· web viewas we know that an 18 bit multiplier already exists in spartan 3, the main idea is to...
TRANSCRIPT

Abstract
The Image and digital signal processing applications require high floating point
calculations throughput, and nowadays FPGAs are being used for performing these
Digital Signal Processing (DSP) operations. Floating point operations are hard to
implement directly on FPGAs because of the complexity of their algorithms. On the
other hand, many scientific problems require floating point arithmetic with high levels of
accuracy in their calculations. Therefore, we have explored FPGA implementations of
multiplication for IEEE single precision floating-point numbers. For floating point
multiplication, in IEEE single precision format we have to multiply two 24 bit mantissas.
As we know that an 18 bit multiplier already exists in Spartan 3, the main idea is
to use the existing 18 bit multiplier with a dedicated 24 bit multiplier so as to perform
floating-point arithmetic operations with atmost precision and accuracy and also to
implement the prototyping on a Xilinx Spartan 3 FPGA using VHDL.
1

CHAPTER 1
INTRODUCTION1.1 Introduction
Image and digital signal processing applications require high floating point
calculations throughput, and nowadays FPGAs are being used for performing these
Digital Signal Processing (DSP) operations. Floating point operations are hard to
implement on FPGAs as their algorithms are quite complex. In order to combat this
performance bottleneck, FPGAs vendors including Xilinx have introduced FPGAs with
nearly 254 18x18 bit dedicated multipliers. These architectures can cater the need of high
speed integer operations but are not suitable for performing floating point operations
especially multiplication. Floating point multiplication is one of the performance
bottlenecks in high speed and low power image and digital signal processing
applications. Recently, there has been significant work on analysis of high-performance
floating-point arithmetic on FPGAs. But so far no one has addressed the issue of
changing the dedicated 18x18 multipliers in FPGAs by an alternative implementation for
improvement in floating point efficiency. It is a well known concept that the single
precision floating point multiplication algorithm is divided into three main parts
corresponding to the three parts of the single precision format. In FPGAs, the bottleneck
of any single precision floating-point design is the 24x24 bit integer multiplier required
for multiplication of the mantissas. In order to circumvent the aforesaid problems, we
designed floating point multiplication
Although computer arithmetic is sometimes viewed as a specialized part of
CPUdesign, still the discrete component designing is also a very important aspect. A
tremendous variety of algorithms have been proposed for use in floating-point systems.
Actual implementations are usually based on refinements and variations of the few basic
algorithms presented here. In addition to choosing algorithms for addition, subtraction,
multiplication and division, the computer architect must make other choices. What
precisions should be implemented? How should exceptions be handled? This report will
give the background for making these and other decisions.
2

Our discussion of floating point will focus almost exclusively on the IEEE
floating-point standard (IEEE 754) because of its rapidly increasing acceptance.
Although floating-point arithmetic involves manipulating exponents and shifting
fractions, the bulk of the time in floating-point operations is spent operating on fractions
using integer algorithms. Thus, after our discussion of floating point, we will take a more
detailed look at efficient algorithms and architectures.
The pivotal task that lies ahead is to design a floating point multiplier using
VHDL and its FPGA implementation.
Why only floating point ?All data on microprocessors is stored in a binary representation at some level.
After having a good look at what kind of real number representations that could be used
in processors there were only two representations that have come close to fulfilling the
modern day processor needs, they are the fixed and floating point representations. Now,
let us have a brief glance at these representations to have a good understanding of what
made us to go floating point representation.
Table 1.1 Comparision of Floating Point and Fixed Point Representations
Fixed Point Floating Point
Limited range
Number of bits grows for more
accurate results
Easy to implement in hardware
Dynamic range
Accurate results
More complex and higher cost to
implement in hardware
Why only FPGA for prototyping ?
Leading-edge ASIC designs are becoming more expensive and time-
consuming because of the increasing cost of mask sets and the amount of engineering
verification required. Getting a device right the first time is imperative. A single missed
3

deadline can mean the difference between profitability and failure in the product life
cycle. Figure 1 shows how the impact that time-to-market delays can have on product
sales.
Fig 1.1 Declining Product Sales Due to Late-to-Market Designs
Using an FPGA to prototype an ASIC or ASSP for verification of both register
transfer level (RTL) and initial software development has now become standard practice
to both decrease development time and reduce the risk of first silicon failure. An FPGA
prototype accelerates verification by allowing testing of a design on silicon from day one,
months in advance of final silicon becoming available. Code can be compiled for the
FPGA, downloaded, and debugged in hardware during both the design and verification
phases using a variety of techniques and readily available solutions. Whether you're
doing RTL validation, initial software development, and/or system-level testing, FPGA
prototyping platforms provide a faster, smoother path to delivering an end working
product.
4

Table 1.2 Comparision between FPGA and ASIC :
Property FPGA ASIC
Digital and Analog
Capability
Digital only Digital and Analog
Size Larger More smaller
Operating Frequency Lower(up to 400MHz) Higher(up to 3GHz)
Power Consumption Higher Lower
Design Cycle Very Small(few mins) Very long(about 12 weeks)
Mass Production Higher price Lower price
Security More secure less secure
VHDLThe VHSIC (very high speed integrated circuits) Hardware Description
Language(VHDL) was first proposed in 1981. The development of VHDL was originated
by IBM,Texas Instruments, and Inter-metrics in 1983. The result, contributed by many
participating EDA (Electronics Design Automation) groups, was adopted as the IEEE
1076 standard in December 1987.
VHDL is intended to provide a tool that can be used by the digital systems
community to distribute their designs in a standard format.
As a standard description of digital systems, VHDL is used as input and output to
various simulation, synthesis, and layout tools. The language provides the ability to
describe systems, networks, and components at a very high behavioral level as well as
very low gate level. It also represents a top-down methodology and environment.
Simulations can be carried out at any level from a generally functional analysis to a very
detailed gate-level wave form analysis.
5

CHAPTER 2
PROJECT THESIS
2.1 NUMBER REPRESENTATIONS
There are two types of number representations they are:
1. Fixed-point .
2. Floating point.
Now let us have a detailed glance at each of them.
2.1.1 Fixed-Point Representation
In fixed-point representation, a specific radix point - called a decimal point in
English and written "." - is chosen so there is a fixed number of bits to the right and a
fixed number of bits to the left of the radix point. The bits to the left of the radix point are
called the integer bits. The bits to the right of the radix point are called the fractional bits.
Fig 2.1 Fixed-Point Representation
In fixed-point representation, a specific radix point - called a decimal point in
English and written "." - is chosen so there is a fixed number of bits to the right and a
fixed number of bits to the left of the radix point. The bits to the left of the radix point are
called the integer bits. The bits to the right of the radix point are called the fractional bits.
In this example, assume a 16-bit fractional number with 8 magnitude bits and 8
radix bits, which is typically represented as 8.8 representation. Like most signed integers,
fixed-point numbers are represented in two's complement binary. Using a positive
number keeps this example simple
6

To encode 118.625, first find the value of the integer bits. The binary
representation of 118 is 01110110, so this is the upper 8 bits of the 16-bit number. The
fractional part of the number is represented as 0.625 x 2n where n is the number of
fractional bits. Because 0.625 x 256 = 160, you can use the binary representation of 160,
which is 10100000, to determine the fractional bits. Thus, the binary representation for
118.625 is 0111 0110 1010 0000. The value is typically referred to using the hexadecimal
equivalent, which is 76A0.
The major advantage of using fixed-point representation for real numbers is that
fixed-point adheres to the same basic arithmetic principles as integers. Therefore, fixed-
point numbers can take advantage of the general optimizations made to the Arithmetic
Logic Unit (ALU) of most microprocessors, and do not require any additional libraries or
any additional hardware logic. On processors without a floating-point unit (FPU), such as
the Analog Devices Blackfin Processor, fixed-point representation can result in much
more efficient embedded code when performing mathematically heavy operations.
In general, the disadvantage of using fixed-point numbers is that fixed-point
numbers can represent only a limited range of values, so fixed-point numbers are
susceptible to common numeric computational inaccuracies. For example, the range of
possible values in the 8.8 notation that can be represented is +127.99609375 to -128.0. If
you add 100 + 100, you exceed the valid range of the data type, which is called overflow.
In most cases, the values that overflow are saturated, or truncated, so that the result is the
largest representable number.
2.1.2 Floating Point Numbers
The floating-point representation is one way to represent real numbers. A floating-
point number n is represented with an exponent e and a mantissa m, so that:
n = be × m, …where b is the base number (also called radix)
So for example, if we choose the number n=17 and the base b=10, the floating-point
representation of 17 would be: 17 = 101 x 1.7
Another way to represent real numbers is to use fixed-point number representation. A
fixed-point number with 4 digits after the decimal point could be used to represent numbers
such as: 1.0001, 12.1019, 34.0000, etc. Both representations are used depending on the
7

situation. For the implementation on hardware, the base-2 exponents are used, since digital
systems work with binary numbers.
Using base-2 arithmetic brings problems with it, so for example fractional powers of
10 like 0.1 or 0.01 cannot exactly be represented with the floating-point format, while with
fixed-point format, the decimal point can be thought away (provided the value is within the
range) giving an exact representation. Fixed-point arithmetic, which is faster than floating-
point arithmetic, can then be used. This is one of the reasons why fixed-point representations
are used for financial and commercial applications.
The floating-point format can represent a wide range of scale without losing
precision, while the fixed-point format has a fixed window of representation. So for example
in a 32-bit floating-point representation, numbers from 3.4 x 1038 to 1.4 x 10-45 can be
represented with ease, which is one of the reasons why floating-point representation is the
most common solution.
Floating-point representations also include special values like infinity, Not-a-Number
(e.g. result of square root of a negative number).
A float consists of three parts: the sign bit, the exponent, and the mantissa. The
division of the three parts is as follows considering a single-precision floating point
format which would be elaborated in a detailed manner at a later stage
fig 2.2 Floating-Point Representation
The sign bit is 0 if the number is positive and 1 if the number is negative. The
exponent is an 8-bit number that ranges in value from -126 to 127. The exponent is
actually not the typical two's complement representation because this makes comparisons
more difficult. Instead, the value is biased by adding 127 to the desired exponent and
representation, which makes it possible to represent negative numbers. The mantissa is
the normalized binary representation of the number to be multiplied by 2 raised to the
power defined by the exponent
8

Now look at how to encode 118.625 as a float. The number 118.625 is a positive
number, so the sign bit is 0. To find the exponent and mantissa, first write the number in
binary, which is 1110110.101 (get more details on finding this number in the "Fixed-
Point Representation" section). Next, normalize the number to 1.110110101 x 26, which
is the binary equivalent of scientific notation. The exponent is 6 and the mantissa is
1.110110101. The exponent must be biased, which is 6 + 127 = 133. The binary
representation of 133 is 10000101.
Thus, the floating-point encoded value of 118.65 is 0100 0010 1111 0110 1010
0000 0000 0000. Binary values are often referred to in their hexadecimal equivalent. In
this case, the hexadecimal value is 42F6A000.
Thus a Floating-point solves a number of representation problems. Fixed-point
has a fixed window of representation, which limits it from representing very large or very
small numbers. Also, fixed-point is prone to a loss of precision when two large numbers
are divided.
Floating-point, on the other hand, employs a sort of "sliding window" of precision
appropriate to the scale of the number. This allows it to represent numbers from
1,000,000,000,000 to 0.0000000000000001 with ease.
Comparision of Floating-Point and Fixed Point Representations
Fixed Point Floating Point
Limited range
Number of bits grows for more
accurate results
Easy to implement in hardware
Dynamic range
Accurate results
More complex and higher cost to
implement in hardware
9

2.1.3 Floating Point: Importance
Many applications require numbers that aren’t integers. There are a number of
ways that non-integers can be represented. Adding two such numbers can be done with
an integer add, whereas multiplication requires some extra shifting. There are various
ways to represent the number systems. However, only one non-integer representation has
gained widespread use, and that is floating point. In this system, a computer word is
divided into two parts, an exponent and a significand. As an example, an exponent of
( −3) and significand of 1.5 might represent the number 1.5 × 2–3 = 0.1875. The
advantages of standardizing a particular representation are obvious.
The semantics of floating-point instructions are not as clear-cut as the semantics
of the rest of the instruction set, and in the past the behavior of floating-point operations
varied considerably from one computer family to the next. The variations involved such
things as the number of bits allocated to the exponent and significand, the range of
exponents, how rounding was carried out, and the actions taken on exceptional conditions
like underflow and over- flow. Now a days computer industry is rapidly converging on
the format specified by IEEE standard 754-1985 (also an international standard, IEC
559).The advantages of using a standard variant of floating point are similar to those for
using floating point over other non-integer representations. IEEE arithmetic differs from
much previous arithmetic.
2.2 IEEE Standard 754 for Binary Floating-Point Arithmetic
2.2.1 Formats
The IEEE (Institute of Electrical and Electronics Engineers) has produced a
Standard to define floating-point representation and arithmetic. Although there are other
representations, it is the most common representation used for floating point numbers.
The standard brought out by the IEEE come to be known as IEEE 754.
The standard specifies :
1) Basic and extended floating-point number formats
2) Add, subtract, multiply, divide, square root, remainder, and compare
operations .
3) Conversions between integer and floating-point formats
10

4) Conversions between different floating-point formats
5) Conversions between basic format floating-point numbers and decimal strings
6) Floating-point exceptions and their handling, including non numbers (NaNs)
When it comes to their precision and width in bits, the standard defines two
groups: basic- and extended format. The extended format is implementation dependent
and doesn’t concern this project.
The basic format is further divided into single-precision format with 32-bits
wide, and double-precision format with 64-bits wide. The three basic components are
the sign, exponent, and mantissa. The storage layout for single-precision is shown below:
2.2.2 Storage Layout
IEEE floating point numbers have three basic components: the sign, the exponent,
and the mantissa. The mantissa is composed of the fraction and an implicit leading digit
(explained below). The exponent base (2) is implicit and need not be stored.
The following figure shows the layout for single (32-bit) and double (64-bit) precision
floating-point values. The number of bits for each field are shown (bit ranges are in square
brackets):
Sign Exponent Fraction Bias
Single Precision 1 [31] 8 [30-23] 23 [22-00] 127
Double Precision 1 [63] 11 [62-52] 52 [51-00] 1023
Table 2.1 Storage layouts
The Sign Bit
The sign bit is as simple as it gets. 0 denotes a positive number; 1 denotes a
negative number. Flipping the value of this bit flips the sign of the number.
11

The Exponent
The exponent field needs to represent both positive and negative exponents. To do
this, a bias is added to the actual exponent in order to get the stored exponent. For IEEE
single-precision floats, this value is 127. Thus, an exponent of zero means that 127 is
stored in the exponent field. A stored value of 200 indicates an exponent of (200-127), or
73. For reasons discussed later, exponents of -127 (all 0s) and +128 (all 1s) are reserved
for special numbers. For double precision, the exponent field is 11 bits, and has a bias of
1023.
The Mantissa
The mantissa, also known as the significand, represents the precision bits of the
number. It is composed of an implicit leading bit and the fraction bits. To find out the
value of the implicit leading bit, consider that any number can be expressed in scientific
notation in many different ways. For example, the number five can be represented as any
of these:
5.00 × 100
0.05 × 102
5000 × 10-3
In order to maximize the quantity of representable numbers, floating-point
numbers are typically stored in normalized form. This basically puts the radix point after
the first non-zero digit. In normalized form, five is represented as 5.0 × 100.
A nice little optimization is available to us in base two, since the only possible
non-zero digit is 1. Thus, we can just assume a leading digit of 1, and don't need to
represent it explicitly. As a result, the mantissa has effectively 24 bits of resolution, by
way of 23 fraction bits.
12

Putting it All Together
So, to sum up:
1. The sign bit is 0 for positive, 1 for negative.
2. The exponent's base is two.
3. The exponent field contains 127 plus the true exponent for single-precision, or
1023 plus the true exponent for double precision.
4. The first bit of the mantissa is typically assumed to be 1.f, where f is the field of
fraction bits.
Ranges of Floating-Point Numbers
Let's consider single-precision floats for a second. Note that we're taking
essentially a 32-bit number and re-jiggering the fields to cover a much broader range.
Something has to give, and it's precision. For example, regular 32-bit integers, with all
precision centered around zero, can precisely store integers with 32-bits of resolution.
Single-precision floating-point, on the other hand, is unable to match this resolution with
its 24 bits. It does, however, approximate this value by effectively truncating from the
lower end. For example:
11110000 11001100 10101010 00001111 // 32-bit integer
= +1.1110000 11001100 10101010 x 231 // Single-Precision Float
= 11110000 11001100 10101010 00000000 // Corresponding Value
This approximates the 32-bit value, but doesn't yield an exact representation. On
the other hand, besides the ability to represent fractional components (which integers lack
completely), the floating-point value can represent numbers around 2127, compared to 32-
bit integers maximum value around 232.
13

The range of positive floating point numbers can be split into normalized numbers
(which preserve the full precision of the mantissa), and denormalized numbers (discussed
later) which use only a portion of the fractions's precision.
Storage Layout Denormalized NormalizedApproximate
Decimal
Single Precision ± 2-149 to (1-2-23)×2-126 ± 2-126 to (2-2-23)×2127 ± ~10-44.85 to ~1038.53
Double
Precision± 2-1074 to (1-2-52)×2-1022
± 2-1022 to (2-2-
52)×21023± ~10-323.3 to ~10308.3
Table 2.2 Storage layouts ranges
Since the sign of floating point numbers is given by a special leading bit, the range
for negative numbers is given by the negation of the above values.
There are five distinct numerical ranges that single-precision floating-point numbers
are not able to represent:
1. Negative numbers less than -(2-2-23) × 2127 (negative overflow)
2. Negative numbers greater than -2-149 (negative underflow)
3. Zero
4. Positive numbers less than 2-149 (positive underflow)
5. Positive numbers greater than (2-2-23) × 2127 (positive overflow)
Overflow means that values have grown too large for the representation, much in the
same way that you can overflow integers. Underflow is a less serious problem because is
just denotes a loss of precision, which is guaranteed to be closely approximated by zero.
14

Here's a table of the effective range (excluding infinite values) of IEEE floating-point
numbers:
Note that the extreme values occur (regardless of sign) when the exponent is at the
maximum value for finite numbers (2127 for single-precision, 21023 for double), and the
mantissa is filled with 1s (including the normalizing 1 bit).
As the current project being implemented deals with single-precision format a
detailed insight would be preferable
Single precision :
The most significant bit starts from the left
Fig 2.3 Single precision format
The double-precision doesn’t concern this project and therefore will not be
discussed further.
The number represented by the single-precision format is:
value = (-1)s2e × 1.f (normalized) when E > 0 else
15
Binary Decimal
Single ± (2-2-23) × 2127 ~ ± 1038.53
Double ± (2-2-52) × 21023 ~ ± 10308.25

= (-1)s2-126 × 0.f (denormalized)
where
f = (b23-1+b22
-2+ bin +…+b0
-23) where bin =1 or 0
s = sign (0 is positive; 1 is negative)
E =biased exponent; Emax=255 , Emin=0. E=255 and E=0 are used to
Represent special values.
e =unbiased exponent; e = E – 127(bias)
A bias of 127 is added to the actual exponent to make negative exponents possible
without using a sign bit. So for example if the value 100 is stored in the exponent
placeholder, the exponent is actually -27 (100 – 127). Not the whole range of E is used to
represent numbers.
As you may have seen from the above formula, the leading fraction bit before the
decimal point is actually implicit (not given) and can be 1 or 0 depending on the exponent
and therefore saving one bit. Next is a table with the corresponding values for a given
representation to help better understand what was explained above.
16

2.3 Table showing some of the basic representations using single precision IEEE 754
Standard:
Sign(s) Exponent(e) Fraction Value
0
00000000 00000000000000000000000 +0
(positive zero)
1
00000000 00000000000000000000000 -0
(negative zero)
1
00000000 10000000000000000000000 -20-127x0.(2-1)=
-20-127x 0.5
0
00000000 00000000000000000000001 +20-127x0.(2-23)
(smallest value)
0
00000001 01000000000000000000000 +21-127x1.(2-2)=
+21-127x1.25
0
10000001 00000000000000000000000 +2129-127x1.0= 4
0
111111
11
00000000000000000000000 + infinity
1
111111
11
00000000000000000000000 - infinity
0
111111
11
10000000000000000000000 Not a Number(NaN)
1 11111111 10000100010000000001100 Not a Number(NaN)
Exceptions
The IEEE standard defines five types of exceptions that should be signaled
through a one bit status flag when encountered.
17

Invalid Operation
Some arithmetic operations are invalid, such as a division by zero or square root
of a negative number. The result of an invalid operation shall be a NaN. There are two
types of NaN, quiet NaN (QNaN) and signaling NaN (SNaN). They have the following
format, where s is the sign bit:
QNaN = s 11111111 10000000000000000000000
SNaN = s 11111111 00000000000000000000001
The result of every invalid operation shall be a QNaN string with a QNaN or
SNaN exception. The SNaN string can never be the result of any operation, only the
SNaN exception can be signaled and this happens whenever one of the input operand is a
SNaN string otherwise the QNaN exception will be signaled. The SNaN exception can
for example be used to signal operations with uninitialized operands, if we set the
uninitialized operands to SNaN. However this is not the subject of this standard.
The following are some arithmetic operations which are invalid operations and
that give as a result a QNaN string and that signal a QNaN exception:
1) Any operation on a NaN
2) Addition or subtraction: ∞ + (−∞)
3) Multiplication: ± 0 × ± ∞
4) Division: ± 0/ ± 0 or ± ∞/ ± ∞
5) Square root: if the operand is less than zero
Division by Zero
The division of any number by zero other than zero itself gives infinity as a result.
The addition or multiplication of two numbers may also give infinity as a result. So to
differentiate between the two cases, a divide-by-zero exception was implemented.
Inexact
This exception should be signaled whenever the result of an arithmetic operation
is not exact due to the restricted exponent and/or precision range.
Overflow
The overflow exception is signaled whenever the result exceeds the maximum
value that can be represented due to the restricted exponent range. It is not signaled when
18

one of the operands is infinity, because infinity arithmetic is always exact. Division by
zero also doesn’t trigger this exception.
Infinity
This exception is signaled whenever the result is infinity without regard to how
that occurred. This exception is not defined in the standard and was added to detect faster
infinity results.
Zero
This exception is signaled whenever the result is zero without regard to how that
occurred. This exception is not defined in the standard and was added to detect faster zero
results.
Underflow
Two events cause the underflow exception to be signaled, tininess and loss of
accuracy. Tininess is detected after or before rounding when a result lies between ±2Emin.
Loss of accuracy is detected when the result is simply inexact or only when a
denormalization loss occurs. The implementer has the choice to choose how these events
are detected. They should be the same for all operations. The implemented FPU core
signals an underflow exception whenever tininess is detected after rounding and at the
same time the result is inexact.
Rounding Modes
Since the result precision is not infinite, sometimes rounding is necessary. To
increase the precision of the result and to enable round-to-nearest-even rounding mode, three
bits were added internally and temporally to the actual fraction: guard, round, and sticky bit.
While guard and round bits are normal storage holders, the sticky bit is turned ‘1’ when ever
a ‘1’ is shifted out of range.
As an example we take a 5-bits binary number: 1.1001. If we left-shift the number
four positions, the number will be 0.0001, no rounding is possible and the result will not be
accurate. Now, let’s say we add the three extra bits. After left-shifting the number four
positions, the number will be 0.0001 101 (remember, the last bit is ‘1’ because a ‘1’ was
19

shifted out). If we round it back to 5-bits it will yield: 0.0010, therefore giving a more
accurate result.
The standard specifies four rounding modes :
Round to nearest even
This is the standard default rounding. The value is rounded up or down to the
nearest infinitely precise result. If the value is exactly halfway between two infinitely
precise results, then it should be rounded up to the nearest infinitely precise even.
For example: Unrounded Rounded
3.4 3
5.6 6
3.5 4
2.5 2
Round-to-Zero
Basically in this mode the number will not be rounded. The excess bits will simply
get truncated, e.g. 3.47 will be truncated to 3.4.
Round-Up
The number will be rounded up towards +∞, e.g. 3.2 will be rounded to 4, while -3.2
to -3.
Round-Down
The opposite of round-up, the number will be rounded up towards -∞, e.g. 3,2 will be
rounded to 3, while -3,2 to -4.
2.3 Floating Point Unit
2.3.1 Introduction
20

The floating point unit (FPU) implemented during this project, is a 32-bit
processing unit which allows arithmetic operations on floating point numbers. The FPU
complies fully with the IEEE 754 Standard
The FPU supports the following arithmetic operations:
1. Add
2. Subtract
3. Multiply
4. Divide
5. Square Root
For each operation the following rounding modes are supported:
1. Round to nearest even
2. Round to zero
3. Round up
4. Round down
Since this project deals with Floating point multiplication the main emphasis lays on
the steps involved in the multiplication of two floating point numbers.
2.4 Floating-point Multiplication
2.4.1 Multiplication of floating point numbers
21

In the following sections, the basic algorithm for multiplication operation will be
outlined. For more exact detail please see the VHDL code, the code was commented as
much as possible.
Multiplication is simple. Suppose you want to multiply two floating point numbers, X
and Y.
Here's how to multiply floating point numbers.
1. First, convert the two representations to scientific notation. Thus, we explicitly
represent the hidden 1.
2. Let x be the exponent of X. Let y be the exponent of Y. The resulting exponent
(call it z) is the sum of the two exponents. z may need to be adjusted after the
next step.
3. Multiply the mantissa of X to the mantissa of Y. Call this result m.
4. If m is does not have a single 1 left of the radix point, then adjust the radix point
so it does, and adjust the exponent z to compensate.
5. Add the sign bits, mod 2, to get the sign of the resulting multiplication.
6. Convert back to the one byte floating point representation, truncating bits if
needed.
22

2.4.2 Multiplication Algorithm
23

2.4.3 Why Choose This Algorithm?
The algorithm is simple and elegant due to the following attributes
– Use small table-lookup method with small multipliers
– Very well suited to FPGA implementations
– Block RAM, distributed memory, embedded multiplier
– Lead to a good tradeoff of area and latency
– Can be fully pipelined
– Clock speed similar to all other components
The multiplication can also be done parallelly to save clock cycles, but it has to be
done at the cost of hardware. The hardware needed for the parallel 32-bit multiplier is
approximately 3 times that of serial.
To demonstrate the basic steps, let’s say we want to multiply two 5-digits FP numbers:
2100 × 1.1001
× 2110 × 1.0010
_________________
Step1: multiply fractions and calculate the result exponent.
1.1001
× 1.0010
_________________
1.11000010
so fracO= 1.11000010 and eO = 2100+110-bias = 283
Step 2: Round the fraction to nearest-even
fracO= 1.1100
Step 3: Result 283 × 1.1100
24

CHAPTER 3
Implementation Strategies:
3.1 Implementation Choices VLSI Implementation Approaches
Full Custom Semi Custom
Cell-based Array-based
Standard Cells Macro Cells Prediffused Prewired(FPGA's)
The various approaches in the design of an IC are:
To identify the characteristics used to categorize the different types of VLSI
methodologies into full custom, semi-custom and standard design
To classify a given IC into one of the above groups
To evaluate and decide on the most optimal design method to implement the
IC for a given case study
To describe the different stages of the design cycle
To identify an ASIC family
To summarize the main features of an FPGA architecture
To describe the FPGA development cycle
Now let us have a good look at each of these implementation strategies and try to
reason out why the FPGA is the most preferred one
25

3.1.1 Full-Custom ASIC :
Introduction : Full-custom design is a methodology for designing integrated circuits by
specifying the layout of each individual transistor and the interconnections between them.
Alternatives to full-custom design include various forms of semi-custom design, such as
the repetition of small transistor subcircuits; one such methodology is the use of standard
cell libraries (standard cell libraries are themselves designed using full-custom design
techniques).
Applications :
Full-custom design potentially maximizes the performance of the chip, and
minimizes its area, but is extremely labor-intensive to implement. Full-custom design is
limited to ICs that are to be fabricated in extremely high volumes, notably certain
microprocessors and a small number of ASICs.
Draw backs:
The main factor affecting the design and production of ASICs is the high cost of
mask sets and the requisite EDA design tools. The mask sets are required in order to
transfer the ASIC designs onto the wafer.
3.1.2 Semi Custom Design :
Semi-custom ASIC's, on the other hand, can be partly customized to serve
different functions within its general area of application. Unlike full-custom ASIC's,
semi-custom ASIC's are designed to allow a certain degree of modification during the
manufacturing process. A semi-custom ASIC is manufactured with the masks for the
diffused layers already fully defined, so the transistors and other active components of the
circuit are already fixed for that semi-custom ASIC design. The customization of the final
ASIC product to the intended application is done by varying the masks of the
interconnection layers, e.g., the metallization layers.
26

The semi custom design can be categorized as shown below
Semi Custom
Cell-based Array-based
Standard Cells Macro Cells Pre-diffused Pre- wired(FPGA's)
Cell based :
Standard cells :In semiconductor design, standard cell methodology is a method of designing
application-specific integrated circuits (ASICs) with mostly digital-logic features.
Standard cell methodology is an example of design abstraction, whereby a low-level
very-large-scale integration (VLSI) layout is encapsulated into an abstract logic
representation (such as a NAND gate). Cell-based methodology (the general class to
which standard cells belong) makes it possible for one designer to focus on the high-level
(logical function) aspect of digital design, while another designer focuses on the
implementation (physical) aspect. Along with semiconductor manufacturing advances,
standard cell methodology has helped designers scale ASICs from comparatively simple
single-function ICs (of several thousand gates), to complex multi-million gate system-on-
a-chip (SoC) devices.
A rendering of a small standard cell with three metal layers (dielectric has been
removed). The sand-colored structures are metal interconnect, with the vertical pillars
being contacts, typically plugs of tungsten. The reddish structures are polysilicon gates,
and the solid at the bottom is the crystalline silicon bulk.
27

Fig 3.1 Standard Cell
Advantages
Standard Cell design uses the manufacturer's cell libraries that have been
used in potentially hundreds of other design implementations and therefore are of much
lower risk than full custom design. Standard Cells produce a design density that is cost
effective, and they can also integrate IP cores and SRAM (Static Random Access
Memory) effectively, unlike Gate Arrays.
Disadvantages
Fabrication remains costly and slow
Application of standard cell
Strictly speaking, a 2-input NAND or NOR function is sufficient to form any
arbitrary Boolean function set. But in modern ASIC design, standard-cell methodology is
practiced with a sizable library (or libraries) of cells. The library usually contains
multiple implementations of the same logic function, differing in area and speed. This
variety enhances the efficiency of automated synthesis, place, and route (SPR) tools.
Indirectly, it also gives the designer greater freedom to perform implementation trade-
offs (area vs. speed vs. power consumption). A complete group of standard-cell
descriptions is commonly called a technology library.
28

MACRO CELLS :
•It is a complex cell which is more excellent then standard cell.
•Standardizing at the logic gate level is attractive for random logic functions but it turns
out to be inefficient for more complex structures such as multipliers ,memories and
embedded up and DSPs.
• So,we need macrocell which is high efficient cell.
3.2 Array Based Implementation:
Gate Array
3.2.1 Introduction
In view of the fast prototyping capability, the gate array (GA) comes after the
FPGA.
Design implementation of FPGA chip is done with user programming,
Gate array is done with metal mask design and processing.
Gate array implementation requires a two-step manufacturing process:
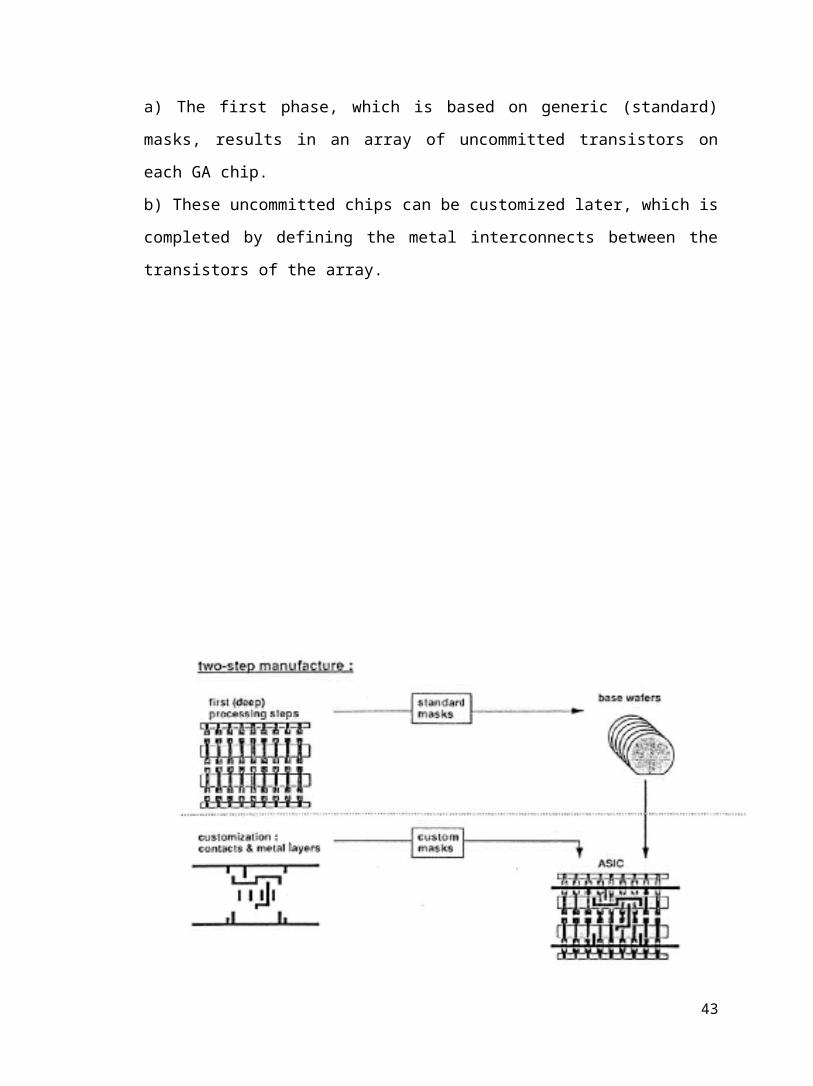
a) The first phase, which is based on generic (standard) masks, results in an array of
uncommitted transistors on each GA chip.
b) These uncommitted chips can be customized later, which is completed by defining the
metal interconnects between the transistors of the array.
29

Fig 3.2 Two step manufacturing of gate arrays
It is a regular structure Approach.
It is also called Programmable logic Array(PLA)
This Approach is adopted by major up design companies such as Intel,DEC.
Advantage:
Lower NRE
Disadvantage:
Lower performance ,lower integration density, higher power dissipation
There are two types of approaches :
Pre-diffused (or mask-programmable)Arrays
Prewired Array
Prediffused Array based Approach :
In this approach, batches of wafers containing arrays of primitive cell or transistor
are manufactured and stored.
All the fabrication steps needed to make transistor are standardized and executed
without regard to the final application.
30

To transform these uncommitted into actual design, only the desired
interconnections have to be added, determining the overall function of the chip
with only few metallization steps.
These layer can be designed and applied to premanufactured wafers much more
rapidly, reducing the turn around time to a week or less.
This approach is also called gate array or sea of gate approach depending on the
style of the prediffused.
There are Two types of gate array approaches
(1) channelled gate array approach
(2) channelless gate array approach(sea of gate approach).
Channelled (vs) channelless gate array :
Channelled gate array approach places the cells in rows separated by wiring
channels.
In channelless gate array approach routing channels can be eliminated and routing
can be performed on the top of the primitive cells with metallization
layer(occasionally leaving a cell unused ).
31

3.2.2 Field Programmable Gate Arrays (FPGAs)In 1985, a company called Xilinx introduced a completely new idea: combine the
user control and time to market of PLDs with the densities and cost benefits of gate arrays.
Customers liked it – and the FPGA was born. Today Xilinx is still the number-one FPGA
vendor in the world.
An FPGA is a regular structure of logic cells(or modules) and interconnect, which
is under your complete control. This means that you can design, program, and make
changes to your circuit whenever you wish. The Field Programmable Gate Array is a
device that is completely manufactured, but that remains design independent. Each FPGA
vendor manufactures devices to a proprietary architecture. However the architecture will
include a number of programmable logic blocks that are connected to programmable
switching matrices. To configure a device to a particular functional operation these
switching matrices are programmed to route signals between the individual logic blocks.
With FPGAs now exceeding the 10 million gate limit(the Xilinx VirtexII FPGA is
the current record holder), you can really dream big.
3.2.2.1 FPGA Architecture
Channel Based Routing
Post Layout Timing
Tools More Complex than CPLDs
Fine Grained
Fast register pipelining
There are two basic types of FPGAs: SRAM-based reprogrammable(Multi-time
Programmed MTP) and (One Time Programmed) OTP. These two types of FPGAs differ
in the implementation of the logic cell and the mechanism used to make connections in the
device.
The dominant type of FPGA is SRAM-based and can be reprogrammed as often
as you choose. In fact, an SRAM FPGA is reprogrammed every time it’s powered up,
because the FPGA is really a fancy memory chip. That’s why you need a serial PROM or
system memory with every SRAM FPGA.
32

Fig 3.3 Field Programmable Gate Array Logic (FPGA)
3. 2.2.2 Types of FPGA :
Fig 3.4 Types Of FPGA
In the SRAM logic cell, instead of conventional gates, an LUT determines the
output based on the values of the inputs. (In the “SRAM logic cell” diagram above, six
different combinations of the four inputs determine the values of the output.) SRAM bits
are also used to make connections.
OTP FPGAs use anti-fuses (contrary to fuses, connections are made, not “blown”
during programming) to make permanent connections in the chip. Thus, OTP FPGAs do
not require SPROM or other means to download the program to the FPGA. However,
every time you make a design change, you must throw away the chip! The OTP logic cell
is very similar to PLDs, with dedicated gates and flip-flops.
33

Table 3.1Comparison between OTP FPGA and MTP FPGA
Property OTP FPGA MTP FPGA
Speed Higher (current flows in
wire)
Lower (current flows in
Transistors)
Size Smaller Larger
Power consumption Lower Higher
Working
environment
Radiation hardened No radiation hardened
Price Almost the same Almost the same
Design cycle Programmed only once Programmed Many times
Reliability
More(single chip) Less(2chips,FPGA&PROM)
Security
More secure Less secure
Table 3.2 Comparision between FPGA and ASIC :
Property FPGA’S ASICS
Digital and Analog
Capability
Digital only Digital and Analog
Size Larger More smaller
Operating Frequency Lower(up to 400MHz) Higher(up to 3GHz)
Power Consumption Higher Lower
Design Cycle Very Small(few mins) Very long(about 12 weeks)
Mass Production Higher price Lower price
Security More secure less secure
34

Fig 3.5 FPGA Architecture
A logic circuit is implemented in an FPGA by partitioning logic into individual
logic modules and then interconnecting the modules by programming switches. A large
circuit that cannot be accommodated into a single FPGA is divided into several parts each
part is realized by an FPGA and these FPGAs are then interconnected by a Field-
Programmable Interconnect Component (FPIC ) .
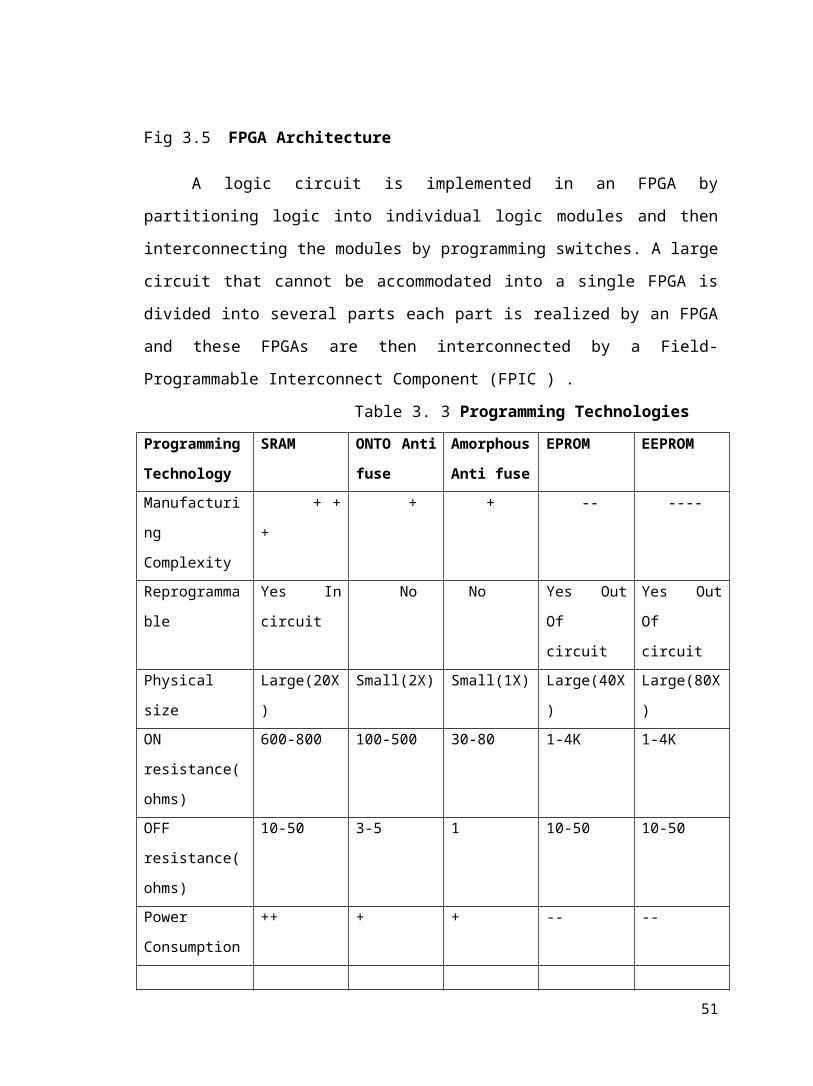
Table 3. 3 Programming Technologies
Programming
Technology
SRAM ONTO Anti
fuse
Amorphous
Anti fuse
EPROM EEPROM
Manufacturing
Complexity
+ + + + + -- ----
Reprogrammable Yes In circuit No No Yes Out Of
circuit
Yes Out Of
circuit
Physical size Large(20X) Small(2X) Small(1X) Large(40X) Large(80X)
ON
resistance(ohms)
600-800 100-500 30-80 1-4K 1-4K
OFF
resistance(ohms)
10-50 3-5 1 10-50 10-50
Power
Consumption
++ + + -- --
Volatile Yes No No No No
35
Logic Block

3.2.2.3 FPGA DESIGN FLOW In this part we are going to have a short introduction on FPGA design flow. A
simplified version of design flow is given in the following diagram.
Fig 3.6 FPGA Design Flow
Design Entry
There are different techniques for design entry. Schematic based, Hardware
Description Language and combination of both etc. . Selection of a method depends on
the design and designer. If the designer wants to deal more with Hardware, then
Schematic entry is the better choice. When the design is complex or the designer thinks
the design in an algorithmic way then HDL is the better choice. Language based entry is
faster but lag in performance and density. HDLs represent a level of abstraction that can
isolate the designers from the details of the hardware implementation. Schematic based
entry gives designers much more visibility into the hardware. It is the better choice for
those who are hardware oriented. Another method but rarely used is state machines. It is
the better choice for the designers who think the design as a series of states. But the tools
for state machine entry are limited. In this documentation we are going to deal with the
HDL based design entry.
Synthesis
The process which translates VHDL or Verilog code into a device netlist formate.
i.e a complete circuit with logical elements( gates, flip flops, etc…) for the design. If the
design contains more than one sub-designs, ex. to implement a processor, we need a CPU
as one design element and RAM as another and so on, then the synthesis process
generates netlist for each design element Synthesis process will check code syntax and
36

analyze the hierarchy of the design which ensures that the design is optimized for the
design architecture, the designer has selected. The resulting netlist(s) is saved to an NGC(
Native Generic Circuit) file (for Xilinx Synthesis Technology (XST)).
FPGA Synthesis
Implementation
This process consists a sequence of three steps
1. Translate
2. Map
3. Place and Route
Translate process combines all the input netlists and constraints to a logic design file.
This information is saved as a NGD (Native Generic Database) file. This can be done
using NGD Build program. Here, defining constraints is nothing but, assigning the ports
in the design to the physical elements (ex. pins, switches, buttons etc) of the targeted
device and specifying time requirements of the design. This information is stored in a file
named UCF (User Constraints File).Tools used to create or modify the UCF are PACE,
Constraint Editor etc.
FPGA Translate
37

Map process divides the whole circuit with logical elements into sub blocks such that
they can be fit into the FPGA logic blocks. That means map process fits the logic defined
by the NGD file into the targeted FPGA elements (Combinational Logic Blocks (CLB),
Input Output Blocks (IOB)) and generates an NCD (Native Circuit Description) file
which physically represents the design mapped to the components of FPGA. MAP
program is used for this purpose.
FPGA map
Place and Route PAR program is used for this process. The place and route process
places the sub blocks from the map process into logic blocks according to the constraints
and connects the logic blocks. Ex. if a sub block is placed in a logic block which is very
near to IO pin, then it may save the time but it may effect some other constraint. So trade
off between all the constraints is taken account by the place and route process.
The PAR tool takes the mapped NCD file as input and produces a completely
routed NCD file as output. Output NCD file consists the routing information.
FPGA Place and route
38

Device Programming
Now the design must be loaded on the FPGA. But the design must be converted to
a format so that the FPGA can accept it. BITGEN program deals with the conversion.
The routed NCD file is then given to the BITGEN program to generate a bit stream
(a .BIT file) which can be used to configure the target FPGA device. This can be done
using a cable. Selection of cable depends on the design.
Here is a Xilinx spartan3 Fpga board which we have used for programming
Fig 3.7 FPGA Board
Design Verification
Verification can be done at different stages of the process steps.
Behavioral Simulation (RTL Simulation) This is first of all simulation steps; those are
encountered throughout the hierarchy of the design flow. This simulation is performed
before synthesis process to verify RTL (behavioral) code and to confirm that the design is
functioning as intended. Behavioral simulation can be performed on either VHDL or
Verilog designs. In this process, signals and variables are observed, procedures and
functions are traced and breakpoints are set. This is a very fast simulation and so allows
the designer to change the HDL code if the required functionality is not met with in a
short time period. Since the design is not yet synthesized to gate level, timing and
resource usage properties are still unknown.
39

Functional simulation (Post Translate Simulation) Functional simulation gives
information about the logic operation of the circuit. Designer can verify the functionality
of the design using this process after the Translate process. If the functionality is not as
expected, then the designer has to made changes in the code and again follow the design
flow steps.
Static Timing Analysis This can be done after MAP or PAR processes Post MAP timing
report lists signal path delays of the design derived from the design logic. Post Place and
Route timing report incorporates timing delay information to provide a comprehensive
timing summary of the design.
3.2.2.4 Why only FPGA for prototyping ? Leading-edge ASIC designs are becoming more expensive and time-consuming
because of the increasing cost of mask sets and the amount of engineering verification
required. Getting a device right the first time is imperative. A single missed deadline can
mean the difference between profitability and failure in the product life cycle. Figure 1
shows how the impact that time-to-market delays can have on product sales.
Fig 3.8 Declining Product Sales Due to Late-to-Market Designs
40

Using an FPGA to prototype an ASIC or ASSP for verification of both register
transfer level (RTL) and initial software development has now become standard practice
to both decrease development time and reduce the risk of first silicon failure. An FPGA
prototype accelerates verification by allowing testing of a design on silicon from day one,
months in advance of final silicon becoming available. Code can be compiled for the
FPGA, downloaded, and debugged in hardware during both the design and verification
phases using a variety of techniques and readily available solutions. Whether you're
doing RTL validation, initial software development, and/or system-level testing, FPGA
prototyping platforms provide a faster, smoother path to delivering an end working
product.
3.2.2.5 Applications of FPGAsFPGAs have gained rapid acceptance and growth over the past decade because
they can be applied to a very wide range of applications. A list of typical applications
includes: random logic, integrating multiple SPLDs, device controllers, communication
encoding and filtering, small to medium sized systems with SRAM blocks, and many
more.
Other interesting applications of FPGAs are prototyping of designs, to be
implemented in gate arrays, and also emulation of entire large hardware systems. The
former of these applications might be possible using only a single large FPGA (which
corresponds to a small Gate Array in terms of capacity), and the latter would entail many
FPGAs connected by some sort of interconnect; for emulation of hardware, QuickTurn
[Wolff90] (and others) has developed products that comprise many FPGAs and the
necessary software to partition and map circuits.
Another promising area for FPGA application, which is only beginning to be
developed, is the usage of FPGAs as custom computing machines. This involves using
the programmable parts to “execute” software, rather than compiling the software for
execution on a regular CPU. The reader is referred to the FPGA-Based Custom
Computing Workshop (FCCM) held for the last four years and published by the IEEE.
When designs are mapped into CPLDs, pieces of the design often map naturally
to the SPLD-like blocks. However, designs mapped into an FPGA are broken up into
logic block-sized pieces and distributed through an area of the FPGA. Depending on the
FPGA’s interconnect structure, there may be various delays associated with the
41

interconnections between these logic blocks. Thus, FPGA performance often depends
more upon how CAD tools map circuits into the chip than is the case for CPLDs.
We believe that over time programmable logic will become the dominant form of
digital logic design and implementation. Their ease of access, principally through the low
cost of the devices, makes them attractive to small firms and small parts of large
companies. The fast manufacturing turn-around they provide is an essential element of
success in the market. As architecture and CAD tools improve, the disadvantages of
FPDs compared to Mask-Programmed Gate Arrays will lessen, and programmable
devices will dominate.
42
CHAPTER 4
Results4.1 Synthesis Results
4.1.1 Block Diagram :
Fig 4.1 RTL schematic of a floating point multiplier
4.1.2 Timing Report
Clock Information:
------------------
No clock signals found in this design
Asynchronous Control Signals Information:
----------------------------------------
No asynchronous control signals found in this design
Timing Summary:
43

---------------
Speed Grade: -4
Minimum period: No path found
Minimum input arrival time before clock: No path found
Maximum output required time after clock: No path found
Maximum combinational path delay: 16.456ns
Timing Detail:
--------------
All values displayed in nanoseconds (ns)
Timing constraint: Default path analysis
Total number of paths / destination ports: 678 / 23
-------------------------------------------------------------------------
Delay: 16.456ns (Levels of Logic = 6)
Source: a<2> (PAD)
Destination: c<27> (PAD)
Data Path: a<2> to c<27>
Gate Net
Cell:in->out fanout Delay Delay Logical Name (Net Name)
---------------------------------------- ------------
IBUF:I->O 1 0.821 0.801 a_2_IBUF (a_2_IBUF)
MULT18X18:A5->P13 16 3.370 1.305
Mmult_temp_op_submult_3 (Mmult_temp_op_submult_3_13)
LUT3:I2->O 5 0.551 0.989 exp_tmp2<7>11 (N0)
LUT4:I2->O 2 0.551 1.072 exp_tmp2<4>11 (N71)
LUT2:I1->O 1 0.551 0.801 exp_tmp2<4>2 (exp_tmp2<4>)
OBUF:I->O 5.644 c_26_OBUF (c<26>)
44

----------------------------------------
Total 16.456ns (11.488ns logic, 4.968ns route)
(69.8% logic, 30.2% route)
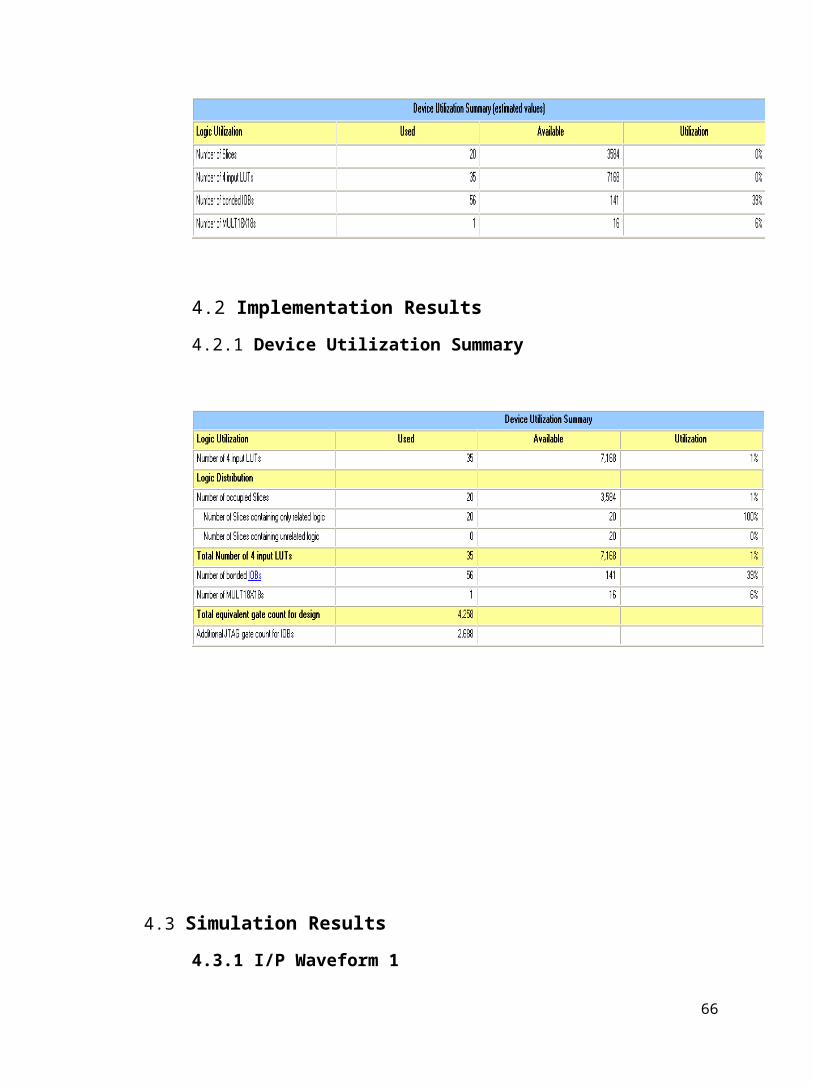
4.1.3 Device Utilization Summary
4.2 Implementation Results
4.2.1 Device Utilization Summary
45

4.3 Simulation Results
4.3.1 I/P Waveform 1
46

4. 3.2 I/P Waveform 2
4.3.3 O/P Waveform
47

48

CHAPTER 5
Conclusion and Future Enhancements
5.1 Conclusion Thus, we have successfully implemented float point multiplication for IEEE -754
Single precision floating point numbers on Xilinx Spartan 3E FPGA using VHDL.
5.2 Scope for Future Work
The future enhancements would be
1.To take denormalized inputs and convert them to normalized form and perform floating
point multiplication using single precision IEEE 754 standards.
2.To Design a floating point unit, which could be in future put into use in the FPU core
to design a coprocessor which performs floating point arithmetic operations with
atmost precision and accuracy.
3. To design a fpu core unit using pipelining with the emphasis being mainly on reducing
the number of clock cycles required to execute each operation.
4. A common post-normalization unit for all arithmetic operations will not used, although it
would be possible to combine them all in one unit. It will not be done so because:
Post-normalizations differ from one arithmetic operation to another
Most importantly, less clock cycles are needed for some operations
Hardware can be saved if not all operations are wanted
49

Source CodeProgram for Floating -point Multiplier :
LIBRARY ieee ;
USE ieee.std_logic_1164.ALL;
USE ieee.std_logic_unsigned.ALL;
ENTITY pre_norm_fmul IS
PORT(
opa : IN std_logic_vector (31 downto 0) ;
opb : IN std_logic_vector (31 downto 0) ;
exp_ovf : OUT std_logic;
output : OUT std_logic_vector(31 downto 0)
);
END pre_norm_fmul ;
ARCHITECTURE arch of pre_norm_fmul IS
signal signa, signb : std_logic ;
signal sign_d : std_logic ;
signal expa, expb : std_logic_vector (7 downto 0);
signal expa_int, expb_int : std_logic_vector (8 downto 0);
signal exp_tmp1 : std_logic_vector (7 downto 0);
signal exp_tmp1_int : std_logic_vector (8 downto 0);
50
signal exp_tmp2 : std_logic_vector (7 downto 0);
signal signacatsignb : std_logic_vector(1 DOWNTO 0);
signal temp_op : std_logic_vector(7 downto 0);
signal fracta_temp : std_logic_vector (23 downto 0);
signal fractb_temp : std_logic_vector (23 downto 0);
signal exp_tmp2_int : std_logic_vector (8 downto 0);
signal res:std_logic_vector(22 downto 0) ;
BEGIN
-- Aliases
signa <= opa(31);
signb <= opb(31);
expa <= opa(30 downto 23);
expb <= opb(30 downto 23);
-- Calculate Exponent
expa_int <= '0' & expa;
expb_int <= '0' & expb;
exp_tmp1_int <=(expa_int+expb_int);
exp_tmp2_int <=((exp_tmp1_int) - X"7F");
exp_tmp1 <= exp_tmp2_int(7 DOWNTO 0);
exp_ovf <= exp_tmp2_int(8);
51

signacatsignb <= signa & signb;
-- Determine sign for the output
PROCESS (signacatsignb)
BEGIN
CASE signacatsignb IS
WHEN "00" => sign_d <= '0';
WHEN "01" => sign_d <= '1';
WHEN "10" => sign_d <= '1';
WHEN OTHERS => sign_d <= '0';
END CASE;
END PROCESS;
fracta_temp<=('1' & opa(22 downto 0)) ;
fractb_temp<=('1' & opb(22 downto 0)) ;
temp_op<= fracta_temp*fractb_temp;
process(temp_op,res,exp_tmp1)
begin
if (temp_op(47)='1') then res<=temp_op(46 downto 24);
exp_tmp2<=exp_tmp1+1;
else
res<=temp_op(45 downto 23);
exp_tmp2<=exp_tmp1;
52

end if;
END PROCESS;
output<=sign_d&exp_tmp2&res;
END arch;
53

Test bench for floating point multiplier:
LIBRARY ieee;
USE ieee.std_logic_1164.ALL;
USE ieee.std_logic_unsigned.all;
USE ieee.numeric_std.ALL;
ENTITY tb_new_vhd IS
END tb_new_vhd;
ARCHITECTURE behavior OF tb_new_vhd IS
-- Component Declaration for the Unit Under Test (UUT)
COMPONENT pre_norm_fmul
PORT(
opa : IN std_logic_vector(31 downto 0);
opb : IN std_logic_vector(31 downto 0);
exp_ovf : OUT std_logic;
output : OUT std_logic_vector(31 downto 0)
);
END COMPONENT;
54

--Inputs
SIGNAL opa : std_logic_vector(31 downto 0) := (others=>'0');
SIGNAL opb : std_logic_vector(31 downto 0) := (others=>'0');
--Outputs
SIGNAL exp_ovf : std_logic;
SIGNAL output : std_logic_vector(31 downto 0);
BEGIN
-- Instantiate the Unit Under Test (UUT)
uut: pre_norm_fmul PORT MAP(
opa => opa,
opb => opb,
exp_ovf => exp_ovf,
output => output
);
opa<="00110001101100000000000000000000";
opb<= "00110110111100000000000000000000";
END ;
55

REFERENCES
1. IEEE computer society: IEEE Standard 754 for Binary Floating-Point Arithmetic,
1985.
2. David Goldberg: What Every Computer Scientist Should Know About Floating-Point
Arithmetic.
3. W. Kahan: IEEE Standard 754 for Binary Floating-Point Arithmetic, 1996
4. www.scribd.com.
5. M. R. Santoro, G. Bewick, and M. A. Horowitz, “Rounding algorithms for IEEE
multipliers,”
6. D. Stevenson, “A proposed standard for binary floating point arithmetic,”
7. Naofumi Takagi, Hiroto Yasuura, and Shuzo Yajima. High-speed VLSI
multiplication algorithm
8. “IEEE Standard for Binary Floating-point Arithmetic".
56

Appendix
TOOLS
Introduction:
The various tools used to implement hamming encoder and decoder are as follows:
XILINX ISE 9.2 VHDL
XILINX ISE 9.2:
This is a software designing tool used to design Field Programmable Gate
Arrays (FPGA devices) with Hardware Description Languages (HDLs). It includes
the following sections:
Device Support.
Hardware Description Languages.
Advantages of Using HDLs to Design FPGA Devices.
Designing FPGA Devices with HDLs.
Device Support:
The ISE software supports the following devices:
Virtex.
Virtex-II.
Virtex-E.
Virtex-II PRO.
Virtex-II PRO X.
Virtex-4 (SX/LX/FX).
57

Spartan.
Spartan-II.
Spartan-IIE.
Spartan-3.
Spartan-3E.
CoolRunner. XPLA3.
CoolRunner-II.
XC9500. ( XL/XV).
Typical design flow:
A typical design flow for designing VLSI IC circuits is as shown in the fig 6.1.
58

Specifications: specifications describe abstractly the functionality, interface, and
overall architecture of the digital circuit to be designed.
Behavioral description: the behavioral description is manually converted to an
RTL description in an HDL
Logic synthesis tools convert the RTL description to a gate-level netlist.
The gate-level netlist is input to an automatic place and route tool, which creates a
layout. The layout is verified and then fabricated ona a chip.
EDA tools will help the designer convert the behavioral description to a final IC
chip.
Hardware Description Languages: Hardware Description Languages (HDLs)
are used to describe the behavior and structure of system and circuit designs.
Advantages of Using HDLs to Design FPGA Devices: Using HDLs to design
high-density FPGA devices has the following advantages:
Down Approach for Large Projects.
Functional Simulation Early in the Design Flow.
Synthesis of HDL Code to Gates
Early Testing of Various Design Implementations.
Reuse of RTL Code.
Top-Down Approach for Large Projects: The top-down approach to system design
supported by HDLs is advantageous for large projects that require many designers
working together. After determining the overall design plan, designers can work
independently on separate sections of the code.
Functional Simulation Early in the Design Flow: You can verify the functionality of
your design early in the design flow by simulating the HDL description. Testing design
decisions before the design is implemented at the RTL or gate level allows you to make
any necessary changes early in the design process. Synthesis of HDL Code to Gates
Hardware description can be synthesized to target the FPGA implementation.
This step:
59

Decreases design time by allowing a higher-level specification of the design
rather than specifying the design from the FPGA base elements.
Generally reduces the number of errors that can occur during a manual
translation of a hardware description to a schematic design.
Allows you to apply the automation techniques used by the synthesis tool (such
as machine encoding styles and automatic I/O insertion) during the optimization
of design to the original HDL code. This results in greater optimization and
efficiency.
Early Testing of Various Design Implementations: HDLs allow to test different
implementations of your design early in the design flow. Use the synthesis tool to
perform the logic synthesis and optimization into gates.
Designing FPGA Devices with VHDL: VHSIC Hardware Description
Language (VHDL) is a hardware description language for designing Integrated
Circuits (ICs). It was not originally intended as an input to synthesis, and many
VHDL constructs are not supported by synthesis software. However, the high level of
abstraction of VHDL makes it easy to describe the system-level components and test
benches that are not synthesized. In addition, the various synthesis tools use different
subsets of the VHDL language.
Various steps :
1. .Getting Started.
2. .Create a New Project.
3. .Create an HDL Source.
4. .Design Simulation.
5. .Create Timing Constraints.
60

6. .Implement Design and Verify Constraints.
7. .Reimplement Design and Verify Pin Locations.
8. .Download Design to the Spartan.-3 Demo Board.
Step1.Getting Started:
Software Requirements
ISE 9.2
Step 2.Create a New Project
To create a new project:
1. Select File > New Project... The New Project Wizard appears.
2. Type tutorial in the Project Name field.
3. Enter or browse to a location (directory path) for the new project. A tutorial
subdirectory is created automatically.
4. Verify that HDL is selected from the Top-Level Source Type list.
5. Click Next to move to the device properties page.
6. Fill in the properties in the table as shown below:
Product Category: All
Family: Spartan3
Device: XC3S400
Package: PQ208
Speed Grade: -5
Top-Level Source Type: HDL
Synthesis Tool: XST (VHDL/Verilog)
61

Simulator: ISE Simulator (VHDL/Verilog)
Preferred Language: VHDL
Verify that Enable Enhanced Design Summary is selected.
Leave the default values in the remaining fields.
7. Click Next to proceed to the Create New Source window in the New Project
Wizard. At the end of the next section, your new project will be complete.
Step 3.Create an HDL Source
In this section, we will create the top-level HDL file for your design.
Determine the language that you wish to use for the tutorial. Then, continue either to
the .Creating a VHDL Source. section below, or skip to the .Creating a Verilog
Source. section.
Create a VHDL source file for the project as follows:
1. Click the New Source button in the New Project Wizard.
2. Select VHDL Module as the source type.
3. Type in the file name counter.
4. Verify that the Add to project checkbox is selected.
5. Click Next.
6. Declare the ports for the counter design by filling in the port information as shown
below:
7. Click Next, then Finish in the New Source Wizard - Summary dialog box to
complete the new source file template.
8. Click Next, then Next, then Finish.
62

The source file containing the entity/architecture pair displays in the Workspace, and
the counter displays in the Source tab
Final Editing of the VHDL Source
1. Add the intermediate signal declaration
2. The next step is to add the behavioral description for therequired program.
3. Save the file by selecting File → Save.
Checking the Syntax of the program
When the source files are complete, check the syntax of the design to find errors and
types.
1. Verify that Implementation is selected from the drop-down list in the Sources
window.
2.You must correct any errors found in your source files. You can check for errors in
the Console tab of the Transcript window. If you continue without valid syntax, you
will not be able to simulate or synthesize your design.
3. Close the HDL file.
Step 4.Design Simulation
Verifying Functionality using Behavioral Simulation
Create a test bench waveform containing input stimulus you can use to verify the
functionality of the required program. The test bench waveform is a graphical view of
a test bench.
Create the test bench waveform as follows:
1. Select the HDL file in the Sources window.
63

2. Create a new test bench source by selecting Project → New Source.
3. In the New Source Wizard, select Test Bench WaveForm as the source type, and
type name in the File Name field.
4. Click Next.
5. The Associated Source page shows that you are associating the test bench
waveform with the source file. Click Next.
6. The Summary page shows that the source will be added to the project, and it
displays the source directory, type, and name. Click Finish.
7. You need to set the clock frequency, setup time and output delay times in the
Initialize Timing dialog box before the test bench waveform editing window opens.
8. Click Finish to complete the timing initialization.
9. The blue shaded areas that precede the rising edge of the CLOCK correspond to the
Input Setup Time in the Initialize Timing dialog box. Toggle the DIRECTION port to
define the input stimulus for the counter design as follows:
Click on the blue cell at approximately the 300 ns to assert DIRECTION high so
that the counter will count up.
Click on the blue cell at approximately the 900 ns to assert DIRECTION low so
that the counter will count down.
10. Save the waveform.
11. In the Sources window, select the Behavioral Simulation view to see that the test
bench waveform file is automatically added to your project.
12. Close the test bench waveform. Simulating Design Functionality Verify that the
64

design functions as you expect by performing behavior simulation as follows:
1. Verify that Behavioral Simulation and test bench waveform ,which we have given
a name are selected in the Sources window.
2. In the Processes tab, click the .+. to expand the Xilinx ISE Simulator process and
double-click the Simulate Behavioral Model process.
The ISE Simulator opens and runs the simulation to the end of the test bench.
3. To view your simulation results, select the Simulation tab and zoom in on the
transitions.
4. Verify that the design is working as expected.
5. Close the simulation view. If you are prompted with the following message, .You
have an active simulation open. Are you sure you want to close it?., click Yes to
continue.
You have now completed simulation of your design using the ISE Simulator.
VHDL :
VHDL is an acronym for VHSIC Hardware Description Language (VHSIC) is
an acronym for very high speed integrated circuits)it is a hardware description language
that can be used to model a digital system at many levels of abstraction, ranging from the
algorithmic level to the gate level .The complexity of the digital system being modeled
could vary from that of a simple gate to a complete digital electronic system ,or any thing
in between the digital system can be described hierarchically .timing can also be
explicitly modeled in the same description.
The VHDL language can be regarded as an integrated amalgamation of the
65
following languages:
1:sequential language+
2:concurrent language+
3:net-list language+
4:timing specifications+
5:waveform generation language =>VHDL
Therefore , the language has the constructs that enable us to express the
concurrent or sequential behavior of a digital system with or without timings .it also
allows us to model the system as an inter-connection of components .Test waveforms can
also be generated using the same constructs. The language not only defines the syntax but
also defines very clear simulation semantics for each language construct, therefore
models written in this language can be verified using a VHDL simulator .it is strongly
typed language and is often verbose to write .it inherits many of its features,especially the
sequential language part, from the Ada programming language. Because VHDL provides
an extensive range of modeling capabilities, it is often difficult to understand .the
complete language ,however ,has sufficient power to capture the descriptions of the most
complex chips to a complete electronic system.
66