distributed deep learning_framework_spark_4_may_2015_ver_0.7
TRANSCRIPT

© Tally Solutions Pvt. Ltd. All Rights Reserved
Distributed Deep Learning Framework over Spark
Dr. Vijay Srinivas Agneeswaran,
Director and Head, Data Sciences,
Tally Analytics Pvt. Ltd.
Bangalore, India and
Sai Sagar,
Software Engineer,
Impetus Infotech India Pvt. Ltd.

© Tally Solutions Pvt. Ltd. All Rights Reserved 22
Contents
Basics of Artificial Neural NetworksIntroduction
DLNs for Face Recognition, Different kinds of deep layered networks
Deep Layered Networks
Success stories and applications of DLNs
DLN Applications
Challenges in Realizing Distributed DLNs, our Spark based Distributed DLN Framework
Distributed DLNs
Audio Sentiment Analysis
Proof of Concept
© Tally Solutions Pvt. Ltd. All Rights Reserved 33
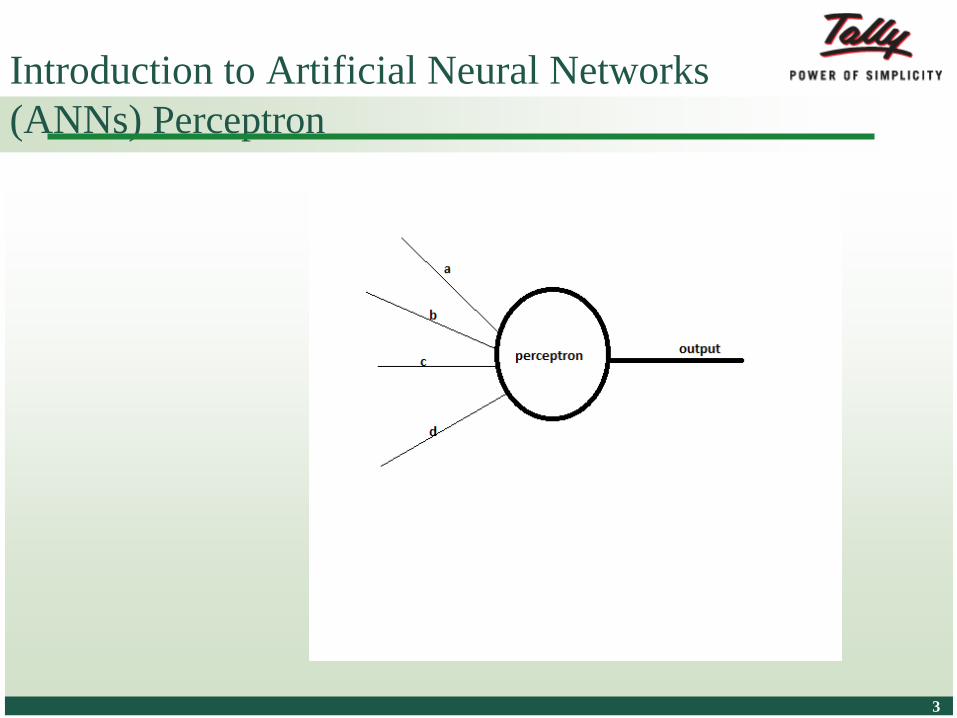
Introduction to Artificial Neural Networks
(ANNs) Perceptron
© Tally Solutions Pvt. Ltd. All Rights Reserved 44
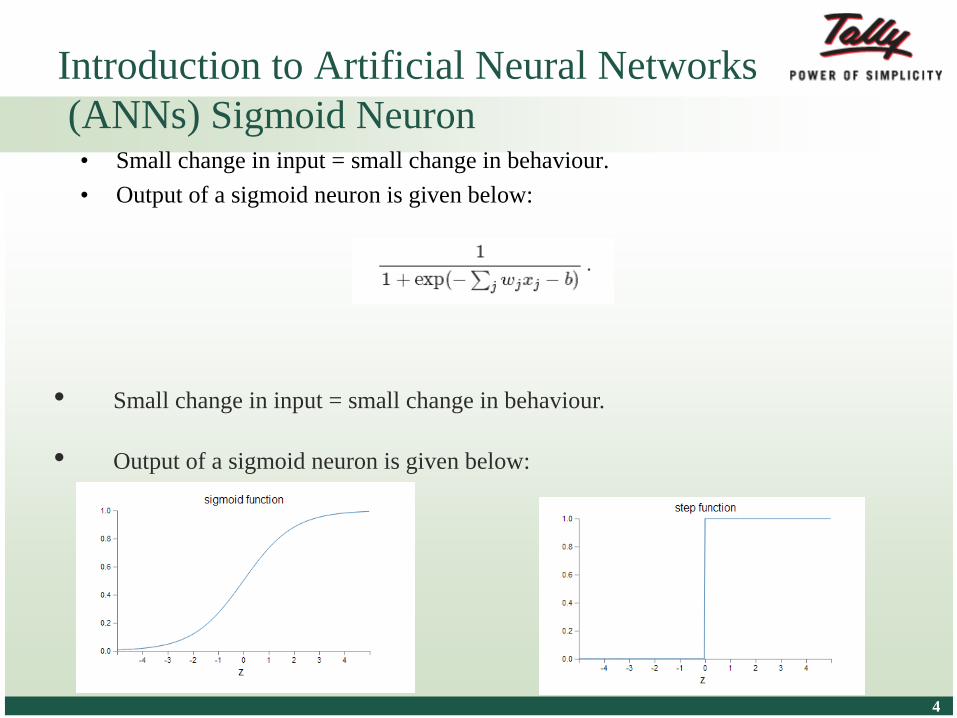
Introduction to Artificial Neural Networks
(ANNs) Sigmoid Neuron• Small change in input = small change in behaviour.
• Output of a sigmoid neuron is given below:
• Small change in input = small change in behaviour.
• Output of a sigmoid neuron is given below:
© Tally Solutions Pvt. Ltd. All Rights Reserved 55
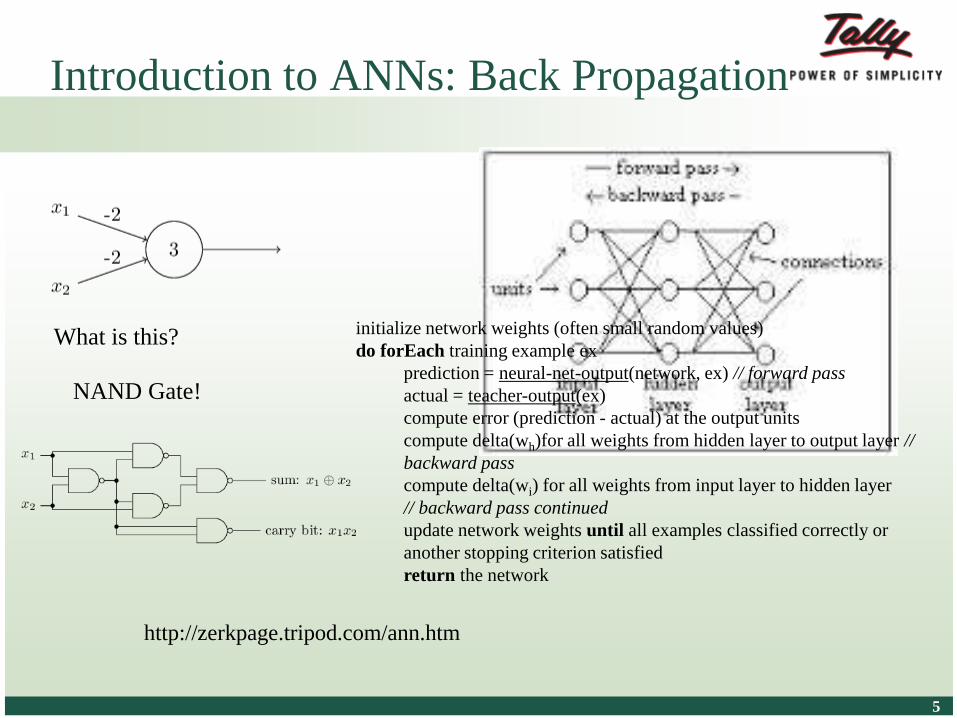
Introduction to ANNs: Back Propagation
http://zerkpage.tripod.com/ann.htm
What is this?
NAND Gate!
initialize network weights (often small random values)
do forEach training example ex
prediction = neural-net-output(network, ex) // forward pass
actual = teacher-output(ex)
compute error (prediction - actual) at the output units
compute delta(wh)for all weights from hidden layer to output layer //
backward pass
compute delta(wi) for all weights from input layer to hidden layer
// backward pass continued
update network weights until all examples classified correctly or
another stopping criterion satisfied
return the network
© Tally Solutions Pvt. Ltd. All Rights Reserved 66
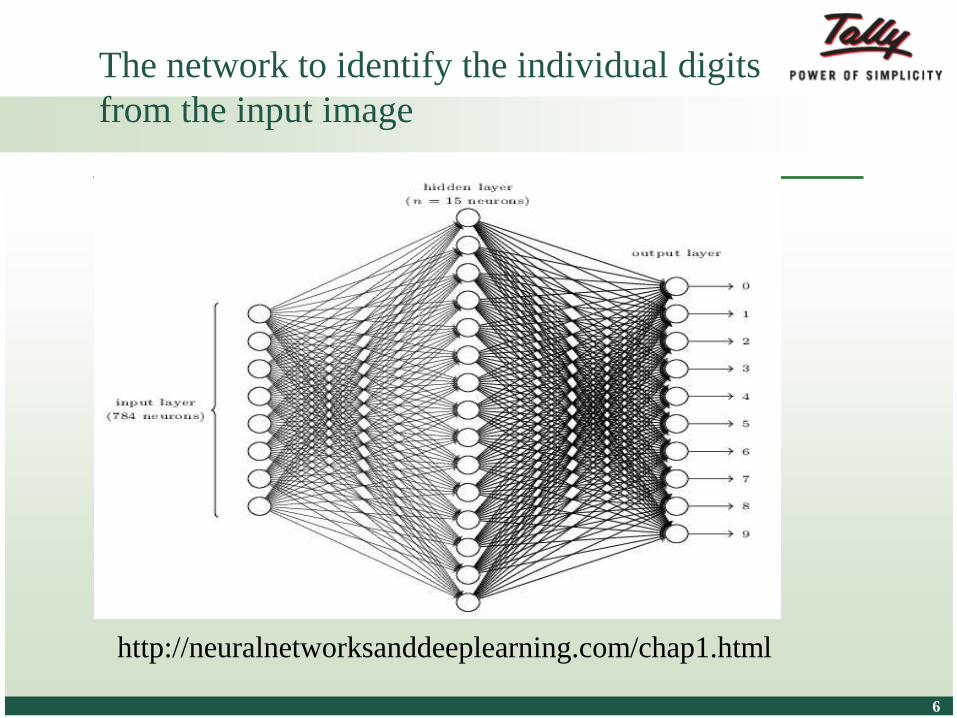
The network to identify the individual digits
from the input image
http://neuralnetworksanddeeplearning.com/chap1.html
© Tally Solutions Pvt. Ltd. All Rights Reserved 77
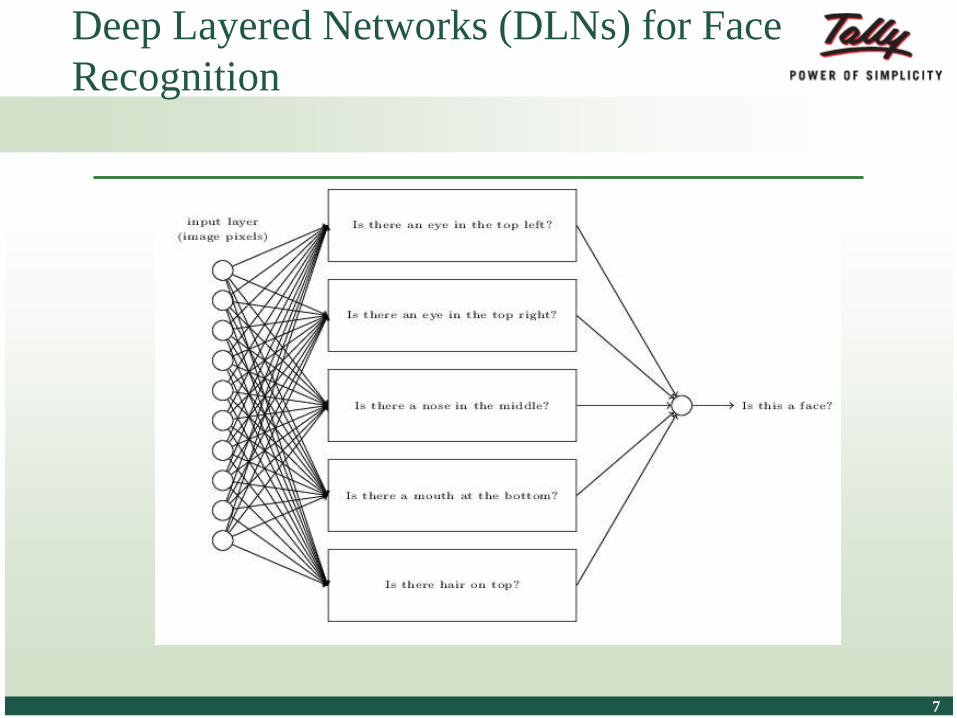
Deep Layered Networks (DLNs) for Face
Recognition
© Tally Solutions Pvt. Ltd. All Rights Reserved 88
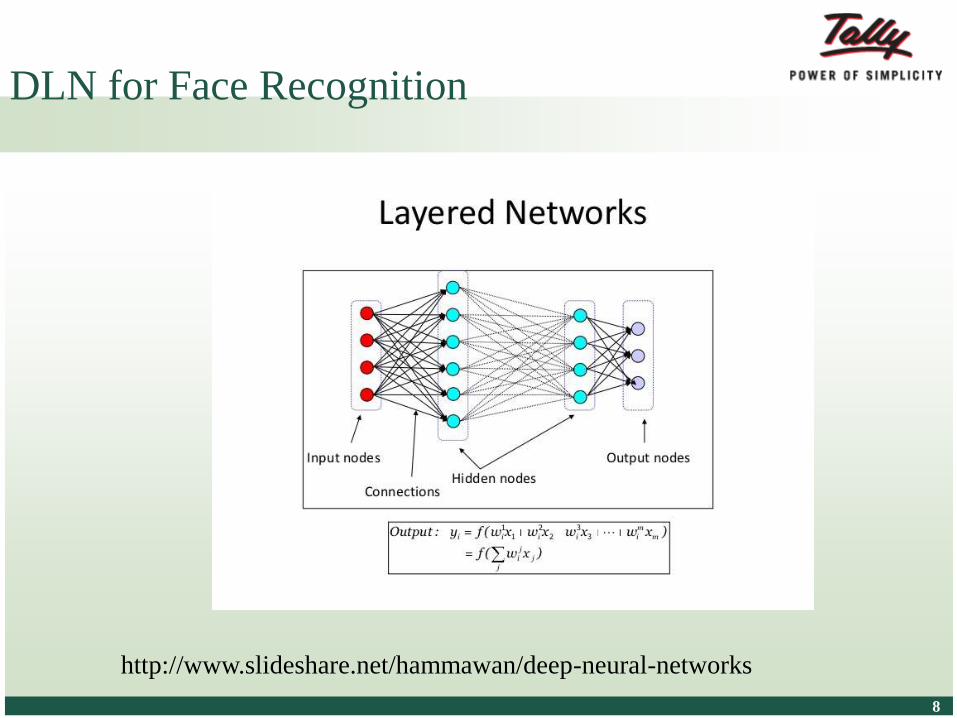
DLN for Face Recognition
http://www.slideshare.net/hammawan/deep-neural-networks

© Tally Solutions Pvt. Ltd. All Rights Reserved 99
Deep Learning Networks: Learning
No general learning
algorithm (No-free-
lunch theorem by
Wolpert1996).
Learning algorithm
for specific tasks
Limitatio
ns of BP
Hinton’s deep belief
networks as stack
of
RBMs.
Lecun’senergy based
learning for DBNs.
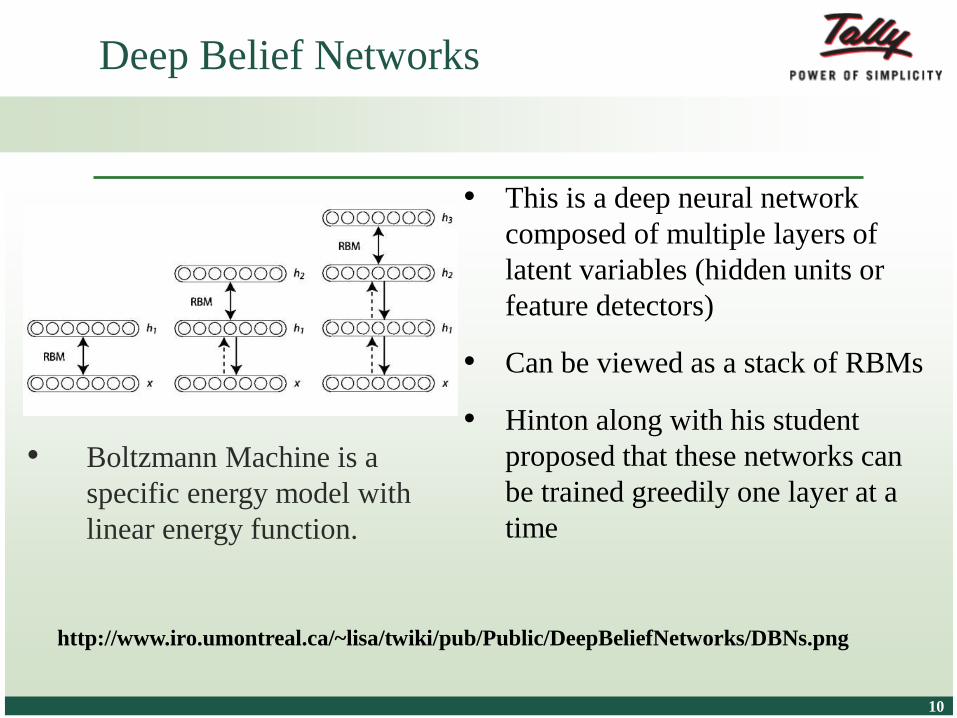
© Tally Solutions Pvt. Ltd. All Rights Reserved 1010
• This is a deep neural network
composed of multiple layers of
latent variables (hidden units or
feature detectors)
• Can be viewed as a stack of RBMs
• Hinton along with his student
proposed that these networks can
be trained greedily one layer at a
time
Deep Belief Networks
http://www.iro.umontreal.ca/~lisa/twiki/pub/Public/DeepBeliefNetworks/DBNs.png
• Boltzmann Machine is a
specific energy model with
linear energy function.

© Tally Solutions Pvt. Ltd. All Rights Reserved 1111
• Aim of auto encoders network is to learn a
compressed representation for set of data
• Is an unsupervised learning algorithm that
applies back propagation, setting the target
values equal to inputs (identity function)
• Denoising auto encoder addresses identity
function by randomly corrupting input that
the auto encoder must then reconstruct or
denoise
• Best applied when there is structure in the
data
• Applications : Dimensionality reduction,
feature selection
Other DL Networks: Auto Encoders (Auto-
associators or Diabolo Network)
© Tally Solutions Pvt. Ltd. All Rights Reserved 1212
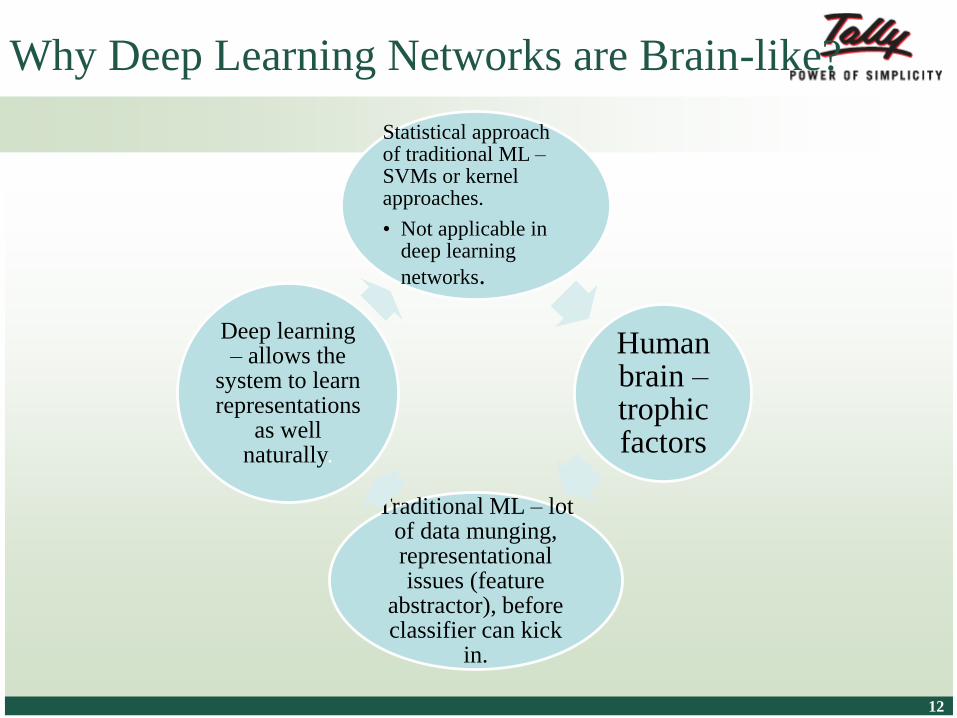
Why Deep Learning Networks are Brain-like?
Statistical approach of traditional ML –SVMs or kernel approaches.
• Not applicable in deep learning
networks.
Human brain –trophic factors
Traditional ML – lot of data munging, representational issues (feature
abstractor), before classifier can kick
in.
Deep learning – allows the
system to learn representations
as well naturally.
© Tally Solutions Pvt. Ltd. All Rights Reserved 1313
Copyright @Impetus Technologies, 2014
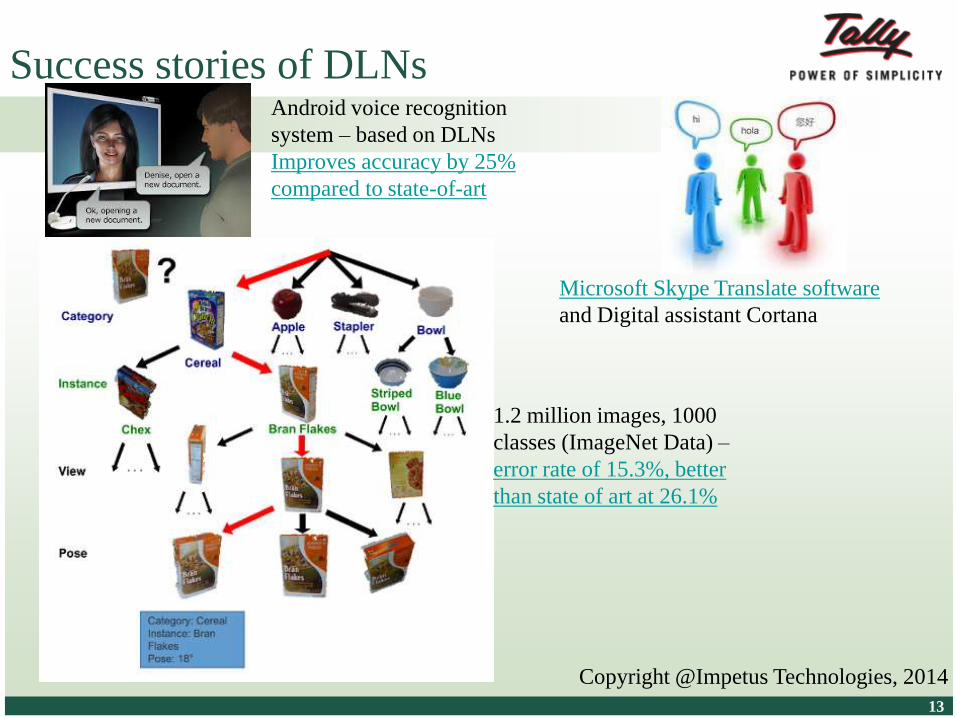
Success stories of DLNsAndroid voice recognition
system – based on DLNs
Improves accuracy by 25%
compared to state-of-art
Microsoft Skype Translate software
and Digital assistant Cortana
1.2 million images, 1000
classes (ImageNet Data) –
error rate of 15.3%, better
than state of art at 26.1%

© Tally Solutions Pvt. Ltd. All Rights Reserved 1414
Success stories of DLNs…..
Senna system – PoS tagging, chunking, NER, semantic role
labeling, syntactic parsing
Comparable F1 score with state-of-art with huge speed
advantage (5 days VS few hours).
DLNs VS TF-IDF: 1 million
documents, relevance search. 3.2ms VS
1.2s.
Robot navigation

© Tally Solutions Pvt. Ltd. All Rights Reserved 1515
Potential Applications of DLNs
Speech recognition/enhancement
Video sequencing
Emotion recognition (video/audio),
Malware detection,
Robotics – navigation.
multi-modal learning (text and image).
Natural Language Processing

© Tally Solutions Pvt. Ltd. All Rights Reserved 1616
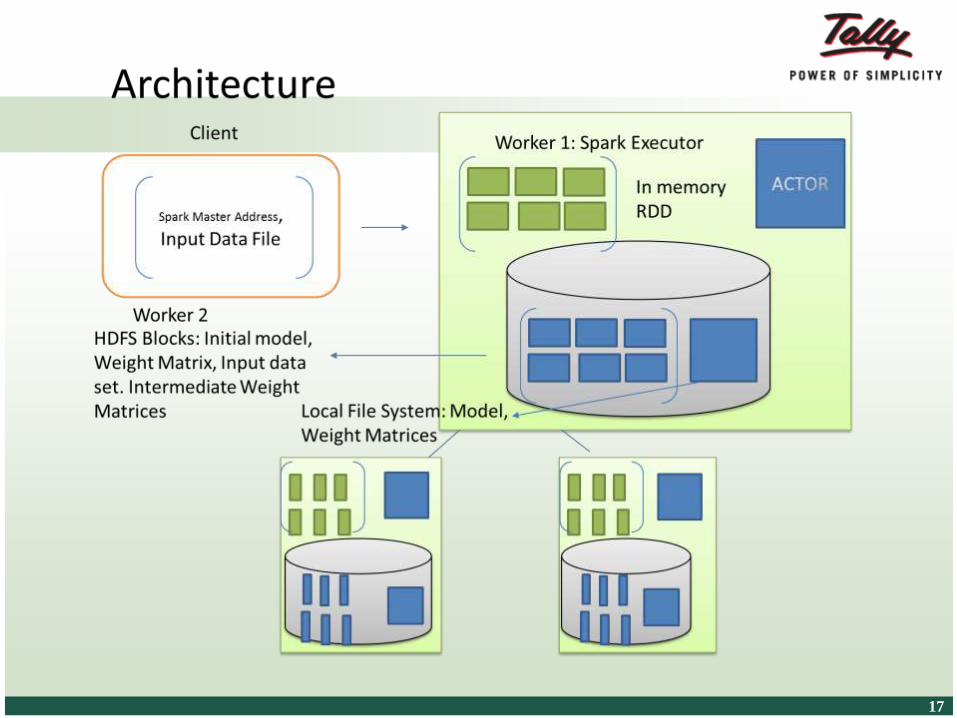
Challenges in Realizing DLNs
Large no. of training examples – high
accuracy.
• Large no. of parameters can also improve accuracy.
Inherently sequential nature – freeze up one
layer for learning.
GPUs to improve training speedup
• Limitations –CPU_to_GPU data transfers.
Distributed DLNs –Jeffrey Dean’s work.
© Tally Solutions Pvt. Ltd. All Rights Reserved 1717

© Tally Solutions Pvt. Ltd. All Rights Reserved 1818
WiP: Proof of Concept
• Sentiment analysis of continuous speech data
• Stacking RBMs to make a deep belief network.
– First a GRBM (Gaussian RBM) is trained to model a window of frames of
real-valued acoustic coefficients.
– Then the states of the binary hidden units of the GRBM are used as data
for training an RBM.
– This is repeated to create as many hidden layers as desired.
– Then the stack of RBMs is converted to a single generative model, a
DBN, by replacing the undirected connections of the lower level RBMs by
top-down, directed connections.
– Finally, a pre-trained DBN-DNN is created by adding a “softmax” output
layer that contains one unit for each possible state of each HMM. The
DBN-DNN is then discriminatively trained to predict the HMM state
corresponding to the central frame of the input window in a forced
alignment
•

© Tally Solutions Pvt. Ltd. All Rights Reserved 1919
• ANN to Distributed Deep Learning
• Key ideas in deep learning
• Need for distributed realizations.
• DistBelief, deeplearning4j etc.
• Our work on large scale distributed deep learning
• Deep learning leads us from statistics based machine
learning towards brain inspired AI.
Conclusions

© Tally Solutions Pvt. Ltd. All Rights Reserved 2020
• Tally
• Accounting/business software – widely used in SME.
• 100 million customers worldwide.
• Tally Analytics is a new startup
• Trying to create value from the business data of Tally.
• Supply chain – use of AI in inventory prediction, creating
value in supply chain data.
• What is sold where, when and at what price. All pervading
data?
• We are hiring. Send CVs to [email protected].
Current Work
© Tally Solutions Pvt. Ltd. All Rights Reserved 2121
Thank You!
Contact Details:Twitter: a_vijaysrinivas
LinkedIn (Please write an introductory note before connecting): https://in.linkedin.com/in/vijaysrinivasagneeswaran
Email: [email protected]

© Tally Solutions Pvt. Ltd. All Rights Reserved 2222
Copyright @Impetus Technologies, 2014
• RBM are Energy Based Models (EBM)
• EBM associate an energy with every configuration of a system
• Learning corresponds to modifying the shape of energy
function, so that it has desirable properties
• Like in physics, lower energy = more stability
• So, modify shape of energy function such that the desirable
configurations have lower energy
Energy Based Models
http://www.cs.nyu.edu/~yann/research/ebm/loss-func.png
© Tally Solutions Pvt. Ltd. All Rights Reserved 2323
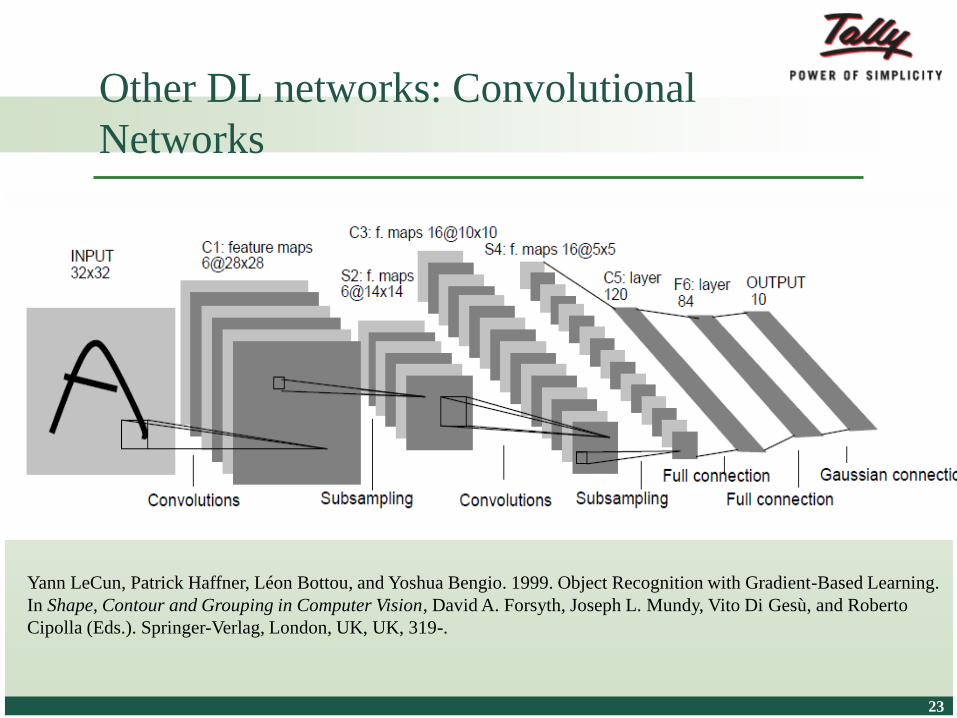
Other DL networks: Convolutional
Networks
Yann LeCun, Patrick Haffner, Léon Bottou, and Yoshua Bengio. 1999. Object Recognition with Gradient-Based Learning.
In Shape, Contour and Grouping in Computer Vision, David A. Forsyth, Joseph L. Mundy, Vito Di Gesù, and Roberto
Cipolla (Eds.). Springer-Verlag, London, UK, UK, 319-.

© Tally Solutions Pvt. Ltd. All Rights Reserved 2424
• Recurrent Neural networks
• Long Short Term Memory (LSTM), Temporal data
• Sum-product networks
• Deep architectures of sum-product networks
• Hierarchical temporal memory
• online structural and algorithmic model of neocortex.
Other Brain-like Approaches

© Tally Solutions Pvt. Ltd. All Rights Reserved 2525
• Connections between units form a Directed cycle i.e. a
typical feed back connections
• RNNs can use their internal memory to process
arbitrary sequences of inputs
• RNNs cannot learn to look far back past
• LSTM solve this problem by introducing stem cells
• These stem cells can remember a value for an arbitrary
amount of time
Recurrent Neural Networks

© Tally Solutions Pvt. Ltd. All Rights Reserved 2626
• SPN is deep network model and is a directed acyclic
graph
• These networks allow to compute the probability of an
event quickly
• SPNs try to convert multi linear functions to ones in
computationally short forms i.e. it must consist of
multiple additions and multiplications
• Leaves correspond to variables and nodes correspond
to sums and products
Sum-Product Networks (SPN)

© Tally Solutions Pvt. Ltd. All Rights Reserved 2727
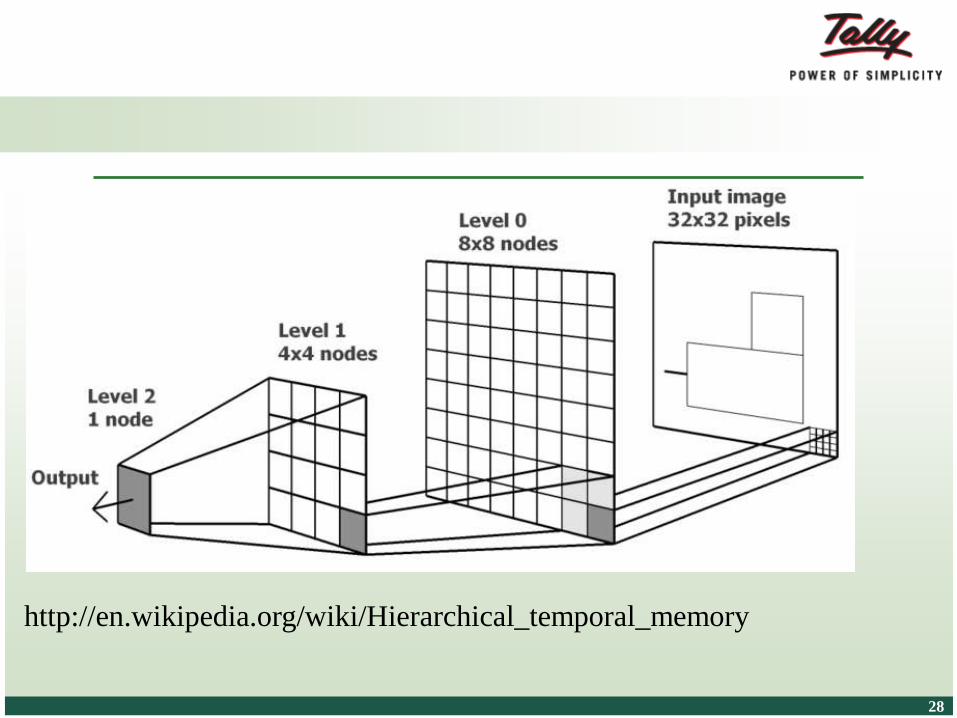
• Is a online machine learning model developed by Jeff
Hawkins
• This model learns one instance at a time
• Best explained by online stock model. Today’s situation
of stock helps in prediction of tomorrow’s stock
• A HTM network is tree shaped hierarchy of levels
• Higher hierarchy levels can use patterns learned at lower
levels. This is adopted from learning model adopted by
brain in the form of neo cortex
Hierarchical Temporal Memory
© Tally Solutions Pvt. Ltd. All Rights Reserved 2828
http://en.wikipedia.org/wiki/Hierarchical_temporal_memory

© Tally Solutions Pvt. Ltd. All Rights Reserved 2929
Mathematical Equations
• The Energy Function is defined as follows:
b’ and c’ are the biases
𝐸 𝑥, ℎ = −𝑏′𝑥 − 𝑐′ℎ − ℎ′𝑊𝑥
where, W represents the weights connecting
visible layer and hidden layer.
© Tally Solutions Pvt. Ltd. All Rights Reserved 3030
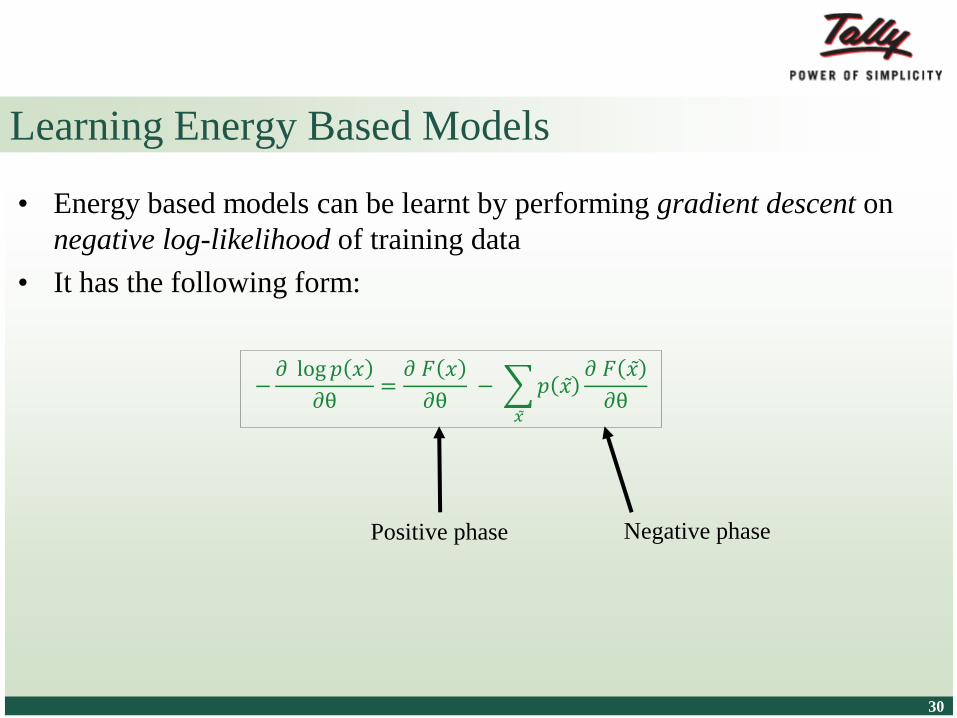
Learning Energy Based Models
• Energy based models can be learnt by performing gradient descent on
negative log-likelihood of training data
• It has the following form:
−𝜕 log 𝑝 𝑥
𝜕θ=𝜕 𝐹 𝑥
𝜕θ−
𝑥̃
𝑝 𝑥 𝜕 𝐹 𝑥
𝜕θ
Positive phase Negative phase