scalable and scalably-verifiable sequential synthesis alan mishchenko mike case robert brayton uc...
TRANSCRIPT

Scalable and Scalably-Verifiable Scalable and Scalably-Verifiable Sequential SynthesisSequential Synthesis
Alan Mishchenko Mike Case Robert BraytonAlan Mishchenko Mike Case Robert Brayton
UC BerkeleyUC Berkeley

22
OverviewOverview
IntroductionIntroduction ComputationsComputations
SAT sweepingSAT sweeping InductionInduction PartitioningPartitioning
VerificationVerification ExperimentsExperiments Future workFuture work

33
IntroductionIntroduction Combinational synthesisCombinational synthesis
Cuts at the register boundaryCuts at the register boundary Preserves state encoding, scan chains & test vectorsPreserves state encoding, scan chains & test vectors No sequential optimization – easy to verifyNo sequential optimization – easy to verify
Sequential synthesisSequential synthesis Runs retiming, re-encoding, use of sequential don’t-cares, etcRuns retiming, re-encoding, use of sequential don’t-cares, etc Changes state encoding, invalidates scan chains & test vectorsChanges state encoding, invalidates scan chains & test vectors Some degree of sequential optimization – non-trivial to verifySome degree of sequential optimization – non-trivial to verify
Scalably-verifiable sequential synthesisScalably-verifiable sequential synthesis Merges sequentially equivalent registers and internal nodesMerges sequentially equivalent registers and internal nodes Minor change to state encoding, scan chains & test vectorsMinor change to state encoding, scan chains & test vectors Some degree of sequential optimization – easy to verify!Some degree of sequential optimization – easy to verify!
44
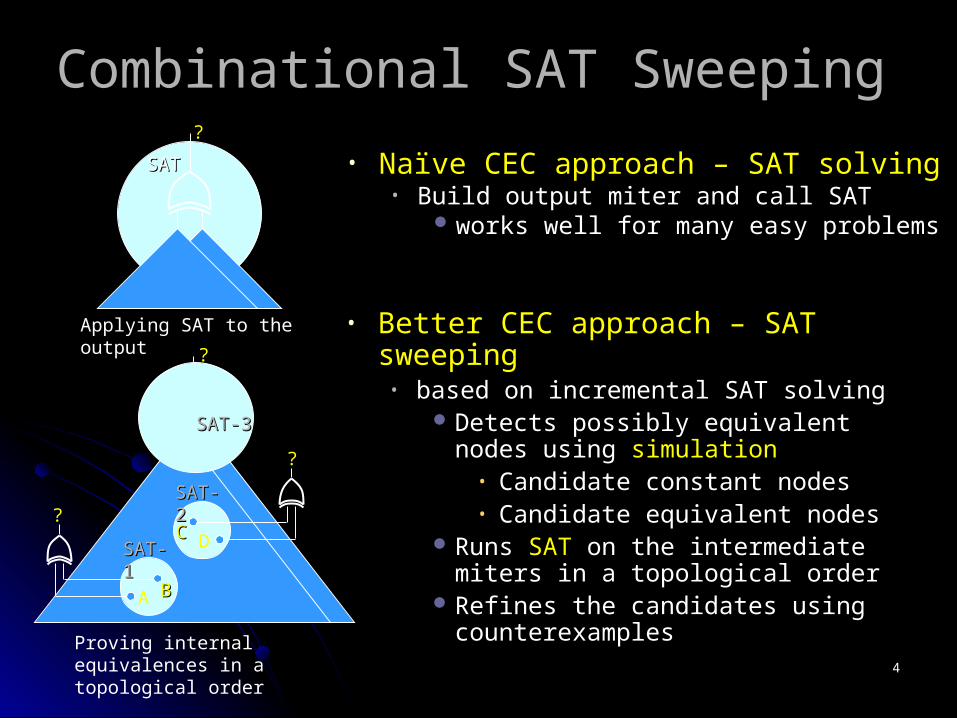
Combinational SAT SweepingCombinational SAT Sweeping
• Naïve CEC approach – SAT solvingNaïve CEC approach – SAT solving• Build output miter and call SATBuild output miter and call SAT
works well for many easy problemsworks well for many easy problems
• Better CEC approach – SAT sweepingBetter CEC approach – SAT sweeping • based on incremental SAT solvingbased on incremental SAT solving
Detects possibly equivalent nodes Detects possibly equivalent nodes using using simulationsimulation
• Candidate constant nodesCandidate constant nodes• Candidate equivalent nodesCandidate equivalent nodes
Runs Runs SATSAT on the intermediate miters in on the intermediate miters in a topological ordera topological order
Refines the candidates using Refines the candidates using counterexamplescounterexamples
Applying SAT to the output
?
SATSAT
Proving internal equivalences in a topological order
A BB
SAT-1SAT-1
?
DCC
SAT-2SAT-2
?
?
SAT-3SAT-3

55
Sequential SAT SweepingSequential SAT Sweeping
Sequential SAT sweepingSequential SAT sweeping is similar to combinational is similar to combinational one in that it detects node equivalencesone in that it detects node equivalences The difference is, the equivalences are The difference is, the equivalences are sequentialsequential
They hold only in the reachable state spaceThey hold only in the reachable state space
Every comb. equivalence is a seq. one, not vice versaEvery comb. equivalence is a seq. one, not vice versa It makes sense to run comb. SAT sweeping beforehandIt makes sense to run comb. SAT sweeping beforehand
Sequential equivalence is proved by K-step inductionSequential equivalence is proved by K-step induction Base caseBase case Inductive caseInductive case
Efficient implementation of induction is key!Efficient implementation of induction is key!

66
Base Case Inductive CaseBase Case Inductive Case
Proving internal equivalences in a topological order in frame K
A
B
SAT-1D C
SAT-2
A
B
D C
A
B
D C
Assuming internal equivalences to in uninitialized frames 0 through K-1
0
0
0
0
?
?
Symbolic state
PI0
PI1
PIk
A
B
SAT-3D C
SAT-4
A
B
SAT-1D C
SAT-2
?
?
?
?
PI0
PI1
Initial state
Candidate equivalences: {A,B}, {C,D}
Proving internal equivalences in initialized frames 0 through K-1

77
Efficient ImplementationEfficient Implementation Two observations:Two observations:
Both base and inductive cases of K-step induction are runs of Both base and inductive cases of K-step induction are runs of combinational SAT sweepingcombinational SAT sweeping
Tricks and know-hows of combinational sweeping are applicable Tricks and know-hows of combinational sweeping are applicable The same integrated package can be usedThe same integrated package can be used
Starts with simulationStarts with simulation Performs node checking in a topological orderPerforms node checking in a topological order Benefits from the counter-example simulationBenefits from the counter-example simulation
Speculative reductionSpeculative reduction Has to do with how the assumptions are madeHas to do with how the assumptions are made (see next slide) (see next slide)

88
Speculative ReductionSpeculative Reduction Inputs to the inductive caseInputs to the inductive case
Sequential circuitSequential circuit The number of frames to unroll (K)The number of frames to unroll (K) Candidate equivalence classes Candidate equivalence classes
One node in each class is designated as One node in each class is designated as the representative nodethe representative node Currently the representatives are the first nodes in a topological orderCurrently the representatives are the first nodes in a topological order
Speculative reductionSpeculative reduction moves fanouts to the representative nodes moves fanouts to the representative nodes Makes 80% of the constraints redundantMakes 80% of the constraints redundant Dramatically simplifies the resulting timeframes (observed 3x reductions)Dramatically simplifies the resulting timeframes (observed 3x reductions) Leads to saving 100-1000x in runtime during incremental SAT solvingLeads to saving 100-1000x in runtime during incremental SAT solving
AB
Adding assumptions without speculative reduction
0
AB
Adding assumptions with speculative reduction
0

99
Partitioning for InductionPartitioning for Induction A simple output-partitioning algorithm was implementedA simple output-partitioning algorithm was implemented
One person-day of programmingOne person-day of programming CEC and induction became more scalableCEC and induction became more scalable
Typical reduction in runtime is 20x for a 1M-gate designTypical reduction in runtime is 20x for a 1M-gate design Partitioning is meant to make SAT problems smallerPartitioning is meant to make SAT problems smaller
The same partitioning is useful for parallelization!The same partitioning is useful for parallelization!
Partitioning algorithmPartitioning algorithm Pre-processing:Pre-processing: For all POs, finds PIs they depend on For all POs, finds PIs they depend on Main loop:Main loop: For each PO, in a degreasing order of support size For each PO, in a degreasing order of support size
Finds a partition by looking at the supportsFinds a partition by looking at the supports Chooses partition with min linear combination of attraction and repulsion Chooses partition with min linear combination of attraction and repulsion
(determined by the number of common and new variables in this PO)(determined by the number of common and new variables in this PO) Imposes restrictions on the partition sizeImposes restrictions on the partition size
Post-processing:Post-processing: Compacts smaller partitions Compacts smaller partitions Complexity:Complexity: O( numPis(AIG) * numPos(AIG) ) O( numPis(AIG) * numPos(AIG) )

1010
Partitioning Details Partitioning Details Currently induction is partitioned only for register correspondence
In this case, it is enough to partition only one timeframe! In each iteration of induction
The design is re-partitioned Nodes in each candidate equiv class are added to the same partition Constant candidates can be added to any partition Candidates are merged at the PIs and proved at the POs After proving all partitions, the classes are refined
The partitioned induction has the same fixed-point as the monolithic induction while the number of iterations can differ (different c-examples lead to different refinements)
BA = DC =
B’A’ =?
BA = DC =
D’C’ =?
Illustration for two cand equiv classes: {A,B}, {C,D}
Partition 1
Partition 2
BA DC
B’A’ D’C’
One timeframe of the design

1111
Other ObservationsOther Observations
Surprisingly, the following are found to be of little or no Surprisingly, the following are found to be of little or no importance for speeding up the inductive proverimportance for speeding up the inductive prover The quality of initial equivalence classesThe quality of initial equivalence classes
How much simulation (semi-formal filtering) was appliedHow much simulation (semi-formal filtering) was applied AIG rewriting on speculated timeframesAIG rewriting on speculated timeframes
Although AIG can be reduced 20%, incremental SAT runs the sameAlthough AIG can be reduced 20%, incremental SAT runs the same The quality of AIG-to-CNF conversionThe quality of AIG-to-CNF conversion
Naïve conversion (1 AIG node = 3 clauses) works just fineNaïve conversion (1 AIG node = 3 clauses) works just fine
Open question: Given these observations, how to speed Open question: Given these observations, how to speed up this type of incremental SAT?up this type of incremental SAT?

1212
Verification after PSSVerification after PSS
Poison and antidote are the same!Poison and antidote are the same! The same inductive prover is usedThe same inductive prover is used
during synthesisduring synthesis – to prove seq – to prove seq equivalence of registers and nodesequivalence of registers and nodes
during verificationduring verification – to prove seq – to prove seq equivalence of registers, nodes, and equivalence of registers, nodes, and POs of two circuitsPOs of two circuits
Verification is “unbounded” and Verification is “unbounded” and “general-case”“general-case” No limit on the input sequence is No limit on the input sequence is
imposed (unlike BMC)imposed (unlike BMC) No information about synthesis is No information about synthesis is
passed to the verification toolpassed to the verification tool The runtimes of synthesis and The runtimes of synthesis and
verification are comparableverification are comparable Scales to 10K-register designs – Scales to 10K-register designs –
due to partitioning for inductiondue to partitioning for inductionX X
…
N1 N2
M
X
N1
Synthesis problem
Equivalence checking problem

1313
Integrated SEC Flow Integrated SEC Flow The following is the sequence of transformations currently applied by the The following is the sequence of transformations currently applied by the
integrated SEC in ABC (command “dsec”)integrated SEC in ABC (command “dsec”) creating sequential miter creating sequential miter (“miter -c”)(“miter -c”)
PIs/POs are paired by name; if some registers have don’t-care init values, they are PIs/POs are paired by name; if some registers have don’t-care init values, they are converted by adding new PIs and muxes; all logic is represented in the form of an AIGconverted by adding new PIs and muxes; all logic is represented in the form of an AIG
sequential sweep sequential sweep (“scl”)(“scl”) removes logic that does not fanout into POsremoves logic that does not fanout into POs
structural register sweep structural register sweep (“scl -l”)(“scl -l”) removes stuck-at-constant and combinationally-equivalent registersremoves stuck-at-constant and combinationally-equivalent registers
most forward retimingmost forward retiming (“retime –M 1”) (disabled by switch “–r”, e.g. “dsec –r”) (“retime –M 1”) (disabled by switch “–r”, e.g. “dsec –r”) moves all registers forward and computes new initial statemoves all registers forward and computes new initial state
partitioned register correspondence partitioned register correspondence (“lcorr”)(“lcorr”) merges sequential equivalent registers (completely solves SEC after retiming)merges sequential equivalent registers (completely solves SEC after retiming)
combinational SAT sweeping combinational SAT sweeping (“fraig”)(“fraig”) merges combinational equivalent nodes before running signal correspondencemerges combinational equivalent nodes before running signal correspondence
for ( K = 1; K for ( K = 1; K 16; K = K * 2 ) 16; K = K * 2 ) signal correspondencesignal correspondence (“ssw”) // merges seq equivalent signals by K-step induction (“ssw”) // merges seq equivalent signals by K-step induction AIG rewritingAIG rewriting (“drw”) // minimizes and restructures combinational logic (“drw”) // minimizes and restructures combinational logic most forward retimingmost forward retiming // moves registers forward after logic restructuring // moves registers forward after logic restructuring sequential AIG simulationsequential AIG simulation // targets satisfiable SAT instances // targets satisfiable SAT instances
post-processing post-processing (“write_aiger”)(“write_aiger”) if sequential miter is still unsolved, dumps it into a file for future useif sequential miter is still unsolved, dumps it into a file for future use

1414
Example of PSS in ABCExample of PSS in ABCabc 01> r iscas/blif/s38417.blifabc 01> r iscas/blif/s38417.blif // reads in an ISCAS’89 benchmark// reads in an ISCAS’89 benchmark
abc 02> st; psabc 02> st; ps // shows the AIG statistics after structural hashing// shows the AIG statistics after structural hashings38417 : i/o = 28/ 106 lat = 1636 and = 9238 (exor = 178) lev = 31s38417 : i/o = 28/ 106 lat = 1636 and = 9238 (exor = 178) lev = 31
abc 03> ssw –abc 03> ssw –K 1 -K 1 -vv // performs one round of signal correspondence using simple induction // performs one round of signal correspondence using simple inductionInitial fraiging time = 0.27 secInitial fraiging time = 0.27 secSimulating 9096 AIG nodes for 32 cycles ... Time = 0.06 secSimulating 9096 AIG nodes for 32 cycles ... Time = 0.06 secOriginal AIG = 9096. Init 2 frames = 84. Fraig = 82. Time = 0.01 secOriginal AIG = 9096. Init 2 frames = 84. Fraig = 82. Time = 0.01 secBefore BMC: Const = 5031. Class = 430. Lit = 9173.Before BMC: Const = 5031. Class = 430. Lit = 9173.After BMC: Const = 5031. Class = 430. Lit = 9173.After BMC: Const = 5031. Class = 430. Lit = 9173. 0 : Const = 5031. Class = 430. L = 9173. LR = 1928. NR = 3140.0 : Const = 5031. Class = 430. L = 9173. LR = 1928. NR = 3140. 1 : Const = 4883. Class = 479. L = 8964. LR = 1554. NR = 2978.1 : Const = 4883. Class = 479. L = 8964. LR = 1554. NR = 2978.…… 28 : Const = 145. Class = 177. L = 756. LR = 198. NR = 9099.28 : Const = 145. Class = 177. L = 756. LR = 198. NR = 9099. 29 : Const = 145. Class = 176. L = 753. LR = 195. NR = 9090.29 : Const = 145. Class = 176. L = 753. LR = 195. NR = 9090.SimWord = 1. Round = 2025. Mem = 0.38 Mb. LitBeg = 9173. LitEnd = 753. ( 8.21 %).SimWord = 1. Round = 2025. Mem = 0.38 Mb. LitBeg = 9173. LitEnd = 753. ( 8.21 %).Proof = 5022. Cex = 2025. Fail = 0. FailReal = 0. C-lim = 10000000. ImpRatio = 0.00 %Proof = 5022. Cex = 2025. Fail = 0. FailReal = 0. C-lim = 10000000. ImpRatio = 0.00 %NBeg = 9096. NEnd = 8213. (Gain = 9.71 %). RBeg = 1636. REnd = 1345. (Gain = 17.79 %).NBeg = 9096. NEnd = 8213. (Gain = 9.71 %). RBeg = 1636. REnd = 1345. (Gain = 17.79 %).AIG simulation = 2.25 secAIG simulation = 2.25 secAIG traversal = 0.01 secAIG traversal = 0.01 secSAT solving = 3.71 secSAT solving = 3.71 sec Unsat = 0.16 secUnsat = 0.16 sec Sat = 3.55 secSat = 3.55 sec Fail = 0.00 secFail = 0.00 secClass refining = 0.38 secClass refining = 0.38 secTOTAL RUNTIME = 8.51 secTOTAL RUNTIME = 8.51 sec
abc 04> psabc 04> ps // shows the AIG statistics after merging equivalent registers and nodes// shows the AIG statistics after merging equivalent registers and nodess38417 : i/o = 28/ 106 lat = 1345 and = 8213 (exor = 116) lev = 31s38417 : i/o = 28/ 106 lat = 1345 and = 8213 (exor = 116) lev = 31
abc 04> dsec –rabc 04> dsec –r // runs the unbounded SEC on the resulting network against the original one// runs the unbounded SEC on the resulting network against the original oneNetworks are equivalent. Time = 15.59 secNetworks are equivalent. Time = 15.59 sec

1515
Experimental ResultsExperimental Results
Public benchmarksPublic benchmarks 25 test cases25 test cases
ITCITC ’99’99 ( (b14b14, , b15b15, , b17b17, , b20b20, , b21b21, , b22b22)) ISCASISCAS ’89 ’89 (s13207, s35932, s38417, s38584)(s13207, s35932, s38417, s38584) IWLSIWLS ’05’05 (systemcaes, systemcdes, tv80, usb_funct, vga_lcd, (systemcaes, systemcdes, tv80, usb_funct, vga_lcd,
wb_conmax, wb_dma, ac97_ctrl, aes_core, des_area, des_perf, wb_conmax, wb_dma, ac97_ctrl, aes_core, des_area, des_perf, ethernet, i2c, mem_ctrl, pci_spoci_ctrl)ethernet, i2c, mem_ctrl, pci_spoci_ctrl)
Industrial benchmarksIndustrial benchmarks 50 test cases50 test cases
Nothing else is knownNothing else is known
Workstation Workstation Intel Xeon 2-CPU 4-core, 8Gb RAMIntel Xeon 2-CPU 4-core, 8Gb RAM

1616
ABC ScriptsABC Scripts BaselineBaseline
cchoice;hoice; ifif; c; choice;hoice; ifif; c; choice;hoice; ifif // comb synthesis and mapping // comb synthesis and mapping
Register correspondence (Reg Corr)Register correspondence (Reg Corr) sscl –lcl –l // structural register sweep // structural register sweep llcorrcorr // register correspondence using partitioned induction // register correspondence using partitioned induction ddsec –rsec –r // SEC // SEC cchoice;hoice; ifif; c; choice;hoice; ifif; c; choice;hoice; ifif // comb synthesis and mapping // comb synthesis and mapping
Signal correspondence (Sig Corr)Signal correspondence (Sig Corr) sscl –lcl –l // structural register sweep // structural register sweep llcorrcorr // register correspondence using partitioned induction // register correspondence using partitioned induction ssswsw // signal correspondence using non-partitioned induction // signal correspondence using non-partitioned induction ddsec –rsec –r // SEC // SEC cchoice;hoice; ifif; c; choice;hoice; ifif; c; choice;hoice; ifif // comb synthesis and mapping // comb synthesis and mapping

1717
Public BenchmarksPublic BenchmarksRegisters / Area / Delay
Baseline Reg Corr Ratio Sig Corr Ratio
Registers 809.9 610.9 0.75 544.3 0.67
6-LUTs 2141 1725 0.80 1405 0.65
Delay 6.8 6.33 0.93 5.83 0.86
Runtime
Reg Corr Sig Corr SEC Synt & Map Total
Geomean 7.186 29.846 81.583 16.760 135.376
Percentage 0.05 0.22 0.60 0.12 1.00
Columns “Baseline”, “Reg Corr” and “Sig Corr” show geometric means.

1818
ITC / ISCAS Benchmarks (details)ITC / ISCAS Benchmarks (details)
Examples Baseline Reg Corr Sig Corr PI PO LUT Lat Lev LUT Lat Lev LUT Lat Lev b14 32 54 1144 245 13 1090 215 13 1122 215 13
b15 36 70 2027 449 14 1930 415 15 1940 415 15
b17 37 97 6086 1415 18 2356 611 15 2327 604 14
b20 32 22 2454 490 14 2400 429 14 2398 429 14
b21 32 22 2439 490 15 2395 429 15 2324 429 15
b22 32 22 3720 735 14 3602 611 14 3493 611 14
s13207 31 121 655 669 5 255 195 3 252 193 3
s35932 35 320 2720 1728 2 2336 1472 2 2336 1472 2
s38417 28 106 2130 1636 6 1859 1348 6 1848 1345 6
s38584 12 278 2242 1452 6 1199 843 4 1120 784 4
Geomean 2141 809.9 6.8 1725 610.9 6.33 1405 544.3 5.83
Ratio 1.00 1.00 1.00 0.80 0.75 0.93 0.65 0.67 0.86 Ratio 1.00 1.00 1.00 0.81 0.89 0.92

1919
IIWLS’05 Benchmarks (details)IIWLS’05 Benchmarks (details)Examples Baseline Reg Corr Sig Corr
PI PO LUT Lat Lev LUT Lat Lev LUT Lat Lev systemcaes 260 129 1851 670 8 1796 670 8 1795 670 8
systemcdes 132 65 405 190 7 419 190 6 476 190 5
tv80 14 32 1787 359 11 1834 350 10 110 64 3
usb_funct 128 121 3095 1746 6 3044 1722 6 2758 1602 6
vga_lcd 89 109 28939 17079 6 26891 16001 6 22274 12882 6
wb_conmax 1130 1416 10303 770 6 9851 770 6 9865 770 6
wb_dma 217 215 1037 563 6 898 521 4 879 490 4
ac97_ctrl 84 48 2798 2199 3 2792 2199 3 2570 1985 3
aes_core 259 129 2951 530 5 2958 527 5 2962 527 5
des_area 240 64 937 128 7 867 64 7 872 64 7
des_perf 234 64 5516 8808 4 5525 8746 4 5518 8746 4
ethernet 98 115 11939 10544 6 1396 883 6 1357 849 6
i2c 19 14 232 128 3 247 126 3 217 126 3
mem_ctrl 115 152 1916 1083 7 1890 1046 7 1854 1046 5
pci_spoci_ctrl 25 13 238 60 4 238 60 4 41 33 3
Geomean 2141 809.9 6.8 1725 610.9 6.33 1405 544.3 5.83
Ratio 1.00 1.00 1.00 0.80 0.75 0.93 0.65 0.67 0.86 Ratio 1.00 1.00 1.00 0.81 0.89 0.92

2020
ITC / ISCAS Benchmarks (runtime)ITC / ISCAS Benchmarks (runtime)
Example Statistics Runtime Distribution PI PO Lat RegCorr SigCorr SEC Mapping Total
b14 32 54 245 0.03 0.31 0.63 7.65 8.62
b15 36 70 449 0.34 6.26 11.79 12.24 30.63
b17 37 97 1415 0.67 11.32 19.23 12.46 43.68
b20 32 22 490 0.1 1.79 2.87 15.72 20.48
b21 32 22 490 0.11 2.55 3.96 16.54 23.16
b22 32 22 735 0.13 2.9 6.88 22.66 32.57
s13207 31 121 669 0.06 0.22 0.31 0.46 1.05
s35932 35 320 1728 0.57 1.83 5.43 5.47 13.3
s38417 28 106 1636 1.05 2.65 8.59 6.09 18.38
s38584 12 278 1452 0.7 1.12 4.11 3.36 9.29
Geomean 809.9 7.18 29.84 81.58 16.76 135.37 Ratio 5.31% 22.05% 60.26% 12.38% 100.0%

2121
IWLS’05 Benchmarks (runtime)IWLS’05 Benchmarks (runtime)Example Statistics Runtime Distribution
PI PO Lat RegCorr SigCorr SEC Mapping Total systemcaes 260 129 670 0.07 1.42 2.81 11.17 15.47
systemcdes 132 65 190 0.01 0.07 0.09 3.7 3.87
tv80 14 32 359 0.22 0.94 1.28 0.46 2.9
usb_funct 128 121 1746 1.95 12.65 29.64 11.36 55.6
vga_lcd 89 109 17079 165.01 570.28 1830.19 78.85 2644.33
wb_conmax 1130 1416 770 0.64 17.08 2.03 45.03 64.78
wb_dma 217 215 563 0.11 0.49 1.29 2.54 4.43
ac97_ctrl 84 48 2199 0.69 14.83 25.31 6.38 47.21
aes_core 259 129 530 0.14 1.25 1.65 27.51 30.55
des_area 240 64 128 0.01 0.13 0.1 5.45 5.69
des_perf 234 64 8808 1.1 81.97 49.44 113.52 246.03
ethernet 98 115 10544 4.93 3.68 19.66 4.15 32.42
i2c 19 14 128 0.03 0.11 0.19 0.7 1.03
mem_ctrl 115 152 1083 0.96 10.21 11.96 5.4 28.53
pci_spoci_ctrl 25 13 60 0.03 0.09 0.15 0.15 0.42
Geomean 809.9 7.18 29.84 81.58 16.76 135.37 Ratio 5.31% 22.05% 60.26% 12.38% 100.0%

2222
Industrial BenchmarksIndustrial BenchmarksRegisters / Area / Delay
Baseline Reg Corr Ratio Sig Corr Ratio
Registers 1583 1134 0.71 1084 0.68
6-LUTs 7472 6751.5 0.90 6360 0.85
Depth 8.5 8.5 1.00 8.5 1.00
Runtime
Reg Corr Sig Corr SEC Synt & Map Total
Geomean 3.31 74.28 41.10 40.60 159.30
Ratio 0.02 0.47 0.26 0.25 1.00
In case of multiple clock domains, optimization was applied only to the domain with the largest number of registers.

2323
FutureFuture Continue tuning for scalabilityContinue tuning for scalability
Speculative reductionSpeculative reduction PartitioningPartitioning
Experiment with new ideasExperiment with new ideas Unique-state constraintsUnique-state constraints Interpolate when induction failsInterpolate when induction fails Synthesizing equivalenceSynthesizing equivalence
Go beyond merging sequential equivalencesGo beyond merging sequential equivalences Add logic restructuring using subsets of unreachable statesAdd logic restructuring using subsets of unreachable states Add retiming (improves delay on top of reg/area reductions)Add retiming (improves delay on top of reg/area reductions) Add iteration (led to improvements in other synthesis projects)Add iteration (led to improvements in other synthesis projects) etcetc