outline 1) goal-directed feature learning (weber & triesch, ijcnn 2009) task 4.1 visual...
Post on 22-Dec-2015
219 views
TRANSCRIPT

Outline
1) Goal-Directed Feature Learning (Weber & Triesch, IJCNN 2009) Task 4.1 Visual processing based on feature abstraction
2) Emergence of Disparity Tuning (Franz & Triesch, ICDL 2007) Task 4.3 Learning of attention and vergence control
3) From Exploration to Planning (Weber & Triesch, ICANN 2008) Task 6.4 Learning hierarchical world models for planning

Outline
1) Goal-Directed Feature Learning (Weber & Triesch, IJCNN 2009) Task 4.1 Visual processing based on feature abstraction
2) Emergence of Disparity Tuning (Franz & Triesch, ICDL 2007) Task 4.3 Learning of attention and vergence control
3) From Exploration to Planning (Weber & Triesch, ICANN 2008) Task 6.4 Learning hierarchical world models for planning
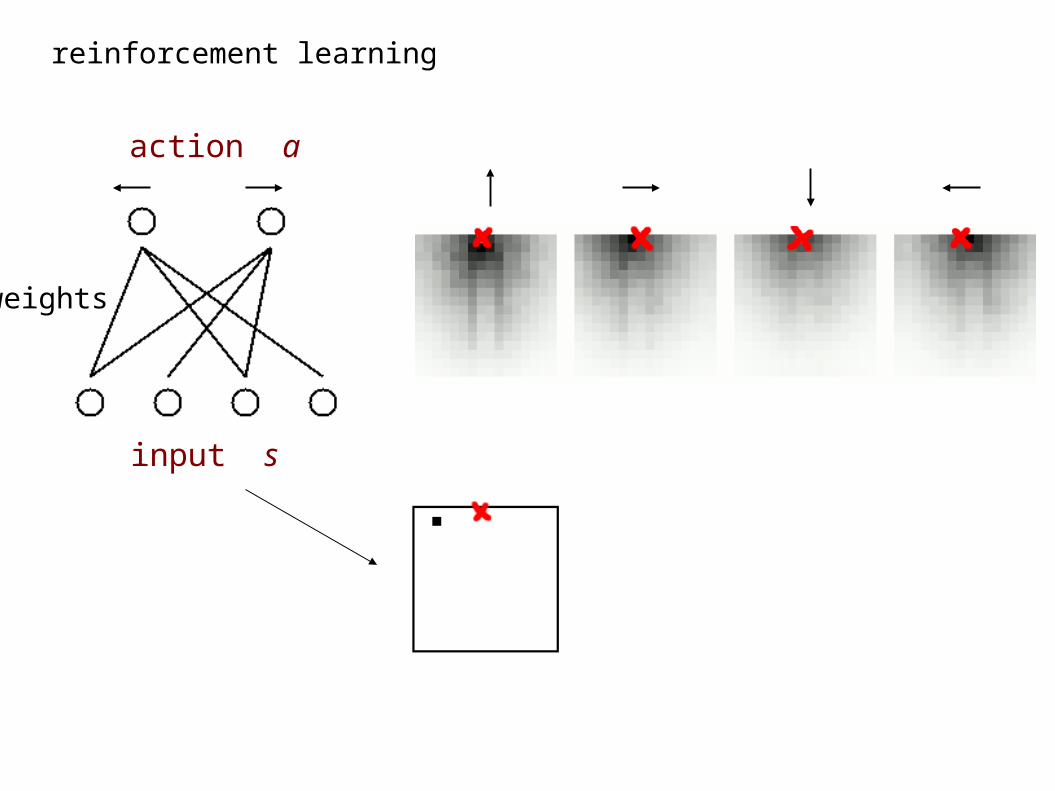
reinforcement learning
input s
action a
weights
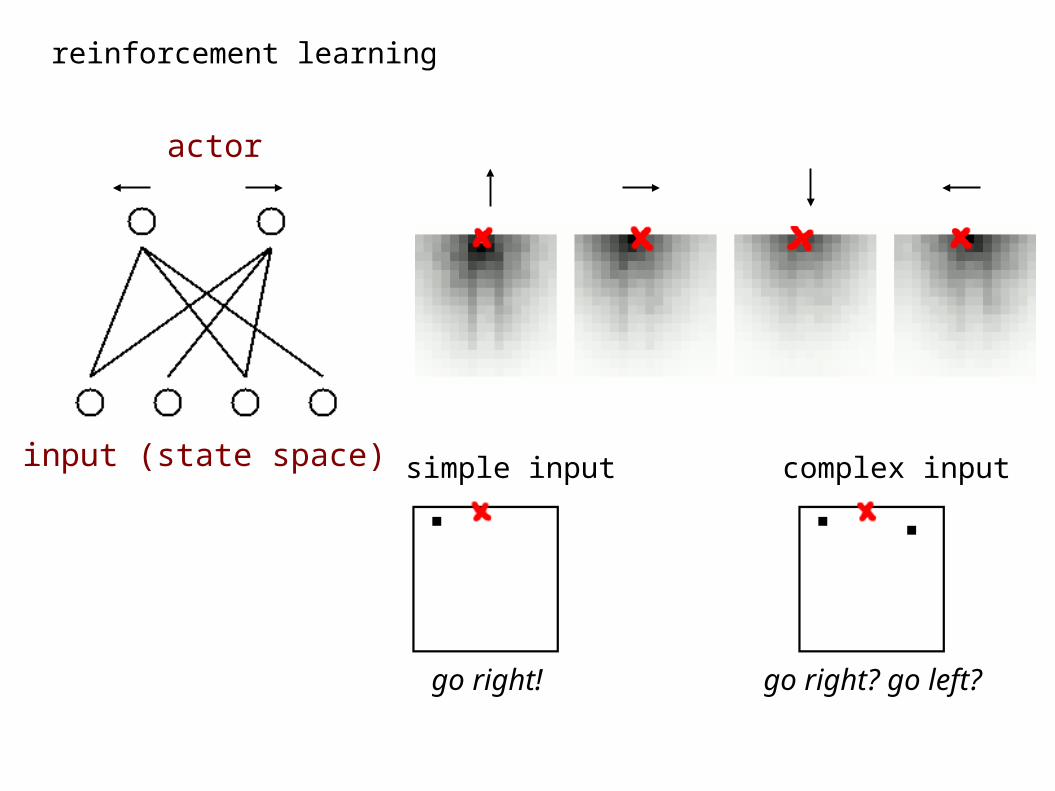
actor
go right? go left?
simple input
go right!
complex input
reinforcement learning
input (state space)

sensory input
reward
action
complex input
scenario: bars controlled by actions, ‘up’, ‘down’, ‘left’, ‘right’;
reward given if horizontal bar at specific position
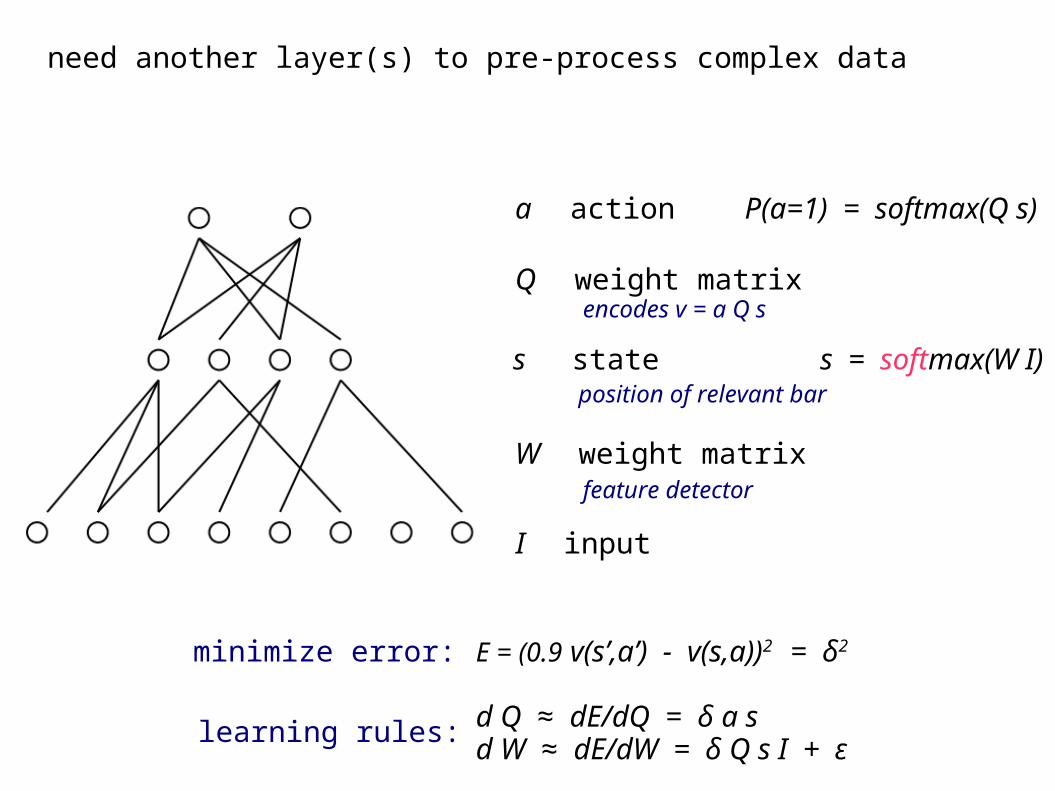
need another layer(s) to pre-process complex data
P(a=1) = softmax(Q s)a action
s state
I input
Q weight matrix
W weight matrix
position of relevant bar
encodes v = a Q s
feature detector
s = softmax(W I)
E = (0.9 v(s’,a’) - v(s,a))2 = δ2
d Q ≈ dE/dQ = δ a sd W ≈ dE/dW = δ Q s I + ε
minimize error:
learning rules:
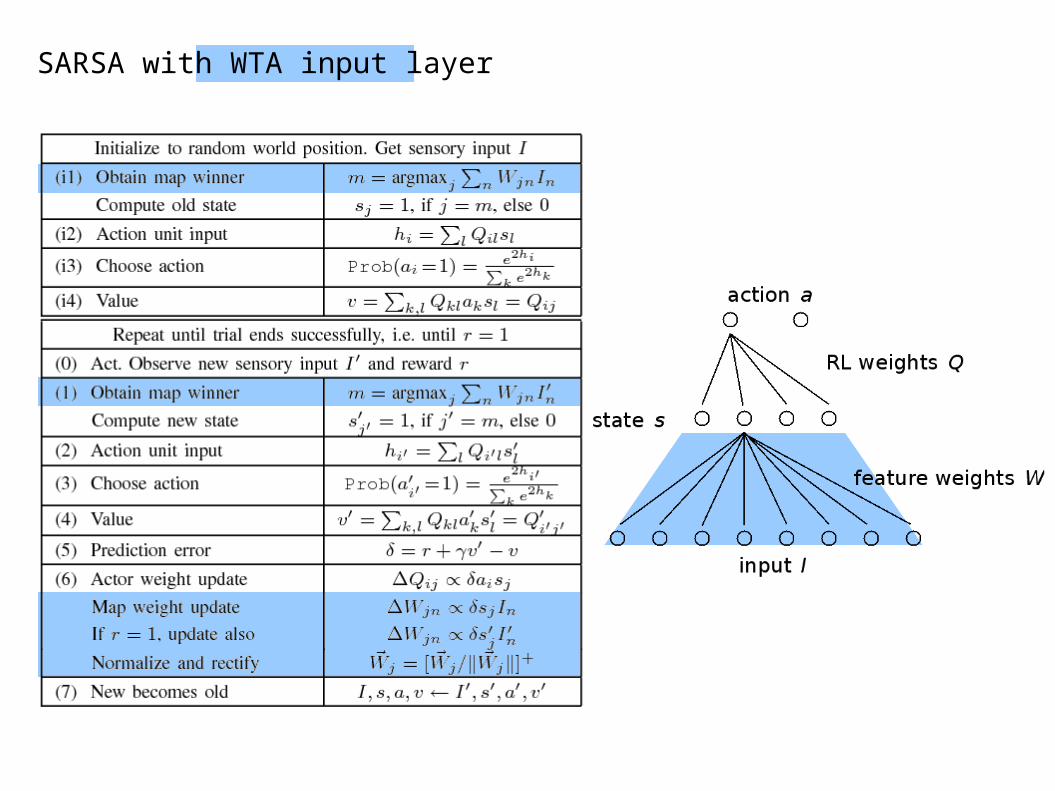
SARSA with WTA input layer
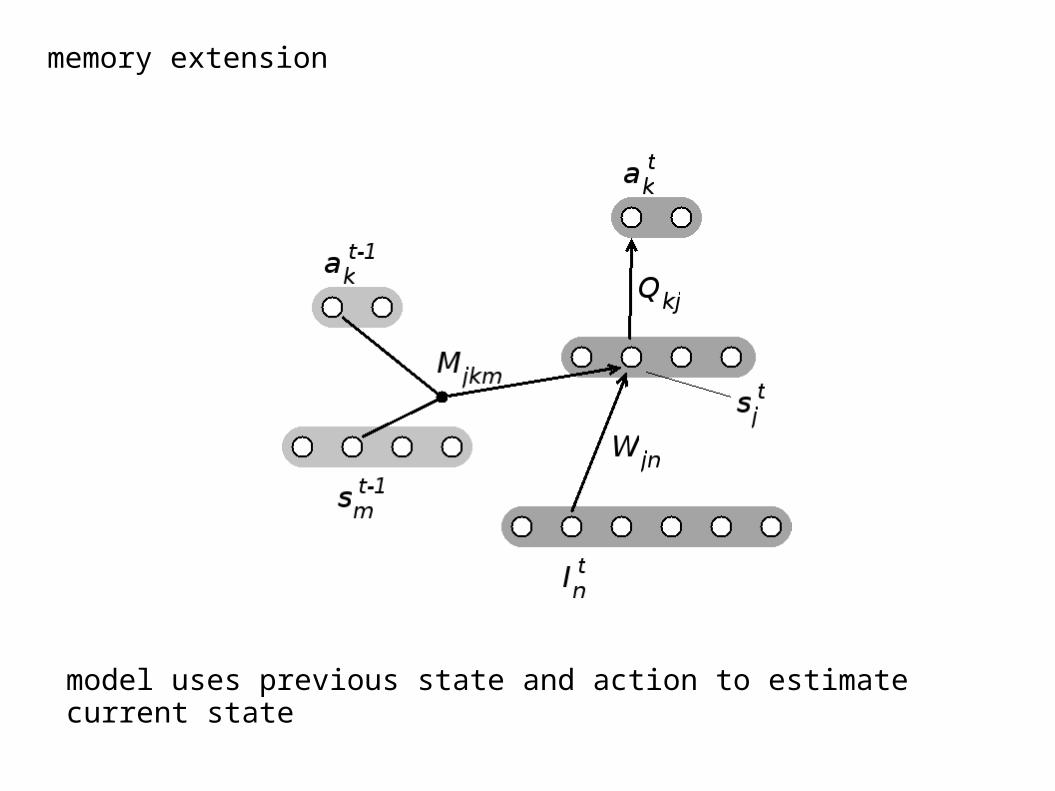
memory extension
model uses previous state and action to estimate current state

RL action weights
feature weights
data
learning the ‘short bars’ data
reward
action
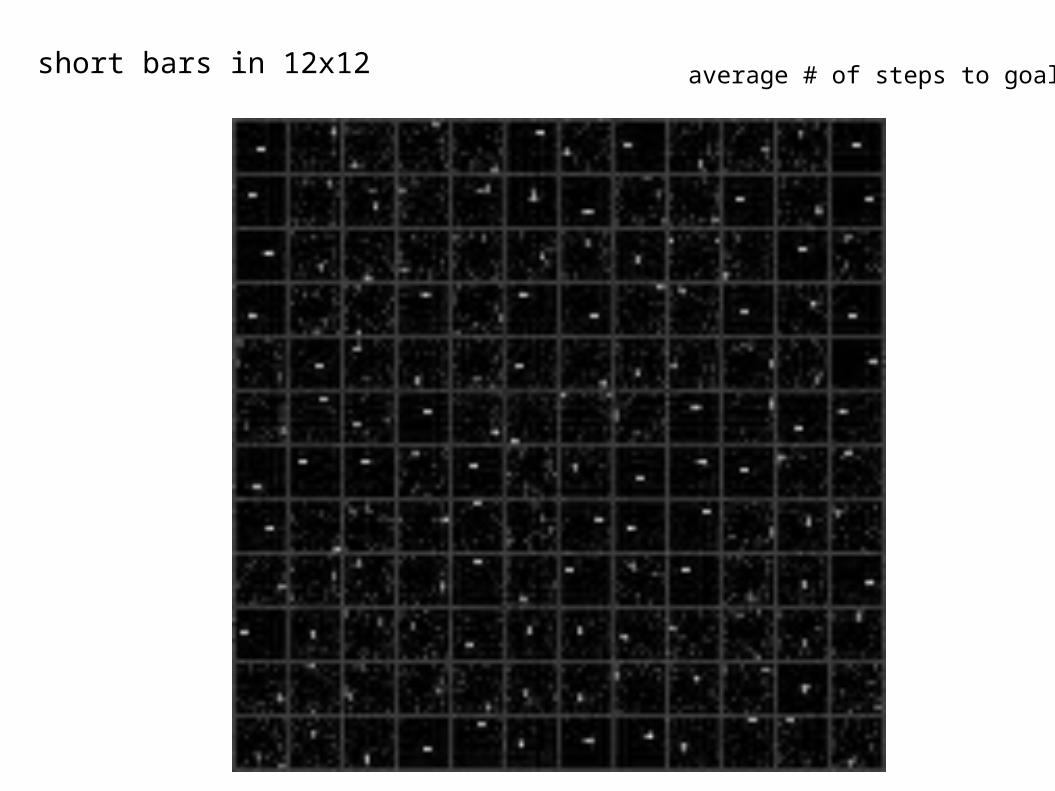
short bars in 12x12 average # of steps to goal: 11

RL action weights
feature weights
input reward 2 actions (not shown)
data
learning ‘long bars’ data
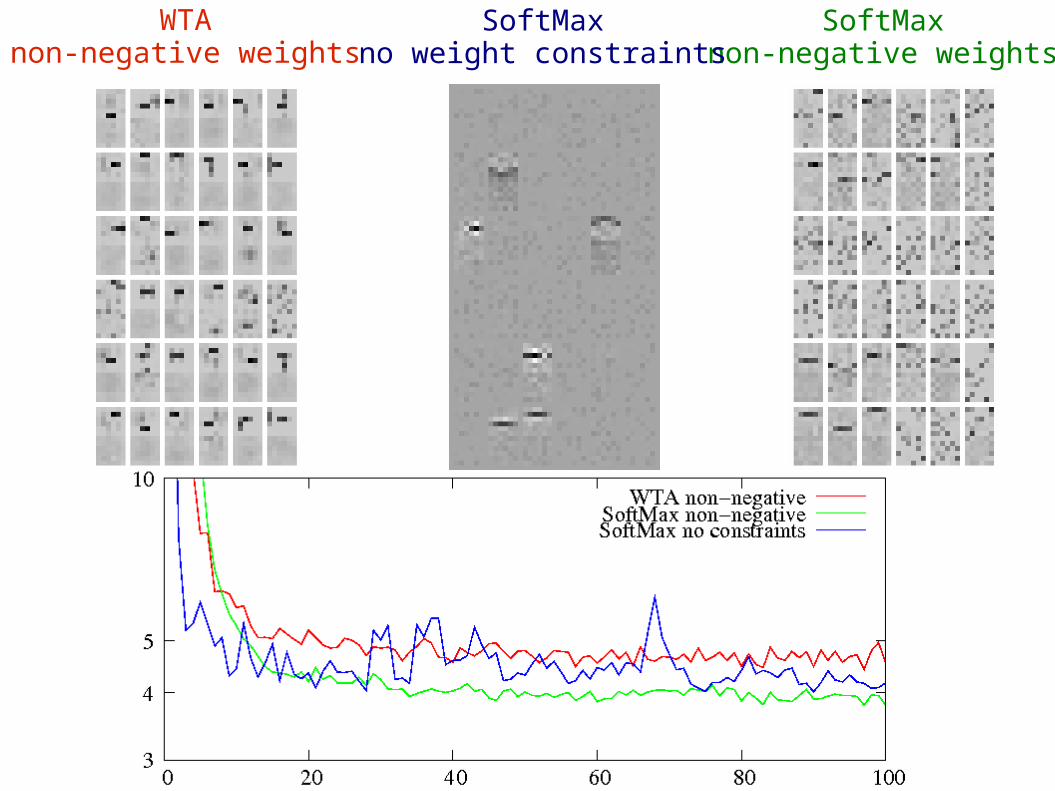
WTAnon-negative weights
SoftMaxnon-negative weights
SoftMaxno weight constraints

models’ background:
- gradient descent methods generalize RL to several layers Sutton&Barto RL book (1998); Tesauro (1992;1995)
- reward-modulated Hebb Triesch, Neur Comp 19, 885-909 (2007), Roelfsema & Ooyen, Neur Comp 17, 2176-214 (2005); Franz & Triesch, ICDL (2007)
- reward-modulated activity leads to input selection Nakahara, Neur Comp 14, 819-44 (2002)
- reward-modulated STDP Izhikevich, Cereb Cortex 17, 2443-52 (2007), Florian, Neur Comp 19/6, 1468-502 (2007); Farries & Fairhall, Neurophysiol 98, 3648-65 (2007); ...
- RL models learn partitioning of input space e.g. McCallum, PhD Thesis, Rochester, NY, USA (1996)
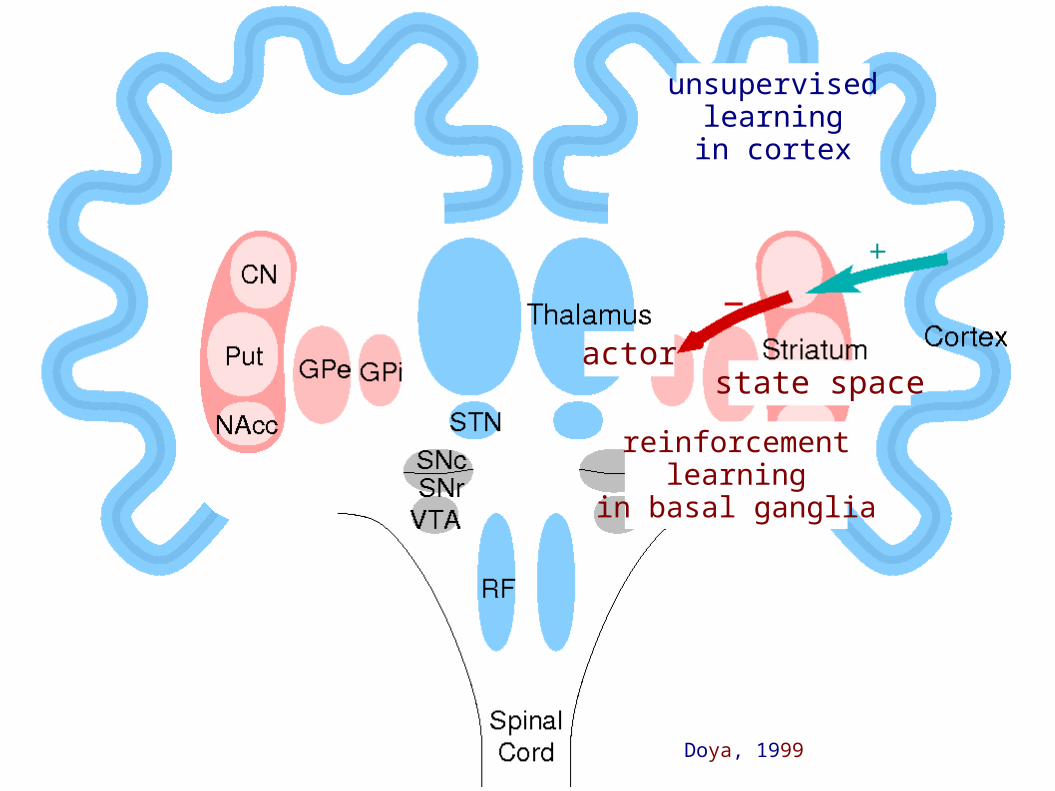
unsupervisedlearningin cortex
reinforcementlearning
in basal ganglia
state spaceactor
Doya, 1999

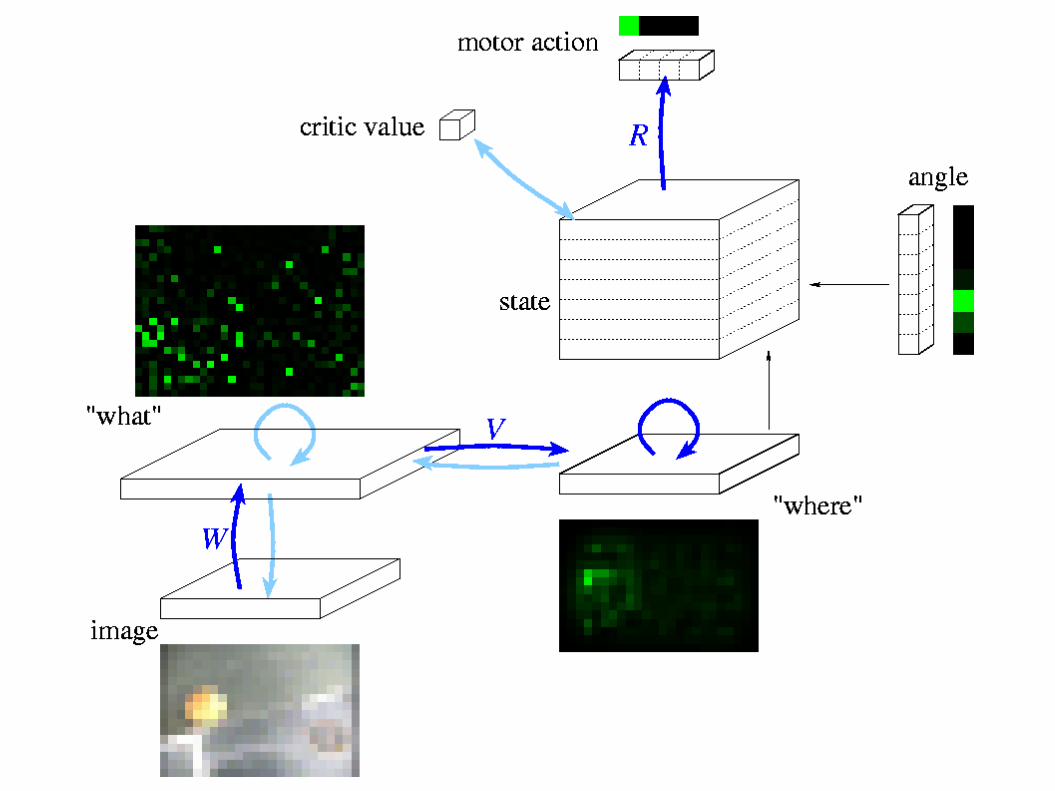

Discussion
- may help reinforcement learning work with real-world data
... real visual processing!

Outline
1) Goal-Directed Feature Learning (Weber & Triesch, IJCNN 2009) Task 4.1 Visual processing based on feature abstraction
2) Emergence of Disparity Tuning (Franz & Triesch, ICDL 2007) Task 4.3 Learning of attention and vergence control
3) From Exploration to Planning (Weber & Triesch, ICANN 2008) Task 6.4 Learning hierarchical world models for planning
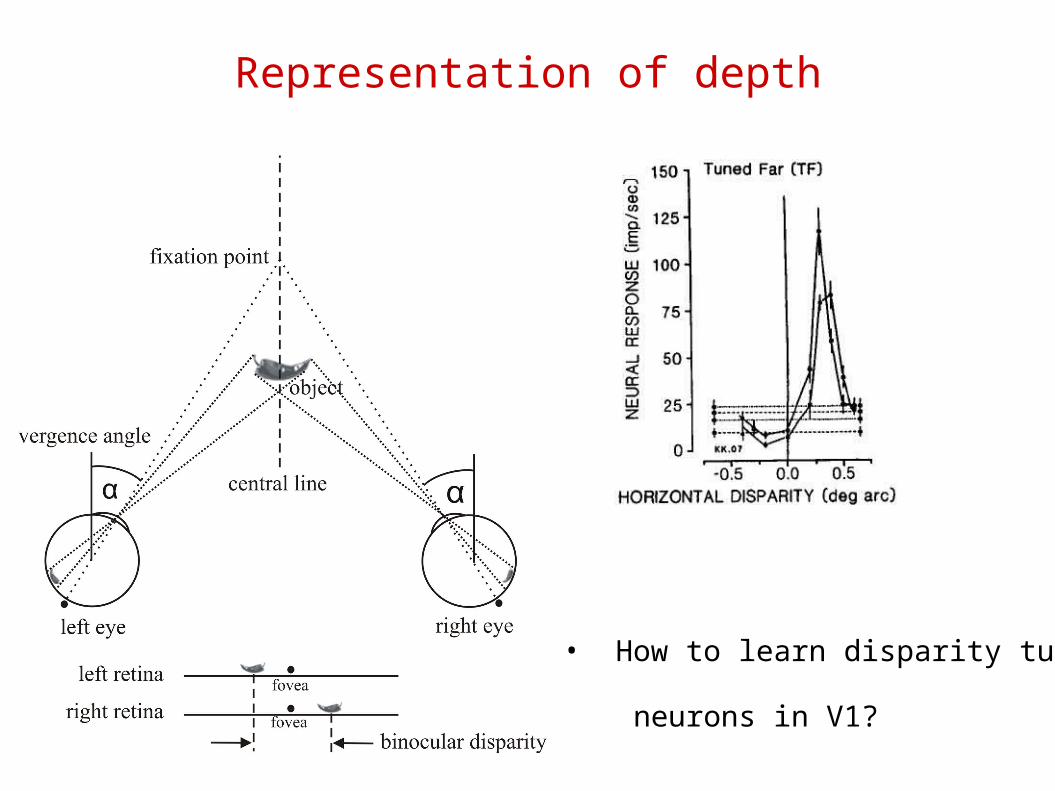
Representation of depth
• How to learn disparity tuned
neurons in V1?
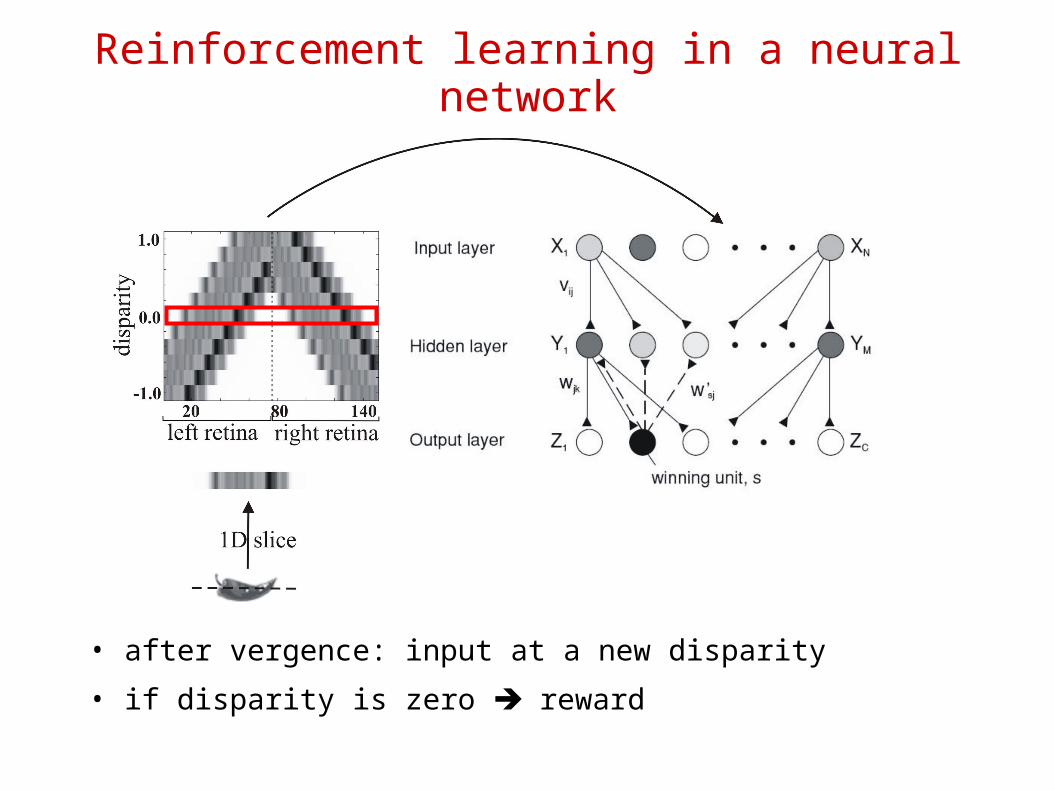
Reinforcement learning in a neural network
• after vergence: input at a new disparity
• if disparity is zero reward

Attention-Gated Reinforcement Learning
Hebbian-like weight learning:
(Roelfsema, van Ooyen, 2005)
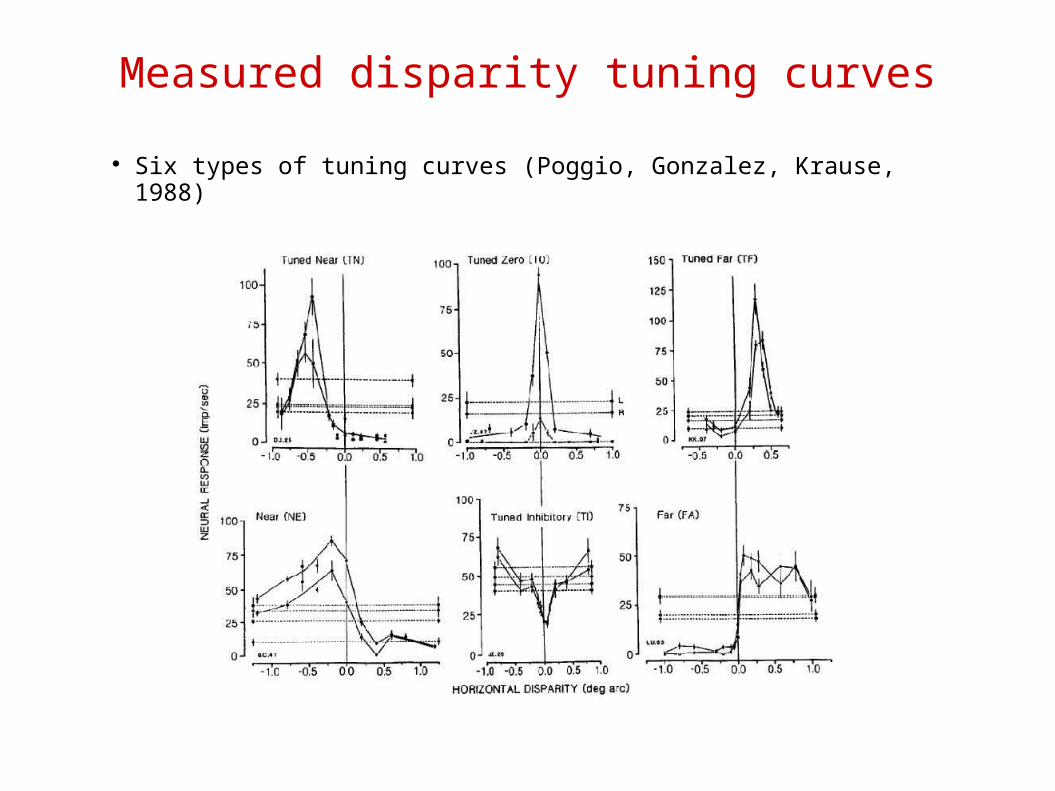
Six types of tuning curves (Poggio, Gonzalez, Krause, 1988)
Measured disparity tuning curves
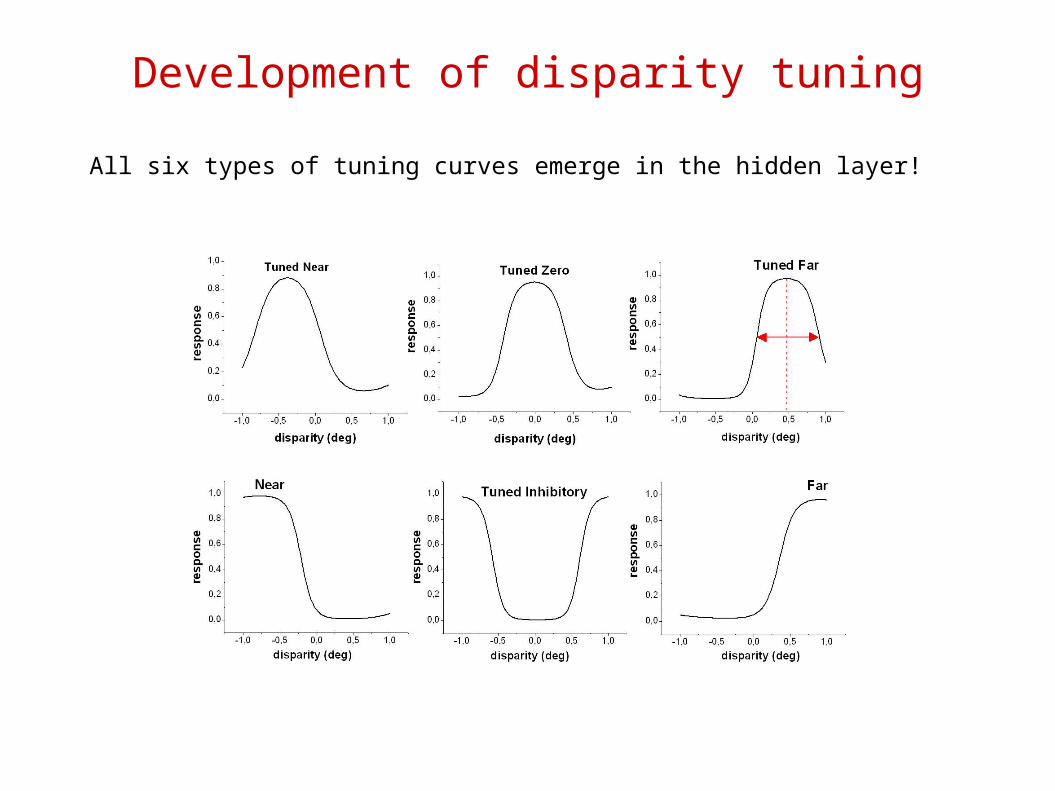
All six types of tuning curves emerge in the hidden layer!
Development of disparity tuning

Discussion
- requires application
... use 2D images from 3D space
... open question as to the implementation of the reward
... learning of attention?

Outline
1) Goal-Directed Feature Learning (Weber & Triesch, IJCNN 2009) Task 4.1 Visual processing based on feature abstraction
2) Emergence of Disparity Tuning (Franz & Triesch, ICDL 2007) Task 4.3 Learning of attention and vergence control
3) From Exploration to Planning (Weber & Triesch, ICANN 2008) Task 6.4 Learning hierarchical world models for planning
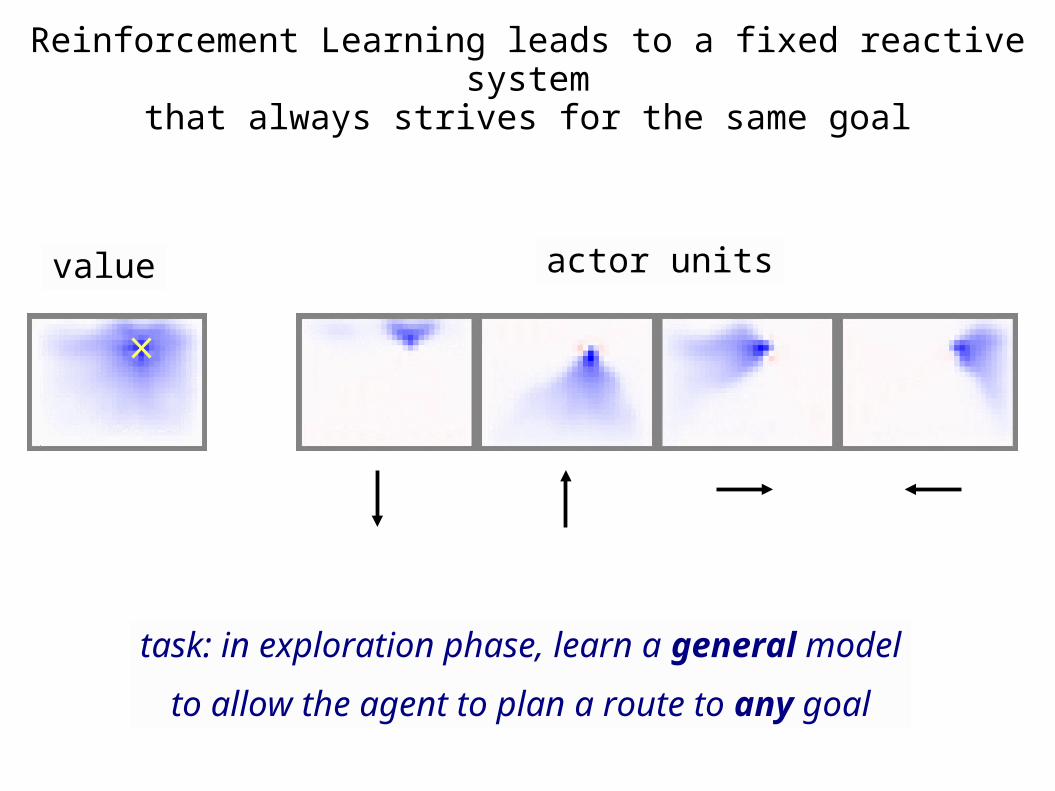
Reinforcement Learning leads to a fixed reactive systemthat always strives for the same goal
value actor units
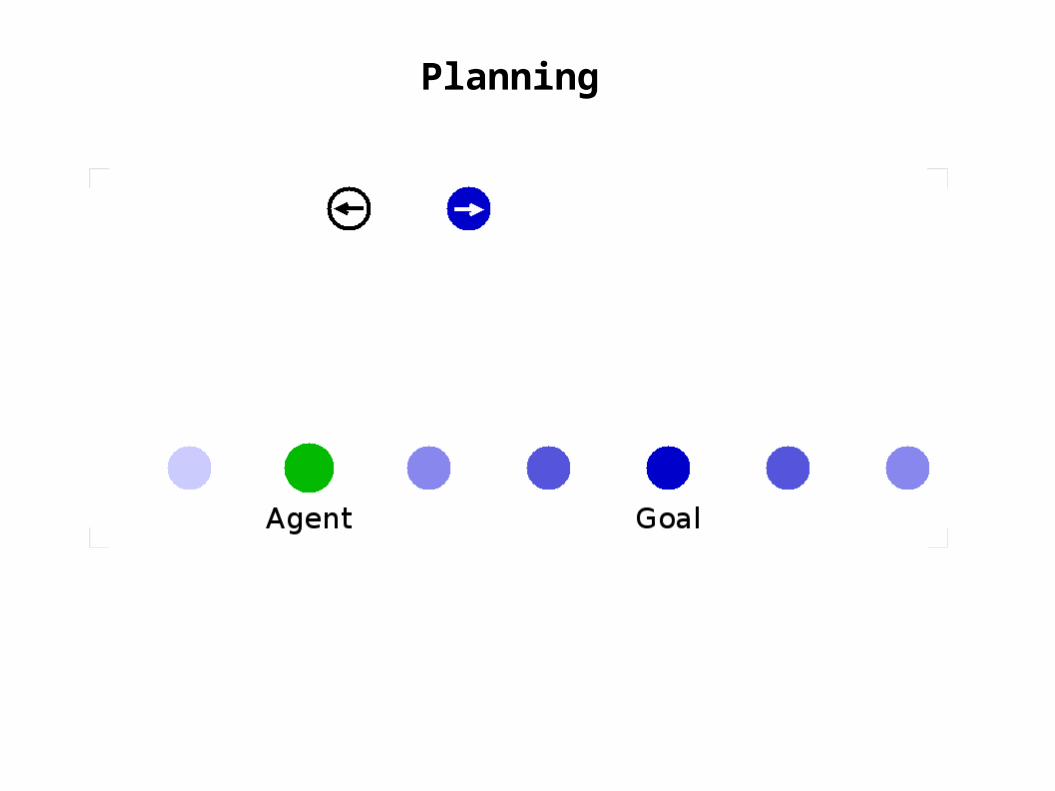
task: in exploration phase, learn a general model
to allow the agent to plan a route to any goal

Learning
actor
state space
randomly move aroundthe state space
learn world models:● associative model● inverse model● forward model
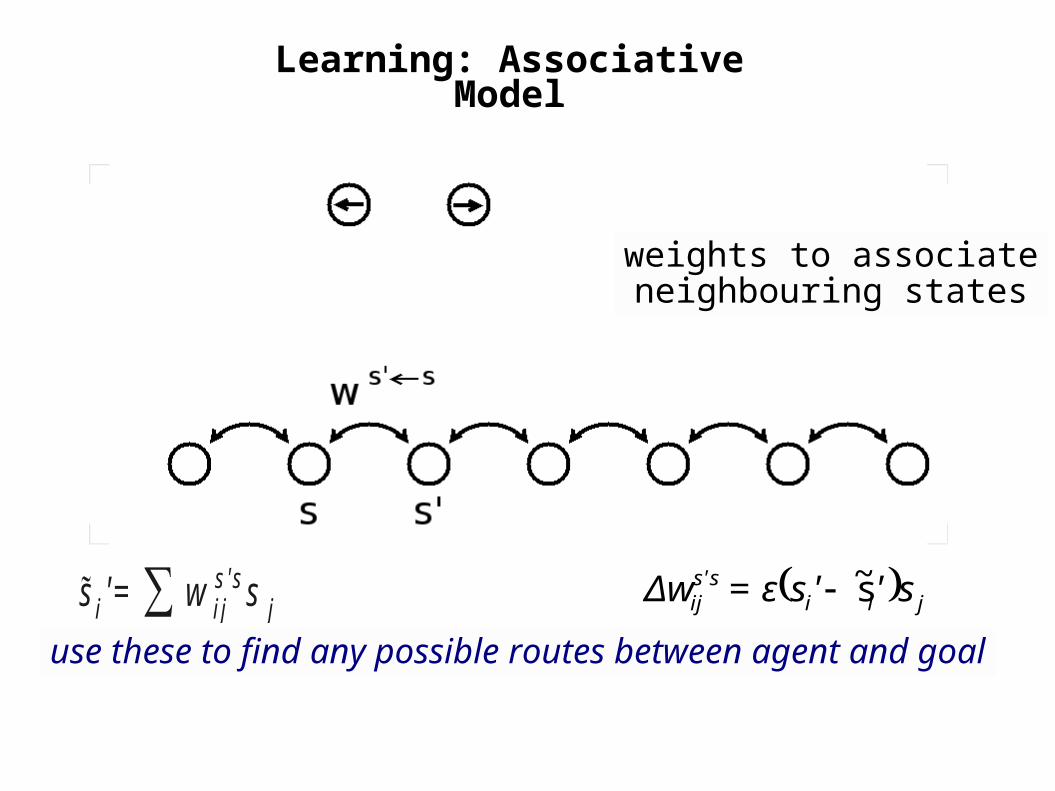
Learning: Associative Model
weights to associateneighbouring states
use these to find any possible routes between agent and goal
si '=∑ w ijs'ss j
jiiss'
ij s''sε=Δw s~
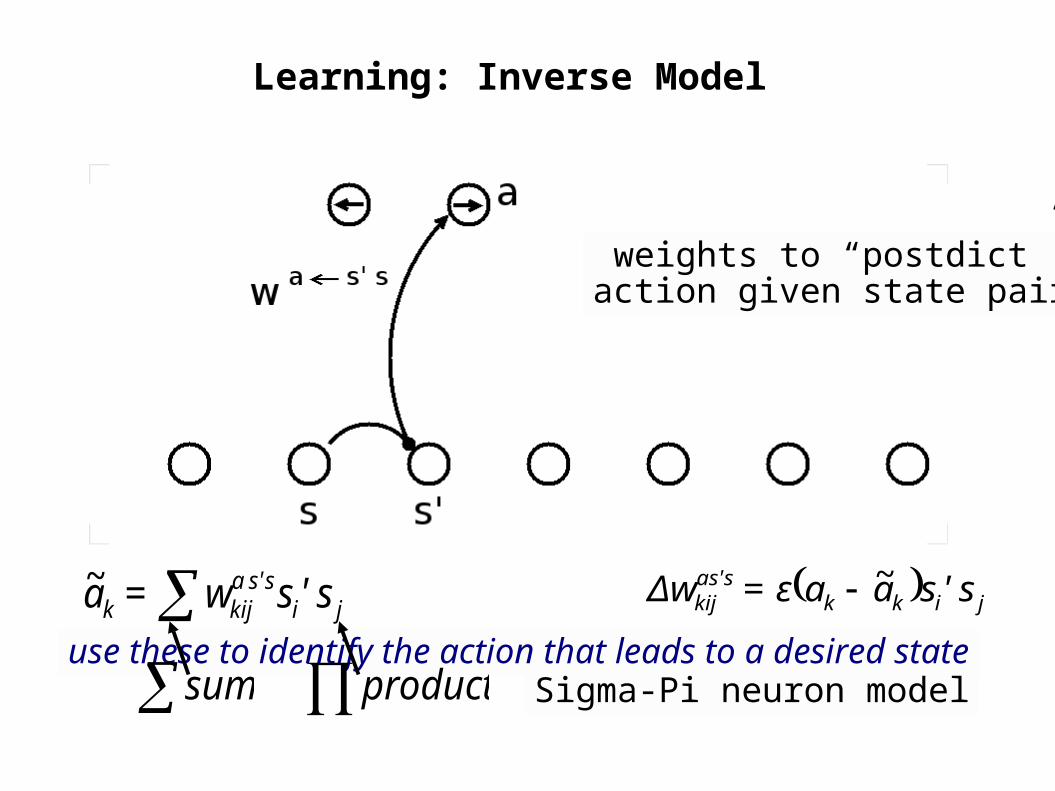
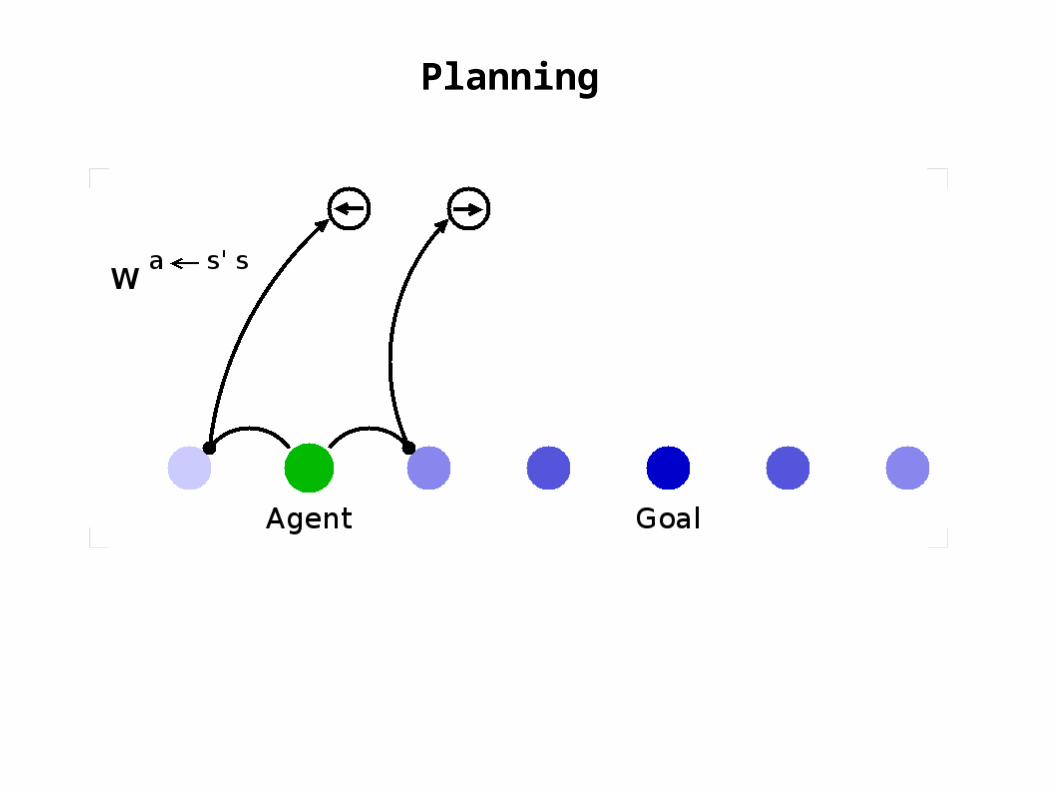
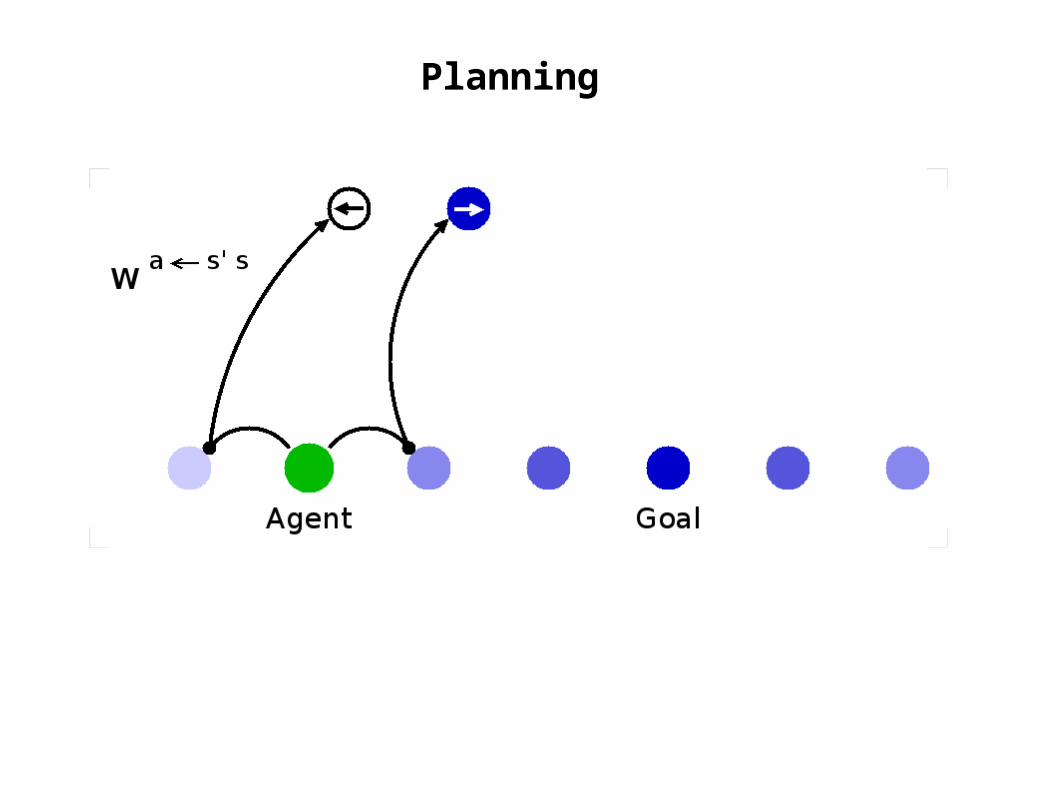
Learning: Inverse Model
weights to “postdict”action given state pair
use these to identify the action that leads to a desired stateji
s s'akijk s'sw=a ~ jikk
sas'kij s'saaε=Δw ~
sum product Sigma-Pi neuron model
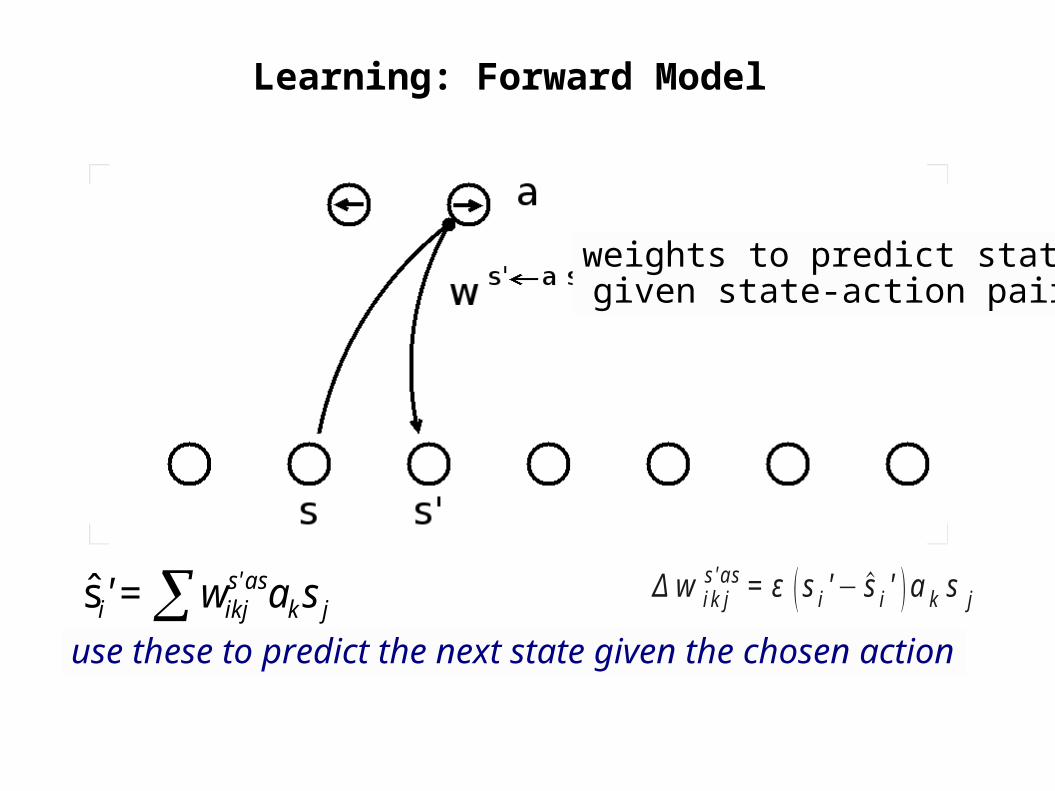
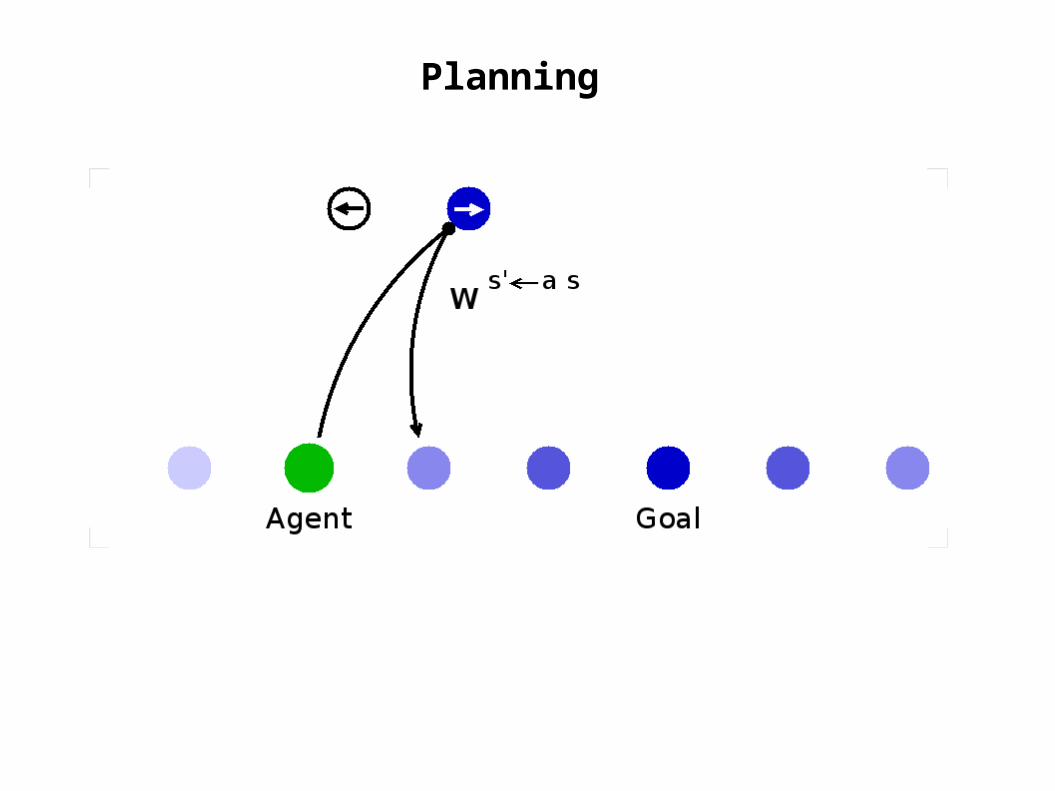
Learning: Forward Model
weights to predict stategiven state-action pair
use these to predict the next state given the chosen actionjk
ass'ikji saw=' s Δw ik j
s'as=ε si '− si ' ak s j
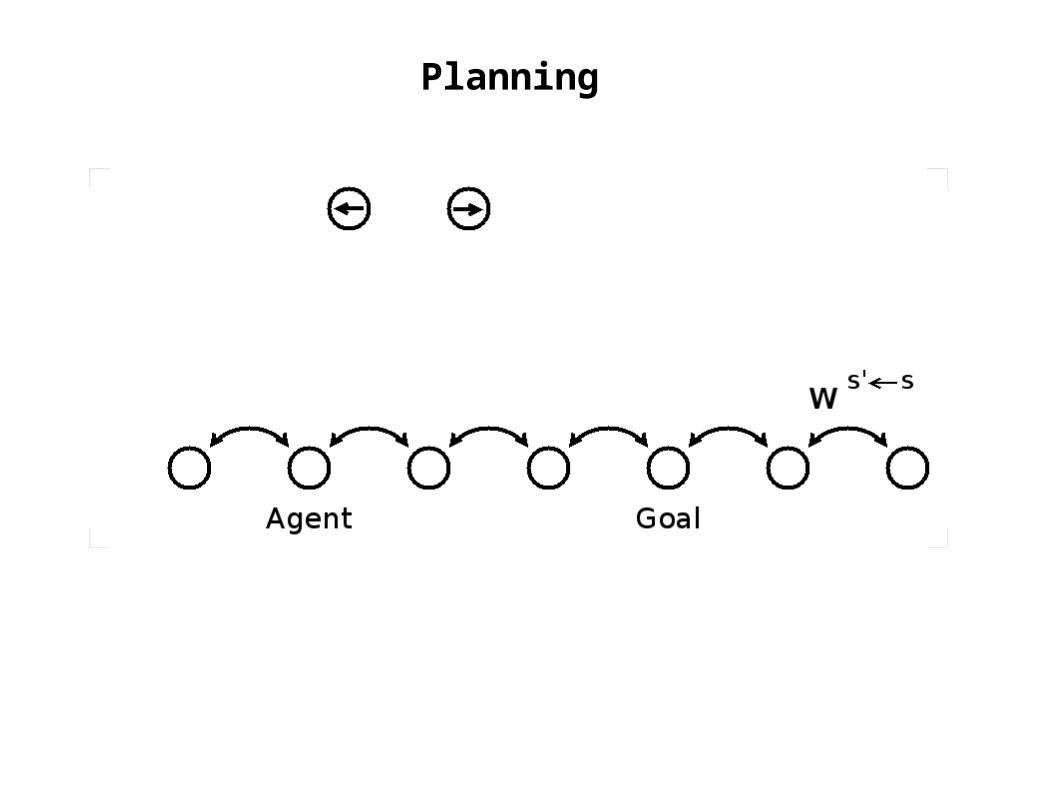
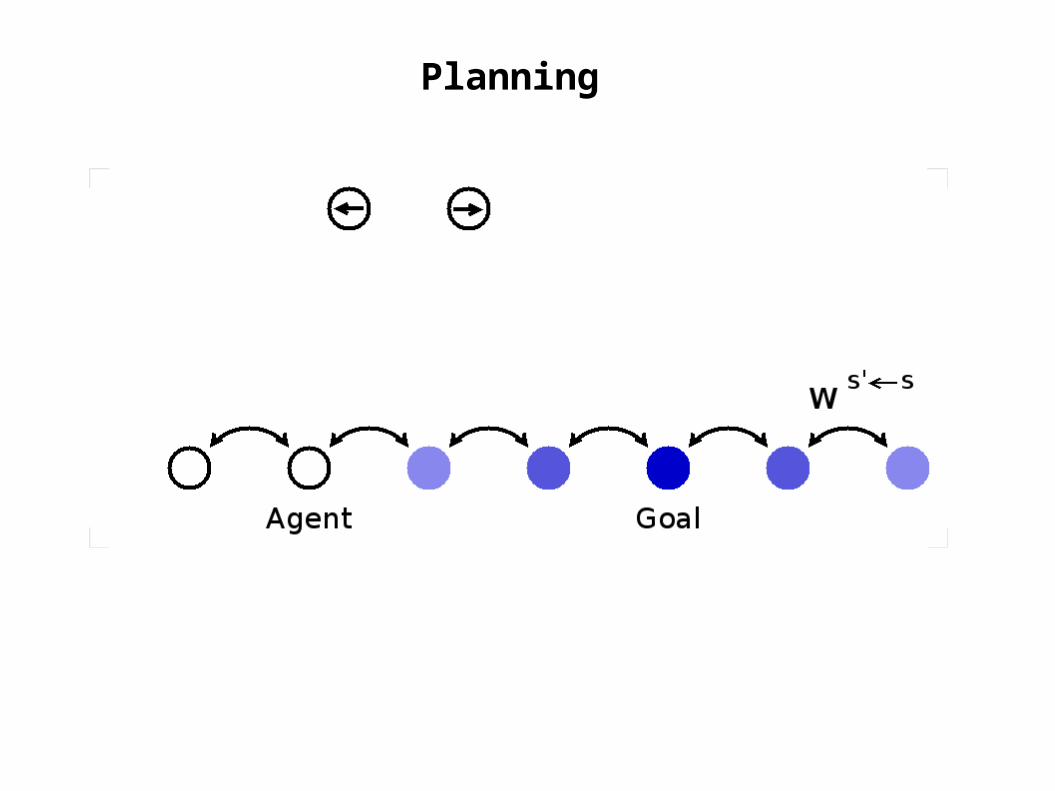
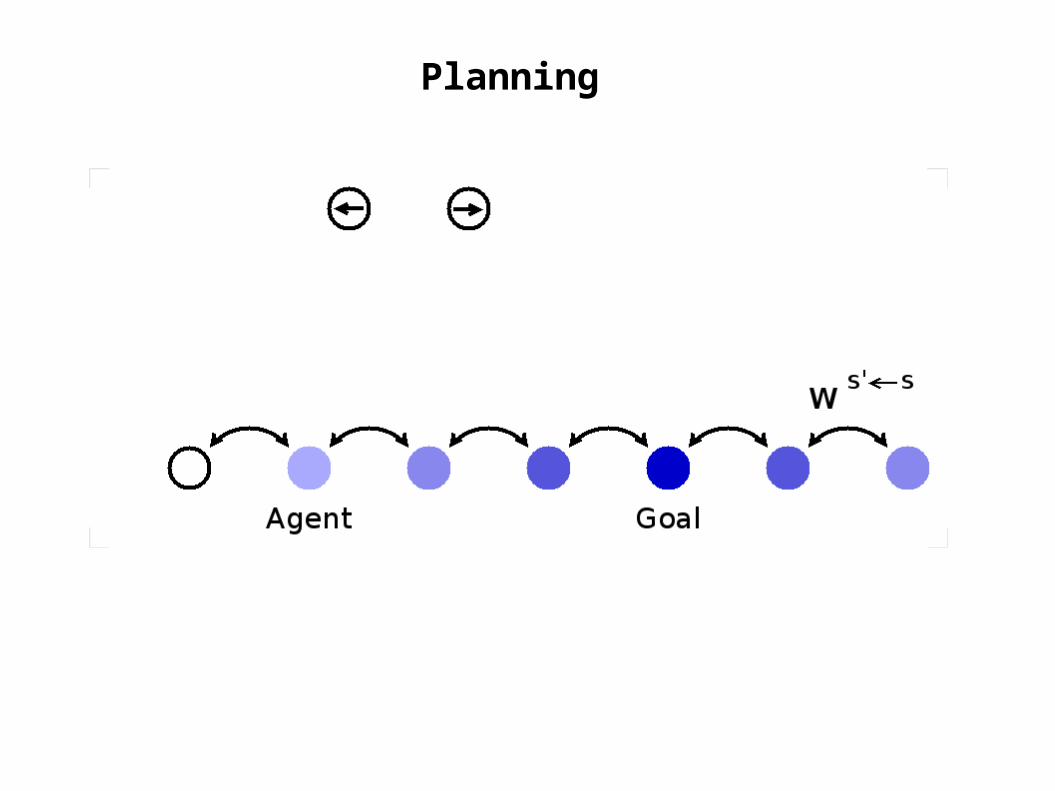
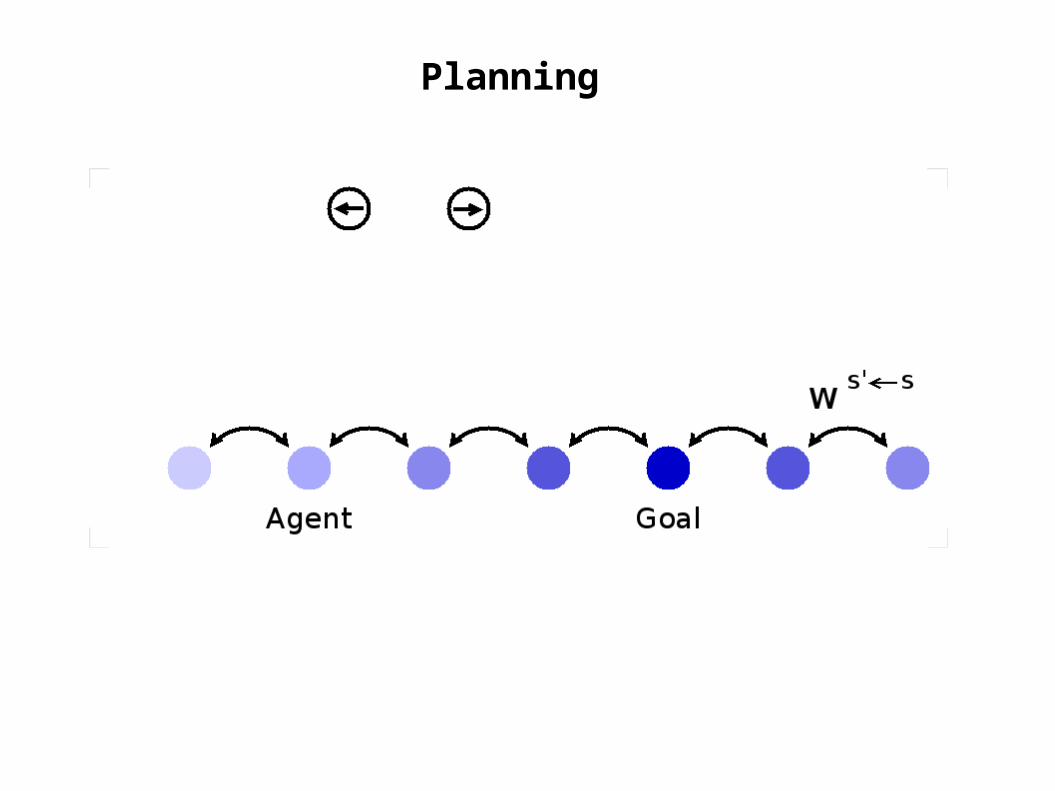
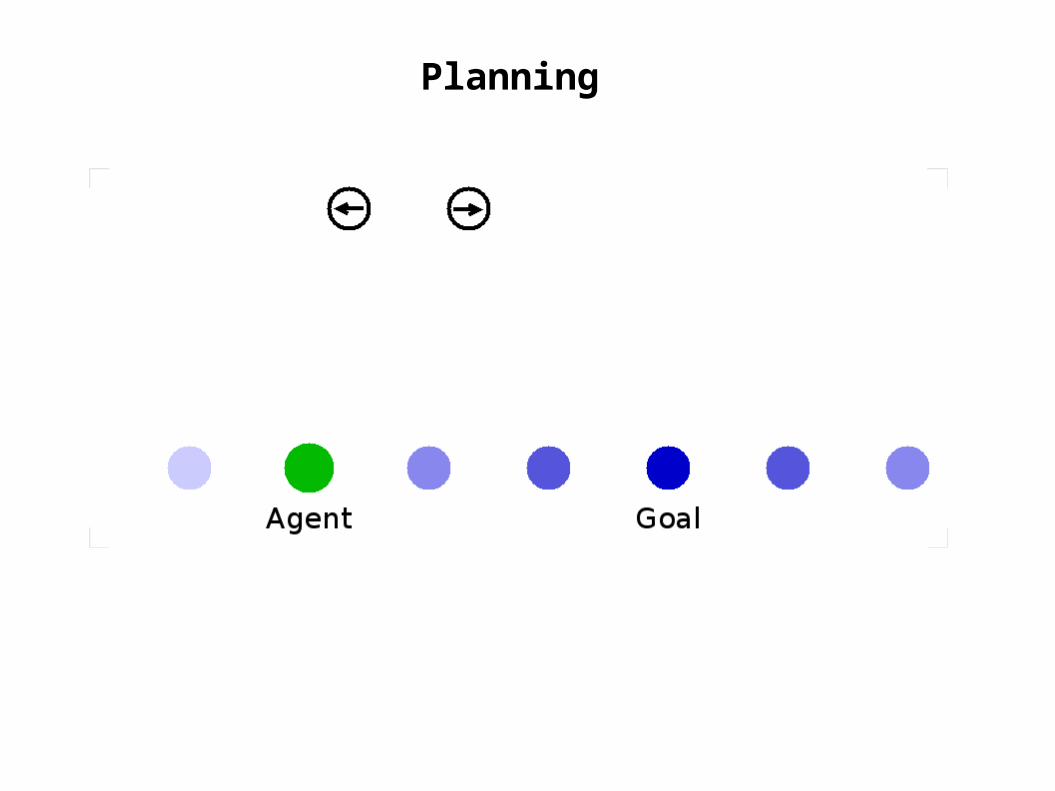
Planning
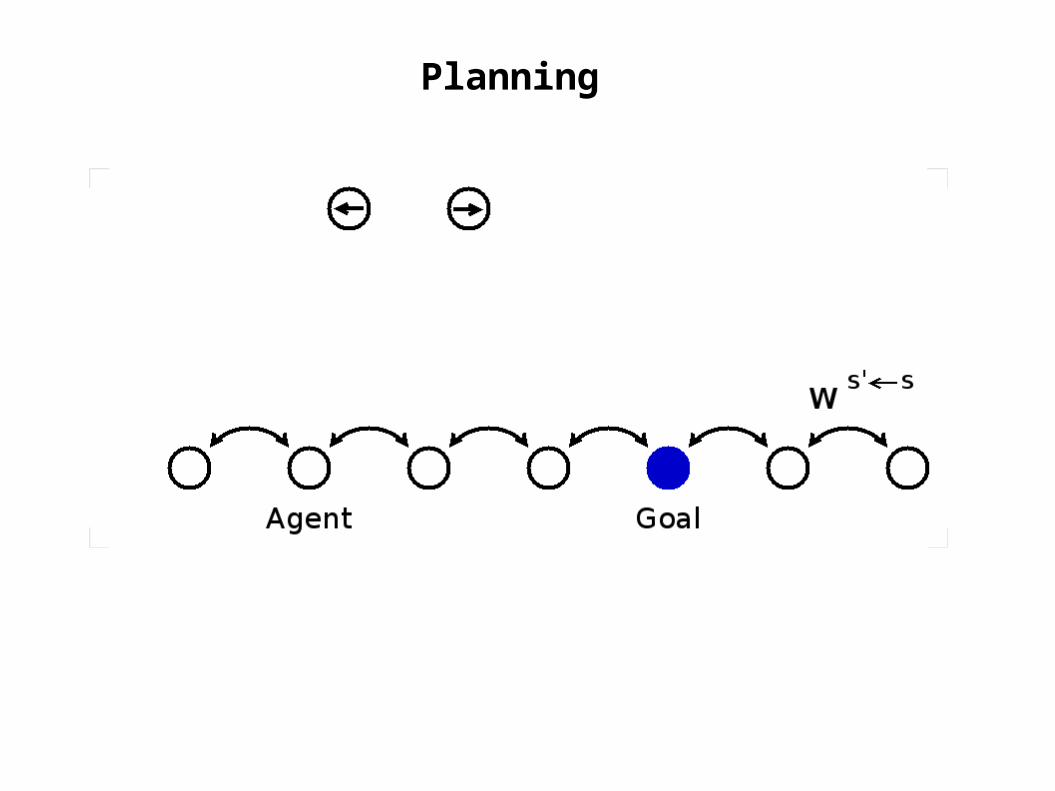
Planning
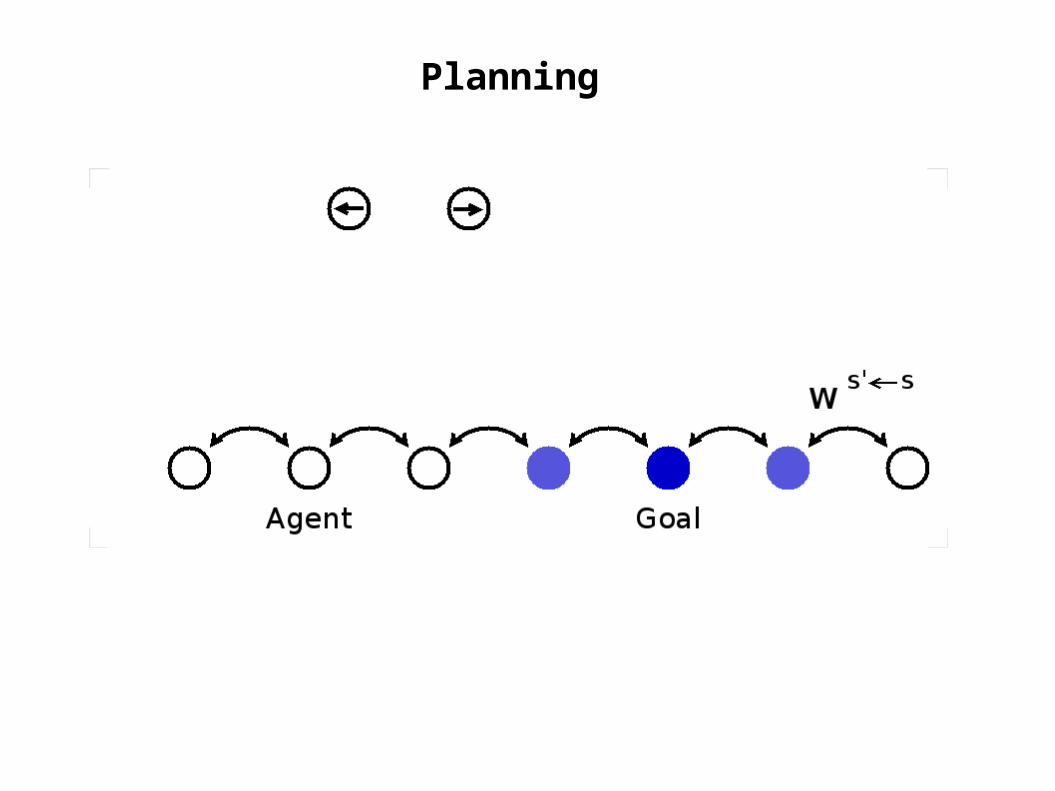
Planning
Planning
Planning
Planning
Planning
Planning
Planning
Planning
Planning
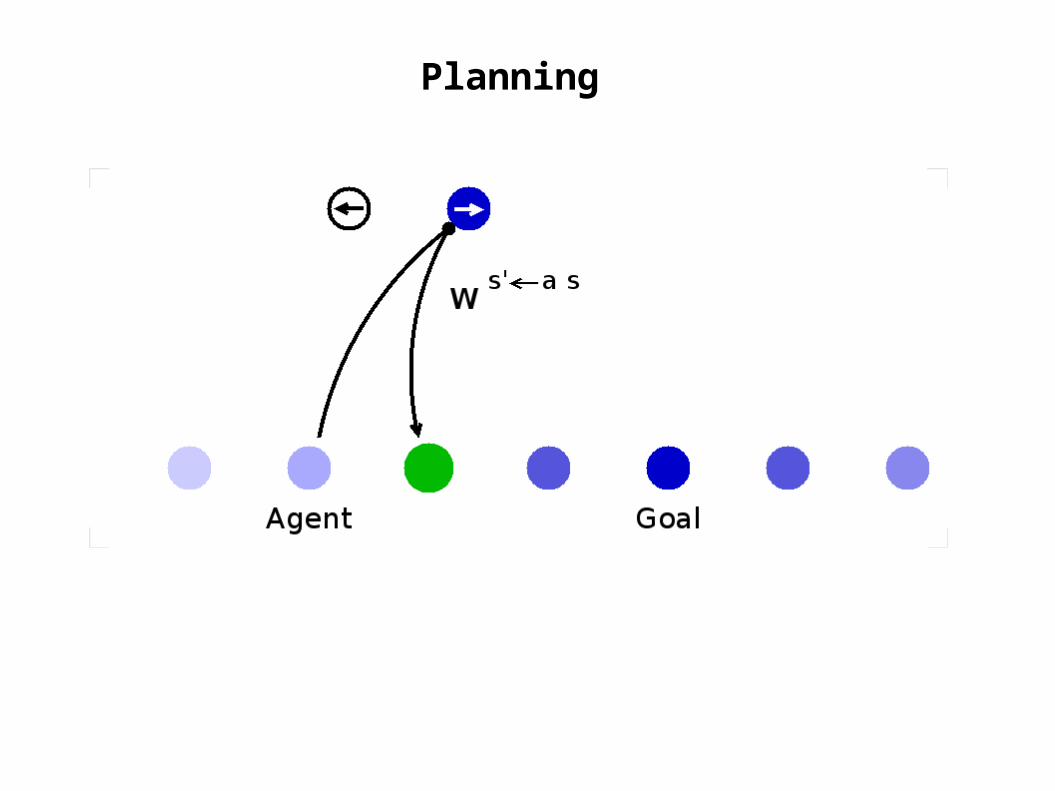
Planning
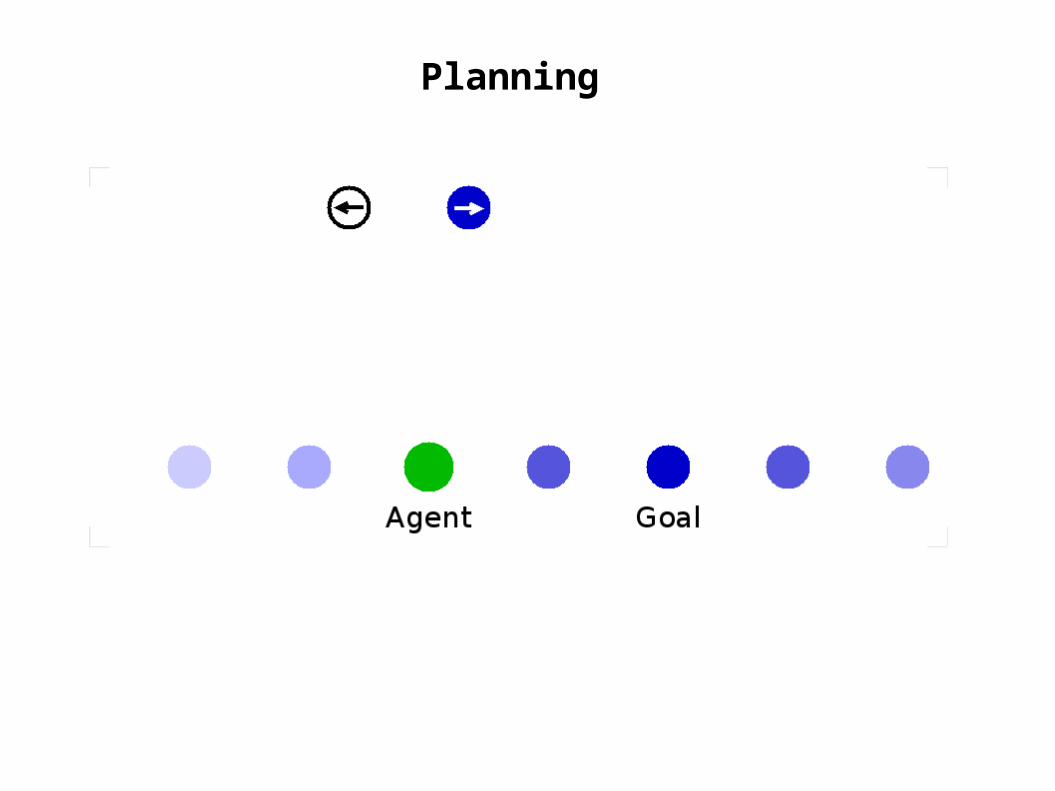
Planning
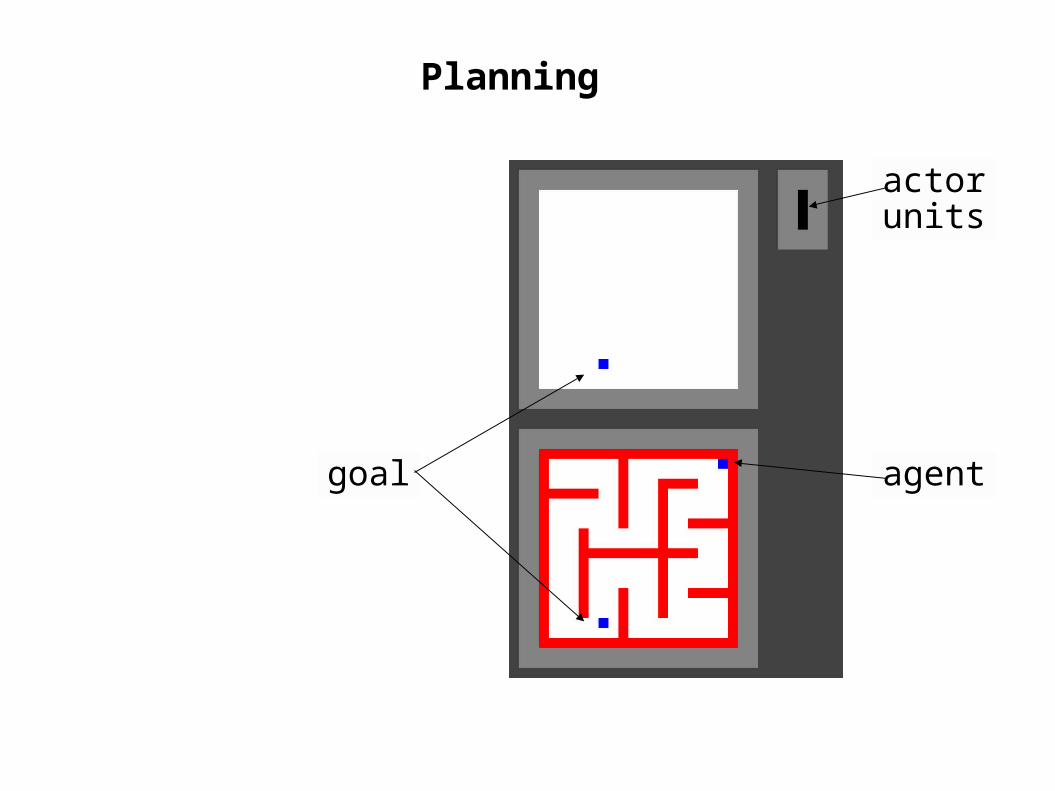
Planning
goal
actorunits
agent
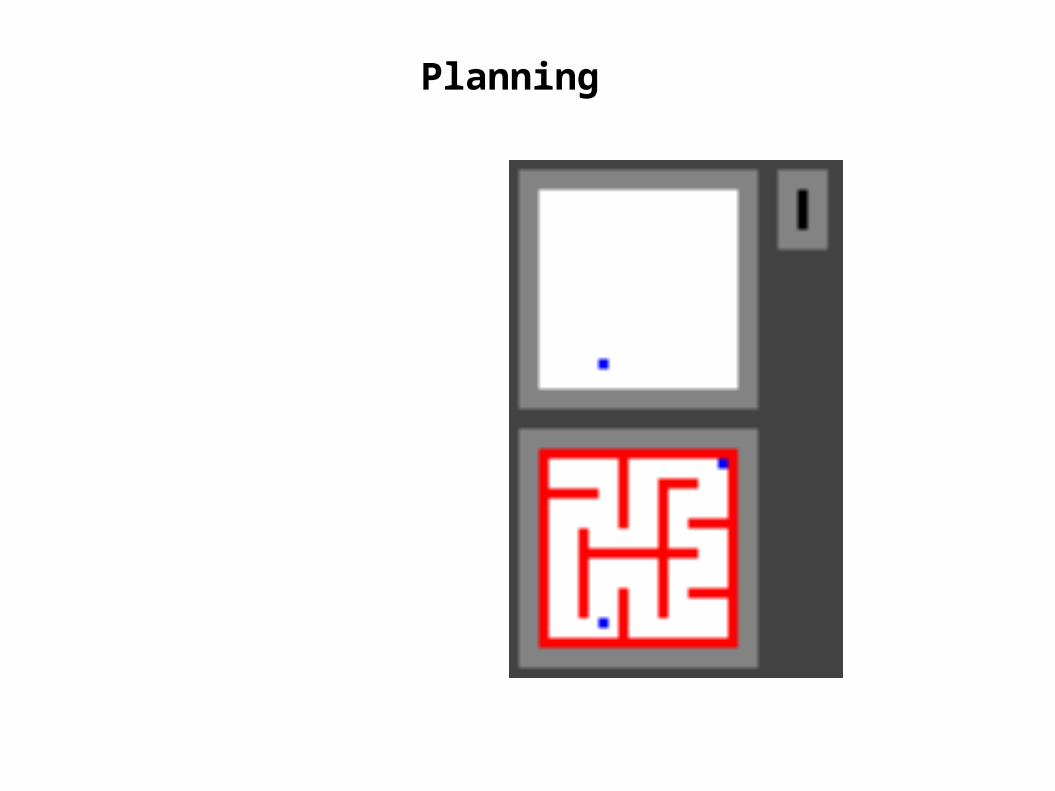
Planning

Discussion
- requires embedding
... learn state space from sensor input
... only random exploration implemented
- tong ... hand-designed planning phases
... hierarchical models?