javier macías-guarasa international computer science institute berkeley, ca - usa acoustic...
Post on 18-Dec-2015
214 views
TRANSCRIPT

Javier Macías-GuarasaInternational Computer Science Institute
Berkeley, CA - USA
Acoustic Adaptation and Accent Identification in the ICSI MR and FAE Corpora

2
Overview
• Introduction• Acoustic adaptation
– MR SI task– MR SD task
• Accent identification– MR SI task– FAE task
• Conclusions• Future work

3
Introduction (I)
• Work on improving WER for non-native speakers in the ICSI MR corpus
• General details on the Meeting Recording corpus:– Number of speakers: 61– Speech segmented: 85:08:21– Number of accents: 15– ‘Workable’ accents:
• American 53:12:35 15m+8f• German 11:37:01 10m+2f• Spanish 04:38:24 4m+1f• British 01:03:45 2m+0f just for reference

4
Introduction (II)
• Initial idea:– Pronunciation modeling for non native
speakers
• Acoustic adaptation techniques to be tested first:– SRI Decipher system capabilities:
• MAP/MLLR/PhoneLoop
– Analyze different strategies
• Speaker dependent and independent tasks

5
Introduction (III)
• Accent identification:– Needed to effectively use accent-dependent
models in a real-world system– Emphasis in ‘practical’ approaches using,
again, SRI Decipher capabilities
• MR task is a difficult acoustic environment:– Low number of speakers/speech material– Certain speakers dominance (more details?)
• FAE task also approached
8
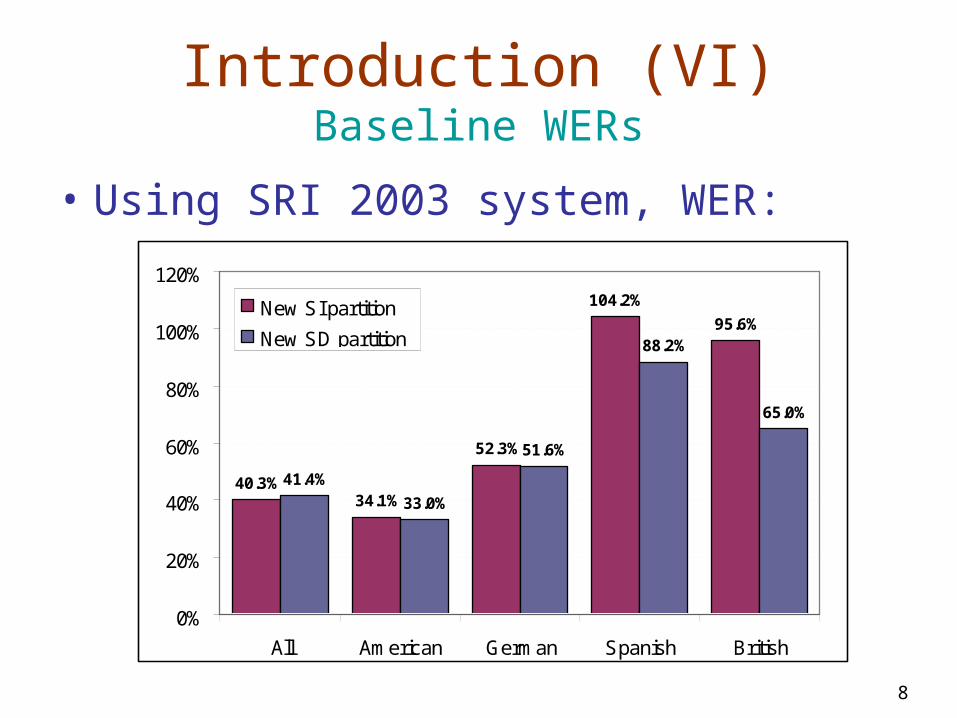
Introduction (VI)Baseline WERs
• Using SRI 2003 system, WER:
40.3%34.1%
52.3%
104.2%
95.6%
41.4%
33.0%
51.6%
88.2%
65.0%
0%
20%
40%
60%
80%
100%
120%
All American German Spanish British
New SI partition
New SD partition

11
Acoustic adaptation (I)
• Initial studies with old partitioning shows that global task adaptation through MAP is the best approach:– Accent-dependent MAP adaptation also promising
• Initial attempt to do full retraining using 16KHz speech (also 8KHz speech as reference):– Very bad results (more details?)
• Worse than baseline!!
– Too few speakers in the training set given the task partition (speaker independent)

12
Acoustic Adaptation (II) Previous work
• Interest in language learning tools (CALL)
• Standard acoustic adaptation techniques– MAP/MLLR using L1 or L2 speech data– Model interpolation– Clustering– Sufficient for high proficiency speakers
• Pronunciation modeling:– Little (if any) success reported

14
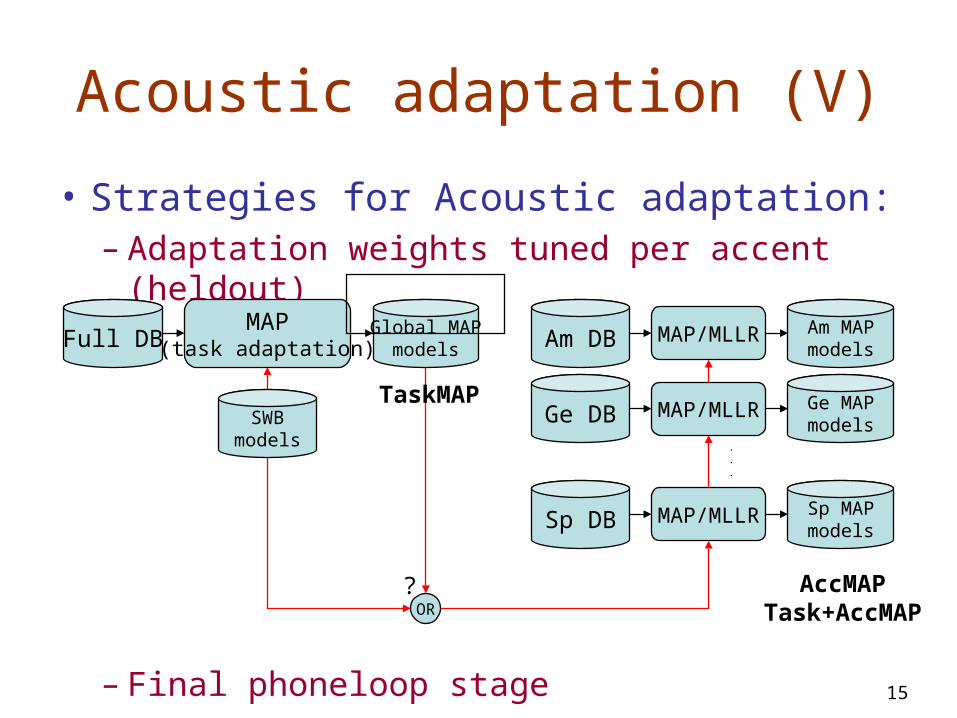
Acoustic Adaptation (IV) Objectives
• Strategies for SI task, ¿combined improvement?:– Task MAP adaptation (TaskMAP)– Accent dependent MAP (AccMAP)– TaskMAP followed by AccMAP/MLLR
• Strategies for SD task:– Task MAP adaptation (TaskMAP) (includes
speaker adaptation)– Per speaker MAP adaptation (SpkMAP)
15
Acoustic adaptation (V)
• Strategies for Acoustic adaptation:– Adaptation weights tuned per accent (heldout)
– Final phoneloop stage
MAP(task adaptation)Full DB MAP/MLLR
SWBmodels
MAP/MLLR
MAP/MLLR
Global MAPmodels
.
.
.
Am DB
Ge DB
Sp DB
Am MAPmodels
Ge MAPmodels
Sp MAPmodels
OR?
TaskMAP
AccMAPTask+AccMAP

17
Acoustic Adaptation (VII) MR Speaker Independent Task
• SI adaptation summary, WER:
34.1%
52.3%
104.2%
95.6%
30.4%
42.3%
93.2%87.9%
0%
20%
40%
60%
80%
100%
120%
American German Spanish British
Baseline SI
TaskMAP-optimal
AccMAP-optimal
TaskMAP + AccMAP-optimal
+ phoneloop pass2

18
Acoustic Adaptation (VIII) MR Speaker Independent Task
• SRI 5xRT system:– Using new dictionary and interpolated LMs– Using best map adapted models for mel
features– Still some bugs in the process (more details?)
American German Spanish BritishBest single system 30.4% 42.3% 93.2% 87.9%
SRI 5xRT system adapted 33.6% 44.9% 86.6% 79.7%SRI 5xRT system STD 31.0% 44.1% 93.4% 78.7%
err (%rel) [ 10.5% ] [ 6.1% ] [ -7.1% ] [ -9.3% ]

20
Acoustic Adaptation (X) MR Speaker Dependent Task
• SD adaptation summary, WER:
33.0%
51.6%
88.2%
65.0%
29.5%
37.1%
54.3%
60.4%
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
American German Spanish British
Baseline SDTaskMAP-optimalSpkMAP-optimal+ phoneloop pass2

21
Accent Identification (I)• Background:
– Techniques similar to Language Identification– GMM based:
• Broad collection of features• GMM tokenizers
– Broad phonetic classes + HMMs– LM/AM score comparison– Based on phonotactic characteristics:
• PPRLM, PRLM
– More complex than LID– Hard to compare rates: No previous work in MR/FAE

23
Accent Identification (II) Objectives
• Strategy: Use SRI Decipher characteristics– Practical approach: Reasonable run times– GMM classification module (for gender detection)
• Evaluate standard features and normalizations
– Hypothesis driven, phone recognition:• CD/CI models • Recognition using flat Phone LM or flat LM• View as a text classification problem
– Phone LM driven:• PRLM/PRLM
– Combination using NNs

24
Accent Identification (III) MR data: MM classification approach
• GMM results for MR corpus:– Unbalanced data tested over and under
sampling– Use different features & normalization:
• No significant differences (except when using voicing features):
– lack of data– ~Uniform channels
23855 5814 2335 288American German Spanish British ID rate Naive rate err (%rel)
fc downsampling 256 96.1% 65.9% 0.0% 0.0% 82.9% 73.9% -34.5%fc 2048 96.1% 71.6% 0.0% 0.0% 83.9% 73.9% -38.2%

25
Accent Identification (IV) MR data: GMM classification approach
• GMM results for MR corpus :– As a function of utterance length task
AM-GE-SP-BR
60%
65%
70%
75%
80%
85%
90%
95%
100%
1 10 100> Utterance length (in seconds)
AI
rate
Chance
256

26
Accent Identification (V) MR data: Hypothesis driven approach
• Text classification view using MR data:– Input from phone recognition:
• From free phone recognition (CD/CI models, full/flat PLM)
– Rainbow: CMU tool for text classification• Naive bayes classification technique• N-grams (1..6)• No further restrictions (feature selection, stop list,
etc.)
27
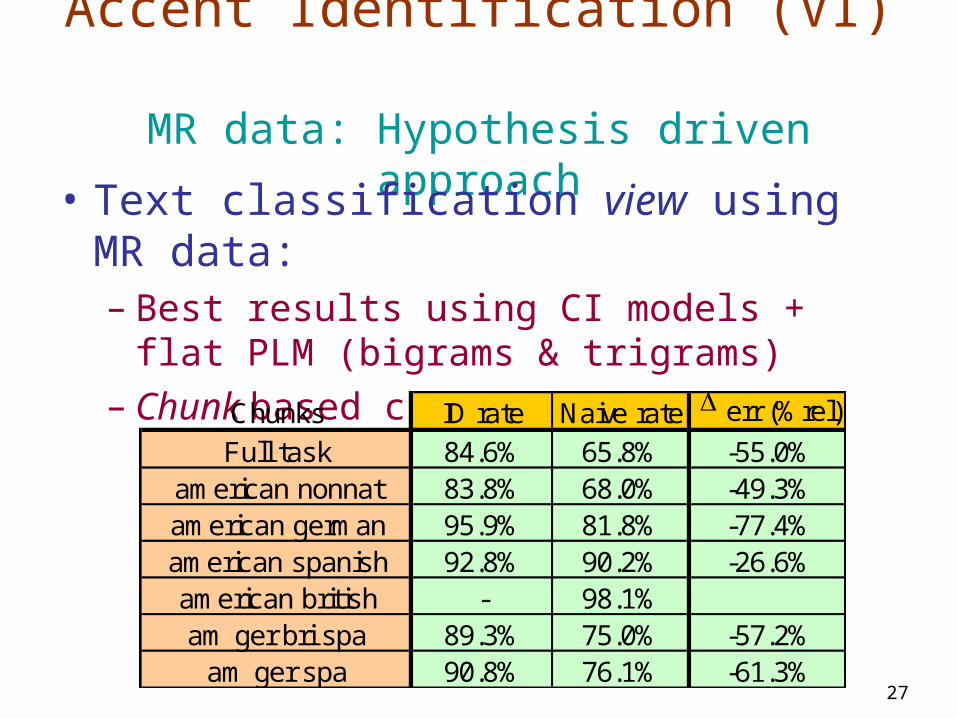
Accent Identification (VI) MR data: Hypothesis driven approach
• Text classification view using MR data:– Best results using CI models + flat PLM
(bigrams & trigrams)– Chunk based classification rates (simulation):
Chunks ID rate Naive rate err (%rel)
Full task 84.6% 65.8% -55.0%american nonnat 83.8% 68.0% -49.3%american german 95.9% 81.8% -77.4%american spanish 92.8% 90.2% -26.6%american british - 98.1%am ger bri spa 89.3% 75.0% -57.2%
am ger spa 90.8% 76.1% -61.3%

28
Accent Identification (VII) MR data: Hypothesis driven approach
• Text classification view using MR data:– Utterance based classification rates
(simulation):
– Need longer sequences!!
Utterances ID rate Chunk rate Naive rate err (%rel)
Full task 64.88% 84.6% 66.8% 5.7%american nonnat 65.21% 83.8% 69.1% 12.6%american german 80.16% 95.9% 92.1% 152.4%american spanish 91.79% 92.8% 92.1% 4.5%american british 80.42% - 97.0% 544.1%am ger bri spa 73.19% 89.3% 74.8% 6.3%
am ger spa 74.94% 90.8% 76.6% 7.0%

29
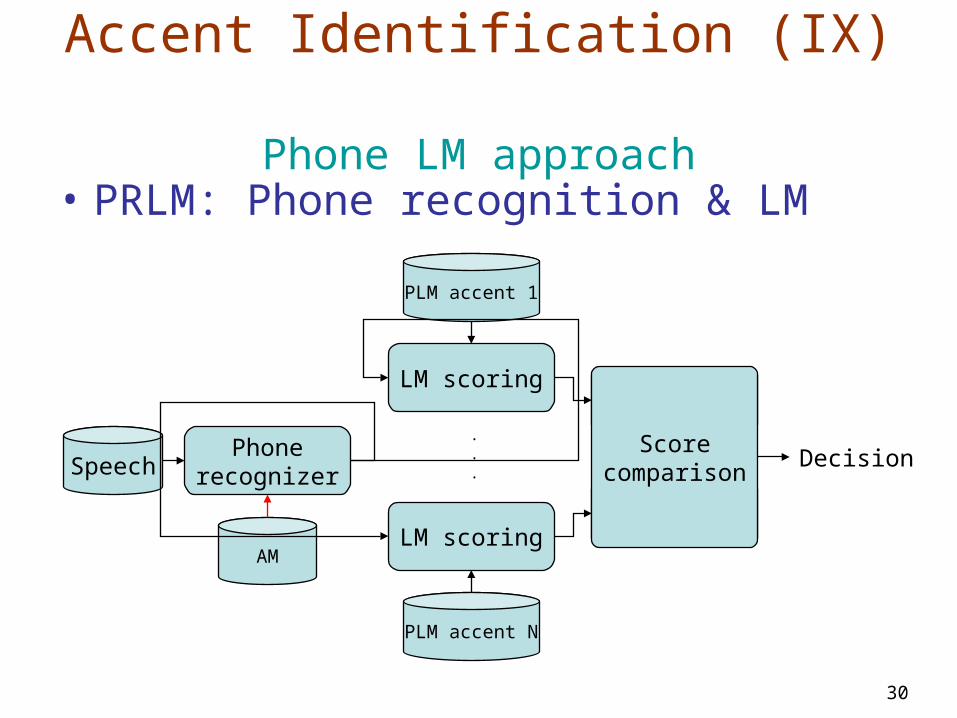
Accent Identification (VIII) MR data: Hypothesis driven approach
• Text classification view using MR data:– Real partition classification rates:
– Worse-than-chance rates if utterance based (pending to do length-dependent AI task)
Chunks RealPartition ID rate ID simul Naive rate err (%rel)
Full taskamerican nonnat 75.46% 83.8% 71.2% -14.9%american german 75.16% 95.9% 73.9% -5.0%american spanish 95.24% 92.8% 92.1% -40.0%american british 91.45% - 92.2% 10.2%am ger bri spa 67.68% 89.3% 64.0% -10.2%
am ger spa 73.01% 90.8% 69.3% -12.0%
30
Accent Identification (IX) Phone LM approach
• PRLM: Phone recognition & LM
PhonerecognizerSpeech
AMLM scoring
LM scoring
PLM accent 1
PLM accent N
Scorecomparison
Scorecomparison
Scorecomparison
Decision...

31
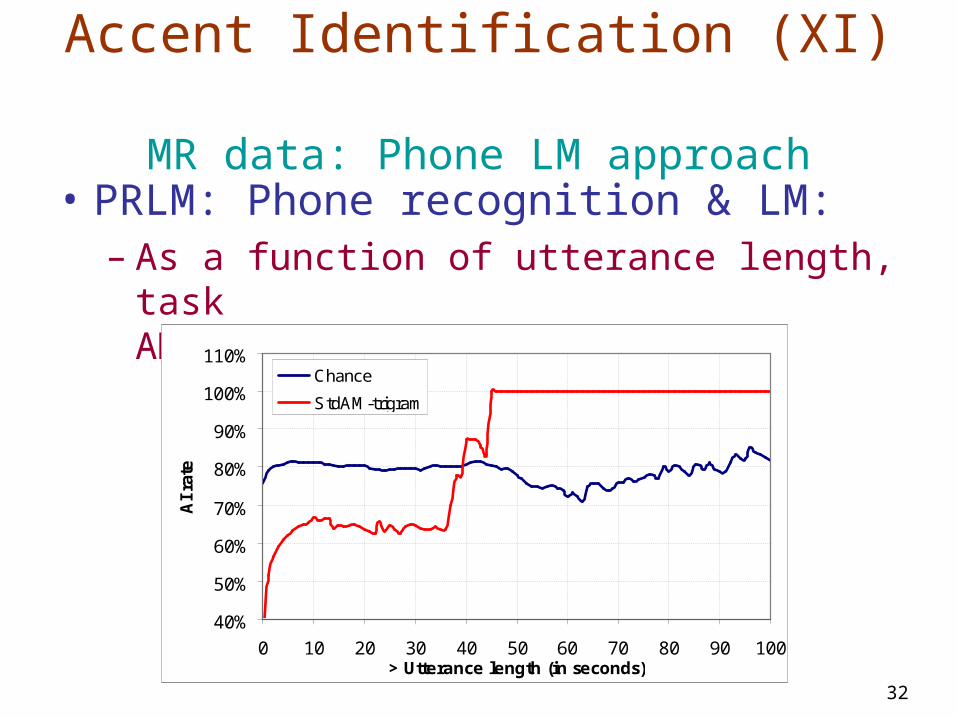
Accent Identification (X) Phone LM approach
• PRLM: Phone recognition & LM– Tested different AMs for phonetic string
generation:• Std forced• Std SWB• MAP adapted per accent• Best is Std SWB
– Tested 1-6gram: • Best is trigram
– But very poor results
32
Accent Identification (XI) MR data: Phone LM approach
• PRLM: Phone recognition & LM:– As a function of utterance length, task
AM-GE-SP-BR: Very bad results
40%
50%
60%
70%
80%
90%
100%
110%
0 10 20 30 40 50 60 70 80 90 100> Utterance length (in seconds)
AI
rate
Chance
StdAM-trigram

33
Accent Identification (XII) Phone LM approach
• PPRLM: Parallel Phone recognition & LM
Phonerecognizer Models Z
Speech
LM scoringAccent z
Avg accent a
Decision
.
.
.
Phonerecognizer Models A
.
.
.
LM scoringAccent a
LM scoringAccent z
.
.
.
LM scoringAccent a
Avg accent aAvg accent a
Scorecomparison
ScorecomparisonAvg accent a
Avg accent aAvg accent z
.
.
.
Scorecomparison

34
Accent Identification (XIII) FAE database
• Experiments with the FAE database:– 4500 speakers: More acoustic context– 20 seconds per speaker– Proficiency is labeled
• Strategy:– Apply standard techniques – Possibly:
• Use FAE-generated models in MR data
35
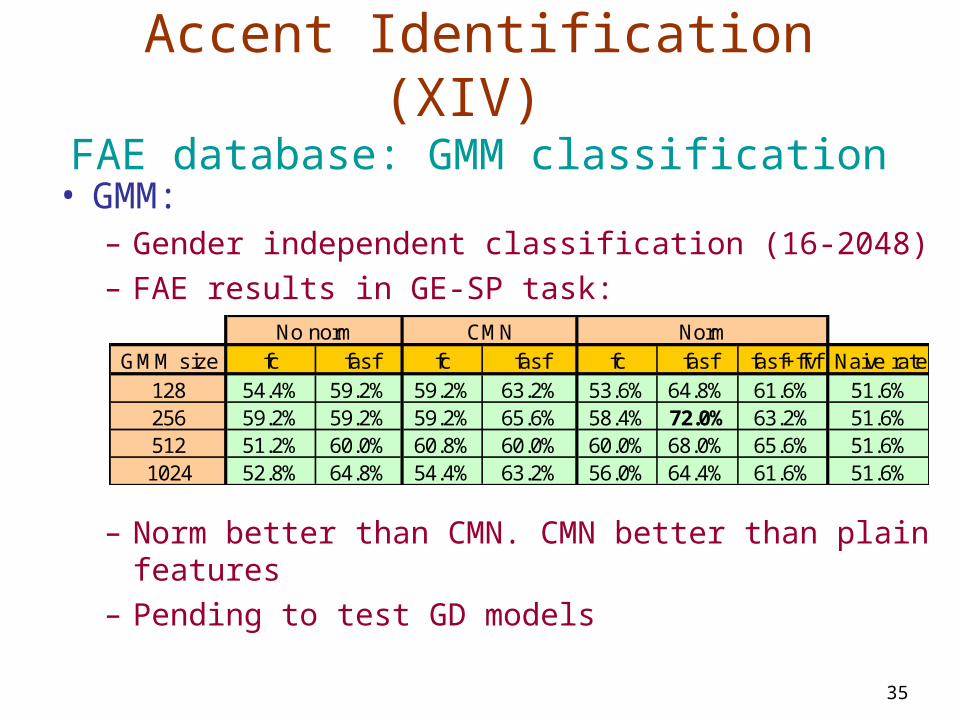
Accent Identification (XIV) FAE database: GMM classification
• GMM:– Gender independent classification (16-2048)– FAE results in GE-SP task:
– Norm better than CMN. CMN better than plain features– Pending to test GD models
GMM size fc fasf fc fasf fc fasf fasf+ffvf Naive rate128 54.4% 59.2% 59.2% 63.2% 53.6% 64.8% 61.6% 51.6%256 59.2% 59.2% 59.2% 65.6% 58.4% 72.0% 63.2% 51.6%512 51.2% 60.0% 60.8% 60.0% 60.0% 68.0% 65.6% 51.6%1024 52.8% 64.8% 54.4% 63.2% 56.0% 64.4% 61.6% 51.6%
NormNo norm CMN

36
Accent Identification (XV) FAE database: GMM classification
• GMM:– Combining FAE models with MR data:
• Using frame_cepstrum + CMN (GMM 256)
– Combination is possible, but more experiments are needed!!
GS-SP task German Spanish ID rate Naive rate err (%rel)
MR models 81.1% 40.0% 72.3% 66.0% -18.6%FAE models (cmn) 100.0% 21.9% 73.4% 66.0% -21.8%

37
Accent Identification (XVI) FAE database: hypothesis driven
• Text classification view:– FAE results:
– Better than chance but, still, far from useful– Pending to test FAE models in MR data
ID rate Naive rate err (%rel)
GE-SP 58.9% 51.6% -15.0%FR-GE-IT-SP 36.2% 28.9% -10.3%ALL accents 13.2% 9.4% -4.3%13 accents 17.7% 12.2% -6.2%

38
Accent Identification (XVII) FAE database: Phone LM approach
• PRLM/PPRLM:– Pending
• GMM better than text based classification. GE-SP task, for example:– GMM: 72.0% – Text-based: 58.9%
• Results as a function of speech length to be evaluated

39
Conclusions
• Acoustic adaptation is important to face non-native accents:– MAP adaptation provided best results:
• Task adaptation+accent adaptation
– Work on tuning adaptation weights for SD & SI task (magnitude differences)
– Low proficiency speakers need additional improvements
• Non native speech recognition may not be solvable!

40
Conclusions
• Accent identification:– Proved to be more difficult than LID– Different techniques applied:
• GMM techniques and text classification techniques showed promising results
• Standard PRLM strategy didn’t work as expected (score normalization needed?)
– PPRLM to be tested– Integration to be tested

41
Future work
• Finish current experimentation:– Accent identification:
• Test features and normalizations in GMM and phone LM based
• Test acoustic scores ratios• Test LM scores• Test NN based combination
– NonNat speech characterization:• Errors phone/word• Model ‘usage’ distributions

42
Future work
• Pronunciation modeling:– Evaluation of pronunciation variants found in the
SRI SWB dictionary for NonNat speech– Rule based:
• Rules in German (from Silke Goronzy’s work)• Rules in Spanish• ‘Speaking mode’ probability estimation (accent + …)
• Use of new databases (FAE, TED, Fisher)

43
Future work
• A note on work on pronunciation modeling in the MR task:– The MR corpus is not suitable for data-driven
pronunciation modeling:• High error rates for non native speakers & limited number of
them• Rule based methods are to be tested first
– Initial work on evaluating current pronunciation alternatives is needed
– I got relevant rules for initial testing in German and Spanish

44
Thank you!!
• To ICSI and the ICSI Speech Group, with special emphasis to:– Morgan– Andreas– Qifeng, Barry, Adam, Yang, Yan, Dave, Jeremy,
…– Sven & all international visitors– The FrameNet people (Miriam, Michael & Co.)– Staff, specially Lila, María Eugenia and Diane

45
46
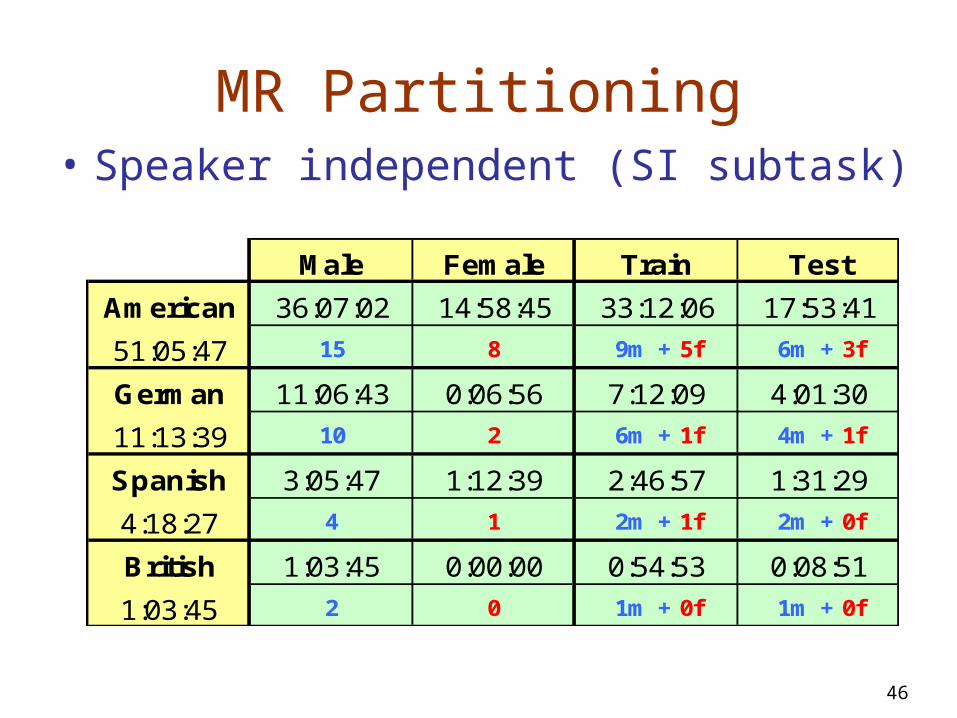
MR Partitioning• Speaker independent (SI subtask)
Male Female Train Test
American 36:07:02 14:58:45 33:12:06 17:53:41
51:05:47 15 8 9m + 5f 6m + 3f
German 11:06:43 0:06:56 7:12:09 4:01:30
11:13:39 10 2 6m + 1f 4m + 1f
Spanish 3:05:47 1:12:39 2:46:57 1:31:29
4:18:27 4 1 2m + 1f 2m + 0f
British 1:03:45 0:00:00 0:54:53 0:08:51
1:03:45 2 0 1m + 0f 1m + 0f

47
Full retraining
• Initial attempt to do full retraining using 16KHz speech:– With old partitioning
– Too few speakers in the training set given the task partition (speaker independent)
All American NonNatSWB models 44.1% 34.5% 82.6%Retrain16K+SWBwordnets 53.0% 46.2% 80.1%Retrain16K+SWBwordnets+newHLDA 51.7% 44.6% 79.8%Retrain8K+SWBwordnets 46.8% 40.5% 72.1%Retrain8K+SWBwordnets+newHLDA

48
Speaker dominance
• Few speakers concentrate most speech material: spkID #length
me013 13:53fe008 6:32me011 5:37mn015 4:55me018 4:19mn007 4:16fe016 3:55me010 3:47mn017 3:01
total 50:15

50
Acoustic adaptation (IV)
• SI TaskMAP adaptation, WER:
– Optimal map weight ~proportional to size of accented speech subset
– Bigger improvements in non native accents– Bigger improvements for bigger data size
All NonNat American German Spanish British
Baseline SI 40.3% 64.5% 34.1% 52.3% 104.2% 95.6%
TaskMAP-optimal 37.8% 57.9% 32.5% 46.4% 95.2% 88.5% err (%rel) [ -6.2% ] [ -10.2% ] [ -4.7% ] [ -11.3% ] [ -8.6% ] [ -7.4% ]

51
Acoustic adaptation (IV)
• SI AccMAP adaptation, WER:
– Similar trends than TaskMAP, but no further improvements, except german benefits from task data!
American German Spanish BritishBaseline SI 34.1% 52.3% 104.2% 95.6%
TaskMAP-optimal 32.5% 46.4% 95.2% 88.5% err (%rel) [ -4.7% ] [ -11.3% ] [ -8.6% ] [ -7.4% ]
AccMAP-optimal 32.5% 46.0% 96.8% 91.9% err (%rel) [ -4.9% ] [ -13.6% ] [ -7.8% ] [ -4.2% ]
Optimal Weight 5 40 40 50

52
Acoustic adaptation (IV)
• SI TaskMAP+AccMAP adaptation, WER:
– Small improvements over TaskMAP– Also tested MLLR instead
(taskMAP+AccMLLR), but no improvements
American German Spanish BritishBaseline SI 34.1% 52.3% 104.2% 95.6%
TaskMAP-optimal 32.5% 46.4% 95.2% 88.5% err (%rel) [ -4.7% ] [ -11.3% ] [ -8.6% ] [ -7.4% ]
+ AccMAP-optimal 32.5% 45.8% 95.0% 88.6% err (%rel) [ 0.0% ] [ -1.3% ] [ -0.2% ] [ 0.1% ]
Optimal Weight 5 20 30 40

53
Gender ID issues
• Gender identification:– Per chunk gender ID:
– Per utterance gender ID:
#chunks Male Female ID rateTrue male 350 100.0% 0.0%
True female 97 8.3% 91.8%
#utterances Male Female ID rateTrue male 68304 100.0% 0.0%
True female 19563 2.9% 97.1%
98.2%
99.4%
#utterances Male Female ID rateTrue male 68304 88.5% 11.5%
True female 19563 22.6% 77.4%86.0%

54
Acoustic AdaptationSRI 5xRT System results
British 002-mel 002-mel-expanded 005-plp 005-plp-rescored roverSTD 91.5 89.3 78.2 80.6 78.7Adapted 87.9 84.3 78.8 79.7 79.7BestSimple 87.9------------------------------------------------------------------------------Spanish 002-mel 002-mel-expanded 005-plp 005-plp-rescored roverSTD 97.5 94.2 95.9 95.1 93.4Adapted 88.0 85.1 88.4 88.2 86.6BestSimple 93.2------------------------------------------------------------------------------German 002-mel 002-mel-expanded 005-plp 005-plp-rescored roverSTD 50.7 47.6 44.7 44.5 44.1Adapted 45.8 45.8 44.4 44.5 44.9BestSimple 42.3------------------------------------------------------------------------------American 002-mel 002-mel-expanded 005-plp 005-plp-rescored roverSTD 36.3 33.2 31.2 30.8 31.0Adapted 33.6 34.3 33.3 33.1 33.6BestSimple 30.4