analisis big data final
DESCRIPTION
Descripcion de componentes Big DataTRANSCRIPT

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 1/19
ANÁLISIS CON BIG DATA | HDC BPO Services
0
2-1-2016 Análisis con BigDataHDC BPO Services
UNIVERSIDAD NACIONAL TECNOLOGICA DE LIMA SUR
Integrantes:
De la Cruz Reyes Steven
Sanchez Calancha Katherine
Zamudio Martinez Luis Orlando
Docente:
Reátegui Morales Juan Carlos
Curso:
Auditoria y Seguridad de la Información

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 2/19
ANÁLISIS CON BIG DATA | HDC BPO Services
1
CONTENIDOINTRODUCCIÓN ........................................................................................................................................ 2
ANÁLISIS .................................................................................................................................................... 3
1.1. ¿QUE ES BIG DATA? ................................................................................................................ 3
1.2. RESEÑA HISTÓRICA ................................................................................................................. 3
1.3. TIPOS DE DATOS ..................................................................................................................... 4
1.4. LAS CINCO V ............................................................................................................................ 5
1.5. TIPO S DE INFO RMACIÓN ....................................................................................................... 6
1.6. COMPONENTES DE UNA PLATAFORMA BIG DATA ............................................................. 6
1.7. BIG DATA Y EL C AMPO DE INVESTIGACIÓN....................................................................... 10
1.8. ARQUITECTURA BIG DATA ................................................................................................... 11
ANÁLISIS APLICATIVO ............................................................................................................................ 13
2.1. EMPRESA ................................................................................................................................ 13
2.2. HERR AMIENTA MICROSTRATEGY ....................................................................................... 13
2.3. ANALISIS DE BIG DATA CON LA HERRAMIENTA MICROSTRATEGY ................................. 14
CONCLUSIONES ...................................................................................................................................... 18
Ilustración 1- Tipos de datos de Big Data ...................................................................................... 4
Ilustración 2- Ejemplo de HDFS ..................................................................................................... 7
Ilustración 3- Ejemplo de MapReduce .......................................................................................... 7
Ilustración 4- Flujo de trabajo en Oozie ........................................................................................ 9
Ilustración 5- Arquitectura Big Data por capas ........................................................................... 12

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 3/19
ANÁLISIS CON BIG DATA | HDC BPO Services
2
INTRODUCCIÓNEl primer cuestionamiento que posiblemente llegue a su mente en este momento es ¿Quées Big Data y porqué se ha vuelto tan importante? pues bien, en términos generalespodríamos referirnos como a la tendencia en el avance de la tecnología que ha abierto laspuertas hacia un nuevo enfoque de entendimiento y toma de decisiones, la cual esutilizada para describir enormes cantidades de datos (estructurados, no estructurados ysemi-estructurados) que tomaría demasiado tiempo y sería muy costoso cargarlos a un
base de datos relacional para su análisis. De tal manera que, el concepto de Big Data aplicapara toda aquella información que no puede ser procesada o analizada utilizandoprocesos o herramientas tradicionales.
Además del gran volumen de información, esta existe en una gran variedad de datos quepueden ser representados de diversas maneras en todo el mundo, por ejemplo dedispositivos móviles, audio, video, sistemas GPS, incontables sensores digitales enequipos industriales, automóviles, medidores eléctricos, veletas, anemómetros, etc., loscuales pueden medir y comunicar el posicionamiento, movimiento, vibración,temperatura, humedad y hasta los cambios químicos que sufre el aire, de tal forma quelas aplicaciones que analizan estos datos requieren que la velocidad de respuesta sea lo
demasiado rápida para lograr obtener la información correcta en el momento preciso.Estas son las características principales de una oportunidad para Big Data.
Es importante entender que las bases de datos convencionales son una parte importantey relevante para una solución analítica. De hecho, se vuelve mucho más vital cuando seusa en conjunto con la plataforma de Big Data. Pensemos en nuestras manos izquierda yderecha, cada una ofrece fortalezas individuales para cada tarea en específico. Porejemplo, un beisbolista sabe que una de sus manos es mejor para lanzar la pelota y la otrapara atraparla; puede ser que cada mano intente hacer la actividad de la otra, mas sinembargo, el resultado no será el más óptimo.

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 4/19
ANÁLISIS CON BIG DATA | HDC BPO Services
3
ANÁLISIS
1.1. ¿QUE ES BIG DATA?
Debido al gran avance que existe día con día en las tecnologías de información, lasorganizaciones se han tenido que enfrentar a nuevos desafíos que les permitan analizar,descubrir y entender más allá de lo que sus herramientas tradicionales reportan sobre suinformación, al mismo tiempo que durante los últimos años el gran crecimiento de lasaplicaciones disponibles en internet (geo-referenciamiento, redes sociales, etc.) han sidoparte importante en las decisiones de negocio de las empresas.
1.2. RESEÑA HISTÓRICA
Los seres humanos estamos creando y almacenando información constantemente y cadavez más en cantidades astronómicas. Se podría decir que si todos los bits y bytes de datos
del último año fueran guardados en CD's, se generaría una gran torre desde la Tierra hastala Luna y de regreso.
Esta contribución a la acumulación masiva de datos la podemos encontrar en diversas
industrias, las compañías mantienen grandes cantidades de datos transaccionales,
reuniendo información acerca de sus clientes, proveedores, operaciones, etc., de la
misma manera sucede con el sector público. En muchos países se administran enormes
bases de datos que contienen datos de censo de población, registros médicos, impuestos,
etc., y si a todo esto le añadimos transacciones financieras realizadas en línea o por
dispositivos móviles, análisis de redes sociales (en Twitter son cerca de 12 Terabytes de
tweets creados diariamente y Facebook almacena alrededor de 100 Petabytes de fotos y
videos), ubicación geográfica mediante coordenadas GPS, en otras palabras, todas
aquellas actividades que la mayoría de nosotros realizamos varias veces al día con
nuestros "Smartphone", estamos hablando de que se generan alrededor de 2.5
quintillones de bytes diariamente en el mundo.
1 quintillón = 10^30 = 1,000,000,000,000,000,000,000,000,000,000
De acuerdo con un estudio realizado por Cisco, entre el 2011 y el 2016 la cantidad detráfico de datos móviles crecerá a una tasa anual de 78%, así como el número dedispositivos móviles conectados a Internet excederá el número de habitantes en elplaneta. Las naciones unidas proyectan que la población mundial alcanzará los 7.5 billones
para el 2016 de tal modo que habrá cerca de 18.9 billones de dispositivos conectados a lared a escala mundial, esto conllevaría a que el tráfico global de datos móviles alcance 10.8Exabytes mensuales o 130 Exabytes anuales. Este volumen de tráfico previsto para 2016equivale a 33 billones de DVDs anuales o 813 cuatrillones de mensajes de texto.
Pero no solamente somos los seres humanos quienes contribuimos a este crecimientoenorme de información, existe también la comunicación denominada máquina a máquina(M2M machine-to-machine) cuyo valor en la creación de grandes cantidades de datostambién es muy importante. Sensores digitales instalados en contenedores paradeterminar la ruta generada durante una entrega de algún paquete y que estainformación sea enviada a las compañías de transportación, sensores en medidores
eléctricos para determinar el consumo de energía a intervalos regulares para que seaenviada esta información a las compañías del sector energético.

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 5/19

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 6/19
ANÁLISIS CON BIG DATA | HDC BPO Services
5
1.4. LAS CINCO V
Es común que cuando se hable de Big Data se haga referencia a grandes cantidades dedatos. Pero es más que eso. Para describir mejor lo que representa, frecuentemente sehabla de las cinco V -IBM fue la que empezó definiendo tres V y luego se han añadido
las otras dos dependiendo de la fuente que definen perfectamente los objetivos queeste tipo de sistemas buscan conseguir:
Volumen: un sistema Big Data es capaz de almacenar una gran cantidad de datosmediante infraestructuras escalables y distribuidas. En los sistemas dealmacenamiento actuales empiezan a aparecer problemas de rendimiento al tenercantidades de datos del orden de magnitud de petabytes o superiores. Big Data estápensado para trabajar con estos volúmenes de datos.
Velocidad: una de las características más importantes es el tiempo de procesado yrespuesta sobre estos grandes volúmenes de datos, obteniendo resultados en
tiempo real y procesándolos en tiempos muy reducidos. Y no sólo se trata deprocesar sino también de recibir, hoy en día las fuentes de datos pueden llegar agenerar mucha información cada segundo, obligando al sistema receptor a tener lacapacidad para almacenar dicha información de manera muy veloz.
Variedad: las nuevas fuentes de datos proporcionan nuevos y distintos tipos yformatos de información a los ya conocidos hasta ahora -como datos noestructurados-, que un sistema Big Data es capaz de almacenar y procesar sin tenerque realizar un pre-proceso para estructurar o indexar la información.
Variabilidad: las tecnologías que componen una arquitectura Big Data deben serflexibles a la hora de adaptarse a nuevos cambios en el formato de los datos -tantoen la obtención como en el almacenamiento- y su procesado. Se podría decir que laevolución es una constante en la tecnología de manera que los nuevos sistemasdeben estar preparados para admitirlos.
Valor: el objetivo final es generar valor de toda la información almacenada a travésde distintos procesos de manera eficiente y con el coste más bajo posible.
De esta manera, un sistema Big Data debe extraer valor -en forma de nuevainformación, por ejemplo- sobre grandes volúmenes de datos, de la manera más rápiday eficiente posible, adaptándose a todos los formatos -estructurados o no- existentes yfuturos.

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 7/19
ANÁLISIS CON BIG DATA | HDC BPO Services
6
1.5. TIPOS DE INFORMACIÓN
Se puede hablar de una clasificación de los tipos de datos según sea su naturaleza uorigen que también ayuda a entender mejor el porqué de la evolución de los sistemas
de explotación de la información hacia Big Data:
Datos estructurados: es información ya procesada, filtrada y con un formatoestructurado. Es el tipo de datos que más se usan hoy en día.
Datos semi-estructurados: es información procesada y con un formato definidopero no estructurado. De esta manera se puede tener la información definidapero con una estructura variable.
Dos ejemplos son las bases de datos basadas en columnas y los ficheros coninformación en un lenguaje de etiquetas (HTML o XML).
Datos no estructurados: es información sin procesar y que puede tener cualquierestructura.
Se puede encontrar cualquier formato: texto, imagen, vídeo, código, etc. Losdirectorios de logs de aplicaciones o la información colgada en las redes socialesson buenos ejemplos de datos no estructurados.
La manera de trabajar hoy en día implica almacenar solamente datos de tipoestructurado o semi- estructurado, obligando a pasar por un proceso de filtrado ytransformación los datos no estructurados.
Este proceso radica en un coste y en una pérdida inevitable de datos que cada vez esmás difícil ignorar, ya que va totalmente en contra de las cinco V comentadasanteriormente y que un sistema de explotación de la información busca obtener -especialmente de la variedad, variabilidad y velocidad de recolección de información.
1.6. COMPONENTES DE UNA PLATAFORMA BIG DATA
Las organizaciones han atacado esta problemáticadesde diferentes ángulos. Todas esas montañas deinformación han generado un costo potencial al nodescubrir el gran valor asociado.
Desde luego, el ángulo correcto que actualmente tiene el liderazgo en términos depopularidad para analizar enormes cantidades de información es la plataforma de códigoabierto Hadoop.
Hadoop está inspirado en el proyecto de Google File System (GFS) y en el paradigma deprogramación MapReduce, el cual consiste en dividir en dos tareas (mapper – reducer)para manipular los datos distribuidos a nodos de un clúster logrando un alto paralelismoen el procesamiento, Hadoop está compuesto de tres piezas:

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 8/19
ANÁLISIS CON BIG DATA | HDC BPO Services
7
A. Hadoop Distributed File System (HDFS)
Los datos en el clúster de Hadoop son divididos en pequeñas piezas llamadas bloquesy distribuidas a través del clúster; de esta manera, las funciones map y reduce puedenser ejecutadas en pequeños subconjuntos y esto provee de la escalabilidad necesaria
para el procesamiento de grandes volúmenes.
La siguiente figura ejemplifica como los bloques de datos son escritos hacia HDFS.Observe que cada bloque es almacenado tres veces y al menos un bloque se almacenaen un diferente rack para lograr redundancia.
B.
Hadoop MapReduce
MapReduce es el núcleo de Hadoop. El término MapReduce en realidad se refiere ados procesos separados que Hadoop ejecuta. El primer proceso map, el cual toma unconjunto de datos y lo bueno convierte en otro conjunto, donde los elementosindividuales son separados en tuplas (pares de llave/valor).
El proceso reduce obtiene la salida de map como datos de entrada y combina las tuplasen un conjunto más pequeño de las mismas. Una fase intermedia es la denominadaShuffle la cual obtiene las tuplas del proceso map y determina que nodo procesará
estos datos dirigiendo la salida a una tarea reduce en específico.
La siguiente figura ejemplifica un flujo de datos en un proceso sencillo de MapReduce.
Ilustración 2- Ejemplo de HDFS
Ilustración 3- Ejemplo de MapReduce

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 9/19
ANÁLISIS CON BIG DATA | HDC BPO Services
8
C. Hadoop Common
Hadoop Common Components son un conjunto de librerías que soportan variossubproyectos de Hadoop, proyectos relacionados:
-
Avro
Es un proyecto de Apache que provee servicios de serialización. Cuando se guardandatos en un archivo, el esquema que define ese archivo es guardado dentro delmismo; de este modo es más sencillo para cualquier aplicación leerloposteriormente puesto que el esquema está definido dentro del archivo.
-
Cassandra
Cassandra es una base de datos no relacional distribuida y basada en un modelo dealmacenamiento de <clave-valor>, desarrollada en Java. Permite grandesvolúmenes de datos en forma distribuida. Twitter es una de las empresas que utiliza
Cassandra dentro de su plataforma.
-
Chukwa
Diseñado para la colección y análisis a gran escala de "logs". Incluye un toolkit paradesplegar los resultados del análisis y monitoreo.
-
Flume
Es la tarea principal es dirigir los datos de una fuente hacia alguna otra localidad,en este caso hacia el ambiente de Hadoop. Existen tres entidades principales:sources, decorators y sinks.
Un source es básicamente cualquier fuente de datos, sink es el destino de unaoperación en específico y un decorator es una operación dentro del flujo de datosque transforma esa información de alguna manera, como por ejemplo comprimir odescomprimir los datos o alguna otra operación en particular sobre los mismos.
- HBase
Es una base de datos columnar (column-oriented database) que se ejecuta en HDFS.HBase no soporta SQL, de hecho, HBase no es una base de datos relacional. Cadatabla contiene filas y columnas como una base de datos relacional.
HBase permite que muchos atributos sean agrupados llamándolos familias decolumnas, de tal manera que los elementos de una familia de columnas sonalmacenados en un solo conjunto. Facebook utiliza HBase en su plataforma desdeNoviembre del 2010.
-
Hive
Es una infraestructura de data warehouse que facilita administrar grandesconjuntos de datos que se encuentran almacenados en un ambiente distribuido.Hive tiene definido un lenguaje similar a SQL llamado Hive Query Language(HQL),estas sentencias HQL son separadas por un servicio de Hive y son enviadas aprocesos MapReduce ejecutados en el cluster de Hadoop.

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 10/19
ANÁLISIS CON BIG DATA | HDC BPO Services
9
Fue donado por IBM a la comunidad de software libre. Query Language forJavascript Object Notation (JSON) es un lenguaje funcional y declarativo quepermite la explotación de datos en formato JSON diseñado para procesar grandesvolúmenes de información. Para explotar el paralelismo, Jaql reescribe los queries
de alto nivel (cuando es necesario) en queries de "bajo nivel" para distribuirloscomo procesos MapReduce.
Internamente el motor de Jaql transforma el query en procesos map y reduce parareducir el tiempo de desarrollo asociado en analizar los datos en Hadoop. Jaqlposee de una infraestructura flexible para administrar y analizar datossemiestructurados como XML, archivos CSV, archivos planos, datos relacionales,etc.
- Lucene
Es un proyecto de Apache bastante popular para realizar búsquedas sobre textos.Lucene provee de librerías para indexación y búsqueda de texto.
Ha sido principalmente utilizado en la implementación de motores de búsqueda(aunque hay que considerar que no tiene funciones de "crawling" ni análisis dedocumentos HTML ya incorporadas).
El concepto a nivel de arquitectura de Lucene es simple, básicamente losdocumentos son dividos en campos de texto (fields) y se genera un índice sobreestos campos de texto. La indexación es el componente clave de Lucene, lo que lepermite realizar búsquedas rápidamente independientemente del formato delarchivo, ya sean PDFs, documentos HTML, etc.
- Oozie
Oozie es un proyecto de código abierto que simplifica los flujos de trabajo y lacoordinación entre cada uno de los procesos. Permite que el usuario pueda definiracciones y las dependencias entre dichas acciones.
Un flujo de trabajo en Oozie es definido mediante un grafo acíclicollamado Directed Acyclical Graph (DAG), y es acíclico puesto que no permite ciclosen el grafo; es decir, solo hay un punto de entrada y de salida y todas las tareas ydependencias parten del punto inicial al punto final sin puntos de retorno.
Un ejemplo de un flujo de trabajo en Oozie se representa de la siguiente manera:
Ilustración 4- Flujo de trabajo en Oozie

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 11/19
ANÁLISIS CON BIG DATA | HDC BPO Services
10
Pig
Inicialmente desarrollado por Yahoo para permitir a los usuarios de Hadoopenfocarse más en analizar todos los conjuntos de datos y dedicar menostiempo en construir los programas MapReduce. Tal como su nombre lo indica
al igual que cualquier cerdo que come cualquier cosa, el lenguaje PigLatin fuediseñado para manejar cualquier tipo de dato y Pig es el ambiente de ejecucióndonde estos programas son ejecutados, de manera muy similar a la relaciónentre la máquina virtual de Java (JVM) y una aplicación Java.
ZooKeeper
ZooKeeper es otro proyecto de código abierto de Apache que provee de unainfraestructura centralizada y de servicios que pueden ser utilizados poraplicaciones para asegurarse de que los procesos a través de un cluster seanserializados o sincronizados.
Internamente en ZooKeeper una aplicación puede crear un archivo que sepersiste en memoria en los servidores ZooKeeper llamado znode. Este archivoznode puede ser actualizado por cualquier nodo en el cluster, y cualquier nodopuede registrar que sea informado de los cambios ocurridos en ese znode; esdecir, un servidor puede ser configurado para "vigilar" un znode en particular.
De este modo, las aplicaciones pueden sincronizar sus procesos a través de uncluster distribuido actualizando su estatus en cada znode, el cual informará alresto del cluster sobre el estatus correspondiente de algún nodo en específico.
Una plataforma de Big Data consiste de todo un ecosistema de proyectos queen conjunto permiten simplificar, administrar, coordinar y analizar grandesvolúmenes de información.
1.7. BIG DATA Y EL CAMPO DE INVESTIGACIÓN
Los científicos e investigadores han analizado datos desde ya hace mucho tiempo, lo queahora representa el gran reto es la escala en la que estos son generados.
Esta explosión de "grandes datos" está transformando la manera en que se conduce unainvestigación adquiriendo habilidades en el uso de Big Data para resolver problemas
complejos relacionados con el descubrimiento científico, investigación ambiental ybiomédica, educación, salud, seguridad nacional, entre otros.
De entre los proyectos que se pueden mencionar donde se ha llevado a cabo el uso deuna solución de Big Data se encuentran:
El Language, Interaction and Computation Laboratory (CLIC) en conjunto con laUniversidad de Trento en Italia, son un grupo de investigadores cuyo interés es elestudio de la comunicación verbal y no verbal tanto con métodos computacionalescomo cognitivos.
Lineberger Comprehensive Cancer Center - Bioinformatics Group utiliza Hadoop y HBasepara analizar datos producidos por los investigadores de The Cancer GenomeAtlas(TCGA) para soportar las investigaciones relacionadas con el cáncer.

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 12/19
ANÁLISIS CON BIG DATA | HDC BPO Services
11
El PSG College of Technology, India, analiza múltiples secuencias de proteínas paradeterminar los enlaces evolutivos y predecir estructuras moleculares. La naturaleza delalgoritmo y el paralelismo computacional de Hadoop mejora la velocidad y exactitud deestas secuencias.
El Instituto de Tecnología de la Universidad de Ontario (UOIT) junto con el Hospital deToronto utilizan una plataforma de big data para análisis en tiempo real de IBM (IBMInfoSphere Streams), la cual permite monitorear bebés prematuros en las salas deneonatología para determinar cualquier cambio en la presión arterial, temperatura,alteraciones en los registros del electrocardiograma y electroencefalograma, etc., y asídetectar hasta 24 horas antes aquellas condiciones que puedan ser una amenaza en lavida de los recién nacidos.
Los laboratorios Pacific Northwest National Labs PNNL) utilizan de igual manera IBMInfoSphere Streams para analizar eventos de medidores de su red eléctrica y en tiemporeal verificar aquellas excepciones o fallas en los componentes de la red, logrando
comunicar casi de manera inmediata a los consumidores sobre el problema paraayudarlos en administrar su consumo de energía eléctrica.
La esclerosis múltiple es una enfermedad del sistema nervioso que afecta al cerebro y lamédula espinal. La comunidad de investigación biomédica y la Universidad del Estadode Nueva York (SUNY) están aplicando análisis con big data para contribuir en laprogresión de la investigación, diagnóstico, tratamiento, y quizás hasta la posible curade la esclerosis múltiple.
Con la capacidad de generar toda esta información valiosa de diferentes sistemas, lasempresas y los gobiernos están lidiando con el problema de analizar los datos para dospropósitos importantes: ser capaces de detectar y responder a los acontecimientosactuales de una manera oportuna, y para poder utilizar las predicciones del aprendizajehistórico.
Esta situación requiere del análisis tanto de datos en movimiento (datos actuales) comode datos en reposo (datos históricos), que son representados a diferentes y enormesvolúmenes, variedades y velocidades.
1.8. ARQUITECTURA BIG DATA
La arquitectura Big Data está compuesta generalmente por cinco capas: recolección
de datos, almacenamiento, procesamiento de datos, visualización y administración.
Esta arquitectura no es nueva, sino que ya es algo generalizado en las soluciones deBusiness Intelligence que existen hoy en día. Sin embargo, debido a las nuevasnecesidades cada uno de estos pasos ha ido adaptándose y aportando nuevastecnologías a la vez que abriendo nuevas oportunidades.

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 13/19
ANÁLISIS CON BIG DATA | HDC BPO Services
12
En la Ilustración 5, se puede observar el flujo que la información tendría en unaarquitectura Big Data, con orígenes de datos diversos -bases de datos, documentos odatos recibidos en streaming que se reciben y almacenan a través de la capa derecolección de datos, con herramientas específicamente desarrolladas para talfunción. Los datos recibidos pueden procesarse, analizarse y/o visualizarse tantas
veces como haga falta y lo requiera el caso de uso específico.
Ilustración 5- Arquitectura Big Data por capas

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 14/19
ANÁLISIS CON BIG DATA | HDC BPO Services
13
ANÁLISIS APLICATIVO
2.1. EMPRESA
Hdc es una empresa multinacional con diecisiete años deexperiencia en el campo de la consultoría de negocios e IT yque cuenta con más de 10.000 profesionales de distintossectores. Fundada en Perú el año 1996, actualmente operaen países de Latinoamérica.
Está dedicada a ofrecer soluciones de negocio, estrategia ydesarrollo, mantenimiento de aplicaciones tecnológicas youtsourcing; cubriendo los sectores de telecomunicaciones,entidades financieras, industria, utilities & energía, seguros,administraciones públicas, media y sanidad.
Hdc cuenta con cinco líneas o unidades de negocio:
Business consulting: se encarga de los proyectos de estrategia corporativa, consultoría denegocio e ingeniería de procesos. Su actividad se centra en el conocimiento sectorial, en lainnovación de servicios y en la especialización.
Solutions: se enfoca en la definición, diseño e implantación de soluciones tecnológicas y ala gestión y operación de aplicaciones, infraestructuras y procesos de outsourcing. Se buscael uso de metodologías para aumentar la calidad, traspaso de producción a centros de altorendimiento y para la especialización funcional y tecnológica.
Centers: se basa en la utilización de alto rendimiento. Gracias a los más de cuatro años deexperiencia ya cuenta con la estructura y las capacidades para realizar actividades de formaindustrializada. Tiene centros en Sevilla, Murcia, Alicante, Temuco, San Miguel de Tucumány Uberlandia.
Business Process Outsourcing (BPO): se orienta a ofrecer servicios de externalización deprocesos de negocio bajo acuerdos de nivel de servicios, facilitando a sus clientes disponerde mayor capacidad interna para realizar funciones que le aporten más valor a su negocio.
Initiatives: investiga las posibilidades que ofrece el mercado para abrir nuevos negocios enlos que invertir con sus clientes.
También cuenta con una división especializada en el asesoramiento financiero, la FAS(Financial Advisory Services).
2.2. HERRAMIENTA MICROSTRATEGY
MicroStrategy es el único gran proveedor de software Business Intelligence que no haparticipado en el festín de adquisiciones y fusiones de los últimos años. Gracias a ello, se haconvertido en el primer proveedor independiente de software Business Intelligence, y siguefocalizado totalmente en este sector. Por este motivo, y por las funcionalidades de suplataforma, se trata de una opción a tener muy en cuenta en cualquier nuevo proyectoBusiness Intelligence.
MicroStrategy se fundó en 1989, antes incluso que BO, y desde entonces ha construido unaplataforma que cubre todas las necesidades BI empresariales, desde el clásico reporting

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 15/19
ANÁLISIS CON BIG DATA | HDC BPO Services
14
hasta elaborados y vistosos dashboards, pasando por el análisis OLAP. Se diferencia de losgrandes proveedores en que su arquitectura es más clara y homogénea. Su plataforma esrealmente una plataforma BI (y no un conglomerado de productos diversos). Básicamente,el catálogo de productos de la plataforma Micrstrategy v9 incluye:
Microstrategy Intelligence Server. Se trata del "servidor analítico" que centraliza las
peticiones de los clientes. A este servidor se le pueden añadir funcionalidades a través deuna serie de módulos de la plataforma (Microstrategy Report Services, Microstrategy OLAPServices, Microstrategy Distribution Services, etc.)
Microstrategy Web. Es el entorno interactivo de la plataforma para realizar reporting yanálisis desde un entorno web.
Microstrategy Desktop. Es la aplicación Windows que ofrece la funcionalidad BI de laplataforma, incluyendo el desarrollo, ejecución y administración de los proyectos BI (secomplementa con otros productos para las funcionalidades más técnicas y administrativas:Microstrategy Architect, Microstrategy Enterprise Manager, etc.)
Esta plataforma incluye productos y funcionalidades para cubrir cualquier necesidad BI, queellos dividen en los que denominan los "5 estilos de BI":
1.
Scorecards y dashboards2.
Reporting corporativo3.
Análisis OLAP4. Análisis avanzado y predictivo5.
Alertas y notificaciones proactivas
Desde mi punto de vista, las fortalezas fundamentales de Microstrategy son el análisis OLAPy sus nuevos e impactantes dashboards.
El análisis OLAP se realiza a partir de unos "cubos ROLAP virtuales", es decir, que en lugar deutilizar cubos (tipo Cognos Powerlay), atacan directamente a una base de datos relacional(tipo BO Web Intelligence). Además, disponen de una tecnología de "cubos en-memoria"para mejorar significativamente el rendimiento y la escalabilidad. De esta manera, consiguenlo mejor de cada arquitectura. Resumiéndolo mucho, podríamos decir que se trata de unanálisis OLAP tan sencillo y ágil como el de Cognos Powerplay, aunque con la potencia deuna arquitectura ROLAP como la de BO.
Los scorecards y dashboards de Microstrategy emplean la tecnología flash, y consiguen unosresultados realmente atractivos. Lo mejor es verlos directamente.El análisis OLAP de Microstrategy únicamente permite trabajar con un bloque deinformación, por lo que si se quieren informes más elaborados ya se tiene que trabajar con
"documentos". La elaboración de estos "documentos" (y de los "dashboards") está enfocadaa un usuario algo más técnico.
2.3. ANALISIS DE BIG DATA CON LA HERRAMIENTA MICROSTRATEGY
Creación de Cubos
Tanto SQL definido por el usuario como el Generador de consultas son herramientas deMicroStrategy que se utilizan como métodos alternativos para obtener acceso a sus datosempresariales y crear informes.
SQL definido por el usuario
Es una herramienta de MicroStrategy que le permite escribir sus propias sentencias SQL yejecutarlas directamente en un warehouse o almacén de datos operativos, lo que le permite

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 16/19
ANÁLISIS CON BIG DATA | HDC BPO Services
15
controlar plenamente el acceso a los datos. Tradicionalmente, MicroStrategy Engine seutiliza para generar código SQL que se ejecute en una base de datos relacional específica yobtener resultados para un informe deseado.
Además de elaborar informes de la manera tradicional, también puede utilizar sus propiassentencias SQL personalizadas para generar informes desde sistemas operacionales
incluidos en un proyecto de MicroStrategy.
Esta capacidad puede ahorrarle tiempo, puesto que no tendrá que incluir previamente losdatos en un data mart o en un warehouse. La función de SQL definido por el usuario permiteutilizar sus propias sentencias SQL para acceder a los datos de varios orígenes de datos ODBC,lo que incluye bases de datos relacionales, archivos de Excel y archivos de texto, siempre quese incluyan en el entorno de MicroStrategy.
Puesto que deberá crear sus propias sentencias SQL para elaborar informes con SQL definidopor el usuario, se requiere un conocimiento amplio de cómo crear y usar sentencias SQL.Para obtener más información sobre la creación de informes de SQL definido por el usuario,consulte el capítulo sobre consultas de SQL personalizadas de la Guía avanzada de
elaboración de informes de MicroStrategy.
Generador de consultas
El Generador de consultas le proporciona una interfaz gráfica de usuario que le guía en lageneración de consultas SQL capaces de adaptarse a distintos modelos de datos. ElGenerador de consultas le permite ejecutar consultas en orígenes de datos ODBC que nopermiten acomodar con facilidad el modelo de esquema de atributos y hechos. Esto incluyelas bases de datos que consisten en una colección de tablas sin formato, en lugar de estardefinidas en tablas de hechos y lookup.
El Generador de consultas es una forma rápida de obtener acceso fácil a los orígenes de
datos ODBC sin tener que escribir código SQL, que es necesario con la herramienta SQLdefinido por el usuario. Puede crear consultas para ejecutarlas en tablas de bases de datosimportadas, lo que permite comenzar a elaborar informes y análisis con MicroStrategy sintener que llevar a cabo el paso de creación del proyecto en el que se modelan esquemas deatributos y hechos. (Este paso es necesario para el motor ROLAP de MicroStrategy paradefinir esquemas de atributos y hechos). También puede importar tablas al Catálogo deWarehouse de un proyecto mediante el Generador de consultas.
El Generador de consultas permite disponer de un mayor control del código SQL generadopara consultar los sistemas de bases de datos sin tener que poseer conocimientos profundossobre cómo crear sentencias SQL. Es fundamental tener un conocimiento básico de cómo seutilizan las tablas, las columnas y los joins en las sentencias SQL para crear consultas.
Visualización de Estructura de proyecto HDEC
7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 17/19
ANÁLISIS CON BIG DATA | HDC BPO Services
16
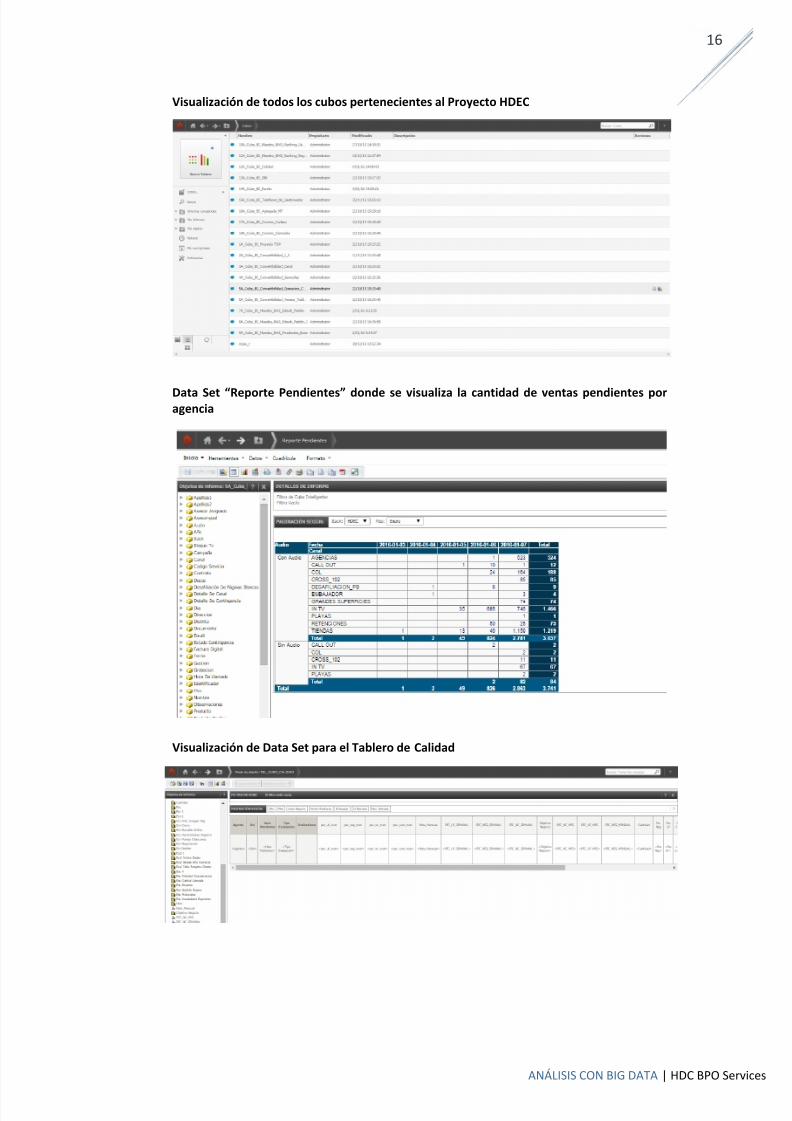
Visualización de todos los cubos pertenecientes al Proyecto HDEC
Data Set “Reporte Pendientes” donde se visualiza la cantidad de ventas pendientes poragencia
Visualización de Data Set para el Tablero de Calidad
7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 18/19
ANÁLISIS CON BIG DATA | HDC BPO Services
17
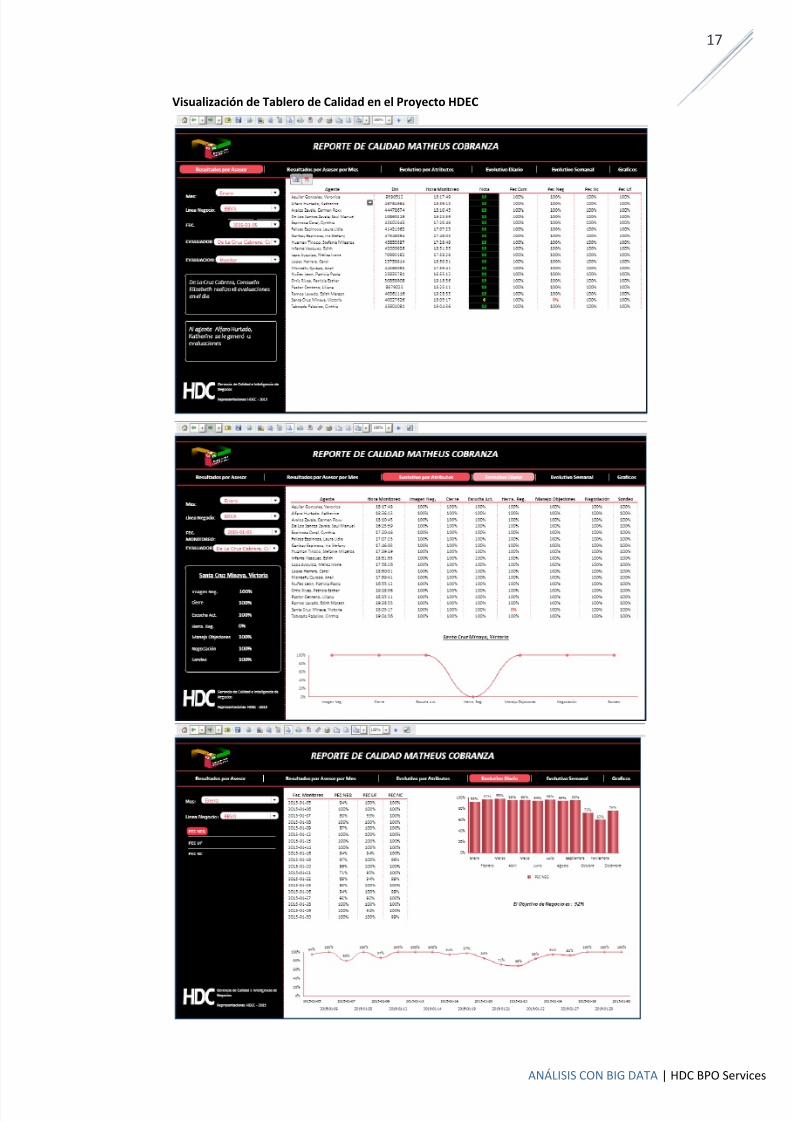
Visualización de Tablero de Calidad en el Proyecto HDEC

7/21/2019 Analisis Big Data Final
http://slidepdf.com/reader/full/analisis-big-data-final 19/19
18
CONCLUSIONES
La naturaleza de la información hoy es diferente a la información en el pasado. Debido a
la abundancia de sensores, micrófonos, cámaras, escáneres médicos, imágenes, etc. ennuestras vidas, los datos generados a partir de estos elementos serán dentro de poco el
segmento más grande de toda la información disponible.
El uso de Big Data ha ayudado a los investigadores a descubrir cosas que les podrían haber
tomado años en descubrir por si mismos sin el uso de estas herramientas, debido a la
velocidad del análisis, es posible que el analista de datos pueda cambiar sus ideas
basándose en el resultado obtenido y retrabajar el procedimiento una y otra vez hasta
encontrar el verdadero valor al que se está tratando de llegar.
Como se pudo notar en el presente artículo, implementar una solución alrededor de Big
Data implica de la integración de diversos componentes y proyectos que en conjunto
forman el ecosistema necesario para analizar grandes cantidades de datos.
Sin una plataforma de Big Data se necesitaría que desarrollar adicionalmente código que
permita administrar cada uno de esos componentes como por ejemplo: manejo de
eventos, conectividad, alta disponibilidad, seguridad, optimización y desempeño,
depuración, monitoreo, administración de las aplicaciones, SQL y scripts personalizados.
IBM cuenta con una plataforma de Big Data basada en dos productos principales: IBM
InfoSphere BigInsights™ e IBM InfoSphere Streams™, además de su reciente adquisición
Vivisimo, los cuales están diseñados para resolver este tipo de problemas. Estas
herramientas están construidas para ser ejecutadas en sistemas distribuidos a gran escala
diseñados para tratar con grandes volúmenes de información, analizando tanto datos
estructurados como no estructurados.
Dentro de la plataforma de IBM existen más de 100 aplicaciones de ejemplo recolectadas
del trabajo que se ha realizado internamente en la empresa para casos de uso e industrias
específicas. Estos aplicativos están implementados dentro de la solución de manera que
las organizaciones puedan dedicar su tiempo a analizar y no a implementar.