1 an evaluation of multi-resolution storage for sensor networks deepak ganesan, ben greenstein,...
Post on 20-Dec-2015
214 views
TRANSCRIPT

11
An Evaluation of Multi-resolution An Evaluation of Multi-resolution Storage for Sensor NetworksStorage for Sensor Networks
Deepak Ganesan, Ben Greenstein, Deepak Ganesan, Ben Greenstein,
Denis Perelyubskiy, Deborah Estrin (UCLA) , Denis Perelyubskiy, Deborah Estrin (UCLA) , John Heidemann (USC/ISI)John Heidemann (USC/ISI)
Presenter: Vijay SundaramPresenter: Vijay Sundaram

22
Constructing the hierarchyConstructing the hierarchy
Initially, nodes fill up their own storage with raw sampled data.
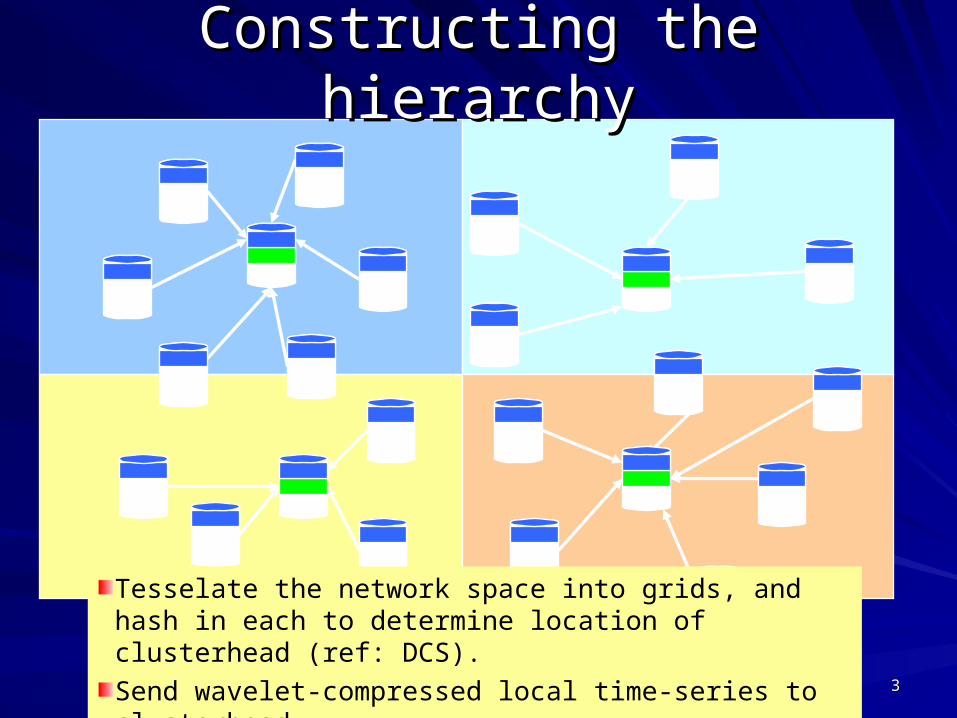
33
Constructing the hierarchyConstructing the hierarchy
Tesselate the network space into grids, and hash in each to determine location of clusterhead (ref: DCS).
Send wavelet-compressed local time-series to clusterhead.

44
Processing at each levelProcessing at each level
x
time
y
…
Get compressed summaries from children.
Decode Re-encode at lower resolution and forward to parent.
Store incoming summaries locally for future search.
Wavelet encoder/decoder
55
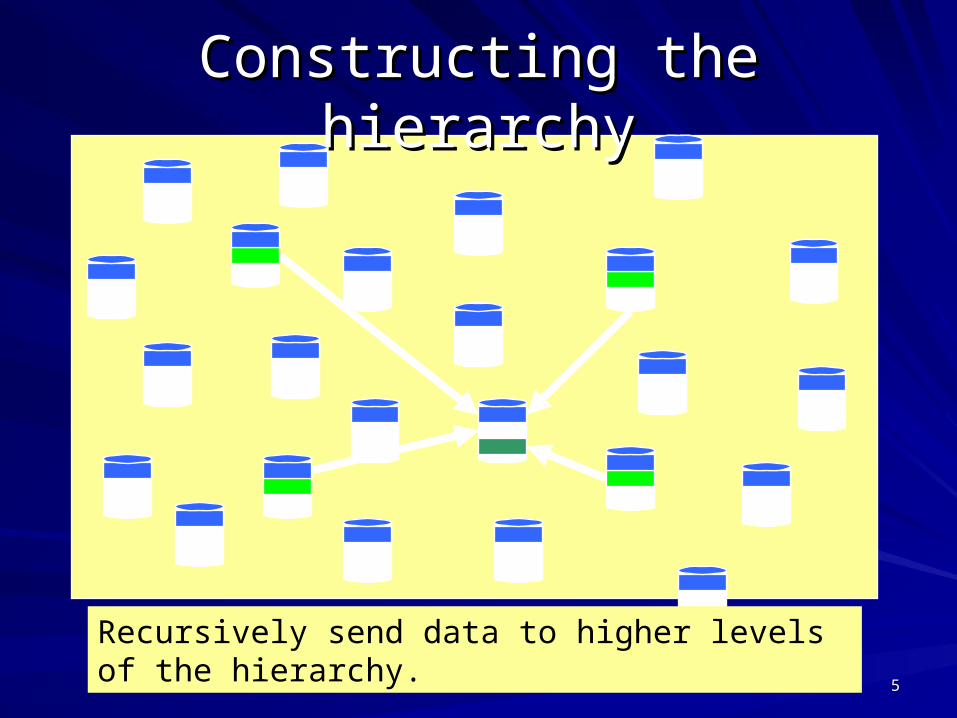
Constructing the hierarchyConstructing the hierarchy
Recursively send data to higher levels of the hierarchy.
66
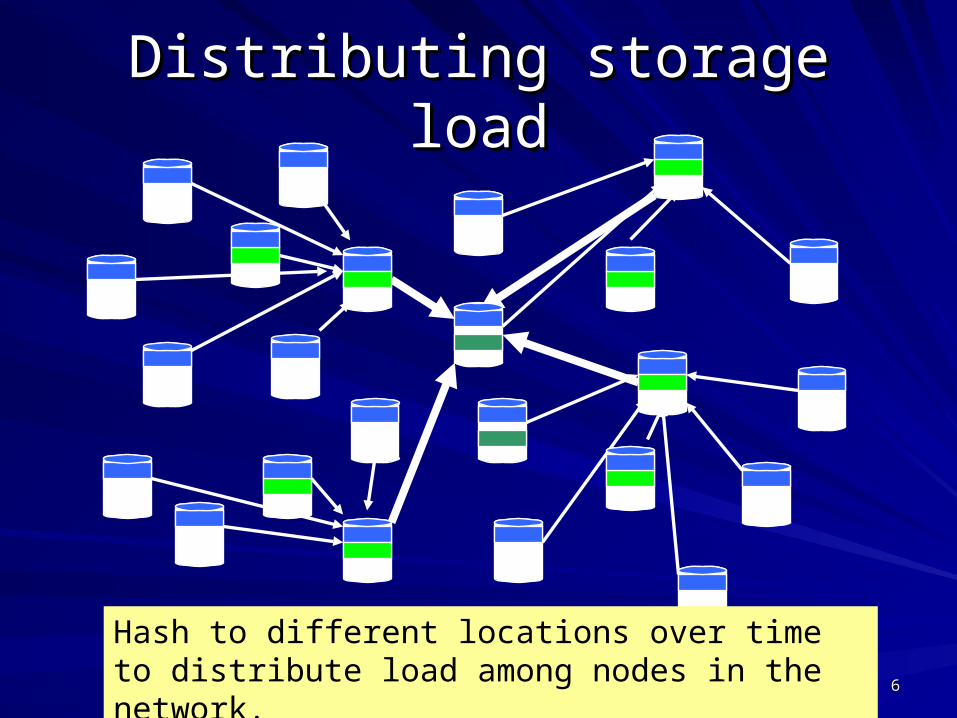
Distributing storage loadDistributing storage load
Hash to different locations over time to distribute load among nodes in the network.

77
Eventually, all available storage gets filled, and Eventually, all available storage gets filled, and we have to decide when and how to drop we have to decide when and how to drop summaries.summaries.
Allocate storage to each resolution and use each Allocate storage to each resolution and use each allocated storage block as a circular buffer.allocated storage block as a circular buffer.
What happens when storage fills What happens when storage fills up?up?
Local Storage Allocation
Res 1Res 2Res 3Res 4
Local storage capacity
88
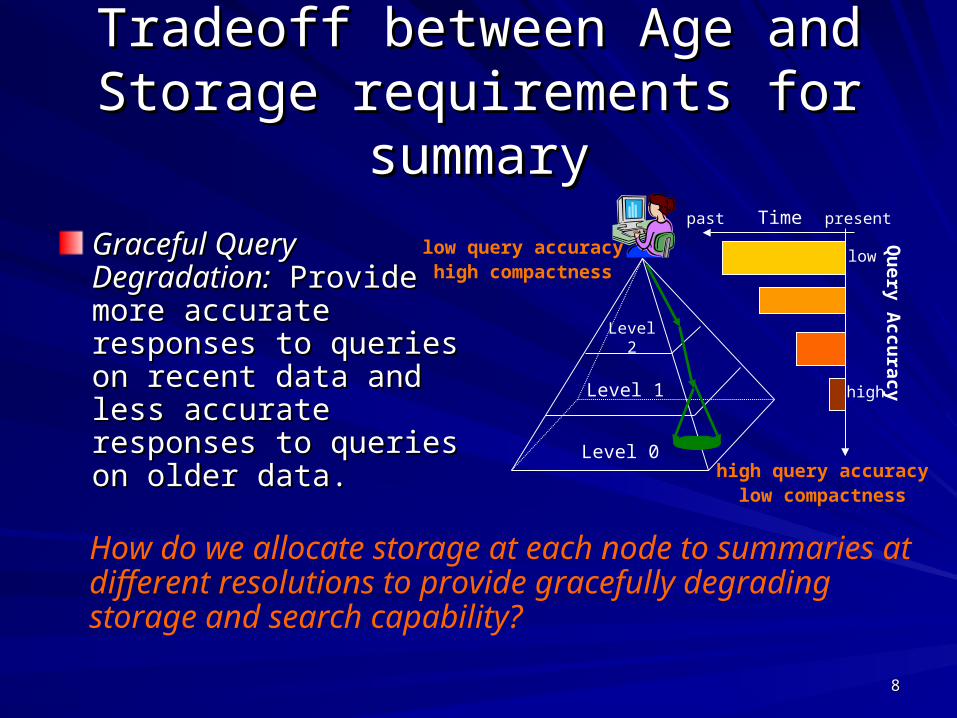
Graceful Query Graceful Query Degradation:Degradation: Provide Provide more accurate responses more accurate responses to queries on recent data to queries on recent data and less accurate and less accurate responses to queries on responses to queries on older data.older data.
Tradeoff between Age and Storage Tradeoff between Age and Storage requirements for summaryrequirements for summary
Level 0
Level 1
Level 2
Time presentpast
Qu
ery
Accu
racy
high query accuracylow compactness
low query accuracyhigh compactness
low
high
How do we allocate storage at each node to summaries at different resolutions to provide gracefully degrading storage and search capability?
99
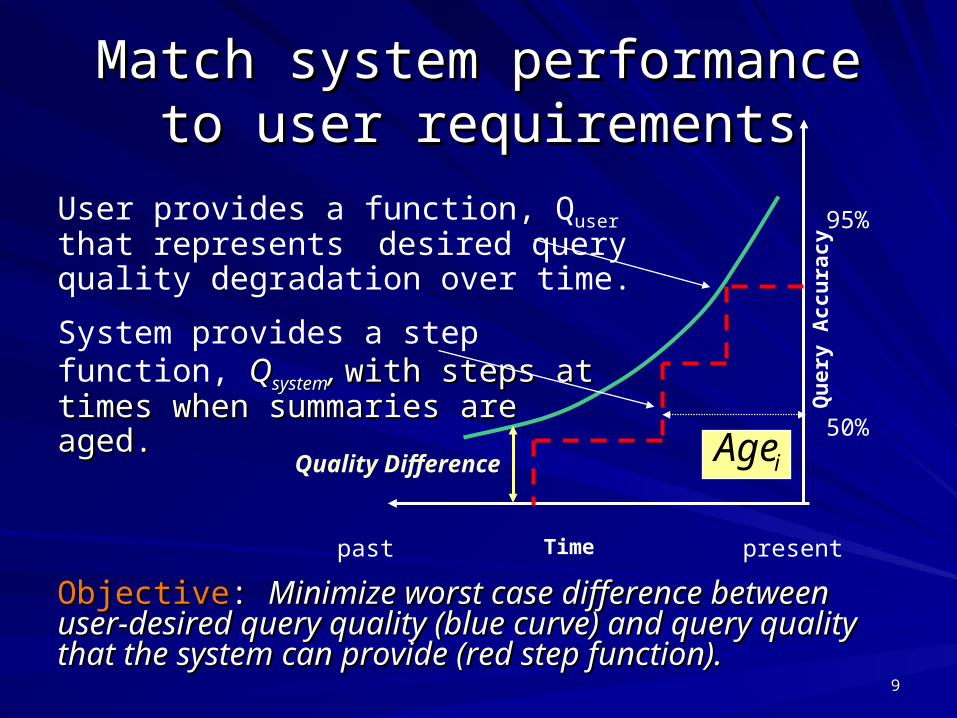
Match system performance to user Match system performance to user requirementsrequirements
ObjectiveObjective: : Minimize worst case difference between user-Minimize worst case difference between user-desired query quality (blue curve) and query quality that the desired query quality (blue curve) and query quality that the system can provide (red step function).system can provide (red step function).
Quality Difference
Time
Qu
ery
Accu
racy
presentpast
User provides a function, Quser that represents desired query quality degradation over time.
System provides a step function, QQsystemsystem, , with steps at times when with steps at times when summaries are aged.summaries are aged.
iAge
95%
50%

1010
What do we know?What do we know?
GivenGiven– NN sensor nodes. sensor nodes.– Each node has storage capacity, Each node has storage capacity, SS..– Users ask a set of typical queries, Users ask a set of typical queries, T.T.
– Data is generated at resolution i at rate Data is generated at resolution i at rate RRii..
– D(q,k)D(q,k) – Query Error when drilldown for query – Query Error when drilldown for query qq terminates at level terminates at level k.k.
– QQuseruser - User-desired quality degradation. - User-desired quality degradation.

1111
Determining Query Quality from Determining Query Quality from multiple queriesmultiple queries
Error
50%
5%
Edge Query: Find nodes along a boundary between high and low precipitation areas.
Max Query: Find the node which has the maximum precipitation in January.
We need to translate the performance of different Drill-down queries to a single “query quality” metric.
Only coarsest summaryis queried.
All resolutions (from coarsest to finest) are queried

1212
Definition: Query QualityDefinition: Query Quality
Given:Given:– TT = set of typical queries. = set of typical queries.– D(q,k)D(q,k) = Query error when drill-down for query = Query error when drill-down for query q q in in
set set TT terminates at resolution terminates at resolution k.k.
The query quality for queries that refer to data The query quality for queries that refer to data at time at time t t in the past, in the past, QQsystemsystem(t),(t), if if k k is the finest is the finest
available resolution is:available resolution is:
Tq
),(|T|
1)( kqDt
systemQ

1313
How many levels of resolution, How many levels of resolution, kk are available at time are available at time t t ??
Given:Given:– RRii = Total transmitted data rate from level i = Total transmitted data rate from level i
clusterheads to level i+1 clusterheads.clusterheads to level i+1 clusterheads.
Define sDefine sii = Storage allocated to each node for = Storage allocated to each node for summaries at resolution i.summaries at resolution i.
Level i
i
ii RNs
Age Level i+1

1414
Storage Allocation: Constraint-Storage Allocation: Constraint-Optimization problemOptimization problem
ObjectiveObjective: Find {s: Find {sii}, i=1..log}, i=1..log44N N that:that:
Given constraints:Given constraints:– Storage constraintStorage constraint: Each node : Each node
cannot store any greater than its cannot store any greater than its storage limit.storage limit.
– Drill-down constraintDrill-down constraint: It is not : It is not useful to store finer resolution useful to store finer resolution data if coarser resolutions of the data if coarser resolutions of the same data is not present.same data is not present.
)()( ..0- t
max min tQtQ systemuser
SsN
ii
4log
1
ii AgeAge 1

1515
Determining Rate and Drilldown Determining Rate and Drilldown query errorquery error
iRHow do we determine How do we determine communication rates to, say, communication rates to, say, bound query error?bound query error?
How do we determine the drill-How do we determine the drill-down query error when prior down query error when prior information about deployment information about deployment and data is limited?and data is limited?
),( kqD
Assume: Rates are fixed a-priori by Assume: Rates are fixed a-priori by communication constraints.communication constraints.

1616
Solve ConstraintOptimization
Prior information about sampled Prior information about sampled datadata
Omniscient StrategyBaseline. Use all data to decide optimal allocation.
Training Strategy(can be used when small training dataset from initial deployment).
Greedy Strategy(when no data is available, use a simple weighted allocation to summaries).
Coarse Finer Finest
1 : 2 : 4
No a priori information
full a priori information

1717
Distributed trace-driven Distributed trace-driven implementationimplementation
Linux implementation for ipaq-class nodes Linux implementation for ipaq-class nodes – uses Emstar (J. Elson et al), a Linux-based uses Emstar (J. Elson et al), a Linux-based
emulator/simulator for sensor networks.emulator/simulator for sensor networks.– 3D Wavelet codec based on freeware by Geoff Davis 3D Wavelet codec based on freeware by Geoff Davis
available at: available at: http://http://www.geoffdavis.netwww.geoffdavis.net..– Query processing in Matlab.Query processing in Matlab.
Geo-spatial precipitation datasetGeo-spatial precipitation dataset– 15x12 grid (50km edge) of precipitation data from 1949-1994, 15x12 grid (50km edge) of precipitation data from 1949-1994,
from Pacific Northwestfrom Pacific Northwest††. (. (Caveat: Not real sensor data).Caveat: Not real sensor data).
System parametersSystem parameters– compression ratio: compression ratio: 6:12:24:48.6:12:24:48.– Training set: Training set: 6% of total dataset.6% of total dataset.
†M. Widmann and C.Bretherton. 50 km resolution daily precipitation for the Pacific Northwest, 1949-94.

1818
How efficient is search?How efficient is search?
Search is very efficient (<5% of network queried) and accurate for different queries studied.

1919
Comparing Aging strategiesComparing Aging strategies
Training performs within 1% to optimal . Careful selection of parameters for the greedy algorithm can provide surprisingly good results (within 2-5% of optimal).

2020
Future Research DirectionsFuture Research DirectionsStructured node placement Structured node placement (regular/grid) may not be (regular/grid) may not be possible due to terrain possible due to terrain conditions. conditions. Extend current techniques Extend current techniques to use wavelet schemes to use wavelet schemes that handle irregularity †. that handle irregularity †. Extend training schemes to Extend training schemes to be online.be online.Implementation on motes.Implementation on motes.
†Debauchies, Guskov, Schroder, Sweldons: Wavelets on irregular point sets
Node placement at James Reserve

2121
SummarySummary
Progressive aging of summaries can be used to support Progressive aging of summaries can be used to support long-term spatio-temporal queries in resource-long-term spatio-temporal queries in resource-constrained sensor network deployments.constrained sensor network deployments.We describe two algorithms: a training-based algorithm We describe two algorithms: a training-based algorithm that relies on the availability of training datasets, and a that relies on the availability of training datasets, and a greedy algorithm can be used in the absence of such greedy algorithm can be used in the absence of such data.data.Our results show that Our results show that – training performs close to optimal for the dataset that we study. training performs close to optimal for the dataset that we study. – the greedy algorithm performs well for a well-chosen summary the greedy algorithm performs well for a well-chosen summary
weighting parameter.weighting parameter.