evolutionary taxonomy construction from dynamic tag space
TRANSCRIPT

World Wide WebDOI 10.1007/s11280-011-0150-4
Evolutionary taxonomy constructionfrom dynamic tag space
Junjie Yao · Bin Cui · Gao Cong · Yuxin Huang
Received: 10 March 2011 / Revised: 13 August 2011 /Accepted: 17 November 2011© Springer Science+Business Media, LLC 2011
Abstract Collaborative tagging becomes a common feature of current web sites,facilitating ordinary users to annotate and represent online resources. The largecollection of tags and their relationships form a tag space. In this kind of tag space, thepopularity and correlation amongst tags capture the current social interests. Tags arefreely chosen keywords and difficult to organize. As a hierarchical concept structureto represent the subsumption relationships, automatically extracted taxonomies be-come a viable method to manage collaborative tags. However, tags change over time,and it is also imperative to incorporate the temporal tag evolution into the extractedtaxonomies. In this paper, we formalize the problem of evolutionary taxonomygeneration over a large collection of tags. A line of taxonomies are generated toreflect the temporal changes of underlying tag space. The proposed evolutionary tax-onomy framework consists of two novel contributions. First, we develop a context-aware edge selection algorithm for taxonomy extraction. This method is built onseminal association-rule mining algorithm. Second, we propose several strategies
The preliminary version of this paper appeared at WISE 2010.
J. Yao · B. Cui (B) · Y. HuangKey Lab of High Confidence Software Technologies (Ministry of Education)& Department of Computer Science, Peking University, No. 5 Yiheyuan Road,Haidian District, Beijing 100871, People’s Republic of Chinae-mail: [email protected]
J. Yaoe-mail: [email protected]
Y. Huange-mail: [email protected]
G. CongDivision of Information Systems, School of Computer Engineering,Nanyang Technological University, Singapore, Singaporee-mail: [email protected]

World Wide Web
for evolutionary taxonomy fusion, which smooths the newly generated taxonomywith prior ones. We conduct an extensive performance study using a large real-lifeweb page tagging dataset (i.e., Del.ici.ous). The empirical results clearly verify theeffectiveness and efficiency of the proposed approach.
Keywords social media · collaborative tagging · hierarchical taxonomy ·temporal evolution
1 Introduction
Social tagging systems have emerged recently as a powerful way to organizelarge amount of online data (e.g., web page, image, video). Notably, sites suchas Flickr (http://www.flickr.com), Del.icio.us (http://www.delicious.com) and CiteU-Like (http://www.citeulike.org) have been used as the platform for the sharingof photos, bookmarks and publications respectively. Social tagging systems allowordinary users to sieve through large amount of online data by allowing themto annotate and represent the online data. We refer to a large database of tagsin a collaborative tagging system as a tag space. In such a tag space, tags arenot independent and often have strong semantic correlations, such as homonymy,synonymy, subsumption [3, 8, 20]. Additionally, the popularity of tags generallyprovides an intuitive way to understand the interests of communities of users. Mostof current tagging sites present the tags in a tag cloud style, which is easy to beimplemented, but cannot capture the rich semantic correlations among tags.
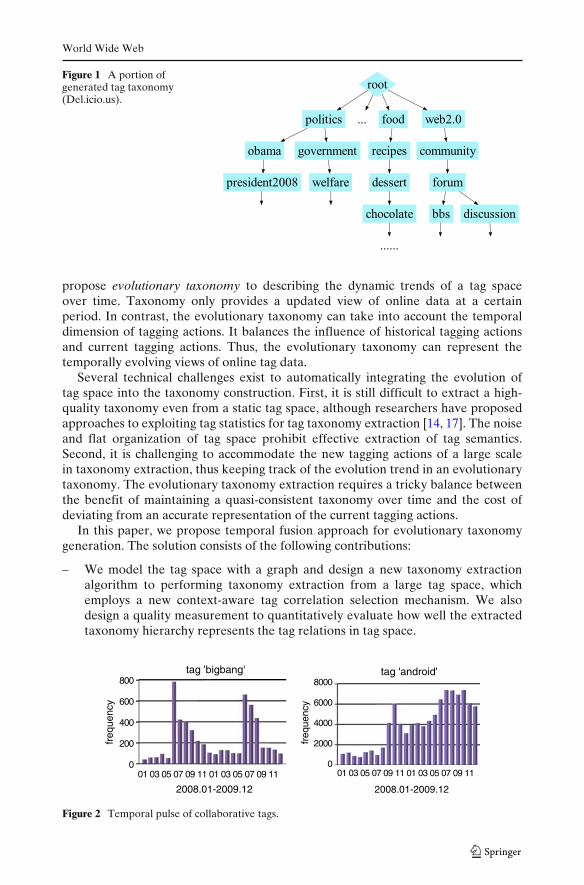
More recently, the taxonomy, a hierarchical concept classification structure, hasattracted growing interest to organize tags. Figure 1 shows a portion of taxonomyconstructed from a sample tag space of Del.icio.us, where the tags in upper levelsrepresent more general concepts. Several automatical taxonomy extraction methodsare proposed, e.g. in [10, 14, 17]. Taxonomies for tag space are different from formalpredefined ontologies by domain experts, which are not suitable to dynamic tag spacein collaborative tagging systems, as tags are not restricted by a controlled vocabularyand cover a variety of domains [12]. Taxonomies can be used to flexibly describe thecorpora content with varying granularity and facilitate the hierarchical browsing. Theapplication of taxonomy is especially valuable for online resource organization andinteractive user navigation [11].
An important character of collaborative tag space is that a tag space is a dynamicdatabase, with millions of tagging actions being performed each week [13]. Bywatching the behavior of users in tag space over time, we can explore the evolutionof community focus, and thus understand the pulse of users’ interests.
In a user provided tagging dataset used in our study, we present two tag changingexample in Figure 2. bigbang (an American sitcom) exposed two bursts in Jun 2008and Jun 2009, during the release of new seasons. Android, a mobile OS from Googlefirst caught eyes because of the release of Android G1 phone in Sep 2008; and in2009, it attracted more and more attention due to the popularity of Android phonesand several OS updates.
Most of current tag taxonomy construction methods treat the tag space as a staticcorpus. However, a stagnant tag taxonomy cannot conform with the underlyingdynamic tag space. To capture such time-dependent correlations between tags, we
World Wide Web
Figure 1 A portion ofgenerated tag taxonomy(Del.icio.us).
propose evolutionary taxonomy to describing the dynamic trends of a tag spaceover time. Taxonomy only provides a updated view of online data at a certainperiod. In contrast, the evolutionary taxonomy can take into account the temporaldimension of tagging actions. It balances the influence of historical tagging actionsand current tagging actions. Thus, the evolutionary taxonomy can represent thetemporally evolving views of online tag data.
Several technical challenges exist to automatically integrating the evolution oftag space into the taxonomy construction. First, it is still difficult to extract a high-quality taxonomy even from a static tag space, although researchers have proposedapproaches to exploiting tag statistics for tag taxonomy extraction [14, 17]. The noiseand flat organization of tag space prohibit effective extraction of tag semantics.Second, it is challenging to accommodate the new tagging actions of a large scalein taxonomy extraction, thus keeping track of the evolution trend in an evolutionarytaxonomy. The evolutionary taxonomy extraction requires a tricky balance betweenthe benefit of maintaining a quasi-consistent taxonomy over time and the cost ofdeviating from an accurate representation of the current tagging actions.
In this paper, we propose temporal fusion approach for evolutionary taxonomygeneration. The solution consists of the following contributions:
– We model the tag space with a graph and design a new taxonomy extractionalgorithm to performing taxonomy extraction from a large tag space, whichemploys a new context-aware tag correlation selection mechanism. We alsodesign a quality measurement to quantitatively evaluate how well the extractedtaxonomy hierarchy represents the tag relations in tag space.
0
200
400
600
800
01 03 05 07 09 11 01 03 05 07 09 11
freq
uenc
y
2008.01-2009.12
tag 'bigbang'
0
2000
4000
6 00 0
8000
01 03 05 07 09 11 01 03 05 07 09 11
freq
uenc
y
2008.01-2009.12
tag 'android'
Figure 2 Temporal pulse of collaborative tags.

World Wide Web
– Taxonomy fusion forms the basis for generating evolutionary taxonomy, and canbe perfectly integrated into the proposed taxonomy extraction algorithm. Wediscuss several strategies to performing taxonomy fusion using historical graphs(to model the historical tag space), historical taxonomies, and current graph.
– We conduct an extensive experimental evaluation on a large real data setcontaining 270 million tagging actions. The results show that our approach cangenerate taxonomy of high quality, both in effectiveness and efficiency.
Evolutionary taxonomy construction is particularly applicable in burgeoning col-laborative environments with increasing online data. To the best of our knowledge,this work is the first attempt to investigate the evolutionary taxonomy problem in atag space. Collaborative tagging systems can benefit from this evolutionary construc-tion for better organization of tagged data, and utilize the evolutionary taxonomy forobject ranking, similar content grouping, and hot resource recommendation. Userscan also better interact with collaborative systems using this concise and updatingtopic taxonomy, which facilitates the navigation and browsing.
The rest of this paper is organized as follows. In Section 2, we briefly review therelated literature. Section 3 presents the proposed taxonomy extraction algorithm.In Section 4, we introduce the approach for evolutionary taxonomy generation.Section 5 describes a performance study and gives a detailed analysis of results.Finally, we conclude this paper and outline the future work.
2 Related work
Collaborative tagging systems have grown in popularity on the current web, whichallow users to freely annotate and represent various types of online resources, e.g.,tag pages, photos, videos and tweets. The huge amount of user generated tags reflectthe interest of millions of users, and have been applied in many fields. For example,Heyman et al. [15] compared the behavior differences between web search and usertagging. Tagging features could be used in retrieval are investigated in [18, 26].The community recommendation strategies amplified by implicit tags was discussedin [22]. Bao et al. [3] checked the tag propagation used for content mining.
Dynamics of collaborative tags Using a data set from Del.icio.us, Golder et al. [12]analyzed the structure of collaborative tagging systems as well as their dynamicaspects. They discovered regularities in user activities, tag frequencies, tag types,bursts of popularity in bookmarking and a remarkable stability in the relativeproportions of tags for a given URL. Halpin et al. [13] examined the dynamics ofcollaborative tagging systems. They introduced a generative model of collaborativetagging and showed that the distribution of the frequencies of tags for “popular” sitesover a long history tend to stabilize into power law distributions.
Dubinko et al. [9] studied the problem of visualizing the evolution of tags withinFlickr. They presented an approach based on a characterization of the most salienttags associated with a sliding interval of time. To combine the related tags togetherinto intuitive event representation, we proposed a sequential graph clustering algo-rithm for bursty event detection on temporal tags [24].

World Wide Web
Taxonomy extraction from tags Tagging is usually treated as a categorizationprocess, in contrast to the pre-optimized classification as exemplified by expert-created Web ontology [13]. Tagging systems allow greater malleability and adaptabil-ity in organizing information than classification systems. The co-occurrence relationsof tags often indicate the semantic aspects of tags, e.g., homonymy, synonymy,subsumption, etc. [6].
Hierarchical organization of concepts in a taxonomy is useful for browsing andorganization. The traditional taxonomy extraction methods can be categorized aspattern based or clustering based ones [23]. The noise and short of context featuresmakes the tag taxonomy extraction difficult. Various of methods have been proposedrecently, e.g., [10, 14, 17].
It was shown in [14] that, simple k-means or agglomerative hierarchical clusteringcannot get satisfactory results for taxonomy extraction. Association rules are able tocapture the co-occurrence relations of tags and thus the semantic relations amongtags. Plangprasopchok et al. [17] utilized user provided subsumption relationshipsto construct a taxonomy structure. However, not all tagging scenarios have theuser provided relationship input and this method is rather limited. Eda et al. [10]presented a topic modeling method to extract the latent semantics of tags and thenbuild the hierarchical structures over it. This method is capable of better conceptfinding but prune to the scalability and topic labeling.
Existing taxonomy extraction algorithms only consider static tag space. However,the tag space keeps evolving due to the huge amount of new tagging activitieseveryday. The static taxonomies will fail to capture the evolving nature of tag space.In this work, we propose to integrate the taxonomy extraction and evolution in thetag space.
3 Context-aware taxonomy extraction
In this section, we first introduce the data model for tags in collaborative taggingsystem, and discuss the proposed correlation selection mechanisms, followed by aheuristic algorithm for context-aware taxonomy extraction. The taxonomy extractionalgorithm discussed here is the foundation of the evolutionary taxonomy generationalgorithms to be presented later in the next section.
3.1 Data model in tag space
In collaborative tagging systems, a tagging action involves user, tag, resource, andtime [5]. We model a tagging action with a quadruple < Usri, Res j, Tagk, Timt >
which says that user i tagged resource j with a set of tags k at time t. Note that, usersmay use multiple tags in a single tagging action, and these tags together describe theresource. We denote the set of quadruples in a tag space as D and the set of distincttags in the tag space as T. For ease of presentation, we do not take the time dimensioninto consideration in the following discussion.
Tag co-occurrence graph We say that there exists a “co-occurrence” relationshipbetween two tags if the two tags are used by the same user to annotate an objectin a single tagging action. Note that we can relax the “co-occurrence” relationship

World Wide Web
definition such that tags tag1 and tag2 have “co-occurrence” relationship if thereexists an object labeled with tags tag1 and tag2 no matter whether they are from thesame or different users, or are tagged at different time. In this paper, we use the firstdefinition in our implementation, but our approach is equally applicable to the latterdefinition.
By establishing a link between two tags if there exists co-occurrence relationshipbetween them, we generate an implicit tag relation graph. We project the quadruplesin a tag space into a basic tag co-occurrence graph, which is an undirected graph,denoted as G = (V, E) where V is the set of vertices and E is the set of undirectededges. Each distinct tag in T corresponds to a vertex in V. There exists an edgebetween two nodes u and v if and only if there exists “co-occurrence” relationshipbetween them.
In tagging systems, the users generally provide multiple tags for an object. Thisstraightforward co-occurrence relations among tags indicate the semantic aspectsunderling collaborative tagging actions, e.g., homonymy, synonymy, subsumption.
Tag association rule graph The tag co-occurrence graph could show the mutualrelationship between tags, but is still not sufficient to capture the rich semantic oftag space. The association rules discovered in tag space are more valuable and canprovide richer semantic of tag relations than co-occurrence relation [16].
We next present the tag association rule graph, where the association rulesdiscovered in a tag space reflect not only the frequencies of co-occurrence tag pairs,but also the consequent and antecedent relationship. Here, we define the frequency,support and confidence of tag co-occurrence relations:
Frequency It represents the number of tagi appearances in the tag space.
Freq(tagi) = |{(Usru, Resr, Tagk)|tagi ∈ Tagk}| .
Support It represents the number of tagging actions which contain both tagi
and tag j.
Supp(tagi, tag j) = |{(Usru, Resr, Tagk)|tagi, tag j ∈ Tagk}| .
Conf idence It represents how likely tag j is given tagi, where Freq(tagi) <
Freq(tag j) and the edge is directed to tag j.
Conf (tagi → tag j) = Supp(tagi, tag j)/Freq(tagi) .
Note that the definitions of frequency and support are the same as those in tradi-tional association rule mining [1]. However, the definition of confidence is differentin that we impose an extra constraint Freq(tagi) < Freq(tag j). This constraint meansthat given a pair of tags {tagi, tag j}, we at most generate one association rule for thispair where the tag with lower frequency will be the antecedent and the other tag willbe consequent. The reason for imposing the constraint is that the statistical weightFrequency typically represents the generality of tag [14], and highly frequent tags areexpected to be located in the higher levels in the taxonomy tree.
Hence we only generate rules from tag with a lower frequency to a tag with ahigher frequency. In addition, we also filter probably noisy edges with low confidenceor low support. The association rule is meaningful only when the confidence is

World Wide Web
significant to a certain degree. The edges with low confidence or support can hardlyrepresent the statistically semantic relation between tags, and hence cannot improvethe taxonomy quality.
We next proceed to define an association rule graph ARG := (V, E ), where
– V is the set of vertices, each of which represents a distinct tag which is alsoattached with a weight vw computed by the tag frequency in the vertex;
– E is the set of directed edges representing the co-occurrence of tag pairs, eachof which is attached with the weights of edge ew and the weights are the supportand conf idence of the association rule represented by the edge.
Figure 3 shows an example of association rule graph of a tag space. For the clarityof presentation, we set the frequency and confidence thresholds when plotting thegraph, so it only shows highly frequent and correlated tags. However, we can still findlots of interesting information from the visualized graph. For example, tags with highfrequency are represented by larger circle, e.g., “design” and “tools”; linked tags aresemantically related, e.g., “software” and “windows”, and the directed tag “software”is more abstract than “windows”; thick line represents highly correlated tags, e.g.,“music” and “mp3”; the tags without out edges are generally more conceptual, suchas “design” and “software”, and are expected to be a good choice for categorical tagof the taxonomy in the tag space.
Figure 3 Tag association rule graph (Del.icio.us).

World Wide Web
3.2 Association rule based extraction
The association rule graph is a concise representation of tag correlation in a tag space.We propose a context aware taxonomy extraction algorithm.
3.2.1 Determining the context-aware conf idence
Introduced previously, the taxonomy generated for tagging system is to help organizethe online content and provide users an hierarchical view of the tag space. Usersusually browse the taxonomy to broaden or narrow down the areas of interests [5],which means it is desirable that the high level concepts can accommodate thesemantics of their children concepts.
The method used in previous work [19] is to set a global confidence thresholdand all rules whose confidence is below the threshold will not be considered fortaxonomy generation. But, such an approach may fail to exclude noisy edges intagging scenario. This is a weakness of [19] by simply applying confidence. Theproblem with confidence is that it is sensitive to the frequency of the antecedent.Caused by the way confidence is calculated, consequents with higher support willbe more likely to produce higher confidence values even if there exists no tightassociation between the tags.
Just use an example from Del.icio.us data (Feb 2008), we find a rule (pakistan →statistics) with 100% confidence, where Freq(pakistan) = 95 and Freq(statistics) =5,985. As the approach in [19], the generated taxonomy must have an edge frompakistan to statistics. However, we cannot figure out the tight relation between them.By checking the relevant webpages, we notice that the rule appears due to “PakistanElections”, while it is not meaningful generally. Such case is quite common in realsystems, which actually can be considered as noise.
Since tags with high frequencies are more likely to be involved in noisy associationrules, and thus a desirable strategy would be to set higher threshold for frequenttags and lower threshold for less frequent tags to eliminate those less meaningfulassociation rules. However it is infeasible to manually specify a threshold for eachtag. Therefore, we propose the context aware edge significance to measure the “realconfidence” of the edge. Here, the context refers to some statistical information ofunderlying tag space, such as frequency of tags with parent-child relationship whichwill be used to calculate the conf idence between two tags.
Suppose we have a weighting parameter w for confidence, if the antecedent andconsequent of an edge have the same frequency, w should be 1; on the other hand,if the frequency of consequent is approaching ∞, w will be approaching 0, wherethe confidence of the edge is nearly meaningless. So the frequency difference of an-tecedent and consequent, Freq(B) − Freq(A), could be ranged from 0 (Freq(B) =Freq(A)) to ∞ (Freq(B) → ∞).
Designing an optimal function to model the effect of Freq(B) − Freq(A) is nota trivial task, because the data distribution of tag space is unpredictable. Since thetag co-occurrence graph is typically very large, to improve the efficiency of weighttuning, we utilize a linear fitting strategy to compute a more reasonable contextaware confidence for each edge.
Intuitively, we can find the small value of Freq(B) − Freq(A) has stronger effecton the utility of confidence. Just use an extreme case, if Freq(B) is approaching∞, the change of Freq(B) does not make much sense, as the confidence is actually

World Wide Web
invalidated already. To deal with the “infinity” problem, we use the MaxFreq toreplace the ∞ in the formula, where MaxFreq is the highest value of frequency inthe tag space. The distribution of the tag frequencies follows power law, therefore thechoice of MaxFreq to represent ∞ is comfortable in this scenario, the effectivenessof which will be verified in our experimental study.
The formula to calculate the context aware confidence CConf (tagi → tag j) ispresented as follows:
CConf (tagi → tag j) = Conf (tagi → tag j) ×(
1 − Freq(tag j) − Freq(tagi)
MaxFreq − Freq(tagi)
).
Our strategy is a better choice than confidence, as it is enhanced with theimplication from tag j to tagi, i.e., from the higher level to lower level, which isconsistent with the philosophy of taxonomy. Another benefit of our strategy is thatit is able to provide smaller confidence threshold in small cliques of the graph, whichmakes the taxonomy more balanced. We also notice that a number of associationrule measures have been proposed in literature [1, 4]. We actually tested some well-known association rule measures to represent the correlation between tags, but theirperformances in tag space are not satisfactory.
For example, the problem of “interest” measure is the tags with low frequencywhich by chance occurs a few times together can result in enormous interest values.Additionally, it only measures co-occurrence but not implication, as it is completelysymmetric, which is not appropriate to extract subsumption relation of taxonomy.Another measure that we explored is “Conviction” [4] that inclines to over-stressthe rules with a high consequent support. In our empirical experiments, we foundthat using the proposed context aware value to select significant edges for taxonomyextraction is more promising in a collaborative tagging system.
According to the above analysis, we observe that an association rule measurewhich is directional and takes in account the frequency of both tags is preferred inthis case. We believe conviction is a better chance than confidence and interest, as itis truly a measure of implication from A to B, which is consistent with the philosophyof taxonomy. In the empirical experiments, we show that using the convict value toselect significant edge for taxonomy extraction is more promising in a collaborativetagging systems.
3.2.2 Extraction steps
In the preprocessing stage, we generate the association rule graph for tag dataset.The taxonomy extraction algorithm takes in tag association rule graph G and a tuningparameter, i.e. confidence pruning threshold Thr to extract taxonomy of a tag space.
We present the sketch of this extraction approach, in Algorithm 1. For each tag,we first compute a context aware confidence for its out edges. By comparing withthreshold Thr, we determine whether an edge is qualified to be inserted into thetree T. From the candidate edge pool, we find the out edge with maximum contextaware confidence for a certain tag, and this edge is inserted into the taxonomy. Theassociated two tags of this edge have father-child relationship in the taxonomy, i.e.,the tag with higher frequency serves as father node in the tree structure. Finally, all

World Wide Web
the tags in T without out edges are collected as top layer concepts in the taxonomy.In the experimental evaluation, we will demonstrate our algorithm based on dynamiccontext-aware confidence strategy is more adaptive.
3.3 Quality metrics of taxonomy
The quality of automatically extracted taxonomies is difficult to measure [23].Human judgement is a natural choice, however performing unbiased assessment onthe taxonomies of a large tag space is an extremely time-consuming task, whichis inapplicable in reality. Another alternative is to compare how “similar” theinduced taxonomies are to hand-crafted taxonomies, such as ODP or WordNet. Thecollaborative tagging behaviors are unpredictable, and tags are typically free textswhich do not rely on a controlled vocabulary.
Tagged objects cover various domains and there exist no general standard tax-onomies in social tagging systems. Existing tag taxonomy extraction work eitherskipped the quantitative evaluation or conducted it on a small static tagging set [10,17]. Even if there is a standard tag taxonomy, tags’ dynamic evolution invalidates thiskind of evaluation. The changing tag space complicates the tag taxonomy evaluation.
Motivated by the using scenarios of taxonomy, we introduce the statistical metricsto measure the quality of induced taxonomy. The general user browsing behaviors ina tagging system are to find the objects tagged with a given tag or more tags, to finda list of the most popular tags, or to find tags with tight correlation with user interest.Therefore, the tag taxonomy should be highly navigable and informative. Takinginto account these motivations, we design two novel quality measures to evaluate theoverall quality of taxonomy.
First, the hierarchical taxonomy structure should have informative “portal” con-cepts (tags), which are expected to be popular and capture the overview of thetag space. Here, we refer the “portal” tags to the first layer tags under the root oftaxonomy. In Figure 1, “politics”, “food” and “web2.0” are portal tags.
Global quality of taxonomy Let top1, top2, . . . , topm be the “portal” tags in thetaxonomy. Freq(topi) could represent this tag’s concept generality [16], thus frequenttags are preferred to be “portal” concepts in the taxonomy. Furthermore, we choosethe geometric average, which is more effective summary for skewed data to measure

World Wide Web
the global quality, instead of arithmetic average, because we also want the “portal”concepts to be more balanced to improve the experience of taxonomy navigation.
Global_Quality(T) =(
m∏i=1
Freq(topi)
) 1m
. (1)
Second, the tags in the subtree rooted a certain “portal” tag should be highly cor-related to provide users satisfactory browsing experience. If we extract a taxonomywith few portal concepts, these portal concepts are generally popular and with largesubtrees, while the tags inside the subtree may not be highly correlated; vice versa.
Local quality of taxonomy It can be considered as the degree of co-relationship ofthe tags within the subtrees of the portal tags.
Local_Quality(T) =∑Ci∈C
m∑j=1
(Conf (tag j → Ci))2 . (2)
where Ci refers to a non-leaf tag in taxonomy, Conf (tag j → Ci) is the product ofthe confidence of the edges in the path from tag j to Ci. Most conceptual clusteringmethods are capable of generating hierarchical category structures, and categoryutility is used to measure the “category goodness” of concept hierarchy [7]. Wemeliorate probability-theoretic definition of category utility given in [21] to facilitateour scenario.
The quality of taxonomy can be measured by these two metrics separately orcombined together by the assigned weights. In the experimental study, we willpresent the performance of taxonomy extraction algorithms under these two metrics.The actual showing cases of the extracted taxonomy demonstrate the feasibility ofthe proposed quality metrics.
4 Temporal fusion for evolutionary taxonomy extraction
The taxonomy extraction methods discussed in Section 3 can generate hierarchicaltaxonomies, but they cannot capture the dynamic natures of the tag space. In thissection, we formalize the problem of evolutionary taxonomy extraction in the tagspace, and propose the temporal fusion mechanisms to integrate the changing tagsover time.
Measurement of taxonomy dif ference Intuitively, evolutionary taxonomy shouldmeet the following two different requirements: the generated taxonomy representthe current status of the underlying tag space and not deviate too much from the oldones in preceding interval.
Formally, let t1, t2, . . . tm be m consecutive temporal intervals, and G1, G2, . . . Gm
be the association rule graph of tags identified for each of the intervalst1, t2, . . . tm. Evolutionary taxonomy generation is to build a sequence of taxonomies,T1, T2, . . . Tm, where Ti is the generated evolutionary taxonomy corresponding to ti,such that Ti satisfies the current tag characteristics represented by Gi and at the sametime, does not deviate too much from the previous tag taxonomy, Ti−1.

World Wide Web
The difference between two taxonomies can be measured with the tree editdistance, which is defined as the minimum cost sequence of edit operations (node in-sertion, node deletion, and label change) that transforms one tree into another [2, 25].In our experimental evaluation, we choose this criteria to measure the differenceof two taxonomy trees T and T ′, and the smaller distance score indicates highersimilarity between taxonomies. We first introduce two baselines, and then presentour new evolutionary taxonomy algorithms which integrate the fusion mechanism.
Approach 1: Local taxonomy evolution To capture the evolution of temporaltaxonomies, the naïve approach generates taxonomies for each consecutive timeinterval, and computes the differences with preceding taxonomy to capture thetaxonomy evolution.
Given the successive temporal graph series G1, G2, . . . Gm, this approach extractsa taxonomy for each time interval using the taxonomy extraction algorithm of Section3. The generated taxonomy at time interval i is independent of tagging history inpreceding intervals.
Although such approach can well represent the snapshot of current tag space,independently extracted taxonomies for a certain time interval may be vulnerable tothe noisy tags or transient tag changes.
Approach 2: Historical taxonomy evolution Another straightforward approach isto compute the taxonomy for a time interval from a “smoothed” graph. This“smoothed” graph is obtained from the combination of the underlying tag associationrule graph at the time interval and all the previous historical graphs. In a successivetemporal graph series G1, G2, . . . Gm, for each time interval ti, we accumulate thetagging history in a new graph G′
i. This graph is a combination of Gi based on thecurrent tag actions and all the previous graphs {G j| j < i}.
To construct the graph G′i, we need to define appropriate weighting for current
tag/correlation and the historical ones. Here we introduce the tag frequency andcorrelation weighting formulas in the graph G′
i:
Freq(tag)′ti = Freq(tag)ti + λ × Freq(tag)′ti−1. (3)
Weight(edge)′ti = Weight(edge)ti + λ × Weight(edge)′ti−1. (4)
where parameter λ is to determine the degree of information decay. The motivationbehind this is that not all old time intervals are equally import for current timeinterval. The exponential decay design can favor newer intervals and also includeold ones.
With Freq(tag)′ti and Weight(edge)′ti , we can build a new association rule graph G′i
with the historical information, from which the historical taxonomy T ′i is extracted.
However, this kind of historical graphs may be indistinguishable between old tag cor-relations and the newly emerged links. It makes the taxonomies for two consecutiveintervals nearly consistent as the historical tag information might be over-weighted.
Approach 3: Taxonomy evolution with one-step fusion We next propose two tempo-ral fusion approaches, where a flexible smoothing strategy is directly adopted in theevolutionary taxonomy generation. The current interval’s graph Gi will be integrated

World Wide Web
with the taxonomy and graph at preceding time interval. The new tag taxonomy isgenerated by fusing the tag and correlation information among them.
In the first fusion strategy, our approach takes the graph and taxonomy ofpreceding time interval into account. Figure 4 shows the procedure of evolutionarytaxonomy construction with Approach 3. The first taxonomy T1 is simply generatedusing the underlying graph. While for the subsequent taxonomies, we fuse theinformation of local graph and preceding taxonomy/tag graph, e.g., fusing the Ti−1,Gi−1 and Gi to generate Ti. The historical tag information can help digest the noisyor burst tag to model the evolutionary taxonomy smoothly.
In this approach, the tags’ frequencies and correlations at interval ti are fused withTi−1 and Gi−1. If the current chosen edge for Ti is reflected consistently in Ti−1,we just add the edge into Ti. When it is different from Ti−1, we have to exploit theinformation in Gi−1 and Gi, to select a suitable edge by edge weight accumulation.
The steps of this fusion method are enumerated in Algorithm 2. We first computecontext aware confidence of out edges from tagi and find the candidate edges fromthe underlying graph. Next we find the out edge < tagi → tagup > with the largestcontext aware confidence from the candidate edges.
The difference of this fusion methods lie at a new edge selection strategy. Atthe fusion stage, if the edge appears in the preceding taxonomy Tt−1, we insert itinto the current taxonomy . Otherwise, we find edge < tagi → tagup′ > from Tt−1,and compare the accumulated confidence of edge < tagi → tagup > and < tagi →tagup′ >. After that, the edge with higher confidence will be included in Tt. Finally,all the tags in T without out edges serve as “portal” concepts in the root node ofgenerated taxonomy.
In comparison with the two former baselines, here the fusion approach cancombine historical information without the construction of summary graph used inApproach 2. However, in Approach 3, we only consider the tags of the precedingtime interval to generate the current taxonomy. Although we could infer some hintsfrom the earlier taxonomy chain T1, T2, . . . Tt−1, some earlier tag information ofgraph may be lost. Therefore, we exploit the historical tag association rule graphto maintain the evolutionary taxonomy in the next fusion method.
Figure 4 Evolutionary taxonomy construction (Approach 3).

World Wide Web
Approach 4: Taxonomy evolution with historical fusion When we select the correla-tion for taxonomy in time interval t, Approach 4 considers the historical graph G′
t−1(defined in Approach 2) in contrast to Approach 3 that uses local graph of precedingtime interval Gt−1. Additionally, we generate G′
t by integrating G′t−1 and Gt for future
usage. Note that, the decaying parameter λ will be applied for graph integration.In Figure 5, we display the procedure of evolutionary taxonomy generation with
Approach 4. The first taxonomy T1 is generated using the underlying graph G1, whichis same as in Approach 3; while we fuse the Gi, Ti−1 and Gi−1’ to generate Ti, andintegrate Gi−1’ and Gi into the historical graph Gi’ for later usage.
Figure 5 Evolutionary taxonomy construction (Approach 4).

World Wide Web
The processing steps of Approach 4 is similar to that of Approach 3. It differsfrom Approach 3 in twofold: (1) at each time interval, Approach 4 generates thehistorical graph by integrating the decayed information of preceding historical graph,this step is similar to Approach 2; and (2) Approach 4 fuses the information oflocal graph, preceding taxonomy and preceding historical graph for evolutionarytaxonomy generation.
Different fusion strategies are discussed in this section. The information they useand the time/space cost the process need are varied. We will report the performancedifference of these four methods.
5 Empirical study
We evaluate the performance of static taxonomy and evolutionary taxonomy extrac-tion algorithms in a real dataset. We collect it from Del.icio.us.,1 which is a socialbookmarking site for storing, sharing, and discovering web bookmarks, and has morethan five million users and 180 million bookmarked URLs. The used subset in thisexperiment consists of 270,502,498 tagging actions,ranging from Jan 2007 to Oct 2008.All the experiments are conducted on a Linux (Redhat) Server, with eight core 2.0GHz processors and 12GB RAM. The tagged data are stored in a RDBMS (MySQL5.1, MyISAM engine).
5.1 Quality of extracted taxonomies
We first evaluate the performance of our proposed taxonomy extraction algorithmby comparing it with existing taxonomy extraction approaches. Reported in [19],the association rule based method performs better than other statistical basedapproaches, such as co-occurrence based method [14]. Hence, we only demonstratethe comparison with association rule method in this paper. To evaluate the quality ofextracted taxonomy, we use the proposed evaluation quality measures, i.e., Globalquality and Local quality.
After the construction of tag association graph, we filter less significant edges,which are probably noise, under a minimum confidence threshold 5% and a mini-mum support threshold 10. In the time intervals, we generate a series of taxonomies,under different confidence thresholds. In contrast to clustering algorithms, suchas k-means clustering which uses k as a tuning factor, our taxonomy extractionalgorithm and the competitor cannot directly control the size of taxonomy. This isreasonable as the underly tag space is unstructured, diverse, and no well-definedformal measure can be applied to evaluate correlation between tags. On the otherhand, two approaches may generate taxonomies with different sizes using the samethreshold value, as we adopt “context aware confidence” in our approach instead oftraditional fixed confidence.
1http://www.delicious.com
World Wide Web
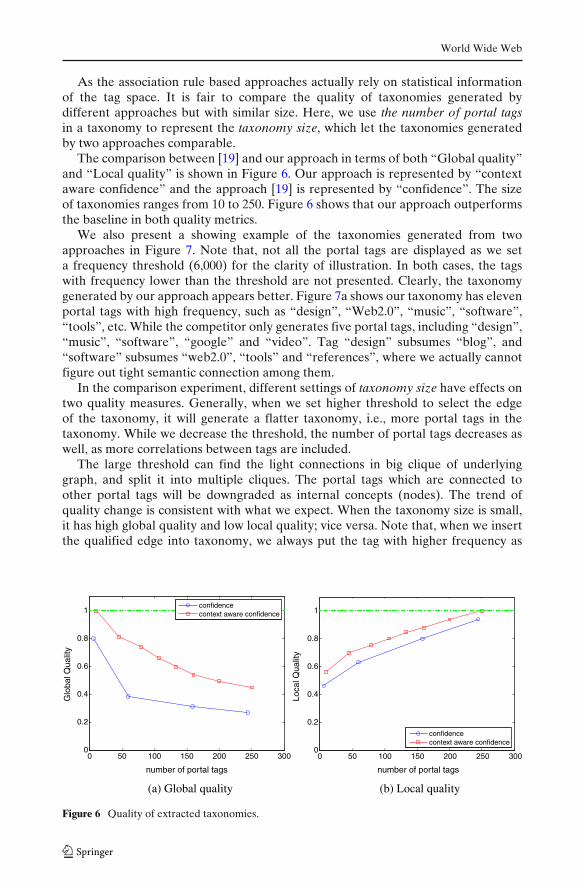
As the association rule based approaches actually rely on statistical informationof the tag space. It is fair to compare the quality of taxonomies generated bydifferent approaches but with similar size. Here, we use the number of portal tagsin a taxonomy to represent the taxonomy size, which let the taxonomies generatedby two approaches comparable.
The comparison between [19] and our approach in terms of both “Global quality”and “Local quality” is shown in Figure 6. Our approach is represented by “contextaware confidence” and the approach [19] is represented by “confidence”. The sizeof taxonomies ranges from 10 to 250. Figure 6 shows that our approach outperformsthe baseline in both quality metrics.
We also present a showing example of the taxonomies generated from twoapproaches in Figure 7. Note that, not all the portal tags are displayed as we seta frequency threshold (6,000) for the clarity of illustration. In both cases, the tagswith frequency lower than the threshold are not presented. Clearly, the taxonomygenerated by our approach appears better. Figure 7a shows our taxonomy has elevenportal tags with high frequency, such as “design”, “Web2.0”, “music”, “software”,“tools”, etc. While the competitor only generates five portal tags, including “design”,“music”, “software”, “google” and “video”. Tag “design” subsumes “blog”, and“software” subsumes “web2.0”, “tools” and “references”, where we actually cannotfigure out tight semantic connection among them.
In the comparison experiment, different settings of taxonomy size have effects ontwo quality measures. Generally, when we set higher threshold to select the edgeof the taxonomy, it will generate a flatter taxonomy, i.e., more portal tags in thetaxonomy. While we decrease the threshold, the number of portal tags decreases aswell, as more correlations between tags are included.
The large threshold can find the light connections in big clique of underlyinggraph, and split it into multiple cliques. The portal tags which are connected toother portal tags will be downgraded as internal concepts (nodes). The trend ofquality change is consistent with what we expect. When the taxonomy size is small,it has high global quality and low local quality; vice versa. Note that, when we insertthe qualified edge into taxonomy, we always put the tag with higher frequency as
0 50 100 150 200 250 3000
0.2
0.4
0.6
0.8
1
number of portal tags
Glo
bal Q
ualit
y
confidencecontext aware confidence
0 50 100 150 200 250 3000
0.2
0.4
0.6
0.8
1
number of portal tags
Loca
l Qua
lity
confidencecontext aware confidence
(a) Global quality (b) Local quality
Figure 6 Quality of extracted taxonomies.

World Wide Web
(a) Context aware confidence (b) Confidence
Figure 7 Showing cases of the extracted taxonomies.
father concept. Therefore, the portal tag always have the higher frequency than itsdescendant. In case that we decrease threshold to reduce the taxonomy size, i.e., thenumber of portal tags, and the correlation between two portal tags becomes higherthan threshold, only the one with higher frequency will remain the portal tag. Onthe contrary, if there are more portal tags in the taxonomy, which also means we usehigher threshold to filter the tag correlations, the correlations between connectedtags are tighter obviously, as all the light edges are already excluded.
For example, we find a connection between programming → ref erence →tools → sof tware in an experimental dataset, where each edge has confidence higherthan 10% and each tag has a quite large sub-tree. Our approach successfully identifiesthem as portal tags, while the baseline method fails even when it generates ataxonomy with larger size.
In this taxonomy extraction experiment, our proposed approach has advantage inboth qualitative and quantitative comparisons. First, our approach is enhanced withthe implication from the abstract concept to more specific topics, and thus providesbetter subsumption capability when evaluating the correlation of abstract-specifictag pairs. Second, our context aware threshold strategy is more robust to noise byactually providing large threshold for large cliques and low threshold for small cliquesin terms of “original confidence”.
We do not report efficiency for taxonomy extraction here, since both approachestake similar time, and generating the association rule graph of the tag space domi-nates the runtime.
5.2 Performance on evolutionary taxonomy extraction
We proceed to evaluate the four fusion approaches for evolutionary extractiondiscussed in Section 4, which adopt the proposed taxonomy extraction algorithm asthe basis.
We evaluate how different methods can trade off the difference between snapshotand historical taxonomies by showing the historical dif ference, i.e., the differencebetween evolutionary taxonomy and historical taxonomy, and snapshot dif ference,i.e., the difference between evolutionary taxonomy and snapshot taxonomy. In our

World Wide Web
implementation, we follow an effective approximation pq-grams of the well-knowntree edit distance [2] to compute the difference between taxonomies, and the smallerdistance indicated higher similarity.
5.2.1 Ef fect of temporal evolution
Figure 8 shows the evolution difference from Jan 2007 to Oct 2008, when λ isset as 0.5. The overall picture of the results is consistent with what was presentedin Section 5.3, i.e., Approach 1 is the most sensitive to the historical taxonomydifference, followed by Approaches 3, 4; while Approach 2 is the most sensitive interms of snapshot difference.
5.2.2 Showing cases
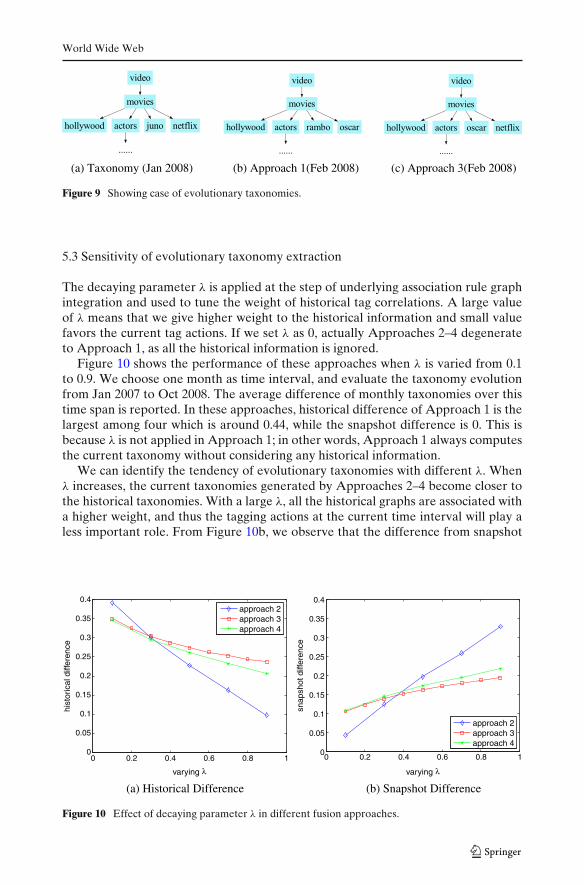
In Figure 9,we illustrate an example of evolutionary taxonomy to show the effectof temporal evolution. Since the taxonomies are generally with large size, e.g.,consisting of tens of thousand tags in our experiments, it is infeasible to show theoverall picture. We only shows a subset of the extracted taxonomy here.
The first taxonomy a is simply generated from tags in Jan 2008. Under “movies”,there were some common topics, e.g., “hollywood”, “actors”, “netflix” (a DVDrental site) and several temporal hot tags, e.g., newly released film “juno”. Thetaxonomy b is the snapshot of Feb 2008, where the newly released movie “rambo”(Rambo 4) and annual academy award “oscar” ceremony appeared. We generatethe taxonomy c with fusion of the historical information. By integrating the previousinformation, the tag “netflix” remains in taxonomy c as it has a higher accumulatedfrequency. “oscar” stays in c because it was a very hot topic in Feb 2008. As atemporally bursty topic, “rambo” was unfavorable in accumulated weighting. Thefusion process aligned it to the root node and filtered it later.
Due to the space constraint, we do not illustrate the taxonomy generated byApproaches 2 and 4. Our results show that they are closer to previous taxonomybecause they integrate more historical information.
1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 100
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
2007−−−2008 2007−−−2008
hist
oric
al d
iffer
ence
approach 1approach 2,λ=0.5approach 3,λ=0.5approach 4,λ=0.5
1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 100
0.05
0.1
0.15
0.2
0.25
0.3
snap
shot
diff
eren
ce
approach 2,λ=0.5approach 3,λ=0.5approach 4,λ=0.5
(a) Historical Difference (b) Snapshot Difference
Figure 8 Temporal evolution of different extraction approaches.
World Wide Web
(a) Taxonomy (Jan 2008) (b) Approach 1(Feb 2008) (c) Approach 3(Feb 2008)
Figure 9 Showing case of evolutionary taxonomies.
5.3 Sensitivity of evolutionary taxonomy extraction
The decaying parameter λ is applied at the step of underlying association rule graphintegration and used to tune the weight of historical tag correlations. A large valueof λ means that we give higher weight to the historical information and small valuefavors the current tag actions. If we set λ as 0, actually Approaches 2–4 degenerateto Approach 1, as all the historical information is ignored.
Figure 10 shows the performance of these approaches when λ is varied from 0.1to 0.9. We choose one month as time interval, and evaluate the taxonomy evolutionfrom Jan 2007 to Oct 2008. The average difference of monthly taxonomies over thistime span is reported. In these approaches, historical difference of Approach 1 is thelargest among four which is around 0.44, while the snapshot difference is 0. This isbecause λ is not applied in Approach 1; in other words, Approach 1 always computesthe current taxonomy without considering any historical information.
We can identify the tendency of evolutionary taxonomies with different λ. Whenλ increases, the current taxonomies generated by Approaches 2–4 become closer tothe historical taxonomies. With a large λ, all the historical graphs are associated witha higher weight, and thus the tagging actions at the current time interval will play aless important role. From Figure 10b, we observe that the difference from snapshot
0 0.2 0.4 0.6 0.8 10
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
varying λ
hist
oric
al d
iffer
ence
approach 2approach 3approach 4
0 0.2 0.4 0.6 0.8 10
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
varying λ
snap
shot
diff
eren
ce
approach 2approach 3approach 4
(a) Historical Difference (b) Snapshot Difference
Figure 10 Effect of decaying parameter λ in different fusion approaches.

World Wide Web
taxonomy is opposite to historical difference. If an approach integrates more histor-ical information, the difference from the snapshot will be bigger as expected. Thismakes the taxonomies for two consecutive time intervals more consistent.
The fusion based approaches, i.e., Approaches 3 and 4, are more stable, as we fusethe historical taxonomy to generate the current taxonomy. The Approach 2 is themost sensitive to the value of λ, e.g., its historical difference decreases from 0.4 to 0.1when λ increases from 0.1 to 0.9. because the decaying factor of Approach 2 is theproduction of historical decayed tag correlations. Additionally, Approach 4 takes theunderlying historical graph into account, its historical difference is smaller than thatof Approach 3.
5.4 Efficiency of evolutionary taxonomy extraction
To test the time cost of these fusion approaches, we test the performance of the Weset the same tuning parameters for different approaches for a fair comparison, suchas decay parameter λ and confidence threshold. We process the taxonomy evolutionof dataset over five runs. The average results for each time interval are presented inTable 1.
The row “Time on graph” in Table 1 shows the time to generate the underlyingassociation rule graph. Approach 1 is the same as Approach 3 as they both needto generate the graph for tags in current time interval. Approaches 2 and 4 takemuch longer time as they need to accumulate the decayed historical information. Therow “Time on taxonomy” shows the time to generate the evolutionary taxonomy.Approaches 1 and 2 are faster than Approaches 3 and 4. This is because Approaches1 and 2 generate the taxonomy from the underlying association rule graph only, whileApproaches 3 and 4 need to compare local graph and preceding graph for taxonomygeneration. Approach 1 is more efficient than Approach 2 because its underlyinggraph has fewer tags. In our experiments, we find that there are about 200,000 distincttags in a month on average. Therefore, Approach 2 maintains the largest number oftags as it accumulates the decayed historical frequency information.
The numbers of tags in the taxonomies generated by Approaches 1, 3 and 4 aresame, as we initiate the evolutionary taxonomy generation from the local tag co-occurrence graph. However, their taxonomy structures are different, as some tagsmight be replaced with the tags from the preceding graph or historical tags.
In this experiment study, we extensively test the effectiveness and efficiency ofthe proposed fusion approaches for evolutionary taxonomy extraction. We findthe feasibility of the Approach 3 both in the extraction quality and applicableperformance. It also has a good stability over parameter choice. The introduced evo-lutionary taxonomy extraction method can well balance both the previous historicalinformation and current fresh news, providing a smoother tag space summarization.
Table 1 Runtime and the counts of tags in extracted taxonomy.
Approaches 1 2 3 4
Time on graph 38 s 290 s 38 s 290 sTime on taxonomy 8.4 s 9.4 s 11 s 11.5 sTag count in taxonomy 4,418 5,290 4,418 4,418

World Wide Web
6 Conclusion and future work
In this paper, we address the problem of evolutionary taxonomy construction incollaborative tagging systems. A novel context aware mechanism is introduced togenerate hierarchical taxonomy from a large tag corpus. Afterwards, we investigatehow the temporal properties of tag correlation can be utilized to model the evolvinghierarchical taxonomy, and propose several strategies to construct evolutionarytaxonomy. We conduct an extensive study using a large real-life dataset which showsthe superiority of proposed method.
Our approach makes an interesting attempt to incorporate temporal dimensioninto taxonomy extraction which improves the current tag organization in collabora-tive tagging sites.
There are several promising future directions of this work. For example, it isvaluable to incorporate more additional semantic information into the taxonomyextraction. It is also interesting to apply the proposed evolutionary taxonomy to dealwith trend detection and tag prediction, and further explore the evolving interests ofonline communities.
Acknowledgements This research was supported by the National Natural Science Foundation ofChina under Grant Nos. 60933004 and 61073019, and HGJ Grant No. 2011ZX01042-001-001.
References
1. Agrawal, R., Imielinski, T.: Mining association rules between sets of items in large databases. In:Prof. of SIGMOD, pp. 207–216 (1993)
2. Augsten, N., Böhlen, M., Gamper, J.: Approximate matching of hierarchical data using pq-grams.In: Proc. of VLDB, pp. 301–312 (2005)
3. Bao, S.-H., Yang, B.-H., Fei, B., Xu, S.-L., Su, Z., Yu, Y.: Social propagation: boosting socialannotations for web mining. World Wide Web 12(4), 399–420 (2009)
4. Brin, S., Motwani, R., Ullman, J.D., Tsur, S.: Dynamic itemset counting and implication rules formarket basket data. In: Prof. of SIGMOD, pp. 255–264 (1997)
5. Cattuto, C., Benz, D., Hotho, A., Stumme, G.: Semantic grounding of tag relatedness in socialbookmarking systems. In: 7th international semantic web conference, pp. 615–631 (2008)
6. Cattuto, C., Schmitz, C., Baldassarri, A., Servedio, V.D.P., Loreto, V., Hotho, A., Grahl, M.,Stumme, G.: Network properties of folksonomies. AI Commun. 20(4), 245–262 (2007)
7. Corter, J.E., Gluck, M.A.: Explaining basic categories: feature predictability and information. In:Psychol. Bull. 111(2), 291–303 (1992)
8. Doan, A.H., Ramakrishnan, R., Halevy, A.Y.: Crowdsourcing systems on the world-wide web.Commun. ACM 54(4), 86–96 (2011)
9. Dubinko, M., Kumar, R., Magnani, J., Novak, J., Raghavan, P., Tomkins, A.: Visualizing tagsover time. In: Proc. of WWW, pp. 193–202 (2006)
10. Eda, T., Yoshikawa, M., Uchiyama, T., Uchiyama, T.: The effectiveness of latent semanticanalysis for building up a bottom-up taxonomy from folksonomy tags. World Wide Web 12(4),421–440 (2009)
11. Fontoura, M., Josifovski, V., Kumar, R., Olston, C., Tomkins, A., Vassilvitskii, S.: Relaxation intext search using taxonomies. In: Proc. of VLDB, pp. 672–683 (2008)
12. Golder, S.A., Huberman, B.A.: Usage patterns of collaborative tagging systems. J. Inf. Sci. 32(2),198–208 (2006)
13. Halpin, H., Robu, V., Shepherd, H.: The complex dynamics of collaborative tagging. In: Proc. ofWWW, pp. 211–220 (2007)
14. Heymann, P., Garcia-Molina, H.: Collaborative creation of communal hierarchical taxonomiesin social tagging systems. Technical Report 2006-10, Stanford University (2006)
15. Heymann, P., Koutrika, G., Garcia-Molina, H.: Can social bookmarking improve web search?In: Proc. of WSDM, pp. 195–206 (2008)

World Wide Web
16. Heymann, P., Ramage, D., Garcia-Molina, H.: Social tag prediction. In: Proc. of SIGIR, pp. 531–538 (2008)
17. Plangprasopchok, A., Lerman, K., Getoor, L.: Growing a tree in the forest: constructing folk-sonomies by integrating structured metadata. In: Proc. of KDD, pp. 949–958 (2010)
18. Schenkel, R., Crecelius, T., Kacimi, M., Michel, S., Neumann, T., Parreira, J.X., Weikum, G.:Efficient top-k querying over social-tagging networks. In: Proc. of SIGIR, pp. 523–530 (2008)
19. Schwarzkopf, E., Heckmann, D., Dengler, D., Kroner, A.: Mining the structure of tag spaces foruser modeling. In: Proc. of the Workshop on Data Mining for User Modeling, pp. 63–75 (2007)
20. Siorpaes, K., Simperl, E.: Human intelligence in the process of semantic content creation. WorldWide Web 13(1), 33–59 (2010)
21. Witten, I.H., Frank, E.: Data Mining: Practical Machine Learning Tools and Techniques. MorganKaufmann, San Francisco (2005)
22. Yahia, S.A., Benedikt, M., Lakshmanan, L.V.S., Stoyanovich, J.: Efficient network aware searchin collaborative tagging sites. In: Proc. of VLDB, pp. 710–721 (2008)
23. Yang, H., Callan, J.: A metric-based framework for automatic taxonomy induction. In: Proc. ofACL, pp. 271–279 (2009)
24. Yao, J.J., Cui, B., Huang, Y.X., Zhou, Y.H.: Bursty event detection from collaborative tags.World Wide Web (2011). doi:10.1007/s11280-011-0136-2
25. Zhang, K., Shasha, D.: Simple fast algorithms for the editing distance between trees and relatedproblems. SIAM J Comput 18(6), 1245–1262 (1989)
26. Zhou, D., Bian, J., Zheng, S., Zha, H., Giles, C.L.: Exploring social annotations for informationretrieval. In: Proc. of WWW, pp. 715–724 (2008)