moving the needle - university of texas at austin
TRANSCRIPT

1
Uri weiser

Assignment by Yale
“Your vision of the future of computer architecture.
From the man who gave us MMX, refused to kill the
golden goose, and worked for a time in the same box
with Mark McDermott”
2

Situation
Flew 11,482 km to greet Yale
Have to fight again with Bob
What can I fill-in after this extraordinary speaker?
Defiantly a challenge
3
My moto:
Sailing - wind shift
wind
Buoy
4
a
a
a
Sailing competitiongetting first
Boat 1
Boat 2
wind
Buoy
- What is the Strategy of Boat 1?
- What is the Strategy of Boat 2?
My Moto: Do not follow Invent5

Uri WeiserProfessor
Technion
Haifa, Israel
Future Architecture Research
Big Data environment6

Outline
Big Data need reduction in energy/task
Power/Energy - the opportunities
Heterogeneous systems – past thoughts
Resource allocation in a Heterogeneous system
Efficient computation reduction of Data
movements
Avoid-the-Valley – past thoughts, deferent perspective
Big Data execution – where should we preform
execution of “Funnel” functions
– The Funnel (MASHPECH)
7

Big Data
reduction in energy/task
Hadoop/Spark Calls for multiple computing engines
taking care of “ONE TASK”
Computing Centers’ attention was shifted from
Performance toward energy saving
The need for huge amount of processing
huge consumption of energy
See Google centers…
8

Power/Energy the opportunities
Heterogeneous Systems –Past findings
Resource allocation in a Heterogeneous system - MA
Efficient computation reduction of Data
movements
Avoid-the-Valley – past thoughts, deferent perspective
Big Data execution – where should we preform
execution of “Funnel” functions
9
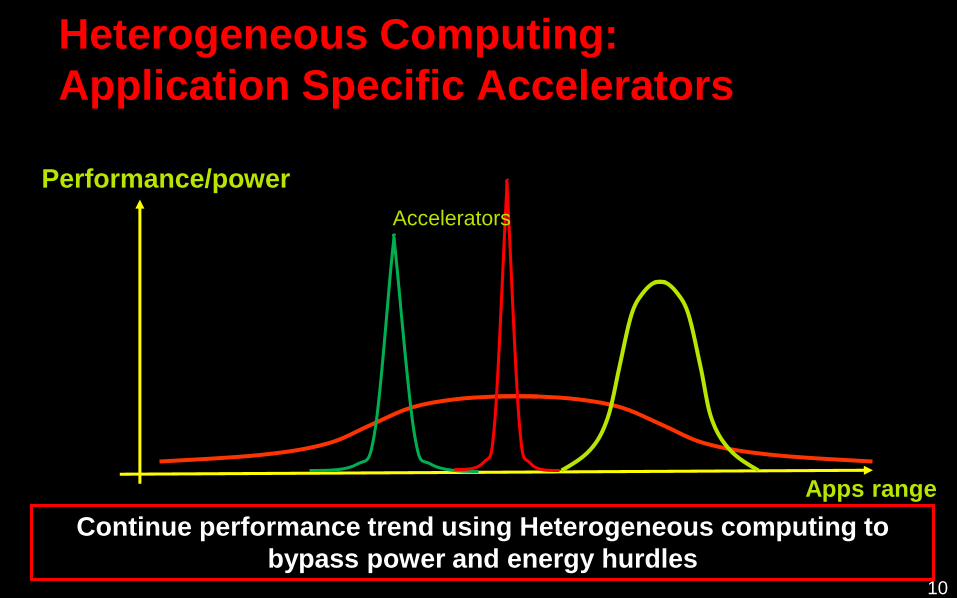
Heterogeneous Computing:
Application Specific Accelerators
Performance/power
Apps range
Continue performance trend using Heterogeneous computing to
bypass power and energy hurdles
Accelerators
10
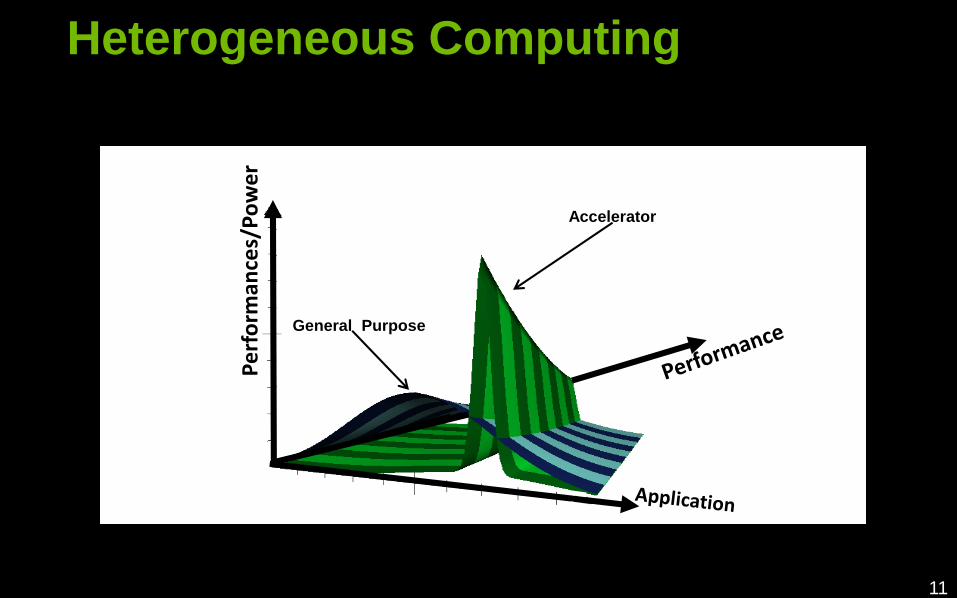
Heterogeneous Computing
Pe
rfo
rman
ces/
Po
we
r
General Purpose
Accelerator
11
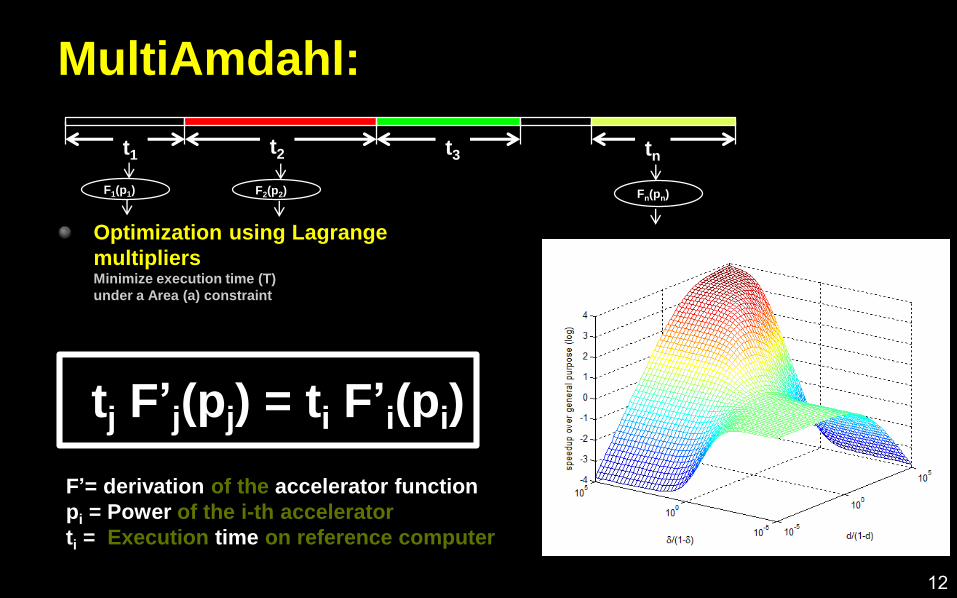
MultiAmdahl:
Optimization using Lagrange
multipliersMinimize execution time (T)
under a Area (a) constraint
t2 t3 tnt1
F1(p1) F2(p2) Fn(pn)
12
tj F’j(pj) = ti F’i(pi)
F’= derivation of the accelerator function
pi = Power of the i-th accelerator
ti = Execution time on reference computer

Power/Energy the opportunities
Heterogeneous Systems –Past findings
Resource allocation in a Heterogeneous system
Efficient computation reduction of Data
movements
Avoid-the-Valley – past thoughts, deferent perspective
Big Data execution – where should we preform
execution of “Funnel” functions
9

Power/Energy the opportunities
Efficient computation reduction of Data
movements
Avoid-the-Valley – past research power implications
The Funnel PreProcessing (FPP):
ak’a “In-Place-Computing” =
Compute at the most energy effective place
14
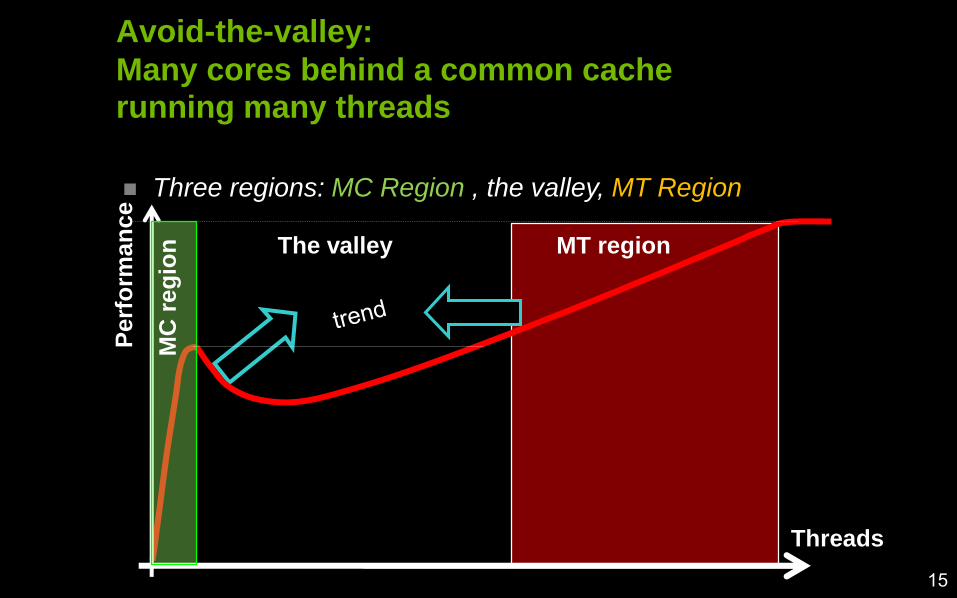
Avoid-the-valley:
Many cores behind a common cacherunning many threads
Three regions: MC Region , the valley, MT Region
Threads
Perf
orm
an
ce
MC
reg
ion MT regionThe valley
15
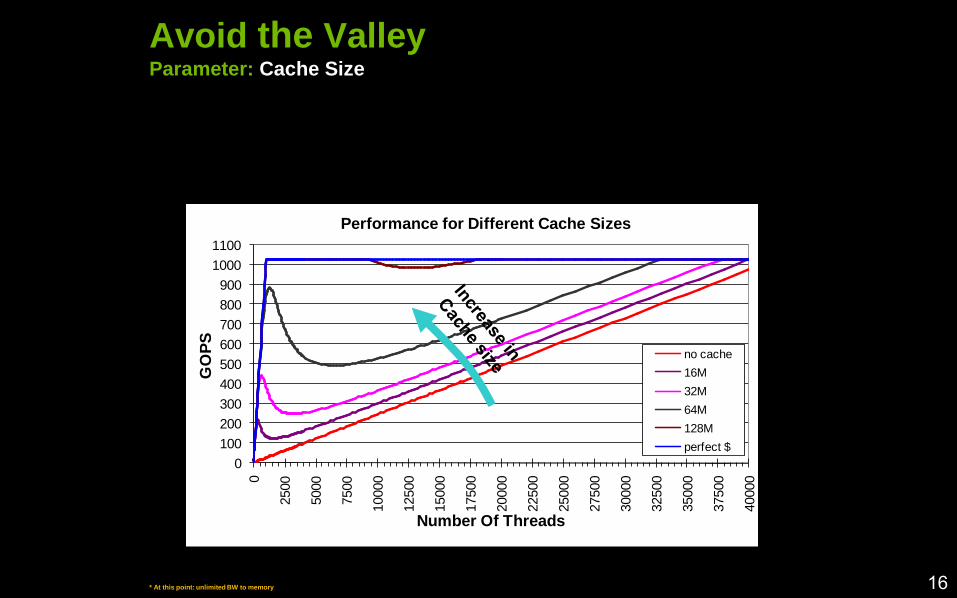
Avoid the ValleyParameter: Cache Size
0
100
200
300
400
500
600
700
800
900
1000
11000
2500
5000
7500
10000
12500
15000
17500
20000
22500
25000
27500
30000
32500
35000
37500
40000
GO
PS
Number Of Threads
Performance for Different Cache Sizes
no cache
16M
32M
64M
128M
perfect $
* At this point: unlimited BW to memory 16
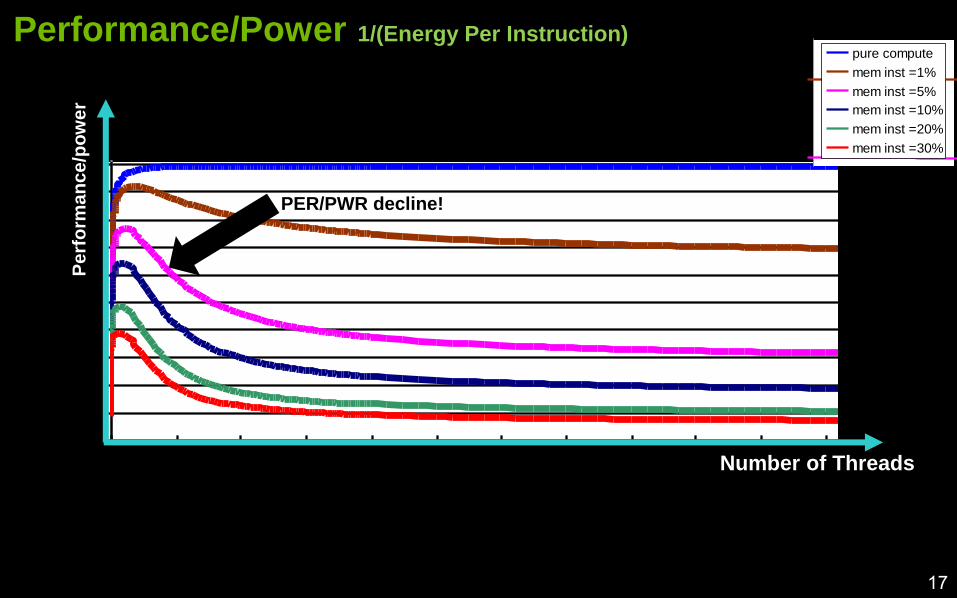
Perf^2/Power
0
1
2
3
4
5
6
7
8
9
10
11
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
11000
12000
13000
14000
15000
16000
17000
18000
19000
20000
Number Of Threads
Perf/P
ower pure compute
mem inst =1%
mem inst =5%
mem inst =10%
mem inst =20%
mem inst =30%
Performance/Power 1/(Energy Per Instruction)
Perf^2/Power
0
1
2
3
4
5
6
7
8
9
10
11
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
11000
12000
13000
14000
15000
16000
17000
18000
19000
20000
Number Of Threads
Perf
/Po
wer pure compute
mem inst =1%
mem inst =5%
mem inst =10%
mem inst =20%
mem inst =30%
17
Number of Threads
Pe
rfo
rma
nc
e/p
ow
er
PER/PWR decline!

Input: Unstructured data
Big Data Data usage message
18
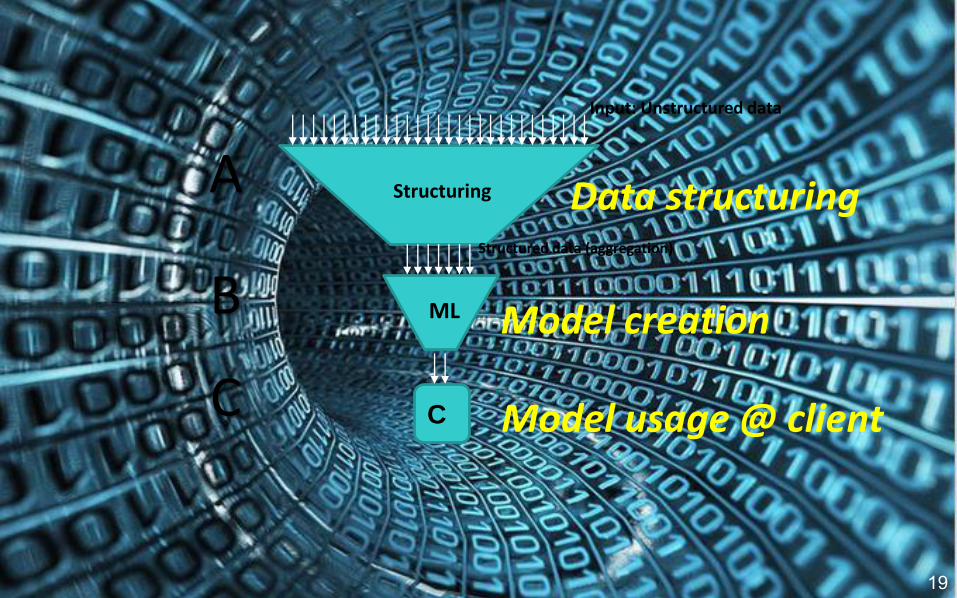
Structuring
Input: Unstructured data
Structured data (aggregation)
A
ML Model creation
Data structuring
C
B
C Model usage @ client
19
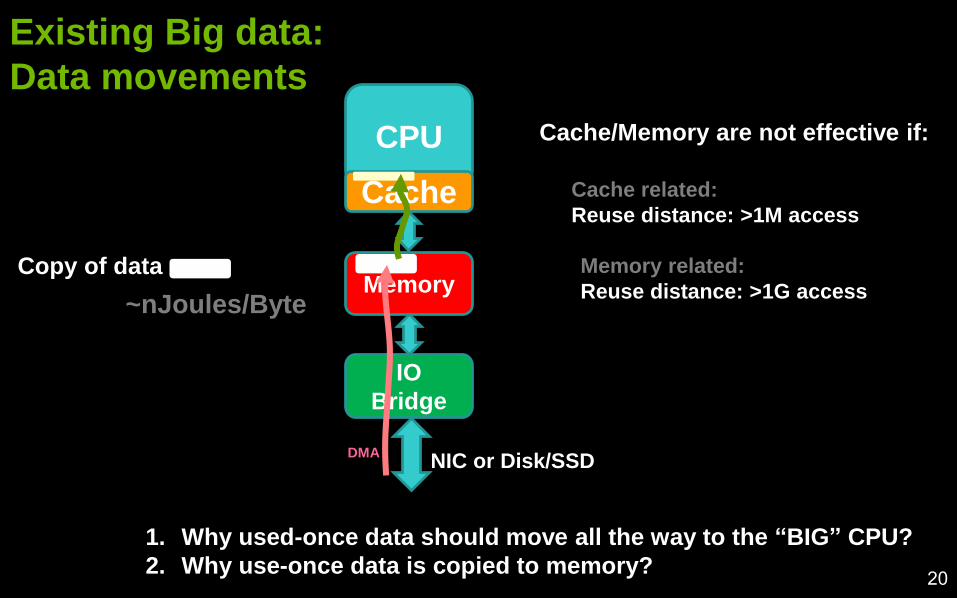
Existing Big data:
Data movements
20
CPU
Cache
Memory
IO
Bridge
Memory related:
Reuse distance: >1G access
Cache related:
Reuse distance: >1M access
Cache/Memory are not effective if:
NIC or Disk/SSD
Copy of data
~nJoules/Byte
1. Why used-once data should move all the way to the “BIG” CPU?
2. Why use-once data is copied to memory?
DMA

Initial analysis: Hadoop-grep memory access
• Analysis of memory Hadoop-grep memory
accesses was performed
• Unique addresses have been identifies
• In each pack (10M memory accesses), we counted;• number of unique addresses that have been single accessed
• number of unique addresses that have been accessed multiple
times
• About 50% of Hadoop-grep memory references
have been single access
21

Big DataSuggestion: Data movements reduction and free-up resources
22
CPU
Cache
Memory
IO Bridge
NIC or Disk/SSD
Process Read-Once data close-to-IO(Funnel PreProcessing FPP)
Implications:
Free huge amount of memory for useful
work (think Hadoop/Spark)
Process funnel functions by small
efficient engines
Save Read/Write DRAM energy
Think about Big Data…
FPP

Open issues for research
SW and OS
Co-Processor or
Heterogeneous system
Compatibility
Application awareness
…
23

Summary
The Funnel functions – execute close to the
data source
Free up system’s memory
Reduction of Data movement
Simple energy efficient engines at the front end
Issues
Compatibility issue: Apps, OS,
Amount of energy saving…
….
24

Thank You
25Maldives' islands