recuperação de informação b cap. 06: text and multimedia languages and properties (introduction,...
Post on 19-Dec-2015
215 views
TRANSCRIPT

Recuperação de Informação B
Cap. 06: Text and Multimedia Languages and
Properties (Introduction, Metadata
and Text)
6.1, 6.2, 6.3
November 01, 1999

Introduction
Text main form of communicating knowledge.
Document loosely defined, denote a single unit of information. can be any physical unit
a file an email a Web Page

Introduction
Document Syntax and structure Semantics Information about itself

Introduction
Document Syntax Implicit, or expressed in a language (e.g, TeX) Powerful languages: easier to parse, difficult to convert
to other formats. Open languages are better (interchange) Semantics of texts in natural language are not easy for
a computer to understand Trend: languages which provides information on
structure, format and semantics being readable by human and computers

Introduction
New applications are pushing for format such that information can be represented independetly of style.
Style: defined by the author, but the reader may decide part of it
Style can include treatment of other media

Metadata “Data about the data”
e.g: in a DBMS, schema specifies name of the relations, attributes, domains, etc.
Descriptive Metadata Author, source, length Dublin Core Metadata Element Set
Semantic Metadata Characterizes the subject matter within the document
contents MEDLINE

Metadata MARC
100 0020 1 $aHagler, Ronald.
245 0074 14$aThe bibliographic...
250 0012 $a3rd. Ed.
260 0052 $aChicago :$bALA, $c1997

Metadata Metadata information on Web documents
cataloging, content rating, property rights, digital signatures
New standard: Resource Description Framework description of Web resources to facilitate
automated processing of information nodes and attched atribute/values pairs
Metadescription of non-textual objects keyword can be used to search the objects
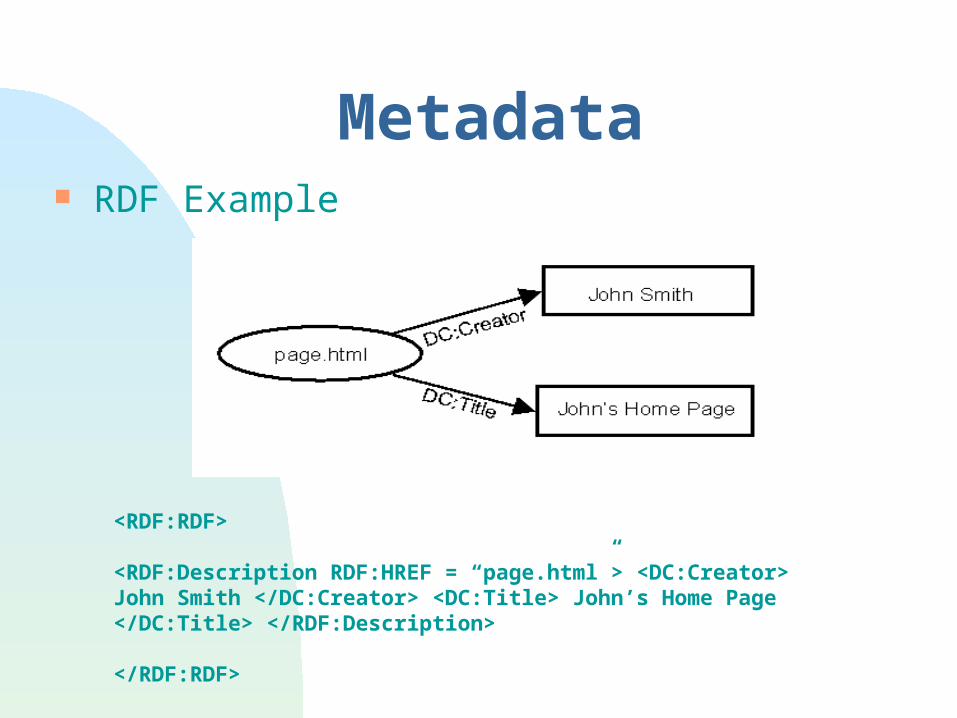
Metadata RDF Example
<RDF:RDF>
<RDF:Description RDF:HREF = “page.html”> <DC:Creator> John Smith </DC:Creator> <DC:Title> John’s Home Page </DC:Title> </RDF:Description>
</RDF:RDF>

Metadata RDF Schema Exemple

Text Text coding in bits
EBCDIC, ASCII Initially, 7 bits. Later, 8 bits
Unicode 16 bits, to accommodate oriental languages

Text Formats
No single format exists IR system should retrieve information from different
formats Past: IR systems convert the documents Today: IR systems use filters

Text Formats
Formats for document interchange (RTF) Formats for displaying (PDF, PostScript) Formats for encode email (MIME) Compressed files
uuencode/uudecode, binhex

Text Information Theory
Amount of information is related to the distribution of symbols in the document.
Entropy:
Definition of entropy depends on the probabilities of each symbol.
Text models are used to obtain those probabilites
ii
i ppE 21
log

Text Example - Entropy
001001011011
12
1log2
1
2
1log2
122
E

Text Example - Entropy
111111111111
01log10log0 22 E

Text Modeling Natural Language
Symbols: separate words or belong to words Symbols are not uniformly distributed
binomial model Dependency of previous symbols
k-order markovian model We can take words as symbols

Text Modeling Natural Language
Words distribution inside documents Zipf´s Law: i-th most frequent word appears 1/i times of
the most frequent word
Real data fits better with between 1.5 and 2.0
V
jV
V
jH
Hin
1
1)(
))(/(

Text Modeling Natural Language
Example - word distibution (Zipf’s Law) V=1000, = 2 most frequent word: n=300 2nd most frequent: n=76 3rd most frequent: n=33 4th most frequent: n=19

Text Modeling Natural Language
Skewed distribution - stopwords Distribution of words in the documents
binomial distribution
Poisson distribution
kk ppk
kkF
)1(
1)(

Text Modeling Natural Language
Number of distinct words Heaps’ Law: Set of different words is fixed by a constant, but the
limit is too high
KnV

Text Modeling Natural Language
Heaps’ Law example k between 10 and 100, is less than 1 example: n=400000, = 0.5
• K=25, V=15811• K=35, V=22135

Text Modeling Natural Language
Length of the words defines total space needed for vocabulary
Heaps’ Law: length increases logarithmically with text size.
In practice, a finit-state model is used space has p=0.2 space cannot apear twice subsequently there are 26 letters

Text Similarity Models
Distance Function Should be symmetric and satisfy triangle inequality
Hamming Distance number of positions that have different characters
reverse
receive

Text Similarity Models
Edit (Levenshtein) Distance minimum number of operations needed to make strings
equal
survey
surgery
superior for modeling syntatic errors extensions: weights, transpositions, etc

Text Similarity Models
Longest Common Subsequence (LCS) survey - surgery
LCS: surey Documents: lines as symbols (diff in Unix)
time consuming similar lines
Fingerprints Visual tools

Conclusions Text is the main form of communicating knowledge. Documents have syntax, structure and semantics Metadata: information about data Formats of text Modeling Natural Language
Entropy Distribution of symbols
Similarity