structured prediction with reinforcement learning
TRANSCRIPT

Structured Prediction With Reinforcement Learning
Guruprasad Zapate
University of Paderborn
1

Outline● Introduction
○ Structured Prediction (SP)
○ Reinforcement Learning (RL)
● SP-MDP framework
● Approximated RL Algorithms
● Conclusion
2

Structured Prediction (SP)● In “normal” machine learning our goal is to learn unknown function
➔ Here input can be any kind of complex objects
➔ And output is a real value number
◆ For e.g classification, regression, density estimation
● Structure Prediction goal is to learn such that:
➔ Where outputs are structured objects
3
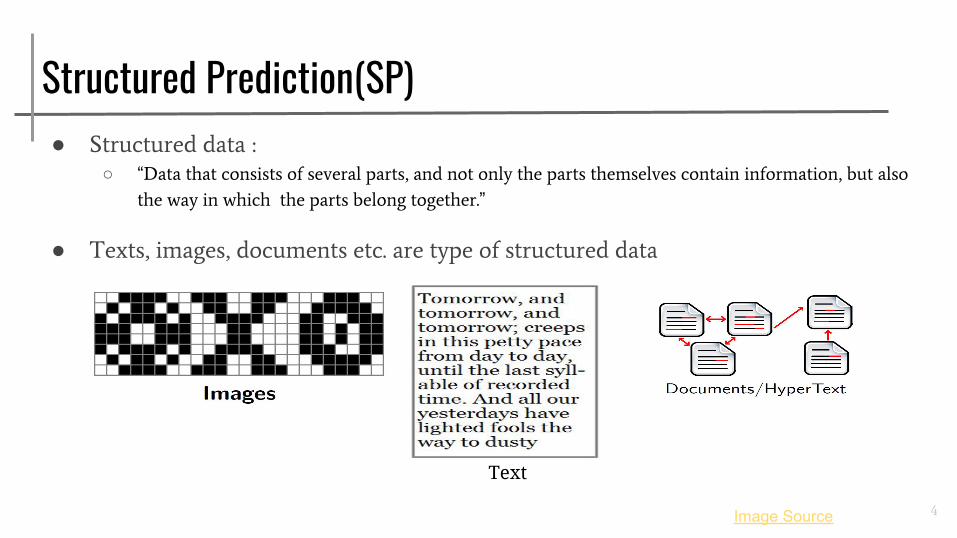
Structured Prediction(SP)● Structured data :
○ “Data that consists of several parts, and not only the parts themselves contain information, but also
the way in which the parts belong together.”
● Texts, images, documents etc. are type of structured data
Text
4 Image Source
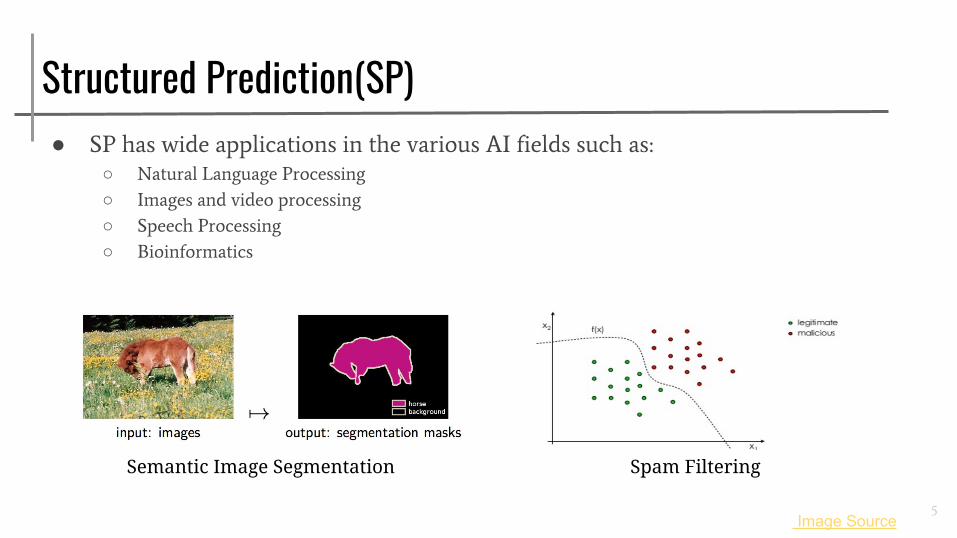
Structured Prediction(SP)● SP has wide applications in the various AI fields such as:
○ Natural Language Processing
○ Images and video processing
○ Speech Processing
○ Bioinformatics
5
Image Source
Semantic Image Segmentation Spam Filtering

Structured Prediction(SP)● Models used to solve SP problems
○ Global Models
■ Focuses on the global characteristics of the data
■ For simplicity classification is also used
■ Linear models such as Perceptron, SVM are customized for structured outputs
■ Conditional Random Fields(CRF) are also widely used
○ Incremental Models
■ Turn learning into sequential process
■ After each step partial output is predicted and model is updated
■ Incremental Parsing, Incremental Prediction are some the few models which uses
incremental approach
6

Reinforcement Learning (RL)● A type of Machine Learning with core idea :
○ To make machines as intelligent as humans, we need to make machines learn like humans
● Learning model contains following entities:
○ Agent (Decision Maker/Learner)
○ Environment (External conditions)
○ States
○ Actions
○ Rewards - the consequence of actions
● Agent learns from interaction with environment through the means of reward
7

Reinforcement Learning (RL)
● Learning procedure in RL
○ Agent observes a state
○ An action is determined by a decision making function (policy)
○ Action is performed and state is changed
○ Reward function assigns rewards from the environment
● Two distinguish characteristics
○ Trial & Error Search
○ Delayed Rewards
8Image Source

MDP Framework● Markov Decision Processes formally describes an environment for RL
● Processes hold Markov property which states:
○ “The future is independent of the past given the present”
● MDP framework contains following components:
○ Set of possible states S○ Set of possible actions A○ A real valued reward function R(s,a)○ State Transition function T to measure each action’s effect in each state
● Next state is only dependent on the current state, past states are insignificant
● Goal is to find an optimal policy that maximizes the total reward
9

SP-MDP Framework ● Structured Prediction Markov Decision Process (SP-MDP)
○ Instantiation of MDP for Structured Prediction
● SP-MDP framework constitutes of following components:
○ States
■ Contains both input and partial output
■ Final states contain complete output
○ Actions
■ Each state has a set of available actions
○ Transition
■ Replaces the partial output by the transformed partial output
○ Rewards
■ Loss function is used to assign rewards for state-action pair
10

SP-MDP Framework
11Image Source
Handwritten digit recognition on sequential data

SP-MDP Framework ● Rewards Integration
○ Per-episode rewards :
■ Only final states are considered for rewards
■ Final reward is negative loss of the predicted output to the correct output
○ Per-decision rewards :
■ Rewards are given after each step for all the states
■ Much richer reward signals
12

Optimal Policy in SP-MDP● Per-episode Rewards
○ Total Reward in one trajectory (state-action sequence from start to finish) for a policy
○ Optimal policy is the one which minimizes the rewards ( due to negative loss)
13

Optimal Policy in SP-MDP● Per-decision Rewards
○ Total Reward in one trajectory for a policy
○ Optimal policy is the one which minimizes the rewards
14

Equivalence between SP and SP-MDP● Learning goal in SP is to minimize the empirical risk
○ Empirical risk measures how much, on average, it hurts to use inferred function as our prediction
algorithm
○ Given parameters and loss function , goal is to minimize the loss
● Minimizing the empirical risk in SP is similar to finding optimal policy in
SP-MDP
● Equivalence helps to use RL algorithms for SP through SP-MDP framework
15

Approximated Value based RL● Quite straightforward approach
● Uses action-value function that assigns the scores for the taken actions
● Employs greedy policy to maximize the score which is defined as
● Discounted rewards are also used which determines current value of the future
rewards
● Linear functions are used for approximation for large MDPs
16

Approximated Value based RL
● SARSA, Q-Learning etc. are widely used value based RL models
● Works well in many applications
● Limitations :
○ Focused on deterministic policies
○ Small change in estimated value can affect the performance
○ Difficult to converge to a policy
○ Very complex in cases of large MDPs
17

Policy gradient RL
● Modify policy parameters directly instead of estimating action values
● Search directly for the optimal policy
● Estimates gradient through simulation
● After each step gradient is updated and stochastic ascent performed on
parameters
● Maximizes the expected reward-per-step
18

Policy gradient RL ● Advantages:
○ Better convergence properties
○ Effective in high–dimensional or continuous action spaces
○ Policy subspace can be chosen according to the task
○ Can learn stochastic policies
● Limitations:
○ Evaluating a policy is typically inefficient and high variance
○ Tends to converge to a local optimum rather than global optimum
19

Using RL algorithms in SP-MDP● Policy is learned in an SP-MDP based on any approximated RL algorithms
● Use policy for inference
● Start with an input and default initial output
● Actions are chosen using linear approximation
● Final states provide complete predicted output
● Complexity for prediction can be given as where:
○ T : maximum number of steps to predict complete output
○ : mean number of available actions
20

Conclusion● We learned & discussed topics
○ Structured Prediction
○ Reinforcement Learning
● Introduced a new framework SP-MDP that links SP & RL
● Introduced widely used RL algorithms
● Discussed how RL algorithms can be used in SP-MDP
21

Q&A● ??!
22