introduction definitions and notationfrahm.web.unc.edu/files/2015/11/21_transfer_learning.pdf · a...
TRANSCRIPT

A SHORT TUTORIAL ON
DOMAIN ADAPTATION AND
TRANSFER LEARNING
Tatiana Tommasi
Postdoctoral Fellow UNC, CS department

OVERVIEW
Introduction Why do we need domain adaptation (DA) and transfer learning (TL)
Definitions and Notation
Challenging questions and Solution Strategies What, How and When to transfer/adapt
Instance Transfer
Model Transfer
Feature Transfer
Summary and useful references

ANALIZE AND INTERPRET VISUAL DATA
people, faces
chair
tables
monitor
book
scene: office, lab
action: sitting, talking
Training and Learning
From the movie “Transcendence”

TRAIN, LEARN, TEST
people, faces
chair
tables
monitor
book
scene: office, lab
action: sitting, talking
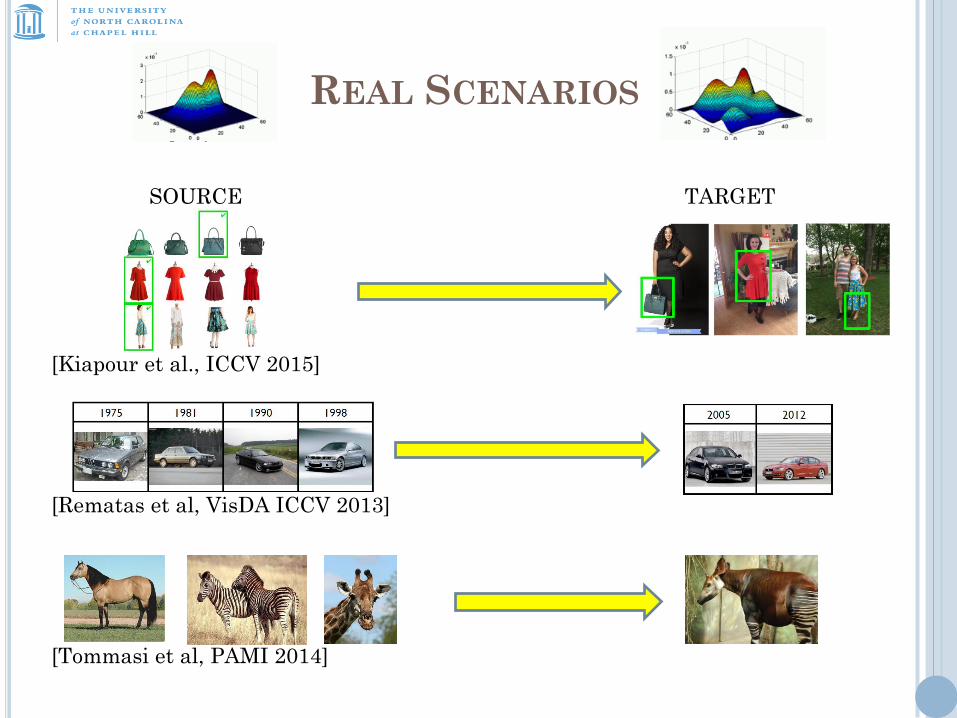
REAL SCENARIOS
[Rematas et al, VisDA ICCV 2013]
[Tommasi et al, PAMI 2014]
[Kiapour et al., ICCV 2015]
SOURCE TARGET
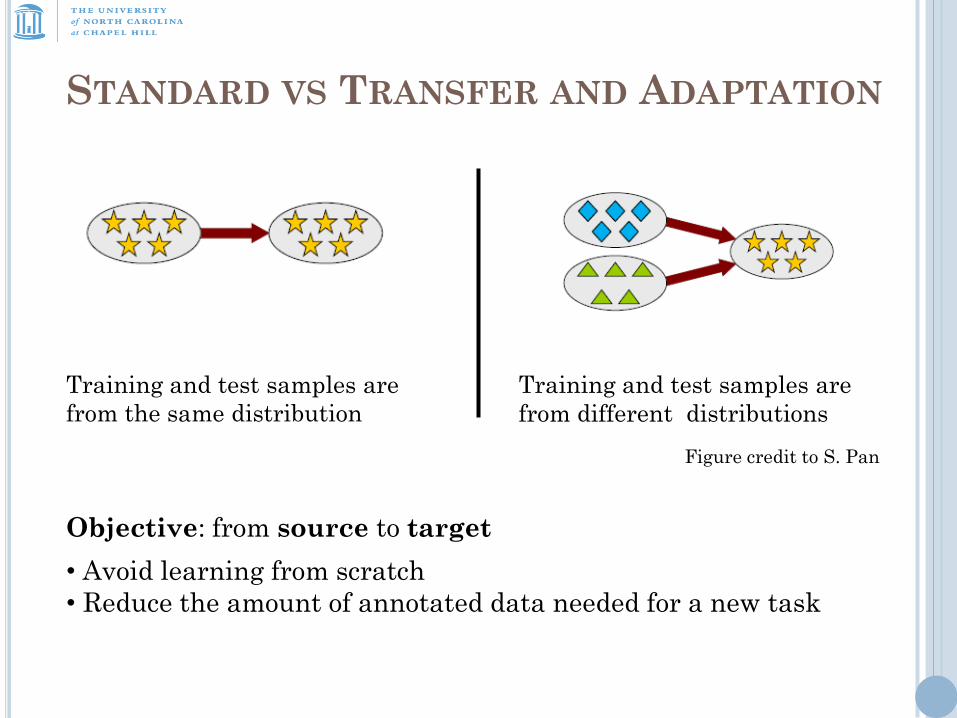
STANDARD VS TRANSFER AND ADAPTATION
Training and test samples are
from the same distribution
Training and test samples are
from different distributions
Objective: from source to target
Figure credit to S. Pan
• Avoid learning from scratch
• Reduce the amount of annotated data needed for a new task

NOTATION
Input variable to a learning system (i.e. observation)
Output variable to a learning system (i.e. label)
Feature and Label Space
Specific values of
Domain: pair of feature space and marginal
distribution.
prediction function.
Task: pair of label space and conditional
probability.

SOURCE AND TARGET MISMATCH
Domain: pair of feature space and marginal
distribution.
prediction function.
Task: pair of label space and conditional
probability.
Different for Source and Target Data
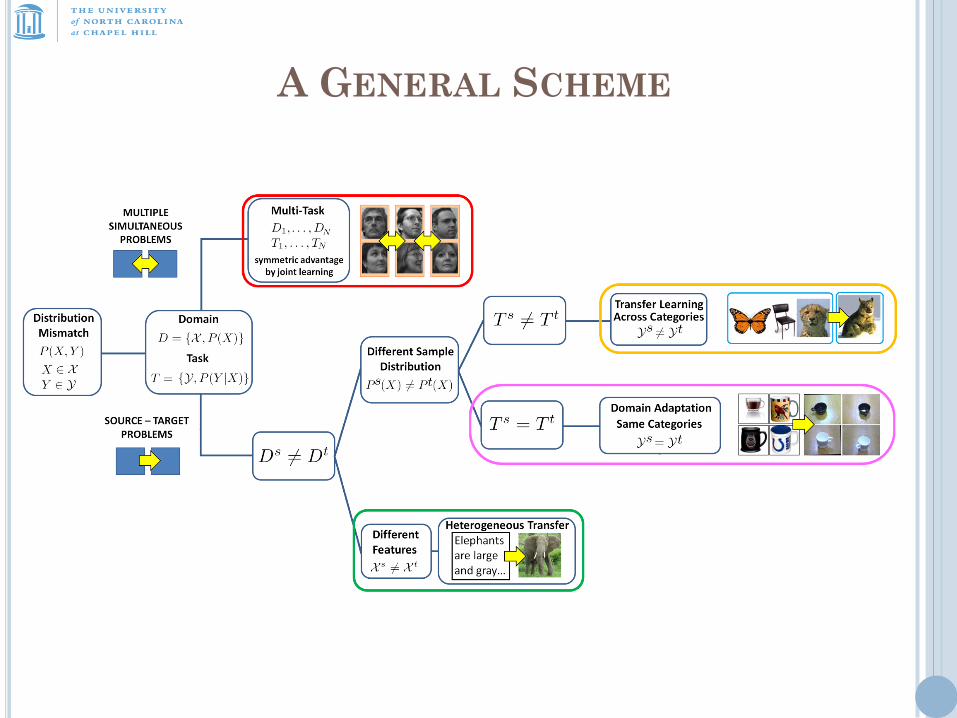
A GENERAL SCHEME

SETTING AND DEFINITIONS
Unsupervised: Source with large amount of labeled data.
Target with no labels.
Semi-Supervised: Source with large amount of labeled data.
Target with a limited amount of labels.
One-shot Learning: Target with one labeled sample.
Zero-shot Learning: Neither the target samples nor their
labels are available at training time. Source and Target share
textual information.

ADVANTAGES AND LIMITS
Number of labeled
target samples
Performance
Learning without adaptation
Learning with adaptation
Negative Transfer
Higher Start
Higher Slope
Same or Better Asymptote
Figure adapted from L. Torrey

WHAT, HOW AND WHEN?
What: Define the knowledge that should be extracted from the
source and used on the target.
How: Define the algorithm that extract this knowledge and
leverages over it.
When: Evaluate the relation among source and target and choose
if transferring/adapting is worthwhile or not.
Select or combine multiple sources.

WHAT, HOW AND WHEN?
What: define the knowledge that should be extracted from the
source and used on the target
Instances: reweight the source samples or sub-select
them.
Features: find a common space where source and
target are close (projection, new representation) .
Models: re-use the source models or their parameters
to initialize the target model.
Combination of the approaches.

INSTANCE TRANSFER
• Learn a classifier to minimize the expected error on the
target domain
• Assume the same posterior across domains
Covariate Shift Assumption
Source
Target

DISTRIBUTION DIFFERENCE
Rewrite the classification error in conditional expectation
Change expectation with respect to the source domain
Identify as the weighted error on the source domain

MAXIMUM MEAN DISCREPANCY
[Borgwardt et al. ISMB 2006]
MMD: Distance between embeddings of the probability
distributions in a reproducing kernel Hilbert space.
MMD and its empirical estimate
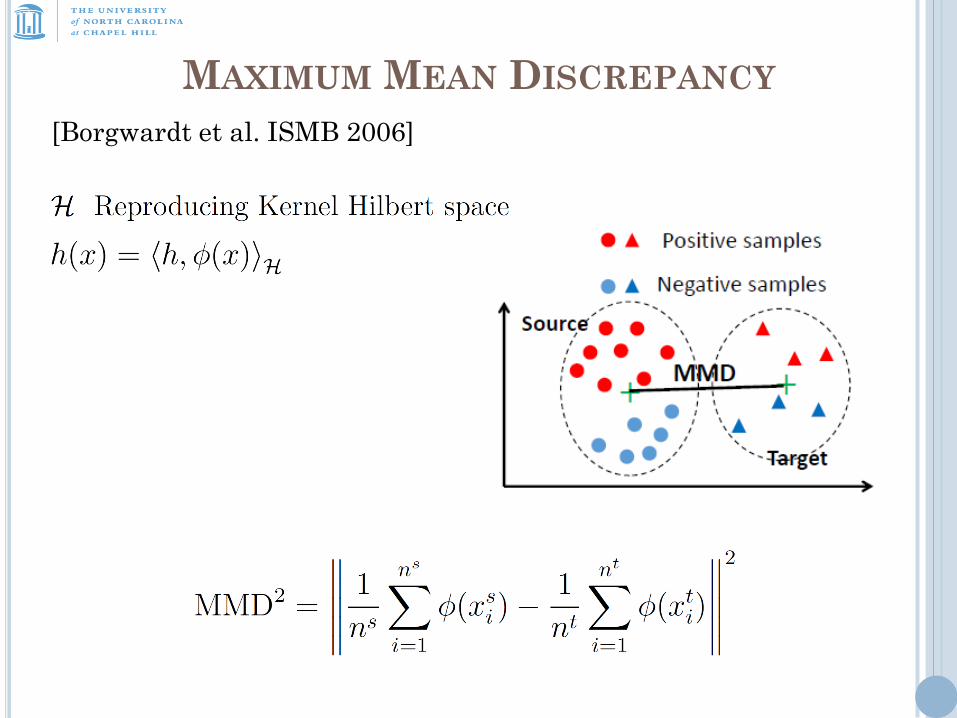
MAXIMUM MEAN DISCREPANCY
[Borgwardt et al. ISMB 2006]

WEIGHT ESTIMATORS
[Huang et al. NIPS 2006]
Kernel Mean Matching: reweighting the training points such that
the means of the training and test points in a reproducing kernel
Hilbert space (RKHS) are close.
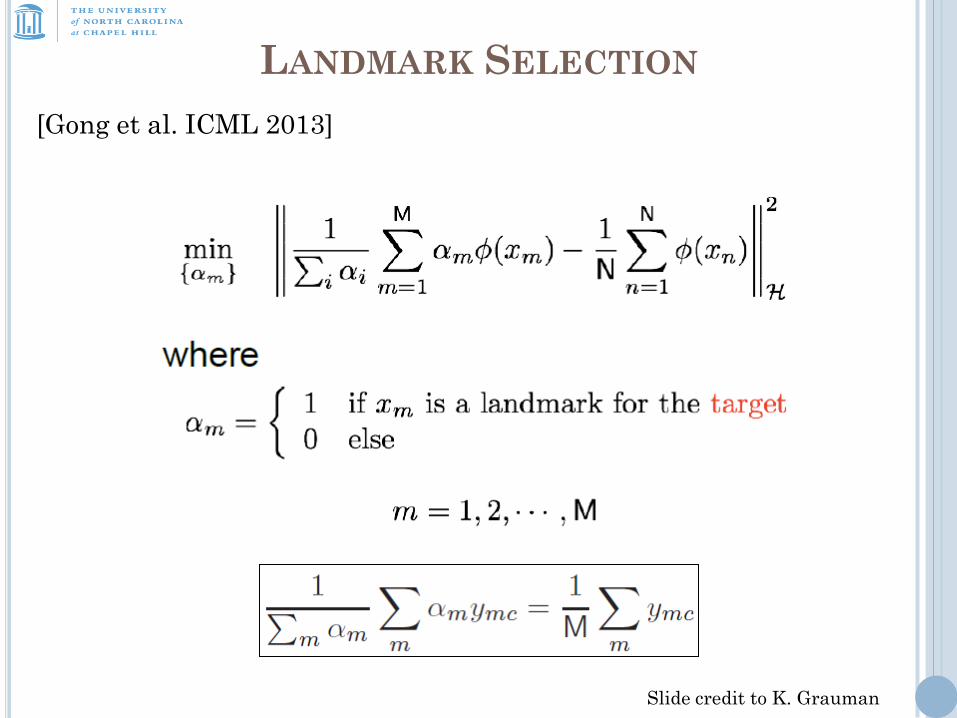
LANDMARK SELECTION
Slide credit to K. Grauman
[Gong et al. ICML 2013]
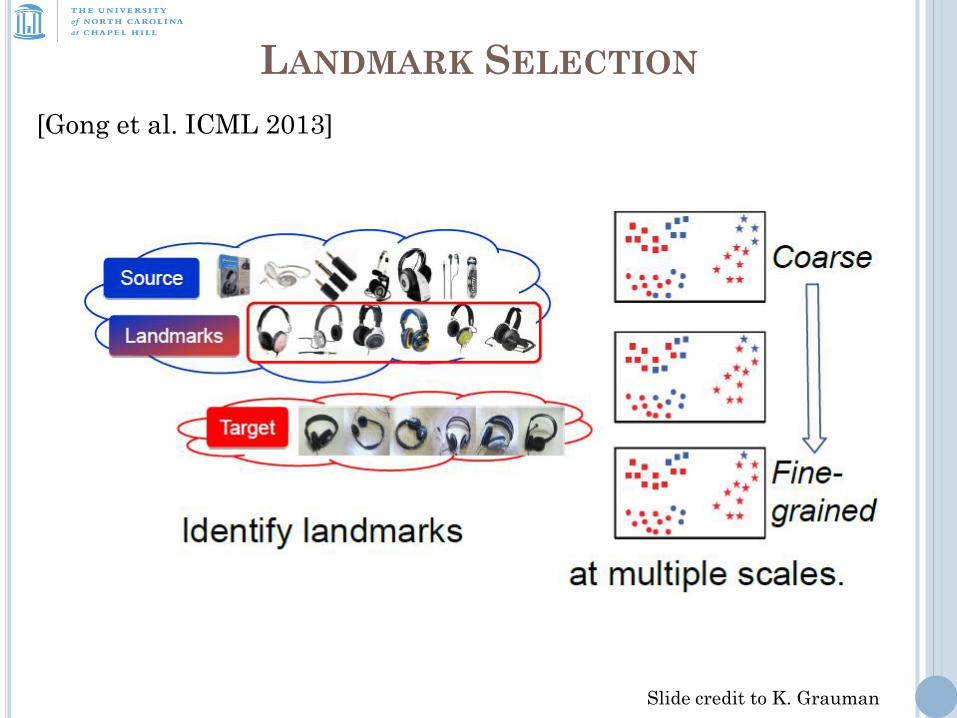
LANDMARK SELECTION
[Gong et al. ICML 2013]
Slide credit to K. Grauman

INSTANCE TRANSFER
• Direct Importance Estimation with Model Selection and Its Application to
Covariate Shift Adaptation. M. Sugiyama, S. Nakajima, H. Kashima, P. von
Buenau, M. Kawanabe. NIPS 2007.
• Discriminative Learning for Differing Training and Test Distributions. S. Bickel,
M. Brűckner, T. Scheffer. ICML 2007.
• Correcting Sample Selection Bias by Unlabeled Data. J. Huang, A. Gretton, K.
M. Borgwardt, B. Schlkopf, A.J. Smola. NIPS, 2006.
• Covariate Shift by Kernel Mean Matching. A. Gretton, A. Smola, J.Huang, M.
Schmittfull, K. Borgwardt, B. Scholkopf. NIPS 2007.
• Transfer Learning by Borrowing Examples. J. Lim , R. Salakhutdinov, A.
Torralba. NIPS 2012.
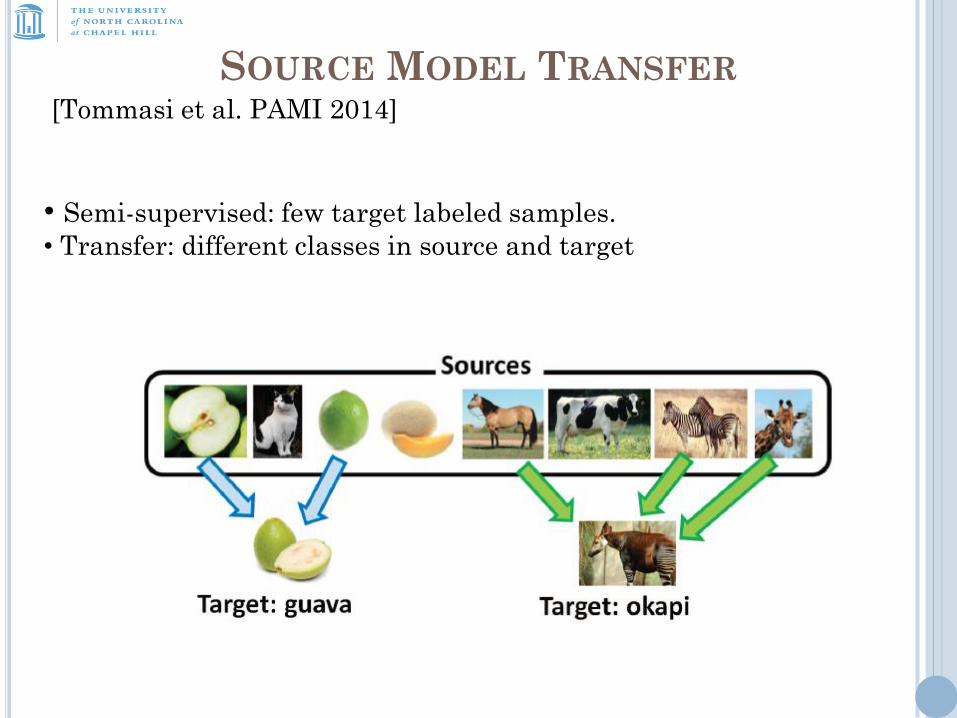
SOURCE MODEL TRANSFER [Tommasi et al. PAMI 2014]
• Semi-supervised: few target labeled samples.
• Transfer: different classes in source and target

I want to learn … vs
• Given a set of data
• Find a function
Minimize the structural risk
• Linear function
• Feature mapping with
Optimization problem
SOURCE MODEL TRANSFER [Tommasi et al. PAMI 2014]

I already know … vs
• A source a set of data
• With
• Pre-learned model on the source.
: solution of the learning problem on the source.
SOURCE MODEL TRANSFER [Tommasi et al. PAMI 2014]

How: adaptive regularization.
When, how much: reweighted source knowledge.
1
... b
w
SOURCE MODEL TRANSFER [Tommasi et al. PAMI 2014]
1 2 b 2 3 b 3 4 b 4 5 b 6 7 b 7

SOLVE THE TARGET LEARNING PROBLEM
Use the square loss
Solve
Adaptive Least-Square Support Vector Machines
LS-SVM [Suykens et al., 2002]
• square loss: evaluates square error on each sample;
• not sparse: all the training samples contribute to the solution;
• solution: set of linear equations.
[Tommasi et al. PAMI 2014]

In matricial form
where
The model parameters can be calculated by matrix inversion
Solution:
Classifier:
[Tommasi et al. PAMI 2014]
SOLVE THE TARGET LEARNING PROBLEM

LEAVE-ONE-OUT PREDICTION
We can train the learning method on N samples and obtain as
a byproduct the prediction for each training sample as if it
was left out from the training set.
The Leave-One-Out error is an almost unbiased estimator of
the generalization error [Lunz and Brailovsky, 1969].
[Tommasi et al. PAMI 2014]

EVALUATE THE RELEVANCE OF EACH SOURCE
The best values for beta are those producing positive values for
for each i. To have a convex formulation consider
and solve
b chooses from where and how much to transfer.
[Tommasi et al. PAMI 2014]

EXPERIMENTAL EVALUATION
Visual Object Category Detection
Binary problems: Object vs Non-Object
Data sets:
• Caltech 256
Image Features:
• SIFT (BOW)
• Linear Kernel
[Tommasi et al. PAMI 2014]

10 mixed classes, 1 target and 9 sources.
Target
W vs
In turn...
EXPERIMENTAL EVALUATION
[Tommasi et al. PAMI 2014]
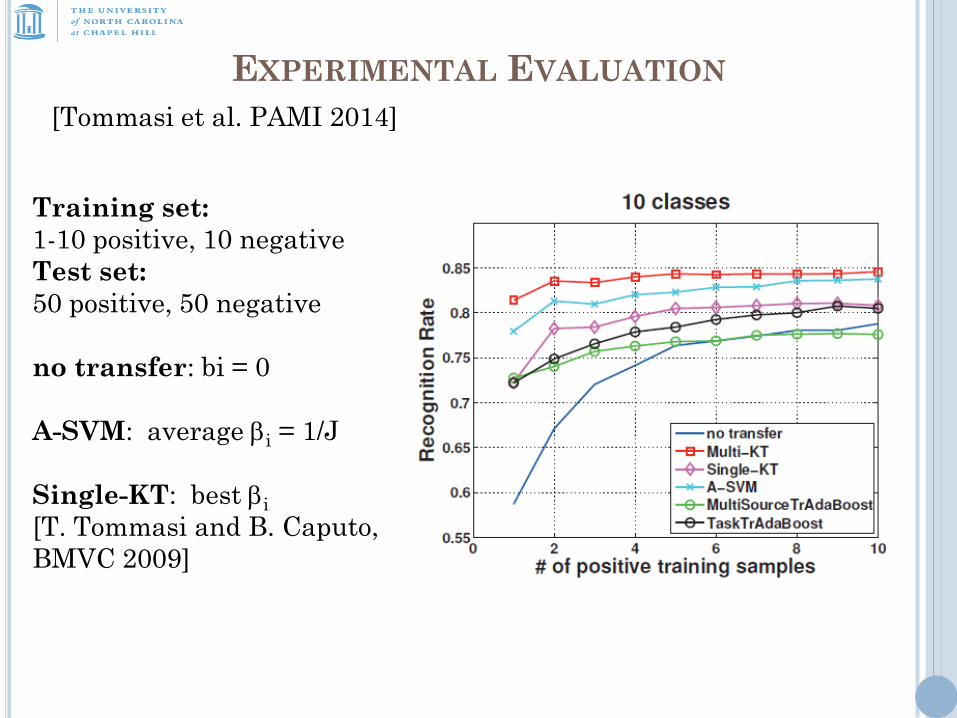
Training set:
1-10 positive, 10 negative
Test set:
50 positive, 50 negative
no transfer: bi = 0
A-SVM: average bi = 1/J
Single-KT: best bi
[T. Tommasi and B. Caputo,
BMVC 2009]
EXPERIMENTAL EVALUATION
[Tommasi et al. PAMI 2014]

EXPERIMENTAL EVALUATION
[Tommasi et al. PAMI 2014]
Training set:
1-10 positive, 10 negative
Test set:
50 positive, 50 negative
no transfer: bi = 0
A-SVM: average bi = 1/J
Single-KT: best bi
[T. Tommasi and B. Caputo,
BMVC 2009]

MODEL TRANSFER
• Multiclass Transfer Learning from Unconstrained Priors, L. Jie, T. Tommasi, B.
Caputo, ICCV 2011
• Domain Adaptation from Multiple Sources via Auxiliary Classifiers. L. Duan, I.
W. Tsang, D. Xu, T. Chua. ICML 2009
• Domain Adaptation from Multiple Sources: A Domain-Dependent Regularization
Approach. L. Duan, D. Xu, I. W. Tsang. T-NNLS, 2012
• Exploiting Web Images for Event Recognition in Consumer Videos: A Multiple
Source Domain Adaptation Approach. L. Duan, D. Xu, S. Chang. CVPR 2012

FEATURE ADAPTATION BY AUGMENTATION
• Semi-supervised approach.
• Repeat the features to have three parts in the final representation:
a generic part, a specific part for the source and a specific part for the
target.
Source domain
Target domain
Same domain
Different domains
[Daumé III , ACL 2007]

FEATURE ADAPTATION BY AUGMENTATION
[Daumé III , ACL 2007]
• The learned model on the new representation autonomously
optimizes the features weights for the two domains: no need to cross-
validate to estimate good hyperparameters or regulate the trade-off
between source and target
• Can be easily extended to a multi-domain approach
K domains:
• Add consistency on the unlabeled target samples
Source (labeled) samples
Target labeled samples
Target unlabeled samples
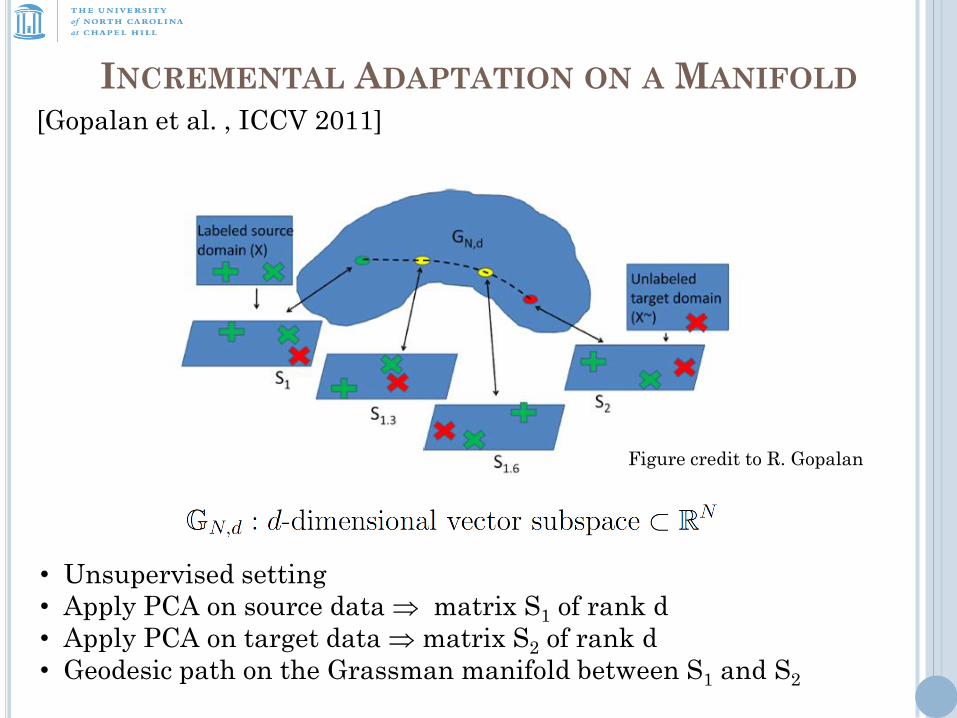
INCREMENTAL ADAPTATION ON A MANIFOLD
Figure credit to R. Gopalan
• Unsupervised setting
• Apply PCA on source data matrix S1 of rank d
• Apply PCA on target data matrix S2 of rank d
• Geodesic path on the Grassman manifold between S1 and S2
[Gopalan et al. , ICCV 2011]
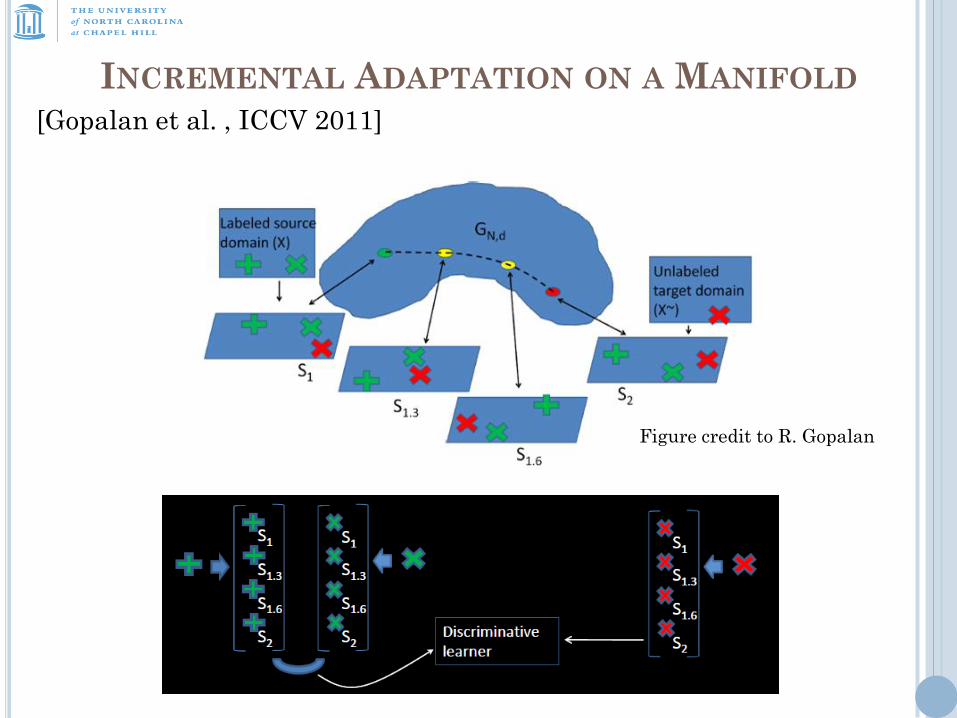
INCREMENTAL ADAPTATION ON A MANIFOLD
Figure credit to R. Gopalan
[Gopalan et al. , ICCV 2011]

GEODESIC FLOW KERNEL [Gong et al. , CVPR 2012]

SUBSPACE ALIGNMENT
Figure credit to B. Fernando
[Fernando et al. , ICCV 2013]
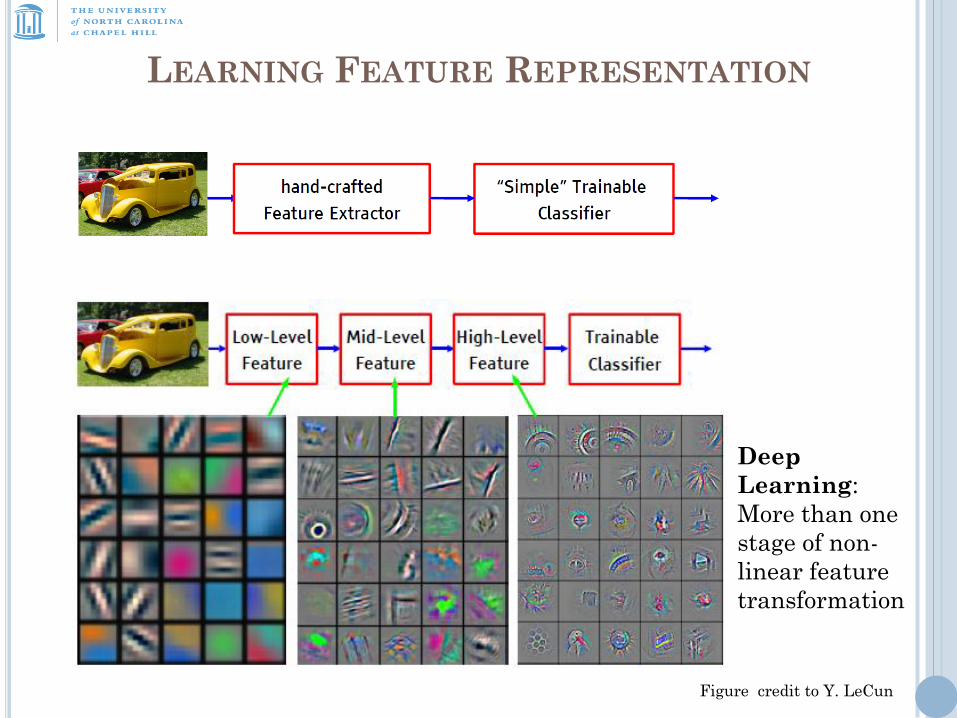
LEARNING FEATURE REPRESENTATION
Deep
Learning:
More than one
stage of non-
linear feature
transformation
Figure credit to Y. LeCun

LEARNING FEATURE REPRESENTATION
High-non linearity makes these features invariant
across domains!
Deep
Learning:
More than one
stage of non-
linear feature
transformation
Figure credit to Y. LeCun
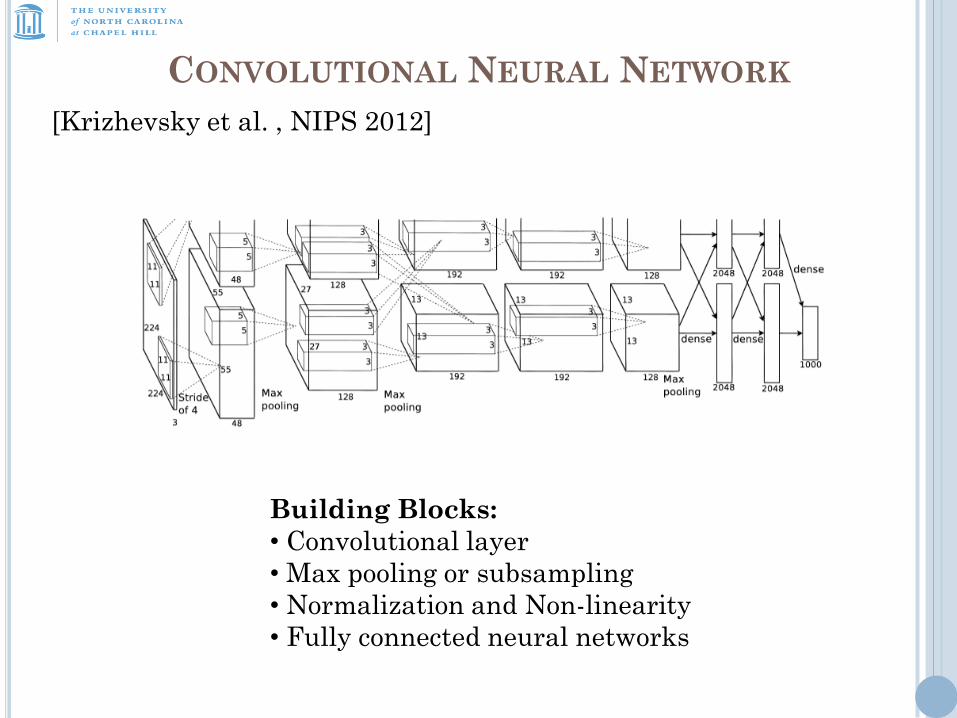
CONVOLUTIONAL NEURAL NETWORK
Building Blocks:
• Convolutional layer
• Max pooling or subsampling
• Normalization and Non-linearity
• Fully connected neural networks
[Krizhevsky et al. , NIPS 2012]
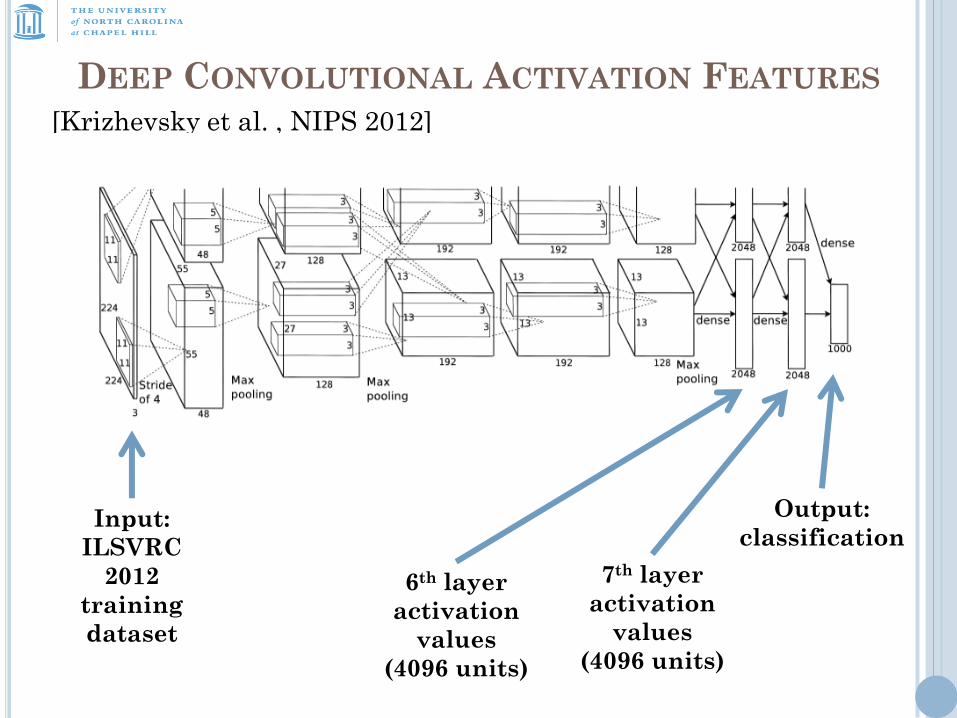
DEEP CONVOLUTIONAL ACTIVATION FEATURES [Krizhevsky et al. , NIPS 2012]
Output:
classification Input:
ILSVRC
2012
training
dataset
6th layer
activation
values
(4096 units)
7th layer
activation
values
(4096 units)
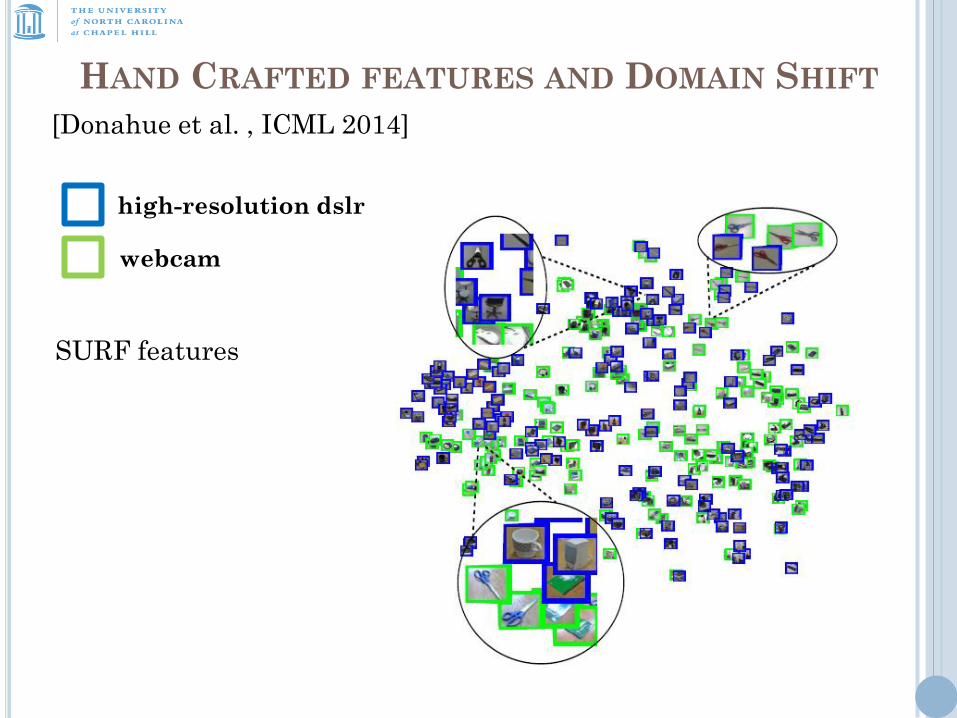
HAND CRAFTED FEATURES AND DOMAIN SHIFT
webcam
high-resolution dslr
SURF features
[Donahue et al. , ICML 2014]

HAND CRAFTED FEATURES AND DOMAIN SHIFT
[Donahue et al. , ICML 2014]
webcam
high-resolution dslr
DECAF6
features

DEEP CONVOLUTIONAL ACTIVATION FEATURES [Krizhevsky et al. , NIPS 2012]
Output:
classification Input:
ILSVRC
2012
training
dataset
6th layer
activation
values
(4096 units)
7th layer
activation
values
(4096 units)

TRANSFERRING CNN WEIGHTS
[Oquab et al., CVPR 2014]
• Will we need to collect millions of annotated images for each new visual
recognition task in the future?
• Use the internal layers of the CNN pre-trained on Imagenet as a generic
extractor of mid-level image representation.

TRANSFERRING CNN WEIGHTS
[Oquab et al., CVPR 2014]
• Will we need to collect millions of annotated images for each new visual
recognition task in the future?
• Use the internal layers of the CNN pre-trained on Imagenet as a generic
extractor of mid-level image representation.

SUMMARY
• Transfer Learning and Domain Adaptation aim at re-using existing
knowledge when facing a new target problem.
• Reducing the amount of new labeled data.
• Different strategies depending on which part of the source
information we want to re-use and how.
http://tommasit.wix.com/datl14tutorial
https://sites.google.com/site/crossdataset/home
http://www1.i2r.a-star.edu.sg/~jspan/SurveyTL.htm
http://www3.ntu.edu.sg/home/dongxu/
http://iris.usc.edu/vision-notes/bibliography/pattern605t1.html
+ Zero-Shot Learning and attributes
+ Self-Taught Learning
+ Multi-Task Learning