • • • • •
34 A, A’, B, C, B’ C’ • • • • • • • • •
35 A, A’, B, B’C, C’ • • • • • • • • • •
36 A, A’, B’B, C’, C • • • • • • • • • •
37 A, A’, B’B, C, C’ • • • • • • • • • •
38 A, A’, B’B, C’C • • • • • • • • • • •
39 A, B, A’, B’, C’, C • • • • • • • • •
40 A, B, A’, B’, C, C’ • • • • • • • • •
41 A, B, A’ B’, C’C • • • • • • • • • •

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 11
Table 1(Continuée)
FalsificateurId. Ordre 12 13 14 21 22 23 24 31 32 33 34 41 42 4342 A, B, A’, C, B’, C’ • • • • • • • • •
43 A, B, A’, B’C, C’ • • • • • • • • • •
44 A, B, C, A’, B’, C’ • • • • • • • • •
45 A, B, A’C, B’, C’ • • • • • • • • • •
46 A, A’B, B’, C’, C • • • • • • • • • •
47 A, A’B, B’, C, C’ • • • • • • • • • •
48 A, A’B, B’, C’C • • • • • • • • • • •
49 A, A’B, C, B’, C’ • • • • • • • • • •
50 A, A’B, B’C, C’ • • • • • • • • • • •
51 A’A, B’, C’, B, C • • • • • • • • • •
52 A’A, B’, B, C’, C • • • • • • • • • •
53 A’A, B’, B, C, C’ • • • • • • • • • •
54 A’A, B’, B, C’C • • • • • • • • • • •
55 A’A, B’, C’B, C • • • • • • • • • • •
56 A’A, B, B’, C’, C • • • • • • • • • •
57 A’A, B, B’, C, C’ • • • • • • • • • •
58 A’A, B, B’, C’C • • • • • • • • • • •
59 A’A, B, C, B’, C’ • • • • • • • • • •
60 A’A, B, B’C, C’ • • • • • • • • • • •
61 A’A, B’B, C’, C • • • • • • • • • • •
62 A’A, B’B, C, C’ • • • • • • • • • • •
63 A’A, B’B, C’C • • • • • • • • • • • •
pour évaluer le second item à 1, sa quantité d’anxiété doit être inférieure à A′. Comme la fonctionf1 est définie de telle sorte que A′ < A (voir Table 1, colonne ‘Ordre’), cela crée une impossibilitélogique. Si la réponse observée est vraiment 21, elle falsifie f1. Comme D contient 16 réponses(bivariées) et que l’image de l’anxiété de Paul – i.e., l’image de [0, max] – par f1 contient septréponses, il y a 16 − 7 = 9 falsificateurs de f1. Ainsi, c’est une possibilité logique que les falsifi-cateurs de f1 ne seront jamais observés lorsqu’on demandera à Paul de s’auto-évaluer, auquel casnous considérerions comme une authentique découverte le fait que ces réponses n’aient jamais étéobservées dans des conditions convenables.
À présent, il devient possible de donner une signification technique aux scores d’anxiété-état associés à ce test à deux items. Si nous connaissions la fonction de mesurage, les réponsespourraient être adéquatement codées par les scores au test, c’est-à-dire par la somme arithmétiquedes étiquettes codant les réponses aux items : la signification théorique du score est clairementordinale, et les degrés réfèrent clairement à un ordre simple, potentiellement faible, des seuils qui setrouvent dans {A, B, C, A′, B′, C′} (pour des détails sur le concept d’ordre simple voir par exempleRoberts, 1985, chapitre 1). De plus, une différence de scores réfère à un nombre d’intervalles et sonsigne indique la direction du changement, par opposition à une distance, dont le mesurage nécessiteune échelle d’intervalle.

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 12
Figure 2. Distribution des 256 réponses test-retest selon le nombre de fonctions explicatives.
3. Tests Empiriques
En pratique, un psychologue intéressé par l’anxiété de Paul et disposant de ses réponsesignore le principe théorique nécessaire à leur interprétation. Il y a 44 = 256 réponses test-retestpossibles dans D2. Le problème consiste donc à examiner la situation épistémique correspondant àchaque cas. Commençons par la réponse 1111. Aucun changement n’est observé entre le test et leretest (11=11), et il n’y a pas besoin d’interpréter les observations en termes d’augmentation ou dediminution de l’anxiété. Toute réponse de la forme 1111, 1144, 4411 ou 4444 peut être expliquéepar les 63 théories possibles de Paul comme sa propre jauge. La réponse suivante est 1112, ce qui,d’après la Table 1 (colonne ‘12’), est compatible avec 25 rangements des seuils. On peut déduire def1, f2, etc. jusqu’à f25 que l’anxiété de Paul a augmenté. Plus généralement, toute réponse peut êtrecompatible avec 0 à 63 fonctions par palier. La distribution des 256 réponses qui ont été classéesselon le nombre de fonctions (ou de rangements des seuils) pouvant les expliquer est représentéesur la Figure 2. Trois situations typiques peuvent être distinguées.
3.1. Implausibilité et DPO-incomparabilité
La première situation correspond aux réponses qui n’ont pas de fonction explicative (bâtongauche sur la Figure 1). Le concept d’ordre produit direct (direct product order, DPO, Barbut etMonjardet, 1970) dans D, et ces corollaires, DPO-comparabilité et DPO-incomparabilité, sont utiles

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 13
pour comprendre qu’une réponse qui falsifie les 63 fonctions explicatives possède une propriétécaractéristique, à savoir que ses composantes test et retest sont DPO-incomparables.
Notons x1x2y1y2 une réponse test-retest. Deux réponses x1x2 et y1y2 sont DPO-comparablessi, pour tout i = 1, 2,
• xi ≤ yi ou• xi ≥ yi.
Plus généralement, la DPO-comparabilité de deux réponses multivariées signifie que l’une dominel’autre comme défini ci-dessus. Deux réponses sont DPO-incomparables si aucune ne dominel’autre. On peut montrer que la DPO-incomparabilité élimine toutes les fonctions explicatives pos-sibles. L’idée principale est que, par définition, le changement de la quantité d’anxiété ne peut pas seproduire simultanément dans des directions opposées. Dans le contexte de notre test à deux items,la DPO-incomparabilité apparaît dans 72/256 ≈ 28% des cas possibles. Le psychologue qui défendl’idée de l’anxiété comme quantité latente pourrait suggérer qu’une erreur de mesure s’est produitequand Paul s’est évalué (e.g., Woodward, 2010). Mais si on sait qu’une erreur est survenue durantle mesurage, les données ne peuvent pas, et ne doivent pas, être utilisées pour une inférence valide,de quoi il résulte qu’aucune conclusion valide ne peut être tirée des données. Ici, nous rejoignonsl’attitude de Kane (2001) vis-à-vis de la falsification, puisque dans ces cas, l’interprétation selonlaquelle les scores x1 + x2 et y1 + y2 réfèrent à des intervalles définis selon une fonction par paliersur [0, max] est "untenable" (p. 339).
3.2. Sous-identification théorique
La seconde situation correspond aux réponses qui sont compatibles avec plus d’une fonctionexplicative (bâtons 2 à 63 de la Figure 2). L’exemple d’une réponse de la forme aaaa a été donnéplus haut. Ainsi, le clinicien peut affirmer que rien n’exclut qu’il existe une fonction expliquantcomment Paul a évalué son anxiété. Et les réponses test et retest peuvent être DPO-comparées detelle sorte qu’il soit possible de déduire, à partir de la prémisse qu’une fonction explicative existe,que Paul est devenu plus ou moins anxieux, ou bien que les réponses ne révèlent pas de changement(ce qui ne veut pas dire qu’il n’y a pas eu de changement). La proposition est donc valide et ellesera valable s’il est vrai que Paul s’est évalué selon une fonction particulière.
3.3. Identification théorique
La troisième situation se produit lorsque les réponses sont compatibles avec exactement unefonction. La Figure 2 (bâton n◦ 1) montre que cette situation se produit dans 32/256 = 12.5% descas possibles. L’ensemble des réponses correspondantes comprend les couples qu’on peut formeravec les paires de l’ensemble
Cl(1) ={{11, 14}, {11, 41}, {12, 14}, {13, 14}, {13, 43}, {14, 14},
{14, 24}, {14, 34}, {14, 44}, {21, 24}, {21, 41}, {31, 34},
{31, 41}, {41, 41}, {41, 42}, {41, 43}, {41, 44}}.
(10)
Par exemple, considérons la réponse 1114. Comme 11 est compatible avec toutes les fonctions,seule la composante 14 apporte de l’information. Le nombre 1 signifie que la quantité d’anxiété dePaul se trouve avant le seuil A (premier item) ; le nombre 4 signifie que la quantité d’anxiété de Paulse trouve après le seuil C′ (second item). Donc, la seule fonction possible est f1, comme indiquédans la Table 1 : dans la colonne ‘14’, il n’y a qu’une cellule vide, qui correspond à la première ligne

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 14
( f1). Ainsi, la prochaine réponse de Paul constituera un test intéressant de cette fonction explicative,puisque la probabilité logique de falsifier ce principe de mesurage vaut 9/16.
3.4. Une nouvelle analyse de données test-retest
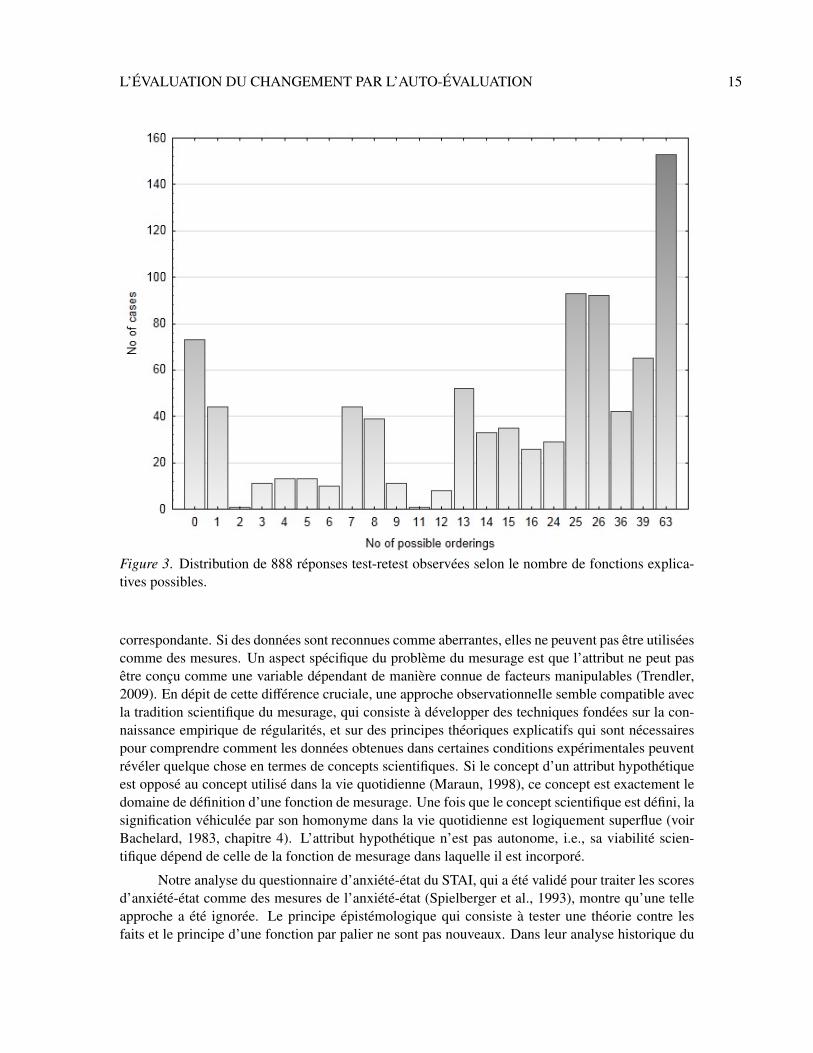
La proportion de faits de DPO-incomparabilité mesure la rareté des observations aber-rantes. En termes de test d’une hypothèse statistique, l’hypothèse statistique est que le nom-bre d’observations aberrantes est nul. Cette hypothèse est l’hypothèse nulle. Si l’impératifméthodologique exige que l’hypothèse nulle coïncide avec l’hypothèse que l’on cherche à rejeter –ce qui, comme Meehl (1967) l’a remarqué, semble étrange du point de vue de la logique du test desthéories –, un repère peut être déduit de la distribution binomiale. Comme nous venons de le voir,la probabilité logique d’observer un fait de DPO-incomparabilité est environ 0,28. En considérantl’échantillon de Vautier et Jmel (2003) qui est composé de 888 répondants, comme l’indépendanceexpérimentale peut être admise (les réponses de Paul n’ont pas influencé les réponses de Julie),l’observation de n faits de DPO-incomparabilité nous permet d’évaluer si ce nombre est significa-tivement petit au regard de la loi de probabilité B(888, .28). Considérons les deux premiers items dela version française du questionnaire d’anxiété-état du STAI, qui sont orienté vers l’anxiété (items3 et 4). Le nombre de faits de DPO-incomparabilité est n(3, 4) = 74, ce qui correspond à une prob-abilité cumulée de 2,38·10−48. Bien que la proportion ne semble pas négligeable, 74/888 ≈ 8%,elle est significativement plus petite que la proportion à laquelle on s’attendrait si les répondantsavaient répondu selon un principe d’équiprobabilité. Cependant, l’équiprobabilité n’a pas d’intérêtthéorique, si on ne suppose pas que les répondants répondent comme des machines aléatoires.
La distribution des 888 réponses classées selon le nombre de leurs fonctions explicativespossibles est représentée dans la Figure 3. La seconde situation – sous-identification théorique– s’est produite 771 fois. Ainsi, dans environ 87% des cas, l’évaluation du cours de l’anxiétédoit s’effectuer dans la situation épistémique de plausibilité et d’indétermination de la fonction demesurage qui pourrait sous-tendre les réponses observées. La troisième situation – identificationthéorique – s’est produite 44 fois. Il est intéressant d’observer les effectifs des paires correspon-dantes. L’ensemble ordonné des cardinaux des classes induites respectives est
Card = (5, 9, 1, 6, 2, 1, 4, 2, 1, 1, 2, 3, 2, 0, 1, 3, 1). (11)
Par exemple, la paire {11, 14} a été observée cinq fois. Si on suppose que les réponses résultentd’un processus de mesurage décrit par les fonctions respectives, les différences individuelles dansl’ensemble des jauges possibles ne peuvent pas être déniées, ce qui détruit la plausibilité d’un mod-èle psychométrique galtonien fondé sur un ordre des seuils unique (voir aussi Borsboom et al., 2009,pp. 158-160, et Krause, 2012, note 2).
4. Discussion
Le problème de l’évaluation du cours de l’anxiété de Paul a été formulé de telle sorte que laquestion est de savoir si un argument valide est valable. Cet argument a la forme
variation dans les données et fonction explicative⇒ variation de la quantité d’anxiété.
Nous proposons de considérer que le mesurage de l’anxiété-état en particulier, et de n’importe quelattribut psychologique instable en général, soulève un problème de valeur (soundness), étant en-tendu que des arguments valides sont exigibles pour une qualification scientifique de l’évaluation
L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 15
Figure 3. Distribution de 888 réponses test-retest observées selon le nombre de fonctions explica-tives possibles.
correspondante. Si des données sont reconnues comme aberrantes, elles ne peuvent pas être utiliséescomme des mesures. Un aspect spécifique du problème du mesurage est que l’attribut ne peut pasêtre conçu comme une variable dépendant de manière connue de facteurs manipulables (Trendler,2009). En dépit de cette différence cruciale, une approche observationnelle semble compatible avecla tradition scientifique du mesurage, qui consiste à développer des techniques fondées sur la con-naissance empirique de régularités, et sur des principes théoriques explicatifs qui sont nécessairespour comprendre comment les données obtenues dans certaines conditions expérimentales peuventrévéler quelque chose en termes de concepts scientifiques. Si le concept d’un attribut hypothétiqueest opposé au concept utilisé dans la vie quotidienne (Maraun, 1998), ce concept est exactement ledomaine de définition d’une fonction de mesurage. Une fois que le concept scientifique est défini, lasignification véhiculée par son homonyme dans la vie quotidienne est logiquement superflue (voirBachelard, 1983, chapitre 4). L’attribut hypothétique n’est pas autonome, i.e., sa viabilité scien-tifique dépend de celle de la fonction de mesurage dans laquelle il est incorporé.
Notre analyse du questionnaire d’anxiété-état du STAI, qui a été validé pour traiter les scoresd’anxiété-état comme des mesures de l’anxiété-état (Spielberger et al., 1993), montre qu’une telleapproche a été ignorée. Le principe épistémologique qui consiste à tester une théorie contre lesfaits et le principe d’une fonction par palier ne sont pas nouveaux. Dans leur analyse historique du

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 16
concept de ‘construit hypothétique’, Lovasz et Slaney (2013) écrivent que "intervening variables . . .denote mathematically defined functions among observables" (p. 26). La quantité d’anxiété jouele rôle d’une variable intervenante dans le contexte d’une fonction de mesurage falsifiable et dansune large mesure, falsifiée. Néanmoins, tout se passe comme si la communauté des utilisateurs desscores d’anxiété-état acceptaient de bonne grâce de mesurer l’anxiété-état sur la base d’une index-ation numérologique (Johnson, 1943) qui imite les résultats numériques des appareils de mesuredigitaux, et d’un effort colossal pour conforter l’idée d’une variable latente dans la tradition galtoni-enne de la doctrine de la validité de construit (Cronbach et Meehl, 1955) et des modèles à variableslatentes (Maraun et Gabriel, 2013; pour des études centrées sur l’anxiété, voir Steyer, Ferring etSchmitt, 1992; Steyer, Majcen, Schwenkmezger et Buchner, 1989; Vautier, 2004; Vautier et Jmel,2003; Vautier et Pohl, 2009),5 avec pour résultat que l’erreur de mesure invalide toute interprétationen termes de scores vrais.
Nous interprétons cette situation comme le symptôme de l’intéressement de la recherche, paropposition à la recherche désintéressée (Michell, 1997a, 1997b; Vautier et al., 2012). La traditionexpérimentale du mesurage scientifique implique qu’aucune technique de mesurage ne peut êtrevalidée si elle résulte de connaissances scientifiques non validées, parce que le fait qu’un instrumentde mesure ne réponde pas normalement aux conditions initiales est visible. En psychologie, lesattributs que l’on veut mesurer ne sont pas appréhendés expérimentalement, i.e., ils ne peuventpas être de véritables variables dépendantes ni des conditions contrôlées dans le sens expérimentaldu terme, ainsi que Trendler (2009) l’a montré. Et la méthodologie galtonienne et probabilistemise en œuvre pour l’analyse les données rend très difficile la détection de la défaillance d’uninstrument. En fait, l’incorporation par défaut de la composante aléatoire dans les modèles demesure psychométriques (e.g., Mellenbergh, 1996) ratifie l’échec du mesurage avant même quel’ajustement du modèle aux données ne soit évalué, et le mesurage est remplacé par l’estimation deparamètres statistiques. De plus, dans la pratique de validation des questionnaires d’auto-évaluation,le répondant, Paul par exemple, n’est jamais considéré comme un appareil de mesure naturel, et cequi est validé est un dispositif linguistique.
Le besoin de mesurer semble plus pressant que le besoin de tester des principes demesurage. Les principes de mesurage devraient expliquer comment l’instrument/répondant fonc-tionne lorsqu’il utilise le questionnaire. Il est difficile de savoir si la communauté manque dediscipline dans le test des théories possibles (Popper, 1959, 1992), aussi bien que de maîtrise dela polysémie du concept de nombre (Cliff, 1992; Essex et Smythe, 1999; Michell, 1997a, 2000;Schönemann, 1994). Il est aussi possible que la communauté rejette une façon de faire de larecherche si cette façon ne garantit pas que des concepts de la vie de tous les jours puissent êtremesurés. Si cela est vrai, on comprend que le problème de la validité n’est pas de savoir si lemesurage s’est produit ou pas, mais plutôt de savoir comment justifier qu’un score psychométriquepuisse être interprété comme une mesure, étant donné que le mesurage a eu lieu d’une manière oud’une autre. Dans les deux cas, il n’est pas surprenant qu’aucun effort sérieux ne soit encouragépour obtenir des faits contrariants, ni même que les faits contrariants soient passés sous silence.
5À cet égard, la manière dont Cizek (2012) définit la validité est exemplaire : "[Validity] is a property of inferencesabout scores, generated by a specific instrument, administered under acceptable conditions to a sample of examinees fromthe intended population" (p. 35).

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 17
4.1. Vers des ‘anxioscopes’ personnels ?
Nous sommes plutôt sceptiques quant à la faisabilité d’anxioscopes personnels. Deux itemsd’anxiété-état génèrent six seuils et, en négligeant l’étendue des intervalles associés, quatre à sixdegrés sur une échelle ordinale (voir Table 1, colonne ‘Ordre’). Les scores d’anxiété-état actuels,qui varient dans {20, 21, . . . , 80}, constituent 61 degrés. Pour que la précision de mesure puisse êtreaccrue de quelques degrés à 61 degrés, il doit être démontré que le mesurage fondé sur quelquesseuils est conquis. La possibilité de mesurer l’anxiété de Paul repose sur l’hypothèse forte de légalitédes réponses de Paul. Borsboom (2008) a noté que "for data patterns to count as measures of somevariable structure, there must be a causal law that connects positions in the variable structure withthe values of measurement outcomes" (pp. 44-45; voir aussi Chang, 2004, pp. 51-52; Krantz, 1972).Mais les réponses aux items sont des actes de langage et, d’après Searle (1983), les actes de langageobéissent à une causalité intentionnelle par opposition à la causalité légale. Ce serait un miraclesi une fonction de mesurage résistait au test consistant à demander aux répondants de s’évaluer àplusieurs reprises ou, en cas de falsification, si on pouvait montrer que les observations aberrantessont rares ou surviennent dans des conditions expérimentales clairement identifiées.
Supposons que le miracle d’une fonction de mesurage persistante arrive, nous avons trouvéun répondant qui répond comme un anxioscope – nous aurions alors à ignorer l’oxymore de Luce(1995), qui résulte du fait qu’il suffit d’informer n’importe quelle personne de ce que ses éval-uations obéissent à une loi pour la rendre capable de la falsifier. L’étape suivante consisterait àvalider non pas un anxioscope, mais un anxiomètre, c’est-à-dire à contrôler la quantité d’anxiété demanière expérimentale de telle sorte qu’une métrique pourrait être établie, comme ce fut le cas pourl’élaboration des thermomètres par exemple (Chang, 2004; Sherry, 2011). Ici le problème demeure :comment manipuler une quantité métaphorique ?
Avant d’examiner les conséquences pratiques de notre analyse, qui va nous conduire àdéfendre une position rigoureusement descriptive pour l’évaluation du changement fondée sur lesauto-évaluations, il convient de répondre à l’objection contre l’opérationnalisme. L’objection con-siste à rejeter la réduction des concepts scientifiques aux opérations empiriques (Chang, 2009). Eneffet, une définition opérationnelle pour un concept scientifique est insuffisante dans une perspectiveréaliste (i.e., lorsqu’on considère que ce à quoi réfère un concept scientifique existe indépendam-ment de l’observateur), puisque les cadres descriptifs ne peuvent pas être identifiés à la réalité,et que les données (ou descriptions) ne peuvent pas être identifiées aux phénomènes (Woodward,2000). Mais ce serait une erreur de croire que les définitions opérationnelles devraient être évitéesdans la recherche scientifique, en particulier si le but est l’élaboration de techniques de mesurage.L’évitement des définitions opérationnelles implique l’évitement de la testabilité, ce qui aboutit àune forme de vérificationnisme (voir Kane, 2001, p. 327, à propos du biais de confirmation dans larecherche pour la validation). Mais la vérification ne peut pas être le seul outil épistémologique pourle progrès scientifique, parce qu’elle est centrée sur les faits qui confirment, tandis que le progrèsscientifique dépend aussi de la détection de nos erreurs (Bachelard, 1983; Popper, 1959, 1992).
L’enjeu scientifique consiste à relier les définitions opérationnelles de telle sorte quele réseau des relations entre les cadres descriptifs constitue le concept scientifique (Granger,1995). C’est pourquoi la fonction de mesurage remplit un rôle constitutif dans notre approche.L’opérationnalisme est un pré-requis pour qu’on soit capable d’affirmer que la quantité d’anxiété,i.e., un point dans [0, max], est mesurée par les réponses à certains items, puisque la significationscientifique de cette affirmation est qu’il existe un ordre des seuils des items. Si aucun ordre ne

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 18
peut être découvert, c’est une question définitoire, et non pas empirique, de décider si les réponsesà un item ‘mesurent’ une sorte d’anxiété, étant entendu que le répondant est capable d’élaborer lasignification de l’item – le contenu de la proposition ainsi que les réponses possibles (‘Non’, etc.).Mais, contrairement à l’ingénieur social qui veut projeter le vecteur des réponses sur une ligne dedécision ("decision line", Coombs, 1964, chapitre 13), ou projeter les personnes testées dans unmonde simplifié d’avatars (Vautier et al., 2012), le scientifique n’est pas en position de décréterun ordre, puisque c’est une question empirique. Nous testons des principes de mesurage fondéssur des définitions opérationnelles. Si, face à des faits falsifiants, nous disqualifions les définitionsopérationnelles au lieu de reconnaître qu’elles nous apprennent que notre désir de mesurer demeureun désir, une sorte de dénégation se produit. Nous ne voyons pas de justification rationnelle pourpersister dans l’emploi d’un langage de mesurage si ses implications logiques ne ‘collent’ pas avecles faits (voir aussi Borsboom et al., 2009; Michell, 1997a, 1997b, 2000, 2006, 2008).
4.2. Conséquences pratiques
Nous allons d’abord examiner la situation dans laquelle l’utilisateur du test conçoitl’évaluation du cours de l’anxiété de Paul dans le language tri-valué de l’augmentation, de la diminu-tion, ou de l’absence de changement. Nous allons montrer que l’exigence d’inférences valables entermes de détection d’une augmentation ou d’une diminution de l’anxiété conduit à un appauvrisse-ment descriptif de l’état clinique de Paul. Ensuite, nous envisagerons ce qu’on peut faire avec unedescription multivariée et riche de l’état clinique de Paul, pourvu qu’un language descriptif plussophistiqué, un language quadri-valué, remplace le language tri-valué.
4.2.1. L’évitement de la DPO-incomparabilité. Un fait de DPO-incomparabilité falsifietoutes les fonctions par palier possibles et, par conséquent, l’argument ‘(données, fonction) alorsconclusion’ est valide mais non valable. Les données laissent l’utilisateur du test sans connaissancepositive sur le cours de l’anxiété de Paul, puisqu’il n’est pas possible de défendre une interprétationplausible de la manière dont Paul a fonctionné lorsqu’il a répondu aux items. La situation concrèteest que le mesurage a échoué. Ainsi, l’utilisateur du test est conduit à minimiser la probabilité detels événements lorsqu’il utilise le test.
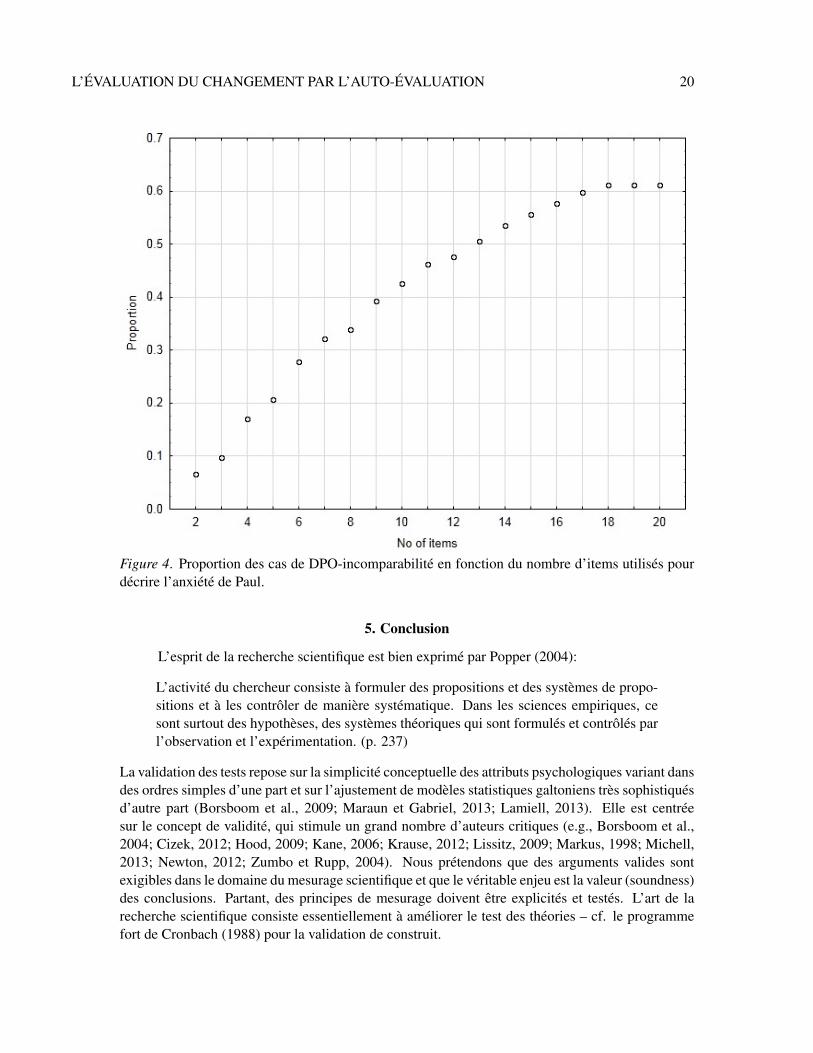
La Figure 4 affiche la proportion des événements de DPO-incomparabilité dans l’échantillonde Vautier et Jmel’s (2003), en fonction du nombre d’items qui sont utilisés pour décrire l’anxiétéde Paul.6 Ainsi, le questionnaire complet est inutile pour tirer une conclusion dans environ 60% descas – les événements au test et au retest sont incomparables. La TCT dit que plus il y a d’items,plus fidèle est la variable des scores. Mais nous avons vu que le problème fondamental de la TCTest qu’elle suppose que les utilisateurs des tests acceptent de tirer des conclusions invalides, l’erreurde mesure ne pouvant être utilement limitée. Le problème théorique est que l’utilisateur du testest engagé par l’hypothèse selon laquelle l’anxiété de Paul peut être conçue comme un attribut quiaugmente, diminue ou reste stable. Malheureusement, une telle hypothèse n’est pas corroborée parl’approche qui combine la description de l’anxiété-état permise par le le questionnaire d’anxiété-état du STAI et le principe d’une fonction par palier. De manière paradoxale, l’hypothèse impliqueque pour vérifier le principe de mesurage, la richesse descriptive de l’état clinique de Paul doit êtreréduite, ce qui semble déraisonnable.
4.2.2. Une théorie descriptive du changement de l’anxiété-état. La situation actuelle estque, dans la plupart des cas, nous ignorons comment les réponses aux items pourraient mesurer un
6Les items ont été ajoutés selon un ordre arbitraire.

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 19
attribut quantitatif hypothétique. Les descriptions empiriques restent disponibles, dans un languagequi est plus complexe que celui d’une fonction par palier falsifiée. Ce language descriptif est quadri-valué, puisque l’anxiété de Paul peut (i) DPO-augmenter, (ii) DPO-diminuer, (iii) partiellementaugmenter et diminuer, ce qui peut se résumer par ‘changer de manière hétérogène’ ou (iv) resterstable.
Etant donné que l’item est évalué sur une échelle de Likert en quatre points, il y a septpossibilités à prendre en compte pour décrire un changement potentiel de l’état anxieux de Paul (etnon pas de sa quantité d’anxiété) :
1. moins trois degrés – de 4 à 1,2. moins deux degrés – de 4 à 2 ou de 3 à 1,3. moins un degré – de 4 à 3, 3 à 2, ou 2 à 1,4. pas de changement – de 4 à 4, 3 à 3, 2 à 2, ou 1 à 1,5. plus un degré – de 1 à 2, 2 à 3, ou 3 à 4,6. plus deux degrés – de 1 à 3 ou 2 à 4,7. plus trois degrés – de 1 à 4.
Ainsi, le cours de l’état d’anxiété (et non pas de l’anxiété-état comme quantité) peut être évaluépar le bais d’une approche multivariée en utilisant un vecteur de sept composantes. Par exemple,considérons les deux 10-uplets de réponses (test et retest) suivants :
Test 1 2 1 1 1 1 1 1 1 1Retest 3 3 2 3 2 3 4 4 2 3Changement +2 +1 +1 +2 +1 +2 +3 +3 +1 +2
(12)
Le vecteur de changement correspondant comptabilise chaque type de changement, soit
δd = 0000442, (13)
où les sept nombres signifient• pas de changement de type ‘−3’,• pas de changement de type ‘−2’,• pas de changement de type ‘−1’,• pas de changement de type ‘pas de changement’,• quatre changements de type ‘+1’,• quatre changements de type ‘+2’ et• deux changements de type ‘+3’,
respectivement.Soient a, b, c et d des nombres dans {0, 1, . . . , 10} tels que a + b + c + d = 10. Un vecteur
de changement de type 000abcd décrit une DPO-augmentation, un vecteur de changement de typeabcd000 décrit une DPO-diminution, un vecteur de changement de type 000a000 décrit la stabilité(et a = 10), et le reste des vecteurs possibles décrit des cas de changement DPO-hétérogènes,qui correspondent à des faits de DPO-incomparabilité. Le language descriptif peut être encoreplus travaillé techniquement, mais ce n’est pas le but de ce cours. Le but principal du cours et demontrer qu’il est possible de réconcilier l’esprit scientifique et les besoins de l’évaluation cliniqued’attributs comme l’anxiété-état, à condition que les raisons qui nous poussent à concevoir l’étatanxieux comme un attribut quantitatif soient examinées de manière critique.
L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 20
Figure 4. Proportion des cas de DPO-incomparabilité en fonction du nombre d’items utilisés pourdécrire l’anxiété de Paul.
5. Conclusion
L’esprit de la recherche scientifique est bien exprimé par Popper (2004):
L’activité du chercheur consiste à formuler des propositions et des systèmes de propo-sitions et à les contrôler de manière systématique. Dans les sciences empiriques, cesont surtout des hypothèses, des systèmes théoriques qui sont formulés et contrôlés parl’observation et l’expérimentation. (p. 237)
La validation des tests repose sur la simplicité conceptuelle des attributs psychologiques variant dansdes ordres simples d’une part et sur l’ajustement de modèles statistiques galtoniens très sophistiquésd’autre part (Borsboom et al., 2009; Maraun et Gabriel, 2013; Lamiell, 2013). Elle est centréesur le concept de validité, qui stimule un grand nombre d’auteurs critiques (e.g., Borsboom et al.,2004; Cizek, 2012; Hood, 2009; Kane, 2006; Krause, 2012; Lissitz, 2009; Markus, 1998; Michell,2013; Newton, 2012; Zumbo et Rupp, 2004). Nous prétendons que des arguments valides sontexigibles dans le domaine du mesurage scientifique et que le véritable enjeu est la valeur (soundness)des conclusions. Partant, des principes de mesurage doivent être explicités et testés. L’art de larecherche scientifique consiste essentiellement à améliorer le test des théories – cf. le programmefort de Cronbach (1988) pour la validation de construit.

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 21
La falsification des principes de mesurage soulève un problème scientifique. Les théories sci-entifiques sont des idéalisations et les idéalisations ne peuvent pas être vraies dans n’importe quellecondition. Par conséquent, le problème est de diagnostiquer si les données que l’on veut interprétercomme des mesures ont été produites dans des conditions convenables ou pas. Si on accepte que lesdonnées sont des mesures, le problème consiste à éviter la sur-précision dans l’interprétation. Parexemple, en supposant qu’une fonction par palier est correcte, l’absence de changement dans lesdonnées n’implique pas l’absence de changement au niveau théorique de la quantité d’anxiété. Sion décide que les données sont aberrantes, ces données ne peuvent pas du tout être utilisées commedes mesures, en particulier si des décisions délicates devaient en dépendre.
Notre approche du mesurage psychologique s’applique à tout attribut labile. Évaluer le coursde l’anxiété de Paul s’avère une tâche difficile, mais la sous-tâche théorique n’est pas insurmontable,puisque la variation d’une quantité hypothétique est intelligible. Le mesurage des attributs qui,par définition, ne varient pas pour un répondant, mais dépendent de manière épistémique de sesréponses, jette un défi plus difficile, pour deux raisons : (i) les variations intra-individuelles falsifientl’hypothèse qu’on mesure un point fixe et (ii) une approche exploitant la variation inter-individuelleexige que les répondants soient interchangeables en tant qu’instruments de mesure.
Il est possible et même probable que les répondants ne puissent pas être décrits comme desinstruments de mesure à cause de leur caractère biologique, social, psychologique ou conscient.Néanmoins, un tel état des choses n’exclue pas une évaluation psychologique fondée sur des signescliniques. Mais il exclut que la communauté intéressée par l’évaluation psychologique fondée surles signes cliniques se comporte comme si des mesures étaient disponibles. Tant que des principesde mesurage n’auront pas été découverts par la recherche dans les réponses des répondants, nous,psychologues, ne sommes pas habilités à affirmer sérieusement que nous mesurons l’anxiété-état dePaul quand nous considérons ses réponses. Ceci est valable pour tout attribut psychologique labilepour lequel nous calculons un score psychométrique par indexation numérologique. Heureusement,parfois, nous n’avons pas besoin de faire cela. Nous pouvons réconcilier le langage de nos cadres de-scriptifs avec le langage de nos construits. Si nos buts pour la prise de décision exigent des échellesfondées sur des notions simplificatrices, nous pouvons choisir de fabriquer des avatars sociaux per-tinents (Vautier et al., 2012), auquel cas la justification de l’ingénierie correspondante relève de lamanière dont les utilisateurs de tests attribuent certains status aux personnes testées dans diversessituations – et l’équité sera un critère essentiel quoique théoriquement ardu. Sinon, nous pouvonschoisir d’adapter nos concepts à la logique de nos cadres descriptifs. La question de savoir si cescadres descriptifs seront scientifiquement féconds pour dépasser le stade de l’opérationnalisme nepeut pas être abordée si l’investigation repose sur des données qui ont été simplifiées par des tech-niques sophistiquées de compression, parce que ces données vont masquer et distordre ce qui a étéobservé en première instance.
References
American Educational Research Association, American Psychological Association, and NationalCouncil on Measurement in Education. (1999). Standards for educational and psychologicaltesting. Washington, DC: American Educational Research Association.
Bachelard, G. (1983). La formation de l’esprit scientifique (12e éd.). Paris: Vrin. (Publié pour lapremière fois en 1938).
Barbut, M., & Monjardet, B. (1970). Ordre et classification, algèbre et combinatoire, tome 1 [Orderand classification, algebra and combinatory, volume 1]. Paris: Hachette.

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 22
Boring, E. G. (1957). A history of experimental psychology (2nd ed.). New York: Appleton-Century-Crofts.
Borsboom, D. (2008). Latent variable theory. Measurement: Interdisciplinary Research and Per-spectives, 6, 25–53.
Borsboom, D., Mellenbergh, G. J., & van Heerden, J. (2004). The concept of validity. PsychologicalReview, 111, 1061–1071.
Borsboom, D., Cramer, A., Kievit, R. A., Scholten, Z., & Franic, S. (2009). The end of constructvalidity. In R. W. Lissitz (Ed.), The concept of validity: Revisions, new directions, and appli-cations (pp. 135–170). Charlotte, NC: Information Age Publishing.
Brown, J. (1992). The definition of a profession: The authority of metaphor in the history of intelli-gence testing, 1890-1930. Princeton, NJ: Princeton University Press.
Chang, H. (2004). Inventing temperature: Measurement and scientific progress. Oxford: OxfordUniversity Press.
Chang, H. (2009). Operationalism. In E. N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy.http://plato.stanford.edu/archives/fall2009/entries/operationalism/.
Cizek, G. J. (2012). Defining and distinguishing validity: Interpretations of score meaning and jus-tification of test use. Psychological Methods, 17, 31–43.
Cliff, N. (1992). Abstract measurement theory and the revolution that never happened. Psychologi-cal Science, 3, 186–190.
Coombs, C. H. (1964). A theory of data. New York: Wiley.Cronbach, L. J. (1988). Five perspectives on validity argument. In H. Wainer & H. I. Braun (Eds.),
Test validity (pp. 3–17). Hillsdale, NJ: Erlbaum.Cronbach, L. J., & Meehl, P. H. (1955). Construct validity in psychological tests. Psychological
Bulletin, 52, 281–302.Danziger, K. (1987). Statistical method and the historical development of research practice in amer-
ican psychology. In L. Krüger, G. Gigerenzer & M. S. Morgan (Eds.), The probabilistic rev-olution, Vol. 2: Ideas in the sciences (pp. 35–47). Cambridge: MIT Press.
Danziger, K. (1990). Constructing the subject: Historical origins of psychological research. NewYork: Cambridge University Press.
Danziger, K., & Dzinas, K. (1997). How psychology got its variables. Canadian Psychol-ogy/Psychologie canadienne, 38(1), 43–48.
Essex, C., & Smythe, W. E. (1999). Between numbers and notions: A critique of psychologicalmeasurement. Theory & Psychology, 9, 739–767.
Fogelin, R. J., & Sinnott-Armstrong, W. (2001). Understanding arguments: An introduction to in-formal logic (6th ed.). Fort Worth, TX: Harcourt.
Granger, G.-G. (1995). La science et les sciences (2nd ed.). Paris: Presses Universitaires de France.Guttman, L. (1944). A basis for scaling qualitative data. American Sociological Review, 9, 139–150.Hood, S. B. (2009). Validity in psychological testing and scientific realism. Theory & Psychology,
19, 451–473.Johnson, H. M. (1935). Some neglected principles in aptitude testing. American Journal of Psychol-
ogy, 47, 159–165.Johnson, H. M. (1943). Index-numerology and measures of impairment. American Journal of Psy-
chology, 56, 551–558.Kane, M. (1992). An argument-based approach to validity. Psychological Bulletin, 112, 527–535.

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 23
Kane, M. (2001). Current concerns in validity theory. Journal of Educational Measurement, 38,319–342.
Kane, M. (2004a). Certification testing as an illustration of argument-based validation. Measure-ment: Interdisciplinary Research and Perspectives, 2, 135–170.
Kane, M. (2004b). The analysis of interpretive arguments: Some observations inspired by the com-ments. Measurement: Interdisciplinary Research and Perspectives, 2, 192–200.
Kane, M. (2006). Validation. In R. L. Brennan (Ed.), Educational measurement (pp. 17–64). Wash-ington, DC: American Council on Education/Praeger.
Kane, M. (2011). The error of our ways. Journal of Educational Measurement, 48, 12–30.Krantz, D. H. (1972). Measurement structures and psychological laws. Science, 175, 1427–1435.Krause, M. S. (2012). Measurement validity is fundamentally a matter of definition, not correlation.
Review of General Psychology, 16, 391–400.Lamiell, J. T. (2003). Beyond individual and group differences. Thousand Oaks: Sage.Lamiell, J. T. (2013). Statisticism in personality psychologists’ use of trait constructs: What is it?
How was it contracted? Is there a cure? New Ideas in Psychology, 31, 65–71.Lissitz, R. W. (2009). The concept of validity: Revisions, new directions, and applications. Charlotte,
NC: Information Age Publishing.Lord, F. M., & Novick, M. R. (1968). Statistical theories of mental test scores. Reading, MA.:
Addison-Wesley.Lovasz, N., & Slaney, K. L. (2013). What makes a hypothetical construct "hypothetical"? Tracing
the origins and uses of the ‘hypothetical construct’ concept in psychological science. NewIdeas in Psychology, 31, 22–31.
Luce, R. D. (1995). Four tensions concerning mathematical modeling in psychology. Annual Reviewof Psychology, 46, 1–26.
Maraun, M. D. (1998). Measurement as a normative practice: Implications of Wittgenstein’s philos-ophy for measurement in psychology. Theory & Psychology, 8, 435–462.
Maraun, M. D., & Gabriel, S. M. (2013). Illegitimate concept equating in the partial fusion ofconstruct validation theory and latent variable modeling. New Ideas in Psychology, 31, 32–42.
Markus, K. A. (1998). Science, measurement, and validity: Is completion of Samuel Messick’ssynthesis possible? Social Indicators Research, 45, 7–34.
Meehl, P. H. (1967). Theory-testing in psychology and physics: A methodological paradox. Philos-ophy of Science, 34, 103–115.
Mellenbergh, G. J. (1996). Measurement precision in test score and item response models. Psycho-logical Methods, 1, 293–299.
Michell, J. (1997a). Quantitative science and the definition of measurement in psychology. BritishJournal of Psychology, 88, 355–383.
Michell, J. (1997b). Reply to Kline, Laming, Lovie, Luce and Morgan. British Journal of Psychol-ogy, 88, 401–406.
Michell, J. (2000). Normal science, pathological science and psychometrics. Theory & Psychology,10, 639–667.
Michell, J. (2002). Do ratings measure latent attributes? Ergonomics, 45, 1008–1010.Michell, J. (2005). The logic of measurement: A realist overview. Measurement: Interdisciplinary
Research and Perspectives, 38, 285–294.

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 24
Michell, J. (2006). Psychophysics, intensive magnitudes, and the psychometricians’ fallacy. Studiesin History and Philosophy of Biological and Biomedical Sciences, 17, 414–432.
Michell, J. (2008). Is psychometrics pathological science? Measurement: Interdisciplinary Researchand Perspectives, 6, 7–24.
Michell, J. (2013). Constructs, inferences, and mental measurement. New Ideas in Psychology, 31,13–21.
Nesselroade, J. R., & Cable, D. G. (1974). "Sometimes, it’s O.K. to factor differences scores"–theseparation of state and trait anxiety. Multivariate Behavioral Research, 9, 273.
Newton, P. E. (2012). Clarifying the consensus definition of validity. Measurement: Interdisci-plinary Research and Perspectives, 10, 1–29.
Popper, K. R. (1959). The logic of scientific discovery. Oxford England: Basic Books.Popper, K. R. (1992). Realism and the aim of science. London: Routledge.Popper, K. R. (2004). Problèmes fondamentaux de la logique de la connaissance. In S. Laugier & P.
Wagner (Eds.), Philosophie des sciences : théories expériences et méthodes. tome 1 (pp. 237–266). Paris: Vrin.
Roberts, F. S. (1985). Measurement theory, with applications to decision-making, utility, and thesocial sciences. Reading, MA: Addison-Wesley.
Schönemann, P. (1994). Measurement: The reasonable ineffectiveness of mathematics in the socialsciences. In I. Borg & P. Mohler (Eds.), Trends and perspectives in empirical social research(pp. 149–160). Berlin: Walter de Gruyter.
Searle, J. R. (1983). Intentionality: An essay in the philosophy of mind. Cambridge, England: Cam-bridge Univerity Press.
Sherry, D. (2011). Thermoscopes, thermometers, and the foundations of measurement. Studies inHistory and Philosophy of Science, 42, 509–524.
Spielberger, C. D., & Rickman, R. L. (1991). Assessment of state and trait anxiety. In N. Satorius,V. Andreoti, G. Cassano, E. Eisenberg, P. Kielholz, P. Pancheri & G. Racagni (Eds.), Anxiety:Psychobiological and clinical perspectives (pp. 69–83). Washington: Hemisphere/Taylor &Francis.
Spielberger, C. D., Vagg, P. R., Barker, L. R., Donham, G. W., & Westberry, L. G. (1980). The factorstructure of the State-Trait Anxiety Inventory. In C. D. Spielberger & I. G. Sarason (Eds.),Stress and anxiety, volume 7 (pp. 95–109). Washington, DC: Hemisphere/Wiley.
Spielberger, C. D., Gorsuch, R. L., Lushene, R., Vagg, P. R., & Jacobs, G. A. (1993). Manuel del’inventaire d’anxiété état-trait forme Y (STAI-Y) [Manual of STAI form Y] (M. Bruchon-Schweitzer & I. Paulhan, Trans. into French). Paris: Editions du Centre de Psychologie Ap-pliquée.
Steyer, R., Majcen, A. M., Schwenkmezger, P., & Buchner, A. (1989). A latent state-trait anxietymodel and its application to determine consistency and specificity coefficients. Anxiety Re-search, 1, 281–299.
Steyer, R., Ferring, D., & Schmitt, M. J. (1992). States and traits in psychological assessment.European Journal of Psychological Assessment, 8, 79–98.
Stigler, S. M. (1986). The history of statistics: The measurement of uncertainty before 1900. Cam-bridge, MA: The Belknap Press of Harvard University Press.
Torgerson, W. S. (1958). Theory and methods of scaling. New York: John Wiley.Trendler, G. (2009). Measurement theory, psychology and the revolution that cannot happen. Theory
& Psychology, 19, 579–599.

L’ÉVALUATION DU CHANGEMENT PAR L’AUTO-ÉVALUATION 25
Vautier, S. (2004). A longitudinal SEM approach to STAI data: Two comprehensive multitrait-multistate models. Journal of Personality Assessment, 83, 167–179.
Vautier, S. (2011). The operationalization of general hypotheses versus the discovery of empiricallaws in psychology. Philosophia Scientiae, 15, 105–122.
Vautier, S. (2013). How to state general qualitative facts in pychology? Quality & Quantity, 47, 49–56.
Vautier, S., & Jmel, S. (2003). Transient error or specificity? An alternative to the staggered equiv-alent split-half procedure. Psychological Methods, 8, 225–238.
Vautier, S., & Pohl, S. (2009). Do balanced scales assess bipolar constructs? The case of the STAIscales. Psychological Assessment, 21, 187–193.
Vautier, S., Mullet, E., & Bourdet-Loubère, S. (2003). The instruction set of questionnaires canaffect the structure of the data: Application to self-rated state anxiety. Theory and Decision,54, 249–259.
Vautier, S., Veldhuis, M., Lacot, E., & Matton, N. (2012). The ambiguous utility of psychometricsfor the interpretative founding of socially relevant avatars. Theory & Psychology, 22, 810–822.
Wheeler, M. (2001). Historical background. In H. E. Kyburg, Jr. & C. H. Teng (Eds.), Uncertaininference (pp. 1–20). Cambridge, UK: Cambridge University Press.
Woodward, J. (2000). Data, phenomena, and reliability. Philosophy of Science, 67, S163–S179.Woodward, J. (2010). Data, phenomena, signal, and noise. Philosophy of Science, 77, 792–803.Zumbo, B. D., & Rupp, A. A. (2004). Responsible modeling of measurement data for appropriate
inferences: Important advances in reliability and validity theory. In D. Kaplan (Ed.), TheSAGE handbook of quantitative methodology for the social sciences (pp. 73–92). ThousandOaks, CA: Sage.