a conservative data flow algorithm for detecting all pairs ...cis.poly.edu/tr/tr-cis-2001-02.pdf ·...
TRANSCRIPT

A Conservative Data Flow Algorithm for
Detecting All Pairs of Statements that May Happen in Parallel for Rendezvous-Based
Concurrent Programs
Gleb Naumovich George S. Avrunin
Department of Computer and Information Science
Technical Report TR-CIS-2001-02
07/30/2001

A ConservativeDataFlow Algorithm for DetectingAll PairsofStatementsthatMay Happenin Parallelfor Rendezvous-Based
ConcurrentPrograms
GlebNaumovich GeorgeS.AvruninDept.of ComputerandInformationScience Dept.of MathematicsandStatistics
PolytechnicUniversity Universityof MassachusettsBrooklyn,NY 11201 Amherst,MA 01003
[email protected] [email protected]
Abstract
Informationaboutwhichpairsof statementsin aconcurrentprogramcanexecutein parallelis importantfor optimizinganddebuggingprograms,for detectinganomalies,andfor improving theaccuracy of dataflow analysis.In thispaper,wedescribeanew dataflow algorithmthatfindsaconservativeapproximationof thesetof all suchpairsfor programsthatusetherendezvousmodelof communication.We havecarriedouta comparisonof theprecisionof ouralgorithmandthatof themostpreciseof theearlierapproaches,MasticolaandRyder’s non-concurrency analysis[15], usingasampleof 159 concurrentAda programsthat includesthe collectionassembledby MasticolaandRyder. For theseexamples,our algorithmwasalmostalwaysmoreprecisethannon-concurrency analysis,in the sensethat thesetofpairs identified by our algorithm aspossiblyhappeningin parallel is a propersubsetof the set identified by non-concurrency analysis.In 140cases,we wereableto useanexponential-timereachabilityanalysisto computethesetof pairsof statementsthatmayhappenin parallel.For thesecases,therewerea totalof only 25pairsidentifiedby ourpolynomial-timealgorithmthatwerenot identifiedby thereachabilityanalysis.
1 Intr oduction
As thenumberandsignificanceof parallelandconcurrentprogramscontinueto increase,sodoestheneedfor methodsto provide developerswith informationaboutthepossiblebehavior of thoseprograms.In this paper, we addresstheproblemof determiningwhich pairsof statementsin a concurrentprogramcanpossiblyexecutein parallel. Infor-mationaboutthis aspectof the behavior of a concurrentprogramhasapplicationsin debugging,optimization(bothmanualandautomatic),detectionof synchronizationanomaliessuchasdataraces,andimproving theaccuracy of dataflow analysis[15].
Theproblemof preciselydeterminingthepairsof statementsthatcanexecutein parallelis undecidable.Instead,we areinterestedin computinga conservativeapproximationof all suchpairsof statements.In this paper, we usethetermMHP information(for MayHappenin Parallel)to referto this approximation.MHP informationis conservativein the sensethat if thereexists a real executionof the programsuchthat two statements��� and ��� from differentthreadsof control happenin parallel,the pair
� ���������� mustbe includedin the MHP information. In this paper, weproposea new polynomial-timedataflow algorithmfor computingconservativeMHP informationfor programswiththerendezvousmodelof concurrency.
1

This work concentrateson languageswith therendezvousmodelof concurrency, suchasAda. Sincemuchof therelatedwork concentratedon analysisof Ada programs,the implementationof our approachandthe experimentalevaluationof this implementationtarget Ada programs.Therefore,in this paperwe usethe Ada terminology, e.g.referringto threadsof control as tasksandto communicationsbetweentasksas rendezvous. The semanticsof thisconcurrency modelareintroducedin Section3.1.
For reasonsof efficiency, in thiswork wedonot takevaluesof theprogramvariablesinto account.Thus,ourcom-putationof MHP informationis basedentirelyonthecontrolflow andsynchronizationsin theprogram.In general,thismakestheMHP informationcomputedby our approachlessprecisethanif informationaboutprogramvariableswastaken into account.Evenwith this simplification,theproblemof computingMHP informationis NP-complete[21].A naive algorithmbasedon analyzingthe statespaceof a program,without taking programvariablesinto account,is exponentialin the numberof programthreadsand thereforeimpractical. In this paper, we empirically comparethe MHP informationcomputedby our algorithmto that computedby the inefficient but moreprecisereachabilityalgorithm.In addition,wecomparetheMHP informationcomputedby ouralgorithmwith thatcomputedby themostpreciseof thepolynomial-timealgorithmsproposedto date,non-concurrencyanalysisof MasticolaandRyder[15].
In our experimentalcomparison,we usea setof 159Ada programsthatincludestheprogramsusedby MasticolaandRydertoevaluatenon-concurrencyanalysis.Ontheseprograms,ouralgorithmfindsall of theMHPpairsidentifiedbynon-concurrencyanalysisin 150cases;in 118cases,ouralgorithmfindspairsthatarenotfoundbynon-concurrencyanalysis.In 9 cases,non-concurrency analysisidentifiespairsthatarenot foundby our algorithmbut, in all of thesecases,ouralgorithmfindsmany morepairsthatarenot identifiedby non-concurrency analysis.For 140cases,wewereableto run thereachabilityanalysis.(In theremainingcases,this precisebut inefficient analysisranout of memory.)Our algorithmfails to find all thepairsof statementsthatcannothappentogetherfor just six of these140programs,missinga totalof just 25 pairs.
Thenext sectiondiscussesrelatedwork. We describetherendezvous-stylesynchronouscommunicationsof Adaandintroducetheprogrammodelusedby our algorithmin Section3. Section4 introducesour MHP algorithm.Sec-tion 5 describesMasticolaandRyder’s non-concurrency analysis,investigatesa relationshipbetweenthe programmodelsusedin non-concurrency analysisandour algorithm,andshows the resultsof the empiricalcomparisonbe-tweenthesetwo approaches.Section6 concludesanddescribesfuturework.
2 RelatedWork
Thepreviousapproacheshave computedthecomplementof MHP informationabouta program,namelycannothap-penin parallel information(calledCan’t HappenTogether, or CHT, by MasticolaandRyder)describingthe setofstatementsthatcannothappenin parallelwith a givenstatement.A conservativeestimateof thestatementsthatcan-not happenin parallelwith a givenstatement� is a setof statementsCHT
� �� suchthatno statementin CHT� ��� can
happenin parallelwith � on any executionof theprogram.Becauseof imprecisionin computingCHT information,theremaybestatementsnot in CHT
� �� thatalsocannothappenin parallelwith � . Thus,thecomplementof CHT� ��
is a conservative estimateof thesetof statementsthatmayhappenin parallelwith � , in thesensethat it containsallstatementsthatmayhappenin parallelwith � , possiblytogetherwith someadditionalstatements.
CallahanandSubhlok[3] proposeda dataflow algorithmthat computes,for a given statementin a concurrentprogram,a setof statementssuchthatall instancesof thosestatementsmustexecutebeforeany instanceof thegivenstatement(B4 analysis).This approachis definedfor concurrentprogramswith a post-wait typeof synchronization(similar to thewait-notify mechanismof Java). This algorithmcomputesB4 relationshipsamongpairsof statementsbasedoncontrolflow within individual threadsof controlandthepatternof postandwait commandsin thosethreads.In theworstcase,thecomplexity of B4 analysisis cubicin thenumberof programstatements.
DuesterwaldandSoffa [5] proposedanalgorithmfor solvingtheB4 problemfor Adaprogramsin thepresenceofproceduresanddemonstratedits usefulnessfor detectingdataracesin concurrentsoftware.Theworst-casecomplexityof this algorithmis alsocubicin thenumberof statementsin theprogram.
2

� ������ ���������������������� ��!" �#�%$�����%�%$�������&�'(�) �+*�����%�%$��,) � " �#���%�+*�%! � " �#�%$-*�%! ����� ���.*� ������ ������/10,�������� ��!�������324���5&�'(��) �6*�6*�������327) � " �#� �%�6*�%! �,/108*
� ������ ������/ 9:�������� ��!�������324���5&�'(��) �6*�-*�������327) � " �#� �%�6*�%! �,/ 9+*Figure1: Illustrationof thecasewhereB4 analysismissesconcurrency information
While computingthe informationaboutprogramstatementsthat cannothappenin parallelbasedon the B4 in-formationaloneis conservative, this approachwill missstatementsthatcannothappenin parallelbut arenot in a B4relationship.Figure1 showsa fragmentof asimpleAdaprogramthatillustratesthispoint. In thisprogram,task �������implementsa sharedlock usedby tasks /10 and /�9 . Task ������ makessurethat only oneothertaskin the programcanexecuteany regionof codebetweencallson entriesacquireandrelease. Therefore,callsto procedures� and � intasks/10 and / 9 cannothappenin parallel.B4 analysiscannotdetectthat
� � � � �3; CHT, because,dependingonwhichof thetasks/10 and / 9 callson entry �#�����32<� �5&�'(�)�� first, callsto � and � canoccurin eitherorder.
MasticolaandRyder[15] extendB4 analysisby deriving concurrency informationto identify additionalpairsofstatementsthatcannever happenin parallel. In this approach,callednon-concurrencyanalysis, four techniquesareappliedrepeatedlyto refinethecan’t happentogether(CHT) informationabouttheprogram.Oneof theserefinementsis a versionof the B4 analysisand the othersusepatternsdetectedin a graphmodel of the programthat providesufficientconditionsfor concludingthatthestatementscorrespondingto two nodesmany neverhappenin parallel.Forexample,oneof the refinementsdetectsthesituationillustratedin Figure1 asan instanceof a commonlyoccurringcritical sectionconstructand thereforedeterminesthat
� � � � �=; CHT. The refinementsaredonerepeatedly, untilnoneof themproducesan improvementof theCHT information. Non-concurrency analysis,like our MHP analysis,relieson inlining of subprograms.Theworst-casecomplexity of this approachis > �@?BA � , where
?is the numberof
statementsin the program. This approachsubsumesthe previous approachesand thus computesthe most preciseinformationto date.Therefore,in this paperwecompareour proposedMHP algorithmto non-concurrency analysis.
3 Program Model
In this section,we introducethe Ada concurrency mechanismand then proposea graphmodel that supportsthismechanism.This modelconservatively capturesall possibleexecutionsof a programandis usedby our algorithmtocomputetheMHP informationfor this program.
3.1 The Task Communication Mechanismof Ada
In Ada,aprogramconsistsof asetof threadsof control,calledtasks, thatmayrun in parallel.Thebasicconstructforcommunicationandsynchronizationbetweentasksis the rendezvous, a form of synchronouscommunication.A taskmaycall on a namedentry in a secondtask;executionof thecalling taskis thenblockeduntil thecalledtaskacceptsthecall andthetwo taskscompletetherendezvous,possiblypassinginformationin bothdirections.We saythatacallwhichhasnotyetbeenacceptedis pending. A taskdeclaringaparticularentry � mayacceptcallsfrom othertasksonthatentryby executingan ���#�%�5$���� statement;if nocallsonthisentryarepending,theacceptingtaskcannotexecutethe ���#�%�%$#��� statementandis blockeduntil a call on entry � is madeby anothertask.
Figure2 containsa codeexamplewith threetasks1. Oneof thesetasks,C ' D�D���) , modelsa sharedbuffer of size1,into which theothertwo tasks,E )8�� ��)(0 and E )8�� ��)�9 , write by calling on entry F )8��� � declaredby the C ' D#D���) task
1Notethatthebodyof theprocedureGIH�G4JG<KMLG4NMO , calledby thewriter tasks,is notshown in thiscodefragment.
3

P5Q�R�SUT�V%WXPY�V#Z�[P5Q�R�SUT�V%WXPY�V5\ [P5Q�R�SU]^�__Y�V`WRYXa�PVbdcefgSh[YXa�PVbi^a5ce�fgSh[YXa�PVbij�V5WXP�Y8kml�QcX^5YonpWga`WMa�P�Yq�Y�V�r [Ya�st]^�__�YV([P5Q�R�SUu%esbt]^�__�YV`WRjV%WXPP�YXav%QcX^�YwnpWMa�P�Y�qY�V([u5Y�q5WMac�eeXxQ�ffYxPdce�fgSh[Q�ffYxPij�V%WXP�Y kml5QcX^�Y�nyWMadWga�P�Y�q�YV�rzs5ej�V%WMPP�Yav5QcX^5Yonm{|l�QcX^5Y8[Ya�s|j�V5WXP�Y8[Q�ffYxPi^a%ce�f�Sh[YXa�s}ceeMx1[Ya�st]^�__�YV([
P5Q�RgSiu%esbiT�V5WXP�Y�V#ZzWRP5eXTV%WXP�Y�n~QVV5Qb8k�Z ���Z����r|e_dWMaP�Y�q�Y�V8[u5Y�q%WgaP5eXTV%WXP�Y�nm{iWMa�WXP5W�Qc�WX�Y8[_5eV}W|WMa,Z����Zg��iceeXx]�^�__�Y�V(�7ce�fgS1[]�^�__�Y�V(��j�V%WXPY8kmP5eXTV%WXP�Y8kIW5rr []�^�__�Y�V(��^a%cefgSh[Ya�sUceeXx1[Ya�s|TV%WXP�Y�V�Z�[P5Q�RgSiu%esbiT�V5WXP�Y�V5\iWRP5eXTV%WXP�Y�n~QVV5Qb8k�Z ���Z����r|e_dWMaP�Y�q�Y�V8[u5Y�q%WgaP5eXTV%WXP�Y�nm{iWMa�WXP5W�Qc�WX�Y8[_5eV}W|WMa,Z����Zg��iceeXx]�^�__�Y�V(�7ce�fgS1[]�^�__�Y�V(��j�V%WXPY8kmP5eXTV%WXP�Y8kIW5rr []�^�__�Y�V(��^a%cefgSh[Ya�sUceeXx1[Ya�s|TV%WXP�Y�V�\ [Figure2: Exampleof Ada taskcommunications
in its specification.By makinganentry call on the entry" ����� of C ' D#D#��) (executingthe statementC ' D#D��%)32 " ���� ),
eachof the writer tasksmakessurethat it hasexclusive accessto the buffer. Task C ' D#D��%) canacceptthis call byexecutingthe statement���#�%�%$#� " ����� . An ���#�5�%$�� statementmay have a body, consistingof codethat is executedbeforecompletionof the rendezvous. The taskwhoseentrycall is acceptedby an �����%�%$�� statementwith a body isblocked for the durationof the call, i.e. until the calledtaskcompletesthe executionof the �����%�%$�� statement.Forexample,thewriter taskspassintegersto thebuffer by calling theentry F )8�� � thathasabody2.
In addition to the implicit non-determinismpresentin Ada programsas a result of concurrency, explicit non-determinismcanbeintroducedby using �%� " � ��� statements.In its basicform, a �%� " ����� statementcontainsanumberof branches;eachbranchmuststartwith an ���#�%�5$�� statement.Whena task reachesa �%� " ����� statement,a non-deterministicchoiceis madeamongthoseleading ���#�%�5$�� statementson the branchesof this �%� " ���� statementforwhich thereis anoutstandingentrycall. Thetaskexecutesthechosen���#�5�%$�� statementandproceedsto executethesubsequentstatementsonthisbranchof the �%� " ����� statement.If noentrycallsarependingfor the �����%�%$�� statementson thebranchesof a �%� " ����� statement,thetaskblocks.
In Ada,thisbasicform of the �5� " ����� statementis augmentedby optionalguards. A guardonabranchof a �5� " �����statementis justapredicate;thebranchmaybeexecutedonly if thispredicateevaluatesto ��)�'�� . Additionally, timeoutandalternativebranchescanbeused.A taskcontaininga �%� " ����� statementwith a timeoutbranchmayblock for nomorethanthe periodof time specifiedin the timeoutstatementwhile waiting for oneof the � �#�%�%$�� statementstobecomeenabled. If this period of time is exceeded,the timeout branchis executedinstead. A task containinga�%� " ����� statementwith an alternative branchfirst checksif any of the ���#�5�%$�� statementson the branchesof the�%� " ����� statementareenabledandif not, it immediatelyexecutesthe alternative branch. Finally, thereis a specialform of the �%� " � ��� statementthat allows placing entry call statementsas first statementson the branchesof the
2Thisexampleis somewhatsilly in thesensethatvaluesareplacedin thebuffer, but not takenoutof thebuffer (avalueinsertedin thebuffer viaa call on �M�G4JMO entrysimply overwritestheold valuein this buffer). We chosethis examplefor its simplicity andwe useit throughoutthepaperfor illustrations.
4

�%� " ����� statement.However, this form of the �%� " ����� statementis very restricted,allowing a singlebranchwith aleadingentrycall statementanda secondbranchthat is eithera timeoutor analternative branch.Our algorithmforcomputingtheMHP informationis capableof handlingall typesof �5� " ����� statements3.
In theexamplein Figure2, the two writer tasksshouldnot beallowedto accessthebuffer simultaneously. Thisrestrictionis implementedby the C ' D#D#��) taskby surroundingits ���#�5�%$�� statementfor entry F )8�� � by �����%�%$�� state-mentsfor entries
" � ��� and '#! " � ��� . Supposethat task E )8�� �%)10 succeedsin makinganentrycall on C ' D#D#��)32 " � ���andproceedsto callingon C ' D#D��%)32 F )8��� � . Evenif task E ) �� ��) 9 is readyto communicatewith task C ' D�D���) onentry" ���� at thispoint, C ' D#D#��) will notbeableto acceptthisentrycall until afterit acceptstheentrycall on '#! " ���� fromE )8��� ��)10 . By this point, task E )8�� �%)10 is donewriting in thebuffer.
Multiple tasksmaymakecallson thesameentry. Sinceonly onetaskis allowedto rendezvouswith theacceptingtaskat a time, eachentryhasanassociatedFIFO queuefor tasksthatarewaiting for their turn4. For thepurposesoftheMHP analysis,thesequeuesdonothaveto bemodeled,becauseaconservativeanalysishasto evaluateall possiblethreadschedulingorders. For example,in Figure2 eachof the tasksE )8�����)10 and E )8��� ��) 9 makesa call on entry" ���� of task C ' D#D���) . During anactualprogramexecution,if both E )8�����)10 and E )8��� ��) 9 arereadyto communicateon thatentrycall, the taskthat issuedthecall first is chosenfor a rendezvouswith task C ' D#D#��) . Sinceour analysishasto applyto all possibletaskschedules,weassumethateitherorderof entrycallsis possible,whichcorrespondstochoosingoneof thetasksE )8��� ��)10 and E )8�� �%) 9 for a rendezvousnon-deterministically.
3.2 A Graph Representationof a Concurrent Program
Weconstructagraph,calledaParallelExecutionGraph(PEG),thatrepresentsthepossibleexecutionsof theprogram.ThePEGis basedon communicationcontrol flow graphs(CCFGs)for eachtask. Theseareessentiallythe sameasconventionalcontrol flow graphs[1], exceptthatwe imposedifferentrestrictionson the regionsof codethat canberepresentedby individualnodes.In particular, weallow CCFGnodesto representregionsof codeincludingbranchingbut restrictthenumberof communicationstatementsthatcanberepresentedby a node.In constructingthePEG,weconnecttheCCFGswith additionalnodesandedgesthatrepresentcommunicationbetweentasks.
For simplicity, in therestof thispaperwesay“node � mayhappenin parallelwith node� ” to meanthatexecutionof at leastoneprogramstatementrepresentedby � may happenin parallelwith executionof at leastoneprogramstatementrepresentedby � . For eachnode � in the PEG,our algorithmconstructsa setM
� � � of nodes. This setrepresentsaconservativeestimateof thesetof nodesthatmayhappenin parallelwith � . ThesetM
� � � is anestimate,not necessarilya precisedetermination,becausetheremaybenodesin M
� � � thatcannotactuallyhappenin parallelwith � . In theremainderof this section,we explain theconstructionof thePEG.
3.2.1 Communication Control Flow Graphs
The representationthat we usefor eachtaskin a programis closelyrelatedto the control flow graph(CFG) repre-sentation.Onesignificantdifferencebetweenour representation,which we call a communicationcontrol flow graph(CCFG), andthe“standard”CFGrepresentationis thegranularityof nodes.While usuallyeachnodein theCFGrep-resentsa regionof codewithout branching,CCFGsdo not have this restriction.Theonly restrictionthatwe placeonnodegranularityis thata CCFGnodecannotrepresentmorethanonetaskcommunicationstatementor, alternatively,one �%� " ����� statement5. Figure3(a)shows the“standard”CFGrepresentationfor a writer taskfrom theexampleinFigure2. In thisCFG,thenodelabeled����� ��! representsthestartof executingthisthread,thenodelabeled��� E )8����.�4�representstheassignmentstatementprecedingtheloop, thenodelabeled
" �#�%$ representsthecomputationof thelooppredicateandincrementof theloop invariant,thenodelabeled
" �#�%$�������� representsthethreeentrycallsin thebody3Furthermore,our approachis capableof handlinga moregeneralform, whereeither KX�g��O��MJ or entry call statementsareusedas leading
statementson thebranchesof ��OML�OX��J statements.4Taskscanbeassigneddifferentpriorities,whichcanaffect theirpositionin theentryqueue.5A ��OML�OX��J statementrepresentsanon-deterministicchoice.Thus,wehaveto representthischoicepointin asinglenode,essentiallyrepresenting
potentiallymany communicationstatements(onefor eachbranchof the ��OML�OX��J statement,exceptbranchesrepresentingtimeouts)with thisnode.
5

loop
end
loop body
begin
toWrite:=
(a) A CFGfor thewritertasks
loop
begin
toWrite:=
end
Buffer.write
Buffer.lock
Buffer.unlock
(b) A CCFGfor thewriter tasks
end
Buffer.write
begin
Buffer.lock
Buffer.unlock
(c) A minimal CCFG for thewriter tasks
Figure3: Examplesof a CFGandaCCFGfor the E )8�� ��) task
of this loop,andthenodelabeled�%! � representsterminationof this task.This CFGis not a CCFGbecausethenodelabeled
" �#�%$�������� representsthreecommunicationstatements.A CCFGrepresentingthewriter taskis shown in Fig-ure3(b). Notethat thebodyof theloop, which wasrepresentedby a singlenodein theCFGof Figure3(a),requiresthreenodesin theCCFG,onefor eachentrycall.
Formally, a CCFGis a tuple�N � E � ComNodes� ComStmt� , whereN is the setof nodes,E � N � N is the setof
edges,ComNodes� N is thesetof all nodesin this CCFGthatrepresentcommunicationamongtasks,andComStmtis a function that, given a CCFGcommunicationnode,returnsa setcontainingdescriptionsof the communicationsrepresentedby this node.This setis emptyif thenodedoesnot representany communications.For example,for theCCFGin Figure3(b), given the nodelabeled ��� E )8����.�4� , function ComStmtreturnsan emptyset,sincethis noderepresentsnocommunicationstatements.GiventhenodelabeledC '�D#D���)32 " ����� , ComStmtreturnsasetcontainingtheentrycall on entry
" ����� of task C ' D#D���) . In general,ComStmtreturnsa setcontainingmorethanonecommunicationstatementonly for nodesthatrepresentAda �%� " ����� statements.
We call a CCFG minimal if the numberof nodesin this CCFG cannotbe reducedby merging nodesthat donot representtask communications.For example,the CCFG in Figure3(b) canbe transformedinto the CCFGinFigure3(c) by removing all nodesexceptthethreenodesrepresentingentrycallsandthe � ���8��! and �%! � nodes.Notethatalthoughthe remainingnodesin the CCFGin Figure3(c) arelabeledin the sameway assomeof the nodesinFigure3(b), they do not have thesamesemantics.While all executionsof a particularstatementin the E )8��� ��) threadare representedby a uniquenodein the CCFGin Figure3(b), differentexecutionsof the samestatementmay berepresentedby differentnodesin the minimal CCFG.For example,incrementingthe loop variable � is represented
6

Buffer.write
. . . . . .
accept write-start
Buffer.lock accept lock
. . . . . .
(a) A PEG fragmentillustrating communicationbetweenthe� �G4JMO�� and ���M�g�MO�� tasksona Lg�M�<� call
Buffer.write
. . . . . .
start
accept write-start
accept write-end
Buffer.unlock accept unlock
. . . . . .
end
(b) A PEG fragmentillustrating communicationbetweenthe� �G4JMO�� and ���M�g�MO�� tasksona �M�G4JMO call
Figure4: Representingcommunicationsbetweentasksin aPEG
bothby thenodelabeledC ' D#D#��)32 " � ��� , for thecasewherethis incrementdoesnot make � exceed100,andtheendnode,for thecasewhere � becomes101,whichcausesthe D���) loop to terminate.
This representationof tasksis similar to TaskInteractionGraphs(TIGs) [12]. Nodesin a TIG for an Ada taskrepresentsetsof controlpathsthroughthis task,eachpathterminatingin a taskcommunicationstatement.A majordifferencebetweenCCFGsandTIGsis that,while anodein aCCFGrepresentsasingletaskcommunicationstatement,a nodein a TIG canrepresentseveraltaskcommunicationstatements.
Ada taskscancall subprograms,which canin turn containtaskcommunicationstatements.In our approach,weinline all subprograms.While it is true that, in the worst-case,this inlining canresult in an explosive growth in thenumberof nodesin the programrepresentation,we believe that in many cases,this growth is only moderate.Thereasonfor this is that if a subprogramandany of the subprogramsthat it calls directly or indirectly do not containtaskcommunicationstatements,thentheCCFGthatcontainsa call to this subprogramwill not changeafter inlining.Thus,beforeinlining a procedure,we constructa CCFGfor it andperformtheinlining only if theresultingCCFGisnon-trivial, thatis, if it containsrepresentationsof taskcommunicationstatements6.
3.2.2 The Parallel ExecutionGraph
We representthe whole programby combiningCCFGsfor individual tasksinto a singleparallel executiongraph(PEG). Weaddspecialnodesrepresentingthepossiblerendezvousbetweencommunicatingtasks,togetherwith edgesconnectingthe new nodesto the nodesrepresentingthe correspondingentry calls and ���#�5�%$�� statementsandtheirsuccessors.We alsoadda uniqueinitial node � init thathasno incomingedgesandhasoutgoingedgesto the beginnodesof all componentCCFGsand a uniquefinal node � fin that hasno outgoingedgesand hasincoming edgesfrom the endnodesof all componentCCFGs. Sinceit is NP-hard to determinewhethera rendezvousinvolving aparticularcall-acceptpaircanactuallyoccur, wecreatenew nodesrepresentingpossiblerendezvousbetweenall pairsof syntactically-matchingentrycallsand ���#�%�%$#� statements.
6Ourapproachdoesnothandlerecursiondirectly, because,in general,theproblemof computingMHP informationfor aprogramwith recursionis undecidable[20]. In somecases,we can replacerecursionwith an equivalent loop that containstask communicationstatementsfrom thesubprogramsparticipatingin therecursion.
7

Buffer.lock
2accept lock
8
Buffer.write3
19
accept write−start
9
20
4
accept write−end
10
21
Buffer.unlock5
accept unlock
11
23
24
25
26
end
12
end6
22
end
18
Buffer.unlock17
16
Buffer.write15
Buffer.lock
14
begin
131
begin begin
7
Writer1 Writer2Buffer
nfin
ninit
Figure5: ThePEGfor theexample
Considerfirst thecaseof anode� representingan � �#�%�%$�� statementwith nobody. For eachnode� representinga call to the entryof such ���#�%�%$#� statement,we createa new noderepresentinga possiblerendezvousbetweenthetaskcontainingthe �����%�%$�� statementrepresentedby � andthe taskcontainingthecall statementrepresentedby � .We addedgesfrom � and � to the new node,andfor eachedgefrom � or � to anothernode � , we replacethatedgeby anedgefrom thenew nodeto � . Figure4(a)shows a fragmentof thePEGfor theexamplein Figure2 (thefull PEGfor this exampleis given in Figure5). This fragmentshows only the creationof a PEGnodeto representthe communicationbetweenoneof the writer tasksandthe C ' D#D#��) taskon a
" ���� entry call. We refer to the newnodesaddedto representpossiblerendezvousasrendezvousnodes, andreferto thenodesin theCCFGsfor thevarioustasksaslocal nodes.In thevisualPEGrepresentationusedin this paper, rendezvousnodes,the initial node,andthefinal nodehave a diamondshapeand local nodeshave a rectangularshape. The CCFGedgeshowing the flow ofcontrol in the writer taskfrom the noderepresentingthe call on C ' D#D��%)32 " ���� to the noderepresentingthe call onC ' D�D���)32 F )8�� � is replacedby theedgefrom the rendezvousnodeto the C ' D#D���)-2 F )8���� node. This correspondstothe fact that control canflow from the C ' D#D#��)32 " � ��� nodeto the C ' D�D���)32 F )8�� � nodeonly aftercompletionof therendezvousat the
" ���� entry.
8

To handle���#�5�%$�� statementswith bodies,we addtwo rendezvousnodes,to representthestartandtheendof therendezvous,andanadditionallocal nodeto representthe fact that the calling taskwaits while thebody is executed.Figure4(b) illustratesthis situationfor a communicationbetweenoneof the writer tasksandthe C ' D#D#��) taskon aF )8��� � entry call. In this fragment,the rendezvousnodelabeled ���#�%�%$#� F )8�� ������� ��)#� representsthe startof therendezvousandtherendezvousnodelabeled���#�%�5$�� F )8��������%! � representstheendof therendezvous.Notethatweuseanadditionalnode(theshadednodein Figure4(b)) to representthetaskmakinganentrycall waiting for thebodyof the ���#�%�5$�� statementin thecalledtaskto finishexecuting.Figure5 showsthefull PEGfor theprogramin Figure2.
In Ada,taskscanbedefinedin two ways.Oneis to declaretasksstatically, asin theexamplein Figure2. All suchtaskscanbegin executionsimultaneouslyat the beginning of the program. Alternatively, onecanusetasktypestodefinetasksthatcanbeinstantiatedandstarteddynamically. If anobjectof a tasktypeis declaredasa local variableof asubprogram,thisobjectis instantiatedandstartedwhenthissubprogramis called.In thispaper, weconcentrateonthesimplercaseof statictasks,but ourapproachis alsocapableof handlingdynamicallystartedtasks,if thenumberofsuchtasksis bounded.AppendixB describesthechangesto thePEGmodelnecessaryto handledynamicallystartedtasks.
We useN andE to denotethe setsof nodesandedgesin the PEG,respectively. We write REND for the setofrendezvousnodesaddedin constructingthePEGandLOCALfor thesetof localnodes.Thus,for thesetN of all PEGnodeswe haveN � REND � LOCAL �z��� init
� � fin � . Formally, aPEGis a tuple�N � E � REND� LOCAL� � init
� � fin� .
Let task� LOCAL � AllTasksbethefunctionthatmapsa local nodeto thetaskwhosestatementsarerepresentedby thatnode,andlet tasks� REND � AllTasks � AllTasksbe the function thatmapsa rendezvousnodeto a pair oftasksparticipatingin thisrendezvous,wherethecallingtaskappearsin thefirst positionandtheacceptingtaskappearsin thesecondpositionin thispair.
Theformal algorithmfor constructinga PEGfor a concurrentAda programfrom a setof CCFGsfor all threadsin this programis givenin Figure6. In this algorithm,we useEntryCall, AcceptNoBody, AcceptWithBodyStart, andAcceptWithBodyEndto referto communicationstatementsof anentrycall, an �����%�%$�� statementwithoutabody, andabeginningandendof an ���#�%�%$#� statementwith abodyrespectively. WealsousefunctionEntryNameto returnthefullyqualified(i.e. includingthe identity of theacceptingtask)nameof theentryassociatedwith a givencommunicationstatement.
As statedin the following theorem,the numberof nodesin the PEG is quadraticin the numberof programstatementsin theworstcase.Wenote,however, that,accordingto ourexperimentalresultspresentedin Section5.5.6,in practicethesizeof thePEGtendsto belinearin thenumberof programstatements.
Theorem1(Worst-casePEG size). Thenumberof nodesin a PEGisat most> ��� ?�� � � , where?
is thesetofstatementsin theprogrammodeledby thePEG.
Proof. Eachstatementin the programmay correspondto a different local nodein the PEG,thereforethe numberof local nodesin the PEG is > ��� ? � � . Eachrendezvousnodein the PEG correspondsto a pair of communicationstatements,an entry call statementandan ���#�%�5$�� statement,suchthat both statementsoperateon the sameentry.Thus, the numberof rendezvousnodesis at most the numberof pairs of statementsfrom the program,and so is> ��� ?�� � � .4 MHP Algorithm
In this sectionwe presentour algorithmfor computingMHP information.We givea high-level overview of thealgo-rithm in Section4.1. Section4.2 introducestherelevantnotation.Section4.3presentsthedetailsof thealgorithmintheform of dataflow equations.Section4.4incorporatestheseequationsinto analgorithmicformulation.Finally, Sec-tion 4.5containstheproofsof terminationandconservativenessof thealgorithm. In addition,this sectionintroducesa moreefficient,althoughmorecomplicated,form of thealgorithmandstatesits worst-casecomplexity bounds.
9

Algorithm 1 (PEG construction).
Input: A CCFG ¡£¢8¤¦¥ N¢7§ E¢4§ ComNodes¢7§ ComStmt¢�¨ for each task ©�¢ in theprogram, ª¬«®1«z¯Output:A PEGfor theprogram
// createa localPEGnodefor eachCCFGnodeandconnectthem:(1) °�I§�ª£«®h«®¯ , for eachnode± from CCFG ¡ ¢ ,(2) Createa PEGnode²´³ LOCAL, sothat task¥µ²¶¨·¤|©�¢ , andassociateit with ±(3) For eachedge ¥µ²1§4±p¨ in eachCCFG(4) if ComStmt¥µ²¶¨1¤U¸(5) createanedgebetweenPEGnodescorrespondingto ² and ± .
// createall rendezvousnodesby matchingtypesof thelocalnodes:(6) °�²(¹6³ LOCAL(7) let ±º¹ bethecorrespondingCCFGnode(8) let »¹ bethesetof communicationstatementsrepresentedby ±º¹ : »¹¼¤ ComStmt¥µ±½¹4¨(9) °�²¶¾-³ LOCAL(10) let ± ¾ bethecorrespondingCCFGnode(11) let » ¾ bethesetof communicationstatementsrepresentedby ± ¾ : » ¾ ¤ ComStmt¥µ± ¾ ¨(12) if task¥µ² ¹ ¨3¿¤ task¥µ²¶¾�¨ , for all pairsof statementsÀ ¹ §<ÀM¾ , where À ¹ ³~» ¹ §<ÀM¾£³~»X¾ ,(13) if ComStmtType¥�À ¹ ¨1¤ EntryCallandComStmtType¥�ÀM¾�¨1¤ AcceptNoBody
andEntryName¥�À�¹�¨1¤ EntryName¥�À ¾ ¨(14) Createa new nodeÁ£³ REND, sothat tasks¥µÁg¨1¤¦¥ task¥µ²1¹4¨�§ task¥µ² ¾ ¨I¨
// createall edgesconnectinglocalandrendezvousnodes:(15) CreatePEGedges¥µ² ¹ §4Á�¨�§g¥µ²¶¾§IÁg¨(16) ° CCFGnodes suchthat Âó Succs¥µ±½¹<¨�ÄÅ ³ Succs¥µ± ¾ ¨(17) let PEGnodeÆų LOCALcorrespondto Â(18) CreatePEGedge ¥µÁX§IÆ%¨
endif(19) if ComStmtType¥�À�¹�¨1¤ EntryCallandComStmtType¥�À ¾ ¨1¤ AcceptWithBodyStart
andEntryName¥�À�¹�¨1¤ EntryName¥�À ¾ ¨(20) find PEGnode²�Ç suchthat ÀgÇ is thethecorresponding
CCFGnodeandComStmtType¥�À Ç ¨1¤ AcceptWithBodyEndand ² ¾ and ² Ç representthesameQ�ffYxP statement
(21) Createnew nodesÁX¹g§IÁ ¾ ³ REND, sothattasks¥µÁ¹4¨·¤ tasks¥µÁ ¾ ¨h¤¦¥ task¥µ²(¹�¨�§ task¥µ² ¾ ¨I¨(22) Createa waitingnodeÈ`³ LOCAL, sothat task¥µÈ3¨1¤ task¥µ² ¹ ¨
// createall edgesconnectinglocalandrendezvousnodes:(23) CreatePEGedges¥µ²(¹�§4ÁX¹<¨�§g¥µ² ¾ §IÁX¹�¨�§g¥µÁ¹g§IÈ3¨�§g¥µÈ�§IÁ ¾ ¨�§�¥µ² Ç §7Á ¾ ¨(24) ° nodes suchthat Âó Succs¥µ±p¾�¨(25) let PEGnodeÆų LOCALcorrespondto Â(26) CreatePEGedge ¥µÁX¹�§IÆ%¨(27) ° CCFGnodes suchthat Âó Succs¥µ±½¹<¨�ÄÅ ³ Succs¥µ± Ç ¨(28) let PEGnodeÆų LOCALcorrespondto Â(29) CreatePEGedge ¥µÁ�¾X§IÆ%¨
endifendif
// createandconnecttheinitial andfinal PEGnodes:(30) createtheinitial andfinal nodes² init and ² fin
(31) °�I§�ª£«®h«®¯(32) Let ² ¢ ³ LOCALbethePEGnodecorrespondingto thestartnodeof CCFG ¡ ¢ and² É¢ ³ LOCALbethePEGnodecorrespondingto theendnodeof CCFG ¡£¢ .(33) CreatePEGedges¥µ² init §I² ¢ ¨�§g¥µ² É ¢ §7² fin ¨
Figure6: Thealgorithmfor constructingaPEGout of acollectionof CCFGs
10

4.1 Overview
The goal of our analysisis to computea set Ê of pairsof statementssuchthat we canbe surethat every pair ofstatementsnot in Ê canneverhappenin parallel.
For eachnode� in thePEG,ouralgorithmconstructsasetM� � � of nodesrepresentingstatementsthatmayhappen
in parallelwith the statementsrepresentedby � . We begin by settingM� � � �ÌË . MHP information is propagated
throughthePEGby “flowing” nodesin M� � � to thesuccessorsof � . Therendezvousnodesandtheinitial nodein the
PEGrepresentthepointsatwhichMHP informationchanges.Ontheonehand,becausesynchronizationpointsimposerestrictionson independentexecutionof tasks,someMHP informationmaybe“killed” uponreachinga rendezvousnode.Ontheotherhand,immediatelyafterasynchronizationpoint, thetasksparticipatingin thissynchronizationcanproceedindependently. Similarly, all tasksstartexecutingindependentlyat the beginningof theprogramexecution.Whena fixedpoint is reached,our algorithmterminatesandthefinal valueof M
� � � is a conservativeestimateof thenodesthatmayhappenin parallelwith � .
Sincerendezvousnodesareconstructedusingsyntacticmatchingof entrycallsand �����%�%$�� statementsin differentthreads,somerendezvousnodesmaybeunreachable, i.e. representsynchronizationpointsthatcannotbereachedonany programexecutions.Using a simplenecessaryconditionbasedon MHP information,our algorithmcandetectsomeunreachablerendezvousnodes,therebyimproving theprecisionof theresultingMHP information.
By its nature,MHP informationis symmetric.Achieving this takesanadditionalstepin our algorithm.Unfortu-nately, this stepmakesit impossibleto representtheMHP algorithmasa purelyforward-or backward-flow dataflowproblem[8] or asa bidirectional[13] dataflow problem.It is for this reasonthatwe presentthealgorithmusingdataflow equationsdescribedin Section4.3. First we presenta simpleversionof thealgorithmthat is easyto understandandfor which it is easyto proveterminationandconservativeness.After thatwe presentanequivalentalgorithmthatis lessintuitivebut haslowerworst-casecomplexity bounds.
4.2 Notation
Our algorithmassociatesthreesetswith eachnode � of thePEG:GEN� � � , IN
� � � , andM� � � . ThesetM
� � � containsnodesthatthealgorithmdeterminedmayhappenin parallelwith � , GEN
� � � containsthenodeswecanplacein M� � �
basedon informationlocal to � , and IN� � � containsthe nodeswe canplacein M
� � � usinginformationpropagatedfrom thepredecessorsof � .
Initially, all threesetsM, IN, andGEN areemptyfor all nodes.Thesesetsarerepeatedlyre-computeduntil thealgorithmreachesa fixedpoint andthesetsdo not change.At this point setM
� � � representsa conservativeestimateof nodeswith whichnode � mayexecutein parallel.
In additionto thesethreesets,we assigna Reach flag to eachrendezvousnode,identifying whether, accordingtothealgorithm,this rendezvousnoderepresentsa reachablerendezvous.This flag is initially setto D�� " �%� . Its valueissetto �#)�'�� if, on someiteration,bothlocal predecessorsof this rendezvousnodebelongto eachother’sM sets.Thismeansthat the algorithmhasdeterminedthat the two local predecessorsmayhappenin parallel,andhencethat therendezvousmayoccur.
4.3 Data Flow Equations
Our approachassociatesthreedataflow equationswith eachnodein the PEG,computingthe currentvaluesof setsGEN, IN, andM for this node. The equationfor computingthe GEN setof a noderelieson the informationaboutwhetherthe nodehasrendezvouspredecessors,in which caseparallelismintroducedby suchpredecessorsmustbetakeninto account.Theequationfor computingtheIN setcombinestheMHP informationthatthenodereceivesfromeachof its predecessors.Finally, theequationfor computingtheM setcombinestheGENandIN setsfor thisnode.Intherestof thissubsection,wedescribethesedataflow equationsin detail.
11

n m
. . . . . .
. . .. . .
c
(a)
1
2
3
c
c
c
m
np. . .
. . . . . .
. . .
. . .
. . .
(b)
n init
n fin
n3
n
n1
2
(c)
Figure7: Illustrationsfor theMHP equations
Reachability flags
Intuitively, a rendezvousrepresentedby arendezvousnodecantakeplaceonly if bothtasksarereadyto participateinit. A necessaryconditionfor a rendezvousto happenis that thepredecessorsof thecorrespondingrendezvousnodemay happenin parallelwith eachother. To improve the precisionof our analysis,we usethis necessaryconditionto determinewhich rendezvousnodescanbe reachable.We associatea Reach flag with eachrendezvousnodetorepresentits reachabilitystatus.Initially, all suchflagsaresetto D#� " �%� . Until theReach flag of a rendezvousnodeissetto ��)�'�� , thealgorithmassumesthat thesynchronizationrepresentedby this nodeis not possible.TheReach flagis setto ��)�'�� whenoneof thepredecessorsof therendezvousnodeis insertedin theM setof theotherpredecessorofthis node. If theReach flag of a rendezvousnodeis still D�� " �%� after thealgorithmreachesa fixedpoint, this meansthatthecommunicationrepresentedby this nodeis not possibleon any executionof theprogram.
GEN sets
ConsiderthePEGfragmentin Figure7(a). Supposethatour algorithmdeterminesthat therendezvousnode Í in thisfragmentis reachable.If the correspondingrendezvousis reachedin the actualprogram,after the executionof thisrendezvous,statementsrepresentedby nodes� and � canexecutein parallel,sincethey belongto two differenttasks.Wecapturethispossibilityby placing � in GEN
� � � and� in GEN� � � . Moregenerally, wehaveto considerasituation
wherea nodecanbea successorof severalrendezvousnodes,suchasnode9 in thePEGin Figure5. So,we obtaintheGENsetof node � by placingin it all nodes� suchthat � and � arebothsuccessorsof a reachablerendezvousnode,or of the initial node.Formally, if � is a local node,let Î¼Ï be thesetconsistingof � init , if � is a successorof� init , andall rendezvousnodesÍ thathave � asa successorandalsohaveReach
� Í � setto ��)�'�� . Then
GEN� � � � ÐÑÓÒÔ�Õ%Ö�× Succs
� � �4ØÙÛÚ �� �task
� � � � task� � �1Ü task
� � �3; tasks� � � ��Ý (1)
Notethat if � is a rendezvousnode,GEN� � � ��Ë , sinceby theconstructionof PEG,a rendezvousnodecannothave
otherrendezvousnodesor theinitial nodeaspredecessors.
12

IN sets
Eachedgein a PEGrepresentstransferof control insidea singletask. A local nodebelongsto a singletask,while arendezvousnodebelongsto two tasks.This differencebetweenlocal andrendezvousnodesresultsin differentwaysof propagatingMHP information.First considera localnode � . TheideabehindcomputingIN setsfor local nodesisthat if a predecessor� of a local node � canhappenin parallelwith somenode� , then � canalsohappenin parallelwith � , becausethesemanticsof transferof control from � to � areindependentof theactivity of othertasks.Thus,theequationfor the IN setfor a localnodesimply computestheunionof M setsof all predecessorsof this node.
If � is arendezvousnode,it canonly executewhenbothof its predecessorshaveexecuted,andsomaynotexecutein parallelwith anodethatcannotexecutein parallelwith bothof its predecessors.Figure7(b)providesanillustration.Supposethatnodes� and� mayhappenin parallel(i.e.,thatnodeÍ � is reachable),andnodes� and� maynothappenin parallel. Sincenode ÍMÞ canhappenonly after both � and � happened,it may not happenin parallelwith node� . Theequationfor the IN setfor a rendezvousnodecomputesthe intersectionof M setsof the two predecessorsofthis node.Notethat this ensuresthata rendezvousnodecannever have nodesin its IN setfrom thetwo taskswhoserendezvousit represents.
Formally, for a localnode� ,IN� � � � ÒÔ�Õ Predsß Ï5à M � � � , (2)
andfor a rendezvousnodeÍ ,IN� Í � �âá£ã Ô�Õ Predsßåä à M
� � � if Reach� Í �Ë otherwise.
(3)
M setsand the symmetry step
WedefineM� � � � IN
� � � � GEN� � � . Up to thispoint thealgorithmis astandardforward-flow dataflow algorithm[8].
However, after computingGEN, IN, and M setsfor eachnode,we have to take an additionalstepto ensurethesymmetry� �æ; M
� � ��.ç � �è; M� � �� by adding� � to M
� � �� if � � wasaddedto M� � �� . Figure7(c) illustrateswhy
this is necessary:without this additionalsteptheM setsof nodes� � and � � are ��1Þ � (sinceGEN� � �M� �é��1Þ � and
IN� � �� �Ó��1Þ � ), but theM setof �1Þ is �� � � (GEN
� �1Þ � �ê��� � � ). Thus, �1Þ ; M� � �� holdsbut � �è; M
� �1Þ � doesnot.
4.4 Worklist Form of the Algorithm
In Figure8, wegiveaworklist versionof theMHP algorithm.Initially, all successorsof theinitial nodeof thePEGareplacedon theworklist. On eachiterationof thealgorithm,onearbitrarynodeis takenoff theworklist andprocessed.Processingof anodeincludescomputingits Reach flagif it is arendezvousnodeandthencomputingits GEN, IN, andM setsaccordingto thedataflow equationsin Section4.3. After that,thesymmetrycomputationis carriedout. Afterthesecomputations,successorsof all nodeswhoseM setschangedareaddedto theworklist7 andthemainiterationofthealgorithmis repeated.Thealgorithmterminateswhentheworklist becomesempty. We defineSuccsNoFinal
� � �for a node � to containall successorsof � exceptthefinal node.By usingSuccsNoFinal to accessthesuccessorsof anodecurrentlyprocessedby thealgorithm,we ensurethatthefinal nodeis neverplacedon theworklist.
4.5 Termination, Conservativeness,and Complexity
In this sectionwe prove thatour algorithmalwaysterminatesandcomputesconservativeMHP information. In addi-tion, wemodify thealgorithmin awaythatcomputesthesameMHP informationastheworklist algorithmin Figure8but is moreefficientandprovethattheworst-casecomplexity of thisefficientalgorithmis cubicin thenumberof PEGnodes.
7Weregardtheworklist asaset,soif anodeis alreadyon theworklist, addingit doesnot changetheworklist.
13

Algorithm 2 (BasicMHP algorithm).
Input : A PEG�N � E � REND� LOCAL� � init
� � fin�
Output : ë8� ; N � a setMHP� � � of PEGnodessuch
that ë8�íì; MHP� � � , � may not happenin parallel
with � .Initialization : TheM setsfor all nodesare initiallyempty, andtheworklist set î initially containsstartnodesfor all tasksin theprogram:For each� ; N, setM
� � � ��Ë .Set îï� Succs
� � init�
Main Loop: We evaluatethe following statementsrepeatedlyuntil îï��Ë(1) �=� a nodefrom î(2) îð�ñî Ú ��� �(3) if � ; RENDthen(4) ��� � � � � � � Preds
� � �(5) Reach
� � � � � � � ; M� � � �<�
(6) if Reach� � � then
(7) NewM � M� � � �1ò M
� � � �endif;
else(8) ComputeGEN
� � �(9) NewM � GEN
� � � �ôó ÔÕ Predsß Ï5à M� � �
endif;(10) if NewM ì� M
� � � then(11) For each� ; �
NewM Ú M� � �<�
// symmetrystep:(12) M
� � � � M� � � �®��� �
(13) îð�ñîõ� SuccsNoFinal� � �
(14) îï��îö� SuccsNoFinal� � �
(15) M� � � � NewM
endif;Finalization:
For each� ; N(16) MHP
� � � � M� � �
Figure8: MHP algorithm
4.5.1 Termination
Lemma 2. Onanyiteration of thealgorithm,thefollowing two statementshold:
1. Nonodesare removedfromanyof theM sets
2. Norendezvousnodeis markedasunreachableif it hasbeenmarkedreachableprior to this iteration
Proof. Weargueby inductiononthenumberof iterations.Onthefirst iteration,oneof thetaskbeginnodesis removedfrom theworklist. By thedefinitionof thePEG,all taskbegin nodesarelocal. Sincein thebeginningof thealgorithmall M setsareemptyandReach flagsof all rendezvousnodesaresetto D�� " �%� , statements(1) and(2) trivially hold.
Assumethatbothstatementsof this lemmahold for iterationsprior to iteration ÷ . Considerfirst the casewherethenode � removedfrom theworklist on iteration ÷ is local. After GEN
� � � is computedon this iteration,it containsall nodesthat it containedon any of the precedingiterations,becausethe computationof GEN
� � � dependsonly onthe reachabilityof � ’s rendezvouspredecessors,and accordingto the induction hypothesis,no suchpredecessorscould changetheir Reach flag from �#)�'�� to D�� " �%� . The computationof set IN
� � � dependsonly on the M setsof� ’s predecessors,which couldnot decreaseon any of theprecedingiterations,accordingto theinductionhypothesis.Therefore,IN
� � � will containall nodesit containedon any of theprecedingiterations.Now, supposethat � is a rendezvousnode. Computationof Reach
� � � dependsonly on the M setsof the twopredecessorsof � . According to the inductionhypothesis,theseM setscould not decreaseon any of the previousiterations,andsoif Reach
� � � wassetto �#)�' � on any of thepreviousiterations,it will besetto ��)�'�� on this iteration.Similarly, theIN setfor � dependsonly on theM setsof � ’s predecessorsandthuscannotdecrease.
For both kinds of nodes,sincetheir IN andGEN setscannotdecreaseon iteration ÷ , their M setsalso cannotdecreaseon this iteration.Thesymmetrystepmayonly addnodesto M setsof othernodes.
14

Theorem3 (Termination).Givena PEGfor a concurrentprogram,theworklist versionof theMHP algorithmwill eventuallyterminate.
Proof. Sinceon eachiterationof the algorithma nodeis removed from the worklist, the statementof this theoremwill follow if we provethatany PEGnodeis addedto theworklist a finite numberof times.A node � is addedto theworklist only if theM setof oneof � ’s predecessorschanges.Accordingto Lemma2, M setsneverdecrease,which,combinedwith thefactthatM setsarefinite (thenumberof elementsin any M setis boundedby
� ød�), impliesthatthe
M setof any of � ’s predecessorscanchangeafinite numberof times.Thestatementof thetheoremfollows.
4.5.2 Conservativeness
Wesaythatanalgorithmfor computingMHP informationisconservativeif, wheneverthereexistsaprogramexecutionon which thesetwo statementshappenin parallel,thealgorithmreportsthat thosestatementsmayhappenin parallel.A conservative algorithmmay, of course,overestimatethesetof pairsof statementsthatmayhappenin parallelandreportthattwo statementsmayhappenin paralleleventhoughthey cannotactuallyexecutein parallel.Our algorithmactuallyreportspairsof nodes,eachof which mayrepresentmorethanonestatement,so theresultsof applyingouralgorithmmustbeinterpretedusingthesetof statementscorrespondingto eachnode.This is complicatedslightly bythefactthatagivenstatementmayberepresentedby morethanonenode.To show thatouralgorithmis conservative,we mustshow that,if statements�� and �� happenin parallelon someexecution,thenthereexist local nodes� � and� � in thePEGsuchthat � � represents��� , � � represents��� , andthealgorithmplaces� � in MHP
� � ��� .To show thatourMHPalgorithmis conservative,weneedto beableto reasonaboutprogramexecutionsin termsof
PEGnodes.Herewepresentareachability-basedmodelfor PEGexecutionsandlateruseit to proveconservativenessof ourMHP algorithm.
Executionof aconcurrentprogramis representedby executionof eachof its tasksandthecommunicationsamongthesetasks.We representtheprogressof theprogramexecutionby identifying thelocal nodethatcorrespondsto thestatementthat is currentlybeingexecutedby eachtaskin theprogram.Let L ù bethesetof local nodesrepresentingstatementsfrom task ú ù . We call a tuple of û local nodes
� � �� ÝåÝåÝ � �(ü � , suchthat eachnodecomesfrom a differenttaskandall tasksarerepresented,a marking. A markingmay representoneor morestatesof a programexecution,whereeachof the tasksexecutessomecoderepresentedby a nodefrom this marking. For example,for the PEGinFigure5,
��ý ��þ��Xÿ��#� is amarkingrepresentingthestatein whichthe E )8�� �%)10 and C ' D#D���) tasksarereadyto rendezvouson F )8���� entryandthe E ) �� ��) 9 taskis waiting for the C ' D�D���) taskto acceptsits entrycall on
" ����� . Note thatnoteverymarkingrepresentsa feasiblestateof aprogramexecution.For example,marking
� ���Xÿ�� �ÿ���� doesnot representa feasibleprogramstate,becauseit correspondsto thewriter tasksaccessingthesharedbuffer at thesametime,whichin reality is precludedby task C ' D#D#��) . We write � ; Ê to indicatethat � is oneof thenodesin marking Ê .
Let MarkingsbethesetL � � L � � Ý ÝåÝ � L ü . Thissetincludesbothfeasibleandinfeasiblemarkings.We definetheinitial markingMinitial to containthebegin nodesfor all tasksin theprogram.
Wesaythatmarking Ê��¶� � ��� � � ÝåÝ Ý � ���ü � is locally reachablefrom marking Êï� � � � � Ý ÝåÝ � � ü � if thesetwo markingsdiffer in only oneposition,sothatthenodein this positionin Ê�� is a controlsuccessorof thenodein this positioninÊ . Formally, � �Xÿ � � û � � �ù ; Succs
� � ù � andë�� �ÿ � � � û � �=ì� � � �� �¦� � ÝThe intuition behindlocal reachabilityis that the programcango from a staterepresentedby marking Ê to a staterepresentedby marking Ê�� without any task interactions. For example,in Figure 5, marking
��� ��� �ÿ ý � is locallyreachablefrom marking
��� �����Xÿ ý � , sincenode8 is a successorof node7 in task C ' D#D���) . This transitioncorrespondsto task C ' D�D���) executinglocally andsodoesnot representany taskinteractions.
We saythatmarking Ê��.� � ��� � � Ý ÝåÝ � ���ü � is rendezvousreachablefrom marking Ê � � � �� Ý ÝåÝ � �(ü � if Ê containstwo nodes� ù�� and � ù�� suchthat � ù�� and � ù�� aredistinctpredecessorsof a rendezvousnode Í and Ê � is identicalto
15

Ê , exceptthat � ù�� and � ù�� arereplacedwith two nodesfrom thesametasksthataresuccessorsof Í . For example,inFigure5, thestaterepresentedby marking
��� ��� �ÿ ý � canbe followedby thestaterepresentedby marking��ý ��þ��Xÿ ý � .
This transitioncorrespondsto tasksE )8��� ��)10 and C ' D#D���) engagingin a rendezvouson entry" ���� , representedby
rendezvousnode19. We write Preds� Ê � for thesetof markingsfrom which Ê is locally or rendezvousreachable.
We say that marking Ê�� is reachable from marking Ê if thereare markings Ê�� � Ê �� ÝåÝåÝ � Ê�� , where Ê��¦�Ê � Ê �¬�ñÊ�� , andfor any �ÿ!� �#" , Ê ù is locally reachableor rendezvousreachablefrom Ê ù%$ � .
We call marking Ê reachableif it is reachablefrom theinitial markingMinitial . Thesetof all reachablemarkingsReachableMarkingsoverapproximatesthesetof feasibleprogramstatesin thesensethatif aprogramstateis feasible,thereexistsa reachablemarkingthat representsit. On the otherhand,theremay be reachablemarkingsthatdo notrepresentany of the feasibleprogramstates,for example,due to the fact that this PEGexecutionmodeldoesnotrepresentvaluesof programvariables.We recursively definethe depthof a reachablemarkingasthe lengthof the“path” from theinitial markingto this marking:
Depth� Ê � � &'( ')
��� if Êï� Minitial*,+�- � Depth� Ê �M�g� Ý ÝåÝ � Depth
� Ê Ô �<�/.�ÿ%� wherePreds� Ê � �:�Ê ��� Ý ÝåÝ � Ê Ô �
undefined� if Ê is not reachable
(4)
In the restof this section,we usethePEGexecutionmodelto prove that the informationcomputedby our MHPalgorithmis conservative. To do this, we computeMHP informationbasedon the PEGexecutionmodelandthencompareit to theMHP informationcomputedby ouralgorithm.Sinceareachablemarkingrepresentsaprogramstate,all thenodesin this markingmayhappenin parallelwith eachother. ComputingtheMHP informationthenreducesto determiningreachabilityfor markings.
We usesetsMHP� � � to representthe setof all nodesthat may happenin parallelwith node � accordingto our
basicMHP algorithm,Algorithm 2. Thefollowing lemmaandtheoremprove that for any pair of nodes� �� � � in thePEG,if thereachabilityapproachindicatesthatthey mayhappenin parallel,thenour algorithmwill do likewise.
Lemma 4 (Local Reachability). Supposemarking Ê�� is locally reachablefrom Ê . If � ; Ê and ��� ; Ê�� arenodesbelongingto thesametask,thenMHP
� � � � MHP� ��� � .
Proof. If �z�¦��� , thestatementof this lemmatrivially follows. Assume�dì����� . By definitionof local reachability, ���is a successorof � in thePEG.Accordingto Equation(2), MHP
� � � � IN� ��� � . Sincethealgorithmaddsthe IN setof
a nodeto theM setof this node,MHP� � � � MHP
� ��� � .We notethat inductionthenimpliesthat, if � and ��� arelocal nodesin thesametaskand ��� canbereachedfrom� withoutgoingthrougha rendezvousnode,thenMHP
� � � � MHP� ��� � .
Theorem 5 (Conservativeness).If nodes � � and � � may happenin parallel in the PEG executionmodel, � � ;MHP
� � � � .Proof. Assumethereexistsa reachablemarking �� suchthat � �� � � ; �� (in otherwords, � � and � � mayhappeninparallelin thePEGexecutionmodel).We will provethat � � ; MHP
� � � � by inductionon thedepthof �� .If Depth
� �� � � � , �� mustbe the initial marking. In this case,whenon someiterationof theMHP algorithmnode � � is taken off the worklist and its GEN set is computedaccordingto Equation(1), � � will be in GEN
� � � � ,becauseboth � � and � � aresuccessorsof theinitial node.
Assumethat Depth� �� � �10 andthat our algorithmdeterminesthat any two nodesbelongingto a markingof
depthlessthan 0 mayhappenin parallel.We will show thatour algorithmdeterminesthat � � and � � mayhappeninparallel.
Let Ê bethepredecessorof Ê�� with thesmallestdepth.By Equation(4), Depth� Ê � � Depth
� Ê�� �32Uÿ �40 2Uÿ .In thefollowing weconsiderseveralcases,basedon whetheror not nodes� � and � � appearin themarking Ê .
First,supposethatboth � � and � � arein Ê . Thenby theinductivehypothesis,� �Ã; MHP� � �� .
16

n1
. . .
. . .
1T
p2
T T2 3. . . . . .
. . . . . .
p
n n
3
2 3
c
(a)
1T T2
. . . . . .
. . . . . .
p
n n
p1 2
21
c
(b)
Figure9: Illustrationsfor thetheoremaboutconservativenessof theMHP algorithm
Second,supposethatnode� � is in Ê and � � is not in Ê . Wehaveto considerseparatelythecaseswheremarkingÊ�� is locally reachableandrendezvousreachablefrom marking Ê . Assumefirst that Ê�� is locally reachablefrom Ê .Let � � bethepredecessorof � � that is in Ê (if thereis no suchpredecessor, � � itself would have to bein Ê ). SinceDepth
� Ê � �50 2�ÿ , by the inductionhypothesis,� � ; MHP� � �� . Accordingto Lemma4, MHP
� � ��� � MHP� � �� ,
which implies � �Ã; MHP� � ��� .
Now assumethat Ê � is rendezvousreachablefrom Ê . Let task� � �M� � ú � and task
� � �� � ú � . Figure 9(a)illustratesthis case.Since� �æ; Ê and � � ì; Ê , ú � doesnot participatein therendezvous8 and ú � participatesin therendezvous. Let ú8Þ betheothertaskthatparticipatesin this rendezvous. Also, let �¶Þ and �1Þ be thenodesfrom thistaskfrom markingsÊ and Ê�� respectively and � �p; Ê bea nodefrom task ú � . Let Í betherendezvousnodethatrepresentsthis rendezvous,i.e. Preds
� Í � �:��� ��� � Þ � , �� �%� �1Þ � ; Succs� Í � .
SinceDepth� Ê � �60 2ñÿ , by the inductionhypothesis,� �ô; MHP
� �¶Þ � , � �½; MHP� � �� , and � �½; MHP
� �¶Þ � .� � ; MHP� � Þ � meansthatthealgorithmconsidersrendezvousnode Í reachable.Accordingto Equation(3), IN
� Í � �M� � � �.ò M
� � Þ � , which meansthat � � ; IN� Í � andhence� � ; M
� Í � . Since � � is a successorof Í , accordingtoEquation(2), � � ; IN
� � � � andhence� � ; M� � � � . Thus,thestatementof thetheoremis provedfor this case.
Finally, supposethat both nodes� � and � � arenot in Ê . The only possibleway this may happenis if Ê�� isrendezvousreachablefrom Ê andtherendezvousin questionis betweenthetasksof � � and � � . Figure9(b) illustratesthis case.Let � � and � � be the nodesin the tasksof � � and � � respectively, suchthat � ��� � �ô; Ê andlet Í be therendezvousnoderepresentingthis rendezvous.
SinceDepth� Ê � ��0 2¦ÿ , by theinductionhypothesis,� � ; MHP
� � �� . This meansthat thealgorithmconsidersÍ reachable.Accordingto Equation(1), � �è; GEN� � �� , andthus � �è; M
� � �� . Thus,thestatementof thetheoremisprovedin this case.
4.5.3 Complexity
Theworst-casecomplexity of theMHP algorithmin Figure8 canbeshown to be > ��� ød� 7 � , whereø
is thesetof PEGnodes.Theefficiency of this algorithmcanbeimproved. In this subsection,we introducea moreefficient versionofouralgorithmandprovethatthecomplexity of theefficientalgorithmis cubicin thesizeof thePEGin theworstcase.
8Excludingthespecialcasewhere 8 ¹ is botha successoranda predecessorof a rendezvousnodethatrepresentstherendezvous. This caseishandledexactly like thelastcasein theproof of this theorem.
17

Algorithm 3 (Efficient MHP algorithm).
Input: A PEG ¥ N § E § REND§ LOCAL§I² init §I² fin ¨ .Output: °�²â³ N a set of PEG nodesM ¥µ²¶¨ such that°�± ³ M ¥µ² ¨:9�± may happenin parallel with ² , and°<;±é¿³ M ¥µ² ¨=9>;± maynothappenin parallel with ² .Initialization:°�²Ó³ N § M ¥µ²¶¨p¤ IN ¥µ² ¨~¤ ReachableComPreds¥µ²¶¨p¤¸%§m°#±Û³ N § Flow ¥µ²(§I±y¨1¤U¸ .Setworklist set ? ¤ Succs¥µ² init ¨ .Main Loop: We evaluatethefollowing statementsrepeat-edlyuntil ? ¤U¸(1) ² ¤ a nodefrom ?(2) ? ¤ ?A@CBM²ED(3) if ²º³ RENDthen(4) BGF ¹ §�F ¾HD-¤ Preds¥µ²¶¨(5) if (notReach ¥µ²¶¨ ) and(F ¹ ³ M ¥IF�¾�¨ ) then(6) Reach ¥µ²¶¨h¤ P�V�^5Y(7) ° À£³ Succs¥µ²¶¨=9(8) insert ² in ReachableComPreds¥�ÀX¨(9) ? ¤ ?KJ Succs¥µ²¶¨
endif(10) IN ¥µ²¶¨h¤¦¥ IN ¥µ²¶¨EJº¥ Flow ¥IF ¹�§I²¶¨ML M ¥IF ¾ ¨I¨GJ¥ M ¥IF ¹ ¨�L Flow ¥IF ¾M§I²¶¨I¨I¨M@ M ¥µ² ¨(11) if (Reach ¥µ²¶¨ )(12) NewM ¤ IN ¥µ²¶¨(13) IN ¥µ²¶¨h¤U¸
else(14) NewM ¤U¸
endif
else// ² is a localnode:(15) °�Á3³ ReachableComPreds¥µ²¶¨N9(16) Remove Á from ReachableComPreds¥µ²¶¨(17) °�±Û³ Succs¥µÁg¨=9(18) if task¥µ±y¨-¿¤ task¥µ²¶¨ and ± ¿³PO,¥µ²¶¨ then(19) insert ± in GEN¥µ²¶¨
endif;(20) IN ¥µ²¶¨h¤ IN ¥µ²¶¨QJSRUT�V PredsWYX[Z Flow ¥IF §7² ¨(21) NewM ¤¦¥ IN ¥µ² ¨QJ GEN¥µ²¶¨I¨Q@ M ¥µ²¶¨(22) IN ¥µ²¶¨h¤U¸
endif;(23) if NewM ¿¤U¸ , then(24) °�±Û³ NewM 9(25) IN ¥µ±y¨(¤ IN ¥µ±y¨QJ,Bg²ED(26) ? ¤ ?KJ,BM±\D(27) ? ¤ ?KJ SuccsNoFinal ¥µ²¶¨(28) M ¥µ²¶¨h¤ M ¥µ²¶¨QJ NewM
endif;(29) °�À£³ SuccsNoFinal ¥µ²¶¨=9(30) Flow ¥µ²(§<ÀM¨1¤ NewM(31) °]Fp³ Preds¥µ²¶¨N9(32) Flow ¥IF §m² ¨h¤U¸After themainloop: °#²½³ N 9if ( ²½³ REND) and(notReach ¥µ² ¨ )
MHP ¥µ²¶¨1¤U¸else
MHP ¥µ²¶¨1¤ M ¥µ²¶¨Figure10: Theefficient versionof theworklist MHP algorithm
To distinguishbetweenthesetsusedin thetwo algorithms,we subscriptall setsin theoptimizedalgorithmwith eff.Thisoptimizedversionof theMHP algorithmlimits theamountof informationpassedamongthenodesin thePEGbysendingeachnodefrom theMeff setof a givennodeto eachof its successorsonly once.TheefficientMHP algorithmis givenin Figure10.
WeassociateasetINeff� � � with eachnode� . Thissetis usedfor storingnodesthathavebeendiscoveredto happen
in parallelwith � usingthesymmetrystepandalsoto holdnodespropagatedinto � from its predecessors.To ensurethata nodeaddedto theMeff setof any node � is propagatedto its successorsonly once,we associate
a setFloweff� � � � � with eachedge
� � � � � in thePEG.Whena node� is processedin themainloop of thealgorithm,nodesfrom the Floweff setsassociatedwith the edgesinto � areusedto updatethe INeff setof � , which is usedforaggregatingall MHP informationpropagatedfrom � ’s predecessors.After Floweff
� � � � � hasbeenusedfor computingINeff
� � � , Floweff� � � � � is resetto beanemptyset.Thisstepensuresthata nodeis propagatedbetween� and � at most
once.After � is processed,thenew nodesaddedto its Meff setareaddedto all Floweff setsassociatedwith theedgesout of � .
Thecomputationof GENeff setsfor localnodesis modifiedsothattheMHP information“generated”by eachof therendezvouspredecessorsof a local nodeis computedonly oncefor this node.This is achievedby keepinga setof all
18

rendezvouspredecessorsfor eachlocal node(setReachableComPredsin Figure10) andremoving rendezvousnodesfrom this setafterthey becomereachableandhavebeenusedfor recomputingtheGENeff setsof their successors.
It is importantthat the efficient MHP algorithmis a correctimplementationof the basicMHP algorithmin thesensethat for a givenPEGgraph,bothalgorithmscomputeidenticalMHP informationfor eachof thenodesin thisgraph.Herewe presentonly an informal treatmentof this proof anddirect thereadersinterestedin thedetailsto thefull proof in AppendixC.
Themain differencebetweenthe two algorithmsis that the basicalgorithmrecomputesthe M setfor a nodeoneachiterationfor this node,usingtheM setsfrom its predecessors,while theefficientalgorithmcomputestheMeff setfor anodeby updatingthepreviousvalueof thisMeff setusingtheINeff setof thisnode.TheINeff setfor anode,in turn,is computedby usingtheFloweff setsassociatedwith edgesenteringthis node.At theendof theefficient algorithm,for any node� eachnodein setMeff
� � � hasbeenplacedin theFloweff setsassociatedwith edgesoutof � exactlyonce.Thus,in thecourseof thealgorithm,all nodesfrom theMeff setsfor all nodesarepassedto theirsuccessorsandsotheMHP informationcomputedby thetwo algorithmsis identical.
Thefollowing theoremstatestheworst-casecomplexity of theefficientMHP algorithm.
Theorem6 (Polynomial-Time Boundedness).Theworst-casetimeboundfor theefficientMHP algorithmis > ���N � Þ �Proof. We assumethat sets,including the worklist, are implementedin sucha way that checkingmembershipandinsertinganelementeachrequireconstanttime (e.g.,with a lookuptable).Thecomplexity of finding theintersectionor unionof two setsis thenlinearin thenumberof elementsin thesmallerof thetwo sets.
A node � is placedon the worklist if the setM� � � , for a predecessor� of � , changes(when a nodeis added
to INeff� � � by symmetry)or aftera rendezvouspredecessorof � is removedfrom thesetReachableComPredseff
� � � .Sincea nodehasat most > ��� ød� � predecessorsandtheM setof a nodecanchangeat most > ��� ød� � times,eachnodecanbeplacedontheworklist atmost > ���N � � � times.Thus,themainloopof thealgorithmis executedatmost > ���N � Þ �times.
The checkin line 5 takes > � ÿ� time. The stepsin lines 6–9 are executedat most oncefor eachrendezvousnode � . Since thereare at most > ���N � � successorsfor eachrendezvous node, lines 7–9 requireat most > ���N � �operationsover thecourseof thealgorithmfor eachrendezvousnode � , andthus > ���N � � � operationsaltogether. Thecomputationin line 10 canbe accomplishedby computingthe sets ^ � � �
Floweff� � �� � �6ò Meff
� � �����BÚ Meff� � � and^ � � �
Floweff� � �5� � �.ò Meff
� � �X�<�3Ú Meff� � � , eachrequiringat most > ���N � � operations,and thensettingINeff
� � � �INeff
� � � �_^ � �_^ � . Thiscanalsobeaccomplishedin > ���N � � operations.Overthefull executionof thealgorithm,eachnodeappearsin Floweff
� � ù � � � atmostonce(notethateachFloweff� �¶ù � � � is setequalto Ë at theendof theloopat lines
31-32).Sothetotalnumberof operationscontributedby eachof ^ � and ^ � is lessthan�¶�
N�for eachrendezvousnode
in thePEG.Thus,over the full executionof thealgorithm,thecomplexity of theoperationin line 10 is > ���N � � � foreachrendezvousnode.Lines3–14thereforerequire > ���N � � � operationsaltogetherfor eachrendezvousnode.
A givenrendezvousnodeis insertedin theReachableComPredseff setsof its successorsat mostonce(in line 8).Thus,for alocalnode� , atmost > ���N � � rendezvousnodesareremovedfrom ReachableComPredseff
� � � in line 16overthecourseof thealgorithm.Eachof theserendezvousnodeshasatmost > ���N � � successorsto beinsertedin GEN
� � � .Therefore,lines16–19require > ���N � � � operationsfor eachlocalnode� , andthus > ���N � Þ � operationsaltogether.
A local node � has > ���N � � predecessors� �� ÝÝXÝ � �E` , sothecomputationat line 20 for that � canbecarriedout byfirst settingINeff
� � � � INeff� � � � Floweff
� � ��� � � , thensettingINeff� � � � INeff
� � � � Floweff� � ��� � � , etc. Sinceover the
full executionof thealgorithm,eachnodeappearsin Floweff� � ù � � � whenline 20 is executedat mostonce,the total
numberof operationscontributedby settingINeff� � � � INeff
� � � � Floweff� � ù � � � over theexecutionof thealgorithm
is lessthan�N�. Sincethenumberof predecessorsis alsoboundedby
�N�, the total numberof operationsinvolvedin
executingline 20 for a given � is > ���N � � � , so the total numberof operationsrequiredto executeline 20 for the fullalgorithmis > ���N � Þ � . For similar reasons,thecomplexity of executingline 21 for thefull algorithmis also > ���N � Þ � .
Lines 25 and26 areexecutedwhenever a node � is taken off the worklist andMeff� � � changes,andrequirea
constantnumberof operations.SinceMeff� � � canonly grow, it canchangeonly > ���N � � times. Soexecutinglines25
19

and26while processingaparticular� requires> ���N � � operationsover thecourseof thealgorithm,andthusa total of> ���N � � � operations.As notedearlier, > ���N � Þ � nodesareplacedon theworklist at line 27. Eachadditionto theworklist requiresone
operation.A nodeis insertedin NewMeff� � � atmostonceoverthecourseof thealgorithmandthereare
�N�possibilities
for � , soline 28 requires> ���N � � � operations.Over thecourseof thealgorithm, > ���N � � nodesareinsertedinto the > ���N � � Floweff setsassociatedwith theedges
outof anode� . Sothenumberof insertionsin to theFloweff setsassociatedwith edgesout � is > ���N � � � , andthetotalnumberof operationsrequiredat line 30 for all � is > ���N � Þ � .
While the efficient MHP algorithmhasbetterworst-casecomplexity boundsthanthe basicMHP algorithm,ourexperimentalresultsin Section5.5.5show thatin practice,thebasicalgorithmseemstoperformbetterthantheefficientone.
5 Comparisonwith Non-concurrencyAnalysis and Reachability Analysis
In thissection,we compareouralgorithmto two alternativewaysof computingMHP informationfor concurrentAdaprograms.Oneof themis thereachabilityapproachdescribedin Section4.5.2thatbuilds all reachablemarkingsandusesthemto computethe MHP information for the program. This reachabilityapproachassumesthat two nodesmayhappenin parallelif they appeartogetherin at leastonereachablemarking. We write MHPReach
� � � to denotethe setof nodesthat may happenin parallelwith node � ascomputedby this reachabilityapproach.As shown inSection4.5.2, this approachyields MHP information that is at leastaspreciseas that of our approach.However,this high precisionof thereachabilityapproachis paidby its high worst-casecomplexity, which is exponentialin thenumberof tasksin theprogram.This meansthat in practice,this reachabilityapproachis not feasiblefor computingMHP information.We useit hereonly to evaluatetheprecisionof ouralgorithm.
Thesecondapproachfor computingMHP informationto whichwecompareouralgorithmis thenon-concurrencyanalysisof MasticolaandRyder[15], themostpreciseof thepolynomial-timealgorithmsfor computingMHP infor-mationproposedto date.Theworst-caseboundfor non-concurrencyanalysisis, likethatfor ouralgorithm,polynomialin thesizeof theprogram.We compareour algorithmto non-concurrency analysisbothanalyticallyandempirically.(Recallthatnon-concurrency analysiscomputescan’t happentogether(CHT) information,essentiallythecomplementof theMHP informationcomputedby our algorithm. For comparison,we convert theoutputof our algorithmto theCHT form.) Non-concurrency analysisrelieson applyingfour refinementsthatiteratively improvetheCHT informa-tion computedfor aprogram.Weprovethattwo of thefour refinementscannotcomputeCHT informationthatis moreprecisethanthatcomputedby our MHP algorithm.Theothertwo refinementscansometimescomputemorepreciseCHT informationthatthatcomputedby ouralgorithm.It is alsopossiblethatouralgorithmcancomputemorepreciseCHT informationthanthat computedby non-concurrency analysis.Our experimentalwork includescomparisonofprecisionof thetwo approacheson asetof mostlysmallAdaprograms.
We introducethe programmodel and the four refinementsusedby non-concurrency analysisin detail in Sec-tion 5.1. Then,in Section5.2,we definea mappingbetweentheprogrammodelof non-concurrency analysisandthePEGmodelthatallows us to comparethe resultsof thetwo approaches.Section5.3 givesananalyticalcomparisonbetweenprecisionof our algorithmandeachof the four refinementsof non-concurrency. We briefly introducethesmalltestprogramsusedin ourexperimentalwork in Section5.4anddescribetheresultsof anexperimentcomparingprecisionandefficiency of thetwo approachesin Section5.5.We concludethissectionwith someobservationsof theexperimentalresults.
20

begin1
accept write-end10
accept write-start9
Buffer.lock2
accept lock8
7
begin
end12
Buffer.unlock5
6end
accept unlock11
3Buffer.write
Buffer.lock14
Buffer.write15
Buffer.unlock17
end18
begin13
init
final
Figure11: Syncgraphfor theexamplein Figure2
5.1 Non-concurrencyAnalysis
5.1.1 SyncGraphs
Unlike the PEGmodelusedby the MHP algorithm, the syncgraph modelusedby non-concurrency analysisusesedges,ratherthannodes,to representrendezvousbetweenprogramtasks.Thegranularityof informationrepresentedby the nodesof a syncgraphis that of the minimal CCFG,introducedin Section3.2.1. In otherwords,eachnodeof the syncgraph,except for the uniqueinitial andfinal nodesandan initial andfinal nodefor eachof the tasks,representsasynchronizationstatementin thetaskto which it belongs9. Figure11showsthesyncgraphfor thereader-writer examplefrom Figure2. For convenience,the numbersassignedto the nodesin this syncgraphcorrespondto the numbersassignedto the nodesof the PEGfor this examplefrom Figure5. For example,in this graph,node2 representsthe following partsof the executionof task E )8�� ��)(0 : (1) startingat the point of the initialization ofE )8��� ��)10 andendingat thepoint wherethefirst synchronizationbetweentasksE ) �� ��)10 and C ' D#D#��) on entry
" �����startsand(2) startingat the point wherethe synchronizationbetweentasksE )8�� �%)10 and C '�D#D���) on entry '�! " �����succeedsandendingat thepointwherethesynchronizationbetweentasksE )8��� ��)10 and C '�D#D���) onentry
" ����� on thenext iterationof theloopstarts.
9Masticola’s implementationof syncgraphsalsousesadditionalnodesto representheadnodesof loops.Thereasonfor this is thattheinforma-tion computedby non-concurrency analysisis usedin astaticdeadlockdetectiontechnique[14] thatrequiresunrolling loops.
21

If node � in a syncgraphrepresentsan entrycall andnode � representsan ���#�5�%$�� statementwithout body forthis entry, the potentialrendezvousbetweenthe tasksof � and � is representedby an undirectedcommunicationedge between� and � . For example,thecommunicationon entry
" ����� is representedin Figure11 asa dashededgebetweennode2 representingthecall on thisentryandnode8 representingtheacceptof thisentry.
Syncgraphsrepresentan ���#�%�%$#� statementwith body by usingtwo distinct nodes,oneto representthe startofthe �����%�%$�� statementandanotherto representtheendof the �����%�%$�� statement.Communicationsinvolving � �#�%�%$��statementswith bodiesarerepresentedwith hyper-edges, connectingthenoderepresentingtheentrycall andthenodesrepresentingthestartandtheendof the ���#�5�%$�� statement.For example,in Figure11, thecommunicationon entryF )8��� � thatinvolvesexecutionof an ���#�%�%$#� statementwith a bodyis representedby a dashededgeconnectingnodes3, 9, and10.
Formally, thesyncgraphmodelof a concurrentprogramis a graph��ø
sync��a ä ��a<b��dc� initial
�dc� final� , where
øsync is a
setof nodes,a ä is a setof directedcontrol edges,and a<b is a setof communicationedges,including hyper-edges.c� initial�]c� final
; øsyncaretwo nodesthatrepresentthestartandtheendof theprogramrespectively.
For eachnode � in the sync graph,non-concurrency analysiscomputesthe set of nodesthat can’t happeninparallel (CHT) with � . In thispaperwe denotethis setCHT
� � � .5.1.2 Refinementsof CHT Inf ormation
Non-concurrency analysisstartswith a crudeapproximationof theCHT informationfor eachnodein thesyncgraphand then graduallyrefinesthis information. Initially, the CHT set for eachsync graphnode � containsall nodesin the task of � , representingthe fact that a task doesnot executein parallelwith itself. The four refinementsofnon-concurrency analysisare thenusedto addnodesfrom other tasksto the CHT sets,thusmakingthe computedinformationmoreprecise.Eachof therefinementsis conservative,in thesensethata node� is not addedto CHT
� � �if thereareany realexecutionsonwhich � couldhappenin parallelwith � . Therefinementsareappliedin anarbitraryorder, until afixedpoint is reached,whichmeansthattheCHT setsof all nodesremainthesameafterapplyingany oftherefinements.
Thefour refinementsareB4analysis, pinninganalysis, critical sectionanalysis, andremoteprocedurecall (RPC)analysis. B4 analysisis a dataflow algorithmthat, for any pair of nodes� and � from the syncgraph,determineswhetherall instancesof � areexecutedbeforeany instancesof � . If that is thecase,it is clearthat � and � cannothappenin parallel,andsoB4 analysisadds� to CHT
� � � and � to CHT� � � .
Pinninganalysisusesthecontrolstructureof thesyncgraphto compute,for agivennode� , asetof nodes?
suchthatat leastoneof the nodesfrom
?mustbe executingwhenever � is executing. If a nodecannothappentogether
with any of thenodesin?
, thenit alsocannothappentogetherwith � . Therefore,all nodesin theintersectionof theCHT setsof thenodesfrom
?areaddedto CHT
� � � .Critical sectionanalysistakesadvantageof thepatternsin syncgraphscorrespondingto theAda implementation
of mutualexclusionregions. If two nodes� and � belongto different tasksbut are in the samemutualexclusionregion, it meansthat thesetwo nodesmay never executeat the sametime, andso � is addedto CHT
� � � and � isaddedto CHT
� � � .Non-concurrency analysisdefinesremoteprocedurecalls (RPCs)asentrycalls thathave corresponding� �#�%�%$��
statementswith bodies.RPCanalysisis basedon thefact thatany node � in thebodyof an ���#�%�5$�� statementmustexecutein parallelwith oneof the entry call nodesfor the entry of this ���#�%�5$�� statement.Thus, if all suchentrycall nodescannothappenin parallelwith somenode � , � canbeaddedto CHT
� � � , similar to theway thatpinninganalysisworks.
5.2 Creating PEGsfr om SyncGraphs
In this sectionwe compareexpressivenessof PEGsandsyncgraphs,introducea restrictedPEGmodel,andprovidea mappingbetweenthenodesin thesyncgraphandthenodesin therestrictedPEGthat is usedlater to comparetheprecisionof non-concurrency analysisandtheMHP algorithm.
22

In general,the PEGmodelprovidesa moreflexible representationof concurrentprogramsthanthe syncgraphmodel. A nodein a syncgraphrepresentseitherthe startor endpointsof a taskor a numberof control pathsthatterminatein one synchronizationpoint, while a nodein a PEG representsa numberof control pathsthat do notnecessarilyterminatein asynchronizationpoint. To comparetheprecisionof thetwo approaches,werestrictthePEGmodelin orderto make it ascloseaspossibleto thesyncgraphmodel.Laterin this sectionwe giveanalgorithmthatconstructsthePEGcorrespondingto a givensyncgraph.
In constructingPEGsout of syncgraphs,we definea mappingbetweenthe nodesof a syncgraphandthe cor-respondingPEG.We usethis mappingin two ways. First, it allows us to performan analyticcomparisonbetweennon-concurrency analysisandtheMHP algorithm. This is doneby usingthemappingto “translate”the refinementsof non-concurrency analysisinto theequivalentrefinementsdoneonthePEGmodel.By analyticallycomparingtheserefinementswith the MHP algorithm,we areableto prove that the MHP algorithmis alwaysat leastaspreciseastwo of the four refinements.We alsodeterminewhat makesthe othertwo refinementsmoreprecisethanthe MHPalgorithmin somecases.Second,we usethe mappingbetweensyncgraphsandPEGsto performan experimentalcomparisonof theprecisionof thetwo approaches.To dothiscomparisononanAdaprogram,wefirst createthesyncgraphfor this programandthenproducethecorrespondingPEG.After that,we run non-concurrency analysison thesyncgraph,producinga CHT setfor eachnodein this graph.We alsorun theMHP algorithmon thePEG,producinga setof MHP informationfor eachnodein this PEG.This MHP informationis thenrepresentedin theCHT form andthemappingbetweenthesyncgraphandthePEGis usedto maptheCHT informationproducedby non-concurrencyanalysisontothePEG.At theendof this process,for eachnodein thePEGwe have two sets,CHTNCA producedbynon-concurrency analysisandCHTMHP producedby theMHP algorithm,thatcanbecompareddirectly.
We restrictthe PEGmodelby requiringthat all successorsof a local nodearerendezvousnodes10. As a result,eachlocalPEGnode,likeasyncgraphnode,representsasetof possiblecontrolpathsbetweencommunicationpoints.All predecessorsof any suchlocal noderepresenttheinitial pointsfor thecontrolpaths,andsuccessorsrepresentthefinal points.
We call the resultingmodel RestrictedPEG (RPEG). To be able to comparethe CHT information computedfor syncgraphswith the MHP informationcomputedfor RPEGs,we computea mappingbetweensyncgraphsandRPEGs.Thismappingis constructedalgorithmicallyby takinganexistingsyncgraphandbuilding thecorrespondingRPEG.Thealgorithmin Figure12 performsthis construction.
Figures13 and 14 illustrate building RPEGsfrom sync graphs. Figure 13 shows the fragmentsof RPEGscorrespondingto simplified hyper-edgesmodelingentry calls on ��e�egfghji statementswithout bodies. Figure 13(a)showsasyncgraphfragmentwith nodek representinganentrycall andnodel representingthecorresponding��e�egfghjistatementwith no body. Figure13(b) shows the correspondingRPEGfragment.The local nodesin the RPEGthathave thesamelabelsasthenodesin thesyncgrapharemappedto thesesyncgraphnodes.In this simplecase,eachsyncgraphnodebecomesa local nodein the RPEGand the communicationis representedby a rendezvousnodelabeledm .
Figure14 representsthe morecomplicatedcaseof creatingfragmentsof RPEGscorrespondingto hyper-edgesmodelingentrycallsto �Qe�edfghji statementswith bodies.Figure14(a)showsa syncgraphfragmentwith nodek repre-sentinganentrycall, nodeljn representingthestartof thecorresponding��e�egfghji statement,andnodeljo representingtheendof this �Qepegfghji statement.Thedashedarrows from the successorsm�q[r�s�s�s�r�m�t of node ljn to node ljo representthe fact that node ljo is alwayseventuallyexecutedafter l�n , unlessthe taskis blocked forever. Figure14(b) showsthecorrespondingRPEGfragment.Notethat in this case,two rendezvousnodesareneeded,m n to representthesyn-chronizationamongthetwo threadsat thestartof the ��e�egfghji statementand m o to representthesynchronizationat theendof this �Qe�egfdhji statement.In addition,a specialwaiting local nodelabeledu is createdin the calling threadtorepresentthefactthatthecalling threadwaitsuntil thecalledthreadcompletestheexecutionof the �Qe�edfghji statementbody. For thepurposeof comparisonof the informationcomputedby non-concurrency analysisandthe MHP algo-rithm, it is importantto notethat local nodesk and u in theRPEGaremappedto a singlenode k in thesyncgraph.Thismeans,for example,thatwe haveto combinetheinformationcomputedfor k and u in theRPEGandcompareit
10All successorsof a rendezvousnodearelocal nodesalready, by thedefinitionof rendezvousnodesin Section3.2.2.
23

Algorithm 4 (Building RPEG).Input: Syncgraph v%w syncr�xzy�r�x n r]{| init r]{| fin }Output:
1. RPEG v N r E r RENDr LOCALr | init r | fin }2. a mappingSyncToRPEG ~gw sync ��� LOCAL andaninversemappingSyncToRPEG� q ~ LOCAL � w sync.
Actions:
1. Create an initial, | initial , and a final, | final, PEG nodes. Set SyncToRPEGv�{| init }�� � | init � ,SyncToRPEGv�{| fin }���� | fin �
2. For each sync node {| , create a local RPEG node | . This correspondencedefines a mappingSyncToRPEGv�{| }C��� | � .
3. ��{��� w sync ~ if v�{| init r�{� } � x<y�� createa controledgev | init r SyncToRPEGvH{� }�} in theRPEG.
4. Assumingthat the programhas � tasks,create� local nodes �gq[r��]�dr�s�s�s�r���� to serve asfinal tasknodes.Connecteachsuchnodeto | fin with a controledge.
5. For eachsimplesyncedgeconnectingtwo syncnodes{| q and {| � createa rendezvousnode.Make a localnode| apredecessorof this rendezvousnodeif |�� SyncToRPEGv�{| q }�� |�� SyncToRPEGv�{| � } .
6. For eachrendezvousnodek with localpredecessors� q and� � makea localnode| asuccessorof k if
v SyncToRPEG� q v�� q } r SyncToRPEG� q v | }�} � x<y � v SyncToRPEG� q vY� � } r SyncToRPEG� q v | }�} � xzy7. For eachsynchyper-edgeconnectingthreesyncnodes{| , {| q , and {| � , where {| representsanentrycall, {| q
representsthe startof an ��e�egfghji body, and {| � representsthe endof this �Qe�edfghji body, createa pair ofrendezvousnodesk�q and kH� . Also createa speciallocal node u to representthetaskthatmakestheentrycall waiting for this call to terminate.Make SyncToRPEGv�{| } andSyncToRPEGv�{| q } thepredecessorsofk q andmake u asuccessorof k q . Makea localnode� asuccessorof k q if v�{| q r SyncToRPEG� q v�� }�} � xzy .Make u andSyncToRPEGv�{| � } thepredecessorsof k � . Makea localnode � asuccessorof k � if
v�{| r SyncToRPEG� q v�� }�} � x y � v�{| �gr SyncToRPEG� q v�� }�} � x ySetSyncToRPEGv�{| }C� SyncToRPEGv�{| }/��� u � .
8. For eachrendezvousnodek with localpredecessors��q and�M� make �] a successorof k if¡ v SyncToRPEG� q vY� q } rd{| fin }�} � x<y/¢ taskvY� q }C�4£�¤��¡ v SyncToRPEG� q vY� � } rd{| fin }�} � x<y/¢ taskvY� � }C�4£�¤Figure12: Thealgorithmfor building aRPEGcorrespondingto a givensyncgraph
with theinformationcomputedfor k in thesyncgraph.The mappingSyncToRPEGbetweenthe nodesin the syncgraphandlocal nodesin the correspondingRPEGis
24

. . .
c
. . .
a
. . .
s1
. . .
1r
. . .
si
. . .
rj. . . . . .
(a) Syncgraph
. . .
s1
. . .
rj
. . .
r1si
. . .
. . . . . .
c a
q
. . . . . .
(b) RPEG
Figure13: Building RPEGsfrom syncgraphs(no ¥ epegfghji bodies)
e
s
a
. . .
a
. . .
c
. . .
s1
. . .
siq1 qj
. . .
1r
. . .
rk
. . . . . .
. . .
(a) Syncgraph
c
qs
w
1q
qe
. . .
r1
qj
. . .
rk
. . .
s1
as
ae
si
. . .
. . . . . .
. . . . . .
. . .
(b) RPEG
Figure14: Building RPEGsfrom syncgraphs(with ¥ e�egfdhji bodies)
25

Algorithm 5.Input : A syncgraph v�w syncr�x<y�r�x n r]{| init r]{| fin } , a setCHTv�{| } associatedwith eachnode {| of the syncgraph,anda RPEG v N r E r RENDr LOCALr | init r | fin } correspondingto thesyncgraphvia mappingSyncToRPEG.Output: A setCHTv | } associatedwith eachnode| of theRPEG.Initialization: � |�� N r CHTv | }C�§¦ .(1) ��{|�� w sync,(2) � |�� SyncToRPEGv�{| } ,(3) let CHTv | }��©¨«ª¬z CHT® ª¯d° SyncToRPEGv�{± }
Figure15: Algorithm for translatingCHT informationfrom syncgraphsto RPEGs
definedasfollows. A local RPEGnodeis placedin SyncToRPEGv�{| } if it is createdto correspondto syncnode {| . Inaddition,waitingnodesin theRPEGaremappedto thecorrespondingentrycall nodesin thesyncgraph.As a result,for any node {| in the syncgraph,SyncToRPEGv�{| } containsa singleRPEGlocal node,except for entry call nodesthatmaycorrespondto acceptstatementswith a body. For suchentrycall nodes,theimageof SyncToRPEGcontainsnot only theRPEGnodethat representsthis entrycall, but alsoall correspondingwaiting nodes.For theexampleinFigure14,SyncToRPEGfor thesyncnode k containstwo localRPEGnodes,k and u .
The following lemmasummarizesthe correspondencebetweensyncgraphsandRPEGsbuilt accordingto thealgorithmin Figure12.
Lemma 7 (Syncgraph — RPEG correspondence).For all {| q r]{| � r]{|²� w sync, where {| q´³� {| init , let | q r | � , and | bethecorrespondingnodesin theRPEG.Then
1. v�{| q rd{| � } � x<y�µ thereexist edges v | q r�¶ } and v·¶]r | � } in theRPEG,where ¶ � REND.
2. v�{| q rd{| � } � x n µ there is ¶ � REND ~ � | q r | � �!� Predsv·¶ } .3. v�{| r]{| q]r]{| � } � x<n , where {| is a call node, {| q and {| � are thebeginningandendsynchronizationsof an ¸j¹�¹�º�»C¼
statementrespectivelyµ¾½j¶ q r�¶ � � REND ~ � | r | q �!� Predsv·¶ q } ¢Pu ¯ � Succsv%¶ q } ¢ � u ¯ r | � �!� Predsv%¶ � }4. v�{| q[rd{| fin } � x y µ thereexist edges v | qdr�¶ } and v%¶]r��] } in theRPEG,where ¶ � RENDand £ is theID of thetask
to which | q belongs.
Proof. Follows from thealgorithmof theRPEGconstruction.
We usethemappingbetweensyncgraphsandRPEGsto translatetheCHT setsassociatedwith thenodesin thesyncgraphto CHT setsassociatedwith thenodesin theRPEG.Thealgorithmfor this translationis givenin Figure15.Observe that theCHT setsassociatedwith thenodesof theRPEG,obtainedby this algorithm,faithfully representintheRPEGmodeltheCHT informationcomputedby non-concurrencyanalysis.Thisargumentis basedonthemeaningassignedto theRPEGnodes.By constructingtheRPEGfrom a syncgraph,we assurethat for any syncgraphnode{| , thestatementsrepresentedby this nodearealsorepresentedby thenodesto which {| is mapped.In otherwords,(1) if a statementis representedby {| , thenit is alsorepresentedby oneof thenodesin SyncToRPEGv�{| } and(2) if astatementis not representedby {| , thenit is alsonot representedby any of thenodesin SyncToRPEGv�{| } . Thus,thesameinformationaboutwhich statementscannothappentogetheris obtainedfrom theCHT setsassociatedwith thenodesof thethesyncgraphandtheCHT setsassociatedwith thenodesof theRPEG.
26

5.3 Analytic Comparison
While our goal is to comparethe precisionof our algorithm to that of non-concurrency analysisas a whole, weinvestigateanalyticallythe relationshipbetweenour algorithmandeachof the four refinementsof non-concurrencyanalysis.We usethemappingbetweensyncgraphsandRPEGsto redefineeachrefinementon theRPEGmodel. Inthis section,we useCHTMHP to denotethe CHT informationcomputedby our algorithmandCHT¿�À�ÁIÂIÂIÂIÁ ¿�à to denotethe CHT informationcomputedon the RPEGby a sequenceof refinements¶ q r�s�s�s�r�¶ , whereeachof ¶ t r�ÄÆÅ�ÇÈÅ £ ,is oneof thePinning, RPC, CritSec, andB4 designations.For example,CHTPinningÁ B4Á Pinning representstheCHT setscomputedon theRPEGby first applyingthepinninganalysisof non-concurrency analysis,thentheB4 analysis,andfinally thepinninganalysisagain.
WesaythattheMHP algorithmsubsumesarefinementif this refinementcannotimprovetheprecisionof theCHTinformationcomputedby the MHP algorithm. Formally, a refinement¶ is subsumedby the MHP algorithm,if, forany sequenceof refinements¶]q]r�s�s�s�r�¶�É , suchthat,for any node |«� N r CHT¿ À ÁIÂIÂIÂIÁ ¿�Ê v | }!Ë CHTMHP v | } , it follows thatCHT¿ À ÁIÂIÂIÂIÁ ¿�Ê�Á ¿ v | }ÌË CHTMHP v | } . In therestof this sectionwe informally show thattheMHP algorithmsubsumestheB4 andpinninganalysisanalyses(thefull proofscanbefoundin AppendixD). In addition,weexplainwhatpreventsouralgorithmfrom subsumingthecritical sectionandRPCanalyses.
5.3.1 Subsumptionof B4
The B4 analysisis a dataflow algorithm that propagatesthe information aboutstatementsall instancesof whichmust executebeforeany instancesof other statementsthroughtwo typesof edges: the control flow edgesin thesyncgraphandcompletoredges.A completoredge v ± r | } is createdif whether| executesdependson whetherthesynchronizationrepresentedby node ± hashappened.TheB4 informationcomputedfor a node | is generatedfromtwo sources.Onesourceis thecontrolpredecessorsof | . Clearly, if somenode± is guaranteedto happenbeforeeachof thepredecessorsof | , it alsohappensbefore| . Theothersourceis thecompletorpredecessorsof | . Similar to thecontrolpredecessors,if somenode ± is guaranteedto happenbeforeeachof thecompletorpredecessorsof | , it alsohappensbefore| , becauseat leastoneof thecompletorpredecessorsof | hasto haveexecutedby thetime | executes.
WeprovethattheMHP algorithmsubsumestheB4 analysisby proving thatwhenever ±A� B4v | } , it is necessarilythecasethat ± ³� MHP v | } . This statementis provedby inductionover thelengthof thepath(includingbothcontrolandcompletoredges)from ± to | .5.3.2 Subsumptionof the Pinning Analysis analysis
The pinninganalysisrefinementis basedon recognizingsituationswherecertaincommunicationscanoccuronly ifothercommunicationshave occurredpreviously. Figure16 shows a simpleexample. In the syncgraphfragmentinFigure16(a),thecommunicationbetweennodes| q and | � happensonly if thecommunicationbetweennodes± q and± � happensfirst. This meansthatnodes| q and | � alwaysexecuteat thesametime (i.e., | q bothstartsandfinishesits executionexactly at thesametime that | � does).Thus,if somenodeis in theCHT setof | q , it canalsobeput intheCHT setof | � , andvice versa.Althoughthegeneraldefinitionof pinninganalysisis morecomplicatedthanthis,hereweusethissimpleexampleto giveanintuitiveexplanationof why theMHP analysissubsumesthis refinement.
Figure16(b) containsthe RPEGfragmentcorrespondingto the syncgraphfragmentin Figure16(a). Note thatthe MHP setsfor nodes| q and | � containthe following information: MHP v | q }S� MHP v%k }�� � | � � r MHP v | � }Í�MHP v%k }Î�²� | q � . Thus,CHTMHP setsfor thesetwo nodesarethesame,just asthepinninganalysisdetermines.Theproof of this subsumptionresultappearsin AppendixD.3.
5.3.3 Partial subsumptionof the RPC and critical sectionanalyses
The RPC and critical sectionanalysesof non-concurrency analysisare related. In this sectionwe describetheserefinementsandshow thattheRPCanalysisis a specialcaseof thecritical sectionanalysis.Thenwe show thata part
27

m m
nn
. . .. . .
. . . . . .
1 2
21
(a) Syncgraph
. . . . . .
1 2n n
m m1 2
. . . . . .
c
(b) RPEG
Figure16: Illustrationof subsumptionof thepinninganalysisby theMHP algorithm
of thecritical sectionanalysisis subsumedby theMHP algorithm. Finally, we illustratea situationwheretheMHPalgorithmfails to find CHT informationidentifiedby theRPCanalysis.
Both the RPCandcritical sectionanalysesusethe principle of widening. Intuitively, this principle capturesthefollowing situation. Let | be a nodein the syncgraphand Ï be a setof nodesin this graphsuchthat whenever |executes,oneof thenodesin set Ï executes.Thenif somenode± cannothappenin parallelwith any of thenodesinÏ , it meansthat ± alsocannothappenin parallelwith | , andsocanbeplacedin CHTv | } .
TheRPCanalysisusestheprincipleof wideningin thefollowing way. Considerthenodesl � and l�Ð in Figure17that form thebodyof an ¥ e�egfghji statement.While eitherof thesenodesis executing,someentrycall to the ¥ e�egfghjistatementmustalsobeexecuting.Thus,oneof k q and k � mustbeexecutingwhenever l � or l�Ð is. Any nodethatcannotexecutein parallelwith both k q and k � thuscannotexecutein parallelwith l � or lpÐ . SupposethatCHTv�k q }����[Ñ q r Ñ � �andCHTv�kH� }C���]Ñ q�r Ñ Ð � . ThenpinninganalysisaddsCHTv�k�q }3Ò CHTv%kH� }C�©Ñ q to CHTv�l�� } andCHTv%l Ð } .
The critical sectionanalysisworks with monitor-like patterns,wheretasksynchronizationsensurethat no morethan one task at a time can executein a certainregion. Figure 18 givesan exampleof a critical section. In thisexample,nodesl�q and l�� representtwo ¥ e�egfghji statementswithout bodies.Two differenttasksmake entrycalls tothese¥ e�egfghji statements,asshown in thefigure. It is easyto seethat it is never possiblethatoneof nodeskH� and k Ðexecutesin parallelwith oneof nodeskHÓ and kHÔ . Thus,nodeskH� , k Ð , kHÓ , and kHÔ comprisea critical section.We willcall thetaskcontainingacceptnodesl q and l � thecritical sectionformingtaskandcall thesetincludingnodel � andany nodesthatmaybebetweenl q and l � thecritical sectionacceptset11. Thecritical sectionconstructscanbeusedfor computingCHT informationin severalways,asdescribedby thefollowing rules:
1. Nodesin the samecritical sectioncannothappentogether. In Figure 18, � kH�gr�k Ð �ÕË CHTv%k�Ó } , � kH�dr�k Ð �ÖËCHTv%k Ô } , � k Ó r�k Ô �_Ë CHTv�k � } , and � k Ó r�k Ô �_Ë CHTv%k�Ð } .
2. Nodesin thecritical sectioncannothappentogetherwith any nodesin thecritical sectionforming taskexceptthenodesin thecritical sectionacceptset. In Figure18, nodeskH�dr�k Ð r�kHÓdr�kHÔ canhappentogetherwith node lp� ,but not any othernodesin thetaskcontainingl � .
11Notethatmultiple ×�Ø�Ø�Ù�ÚHÛ statementpairsin thesametaskcanparticipatein forming a critical region. In this case,thecritical sectionacceptsetincludesnodesbetweenthetwo nodesin eachof thesepairs.
28

1a
a2c1 c2
a3
. . .
. . .
. . .
. . .
. . .
. . .
Figure17: Exampleof theRPCanalysis
1a
a2
. . .
. . .
c1
. . .
. . .
. . .
. . .
c
c
c
c
c
2
3
4
5
6
Figure18: Exampleof thecritical sectionanalysis
3. Theprincipleof wideningis used,wherethenode | from thedefinitionof wideningis oneof thenodesin thecritical sectionandset Ï from this definitionis thecritical sectionacceptset.
4. Theprincipleof wideningis used,wherethenode | from thedefinitionof wideningis oneof thenodesin thecritical sectionacceptsetandset Ï from this definitionis thecritical section.
TheRPCanalysiscanbeviewedasa specialcaseof thecritical sectionanalysis,whereonly thelastof therulesfor thecritical sectionanalysisis used.
Thefollowing theoremstatesthattheMHP algorithmsubsumesthefirst two rulesof thecritical sectionanalysis.The proof is basedon an inductive argumenton the numberof iterationsof the main worklist loop of the MHPalgorithmandappearsin AppendixD.4.
29

task body Resource isbegin loop select
or accept Release; end select; end loop;end Resource;
accept Take;
task body Task1 isbegin Resource.Take; accept Leave do Resource.Release; end Leave;end Task1;
task body Task2 isbegin Resource.Take; accept Leave do Resource.Release; end Leave;end Task2;
Task body Control isbegin Task1.Leave; Task2.Leave;end Control;
(a) Sourcecode
Resource.Take
accept Leave--end
accept Leave--start
Resource.Release
Resource.Take
accept Leave--end
accept Leave--start
Resource.ReleaseTask1.Leave
accept Take--start
accept Take--end
accept Release--start
accept Release--end
Task2.Leave
task
task
task
taskTask1 Task2
Control
Resource
1
2
3
4
5
6
7
8
9
10
11
12
13
14
(b) Syncgraph
Figure19: ExamplewheretheRPCanalysiscomputesmorepreciseinformationthantheMHP algorithm
Theorem 8 (Partial subsumption of the critical sectionanalysisby the MHP algorithm). TheMHP algorithmsubsumesthefirst two rulesof thecritical sectionanalysis.
The MHP algorithm doesnot subsumethe last two rules of the critical sectionanalysis. Figure 19 illustratesa casewherethe RPC analysishelpsnon-concurrency analysiscomputemore preciseinformation than the MHPanalysis.Figure19(a)shows thesourcecodefor a programwheretwo tasksÜ�¥ �]Ý�Þ and Ü�¥ �]Ý�ß contendfor a resourcerepresentedby task à f �gágâjãEedf 12. Task ä ágåji�ãjájæ makessurethat Ü�¥ �[Ý�Þ releasesthe resourcebefore Ü�¥ �]Ý�ß does.Figure19(b)shows thesyncgraphfor this example13. Considernodes10 and7, representingtheendsynchronizationof the ¥ e�egfghji statementfor entry Ü�¥ Ýjf in task à f��gágâjãMegf andtheentrycall to the à fjæ�f ¥ �gf entryof à f��gádâjãEegf in taskÜ�¥ �[Ý�ß respectively. In reality, codecorrespondingto thesetwo nodescannotexecutein parallel,becauseÜ�¥ �]Ý�Þ cannotmakeacall onentry Ü�¥ Ý�f while Ü�¥ �]Ýjß is callingor is gettingreadyto call onentry à fjæ�f ¥ �gf (notethesynchronizationorderimposedby task ä ágåjipã�ájæ ). Non-concurrency analysiscorrectlydeterminesthatthesetwo nodescannothappentogether. Node10 musthappenat thesametime with oneof thenodes1 and5, which representcallson entry Ü�¥ Ýjf .Sincenode7 is in theCHT setsof nodes1 (ascomputedby B4 analysis)and5 (since5 and7 arein thesametask),it is alsoinsertedin CHTv�Ä�ç } . TheMHP analysis,on theotherhand,usesthe(precise)informationthatnode10 mayhappenin parallelwith nodes6 and14, andhencethe (imprecise)conclusionis madethat node10 may happeninparallelwith node7. (Node10 canhappenin parallelwith node6 andit alsocanhappenin parallelwith node14,butit cannothappenin parallelwith nodes6 and14 at thesametime.)
12Thefactthattheloop in task è�Ù�é�ê�ëHì�Ø�Ù is infinite is not significantto this example.13In this syncgraph,theinitial andfinal nodesarenotshown to reducetheclutter.
30

5.4 Setupof the Experiment
StephenMasticolagraciouslyprovideduswith his implementationof non-concurrency analysis,written in C.Weusedthis for ourexperiments,togetherwith ourown implementationof theMHP algorithm,written in Java. In addition,wewroteareachabilitytool tofindall reachableprogramstatesof theRPEGmodel,alsoin Java. Althoughthereachabilitytool runsoutof memoryfor someof our testprograms,in thecaseswhereit ransuccessfully, it determinedthe“ideal”setof pairsof nodesthatmayhappenin parallel.Giventhis set,we computedCHTreach, thesetof pairsof nodesthatcannothappentogetheraccordingto the reachabilityanalysis.We ran the tools on a dual-processorSunEnterprise3500machinewith 2 GB of memory, usingSun’sJava 1.3.0HotSpotVirtual Machine.
In their work on non-concurrency analysis,MasticolaandRyderuseda suiteof 138 concurrentAda programs.Themajority of theseAda programsarevery small,many of themsynthetictestcases,originally designedto testthenon-concurrency tool on avarietyof Adacontrolstructures.25of theprogramsdid nothave loops.Severalgroupsofprogramsrepresentdifferentsizesandvariationsof asinglebasicexample.Wedescribesomeof theseprogramshere.(All otherprogramsaretestprogramsthat containvariousfeaturesof Ada in the presenceof tasksynchronization.Theseprogramsappearto bewrittenwith thesolepurposeof testingMasticola’s implementationof non-concurrencyanalysis.)
The íjî�ï programrepresentsa communicationskeletonfor a borderdefensesystem.This programincludes14tasks,representingentitiesrangingfrom rocketsto graphicaldisplay, andencodesthe logic bindingthebehaviors ofrepresentationsof physicalobjects,suchasrockets,to the actionsof the userinterface. The à�ðjä �gf�ãpñ�f�ã programmodelstheserverview of thenetworksessionprotocollayerandpresentationprotocollayerinteraction,usingonly twotasks,oneto representtheserverbehaviorsandanotherto modelthebehavior of networkingenvironmentof theserver,suchasresponsesby remoteclients.The ä á�æpá�ã � programhasonly threetasksbut acomplicatedcontrolstructureandcomplicatedtaskinteractions.Unfortunately, thisprogramis notwell documentedandwewereonly ableto determinethatit dealswith interactionsbetweendifferenthostcomputers.The î�¥ ã�ijf�� programmodelsa radar-basedweaponssystemandcontains31 interactingtasks,mostof themmodelingeitherphysicalentitiesor connectionsamongtheseentities.The îpí�í programhasa mainprogramthatexchangesmessageswith a taskthatmodelsa databasesystem.
To these138 programswe added21 moreprograms,including a versionof the alternatingbit communicationprotocol[2], a programmodelingkeyboardoperation[7], gasstation[9], Milner’s cyclic scheduler[16], tokenringprotocol [4], andseveral flavors of the dining philosophersexample. (We usedseveral differentsizesof a scalablecyclic scheduler, dining philosophers,gasstation,and token ring examples.) Taking into accountthe fact that theresultingsuiteof 159programscontainsdifferentversionsandsizesof thesameexample,weobtainedapproximately90significantlydifferentexamples.Althoughthis is notacarefullyselectedbenchmarkingsuite,many differentappli-cationdomains,suchascommunicationprotocolsanduserinterfaces,arerepresentedin this suite. Thus,althoughitis unlikely thatthissampleof predominantlysmallprogramsis representativeof concurrentAdaprogramsin general,the resultsthat we obtainedcomparingour approachwith non-concurrency analysisprovide a good initial indica-tion that the MHP algorithmis very often moreprecisethannon-concurrency analysisandalmostaspreciseasthereachability-basedanalysis.
5.5 Experimental Results
We measuretheprecisionof theinformationcomputedby a techniquein termsof thesetof pairsof nodesin thesyncgraphthat this techniquedeterminedcannothappenin parallel. We write ò NCA for the setof CHT pairs found bynon-concurrency analysis,ò MHP for thesetof CHT pairsfoundby theMHP algorithm,and ò reach for thesetof CHTpairsfoundby thereachability-basedalgorithm.
In the following discussionof the results,we separatethe programsampleinto threesubsetsanddiscussthesesubsetsseparately. First,we considerthe25 programswithout loops.For all of theseprograms,whichcomefrom theMasticola-Rydercollection,theMHP algorithmfoundall theCHT pairsfoundby non-concurrency analysis.Second,we describeour resultsfor the9 programsin which non-concurrency analysisdetectedsomeCHT pairsnot foundbyour MHP algorithm.Finally, we describetheresultsfor theremaining125programs,thosewith loopsfor which the
31
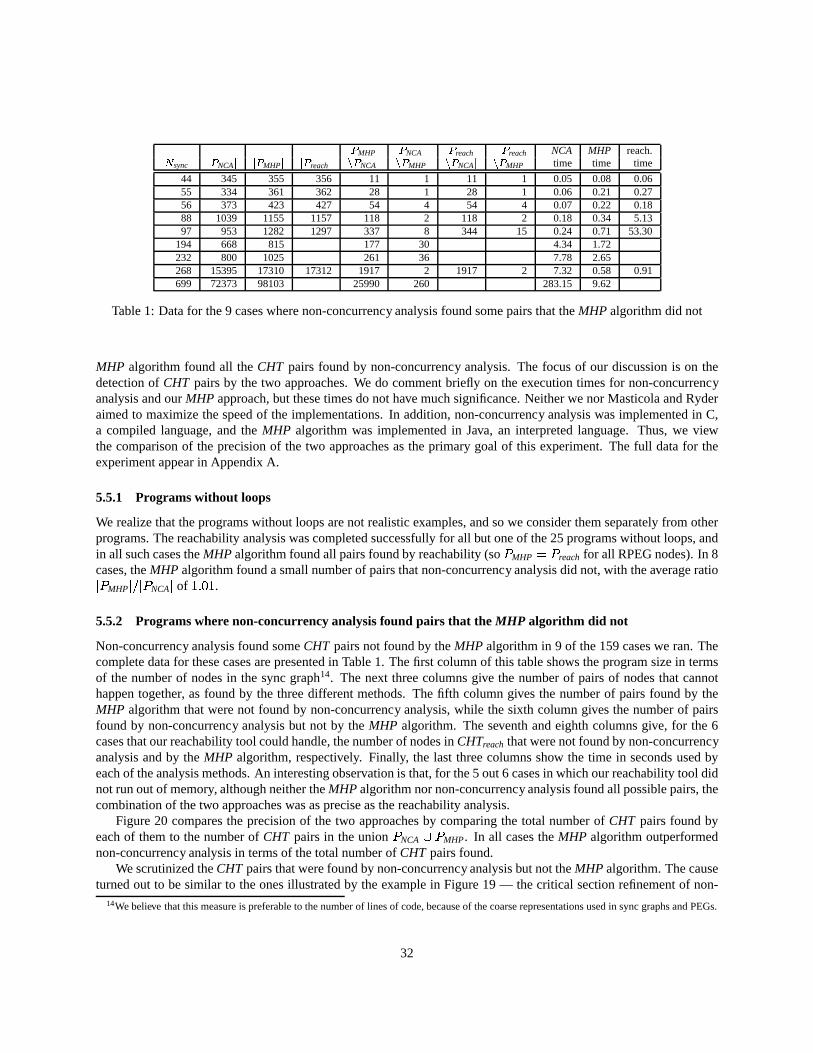
ó ôMHP
ó ôNCA
ó ôreach
ó ôreach NCA MHP reach.ó õ
syncó ó ô
NCAó ó ô
MHPó ó ô
reachó ö�ô
NCAó ö�ô
MHPó ö�ô
NCAó ö�ô
MHPó
time time time
44 345 355 356 11 1 11 1 0.05 0.08 0.0655 334 361 362 28 1 28 1 0.06 0.21 0.2756 373 423 427 54 4 54 4 0.07 0.22 0.1888 1039 1155 1157 118 2 118 2 0.18 0.34 5.1397 953 1282 1297 337 8 344 15 0.24 0.71 53.30
194 668 815 177 30 4.34 1.72232 800 1025 261 36 7.78 2.65268 15395 17310 17312 1917 2 1917 2 7.32 0.58 0.91699 72373 98103 25990 260 283.15 9.62
Table1: Datafor the9 caseswherenon-concurrency analysisfoundsomepairsthattheMHP algorithmdid not
MHP algorithmfound all the CHT pairsfound by non-concurrency analysis.The focusof our discussionis on thedetectionof CHT pairsby the two approaches.We do commentbriefly on theexecutiontimesfor non-concurrencyanalysisandour MHP approach,but thesetimesdo not havemuchsignificance.Neitherwe nor MasticolaandRyderaimedto maximizethespeedof the implementations.In addition,non-concurrency analysiswasimplementedin C,a compiledlanguage,and the MHP algorithm was implementedin Java, an interpretedlanguage.Thus, we viewthe comparisonof the precisionof the two approachesasthe primarygoal of this experiment.The full datafor theexperimentappearin AppendixA.
5.5.1 Programswithout loops
We realizethattheprogramswithout loopsarenot realisticexamples,andsowe considerthemseparatelyfrom otherprograms.Thereachabilityanalysiswascompletedsuccessfullyfor all but oneof the25programswithout loops,andin all suchcasestheMHP algorithmfoundall pairsfoundby reachability(so ò MHP � ò reach for all RPEGnodes).In 8cases,theMHP algorithmfoundasmallnumberof pairsthatnon-concurrency analysisdid not,with theaverageratio÷ ò MHP
÷ ø�÷ ò NCA÷of Ägs ç�Ä .
5.5.2 Programswherenon-concurrencyanalysisfound pairs that the MHP algorithm did not
Non-concurrency analysisfoundsomeCHT pairsnot foundby theMHP algorithmin 9 of the159caseswe ran. Thecompletedatafor thesecasesarepresentedin Table1. Thefirst columnof this tableshows theprogramsizein termsof the numberof nodesin the syncgraph14. The next threecolumnsgive the numberof pairsof nodesthat cannothappentogether, asfound by the threedifferentmethods.The fifth columngivesthe numberof pairsfound by theMHP algorithmthatwerenot foundby non-concurrency analysis,while thesixth columngivesthenumberof pairsfound by non-concurrency analysisbut not by the MHP algorithm. The seventhandeighthcolumnsgive, for the 6casesthatourreachabilitytool couldhandle,thenumberof nodesin CHTreach thatwerenot foundby non-concurrencyanalysisandby the MHP algorithm,respectively. Finally, the last threecolumnsshow the time in secondsusedbyeachof theanalysismethods.An interestingobservationis that,for the5 out6 casesin whichourreachabilitytool didnot runoutof memory, althoughneithertheMHP algorithmnornon-concurrency analysisfoundall possiblepairs,thecombinationof thetwo approacheswasaspreciseasthereachabilityanalysis.
Figure20 comparesthe precisionof the two approachesby comparingthe total numberof CHT pairsfound byeachof themto thenumberof CHT pairsin theunion ò NCA � ò MHP. In all casestheMHP algorithmoutperformednon-concurrency analysisin termsof thetotalnumberof CHT pairsfound.
WescrutinizedtheCHT pairsthatwerefoundby non-concurrency analysisbut not theMHP algorithm.Thecauseturnedout to besimilar to theonesillustratedby theexamplein Figure19 — thecritical sectionrefinementof non-
14Webelieve thatthis measureis preferableto thenumberof linesof code,becauseof thecoarserepresentationsusedin syncgraphsandPEGs.
32

0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Programs in the order of increasing size
Per
cent
age
of th
e nu
mbe
r of p
airs
foun
d by
eith
er M
HP
or N
CA
MHP NCA
Figure 20: Precisioncomparisonfor the 9 caseswherenon-concurrency analysisfound somepairs that the MHPalgorithmdid not.
concurrency analysisis ableto determinethat two nodescannothappenin parallel,wherethe MHP algorithmusestheinformationthatnodes��q and ± mayhappenin parallelandnodes�E� and ± mayhappenin parallel,eventhoughit is impossiblethat all threenodeshappenin parallel, to concludeincorrectly that the rendezvousnode | that is asuccessorof both � q and� � mayhappenin parallelwith ± .
It is possibleto combinetheMHP algorithmwith critical sectionanalysis,similar to thewaythatnon-concurrencyanalysiscombinescritical sectionanalysiswith other refinements.After the MHP algorithmis executedonce,thecritical sectionanalysiswould be appliedto refine the MHP information. If the MHP information is modifiedbythe critical sectionanalysis,the MHP algorithmcanbe re-executed,in sucha way that a node ± is not insertedinthe M setof node | if the critical sectionanalysisdeterminedthat ± and | may not happenin parallel. The MHPalgorithmandcritical sectionrefinementcouldbeappliedrepeatedlyin thiswayuntil neitheris ableto computemorepreciseinformation. Or the analysiscould be haltedafter somespecifiednumberof alternations.The drawbackofthisapproachis thattheworst-casecomplexity of theresultingalgorithmbecomesùúv ÷ w ÷ Ó } , where
÷ w ÷ is thenumberof nodesin thePEG.Basedon our experimentalresults,the improvementin precisionwould likely besmall andinpracticemaynot justify theincreasedanalysistime.
5.5.3 The other 125programs
Theremaining125programsarethosethathave loopsandwheretheMHP algorithmfoundall CHT pairsthatnon-concurrency analysisdid. Of these,thereachabilitytool wasableto run to completionin 110cases.For all of these110cases,theMHP algorithmfoundall thepairsin ò reach. Non-concurrency analysisfoundall thepairsin ò reach inonly 22 cases.
Of these125programs,therewere101casesin whichtheMHP algorithmfoundsomepairsthatwerenot foundbynon-concurrency analysis(in theremaining24cases,theMHP algorithmandnon-concurrency analysisfoundexactlythesamepairs).Figure21plotstheratio
÷ ò MHP÷ ø�÷ ò NCA
÷againsttheprogramsize,measuredasthenumberof nodesin
thesyncgraph.Theaverageprecisionratio÷ ò MHP
÷ ø�÷ ò NCA÷was Ä�s ûMÄ .
33

0
1
2
3
4
5
6
7
8
9
10
11
12
13
0 50 100 150 200 250 300 350 400
Nodes in Sync Graph
(MH
P p
airs
)/(N
CA
pai
rs)
Figure21: The precisionratio÷ ò MHP
÷ ø�÷ ò NCA÷for the 125programswith loopswherethe MHP algorithmfound all
CHT pairsfoundby non-concurrency analysis
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Programs in the order of increasing size
Tim
ing
ratio
NCA MHP
Figure22: Timing comparisonbetweenNCA andMHP
34

5.5.4 Timing Comparison
As wehavementioned,it is hardto comparethetiming performanceof non-concurrency analysisandMHP algorithm,becausethe former is implementedin C, a compiledlanguage,andthe latter is implementedin Java, an interpretedlanguage.Despitethis, we collectedtiming informationfor the two approachesandshow it herefor completeness.Figure22 shows timing comparisonfor 20 largestof our testprograms.For eachprogram,the timing for the fasterapproachis shown asa fractionof thetiming for theslowerapproach.On the20 largestprograms,therewasonly onefor which non-concurrency analysisran fasterthanthe MHP algorithm. On average,for these20 largestprograms,thetiming ratiobetweentheMHP algorithmandnon-concurrency analysiswas0.376.In contrast,for 64programsonwhichat leastoneof thetoolstookmorethan0.1secondsto run,includingthe20largestprograms,theaveragetimingratio betweenthe MHP algorithmandnon-concurrency analysiswas1.068. This suggeststhat the MHP algorithmscalesbetterthannon-concurrency analysis.
5.5.5 Comparisonbetweenthe Efficient and BasicVersionsof the MHP Algorithm.
The experimentalresultspresentedin this paperusean implementationof the basicMHP algorithm. As describedin Section4.5.3, the efficient MHP algorithmhasbetterworst-casecomplexity thanthe basicone. To determineifthis theoreticaladvantagetranslatesinto betterrunning time in practice,we implementedthe efficient MHP algo-rithm andranfour versionsof both thebasicandefficient algorithmon the159Ada examples.Differentversionsofthe algorithmscorrespondto four differentsetimplementations.Threeof theseimplementationswerebasedon theí3ü i ï f�i , ý�¥ �[þ ï f�i , and Ü ã�f�f ï fgi classesfrom the ÿ�¥ ñ ¥�� âji ü æ packageandthelastonewasourown lookup-tableim-plementation.Theoutcomeof this experimentwasunexpected— thebasicMHP algorithmusingthe í3ü i ï fgi -basedset implementationgenerallyhadsignificantly lower running times thanother versionsof both basicandefficientalgorithms. We believe that the main reasonfor this is that in practicethe basicMHP algorithmdoesnot exhibitthe theoreticalworst-casebounds.In addition,the í3ü i ï f�i -basedsetimplementationhasmoreefficient union, inter-section,andsetdifferenceoperationsthanthe otherset implementations.The basicMHP algorithmrelieson theseoperationsmorethantheefficientalgorithm.
5.5.6 The Number of Nodesin the PEG
In addition to comparingthe performanceof the two approaches,we examinedthe questionof potentialquadraticblow-up in the numberof RPEGnodes,statedin Theorem1. We plot the numberof syncgraphnodesagainstthenumberof RPEGnodesin Figure23. The figure alsoshows the least-squaresregressionline, which hasa slopeof1.84.Thecorrelationcoefficient is .984.Thissampleof programsthusoffersstrongsupportfor thehypothesisthat,inpractice,thenumberof RPEGnodesdependslinearly on thenumberof syncgraphnodes.Sincethesizeof thesyncgraphis linearin thenumberof programstatements,thesameappearsto betruefor RPEGs.
6 Conclusions
Informationaboutwhich pairsof statementsmayexecutein parallelhasimportantapplicationsin optimization,de-tectionof anomaliessuchasraceconditions,andimproving theaccuracy of dataflow analysis.Efficient andprecisealgorithmsfor computingthis informationarethereforeof considerablevalue.In thispaper, we havedescribeda dataflow methodfor computingaconservativeapproximationof thesetof pairsof statementsin aconcurrentprogramthatmayexecutein parallel.Theoretically, neithernon-concurrency analysisnorourMHP algorithmhasaclearadvantagein precision. However, basedon our experimentaldata,the MHP algorithmoften is ableto determinethe pairsofstatementsthatmayexecutein parallelmorepreciselythannon-concurrency analysis.
As a partof our experiments,we comparedtheprecisionof theMHP algorithmwith theprecisionof a techniquebasedon theexhaustiveexplorationof theprogramstatespace.While this reachabilitytechnique,beingexponentialin theprogramsize,is not practicalin general,with its helpwe wereableto computepreciseinformationfor many
35

0
200
400
600
800
1000
1200
1400
1600
0 100 200 300 400 500 600 700 800 900
Sync Graph Nodes
RT
FG
No
des
Figure23: Least-squaresfit of thenumberof RPEGnodesto thenumberof syncgraphnodes
examples.For theseexamples,the informationcomputedby theMHP algorithmwasremarkablycloseto thatof thereachabilitytechnique.
At present,theMHP algorithmis beingusedaspartof theFLAVERStool [6,18] for dataflow analysisof concur-rentprograms.
In thefuture,we planto extendtheMHP algorithmto applyto programscontainingprocedureandfunctioncallswithout using inlining. Even in its currentform, the MHP algorithmcanbe easilyusedto supporta limited formof interproceduralMHP analysis,with the restrictionthat proceduresmay not containtaskentry calls. Under thisrestriction,the MHP setscomputedfor procedurecall nodesaresufficient to determinethe MHP setsfor all nodesin this procedure.Thus,if | is a call nodefor procedureò , thenany nodein thebodyof ò mayhappenin parallelwith any nodein MHP v | } , computedtheMHP algorithm.Specialcaremustbetakenwhenthereis a possibilitythata proceduremay be calledby morethanonetask, in which caseexecutionsof multiple instancesof this proceduremay overlapin time. In this case,unlike tasknodes,the MHP setsof nodesfrom the procedurewill containothernodesfrom thesameprocedure.To determinewhetherthis might happen,we have to checkwhetherany of thecallnodesto ò is in theMHP setof any of theothercall nodesto thisprocedure(thishasto bedonerecursively for nestedprocedurecalls),in which casetheMHP setsof all nodesin ò mustcontainall nodesin ò .
In thecaseof procedurescontainingentrycalls,we plan to usea context-sensitive approach,extendingthePEGmodelto includeprocedurecall andreturnedges,similar to theapproachof [10], andmodifying theMHP algorithmaccordingly. Note that the MHP algorithm cannotbe extendedto handlerecursive procedures,sincethe problemof computingMHP information in this caseis undecidable[20]. In practice,we will either attemptto unroll therecursion,if theupperboundon thedepthof therecursionis known, or make a conservativesimplifying assumptionthattheproceduresinvolvedin recursionhappenin parallelwith all statementsin theprogram.
We plan to provide an implementationof the MHP algorithmthat canbe directly appliedto realisticconcurrentprograms.To achieve this, a numberof techniqueshave to beappliedbeforethedataflow analysisdescribedin thispaperis performed.Points-toanalysis[11] thatdeterminesaliasesin theprogram,escapeanalysis[22] thatdeterminesvariablesthat may be sharedby programthreads,and type analysis[19] that aids with resolutionof dynamically
36

dispatchedcallsarenecessaryto handlefeaturespresentin realisticprograms.Usingtheresultsof theseanalysesintheMHP algorithmwill let uscomputemorepreciseMHP information,sincefewersimplifying impreciseassumptionswill have to bemade.
We have alsodevelopedandimplementedanMHP algorithmfor concurrentJava programs[17]. Thedifferencesin theway communicationsbetweenthreadsof controlarerealizedin Ada andJava imply differentprogrammodels.While we areableto usethesamegeneralprinciple for Java astheonewe introducein this paperfor Ada, therearea numberof significantchangesin the dataflow equationsusedby the algorithmfor Java. It will be interestingtoseeif thepracticalprecisionof theMHP algorithmdependson thedifferencesin communicationmechanismsof thedifferentconcurrentlanguages.
Acknowledgments
We thankStephenMasticolaandBarbaraRyderfor graciouslyproviding uswith their non-concurrency analysistoolanda setof sampleAda programsthat we usedin our experiments.We arealsograteful to Lori Clarke, JamiesonCobleigh,andanonymousreviewersfor helpful suggestionson thiswork.
A shortversionof this paperappearedin theProceedingsof the6th InternationalSymposiumon theFoundationsof SoftwareEngineering.
This researchwas partially supportedby the DefenseAdvancedResearchProjectsAgency and the Air ForceResearchLaboratory/IFTDunderagreementsF30602-94-C-0137andF30602-97-2-0032,andby theNationalScienceFoundationunderGrantsCCR-9407182,CCR-9708184,andCCR-0093174.The views, findings,andconclusionspresentedherearethoseof theauthorsandshouldnot be interpretedasnecessarilyrepresentingtheofficial policiesor endorsements,either expressedor implied, of the DefenseAdvancedResearchProjectsAgency, the Air ForceResearchLaboratory/IFTD,theNationalScienceFoundation,or theU.S.Government.
References
[1] A. V. Aho, R. Sethi,andJ.D. Ullman. Compilers: Principles,Techniques,andTools. Addison-Wesley, Reading,MA, 1988.
[2] K. A. Bartlett, R. A. Scantlebury, andP. T. Wilkinson. A noteon reliable full-duplex transmissionover half-duplex lines. Communicationsof theACM, 12(5):260–265,May 1969.
[3] D. Callahan,K. Kennedy, andJ.Subhlok.Analysisof eventsynchronizationin a parallelprogrammingtool. InProceedingsof the2ndACM SIGPLANSymposiumon PrinciplesandPracticeof Parallel Programming, pages21–30,Mar. 1990.
[4] J.C. Corbett. Evaluatingdeadlockdetectionmethodsfor concurrentsoftware. IEEE Transactionson SoftwareEngineering, 22(3):161–180,Mar. 1996.
[5] E.DuesterwaldandM. L. Soffa.Concurrency analysisin thepresenceof proceduresusingadataflow framework.In Proceedingsof the4thACM SIGSOFTWorkshoponSoftwareTesting, Analysis,andVerification, pages36–48,Oct.1991.
[6] M. Dwyer. Data Flow Analysisfor Verifying CorrectnessPropertiesof Concurrent Programs. PhD thesis,Universityof Massachussetts,Amherst,1995.
[7] R. Ford. Concurrentalgorithmsfor real-timememorymanagement.IEEE Software, pages10–23,Sept.1988.
[8] M. S.Hecht.Flow Analysisof ComputerPrograms. North-Holland,New York, 1977.
37

[9] D. P. HelmboldandD. C. Luckham.DebuggingAda taskingprograms.IEEESoftware, 2(2):47–57,Mar. 1985.
[10] S. Horwitz, T. Reps,andM. Sagiv. Demandinterproceduraldataflow analysis.In Proceedingsof the3rd ACMSIGSOFTSymposiumon theFoundationsof SoftwareEngineering, pages104–115,Oct.1995.
[11] W. A. LandiandB. G.Ryder. Pointer-inducedaliasing:A problemtaxonomy. In Proceedingsof ACM SIGPLANSymposiumon Principlesof ProgrammingLanguages, pages93–103,Jan.1991.
[12] D. L. Long andL. A. Clarke. Task interactiongraphsfor concurrency analysis. In Proceedingsof the 11thInternationalConferenceon SoftwareEngineering, pages44–52,May 1989.
[13] S.P. Masticola,T. J.Marlowe,andB. G. Ryder. Latticeframeworksfor multisourceandbidirectionaldataflowproblems.ACM Transactionsof ProgrammingLanguagesandSystems, 17(5):777–803,Sept.1995.
[14] S.P. MasticolaandB. G. Ryder. Staticinfinite wait anomalydetectionin polynomialtime. In Proceedingsof theInternationalConferenceon Parallel Processing, pages78–87,Aug. 1990.
[15] S.P. MasticolaandB. G.Ryder. Non-concurrencyanalysis.In Proceedingsof the4thACMSIGPLANSymposiumon PrinciplesandPracticeof Parallel Programming, pages129–138,May 1993.
[16] R. Milner. A Calculusof CommunicatingSystems, volume92. Springer-Verlag,Berlin, 1980.
[17] G. Naumovich, G. S. Avrunin, andL. A. Clarke. An efficient algorithmfor computingMHP informationforconcurrentJava programs.In Proceedingsof the joint 7th EuropeanSoftware EngineeringConferenceand7thACM SIGSOFTSymposiumon theFoundationsof SoftwareEngineering, pages338–354,Sept.1999.
[18] G. Naumovich, L. A. Clarke, L. J. Osterweil, and M. B. Dwyer. Verification of concurrentsoftware withFLAVERS. In Proceedingsof the 19th International Conferenceon Software Engineering, pages594–595,May 1997.
[19] J.PlevyakandA. A. Chien.Preciseconcretetypeinferencefor object-orientedlanguages.In Proceedingsof theACM SIGPLANConferenceonObject-OrientedProgramming, pages324–340,Oct.1994.
[20] G. Ramalingam. Context-sensitive synchronization-sensitive analysisis undecidable. ACM TransactionsofProgrammingLanguagesandSystems, 22(2):416–430,Mar. 2000.
[21] R. N. Taylor. Complexity of analyzingthesynchronizationstructureof concurrentprograms.ActaInformatica,19:57–84,1983.
[22] J.Whaley andM. Rinard. Compositionalpointerandescapeanalysisfor Java programs.In Proceedingsof theACM SIGPLANConferenceonObject-OrientedProgramming, pages187–206,Oct.1999.
A Full Data for All TestPrograms
Hasó ô
MHPó ô
NCAó ô
reachó ô
reach NCA MHP reach.loops
ó õsyncó ó ô
NCAó ó ô
MHPó ó ô
reachó ö�ô
NCAó ö�ô
MHPó ö�ô
MHPó ö�ô
NCAó
time time time
yes 6 5 5 5 0 0 0 0 0.00 0.00 0.01no 7 7 7 7 0 0 0 0 0.01 0.00 0.01no 7 7 7 7 0 0 0 0 0.00 0.00 0.01
yes 7 7 7 7 0 0 0 0 0.00 0.00 0.01yes 9 4 4 4 0 0 0 0 0.00 0.00 0.01no 10 23 23 23 0 0 0 0 0.00 0.00 0.01no 10 23 23 23 0 0 0 0 0.00 0.00 0.01
38

Hasó ô
MHPó ô
NCAó ô
reachó ô
reach NCA MHP reach.loops
ó õsyncó ó ô
NCAó ó ô
MHPó ó ô
reachó ö�ô
NCAó ö�ô
MHPó ö�ô
MHPó ö�ô
NCAó
time time time
no 11 23 23 23 0 0 0 0 0.00 0.01 0.01no 11 23 23 23 0 0 0 0 0.00 0.01 0.01no 11 23 23 23 0 0 0 0 0.00 0.01 0.01
yes 11 10 10 10 0 0 0 0 0.01 0.01 0.01no 11 23 23 23 0 0 0 0 0.00 0.01 0.01no 11 33 33 33 0 0 0 0 0.00 0.00 0.01no 11 33 33 33 0 0 0 0 0.00 0.00 0.01no 11 33 33 33 0 0 0 0 0.00 0.00 0.01no 12 30 30 30 0 0 0 0 0.01 0.01 0.01
yes 13 7 7 7 0 0 0 0 0.00 0.01 0.01no 13 39 40 40 1 0 0 1 0.01 0.01 0.01no 13 39 40 40 1 0 0 1 0.01 0.01 0.01no 13 39 40 40 1 0 0 1 0.00 0.01 0.01no 13 45 50 50 5 0 0 5 0.01 0.00 0.01no 13 46 51 51 5 0 0 5 0.01 0.00 0.01no 14 48 48 48 0 0 0 0 0.01 0.01 0.01
yes 14 25 25 25 0 0 0 0 0.00 0.03 0.01no 14 48 49 49 1 0 0 1 0.00 0.01 0.01
yes 14 7 10 10 3 0 0 3 0.00 0.01 0.01yes 14 10 10 10 0 0 0 0 0.01 0.01 0.01yes 14 10 10 10 0 0 0 0 0.01 0.01 0.01no 15 48 48 48 0 0 0 0 0.01 0.01 0.01
yes 16 42 46 46 4 0 0 4 0.00 0.01 0.01yes 16 50 50 50 0 0 0 0 0.01 0.00 0.01yes 16 21 25 25 4 0 0 4 0.00 0.00 0.01yes 16 21 25 25 4 0 0 4 0.01 0.00 0.01yes 17 23 24 24 1 0 0 1 0.00 0.02 0.01yes 17 23 24 24 1 0 0 1 0.01 0.02 0.01yes 17 23 24 24 1 0 0 1 0.00 0.02 0.01yes 17 23 24 24 1 0 0 1 0.01 0.02 0.01yes 17 23 24 24 1 0 0 1 0.00 0.02 0.01yes 17 23 24 24 1 0 0 1 0.01 0.02 0.01yes 17 23 24 24 1 0 0 1 0.00 0.02 0.01no 17 82 84 84 2 0 0 2 0.00 0.02 0.01
yes 17 22 23 23 1 0 0 1 0.01 0.02 0.01yes 17 23 24 24 1 0 0 1 0.01 0.02 0.01yes 17 22 23 23 1 0 0 1 0.01 0.02 0.01yes 17 23 24 24 1 0 0 1 0.00 0.02 0.01yes 19 37 40 40 3 0 0 3 0.00 0.02 0.01yes 19 37 40 40 3 0 0 3 0.00 0.02 0.01yes 19 23 23 23 0 0 0 0 0.00 0.01 0.01yes 19 37 40 40 3 0 0 3 0.01 0.02 0.01yes 19 37 40 40 3 0 0 3 0.00 0.02 0.01yes 19 23 23 23 0 0 0 0 0.01 0.01 0.01yes 19 38 43 43 5 0 0 5 0.01 0.02 0.01yes 19 7 7 7 0 0 0 0 0.01 0.02 0.01yes 20 13 18 18 5 0 0 5 0.00 0.03 0.01yes 20 60 60 60 0 0 0 0 0.01 0.04 0.02yes 20 22 23 23 1 0 0 1 0.00 0.02 0.01yes 20 14 14 14 0 0 0 0 0.01 0.03 0.01yes 21 13 14 14 1 0 0 1 0.01 0.03 0.01yes 21 13 14 14 1 0 0 1 0.00 0.03 0.01yes 22 19 20 20 1 0 0 1 0.01 0.03 0.01yes 23 69 77 77 8 0 0 8 0.00 0.02 0.01yes 23 76 76 76 0 0 0 0 0.01 0.05 0.02yes 23 31 32 32 1 0 0 1 0.01 0.03 0.02
39
Hasó ô
MHPó ô
NCAó ô
reachó ô
reach NCA MHP reach.loops
ó õsyncó ó ô
NCAó ó ô
MHPó ó ô
reachó ö�ô
NCAó ö�ô
MHPó ö�ô
MHPó ö�ô
NCAó
time time time
yes 23 23 23 23 0 0 0 0 0.01 0.04 0.01yes 23 108 129 129 21 0 0 21 0.01 0.01 0.01yes 23 23 23 23 0 0 0 0 0.01 0.04 0.01yes 24 27 51 51 24 0 0 24 0.00 0.03 0.01no 24 177 177 177 0 0 0 0 0.01 0.02 0.01
yes 26 10 10 10 0 0 0 0 0.01 0.03 0.01yes 26 19 25 25 6 0 0 6 0.01 0.03 0.01yes 27 148 154 154 6 0 0 6 0.01 0.06 0.03yes 28 308 308 308 0 0 0 0 0.01 0.01 0.01yes 28 79 95 95 16 0 0 16 0.01 0.03 0.01yes 29 76 83 83 7 0 0 7 0.02 0.03 0.01yes 31 92 125 125 33 0 0 33 0.01 0.03 0.03yes 31 39 40 40 1 0 0 1 0.01 0.06 0.06no 35 308 308 308 0 0 0 0 0.03 0.04 0.01
yes 35 148 148 148 0 0 0 0 0.03 0.06 0.05yes 35 99 99 99 0 0 0 0 0.02 0.06 0.03yes 37 134 162 162 28 0 0 28 0.02 0.05 0.05yes 37 134 162 162 28 0 0 28 0.03 0.05 0.05yes 38 45 140 140 95 0 0 95 0.03 0.05 0.01yes 41 243 256 256 13 0 0 13 0.04 0.07 0.03yes 42 67 106 106 39 0 0 39 0.03 0.07 0.02no 43 811 816 816 5 0 0 5 0.04 0.00 0.01
yes 44 345 355 356 11 1 1 11 0.05 0.08 0.06yes 46 331 376 376 45 0 0 45 0.03 0.08 0.04yes 47 463 579 579 116 0 0 116 0.05 0.04 0.01yes 51 63 66 66 3 0 0 3 0.05 0.15 0.70yes 52 326 428 428 102 0 0 102 0.05 0.12 0.21yes 55 802 1012 1012 210 0 0 210 0.04 0.03 0.02yes 55 802 1012 1012 210 0 0 210 0.04 0.03 0.02yes 55 802 1012 1012 210 0 0 210 0.03 0.03 0.02yes 55 802 1012 1012 210 0 0 210 0.03 0.03 0.02yes 55 802 1012 1012 210 0 0 210 0.04 0.03 0.02yes 55 802 1012 1012 210 0 0 210 0.03 0.03 0.02yes 55 334 361 362 28 1 1 28 0.06 0.21 0.27yes 56 373 423 427 54 4 4 54 0.07 0.22 0.18yes 59 400 485 485 85 0 0 85 0.09 0.09 0.06yes 60 452 468 468 16 0 0 16 0.04 0.17 0.11yes 64 152 159 159 7 0 0 7 0.07 0.21 0.64yes 69 577 843 843 266 0 0 266 0.20 0.21 1.02yes 71 1261 1452 1452 191 0 0 191 0.09 0.20 0.10yes 71 1261 1452 1452 191 0 0 191 0.06 0.20 0.10yes 71 115 115 115 0 0 0 0 0.16 0.19 3.68yes 73 90 555 555 465 0 0 465 0.17 0.17 0.02yes 75 108 111 111 3 0 0 3 0.18 0.24 22.89yes 76 287 301 301 14 0 0 14 0.31 0.21 34.49yes 77 1473 1859 1859 386 0 0 386 0.20 0.08 0.02yes 80 137 144 144 7 0 0 7 0.13 0.23 1.88yes 81 627 643 643 16 0 0 16 0.13 0.22 0.25yes 82 348 543 543 195 0 0 195 0.15 0.38 0.66yes 82 251 565 565 314 0 0 314 0.19 0.18 0.02yes 83 867 900 900 33 0 0 33 0.14 0.23 0.63yes 85 548 625 625 77 0 0 77 0.29 0.24 55.51yes 87 726 742 742 16 0 0 16 0.13 0.24 0.28yes 88 1039 1155 1157 118 2 2 118 0.18 0.34 5.13yes 97 953 1282 1297 337 8 15 344 0.24 0.71 53.30yes 104 2977 3443 3443 466 0 0 466 0.21 0.34 0.19
40
Hasó ô
MHPó ô
NCAó ô
reachó ô
reach NCA MHP reach.loops
ó õsyncó ó ô
NCAó ó ô
MHPó ó ô
reachó ö�ô
NCAó ö�ô
MHPó ö�ô
MHPó ö�ô
NCAó
time time time
yes 104 2977 3443 3443 466 0 0 466 0.22 0.34 0.19yes 106 1026 1042 1042 16 0 0 16 0.19 0.33 0.22yes 107 3169 3666 3666 497 0 0 497 0.23 0.35 0.21yes 107 700 890 890 190 0 0 190 0.41 0.26 335.87yes 111 1109 1125 1125 16 0 0 16 0.21 0.32 0.24yes 113 1079 1475 1475 396 0 0 396 0.52 0.86 16.08yes 125 1318 1645 1645 327 0 0 327 0.82 0.88 438.57yes 127 984 1260 276 0 0.62 0.35yes 134 1206 1376 1376 170 0 0 170 1.21 0.58 375.56yes 135 3029 3170 3170 141 0 0 141 0.94 0.36 19.20yes 137 5218 6594 6594 1376 0 0 1376 1.32 0.15 0.06yes 137 352 353 1 0 0.98 0.95yes 137 1644 5220 5220 3576 0 0 3576 0.86 0.09 0.41yes 140 2050 2089 2089 39 0 0 39 0.67 0.35 8.62yes 141 1155 3958 3958 2803 0 0 2803 1.25 0.12 6.36yes 143 180 2210 2210 2030 0 0 2030 1.24 0.39 0.04yes 147 901 2250 2250 1349 0 0 1349 1.39 0.38 0.06yes 147 901 2250 2250 1349 0 0 1349 1.39 0.37 0.06yes 155 401 402 1 0 1.37 1.23yes 156 2339 2714 375 0 2.10 0.52yes 156 2157 6892 6892 4735 0 0 4735 1.20 0.09 0.73yes 163 380 380 0 0 1.92 1.08yes 163 1515 5290 5290 3775 0 0 3775 2.05 0.15 37.42yes 183 560 590 30 0 2.22 1.32yes 183 5226 6437 1211 0 3.49 0.75yes 194 668 815 177 30 4.34 1.72yes 195 456 456 0 0 3.53 1.61yes 202 2329 3474 1145 0 3.16 5.01yes 219 672 708 36 0 4.08 1.98yes 221 1124 1601 477 0 5.14 1.28yes 232 800 1025 261 36 7.78 2.65yes 265 1485 2189 704 0 10.14 1.95yes 268 15395 17310 17312 1917 2 2 1917 7.32 0.58 0.91yes 276 8427 8443 8443 16 0 0 16 1.77 1.62 0.82no 284 24241 24241 0 0 37.15 0.55
yes 309 1890 2865 975 0 16.87 2.86yes 311 30301 35252 35252 4951 0 0 4951 3.79 2.67 2.09yes 385 11493 18942 7449 0 20.35 6.43yes 400 13500 22551 9051 0 35.68 4.06yes 699 72373 98103 25990 260 283.15 9.62
B Handling Dynamically Started Tasks
Figure24 shows the sharedbuffer examplefrom Figure2, modifiedto usetasktypes. Insteadof declaring(largelyrepetitively) tasks
� ã ü ijf�ã�Þ and� ã ü i�f�ã�ß statically, themodifiedprogramdeclaresa singletasktype
� ã ü i�f�ã . Proce-dure ü å ü i � ã ü i�f�ã declaresa singlevariableof this tasktype,causinga taskof type
� ã ü ijf�ã to becreatedandstartedeachtime this procedureis called. Staticallydefinedtask í â����jf�ã calls procedureü å ü i � ã ü i�f�ã twice, creatingtwowriter tasks.Sincewe know this staticboundon thenumberof dynamicallycreatedtasks,we cancreatea finite PEGmodelfor this program.
We usea new nodetype, calledactivationnode,to representcreationof dynamictasks. Activation nodesaresimilar to rendezvousnodesin that they belongto two tasks. Oneof thesetasksis an existing task that createsanew taskandthe othertaskis the onebeingcreated.Figure25 shows a generalform of an activationnode. In thisfigure, the activation nodeis labeled ¥ , the local nodethat startsa new taskis labeledh , the successorsof h in the
41

����� �������������������������������� ���������!�������������#"$����������%'&)(�(*&,+�+.-/��01�,2���3���������3��42�����������#"65 �42.�4������7�48�9�0���1�:�42;&)(�(<&,+�+�7������=�> 0�0���?(@7��A��B�=�> 0�0���?(DC���4��9%6���4�������E%F��-�-)�=�> 0�0���?( > 2�7��A,�B���2� 7����4�?���2� ����������������A���� > ���1�42.��������������G��C���������H����,�I"J����������9�����3��422 > 7�7E���2� �42.��������������9�
���,� =�> 0�0���!����2����� 7��A��B���2����� > 2�7��A,�B���2�����/C���4��9%6K���7 > �L"$�421�42���3����M-)���2� =�> 0�0���9����,�:������� =�> 0�0���1��C���4�����2�N���7 > �L"$�,2���3���������3��,2O�O ���PM�1�42���������7���8���������2 Q������42.�4���������������42.�4��������������7����4���A�A�����17��A,�B���A�A�����:C�������9%RK���7 > �L"S�42!�42����3���M-T��C����������2�N���7 > �L"65 K���7 > �9���2�/C���4��9���A�A����� > 2�7��A,�?���2��7������?���2� =�> 0�0���9�Figure24: Sharedbuffer exampleusingtasktypes
p
a
s1 bsr
. . .
Figure25: Generalform of anactivationnode
CCFGfor this taskare labeled � q ...� ¿ , andthe begin nodein the dynamicallystartedtask is labeled U . Figure26shows thePEGfor theexamplein Figure24. Thetwo instancesof task
� ã ü i�f�ã arelabeled� ã ü i�fgã�Þ and
� ã ü i�f�ã�ß .Thenumbersassociatedwith thenodesarethesameasin thePEGin Figure5 thatcorrespondsto theexamplewithstaticwriter tasks,exceptfor thefour new nodes.Nodes27 and28, both labeled ü å ü i � ã ü i�f�ã , representthecalls toprocedureü å ü i � ã ü i�f�ã . Eachof thesecallstriggerscreationof a
� ã ü ijf�ã task.Activationnodes29 and30 representthis creation.
Modificationsof the MHP algorithmsaretrivial. Sinceeachactivationnodehasa singlepredecessor, the MHPinformationassociatedwith this predecessoris simply propagatedinto the activationnode: M v�l }_� M vY� } , where ldenotesanactivationnodeand� denotesits predecessor. For thepurposeof computingGENsets,activationnodesaretreatedin thesamewayasrendezvousnodes.We conservatively assumethatall activationnodesarereachable.
42

begin
1
Buffer.lock
2accept lock
8
Buffer.write3
19
accept write−start
9
20
4
accept write−end
10
21
Buffer.unlock5
accept unlock
11
23
24
25
26
end
12
end6
22
end
18
Buffer.unlock17
16
Buffer.write15
Buffer.lock
14
begin
13
begin
7
initWriter
27
initWriter
28
29
30
Writer1 Writer2
Buffer
Figure26: ThePEGfor thesharedbuffer examplewith tasktypes
C The Proof of Equivalenceof the Basicand Efficient Versionsof the MHPAlgorithm
Thefollowing lemmasandtheoremsprovethattheefficientandbasicversionsof theMHPalgorithmcomputeidenticalinformation.
Lemma 9. � ± r | � w , if ± � INeff v | } at any point during the efficient MHP algorithm, then eventually ± �MHPeff v | } , unless| is a rendezvousnodethat theefficientalgorithmdeterminesis not reachable.
Proof. Supposethat at somepoint during the efficient MHP algorithmin Figure10 some ± � w getsin INeff v | } .This canhappenin lines (10), (20), or (25). First considerthe casewhen ± is addedto INeff v | } in line (10). If theReacheff flagof | is set, ± will beaddedto NewMeff v | } in line (12) andsubsequentlyaddedto Meff v | } in line (28). If
43

theReacheff flagof | is notset,but is setonsomesubsequentiterationof thealgorithm,± will beplacedin Meff v | } ina similarway. Finally, if theReacheff flagof | is neverset, ± is not placedin Meff v | } .
Considerthecasewhere± is addedto INeff v | } in line (20). If ± is not alreadyin Meff v | } , ± is addedto NewMeff
in line (21)andsubsequentlyto Meff v | } in line (28).If ± is addedto INeff v | } in line (25), it happenson aniterationfor a nodeotherthan | , | would beplacedon the
worklist in line (26). Subsequently, when | is takenoff theworklist, oneof thefirst two casesapplies.
Lemma 10. � ± r�� � N r � |Õ� LOCAL, if ± is addedto Floweff vY�/r | } at somepoint, theneventually ± is addedtoMeff v | } .Proof. Node ± is addedto Floweff vY�/r | } in line (30). SincesetNewM is not emptyon that iteration(it mustcontain± ), successorsof � , including | , areaddedto theworklist in line (27). When | is takenoff theworklist, ± is takenfrom Floweff vY�Îr | } andaddedto INeff v | } in line (20). Accordingto Lemma9, ± will beaddedto Meff v | } .Lemma 11. � ± r%� q r%� � � N r � |²� REND,if ± is addedto Floweff vY� q r | } at somepoint, ± is addedto Floweff vY� � r | }at somepoint,andtheflag Reacheff of | is setat somepoint, theneventually± is addedto Meff v | } .Proof. Node ± is addedto Floweff vY��q]r | } andFloweff v��M�gr | } in line (30),on therespective iterationsfor nodes��q and�M� . In bothcases,| is placedon the worklist in line (27). Considerline (10) that is executedevery time node | istaken off the worklist. Without lossof generalitywe assumethat ± is addedto Floweff vY��q]r | } beforeit is addedtoFloweff v�� � r | } . Supposethat line (10) is executedwhile ±�� Floweff vY� q r | } , but before ± is addedto Floweff vY� � r | } .Then,if ± ³� Meff v�� � r | } , ± is notaddedto INeff v | } . Now supposethatthis line is executedwhile ±A� Floweff vY� � r | } .By this point, ± � Meff vY� q } andtherefore± is addedto IN v | } . Thestatementof this lemmafollows afterusingtheresultof Lemma9.
Theorem 12. Theefficient MHP algorithm correctly implementsthe basicMHP algorithm, in the sensethat MHPsetscomputedby thetwo algorithmsare thesamefor everynodein thePEG:
� |�� w�r MHPeff v | }C� MHP v | } (5)
Proof. First we provethat � |�� w�r MHP v | }�Ë MHPeff v | } (6)
We carryout theproof by inductionon thenumberof iterationsof thebasicMHP algorithm.We will provethat
Statement6. If on � -th stepof thebasicMHP algorithmnode ± is addedto theM setof node | , then ± is addedtoMeff v | } atsomepoint in theefficientMHP algorithm.
After 0 iterationsof thebasicMHP algorithm,� |�� w�r M v | }C�©¦ , sostatement6 trivially holds.Supposethat statement6 holds after � stepsand considerthe �WV Ä -st iteration of the basicMHP algorithm.
Supposethat ± is addedto M v | } , for some± r |�� w . We have to considertwo cases,basedon whether| is a localor rendezvousnode.
Supposefirst that |È� REND. Let Predsv | }���� � q r%� � � . Since ± � M v | } , accordingto thebasicMHP algorithmReach v | } mustbe setto i�ãpâQf , which meansthat � q � M v�� � } . By the inductionhypothesis,� q �YX eff vY� � } , andsoReacheff v | } is setto i�ãpâQf in line (6).
Considerall possiblewaysin which ± couldpropagateinto M v | } . Supposefirst that ± waspropagatedinto | fromits predecessors,whichmeans±A� M v�� q } ¢ ±A� M v�� � } . By theinductionhypothesis,±A� Meff vY� q } ¢ ±A� Meff v�� � } ,andso ± is placedin Floweff vY� q } andFloweff v�� � } . Accordingto Lemma11, ± will beplacedin Meff v | } .
If ± propagatesinto X v | } bysymmetry, it meansthat |²� M v ± } , andsoby theinductionhypothesis|²� Meff v ± } ,which meansthat |²� MHPeff v ± } . In this case,± is insertedin INeff v | } in line (25),andby Lemma9, ±A�ZX eff v | } .
Now supposethat |#� LOCAL. In this case± couldget into X v | } by oneof threeways,via propagationfroma predecessor, by symmetry, andby usingthe GEN rule. First, supposethat ½[� � Predsv | } ~ ± � M v�� } . By theinductionhypothesis,± � Meff v�� } andtherefore± is insertedin Floweff vY�Îr | } . Accordingto Lemma10, ±A� Meff v | } .
44

Thesymmetrycaseis handledin thesamewayasfor rendezvousnodes.Finally, supposethat ± � GENv | } . Let k betherendezvouspredecessorof both ± and | . For ± � GENv | } , it
is necessarythatReach v�k } is setto i�ã�âQf . By the inductionhypothesis,Reacheff v�k } is setto i�ã�âQf . WhenReacheff v%k }becomestrue, k is insertedin ReachableComPredseff v | } in line (8). Subsequently, in line (19), ± is addedto GENeff v | }andthen,in line (21), to NewM.
To completetheproof of this theorem,we needto show that
� |�� w�r MHPeff v | }ÌË MHP v | } (7)
Againwe useinductionandformulatethefollowing statement,which implies(7).
Statement7. If on � -th stepof theefficientMHP algorithmnode± is addedto theMeff setof node| , ±A� M v | } .Statement7 trivially holdsbeforeany iterationsof the main loop of the efficient MHP algorithm,since � | �w�r M v | }�� Meff v | }C�§¦ .Supposethat Statement7 holdsafter � iterationsof the main loop of the efficient algorithm. Consider�[V�Ä ’st
iterationof themainloop of theefficientalgorithm.Supposethat ± is addedto Meff v | } .First assumethat | � REND. If theReacheff flag of | wassetto trueon this iteration, ± couldbeput in Meff v | }
by way of executingline (12). Therefore, ± was put in INeff v | } on either this or one of the previous iterations,by executingline (10). Assume,without loss of generality, that ± � Floweff vY� q r | }ÌÒ Meff v�� � } on that iteration.± � Floweff v�� q r | } meansthat ± wasalsoput in Meff v�� q } on oneof theprecedingiterations,andsoby theinductionhypothesis,± � M vY� q } . Similarly, since ± � Meff vY� � } , thenby theinductionhypothesis,± � M v�� � } . Therefore,±is put in M v | } after | becomesreachablein thebasicalgorithm.
Node ± couldalsobeput in INeff v | } by thesymmetrystepin line (25). Thismeansthat |²� Meff v ± } onapreviousiterationof the efficient algorithmandso by the inductionhypothesis,| � M v ± } andsymmetrystepof the basicalgorithmplaces± in M v | } .
Now considerthecaseof |²� LOCAL. Thenit is eitherthecasethat ±A� GENeff v | } or ±A� INeff v | } . In theformercase,a rendezvouspredecessork of | and ± mustbemarkedasreachableandplacedin theReachableComPredssetof | . This meansthaton somepreviousiterationline (8) is executedfor node k . Thenthetwo local predecessorsof karein theMeff setsof eachotheron thatiteration.By theinductivehypothesis,thesepredecessorsarein theM setsofeachotheron someiterationof thebasicalgorithm. Consequently, theReach flag of k is setto i�ãpâQf and ± is put inGENv | } andsubsequentlyin M v | } .
Thecaseswhere ± is propagatedinto INeff v | } from a predecessorof | or by symmetryarehandledanalogouslyto thecaseof rendezvousnodesabove.
D Subsumptionof SomeNon-concurrencyAnalysisRefinementsby the MHPAlgorithm
D.1 Subsumptionof B4 Analysis
For eachnode | in thesyncgraph,a setReach v | } is created,which containsall nodesin this graphfrom which | isreachablevia controlflow edges.Further, a set \ v | } is built asfollows:\«v | }C� Reach v | } ] � � ÷ |²� Reach vY� }��Intuitively, \«v | } is the setof all nodesthat reach| , but thatarenot reachablefrom | via pathsof finite length. Itis easyto seethat | ³� Reach v | } , asthereis a pathfrom | to | of length0. The algorithmin Figure27 (adaptedfrom [15]) computesB4 informationon a syncgraph.
45

Algorithm 8 (B4 analysis).Input: Syncgraph v%w syncr�x<y�r�x n r]{| init r]{| fin } with theset \ precomputedfor eachnodeandcompletoredges.Output: For each|�� w sync, a set ^´ûMv | } thatincludesall nodesthatareexecutedbefore| .Thefollowing dataflow equationdescribethepropagationof B4 informationthroughthesyncgraph._ w v | }�� `a b
� Preds® ¯d°�cedgf vY� }ihj5� `a by Completors® ¯d°�cedkf v�k }ihj (8)
^_ûEv | }C� _ w«v | }3� \«v | } (9)cedkf v | }C� ^_ûEv | }��:� | � (10)
Figure27: Thealgorithmfor computingB4 informationona syncgraph
1 p1 p2
c2
c3
c
{n, m, k}
n
{n, m} {m} {m, k, l}{n, l}
Figure28: B4 example
Figure28 illustratestheprocessof calculatingthesetsIN, B4, andOUT for | , giventheB4 setsof all othernodes,which areshown next to thenodes.Supposethat k q r�� q r�� � � \«v | } , while k � r�k�Ð ³� \ v | } . ThenthesetsIN, B4, andOUT for | will becomputedasfollows:_ w v | }�� v � ± ��Ò�� ± r���r<l �[}E� v � | r ± ��Ò�� | r'l ��Ò�� | r ± r�� �[}=��� | r ± �^_ûMv | }C��� | r ± �C� \ v | }C��� | r ± r�k�q�r%�3q[r%�E� �cedkf v | }C��� | r ± r�k q r�� q r%� � ����� | �z��� | r ± r�k q r�� q r%� � �
The B4 analysisdirectly contributesto the CHT analysis,sinceif ± � ^_ûMv | } , thenit is alsothe casethat |��CHTv ± } and ±A� CHTv | } .
The B4 algorithm hasthe worst-caseupperboundof ùúv ÷ w ÷ Ð lDm�n3v ÷ w ÷ }�} if the worklist algorithm is usedandùúv ÷ w ÷ Ð } for Tarjan’salgorithm[15].Thefollowing theoremprovesthat theMHP algorithmsubsumestheB4 analysisby proving thatwhenever ± �
B4v | } , it is necessarilythecasethat ± ³� MHP v | } . This statementis provedby inductionover thelengthof thepath(includingbothcontrolandcompletoredges)from ± to | .Theorem13 (MHP algorithm subsumesB4).� |�� LOCAL ~ ±A� ^_ûEv | } � ± ³� MHP v | } .Proof. We presentproof by inductionover thelengthof thepathfrom ± to | . Thepathis not simply a controlpath;in additionto controledgesit canincludecompletoredges,andsothepathsconsideredhererepresentpropagationofB4 informationaroundthesyncgraph,accordingto theB4 Algorithm 8.
46

m
n
(a) Syncgraph
. . .. . .
C
n
m
(b) RPEG
Figure29: Illustrationfor thebasecaseof theB4 subsumptionproof
0 c0p
n
(a) Syncgraph
. . .. . .
K
0p 0
n
c1 c
K’
(b) RPEG
Figure30: Illustrationfor theB4 subsumptionproof
For pathsof length1, two casesarepossible.First, it couldbethat ±A� Predsv | } ¢ ± � \ v | } , in whichcase± ³�MHP v | } , since ± and | arein thesametask.Second,it couldbethatCompletorsv | }���� ± � . Thiscaseis illustratedin Figure29(a).Figure29(b)shows thecorrespondingRPEGfragment. ± ³�:X v6o } sincetaskv ± } � tasksv6o } , andhence± ³�TX v | } by theLOCAL MHP propagationrule.
Supposethatthestatementof thetheoremholdsfor pathsof lengths Å#� .Considera pathof length �eV4Ä . Takeany ±A� w syncr ±A� ^_ûEv | } . Thereareseveralsituationswhere± couldbe
insertedin ^_ûEv | } , accordingto theB4 algorithm.First, let ±A� \«v | } . Accordingto theB4 algorithm,thismeansthat | is reachablefrom ± , but ± is not reachable
from | , usingonly controlflow edges.Trivially, ± ³� MHP v | } , because± and | arein thesametask.Second,let ±A�Zp � Preds® ¯d° cedkf v�� } . Let ±A� cedkf v��rq } , for some�sq � Predsv | } , wherecedgf is definedin B4
algorithm.Thenit is eitherthecasethat ± � �rq , in whichcasetrivially ± ³� MHP v | } , or ±A� ^_ûMv��rq } , in whichcase± ³� MHP vY�sq } by theinductionhypothesis.UsingtheMHP dataflow equations,we canshow ± ³� MHP v | } .Finally, let ± �tp y Completors® ¯d° cedkf v�k } . Let ± � cedgf v%k q } , for some k q � Completorsv | } , where cedkf is
definedin B4 algorithm.Referto Figure30(a).TheRPEGthatcorrespondsto thesyncgraphin Figure30(a)appearsin Figure30(b).Oneof thefollowing musttakeplace:
Case1. ± � k q , in which case± cannotpropagateinto MHP v | } from node \ . Supposethat ± propagatesintoMHP v | } from someothernode \ u . Node k q is anothercompletorof | , so it shouldbe the casethat k q � ^_ûEv%k q }
47

n
1r rk
(a)Syncgraph
n
n’ k
w
r1 r
C C
. . .
. . . . . .
1 k
(b) RPEG
Figure31: Illustrationfor theB4 subsumptionproof
for k q � ^_ûEv | } . By the inductionhypothesis,k qÖ³� MHP v%k q } , andusing the MHP dataflow equationswe provek,q ³� MHP v | } .Case2. ± � ^´ûMv�k,q } , andonceagainwe applytheinductionhypothesisand,usingtheMHP dataflow equations,
similar to case1.Finally, wehaveto considerthecasewhereeither ± or | mapsto two RPEGnodes,accordingto theSyncToRPEG
mapping.Assumefirst that | is a signalnode.For theillustrations,referto Figures31(a)and31(b).Accordingto theSyncToRPEGmapping,MHP v | }C� MHP v | u }�� MHP v%u ¯ } . So,wehaveto provethat ± ³� MHP v | u } ¢ ± ³� MHP v·u ¯ } .
Theproof for | u is thesameinductive proof astheoneabove: ± ³� MHP v | u } � ± ³� MHP v6o } rG� £ r�Ä´Å £ Å�� ,andhence± ³� MHP v·u ¯ } , all usingtheMHP dataflow equations.
Finally, supposethat ± is a signalnode.This meansthatwehave to prove ± u ³� MHP v | } ¢ u ¬ ³� MHP v | } . Theproof of eachof thenon-containmentsis identicalto theinductiveproof in thefirst partof this theorem.
D.2 Subsumptionof the Widening Principle
Sincewe wantto compareeffectivenessof themethodof iterative CHT refinementswith thatof theMHP algorithm,we needa way to compareMHP andCHT sets.Thefollowing definitionsintroducethemathematicalmodelthatweuseto compareresultsobtainedby theMHP algorithmandthenon-concurrency analysison differentmodelsof theprogram.
Definition 9. Let v�w syncr�x y r�xzn�r]{| init rd{| fin } be the syncgraphfor someprogram,andlet v%w:r�x\r | initial r | final } be theRPEGconstructedfrom thesyncgraphusingAlgorithm 4. If vX is a subsetof w sync, wedefine wx vyvX } bywx vzvX }C� {|¬z |} x v v± } . (11)
If X is asubsetof w , we take x � q v X }C��� v|�� w sync÷ x v v| }/Ò X ³�©¦�� . (12)
For asinglenode,we abusethenotationby writing wx v v| } for wx v � v| �]}C� x v v| } and x � q v | } for x v � | �]} .Wewantto comparetheCHT labelingof nodesof asyncgraphwith theMHP labelingof nodesof thecorrespond-
ing RPEG.To do this,we definethefollowing mappingsbetweenlabelings.
48

Definition 10. Let v~ ~�w sync ����� sync be a labelingof syncnodeswith setsof syncnodes(suchasCHT sets). Wedefinea labelingof RPEGnodes, v~9� ~Qw ����� , by settingv~�� v | }C��� wx�� v~ v x � q v | }�}*� if x � q v | } ³�©¦ ,
¦ otherwise.(13)
Similarly, let~ ~Qw ����� bea labelingof nodesin � with setsof RPEGnodes(suchasthecomplementsof MHP
sets).We defineacorrespondinglabelingof syncnodesin v� ,~ � ~�w sync �¾��� sync, by setting~ � v v| }C� x � q `a {¯j�� ® |¯d° ~ v | }Fhj . (14)
In thenext few lemmas,we collectsomefactsaboutthesemappingsthatwill beusedlater.
Lemma 14. Let v± r v|²� w sync. Thenx v v| }3Ò x v v± } ³�©¦ if andonly if | � ± .
Proof. This is clearfrom theconstructionof x .Lemma 15. v v~�� } � � v~ .Proof. Fromthedefinitions,we have
v v~ � } � v v| }�� x � q�� {¯��� ® |¯�° v~ � v | }*���� v±K� w sync
÷ `a x v v± }�Ò {¯��� ® |¯d° v~ � v | }Fhj ³�©¦����� v±K� w sync
÷ `a x v v± }�Ò {¯��� ® |¯d° wx � v~ v x � q v | }�} �9hj ³�4¦Ì�But for |��Wx v v| } , Lemma14 tellsusthat x � q v | }C� v| , sowehave
v v~�� } � v v| }C��� v±K� w sync÷ x v v± }�Ò {|¿ |� ® |¯d° x v v¶ } ³�§¦Ì� .
UsingLemma14 again,we seethat x v v± }�Ò ¨ |¿ |� ® |¯d° x v v¶ } ³�§¦�� � v±A� v~ v v| } . It follows that v v~ � } � � v~ .In general,thecorrespondingresultfor function
~doesn’t hold. Thebestwecansayis thefollowing lemma.
Lemma 16. Suppose|�� LOCAL.Then v ~ � } � v | }�� LOCAL Ò ~ v | } .Proof. Suppose| q � LOCAL Ò ~ v | } , andlet v| q � x � q v | q } . Then x v v| q }�Ò ~ v | } ³�4¦ , so
| q � wx `a x � q `a {¬z�� ® �M� À ® ¯d°·° ~ v ± }ihj hj � v ~ � } � v | } .49

Note that if, say, x v v± }Í� � ± r ±�� � and ± � ~ v | } , but ±�� ø� ~ v | } , then ±�� � v ~ � } � v | } . We don’t needtoworry aboutthis case,however, to provethetheoremneededto translateMHP setsbackto syncgraphs.
Theorem17. If, for all |²� LOCAL, v~ � v | }ÌË ~ v | } , then v~ v v| }�Ë ~ � v v| } for all v|²� w sync.
Proof. The hypothesisandthe definition of the upper- � mapimply that, for all v|©� w sync, v v~�� } � v v| }ÍË ~ � v v| } . Butv v~�� } � � v~ .We now prove a theorememphasizingthe connectionbetweenCHT andMHP setsin the context of widening,
which is usedin subsequentproofs.We begin with someadditionallemmas.
Lemma 18. For all subsetsv� and vX of w sync, wehavewx � v� Ò vX � � wx v�v� }�Ò wx vzvX }Proof. First we provethat wxT� v� Ò vX �ÈË wx v�v� }�Ò wx vyvX } . Take some|È� wx�� v� Ò vX � . This meansthatthereis somev| belongingto both v� and vX with |���x v v| } . Hence,|�� wx v � }3Ò wx v X } .
Now weshow that wx�� v� Ò vX ��� wx v�v� }/Ò wx vzvX } . Take |²� wx v X }�Ò wx v � } . Then
½ v| q � v� ~ |²��x v v| q } and ½ v| � � vX ~ |��Wx v v| � }But accordingto Lemma14, v| q � v| � .Lemma 19. Let vÏ!� w sync. Define v~ |� ~Qw sync ����� sync, asv~ |� v v| }�� v~ v v| }�� `a b|n |� v~ v v� } hj (15)
Supposethat � |�� LOCAL ~ v~ � v | }ÌË ~ v | } (16)
and,for some| q � LOCAL,bn B�� ® |� ° ~ v � }�Ë ~ v | q } (17)
Then v~ u � v | q }�Ë ~ v | q } (18)
Proof. Fromthedefinitionof subscript-*operator(13), we havev~ u � v | q }C� wx � v~ u � x � q v | q } ���By transformingtheright-handside,weobtainv~ u � v | q }C� wx `a v~ � x � q v | q } � � `a b|n |� v~ v v� }ihj hjUsingthedefinitionof wx , we getv~ u � v | q }�� wx � v~ � x � q v | q } ��� � wx `a b|n |� v~ v v� } hj
50

Now, by usingthedefinitionof subscript-*operatoragain,wegetv~ u � v | q }�� v~�� v | q }�� wx `a b|n |� v~ v v� }ihj (19)
Substitutingtheexpressionin theright-handsideof (19) in (18), now we haveto provethatv~ � v | q }/� wx `a b|n |� v~ v v� }ihjAË ~ v | q } (20)
Sincefrom (16)we know v~�� v | q }�Ë ~ v | q } , (20)becomeswx `a�b|n |� v~ v v� }Fhj Ë ~ v | q } (21)
Accordingto Lemma18,we canreplace(21)withb|n |� wxT� v~ v v� }*��Ë ~ v | q } (22)
Since � ��x v�vÏ if andonly if x � q v � } � vÏ , we canreplace(22)withbn �� ®�v }� wx � v~ � x � q v � } � � Ë ~ v | q }
which by definitionof subscript-*operatoris justbn �� ®�v }� v~�� v � }�Ë ~ v | q } (23)
Sincewehave(16), thegiven(17) is sufficient to prove(23).
Now we canprove an importantconnectionbetweenCHT setsand MHP sets. For a node | � w , we write
MHP� v | } for MHP v | }N�²� | � . Note that thecomplementof MHP� v | } , written MHP� v | } , describesa setof nodesin theRPEGthatcannothappenin parallelwith | .Theorem20 (Widening). Let | q � LOCALandlet vÏ1�Öw sync. Supposethat
� |�� LOCAL ~ CHT� v | } Ë MHP� v | } (24)
andMHP� v | q }�Ë {n B�� ® |� ° MHP� v � } (25)
thenCHT
|� � v | q }ÌË MHP� v | q } (26)
Proof. Observe that(25) is equivalentto theconditionthat
MHP� v | q }�� bn B�� ® |� ° MHP� v � }
Thetheoremthenfollows immediatelyfrom Lemma19by taking v~ � CHTand~ � MHP�
51

1
p1
pk11 n0
ax
p
a
xkx
Figure32: A generalcaseof pinninganalysis
nk1
kx
C1
x. . .
. . .. . .. . .
. . . . . .
. . .
Cx
a ax
p
1
11 p1 p
Figure33: RPEGcorrespondingto thesyncgraphin Figure32
D.3 Subsumptionof Pinning Analysis
Theorem21 (BasicMHP algorithm subsumespinning analysis).
Given � |«� w sync ~ CHTv | }!Ë MHP� v | } , after an iteration of pinninganalysisis donefor a node | q � w sync it is
still true for theresultingCHTsetfor | q , CHTu v | q } , thatCHTu v | q }ÌË MHP� v | q } .Proof. To beableto useTheorem20 here,with Ï � Partnersv | } , we haveto provethat
MHP�<v | q }ÌË {� Partners® ¯���° MHP� v�� } (27)
We considerseveralcasesbasedon whetheror not | q is apartof anacceptbodyor asignalnode.First , assumethat | q is notasignalnodeandis neitheraccept-start,noraccept-endnode.Figure32 illustratesthe
generalpatternin asyncgraphusedby thepinninganalysis.Thesetof | q ’s partnersin this figureis
Partnersv | q }C��� � Yt ÷ � £ r�ÄzÅ £ Å � r �jÇ�r�Ä Å�Ç\Å#� �Figure33 containstheRPEGbuilt basedon thesyncgraphin Figure32 accordingto thealgorithm4.
52

. . .
C
p ij n
. . .
Figure34: Illustrationfor case1
t
C
p ij
. . . . . .
Figure35: Illustrationfor case2
After theMHP algorithmterminates,thefollowing equalityholdsfor all reachablelocalnodesin thePEG:
GENv | }/� {�� Preds® ¯d° MHP v%m }C� MHP v | } sTherefore,wecanwrite
MHP� v | q }C���{ �Îq MHP vRo � }/� Partnersv | q }���� | q ����¡ (28)¡ in (28) denotesnodesinto whoseM setsnode | q is propagated(andhencewhich nodesareaddedto X v | q } bysymmetry)duringtheMHP analysis.We show that ¡��§¦ undertheconditionsof this theorem.
Considera node� It for somefixed £ and Ç , Ä�Å £ Å � r�Ä�Å�Ç�Å � . Oneof the conditionsof this theorem,|pinning its partners,specifiesthat � Yt canrendezvousonly with | q andnodesfrom x v CHTv x � q v | q }�}�} . (And hence,
accordingto theconditionof this theorem,MHP� v | q } .)Case1: � It rendezvouswith |
Figure34 illustratesthis case.Node | is not propagatedfrom � It ’s X setinto X v6o } because| ³� X v | } , and| is oneof thepredecessorsof o .
Case2: �E It rendezvouswith ¢ � MHP� v | q }Clearly, in this case,asshown in figure35, since ¢ ³�1X v | q } , by symmetryof theMHP relation, | q ³�1X v£¢ } ,andsoby theCOM propagationrule, | q cannotpropagateinto X vRo } .
Thus,sincenoneof | q ’s partnerscanpropagate| from their X setsinto the X setsof theirsuccessors,¡��4¦ . Itis truefor theMHP setassociatedwith eachof | q ’s partners:
� £ r�Ä!Å £ Å � r �jÇ�r�Ä Å�Ç\ÅÖ� ~ MHP� vY� Yt }�� MHP vRo }���� | q ����� � It � (29)
Now, using(29), we canestimatetheunionof theMHP setsfor all | q ’s partners:{� Partners® ¯���° MHP� v�� }�� �{ �Îq MHP vRoÌ }3��� | q ��� Partnersv | q } (30)
53

1
m’1
n0
m
mr
Figure36: Illustrationfor case2
0
1
n
pkp
Figure37: Illustrationfor case3, syncgraph
The right-handside of (30) is exactly MHP¤¦¥D§�¨�© from (28). Thus, replacingthe right-handside in (30) byMHP¤ ¥£§�¨�© , we obtainthedesirable(27).
Second, assumethat §�¨ is a signalnode.In this case,pinninganalysiscannotbe appliedto §�¨ , sinceit doesnot pin all its partnersto the wave. Referto
Figure36. Let nodeªT« beoneof thepartnersof § ¨ . Evenif ªZ« canonly rendezvouswith § ¨ , it leavesthewaveafterthat,and § ¨ doesnot until ªW¬« leavesthewave.
Third , assume§ ¨ is anaccept-startnode.This caseworks similar to case1, sincethosepartnersthat can rendezvous with § ¨ can be blocked by § ¨ .
Figure38demonstratestheRPEGcorrespondingto thesyncgraphin Figure37.To beableto applytheTheoremaboutwidening20,wehave to prove
MHP¤¦¥D§ ¨ ©� ®¯�° Partners± ²�³'´ MHP¤µ¥·¶9©,¸ (31)
wherePartners¥D§ ¨ ©�¹»º�§ ¼W½!¾ ¿ÁÀ « ¥£§B©�¼ Partners¥£§ ¨ © .Theproof of (31)closelyimitatestheproof for thecase1.Fourth , assumethat § ¨ is an accept-endnode.Thiscaseis trivial. Sinceit is impossiblethat § ¨ in Figure 39
rendezvouswith any of its partners,the pinning analysisis applicableonly if all § ¨ ’s partnerscanrendezvousonlywith nodesfrom MHP ¥£§ ¨ © , andthiswasconsideredasapartof thefirst casein this proof.
D.4 Partial Subsumptionof Critical Sectionand RPC Analyses
Westartby introducingsometerminologyrelevantto critical sectionsin PEGs.Let CSbethesetof all critical sectionsin theprogram,wherethecritical sectionsaredefinedasdescribedin [15]. Similar to thisearlierdefinitionof acriticalsection,any critical section Âü CSconsistsof two parts, ÄL¹Åº�Æ « ¸<ÆkÇÈ , andwe call Æ « and ÆkÇ critical section
54

1 p’k
wp1
wpk
n0p’
Figure38: Illustrationfor case3, RPEG
0n
s
Figure39: Illustrationfor case4
branches, or just branchesfor short. Any branchconsistsof all nodeson that branch,justifying statementssuchas“node § ¼WÆ « ”.
Let BRdenotethesetof all branchesfor all critical sectionsin theprogram:BR ¹Lº�Æ�¾ É)ÄY¼ CS Ê�Ä!¹Ëº�Æ̸ÎÍÆ$È.È .For any node§ in thePEG,wedefinethesetCritSec¥£§B© as
CritSec¥£§B©�¹»º�Æ�¾ ÆI¼ BR Ï�§ ¼WÆ[ÈIn otherwords,for any rendezvousnode  , CritSec¥6ÂЩѹ CritSec¥Ò¶ « ©?Ó CritSec¥Ò¶sÇ�© , where º<¶ « ¸R¶sÇÈz¹ Preds¥RÂЩ .
We definefunctionaloperator Í in thefollowing way. For any critical sectionbranchÆ we define ÍÆ asa criticalsectionbranchsuchthat ÉrÄ�¼ CS Ê�ÄÔ¹Õº�ÆÖ¸ÎÍÆÖÈ . By constructionof critical sections,the following two propertieshold for the Í operator.
1. for any critical sectionbranchÆ , thereexistsa unique ÍÆ .
2. for any critical sectionbranchÆ , ÍÍÆL¹ÔÆWe call ÍÆ a partner of Æ . Also, we overloadthis termby calling ª a critical sectionpartnerof § whenever É�Æ×¼BR Ê�ªØ¼WÆÔÏ̧ ¼ÙÍÆ .
55

. . . . . .. . . . . .
C
1 2p p
m n
Figure40: Case1 of Lemma22
Thedefinitionof whenaLOCALnodebelongsto acritical sectionbranchis thesameasin [15]. For RENDnodeswe define, Ú ÂL¼ REND'ÂL¼ZÆ if ¥·¶ « ¼ZÆS©?Û�¥Ò¶sÇмWÆ�©
Finally, we introducefunction tasksfrom critical sectionbranchesto setsof tasksin theprogramin thefollowingway: Ú Æ˼ BR tasks¥DÆS©Ñ¹ ®² °�Ü�Ý ² ° LOCAL
task¥£§B©Thefollowing lemmaprovesthatthebasicMHP algorithmsubsumesthepartof thecritical sectionrefinementthat
capturesthefactthatnodesin thesamebranchof a critical sectioncanneverhappenin parallel.
Lemma 22. In thebasicMHP algorithm,
1. Twonodesfromthesamecritical sectionbranch areneverput in the Þ setsof each other:Ú § ¼Z½ÅÊ Ú Æß¼ CritSec¥D§B©,¸*ªà¼�ÆLáêãâ¼TÞI¥£§B©�Ï�§1â¼ZÞI¥£ªZ© (32)
2. It is impossiblethat a node § fromcritical sectionbranch Æ that representscall bodiesof a critical sectionisplacedin the Þ setof a nodeª froma taskcontainingnodesin ÍÆ , but ªãâ¼ ÍÆ :Ú §�¼Z½×Ê Ú Æß¼ CritSec¥£§B©,¸<ªÅ¼�äå¼ tasks¥æÍÆ�©?Ï�ªãâ¼ÙÍÆLáתãâ¼TÞI¥D§B©�Ï̧!â¼ZÞI¥£ªZ© (33)
Proof. We prove both resultssimultaneouslyby inductionon thenumberof iterationsof themain loop in theMHPalgorithm.
On the first iterationof the main loop, the node § beingconsideredis successorof § initial . By the definition ofcritical sections,CritSec¥£§B©Ñ¹Ôç , andsoequations(32)and(33) trivially hold.
Supposethatequations(32) and(33) hold after è iterationsof the main loop. Considerè$étê ’st iterationof themainloop. Considerpossibleplacementsof § and ª in thegraph:
1. É)Â#¼ REND Ê�§ë¸<ªØ¼ Succs¥6ÂЩReferto Figure40. Supposefirst that §ë¸<ªì¼:Æ . In this case¶ « ¸D¶EÇ$¼:Æ . Then,by the inductionhypothesis,¶9«Jâ¼ZÞI¥·¶ Ç © andconsequently, í Reach ¥RÂЩ . So,theGEN rulecannotbeusedto produce§/¼WÞI¥DªW© .Supposenow that §/¼�ÆîÏ̪ãâ¼ÙÍÆYÏ֪ż�ät¼ tasks¥ïÍÆ$© . In this case cannotstartor endthis critical section.Then ¶ « ¼/Æ�ÏS¶sÇ�â¼ãÍÆtÏ[¶sÇS¼ äß¼ tasks¥ïÍÆ$© . By the inductionhypothesiswe againobtain ¶ « â¼�ÞI¥·¶EÇ�© andconsequently, í Reach ¥RÂЩ . So,theGENrule cannotbeusedto produce§/¼WÞI¥DªW© .
56

m
s2
p
C
. . .
n
p2 1
Figure41: Case2 of Lemma22
ms1
n
2
C
. . .
p p1
Figure42: Secondpartof Case2 of Lemma22
2. íëÉ)Â#¼ REND Ê�§ë¸<ªÙ¼ Succs¥6ÂЩAgain, first we considerthecasewhere §ë¸<ªð¼GÆ . Let  beany of Preds¥D§B© . Referto Figure41. If  doesnot start Æ , then ¶�«T¼tÆ andby the inductionhypothesisªñâ¼�ÞI¥·¶�«,©[áòªòâ¼�ÞI¥RÂЩ . Supposenow that startsthis critical section. Then, if Æ consistsof call bodies,since ¶ Ç â¼óÍÆ , by the inductionhypothesis,ªôâ¼1ÞI¥·¶ Ç ©káõªöâ¼1ÞI¥RÂЩ . If Æ consistsof critical sectionbodies,thentask¥£§B©z¹ task¥£ªZ© andso triviallyªãâ¼WÞI¥D§B© . In any case,ª cannotpropagateinto ÞI¥£§B© through  .
Now suppose§î¼1Æ»ÏTªöâ¼÷ÍÆ�ÏTªõ¼1äø¼ tasks¥æÍÆ$© . Again, let  beoneof Preds¥D§B© . Referto Figure41.Suppose doesnot startthis critical section.Then ¶ « ¼ Æ , andby the inductionhypothesisªöâ¼1ÞI¥·¶ « ©záªùâ¼åÞI¥6ÂЩ . If  startsthis critical section,then it is the casethat task¥DªW©$¹ task¥·¶ Ç © (since ÍÆ representscritical sectionbodies),andso ªãâ¼TÞI¥Ò¶ Ç ©�áêãâ¼WÞI¥6ÂЩ . As aresult, ª cannotpropagateinto ÞI¥£§B© through . Now wehaveto show that § doesnotpropagateinto ÞI¥£ªZ© . Let  beany of Preds¥DªW© . Referto Figure42.Suppose doesnot endthis critical section.Thenby theinductionhypothesis§Ôâ¼ ÞI¥·¶ Ç ©µá÷§åâ¼:ÞI¥6ÂЩ . If doesendthis critical section,then ¶�«�¼�Æ , andby the inductionhypothesis§tâ¼ ÞI¥·¶�«4©yáõ§åâ¼ ÞI¥6ÂЩ . Ineithercase,§ doesnot propagateinto ÞI¥£ªZ© through  .
Corollary 23. For any critical sectionbranch Æ such that ¾ tasks¥æÍÆS©�¾B¹úê it is impossiblethat any node §t¼GÆ is
57

placedin the Þ setof a nodeª froma taskcontainingnodesin ÍÆ , but ªûâ¼úÍÆ :Ú § ¼�½×Ê Ú Æ˼ CritSec¥£§B©4¸*ªØ¼�ät¼ tasks¥ ÍÆ�©BÏ̪ûâ¼ ÍÆLáãªÃâ¼ZÞI¥D§B©�Ï�§1â¼ZÞI¥£ªZ©Proof. This resultfollows from (33), sincein thatequation ÍÆ representscritical sectionbodies,andby definitionallcritical sectionbodiesfor a givencritical sectionarelocatedin onetask. This is theonly propertyof critical sectionbodiesusedin theproof of (33).
58