institute of intelligent power electronics – ipe page1 data clustering methods docent xiao-zhi gao...
TRANSCRIPT

Institute of Intelligent Power Electronics – IPEPage1
Data Clustering Methods
Docent Xiao-Zhi GaoDepartment of Electrical Engineering and Automation

Institute of Intelligent Power Electronics – IPEPage2
Data Clustering Data clustering is for data organization,
data compression, and model construction
Clustering partitions a data set into groups such as similarity within a group is larger than that among groups
Similarity needs to be defined– Metric of difference between two input
vectors
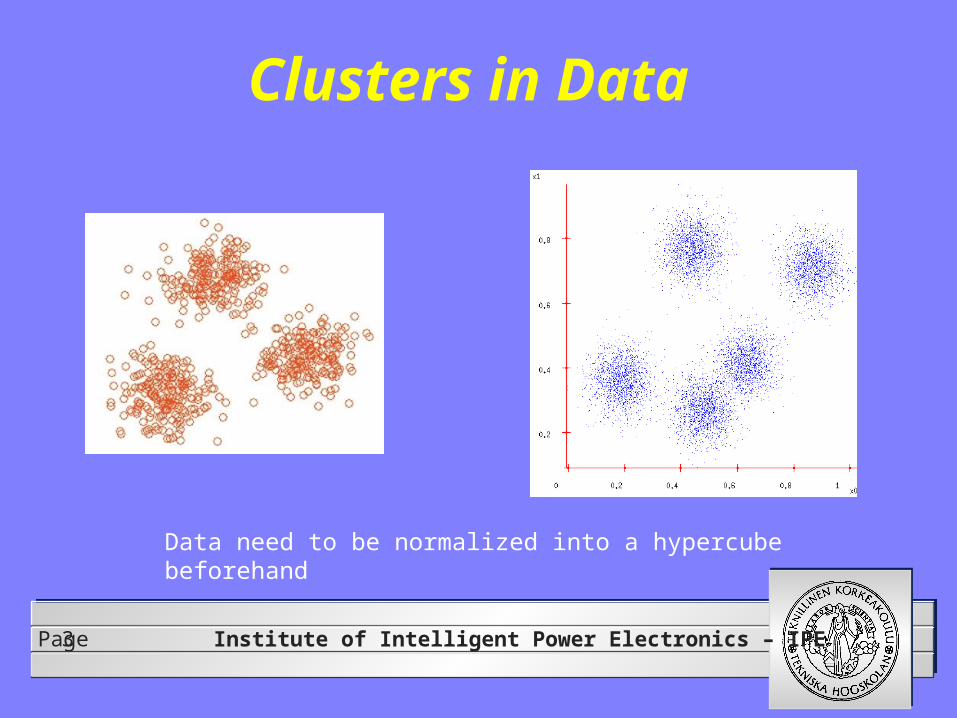
Institute of Intelligent Power Electronics – IPEPage3
Clusters in Data
Data need to be normalized into a hypercube beforehand

Institute of Intelligent Power Electronics – IPEPage4
Similarity?

Institute of Intelligent Power Electronics – IPEPage5
Similarity Similarity can be defined as distances
between two vectors in the data space
There are a few choices– Euclidean distance (real-values)– Hamming distance (binary or symbols)– Manhattan distance (any)
nxxx ,,, 21 x nyyy ,,, 21 y

Institute of Intelligent Power Electronics – IPEPage6
Euclidean Distance Euclidean distance between two vectors
is defined as:
n
iiinn yxyxyxyxd
1
22222
211 )()()()(),( yx

Institute of Intelligent Power Electronics – IPEPage7
Hamming Distance Hamming distance is the number of
positions at which the corresponding symbols of two vectors are different
For example, – "toned" and "roses" is 3– "1011101" and "1001001" is 2– "2173896" and "2233796" is 3

Institute of Intelligent Power Electronics – IPEPage8
Manhattan Distance Manhattan distance (city block distance)
is equal to the length of all paths connecting the two vectors along all segments
Taxicab geometry

Institute of Intelligent Power Electronics – IPEPage9
K-Means Clustering Method K-means clustering method partitions a
collection of n vectors into c groups Gi, i=1, 2, ..., c, and finds the cluster centers in these groups so as to minimize a given dissimilarity measurement

Institute of Intelligent Power Electronics – IPEPage10
K-Means Clustering Method
The dissimilarity measurement (cost function) can be calculated using Euclidean distance in K-means clustering method

Institute of Intelligent Power Electronics – IPEPage11
K-Means Clustering Method
The binary membership matrix U is cxn martrix defined as follows:
Xj belongs to group i, if ci is the closest center among all the centers

Institute of Intelligent Power Electronics – IPEPage12
K-Means Clustering Method
To minimize the cost function J, the optimal center of a group should be the mean of all the vectors in that group:

Institute of Intelligent Power Electronics – IPEPage13
K-Means Clustering Method K-means clustering method is an
iterative algorithm to find cluster centers

Institute of Intelligent Power Electronics – IPEPage14
K-Means Clustering Method There is no guarantee that it can converge
to an optimal solution– Optimization methods might be used to deal
with cost function J The performance of k-means clustering
method depends on the initial cluster centers– Front-end methods should be employed to find
good initial centers

Institute of Intelligent Power Electronics – IPEPage15
K-Means Clustering Method K-means clustering method might have
problems with clusters of– different densities– non-globular shapes
K-means clustering method is a ’hard’ data clustering approach– Data should belong to clusters to degrees
» Fuzzy k-means method

Institute of Intelligent Power Electronics – IPEPage16
Clusters of Different Densities
c=3

Institute of Intelligent Power Electronics – IPEPage17
Clusters of Non-globular Shapes
c=2

Institute of Intelligent Power Electronics – IPEPage18
Butterfly Data

Institute of Intelligent Power Electronics – IPEPage19
Mountain Clustering Method Mountain clustering method (Yager,
1994) approximates clusters based on density measure of data
Mountain clustering method can be used either as a stand-alone algorithm or for obtaining initial clusters of other data clustering approaches

Institute of Intelligent Power Electronics – IPEPage20
Mountain Clustering Method Step 1: Form a grid in the data space,
and the intersections of the grid line are considered as center candidates of clustering, denoted as a set V– Not necessarily evenly spaced– A fine gridding is needed, but can increase
computation burden

Institute of Intelligent Power Electronics – IPEPage21
Mountain Clustering Method Step 2: Construct mountain functions
representing data density measure. The height of the mountain function at v is:

Institute of Intelligent Power Electronics – IPEPage22
Mountain Clustering Method Each input vector x contributes to the
heights of mountain functions at v The contribution is inversely
proportional to their distances d(x, v) Mountain function is a measure of data
density (higher if more data points are located nearby)

Institute of Intelligent Power Electronics – IPEPage23
Mountain Clustering Method
Step 3: Select cluster centers and destruct mountain functions
The points with the largest mountain heights are selected as cluster centers

Institute of Intelligent Power Electronics – IPEPage24
Mountain Clustering Method The just-identified centers are often
surrounded by input data with high density
The effects of just-identified centers should be eliminated
The mountain functions are revised by substracting a scaled Gaussian function

Institute of Intelligent Power Electronics – IPEPage25
Mountain Functions
may affect the smoothness of mountain functions
0.02 0.1 0.2

Institute of Intelligent Power Electronics – IPEPage26
Mountain Destruction
Cluster centers are selected, and mountains are destructed sequentially

Institute of Intelligent Power Electronics – IPEPage27
Subtractive Clustering Mountain clustering method is simple
but time consuming with growth of dimensions of data
Replace grid points with data points in mountain clustering, and we can get subtractive clustering (Chiu, 1994)– Only data points are considered as cluster
center candidates

Institute of Intelligent Power Electronics – IPEPage28
Subtractive Clustering The density measure of data point
The density measure of each data point is revised sequentially
ix

Institute of Intelligent Power Electronics – IPEPage29
Conclusions Three typical off-line data clustering
methods are introduced They often operate in the batch mode The prototypes characterizing data sets
found by the data clustering methods can be used as ’codebooks’

Institute of Intelligent Power Electronics – IPEPage30
An Application Example

Institute of Intelligent Power Electronics – IPEPage31
Computer Exercises I
0 1 2 3 4 5 60
1
2
3
4
5
6
7
8
AB

Institute of Intelligent Power Electronics – IPEPage32
Computer Exercises II