big data to smart data : process scenario
TRANSCRIPT

BIG DATA TO SMART DATAPROCESS SCENARIO
REAL-TIMEANALYTICS
CHAKER ALLAOUI

TABLE OF CONTENTS
• Input Data • Big Data • JSON Format • Apache Zookeeper
01 02 03 04INTRO
• Apache Storm • Apache Kafka • Apache Cassandra • Apache Spark
05 06 07 08
• SparkSQL • SparkUI • D3 • SMART DATA
09 10 11 12
Process Scenario

PROCESS SCENARIOBig Data to SMART Data

Creative process
Analytical process
Big data, indicates theexplosion of the volume of thedata scanned, collected byprivate individuals, publicactors, IT applications whichinclude users communities onthe scale of the planet. It willbe enough to quote someexamples more or less knownby all: Google, its searchengine and its services ofdepartments; networks saidsocial: Facebook and his billionusers who put down images,texts, exchanges; sites ofsharing and distribution andbroadcasting of images andphotos “Flickr”; the communitysites (blogs, forums, wikis);administrative departmentsand their
Process Scenario: Analytical & Creativescanned exchanges. In the center of all thesevacuum cleaners of data, we find Internet,Web, and its capacity to be federated in thespace scanned by the billions of users, butalso sensors' profusion of all kinds,accumulating scientific data with anunpublished rhythm (satellite pictures forexample). To remain in Web, all themessages, all the documents there, all theimages and the videos are got byapplications which, in exchange for thesupplied services of departments,accumulate of immense data banks.
We speak in million waiters for Google,Facebook or Amazon, stored in immensesheds which, besides, consume a notinsignificant part of the producedelectricity. And the movement seems to goaccelerating.Where from the necessity of presenting asystem of combination of these multiplesources. Thus the idea is to create acomplete scenario of a transformationprocess of these data of exploitable massin data and presentational to facilitatetheir management and make implementthe decision-making computing toanalyze and federate these data.The solution contains open sourcesoftware's the majority of which arestemming from projects of the Apache.
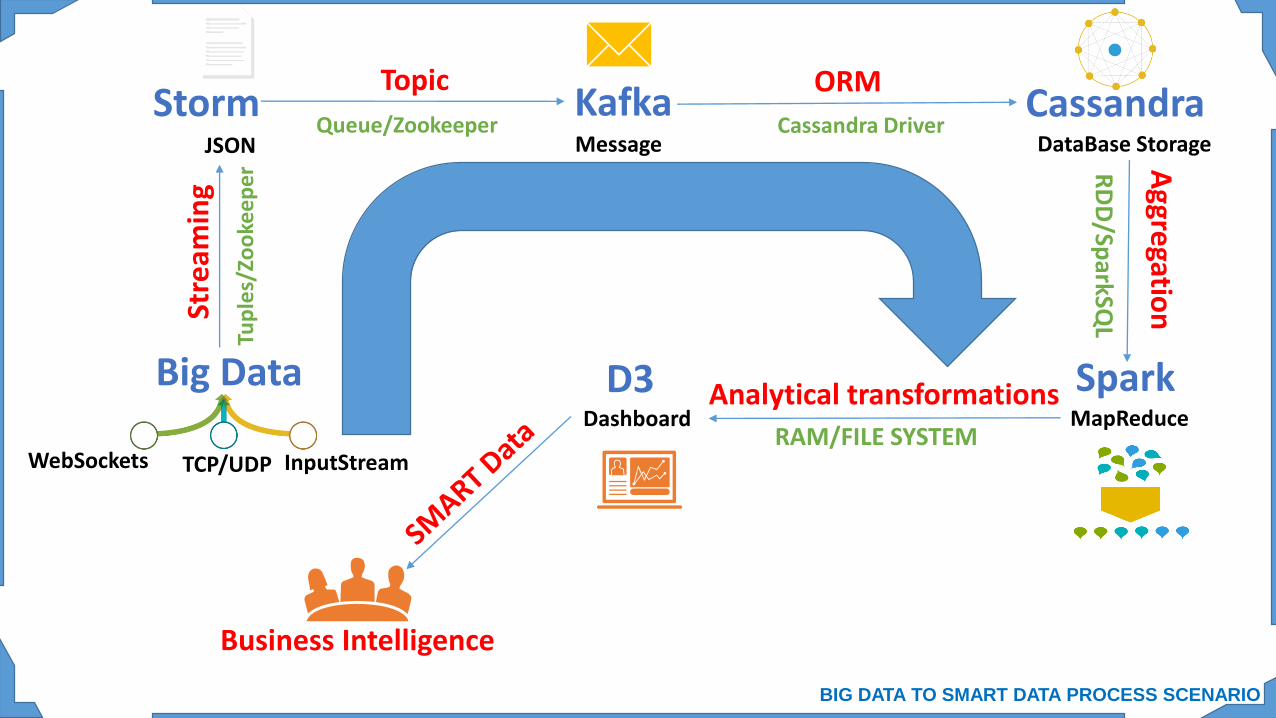
Message
MapReduceDashboard
JSON
Kafka Cassandra
SparkD3
Storm
WebSockets
Stre
amin
g
Topic ORMA
ggregatio
n
Big Data
Tup
les/
Zoo
keep
er
Queue/Zookeeper Cassandra Driver
RD
D/Sp
arkSQL
RAM/FILE SYSTEM
Analytical transformations
TCP/UDP
DataBase Storage
Business Intelligence
InputStream
BIG DATA TO SMART DATA PROCESS SCENARIO

Input DataWebSocketsTCP/UDPInputStream

Data
WebSocketsThe protocol Web Socket aims atdeveloping a communicationchannel full house-duplex on asocket TCP for the browsers andthe Web servers. The increasingWeb interactivity of theapplications, consecutive to theimprovement of the performancesof the browsers, quickly madenecessary the development oftechniques of bidirectionalcommunications between the Webapplication and the processesserver. Techniques based on thecall by the customer of the object“XMLHttpRequest” and using HTTPrequests with a long TTL stored bythe server for a later answer to thecustomer allowed to mitigate thislack by Ajax.
TCP/UDPUDP is a directed protocol "notconnection", when a machineA sends packages aimed at amachine B, this flow isunidirectional. Indeed, thedata transmission is madewithout warning the addressee(machine B), and the addresseereceives the data withoutmaking of acknowledgementof receipt towards thetransmitter (machine A).TCP is directed "connection".When a machine A sends datatowards a machine B, themachine B is prevented of thearrival of the data, and testifiesof the good reception of thesedata by an acknowledgementof receipt.
InputStreamThe InputSream allow to theseprocesses of sending and datareception. Flows always processthe data in a sequential way.Flows can be divided into severalcategories: the flows of treatmentand processing of characters andthe flows of treatment ofbytes(octets).The flows of streams can be webservices, flus of data comingfrom social networks such:Tweeter API....
Data: WebSockets-TCP/UDP-InputStream
Binary Data
Structured Data
Unstructured Data
API Interface
http://fr.wikipedia.org (Traduction)

Read Content: cURLTo read the contents of a Web source, we are going tomanipulate: " cURL " (Customer URL Request Library), itis an on-line interface of command intended to getback the contents of an accessible resource by anetwork. The resource is indicated by means of an URLand has to be of a type supported by the software, hecan be so used as customer REST API.The library supports in particular protocols FTP, FTPS,HTTP, HTTP, TFTP, SCP, SFTP, Telnet, DICT, FILE andLDAP. The writing can be made in HTTP by using thePOST and PUT commands.CURL is a generic interface allowing us to handle aflow of data.The attached example presents the reading of onecontained by a present file JSON on a server inlocalhost.The idea is to know how the software of streaming treatan information received by remote server.Example: curl readed Content by GET Method:
> curl –i –H « Accept: application/json » -H « Content-Type:application/json » http://www.host.com/data.json
cURL command: JSON Stream

BIG DATAVolume-ValueVelocity-Variety

The initial definition given bythe cabinet McKinsey andCompany in 2011 turned atfirst to the technologicalquestion, with the famous ruleof 3V:A big Volume of data, animportant Variety of the samedata and a Processing speedbeing sometimes similar to thereal time.These technologies weresupposed to answer theexplosion of the data in thedigital landscape "datadeluge ". Then, these qualifiersevolved, with a more economicvision carried by the 4th V:
Big Data comes along with thedevelopment of applications withanalytical aim, which process thedata to pull it of the sense. Theseanalyses are called Big Analytics or "grinding of data ". They concerncomplex quantitative data withmethods of distributed calculation.In 2001, a research paper of theMETA GROUP defines the stakesinherent to the growth of the data asbeing three-dimensional:
The complex analyses indeedanswer the said rule " 3V "(volume, velocity and variety).This model is still widely usedtoday to describe thisphenomenon.The annual world averagegrowth rate of the market ofthe technology and theservices of departments of BigData over the period 2011-2016 should be 31,7 %. Thismarket should so affect 23,8billion dollars in 2016(according to IDC in March,2013). Big Data should alsorepresent 8 % of the EuropeanGDP(GROSS DOMESTICPRODUCT) in 2020.
Organize Data
Centralize Data
Combine Data
Support Decision
Big Data
http://recherche.cnam.fr/equipes/sciences-industrielles-et-technologies-de-l-information/big-data-decodage-et-analyse-des-enjeux-661198.kjsp
The Value

Volume: it is a relative dimension: Big Data as notedit Lev Manovitch in 2011 defined formerly " the bigenough data sets to require super computers ", buthe quickly became possible to use standard softwareon desktop computers to analyze or co-analyze vastdata sets. The volume of the stored data is rapidlygrowing: the digital data created in the worldwould have passed of 1,2 Z-octets a year in 2010 to1,8 Z-octets in 2011.
Velocity: Represent at the sametime the frequency to which thedata are generated, captured andshared and updated. Increasingflows of data must be analyzed inreal-time to meet the needs ofprocesses stopwatch sensitive. Forexample, the systems set up by thestock exchange and thecompanies must be capable ofprocessing these data before anew cycle of generation began,with the risk for the man to lose abig part of the control of thesystem when the main operatorsbecome "robots" capable of throwof the orders of purchase or ofsale of the order of nanosecond,without arranging all the criteriaof analysis for the average andlong term.
Then 2,8 Z-octets in 2012 andwill amount to 40 Z-octets in2039. For example Twittergenerated in January, 2013, 7 inthe daytime.Variety: The volume of Big Dataputs dated-centers in front of areal challenge: the variety of thedata. It is not about traditionalrelational data, these data are raw,semi-structured even notstructured. They are complex dataresulting from Web, in thesize(format) text and images(Image Mining). They can bepublic (Open Data, Web of thedata), geography demographic byisland (IP addresses), or be amatter of the property of theconsumers. What returns themwith difficulty usable with thetraditional tools of managementsof data to take out the best of it.
http://fr.wikipedia.org/wiki/Big_data (Traduction)

JSONJavaScriptObject Notation

JSON: formatJSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read andwrite. It is easy for machines to parse and generate. It isbased on a subset of the JavaScript ProgrammingLanguage, Standard ECMA-262 3rd Edition - December1999. JSON is a text format that is completely languageindependent but uses conventions that are familiar toprogrammers of the C-family of languages, including C,C++, C#, Java, JavaScript, Perl, Python, and many others.These properties make JSON an ideal data-interchange.
JSON is built on two structures:A collection of name/value pairs. In variouslanguages, this is realized as an object, record,structure, dictionary, hash table, keyed list, orassociative array.An ordered list of values. In most languages,this is realized as an array, vector, list, orsequence.These are universal data structures. Virtuallyall modern programming languages supportthem in one form or another. It makes sensethat a data format that is interchangeable withprogramming languages also be based on thesestructures.In JSON, they take on these forms:An object is an unordered set of name/valuepairs. An object begins with { (left brace) andends with } (right brace). Each name isfollowed by : (colon) and the name/value pairsare separated by , (comma).
Structured Data
Universal
Speed Treatments
Riche Componentshttp://json.org/
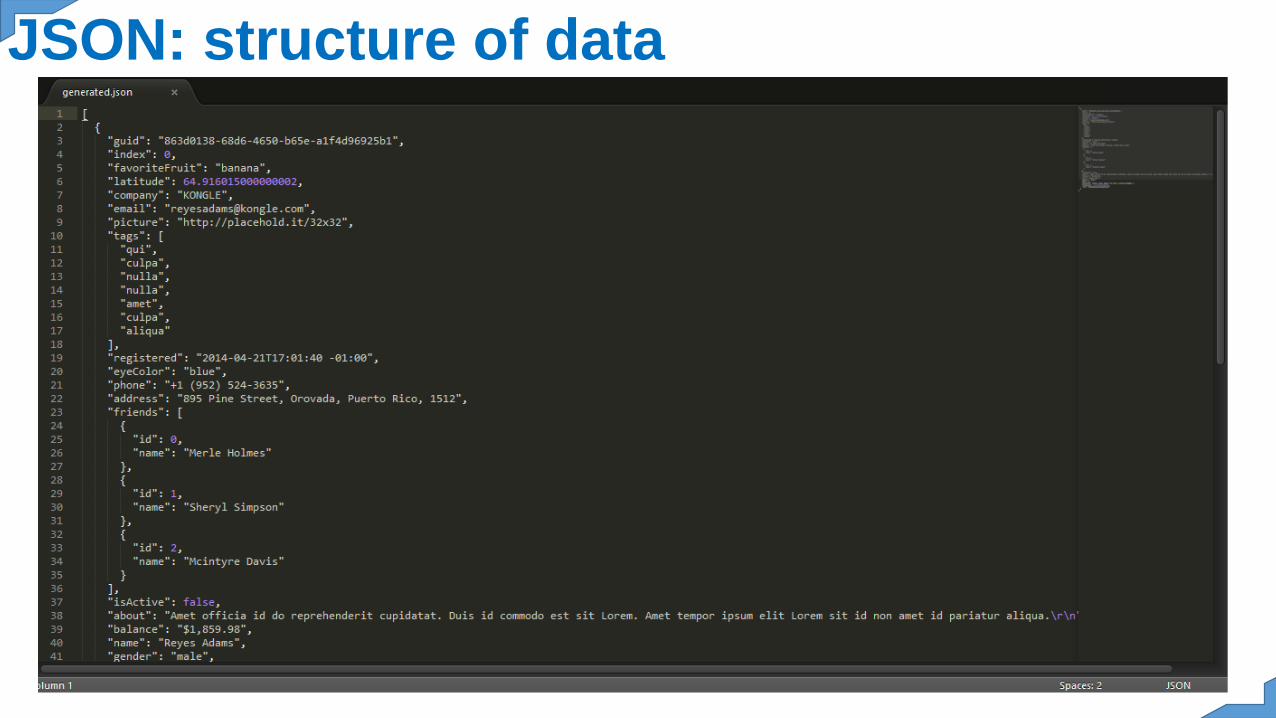
JSON: structure of data

APACHE ZOOKEEPERWorking with distributed systems

APACHE ZOOKEEPER ZooKeeper
Apache Zookeeper is a frameworkto federate the communicationsbetween distributed systems, itworks by supplying a space reportshared by all the authorities ofsame set servers. This spacememory is hierarchical, in the styleof a system of file compound ofdirectories and files. He isdistributed, consists of severalmachines connected between themand who solve together a problem,by opposition with a centralizedsystem, thus a big unique machinewhich sets quite at hisexpense(under his responsibility).The case of Google, for which nounique machine could not handleall the requests. The simple fact ofhaving several machines whichhave to work together is a source
of problems, among which:The resistance in thebreakdowns: if a machinebreaks down in the network,that to make. If she is the onlyone to carry importantinformation, these are lost. Inthis case, we adjust thequestion with the redundancyof the information, duplicatedon several machines. Theconsistency of the information,in particular if she isduplicated. The purpose is tooffer an independence of hervalue of the datum with regardto
compared with his source: we wantto avoid that every machine carriesa different version, of aninformation which we need. Thedistribution of the loadresponsibility: how well manage hisresources to avoid that a singlemachine is too much requested,while the others are inactive.How is a request emitted by acustomer handled, Which makeshim? And how guarantee that theresult is the voucher, independentlyof the machine which handled thequestion. It is the said problem ofthe consensus: we say that there isconsensus if two machines havingthe same initial data give the sameresult for the same treatment.
Distributed
Local Implements
Cloud Implements
Orchestrator
http://blog.zenika.com/index.php?post/2014/10/13/Apache-Zookeeper-facilitez-vous-les-systemes-distribues2

Distributed systemsThe communication between theauthorities or the machines takesplace in asynchronous mode. Forexample, you want to send amessage in a set of authorities ( acluster) to launch a treatment andprocessing. You also need to knowif an authority is operational. Tocommunicate well, an used methodconsists of a tail. This one allows tosend messages directly or bysubject, of lira in a asynchronousway. The communication in modeto cluster takes place exactly as acommunication, in local mode withseveral processes, and pass by thecoordination in the use custom ofthe resources. Concretely, when aknot writes on a file, it is preferablethat he puts a bolt, visible by allother knots, on said file.
A distributed system of filesdoes not wish to know thatsuch file is on the authoritything. He wants to be under theillusion to treat and manipulatea unique system of files, exactlyas on a single machine. Themanagement of the distributionof the resources, with what todo if an authority does notanswer, is not useful to know.A service of department ofnaming: to present him,certainly in a rough way, wewould like a kind of<MapString, Object > who isdistributed on the network,whom all the authorities canuse. A typical example wouldbe JNDI. The purpose of theservice of department ofnaming consists in
Have a system distributed by access to objects.A strong system of treatment and processing of therequests is distributed architecture which welcomesreal time data. In the case of a structure advanced, wewish not to lose the slightest given such as: the stock-exchange orders, the idea is to make a treatment andprocessing which gets back the data of an authoritybefore it breaks down or takes out of networks. Theapproach of Zookeeper is to choose a leader in everyputting on of system, and the latter who assures andinsures the information sharing and the frames in thewhich an information has to be to persist in the systemto keep the track, by taking account in the opinion ofevery Znodes or exactly the answer to make protect aninformation, so an upper number in n/2 where n isthe number.

ZOOKEEPER: ZNodes> .\bin\zkServer.cmd> .\bin\zkCli.cmd 127.0.0.1:2181
Zookeeper nodes list
Zookeeper daemon

APACHE STORMReal-Time Streaming
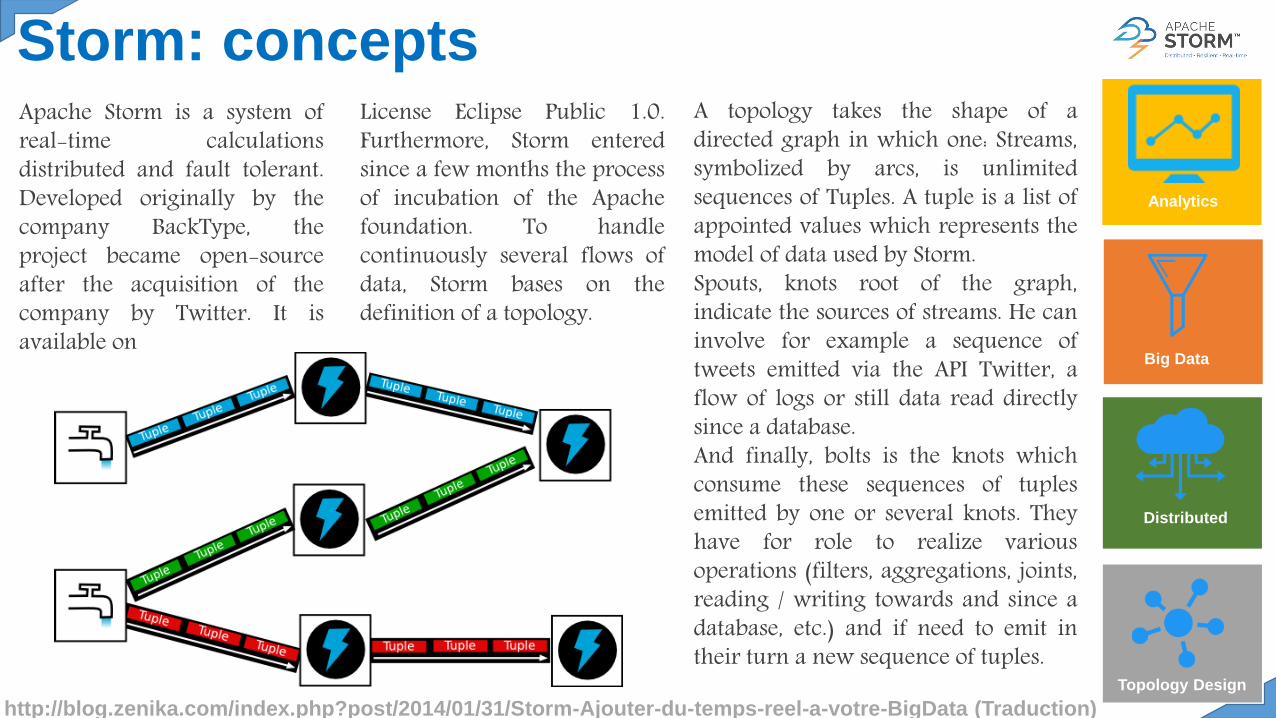
Apache Storm is a system ofreal-time calculationsdistributed and fault tolerant.Developed originally by thecompany BackType, theproject became open-sourceafter the acquisition of thecompany by Twitter. It isavailable on
License Eclipse Public 1.0.Furthermore, Storm enteredsince a few months the processof incubation of the Apachefoundation. To handlecontinuously several flows ofdata, Storm bases on thedefinition of a topology.
A topology takes the shape of adirected graph in which one: Streams,symbolized by arcs, is unlimitedsequences of Tuples. A tuple is a list ofappointed values which represents themodel of data used by Storm.Spouts, knots root of the graph,indicate the sources of streams. He caninvolve for example a sequence oftweets emitted via the API Twitter, aflow of logs or still data read directlysince a database.And finally, bolts is the knots whichconsume these sequences of tuplesemitted by one or several knots. Theyhave for role to realize variousoperations (filters, aggregations, joints,reading / writing towards and since adatabase, etc.) and if need to emit intheir turn a new sequence of tuples.
Storm: concepts
Analytics
Big Data
Distributed
Topology Design
http://blog.zenika.com/index.php?post/2014/01/31/Storm-Ajouter-du-temps-reel-a-votre-BigData (Traduction)

The grouping of flows answersthe following question: when atuple is emitted, towardswhich bolts he must bemanaged? In other words, it isa question of specifying theway flows are partitionedbetween the variousauthorities of the samecomponent spout or bolt. Forthat purpose, Storm supplies aset of predefined groupings,among which here are themain definitions:* Shuffle grouping: tuples israndomly distributed towardsthe various bolts authorities ina way that each receives anequal number of tuples.* Fields grouping: the flow ispartitioned according to oneor several fields.
Streams: grouping, worker, executor* All grouping: the flow isanswered towards all theauthorities. This method is to beused with precaution because itgenerates so many flows as thereis of authorities.* Global grouping: the wholeflow is redirected towards thesame authority. In the case,where there is several for thesame bolt, the flow is thenredirected towards that havingthe smallest identifier. When atopology is submitted to Storm,this one distributes all thetreatments and processing
implemented by your components through thecluster. Every component is then executed in parallelon one or several machines.Storm executes a topology compound of spout andtwo bolts. For every topology, Storm manages a set ofdifferent entities:One " worker process " is a JVM running on amachine of the cluster. It has for role to coordinatethe execution of one or several components (spouts orbolts) belonging to the same topology. (the number ofworkers associated to a topology can change in time.)A "executor" is a thread launched by one " workerprocess ". It is in charge of executing one or several"task" for a bolt or specific spout. (the number ofexecutive).
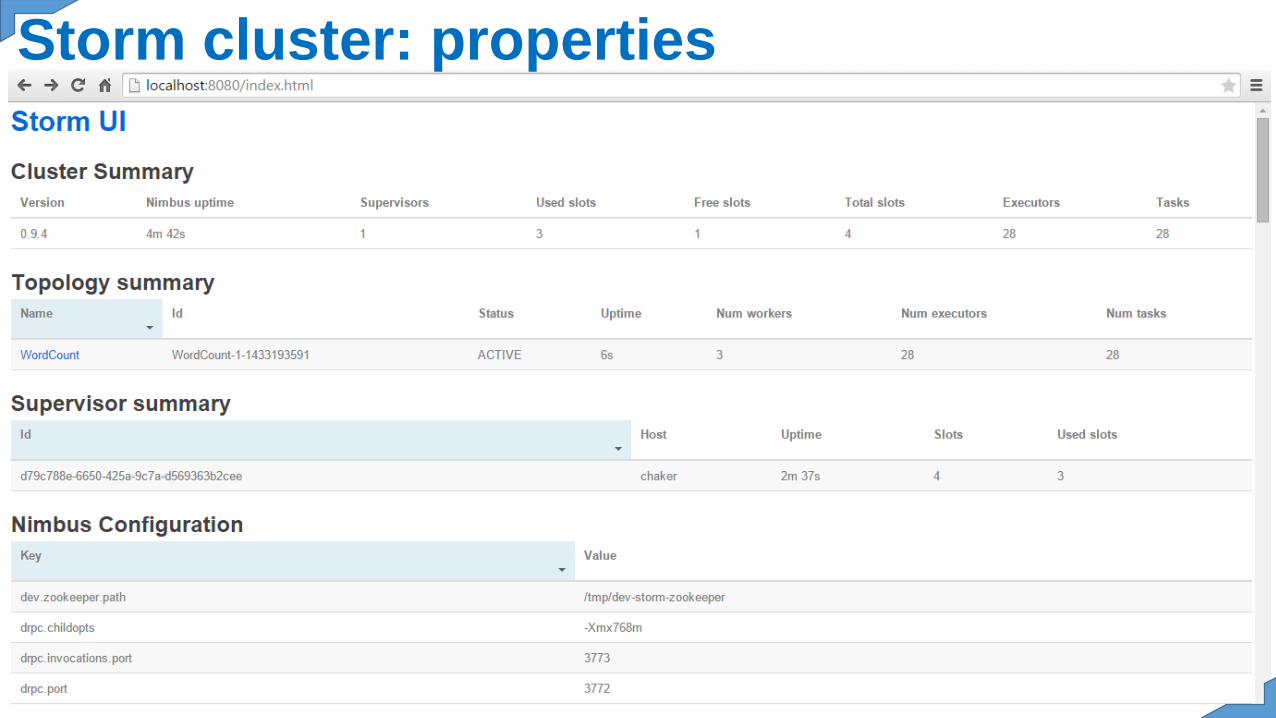
Storm cluster: properties

Storm: spouts, bolts

Storm: Topology analytics

Storm: JSON Receiver spouts
Parse JSON Stream with Storm Java API

APACHE KAFKAProducer-Consumer of Content

Apache published Kafka 0.8, the firstmajor version of Kafka since theproject became a project of top levelof the Apache Software Foundation.Apache Kafka is a directed systemmessage of type publication-subscription implemented astransactional system of tracksdistributed, adapted for theconsumption of on-line andoutstanding messages. It is about adirected system message developedoriginally to LinkedIn for thecollection and the distribution of highvolumes of events and data of trackwith low latency. The last versionincludes the replication intra-clusterand the support of multipledirectories of data. The files of trackcan be switched around by age, andthe levels of track can be
Valued dynamically by JMX. Atool of performance test wasadded, to help to handle theconcerns and to look for theimprovements concerning theperformances. Kafka is a serviceof department of committed oftracks distributed, partitioned andanswered.The producers publish messagesin subjects Kafka,
The consumers subscribe tothese subjects and consumemessages. A waiter in acluster Kafka is called anintermediary. For everysubject, the cluster Kafkamaintains a partition for theload increase, theparallelism and theresistance in thebreakdowns.
Live Transmit
Distributed
Memory
Tracability
http://www.infoq.com/fr/news/2014/01/apache-afka-messaging-system (Traduction)
Apache Kafka

The system is checked andcontrolled by the consumer. Atypical consumer will treat themessage following in the list,although he can consumemessages in any order, becausethe cluster Kafka keeps all themessages published for aperiod of configurable time. Itreturns the very economicconsumers, because they goand come without a lot ofimpact on the cluster, andauthorize the consumersdisconnected as
Clusters Hadoop. Theproducers are capable ofchoosing the subject, and thepartition within the subject, inwhich to publish the message.The consumers auto-affect aname of group of consumer,and every message isdistributed to a consumer inevery group of subscribedconsumers. If all theconsumers have differentgroups, then messages arebroadcast to every consumer.Kafka can be used as amiddleware of traditionalmessage. He offers a high flowand has capacities of partitionnative, of replication andresistance in the breakdowns,what makes it a good solutionfor them
applications of treatment and processing of large-scalemessages. Kafka can be also used for the follow-up ofWeb sites on strong volume. The activity of the site canbe published and handled in real time, or loaded insystem of warehouse of data Hadoop or except line.Kafka can be also used as solution of aggregation oftracks. Instead of working with files, tracks can betreated as flows of messages. Kafka is used to LinkedInand he manages more than 10 billion writings a daywith a steady load which borders 172 000 messages persecond. There is a massive use of support medium ormulti-subscribers
Kakfa Topic
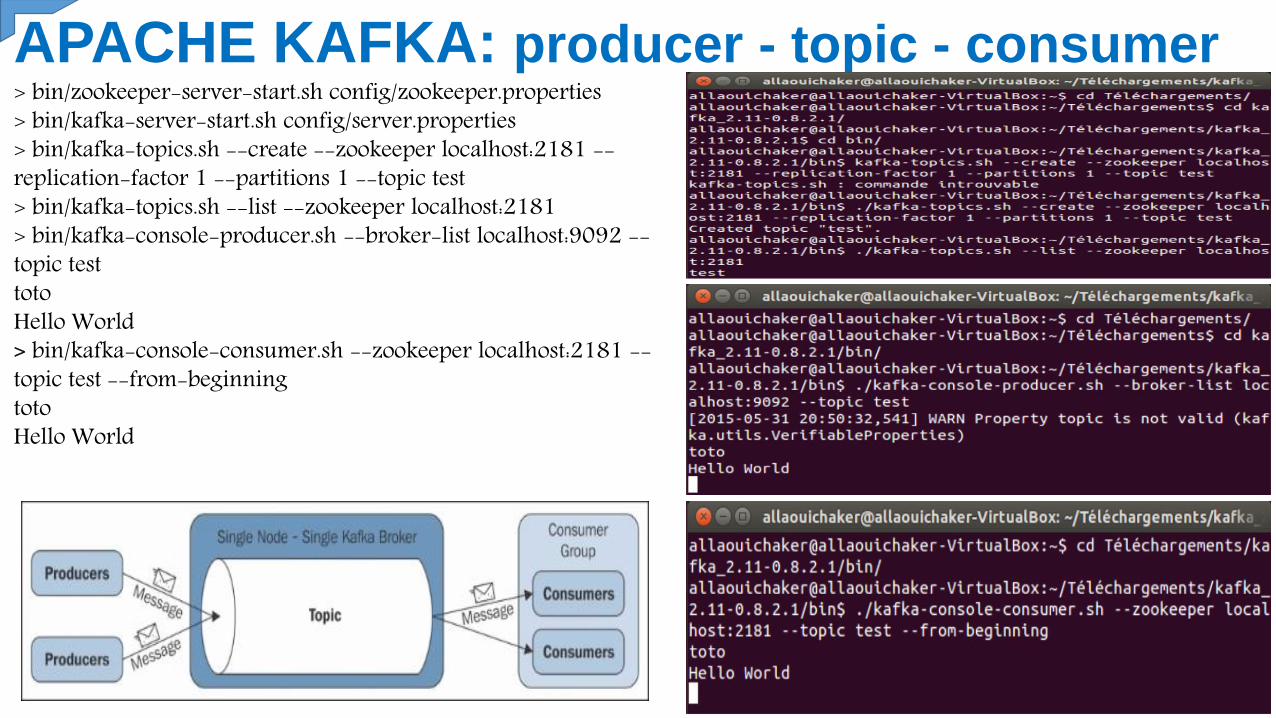
APACHE KAFKA: producer - topic - consumer> bin/zookeeper-server-start.sh config/zookeeper.properties> bin/kafka-server-start.sh config/server.properties> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test> bin/kafka-topics.sh --list --zookeeper localhost:2181> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test totoHello World> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginningtotoHello World

APACHE KAFKA: JSON format transmitimport java.io.FileInputStream;import java.io.IOException;import java.util.Properties;import kafka.producer.KeyedMessage;import kafka.producer.ProducerConfig;public class KafkaProducer {private static kafka.javaapi.producer.Producer<Integer, String> producer = null;private static String topic = "topic_message";private static Properties props = new Properties();public KafkaProducer() { }public void sendMessage() {try {props.put("serializer.class", "kafka.serializer.StringEncoder");props.put("metadata.broker.list", « 127.0.0.1:9092");producer = new kafka.javaapi.producer.Producer<Integer, String>(new ProducerConfig(props));BufferedReader br = null;String sCurrentLine;br = new BufferedReader(new FileReader("data.json"));while ((sCurrentLine = br.readLine()) != null) {producer.send(new KeyedMessage<Integer, String>(topic, sCurrentLine));}producer.send(new KeyedMessage<Integer, String>(topic, new String(content)));} catch (IOException e) {e.printStackTrace();}finally {try {if (br != null)br.close();} catch (IOException ex) {ex.printStackTrace();}}}}

APACHE CASSANDRANoSQL DataBase

Replication indicates the numberof knots where the datum isanswered. Besides, Cassandra'sarchitecture defines the term ofcluster as being a group of atleast two knots and one dated tocenter as being relocatedclusters. Cassandra allows toinsure the replication throughdifferent dated to center. Theknots which fell can be replacedwithout unavailability of theservice of department.· Decentralized: in a cluster allthe knots are equal. He not thereno notion of master, neither ofslave, nor process which wouldhave at her expense themanagement, nor even ofbottleneck at the level of thenetwork part. The protocol
Apache Cassandra is a database ofthe family very fashionableNoSQL. She is classified amongdirected bases columns just likeHBase, Apache Accumulo, BigTable. This base was originallydeveloped by engineers ofFacebook for their in-house needsbefore being put at the disposal ofthe general public in open-source.CHARACTERISTICS· Fault tolerance: the data of a knot(a knot is Cassandra's authority)are automatically answeredtowards other knots ( variousmachines). So, if a knot is out oforder the present data areavailable through other knots. Theterm of factor of
GOSSIP insures overdraft, thelocation and the collection of allthe information on the state of theknots of a cluster.· rich Model of data: the model ofdata proposed by Cassandrabased on the notion of key / valueallows to develop numerous casesof use in the world of Web.· Elastic: the scalability is linear.The debit of writing and readingincreases in a linear way when anew server is added in the cluster.Besides, Cassandra assures thatthere will be no unavailability ofthe system nor the interruption atthe level of the applications.
Analytics
Storage
Distributed
Memory
APACHE Cassandra: NoSQL DataBase
http://www.infoq.com/fr/articles/modele-stockage-physique-cassandra-details (Traduction)

In the world of databases NoSQL, weoften hear about the Theorem CAP.This theorem establishes 3parameters on which we can play toconfigure a distributed databaseThe coherence (C for Consistency)The availability (A for Availability)The fault tolerance and in thenetwork cuts (P for Partition-Tolerance)The theorem postulates that for anydistributed database, we can chooseonly 2 of these 3 parameters, ever 3at the same time. In theory, we canthus choose the following couples:a. Coherence and availability (CA)thus not resistant in thebreakdowns.b. Coherence and 100% thusunavailable fault tolerance ( CP) thisequal ( A )
c. Availability and 100% thusnot coherent fault tolerance (AP) this equal ( C )This is the theory. In practice,we realize that the parameterP is more or less imposed.Indeed, the network cuts ithappens, it is inevitable. As aresult, the choice amountsafter all to CP or AP. Cassandraclearly chooses of AP for afault tolerance and an absoluteavailability.
In return, Cassandra sacrifices the absolvedcoherence (in the sense(direction) ACID of the term)against a final coherence, that is a strong coherenceobtained after a convergence of the data or AP.Cassandra clearly chooses of AP for a fault toleranceand an absolute availability. In return, Cassandrasacrifices the absolved coherence (in thesense(direction) ACID of the term) against a finalcoherence, that is a strong coherence obtained after aconvergence of the data or AP. Cassandra clearlychooses of AP for a fault tolerance and an absoluteavailability. In return, Cassandra sacrifices theabsolved coherence (in the sense ACID of the term)against a final coherence
CAP Theorem
http://www.infoq.com/fr/articles/cap-twelve-years-later-how-the-rules-have-changed

CQLSHCQL wants to say CassandraQuery Language, and we arein the version 4. The firstversion was an experimentalattempt to introduce alanguage of request forCassandra. The second versionof CQL was conceived ordesigned to re-beg wide rowsbut was not rather flexible toadapt itself to all
The types of modelling whoexist in Apache Cassandra.However, it is recommended touse rather the second key ofindexation positioned on thecolumn containing thedeliberate information. Indeed,to use the strategy Ordered-Partitionners has the followingconsequences: the sequentialwriting can pull hotspots: ifthe application tries to write or
To update sequential set lines, then the writing willnot be distributed in the cluster; an overheadincreased for the administration of the load hesitatein the cluster: the administrators have to calculatemanually the beaches of tokens to distribute them inthe cluster; uneven distribution of load for families ofmultiple columns.The interface of CQLSH is written in python, thusrequires the installation of the utility python for aversion superior to 2.7 to be able to benefit from thisinterface of direct communication with the databaseCassandra. The language of request in version 4 isvery similar to the SQL2. So several terms are thesame, but their utilities a primary key in Cassandra isdifferent, for example is not equivalent
Example:CREATE TABLE developer(
developer_id bigint,firstname text,lastname text,age int,task varchar,PRIMARY KEY(developer_id));CQLSH 4.1 python interface

Apache Cassandra is a systemallowing to manage a bigquantity of data in adistributed way. The latter canbe structured, semi-structuredor not structured by the whole.Cassandra was conceived to behighly scalable on serverslarge number not whilepresenting a Single Of Failure (SPOF). Cassandra supplies adynamic plan of data to offer amaximum of flexibility andperformance. But to includewell this tool, it is necessary toassimilate first of all thevocabulary
- Cluster: a cluster is agrouping of the knots whichcommunicate themselves forthe management of data.- Keyspace: it is the equivalentof a database in the world ofthe relational databases. Tonote that it is possible to haveseveral "Keyspaces" on thesame server.- Column ( Column): a columnconsists of a name, a value anda timestamp.- Line ( Row): columns aregrouped(included) in Rows.Row is represented by a keyand a value.
It is possible to configure the partition for a family ofcolumns by specifying that we want that it is managedwith type Ordered-Partitioners strategy. This mode can,indeed, have an interest if we wish to get back abeach(range) of lines between two values (thing whichis not possible if the hash MD5 of the keys of lines isused). It is possible to configure the partition for afamily of columns by specifying that we want that it ismanaged with type Ordered-Partitioners strategy. Thismode can, indeed, have an interest if we wish to getback a range of lines between two values (thing whichis not possible if the hash MD5 of.
C* Cluster and system architecture
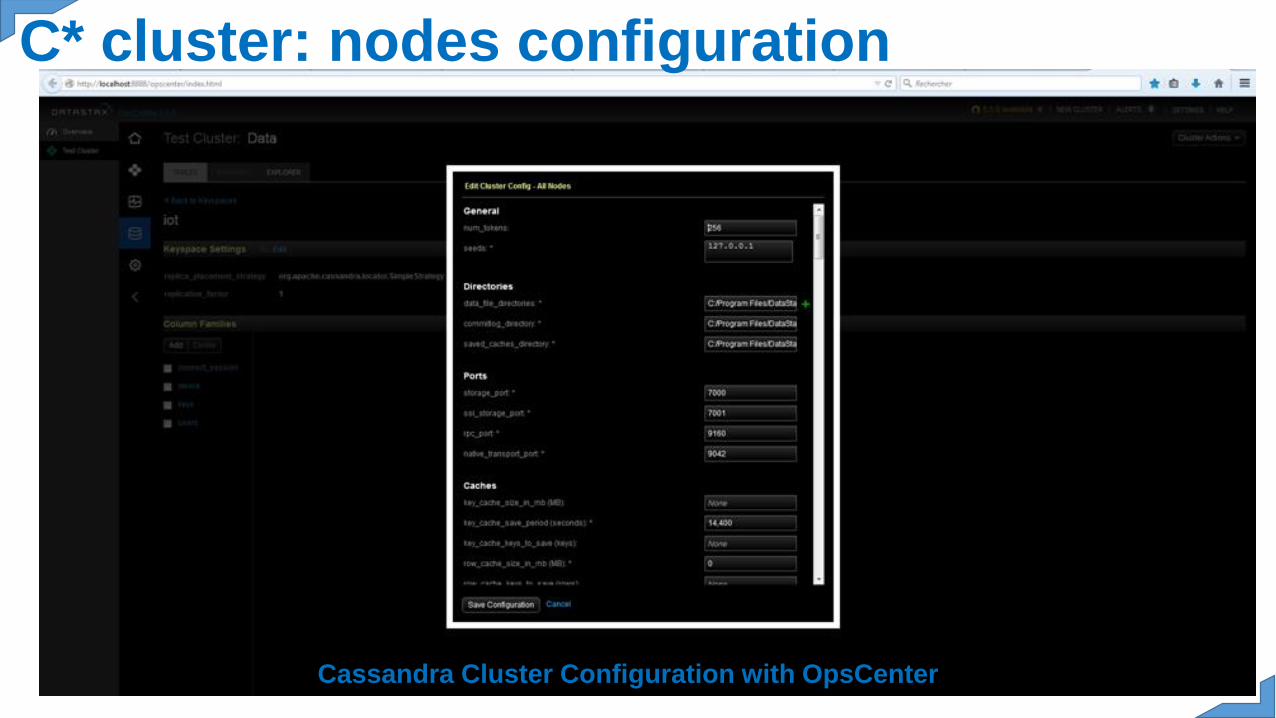
C* cluster: nodes configuration
Cassandra Cluster Configuration with OpsCenter

C* Storage Data: Modelimport java.io.Serializable;import java.util.Date;import java.util.UUID;import javax.persistence.Column;import javax.persistence.Entity;import javax.persistence.Id;import org.apache.commons.lang3.builder.EqualsBuilder;import org.apache.commons.lang3.builder.HashCodeBuilder;import org.apache.commons.lang3.builder.ToStringBuilder;import org.apache.commons.lang3.builder.ToStringStyle;import org.easycassandra.Index;@Entity(name = "tweet")public class Tweet implements Serializable {@Idprivate UUID id;@Index@Column(name = "nickName")private String nickName;@Column(name = "message")private String message;@Column(name = "time")private Date time;
public UUID getId() {return id; }public void setId(UUID id) {this.id = id;}public String getNickName() {return nickName; }public void setNickName(String nickName) {this.nickName = nickName;}public String getMessage() {return message;}public void setMessage(String message) {this.message = message;}public Date getTime() {return time;}public void setTime(Date time) {this.time = time; }@Overridepublic boolean equals(Object obj) {if(obj instanceof Tweet) {Tweet other = Tweet.class.cast(obj);return new EqualsBuilder().append(id, other.id).isEquals();}return false;}@Overridepublic int hashCode() {return new HashCodeBuilder().append(id).toHashCode();}@Overridepublic String toString() {return ToStringBuilder.reflectionToString(this,ToStringStyle.SHORT_PREFIX_STYLE);}}

C* Storage Data: Repository-Requestimport java.util.List;import java.util.UUID;import org.easycassandra.persistence.cassandra.Persistence;public class TweetRepository {private Persistence persistence;public List<Tweet> findByIndex(String nickName) {return persistence.findByIndex("nickName", nickName, Tweet.class);}{this.persistence = CassandraManager.INSTANCE.getPersistence();}public void save(Tweet tweet) {persistence.insert(tweet);}public Tweet findOne(UUID uuid) {return persistence.findByKey(uuid, Tweet.class);}}
import java.util.Date;import java.util.UUID;public class App{public static void main( String[] args ){TweetRepository personService = new TweetRepository();Tweet tweet = new Tweet();tweet.setNickName("allaoui chaker");UUID uuid = UUID.randomUUID();tweet.setId(uuid);tweet.setNickName("allaoui chaker");tweet.setMessage("test cassandra mapping");tweet.setTime(new Date());tweet.setId(UUID.randomUUID());personService.save(tweet);Tweet findTweet=personService.findOne(uuid);System.out.println(findTweet);}}
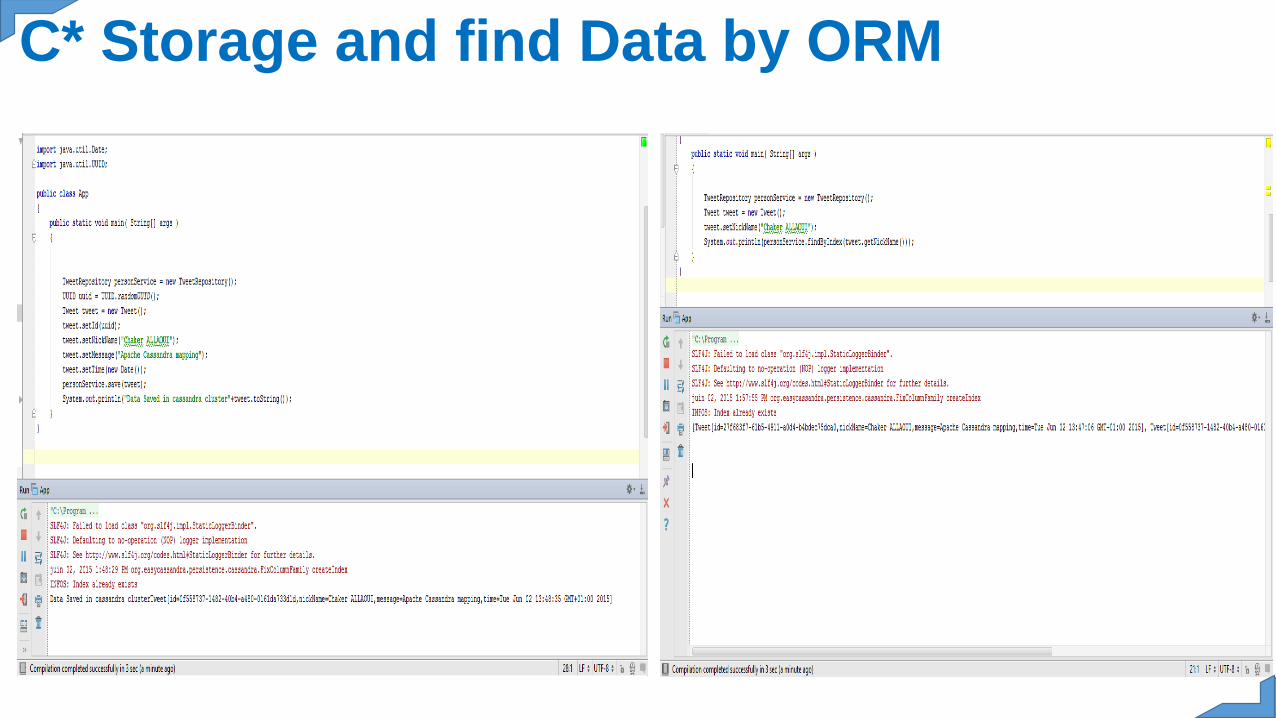
C* Storage and find Data by ORM

EasyCassandra ORM Mapping Data into Cassandra

APACHE SPARKBig Data Eco-System

ECO-SYSTEME APACHE SPARK

Apache Spark is a framework ofprocessing open source Big Databuilt to make sophisticatedanalyses and conceived for thespeed and the ease of use. This onewas originally developed byAMPLab, of the University UCBerkeley, in 2009 and open sourcepast in the form of project Apachein 2010. Spark presents severaladvantages with regardto(compared with) the othertechnologies big dated andMapReduce as Hadoop and Storm.At first, Spark proposes aframework complete and unified tomeet the needs of processing BigData for diverse sets of data,diverse by their nature (text,graph) as well as by the type ofsource.
Then, Spark allows applicationson clusters Hadoop to be executeduntil 100 times as fast in memory,10 times as fast on record. Heallows you to write quicklyapplications in Java, Scala orPython and includes a set of morethan 80 operators top-level.
Furthermore, it is possible touse him in a interactive way torebeg the data since a Shell.Finally, besides the operationsof Map and Reduce, Sparksupports the SQL requests andthe streaming of data andproposes features of ML.
Analytics
Distributed
Local Implements
Cloud Implements
Apache Spark: SQL, Streaming, ML, GraphX
http://www.infoq.com/fr/articles/apache-spark-introduction (Traduction)

RDDResilient Distributed Datasets(based on the publication ofresearch for Matei), or RDD, isa concept at the heart of theframework Spark. You can seea RDD as a table in a database.This one can carry(wear) quitetypical of data and is stored bySpark in various partitions.The RDD allows to re-arrange(re-settle) thecalculations and to optimizethe treatment(processing).They are also fault tolerantbecause a RDD knows how torecreate and to recalculate itsdata set. The RDD isimmutable. To obtain amodification of a RDD, It isnecessary to apply to it atransformation, which willreturn a new RDD,
the original will remainunchanged. The RDD supportstwo types of operations:transformations and actions. Itis necessary to apply to it atransformation, which willreturn a new RDD,
the original will remain unchanged. The RDDsupports two types of operations: thetransformations and the actions it is necessary toapply to it a transformation, which will return anew RDD, the original will remain unchanged.The RDD supports two types of operations: thetransformations and the actions it is necessary toapply to it a transformation, which will return anew RDD, the original will remain unchanged.The RDD supports two types of operations: thetransformations and the actions it is necessary toapply to it a transformation, which will return anew RDD, the original will stay.
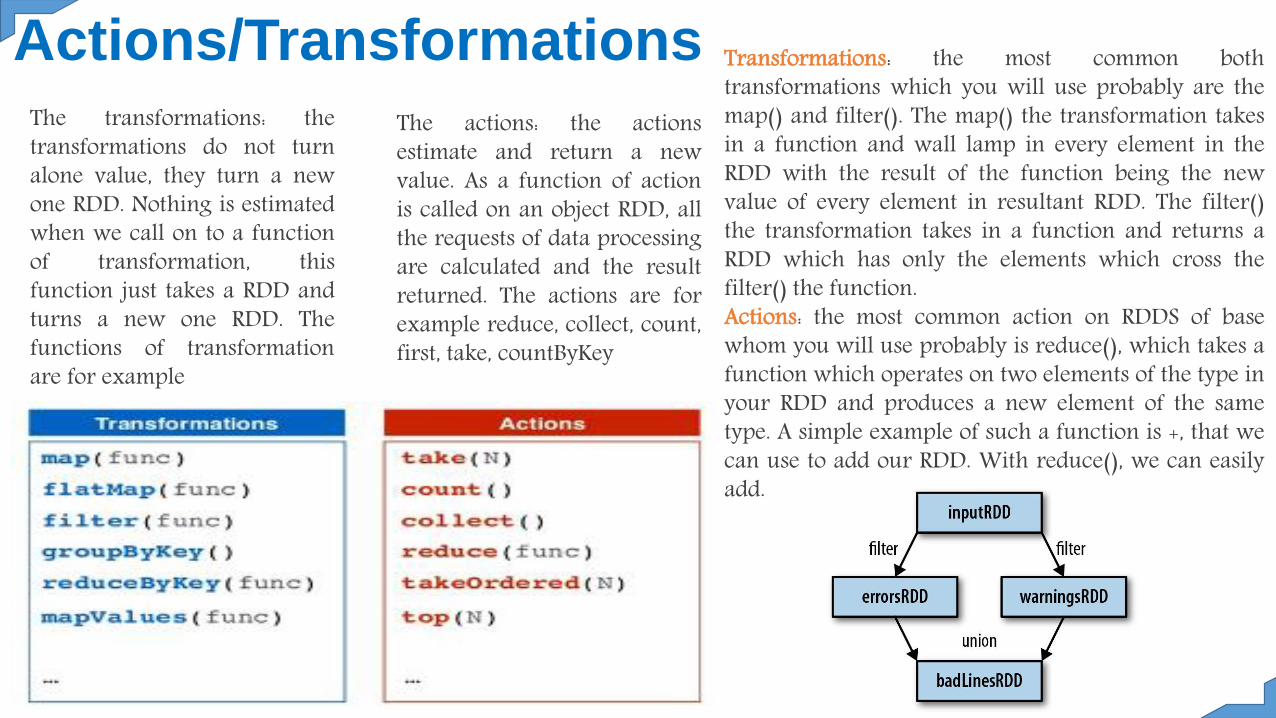
Actions/TransformationsThe transformations: thetransformations do not turnalone value, they turn a newone RDD. Nothing is estimatedwhen we call on to a functionof transformation, thisfunction just takes a RDD andturns a new one RDD. Thefunctions of transformationare for example
The actions: the actionsestimate and return a newvalue. As a function of actionis called on an object RDD, allthe requests of data processingare calculated and the resultreturned. The actions are forexample reduce, collect, count,first, take, countByKey
Transformations: the most common bothtransformations which you will use probably are themap() and filter(). The map() the transformation takesin a function and wall lamp in every element in theRDD with the result of the function being the newvalue of every element in resultant RDD. The filter()the transformation takes in a function and returns aRDD which has only the elements which cross thefilter() the function.Actions: the most common action on RDDS of basewhom you will use probably is reduce(), which takes afunction which operates on two elements of the type inyour RDD and produces a new element of the sametype. A simple example of such a function is +, that wecan use to add our RDD. With reduce(), we can easilyadd.

Spark: cluster managerA cluster Spark consists of a Master's degree and one or severalworkers. The cluster must be started and remain active to be able toexecute applications. The Master's degree has for the only oneresponsibility the management of the cluster and it does not thusexecute code MapReduce. Workers, on the other hand, is theexecutive. It is them who bring resources to the cluster, worthknowing(namely) of the memory and the hearts of treatment.To execute a treatment on a cluster Spark, it is necessary to submitan application the treatment of which will be piloted by a driver.Two modes of execution are possible:- Customer mode: the driver is created on the machine whichsubmits the application- Mode to cluster: the driver is created inside the cluster.Communication within the cluster.Workers establishes a bidirectional communication with theMaster's degree: the worker connects in the Master's degree to opena channel in a sense, then the Master's degree connects in theworker to open a channel in the inverse sense. It is thus necessarythat the various knots of the cluster can join correctly (resolutionDNS). The communication between knots is made with theframework Akka. It is useful to know to identify the lines of logshandling exchanges between knots.
The knots of the cluster (Master's degree as workers)expose besides a Web interface allowing to watch thestate of the cluster as well as the progress(promotion)of treatments. Every knot thus opens two ports:- A port for the internal communication: port 7077 bydefault for the Master's degree, the random port forworkers.- A port for the Web interface: port 8080 by defaultfor the Master's degree, the port 8081 by default forworkers.The creation of a cluster Spark allows to run the powerof treatment of several machines. His implementationis relatively simple. It will simply be necessary to becareful to return the Master's degree cancel by usingZooKeeper. Besides, the execution of an applicationdoes not require modification of the code of treatment.The main constraint is to make sure that the data areread and written since distributed systems.

http://www.infoq.com/fr/articles/apache-spark-introduction
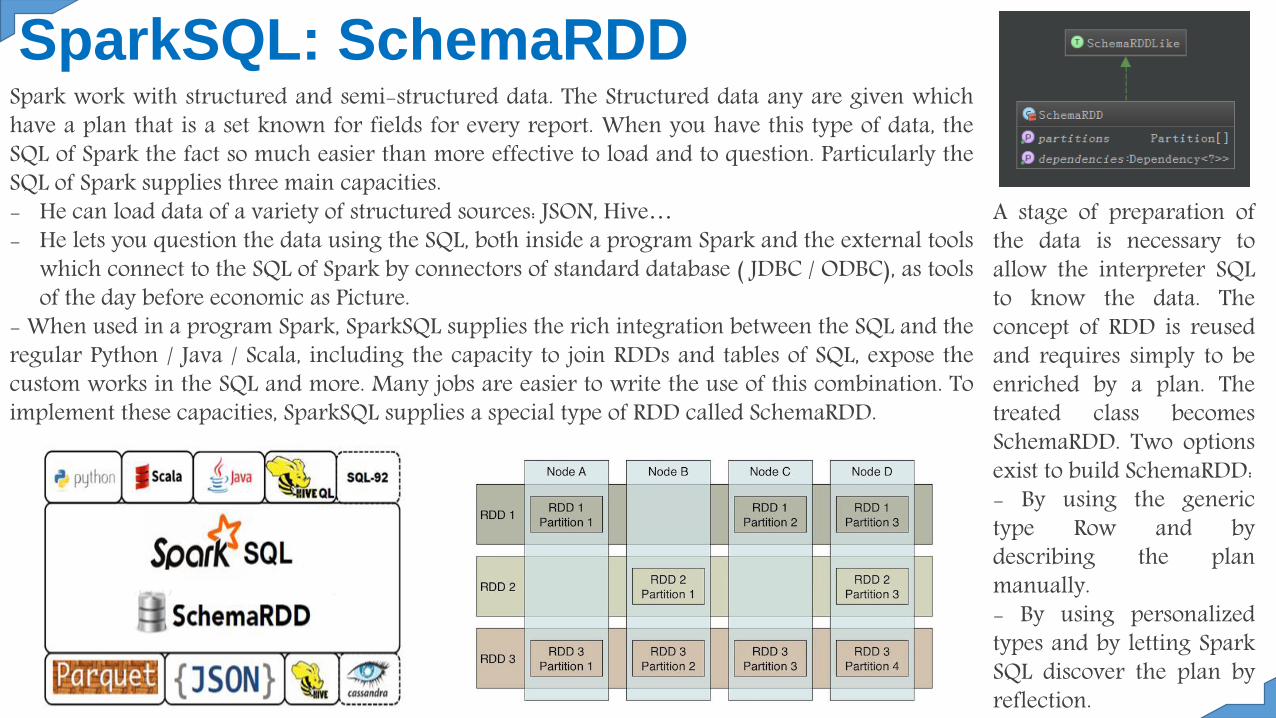
SparkSQL: SchemaRDDSpark work with structured and semi-structured data. The Structured data any are given whichhave a plan that is a set known for fields for every report. When you have this type of data, theSQL of Spark the fact so much easier than more effective to load and to question. Particularly theSQL of Spark supplies three main capacities.- He can load data of a variety of structured sources: JSON, Hive…- He lets you question the data using the SQL, both inside a program Spark and the external tools
which connect to the SQL of Spark by connectors of standard database ( JDBC / ODBC), as toolsof the day before economic as Picture.
- When used in a program Spark, SparkSQL supplies the rich integration between the SQL and theregular Python / Java / Scala, including the capacity to join RDDs and tables of SQL, expose thecustom works in the SQL and more. Many jobs are easier to write the use of this combination. Toimplement these capacities, SparkSQL supplies a special type of RDD called SchemaRDD.
A stage of preparation ofthe data is necessary toallow the interpreter SQLto know the data. Theconcept of RDD is reusedand requires simply to beenriched by a plan. Thetreated class becomesSchemaRDD. Two optionsexist to build SchemaRDD:- By using the generictype Row and bydescribing the planmanually.- By using personalizedtypes and by letting SparkSQL discover the plan byreflection.

val sqlContext = new org.apache.spark.sql.SQLContext(sc)val people = sqlContext.jsonFile("./data/data.json")people.printSchema()people.registerTempTable("people")people.count()people.first()val r=sqlContext.sql("select * from people where nom='allaoui'").collect()
SparkSQL/UI: SqlContext jobs statistics
SQLContext: Scala

SparkSQL/UI: SqlContext stages statistics

import org.apache.commons.lang.StringUtils;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;import static com.datastax.spark.connector.japi.CassandraJavaUtil.*;import com.datastax.spark.connector.japi.CassandraRow;public class FirstRDD {public static void main(String[] args) {SparkConf conf = new SparkConf(true).set("spark.cassandra.connection.host", "127.0.0.1").setAppName("CassandraConnection").setMaster("local[*]");JavaSparkContext sc = new JavaSparkContext("local[*]", "test", conf);JavaRDD<String> cassandraRowsRDD = javaFunctions(sc).cassandraTable("java_api","products").map(new Function<CassandraRow, String>() {@Overridepublic String call(CassandraRow cassandraRow) throws Exception {return cassandraRow.toString();}});System.out.println("--------------- SELECT CASSANDRA ROWS ---------------");System.out.println("Data as CassandraRows: \n" + StringUtils.join(cassandraRowsRDD.toArray(), "\n"));}}
SparkSQL with cassandraRDD
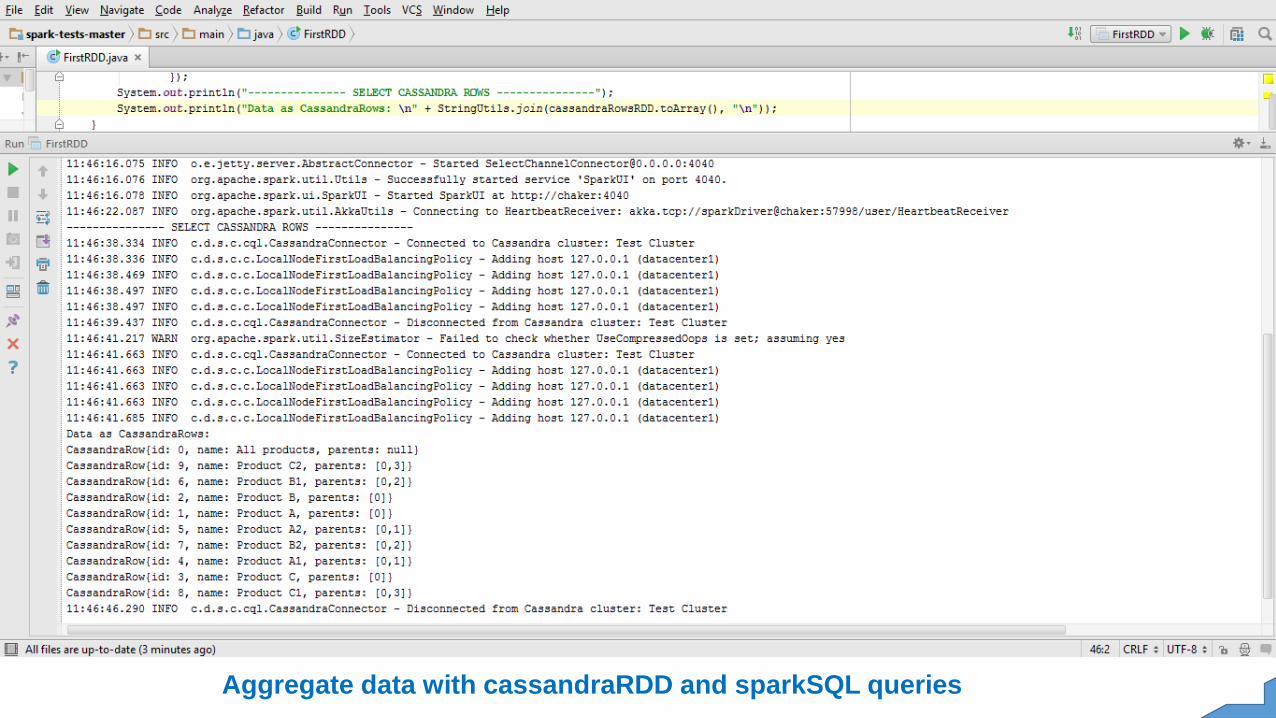
Aggregate data with cassandraRDD and sparkSQL queries

SparkConf conf = new SparkConf(true).set("spark.cassandra.connection.host", "127.0.0.1").setAppName("SparkCassandra").setMaster("local[*]");JavaSparkContext sc = new JavaSparkContext("local[*]", « CassandraActionsSpark", conf);JavaRDD<String> cassandraRowsRDD = javaFunctions(sc).cassandraTable("network", "storage").map(new Function<CassandraRow, String>() {@Overridepublic String call(CassandraRow cassandraRow) throws Exception {return cassandraRow.toString();}});System.out.println("StringUtils.join(cassandraRowsRDD.toArray()));System.out.println(cassandraRowsRDD.first());System.out.println(cassandraRowsRDD.collect());System.out.println(cassandraRowsRDD.id());System.out.println(cassandraRowsRDD.countByValue());System.out.println(cassandraRowsRDD.name());System.out.println(cassandraRowsRDD.count());System.out.println(cassandraRowsRDD.partitions());
Spark Actions with CassandraRowRDD

Actions functions with cassandraRowsRDD and sparkSQL queries

package scala.exampleobject Person {var fisrstname:String="CHAKER"var lastname:String="ALLAOUI"def show(){println(" Firstname : "+ firstname+" Lastname : "+ lastname)}}def main(args: Array[String]){Person p=new Person()println("Show Infos")p.show()}}
SparkUI: Monitoring
val textFile = sc.textFile("DATA.txt")textFile.count()textFile.first()val linesWithSpark = textFile.filter(line => line.contains("Spark"))textFile.filter(line => line.contains("Spark")).count()
There are several manners to check(control) Spark applications: whosepillar of monitoring and external instrumentation SparkUI is. ChaqueSparkContext launches Web UI, by default on the port 4040, whichshows useful information on the application. This includes:A list of stages of planner and try.A summary of sizes RDD and use of report memory.Environmental information.Information on executive common.You can have access to this interface by opening simply"http://hostname:4040" in an Internet browser. If multiple SparkContextwhich run on the same host, they will be available listens to it on thesuccessive ports beginning with 4040, 4041, 4042
SparkContext: Scala
Note that this information is only available fora period of life of the application by default.To see the depiction of SparkUI and takeadvantage of the interface of monitoring, put "spark.eventLog.enabled " in " true ". Thisconfigures Spark to register(record) theevents which contain the necessaryinformation to monitor the events of Spark inSparkUI and visualize the persisted data.

SparkUI: SparkContext jobs statistics

SparkUI: SparkContext stages statistics

import java.lang.Mathval textFile = sc.textFile("DATA.txt")textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)wordCounts.collect()
MapReduce: map, key, value, reduceSpark offers an alternative to MapReduce because he executes the jobs in micro-prizes(micro-lots) with intervals of fiveseconds or less. Or a kind of fusion between the batch and the real time or almost. He supplies also more stability than othertools of real-time treatment, as Twitter Storm, transplanted on Hadoop.The software can be used for a big variety of uses, as an analysis perms real time data, and, thanks to a software library, morenumerous jobs for the in-depth calculations involving the machine learning and the graphic processing. With Spark,developers can simplify the complexity of the code MapReduce and write requests of analysis of data in Java, Scala or Python,by using a set of 80 high-level routines.With this version 1.0 of Spark, Apache proposes from now on a stable API, which developers can use to interact with their ownapplications. Other novelty of the version 1.0, a component Spark SQL to reach the structured data, so allowing the data to bequestioned beside data not structured during an analytical operation.Spark Apache is of course compatible with the system of files HDFS (Of Hadoop Distributed File System), as well as othercomponents such as YARN (Yet Another Resource Negotiator) and the distributed database HBase. The University of California,and more exactly the laboratory AMP (Algorithms, Machines and People) of Berkeley is at the origin of the development ofSpark which the Apache foundation adopted as project in June, 2013. IT companies as Cloudera, Pivotal, IBM, Intel and MapRhave already begun to integrate Spark into their distribution Hadoop.SparkContext MapReduce: Scala
http://www.lemondeinformatique.fr/actualites/lire-la-fondation-apache-reveille-hadoop-avec-spark-57639.html

SparkUI: MapReduce statistics

Data-Driven DocumentsData Graphical Design

Data-Driven Documents
Presentational
Big Data
Design
Riche Components
The exponential production of data by the computersystems is a well established fact. This reality feeds thephenomenon Big dated. The statistical or predictiveanalysis has to call on(appeal) to the art of the visualrepresentation of the data to give meaning to them andinclude them better. The Display(Visualization) of thedata or Dated visualization is called to set a growingplace and it is true in proportion to the volume of dataproduced by information systems.As such, we are absolutely convinced that the D3bookshop, the object of this article, will take all its placeand it is true not only because of its esthetic qualitiesthere. Created by Mike Bostock, D3 is often presented asa graphic bookshop while its acronym - D3 for DataDriven Documents - shows that it is at first, followingthe example of jQuery, a Javascript bookshop facilitatingthe manipulation of a tree DOM. D3 implementsroutines allowing to load(charge) external data amongwhich the size(format) JSON, XML, CSV or text is nativesupported. The developer writes the logic oftransformation(processing) of the data in HTML elementsor SVG to have a representation of it.
So, the representation can take as well theshape of a picture(board) ( HTML elements) asa curve (elements SVG). D3 thus allows toproduce Directed Documents Given. Whoseseveral models are available on the sitewww.d3js.org.
JSON File presentation: DENDROGRAM
D3.js (or D3 for Data-DrivenDocuments) is a Javascriptgraphic library(bookcase)which allows the display ofdigital data under a graphicand dynamic shape. It is abouta tool mattering for theconformation for thestandards W3C which uses thecommon SVG technologies,Javascript and CSS for thevisualization of data. D3 is theofficial successor of theprecedent frameworkProtovis1. Contrary to theother libraries, this one allowsa more ample control of thevisual result final. Hisdevelopment popularized in20113, at the release of theversion 2.00 in August, 2014.In August, 2012, the libraryhad affected the version2.10.05.
Integrated into a HTML,the Javascript library D3.jsuses pre-constructedfunctions of Javascript toselect elements, createobjects SVG, stylize them,or add it transitions,dynamic effects or tooltips.These objects can be alsostylized on a large scale bymeans of the famouslanguage CSS.Furthermore, big databaseswith associated values canfeed the Javascriptfunctions to generateconditional and/or richgraphic documents. Thesedocuments are most of thetime graphs.Databases can be undernumerous formats, most ofthe time JSON, CSV,GeoJSON
So, the data analysis is the process which consists inexamining and in interpreting data to develop answers toquestions. The main stages of the process of analysisconsist in encircling the subjects of analysis, indetermining the availability of appropriate data, indeciding on methods that there is good reason to use toanswer the questions of interest, to apply the methods andto estimate, to summarize and to communicate the results.
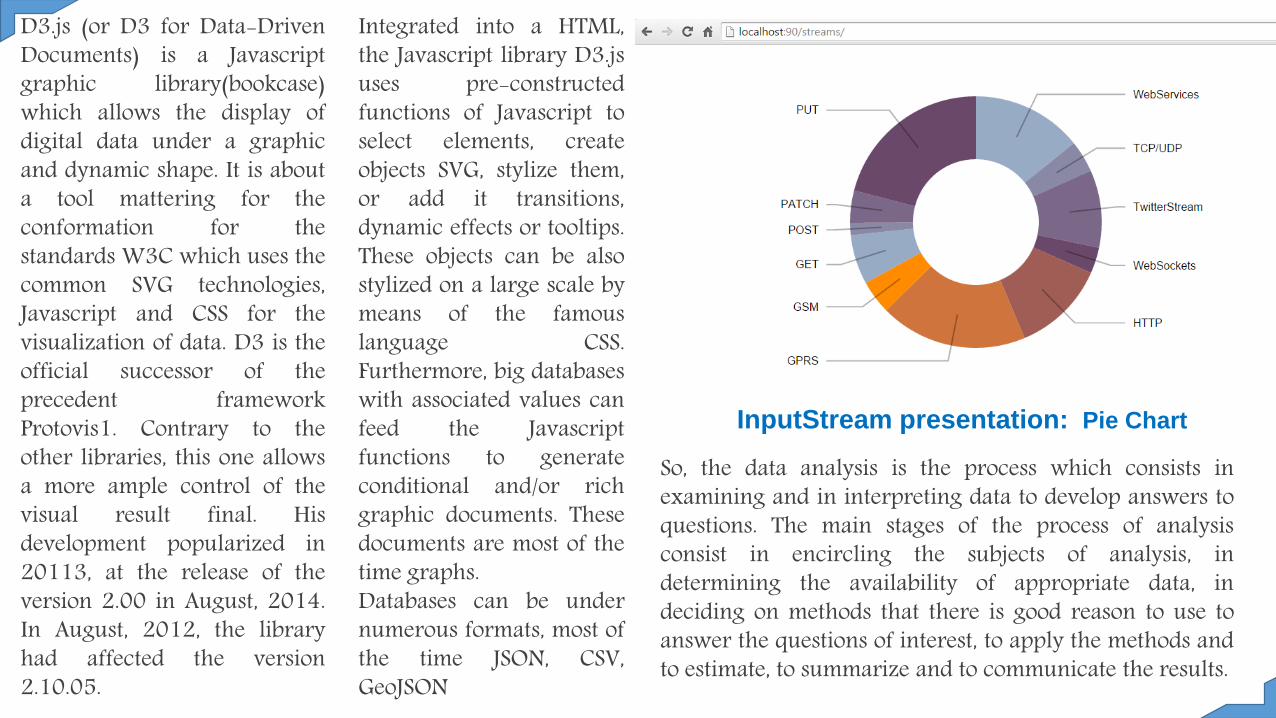
InputStream presentation: Pie Chart

Graphical presentation possible with D3

SMART DATADecisional Force

SMART DataSMART DATA
Presentational
Design
Support Decision
Smart
Today, Big Data is for the marketing managers at the same time an incredible source of data on theconsumers and, at the same time, an incredible challenge to be raised. Marketing strategies "digital" takeinto account from now on texts, conversations, behavior, etc. in an environment or the volume of thisinformation to be handled grow in a exponential way. He would thus be totally imaginary to imagine tomanage the entire these data. And The stake in the digital marketing is thus from now on the intelligentmanagement of Big Data to identify, classify and run the information consumer significant allowing theprofessionals of the marketing to set up their strategies.Smart Data is the process which allows to cross raw data in information ultra qualified on each of theconsumers. The objective is to have a vision in 360 ° customers, basing on information collected throughadapted marketing mechanisms, that they are classic or innovative (quizzes, social networks, purchasesduring checking out, use of the mobile applications, the geo-localization, etc.). To reach there, companiesare equipped with marketing platforms crosses-channels capable of storing and of analyzing everyinformation "to push" the good message at the best moment for every consumer. The final goal is not only toseduce new customers but especially to increase their satisfaction and their loyalty by anticipating their.It means, among others, establishing a real dialogue with each of his customers and measuring effectivelythe marketing and commercial performances of the mark.To target in a fine way according to several criteria while respecting the preferences customers, to managethe customization, the relevance and the coherence of messages cross channel freed by e-mail, mail, Weband call center became imperatives which Smart Data allows finally to tackle in a effective way.Let us forget "Big" and let us interest we "Smart" because the relevance of marketing strategies will alwaysdepend on the data quality customers.

SMART DATA: Data Transformations
Data Sources: WebSockets, TCP/UDP, InputStreamData Movement: Apache Storm, Apache kafkaData Storage: Apache Cassandra, Apache SparkData Presentation: Data-Driven Documents
Integrated into a HTML Web page, the Javascript library D3.js usespre-constructed functions of Javascript to select elements, createobjects SVG, stylize them, or add to it transitions, dynamic effects ortooltips. These objects can be also stylized on a large scale by means ofthe famous language CSS. Furthermore, big databases with associatedvalues can feed the Javascript functions to generate conditional andrich graphic documents.
SMART DATA: Process Scenario
Synthesis

BIBusiness Intelligence

Keywords
WebSockets – HTTP – TCP/UDP – InputStream – TwitterStream – WebServices – JSON – Data - Big Data – SMART DATA -Process Big Data – Business Iintelligence – Data Storage – Data Sources – Data Presentation – Data Mining - DataExploration - Apache Storm – Apache Zookeeper – Apache Kafka – Apache Cassandra – Apache Spark – SparkSQL –SparkUI – D3 - Data-Driven Documents – Storm cluster – StormUI – Storm Topology – Zookeeper cluster – Distrubutedserver – Topics – Message – Queue – Data Transmit – OpsCenter – EasyCassandra- Keyspace – Column – CQLSH -CassandraColumn – CassandraRow- Cassandra cluster – Storage Data – Aggregation – RDD – SchemaRDD - Spark Actions– Spark Transformations – Spark cluster - MapReduce – Jobs – Stages – Excutors – Data Transformations –SMART – Apache

Links
Apache Stormhttps://storm.apache.org
Apache Zookeeperhttps://zookeeper.apache.org
Apache Kafkahttp://kafka.apache.org/
Apache Cassandra
https://spark.apache.org
Data-Driven Documentshttp://d3js.org/
Apache Spark
http://cassandra.apache.org

Idea Create Refine
Contact
Visit my profile in LinkedIn
Visit my website
http://tn.linkedin.com/in/chakerallaoui
http://allaoui-chaker.github.io