software transactional memory nir shavit tel-aviv university and sun labs “where do we come from?...
Post on 22-Dec-2015
215 views
TRANSCRIPT

Software Transactional Memory
Nir ShavitTel-Aviv University and Sun Labs
“Where Do We Come From? What Are We? Where Are We Going?”

Traditional Software Scaling
2
User code
TraditionalUniprocessor
Speedup1.8x1.8x
7x7x
3.6x3.6x
Time: Moore’s law

Multicore Software Scaling
User code
Multicore
Speedup 1.8x1.8x
7x7x
3.6x3.6x
Unfortunately, not so simple…

Real-World Multicore Scaling
4
1.8x1.8x 2x2x 2.9x2.9x
User code
Multicore
Speedup
Parallelization and Synchronization require great care…

Amdahl’s Law:
Speedup = 1/(ParallelPart/N + SequentialPart)
Pay for N = 8 cores SequentialPart = 25%
Speedup = only 2.9 times!
Why?
Effect of 25% becomes more accute as num of cores grows 2.3/4, 2.9/8, 3.4/16, 3.7/32………4/∞

Shared Data Structures
75%Unshared
25%Shared
c c
c c
c cc c
CoarseGrained
c
cc
c
c
c
c c
c c
c c
c cc c
FineGrained c c
cc
cc
cc
The reason we get
only 2.9 speedup
75%Unshared
25%Shared

A FIFO Queue
b c d
TailHead
a
Enqueue(d)Dequeue() => a

A Concurrent FIFO Queue
Object lock
b c d
TailHead
a
P: Dequeue() => a Q: Enqueue(d)
Simple Code, easy to prove correct
Contention and sequential bottleneck

Fine Grain Locks
b c d
TailHead
a
P: Dequeue() => a Q: Enqueue(d)
Finer Granularity, More Complex Code
Verification nightmare: worry about deadlock, livelock…

Fine Grain Locks
b c d
TailHead
a
P: Dequeue() => a Q: Enqueue(b)
b
TailHead
a
Worry how to acquire multiple locks
Complex boundary cases: empty queue, last item

Lock-Free (JDK 1.5+)
b c d
TailHead
a
P: Dequeue() => a Q: Enqueue(d)
Even Finer Granularity, Even More Complex Code
Worry about starvation, subtle bugs, hardness to modify…
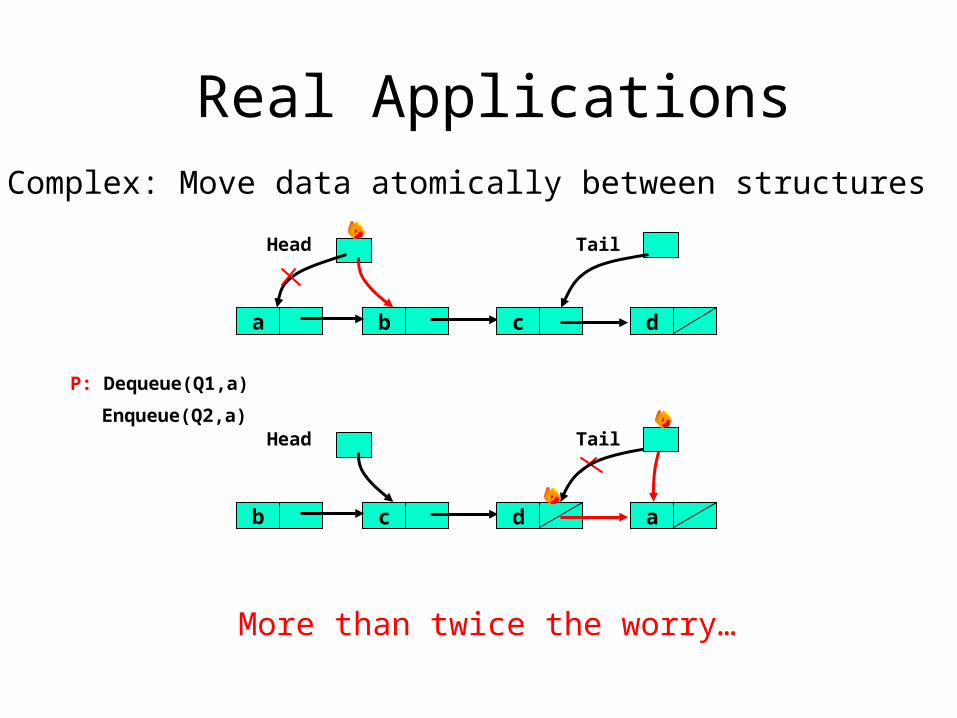
Real ApplicationsComplex: Move data atomically between structures
More than twice the worry…
b c d
TailHead
a
P: Dequeue(Q1,a)
c d a
TailHead
b
Enqueue(Q2,a)

Transactional Memory[HerlihyMoss93]

Promise of Transactional Memory
b c d
TailHead
a
P: Dequeue() => a Q: Enqueue(d)
Don’t worry about deadlock, livelock, subtle bugs, etc…
Great Performance, Simple Code

Promise of Transactional Memory
b c d
TailHead
a
P: Dequeue() => a Q: Enqueue(d)
b
TailHead
a
TM deals with boundary cases under the hood
Don’t worry which locks need to cover which variables when…

For Real ApplicationsWill be easy to modify multiple structures atomically
Provide Serializability…
b c d
TailHead
a
P: Dequeue(Q1,a)
c d a
TailHead
b
Enqueue(Q2,a)

Using Transactional Memory
enqueue (Q, newnode) {
Q.tail-> next = newnode
Q.tail = newnode
}

Using Transactional Memory
enqueue (Q, newnode) {
atomic{
Q.tail-> next = newnode
Q.tail = newnode
}
}

Transactions Will Solve Many of Locks’ Problems
No need to think what needs to be locked, what not, and at what granularity
No worry about deadlocks and livelocks
No need to think about read-sharing
Can compose concurrent objects in a way that is safe and scalable
But there are problems!

Hardware TM [HerlihyMoss93]
Hardware Transactions 20-30…but not ~1000 instructions long
Diff Machines… expect different hardware support
Hardware is not flexible…abort policies, retry policies, all application dependent…

Software Transactional Memory[ShavitTouitou94]
The semantics of hardware transactions…today
Tomorrow: serve as a standard interface to hardware
Allow to extend hardware features when they arrive
Still, we need to have reasonable performance…
Today’s focus…

The Brief History of STM19
94S
TM (S
havi
t,Tou
itou)
2003
DS
TM (H
erlih
y et
al)
2003
WS
TM (F
rase
r, H
arris
)
Lock-free
2003
OS
TM (F
rase
r, H
arris
)
2004
AS
TM (M
arat
he e
t al)
2004
T-M
onito
r (Ja
gann
atha
n…)
Obstruction-free Lock-based
2005
Lock
-OS
TM (E
nnal
s)
2004
Hyb
ridTM
(Moi
r)
2004
Met
a Tr
ans
(Her
lihy,
Sha
vit)
2005
McT
M (S
aha
et a
l)
2006
Ato
mJa
va (H
indm
an…
)
1997
Tran
s S
uppo
rt TM
(Moi
r)
2005
TL1/
2 (D
ice,
Sha
vit))
2004
Sof
t Tra
ns (A
nani
an, R
inar
d)
2007-9…New lock based STMs from IBM, Intel,
Sun, Microsoft

As Good As Fine Grained Locking
Postulate (i.e. take it or leave it): If we could implement fine-grained locking with the same simplicity of course grained, we would never think of building a transactional memory.
Implication: Lets try to provide STMs that get as close as possible to hand-crafted fine-grained locking.

Subliminal Cut
25

Transactional Consistency
• Memory Transactions are collections of reads and writes executed atomically
• Tranactions should maintain internal and external consistency– External: with respect to the interleavings
of other transactions.– Internal: the transaction itself should
operate on a consistent state.

External Consistency
Application Memory
X
Y
4
2
8
4
Invariant x = 2y
Transaction A: Write xWrite y
Transaction B: Read xRead y Compute z = 1/(x-y) = 1/4

Locking STM Design Choices
PS = Lock per Stripe (separate array of locks)
PO = Lock per Object(embedded in object)
Map Array of Versioned-Write-Locks
Application Memory
V#

Encounter Order Locking (Undo Log)
1. To Read: load lock + location2. Check unlocked add to Read-Set3. To Write: lock location, store value 4. Add old value to undo-set5. Validate read-set v#’s unchanged6. Release each lock with v#+1
V# 0 V# 0
V# 0
V# 0
V# 0
V# 0
V# 0
X V# 1
V# 0 Y V# 1
V# 0 V# 0
Mem Locks
V#+1 0
V#+1 0
V# 0
V# 0
V# 0
V#+1 0
V# 0
V# 0
V# 0
V# 0
V#+1 0
V# 0
X
Y
Quick read of values freshly written by the reading transaction
[Ennals,Saha,Harris,TinySTM,SwissTM…]
Blue code does not change memory, red does

Commit Time Locking (Write Log)
1. To Read: load lock + location2. Location in write-set? (Bloom Filter)3. Check unlocked add to Read-Set4. To Write: add value to write set5. Acquire Locks6. Validate read/write v#’s unchanged7. Release each lock with v#+1
V# 0 V# 0
V# 0
V# 0
V# 0
V# 0
V# 0
V# 0
V# 0 V# 0
V# 0 V# 0
Mem Locks
V#+1 0
V# 0
V# 0
Hold locks for very short duration
V# 1
V# 1
V# 1 X
Y
V#+1 0
V# 1 V#+1 0
V# 0
V#+1 0
V# 0
V# 0
V# 0
V# 0
V#+1 0
V# 0
X
Y
[TL,TL2,SkySTM…]

COM vs. ENC High Load
ENC
Hand
Lock
COM
Red-Black Tree 20% Delete 20% Update 60% Lookup

COM vs. ENC Low Load
COMENC
Hand
Lock
Red-Black Tree 5% Delete 5% Update 90% Lookup

Problem: Internal Inconsistency
• A Zombie is a currently active transaction that is destined to abort because it saw an inconsistent state
• If Zombies see inconsistent states errors can occur and the fact that the transaction will eventually abort does not save us

Internal Inconsistency
Application Memory
X
Y
4
2
8
4
Invariant x = 2y
Transaction A: Write xWrite y
Transaction B: Read x = 4
Transaction B: Read y = 4 {trans is zombie}Compute z = 1/(x-y)
DIV by 0 ERROR

Past Approaches
1. Design STMs that allow internal inconsistency.
2. To detect zombies introduce validation into user code at fixed intervals or loops, used traps, OS support
3. Still there are cases where zombie’s cannot be detected infinite loops in user code…

Global Clock [TL2/SnapIsolation]
• Have a shared global version clock
• Incremented by writing transactions (as infrequently as possible)
• Read by all transactions
• Used to validate that the state viewed by a transaction is always consistent
[DiceShalevShavit06/ReigelFelberFetzer06]

TL2 Version Clock: Read-Only Trans
1. RV VClock2. To Read: read lock, read mem,
read lock, check unlocked, unchanged, and v# <= RV
3. Commit.
87 0 87 0
34 0
88 0
V# 0
44 0
V# 0
34 0
99 0 99 0
50 0 50 0
Mem Locks
Reads form a snapshot of memory.No read set!
100 Vclock (shared)
87 0
34 0
99 0
50 0
87 0
34 0
88 0
V# 0
44 0
V# 0
99 0
50 0
100 RV (private)

TL2 Version Clock: Writing Trans
1. RV VClock2. To Read/Write: check unlocked
and v# <= RV then add to Read/Write-Set
3. Acquire Locks4. WV = F&I(VClock)5. Validate each v# <= RV6. Release locks with v# WV
Reads+Inc+Writes=serializable
100 VClock
87 0 87 0
34 0
88 0
44 0
V# 0
34 0
99 0 99 0
50 0 50 0
Mem Locks
87 0
34 0
99 0
50 0
34 1
99 1
87 0
X
Y
Commit
121 0
121 0
50 0
87 0
121 0
88 0
V# 0
44 0
V# 0
121 0
50 0
100 RV
100120121
X
Y

How we learned to stop worrying and love the clock
Version clock rate is a progress concern, not a safety concern, so ..– (GV4) if failed to increment VClock
using CAS use VClock set by winner – (GV5) use WV = VClock + 2; inc VClock
on abort– (GV7) localized clocks… [AvniShavit08]

Uncontended Large Red-Black Tree5% Delete 5% Update 90% Lookup
Hand-crafted
TL/PSTL2/PS
Ennals
FraserHarrisLock-free
TL/PO TL2/P0

Contended Small RB-Tree30% Delete 30% Update 40% Lookup
Ennals
TL/P0
TL2/P0

Implicit Privatization [Menon et al]
• In real apps: often want to “privatize” data
• Then operate on it non-transactionally
• Many STMs (like TL2) based on “Invisible Readers”
• Invisible Readers/Writers are a problem if we want implicit privatization…

Privatization Pathology
b c da
P: atomically{ a.next = c; } // b is private b.value = 0;
P
P: atomically{ a.next = c; } // b is private b.value = 0;
0
P: atomically{ a.next = c; } // b is private b.value = 0;
P privatizes node b then modifies it non-transactionally

Privatization Pathology
b c da
P: atomically{ a.next = c; } // b is private b.value = 0;
Q: atomically{ tmp = a.next; foo = (1/tmp.value) }
P
P: atomically{ a.next = c; } // b is private b.value = 0;
Q: atomically{ tmp = a.next; foo = (1/tmp.value) }
0
P: atomically{ a.next = c; } // b is private b.value = 0;
Q
Invisible reader Q cannot detect non-transactional modification to node b
Q: atomically{ tmp = a.next; foo = (1/tmp.value) }
Q: divide by 0 error

Solving the Privatization Problem
• Visible Writers – Reads are made aware of overlapping writes
[DiceShavit07/M4,Gottschlich Connors07, SpearMichaelVonPraun08 …]
• Visible Readers– Writes are made aware of overlapping reads
[EllenLevLuchangcoMoir07/SNZI, DiceShavit09/Bytelocks…]
b
P
Q

Visible Readers
• Use read-write locks. Transactions also lock to read.
• Privatization is immediate…• But RW-locks will make us burn in
coherence traffic hell: CAS to increment/decrement reader-count
• Which is why we had invisible readers in the first place
Or is
it ?

• A new read-write lock for multicores
• Common case: no CAS, only store + membar to read
• Claim: on modern multicores cost of coherent stores not too bad…
Read-Write Bytelocks [DiceShavit09]
MapArray of read-write byte-locks
a bytelock
Application Memory

49
The ByteLock Lock Record• Writer ID• Visible readers :
– Reader count for unslotted threads• CAS to increment and decrement
– Reader array for slotted threads• Array of atomically addressable bytes • 48 or 112 slots, Write + Membar to Modify
wrtid rdcnt
Single $ line
0 1 0 0 1
Slots
1 2 3 4 5
a byte per slot
traditional
Writer id counter for unslotted

50
ByteLock Write
0 30 1 0 0 1
Mem1 2 3 4 5
wrtid rdcnt
Writer i
i
CAS
Intel, AMD, Sun read 8 or 16 bytes at a time
Spin until all 0
Writers wait till readers drain out
X
51
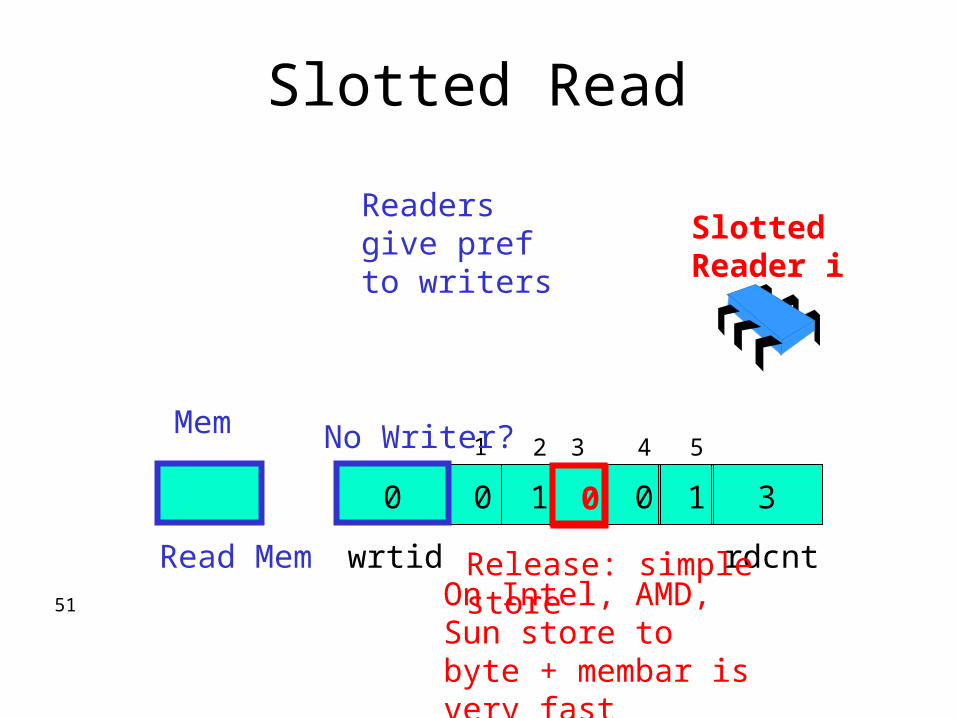
Slotted Read
0 30 1 0 0 1
Mem1 2 3 4 5
wrtid rdcnt
Slotted Reader i
Readers give pref to writers
1
No Writer?
0
Read MemOn Intel, AMD, Sun store to byte + membar is very fast
Release: simple store

53
Unslotted Read
i 30 1 0 1
Mem1 2 3 4 5
wrtid rdcnt
Unslotted Reader i
4
CASIf non-0
Unslotted readers like in traditional RW
3
Decrement using CAS and wait for writer to go away

54Transact 2009
Mutex
TLRWBytelock128 slot
ByteLock Performance
TLRWInc/dec
read counters
TLRWBytelock48 slot
TL2-GV6PS

Where we are heading…
• A lot more work on performance – Visible writers, visible readers
• Think GC, game just begun – Improve single threaded– Amazing possibilities for compiler optimization– OS support
• Explosion of new STMs– ~100 TM papers in last couple of years

A bit further down the road…
• Transactional Languages– No Implicit Privatization Problem…– Composability
• And when hardware TM arrives…– Contention management– New possibilities for extending and
interfacing…

Need Experience with Apps
• Today– MSF, Quake, Apache, FenixEDU (Large
Distributed App),Student Trials in Germany and US…
• Need a lot more transactification of applications– Not just rewriting of concurrent apps– But actually applications that are parallelized from
scratch using TM

Thanks!