instructor: erol sahin hypertreading, multi-core architectures, amdahl’s law and review ceng331:...
TRANSCRIPT

Instructor:
Erol Sahin
Hypertreading, Multi-core architectures,Amdahl’s Law and Review CENG331: Introduction to Computer Systems14th Lecture
Acknowledgement: Some of the slides are adapted from the ones prepared by R.E. Bryant, D.R. O’Hallaron of Carnegie-Mellon Univ.

– 2 –
Computation power is never enough
Our machines are million times faster than ENIAC..Yet we ask for more..
To make sense of universe To build bombs To understand climate To unravel genome
Upto now, the solution was easy: Make the clock run faster..

– 3 –
Hitting the limits…
No more.. We’ve hit the fundamental limits on clock speed: Speed of light: 30cm/nsec in vacuum and 20 cm/nsec in copper In a 10GHz machine, signals cannot travel more than 2cm in
total In a 100GHz, at most 2mm, just to get the signal from one end
to another and back
We can make computers as small as that, but we face with other problems: More difficult to design and verify
.. and fundamental problems Heat dissipation! Coolers are already bigger than the CPUs..
Going from 1MHz to 1GHz was simply engineering the chip fabrication process, not from 1GHz to 1 THz..

– 4 –
Parallel computers
New approach: Build parallel computers
Each computer having a CPU running at normal speeds Systems with 1000 CPU’s are already available..
The big challenge: How to utilize parallel computers to achieve speedups
Programming has been mostly a “sequential business”» Parallel programming remained exotic
How to share information among different computers How to coordinate processing? How to create/adapt OSs?

Instructor:
Erol Sahin
Superscalar architectures, Simultenous Multi-threadingCENG331: Introduction to Computer Systems14th Lecture
Acknowledgement: Some of the slides are adapted from the ones prepared by Neil Chakrabarty and William May
– 6 –
Threading AlgorithmsTime-slicing
A processor switches between threads in fixed time intervals. High expenses, especially if one of the processes is in the wait state.
Switch-on-event Task switching in case of long pauses Waiting for data coming from a relatively slow source, CPU resources
are given to other processes

– 7 –
Threading Algorithms (cont.)
Multiprocessing Distribute the load over many processors Adds extra cost
Simultaneous multi-threading Multiple threads execute on a single processor without switching. Basis of Intel’s Hyper-Threading technology.

– 8 –
Hyper-Threading ConceptAt each point of time only a part of processor resources is used
for execution of the program code.
Unused resources can also be loaded, for example, with parallel execution of another thread/application.
Extremely useful in desktop and server applications where many threads are used.

– 9 –

– 10 –
Hyper-Threading Architecture
First used in Intel Xeon MP processor Makes a single physical processor appear as multiple
logical processors.Each logical processor has a copy of architecture state.Logical processors share a single set of physical
execution resources

– 11 –
Hyper-Threading Architecture
Operating systems and user programs can schedule processes or threads to logical processors as if they were in a multiprocessing system with physical processors.
From an architecture perspective we have to worry about the logical processors using shared resources. Caches, execution units, branch predictors, control logic, and buses.

– 12 –
Advantages
Extra architecture only adds about 5% to the total die area.
No performance loss if only one thread is active. Increased performance with multiple threads
Better resource utilization.

– 13 –
Disadvantages
To take advantage of hyper-threading performance, serial execution can not be used. Threads are non-deterministic and involve extra design Threads have increased overhead

Instructor:
Erol Sahin
Multi-Core processorsCENG331: Introduction to Computer Systems14th Lecture
Acknowledgement: Some of the slides are adapted from the ones prepared by Neil Chakrabarty and William May

– 15 –
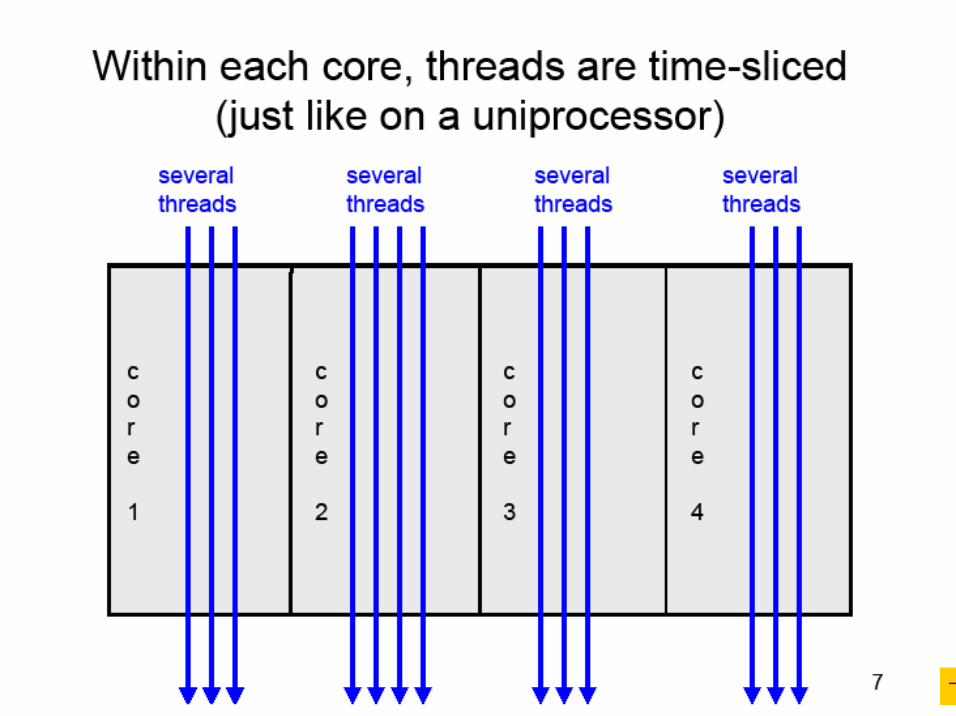
Multicore chipsRecall Moore’s law:
The number of transistors that can be put on a chip will double every 18 months!
Still holds! 300 million transistors on an Intel Core 2 Duo class chip
Question: what do you do with all those transistors?
Increase cache.. But we already have 4MB caches.. Performance gain is little.
Another option: put two or more cores on the same chip (technically die)
Dual-core and quad-core chips are already on the market
80-core chips are manufactured.. More will follow.
– 16 –
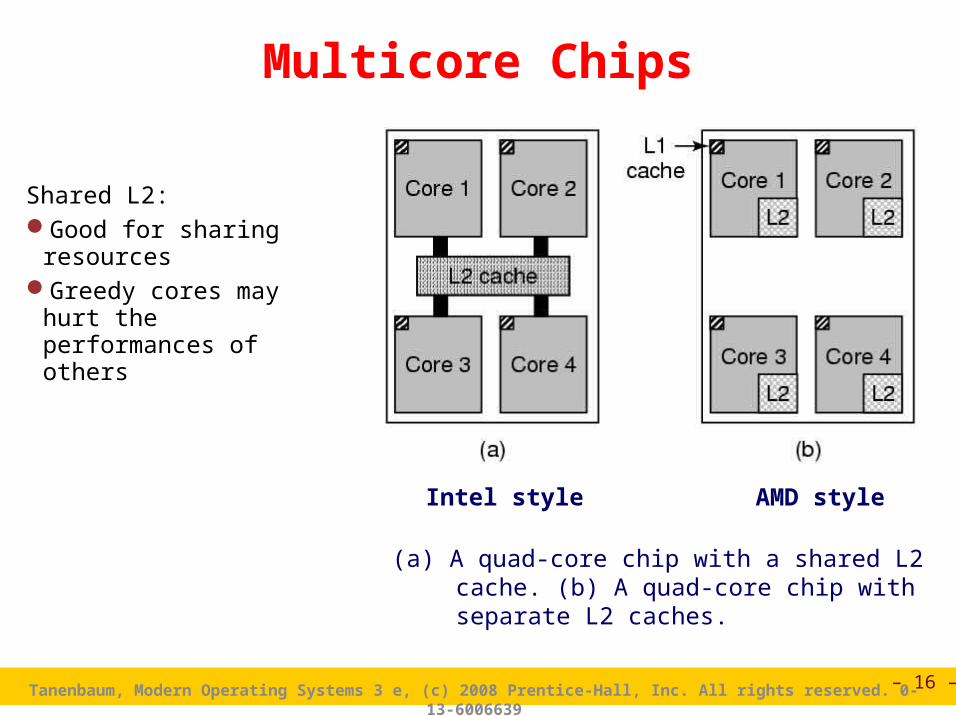
(a) A quad-core chip with a shared L2 cache. (b) A quad-core chip with separate L2 caches.
Multicore Chips
Tanenbaum, Modern Operating Systems 3 e, (c) 2008 Prentice-Hall, Inc. All rights reserved. 0-13-6006639
Intel style AMD style
Shared L2:Good for sharing resourcesGreedy cores may hurt the
performances of others
– 17 –

– 18 –
Comparison: SMT versus Multi-core
Multi-core
• Several cores each designed to be smaller and not too powerful
• Great thread-level parallelism
SMT
• One large, powerful superscalar core
• Great performance on running a single thread
• Exploits instruction-level parallelism

– 19 –
Cloud Computing and Server farms
Cloud computing
Server farms

Instructor:
Erol Sahin
Amdahl’s Law and Review CENG331: Introduction to Computer Systems14th Lecture
Acknowledgement: Some of the slides are adapted from the ones prepared by R.E. Bryant, D.R. O’Hallaron of Carnegie-Mellon Univ.

– 21 –
Performance Evaluation
This week Performance evaluation Amdahl’s law Review

– 22 –
ProblemYou plan to visit a friend in Cannes France and must decide whether it is worth it to take the Concorde SST or a 747 from NY (New York) to Paris, assuming it will take 4 hours LA (Los Angeles) to NY and 4 hours Paris to Cannes.

– 23 –
Amdahl’s LawYou plan to visit a friend in Cannes France and must decide
whether it is worth it to take the Concorde SST or a 747 from NY(New York) to Paris, assuming it will take 4 hours LA (Los Angeles) to NY and 4 hours Paris to Cannes.
time NY Paris total trip time speedup over 747
747 8.5 hours 16.5 hours 1SST 3.75 hours 11.75 hours 1.4
Taking the SST (which is 2.2 times faster) speeds up the overall trip by only a factor of 1.4!

– 24 –
Speedup
T1 T2
Old program (unenhanced)T1 = time that can NOT
be enhanced.
T2 = time that can be enhanced.
T2 = time after the enhancement.
Old time: T = T1 + T2
T1 = T1 T2 T2
New program (enhanced)
New time: T = T1 + T2
Speedup: Soverall = T / T

– 25 –
Computing SpeedupTwo key parameters:
Fenhanced = T2 / T (fraction of original time that can be improved)Senhanced = T2 / T2 (speedup of enhanced part)
T = T1 + T2 = T1 + T2 = T(1-Fenhanced) + T2 = T(1 – Fenhanced) + (T2/Senhanced) [by def of Senhanced] = T(1 – Fenhanced) + T(Fenhanced /Senhanced) [by def of Fenhanced] = T((1 – Fenhanced) + Fenhanced/Senhanced)
Amdahl’s Law: Soverall = T / T = 1/((1 – Fenhanced) + Fenhanced/Senhanced)
Key idea: Amdahl’s Law quantifies the general notion of diminishing returns. It applies to any activity, not just computer programs.

– 26 –
Amdahl’s Law Example
Trip example: Suppose that for the New York to Paris leg, we now consider the
possibility of taking a rocket ship (15 minutes) or a handy rip in the fabric of space-time (0 minutes):
time NY->Paris total trip time speedup over 747
747 8.5 hours 16.5 hours 1
SST 3.75 hours 11.75 hours 1.4
rocket 0.25 hours 8.25 hours 2.0
rip 0.0 hours 8 hours 2.1

– 27 –
Lesson from Amdahl’s LawUseful Corollary of Amdahl’s law:
1 Soverall 1 / (1 – Fenhanced)
Fenhanced Max Soverall Fenhanced Max Soverall
0.0 1 0.9375 16
0.5 2 0.96875 32
0.75 4 0.984375 64
0.875 8 0.9921875 128
Moral: It is hard to speed up a program.
Moral++ : It is easy to make premature optimizations.

– 28 –
Other MaximsSecond Corollary of Amdahl’s law:
When you identify and eliminate one bottleneck in a system, something else will become the bottleneck
Beware of Optimizing on Small Benchmarks Easy to cut corners that lead to asymptotic inefficiencies

– 29 –
Review: Time to look back!

– 30 –
Take-home message: Nothing is real!

– 31 –
Great Reality #1: Int’s are not Integers, Float’s are not Reals
Example 1: Is x2 ≥ 0? Float’s: Yes! Int’s:
40000 * 40000 --> 1600000000 50000 * 50000 --> ??
Example 2: Is (x + y) + z = x + (y + z)? Unsigned & Signed Int’s: Yes! Float’s:
(1e20 + -1e20) + 3.14 --> 3.14 1e20 + (-1e20 + 3.14) --> ??

– 32 –
Great Reality #2: You’ve Got to Know AssemblyChances are, you’ll never write program in assembly
Compilers are much better & more patient than you are
But: Understanding assembly key to machine-level execution model Behavior of programs in presence of bugs
High-level language model breaks down Tuning program performance
Understand optimizations done/not done by the compiler Understanding sources of program inefficiency
Implementing system software Compiler has machine code as target Operating systems must manage process state
Creating / fighting malware x86 assembly is the language of choice!

– 33 –
Great Reality #3: Memory MattersRandom Access Memory Is an Unphysical Abstraction
Memory is not unbounded It must be allocated and managed Many applications are memory dominated
Memory referencing bugs especially pernicious Effects are distant in both time and space
Memory performance is not uniform Cache and virtual memory effects can greatly affect program
performance Adapting program to characteristics of memory system can lead to
major speed improvements

– 34 –
Great Reality #4: There’s more to performance than asymptotic complexity
Constant factors matter too!
And even exact op count does not predict performance Easily see 10:1 performance range depending on how code written Must optimize at multiple levels: algorithm, data representations,
procedures, and loops
Must understand system to optimize performance How programs compiled and executed How to measure program performance and identify bottlenecks How to improve performance without destroying code modularity
and generality

– 35 –
Great Reality #5: Computers do more than execute programs
They need to get data in and out I/O system critical to program reliability and performance
They communicate with each other over networks Many system-level issues arise in presence of network
Concurrent operations by autonomous processes Coping with unreliable media Cross platform compatibility Complex performance issues

– 36 –
What waits for you in the future?

– 37 –
New tricks to learn..

– 38 –
Coming to a classroom next to you in Spring semester:334- Int. to Operating systems
Processes and threads Synchronization, semaphores, monitors
Assignment 1: Synchronization CPU scheduling policies
Assignment 2: System calls and scheduling Virtual memory, paging, and TLBs
Assignment 3: Virtual memory Filesystems, FFS, and LFS
Assignment 4: File systems RAID and NFS filesystems