(manning, raghavan, schutze) - texas state universityjg66/teaching/4315/notes/... · 2017-04-20 ·...
TRANSCRIPT

Introduction to Information Retrieval(Manning, Raghavan, Schutze)
Chapter 19Web search basics

1. Brief history and overview
n Early keyword-based enginesn Altavista, Excite, Infoseek, Inktomi, ca. 1995-1997
n A hierarchy of categoriesn Yahoo!n Many problems, popularity declined. Existing variants
are About.com and Open Directory Project
n Classical IR techniques continue to be necessary for web search, by no means sufficientn E.g., classical IR measures relevancy, web search
needs to measure relevancy + authoritativeness

Web search overview
The Web
Ad indexes
Web Results 1 - 10 of about 7,310,000 for miele. (0.12 seconds)
Miele, Inc -- Anything else is a compromise At the heart of your home, Appliances by Miele. ... USA. to miele.com. Residential Appliances. Vacuum Cleaners. Dishwashers. Cooking Appliances. Steam Oven. Coffee System ... www.miele.com/ - 20k - Cached - Similar pages
Miele Welcome to Miele, the home of the very best appliances and kitchens in the world. www.miele.co.uk/ - 3k - Cached - Similar pages
Miele - Deutscher Hersteller von Einbaugeräten, Hausgeräten ... - [ Translate this page ] Das Portal zum Thema Essen & Geniessen online unter www.zu-tisch.de. Miele weltweit ...ein Leben lang. ... Wählen Sie die Miele Vertretung Ihres Landes. www.miele.de/ - 10k - Cached - Similar pages
Herzlich willkommen bei Miele Österreich - [ Translate this page ] Herzlich willkommen bei Miele Österreich Wenn Sie nicht automatisch weitergeleitet werden, klicken Sie bitte hier! HAUSHALTSGERÄTE ... www.miele.at/ - 3k - Cached - Similar pages
Sponsored Links
CG Appliance Express Discount Appliances (650) 756-3931 Same Day Certified Installation www.cgappliance.com San Francisco-Oakland-San Jose, CA Miele Vacuum Cleaners Miele Vacuums- Complete Selection Free Shipping! www.vacuums.com Miele Vacuum Cleaners Miele-Free Air shipping! All models. Helpful advice. www.best-vacuum.com
Web spider
Indexer
Indexes
Search
User
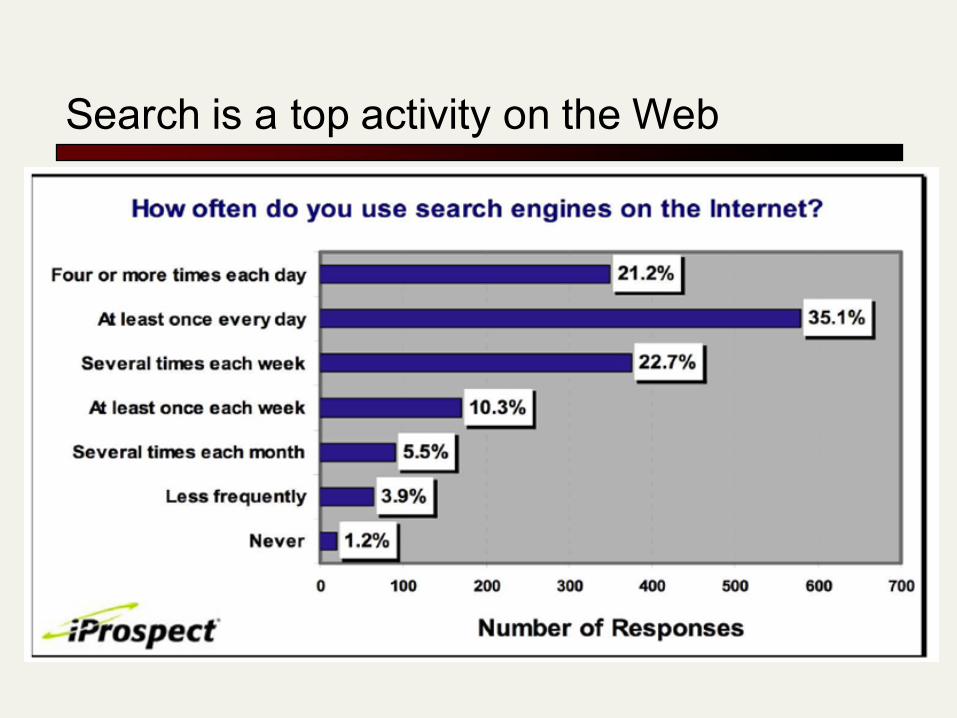
Search is a top activity on the Web

Without search engines, the web wouldn’t work
n Without search, content is hard to findn Without search, there’s no incentive to create content
n Why publish something if nobody will read it?n Why publish something if I don’t’ get ad revenue from it?
n Interest aggregationn Unique feature of the Web: a small number of geographically dispersed
people with similar interests can find each othern Elementary school kids with hemophilian People interested in translating R5R5 Scheme into relatively portable C
(open source project)n Interest aggregation without search engines is not possible
n Somebody needs to pay for the webn Servers, web infrastructure, content creationn A large part today is paid by search ads

Web IR: Differences from traditional IR
n Links: The web is a hyperlinked document collectionn Queries: web queries are different, more varied and there are a lot of
themn How many? 108 every day, approaching 109
n Users: users are different, more varied and there are a lot of themn How many? 109
n Documents: documents are different, more varied and there are a lot of themn How many? ~ 1011. Indexed 1010
n Context: context is more important on the web than in many other IR applications
n Ads and spam

2. Web characteristics
n Web documentn Size of the Webn Web graphn Spam

The Web document collectionn No design/co-ordinationn Distributed content creation, linking,
democratization of publishingn Content includes truth, lies, obsolete
information, contradictions … n Unstructured (text, html, …), semi-
structured (XML, annotated photos), structured (Databases)…
n Scale much larger than previous text collections
n Growth – slowed down from initial “volume doubling every few months”but still expanding
n Content can be dynamically generatedn Mostly ignored by crawlers
The Web
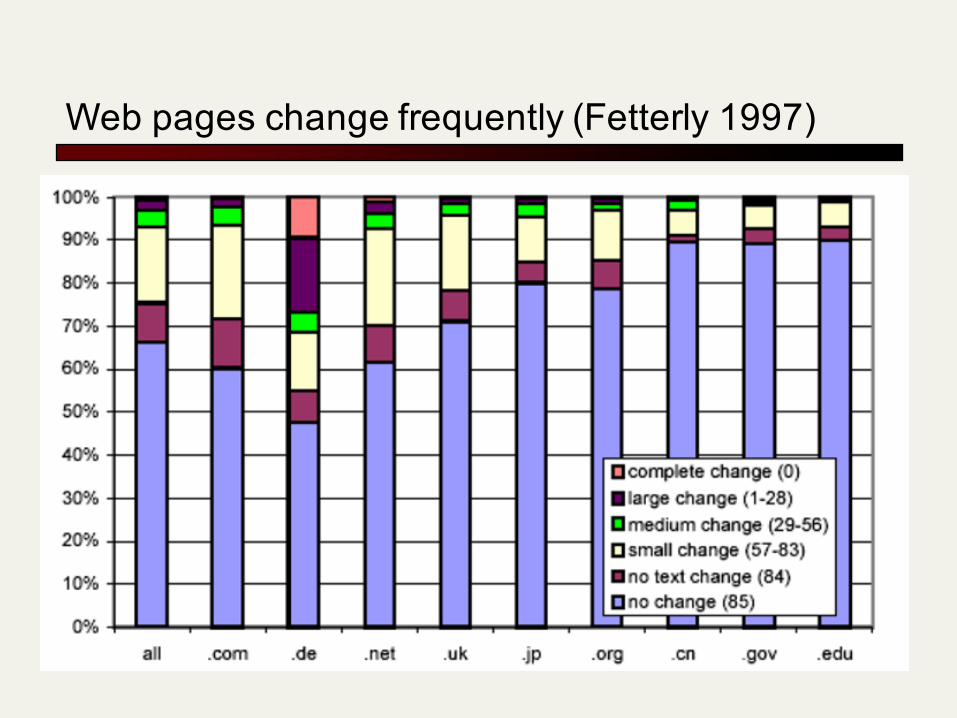
Web pages change frequently (Fetterly 1997)

Duplicate documents
n Significant duplication: 30-40% duplicates in some studiesn Duplicates in search results were common in early days of
the Webn Today’s search engines eliminate duplicates very
effectivelyn Key for high user satisfaction

Duplicate detection
n The web is full of duplicated contentn Strict duplicate detection = exact match
n Not as commonn But many, many cases of near duplicates
n E.g., Last modified date the only difference between two copies of a page
n Various techniquesn Fingerprint, shingles, sketch
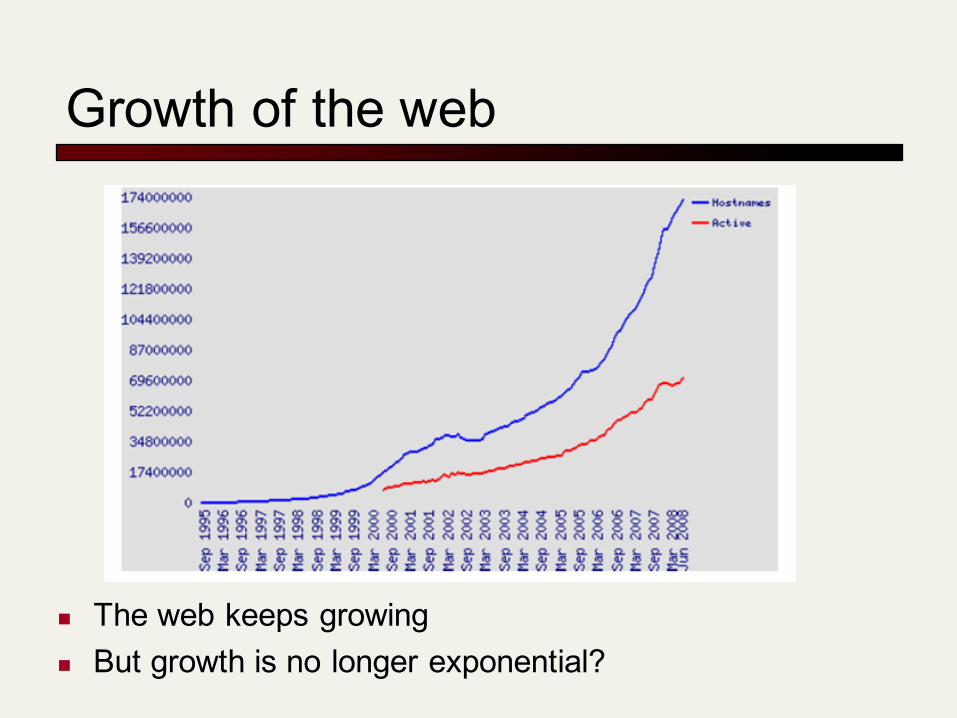
Growth of the web
n The web keeps growingn But growth is no longer exponential?

Size of the web: issues
n How to define size? Number of web serves? Number of pages? Terabytes of data available?n Some servers are seldom connected
n example: your laptop running a web servern Is it part of the web?
n The “dynamic” web is infiniten Any sum of two numbers is its own dynamic page on Google (e.g., “2+4”)

What can we attempt to measure?
n The relative sizes of search engines n Issues
n Can I claim a page in the index if I only index the first 4000 bytes?
n Can I claim a page is in the index if I only index anchor text pointing to the page?
n There used to be (and still are?) billions of pages that are only indexed by anchor text
n How would you estimate the number of pages indexed by a web search engine?

Simple methods for determining a lower bound
n OR-query of frequent words in a number of languagesn http://ifnlp.org/ir/sizeoftheweb.htmln According to this query: Size of web >= 21,450,000,000 on 2007.07.07 and >= 25,350,000,000 on 2008.07.03n But page counts of google search results are only rough estimates

web graph
n The Web is a directed graphn Not strongly connected, i.e., there are pairs of pages such that
one cannot reach the other by following linksn Links are not randomly distributed, rather, power law
n Total # of pages with in-degree i is proportional to 1/ia
n The web has a bowtie shapen Strongly connected component
(SCC) in the centern Many pages that get linked to,
but don’t link (OUT)n Many pages that link to other
pages, but don’t get linked to (IN)n IN and OUT similar size, SCC somehow larger

Goal of spamming on the webn You have a page that will generate lots of revenue for
you if people visit itn Therefore, you’d like to redirect visitors to this pagen One way of doing this: get your page ranked highly in
search results

Simplest formsn First generation engines relied heavily on tf/idfn Hidden text: dense repetitions of chosen keywords
n Often, the repetitions would be in the same color as the background of the web page. So that repeated terms got indexed by crawlers, but not visible to humans on browsers
n Keyword stuffing: misleading meta-tags with excessive repetition of chosen keywords
n Used to be effective, most search engines now catch these
n Spammers responded with a richer set of spam techniques
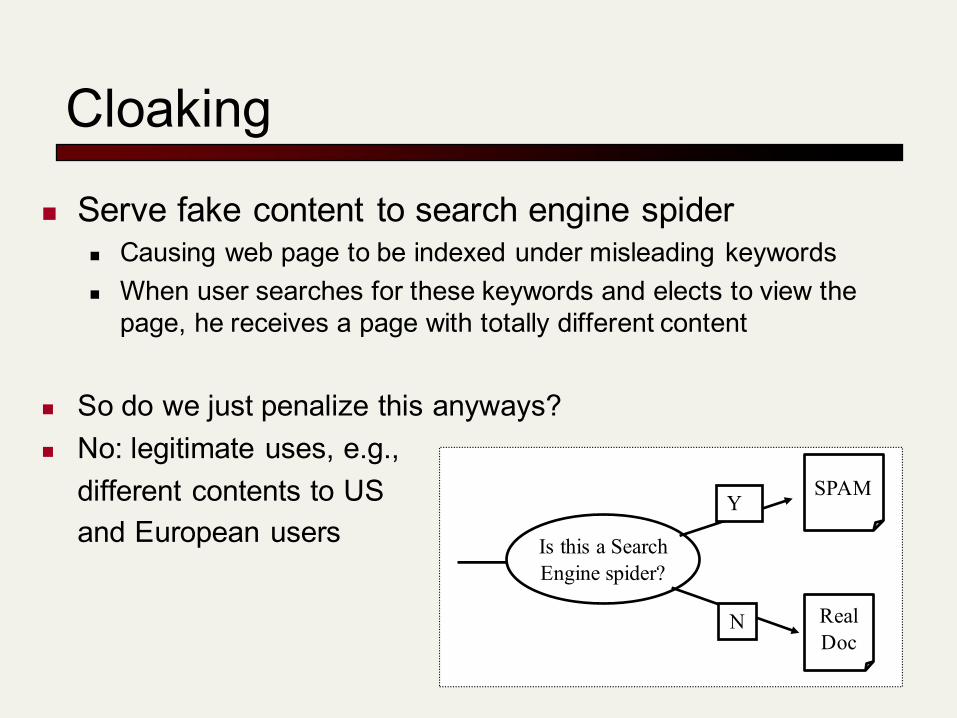
Cloaking
n Serve fake content to search engine spidern Causing web page to be indexed under misleading keywordsn When user searches for these keywords and elects to view the
page, he receives a page with totally different content
n So do we just penalize this anyways?n No: legitimate uses, e.g.,
different contents to USand European users Is this a Search
Engine spider?
Y
N
SPAM
RealDoc

More spam techniquesn Doorway page
n Contains text/metadata carefully chosen to rank highly on selected keywords
n When a browser requests the doorway page, it is redirected to a page containing content of a more commercial nature
n Lander pagen Optimized for a single keyword or a misspelled domain name,
designed to attract surfers who will then click on ads
n Duplicationn Get good content from somewhere (steal it or produce it by yourself)n Publish a large number of slight variations of itn For example, publish the answer to a tax question with the spelling
variations of “tax deferred”…

Lander page
n Number of hit on Google for the search “composita”n The only purpose of this page: get people to click on
the ads and make money for the page owner

Link spamn Create lots of links pointing to the page you want to
promoten Put these links on pages with high (at least non-zero)
pagerankn Newer registered domains (domain flooding)n A set of pages pointing to each other to boost each
other’s pagerank (mutual admiration society)n Pay somebody to put your link on their highly ranked
page (“schuetze horoskop” example”)n http://www-csli.stanford.edu/~hinrich/horoskop-schuetze.html
n Leave comments that include the link on blogsn Link farm

Search engine optimization
n Promoting a page is not necessarily spamn It can also be a legitimate business, which is called SEO
n You can hire an SEO firm to get your page highly rankedn Motives
n Commercial, political, religious, lobbiesn Promotion funded by advertising budget
n Operatorsn Contractors (Search Engine Optimizers) for lobbies, companiesn Web mastersn Hosting services
n Forumsn E.g., Web master world ( www.webmasterworld.com )

More on spam
n Web search engines have policies on SEO practices they tolerate/blockn http://help.yahoo.com/help/us/ysearch/index.htmln http://www.google.com/intl/en/webmasters/
n Adversarial IR: the unending (technical) battle between SEO’s and web search engines
n Research http://airweb.cse.lehigh.edu/

The war against spamn Quality indicators - prefer authoritative pages based on:
n Votes from authors (linkage signals)n Votes from users (usage signals)n Distribution and structure of text (e.g., no keyword stuffing)
n Robust link analysisn Ignore statistically implausible linkage (or text)n Use link analysis to detect spammers (guilt by association)
n Spam recognition by machine learningn Training set based on known spam
n Family friendly filtersn Linguistic analysis, general classification techniques, etc.n For images: flesh tone detectors, source text analysis, etc.
n Editorial interventionn Blacklistsn Top queries auditedn Complaints addressedn Suspect pattern detection

3. Advertising as economic model
n Sponsored search ranking: Goto.com (morphed into Overture.com → Yahoo!)n Your search ranking depended on how much you paidn Auction for keywords: casino was expensive!n No separation of ads/docs
n 1998+: Link-based ranking pioneered by Googlen Blew away all early enginesn Google added paid-placement “ads” to the side,
independent of search resultsn Strict separation of ads and results

First generation of search ads: Goto (1996)
n No separation of ads/docs. Just one results!n Buddy Blake bid the maximum ($0.38) for this searchn He paid $0.38 to Goto every time somebody clicked on the linkn Upfront and honest. No relevance ranking, but Goto did not pretend
there was any.
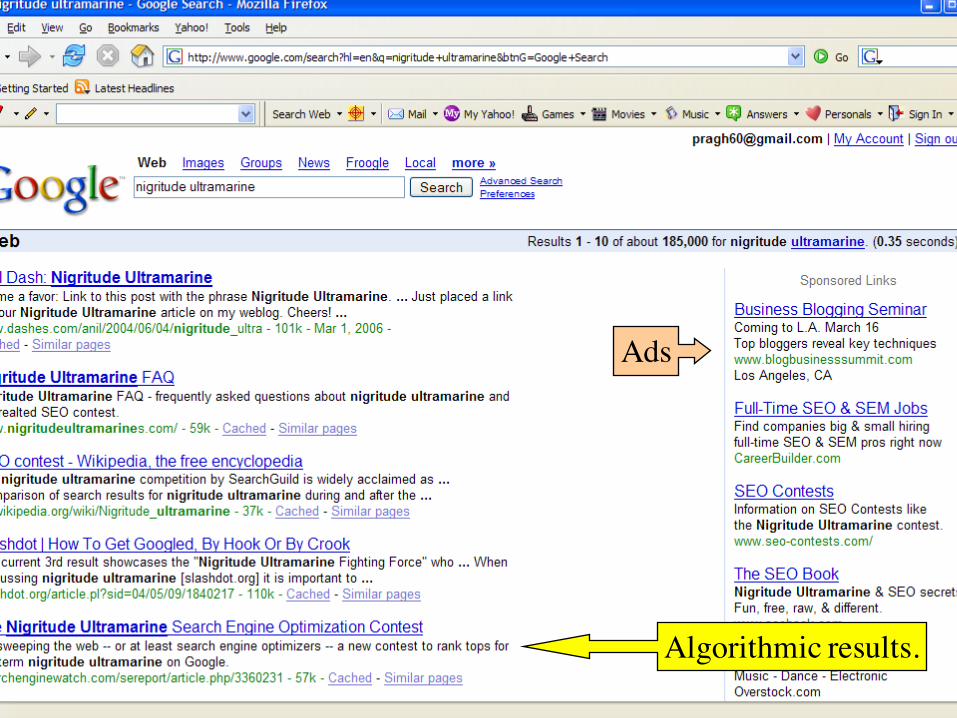
Algorithmic results.
Ads

Search ads: a win-win-win?
n The search engine company gets revenue every time somebody clicks on an ad.
n The user only clicks on an ad if they are interested in the ad.n Search engines punish misleading and nonrelevant ads.n As a result, users are often satisfied with what they find after
clicking on an ad.n Being willing to pay for ads on a search engine is a quality signal
(one of many) that users take into account.n The advertiser finds new customers in a cost-effective
way

The appeal of search ads to advertisers
n Why is web search potentially more attractive for advertisers than TV spots, newspaper ads or radio spots?
n Someone who just searched for “Saturn Aura Sport Sedan” is infinitely more likely to buy one than a random person watching TV.
n Most importantly, the advertiser only pays if the customer took an action indicating interest (i.e., clicking on the ad)

But frequently it’s not a win-win-win
n Example: keyword arbitragen Buy a keyword at Googlen Then redirect traffic to a third party that is paying much
more than you have to pay to Googlen This rarely makes sense for the user
n Ad spammers keep inventing new tricksn The search engines need time to catch up with them
n Click spam: refers to clicks on sponsored search results not from bona fide search usersn E.g., a devious advertiser may attempt to exhaust the advertising
budget of a competitor by clicking repeatedly (through robotic click generator) on his sponsored search ads.

4. Search user experiences
n Usersn User queriesn Query distributionn User’s empirical evaluations

Users of web search
n Use short queries (average < 3)n Rarely use operatorsn Don’t want to spend a lot of time on composing a queryn Only look at the first couple of resultsn Want a simple UI, not a search engine start page
overloaded with graphicsn Extreme variability in terms of user needs, user
expectations, experience, knowledge, …n Industrial/developing world, English/Estonian, old/young,
rich/poor, differences in culture and classn One interface for hugely divergent needs

User query needsn Need [Brod02, RL04]
n Informational – want to learn about something (~40% / 65%)n Not a single page containing the info
n Navigational – want to go to that page (~25% / 15%)
n Transactional – want to do something (web-mediated) (~35% / 20%)n Access a service
n Downloads
n Shop
n Gray areasn Find a good hubn Exploratory search “see what’s there”
Low hemoglobin
United Airlines
Seattle weatherMars surface images
Canon S410
Car rental Brasil

Query distribution (1)

Query distribution (2)
n Queries have a power law distributionn Recall Zipf’s law: a few very frequent words, a large
number of very rare wordsn Same here very frequent queries, a large number of very
rare queriesn Examples of rare queries: search for names, towns,
books etcn The proportion of adult queries is much lower than 1/3

Users’ empirical evaluation of resultsn Quality of pages varies widely
n Relevance is not enoughn Other desirable qualities (non IR!!)
n Content: Trustworthy, diverse, non-duplicated, well maintainedn Web readability: display correctly & fastn No annoyances: pop-ups, etc
n Precision vs. recalln On the web, recall seldom matters
n What mattersn Precision at 1? Precision above the fold?n Comprehensiveness – must be able to deal with obscure queries
n Recall matters when the number of matches is very small

Users’ empirical evaluation of engines
n Relevance and validity of resultsn UI – Simple, no clutter, error tolerantn Trust – Results are objectiven Coverage of topics for polysemic queriesn Pre/Post process tools provided
n Mitigate user errors (auto spell check, search assist,…)n Explicit: Search within results, more like this, refine ...n Anticipative: related searches
n Deal with idiosyncrasiesn Web specific vocabulary
n Impact on stemming, spell-check, etcn Web addresses typed in the search boxn …