big data essentials meetup @ ibm ljubljana 23.06.2015
TRANSCRIPT


Agenda
• Massive Parallel Processing concepts
• Overview of Hadoop Architecture
• Processing Engines
• Map Reduce
• Spark
• Hive, Pig, BigSQL
• Hadoop distributions
• Stream processing
• Advanced analytics on Hadoop


Big Data
An umbrella term that really means
“analytics at scale on any kind of data”
It is about :
Scalability
Cost reduction (per terabyte or of
infrastructure)
Variety of formats to analyze
New types of analytics

Use Cases
Telco
Mediation
Geolocation / fencing
Call archival
Lawful intercept
…
Banking
Counter-fraud
Regulatory
compliance
Analyzing customer
behavior


Definition
Perform a set of coordinated
computations in parallel (wiki def.)
Grid computing
Cluster computing
Why? To make things faster
To count buttons of people on a stadium can
be done in 34* days by 1 person or in 50
minutes* by 1000 persons

Types of systems
Shared Memory (SMP) Simple in implementing
data processing features
Expensive to scale
Shared Disk clusters Easier to implement
storage layer
Bottlenecked above storage layer
Harder to scale
Shared nothing clusters
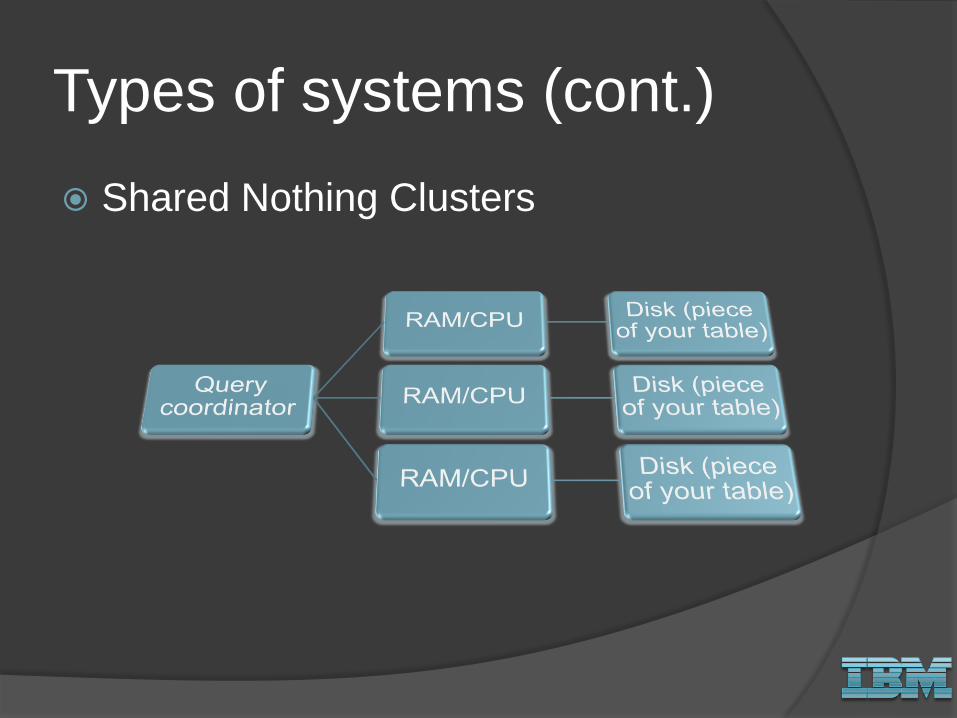
Types of systems (cont.)
Shared Nothing Clusters

Types of systems (cont.)
Relational Database management system
SQL Support
ACID (Atomicity, Consistency, Isolation,
Durability)
All interfaces lower than SQL are hidden
Netezza
General Processing frameworks
Lower level interfaces exposed
MPI
Hadoop

Notable systems
MPP RDBMS Teradata ~ 1980
Netezza ~ 2000
Hadoop ~ 2006

NoSQL
CAP Theorem Consistency, Availability, Partition tolerance
Pick 2
BASE in contrast to ACID
Cloudant, HBASE
Different database genres Graph
Document Store
Columnar
Key Value


Hadoop
Distributed platform for thousands of nodes
Data storage and computation framework
Open source
Runs on commodity hardware
Flexible – everything is loosely coupled

Hadoop benefits
Linear scalability
Software resilience rather than
expensive hardware
“Schema on read”
Parallelism
Variety of tools

The Hadoop Filesystem (HDFS) Driving principals
Files are stored across the entire cluster
Programs are brought to the data, not the data to the program
Distributed file system (DFS) stores blocks across the whole cluster
Blocks of a single file are distributed across the cluster
A given block is typically replicated as well for resiliency
Just like a regular file system, the contents of a file is up to the application
Unlike a regular file system, you can ask it “where does each block of my file live?”
FILE BLOCK
S

Hadoop Distributed File System
HDFS
Stores files in folders
Nobody cares what’s in your files
Chunks large files into blocks (~64MB-2GB)
3 replicates of each block (by default)
Blocks are scattered all over the place
FILE BLOCK
S
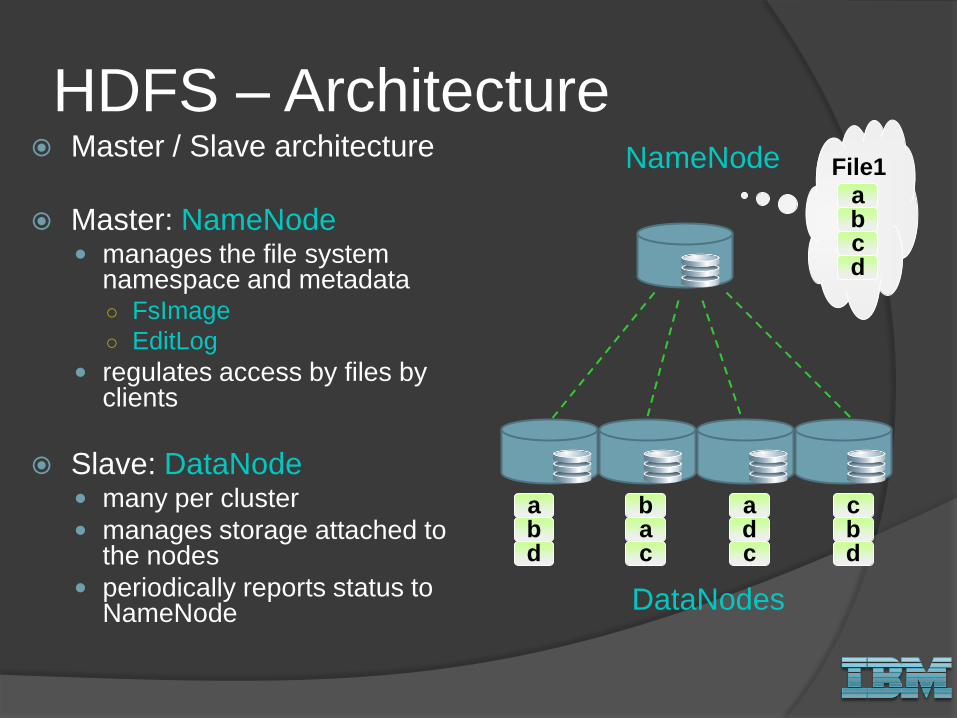
HDFS – Architecture Master / Slave architecture
Master: NameNode manages the file system
namespace and metadata ○ FsImage
○ EditLog
regulates access by files by clients
Slave: DataNode many per cluster
manages storage attached to the nodes
periodically reports status to NameNode
a a
a b
b b
d d
d c c
c
File1
a b c d
NameNode
DataNodes

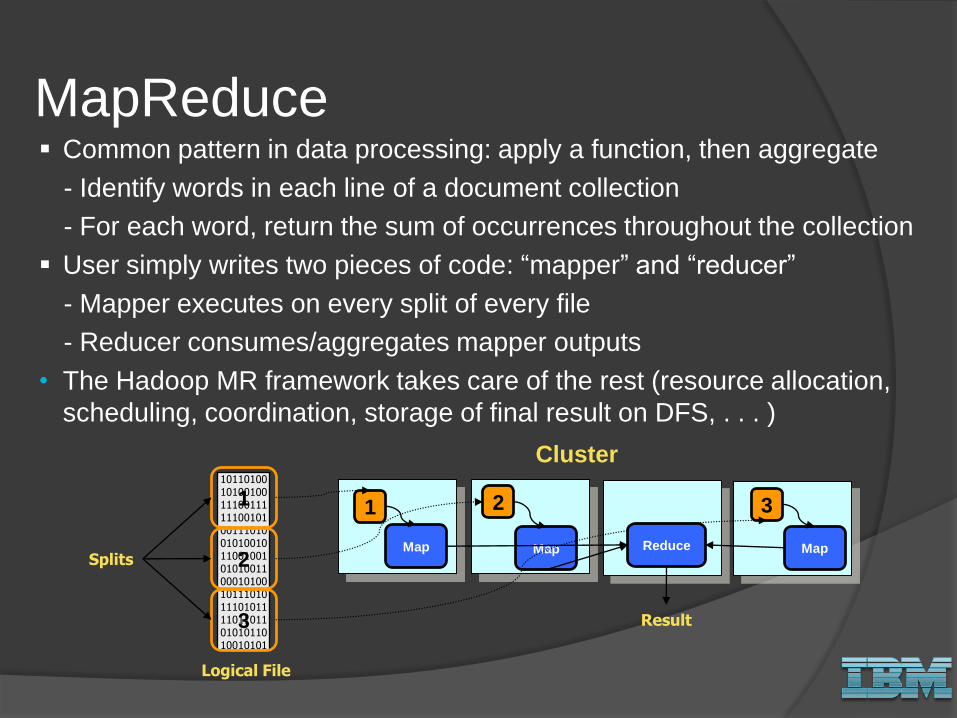
Common pattern in data processing: apply a function, then aggregate
- Identify words in each line of a document collection
- For each word, return the sum of occurrences throughout the collection
User simply writes two pieces of code: “mapper” and “reducer”
- Mapper executes on every split of every file
- Reducer consumes/aggregates mapper outputs
• The Hadoop MR framework takes care of the rest (resource allocation,
scheduling, coordination, storage of final result on DFS, . . . )
1011010010100100111001111110010100111010010100101100100101010011000101001011101011101011110110110101011010010101
1
2
3
Logical File
Splits
1
Cluster
3 2
Map Map Map Reduce
Result
MapReduce

Logical MapReduce Example: Word
Count
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Hello World Bye World
Hello IBM
Content of Input Documents
Reduce (final output):
< Bye, 1>
< IBM, 1>
< Hello, 2>
< World, 2>
Map 1 emits:
< Hello, 1>
< World, 1>
< Bye, 1>
< World, 1>
Map 2 emits:
< Hello, 1>
< IBM, 1>

MapReduce processing
Hello World Bye World
Hello IBM
Input Documents
Reduce (final output):
< Bye, 1>
< IBM, 1>
< Hello, 2>
< World, 2>
Map 1 emits: < Hello, 1>
< World, 1>
< Bye, 1>
< World, 1> Map 2 emits: < Hello, 1>
< IBM, 1>

Spark
Spark brings two significant value-adds: Bring to Map Reduce the same added value that
databases (and parallel databases) brought to query processing: ○ Let the app developer focus on the WHAT (they need to ask) and
let the system figure out HOW (it should be done).
○ Enable faster higher level application development through higher level constructs and concepts: (RDD concept)
○ Let the system deal with performance (as part of the HOW) Leveraging memory (Bufferpools, Caching RDDs in memory)
Maintaining sets of dedicated worker processes ready to go (subagents in DBMS, Executors in Spark)
○ Enabling interactive processing (CLP, SQL*Plus, spark-shell, etc….)
Be one general purpose engine for multiples types of workloads (SQL, Streaming, Machine Learning, etc…)

Spark (cont.) Apache Spark is a fast, general
purpose, easy-to-use cluster computing system for large-scale data processing Fast
○ Leverages aggressively cached in-memory distributed computing and dedicated
App Executor processes even when no jobs
are running
○ Faster than MapReduce
General purpose ○ Covers a wide range of workloads
○ Provides SQL, streaming and complex analytics
Flexible and easier to use than Map Reduce ○ Spark is written in Scala, an object oriented,
functional programming language
○ Scala, Python and Java APIs
○ Scala and Python interactive shells
○ Runs on Hadoop, Mesos, standalone or
cloud
Logistic regression in Hadoop and Spark
Spark Stack
val wordCounts =
sc.textFile("README.md").flatMap(line =>
line.split(" ")).map(word => (word,
1)).reduceByKey((a, b) => a + b)
WordCount
Spark (cont.)

Pig
Pig is a query language that runs MapReduce jobs
Higher-level than MapReduce: write code in terms of GROUP BY, DISTINCT, FOREACH, FILTER, etc.
Custom loaders and storage functions make this good glue A = LOAD ‘data.txt’
AS (name:chararray, age:int, state:chararray);
B = GROUP A BY state;
C = FOREACH B GENERATE group, COUNT(*), AVG(age);
dump c;

Hive
SQL Engine on top of MapReduce
Rapidly developed, lots of features
Query language – HiveQL – is deviant
from ANSI
Lack of cost based query optimizer,
statistics, and many other features
Not responsive enough for small jobs

BigSQL
Data shared with Hadoop ecosystem
Comprehensive file format support
Superior enablement of IBM and Third Party
software
Modern MPP runtime
Powerful SQL query rewriter
Cost based optimizer
Optimized for concurrent user throughput
Results not constrained by memory
Distributed requests to multiple data sources
within a single SQL statement
Main data sources supported:
DB2 LUW, Teradata, Oracle, Netezza,
Informix, SQL Server
Advanced security/auditing
Resource and workload management
Self tuning memory management
Comprehensive monitoring
Comprehensive SQL Support
IBM SQL PL compatibility
Extensive Analytic Functions


A lot of buzzwords
Ambari – web admin interface
Zookeper – distributed object sync
Hbase – NoSQL key/value store
Flume – buffered ingestion
Sqoop – Database import/export
Oozie – workflow manager
YARN – cluster resource manager
Nagios/Ganglia – monitoring, metrics



Hortonworks HDP

Cloudera

IBM BigInsights
Text Analytics
POSIX Distributed
Filesystem
Multi-workload, multi-tenant
scheduling
IBM BigInsights
Enterprise Management
Machine Learning on
Big R
Big R (R support)
IBM Open Platform with Apache Hadoop*
(HDFS, YARN, MapReduce, Ambari, Hbase, Hive, Oozie, Parquet, Parquet Format, Pig, Snappy, Solr, Spark, Sqoop, Zookeeper, Open JDK, Knox, Slider)
IBM BigInsights
Data Scientist
IBM BigInsights
Analyst
Big SQL
BigSheets
Industry standard SQL
(Big SQL)
Spreadsheet-style
tool (BigSheets)
Free Quick Start (non production):
• IBM Open Platform
• BigInsights Analyst, Data Scientist
features
• Community support
. . .
IBM BigInsights for
Apache Hadoop


Overview
Analyzing data on the fly vs. storing it
Sometimes both has to be done
Batch vs. Stream processing
Low latency needs special design considerations
Processing is done on “windows” rather then on tables/dataframes
Engines differ by architecture, development tools, latency

Apache Flume
Agents can be
installed on variety
of platforms
Collectors buffer
data and put to
HDFS
Reliable
Limited to micro
batch data collection
server agent
Collector server agent
server agent
HDFS

Spark Streaming
Micro batch engine
Reliable
Integrated with Spark

Apache Storm
Twitter project
now in Apache
Development in
Java
Bolts and Spouts
Guaranteed
record delivery

Infosphere Streams
Most performing and sophisticated streaming engine
Easy IDE
Declarative streaming language
Parallel execution framework
Many advanced toolkits Video, audio, signal
processing, finance, geospatial, integration, etc
Integrated with enterprise tools



Data Science Life: Two Main
Tasks 1) Exploration: We don’t have any special attribute we want
to predict. Rather we want to understand the structure
present in the data. Are there clusters? Non-obvious
relationships?
- Also referred to as “unsupervised learning”
- E.g., K-means clustering
Use Cases -> Understanding categories of customers, cross-
selling opportunities, etc…
2) Prediction: The data contains a particular attribute
(called the target attribute) and we want to learn how the
target attribute depends on the other attributes.
- Also referred to as “supervised learning”
- E.g., Support vector machines
Use Cases -> Building a model to predict customer
churn, fraud, etc…

Data Science Life: Tools at Present
SQL (42%) R
(33%) Python (26%)
Excel (25%)
Java Ruby C++
(17%)
SPSS SAS (9%)

Data Science Life: Skillset of the Data
Scientist
Statistician
Software Engineer
Business Analyst
Process Automation
Parallel Computing
Software Development
Database Systems
Mathematics Background
Analytic Mindset
Domain Expertise
Business Focus
Effective Communication

CRISP-DM: Cross Industry Standard
Process for Data Mining
The Typical Data Science Workflow


The Architect: What is Open Source R?
What is CRAN?
R is a powerful programming language and environment for statistical computing and graphics.
R offers a rich analytics ecosystem: Full analytics life-cycle
○ Data exploration
○ Statistical analysis
○ Modeling, machine learning, simulations
○ Visualization
Highly extensible via user-submitted packages ○ Tap into innovation pipeline contributed to by highly-regarded statisticians
○ Currently 4700+ statistical packages in repository
○ Easily accessible via CRAN, the Comprehensive R Archive Network
R is the fastest growing data analysis software ○ Deeply knowledgeable and supportive analytics community
○ The most popular software used in data analysis competitions
○ Gaining speed in corporate, government, and academic settings
49


Big R Architecture
1 Scalable
Algorithms
Scalable Data
Processing Native
R functions
R User
Interface
2 3

User Experience for Big R
Connect to BI cluster
Data frame proxy to large data file
Data transformation step
Run scalable linear regression on cluster

IBM System ML
Collection of distributed algoritms
Currently embedded in BigR
Contributed to Spark on 15.06.15


SPSS on Hadoop


Python for data analysis
Ipython notebooks
Pandas/numpy
Scikit
matplotlib
Python Spark API


Collection of distributed
algorithms



Want to learn more? Download Quick Start offering
Test drive the technologies
Links all available from HadoopDev – https://developer.ibm.com/hadoop/