product information management - mds.eu · pim marketing content-basis marketing management...
TRANSCRIPT

CONTENTSERV
Product Sheet
PRODUCT INFORMATION MANAGEMENT
Next generation Contextual PIM

Product Information Management
ONBOARDING PORTALPIM
MARKETINGCONTENT-BASIS
MARKETINGMANAGEMENT
MARKETINGOUTPUT MANAGEMENT
MARKETING INTELLIGENCE
Core System
PIM
Marketing Resource Management
Multichannel Publishing
Reporting andMarketing Intelligence
Composition
Format generation
Interfaces
Administration of class and relationship model Match and Merge Write APISearch- and
filter functionsDashboards
and User Views
Responsibilities and User Rights
Inheritance andData Transfer
Bulk DataEditingCollections
Tasks andAnnotations
MultidimensionalVariants
Versions and Derivates Read API
Hierarchicalstructures
Workflows and Lifecycle
Products (PIM)
Media Assets (MAM)
EditorialProjectsText Assets
EntityManagement
Campaigns andPromotions
Budgets andTargets
Context and TranslationManagement
AdvertisementPlanning
Whiteboard Composer Self ServiceViews
XML andJSONOutput
DTPOutput
InDesign
HTMLOutput
PDFOutput
OfficeOutput
A/B andMultitesting
ChannelPerformance Affinity Engine
Data Quality, Reportingand Data Discovery
Rule-basedplanning and assignment
Export (Filter and Configuration) Context optimized Realtime Delivery
Import, staging and supplier/vendor onboarding
Standard Format Upload (ETL based)
Ecxel and CSV upload (Mapping Wizard based) Web Based Editing
Fig. 1: Overview of the PIM system and optional add-ons
2
Contents
Introduction 3
Key Features to look out for: The PIM Features most frequently asked for by Customers 4
Usability and Efficiency 6
Match and Merge 18
Bulk Data Editing 20
Multidimensional Variants 24
Versions and Derivates 28
Import, staging and supplier/vendor onboarding 32
Context optimised Realtime Delivery 36

Product Sheet | CONTENTSERV AG
About Customer ExperienceThe digital customer experience is widely synonymous with giving the right message, to the right person at the right time.Contextualisation is the adjustment of assortment and product presentation to a specific audience or an individual known customer, additionally adapted to the situation (e.g. weather, geolocation, device) at the time of interaction.
Why Contextual PIMManaging the contextualization for the homepage and a hand-ful of subsequential pages alongside a well-organized custo-mer journey can be handled just like that. Doing the same for thousands of products is a huge organizational challenge. This is where a contextual PIM comes into play. Seamlessly create marketing products from imported articles, enrich these with valuable content and then differentiate these by creating the variants required for efficient, targeted communication.
Why CONTENTSERVCONTENTSERV is one of the pioneers in the PIM market, with a successful track record starting in the late 90s. We have always focused on rich content PIM and we are one of the very few pioneers worldwide in bringing context to large product assortments. For long, we have gathered valuable experience with the processes and the high end software architecture required to deliver contextualised content in realtime.
Introduction
Digitalisation and Customer Experience (CX) are both prominent ideas, expressing the disruptive technology-driven change in marketing. While CX has been a game-changer in CRM, Marketing Automation and Web Experience Management, it looks like Product Information Management is missing a trend.
Key Aspects
¬ Customer Experience initiatives drive the need for contextual product commu-nication
¬ Managing large numbersof products across multiple divisions and regional organizations
¬ Context exponentially increases the complexity in handling product data
¬ Context requires realtime delivery of optimised assortment and presentation
¬ Current PIM solutions are too static for the highly dynamic contextual commu-nication
¬ A new grid-based architecture and new generation of PIM is required
¬ A multitude of channel systems require context-optimized product information
3

Product Information Management
ONBOARDING PORTALPIM
Key Features to look out for The PIM Features most frequently asked for by Customers
Your customers expect consistent product information across all touchpoints. A modern customer journey often involves many steps – from the first contact to the final purchase. Hopping from channel to channel, customers jump from leaflets and print catalogues to the website or e-commerce platform – from social websites to shops, market places or call centres. Such a long customer journey needs to be fuelled with accurate and consistent product information at any touchpoint.
Fully integrated Media and Text Asset Management (DAM) SWIFT based cluster technology for worldwide delivery full transparency which digital asset was used when and where high performance rendering of derived formats and sizes Localization and Translation Management for attributes and richt content
Data Quality and Master Data Management Integrated Data Quality Strategy for Import Staging, Core and Export Staging. Data Stewardship based on sophisticated Data Governance model. Rule-based classification, matching and linking. Match and Merge for Golden Record / Set creation.
Data Editing: Usability and Comfort Easy to use and appealing, fully responsive multi-device user interface. Grid editing, bulk editing, merging and comparison in one smart and integrated interface. Advanced Search with similarity / fuzzy search and auto-matching for assigning relationships. Instant channel previews and channel performance reports with option to adjust preview to a buying persona / situation perspective.
Inbuilt product campaign & promotion management Plan campaigns and promotions for known (1:1) and anoymous (cluster based) customers in a visual editorial calendar Balance and distribute across time and targets to avoid over-solicitation Optimize response by promoting the right products to the right targets at the right time Maximize success by tailoring pricing, presentation and messages to the context and situation
4
Product Sheet | CONTENTSERV AG
Process Control: Orchestration and Compliance Fully integrated Graphical Workflow Engine to improve digitalization of processes. Messaging and notifications according to responsibilities (RACI-VS model). Dashboard for orchestrating workflows, tasks, data quality and reporting. Full version history, audit trail, archiving strategy and version rollback with merge strategy.
Architecture: Scaling and Performance Multi Data Center deployment option for minimum latency global access. Fully scalable export staging area with triggered, scheduled and realtime data delivery. Fully scalable import staging area with bulk update interface and multi-supplier staging zones. Polyglot persistence for a maximum of scalability and performance.
Handling of non-product entities and their relationship with products Outlets and their product affinities. Suppliers / Vendors and their product performance. Key accounts and their specific preferences. Buying Personas, representing audiences and customer clusters.
IT Strategy: Safety and fast ROI Simple migration from Cloud to On-Premise. Data Modelling and Visual Form Editing via user interface. Pre-packaged configurations for verticals and out-of-the box integrations. Full data model and data dump in readable format for system migration.
Vendor and Supplier onboarding Quick and configuration-based deployment of supplier and vendor portals. Gradual hand-over of responsibilities for supplier and vendor scenarios. Channel performance insights for vendors and suppliers.
Multichannel performance For collaborating (paid) channels / media - Splitting of products into sales (distinct SKUs) and marketing variants (same SKUs) - Search Engine Optimization (SEO) via smart Text Asset Management - Marketplace Optimization via intelligent Product transformation For owned channels / media - Connectors to leading e-commerce solution and web experience management solutions. - Fully integrated Print Output Management with easy-to-use Whiteboard. - Optimized content for “next best offer” For earned channels / media - Editorial Product Content Marketing - Optimizing product content for audiences. - Creating awareness with storytelling: Relevant and useful content.
5

Product Information Management
ONBOARDING PORTALPIM
Current Challenges Find easily in an abundance of contentThe number of SKUs is constantly increasing. And so is the richness of the content provided for each SKU. The result is a vast abundance of data sets, often in the millions. Multiplied by the number of attributes, the count of attributes reaches the one billion mark. And with contextual marketing, this number grows even further.
Finding the right product, with the right attributes in such a huge data repository requires high end and yet user-friendly search. This challenge can only be solved with the power of similarity search, fuzzy search, faceted search and scoring & ranking algorithms.
Collaboration across organisational boundariesThe information supply chain for launching and updating rich content products spans a multitude of teams, departments, organisational units all the way to external partners. Suppliers and vendors provide master data that is checked, merged and cleansed by data stewards. Once the golden record is created, the journey really begins: Channel owners, target group specia-lists and local subsidiaries contribute content that they require to reach their marketing goals. Agencies, content aggregators and freelancers provide videos, storytelling content, additio-nal photos and all of it needs review and aggregation. Even customers eventually provide content such as reviews, ratings and product stories.
In order to orchestrate such a complex information supply chain produce in a unique customer journey, clear responsibilities,
sophisticated workflows and intelligent processes around tasks, annotations, reviews and approvals are key.
On timeProduct lifecycles are becoming shorter and shorter. And the lead time for a product launch is reduced in the same way. Having incomplete or unfit product information at the product launch date is a worst case scenario. The new, long-awaited graphics card, Apple device or fashion outfit is available at your competitor while you are still struggling to get the product information right and approved? This would be a complete catastrophe - the loss in sales and the brand damage would be considerable.
In spite of all technology support: Launching a new product remains a highly complex and largely creative project. A project that requires proper project management support, with teams, capacities, tasks and timelines orchestrated, visualised and process-enabled.
Hard to motivateKeying in data? Or contributing to a supreme customer expe-rience in a unique customer journey?Providing unique and relevant product information is a task only very few specialists can perform. Instead of taking ownership, this task is typically pushed away with a call for suppliers provi-ding the data and subsequent automated data manipulation and cleansing. Ideally, available facts should be onboarded using supplier portals, but editorial rich content requires personal attention of those who know best how to put the product into the right context.
A key aspect for motivation has always been the creation of
Usability and Efficiency
Managing hundreds of thousands of product data sets is a tedious task. Explaining products, with all their details and benefits to numerous target groups optimised for the current situa-tion is a Herculean task. And it is not a task that could possibly be delegated to dummies. Positioning a company's product with the right messages to the right person at the right time is core strategic business that involves the best and most creative people across marketing, sales, product management, training department as well as numerous external content and localisation providers. Supreme usability is key for acceptance among these highly qualified specialists. And not wasting their time is key when considering the cost and the salary levels involved.
6

Product Sheet | CONTENTSERV AG
visual previews in the context of the channel, the situation and the audience. This makes the difference in motivation, in perception whether one is contributing to a unique customer journey or it is only about keying in data.
Learn and growFor long, marketing has been about "gut feelings". Today, it is the era of data – and it would be negligent not to make use of this data at the point where it is most needed – where one single phrase, image or video can make the difference in sales success, brand perception and customer satisfaction. It is vital, to bring feedback from sales channels, social media and custo-mers right to the core of your organisation.
Product returns are particularly high on one product? Maybe it is the product description that implies a property or quality the product does not have. Or the product image shows a colour that is different than the one the customer will see when unpa-cking the delivery.
Technical data and promised features are incorrect? And your customers are already talking about it on market places and social media? If you get to know it fast, you can act fast - before regulatory authorities force you to act fast.
The idea of targeting regional audiences, gender or cultures with tailor-made messages does not work out? One audience might even be offended by the messages? Get to know fast, and you can adjust your campaigns.
Learning and growing in an organisation means: Verify your gut feelings by measuring relevant KPIs. And bring these facts and figures right to the person, who is stage-managing the customer experience.
The solution
The solution is simple: It lies in empowering your employees to do what they always wanted to do. Closely follow what custo-mers are saying and thinking, while reacting quickly to changing market needs. Make sure your employees know they are not merely cutting stones, but building a cathedral.
Supreme user experience and maximum efficiency is achie-ved by the following features:
h Integrated approach for product data, editorial content and media asset management Quickly toggle between products, media assets and rich editorial content. Search across objects and browse them in a master taxonomy. Get integrated usage and reference reports across objects. Easily set up workflows that span across object, e.g. an image request process triggered from a product.
h User friendly forms with responsive design Access editing, reporting and previews from desktop, tablet and smartphone equally. Quick navigation using keyboard and context sensitive help for fast and easy usage.
h Backend with visual configuration Create tailor-made forms for the specific needs of each role and product class. Make sure that the data model can evolve without customization efforts required.
h Search Find products, media assets and rich content faster with similarity and fuzzy search. Narrow down search results by adding tag-based filters ad-hoc (faceted search). Save and share search results or process results via bulk editing, compare or merge views.
h Collections Create collections of to-do lists, personal favourites or recommendations. Move collections through a workflow, bulk-data edit the contained data sets or compare and merge.
h Dynamic tree views Create dynamic hierarchies based on group-by and filter criteria. Access products, images and content in the taxonomy and structure best suited to you own needs.
h Dashboards Configure personal dashboards with inboxes for tasks / workflows, reporting KPIs and many useful shortcuts.
7

Product Information Management
ONBOARDING PORTALPIM
Provide relevant information where it is needed in a simple, legible and smart way. Mix dashboard tiles from all areas of the application - products, media assets, rich content or backend functions equally. Create dashboards on single product level, category level, module or application level.
h Responsibility management with RACI-VS & notifications Responsible: product owners manage New Product Introductions (NPIs), decide product updates and merge conflicting data. Accountable: Senior management supervise the performance of product owners and takes important decisions on budgets and approvals. Consulted: Contributors with special expertise contribute valuable information, rich content or media assets, while the owner is notified about updates and the need for merging and consolidating changes. Informed: Subscribers or team members get informed about updates. Notifications can be defined on attribute level, limited to tagged versions being achieved or final release. Verify: Lecturers and reviewers verify products and their content for compliance with corporate wording, laws, standards, norms and branding. Sign-off: The final approval can be handled by the accountable senior manager, but it is frequently delegated to a trusted person.
h Tasks and annotations Tasks are created, delegated, approved and closed based on workflow rules and responsibility management. Tasks can refer to products such as products, media assets, rich content, single attributes and text assets equally. Assign tasks by team managers, based on active assumption or based on automated patterns (round robin, least workload,...). Track timelines, capacities, workloads and milestones based on calendar views and reports.
h Sophisticated workflows An event-driven architecture (EDA) can trigger actions to automate workflows, assign tasks and fuel Inboxes
Events include version merge / inheritance / data transfer conflicts, updates on observed fields, data quality exceptions and the reaching of critical thresholds in reporting services. Workflows can be built from scratch or based on pre-configured workflow modules. Workflows can be highly standardised or extended ad-hoc when complex projects require more dynamics. Workflows can be integrated with Enterprise Workflow Engines.
h Project management Setup and assign teams for standard tasks or on demand when setting up a project. Use project management for New Product Intro- ductions, high-end content creation and for setting up campaigns, promotions and extensive publications. Set milestones, define timelines, budgets and capacities for control and transparency.
h Preview function (channel / context / audience) View any content from the customer's perspective – optimised on their personal profile, the situation and the channel used. Motivate content and product managers by giving them a preview on what their editing work is about – creating supreme customer experience. Eliminate errors by providing layout and context at the earliest possible stage. Visualise data quality and move away from showing abstract data to highlighting useful information.
h Powerful inheritance and data transfer functions Inheritance from the taxonomy tree ensures that common properties are consistently propagated for all child objects. Set up which attributes are strictly inherited and where transfer of data only takes place after acknowledgement from a user. Propagate data sideways via data transfer, e.g. to transfer SKU, supplier and keywords from a product to the image used as main image for this product.
8

Product Sheet | CONTENTSERV AG
The Benefits
¬ Involve and commit knowledge-carriers simply by making it fun and fulfilling to work in product content creation
¬ Save up to 50% in time and cost for data management, while improving the quality of the output
¬ Make context marketing affordable on a large scale, by maximising efficiency
¬ Improve customer experience by ensu-ring that those contribute valuable data who know most about the products, in their systems and environments
Dynamically resolve conflicting data transfers using auto-merge rules or by a manual merge. Save time, improve data consistency and improve operational efficiency using inheritance and data transfer wherever possible.
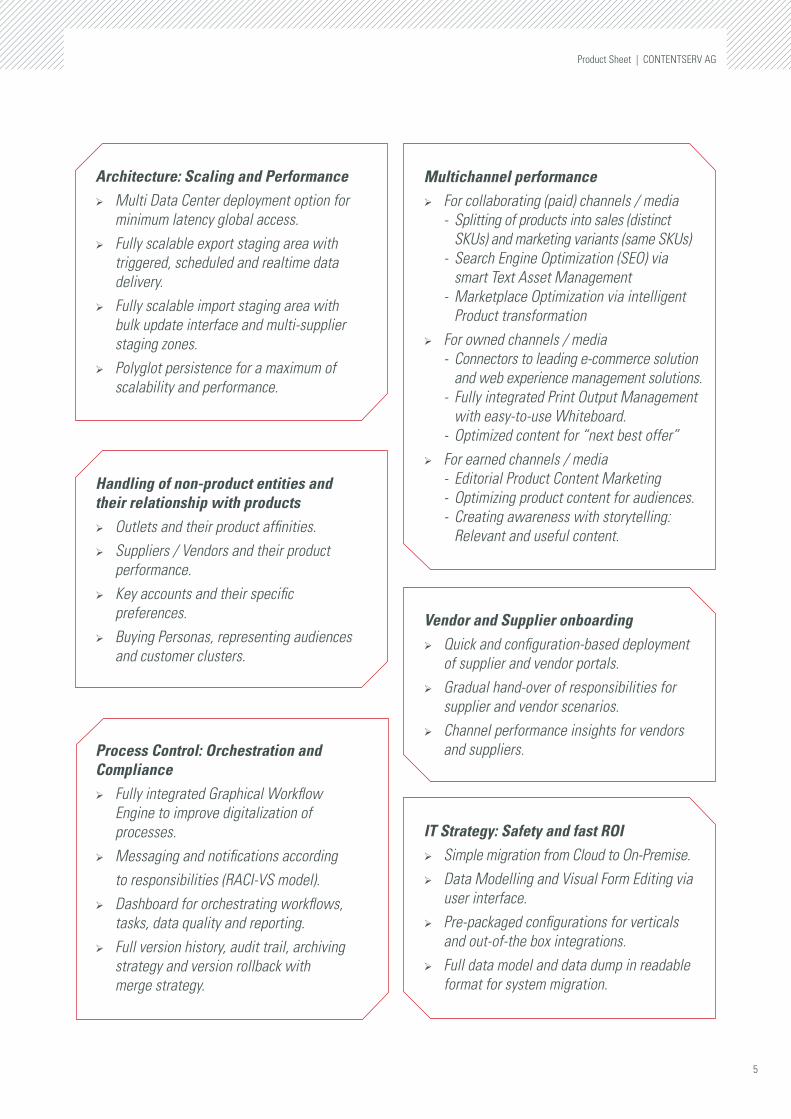
Usability and efficiency is about design, smooth operations and joy in working with the product. We can only provide a small glimpse of our products with the following collection of screenshots. Our product is designed for usability and efficiency, because it is is everybody’s philosophy and goal: from product management, to developers to quality assurance. And finally, getting feedback from our customers in user groups and based on constant interaction is the most valuable driver for supreme usability. PIM / MAM - tight connection (Fig. 2)
h Access images from the MAM seamlessly.
h The screen shows the selection and filtering of matching images for the product.
Our Solution: Usability and Efficiency
Fig. 2: PIM / MAM - tight connection
9
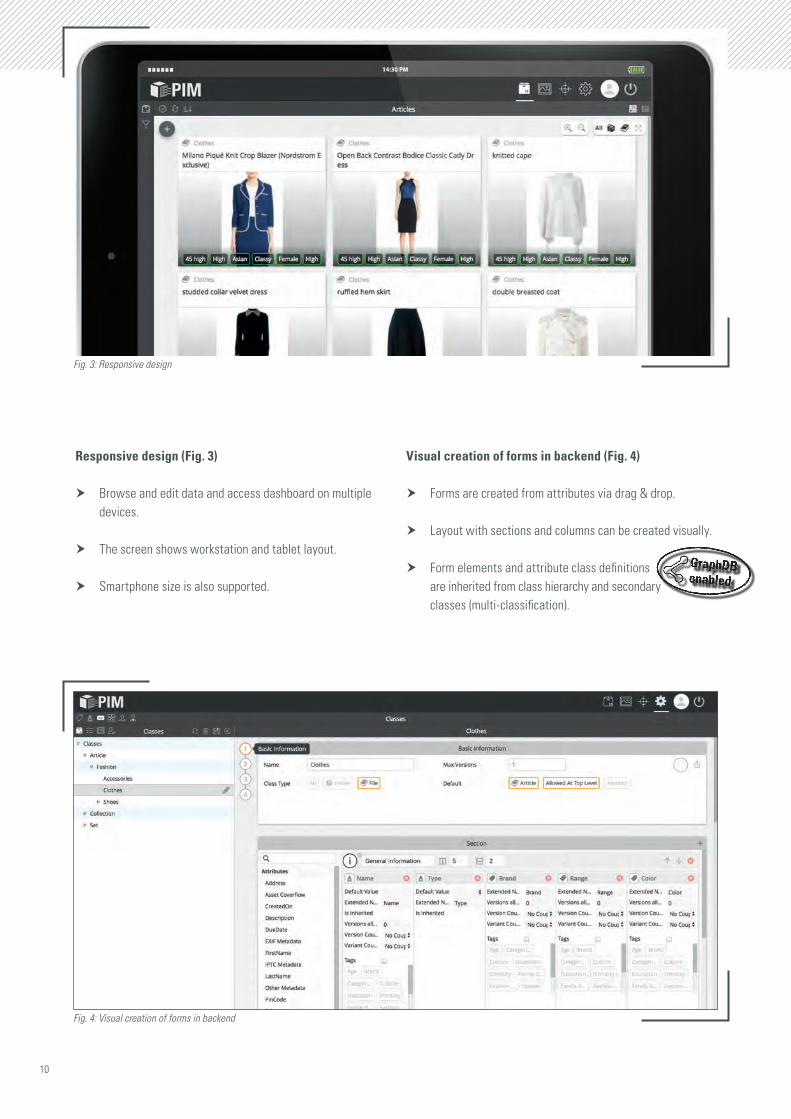
Responsive design (Fig. 3)
h Browse and edit data and access dashboard on multiple devices.
h The screen shows workstation and tablet layout.
h Smartphone size is also supported.
Visual creation of forms in backend (Fig. 4)
h Forms are created from attributes via drag & drop.
h Layout with sections and columns can be created visually.
h Form elements and attribute class definitions are inherited from class hierarchy and secondary classes (multi-classification).
Fig. 3: Responsive design
Fig. 4: Visual creation of forms in backend
10
Product Sheet | CONTENTSERV AG
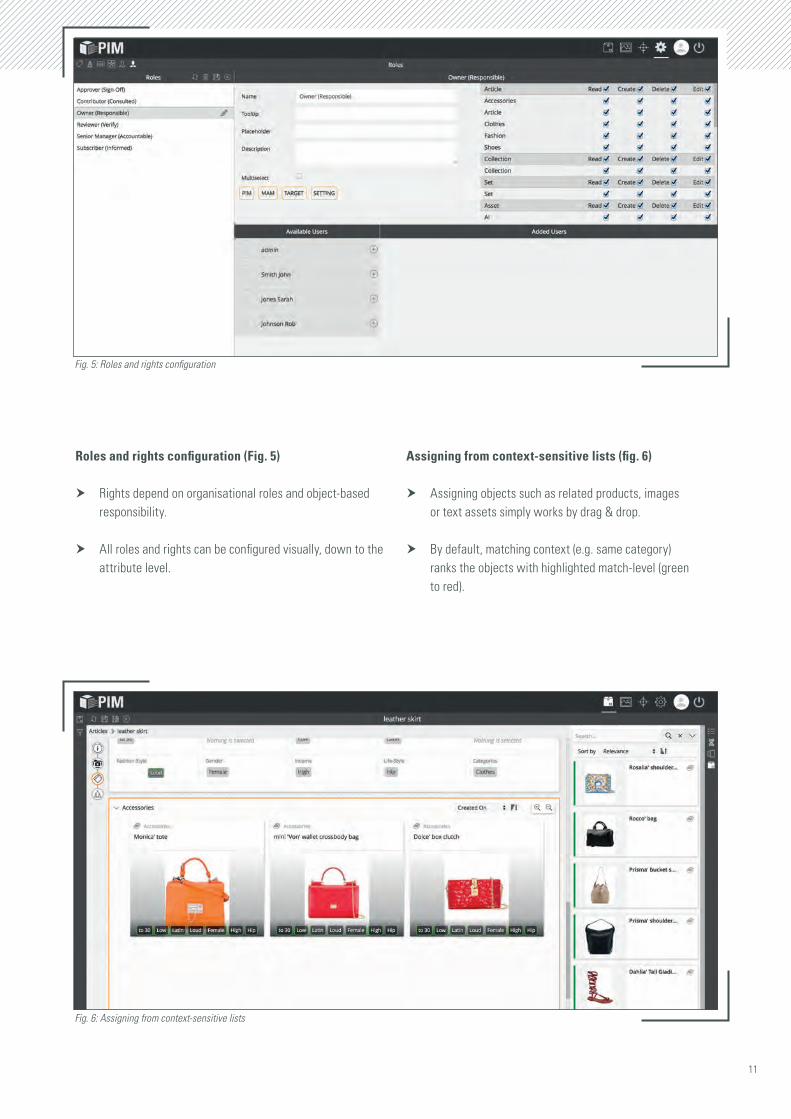
Roles and rights configuration (Fig. 5)
h Rights depend on organisational roles and object-based responsibility.
h All roles and rights can be configured visually, down to the attribute level.
Assigning from context-sensitive lists (fig. 6)
h Assigning objects such as related products, images or text assets simply works by drag & drop.
h By default, matching context (e.g. same category) ranks the objects with highlighted match-level (green to red).
Fig. 5: Roles and rights configuration
Fig. 6: Assigning from context-sensitive lists
11
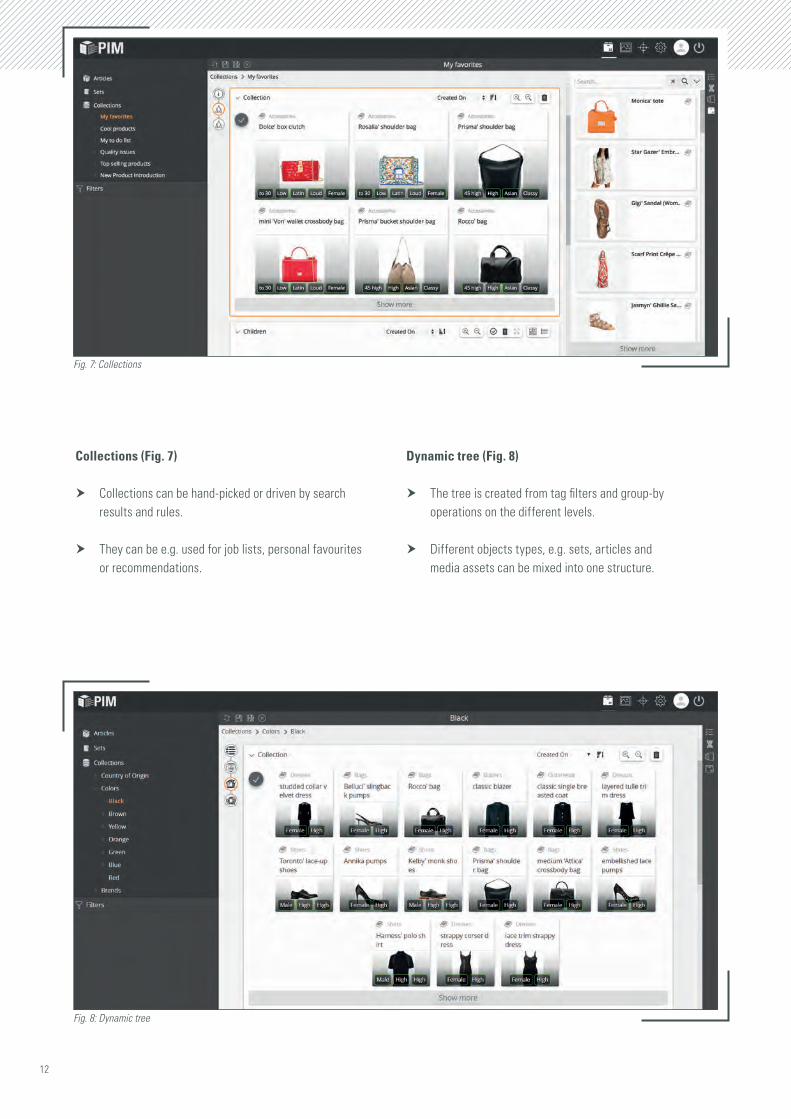
Collections (Fig. 7)
h Collections can be hand-picked or driven by search results and rules.
h They can be e.g. used for job lists, personal favourites or recommendations.
Dynamic tree (Fig. 8)
h The tree is created from tag filters and group-by operations on the different levels.
h Different objects types, e.g. sets, articles and media assets can be mixed into one structure.
Fig. 7: Collections
Fig. 8: Dynamic tree
12
Product Sheet | CONTENTSERV AG
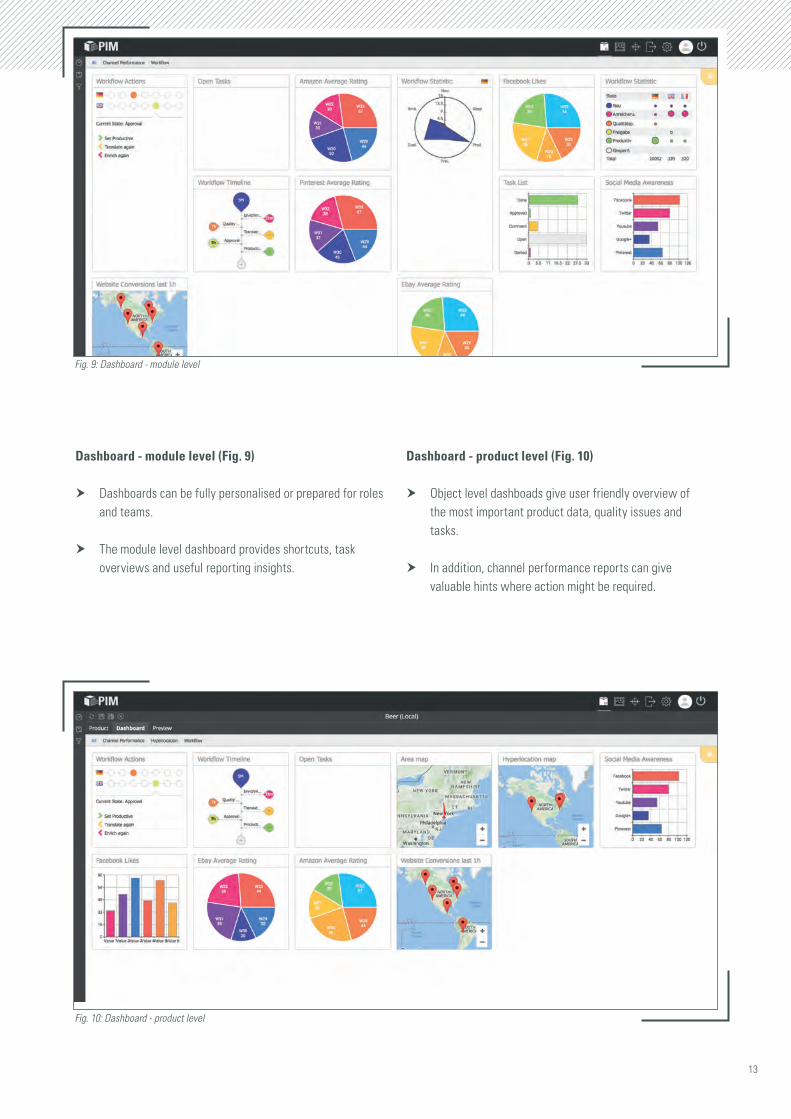
Dashboard - module level (Fig. 9)
h Dashboards can be fully personalised or prepared for roles and teams.
h The module level dashboard provides shortcuts, task overviews and useful reporting insights.
Dashboard - product level (Fig. 10)
h Object level dashboads give user friendly overview of the most important product data, quality issues and tasks.
h In addition, channel performance reports can give valuable hints where action might be required.
Fig. 9: Dashboard - module level
Fig. 10: Dashboard - product level
13
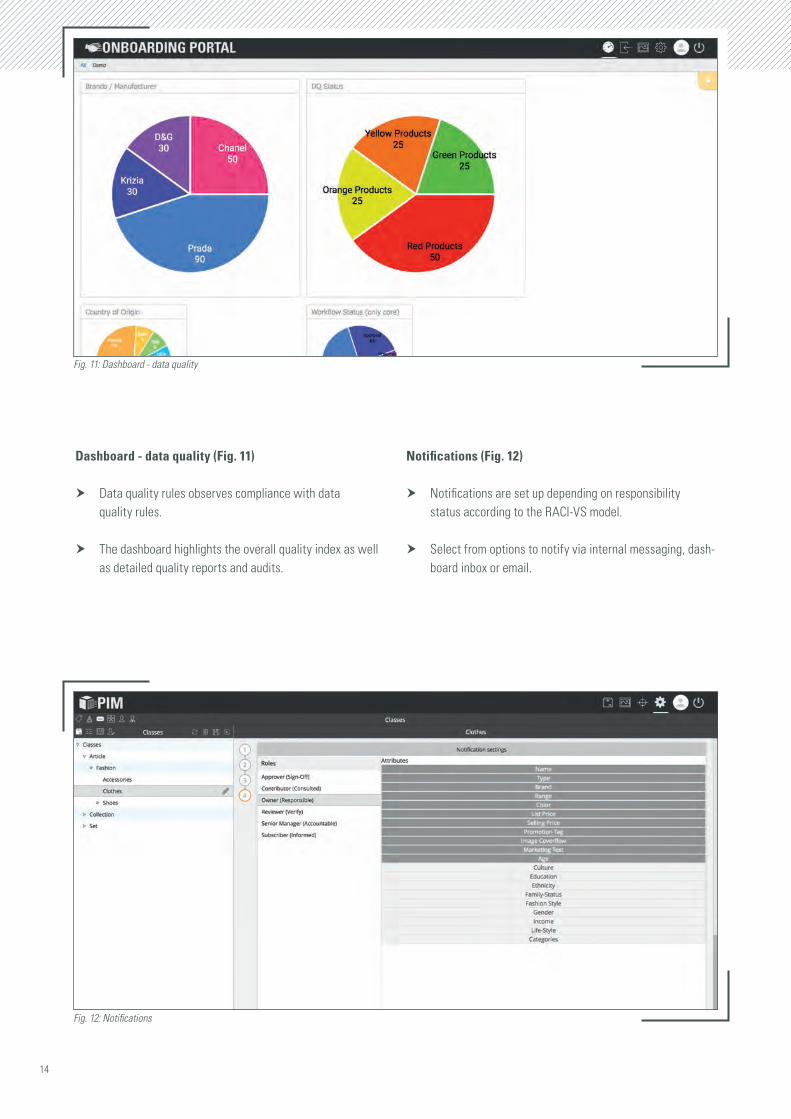
Dashboard - data quality (Fig. 11)
h Data quality rules observes compliance with data quality rules.
h The dashboard highlights the overall quality index as well as detailed quality reports and audits.
Notifications (Fig. 12)
h Notifications are set up depending on responsibility status according to the RACI-VS model.
h Select from options to notify via internal messaging, dash-board inbox or email.
Fig. 11: Dashboard - data quality
Fig. 12: Notifications
14
Product Sheet | CONTENTSERV AG
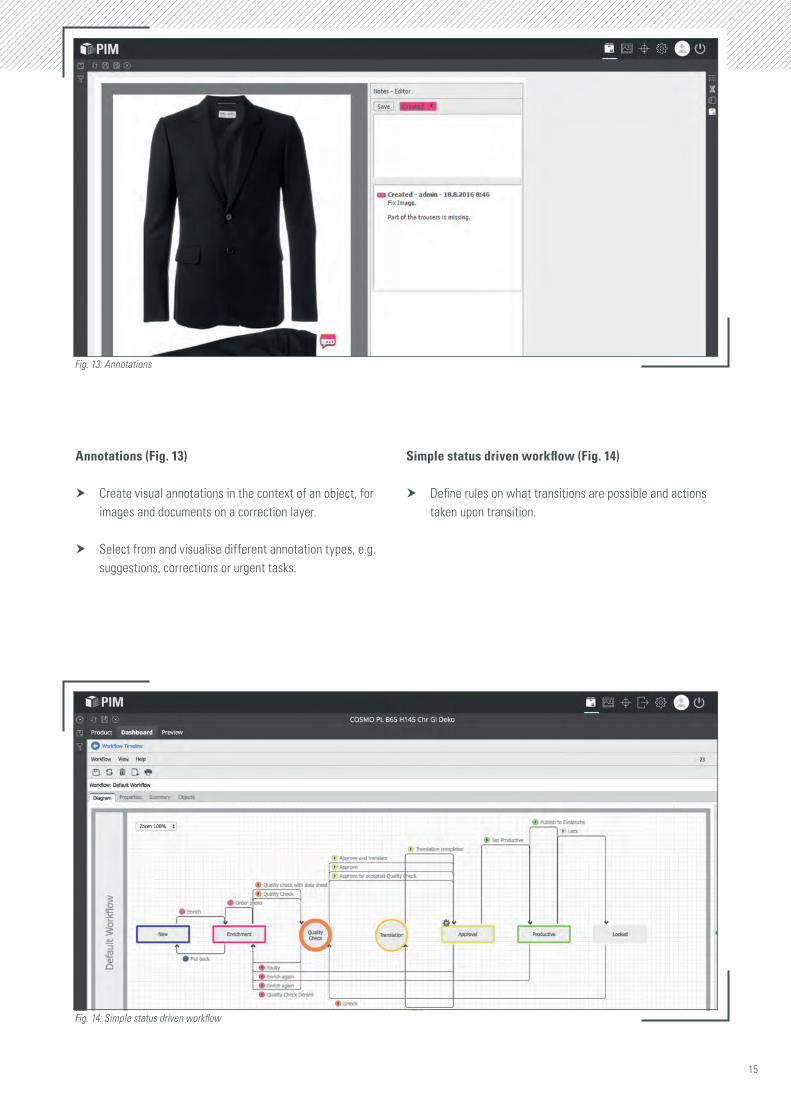
Annotations (Fig. 13)
h Create visual annotations in the context of an object, for images and documents on a correction layer.
h Select from and visualise different annotation types, e.g. suggestions, corrections or urgent tasks.
Simple status driven workflow (Fig. 14)
h Define rules on what transitions are possible and actions taken upon transition.
Fig. 13: Annotations
Fig. 14: Simple status driven workflow
15
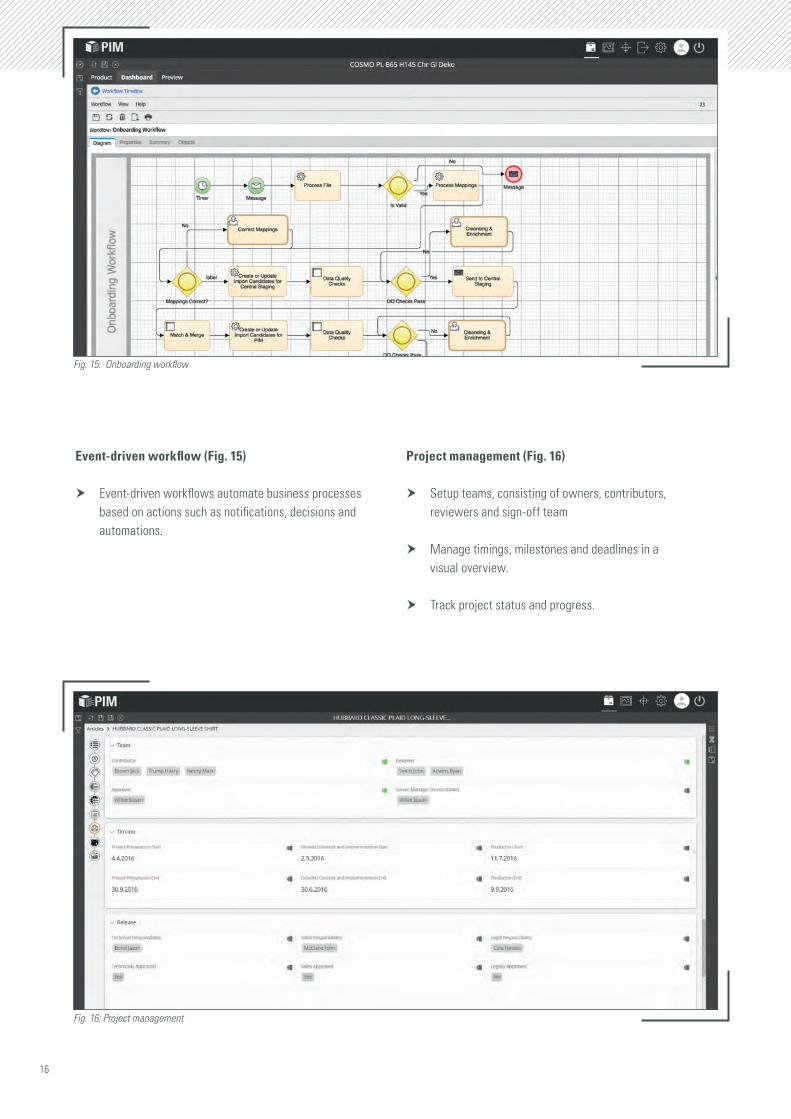
Event-driven workflow (Fig. 15)
h Event-driven workflows automate business processes based on actions such as notifications, decisions and automations.
Project management (Fig. 16)
h Setup teams, consisting of owners, contributors, reviewers and sign-off team
h Manage timings, milestones and deadlines in a visual overview.
h Track project status and progress.
Fig. 15: Onboarding workflow
Fig. 16: Project management
16
Product Sheet | CONTENTSERV AG
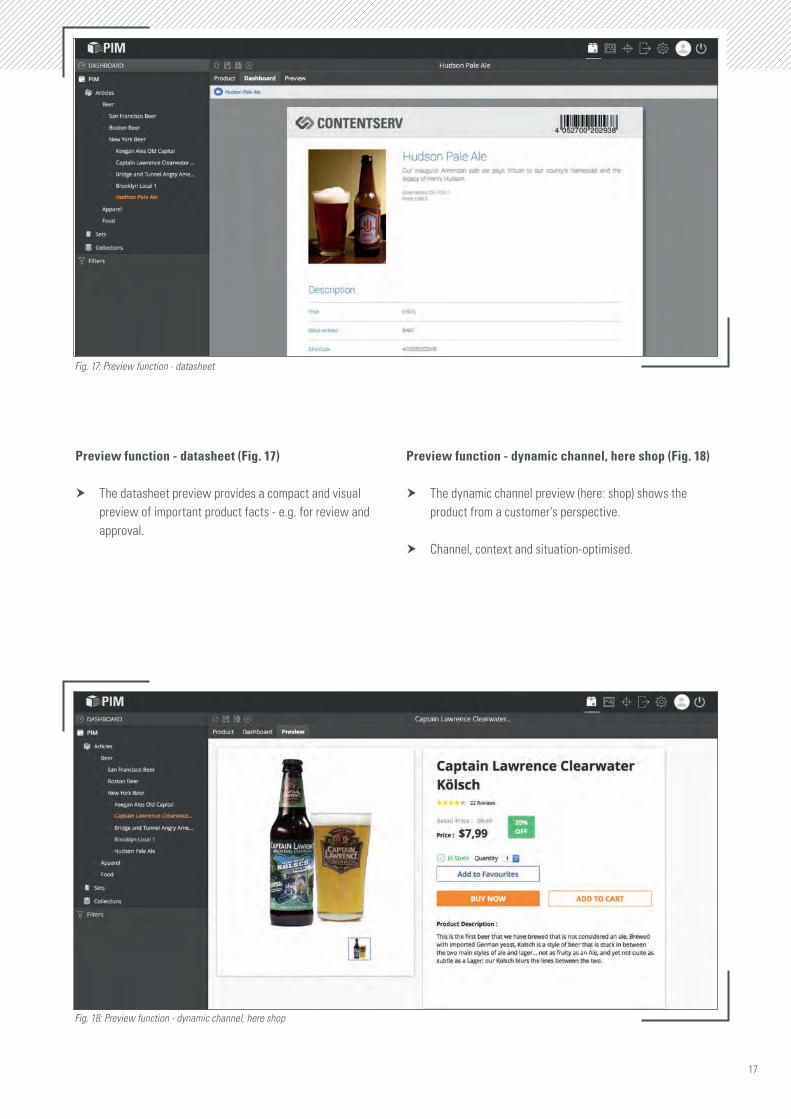
Preview function - datasheet (Fig. 17)
h The datasheet preview provides a compact and visual preview of important product facts - e.g. for review and approval.
Preview function - dynamic channel, here shop (Fig. 18)
h The dynamic channel preview (here: shop) shows the product from a customer's perspective.
h Channel, context and situation-optimised.
Fig. 17: Preview function - datasheet
Fig. 18: Preview function - dynamic channel, here shop
17

Product Information Management
ONBOARDING PORTALPIM
Current Challenges Richer content for an ever increasing number of SKUs? With the current manpower? It is possible with a smart strategy of composing sets from golden record SKUs:
Creating Product Sets from SKUsProduct data in ERP or PLM systems is typically at a single physical article or so-called Stock Keeping Unit (SKU) level. Cu-stomers expect a product presentation that is based on master products and different variants. An additional benefit: Common properties can be edited once, at the set level.
Golden record creation for SKUs In addition, different data sources and suppliers might have con-flicting data for one single article, where each data source is provi-ding better information for a specific set of fields. The challenge is to cherry-pick most ideal data in a best-of-content process.
Merging input from content contributors When multiple users across international organisational units or external content contributors and aggregators contribute to the same product dataset, such contributions will need consolidati-on by a central product owner.
The solution
The solution lies in an efficient match and merge process:
h Match data sets based on category, tags / keywords and attribute similarity
h Merge data sets by comparing, highlighting differences, counting occurrences and selecting the best option for each attribute.
Our Solution: Match and Merge
We know that match and merge is a complex process that needs excellent automation support while providing supreme user experience to facilitate an efficient manual merge:
h Different product data sets to be merged are presented in the columns
Match and Merge
Creating golden records is about de-duplicating redundant and conflicting data, while ho-nouring information from various sources of information. An even more compelling challenge is the creation of sets or virtual products, which act as representative objects for a number of variants such as flavours, colours, sizes or materials. At the heart of both is a powerful match and merge feature.
The Benefits
¬ Improve data quality by considering various input sources for creating a golden record
¬ Allow international subsidiaries and channel or target group owners to con-tribute to the data management process, while ensuring consistency via a central merge process
¬ Allow concurrent users to work in parallel, while conflicts are resolved when and to the extent they occur
¬ Save manual data editing time by quickly assuming values proposed by source systems or via supplier onboarding process
18

Product Sheet | CONTENTSERV AG
h The attributes, tags, images or relationships to be merged are shown in the rows
h The column to the left is the target, in this case a header dataset (Set) to be created
h The column match shows different values and their occurrences (in percent and absolute) in the data sets to be merged
h To take over a value for merge into the target, a simple click – either in the match section or onto the attribute of the dataset attributes is sufficient
h A green check in the merged dataset columns show that the most frequent attribute set is merged (typically based on auto-merge) - typically multiple checkboxes apply where the same value exist
h A yellow check in the merged dataset columns show that an alternative attribute or attribute set is merged (typically based on manual merge)
What we do better A maximum of automation, with a highly efficient manual process where required:
h Automerge with configurable thresholds when to trigger a manual merge
h Visual highlighting of most frequent / maximum / minimum / average values
h Merge action is memorised by the system, with update notifications taking place based on configurable thresholds when additional values / changes in other values change the balance that might have led to the selection of criteria when a value change in the merged value might require the merge process to be re-iterated
h Immediate editing can be done in the merge field, e.g. when a text field is created to create a summary of different text items.
Fig. 19: The merge screen, here used to create a bundle ("style") from different SKUs, collecting attributes, tags and image data on the bundle level.
Summary
Match and Merge is a standard feature in any Enterprise PIM that is fit to create golden records. The key to maximum benefit is to balance rulebased auto-merge against a very user friendly manual merge where required.
19

Product Information Management
ONBOARDING PORTALPIM
Current Challenges One of the biggest challenges in managing product data is the ever increasing number of Stock Keeping Units (SKUs) and the multiplication of growth by marketing variants.
Large assortmentsEspecially when handling products that exist in multiple languages, variants and configurations, the amount of data to be handled explodes. While many attributes remain unchanged across several product variants, there are specific attributes or relationships of the variants that require clear differentiation.
Unwanted differencesDe-central ownership and distributed responsibilities can lead to differences in communication where actually consistency is required. The best way to detect and level out such unwanted differences is to edit data sets in an overview that highlights differences and that allows for levelling out any unwanted difference in attributes.
Multidimensional dataWhenever data has to be available for multiple dimensions, only efficient grid editing allows correct, complete and efficient manipulation of data. The basic use cases are:
h Prices and availabilities differ by sales channel, region, season or other dimensions
h Relationships between products such as "is a suitable option for" can depend on environmental parameters such as model, year & configuration
h Product communication is contextualised by catering to the needs of different audiences, situations, cultural regions or touch points.
The Solution A well-engineered bulk editing feature can tackle the above business problems and provide a solution that maximises effici-ency while ensuring optimal consistency:
h use bulk editing to edit similar products, products within one category or result sets of search & consistency checks
h highlight differences between data sets in the grid
h manage multidimensional data by "slicing and dicing" complex cubes to editable grids (see Fig. 20)
h level out heterogeneous data by applying the most suitable value to all selected data sets
h apply one consistent value to all selected data sets with one click.
Bulk Data Editing
When handling large assortments of products, images and editorial content, an efficient management of similar data sets via mass or bulk data editing is vital. Bulk data editing makes it possible to edit data in a table-style grid view ("Excel® like") while at the same time providing functions to apply the same value to a whole set of objects.
Fig. 20 Slicing is eliminating a dimension, resul-ting in a flat slice. Dicing is reducing the size of a cube, without eliminating a dimension.
20

Product Sheet | CONTENTSERV AG
Smooth and swift operations and a combination of compare and merge functions available for bulk editing are essential and unique benefits.
Bulk Data Editing for all relevant objectsBulk editing is standard for attributes - we allow editing of all objects in grid mode (Fig. 21). All fields shown are fully grid editable:
h attribute values and their units
h tags and – if applicable – their affinities
h assigned images and text assets
h relationships to other objects
h to apply the same value to all (selected) records, simply double click on an existing value or provide a master value in the header section
h calculations based on formulas are ideally suited to manage conversions and price increases
Our Solution for Bulk Data Editing
Fig. 21: Bulk editing in a grid. One can assign a value to all by entering such values in the header or by applying an existing value to all datasets with one click.
The Benefits
¬ Save time & money in data editing
¬ Ensure consistency and thus higher data quality across a large number of data sets
¬ Differentiate communication and pricing efficiently across multiple target groups, sales channels and regions
¬ Use Bulk Editing whenever you need an overview and comparison of products, no matter if ad-hoc, as part of data onboarding or as part of a workflow that processes lists of products
21

Bulk editing and merging are very related, as both are about checking, comparing and harmonising data across a set of data objects (Fig. 22):
h the grid and bulk editing view can be toggled to show in comparison & merge view, when levelling out data is the primary goal
h cell values can be dragged & dropped onto other cells to make them the same
h cell values can be assigned to all datasets with one click
With context marketing, configurable products and price diffe-rentiation, data is becoming multidimensional (Fig. 23):
h a specific form of bulk data editing is a multidimensional data editing grid
h in this example, a multidimensional price grid with prices differentiated by colour of the product, by season and by region / single outlet is edited for a single product
h the data editing grid can be dynamically configured by adding / removing filters and pivoting dimensions
What we do better It's the small and well-engineered details that make a big difference:
h Any list, search, consistency check or collection can be the basis for a bulk editing grid
h The attributes shown in the bulk editing grid can be confi-gured in public or user-specific attribute collections
h We can bulk edit relationships to other objects.
h We can compare and highlight differences in the grid view – just the same way you have it in match&merge
h We can toggle between bulk editing and merge view – depending on whether individual editing or levelling out data is the focus
h We can calculate and assign values such as average, most frequent, lowest, highest, count and many other custom calculations
h We have a cell-merge view that merges neighbouring cells with the same value for a very visual overview on the data
Fig. 22: Match and merge view for a similar list of products in grid view.
22

Product Sheet | CONTENTSERV AG
Fig. 23: Multidimensional data editing grid
Summary
Bulk data editing is a standard feature in any Enterprise PIM system that handles large assortments of products.
The key feature for highly efficient editing of complex data is an integrated bulk editing concept that encompasses multidimensional data, merging and levelling out, comparing & highlighting across several content modules such as PIM, MAM, Editorial, Promotion and Campaign Data.
23

Product Information Management
ONBOARDING PORTALPIM
Current Challenges Optimised product selection for audiencesA successful customer journey starts with an appealing offer. Each audience has different preferences on their product selection. It is more than "women like shoes and men like cars". Data on profiles and buyer personas are readily available. But is the content fit for targeted communication? Who goes for what food is most obviously depending on many parameters such as socioeconomics, gender, cultural and religious background, lifestyle, education, age group and many more.
Optimized product selection for situationIn product promotions, the time of the day, weather conditions, geo location and many more parameters drive what creates the biggest success. Would you promote tea or coffee as drink of the day on a hot summer night? Or ice-cold Coke on a cold winter morning? The right selection of products will make the difference between a top and a flop promotion.
Optimized product presentationDiffentiating communication is not only about promoting the right products. It is also about presenting these products in a most ideal way. High-end and classy, flashy and young or grun-ge style? Today's successful brands manage to cater for both, by differentiating between image world, wording and content to the tastes of their target group.
Optimized recommendationsWhat accessories are suitable? What other products would be a similarly good fit? It all again depends on whom you are talking to. And in what situation your customer is currently in.
Content creation for large amounts of product and contentThe problem is not to do it once, in a focused effort that shows the power of contextual communication. The challenge is to do it for hundreds of thousands of products, for hundreds of topics and news published every week, for millions of media assets. And to enable multiple departments to collaborate in creating content that is fit for targeted communication.
Multidimensional Variants
The right message, to the right person at the right time. This requires elaborate variants management, where images are optimized for cultural regions, product descriptions fine-tuned for audiences, technical data adjusted for customer groups, prices for any combination of region, sales channel up to the single POS or the device being used. Multidimensional variants are about efficiently handling a differentiated marketing communication.
24

Product Sheet | CONTENTSERV AG
The solution
A user-friendly, consistent and yet well-engineered variants management based on tags and dimensions enables large organisations with distributed teams to master this challenge:
h Tag content with suitability Tag products, media assets and editorial content for suitability for different audiences and context. By tagging products – or alternatively images or editorial topics – with affinities for situations or audiences, it is possible to select and target the best matches for any combination of buying persona and contextual situation. The scoring based matching can take place in selection lists – e.g. when planning a campaign within the system – or during realtime delivery to digital channel systems.
h Create attribute variants Create variants on the attribute level and tag the context each variant is most suitable for. By tagging each attribute variant, it is possible to differentiate where it is most beneficial: Prices by region, images by gender and cultural regions, descriptions by language and audience, specs and technical data by phase in the customer journey.
h Tag relationships Use tagging for relationships to score the suitability of each reference. A pair of shoes might be a perfect fit for a skirt, a battery a perfect fit for a flashlight. A charger cable might be viable, but not recommended. Or a spare part might fit, but only with limitations. A cell phone case might be a perfect accessory, but limited to female audience. A wireless speaker might exactly fit, but only address younger audience.
h Create affinities to audiences Regional: Define assortments and specs that have different affinities to a continent, country or state. Cultural: Tag products and attributes to be more suitable for specific cultural groups.
Education, gender, socioeconomics: Tag products for specific affinities to higher / lower education, male / female or wealthy / less wealthy audiences. Create affinities to situations Communication channel: Tag products and content to be more or less suitable for channels such as web shop, print, adwords or social media. Season, date and time of the day: Some offers work better on weekends, in the morning or during winter season. Weather, geo-location: Tag content for suitability depending on the situational context. Create content and attribute variants that adapt to available space on different touchpoints and devices.
The Benefits
¬ Boost sales and increase conversion rates by micro-targeted campaigns that cater to the needs of your audience.
¬ Increase marketing efficiency and campaign success by situation- optimised communication.
¬ Ensure that the benefits of contextual marketing become available for a large product assortment and for a huge content repository.
¬ Ensure that targeting knowledge that resides in the heads of individual employees becomes part of an organi-sational learning process.
25
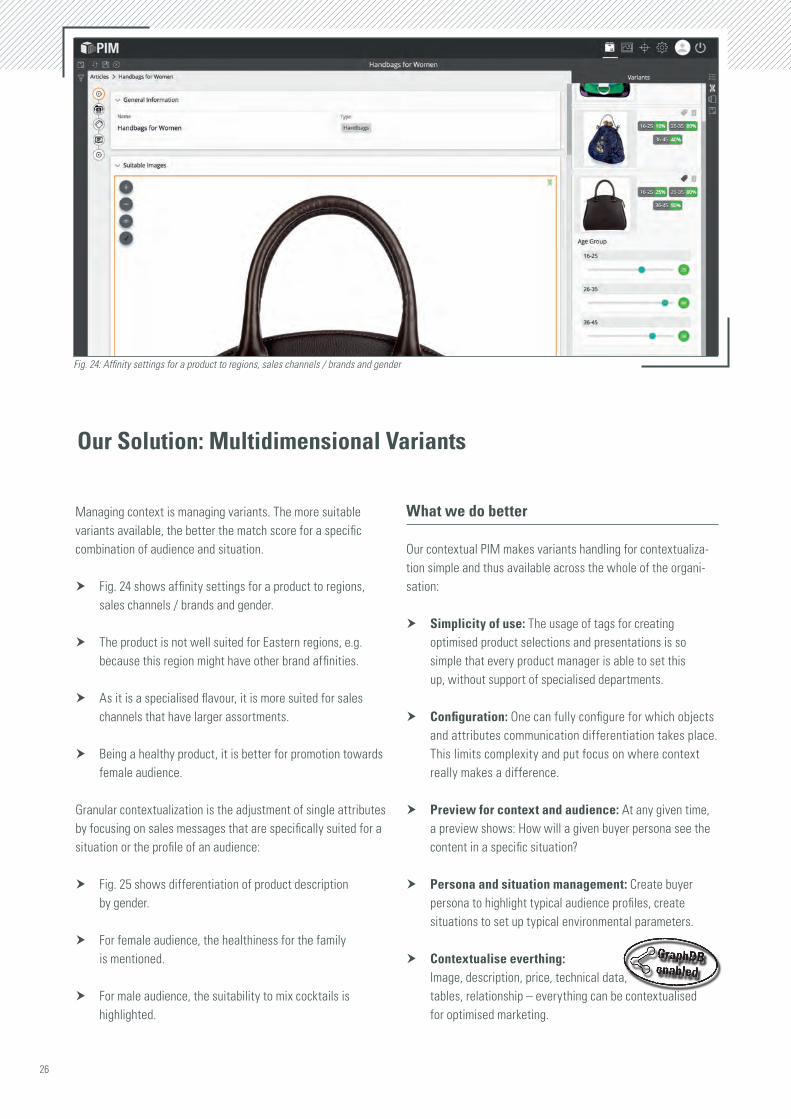
Managing context is managing variants. The more suitable variants available, the better the match score for a specific combination of audience and situation.
h Fig. 24 shows affinity settings for a product to regions, sales channels / brands and gender.
h The product is not well suited for Eastern regions, e.g. because this region might have other brand affinities.
h As it is a specialised flavour, it is more suited for sales channels that have larger assortments.
h Being a healthy product, it is better for promotion towards female audience.
Granular contextualization is the adjustment of single attributes by focusing on sales messages that are specifically suited for a situation or the profile of an audience:
h Fig. 25 shows differentiation of product description by gender.
h For female audience, the healthiness for the family is mentioned.
h For male audience, the suitability to mix cocktails is highlighted.
What we do better Our contextual PIM makes variants handling for contextualiza-tion simple and thus available across the whole of the organi-sation:
h Simplicity of use: The usage of tags for creating optimised product selections and presentations is so simple that every product manager is able to set this up, without support of specialised departments.
h Configuration: One can fully configure for which objects and attributes communication differentiation takes place. This limits complexity and put focus on where context really makes a difference.
h Preview for context and audience: At any given time, a preview shows: How will a given buyer persona see the content in a specific situation?
h Persona and situation management: Create buyer persona to highlight typical audience profiles, create situations to set up typical environmental parameters.
h Contextualise everthing: Image, description, price, technical data, tables, relationship – everything can be contextualised for optimised marketing.
Our Solution: Multidimensional Variants
Fig. 24: Affinity settings for a product to regions, sales channels / brands and gender
26

Product Sheet | CONTENTSERV AG
h Unique tags across modules: Tags can be universal, so different modules like PIM, MAM, Editorial, Promotions and Campaigns all talk the same language.
h Available for MAM and editorial content equally: Manage motives with optimised media asset variants. Create content that adjusts and focuses on your audience's needs.
Fig. 25: Differentiation of product description based on time of the day
Summary
Multidimensional variants management is a highly innovative feature. It is typically not available in other PIM and MDM systems. The concept of customer experience – the optimisation of communication based on audience and context – has been largely driven by the Web CMS systems, nowadays calling themselves Web Experience Management solutions. The concept has a proven track record of success, expressed in higher sales and supreme customer satisfaction. Now it is time to transition these concepts to also work with a large pool of products, managed across an international product- and content management team. It is time for customer experience aware PIM solutions.
27

Product Information Management
ONBOARDING PORTALPIM
Current Challenges Decentral co-ownershipDifferent contributors across regions or organisational respon-sibilities require that their proposed changes are versioned in a way that original values can be recovered by version rollback or merging ( > see match and merge). This way, changes, e.g. from a local product management in a foreign country, can be considered as pending, until they are accepted or merged by the central owner.
Proof of changeProcesses required by corporate compliance or certifications such as ISO and FDA demand a seamless audit trail for current and past releases of product information. Depending on the jurisdiction, such data might need to be available for ten years and beyond.
Future versions and release managementA product needs to be available in multiple channels based on a released communication status, while future communication releases are already under preparation? The current release only undergoes corrections, while major changes are applied to a future release? Handling and preparing future communication releases is a typical problem in a market with ever shortening times to market.
The solution
Versions mean control, and control means traceability and com-pliance. With a sophisticated version management the above business problems are efficiently:
h Store a temporary version when auto-saving or committing an intermediate status of change.
h Store a minor or major tagged version, when a reliable or approved status has been reached.
h Recover past versions by full restore or partial restore via merge at any time.
h Branch off dependent versions, when local ownership is required.
h Move older versions to an archive database, where these can be researched and recovered when required.
Versions and Derivates
Versioning is the storage of different versions of a data set. Versions can evolve over time – resulting in a version history. Or they can exist in parallel, with various versions of a product depending on a master product. In order to not congest the system with too many data sets, the archiving strategy is typically closely coupled with versioning, where older versions are moved to an archive after a maximum number of allowed versions is reached.
The Benefits
¬ Improve process security by providing a complete audit trail for all changes.
¬ Maximize organisational efficiency by delegating co-ownership for data management to local subsidiaries.
¬ Save manual research and data ma-nagement time for recovery of past versions.
¬ Improve time to market by working on future communication releases, while a stable version is published
¬ Save on IT cost by moving past versions into a low operation cost archive database
28
Product Sheet | CONTENTSERV AG
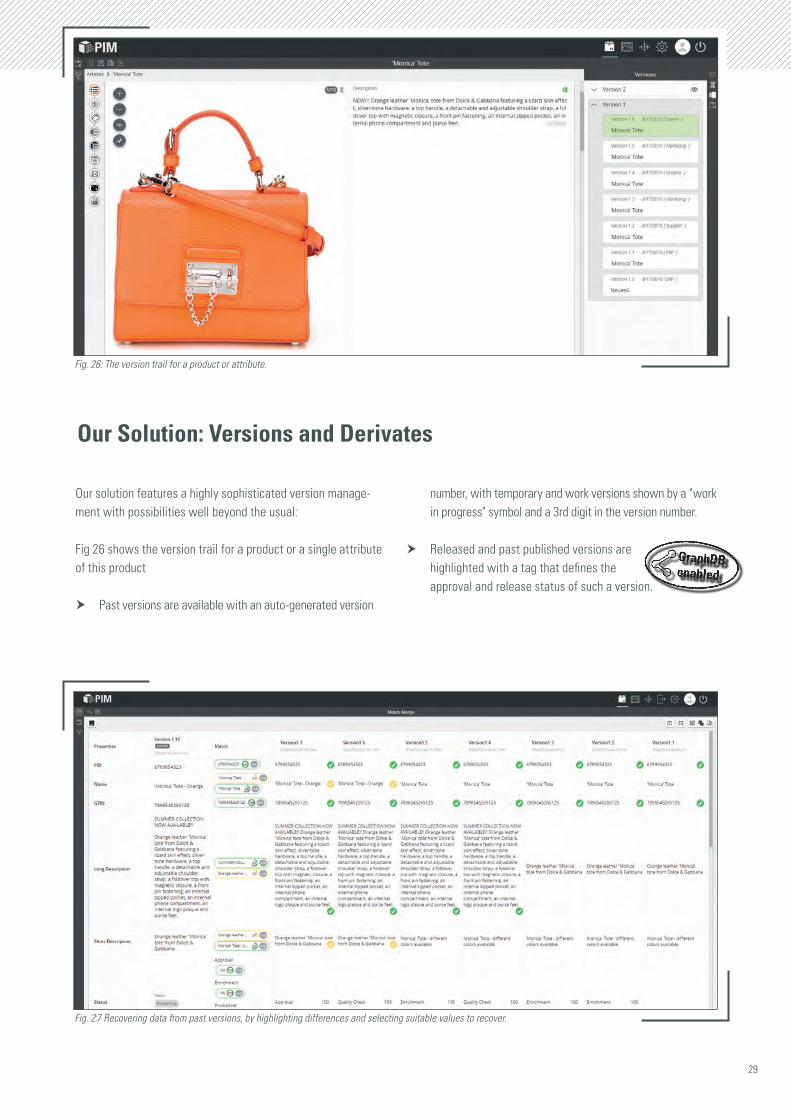
Fig. 26: The version trail for a product or attribute.
Fig. 2:7 Recovering data from past versions, by highlighting differences and selecting suitable values to recover.
Our solution features a highly sophisticated version manage-ment with possibilities well beyond the usual:
Fig 26 shows the version trail for a product or a single attribute of this product
h Past versions are available with an auto-generated version
number, with temporary and work versions shown by a "work in progress" symbol and a 3rd digit in the version number.
h Released and past published versions are highlighted with a tag that defines the approval and release status of such a version.
Our Solution: Versions and Derivates
29

h A click on the recover symbol sets the whole current version back to the past state. In case referenced objects are not available in their past version, a conflict resolution is triggered.
h When selecting one or more past versions, a version com-pare and merge screen highlights differences and allows partial recovery of past data sets.
Fig. 27 shows how data can be recovered from past versions:
h Selecting a column will highlight the differences (see green / red highlighting) between the selected version and all other versions.
h A new current version can be merged by collecting data from all available versions via match & merge process ( > see match&merge).
h The same way, concurrent user conflicts when writing to the same attribute and dataset can be resolved by version merge
Fig. 28 shows how version changes can be audited to the user and data source
h Each version has a time stamp and information what user or what data source has changed which attribute
h The evolution of an object can be shown in an audit trail, either timeline
Fig. 29 shows how a change in one version can trigger updates on coupled versions
h The exclamation mark highlights that data updates from coupled master products are available for manual update
h In the merge view, the coupling status is highlighted and either automatically or manually transferred or ignored.
What we do better
h We always maintain referential integrity. This means we always assure that all objects are available (not moved to archive) in all referenced versions.
h We allow versioning on the objects, as well as on selected individual attributes of the object.
h We suggest updates of the relationship by notifications, when new versions of a referenced object become available.
h For branched-off versions, we allow different coupling states to define the impact of changes in the master version: Dynamically coupled fields directly change all branched-off versions.
Fig. 28: Audit trail for versions.
30

Product Sheet | CONTENTSERV AG
Coupled fields change the branched-off versions in a manual update & merge process. Uncoupled fields do not have an impact on branched off versions
h Creating branched-off clones As a decision by the local version owner As a decision by the central version owner, when merging of local version cannot be performed
h Update management for transferring changes from the master version to all branched-off versions.
Fig. 29: Update notifications for version update when versions are coupled.
Summary
Versioning is a standard feature in any Enterprise PIM system that handles audit trails and de-central ownership efficiently.
The key to a maximum benefit is efficient handling of multiple branched-off versions under local responsibility while ensuring the propagation of impor-tant updates to all dependent versions. Only such a process can strike a balance between global synergies and local customer orientation.
31

Product Information Management
ONBOARDING PORTALPIM
Current Challenges Multiple data sourcesWhen creating truly rich content for a supreme customer experience, many data sources can provide valuable product data. While ERP focuses on financial and logistics data, PLM adds technical expertise, Web CMS and content aggregators add rich editorial content and data pools such as GDSN might contribute additional aspects. But what if data provided via different sources is contradictory for the same attribute? In that case, import has to consider and resolve these in a best of content selection process. This is where rules come into play, and if the rules cannot solve the contradiction, then it is up to a data steward to decide.
Data qualityWhile MDM systems have been able to provide good solutions to consistent master data, the quest for data quality remains a con-stant challenge involving each and every system in the information chain. No single system can be aware of all the facets of truth and a true multichannel PIM has to aggregate and assure data quality across many different systems that provide valuable content for the customer journey. This involves checking any source of import for data quality issues. And what may seem perfectly right for one purpose could be out of bounds for another purpose.
Master product and variants creationCreating a master product that represents various product va-riants plays an important role in minimising data management cost. Especially the explosion of content variants in marketing that is associated with targeting audiences and with situational marketing drives the need for an efficient handling of master products. When organising a great customer journey, it is definitely about convincing a customer about a basic product first. Showing an abundance of options (e.g. colours, sizes and materials) should always be a second step.
The import staging area becomes the most important gate-keeper for consolidating data from numerous sources onto one master product, right from the start.
Long Tail Long Tail is the rise of C-articles in times of e-commerce with low sales and low logistics cost. Specialised and seldomly sold C-articles accordingly can be sold via drop shipping, often based on established market places or online stores "on request only". In order to offer such C-articles efficiently, an important aspect is the minimisation of cost (data maintenance) and risk (wrong data and subsequent issues involved) in conjunction with products and data owned by suppliers. A sophisticated onboarding system is required to assure these strategic goals.
Supplier and vendor onboardingThe goal of supplier onboarding is to minimise time to market, cost involved in data management and to maximise the quality of content. This happens by seamlessly re-using valuable product content created by manufacturers or distributors of products in internal product communication. Supplier onboar-ding ensures that product content is not reinvented, but put into the right context and enriched for the relevant audiences and situations. In addition, retailers cannot efficiently assume responsibility for master data that needs to comply with laws such as alcohol contained in drinks, allergens contained in food or ingredients a medication is made of. It is imperative to delegate responsibility for such data to the producer.
The solution
A sophisticated staging area concept, where all sources of information have to enter via one unified gate
h Helps to keep unclean data out of the system by rejecting faulty or non-compliant data sets or fields.
Import, staging and supplier/vendor onboarding
Importing data from trusted data sources, as well as offloading parts of the data manage-ment to suppliers and other contributors working outside the core system is challenging: Any import – especially when fully automated – is an open door for poor data quality. To make sure data is enriched and improved and not changed for the worse, sophisticated procedures are required to separate the chaff from the wheat.
32

Product Sheet | CONTENTSERV AG
The Benefits
¬ Save valuable time and money for repeating tasks that have already been performed elsewhere.
¬ Improve data quality by building on tru-sted data, while keeping contradictory or poor quality data out.
¬ Shorten time to market by improving instead of rebuilding the product data.
¬ Improve customer experience by ensu-ring that those contribute valuable data who know most about the products, in their systems and environments.
h Allows for fully automated import, when the data complies with all consistency checks.
h Can dynamically require a manual process for map- ping, cleansing or intermediate editing of problematic data sets.
h Helps manage the data upload, validation and editing by content contributors such as suppliers, agencies or de-centralized business units.
The needs of suppliers, vendors and data contributors are different. And depending on the trust level for each, different variants of an onboarding portal will be required. This is why efficient an easy setup is imperative. Fig. 30 shows an auto-generated form for editing of data either
h directly by the source owner (supplier, system administra-tor, data contributor), e.g. after upload.
h Or by the central content owner (product manager, purchaser, catalogue manager,…), e.g. after hand-over.
h Data editing can be limited to show only records with issues, and within these records the attributes again can be limited to show only fields with issues.
h Red flag means: The record or the field contains data that prevents an import
h Yellow flag means: The record or the field violates rules, but an import can still take place
The forms are driven by the class model and
h may contain some or all of the core data model fields required for a product
Our Solution for Import, staging and supplier/vendor onboarding
Fig. 30: Editing data in the import staging area - problematic records and fields are highlighted in red / orange / yellow
33

Product Information Management
ONBOARDING PORTALPIM
h may contain additional fields required for import purposes, that can be disregarded after transformation
h may contain read-only fields, e.g. to provide additional information from the source system for easier look-up, although not relevant to the subsequent processes
Depending on the type of field, a change from the source system will or will not drive the creation of a new version with subsequent change management.
The overall process for importing, onboarding and aggregating data from various sources is a process that looks complex, but breaking it down into steps makes it manageable. Fig. 31 shows a process and architecture with multiple staging areas aggre-gating data from different source systems, across different locations and trust zones.
What we do better You can patch your imports together. Or you can set up a stra-tegic solution that grows with the ever increasing sources of information that contribute to a supreme customer experience:
h All write access happens via one unified and fully scalable strategy. From API-based system integration, batch import to supplier onboarding.
h Write commits to the global repository happen after resolving relationships, checking data consistency and improving data quality via rules or manual editing.
h We can gradually evolve the import syndication strategy from a manual to semi-automated to a fully automated process via the staging area.
h We can aggregate data from single stock keeping units to marketing products already upon import – offering a wide choice of rule-based options.
h We ensure that data quality and consistency checks create any load on the global data repository, as the complete data model is replicated to the staging areas.
Summary
Clean master data has become a commodity. The challenge has shifted to enriching master data with relevant and meaningful content, adjusted to the information needs of the targeted audience within the current situation.
In order not to waste time with keying in readily available data again and again, a very efficient and highly sophisticated import syndication module is an absolute must. Only when an abundance of single articles is efficiently bundled to meaningful marketing products is further enrichment and con-textualisation process one that can be handled with reasonable effort.
34

Product Sheet | CONTENTSERV AG
Stage 1 connector(ETL / automap)
Local staging area 4
CSV
hotfolder
Cassandra
Centrally owned dataStaging area
Drop zone A
apply matching & transformation rules
manuallyedit data
Multi YZ sytsem......e.g. XY different suppliers
JSON XML
FTP
Stage 2 data loader
Cassandra
Centrally owned dataStaging area
Drop zone A Drop zone B
Best of content merge
resolve referenced targets
check datastructure
apply matching & transformation rules
check constraints
manuallyedit data
Stage 1 connector(ETL / automap)
Local staging area 1
Stage 2 data loader
JSON XML CSV EXCEL
MQ APIhotfolderFTP
Stage 1 connector(ETL / automap)
Local staging area 2
Stage 2 data loader
JSON XML CSV EXCEL
MQ APIhotfolderFTP
Cassandra
Centrally owned dataStaging area
Drop zone A Drop zone B
Best of content merge
resolve referenced targets
check datastructure
apply matching & transformation rules
check constraints
manuallyedit data
Source system owned datae.g. ERP and PLM system
Stage 1 connector(ETL / automap)
Local staging area 3
Stage 2 data loader
JSON XML CSV EXCEL
MQ APIhotfolderFTP
Cassandra
Centrally owned dataStaging area
Drop zone A
resolve referenced targets
check datastructure
apply matching & transformation rules
check constraints
manuallyedit data
Contributorse.g. Agency upload
Message Bus
Global Data Repository
1 Can consist of several files, with option to upload as zip file or single files. Media assets and data are provided separately.
2 The transport of files can be mixed, e.g. data files via MQ, media assets via FTP. Manual upload and loading via API is also possible.
3 Mapping is based on stored mapping profiles. New attributes or attribute values for list of values can be mapped during the import process. Another setup, e.g. for silent mode interfaces is to ignore new fields or to abort the import upon detection.
4 Different staging areas can be required for different security and trust levels, server locations and per use case - e.g. for vendor / supplier onboarding, backend system connection and loading data from data contributors.
5 The drop zones have the same structure as the staging area itself. As they are owned by the source system, it is possible to have redundant data sets across drop zones. Checking, cleansing and manual editing of the data can take place at this point, depending on distribution of responsibility.
6 Matching and transformation rules e.g. include: mapping of attribute values to tags, scanning text for keywords with auto-assignment of corresponding tags, setting numbers to the right precision, resolving abbreviations and codes to clear text.
7 The syntax check assures that all data is provided in a structure that allows processing. Media assets are checked for integrity.
8 This steps checks data e.g. for maximum number of characters, precision, maximum amount of relationships / tags, validation patterns, blacklisted words,...). Fields containing problematic data will be flagged red (leads to a rejection of complete record), orange (attribute will be skipped) or yellow (can be imported with warnings / limitations).
9 Manual editing is typically focused only on remediating problematic records and fields. Optionally, a supplier / vendor can create products in the user interface oft he staging area itself.
10 The resolution of references (e.g. product to accessory, product to taxonomy, product to image, product to text asset) happens against objects contained in the import itself, as well as those available in the core system. Relations will be established to existing objects (based on exact or similarity match) or towards newly created objects contained in the import.
11 The best of content merge is inherently a task of the central system owner, as it is about selecting best options in case of conflicting data across different data supplies, residing in different drop zones. Manual merge will focus on conflicting records / attributes only. Automatic merge is based on rules, e.g. take longest description, largest image file, most precise value, lowest price,...).
12 The staging area is created based on the class model available in the core system. Which attributes are exposed with what alias in each onboarding portal and the configuration of temporary attributes are settings per import staging area.
13 Green flagged records are handed over to central ownership and hence cannot be further edited by the supplying party unless handed back. Match and mege compares data in the core system against the new data provided when an individual decision is required, what records and fields to update.
14 Similar to exports, the data and the data model required for imports are replicated to the import staging clusters via message bus.
15 The stage 2 data loader writes – typically fully consistent and resolved data – to the core system. Depending on the setting, this would involve clean data only (green) or also problematic data also (yellow).
16 The Message Bus – based on JMS or customer specific EAI software - ensures transactional safety and failover for write operations across distributed systems.
17 The Global Data Centre consolidates and re-distributes all data to local clusters. This is where conflicts in case of concurrent operations are resolved.
17
16
15
14
12
1098
11
6 7
5
4
3
2
1
13
11
Supplier owned datae.g. two different suppliers
Fig. 31: Process and architecture with multiple staging areas aggregating data from different source systems, across different locations and trust zones.
Legend:
1 Can consist of several files, with option to upload as zip file or single files. Media assets and data are provided separately. 2 The transport of files can be mixed, e.g. data files via MQ, media assets via FTP. Manual upload and loading via API is also possible .
3 Mapping is based on stored mapping profiles. New attributes or attribute values for list of values can be mapped during the import process. Another setup, e.g. for silent mode interfaces is to ignore new fields or to abort the import upon detection. 4 Different staging areas can be required for different security and trust levels, server locations and per use case - e.g. for vendor / supplier onboarding, backend system connection and loading data from data contributors. 5 The drop zones have the same structure as the staging area itself. As they are owned by the source system, it is possible to have redundant data sets across drop zones. Checking, cleansing and manual editing of the data can take place at this point, depending on distribution of responsibility. 6 Matching and transformation rules e.g. include: mapping of attribute values to tags, scanning text for keywords with auto-assignment of corresponding tags, setting numbers to the right precision, resolving abbreviations and codes to clear text. 7 The syntax check assures that all data is provided in a structure that allows processing. Media assets are checked for integrity. 8 This steps checks data e.g. for maximum number of characters, precision, maximum amount of relationships / tags, validation patterns, blacklisted words,...). Fields containing problematic data will be flagged red (leads to a rejection of complete record), orange (attribute will be skipped) or yellow (can be imported with warnings / limitations). 9 Manual editing is typically focused only on remediating problematic records and fields. Optionally, a supplier / vendor can create products in the user interface of the staging area itself. 10 The resolution of references (e.g. product to accessory, product to taxonomy, product to image, product to text asset) happens against objects contained in the import itself, as well as those available in the core system. Relations will be established to existing objects (based on exact or similarity match) or towards newly created objects contained in the import. 11 The best of content merge is inherently a task of the central system owner, as it is about selecting best options in case of conflicting data across different data supplies, residing in different drop zones. Manual merge will focus on conflicting records / attributes only. Automatic merge is based on rules, e.g. take longest description, largest image file, most precise value, lowest price,...). 12 The staging area is created based on the class model available in the core system. Which attributes are exposed with what alias in each onboarding portal and the configuration of temporary attributes are settings per import staging area. 13 Green flagged records are handed over to central ownership and hence cannot be further edited by the supplying party unless handed back. Match and merge compares data in the core system against the new data provided when an individual decision is required, what records and fields to update. 14 Similar to exports, the data and the data model required for imports are replicated to the import staging clusters via message bus. 15 The stage 2 data loader writes – typically fully consistent and resolved data – to the core system. Depending on the setting, this would involve clean data only (green) or also problematic data also (yellow). 16 The Message Bus – based on JMS or customer specific EAI software - ensures transactional safety and failover for write operations across distributed systems.
17 The Global Data Centre consolidates and re-distributes all data to local clusters. This is where conflicts in case of concurrent operations are resolved.
35

Product Information Management
ONBOARDING PORTALPIM
Current Challenges Multiple systems need context specific dataDigital marketing involves a multitude of systems: Online shops, E-Mail Marketing systems, Web Experience Management / Web Content Management systems, Marketing Automation, Apps and many more. And all of them need one thing more urgently than ever: relevant and meaningful content, adjusted to the specific situation and profile for a supreme customer experience.
Refactoring or replacing all these systems is not an option. But creating high-value product and editorial content in siloed channel systems inevitably results in an organisational content collapse. A central contextual content strategy is required.
Divisions, country subsidiaries, brandsDigital marketing has evolved to be a high-tech strategic initiative. As such, the investments in technology, processes and organisational development are far beyond the capabilities of decentral marketing units.
Systemic boundaries that were created to allow local action have become obsolete as context has become a key aspect of modern marketing. And the boundaries for differentiating customer experience are no longer on national levels, but much more refined and subtle. A context driven, high quality content strategy has to stretch across divisions, regional subsidiaries and brands. With central repositories, de-central adaptation and local content delivery clusters that minimize bandwidth and latency issues involved in a centralised data center strategy.
Data drivenDepending on the communication channel / touchpoint and the
kind of relationship with a customer involved in digital interaction, the available insights for targeted communication will greatly vary:
h A known customer, when using an App or when logged into a Website provides a whole new universe of profiling.
h Using dynamic profiling, a hypothetical customer profile is generated on the fly, with content optimised with every insight gained during the customer journey.
h Promotions and campaigns to larger audiences can be based on profiles available for a cluster of customers.
The amount of available profile data varies. But one thing always applies: all data – no matter if knowledge or valid assumptions – should be used for optimising communication.
Different requirements of channel systemsDepending on the dynamics and capabilities, the required data syndication process can involve:
h Scheduled export of fully static data, with reduced comple-xity of multidimensional data, e.g. when providing data for printed material, which by its nature is limited to dimensions.
h Scheduled export of data with product or attribute variants provided in multidimensional tables with the channel system handling the selection of the best available set of data.
h Realtime data delivery, where product selections, adjust-ment of presentation up to the rendering of previews is handled by a cluster of delivery servers.
The best option depends on a balanced consideration of opera-tional safety, capabilities of each channel system and dynamics required in the respective digital communication channel.
Context optimised Realtime Delivery
Digital communication has gone contextual: Dynamic pricing, images adjusted to the audience, content optimized for interests and products matching the buyer persona are all current challenges. And the customer wants more: Product descriptions and technical data should target the specific information needs of each buyer. Unlimited marketing opportuni-ties that require unlimited flexibility in data-driven communication.
36

Product Sheet | CONTENTSERV AG
The solution
Digital and non-digital channel systems are scattered across a multitude of locations. Their requirements are as individual as their numbers are large. We have a unique syndication strategy across all channels – no matter if they are static or contextual:
h Scheduled exports prefilter products to reduce to the required data set reduce dimensions by slicing and dicing – resolve to a level the target system can handle handle final transformations and aggregations via an ETL process
h MQ based / triggered provide delta from last export provide data when triggered by internal or external event assure a safe handling via Message Queue (MQ)
h Realtime provide products, media assets and editorial content choice of providing - data (XML, JSON) for formatting by target system - pre-layouted data (HTML, PDF) with on-the-fly rendering by the built-in template engine.
Adjust scoring for optimal contextualisation:
h Apply default settings for object selection (e.g. product, content, media asset) for attribute value selection (e.g. imperial vs. metric, technical language vs. simple language) for the optimised relationships (e.g. what recommen dations to focus on)
h Custom adjustment of scoring is dynamically ap-plied based on the session data known preferences of the customer special responsiveness to specific context
Build a central content base, ensure decentral content contribu-tion, operate local content delivery clusters:
h all data changes commit to a globally available data repository
h changed data is hence replicated to numerous local delive-ry servers and reduced to what is relevant in the regional context.
The Benefits
¬ Save money, time and improve time-to-market by a central contextualisation strategy
¬ Reduce system complexity by centrali-sing content and contextualisation in a central content engine
¬ Use synergies and learn across divisi-ons, countries and brands
¬ Collect, visualise and capitalise on data collected across a multitude of channels
37

Message Bus
Global Data Repository
JSON
Stage 1 FilterRegion > Asia
Channel > Webshop, App, WebCMS
TomcatElastic Search
CassandraSwift
Local Delivery Cluster 1
Stage 2 context optimizerAudienceSituation
XML HTML PDF JSON
TomcatElastic Search
CassandraSwift
Local Delivery Cluster 2
Stage 2 context optimizerAudienceSituation
XML HTML PDF
Stage 1 FilterRegion > Europe
Channel > App, WebCMS
JSON
Stage 1 FilterRegion > Europe
Channel > Webshop
TomcatElastic Search
CassandraSwift
Local Delivery Cluster 3
Stage 2 context optimizerAudienceSituation
XML HTML PDF JSON
TomcatElastic Search
CassandraSwift
Local Delivery Cluster 4
Stage 2 context optimizerAudienceSituation
XML HTML
Stage 1 FilterRegion > Europe
Channel > App, WebCMS
All our export setups are visually configured in a syndication configurator: Fig. 32 shows the overall architecture, consisting of (from bottom to top):
h A global data repository that can be deployed across multiple data centers.
h A stage 1 filter process that provides only data required for local delivery, in this example with a filter for region (Europe vs. Asia) and channels (separation of Webshop cluster from Web CMS and App cluster)
h A grid-based delivery cluster that replicates data from the global repository via Swift and Cassandra synchronisation.
h A stage 2 context optimiser that selects the best available content for the audience and situation based on scoring mechanisms for the individual session.
h The provisioning of data either as plain XML / JSON or
rendered to HTML / PDF
h The delivery of media assets in realtime, either embedded (for HTML and PDF) or as separate file.
Fig. 33 shows sample context optimisation settings for (from top to bottom):
h Products, where gender, culture and income class are particularly decisive for the best product selection.
h Editorial content, where the personality type and interest are key to selecting the best content.
h Pricing attributes, where the device used (e.g. smartphone or workstation) and the income class are highly relevant.
h Accessory relationship, where income class and gender drive the right choice of accessories.
h Spare parts relationships, with very limited contextualisa-tion and with only marginal impact of the income class.
Our Solution: Context optimised Realtime Delivery
Fig. 32: Architecture for centralised content strategy in conjunction with decentral content delivery
38

Product Sheet | CONTENTSERV AG
What we do better Realtime delivery is a huge technological challenge. We make it work safely:
h Unlimited scalability by cluster technology. Proven and tested.
h Settings for asynchronous, eventually consistent and consistent replication to the delivery servers.
h Worldwide cluster-based delivery of media assets with swift object store technology.
h Limit dimensions – all the way down to one – if a target system cannot handle multidimensional data.
h We make contextualisation understandable – for editors and dev operations equally.
Summary
Context marketing is a proven way to boost sales and improve customer ex-perience. A central content engine with realtime delivery capabilities is the most strategic approach to power a large number of channel systems with supreme content that is ideally contextualised to audience and situation.
39
Fig. 33: Settings for realtime delivery with context optimised settings for product selection, displayed list & promotion price and marketing text.

CONTENTSERV
CONTENTSERV AGHauptstrasse 19CH-9042 Speicher [email protected]
© Copyright ContentSphere International AG 2016