hpc research @ unm: x10’ding graph analysis
DESCRIPTION
HPC Research @ UNM: X10’ding Graph Analysis. Mehmet F. Su ECE Dept. - University of New Mexico Joint work with advisor: David A. Bader {mfatihsu, dbader} @ ece.unm.edu. Acknowledgment of Support. National Science Foundation - PowerPoint PPT PresentationTRANSCRIPT

HPC Research @ UNM: X10’ding Graph Analysis
Mehmet F. SuECE Dept. - University of New Mexico
Joint work with advisor: David A. Bader{mfatihsu, dbader} @ ece.unm.edu

Acknowledgment of Support
National Science Foundation CAREER: High-Performance Algorithms for Scientific Applications (00-93039) ITR: Building the Tree of Life -- A National Resource for Phyloinformatics and Computational
Phylogenetics (EF/BIO 03-31654) DEB: Ecosystem Studies: Self-Organization of Semi-Arid Landscapes: Test of Optimality Principles
(99-10123) ITR/AP: Reconstructing Complex Evolutionary Histories (01-21377) DEB Comparative Chloroplast Genomics: Integrating Computational Methods, Molecular Evolution,
and Phylogeny (01-20709) ITR/AP(DEB): Computing Optimal Phylogenetic Trees under Genome Rearrangement Metrics (01-
13095) DBI: Acquisition of a High Performance Shared-Memory Computer for Computational Science and
Engineering (04-20513). IBM PERCS / DARPA High Productivity Computing Systems (HPCS) PACI: NPACI/SDSC, NCSA/Alliance, PSC DOE Sandia National Laboratories

Outline
About the speakerGraph theoretic problems: what and whyOur researchIBM PERCS performance evaluation
tools: SSCA-2 and X10Some tool ideas for better productivity

About the speaker: Mehmet F. Su
Education BS Physics (Bilkent University, Ankara, Turkey) Physics Dept, Iowa State University, Ames, IA PhD track, ECE Dept, University of New Mexico,
Albuquerque, NM Past and Present External Collaborations
Condensed Matter Physics Group, Ames National Laboratory, Ames, IA
HPC apps. in comp. biology, photonics, comp. electromagnetism
Photonic Microsystems Technologies Group, Sandia National Laboratories, Albuquerque, NM
HPC apps. in photonics and comp. electromagnetism

The Tree of Life
Social Networks Manhattan, NY
Power Distribution in Boylan Heights,
Raleigh, NC
Air Transportation
National Highway US Internet Backbone
US Power Grid’sControl Area Operators (CAO).
Portland, OR

Characteristics of Graph Problems
Graphs are of fundamental importance Many fast theoretic PRAM algorithms but few fast
parallel implementations Irregular problems are challenging
Sparse data structures Hard to partition data Poor locality hinders cache performance
Parallel graph and tree algorithms Building blocks for higher-level parallel algorithms Hard to achieve parallel speedup (very fast sequential
implementations)

Our Group’s Impact
Our results demonstrate the first parallel implementations of several combinatorial problems that for arbitrary, sparse instances in comparison run faster than the best sequential implementations:
list ranking spanning tree, minimum spanning forest, rooted spanning
tree ear decomposition tree contraction and expression evaluation maximum flow using push-relabel
Our source code is freely-available under the GNU General Public License (GPL).
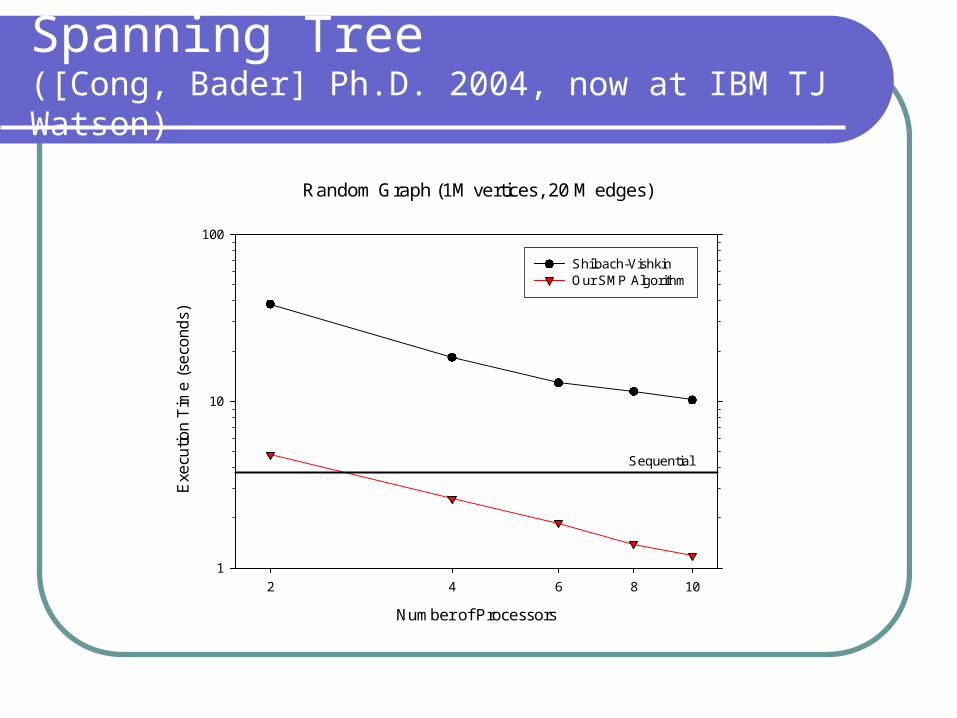
Spanning Tree([Cong, Bader] Ph.D. 2004, now at IBM TJ Watson)
Random Graph (1M vertices, 20 M edges)
Number of Processors
2 4 6 8 10
Exe
cutio
n T
ime
(se
con
ds)
1
10
100
Sequential
Shiloach-VishkinOur SMP Algorithm

High-End SMP Servers
IBM pSeries 690 “Regatta”: 32-way Power4+ 1.7GHz, 32GB RAM
Streams Triad: 58.9 GB/s
• IBM pSeries 575: 2U Rackmount, 8-way SMP, up to 256 GB RAM, up to 1024-proc configuration w/ single cluster 1600• Streams Triad (8 p5 1.9 GHz procs): 55.7 GB/s

About SSCA-2
DARPA High Productivity Computing Systems (HPCS) Program Productivity Benchmarks: Scalable Synthetic Compact
Application (SSCA) SSCA-2 = Graph Analysis (directed multigraph with
labeled edges) Simulate large-scale graph problems Multiple analysis techniques, single data
Four computational kernels Integer and character ops., no floating point
Emphasizes integer operations, irregular data access, choice of data structure
Data structure not modified across kernels

SSCA-2 Structure
Scalable Data Generator produces random, but structured, set of edges
Kernel 1 Builds the graph data structure from the set of edges
Kernel 2 Searches multigraph for desired maximum integer weight, and desired string weight (labels)
Kernel 3 Extracts desired subgraphs, given start vertices and path length
Kernel 4 Extracts clusters (cliques) to help identify the underlying graph structure

About X10
New programming language, in development by IBM
Better productivity, more scalability Shorten development/test cycle time Object oriented New ways to express
Parallelism Data access Aggregate operations (scan, reduce etc.)
Rule out/catch more programming errors, bugs

Implementation of SSCA-2
Designed and implemented parallel shared memory code (C with POSIX threads) for SSCA-2 [Bader/Madduri]
Interested in X10 implementationEvaluate productivity with X10 and its
development environment (Eclipse)Evaluate SSCA-2 performance on new
systems once X10 is fully optimized

Tool Ideas for Better Productivity
Wizard-like interfaces *NIXes, powerful development environments, cascaded
menus shock many programmers Intuitive visualization for data
With zoom/agglomeration, like online street maps Library/package indexing tool
Help resolve unresolved symbols, allow manual override w/ choices
Autoconf/Automake counterparts Determine external dependencies/library symbols
automatically for any environment Better branch prediction/feedback mechanism
Collect data over multiple runs

Tool Ideas (cont’d)
Better binding, architecture dependent optimizer Detect environment properties at run time
Integrated tools to help identify performance hot spots and reasons Profile for cache misses, branch prediction issues, check
useful tasks performed concurrently, lock contamination Visualization to indicate high level compiler
optimizations on Eclipse editor window Arrows for loop transforms, code relocations, annotations,
different colors for propagated constants, evaluated expressions etc.
Intermediate language/assembly viewer Compiler optimizations, register scheduling, SWP annotated Assembly listing from many compilers give similar info

IBM Collaborators
PERCS Performance Ram Rajamony Pat Bohrer Mootaz Elnozahy
X10 evaluation Vivek Sarkar Kemal Ebcioglu Vijay Saraswat Christine Halverson Catalina M. Danis Jason Ellis
Advanced Computing Technologies David Klepacki Guojing Cong

Backup Slides

SSCA #2: Graph Analysis Overview
Application: Graph Theory - Stresses memory access; uses integer and character operations (no floating point)
Scalable Data Generation + 4 Computational Kernels
Scalable Data Generator creates a set of edges between vertices to form a sparse directed multi-graph with:
Random number of randomly sized cliques Random number of intra-clique directed parallel edges Random number of gradually 'thinning' edges linking the
cliques No self loops Two types of edge weight labels: integer and character string
only integer weights considered in present implementation Randomized vertex numbers
Directed weighted multigraph with no self-loops

Scalable Data Generation
Creates a set of edges between vertices to form a sparse directed multigraph with:
Random number of randomly sized cliques Random number of intra-clique directed parallel edges Random number of gradually 'thinning' edges linking
the cliques No self loops Two types of edge weight labels: integer and character
string only integer weights considered in present implementation
Randomized vertex numbers Vertices should be permuted to remove any locality for Kernel
4

Kernel 1 – Graph Generation
Construct a sparse multi-graph from lists of tuples containing vertex identifiers, implied direction, and weights that represent data assigned to the implied edge.
The multi-graph can be represented in any manner, but it cannot be modified between subsequent kernels accessing the data.
There are various representations for sparse directed graphs - including (but not limited to) sparse matrices and (multi-level) linked lists.
This kernel will be timed.

Kernel 2 – Classify large sets
Examine all edge weights to determine those vertex pairs with the largest integer weights and those vertex pairs with a specified string weight (label).
The output of this kernel will be two vertex pair lists - i.e., sets - that will be saved for use in the following kernel.
These two lists will be start sets SI and SC for integer start sets and character start sets respectively.
The process of generating the two lists/sets will be timed.

Kernel 3 – Extracting Subgraphs
Produce a series of subgraphs consisting of vertices and edges on paths of length k from the vertex pairs start sets SI and SC.
A possible computational kernel for graph extraction is Breadth First Search.
The process of extracting the graph will be timed.

Kernel 4 – Clique Extraction
Use a graph clustering algorithm to partition the vertices of the graph into subgraphs no larger than a maximum size so as to minimize the number of edges that need be cut.
the kernel implementation should not utilize a priori knowledge of the details in the data generator or the statistics collected in the graph generation process
heuristic algorithms that determine the clusters in near-linear time are permitted - O(V)
The process of identifying the clusters and their interconnections will be timed.

X10 Design
Builds over an existing OO language (Java) to shorten learning curve
Has new constructs for commonly used data access patterns (distributions)
Commonly used parallel programming environments today… Message passing, no shared memory (MPI) Shared memory, implicit thread control (OpenMP) Shared memory, explicit thread control (Threads) Partitioned global shared mem, explicit thread control (UPC) PG shared, implicit thread control (HPF)
… can these not be blended?
PG shared = can specify affinity to a thread

X10 Design (cont’d)
Supports shared memory, allows local memory, shared memory is partitioned (places)
Operation can run at a place where data resides… (async) … or data can be sent to a place to get evaluated (future) Supports short-hand definitions for array regions & data
distribution, extended iterators (foreach variants) Generalized barriers (clocks) supporting more flexible operations
(can operate/wait on multiple clocks), can freeze a variable until a clock advance (clocked final)
Supports aggregate parallel operators (scan, reduction) in operator form (not like MPI calls)
Supports atomic sections (unconditional, conditional), conditional sections lock on a logical condition (run “when” something is true)
Weak memory consistency model (enables better optimizations)