probabilistic context free grammar language structure is not linear the velocity of seismic waves...
Post on 19-Dec-2015
223 views
TRANSCRIPT

Probabilistic Context Free Grammar

Language structure is not linear
The velocity of seismic waves rises to…

Context free grammars – a reminder
A CFG G consists of - A set of terminals {wk}, k=1, …, V A set of nonterminals {Ni}, i=1, …, n A designated start symbol, N1
A set of rules, {Niπj} (where πj is a sequence of terminals and nonterminals)

A very simple example
G’s rewrite rules – SaSb Sab
Possible derivations – SaSbaabb SaSbaaSbbaaabbb
In general, G creates the language anbn

Modeling natural language
G is given by the rewrite rules – SNP VP NPthe N | a N Nman | boy | dog VPV NP Vsaw | heard | sensed | sniffed

Recursion can be included
G is given by the rewrite rules – SNP VP NPthe N | a N Nman CP | boy CP | dog CP VPV NP Vsaw | heard | sensed | sniffed CPthat VP | ε

Probabilistic Context Free Grammars
A PCFG G consists of – A set of terminals {wk}, k=1, …, V A set of nonterminals {Ni}, i=1, …, n A designated start symbol, N1
A set of rules, {Niπj} (where πj is a sequence of terminals and nonterminals)
A corresponding set of probabilities on rules
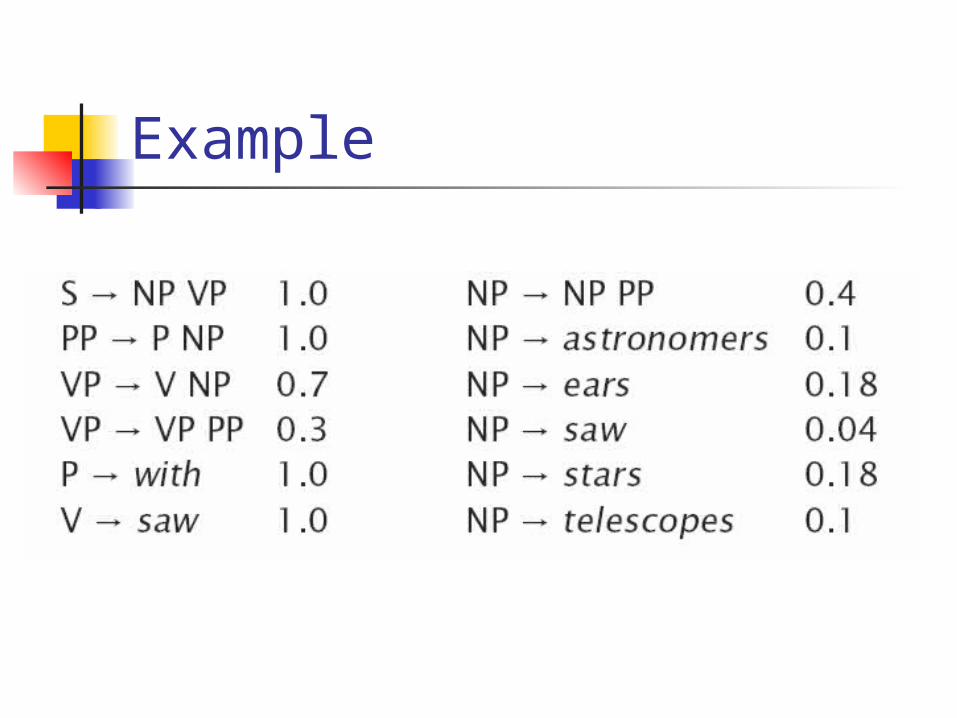
Example
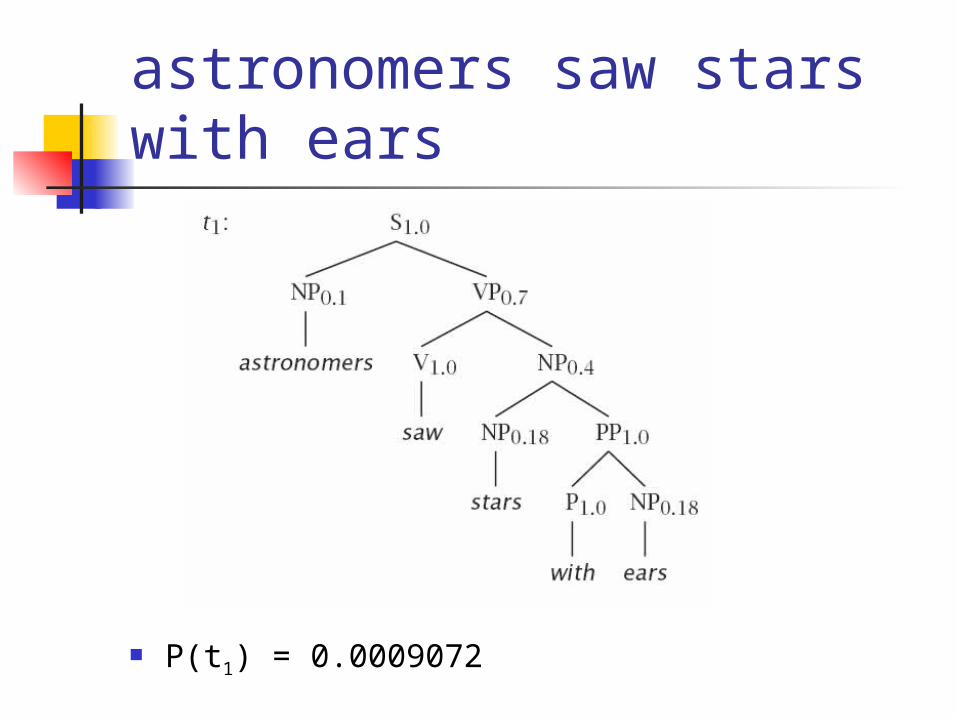
astronomers saw stars with ears
P(t1) = 0.0009072
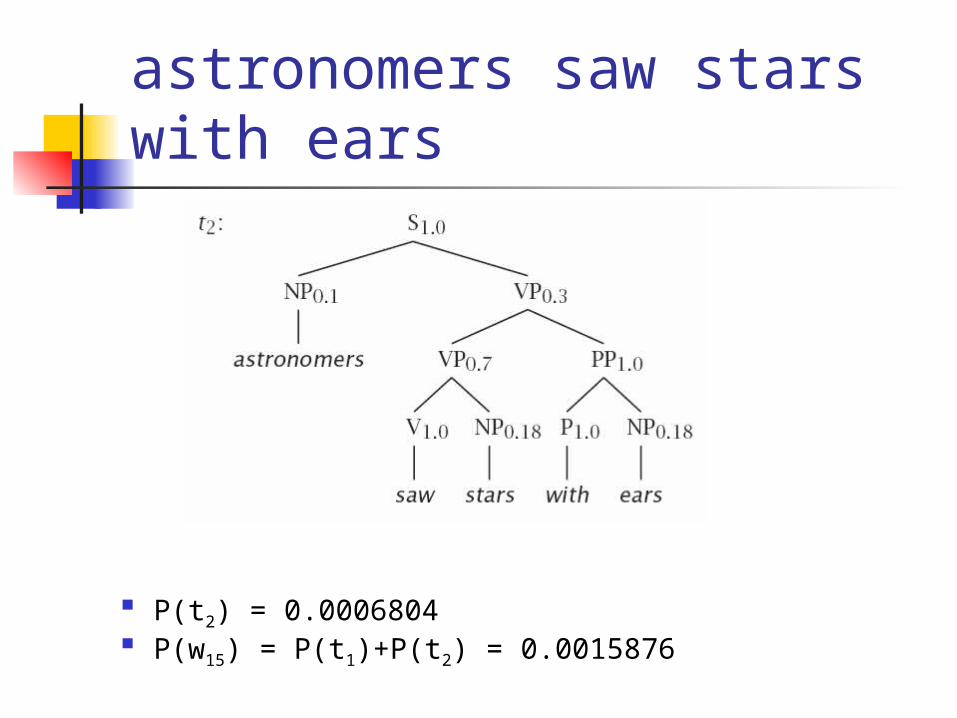
astronomers saw stars with ears
P(t2) = 0.0006804 P(w15) = P(t1)+P(t2) = 0.0015876

Training PCFGs
Given a corpus, it’s possible to estimate rule probabilities to maximize its likelihood
This is regarded a form of ‘grammar induction’ However the rules of the grammar
must be pre-given

Questions for PCFGs What is the probability of a sentence w1n
given a grammar G – P(w1n|G)? Calculated using dynamic programming
What is the most likely parse for a given sentence – argmaxtP(t|w1n, G) Likewise
How can we choose rule probabilities for the grammar G that maximize the probability of a given corpus? The inside-outside algorithm

Chomsky Normal Form
We will be dealing only with PCFGs of the above-mentioned form
That means that there are exactly two types of rules – NiNjNk
Niwj

Estimating string probability Define ‘inside probabilities’ –
We would like to calculate
A dynamic programming algorithm Base step
( , ) ( | , )pqj pq jp q P w N G
11 1 1 1( | ) ( | , ) (1, )m m mP w G P w N G m
( , ) ( | , ) ( | )j jj k kk kk k P w N G P N w G

Estimating string probability
Induction step1
,
( , ) ( ) ( , ) ( 1, )q
j r sj r s
r s d p
p q P N N N p d d q

Drawbacks of PCFGs Do not factor in lexical co-occurrence Rewrite rules must be pre-given
according to human intuitions The ATIS-CFG fiasco
The capacity of PCFG to determine the most likely parse is very limited As grammars grow larger, they become
increasingly ambiguous The following sentences look the same to a
PCFG, although suggest different parses I saw the boat with the telescope I saw the man with the scar

PCFGs – some more drawbacks Have some inappropriate biases
In general, the probability of a smaller tree will be larger than a larger one
Most frequent length for Wall Street Journal sentences is around 23 words
Training is slow and problematic Converges to a local optimum Non-terminals do not always
resemble true syntactic classes

PCFGs and language models Because they ignore lexical co-
occurrence, PCFGs are not good as language models
However, some work has been done on combining PCFGs with n-gram models PCFGs modeled long-range syntactic
constraints Performance generally improved

Is natural language a CFG?
There is an on-going debate on the CFG’ness of English
There are some languages that can be shown to be more complex than CFGs
For example, Dutch –

Dutch oddities
Dat Jan Marie Pieter Arabisch laat zien schrijvenTHAT JAN MARIE PIETER ARABIC LET SEE WRITE“that Jan Let Marie see Pieter write Arabic”
However, from a purely syntactic view point, this is just – dat PnVn

Other languages
Bambara (Malinese language) has non-CF features, in the form of – AnBmCnDm
Swiss-German as well However, CFGs seem to be a good
approximation for most phenomena in most languages

Grammar Induction
With ADIOS(“Automatic DIstillation Of
Structure”)

Previous work
Probabilistic Context Free Grammars
‘Supervised’ induction methods Little work on raw data
Mostly work on artificial CFGs Clustering

Our goal
Given a corpus of raw text separated into sentences, we want to derive a specification of the underlying grammar
This means we want to be able to Create new unseen grammatically correct
sentences Accept new unseen grammatically correct
sentences and reject ungrammatical ones

What do we need to do?
G is given by the rewrite rules – SNP VP NPthe N | a N Nman | boy | dog VPV NP Vsaw | heard | sensed | sniffed

ADIOS in outline
Composed of three main elements A representational data structure A segmentation criterion (MEX) A generalization ability
We will consider each of these in turn

Is that a dog?
(6)102(5)(4)102 (3)
(4)
101
101)1( (2) 101 (3)
103
(1)
104
(1)
(2)
104
(3)
(2)(3)
103
(6)
(5)
(7)
(6)
)6(
(5)
where
104
(4)the
dog ? END
(4)
(5)
a
andhorse
)2( that
cat
102(1)BEGIN is
Is that a cat?Where is the dog? And is that a horse?
nodeedge
The Model: Graph representation with words as vertices and sentences as paths.

ADIOS in outline
Composed of three main elements A representational data structure A segmentation criterion (MEX) A generalization ability

Toy problem – Alice in Wonderland
a l i c e w a s b e g i n n i n g t o g e t v e r y t i r e d o f s i t t i n g b y h e r s i s t e r o n t h e b a n k a n d o f h a v i n g n o t h i n g t o d o o n c e o r t w i c e s h e h a d p e e p e d i n t o t h e b o o k h e r s i s t e r w a s r e a d i n g b u t i t h a d n o p i c t u r e s o r c o n v e r s a t i o n s i n i t a n d w h a t i s t h e u s e o f a b o o k t h o u g h t a l i c e w i t h o u t p i c t u r e s o r c o n v e r s a t i o n

Detecting significant patterns
Identifying patterns becomes easier on a graph Sub-paths are automatically aligned
search path
4 5
1
2
36 7
e1 end
5 4
7
1
23
vertex
path
begin
8
e4 e5 e6
86
A
e3e2
9Initialization
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p
e1 e2 e3 e4 e5
significantpattern
PR)e2|e1(=3/4
PR)e4|e1e2e3(=1
PR)e5|e1e2e3e4(=1/3
PL)e4(=6/41
PL)e3|e4(=5/6
PL)e2|e3e4(=1
PL)e1|e2e3e4(=3/5
PL
SLSR
PR
PR)e1(=4/41
PR)e3|e1e2(=1
begin end
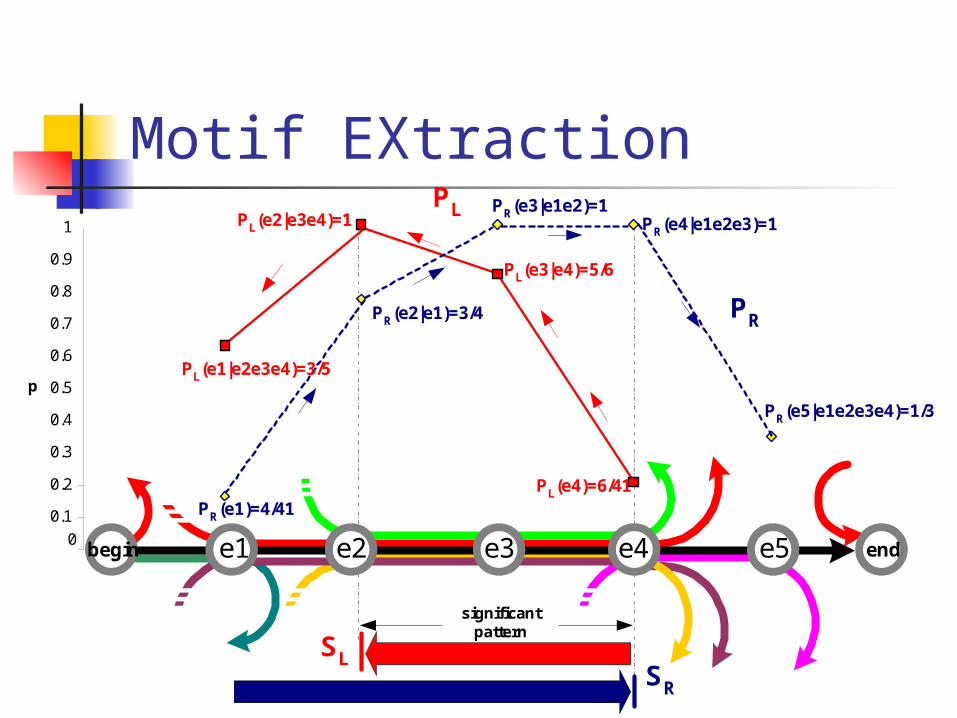
Motif EXtraction

The Markov Matrix
The top right triangle defines the PL probabilities, bottom left triangle the PR probabilities
Matrix is path-dependent

1
BEGIN e1 e2 e3 e4 e5 e6 END
BEGIN8/41 2/ 4
1/ 3 1 1
e12/8 4/41
1 1
e21/2 1 1
1 1
e31 1
1/ 2 1
e41 1 1 1
1/2
e51 1/3
e61 1 1 1
1 1/8
END 8/ 411 1 1 1
1
1
1
1
1
1
B
1
1
3/4
1/5
5/6
6/41
3/6
1/3
5/41
3/5
1/3
1/5
3/5
5/6
6/41
2/6
1/2
1/2 1/2
2/41
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p
e1 e2 e3 e4 e5
significantpattern
PR)e2|e1(=3/4
PR)e4|e1e2e3(=1
PR)e5|e1e2e3e4(=1/3
PL)e4(=6/41
PL)e3|e4(=5/6
PL)e2|e3e4(=1
PL)e1|e2e3e4(=3/5
PL
SLSR
PR
PR)e1(=4/41
PR)e3|e1e2(=1
begin end
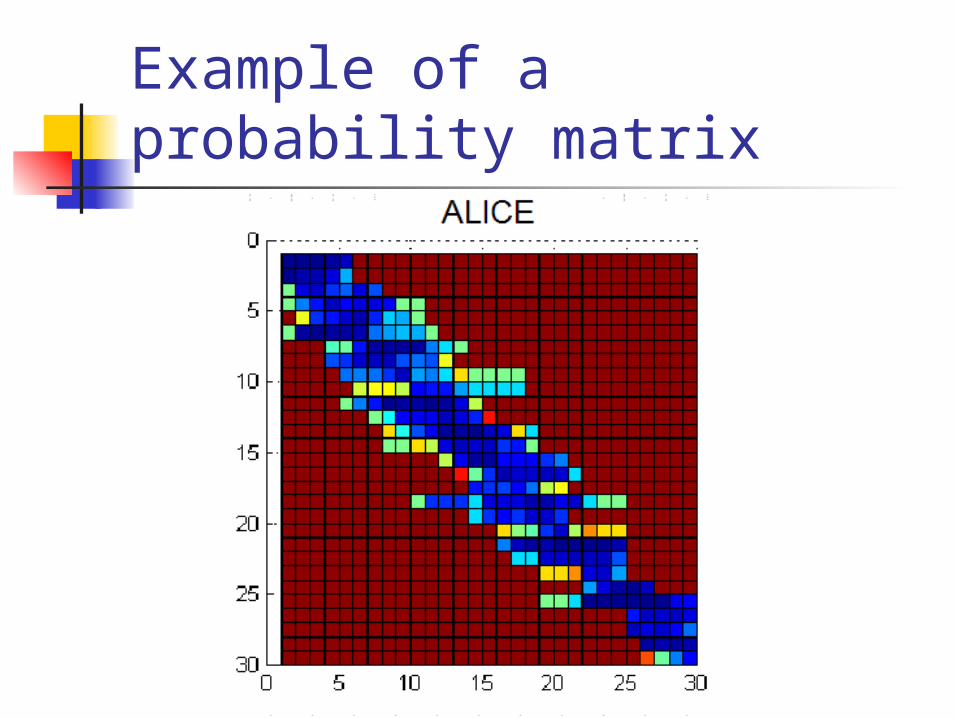
Example of a probability matrix
search path1
2
36 7
e1 end
5 4
7
1
2
3
vertex
begin
8
e4 e5 e6
54
76
5 4
6 73
e2
new vertex
86
11
e3e2
e3
9
3
9
e4
8
8
C rewiring
e2 e3 e4
P1
4 5
path9
9
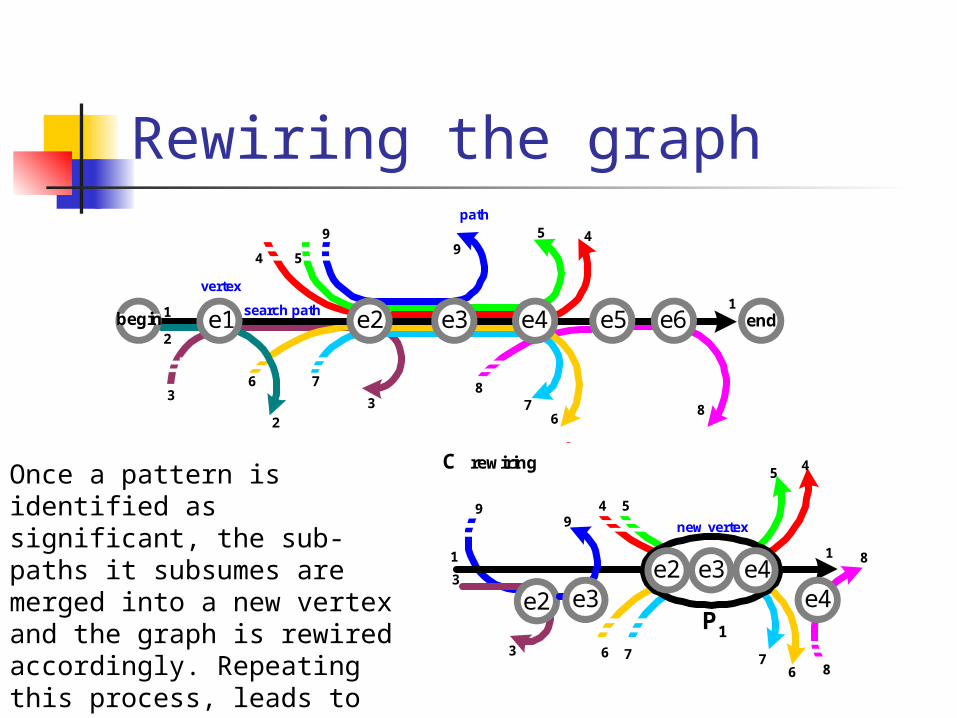
Rewiring the graph
Once a pattern is identified as significant, the sub-paths it subsumes are merged into a new vertex and the graph is rewired accordingly. Repeating this process, leads to the formation of complex, hierarchically structured patterns.

MEX at work

ALICE motifsWeight Occurrences Length
conversation 0.98 11 11whiterabbit 1.00 22 10caterpillar 1.00 28 10interrupted 0.94 7 10procession 0.93 6 9mockturtle 0.91 56 9beautiful 1.00 16 8important 0.99 11 8continued 0.98 9 8different 0.98 9 8atanyrate 0.94 7 8difficult 0.94 7 8surprise 0.99 10 7appeared 0.97 10 7mushroom 0.97 8 7thistime 0.95 19 7suddenly 0.94 13 7business 0.94 7 7nonsense 0.94 7 7morethan 0.94 6 7remember 0.92 20 7consider 0.91 10 7
curious 1.00 19 6hadbeen 1.00 17 6however 1.00 20 6perhaps 1.00 16 6hastily 1.00 16 6herself 1.00 78 6footman 1.00 14 6suppose 1.00 12 6silence 0.99 14 6witness 0.99 10 6gryphon 0.97 54 6serpent 0.97 11 6angrily 0.97 8 6croquet 0.97 8 6venture 0.95 12 6forsome 0.95 12 6timidly 0.95 9 6whisper 0.95 9 6rabbit 1.00 27 5course 1.00 25 5eplied 1.00 22 5seemed 1.00 26 5remark 1.00 28 5
Weight Occurrences Length

ADIOS in outline
Composed of three main elements A representational data structure A segmentation criterion (MEX) A generalization ability

Generalization
E1
took chair
equivalent paths
bed
table
the
5
to
E1
table
bed
chair
L
took the to
identification of candidate equivalenceclasses
newequivalence class

Bootstrapping
E1E2
blue
green
redthe
E1E2
green
blue table
bedbed
to
table
chair
bed
L
storedequivalence class
equivalent pathsbootstrapping
tochairtook red
newequivalence class

Determining L
Involves a tradeoff Larger L will demand more context
sensitivity in the inference Will hamper generalization
Smaller L will detect more patterns But many might be spurious

The ADIOS algorithm
Initialization – load all data into a pseudograph
Until no more patterns are found For each path P
Create generalized search paths from P Detect significant patterns using MEX If found, add best new pattern and
equivalence classes and rewire the graph

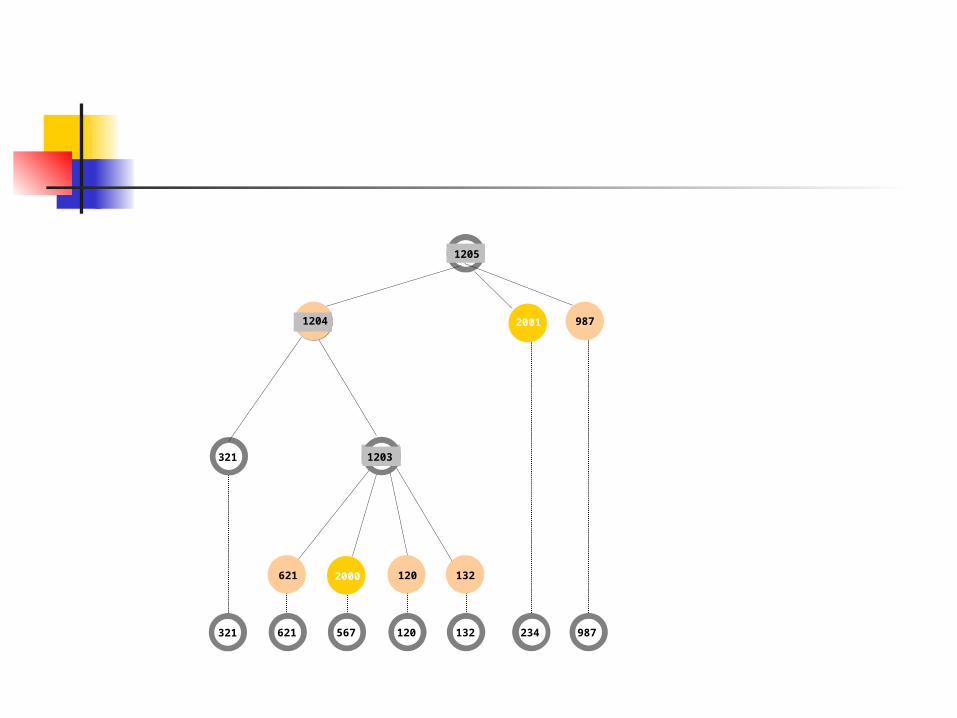
1205
567 321120132234 621987
321234987 1203
567 321120132234 621987 2000
321234987 1203 3211203
234987 1204
987 2001 1204
The Model: The training process

1205
567 321120132234 621987
1203
567120132 6212000
3213211203
1204
987 2001 1204
1205
567321 120 132 234621 987
567
120 132621 2000
321
321 1203
98720011204

Example
uice,kid,knife,ladder,lid,matter,milk,minute,mommy,mouth,nap,nose,number,people,picnic,picture,pie,pretend,question,ride,right,salad,second,smile,snack,snow,snowman,spoon,steak,step,store,story,table,time,toaster,top,tower,truck,try,window,wood,
t,salad,second,smile,snack,snow,snowman,spoon,steak,step,store,story,table,time,toaster,top,tower,truck,try,window,wood,
to go
ba
ckh
om
eo
uts
ide
po
tty
up
tha
tth
e
1405
lad
de
r1404
inth
at
the
ba
ckb
ed
roo
mb
en
chb
ox
car
cha
irci
rcle
clo
set
cup
ga
rag
eh
ou
seo
ne
ove
nre
frig
era
tor
sno
wsq
ua
retr
uck
1458
1457)0.56(
1904
1903 )0.15(
1405
)1(
do
you
ha
ve
like
wa
nt
1679
1678
)1(
rephrase sentences by ADIOSoriginal sentences from CHILDES
(a)
(b)
I'll play with the toys and you play with your bib.there's another bar+b+que.there's a chicken!play with the dolls and the roof?
oh ; the peanut butter can go up there .you better finish it.we better hold that ; then.uh ; that's another little girl!should we put this stuff in in another chick?
I'll play with the eggs and you play with your Mom.there's another chicken.there's a square!play with the cars and the people?
should we put this chair back in the bedroom?
oh ; the peanut butter can sit right there.you better eat it.we better finish it ; then.yeah ; that's a good one!

More Patterns

Evaluating performance
In principle, we would like to compare ADIOS-generated parse-trees with the true parse-trees for given sentences
Alas, the ‘true parse-trees’ are subject to opinion Some approaches don’t even suppose
parse trees

Evaluating performance Define
Recall – the probability of ADIOS recognizing an unseen grammatical sentence
Precision – the proportion of grammatical ADIOS productions
Recall can be assessed by leaving out some of the training corpus
Precision is trickier Unless we’re learning a known CFG

The ATIS experiments ATIS-NL is a 13,043 sentence corpus of
natural language Transcribed phone calls to an airline
reservation service ADIOS was trained on 12,700 sentences
of ATIS-NL The remaining 343 sentences were used to
assess recall Precision was determined with the help of 8
graduate students from Cornell University

The ATIS experiments
ADIOS’ performance scores – Recall – 40% Precision – 70%
For comparison, ATIS-CFG reached – Recall – 45% Precision - <1%(!)

ADIOS/ATIS-N comparison
0.00
0.20
0.40
0.60
0.80
1.00
ADIOS ATIS-N
Pre
cis
ion
A B
Chinese
Spanish
French
English
Swedish
Danish
C
D E

An ADIOS drawback
ADIOS is inherently a heuristic and greedy algorithm Once a pattern is created it remains
forever – errors conflate Sentence ordering affects outcome
Running ADIOS with different orderings gives patterns that ‘cover’ different parts of the grammar

An ad-hoc solution Train multiple learners on the corpus
Each on a different sentence ordering Create a ‘forest’ of learners
To create a new sentence Pick one learner at random Use it to produce sentence
To check grammaticality of given sentence If any learner accepts sentence, declare as
grammatical
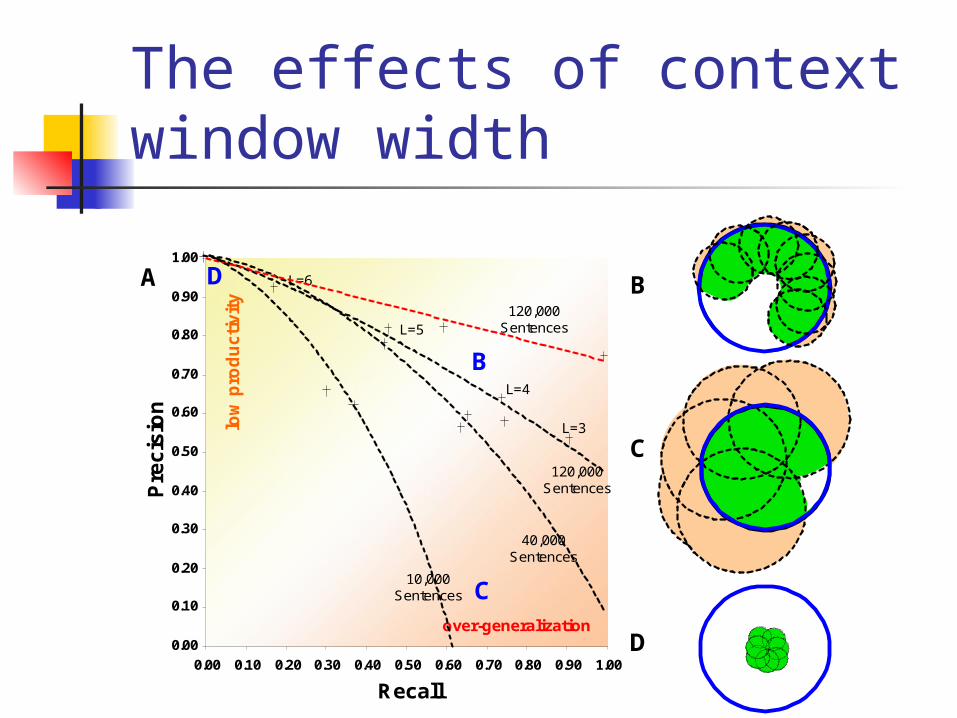
The effects of context window width
0
0. 1
0. 2
0. 3
0. 4
0. 5
0. 6
0. 7
0. 8
0. 9
1
0 0. 1 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 0. 9 1
C
D
B
G
Recall
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00
Pre
cis
ion
over-generalization
low
pro
du
cti
vit
y
A
B
C
D L=6
L=5
L=4
L=3
10,000Sentences
120,000Sentences
40,000Sentences
0
0. 1
0. 2
0. 3
0. 4
0. 5
0. 6
0. 7
0. 8
0. 9
1
0 0. 1 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 0. 9 1
F
0
0. 1
0. 2
0. 3
0. 4
0. 5
0. 6
0. 7
0. 8
0. 9
1
0 0. 1 0. 2 0. 3 0. 4 0. 5 0. 6 0. 7 0. 8 0. 9 1
E
120,000Sentences

Meta-analysis of ADIOS results
Define a pattern spectrum as the histogram of pattern types for an individual learner A pattern type is determined by its
contents E.g. TT, TET, EE, PE…
A single ADIOS learner was trained with each of 6 translations of the bible

Pattern spectraT
T
TE
TP
ET
EE
EP
PT
PE
PP
TTT
TTE
TTP
TE
T
TE
E
TE
P
TP
T
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
English
Spanish
Swedish
Chinese
Danish
French
0.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
0 200 400 600 8000.60
0.65
0.70
0.75
0.80
0.85
0.90
0.95
1.00
0 200 400 600 800
A B
Chinese
Spanish
French
English
Swedish
Danish
C
D E

Language dendogram
TT TE TP ET EE EP PT PE PPTT
TTT
ETT
PTE
TTE
ETE
PTP
T
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
A B
Chinese
Spanish
French
English
Swedish
Danish
C
D E

To be continued…