a diagonal-interconnect architecture and its application to risc core design mutsunori igarashi,...
Post on 20-Dec-2015
214 views
TRANSCRIPT

A Diagonal-Interconnect Architecture and Its Application to
RISC Core DesignMutsunori Igarashi, Takashi Mitsuhashi, Andy Le, Shardul Kazi,
Yang-Trung Lin, Aki Fujimura, Steve TeigISSCC 2002
Additional material from http://www.xinitiative.org/

100
100
141.
4214 141< 100+ 100
~30% less wirelength


benefits
• Circuit efficiency– Wirelength reduction = 20%– Via-count reduction= 30%– Core-area reduction = 10%
• Wirelength reduction makes the routing problem easier to solve, resulting in faster timing closure, improved reliability and a reduction in signal integrity problems.

RISC CORE DESIGN
• Critical path delay improvement of 0.99ns
• 19.8% faster operating frequencies
Register-to-register path delays
Technology = 0.18ummetal layers = 6750Kgates + SRAMTarget Frequency = 200 MHz
W:13%
V:28%
W:21%
V:39%
W:25%
V:37%
W:22%
V:32%

X routing in commercial products
• June 2004 – Toshiba Corp. X architecture diagonal routing for metal layers 4 and 5.
• TC90400XBG : 130-nanometer, 2.7-million-gate design for the digital video broadcast and home entertainment markets.
• "The X design was timing out at 11 percent faster — about 180 MHz — than the conventional design, and the logic area was 10 percent smaller.”
– Takashi Yoshimori. Toshiba technology executive for SoC design Yield = 80% (for first wafer)Yield = 80% (for first wafer)

hurdles
• Yield questions
• Mask generation and cost
• Design and verification tools

Simple Routing Example
D
R
R
Ito et al “Diagonal routing in high performance microprocessor design,” ASP-DAC 24-27 Jan. 2006

Interested in X-routing algorithms?
• Das et al “Manhattan-diagonal routing in channels and switchboxes,” ACM Trans. Des. Autom. Electron. Syst. 9, 1 (Jan. 2004), 75-104
• Ito et al “Diagonal routing in high performance microprocessor design,” ASP-DAC 24-27 Jan. 2006

Track Assignment: A Desirable Intermediate Step Between Global Routing and
Detailed RoutingShabbir Batterywala, Narendra Shenoy,
William Nicholls and Hai Zhou
Presenter: Yiwen Shi

Background & Motivation• Given the entire subregions by the global router, searching in
detailed routing stage and rip-up & re-route stage are very time consuming
• Simple two stages of global routing & detailed routing cannot appropriately address problems arising from signal delay, cross-talk and process constraints
Integrate an intermediate stage of track assignment between global and detailed routing!
Benefit:• Fully utilizes the information generated by the global router• The efficient usage of routing resources since most of the routes are
laid in straight lines• Track assignment introduces a stage where nets are routed in
parallel• The neighborhood information for large nets can be easily
calculated optimize DFM issues

Track Assignment Assign long global routes (routes running over at least one whole
global cell), iroutes, to underlying routing resources The routing resources are present in gridlines (tracks) and vias

Cost Metrics• Plane: put longer iroutes on higher layers• Track obstruction: capture assignability of an iroute to a track• Via obstruction: prevent iroutes from being assigned to tracks that
will be hard to connect• Planar anchoring: minimize jogs & wire length – assign iroute as
close as possible to other net components and assignd iroutes of its underlying net
• Via anchoring: minimize vias – similar to planar anchoring, in z-direction
• Other consideration: DFM issues & interplay across these cost components (weights)

Weighted Bipartite Matching & Look-Ahead Heuristic
Select a set of mutually conflicting iroutes (largest clique) and use a minimum weighted bipartite matching (shortest augmenting path) to assign them to different tracks
Look-Ahead:
If any iroute becomes uniquely assignable to a track, we accept this assignment immediately
Without Look-Ahead
With Look-Ahead
Iroute overlap &Bipartite assignment& Combination
NP complete problem

Top leveltrack assignment algorithm

Experimental Results & Conclusions
The suggested track assignment stage reduces the run-time of overall routing process
Future work: • Incorporate other costs which address crosstalk, timing, congestion,
antennae effect and other DFM problems• Calculate gridlines efficiently in an environment where wirewidths
could differ on the same layer

BoxRouter: A New Global Router Based on Box Expansion and
Progressive ILP
Minsik Cho and David Z. PanECE Dept. Univ. of Texas at Austin
DAC 2006, July 24-28

Introduction
• Global Routing – plans approximate route of each net to reduce complexity of detailed router
• Goal: Optimize wire density during global routing– Improve manufacturability– Potential to feedback interconnect information

Steps
• PreRouting captures congested areas• BoxRouting starts in most congested area
and expands box to cover entire chip• Progressive integer linear programming
(ILP) technique to route wires in box• Maze routing algorithm for rest of wires• PostRouting reroutes wires without rip-up
– Parameter controls trade-off between length and routability
BoxRouter
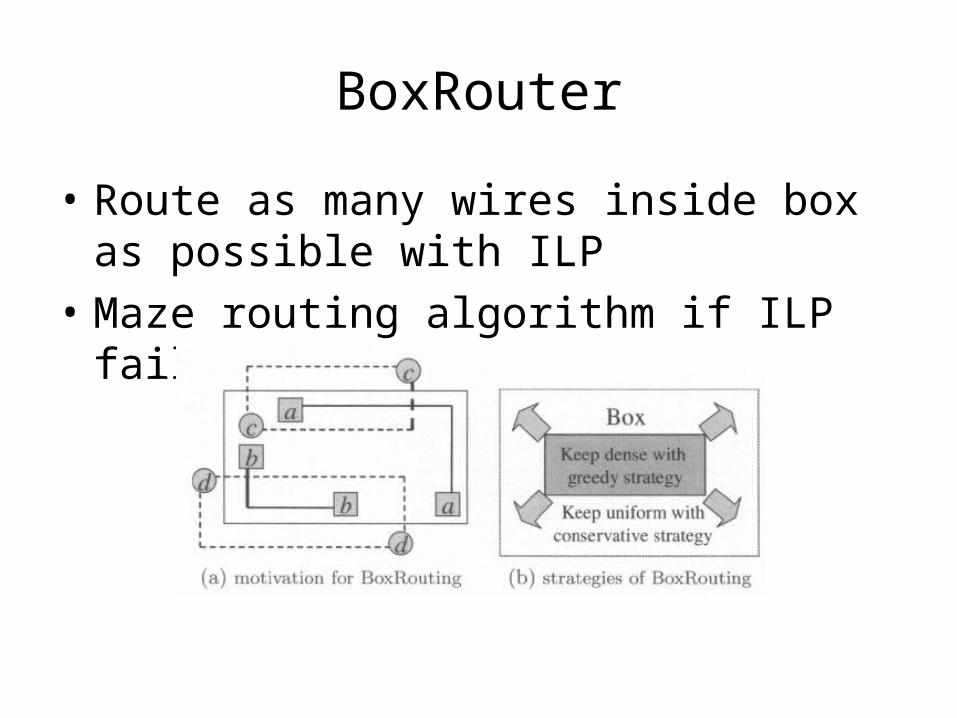
• Route as many wires inside box as possible with ILP
• Maze routing algorithm if ILP fails

Algorithm

Steps
1) PreRouting – Identify congested area
2) Box around congested area
3) ILP routing between G-cells
4) Maze routing 5) Expand box 6) Repeat

PostRouting
• Start from congested area
• Reroute wires to reduce length (if possible)
• Reroute surrounding wires
• Repeat
• Parameter controls cost function– Wirelength vs. routability

Experimental Results
• Larger box expansion can improve results at a cost of runtime
• Compared to Labyrinth– Reduce wirelength by 14.3%– Reduce overflow by 91.7%
• Compared to Fengshui– Reduce overflow by 79%
• Compared to multicommodity flow-based router– 15.7x faster– 4.2% shorter wirelength